Инструкция по настройке Key Collector для эффективного парсинга. Яндекс директ парсинг
Как составить семантическое ядро запросов. Как расширить
Как парсить? Расширение базовой семантики. 2 шаг в Директе.Reviewed by Владислав Челпаченко on Sep 9Rating: 5.0
Здравствуйте, уважаемые коллеги и друзья!
Что такое парсинг и как этим правильно заниматься? Как расширить ваше семантическое ядро в сотни и тысячи раз?


В этой статье мы разберём два способа расширения семантического ядра.

Как составить семантическое ядро?
В прошлой статье мы познакомились с составлением басовой семантики. У вас получился набор слов, из которого можно составить более 50 фраз. Теперь я расскажу каким образом увеличить это число в 10, а может и в 1000 раз в зависимости от ниши. Сбор ключевиков, или составление семантического ядра, называется парсингом. Я предлагаю два способа расширения семантики, оба из них подходят под определенные задачи: - Assistant. Это модуль для браузера, который помогает одним нажатием кнопки отправить в буфер обмена все фразы на странице вордстата.
- KeyCollector. Это программа, которая за вас собирает 40 страниц выдачи в вордстате.
Далее, для каждого сервиса мы разберём принцип составления семантики.
Wordstat Assistant
Я покажу на примере браузера Mozilla. Для начала необходимо установить сам модуль. Сделать это можно в разделе «Дополнения» в главном меню (правый верхний угол).

В поиске напишите «Wordstat» и установите плагин «Yandex Wordstat Assistant». Перезапустите браузер.

Теперь, когда вы будете искать ключевые фразы в вордстате, то рядом будет окошко данного плагина, который позволяет одним нажатием мышки добавлять только подходящие вам фразы.

Фразы, которые получились при пересечении базовых слов, нужно вписывать в вордстат и взять оттуда только необходимые ключевики. Лучше всего для этого создать excel-таблицу, в которой под каждой составляющей скелета вписать найденные ключевики.
Какую программу использовать для сбора семантического ядра?KeyCollector или Словарёк?
Эта программа является платной, но существует бесплатная версия, которой хватит для составления семантики. Скачать ееё можно на этом сайте. После установки нужно создать проект и, программа сразу предложит его сохранить.

Перед тем, как собирать семантику настроим программу:
- В предыдущей статье мы составили «скелет» базовой семантики, теперь необходимо по нему составить разнообразные ключевики. Сделать это можно с помощью сервиса генератора фраз. Под каждую составляющую скелета создаём свою группу.
- Выбираем регион/город/район показов. Если вы собираетесь продавать свой товар или услугу только в Москве, то нет смысла брать семантику по всей России. Таким образом вы устраняете из будущей семантики лишний мусор.
- Настройка программы. Здесь нас интересует всего 1 раздел, о котором поговорим чуть ниже.
- Вписывание получившихся фраз и начало сбора семантики.

В 3 пункте нас интересует раздел с аккаунтами яндекса, с помощью которых программа будет пользоваться вордстатом. Программа работает достаточно быстро, и система яндекса может воспринять это как атаку на свои сервера, поэтому ни в коем случае не вписывайте туда свой личный аккаунт, создайте 7-10 сторонних аккаунтов.

Теперь программа готова к запуску. Возвращаемся к 4 пункту и жмём на кнопку с красной иконкой. Перед нами откроется окно, выставите настройки такие же, как на скриншоте:

