Содержание
гайд по работе со статистикой запросов и подбору ключевых слов
Содержание
- Что показывает Вордстат
- Операторы в Яндекс Вордстат: что это и как пользоваться ими
- Как автоматизировать работу с ключевыми фразами в Вордстат
- Советы по применению Вордстата в бизнесе и рекламе
Вордстат — бесплатный сервис Яндекса, который показывает статистику запросов в одноименном поисковике. Это ценный инструмент для маркетологов и предпринимателей. Можно изучить потребности аудитории, выявить популярные формулировки запросов по товару или услуге, составить семантику сайта и многое другое. Но не все знают о дополнительных возможностях Вордстата, которые сделают этот инструмент еще полезнее для работы. В материале рассказываем, как узнать статистику самых популярных запросов в Яндекс Вордстат по регионам и устройствам, где применять операторы и что поможет автоматизировать поиск ключевиков.
Что показывает Вордстат
Сервис можно открыть по ссылке: wordstat. yandex.ru. Этот официальный сайт доступен с десктопов и мобильных, функционирует в различных браузерах. Для использования не нужно иметь аккаунт в Яндексе и быть авторизованным.
yandex.ru. Этот официальный сайт доступен с десктопов и мобильных, функционирует в различных браузерах. Для использования не нужно иметь аккаунт в Яндексе и быть авторизованным.
Подбор ключевых слов через сервис Яндекс Wordstat
Главное назначение Вордстата — прогноз частотности, то есть количества показов по запросам. Вы указываете в строке Wordstat ключевое слово, которое вас интересует, например, «сквозная аналитика». Нажимаете кнопку «Подобрать».
Интерфейс Яндекс Вордстат
Сервис за доли секунды извлекает информацию из статистики Яндекса и выдает вам в левом столбце список с цифрами — сколько раз ваш запрос искали за последний месяц.
Также вы увидите список частых запросов, в которых были слова «сквозная аналитика» и что-то еще, например, «настройки». По цифре напротив — частотности — вы можете понять, насколько та или иная формулировка была в тренде.
В правом столбце показываются запросы, которые похожи на введенный по смыслу. Это то, что ищут вместе с какими-то из тех запросов, которые приведены слева. Благодаря им вы можете подобрать для своей ниши дополнительные запросы для семантики сайта или идей контента. Аналог функционала Вордстата есть в Планировщике ключевых слов в Гугле, если вы работаете через Google Adwords.
Благодаря им вы можете подобрать для своей ниши дополнительные запросы для семантики сайта или идей контента. Аналог функционала Вордстата есть в Планировщике ключевых слов в Гугле, если вы работаете через Google Adwords.
Дополнительные функции: статистика по регионам, типам устройств и история запросов
В Вордстате есть и расширенные опции поиска. Вы можете отфильтровать статистику запроса по регионам и по типам устройств пользователей. А еще — изучить историю запросов пользователей в зависимости от времени.
- Статистика по регионам
Функция позволяет спрогнозировать спрос для своего региона или тех городов, где доступно ваше предложение. Логично, что одну и ту же продукцию могут часто искать в крупных городах и почти не интересоваться ей в небольших населенных пунктах. И что есть особые регионы со специфическими интересами потребителей: текстиль в Иваново, пляжные принадлежности в Краснодаре и так далее.
Чтобы задать конкретную локацию для статистики запросов, нажмите на «Все регионы» и в выпадающем окне отметьте галочками нужные места. Затем нажмите «Выбрать». Можно, например, как посмотреть статистику ключевых запросов в России, так и сузить поиск до отдельного города.
Затем нажмите «Выбрать». Можно, например, как посмотреть статистику ключевых запросов в России, так и сузить поиск до отдельного города.
Эта опция полезнее всего для регионального бизнеса — например, небольших местных кафе или магазинов без доставки.
Есть и другая функция — анализ поисковых запросов по популярности в одном регионе по сравнению с другими. Так вы сможете выбрать точку с наибольшим спросом. Это полезно, если вы планируете открывать филиал или запускать рекламу по геолокации.
Выберите под строкой поиска пункт «По регионам». Сервис покажет не только число показов в месяц, но и «Региональную популярность» по сравнению с другими локациями. Если этот параметр больше 100%, то в этом регионе темой интересуются чаще, чем в других.
Из примера видно, что высокий интерес к сквозной аналитике показывают Москва, Краснодар и его округ.
- Статистика по типам устройств
Запускать рекламу через партнерскую сеть или в приложениях? Где люди чаще ищут вашу услугу — дома с компьютера или в дороге с телефона? Какой версии сайта уделять больше внимания — десктопной или мобильной? Если у вас нет однозначного ответа на подобные вопросы, изучите статистику по типам устройств.
Под строкой поиска выберите нужный вариант — десктопы или мобильные.
Чтобы сравнить частоту запросов с десктопов и с мобильных, переключайтесь между этими двумя вкладками и сопоставляйте значения напротив одинаковых фраз.
Обратите внимание: в понятие мобильных устройств включаются телефоны, смартфоны и планшеты. Если вам нужно рассмотреть лишь первые, то выберите вариант «Только телефоны».
На уточнение, что такое десктопы в Яндекс Вордстат, ответить достаточно просто: это персональные компьютеры, ноутбуки, макбуки. В статистике вы увидите количество запросов со всех этих типов устройств.
Данная функция полезна не только для непосредственного запуска рекламы, но и для лучшего понимания целевой аудитории. Если ваша ЦА на ходу ищет техники релаксации с телефона, то это совсем другой темп жизни, чем при комфортном поиске дома или на работе с ПК.
- История запросов
Если вам нужно проанализировать, как интерес пользователей к вашему запросу менялся со временем, используйте пункт «История запросов» под строкой Вордстата.
Вы увидите график: число запросов в зависимости от месяца. Статистика приводится за последние два года. Вы можете выбрать более детальную статистику, если отметите под строкой поиска разбивку не по месяцам, а по неделям.
Можно изучить тенденцию спроса на графике, а можно — по численным данным в таблице. В ней, как и на графике, приведены значения для 24 последних месяцев.
В истории запросов приводится абсолютное и относительное значение в Яндекс Вордстат. Первое показывает число запросов, второе — число запросов, деленное на количество показов результатов поиска Яндекса за соответствующий месяц.
Если вам нужно посмотреть только одну из величин на графике, вы можете выбрать это по кнопке «Абсолютное» или «Относительное» под ним.
Несмотря на то, что сквозная аналитика — запрос достаточно «круглогодичный», в отличие от рассады или дубленок, на графике есть взлеты и падения спроса. Например, недавний пик интереса к этой теме был в феврале, когда рынок трансформировался из-за блокировки привычных рекламных площадок.
Как и для статистики по словам и регионам, вы можете вывести историю запросов только с мобильных или десктопных устройств. Для этого выберите соответствующую кнопку под строкой поиска. В примере выше выбран вариант «Мобильные».
