Содержание
Парсер: что это такое простыми словами
Скопировано
Содержание
Парсер — это программа для сбора и систематизации информации, размещенной на различных сайтах. Источником данных может служить текстовое наполнение, HTML-код сайта, заголовки, пункты меню, базы данных и другие элементы. Процесс сбора информации называется парсинг (parsing).
Парсеры используются в интернет-маркетинге для сбора информации с сайтов-конкурентов, а также для анализа собственных веб-ресурсов. Они позволяют обрабатывать большие массивы данных в автоматическом режиме. Это ускоряет и упрощает проведение маркетинговых исследований.
Схема работы парсера
Как работает парсер
Термин «парсинг» произошел от английского глагола to parse, означающего в переводе с английского «по частям». Процесс представляет собой синтаксический анализ любого набора связанных друг с другом данных. В общем виде парсинг выполняется в несколько этапов:
- Сканирование исходного массива информации (HTML-кода, текста, базы данных и т.
 д.).
д.). - Вычленение семантически значимых единиц по заданным параметрам — например заголовков, ссылок, абзацев, выделенных жирным шрифтом фрагментов, пунктов меню.
- Конвертация полученных данных в формат, удобный для изучения, а также их систематизация в виде таблиц или отчетов для дальнейшего использования.
 д.).
д.).Объектом парсинга может быть любая грамматически структурированная система: информация, закодированная естественным языком, языком программирования, математическими выражениями и т.д. Например, если исходный массив данных представляет собой HTML-страницу, парсер может вычленить из кода информацию и перевести ее в текст, понятный для человека. Или конвертировать в JSON — формат для приложений и скриптов.
Доступ парсера к сайту возможен:
- через протоколы HTTP, HTTPS или веб-браузер;
- с использованием бота, имеющего права администратора.
Получение данных парсером — семантический анализ исходного массива информации. Программа разбивает его на отдельные части (лексемы): слова, словосочетания и т. д. Парсер проводит их грамматический анализ, преобразуя линейную структуру текста в древовидную (синтаксическое дерево). Такая форма упрощает «понимание» информационного массива компьютерной программой и бывает двух типов:
д. Парсер проводит их грамматический анализ, преобразуя линейную структуру текста в древовидную (синтаксическое дерево). Такая форма упрощает «понимание» информационного массива компьютерной программой и бывает двух типов:
- дерево зависимостей — такая структура состоит из компонентов, находящихся в иерархических отношениях друг к другу;
- дерево составляющих — в структуре этого типа компоненты находятся в тесной зависимости друг с другом, но без иерархических отношений.
Также результат работы парсера может представлять собой сочетание моделей. Программа действует по одному из двух алгоритмов:
- Нисходящий парсинг. Анализ осуществляется от общего к частному, а синтаксическое дерево разрастается вниз.
- Восходящий парсинг. Анализ и построение синтаксического дерева осуществляются снизу вверх.
Выбор конкретного метода парсинга зависит от конечной цели. В любом случае, парсер должен уметь вычленять из общего массива только необходимые данные, а также преобразовывать их в удобный для решения задачи формат.
Преимущества и недостатки парсеров
Применение программ-парсеров позволяет:
- автоматизировать процесс анализа и снижать нагрузку на сотрудников, перенаправлять их время и силы на решение других задач;
- ускорять анализ большого объема информации — например, нескольких сотен страниц интернет-магазина или обширную базу данных;
- выявлять ошибки на сайте или в любом другом информационном продукте, если в программе заданы настройки на их поиск.
К недостаткам парсеров можно отнести не всегда релевантный анализ данных. Однако в большинстве случаев это зависит от возможностей программы, качества ее настройки пользователем. В большинстве случаев информация, выдаваемая парсером, требует незначительной обработки для дальнейшего использования.