Впишите в окошки составленные пересечённые слова и нажмите на кнопку «начать сбор». В зависимости от вашей базовой семантики сбор может длится от 1 часа до нескольких дней. Компьютер при этом нельзя выключать, иначе закроется программа.
На этом методика парсинга закончена. В следующей статье я разберу тему минусация — как очистить составленную семантику и не показываться по ненужным запросам.
Если вы до сих пор не знаете, что такое контекстная реклама, то обязательно прочтите эту статью, а если вам требуется срочно запустить директ, то я показываю, как это сделать в статье «Как быстро запустить Яндекс.Директ?».
Также напоминаю, что вы можете пройти курс по Яндекс.Директу, если появилось желание профессионально изучить директ.
Пишите в комментариях ваши трудности по настройке директа, на все вопросы обязательно ответят. Успехов!
P.S. Понравилась статья? Подпишитесь на обновления блога, чтобы не пропустить следующую.
www.chelpachenko.ru
Инструкция по настройке Key Collector для эффективного парсинга
Key Collector - незаменимый инструмент при сборе семантического ядра для сайта или контекстной рекламы. Но прежде чем запускать парсинг, программу необходимо грамотно настроить. Это позволит провести сбор фраз максимально быстро и с наименьшими затратами на антикапчу.
В этой статье мы пройдемся по основным настройкам программы, подготовим инструмент, а уже саму методику сбора, чистки и расширения семантики будем рассматривать в других статьях. Эта статья открывает цикл материалов, посвященных работе с Key Collector.
Весь цикл статей:
- Настройка Key Collector для сбора (эта статья)
- Методика сбора (парсинга) фраз в Key Collector.
- Эффективная чистка в Key Collector.
- Принципы группировки (кластеризации) фраз в Key Collector (в работе, ссылка появится позже)
- Учет, фильтры и лайфхаки при работе в Key Collector (в работе, ссылка появится позже)
Установка программы
Если вы еще не знакомы с программой Key Collector, то ее необходимо скачать здесь. Там даны указания по тому, каким образом осуществляется покупка и установка программы. После того, как программа установлена и активирована можно переходить к следующему шагу.
Важно! Key Collector - программа, которая работает под Windows и на компьютеры Mac (Macbook, Macbook Air) с OSx не установится. Обойти это ограничение можно установкой виртуальной машины Windows, к примеру посредством утилиты Parallels Desktop.
Прокси и аккаунты Яндекс.Директ
Для работы с Key Collector мы настоятельно рекомендуем приобрести (взять в аренду на неделю или на месяц) как минимум 1 прокси-сервер. Это необходимо для того, чтобы обезопасить свой основной IP адрес от возможных блокировок, которые могут возникнуть в ходе работы Key Collector со статистическими источниками типа Яндекс.Вордстат и Яндекс.Директ.
Одного прокси будет вполне достаточно, чтобы потренироваться и понять принцип работы программы. Хорошие, индивидуальные прокси предоставляет сайт proxy-sale.com. Берем те, что для работы в Key Collector.
После покупки сервис высылает вам на почту учетные данные прокси и свежий аккаунт Яндекс.Директа, который также нам потребуется. В дальнейшем, при необходимости количество прокси можно будет увеличить, просто докупив (арендовав) столько сколько нужно.
Сейчас нам нужно просто понять принцип настройки Key Collector, а дальнейшую докрутку можно будет сделать потом.
Переходим в настройки программы - нажимаем на иконку "шестеренки" в панели управления.
 Фото 1: Меню настроек Key Collector.
Фото 1: Меню настроек Key Collector.Учетки для Yandex.Direct
Переходим в раздел настроек “Yandex.Direct” (Парсинг -> Yandex.Direct).
Вводим необходимые данные: логин и пароль от аккаунта Яндекс.Директ, IP прокси, порт, логин и пароль. Эти данные должны быть в письме, которое вы получили от proxy-sale. Вы можете добавить прокси вручную построчно или добавить из буфера обмена списком. Обратите внимание на формат, который требует Key Collector при вводе данных списком. Будьте внимательны и не перепутайте логин и пароль от учетки Яндекс.Директ с логином и паролем прокси сервера.
 Фото 2: На первом шаге мы только вносим данные учетки и прокси, настройки будем делать потом. Это уменьшит количество ошибок и возможных проблем.
Фото 2: На первом шаге мы только вносим данные учетки и прокси, настройки будем делать потом. Это уменьшит количество ошибок и возможных проблем.Сейчас, мы внесли данные и, тем самым, привязали учетку Яндекс.Директ к прокси серверу. Теперь все запросы в Yandex.Wordstat, Yandex.Direct или поисковую выдачу будут идти с одного и того же IP адреса (IP адрес прокси сервера) и с одной и той же учетки.
Такая привязка значительно повышает стабильность парсинга, уменьшает количество показов капчи (проверки на робота), что в итоге приводит к более быстрому сбору данных и уменьшению общего времени, затрачиваемого на сбор.
После того, как данные внесены, нам необходимо установить количество потоков в блоке 2 равным количеству прокси, которые мы приобрели. В нашем случае устанавливаем это значение равным 1 и переходим к следующему этапу.
Вкладка "Сеть"
Сюда мы должны добавить наш(и) прокси и установить ряд дополнительных настроек.
 Фото 3: Основные зоны интереса во вкладке "Сеть".
Фото 3: Основные зоны интереса во вкладке "Сеть".Первым делом добавляем прокси в таблицу №1, отмеченную на скриншоте . Можно внести построчно, вручную или нажать кнопку "Добавить из буфера" и внести списком. Указываем IP сервера, порт, логин и пароль прокси сервера (не учетки Яндекс.Директа!). Берем эти данные из письма, которое прислал нам сервис, в котором мы приобрели прокси.
Обратите внимание на формат, который требует Key Collector, при внесении прокси списком! Если вы часто меняете прокси и работаете с большим объемом данных, то мы рекомендуем сделать формулу в Google Spreadsheets, которая бы приводила данные в нужный для Key Collector формат.
Основные настройки (2)
- Использовать прокси серверы. Включаем данную опцию поставив галочку, HTTP остается без изменений. Для простоты, мы будем использовать HTTP прокси. SOCKS протокол требует большей сноровки и опыта и в некоторых случаях работает с ошибками, что может привести к невозможности продолжения работы.
- Деактивация прокси, не прошедших проверку. Включаем, это мера предосторожности в случае, если возникли какие-то проблемы с прокси. После 360 секунд системой будет проведена повторная попытка подключения.
Проверка прокси (3)
Выставляем количество количество потоков равным количеству прокси. Т.е. если у нас 1 прокси, то ставим 1.
После этого мы отмечаем наши прокси галочкой (активируем их), чтобы каждая строка в блоке 1 была выделена зеленым цветом и запускаем проверки (одну за другой, по очереди):
- Проверить в ПС Yandex
- Проверить в Yandex.Wordstat
Проверки нужны для того, чтобы понять все ли в порядке с настройками, учеткой Яндекс.Директ и прокси сервером(ами). Если Key Collector заблокировал прокси (пометил строку красным цветом) в блоке 1 после проверки через ПС Яндекс, то проблема в настройке самого прокси сервера. Возможно, неверно введен логин, пароль или порт прокси сервера. Если же прокси не прошел проверку через Yandex.Wordstat, то проблема уже в настройках учетки Яндекс.Директ.
Последовательная проверка позволяет быстро локализовать ошибку и оперативно исправить причину.
Антикапча
Для автономной работы программы нам необходимо будет зарегистрироваться в сервисах, которые предоставляют услуги “Антикапчи”. Бюджет на данные сервисы нужен небольшой, однако это позволит использовать КК в автономной режиме. Ниже представлен перечень поддерживаемых Кей Коллектором сервисов:
 Фото 4: Перечень сервисов, которые поддерживаются программой и предоставляют услуги по разгадыванию капчи.
Фото 4: Перечень сервисов, которые поддерживаются программой и предоставляют услуги по разгадыванию капчи.Выбираем понравившийся сервис и регистрируемся в нем. Вносим 100-500р на баланс, получаем API ключ, который нужно будет внести в настройки ниже.
 Фото 5: Настройки антикапчи (автоматическое распознавание captcha).
Фото 5: Настройки антикапчи (автоматическое распознавание captcha).В ходе парсинга, статистические источники показывают пользователю капчу (проверка на робота), чтобы убедиться, что их использует человек и чтобы ограничить автоматический парсинг.
Во вкладке Настройки -> Антикапча -> Автораспознавание необходимо выбрать сервис, который вы решили использовать и ввести предоставленный вам ключ. После ввода ключа следует перезагрузить программу, чтобы Key Collector активировал ключ.
Также, вы можете ввести ограничение капч на один сеанс, то есть если в ходе сбора данных количество капч будет превышать указанный параметр - антикапча перестает работать. После перезапуска Кей Коллектора счетчик сбрасывается. Мы рекомендуем указать значение параметра равным 5000.
Настройки парсинга
Первым в списке настроек программы находится большой раздел "Парсинг", который отвечает за настройку сбора данных из разных источников.
Общие настройки
Настраиваем раздел “Общие” следующим образом:
 Фото 6: Основные настройки парсинга.
Фото 6: Основные настройки парсинга.Основные комментарии к настройке:
- Добавлять в таблицу фразы, содержащие не более N слов. Как показывает практика, оптимальным количеством слов является 10. Именно с этим числом мы можем получить как высокочастотные, так и среднечастотные и низкочастотные запросы. Хвост запроса мы терять не хотим, однако и сбор пустых по частотности запросов нас тоже не интересует. 10 слов в запросе вполне отвечает данным требованиям.
- Количество повторных попыток загрузки страниц. В случае сбоя именно это количество повторных попыток сделает программа. Стандартное значение 30. Не меняем его, т.к. этого вполне достаточно для корректной работы программы.
- Таймаут ожидания ответа от сервиса. Время ожидания загрузки страниц из сервисов. Стандартная настройка в 30000 мс подойдет для проектов любого размера.
- Режим сбора. В данном пункте должно быть отмечено “Строки с неполученными данными” - для строк с отсутствующей информацией будут собираться данные в программе, это сократит время сбора, так как не будет повторных проверок уже заполненных данных.
- Фильтрация символов. В примере указан довольно большой перечень символов, который будет удаляться при парсинге. Нас не интересует экспрессивность выражения потребностей пользователя в поиске, а интересует сам смысл его запроса. В то же время, такие символы как “-” и “.” могут употребляться разными пользователями по-разному, например со знанием правил написания того или иного запроса и без. Чтобы привести все к единому виду, заменяем данные символы на пробел. Замена буквы ё на е так же является корректировкой различия между запросами пользователя. Нет разницы, поступил запрос в формате ёжик или ежик, так как они несут один семантический смысл. Поэтому для удобства приводим все фразы к единому виду по данному параметру.