Операторы в Яндекс Вордстат: что это и как пользоваться ими
Операторы — это специальные символы, которые помогают уточнить поисковый запрос, его язык и синтаксис. Разберем инструкцию по работе с шестью операторами, которые помогут вам упростить и расширить поиск статистики в Вордстате.
- Кавычки
Оператор «» фиксирует число слов в запросе и сами слова. Это значит, что по запросу «сквозная аналитика» Вордстат покажет вам данные поиска только этой формулировки. Например, варианты «настройка сквозной аналитики» или «сквозная аналитика ROMI center» в показанную статистику не войдут.
Для точной формулировки нашлось 639 показов за месяц. А в таблице уже приводится статистика для различных словоформ запроса — их более 5000. Это то же самое, как если бы вы искали без оператора кавычек.
Это то же самое, как если бы вы искали без оператора кавычек.
- Плюс
Оператор + включает в ваш запрос точные формы предлогов и стоп-слов, то есть местоимений, частиц, междометий.
Если искать просто «сквозная аналитика в маркетинге», то сервис покажет все запросы со словами «сквозная», «аналитика» и «маркетинг». А вариант «сквозная аналитика +в маркетинге» предоставит вам возможность просмотра частотности только этой фразы — именно с предлогом «в».
- Минус
Знак минуса — исключает из результатов запросы, которые не содержали слово, написанное после этого оператора. Например, если вы предлагаете сквозную аналитику без бесплатного пробного периода, то можете исключить нерелевантные запросы через формулировку «сквозная аналитика -бесплатно».
4991 показ — это статистика для пользователей, которые искали сквозную аналитику без слова «бесплатно». А если не исключать их из результатов, то получится 5020 запросов.
С помощью оператора минус вы можете исключать те слова, которые не связаны с вашим бизнесом, но часто встречаются в нужных вам ключевиках. Например, «своими руками», «даром», «доставка в день заказа». Такие слова, которые нужно исключить из ключевиков, в рекламе называют минус-словами или минусовками.
Например, «своими руками», «даром», «доставка в день заказа». Такие слова, которые нужно исключить из ключевиков, в рекламе называют минус-словами или минусовками.
- Восклицательный знак
Оператор ! фиксирует форму слова, которое следует за ним. То есть оно будет искаться четко в том же падеже, числе и времени, которое вы ввели.
Например, вам нужно зафиксировать форму слов «курсы» и «аналитике». Тогда используйте запрос «!курсы по !аналитике».
Восклицательный знак можно применить ко всем словам в запросе, а можно только к некоторым.
- Квадратные скобки
Оператор [] фиксирует порядок слов в запросе, учитывая словоформу и стоп-слова. Когда вы заключаете фразу полностью в квадратные скобки, то можете узнать, сколько запросов получит именно такая постановка фразы.
В примере ниже формулировка «курсы по аналитике» получила всего 735 запросов за месяц.
- Круглые скобки и разделитель
Оператор (|) помогает найти статистику по нескольким фразам одновременно. Если вы предлагаете услуги, которые можно искать с близкими формулировками, то можно искать сразу обе и смотреть общую частотность.
Если вы предлагаете услуги, которые можно искать с близкими формулировками, то можно искать сразу обе и смотреть общую частотность.
Например, фразы «курсы по маркетингу» и «курсы по рекламе» можно найти разом, если ввести «курсы по (маркетингу|рекламе)». Те слова, которые вы разделяете символом |, считаются для сервиса синонимами и ищутся вместе с теми, которые стоят за скобками.
Вы можете комбинировать операторы, чтобы где-то зафиксировать форму слова, а где-то — допустить вольность в выборе синонима. Пример: «курсы по (маркетингу|рекламе) -бесплатно».
С такой формулировкой вы допускаете взаимозаменяемость слов «маркетинг» и «реклама», но исключаете запросы, содержащие слово «бесплатно».
Эти операторы действуют так же, как и в Яндекс.Директ, где вы настраиваете объявления на определенные формулировки ключевиков.
Как автоматизировать работу с ключевыми фразами в Вордстат
Из предыдущих разделов вы узнали, как получить от Вордстата нужную статистику. Но что делать, если нужно таким образом проработать сотню или тысячу разных ключевиков? Работу упростят и ускорят специальные программы.
Но что делать, если нужно таким образом проработать сотню или тысячу разных ключевиков? Работу упростят и ускорят специальные программы.
- Плагин Yandex Wordstat Helper
Скачайте бесплатный плагин по указанной ссылке, чтобы он появился в вашем браузере. Его виджет появится слева на странице Вордстата.
Теперь при поиске на сервисе около слов в списке будет отображаться значок плюса. По клику на + вы можете сохранить запрос в группе. Для удаления нужно нажать на минус.
В итоге у вас сформируются удобные списки запросов, которые релевантны вашему предложению. Вы можете сортировать сохраненные ключевики по алфавиту или частотности. В парсере доступна также проверка запросов на дубли и массовое удаление слов онлайн.
Плагин автоматически открывается, когда вы заходите на страницу Вордстата. Чтобы прекратить работу с плагином, удалите его в настройках браузера — раздел «Расширения» или «Дополнения».
- Плагин Yandex Wordstat Assistant — YWA
Этот вариант автоматизации похож на предыдущий — можно сохранять запросы в свой список, если нажать на плюс рядом с ними.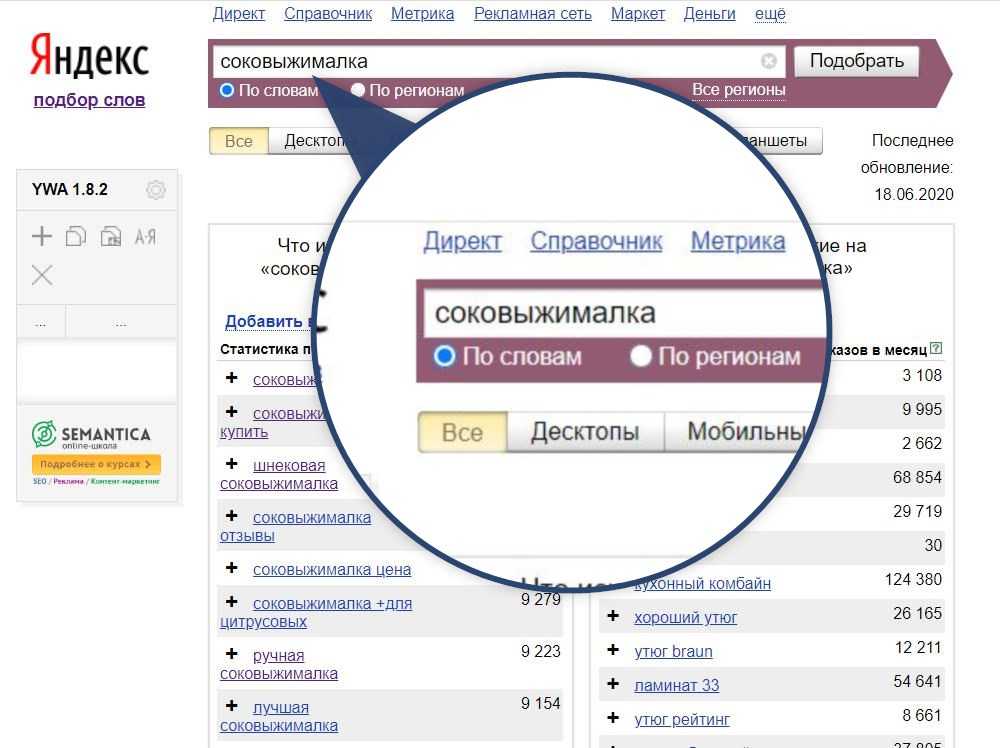 Отличие в том, что вы можете скопировать полученные запросы и их частотность и перенести в другое приложение. Например, в Excel или Блокнот.