Применение парсеров
Парсинг применяется в любых областях, где требуется проанализировать и систематизировать большой объем данных:
- В программировании. Компьютер может воспринимать и «понимать» только машинный код — набор нулей и единиц. Чтобы заставить машину выполнить какую-либо операцию, человек использует языки программирования, которые непонятны компьютеру. Поэтому специальное приложение сначала проводит парсинг написанной пользователем программы и переводит полученные данные в бинарный машинный код.
- В создании сайтов. Как и языки программирования, языки разметки (например HTML) непонятны компьютеру. Чтобы он смог отобразить HTML-разметку в виде визуально структурированного и понятного интерфейса сайта, парсер браузера анализирует исходный код страницы, вычленяет нужные данные, переводит их в понятный машине формат. Также парсинг позволяет выявить ошибки и недочеты в созданном сайте.
- Веб-краулинг. Это частный случай парсинга. Робот-парсер поисковика в ответ на запрос пользователя просматривает релевантные ему сайты, после чего выбирает наиболее подходящую по содержанию страницу. Особенность краулеров в том, что они не извлекают данные со страниц, как другие парсеры, а ищут в них совпадения с запросом пользователя.
- Агрегация новостей. Для упорядоченной подачи новостей сайты-агрегаторы или новостные агентства используют парсеры. Они собирают обновления со всех доступных источников, анализируют их и подают сотрудникам для конечной редактуры и публикации.
- Интернет-маркетинг. В SEO и SMM с помощью парсеров собираются и анализируются данные пользователей, товарные позиции в интернет-магазинах, метатеги (заголовки, title и description), ключевые слова и другая информация. Эти данные используются для оптимизации сайта, продвижения коммерческих групп в социальных сетях, настройки таргетированной и контекстной рекламы. Проверка размещенного на веб-ресурсе текста на плагиат также является разновидностью парсинга.
- Мониторинг цен. Парсерами можно извлечь расценки товаров на сайтах-конкурентах, чтобы проанализировать текущую ситуацию на рынке и выработать ценовую политику. Также с их помощью можно привести прайс-листы на собственном сайте в соответствие с ценами у поставщиков.
 Чтобы заставить машину выполнить какую-либо операцию, человек использует языки программирования, которые непонятны компьютеру. Поэтому специальное приложение сначала проводит парсинг написанной пользователем программы и переводит полученные данные в бинарный машинный код.
Чтобы заставить машину выполнить какую-либо операцию, человек использует языки программирования, которые непонятны компьютеру. Поэтому специальное приложение сначала проводит парсинг написанной пользователем программы и переводит полученные данные в бинарный машинный код.

Программы-парсеры
В веб-разработке и продвижении используется большое количество бесплатных и платных программ для парсинга сайтов. К числу самых популярных относятся:
- Screaming Frog SEO Spider. Это британская программа для комплексного анализа сайтов со множеством полезных опций. Она осуществляет поиск битых ссылок, входящих и исходящих ссылок, выявляет дубли метатегов и заголовков, ключевые слова, отдельные URL и т.д. Среди полезных дополнительных опций — генерация sitemap, сканирование сайтов, требующих оптимизации, проверка файла robots.txt. Программа имеет бесплатную версию, но функционал ограничен базовыми возможностями.
Логотип Screaming Frog
- ComparseR. Это приложение также позволяет парсить сайты, но у нее отсутствует функция поиска внутренних и внешних ссылок. В остальном оно не уступает Screaming Frog по возможностям, хотя имеются ограничения по производительности при анализе крупных сайтов — например, интернет-магазинов или больших информационных порталов. Дополнительным преимуществом является более удобный интерфейс, упрощающий освоение программы и ее использование.
 Дополнительным преимуществом является более удобный интерфейс, упрощающий освоение программы и ее использование.
