Урок 316 Как снять позиции сайта с помощью программы SERP Parser. Директ парсер что такое
Что такое парсер? | Datacol

Парсер — это программа, которая выполняет автоматизированный сбор контента или другой информации с веб-сайтов. Зачастую http парсера делают десктопными, но существуют и онлайн парсера сайтов. В большинстве случаев десктопные парсера более удобные и функциональные, но для выполнения некоторых задач вполне подойдет и online парсер. Парсера используют специалисты из многих сфер: маркетологи, SEO специалисты, сателлитчики, контент-менеджеры, владельцы интернет магазинов и т. д.
Парсинг можно условно разделить на три этапа:
1. Получение контента. Под получением контента понимается загрузка кода веб-страницы. Из нее необходимо будет извлечь данные.
2. Извлечение и преобразование собранной информации. На этом этапе происходит извлечение необходимых данных из кода страницы, полученного на первом этапе. Также происходит преобразование полученных данных к нужному формату.
3. Генерация результата. Это последний этап работы парсера. Происходит запись полученных данных в требуемый формат (чаще всего информация сохраняется в файловые форматы, CMS или базы данных).
Задачи, которые выполняются с помощью парсера
В первую очередь парсер используют для автоматического сбора информации, многие собирают информацию с веб-сайтов для рерайта, копирайта, также его используют контент менеджеры и владельцы интернет магазинов в работе по наполнению интернет магазина товарами.
Зачастую парсинг сайтов используют в следующих целях:
- Поддержание актуальности информации. Чаще всего применяется в тех сферах, где информация может быстро потерять актуальность.
- Частичное или полное копирование информации с веб-сайта для последующего размещения на своих ресурсах. Этот метод зачастую используют в сателлитах. Собранную информацию можно уникализировать при помощи автоматического перевода или синонимизации.
- Объединение информации, собранной из разных источников на одном ресурсе (например, объединение новостных потоков или вакансий с сайтов работы на одном сайте)
Универсальный парсер Datacol отлично справляется с этими и многими другими задачами, связанными со сбором информации в интернете.
Преимущества парсинга сайтов
Вы наверняка смогли убедиться, что парсера в значительной мере упрощают, или же полностью автоматизируют выполнение многих задач, на которые вы могли потратить не один день. Поэтому использование парсера сайтов довольно целесообразно и экономически эффективно. Скачать парсер Datacol можно по этой ссылке.
web-data-extractor.net
Что такое парсер (граббер)? | myblaze.ru

- То же, что граббер, т. е. скрипт или программа, которые используются для сбора информации с сайтов для последующего размещения на собственных ресурсах.
- Первоначально под парсингом подразумевался процесс поиска определенной информации в большом фрагменте текста, а так же разбиение данных на смысловые части.
Примеры использования парсеров
Парсеры и грабберы используются в следующих случаях:
- Поддержание информации в актуальном состоянии. Применимо в таких областях, где информация быстро теряет актуальность и уже неприменима спустя буквально несколько минут. В таких случаях ручное ее редактирование практически невозможно или требует колоссальных затрат человеческих ресурсов. Например, для отображения курса валют или погоды.
- Полное или частичное копирование материалов сайта с последующим размещением этих материалов на своих ресурсах. Например, для использования на сателлитах. При этом текст может быть предварительно пропущен через синонимайзер или обработан рерайтером для повышения уникальности. Очень часто парсингу подвергаются сайты с отзывами о кино и книгах, а так же сайты с рецептами, текстами песен и стихов.
- Объединение потоков информации из разных источников в одном месте и ее постоянное обновление. Например, существуют агрегаторы, которые собирают все предложения с сайтов по фрилансу в одном месте. Они позволяют моментально отслеживать все предложения и быть одним из первых откликнувшихся на предложение работодателя. Агрегирование новостных потоков из нескольких источников и так далее.
Как работают парсеры (грабберы)
Они могут писаться на любом языке программирования, где есть поддержка регулярных выражений. Например, на PHP. Кстати, я начал серию уроков по PHP для начинающих, можете ознакомиться хотя бы в общих чертах. Это полезно. Лично я предпочитаю работать с C#, т.к. привык к нему еще с университета.Сердцем любого парсера является регулярное выражение. Если коротко, то оно представляет собой набор метасимволов, которые служат своего рода маской для поиска информации.Примеры регулярных выражений вы можете сами найти в интернете, т.к. их синтаксис зависит от конкретного языка программирования.
Теперь вы знаете что такое парсет и граббер и сможете рассказать об этом друзьям при необходимости ;)
myblaze.ru
как снять позиции сайта правильно