Отличие в том, что вы можете скопировать полученные запросы и их частотность и перенести в другое приложение. Например, в Excel или Блокнот.
Для начала работы с этим бесплатным плагином его тоже нужно скачать из интернет-магазина Chrome и установить в браузере. Виджет Ассистента будет появляться слева на странице Вордстата.
Ваши списки сохранятся даже после закрытия вкладки Вордстата. Можно выбрать способ сортировки ключевиков, проверить дубли, смотреть разные данные в отдельных вкладках браузера. Для удаления плагина, как и в предыдущем случае, нужно зайти в настройки расширений.
Существуют более сложные способы автоматизации, например, создание собственного приложения. Метод называют API Wordstat, и для его применения потребуются базовые навыки работы с кодами и регистрация приложения на OAuth-сервере Яндекса. Для этого лучше обратиться к разработчику или вебмастеру.
Советы по применению Вордстата в бизнесе и рекламе
Мы разобрали основные возможности Яндекс Вордстата. Теперь перейдем к частностям и советам — как эффективнее применить этот инструмент в 2022 году для конкретных процессов.
Теперь перейдем к частностям и советам — как эффективнее применить этот инструмент в 2022 году для конкретных процессов.
Для запуска контекстной рекламы
Сначала проведите в отделе маркетинга и контента мозговой штурм: какие слова и фразы ассоциируются у покупателей с вашим предложением. Особое внимание уделите глаголам, намерению: в запросе должно быть выражение желания приобрести ваш продукт, а не просто изучить тему.
Примеры запросов на тему курсов аналитики:
- обучение аналитике;
- аналитика курсы с нуля;
- научиться аналитике;
- как стать аналитиком.
Теперь вы можете изучать статистику по этим запросам в Вордстате. Если ваш бизнес работает в конкретном регионе, обязательно укажите это.
Исследуйте запросы, которые похожи на заданные вами. Сравните, какие формулировки наиболее популярны в нужном регионе. Если нужно расширить семантику по конкретному варианту, просто кликните по нему. Например, вы нажали на запрос «аналитик +с нуля курсы».
Так вы постепенно наберете самые подходящие запросы, пользующиеся популярностью. Можно сохранять их через плагины Wordstat Helper или Wordstat Assistant и делить их на удобные группы.
Обратите внимание на частотность собранных запросов:
- для рекламы в РСЯ достаточно набрать основные запросы — высокочастотные, короткие, которые ассоциируются с вашим предложением у большинства людей, например, «сквозная аналитика»;
- для рекламы на поиске используйте подбор более узких запросов, чтобы по точным ключевикам ваше объявление получило высокие позиции в выдаче и релевантные клики, пример — «сквозная аналитика ROMI center пробный период подключить».
Для продвижения сайта в поисковой выдаче
Сайты, особенно крупные, нуждаются в широком и подробном семантическом ядре. Так называют набор ключевиков, которые отражают суть вашего предложения клиентам. По словам из семантического ядра поисковые алгоритмы смогут найти ваш сайт и предложить его пользователям, которые ищут ваш товар или услугу.
Вордстат помогает собрать идеи и широкие ключевые запросы. Если вам нужно больше вариаций, то пользуйтесь сервисами вроде Key Collector. Там вам высветятся все возможные вариации фраз по вашему широкому запросу.
Чтобы собрать все запросы с высоким рейтингом, которые вы потом используете в Key Collector, отработайте идеи из мозгового штурма. Просто вводите ваши варианты и смотрите, какие еще запросы можно взять на заметку. Сохранять их можно через те же плагины Wordstat Helper или Wordstat Assistant.
Обязательно обратите внимание на правый столбец. Там вы можете найти идеи похожих запросов, которые тоже подходят вашему бизнесу и помогут продвинуть сайт в топ выдачи.
Собранные ключевики нужно распределить по структуре сайта. Самые широкие высокочастотные запросы используются на главной странице, в оглавлении каталогов, а более конкретные — в карточках товара, например, «кондиционер для дома LG белого цвета».
При поиске идей для контента
Через Вордстат вы можете не только собрать запросы для рекламы или оптимизации сайта, но почерпнуть идеи для контента. Это важно для компаний, которые ведут блог или корпоративные соцсети.
Это важно для компаний, которые ведут блог или корпоративные соцсети.
Введите ключевые фразы, которые по вашему предположению интересуют целевую аудиторию. В правом столбце вы увидите близкие по смыслу запросы, а в левом — дополнительные уточнения, которые популярны в поиске.
Система поиска формулировок из левого и правого столбца поможет вам собрать новые темы для блога или даже полноценный контент-план. В материале мы рассказали, как проверить частотность поисковых запросов в Яндекс через Вордстат, какие возможности есть у этого сервиса и как их эффективно применять. Вам же осталось лишь изучить запросы в своей нише и получать больше трафика по самым популярным из них.
Частые вопросы
Что такое Вордстат?
Это бесплатный сервис Яндекса, в котором можно узнать частотность запросов. Вордстат берет данные из статистики поисковика и отображает, сколько раз пользователи искали вашу фразу. Можно рассмотреть историю запросов в зависимости от времени, сделать выборку по конкретному региону или типу устройств.
Зачем бизнесу использовать Вордстат?
Если вы продвигаетесь в Интернете, нужно понимать, какие из ваших ключевиков популярнее других. Так вы подберете самые эффективные формулировки для объявлений, соцсетей, контента. Еще при изучении различных ключевиков вы лучше узнаете потребности своей целевой аудитории.
Можно ли не искать ключевики вручную?
Для упрощения работы в Вордстате есть два популярных плагина: Yandex Wordstat Helper и Yandex Wordstat Assistant. Они помогут вам как выгрузить, так и сохранить собранные ключевики вместе с актуальной частотностью. Для продвинутой автоматизации поиска вы можете создать свое приложение через API Wordstat. Также есть другие сервисы поиска запросов, например, Key Collector. Однако они чаще всего платные.