Дополнительным преимуществом является более удобный интерфейс, упрощающий освоение программы и ее использование.Логотип парсера Comparser
- Netpeak Spider. Одно из самых популярных приложений для парсинга, ориентированное на работу с крупными сайтами (с миллионом и более страниц). Среди преимуществ — наличие всего набора инструментов для анализа и продвижения веб-ресурсов разного типа, настраиваемые фильтры параметров, дополнительные опции наподобие генерации HTML-карты сайта, поиска ссылок nofollow, выгрузки отчетов и т.д. Единственный недостаток — полный функционал доступен по подписке, которую нужно регулярно продлевать.
Логотип Netpeak Spider
- Xenu Link Sleuth. Бесплатный парсер, предназначенный для поиска битых ссылок и других ошибок на сайте. Xenu нельзя использовать для комплексного и подробного анализа веб-ресурсов. Также есть проблемы с производительностью, но с учетом доступности недостатки приемлемы.
Можно ли использовать парсеры
Распространено мнение, что парсинг сайтов как минимум неэтичен, а в некоторых случаях и незаконен.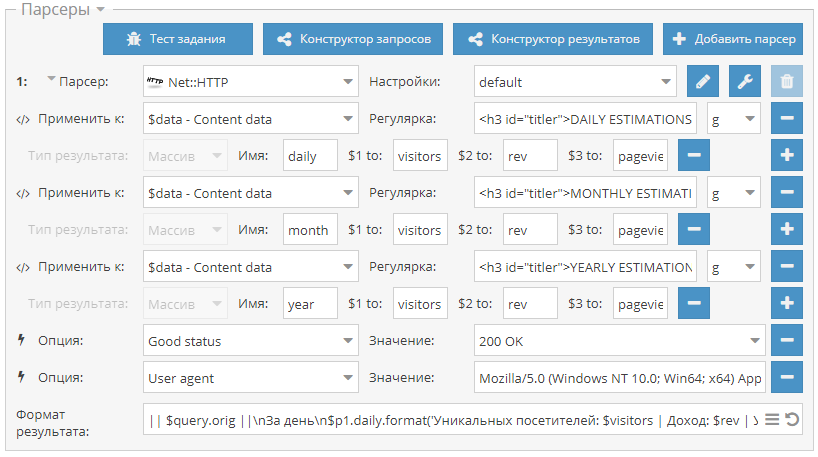 Действительно, парсеры собирают информацию с чужих веб-ресурсов, баз данных и других источников. Однако в большинстве случаев сведения находятся в открытом доступе, то есть использование программ не нарушает закон. Противозаконным может стать применение данных, например:
Действительно, парсеры собирают информацию с чужих веб-ресурсов, баз данных и других источников. Однако в большинстве случаев сведения находятся в открытом доступе, то есть использование программ не нарушает закон. Противозаконным может стать применение данных, например:
- для спам-рассылки и звонков. Это нарушает закон о защите персональных данных;
- копирование и использование информации с сайта-конкурента на собственном ресурсе. Это может нарушать авторские права.
В целом, парсинг не нарушает нормы законодательства и этики. Автоматизированный сбор информации позволяет сделать сайт и реализуемый с его помощью продукт более удобным для клиентов.
Скопировано
Парсинг данных с сайтов: что это и зачем он нужен
Парсинг обычно применяют, когда нужно быстро собрать большой объем данных. Его выполняют с помощью специальных сервисов — парсеров. В этой статье мы разберем, с какой целью можно использовать парсинг, что он позволяет узнать о конкурентах и законен ли он. Также мы рассмотрим, как пошагово спарсить данные с помощью одного из инструментов.
Также мы рассмотрим, как пошагово спарсить данные с помощью одного из инструментов.
Время чтения 17 минут
- Что такое парсинг
- Способы применения парсинга
- Что могут узнать конкуренты с помощью парсинга
- Законно ли парсить сайты
- Этапы парсинга
- Как парсить данные
- Как защитить свой сайт от парсинга
- Выводы
Что такое парсинг
Парсинг — это процесс автоматического сбора данных и их структурирования.
