Содержание
Проверка домена сайта по показателям сервисом SEO-Monster
Сервис проверки доменов SEO-Monster поможет провести быстрый комплексный анализ сайта в несколько кликов мышкой. Сайт был создан в 2008 году и продолжает развиваться, постоянно добавляя новые функции.
В настоящее время доступен следующий инструментарий:
- Полный SEO-анализ
- Информеры для сайта
- Определение стоимости ссылки
- Массовая проверка тИЦ и PR
- Шифрование в MD5
- Онлайн-генератор паролей
- Проверка скорости Интернета
- Можно узнать ваш IP-адрес
- Сервис Whois
- Даты апдейтов (обновлений) Яндекс и Google поисковой выдачи и показателей
Сегодня мы рассмотрим основной инструмент SEO-Monster – комплексный анализ сайта, который доступен на главной странице. Комплексная проверка сайта занимает менее секунды. Сразу же после анализа будет сгенерирован полный отчет со следующей информацией:
- Сведения о сайте со скриншотом
- Расположение сервера
- Хостинг
- Whois
- CMS сайта
- тИЦ, PR, WR
- Проверка на склейку
- Наличие в каталогах
- Установленные счетчики статистики
- Обратные ссылки
- Проиндексированные страницы
- Доступная статистика сайта LiveInternet
- Позволяет сайт проверить на ошибки кода
- Возможность проверить сайт на плагиат
- Позволяет загрузить историю сайта в webarchive.
 org
org - Все внешние и внутренние ссылки на главной странице сайта
- Предлагает установить код информера тИЦ и PR сайта
 org
org
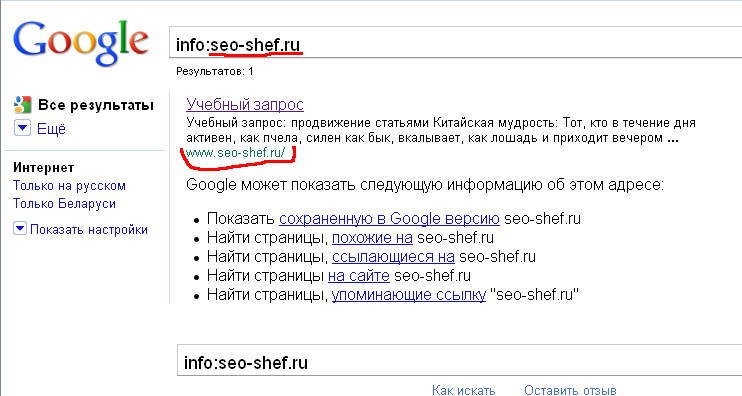
Чтобы вам было более наглядно, сделаем SEO-проверку сайта известного блогера Сергея Кокшарова – devaka.ru
Чтобы проверить сайт, введите свой домен в поле проверки (1) и нажмите кнопку «Проверить».
В первой части созданного отчета SEO-проверки сайта содержатся основные сведения: скриншот, заголовок, описание, ключевые слова, размер страницы, кодировка, ip, расположение сервера, хостинг и CMS сайта. Если нажать на ссылку (2), можно получить Whois информацию по домену: кто владелец, регистрант, DNS, дату регистрации и окончания и т. д. По ссылке (3) доступна информация по хостингу. А кликнув по ссылке (4) можно увидеть все сайты, расположенные на этом же сервере.
В следующем блоке отчета отображается информация о Яндекс тИЦ – блок (5) и Google PR – блок (6), а также возможность склейки. В блоке (7) можно увидеть наличие регистраций в известных каталогах Рунета. Если проверка не удалась, то всегда можно сайт проверить, кликнув на ссылку «Проверить» напротив соответствующего каталога. Блок (8) определяет наличие кода установленных счетчиков статистики на сайте. Если данные статистики доступны для просмотра, то отображается ссылка «Посмотреть статистику», пройдя по которой загрузится полная статистика для выбранного сайта.