Следующая статья: « Фиды в Яндекс.Директ: как создать и добавить
Содержание
- Что показывает Вордстат
- Операторы в Яндекс Вордстат: что это и как пользоваться ими
- Как автоматизировать работу с ключевыми фразами в Вордстат
- Советы по применению Вордстата в бизнесе и рекламе
Оцените статью:
Средняя оценка: 4. 6 Количество оценок: 76
6 Количество оценок: 76
Понравилась статья? Поделитесь ей:
Подпишитесь на рассылку ROMI center: Получайте советы и лайфхаки, дайджесты интересных статей и новости об интернет-маркетинге и веб-аналитике:
Вы успешно подписались на рассылку. Адрес почты:
Читать также
Как увеличить продажи в несколько раз с помощью ROMI center?
Закажите презентацию с нашим экспертом. Он просканирует состояние вашего маркетинга, продаж и даст реальные рекомендации по её улучшению и повышению продаж с помощью решений от ROMI center.
Запланировать презентацию сервиса
Попробуйте наши сервисы:
Импорт рекламных расходов и доходов с продаж в Google Analytics
Настройте сквозную аналитику в Google Analytics и анализируйте эффективность рекламы, подключая Яндекс Директ, Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистов
Попробовать бесплатно
Импорт рекламных расходов и доходов с продаж в Яндекс Метрику
Настройте сквозную аналитику в Яндекс.
 Метрику и анализируйте эффективность рекламы, подключая Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистов
Метрику и анализируйте эффективность рекламы, подключая Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистовПопробовать бесплатно
Система сквозной аналитики для вашего бизнеса от ROMI center
Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Попробовать бесплатно
 Метрику и анализируйте эффективность рекламы, подключая Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистов
Метрику и анализируйте эффективность рекламы, подключая Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистовСквозная аналитика для Google Analytics позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Подробнее → Попробовать бесплатно
Сквозная аналитика для Яндекс.
Метрики позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Подробнее → Попробовать бесплатно
Сквозная аналитика от ROMI позволит высчитывать ROMI для любой модели аттрибуции Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Подробнее → Попробовать бесплатно
 Метрики позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Метрики позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Как пользоваться Яндекс Wordstat. Инструкция к статистике ключевых запросов — блог Aitarget One
Перед запуском контекста не обойтись без сбора семантического ядра. По ключевым фразам настраивается выдача поисковых объявлений. А еще по ним алгоритмы РСЯ определяют, на какой тематической площадке ваши объявления сработают лучше всего.
А еще по ним алгоритмы РСЯ определяют, на какой тематической площадке ваши объявления сработают лучше всего.
В статье покажем, как правильно собрать «ключевики» и проверить результативность запросов.
Как собрать запросы для Яндекс Директ
Для сбора используют электронные таблицы (Microsoft Excel, Google Таблицы, Яндекс Документы, Мой Офис и прочие) и инструмент Яндекса — Wordstat.
Шаг 1. Соберите интуитивные запросы
Составляя семантическое ядро, важно представлять, по каким словам вас ищут потенциальные покупатели. Если вы продаете квартиры бизнес-класса, то пользователи, которые ищут «купить недорогую квартиру» или «снять квартиру» — не ваши клиенты. Поэтому сразу выделяйте в отдельный столбик минус-фразы, чтобы отсечь нецелевую аудиторию.
В один столбец таблицы внесите фразы, по которым, очевидно, ищут ваш продукт. В другой столбик вынесите минус-слова. Например, если продаете готовое постельное белье, подойдут запросы «купить постельное белье», «комплект постельного белья», «двуспальный комплект» и тому подобные. Минус-словами будут те, которые не относятся к бизнесу — «постирать», «сшить», «размеры».
Минус-словами будут те, которые не относятся к бизнесу — «постирать», «сшить», «размеры».
Можно воспользоваться подсказками, которые появляются при вводе названия вашего продукта в поиск Яндекса.
Шаг 2. Расширьте семантическое ядро при помощи Яндекс Wordstat
Перейти в сервис можно прямо из кабинета Яндекс Директ по кнопке «Подбор слов» или напрямую на wordstat.yandex.ru.
Ключевые фразы, которые вы придумали в предыдущем шаге, вводите по очереди в строку поиска.
Фразы больше 8 слов Яндекс Wordstat не воспринимает, но по таким длинным запросам ищут что-либо менее 10 раз в месяц.
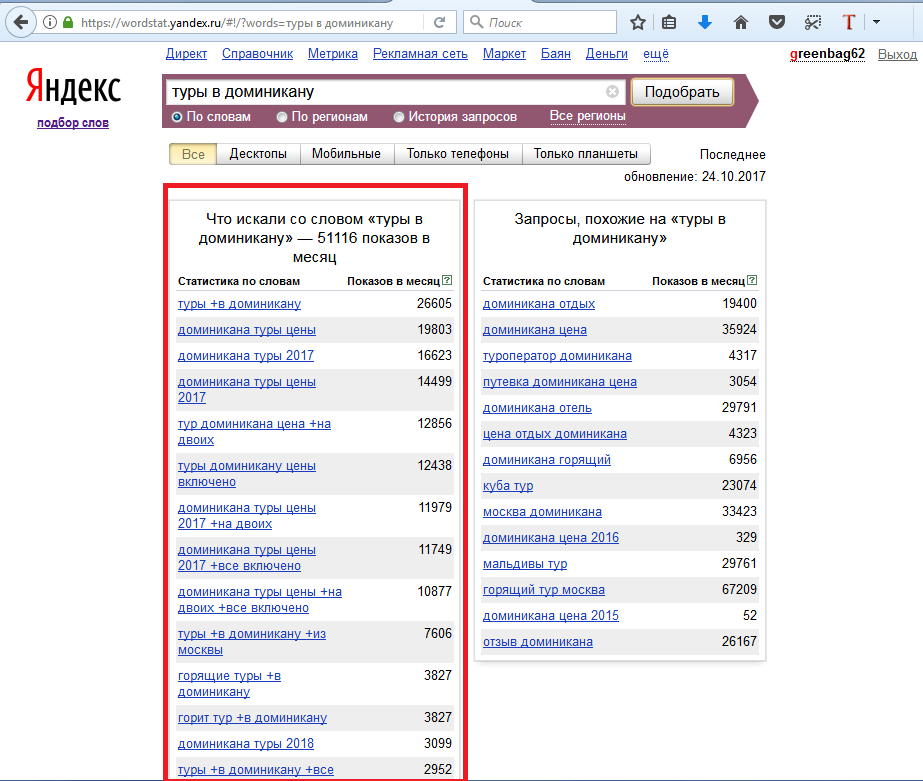
Не забывайте выбрать регион, на который будет показана реклама, или всю Россию. На скриншоте ниже показан пример с постельным бельем.
Первый запрос в левой колонке включает в себя все следующие запросы. На скриншоте «постельное белье» искали 299 302 раза. Из них 67 464 раза юзеры хотели именно «купить постельное белье», а 19 260 — «купить постельное белье в Москве». Учтите, что это количество показов за прошедший месяц, а не гарантированные показы объявления, запущенного с такой ключевой фразой.
Учтите, что это количество показов за прошедший месяц, а не гарантированные показы объявления, запущенного с такой ключевой фразой.