Специальные программы или сервисы-парсеры «обходят» сайт и собирают данные, которые соответствуют заданному условию.
Простой пример: допустим, нужно собрать контакты потенциальных партнеров из определенной ниши. Вы можете это сделать вручную. Надо будет заходить на каждый сайт, искать раздел «Контакты», копировать в отдельную таблицу телефон и т. д. Так на каждую площадку у вас уйдет по пять-семь минут. Но этот процесс можно автоматизировать. Задаете в программе для парсинга условия выборки и через какое-то время получаете готовую таблицу со списком сайтов и телефонов.
Плюсы парсинга очевидны — если сравнивать его с ручным сбором и сортировкой данных:
- вы получаете данные очень быстро;
- можно задавать десятки параметров для составления выборки;
- в отчете не будет ошибок;
- парсинг можно настроить с определенной периодичностью — например, собирать данные каждый понедельник;
- многие парсеры не только собирают данные, но и советуют, как исправить ошибки на сайте.
В сети достаточно много программ для парсинга. Они могут находиться в «облаке» или «коробке»:
- облачная версия — это SaaS, вам нужно будет зарегистрироваться и работать с сервисом прямо в браузере;
- коробочная версия — решение, которое нужно установить на ваш компьютер, и работать с ним в окне программы.
В обоих случаях вы платите за доступ к парсеру в течение какого-то времени. Например, месяца, года или нескольких лет.
Способы применения парсинга
Область применения парсинга можно свести к двум целям:
- анализ конкурентов, чтобы лучше понимать, как они работают, и заимствовать у них какие-то подходы;
- анализ собственной площадки для устранения ошибок, быстрого внедрения изменений и т. д.
 д.
д.Пример того, что может предложить один из парсеров для поиска, устранения ошибок и прокачки SEO
Мы регулярно используем парсер для блога Ringostat. Например, когда нужно найти изображения, к которым по какой-то причине не прописан атрибут Alt. Поисковики считают это ошибкой и могут понизить в выдаче тот сайт, на котором много таких иллюстраций. Даже страшно представить, сколько времени потребовалось бы на ручной поиск таких картинок. А благодаря парсеру мы получаем список со ссылками за несколько минут.
Теперь давайте рассмотрим для каких целей еще можно использовать парсинг.
- Исследование рынка. Парсинг позволяет быстро оценить, какие товары и цены у конкурентов.
- Анализ динамики изменений. Парсинг можно проводить регулярно, чтобы оценивать, как менялись какие-то показатели. Например, росли или падали цены, изменялось количество онлайн-объявлений или сообщений на форуме.
- Устранение недочетов на собственном ресурсе. Выявление ошибок в мета-тегах, битых ссылок, проблем с редиректами, дублирующихся элементов и т. д.
- Сбор ссылок, ведущих на вашу площадку. Это поможет оценить работу подрядчика по линкбилдингу. Как проверять внешние ссылки и какими инструментами это делать, подробно описано в статье. Пример такого отчета:
- Наполнение каталога интернет-магазина. Обычно у таких сайтов огромное количество позиций и уходит много времени, чтобы составить описание для всех товаров. Чтобы упростить этот процесс, часто парсят зарубежные магазины и просто переводят информацию о товарах.
- Составление клиентской базы. В этом случае парсят контактные данные, например, пользователей соцсетей, участников форумов и т. д. Но тут стоит помнить, что сбор информации, которой нет в открытом доступе, незаконен.
- Сбор отзывов и комментариев на форумах, в соцсетях.
- Создание контента, который строится на выборке данных. Например, результаты спортивных состязаний, инфографики по изменению цен, погоды и т. д.
 Выявление ошибок в мета-тегах, битых ссылок, проблем с редиректами, дублирующихся элементов и т. д.
Выявление ошибок в мета-тегах, битых ссылок, проблем с редиректами, дублирующихся элементов и т. д. д.