- Приводить слова в нижний регистр. Также является удобной настройкой для приведения всех фраз к единому формату.
Наша конечная цель - получить список ключевых фраз в едином, понятном формате. Это упростит дальнейшую работу и облегчит процесс чистки и поиска дублей.
Yandex.Wordstat
Для сбора с Вордстата программа использует аккаунты, прописанные в настройках Яндекс.Директа (Настройки -> Парсинг -> Yandex.Direct), которые мы заполнили ранее.
 Фото 7: Настройки парсинга Yandex.Wordstat.
Фото 7: Настройки парсинга Yandex.Wordstat.Комментарии к настройке:
- “Глубина парсинга” и “Парсить страниц”. Глубина парсинга работает только для сбора ключевых фраз. Для глубины парсинга рекомендуемое значение 0. Если мы ставим значение отличное от 0, то Key Collector будет делать парсинг вложенных фраз (фраз, которые "приехали" в результате прошлой попытки сбора). Потенциально, такой подход может вылиться в непредсказуемое время на парсинг ключей, т.к. мы никогда не знаем какое количество фраз мы получим при сборе той или иной фразы. Стратегию парсинга мы будем более подробно рассматривать в других статьях. Пока, для оптимального результата ставим 0 для глубины парсинга и 40 для количества страниц.
- Добавлять в таблицу фразы с частотами от X до Y. Мы можем задать минимальную частоту фразы для сбора сразу на этапе парсинга. Однако диапазон лучше оставить максимальным, чтобы не упустить интересные формулировки и запросы. В последующем мы сможем избавиться от низкочастотных запросов в пару кликов.
- Не снимать частоты для фраз с базовой частотой равной или ниже чем N. Данная настройка позволяет нам экономить время сбора данных при настройке на 0, так как базовая частота 0 нас в общем то не интересует, это пустые фразы, по которым нет спроса.
- Автоматически записывать 0 в колонки частот “ “ и “!”, если базовая частота 0. Опять же экономия времени на проверку частотности, так как данные автоматически будут заполнены, мы не будем собирать для них указанные частоты.
- Маска запросов пользовательского формата. Выставляем значение “[!QUERY]”, таким образом мы автоматически проставим нужные операторы для запросов и получим максимально точные цифры.
- Задержки между запросами от X до Y. Как показывает практика, значение от 25000 до 30000 вполне уместно и является близким к естественному. При возникновении блокировок мы всегда сможем изменить данный параметр в большую сторону.
- Деактивация потоков. Количество потоков ставим равному количеству прокси серверов, которые мы настроили на прошлом этапе. Деактивацию потоков выставляем так, как указано на скриншоте. Система будет уменьшать кол-во потоков если по какой то причине прокси сервер выходит из строя, что нам и нужно.
- При использовании группировки по месяцам. В данном случае оптимально будет установить “последний год” для учета актуальных данных.
- Настройки режима “Собрать все виды частот”. Здесь вы можете настроить какие частоты надо собрать при использовании данного инструмента. Можно ничего не менять, т.к. в дальнейшем, при сборе мы всегда будем собирать частотности последовательно.
 Фото 8: Можно задать какие именно частоты будут собираться при выборе опции "Собрать все виды частот".
Фото 8: Можно задать какие именно частоты будут собираться при выборе опции "Собрать все виды частот".Yandex.Direct
 Фото 9: Настройки работы с сервисом Yandex.Direct.
Фото 9: Настройки работы с сервисом Yandex.Direct.- Задержки между запросами. Задержку между запросами лучше установить от 10000 до 15000 мс, чтобы не получить блокировку и не нагружать систему. Директ очень чувствителен к парсингу и выдает много капч при агрессивном сборе.
- Количество потоков. Ставим кол-во потоков равным количеству прокси. Настройки деактивации ставим как указано на скриншоте.
Google Adwords
Настройки источников Google Adwords как правило остаются стандартными, так как имеют ограничения, о которых нас предупреждает Кей Коллектор.
 Фото 10: Настройки Google Adwords.
Фото 10: Настройки Google Adwords.В целом, менять их нет необходимости. Использование точной частоты из Google Adwords когда-то использовалось для инструмента “Анализ неявных дублей”, так как точная частотность из Adwords учитывает порядок слов. На данный момент эту задачу решает сбор точной частотности по маске QUERY через Яндекс (так называемый оператор скобки [], учитывающий последовательность слов в фразе).
Rambler Adstat
Настройки для Rambler Adstat также оставить в стандартном режиме, так как данная система не используется в сборе данных. Подсказки из Rambler можно получить без регистрации и настройки аккаунтов. В целом, Rambler Adstat - устаревший инструмент и не содержит нужного объема семантики для того, чтобы было уместным тратить время на сбор данных из него. Об актуальных на сегодняшний день источниках можно прочитать в этой статье.
 Фото 11: Настройки Rambler Adstat.
Фото 11: Настройки Rambler Adstat.Поисковая выдача
Во вкладке “Поисковая выдача” меняем количество потоков в зависимости от количества прокси, отключаем использование основного IP адреса и переключаем режим деактивации потоков.
Блок настроек Yandex.XML игнорируем и не меняем там ничего. В нашей работе мы не будем пользоваться XML сервисом Яндекса, поэтому активировать его нет необходимости.
 Фото 12: Настройки работы с поисковой выдачей Yandex.
Фото 12: Настройки работы с поисковой выдачей Yandex.Устанавливаем кол-во потоков и настройки деактивации одинаково для всех источников, с которыми мы собираемся работать: Yandex, Google, YouTube, Mail.ru.
 Фото 13: Настройки работы с поисковой выдачей Google, YouTube, Mail.ru.
Фото 13: Настройки работы с поисковой выдачей Google, YouTube, Mail.ru.Подсказки
В разделе “Подсказки" проводим аналогичные настройки: выставляем количество потоков в зависимости от количества прокси, отключаем использование основного IP адреса и меняем режим деактивации потоков.
 Фото 14: Настройки работы с поисковыми подсказками.
Фото 14: Настройки работы с поисковыми подсказками.Mail.ru
Mail.ru не используется напрямую в ходе парсинга как источник, однако проводим настройку аналогичную подсказкам и выдаче: количество потоков, их деактивация и ограничение использования основного IP адреса.
 Фото 15: Настройки работы со статистикой Mail.ru.
Фото 15: Настройки работы со статистикой Mail.ru.Прочее
Раздел “Прочее” включает в себя две настройки, которые можно оставить в стандартном положении. Мы будем использовать антикапчу, поэтому нам выгодно оставить все как есть и имитировать разгадывание капчи (разумеется через сервис антикапчи) с того же самого IP адреса, которому она была показана поисковой системой. Это благоприятно влияет на стабильность парсинга и уменьшает количество капч, которые показывают сервисы.
 Фото 16: Прочие настройки Key Collector.
Фото 16: Прочие настройки Key Collector.Итоги
Итак, мы прошлись по основным настройкам Key Collector, подготовили инструмент для парсинга в автономном режиме. Первоначальная настройка инструмента действительно может занять немало времени, но сэкономит вам много времени в дальнейшем, т.к. настроенная подобным образом программа работает на автопилоте и не требует внимания и контроля. Ее можно установить на виртуальную машину и оставить на ночь, не переживая о том, что парсинг остановится по той или иной причине.
В следующих статьях мы рассмотрим стратегию парсинга ключей, которая дает полную семантику. Эта стратегия одинаково хорошо подходит как для сбора семантического ядра для сайта, так и для семантики под контекстную рекламу, например для Яндекс.Директ.
semyadro.pro
Парсинг ключевых фраз для объявлений в Яндекс Директ
ЭКСКЛЮЗИВНЫЕ СХЕМЫ ЗАРАБОТКА ТУТКлючевые фразы, в зависимости от частоты их употребления в поиске, обычно делят на 3 группы:
- ВЧ (высокочастотные запросы). Частотность по вордстату от 3000-5000 (в зависимости от ниши адекватная частотность для ВЧ разная). Пример ВЧ запроса
- СЧ (среднечастотные запросы). Частотность по вордстату от 100 до 3000-5000. Пример СЧ запроса
- НЧ (низкочастотные запросы). Частотность по вордстату до 100. Пример НЧ запроса
Ваши собранные маски ключевых слов в большинстве своём должны быть ВЧ-запросами.
Маски состоят из множества СЧ и НЧ запросов. Наша задача — получить из масок все эти СЧ и НЧ запросы. На языке рекламы этот процесс называется парсингом (сбором).
Парсинг с помощью «Мутагена»
Для парсинга я советую очень простой и эффективный сервис «Мутаген»
Стоит он очень и очень дёшево. 1 запрос стоит всего 2 копейки! Он очень прост в использовании, работает быстро и даёт качественный результат.
Регистрируетесь. Заходите в «Новое масс задание», выбираете справа «Ключи wordstat 2000» и задаёте список ваших масок:
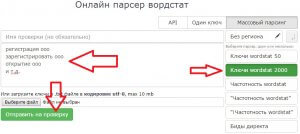 Парсинг ключевиков в Мутагене для рекламы в Яндекс.Директ
Парсинг ключевиков в Мутагене для рекламы в Яндекс.ДиректАвтоматически запросы собираются без привязки к региону. Советую так и собирать, т.к. нам в идеале надо собрать максимум ключевых запросов по своей нише. После парсинга просто скачиваете готовый список.
Почему я советую именно данный сервис?
Есть разные программы для парсинга, например — Key Collector и Slovoeb. Стоимость «Key Collector» в десятки раз выше использования Мутагена (от 1800 рублей на май 2018 г.). А Slovoeb бесплатная программа, но в последнее время очень нестабильная.
Автоматический парсинг довольно сложный процесс. В отличие от программ «Мутаген» не надо настраивать. Весь функционал проработан и настроен внутри сервиса.
Всё, что необходимо — это задать список масок, отправить их на проверку и через некоторое время скачать полный список фраз по этим маскам. И стоит это копейки. Быстро и эффективно.
Парсинг с помощью бесплатной утилиты
Утилита для сбора и генерации ключевых фраз tools.yaroshenko.by
Это дополнительный и вспомогательный инструмент. Используйте при необходимости. Утилита бесплатна.
Для практического примера берём нишу — «окна».
Утилиту можно использовать в любой нише. Посмотрим, что можно сделать на примере «окон». Это достаточно полезная утилита, когда необходим список целевых горячих ключевых фраз. Также можно использовать утилиту непосредственно для генерации масок ключевых фраз.
Берем исходные ВЧ запросы:
- окна пластиковые
- окна пвх
- окна из пластика
- стеклопакеты
Идём в утилиту и добавляем все модели в первую колонку (это основные запросы):