В блоке (7) можно увидеть наличие регистраций в известных каталогах Рунета. Если проверка не удалась, то всегда можно сайт проверить, кликнув на ссылку «Проверить» напротив соответствующего каталога. Блок (8) определяет наличие кода установленных счетчиков статистики на сайте. Если данные статистики доступны для просмотра, то отображается ссылка «Посмотреть статистику», пройдя по которой загрузится полная статистика для выбранного сайта.
В блоке (9) формируются ссылки для загрузки отчета по обратным ссылкам из поисковых систем. При клике по соответствующей ссылке «смотреть» загрузится соответствующая выдача. Блок (10) отображает количество страниц в индексе соответствующих поисковиков, с возможностью самостоятельной загрузки полной выдачи.
Для удобства в отчете присутствует график и данные доступной статистики LiveInternet за последний месяц.
В дополнительных инструментах есть возможность проверить онлайн сайт на наличие ошибок в коде – ссылка (11), проверить текст на плагиат – (12) и изучить историю сайта – (13).
Блоки (14) и (15) в данном отчете не отображаются. Но тут владелец сайта предлагает воспользоваться сервисом Webeffector.
Последний информационный блок (16) выводит список внешних и внутренних ссылок, расположенных на главной странице сайта.
В последней части отчета предлагается установить код информера тИЦ и PR на собственный сайт – показан пример его отображения (17).
В заключение хотелось бы отметить скорость работы и удобство сервиса SEO-Monster, который позволяет очень быстро проверить онлайн свой или чужой сайт. Ведь не секрет, что некоторые вебмастера тратят очень много времени, чтобы сайт проверить сразу в нескольких поисковых системах.
Автор: Александр Шилов
Please enable JavaScript to view the comments powered by Disqus.
| ДОМЕНЫ с ТИЦ10 и ТИЦ20 почти даром Здравствуйте! Все знают как актуальны домены с ТИЦ. Все вебмастера хотят чтобы у своего сайта был ТИЦ хотя бы отличны от нуля ТИЦ10 ТИЦ 20 ну и конечно больше. Ну и все знают насколько это трудоемкий процесс, сколько нужно времени и нервы плюс денежное средств чтобы добиться чтобы у сайта был ТИЦ. Поэтому у меня кого интересует этот вопрос очень выгодное предложение. По другому я продаю домены с ТИЦ 20 и ТИЦ 10 (Только я прошу иметь в виду не сайт а домены для регистрирования) Почти что даю даром за копейки, очень дешево, конечно те у которых всегда в башке задние мысли сразу поищут подвох в моей предложение. Это потому, что эти люди сами способны обманывать. А я вам гарантирую домен с ТИЦ20 и ТИЦ10 для регистрирования. Немного для для понятия, домены старые у них когда-то были сайты но их бросили, а я нашел способ найти их пока они свободны. Почти за бесценки, ну например с ТИЦ за сотню деревянных/ Кому интересно это предложение прошу подробности в имейл: [email protected] [email protected] Предложение реальное вы сможете домен проверить на склейки ТИЦ, на АГС и на наличиеТИЦ сервисы я вам подскажу, да они известные например на АГС проверяют здесь: http://yaca.yandex.ru/yca/cy/ch/ если проверяете домен то тогда ссылка будет выглядеть вот так http://yaca.yandex.ru/yca/cy/ch/site.ru Т. е. имя домена добавляете ссылку яндекса если домен под АГС то яндекс его не определит и укажет ТИЦ0 даже если домен с ТИЦ100, а если все в порядке укажет, что сайт в каталоге не описан ну покажет его реальный ТИЦ в нашем случае или 10 или 20 потому, что у меня домены с ТИЦ10 и с ТИЦ20 по вашему желанию. Подскажу и другие сервисы для проверки склейки ТИЦ и для определение ТИЦ а то, что домен доступен для регистрации это вы можете проверить в любом сервисе для регистрации или же в хостинге. Внимание! Еще раз для не понятливых я вам даю не сайт а свободное доменное имя которую вы