д.Кстати, недобросовестные люди могут использовать парсеры для DDOS-атак. Если одновременно начать парсить сотни страниц сайта, то площадку можно «положить» на какое-то время. Это, разумеется, незаконно — об этом подробнее ниже От подобных атак можно защититься, если на сервере установлена защита.
Что могут узнать конкуренты с помощью парсинга
В принципе, любую информацию, которая размещена на вашем сайте. Чаще всего ищут:
- цены;
- контакты компании;
- описание товаров, их характеристик и в целом контент;
- фото и видео;
- информацию о скидках;
- отзывы.
Проводить такую «разведку» могут не только конкуренты. Например, журналист может провести исследование, правда ли интернет-магазины предоставляют настоящие скидки на Черную пятницу. Или искусственно завышают цены незадолго до нее и реальную цену выдают за скидку. С этой целью он может заранее спарсить цены десятка интернет-магазинов и сравнить с ценами на Черную пятницу.
Законно ли парсить сайты
Если кратко, то законно — если вы парсите информацию, которая есть в открытом доступе. Это логично, ведь так любой человек и без парсера может собрать интересующие данные. Что преследуется законом:
- парсинг с целью DDOS-атаки;
- сбор личных данных пользователей, которые находятся не на виду — например, в личном кабинете, указывались при регистрации и т. д.;
- парсинг для воровства контента — например, перепост чужих статей под своим именем, использование авторских фото не из бесплатных стоков;
- сбор информации, которая составляет государственную или коммерческую тайну.
Рассмотрим это подробнее с точки зрения законодательства Украины.
Согласно ЗУ «Об информации», информация по режиму доступа делится на общедоступную и информацию с ограниченным доступом. В свою очередь информация с ограниченным доступом делится на конфиденциальную, гостайну и служебную. Определения каждого вида содержатся в ЗУ «О доступе к публичной информации.
В большей степени любой спор касательно незаконного парсинга и/или распространения информации касается именно конфиденциальных данных.
- Информация о физлице, которая может его идентифицировать, априори является конфиденциальной и может быть использована только по согласию. Поэтому, чтобы парсинг был законным, парсить нужно либо деперсонифицированные данные, либо получать согласие распорядителя информации — владельца сайта, на котором зарегистрирован пользователь.
- Если речь идет об информации, не являющейся персональной, она может считаться конфиденциальной, только если ее владелец определил ее как таковую. Так, чаще всего на сайтах размещается либо политика конфиденциальности, либо правила пользования сайтом. В этом документе/на этой странице указаны права и обязанности посетителей/пользователей, которые нужно соблюдать. Поэтому перед парсингом стоить проверить, не запрещен ли сбор информации и использование данных сайта.
Также важным является возможное нарушение авторских установленных ЗУ «Об авторских и смежных правах» и ГКУ. Перед парсингом нужно понимать, что любой тип контента защищен авторским правом с момента его создания. И только автор определяет как (платно/бесплатно), где (статья/сайт/реклама) и сколько (на протяжении срока действия лицензии/бессрочно) можно использовать его творение.
Перед парсингом нужно понимать, что любой тип контента защищен авторским правом с момента его создания. И только автор определяет как (платно/бесплатно), где (статья/сайт/реклама) и сколько (на протяжении срока действия лицензии/бессрочно) можно использовать его творение.
Даже при условии правомерности парсинга, его осуществление не должно подрывать нормальную работу сайта, который парсят. Если из-за парсинга информации произойдет сбой и утечка или подделка данных, то подобные действия могут расцениваться как несанкционированное вмешательство в работу сайта, что является нарушением согласно УК Украины.
Есть еще один нюанс. Представим, что одна компания долго разрабатывала продукт, вкладывала деньги, чтобы собрать базу пользователей или покупателей, а другая спарсила все и за несколько недель создала практически аналогичный сервис или продукт. Подобные действия при наличии весомой доказательной базы могут расцениваться как нарушение условий конкуренции согласно ЗУ «О защите от недобросовестной конкуренции».