В Яндекс Wordstat есть операторы, которые могут вам пригодиться:
- Знак «+» перед словом дает инструменту сигнал обязательно учитывать слово при поиске. В противном случае сервис будет игнорировать стоп-слова — предлоги, союзы, частицы и прочие, которые сами по себе не передают значение. Иногда без них смысл запроса искажается. Например, запрос «ткани для постельного белья» без предлога «для» может обозначать как материал для белья, так и, наоборот, белье из ткани. Поэтому Яндекс Wordstat разрешает оставить предлог в поиске, закрепив его оператором «+».
- Знак «–» позволяет убрать фразы с минус-словами, которые вы выделили на первом шаге. Иногда так удобнее, чем копировать в табличный файл всю колонку, а потом вручную удалять «минусы». В примере речь идет о продаже готового постельного белья, поэтому нам не нужны пользователи, которые ищут ткани для него, белье из IKEA, размеры. Скопируйте эти ключи в свой файл в графу минус-слов. Затем добавьте их в поиск Wordstat к основному запросу без запятых через пробел и обязательно с оператором «–».
 Скопируйте эти ключи в свой файл в графу минус-слов. Затем добавьте их в поиск Wordstat к основному запросу без запятых через пробел и обязательно с оператором «–».
Скопируйте эти ключи в свой файл в графу минус-слов. Затем добавьте их в поиск Wordstat к основному запросу без запятых через пробел и обязательно с оператором «–».Теперь скопируйте весь столбик выдачи в таблицу как основу семантического ядра.
Обратите внимание и на правую колонку Wordstat — здесь указаны ключевые слова, похожие на ваш запрос. Возможно, среди них тоже есть подходящие.
Шаг 3. Оцените количество запросов с разных типов устройств
В этом тоже поможет Яндекс Wordstat. Нажимая на фильтры «Десктопы», «Мобильные» и далее, вы увидите спрос. По этим результатам вы можете распределить бюджет показов на разных типах устройств в настройках рекламной кампании.
Теперь запустите рекламную кампанию с таргетингом по ключевым словам. Вам в помощь статья «Как настроить поисковую рекламу в Яндекс.Директе».
Как посмотреть статистику запросов в Яндекс Директ
После запуска кампании регулярно проверяйте, как работают собранные фразы. Дают ли они лиды, которые конвертируются? Не приводят ли ненужные переходы? Первые недели отслеживать эффективность показов по ключевым фразам нужно каждый день. Используйте для этого статистику в Директе.
Дают ли они лиды, которые конвертируются? Не приводят ли ненужные переходы? Первые недели отслеживать эффективность показов по ключевым фразам нужно каждый день. Используйте для этого статистику в Директе.
Общая статистика
В этом отчете при активации чекбокса «Показать статистику по объявлениям» отображаются данные по ключевым фразам.
В таблице собраны данные по запросам, в том числе и по удаленным.
Показатели позволяют оценить эффективность отдельных ключевых фраз.
Фразы по дням
В этом отчете можно детализировать конкретный период открутки рекламы.
Активируя чекбоксы «всего», «поиск» или «сети», вы получите данные о показах на площадках с разбивкой по дням.
Поисковые запросы
Этот отчет отражает, какие слова искали пользователи, которые увидели ваши объявления, и как эти запросы соотносятся с заданными ключевиками. Можно выбрать, какие параметры будут показаны в отчете.
Статистика за 180 дней выводится в отчете следующим образом:
- Поисковые запросы, которые ищут в сети;
- Условие, на основании которого система показала объявление. Согласно справке Яндекс Директ, это могут быть ключевая фраза, автотаргетинг или условие нацеливания для динамических объявлений;
- Категория таргетинга, к которой относится запрос;
- Тип соответствия — в справке обозначен как «связь между исходной ключевой фразой и фразой, по которой показано объявление»;
- Подобранные фразы — ключи, подходящие по смыслу или подобранные алгоритмом на основе условий показа;
- Другие запросы — в этот пункт собраны фразы, у которых мало показов и нет кликов, а также те, которые искали менее 60 минут назад. Возможно, эти запросы получали клики в ходе других рекламных кампаний, в отчете они отобразятся отдельно.
Обработка результатов отчетов
Теперь вы знаете, какие пользовательские запросы приносили больше всего показов, кликов и имели высокий CTR (показан в «Общей статистике», про которую мы написали выше). Добавьте их в ключевые фразы новой кампании. Запросы, которые не принесли показов и переходов, лучше внести в минус-фразы и не тратить бюджет на показы по ним.
Добавьте их в ключевые фразы новой кампании. Запросы, которые не принесли показов и переходов, лучше внести в минус-фразы и не тратить бюджет на показы по ним.
Прямо из отчета «Поисковые запросы» внесите изменения в семантическое ядро. Поставьте галочку в чекбоксы нужных фраз, затем внизу кликните, куда их поместить — в минус-фразы или в ключевые фразы.
После нажатия «Добавление…» откроется окно редактирования. К запросам можно будет добавить операторы +, ! и [].
Зачем они нужны:
- Знак «+» сохранит в поиске стоп-слова (предлоги).
- Знак «!» требует искать фразу дословно. Например, вы хотите продавать оптом по запросу «школьные столы», а ваше объявление показывается тем, кто ищет один «школьный стол».
- Заключив фразу в квадратные скобки «[]», вы запрещаете менять последовательность слов, что важно для продажи путешествий, билетов, отправки грузов. Например, ваше объявление показывается по запросу «доставка грузов Москва-Брянск», и вы не хотите, чтобы по нему переходили те, кому нужно что-то отправить из Брянска в Москву.

Отредактировав семантику, укажите ставки по новым ключам и сохраните изменения.
Обратите внимание:
- Новые запросы добавляются в ту группу объявлений, статистику которой вы смотрите. Возможно, группе не хватит лимита ключевых фраз. Тогда она будет автоматически скопирована с фразами, превышающими лимит. Если две одинаковые группы с разными ключами не устраивают, вернитесь назад и удалите часть старых или новых запросов. Либо снизьте количество групп в рекламной кампании, тогда лимит для них вырастет.
- Если новая минус-фраза дублирует ключ, система покажет предупреждение. Придется решить, в каком качестве оставить этот запрос.
- Лимит на минус-фразы также может быть превышен — появится предупреждение. Яндекс Директ допускает минус-фразы до 4096 символов без пробелов на одну группу объявлений и до 20 000 — на кампанию. Можно сделать новую группу либо сократить список.
Полезные советы
- Используйте опечатки и просторечные названия. Популярные опечатки и запросы в неправильной раскладке клавиатуры поисковик исправляет. А вот нераспространенные опечатки или варианты написания Справка Яндекс Директ рекомендует добавить в список ключевых слов. Пример: «су-вид» и «су вид» для «сувид» (способ приготовления пищи, для которого продается оборудование).
- Напишите названия иностранных брендов и латиницей, и кириллицей. Например, «мультиварка Redmond» и «мультиварка Редмонд». Пользователи порой пишут так, как говорят.