сможете регистрировать у любого регистратора. Сами проверяете домен на занятость, на склейки и на наличие ТИЦ. До ВАС и до передачи домена эти парметры проверяю. Я сам а потом уже передаю вам. Так, что отговорки не пройдут! ЕЩЕ внимание! После сделки я уже никакой претензии не принимаю! Вы сами проверяете параметры домена и берете его после уже для меня не интересно. Ну САМОЕ ГЛАВНОЕ то, что я вас не обманываю домены или с ТИЦ10 или сТИЦ20 по вашему желанию! Прошу внимательно читать все это чтобы а потом если ВАМ интересно мое предложение то в имейл: [email protected] [email protected] Выбор на красивое доменное имя тоже не расчитывайте просто можете выбрать короткое или длинное доменное имя это я сделаю. Принимаю только вебмоне и Payeer
|
|
 biz
biz

 biz
bizAWS Glue 101: все, что вам нужно знать, из полного пошагового руководства | Кевин Бок
Фото Эрики Пульезе из Pexels
Вы когда-нибудь задумывались, как крупные технологические компании проектируют свои производственные конвейеры ETL? Заинтересованы в том, чтобы узнать, как TB, ZB данных легко захватываются и эффективно анализируются в базу данных или другое хранилище для удобного использования учеными и аналитиками данных?
В этом посте я подробно объясню ( с графическим представлением! ) дизайн и реализацию процесса ETL с использованием сервисов AWS (Glue, S3, Redshift). Любой, у кого нет предыдущего опыта и знакомства со стеками AWS Glue или AWS (или даже глубоким опытом разработки), должен легко пройти через это. Пошаговое руководство к этому посту должно послужить хорошим начальным руководством для тех, кто заинтересован в использовании AWS Glue.
Прежде чем мы углубимся в пошаговое руководство, давайте кратко ответим на три (3) часто задаваемых вопроса:
Что такое AWS Glue?
Каковы особенности и преимущества использования клея?
Каков реальный сценарий?
Так что же такое клей? AWS Glue — это просто бессерверный инструмент ETL. ETL относится к трем (3) процессам, которые обычно необходимы в большинстве процессов анализа данных/машинного обучения: извлечение, преобразование, загрузка. Извлечение данные из источника, преобразование их в правильном направлении для приложений, а затем загрузка их обратно в хранилище данных. А AWS помогает нам творить чудеса. Пользовательский интерфейс консоли AWS предлагает нам простые способы выполнить всю задачу до конца. Никаких дополнительных скриптов кода не требуется.
- Каталог данных: Каталог данных содержит метаданные и структуру данных.
- База данных: Используется для создания или доступа к базе данных для источников и целей.
- Таблица: Создайте одну или несколько таблиц в базе данных, которые могут использоваться источником и целью.
- Искатель и классификатор: Искатель используется для извлечения данных из источника с использованием встроенных или пользовательских классификаторов. Он создает/использует таблицы метаданных, предварительно определенные в каталоге данных.
- Задание: Задание — это бизнес-логика, выполняющая задачу ETL. Внутри Apache Spark с языком python или scala пишет эту бизнес-логику.
- Триггер: Триггер запускает выполнение задания ETL по запросу или в определенное время.
- Конечная точка разработки: Создает среду разработки, в которой сценарий задания ETL можно тестировать, разрабатывать и отлаживать.

Чем полезен клей? Вот некоторые из преимуществ его использования в вашей собственной рабочей области или в организации
- AWS Glue сканирование всех доступных данных с помощью сканера
- Окончательно обработанные данные могут храниться в разных местах (Amazon RDS, Amazon Redshift, Amazon S3 и т. д.)
- Это облачный сервис. На локальную инфраструктуру деньги не нужны.
- Это экономичный вариант, поскольку это бессерверная служба ETL.