Попробуем сгенерировать много очень горячих целевых запросов («купить», «стоимость», брендовые запросы и т.д.).
Для этого заполняем остальные колонки словами, которые могут задавать Ваши потенциальные клиенты на поиске Яндекса (подумайте, в каждой нише всё индивидуально). Вот примерный итог по окнам:

Далее нажимаете кнопку «Получить ключевые слова» и получаете сгенерированный список фраз. Его Вы можете скопировать и сохранить для последующей работы.
Данную утилиту можно использовать в любой нише, но при выборе схемы использования утилиты надо опираться на нишу, т.к. в каждой из них свои возможности и задачи.
mmanual.biz
Основные настройки Key Collector
В этой статье поговорим о самом главном – как правильно настроить Key Collector.
В последнее время Яндекс вслед за Гуглом заметно «подкрутил гайки» и усложнил сбор статистики выдачи. Возможно, здесь ситуация временная и связана с недавним АГС40, возможно, проблемы со съемом конкуренции сохранятся навсегда. Выход есть, я о нем расскажу. С Гугл традиционно все сложно, под настройками буду давать комментарии.
Начнем с подготовки необходимых аккаунтов
IP-адрес
Уточните, какой у Вас IP адрес – динамический или статический. При парсинге периодически может блокироваться IP. С динамическим «лечится» все просто – перезагрузкой модема. Статический – хуже, если не использовать специальные сервисы, блокировка может продлиться несколько дней.
Проверить IP можно при помощи сервиса “Интернетометр”. Запишите свой адрес, потом перезагрузите модем и зайдите повторно. Не забудьте очистить кэш браузера. Если цифры отличаются – все в порядке, если они одинаковые – IP статический. В этом случае я рекомендую использовать сервис VPN.
В последнее время Яндекс начал банить по подсетям. В этом случае не срабатывает и перезагрузка динамического адреса. Тут все от провайдера зависит, - какой адрес он Вам будет выдавать. Так что и на динамическом иногда приходится прибегать к услугам этого сервиса.
Аккаунты в Яндекс Директе
Зарегистрируйте 10 (рекомендую это количество) аккаунтов в Яндекс Директ. Регистрируйтесь именно по ссылке http://direct.yandex.ru. Выбираете логин, пароль, упрощенный интерфейс и обязательно нажимаете кнопку «начать пользоваться сервисом». Потом разлогиниваетесь и логинитесь повторно!!!! Появится предупреждение об отсутствующем телефоне. Жмите «продолжить», потом опять выберите страну и нажмите кнопку «Начать пользоваться сервисом». Потом разлогиниваетесь и регистрируете следующий аккаунт. Я регистрировал все аккаунты сразу, адрес не менял, куки не чистил. Все работает, как часы.
Довольно часто свежие аккаунты в Директе не запускаются с первого раза! Не надо паниковать, все можно поправить. Смотрите «журнал событий» в нижней части программы. Когда запустите парсинг частотностей вордстата через Директ, должны последовательно появиться надписи об авторизации в каждом из аккаунтов. Если это не происходит, а появляются записи, что не удалось авторизоваться – делаем так:
- Останавливаем парсинг, идем в настройки→парсинг→Яндекс Директ и нажимаем большую кнопку «принудительно очистить данные об авторизации». Потом вручную, через браузер логинимся во всех зарегистрированных аккаунтах и опять жмем кнопку «начать пользоваться сервисом». Залогинились, нажали, разлогинились. И так во всех аккаунтах.
- Потом опять запускаем сбор и смотрим – если запустились все аккаунты – ОК, работаем. Если этого опять не произошло – чистим данные об авторизации, логинимся вручную в браузере и создаем «фейковое» объявление. Вам все равно, пройдет оно модерацию или нет. Главное, чтобы при входе в аккаунт Вас отправляло не на страницу создания объявлений, а на страницу «мои объявления».
Аккаунты нельзя использовать для реальных рекламных кампаний!!!! Это технические учетные записи, которые могут быть заблокированы в любой момент!
Антигейт
Обязательно нужен аккаунт в antigate.com. Оттуда берем свой ключ и вводим в соответствующее окно в настройках→Антикапча. В последнее время в Антигейт разделена статистика для русских и английских капчей. Работников с кириллицей не хватает, но администрация сервиса заверила, что увеличит количество таких сотрудников и ставки по кириллическим капчам пойдут вниз.
Общее правило при работе: если какой-то процесс не работает, программа дает ошибки и принудительно его останавливает, чаще всего все лечится уменьшением количества потоков и увеличением задержек и таймаута.
Настройки на вкладках программы
После запуска на верхней панели нажимаем этот значок и заходим в настройки.
 Настройки
Настройки
Парсинг→Общие
 Парсинг→Общие
Парсинг→Общие
Ограничение по количеству слов целесообразно выставлять не более 7, более длинные могут вызвать ошибки в дальнейшей обработке. Таймаут не стесняемся задавать побольше от 30000-50000 мс. Режим сбора ставим “строки с неполученными данными”, чтобы заполнялись пустые таблицы и не перезаписывались уже имеющиеся данные. Это поможет сократить время сбора.
В фильтре символов можно расширить набор символов для замены на пробел. Ну тут, думаю, все понятно.
Парсинг→Вордстат