Этапы парсинга
Если не погружаться в технические подробности, то парсинг строится из таких этапов:
- пользователь задает в парсере условия, которым должна соответствовать выборка — например, все цены на конкретном сайте;
- программа проходится по сайту или нескольким и собирает релевантную информацию;
- данные сортируются;
- пользователь получает отчет — если проводилась проверка на ошибки, то критичные выделяются контрастным цветом;
- отчет можно выгрузить в нужном формате — обычно парсеры поддерживают несколько.
Пример отчета Netpeak Spider, где критичные ошибки выделяются красным цветом. Источник
Как парсить данные
Теперь давайте более подробно рассмотрим, как парсить данные. Разберем его в разрезе довольно частой задачи для менеджера — собрать базу для «холодного» обзвона. В качестве примера возьмем парсер Netpeak Checker, с которым работаем и сами.
Допустим, наша компания продает оборудование для салонов красоты. И сотруднику нужно собрать базу контактов таких компаний, чтобы позвонить и предложить им наш товар. Обычно на старте готового списка площадок у менеджера нет. Поэтому для поиска можно использовать встроенный в программу инструмент «Парсер поисковых систем».
И сотруднику нужно собрать базу контактов таких компаний, чтобы позвонить и предложить им наш товар. Обычно на старте готового списка площадок у менеджера нет. Поэтому для поиска можно использовать встроенный в программу инструмент «Парсер поисковых систем».
Вводим в нем нужные запросы — «салон красоты», «парикмахерская», «бьюти-процедуры».
На вкладке «Настройки» выбираем поисковую систему и количество результатов — например, топ-10 или все результаты выдачи. В дополнительных настройках указываем язык выдачи и параметры геолокации, чтобы в результаты попадали салоны красоты только из нужного нам региона. Сохраняем настройки и нажимаем «Старт», чтобы начать парсинг.
Чтобы провести парсинг номеров телефонов с главных страниц найденных сайтов, нажимаем на кнопку «Перенести хосты». После этого ссылки отобразятся в основной таблице программы.
Теперь, когда у нас есть полный список салонов, на боковой панели в разделе параметров «On-Page» отмечаем пункт «Телефонные номера» и нажимаем «Старт». Все найденные телефоны с сайтов и их число будут внесены в соответствующих колонках основной таблицы результатов.
Все найденные телефоны с сайтов и их число будут внесены в соответствующих колонках основной таблицы результатов.
Если бы у нас заранее был собран перечень необходимых адресов, мы могли бы их просто загрузить в программу и точно так же собрать телефоны.
Сохраняем данные в формате CSV, нажав кнопку «Экспорт».
Вот и все — мы получили список салонов и их телефонов.
Кстати, сэкономить время можно не только за счет парсинга. Вы в любом случае тратите где-то минуту, чтобы набрать номер на телефоне. Если в вашем списке хотя бы 50 компаний, на это в сумме уйдет почти час. Но есть способ тратить на набор номера одну секунду. Это Ringostat Smart Phone — умный телефон, встроенный прямо в браузер Chrome. Он позволяет звонить, просто нажав на номер, расположенный на любом сайте, в карточке CRM или просто в таблице. Как в нашем примере.
Подключите Ringostat, установите расширение и сможете обзвонить базу за минимальное время. При желании ее можно сразу перенести в CRM и звонить уже оттуда с помощью Ringostat Smart Phone. Тут видно, что звонок происходит мгновенно:
Тут видно, что звонок происходит мгновенно:
Этот процесс описан в статье «Лайфхак для менеджера: как подготовить базу за минимальное время».
Как защитить свой сайт от парсинга
Как мы упоминали выше, парсинг не всегда используют в нормальных целях. Если вы боитесь атаки со стороны конкурентов, площадку можно защитить. Существует несколько способов, как это сделать.