- Это быстро. Он сразу дает вам код Python/Scala ETL.
 д.)
д.)Вот практический пример использования AWS Glue.
Игровое программное обеспечение ежедневно производит несколько МБ или ГБ игровых данных пользователя. Сервер, который собирает пользовательские данные из программного обеспечения, отправляет данные в AWS S3 каждые 6 часов (соединение JDBC соединяет источники данных и цели с помощью Amazon S3, Amazon RDS, Amazon Redshift или любой внешней базы данных).
Мы, компания, хотим предсказать продолжительность игры, учитывая профиль пользователя. Чтобы выполнить задачу, команды инженеров данных должны получить все необработанные данные и правильно их предварительно обработать. Glue предлагает Python SDK, в котором мы могли бы создать новый Python-скрипт Glue Job, который упростил бы ETL. Код работает поверх Spark (распределенной системы, которая может ускорить процесс), которая автоматически настраивается в AWS Glue. Благодаря Spark данные будут разделены на небольшие фрагменты и обрабатываться параллельно на нескольких машинах одновременно.
Благодаря Spark данные будут разделены на небольшие фрагменты и обрабатываться параллельно на нескольких машинах одновременно.
Извлечение — Скрипт будет считывать все данные об использовании из корзины S3 в один фрейм данных (вы можете представить фрейм данных в Pandas)
Преобразование — Допустим, исходные данные содержат 10 разных журналов. в секунду в среднем. Команда аналитиков хочет, чтобы данные собирались каждую минуту с определенной логикой.
Загрузка — Запись обработанных данных обратно в другую корзину S3 для команды аналитиков.
В рамках проекта мы будем использовать образец CSV-файла из набора данных Telecom Churn (данные содержат 20 различных столбцов. Целью набора данных является бинарная классификация, и цель состоит в том, чтобы предсказать, не будет ли каждый человек продолжайте подписываться на телеком на основе информации о каждом человеке.Описание данных и набор данных, которые я использовал в этой демонстрации, можно загрузить, нажав на эту ссылку Kaggle).
Фото автора
Вам нужна соответствующая роль для доступа к различным службам, которые вы собираетесь использовать в этом процессе. Роль IAM аналогична пользователю IAM тем, что это удостоверение AWS с политиками разрешений, которые определяют, что удостоверение может и не может делать в AWS. Когда вы получаете роль, она предоставляет вам временные учетные данные безопасности для вашего сеанса роли. Подробнее о ролях IAM можно узнать здесь
- Откройте консоль Amazon IAM
- Щелкните Роли → Создать роль .
- Выберите службу Glue из « Выберите службу, которая будет использовать эту роль».
- Выберите Glue из раздела « Выберите вариант использования ».
- Нажмите Далее: Теги . Оставьте поле Добавить теги пустым. Создать роль.
- Теперь ваша роль получает полный доступ к AWS Glue и другим сервисам
Фото автора
- В консоли Amazon S3 нажмите на Создать корзину , где можно хранить файлы и папки.

Фото автора
- Введите имя корзины , выберите Регион и нажмите Далее
- Остальные настройки конфигурации теперь могут оставаться пустыми. Нажмите Далее , чтобы создать корзину S3.
- Создайте новую папку в своей корзине и загрузите исходные файлы CSV
- (Необязательно) Перед загрузкой данных в ведро можно попробовать сжать размер данных в другой формат (т.е. паркет) с помощью нескольких библиотек на питоне
Фото автора
Для того чтобы добавить данные в каталог данных Glue, который помогает хранить метаданные и структуру данных, нам нужно определить базу данных Glue как логический контейнер.
Итак, нам нужно инициализировать базу данных клея.