Добрый день! Сегодня ознакомлю вас с одним из своих любимых SEO-инструментов, который я очень часто использую в своей работе. Это программа SERP Parser, который позволяет снимать позиции сайта.
Многие, особенно начинающие, скажут/подумают: "Зачем мне снимать позиции, я же не профессиональный оптимизатор". Но знание тех "ключей", которые находятся в ТОП-50 (именно они очень ценны), может оказаться "под руку". Их проще продвинуть в ТОП-10, нежели другие запросы. Да и, если мы постоянно работаем над сайтом, мы должны знать: правильно ли мы все делаем, есть ли рост позиций?
Также встречается следующий вопрос, который вызывает затруднение: "А где мне взять эти ключи, по которым нужно снимать позиции?" . Отвечаю, как делаю это я:
- Открываю свою любимую SEO программу KeyCollector (конечно, следующие действия можно производить вручную).
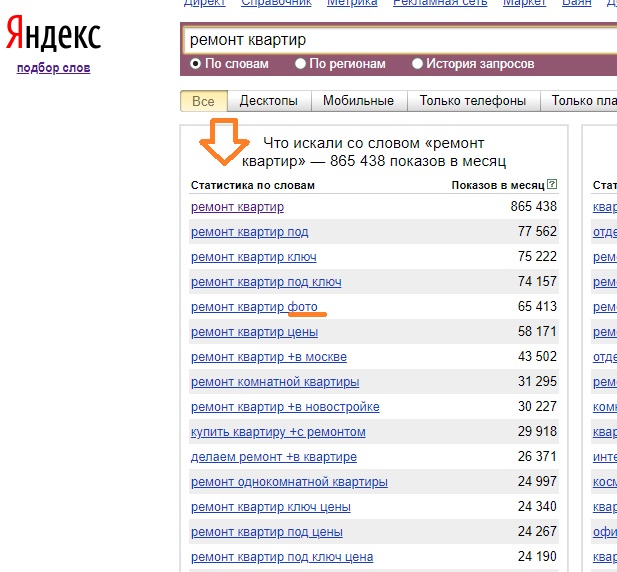
- Там есть 3 замечательные кнопки, которые помогают выгрузить ключевые слова, по которым заходят на наш сайт. Выгружаем эти ключевые слова (если Вы пользуетесь только одним из сервисов - Liveinternet, Яндекс Метрика или Google Analytics - тоже достаточно):

- Обычно я снимаю "ключевики" за последний квартал:

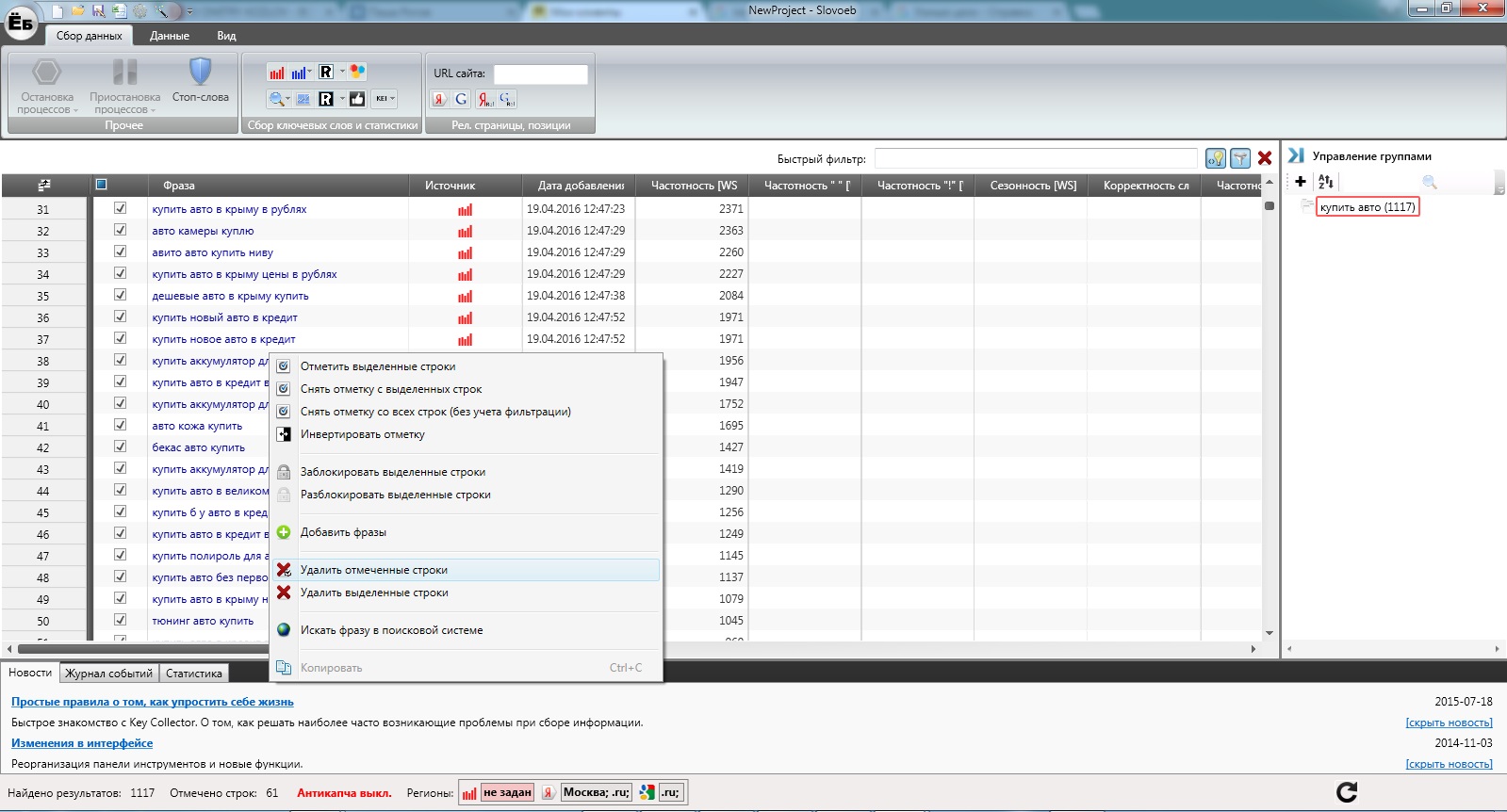
- Из полученного огромного количество ключевых слов, нужно "выкинуть мусор". Я снимаю у полученных слов точную частотность (снова Кейколлектор, если его нет, можете использовать СловоЁб). Частотность у которых меньше определенного количества (смотря сколько ключей в итоге надо), автоматически удаляю.
- Из оставшихся снова все перебираю и оставляю только необходимые запросы.
Итак, вернемся к "Серп Парсеру". Хочу отметить, что данный инструмент я действительно использую постоянно и данный обзор не является "заказным". Я долгое время выбирал чем и как снять позиции сайта. Для меня было важно, чтобы информация была:
- актуальной, позиции отображались правильно;
- бесплатной или максимально дешевой;
- наглядно демонстрирующей позиции сайта для предоставления отчетов клиентам.
Как оказалось, многие программы работали не совсем правильно: я присылаю отчет клиенту, что сайт по данному запросу находится на 6-ой позиции допустим, а на самом деле он оказывается на 11-ой. Попадал немного в неприятные ситуации. Конечно, тут надо помнить о персонализированном поиске, чтобы узнать на каком месте действительно находится ваш сайт по какому-либо запросу, нужно перейти в режим "Инкогнито" в Google Chrome (Ctrl+Shift+N), ввести запрос, указать необходимый регион и смотреть.
SERP Parser проявила себя как программа, которая полностью удовлетворяет моим этим основным трем потребностям. Она бесплатная первые 14 дней. Можете воспользоваться всеми прелестями ее за этот период, снять позиции сайта и решить: стоит ли за нее платить (причем не нужно платить какие-то баснословные деньги, о тарифах - ниже)?
Если вы решились испытать программу, для начала нужно скачать SERP Parser (бесплатно).
План урока по программе SERP Parser:
- Как работать с программой.
- Отчеты SERP Parser.
- Настройки SERP Parser.
- Тарифные планы.
- Использовать SERP Parser или снимать позиции онлайн?
SERP Parser: большая инструкция по применению
Как работать с программой SERP Parser
- При первом запуске программа предложит создать новый проект, просто нажимаем "Далее":