- Ограничьте число действий, которые можно совершить на вашей площадке за определенное время. Например, разрешите только три запроса в течение минуты с одного IP-адреса.
- Отслеживайте подозрительную активность. Если заметили сильно много запросов с одного адреса, запретите ему доступ. Или показывайте reCAPTCHA, чтобы пользователь подтвердил, что он человек, а не бот или парсер.
- Создайте учетную запись, чтобы действия на сайте мог совершать зарегистрированный посетитель.
- Идентифицируйте всех, кто заходит на площадку. Например, по скорости заполнения формы или месту нажатия на кнопку. Есть скрипты, которые позволят собирать информацию о местонахождении пользователя, разрешении экрана.
- Скройте информацию о структуре сайта. Пусть доступ к ней будет только у администратора.
- Обращайте внимание на похожие или идентичные запросы, одновременно поступающие с разных IP-адресов. Парсинг может быть распределенным. Например, через прокси-сервера.
 Есть скрипты, которые позволят собирать информацию о местонахождении пользователя, разрешении экрана.
Есть скрипты, которые позволят собирать информацию о местонахождении пользователя, разрешении экрана.В любом случае, помните, что всегда есть риск заблокировать реального пользователя, а не программу. Поэтому тут вам решать, что важнее — безопасность сайта или риск потери потенциального клиента.
Выводы
- Парсинг — это сбор и сортировка данных с определенными параметрами. У этого инструмента масса преимуществ: скорость, отсутствие ошибок в выборке, возможность проводить парсинг регулярно. Плюс, многие парсеры не просто собирают данные, но и советуют, как исправить критические ошибки на вашем сайте.
- Парсинг используется для анализа конкурентов, исследования рынка, поиска и устранения ошибок на собственной площадке, создания контента. Интернет-магазины используют его, чтобы переводить описания товаров с иностранных площадок.
- Парсинг вполне законен, если вы собираете информацию, которая есть в открытом доступе. Нельзя проводить его, чтобы «положить» ресурс конкурента, украсть чужой контент или получить данные, не предназначенные для общего доступа.
- Если боитесь атаки на свой сайт, парсинг можно выявить и запретить. Способов существует несколько, но многие парсеры хвастаются в сети, что умеют их обходить. Плюс, вы всегда рискуете заблокировать «живого» человека
 Интернет-магазины используют его, чтобы переводить описания товаров с иностранных площадок.
Интернет-магазины используют его, чтобы переводить описания товаров с иностранных площадок.Грамматика ссылок
Дэви Темперли Дэниел Слейтор Джон Лафферти
Link Grammar Parser — синтаксический анализатор английского языка, основанный на
грамматика ссылок, оригинальная теория синтаксиса английского языка. Учитывая приговор,
система приписывает ему синтаксическую структуру, состоящую из
набор помеченных ссылок, соединяющих пары слов. Парсер также
производит «составное» представление предложения (показывая существительное
словосочетания, глагольные словосочетания и др. ).
).
Мы сделали всю систему доступной для загрузки в Интернете.
Система написана на универсальном коде C и работает на любой платформе с
компилятор Си. Существует интерфейс прикладной программы (API) для создания
Парсер легко встроить в другие приложения.
С декабря 2004 года мы выпускаем парсер под новой
лицензия; лицензия разрешает неограниченное использование в коммерческих
приложений, а также совместим с GNU GPL (общедоступной
Лицензия). Посмотреть лицензию можно здесь. Мы
также выпускают версию 4.1b, которая идентична версии 4.1.
(выпущена в 2000 г.), за исключением того, что заявления о лицензировании отражают
новая лицензия.