Поскольку наша база данных клея готова, нам нужно передать наши данные в модель. Итак, что мы пытаемся сделать, так это: мы создадим сканеры, которые в основном сканируют все доступные данные в указанной корзине S3.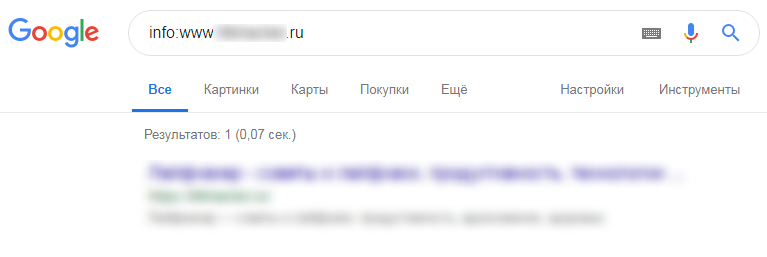 Сканер автоматически определяет наиболее распространенные классификаторы, включая CSV, JSON и Parquet.
Сканер автоматически определяет наиболее распространенные классификаторы, включая CSV, JSON и Parquet.
Фото автора
- На левой панели консоли AWS Glue нажмите Crawlers -> Добавить Crawler
- Нажмите синюю кнопку Добавить сканер .
- Присвойте краулеру имя , и оставьте как есть для «Укажите тип краулера»
Фото автора
- В хранилище данных , выберите S3 и выберите созданную вами корзину. Разверните, чтобы выбрать папку read
Фото автора
- В роли IAM , выберите роль, которую вы создали выше
- Оставьте частоту на «Запуск по запросу». Вы всегда можете изменить расписание работы поискового робота в соответствии с вашими интересами позже.
- В Output укажите базу данных Glue, которую вы создали выше ( sampledb )
Фото автора
- Затем будет создан Glue Crawler, который читает все файлы в указанной корзине S3
- Установите флажок и Запустите сканер, нажав Запустить Crawler
- Когда это будет сделано, вы должны увидеть его статус «Остановка». И указаны «Последнее время выполнения» и «Добавленные таблицы».
 И указаны «Последнее время выполнения» и «Добавленные таблицы».
И указаны «Последнее время выполнения» и «Добавленные таблицы».Фото автора
- Затем Базы данных → Таблицы на левой панели позволяют проверить, были ли таблицы созданы сканером автоматически.
Имея окончательные таблицы, мы знаем, что можно создавать Glue Jobs, которые можно запускать по расписанию, по триггеру или по запросу. Интересная вещь в создании заданий Glue заключается в том, что на самом деле это может быть почти полностью основанным на графическом интерфейсе действием, с помощью всего нескольких нажатий кнопок, необходимых для автоматической генерации необходимого кода Python. Однако я внесу несколько правок, чтобы синтезировать несколько исходных файлов и выполнить проверку качества данных на месте. По умолчанию Glue использует объекты DynamicFrame для хранения таблиц реляционных данных, и их можно легко преобразовать в фреймы данных PySpark для пользовательских преобразований.
Обратите внимание, что на этом этапе у вас есть возможность развернуть другую базу данных (например, AWS RedShift) для хранения окончательных таблиц данных, если размер данных от сканера становится большим.
 В рамках проекта мы пропустим это и поместим обработанные таблицы данных обратно в другую корзину S3
В рамках проекта мы пропустим это и поместим обработанные таблицы данных обратно в другую корзину S3Фото автора
- На левой панели нажмите Jobs , затем нажмите Add Job
Фото автора
- Дайте имя и выберите Роль IAM , ранее созданная для AWS Glue
- Выберите Spark для Введите и выберите Spark 2.4, Python 3 для Glue Version
- Вы можете отредактировать количество DPU) в (Значения единиц обработки данных) поле Максимальная емкость из Конфигурация безопасности, библиотеки сценариев и параметры задания (необязательно).
- Остальная конфигурация не является обязательной.
- Выберите таблицу источника данных из Выберите раздел источника данных . Вы можете выбрать только один источник данных.