- В следующем окне "вбиваем" ключевые слова вашего сайта (если вы не знаете, какие вбить, прочитайте начало урока еще раз):

- В том же окне проверяем наличие галочки "Останавливать анализ при обнаружении цели" (зачем нам анализировать всю выдачу?), ограничиваем глубину поиска (я обычно снимаю позиции только для ТОП-100), нажимаем "Далее":

- В следующем окне нажимаем на кнопку "Добавить цель" и "вбиваем" адрес нашего сайта, также можно указать конкурентов, чтобы сравнить себя с ними:

- После того, как нажмете кнопку "Далее", нужно будет указать "Источники" - поисковые системы, в которых нужно снять позиции. Нажимаем "Добавить", проставляем Яндекс и Google. Если же у вас геозависимые запросы (кстати, геозависимость запросов я тоже проверяю в Кейколлекторе), то указываем тот регион, в котором продвигается Ваш сайт. Так как мои запросы информационного характера и не привязаны к определенному региону, я не меняю данную настройку:

- При желании, если вы задали регион, можно сохранить данный профиль, чтобы каждый раз не искать "Москва". В следующий раз можно нажать на кнопку "Загрузить". Нажимаем "Далее".
- В следующем окне оставляете отмеченной галочкой "Запустить проверку позиций после создания проекта" и нажимаемете "Ок":

- Программа предложит сохранить проект, даете ему название и сохраняете в нужно месте. После того, как сохраните, пойдет процесс снятия позиций ключевых слов, он выглядит примерно так:

- Идете пить чай. Время снятия позиций сайта зависит от следующих факторов: количество ключевых слов, позиций вашего сайта (помните, что SERP Parser находит вас, к примеру, на 12-ой позиции, переходит к следующему ключу, если вас там не будет, он будет искать во всем ТОП-100), количество "капчей", "банов", потоков. О последних трех факторах и как ускорить процесс съема позиций сайта читайте в данном же уроке, пункт "Настройки программы SERP Parser" (чуть ниже).
- О том, что съем завершился вы узнаете по следующему сообщению:

- Просто нажимаем на кнопку "Закрыть". И мы плавно переходим в раздел отчета по данному проекту.
Отчеты в SERP Parser
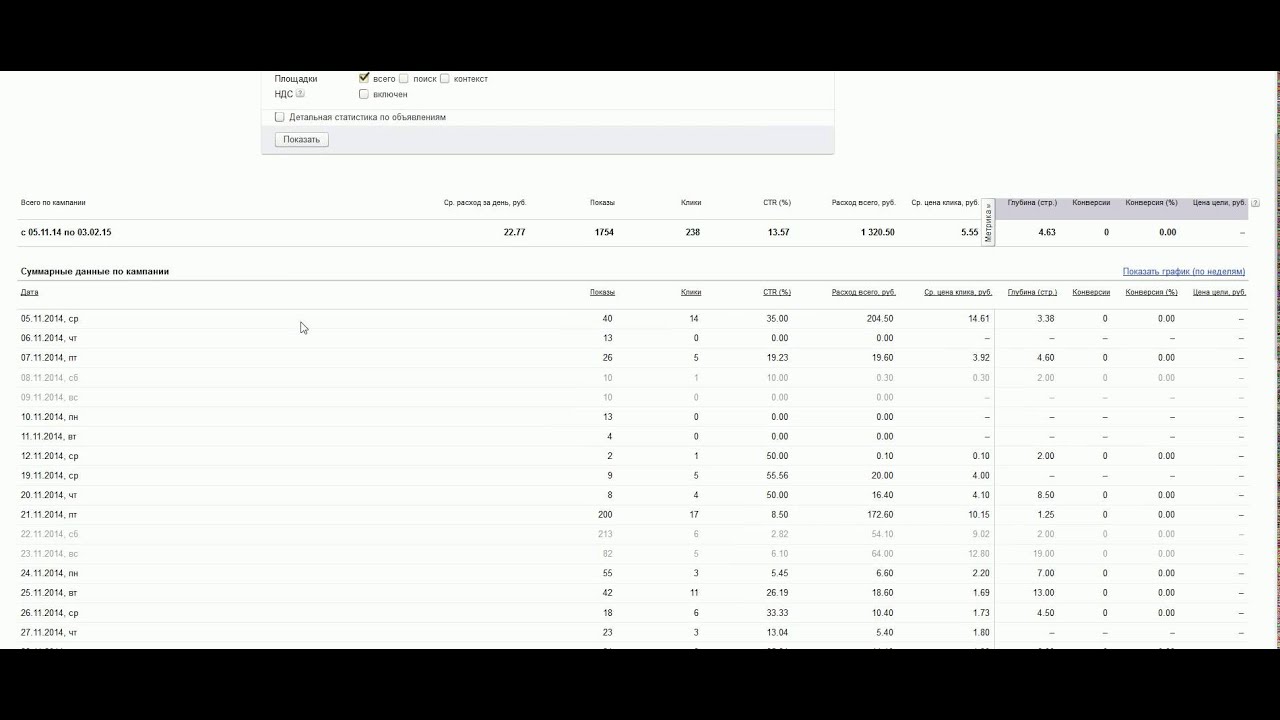
- Сразу же нам в глаза попадет примерно такого вида отчет (стрелочками я указал позиции сайта по запросам):

- Если снять позиции после их изменений (допустим, произошел "апдейт" Яндекса (обновление поисковой выдачи) и мы снова сняли позиции), то график внизу примет такой вид (он отображает изменения по каждому ключевому слову, которое нужно предварительно выбрать):

- Нажав на кнопку "Сводка по проекту", мы видим статистику по всему проекту, всех ключевых слов (сколько процентов от ключей находится в ТОП-3, в ТОП-5 и далее (очень полезно):

- Клиентам же я отправляю отчет по позициям по датам на каждое конкретное ключевое слово. Для этого нажимаю на кнопку "Сводка по дням", выбираю поисковую систему (сначала Яндекс, потом Google), ставлю отметку "За все время":

- И видим следующую картину, которая очень наглядно демонстрирует позиции ключей по датам, когда мы снимали их:

- Экспортирую все это в html формат (если экспортировать в Excel, не будут отображаться значения +1, -3 и т.п.):

- И клиент получает отчет по позициям в таком виде:

- Все наглядно и удобно, клиентов данный вид отчета по позициям очень даже устраивает. Также вы можете просматривать сводку по группе, по источнику, по целям, по датам. Если же у вас большое количество ключей, их можно разбить на несколько разных групп (категорий), просто создаем новую группу и заносим туда их:

- Помимо всего этого, настоятельно рекомендую ознакомиться с официальной документацией данной замечательной программы, там вы узнаете, что такое "Атрибуты" и многое другое.
Настройки SERP Parser
В настройках SERP Parser я практически ничего не трогал, я лишь сделал 3 действия:
- Чтобы не вводить капчу вручную, подключил сервис Antigate, который автоматически распознает капчи (его же я использую в Кейколлекторе).