 Парсинг→Вордстат
Парсинг→Вордстат
Остановимся на особо важных, назначение остальных вы можете прочитать, кликнув на значок вопроса в конце строки или на официальном сайте разработчика.
- Глубина парсинга задается, если вы желаете собрать ключи и потом, по каждому из собранных, спарсить еще порцию. (Если глубина стоит 1, то парсится слово, потом оно добавляется в список фраз и парсится снова и так чем больше число глубины, тем больше кругов ада пройдет программа). Это колоссально замедляет работу программы, поэтому ставим глубину 0.
- Следующий пункт «Добавлять в таблицу фразы с частотностью от» Если вас не интересуют базовые частотности меньше определенного значения или хотите выбрать ключи в узком диапазоне, то эти значения задаются в этой строке. Я обычно выставляю от 20-50 минимальную и до бесконечности максимальную, но все зависит от тематики, иногда бывает необходимо собрать все ключи, вплоть до частотности 5, а ниже уже будут пустышки.
- Если базовая частотность ниже заданного здесь порога, то при сборе фразовой("") и точной("!") такие слова будут пропускаться, что тоже ускоряет процесс работы.
- Чтобы не добавлять в список исходных фраз пустышк, при глубине парсинга больше 0, можно установить здесь ограничение.
- Ввиду ввода русской капчи, что делает ее разгадывание проблематичным для большинства сервисов, нужно не стесняясь ставить большие задержки, чтобы не пришлось доказывать яндексу, что Вы не робот и не схлопотать бан. Рекомендую выставлять значения в интервале от 5000-30000 мс.
- С количеством потоков нужно быть осторожным, ибо ПС не любят многопоточные сборы и сразу их жестко пресекают со всеми вытекающими санкциями. Обычно я снимаю данные в один поток. Да, долго, но зато безопасно. Если же вы работаете через прокси, то целесообразно выставлять до 10 потоков сбора.
- Таймауты ставим от 30-45 тыс. мс.
Частотности " " при анализе ключей я не использую. Если они Вам нужны, поставьте галочку на Собирать частотности вида " "
Обратите внимание на поле «Получать статистику через Yandex Direct»! Если Вы активируете эту функцию, то ключи с вордстата будут парситься не напрямую с сервиса, а при помощи инструмента «Подбор ключей» для рекламодателя в Директе. Таким образом, Вы получите те же ключи, но без риска бана со стороны вордстата за многопоточный сбор. Через Директ ключи снимаются без проблем даже после недавних изменений в выдаче.
Парсинг→Google Adwords
 Парсинг→Google Adwords
Парсинг→Google Adwords
В Гугл Эдвордс используем только одну учетную запись.
Запоминаем!
- Вбиваем логин:пароль без @gmail.com
- Для работы парсинга и сбора статистики Гугла должен быть установлен Интернет Эксплорер версии не ниже 10, система, соответственно, от Виста и выше.
При необходимости здесь так же можно задать глубину парсинга и задержки. Т.к. гугл очень щепетилен к парсерам и сразу отправляет все подозрительное в бан, то задержки рекомендую так же выставлять большие. Если работаете с основного IP, то от 10000-25000 мс.
Парсинг→Rambler Adstat
 Парсинг→Rambler Adstat
Парсинг→Rambler Adstat
С Рамблера статистику я снимаю редко, да и сама ПС относится к таким как я достаточно лояльно и рада любым посещениям, даже роботов. =) Здесь все работает без проблем, поэтому нет смысла задавать большие задержки и парсинг страниц больше 5 (есть реальная возможность при большем значении нахватать мусора).
Парсинг→Социальные сети
 Парсинг→Социальные сети
Парсинг→Социальные сети
Эта функция нужна для создания описания и названия групп ВК. При сборе ядра для сайтов ее я не использую.
Вкладки “Solomono”, “Рекомендации” и “Похожие поисковые запросы” оставим без изменений.
Парсинг→Поисковая выдача