Фото автора
- Добавить подключение JDBC к AWS Redshift. Нам нужно выбрать место, где мы хотели бы хранить окончательные обработанные данные. Вы можете выбрать существующую базу данных, если она у вас есть. Или вы можете перезаписать обратно в кластер S3. В этом уроке мы будем использовать сопоставление по умолчанию. Бизнес-логика также может позже изменить это.
 Вы можете выбрать существующую базу данных, если она у вас есть. Или вы можете перезаписать обратно в кластер S3. В этом уроке мы будем использовать сопоставление по умолчанию. Бизнес-логика также может позже изменить это.
Вы можете выбрать существующую базу данных, если она у вас есть. Или вы можете перезаписать обратно в кластер S3. В этом уроке мы будем использовать сопоставление по умолчанию. Бизнес-логика также может позже изменить это.Фото автора
- Откройте сценарий Python, выбрав имя недавно созданного задания. Нажмите «Действие » -> «Редактировать сценарий ».
- На левой панели показано визуальное представление процесса ETL. На правой панели показан код сценария, а чуть ниже вы можете увидеть журналы запущенного задания.
- Сохраните и выполните задание, нажав «Выполнить задание».
Фото автора
- Получаем историю после запуска скрипта и получаем окончательные данные, заполненные в S3 (или данные готовые для SQL, если у нас был Redshift в качестве конечного хранилища данных)
Подводя итог, мы построили один полный процесс ETL: мы создали корзину S3, загрузили наши необработанные данные в корзину, запустили связующую базу данных, добавили сканер, который просматривает данные в указанной выше корзине S3, создали GlueJobs , который можно запускать по расписанию, по триггеру или по запросу, и, наконец, обновлять данные обратно в корзину S3.
Дополнительная работа, которую можно выполнить, заключается в пересмотре сценария Python, предоставленного на этапе GlueJob, с учетом потребностей бизнеса.
(т.е. улучшить предварительную обработку для масштабирования числовых переменных)
В целом, описанная выше структура поможет вам начать настройку конвейера ETL в любой бизнес-среде.
Для получения более подробной информации об изучении других тем, связанных с наукой о данных, нижеприведенные репозитории Github также будут полезны. Он содержит простые в использовании коды, которые помогут вам начать работу с объяснениями.
- AWS SageMaker в производственной среде
Сквозные примеры, показывающие, как решать бизнес-задачи с помощью Amazon SageMaker и его алгоритма машинного обучения/обучения. - PySpark
Функции и утилиты с примерами реальных данных. Может использоваться для создания полного процесса ETL моделирования данных - Система рекомендаций
Реализации системы рекомендаций на уровне производства в Pytorch. Клонируйте репозиторий и начните обучение, запустив main.py - Обработка естественного языка (NLP)
Полные примеры реализации нескольких методов обработки естественного языка в Python. Упорядочено по уровню сложности обучения
 Клонируйте репозиторий и начните обучение, запустив main.py
Клонируйте репозиторий и начните обучение, запустив main.pyХёнДжун — специалист по данным со степенью в области статистики. Ему нравится делиться знаниями в области науки о данных/аналитики. Напишите ему в LinkedIn для связи.
Ссылка:
[1] Джесси Фредриксон, https://towardsdatascience.com/aws-glue-and-you-e2e4322f0805
[2] Synerzip, https://www.synerzip.com/blog/a- практическое руководство к aws-клею/, Практическое руководство по AWS Glue
[3] Шон Найт, https://towardsdatascience.com/aws-glue-amazons-new-etl-tool-8c4a813d751a, AWS Glue: Amazon’s Новый инструмент ETL
[4] Микаэль Ахонен, https://data.solita.fi/aws-glue-tutorial-with-spark-and-python-for-data-developers/, учебник AWS Glue со Spark и Python для данных разработчики
Как преобразовать данные с помощью ETL с помощью AWS Glue и Amazon Glue Studio — часть 2
В предыдущем блоге вы освоили ETL, используя образец данных о продажах для Amazon Glue Studio и AWS Glue.