- Чтобы избежать банов и блокировок нашего основного IP адреса компьютера, с которого работаем, прописываем прокси-сервера. То есть запросы с программы SERP Parser будут идти с других IP адресов и наш IP-адрес (свой) блокироваться не будет. Крайне рекомендую прописать прокси-сервера. Я беру их бесплатно тут (постоянно обновляются). Данные строчки просто вставляем сюда:

- Количество потоков при снятии позиций я ставлю 10. Все. Больше никаких настроек в данной программе я не трогаю.
Тарифные планы в SERP Parser
Всего 3 тарифных плана, с помощью любого из них можно снять позиции. Отличия в тарифных планах:
- SERP Parser Lite - возможна работа с 1-им проектом. Цена $9.90 в год. Если вы работаете только с 1-им сайтом - идеальный тарифный план для вас.
- SERP Parser Base - дополнительно отображаются показатели частотности и цены клика (Яндекс.Директ и Google Adwords). Также можно работать только с 1-им проектом. Цена $19.90 в год.
- SERP Parser Professional - все тоже самое, что в предыдущем тарифном плане, но работать уже можно с неограниченным количеством проектов. Цена $29.90 в год. Именно этот тарифный план использую я.
Вот для наглядности:

Как видите цены более чем приемлемы. Для убедительности могу посчитать свою, сколько я экономлю.
Что выбрать: SERP Parser или снимать позиции онлайн?
- Количество запросов, которые я снимаю в течении месяца - минимум 3000.
- Снимаю я позиции в среднем 2 раза в месяц. То есть данную цифру умножаем на 2. Получаем 6000.
- Позиции снимаю в Яндексе и Google, что сказывается на количестве проверок, то есть полученную цифру умножаю на 2. Получаем 12 000 проверок в месяц.
- Возьмем тарифные планы онлайн сервиса Allpositions. Допустим, я бы закинул стоимость программы SERP Parser 1000 рублей в данный сервис. 12 000 проверок * 0.06 руб. = 720 рублей. И это за 1 месяц. То есть в год получаем 8 640 рублей, тогда как за SERP Parser я плачу около 1000 рублей в год! Экономия в 8.6 раз.
- Конечно, тут можно придраться, что не каждый из вас снимает позиций такого количества запросов. Может быть вам хватает и 500 запросов в месяц, снимаете их 1 раз в месяц, допустим. 500*2 (2 поисковые системы) = 1000 * 0.06 руб. = 60 рублей в месяц, либо 720 рублей в год. Выбор за вами.
SERP Parser - это второй софт после KeyCollector'а, который я купил. Причем эти два инструмента полностью оправдывают себя. Каждый рубль. Каждую копейку.
Подпишитесь на бесплатные уроки
Понравился урок? Вы не хотите пропускать новые бесплатные уроки по созданию, раскрутке и монетизации блога? Тогда подпишитесь на RSS или на электронный ящик в форме выше и получайте новые уроки мгновенно! Также можете следить за мной в Twitter.
wpnew.ru
A-Parser - продвинутый парсер поисковых систем, WordStat, YouTube, Suggest, PR, etc
Что такое A-Parser?Это быстрый парсер с уклоном на универсальность, удобность и прозводительность.На данный момент умеет парсить:
Поисковые системы
Каждый парсер может парсить ссылки, анкоры, сниппеты, количество страницДля гугла умеет обходить ограничение в 1000 результатов(скоро и для всех остальных парсеров так же будет), т.е. по одному запросу собирает всю выдачу
Для Яндекса есть возможность распознавания каптчи через сервис AntiGate(или любой другой с поддержкой их API)
Парсеры кейвордов
Сервисы поиска ключевых слов
![[IMG]](/800/600/http/a-parser.com/img/parsers/yandex-wordstat.gif) Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики. Может сам подставляет найденные ключевые слова в запросы до указанного уровня.
Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики. Может сам подставляет найденные ключевые слова в запросы до указанного уровня.
- Подсказки и релейтед кеи Google
- Подсказки и релейтед Bing