- Собирайте разные части речи. Например, «кроссовки для бега», «беговые кроссовки», «кроссовки чтобы бегать». Яндекс Директ при показах учитывает разные формы слова, но только в границах одной части речи. Запросы «беговые», «бег» и «бегать» для него не однокоренные слова, а разные.
- Укажите основные синонимы. Собирать все семантически близкие слова не надо, потому что алгоритм автоматически определяет запросы, которые по смыслу подходят ключевой фразе. Дайте основные синонимы, как базу для оптимизации, а дальше алгоритм увидит близкие запросы сам.
- Используйте сленг, профессиональные термины. Их тоже часто вводят как запросы. Например, «сувенирная продукция» и «сувенирка».
 Популярные опечатки и запросы в неправильной раскладке клавиатуры поисковик исправляет. А вот нераспространенные опечатки или варианты написания Справка Яндекс Директ рекомендует добавить в список ключевых слов. Пример: «су-вид» и «су вид» для «сувид» (способ приготовления пищи, для которого продается оборудование).
Популярные опечатки и запросы в неправильной раскладке клавиатуры поисковик исправляет. А вот нераспространенные опечатки или варианты написания Справка Яндекс Директ рекомендует добавить в список ключевых слов. Пример: «су-вид» и «су вид» для «сувид» (способ приготовления пищи, для которого продается оборудование).
Язык запросов — Direct Commander. Справка
- Как сформировать запрос
- Запросы, содержащие несколько условий
- Операторы языка запросов
Язык запросов позволяет вводить сложные критерии выбора объектов, применять различные условия к значениям полей и комбинировать их с помощью логических операторов.
Введите запрос в строку поиска внизу любой вкладки Commander.
Простой поисковый запрос состоит из трех частей:
= Значение оператора поля
Например, запрос:
= текст ~ рейс
показывает все объявления, содержащие слово рейс в столбце Текст.
Начните вводить поисковый запрос после символа = . Когда вы это сделаете, значок появится в строке поиска. Вы можете выбрать имена полей и операторов из всплывающих окон.
Вы можете выбрать имена полей и операторов из всплывающих окон.
При вводе названий и значений полей помните:
При вводе не учитывается регистр.
Если имя или значение поля состоит из нескольких слов, разделенных пробелами, заключите его в кавычки:
= "Заголовок 1" = "Космические путешествия"
Если вам нужно найти подстроку, которая сама содержит кавычки, используйте символ \:
= "Заголовок 1" = " \"Космические путешествия\""
Если вы хотите указать несколько значений, используйте квадратные скобки:
= "Заголовок 1" = [" пространство"; "рейс"]
или
= "Название 1" = [космический полет]
Если поле может содержать фиксированный набор значений (Область отображения, Модерация, Статус, Приоритет и т.
д.), то используйте операторы ~ и !~ квадратными скобками, даже если поле может содержать только одно значение.
 д.), то используйте операторы ~ и !~ квадратными скобками, даже если поле может содержать только одно значение.
д.), то используйте операторы ~ и !~ квадратными скобками, даже если поле может содержать только одно значение.Если критерий поиска был сформулирован неправильно, то значок в строке ввода текста изменится на и появится сообщение об ошибке.
Вы можете использовать и (логическое И) и | (логическое ИЛИ) операторов для выполнения комбинированных запросов.
Операции поиска выполняются строго слева направо, но порядок можно изменить с помощью круглых скобок. Операции, заключенные в скобки, имеют приоритет над стандартным порядком операций.
- Пример 1
= Ключевое слово ~ билет | Ключевое слово ~ отель
Этот запрос возвращает ключевые слова, содержащие слова билет или отель .
- Пример 2
= Ключевое слово ~ билет | Ключевое слово ~ отель и ставка > 1
Этот поисковый запрос будет возвращать ключевые слова, которые одновременно удовлетворяют двум условиям:
Содержит слово билет или отель .
Имеет ставку на поиск больше 1.
- Пример 3
= Ключевое слово ~ билет | (Ключевое слово ~ гостиница и ставка > 1)
Этот поисковый запрос будет возвращать ключевые слова, которые соответствуют хотя бы одному из двух условий:
Содержит слово билет .
Contains the word hotel and has a bid on search greater than 1.
| Operator | Value | Example | Result |
|---|---|---|---|
| ~ | Содержит | = «Регион показа» ~ austr | Выбирает группы объявлений с полем Регион показа, содержащим Австралия или Австрия (и, возможно, некоторые другие регионы) |
| = «Изображение» ~ [черный белый] | Выбирает объявления, в поле «Изображение» которых содержится черный или белый в качестве подстроки | = «Область отображения» ~ [Рекламные сети] | Выбирает кампании со значением Рекламные сети в поле Область отображения |
| !~ | Не содержит | = «Область отображения» !~ austr | Выбирает группы объявлений с полем «Регион отображения», не содержащим Австралия и Австрия |
| = Ключевое слово !~ [ticket hotel] | Выбирает ключевые слова с полем Ключевое слово, не содержащим подстроки hotel ticket и | ||
| = Модерация !~ [В ожидании] | Выбирает объявления, в которых столбец Модерация содержит любое значение, кроме Ожидание . | ||
| = | Равенство/совпадение | = «Регион отображения» = Австралия | Выбирает только те группы, для которых регион отображения установлен на Австралия |
| = Номер = [111111 222222] | Выбирает объявления с номерами 1111 20272 и 61 1 111 20222 | ||
| != | Не равно/не соответствует | = «Отображаемый регион» != Австралия | Выбирает группы, у которых Отображаемый регион отличается от Австралия |
Selects all numbers except 111111 and 222222. | |||
| > | More | = ctr > 0.5 | Selects keywords with a CTR higher than 0.5 |
| < | Less | = ctr < 0.5 | Выбирает ключевые слова с CTR менее 0,5 |
| >= | Больше или равно | = Ставка >= 1 | Выбирает ключевые слова со ставкой при поиске больше или равной 1 |
| <= | Меньше или равно | = Bid <= 1 | Выбирает ключевые слова со ставкой на поиск, которая меньше или равна 1 |
| & | = Текст ~ рейс & Изображение = пробел | Выбирает объявления с текстом, содержащим подстроку Flight , и названием изображения, содержащим подстроку пробел | |
| | | Логическое «ИЛИ» в сложных условиях поиска | = Текст ~ пробел | Текст ~ рейс | Выбирает объявления с текстом, содержащим пробел подстроку ИЛИ рейс подстроку |
Внимание.
Операторы ~ , !~ нельзя использовать для столбцов с числовыми значениями.
Операторы > , >= , < и = можно использовать только для столбцов с числовыми значениями.
Новый алгоритм поиска Яндекса на основе искусственного интеллекта Палех
Недавно Яндекс объявил о своем новом алгоритме поиска Палех, который улучшает то, как Яндекс понимает значение каждого поискового запроса, используя свои глубокие нейронные сети в качестве фактора ранжирования среди других. В конечном счете, новый алгоритм помогает Яндексу улучшить результаты поиска по всем направлениям, но особенно для поисковых запросов с длинным хвостом.