В третьем учебном пособии показано, как можно запрашивать данные из корзины Amazon S3 с помощью Amazon Athena и создавать визуализации данных из таблицы Amazon Athena в Amazon QuickSight, которая ссылается на базу данных продаж, хранящуюся в каталоге данных AWS.
В этом новом руководстве вы узнаете, как:
а) Найдите наборы данных с открытым исходным кодом для своего увлеченного проекта, создайте тестовую или производственную рабочую нагрузку, которую можно использовать с сервисами AWS.
b) Завершите преобразование данных с помощью собственных данных с помощью Amazon Glue и Amazon Glue Studio.
Где можно найти интересные наборы данных с открытым исходным кодом для проектов аналитики и машинного обучения?
- Kaggle.com
- data.gov, data.gov.uk, data.gov.au.
- Поиск данных Google
- Данные переписи напр.
Австралийская перепись
- Репозиторий машинного обучения UCI
Обзор архитектуры решения — AWS Glue
Учебник 1.
 Преобразование данных с помощью AWS Glue
Преобразование данных с помощью AWS Glue
Шаг 1. В этом руководстве загрузите данные DOHMH New York City Restaurant Inspections в виде CSV-файла по этой ссылке
Предварительный просмотр необработанного набора данных:
Шаг 2. Войдите в свою учетную запись AWS. Если у вас нет учетной записи AWS, вы можете создать ее здесь
. Шаг 3. Вы можете следовать приведенным здесь инструкциям, чтобы создать свою первую корзину S3 и присвоить ей имя new-york-restaurant-inspections .
Шаг 4: Нажмите на корзину и выберите Создать папку .
Создайте две папки в корзине Amazon S3 и назовите их RAW и Обработанные соответственно, как показано ниже:
Шаг 5: Загрузка и щелчок Добавить файл в папку Raw
Шаг 6: Установка raby rompion rompion romsist Консоль AWS Glue. Вы можете следить за блогом для более подробной информации.
Вы можете следить за блогом для более подробной информации.
Если вам нужен доступ к дополнительным ресурсам Amazon, таким как блокноты Amazon Sagemaker, вы можете следовать приведенным здесь инструкциям.
Шаг 7. Перейдите к консоли Amazon Glue и в меню слева нажмите Искатель , за которым следует Добавить искатель .
Шаг 8: Укажите имя для сканера. В этом примере мы назовем сканер new york-restaurant-inspection-crawler и нажмем Next .
Шаг 9. Для типа источника искателя выберите Хранилища данных , а затем искатель для всех папок .
Шаг 10. В этом разделе добавьте путь к корзине S3 и выберите CSV-файл из raw папку и нажмите Next .
Шаг 11: Нажмите Да для добавления другого хранилища данных и Далее .
Шаг 12: Повторите шаг 10, но выберите папку Processed * для пути корзины S3.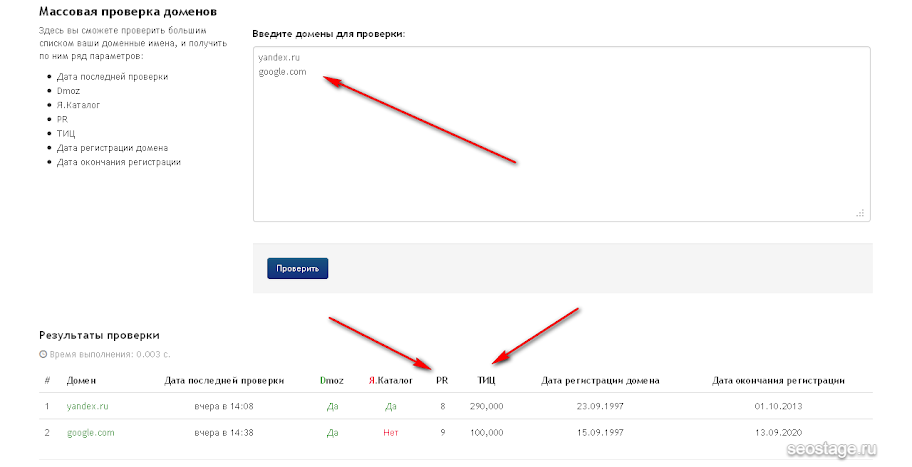 Щелкните Далее .