 Парсинг→Поисковая выдача
Парсинг→Поисковая выдача
Вот эта функция сегодня самая проблемная.
Для начала разберемся, что такое Яндекс XML. Это специальный сервис, который дает возможность отправлять запросы к ПС и получать данные в формате XML. Для каждого сайта, в зависимости от количества траффика (в свете последних изменений) выдается определённый лимит этих запросов, который, можно при желании докупить на специальных биржах. Используя эту квоту, вы можете безболезненно заниматься парсингом, не опасаясь за бан.
По поводу капчи в Яндексе перепробовал кучу прокси сервисов – ничего не помогло. Единственный найденный мной выход – использование XML Яндекса. Если у Вас есть сайты, добавленные в панель вебмастера, вы можете узнать свой лимит тут: http://xml.yandex.ru/limit_info.xml.
Есть два типа настроек XML – yandex.ru и yandex.com. РЕЗУЛЬТАТЫ ВЫДАЧИ ОТЛИЧАЮТСЯ!!!!!
Правильные результаты с учетом региона получаются только при использовании yandex.ru!!!!!! Расхождение есть, даже если задаем выдачу без региона!!!!
Вот результаты парсинга: Смотрите – колонки конкуренция в яндексе, количество главных в яндексе и вхождений в заголовки. Ключи одни и те же.
По yandex.com
 yandex.com
yandex.com
По yandex.ru
 yandex.ru
yandex.ru
Как видите, отличие большое.
С Yandex.com есть фокус – если выбрать эту выдачу и нажать «Сохранить», Вы получите лимит в 10000 запросов. Впрочем, этот лимит можно использовать, например, в плагине Винка для проверки индексации страниц, но никак не для корректного анализа поисковой выдачи.
На странице настроек выбираем «русский (yandex.ru)».
Полученный ключ вводим в соответствующее окно настроек. Отмечаем «Не предлагать к распознаванию капчу XML». В этом случае в пределах лимита запросов скорость 1-2 запроса в секунду в один поток. Вполне хватает.
Единственная проблема с XML от яндекс.ру в том, что здесь лимиты зависят от сайтов в панели вебмастера. Если у Вас нет своих сайтов или недостаточно лимитов, их можно купить. Лимиты поступят на ваш яндекс-аккаунт через сутки после зачисления. 3-5 тысяч запросов «без головной боли» в день обойдутся рублей 500 в месяц.
Обращаю Ваше внимание, что количество потоков в этой таблице относится не только к съему позиций, но и к съему конкуренции KEI и подбору релевантных страниц.
Непосредственно для оценки позиций я программу не использую. В этом случае рекомендую создать проект в Megaindex и вручную добавить ключи. Удобство Мегаиндекса в том, что сервис самостоятельно обновляет позиции с каждым аппом выдачи и можно наглядно отслеживать изменение запроса.
По Гуглу – с одного айпи рекомендую работать в один поток. Тут или медленно, но работать, или быстро – через 100-200 запросов бан. Либо пользоваться прокси. Но и они будут отлетать достаточно быстро, одна за другой.
Парсинг→Подсказки
 Парсинг→Подсказки
Парсинг→Подсказки
Обращаю внимание – есть настройка региона. Если регион не нужен – ставим «0». Если нужен – выбираем из списка регионов яндекса http://hmxblog.ya.ru/replies.xml?item_no=2780
Парсинг→Яндекс Директ
 Парсинг→Яндекс Директ
Парсинг→Яндекс Директ
Рекомендую тут вбить около 10 аккаунтов директа и поставить около 8 потоков. Скорость ощутите сразу.
Парсинг→Рейтинг Mail.ru
 Парсинг→Рейтинг Mail.ru
Парсинг→Рейтинг Mail.ru
Новая функция, с этими настройками все работает. Не забываем снимать с мэйла, т.к. хоть и не большой, но траффик идет оттуда.
Сеть
 Сеть
Сеть
Настройки прокси, если используются. Обращаю внимание, что практически во всех вкладках есть настройки для прокси серверов. Недостаточно их включить только на этой вкладке. Дополнительное включение делается на вкладке Яндекс-Директ и KEI. Кроме того, есть настройки отсева некачественных прокси и «использовать основной IP». При подключении прокси советую основной IP отключать.
Интерфейс→Экспорт
 Интерфейс→Экспорт
Интерфейс→Экспорт
Эти настройки нужны, если Вы будете выгружать результаты работы списком. Я часто выгружаю в CSV, в принципе здесь все интуитивно понять, если не удается – жмем на вопросики справа в строках =)
Интерфейс→Прочее