Как известно большинству читателей State of Digital, поисковые запросы с длинным хвостом классифицируются по запросам, которые поисковая машина обрабатывает очень редко. Существует корреляция между редкостью запроса и его длиной. Как правило, чем короче запрос, тем он чаще встречается, а чем длиннее, тем реже. Такие запросы часто бывают разговорными и подробно описывают что-то, когда пользователь не знает точную фразу или слово, но пытается объяснить поисковику. Например, написать описание фильма, не зная названия, например, «фильм о парне, выращивающем картошку на какой-то планете».
Как правило, чем короче запрос, тем он чаще встречается, а чем длиннее, тем реже. Такие запросы часто бывают разговорными и подробно описывают что-то, когда пользователь не знает точную фразу или слово, но пытается объяснить поисковику. Например, написать описание фильма, не зная названия, например, «фильм о парне, выращивающем картошку на какой-то планете».
Эти длинные запросы заставляют поисковые системы полностью понимать цель запроса, чтобы предлагать наиболее релевантные результаты поиска. Поисковые системы более легко предлагают результаты поиска на основе сходства слов в запросе схожести и релевантности слов в результатах. Проблема запросов с более длинным хвостом заключается в том, что они не так легко совпадают для релевантных синонимов слов, и по этим редким запросам гораздо меньше данных.
Однако запросы с длинным хвостом и результаты поиска могут быть лучше всего сопоставлены путем нахождения и сопоставления сходства значений. Яндекс решил внедрить передовой искусственный интеллект, чтобы улучшить поиск совпадений между запросами и результатами, лучше понимая цель запроса, а не сходство самих слов.
Как компания, специализирующаяся на машинном обучении, Яндекс исторически внедрял машинное обучение в 70% своих продуктов и услуг, начиная с поиска. Совсем недавно с Палехом поисковая команда Яндекса научила свои нейронные сети видеть связи между запросом и документом, даже если они не содержат общих слов.
Этот новый алгоритм был назван в честь российского города Палех из-за жар-птицы на его гербе с длинным хвостом. Яндекс назвал все свои поисковые алгоритмы именами российских городов и выбрал Палех, основываясь на символе длинного хвоста и влиянии этого алгоритма на запросы с длинным хвостом.
В этом блоге рассказывается о динамике машинного обучения, лежащей в основе последнего поискового алгоритма Яндекса Палех, и о том, что отличает его от других способов использования глубоких нейронных сетей для ранжирования веб-поиска.
Что такое машинное обучение? Что такое нейронные сети?
Машинное обучение — это именно то, что оно самообучается, создавая связи из шаблонов входных данных. Как говорит Яндекс, «машина, которая может учиться, — это машина, которая может принимать собственные решения на основе входных алгоритмов, эмпирических данных и опыта». Как только цель поставлена, модели обучаются для достижения этой цели на основе обучающих образцов. Машина учится создавать правила, которые со временем улучшаются по мере того, как она обрабатывает больше данных. На результаты алгоритма влияют миллионы факторов, которые оказываются гораздо более сложными, чем способность человека обрабатывать или программировать.
Как говорит Яндекс, «машина, которая может учиться, — это машина, которая может принимать собственные решения на основе входных алгоритмов, эмпирических данных и опыта». Как только цель поставлена, модели обучаются для достижения этой цели на основе обучающих образцов. Машина учится создавать правила, которые со временем улучшаются по мере того, как она обрабатывает больше данных. На результаты алгоритма влияют миллионы факторов, которые оказываются гораздо более сложными, чем способность человека обрабатывать или программировать.
Нейронные сети — это метод машинного обучения, созданный по образцу нейронов в человеческом мозгу и предназначенный для решения задач, подобных человеческому мозгу. Нейронные сети основаны на реальных числах и могут быть обучены находить отношения в наборе данных после обработки входных данных и распознавания закономерностей. Их можно обучить анализировать изображения, звук или текст, и они применяются для различных целей, таких как распознавание изображений, перевод текста или ранжирование в веб-поиске.
Как Яндекс научил свои нейросети лучше понимать запросы?
Яндекс обучил свои нейронные сети с помощью модели семантического отображения, которая сводит информацию к числам, группирует их на основе значения содержания, проецирует группы на семантическую карту, а затем находит совпадения между группами на основе их близости на карте. Как правило, семантическое отображение находит связи между двумя разными объектами, помещая их в одно и то же семантическое пространство и подтверждая их связи на основе их близости друг к другу. В этом случае ранжирования веб-страниц два объекта, которые проверяются на наличие соединений, — это поисковые запросы и документы или заголовки просканированных страниц.
Прежде чем что-то случилось с отображением, поисковая группа должна была сначала обучить алгоритм, предоставив ему примеры пар запросов и соответствующих заголовков веб-страниц. Этот обучающий набор предоставил нейронным сетям базовое понимание связей, которые поисковая команда Яндекса хотела установить.
Поскольку компьютеры лучше работают с числами, а не со словами, Яндекс затем преобразовал миллиарды поисковых запросов и просканированных страниц в числа. Затем эти числа нужно было организовать так, чтобы за ними стоял смысл. Произвольный набор слов не имеет реального понятия или значения. Только очень определенные наборы слов имеют смысл вместе, и существуют миллионы возможных контекстов. Алгоритм находит небольшие подмножества слов, которые заполнены по смыслу, но это по-прежнему приводит к миллионам возможностей, поэтому числа должны быть сгруппированы. Таким образом, используя метод, называемый уменьшением размерности, матрица сжимает длинный список слов в группу из 300, а затем помещает ее в 300-мерный вектор. Слова могут быть совершенно разными, но если они попадают в один и тот же вектор, то и значение у них похожее. То же самое делается для заголовков просканированных страниц.
Эти семантические векторы затем используются для поиска совпадений на основе их близости.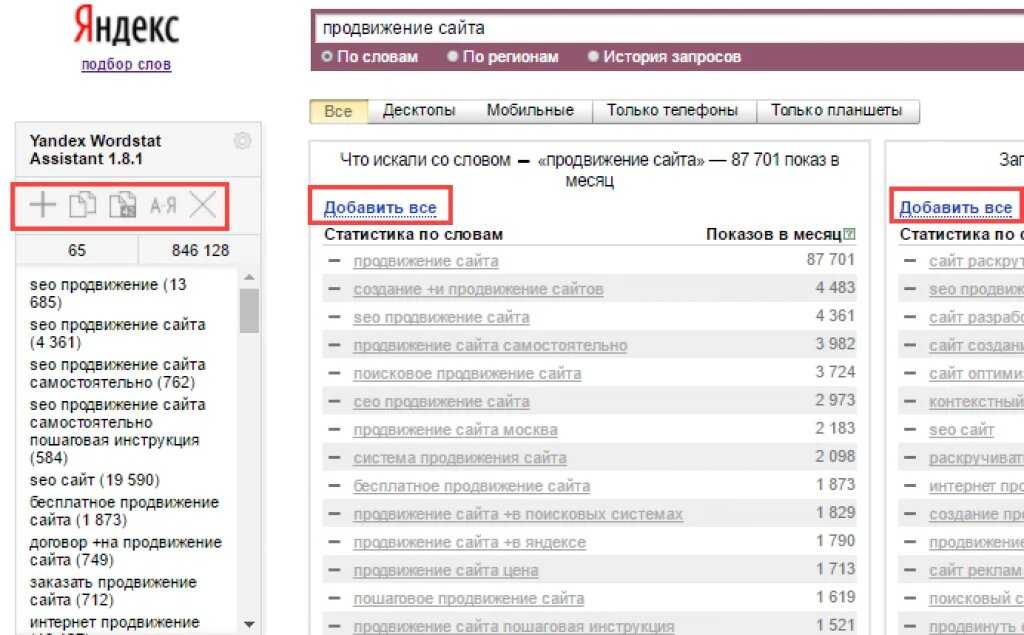 Каждый запрос и заголовок проверяются, чтобы увидеть, насколько близка проекция размерности заголовка к запросу на карте. Точно так же, как слова выглядят в поисковой системе, векторы тоже.