Щелкните Далее .
Шаг 13. Больше не нужно создавать хранилищ данных, нажмите Нет . Щелкните Далее .
Шаг 14. Вы можете выбрать существующую роль IAM для AWS Glue, которая была создана ранее, например «AWSGlueServiceRole-learn-glue-role». Нажмите Далее .
Шаг 15: Создайте расписание для обходчика, выберите в раскрывающемся меню Запускать по требованию .
Шаг 16: Настройте выходные данные сканера. Нажмите Добавить базу данных и укажите имя для базы данных «ресторан-инспекции». Добавьте к имени таблицы префикс Raw . Щелкните Далее .
Шаг 17. Проверьте введенные данные и нажмите Готово .
Детали краулера показаны ниже:
Шаг 18: Щелкните краулер «new-york-restaurant-inspection-crawler» и выберите Запустить краулер для выполнения задания.
Шаг 19: После завершения задания сканера со статусом «готово» вы можете проверить метаданные, щелкнув Таблицы слева.
Вы можете просмотреть следующую схему из каталога данных:
Обзор архитектуры решения — Amazon Glue Studio
Учебник 2. Преобразование данных с помощью Amazon Glue Studio
Шаг 1. Получите доступ к «AWS Glue Studio» из консоли AWS Glue.
Шаг 2. В консоли AWS Glue Studio нажмите Просмотр заданий .
Шаг 3: Выберите параметр Visual с источником и целью и нажмите Create .
Шаг 4: В разделе Свойства узла выберите Корзина S3 , затем Amazon S3
Шаг 5: В узле корзины S3 выберите из параметра Каталог данных имя базы данных, за которым следует имя таблицы, как показано на рисунке. на изображении ниже.
на изображении ниже.
Выберите узел Применить сопоставление .
Шаг 6: В узле «Применить сопоставление» щелкните вкладку Преобразование .
Имеются ли какие-либо переменные, которые были неправильно классифицированы в каталоге данных?
Есть ли какие-либо переменные, которые вам нужны для изменения типа данных?
Есть ли какие-либо столбцы, которые необходимо удалить из набора данных, которые не будут использоваться при анализе данных или для машинного обучения?
Вы можете выполнить некоторые преобразования, такие как изменение переменных даты с типа данных «строка» на «дата».
Вы можете просмотреть список распространенных типов данных в AWS Glue в документации
Шаг 7: Нажмите на вкладку «Схема вывода», проверьте преобразования данных.
Шаг 8: Нажмите на узел S3 Bucket-data target , затем выберите формат Parquet , тип сжатия Snappy и, наконец, выберите путь корзины S3 для обработанной папки данных для вывода преобразованных данных. .
.
Выберите Создать каталог данных при последующих запусках и назовите эту таблицу обработано .
Шаг 9. Щелкните вкладку Script , чтобы просмотреть сгенерированный Python код для этого задания ETL.
Шаг 10: Нажмите на вкладку «Сведения о задании», укажите имя задания, например, задание проверки ресторана, и описание преобразования данных. Измените количество рабочих на 2.
Шаг 11: Нажмите Сохранить и Выполнить , чтобы начать задание ETL.
Шаг 12. Выполнение задания ETL займет несколько минут, и его состояние изменится на «Успешно».
Шаг 13. Вернитесь к консоли AWS Glue и выберите Краулеры в меню слева и повторно запустите «сканер проверки ресторана», нажав Запустить сканер .
После того, как статус изменится на «готово», нажмите Table , чтобы просмотреть обработанную таблицу в каталоге данных на наличие преобразованных типов данных.