- Подсказки, релейтед и трендовые кеи Yahoo
- Подсказки и релейтед Yandex
Параметры сайтов и доменов
![[IMG]](/800/600/http/a-parser.com/img/parsers/alexa.gif) Rank::Alexa - парсер Alexa Rank, парсит глобальный рейтинг, топ рейтинг по стране, саму страну и количество бек-линков
Rank::Alexa - парсер Alexa Rank, парсит глобальный рейтинг, топ рейтинг по стране, саму страну и количество бек-линков![[IMG]](/800/600/http/a-parser.com/img/parsers/majesticseo.gif) Rank::MajestiSEO - парсер количества беклинков с сервиса majesticseo.com, парсит количество ссылающихся страниц, количество уникальных IP-адресов, подсетей класса C и количество уникальных доменов
Rank::MajestiSEO - парсер количества беклинков с сервиса majesticseo.com, парсит количество ссылающихся страниц, количество уникальных IP-адресов, подсетей класса C и количество уникальных доменов![[IMG]](/800/600/http/a-parser.com/img/parsers/semrush.gif) Rank::SEMrush - проверяет рейтинг SEMrush, количество SE траффика и его стоимость, количество Ads траффика и его стоимость
Rank::SEMrush - проверяет рейтинг SEMrush, количество SE траффика и его стоимость, количество Ads траффика и его стоимость![[IMG]](/800/600/http/a-parser.com/img/parsers/opensiteexplorer.gif) Rank::OpenSiteExplorer - проверяет рейтинг домена\страницы по OpenSiteExplorer, а так же количество беклинков и бекдоменов
Rank::OpenSiteExplorer - проверяет рейтинг домена\страницы по OpenSiteExplorer, а так же количество беклинков и бекдоменов![[IMG]](/800/600/http/a-parser.com/img/parsers/google-position.gif) SE::Google:
SE::Google: osition - проверка позиции домена по ключевому слову в Google
osition - проверка позиции домена по ключевому слову в Google- SE::Yandex:osition - проверка позиции домена по ключевому слову в Yandex
- SE::QIP:osition - проверка позиции домена по ключевому слову в search.qip.ru
- SE::Google:ageRank - PR страниц и доменов
- SE::Google::SafeBrowsing - проверка домена в блеклисте гугла(подпись harm в выдачи)
- SE::Yandex::TIC - проверка тематического индекса цитирования домена в Яндексе(тИЦ)
- SE::DMOZ - наличие сайта в каталоге DMOZ
- SE::Google::TrustCheck - проверка сайта на траст(доверие) гугла(дополнительный блок ссылок в выдаче и т.п.)
- Net::Whois - определяет зарегистрирован домен или нет, а так же дату окончания регистрации
- SE::Bing::LangDetect - определение языка сайта через поисковик Bing
- Net::DNS - парсер резолвит домены в IP адреса
- Rank::Category - автоматически определяет категорию сайта на английском языке, категории такие же как в dmoz.org, например google.com - Computers/Internet/Searching
- Rank::CMS - определение около 200 видов CMS на основе признаков. Определяет все популярные форумы, блоги, CMS, гестбуки, вики и множество других типов движков
Парсеры различных сервисов
- SE::YouTube - полноценный парсер YouTube, парсит ссылку на ролик, титл, описание, длину ролика, дату добавления, имя пользователя и количество просмотров. Поддерживает все фильтры YouTube
- SE::Google::Maps - парсер ссылок в результатах выдачи в картах Гугла(Google Maps), позволяет искать сайты привязанные к определенной местности
- SE::Yandex::Direct - парсер direct.yandex.ru, парсит список всех объявлений(титл, текст, домен) и кол-во объявлений по определенному запросу
- SE::Google::Images - парсер Google Images, парсит прямые ссылки на картинки, сниппеты, разрешение и размер
- SE::Bing::Translator - переводчик через сервис www.bing.com/translator/, поддерживает все языки сервиса, включая автоопределение языка оригинала текста
- Util::AntiGate - распознавание каптчи через сервис AntiGate, служит для настройки и тестирования распознавания каптч
- HTML::LinkExtractor - парсит внешние и внутренние
zennolab.com