Каждый запрос и заголовок проверяются, чтобы увидеть, насколько близка проекция размерности заголовка к запросу на карте. Точно так же, как слова выглядят в поисковой системе, векторы тоже.
Чтобы упростить объяснение, давайте предположим, что мы имеем дело с двумерным пространством, поэтому числа рассматриваются как точки на координатной плоскости. Затем заданный запрос и заголовок веб-страницы отображаются на координатной плоскости. Затем можно измерить расстояние между точками запроса и заголовком веб-страницы, чтобы решить, насколько документ релевантен запросу. Чем ближе две точки, тем более релевантен запрос документу.
Почему это особенно полезно для длинных запросов?
Помещая запрос в семантический вектор с заголовком веб-страницы, поисковая система понимает, что запрос и заголовок веб-страницы имеют смысл, даже если они не имеют похожих слов. Раньше алгоритмы были более ограничены поиском сходства на основе синонимов и понятий.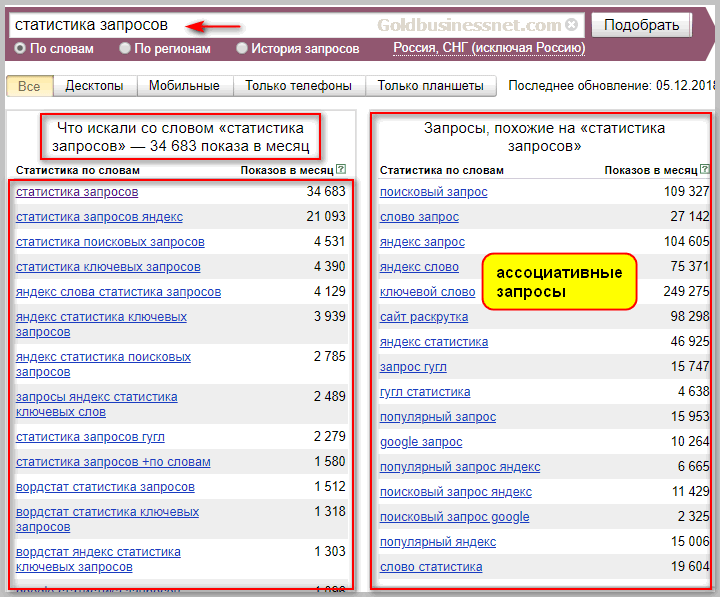 Например, обувь и ботинки или концепция бренда Kayak и настоящего каяка. Однако, как люди, мы знаем, что запросы с длинным хвостом могут не включать слова, совпадающие с похожими словами или понятиями. Используя нейронные сети, поисковая система может найти сходство не только слов, но и значений. Из-за того, что запросы с длинным хвостом обычно требуют результатов, основанных на значении, и для этих редких запросов меньше данных, семантическое сопоставление заполняет пробел.
Например, обувь и ботинки или концепция бренда Kayak и настоящего каяка. Однако, как люди, мы знаем, что запросы с длинным хвостом могут не включать слова, совпадающие с похожими словами или понятиями. Используя нейронные сети, поисковая система может найти сходство не только слов, но и значений. Из-за того, что запросы с длинным хвостом обычно требуют результатов, основанных на значении, и для этих редких запросов меньше данных, семантическое сопоставление заполняет пробел.
Чем подход Яндекса отличается от других?
Яндекс также включает другие цели для обучения своих нейронных сетей. Эти цели включают предсказание длинных кликов, CTR и модели «кликать или не кликать». Вместо того, чтобы просто использовать одну из своих лучших моделей нейронных сетей, Яндекс включает пять. Сравнивая преимущества включения всех своих моделей, поисковая команда Яндекса отмечает гораздо более точные результаты поиска. Используя все свои предыдущие факторы ранжирования плюс свою лучшую модель нейронной сети, Яндекс добился улучшения на 1% по длинным хвостовым запросам. Применяя все свои предыдущие факторы ранжирования и пять моделей нейронных сетей, это улучшение удваивается и приводит к повышению точности запросов с длинным хвостом на 2%.
Применяя все свои предыдущие факторы ранжирования и пять моделей нейронных сетей, это улучшение удваивается и приводит к повышению точности запросов с длинным хвостом на 2%.
Что Яндекс планирует делать с этим в будущем?
Яндекс научил свои нейросети видеть заголовки документов, но поисковая команда в настоящее время работает и над проверкой текстового содержания. При этом поисковая система Яндекса сможет выдавать еще более точные результаты после более детального изучения того, соответствует ли содержание просканированных страниц заданному запросу. На сегодняшний день другие поисковые системы с аналогичной технологией проверяют только заголовки.
Яндекс также работает над внедрением модели с большим количеством просканированных страниц. В настоящее время модель просматривает сотни документов, которые уже отфильтрованы в топ результатов поиска Яндекса. Поисковая команда Яндекса работает над оптимизацией модели на более ранней стадии поиска, чтобы в конечном итоге она охватила миллиарды документов. Чем больше документов сможет включить Яндекс, тем точнее будут результаты поиска.
Чем больше документов сможет включить Яндекс, тем точнее будут результаты поиска.
Помимо общего повышения точности результатов поиска Яндекса, это в целом поможет Яндексу лучше понимать разговорные запросы в будущем.
Что это значит для SEO?
По мере того, как Яндекс совершенствует свою способность обрабатывать диалоговые запросы, остальным SEO-специалистам и онлайн-маркетологам также придется адаптироваться к этому. Как всегда в SEO, несколько факторов ранжирования имеют значение, и трудно сказать, какие из них имеют наибольшее значение. Однако в конечном итоге качественный контент для пользователя всегда был в центре внимания поисковой команды Яндекса. Палех этого не изменит. SEO-специалисты по-прежнему должны учитывать, что нужно пользователю, не сосредотачиваясь на отдельных ключевых словах и не практикуя наполнение ключевыми словами. Пока веб-мастера предоставляют контент, который поможет пользователям Яндекса, машинное обучение Яндекса распознает его.