 Интерфейс→Прочее
Интерфейс→Прочее
С «защитой от дурака», думаю, сами разберетесь.
Активируйте опцию «Не обновлять содержимое таблицы после групповых операций». Это значительно ускоряет работу с большими проектами. В этом случае данные не обновляются автоматически. Их можно обновить при помощи стрелки внизу справа.
Интерфейс→Заголовки таблиц
 Интерфейс→Заголовки таблиц
Интерфейс→Заголовки таблиц
Тут уже все настраиваем под свой вкус и цвет. Заголовки таблиц можно переписать под себя. По умолчанию они крайне неинформативны, поэтому и сделали возможность обозвать их по вашему желанию, да и клиенту будет проще понять, что за цифры в колонке.
Антикапча→Автораспознавание капчи
 Антикапча→Автораспознавание капчи
Антикапча→Автораспознавание капчи
Вбиваем ключ от антигейт. С последними обновлениями программа научилась работать с множеством сервисов антикапчи. Смотря, какой используете, тот ключ и вводите, выбрав кнопочку используемой ниже. Чтобы пробовать распознавать русские головоломки (в антигейте не только индусы работают), снимаем галочку с пункта, который ниже задатчика ограничений.
Антикапча→MegaIndex API
 Антикапча→MegaIndex API
Антикапча→MegaIndex API
Можно использовать API Мегаиндекса. Но это достаточно дорогое удовольствие – 5000 запросов стоят 100 рублей.
KEI
 KEI
KEI
Данные формулы помогаю определить уровень конкуренции на основе полученных данных из ПС Яндекс и ссылочных агрегаторов.
Здесь вводим формулы. Абсолютно все равно, в какую ячейку их вобьете. Просто результаты расчета надо будет смотреть в соответствующей колонке.
Для удобства – формулы в текстовом варианте, можете их скопировать и добавить в программу:
Для оценки сезонных ключей:
- YandexWordstatAverageFreq/YandexWordstatBaseFreq*(YandexWordstatQuotePointFreq +1 )
- YandexWordstatAverageFreq/YandexWordstatBaseFreq*(YandexWordstatQuotePointFreq + 0.0001 )
Для оценки конкуренции и пустышек:
- AverageBudget/AverageTraffic + 0.0001
- YandexWordstatBaseFreq / ( YandexWordstatQuotePointFreq + 0.0001 )
Вот и разобрались с настройками. В следующей статье поговорим об огромном функционале коллектора.
iwsm.ru
Как парсить ключевые слова, чтобы получить профит с Яндекс Директ
Большое количество ключевых слов поможет увеличить объем трафа и позволит уменьшить цену клика, то есть даст больше профита.Словоеб - это бесплатный аналог keycollector, прога нужна для парсинга ключевых слов из поисковой выдачи. Облегчает и автоматизирует работу для тех, кто льет с контекста.
Буду подчеркивать и объяснять, только базовые нужные настройки для всех. Остальные настройки оставьте по умолчанию.
Настройка парсинга
Вкладка Общие:
- Количество фраз в ключевом запросе (например для РСЯ, оптимальное кол-во фраз 2-3)
- Удаление и замена операторов
![[IMG]](/800/600/http/trafa.netproxy.php%3A%2F%2Ftrafa.net%2Fimages_pick%2FImage10012017021910.jpg&hash=c328dea73ad5daf320e4efa0dc3caac9)
Вкладка Yandex.Wordstat:Глубина парсинга от 1 до 5. На случай, если вам нужна максимально большая семантика. Если нет, не ставьте больше 0, иначе время парсинга увеличиться на пару лет.Частотность от 0 до бесконечности. Здесь вы можете задать только высокочастотные запросы или собирать все (к примеру, для РСЯ лучше ставить от 100)
![[IMG]](/800/600/http/trafa.netproxy.php%3A%2F%2Ftrafa.net%2Fimages_pick%2FImage10012017021959.jpg&hash=16e6c772f4602ca1a763ab451b6d015a)
Аналогично настраивается Rambler.Adstat, поисковая выдача и подсказки(правый столбик вордстата).
Вкладка Yandex.Direct:Используйте больше 5 акков для парсинга и не юзайте те, с которых будете лить, можно словить бан за парсинг(для яндекса это спам).
![[IMG]](/800/600/http/trafa.netproxy.php%3A%2F%2Ftrafa.net%2Fimages_pick%2FImage10012017022036.jpg&hash=ae5af87e1f4580df6e5309f6b5c34793)
2. Запуск парсера.Создаем новый проект. Учтите то, что сохраненный проект нельзя будет перезаписать, поэтому изменения будут сохраняться в новом проекте.
Для удобства я структурирую группы парсинга по майндмэпу. Внизу можно выбрать гео, откуда программа будет собирать запросы. Каждый ключ добавляем с новой строки и не забываем ставить галочку, иначе соберете кучу одинаковых запросов.
![[IMG]](/800/600/http/trafa.netproxy.php%3A%2F%2Ftrafa.net%2Fimages_pick%2FImage10012017022116.jpg&hash=121409ab8b7fc891344de880144009cb)
После того, как мы спарсили наши ключ, можно сделать быструю минусацию. Для этого, нажимаем кнопку “Стоп-слова”. Так, как он будет отмечать все запросы, в которых будут присутствовать минус-слова, вводим только те слова, которые даже в словосочетании 100% не могут быть нашими запросами. К примеру, я не продаю копии, и не хочу показываться по запросам реплик, вношу слово “копия” и всего его словоформы и синонимы и нажимаю “Отметить фразы во всех траблицах”.
![[IMG]](/800/600/http/trafa.netproxy.php%3A%2F%2Ftrafa.net%2Fimages_pick%2FImage10012017022149.jpg&hash=feb2a49d447d70ab0e575c124cdf3005)
Ненужные нам запросы отметились в списке, теперь переходим в раздел “Данные” и удаляем их, после можно сохранять список ключей в csv или xlsx(расширение можно изменить в настройках Интерфейса->Экспорт).
Источник: Внимание! У вас нет прав для просмотра скрытого текста. Зарегистрируйтесь или Авторизуйтесь
trafa.net
Настраиваем Кей Коллектор
Для начала стоит зарегистрировать 10-15 аккаунтов Яндекс Директа (они же просто аккаунты Яндекса) и купить штук 5-10 хороших индивидуальных прокси. Скорость парсинга увеличится в разы.
Я уже полгода арендую прокси у Владимира. Отличные индивидуальные прокси по 100р/шт в месяц.
На один аккаунт Яндекс Директа не стоит использовать больше 5 потоков и на один прокси сервер должен быть один поток, иначе увеличивается шанс бана аккаунтов и будет много капчи.
Я использую 15 аккаунтов Яндекса, 5 прокси серверов и парсинг в 5 потоков. Этого вполне достаточно.
Самое главное — соблюдать условие «1 поток на 1 ip». Тогда будет меньше капчи, аккаунты не будут баниться.
Теперь скриншоты настроек. Прошу заметить, что скриншоты приведены при использовании 15 аккаунтов Яндекса и 5 прокси. Если вы работаете в один поток, то настройки будут другими.
Настройки Key Kollector при работе с прокси (много потоков)
Те настройки, что не указаны — оставляем по умолчанию как есть.
Парсинг

В строку «Удалять символы» добавьте следующие символы: !-.+»@><^%:,?’|\/
Настройки парсинга Яндекс Вордстат
Количество потоков ставим 5 т.к. используем 5 прокси. Снимаем галочку с «использовать основной ip адрес».

Настройки парсинга Яндекс Директ

Настройки парсинга Гугл Адвордс

Настройки парсинга поисковой выдачи
Для парсинга поисковой выдачи Яндекса я очень рекомендую использовать XML лимиты. Для этого можно купить их в сервисах типа seozoo.ru.

Подсказки

Настройки сети

Настройки Key Kollector без использования прокси
Если не использовать прокси, то во вкладке «Настройка — Сеть» ничего не указываем.
На вкладке «Парсинг — Яндекс Вордстат» указываем кол-во потоков 1 и ставим галочку на «Использовать основной ip».
На вкладке «Парсинг — Яндекс Директ» нужно указать как минимум 1 аккаунт, но можно до 5. Экспериментальным путем я выяснил, что если использовать 5 аккаунтов на 1 ip, то вполне нормально все парсится, скорость не увеличивается т.к. потоков то все равно 1, просто аккаунты переключаются между собой. Это стоит делать только если вы снимаете частотность на больших объемах ключей. Но вполне достаточно использовать и один аккаунт. Так-же не забываем выставить значение 1 поток и поставить галочку «использовать основной ip».
На вкладке «Парсинг — Поисковая выдача» ставим количество потоков 1 и галочку «использовать основной ip», но это если вы не используете XML лимиты. Если вы используете XML лимиты от сторонних сервисов — можно выставить много потоков, я ставлю 15. Но если пользуетесь своими лимитами — тут лучше ставить 1 поток.
Следующая статья: Составляем структуру сайта
nigilist.pro
Как парсить Яндекс?
Если вы начинающий или опытный сео-оптимизатор, то вам, так или иначе, придется анализировать своих конкурентов, сравнивать их сайты и свои, и думать, что можно сделать лучше, чтобы ваш сайт пробился в топ выдачи Яндекса и Гугла.
В этой статье мы рассмотрим несколько важных аспектов такого вопроса как, парсинг ключевых слов Яндекса и немного затронем тему для аналогии по Google выдаче. Но для начала, давайте разберемся с самим понятием, и узнаем, что такое «парсить». Если говорить общими и понятными словами - это семантический анализ в автоматическом режиме, который проводится или визуально (посредством человека), или программно. То есть, вы анализируете выдачу по определенному запросу, или группе запросов, чтобы выделить по своим критериям лидера выдачи, к которому нужно стремиться и которого нужно побороть.

Парсер ключевых слов Яндекса должен работать через прокси-сервер, который, кстати, можно купить на нашем сайте, или же получить солидную скидку за покупку нескольких прокси одновременно. Прокси по большему счету нужен для того, чтобы во время анализа выдачи не схлопотать бан, а его можно получить очень просто, если Яндекс или Гугл замечают подозрительную активность, они могут, исходя из куков или истории вашего браузера наложить вечный бан по IP, поэтому используют «одноразовые» Proxy.
Парсить можно что угодно, а так как у Яндекса очень много различных сервисов, исходя из их статистики или данных, можно использовать полезную информацию для своих целей. Далее мы рассмотрим основные аспекты парсинга выдачи Яндекса и его сервисов.
Парсинг ключевых слов из выдачи
Это самый популярный вопрос, которым задаются начинающие сеошники или менеджеры, которым нужно продвигать сайт по определенным запросам. Чтобы понять, как это делается в теории, нужно подкрепить информацию небольшой практикой. Этот пример будет основываться на ручном парсинге. Допустим, есть ключ «тест», мы вводим его в строку поиска Яндекса и нам выдает около 110 миллионов ответов. Далее нужно просмотреть все анкоры у сайтов в топе, их ссылки (главная страница сайта, поддомен или же внутренняя страница), снипеты (желательно вчитаться в них и понять, как сделать лучше).
Также, если ваше ключевое слово довольно часто ищут, Яндекс внизу страницы выдачи предложит вам список похожих ключевых слов, а их очень важно учитывать! Еще интересным моментом выступает быстробот, если же сайт попал в топ недавно (справа пишется 4 часа назад), значит на нем «сидит» бот Яндекса, просмотрите этот сайт, и выпишите ключевые его моменты.
Купить прокси для парсинга сейчас
Если вы продвигаете свой сайт по определенному региону или стране, нужно это указать при поиске (выбрать фильтр поиска – справа от строки в самом вверху). Можно сделать небольшую аналогию с парсингом ключевых слов Google, процесс сбора ключевых слов немного отличается, но суть остается та же. И еще стоит напомнить о тех же самых подсказках ключевых слов в Гугл, они очень часто становятся отправной точкой для принятия решений.
Парсер Яндекс Wordstat
Здесь нет ничего сложного, суть данной операции состоит в извлечении нужного количества слов по определенному запросу из огромного количества ключевых слов вордстата. На сегодня существует очень много программ, скриптов и даже виджетов для браузеров, которые будут парсить «яндекс вордстат» в полуавтоматическом режиме. Вам остается только наладить этот процесс и после глазами просмотреть всю полученную информацию, или же снова профильтровать данные по нужным значениям.
Парсер ключевых слов Яндекс Директа
Следующим по популярности сервисом для парсинга выступает «Директ». Если вы хотите составить правильное семантическое ядро, полностью подготовить свою рекламную кампанию в правильном ключе и сделать маркетинговый анализ, то парсинг подсказок с Яндекса и объявлений с Яндекс Директа - вам помогут лучше всего! Для совершения этой операции вам помогут или наши рекомендации по «безобидному» парсингу ключевых фраз, или же ваша уверенность в своих силах и выдержке перед монотонной работой.

Парсер Яндекс Карт
Основу парсинга Яндекс Карт составляет простая информация, которую владельцы сайтов пишут для общего обозревания.
Сюда можно отнести:
- Адрес сайта.
- Адрес физического «представительства».
- Почта для связи (скорее всего для рабочих целей).
- Телефоны для поддержки, или ознакомления клиентов.
Обычно, готовые алгоритмы парсинга берут все данные и группируют их по таблице Excel, оглавляя ее названием предприятия, временем работы, адресом, координатами на карте и другими основными данными.
Заключение
Чтобы облегчить себе работу, вы можете приобрести у нас прокси для парсинга Яндекса, включая выдачу Директ, Вордстат или карты. Помните, что при покупке нескольких прокси, нужно учитывать также их региональную принадлежность, чем дальше они находятся от региона вашей работы, тем дольше будет происходить ответ сервера. Замечено, что при парсинге в России используя прокси из Казахстана или России, ответ сервера мизерный, в то время как при использовании США или Канады, ответ отстает на пару миллисекунд (что в некоторых ситуациях очень критично).
proxy-sale.com