Парсер имеет словарь около 60000 словоформ. В нем есть
охватывает широкий спектр синтаксических конструкций, в том числе многие
редкие и идиоматические. Парсер надежен; он может пропустить
части предложения, которые он не может понять, и назначить некоторые
структуру к остальной части предложения. Он способен обрабатывать неизвестные
словарный запас и делать разумные предположения из контекста и правописания
о синтаксических категориях незнакомых слов. Он имеет знание
Он имеет знание
заглавные буквы, числовые выражения и различные знаки препинания
символы.
Сейчас парсер поддерживается под эгидой
проекта Абиворд. Последние версии включают новые функции
и множество улучшений. Для получения дополнительной информации перейдите на
Абиворд
ссылка на страницу грамматики.
Вот содержание этого сайта:
| Зарегистрироваться | Дайте нам свой адрес электронной почты, чтобы получать уведомления о новых выпусках и обновления на этом сайте. |
| Анализ | Поэкспериментируйте с парсером. |
| Переводчик | Поэкспериментируйте с англо-немецким переводчиком Link Grammar — a простая система перевода, которая демонстрирует один подход к использованию Ссылка Грамматика для перевода. (Больше не поддерживается) |
| Образцы | Список из 900 примеров предложений иллюстрирует диапазон феноменов Английская грамматика, захваченная нашей системой.  |
| Документация | Введение в грамматики ссылок и Link Parser 4.0; подробная документация по текущий словарь; документацию по Link Parser API, для установка парсера ссылок в свои программы. |
| Библиография | Сборник статей по грамматике ссылок. |
| Улучшения | Улучшения в версии 4.0. |
| Палиндромы | Список коротких палиндромов, сгенерированных системой. |
| Скачать | Загрузить все исходные файлы и файлы данных для грамматики ссылок парсер здесь. |
Если у вас есть какие-либо комментарии об этой работе или вы используете ее для своих собственных
целей, мы хотели бы услышать от вас. Вы можете отправить нам электронный
почта.
Благодарности
Описанное здесь исследование было поддержано NSF ,
ARPA и Школа компьютерных наук в Карнеги
Университет Меллона. Особая благодарность Адаму Бергеру
Особая благодарность Адаму Бергеру
за разработку системы постобработки и Деннису Гринбергу за
вклад в систему нулевой ссылки.
Джон Лафферти
Дэниел Слейтор
Дэви Темперли
Дэниел Слейтор
Последнее изменение: сб, 2 апреля, 23:46:55 по восточному поясному времени 2016 г.
Анализ URL-адресов · Введение в Elm
В реалистичном веб-приложении мы хотим показывать разный контент для разных URL-адресов:
-
/поиск -
/search?q=seiza -
/настройки
Как нам это сделать? Мы используем elm/url для разбора необработанных строк в красивые структуры данных Elm. Этот пакет имеет наибольший смысл, если вы просто посмотрите на примеры, поэтому мы и сделаем это!
Пример 1
Допустим, у нас есть арт-сайт, где должны быть действительны следующие адреса:
.
-
/тема/архитектура -
/тема/живопись -
/тема/скульптура -
/блог/42 -
/блог/123 -
/блог/451 -
/пользователь/том -
/пользователь/сью -
/пользователь/судья/комментарий/11 -
/пользователь/судья/комментарий/51
Итак, у нас есть тематические страницы, сообщения в блогах, информация о пользователях и способ поиска отдельных комментариев пользователей. Мы будем использовать модуль
Мы будем использовать модуль Url.Parser для написания синтаксического анализатора URL следующим образом:
import Url.Parser, раскрывающий (Parser, (), int, map, oneOf, s, string)
тип Маршрут
= Строка темы
| Блог
| Строка пользователя
| Строка комментария, целое число
routeParser : Парсер (Маршрут -> а) а
парсер маршрута =
один из
[ карта Тема (s "тема" строка)
, карта Блог (s "blog" int)
, сопоставление пользователя (s "user" строка)
, map Comment (s "user" string s "comment" int)
]
-- /topic/pottery ==> Просто (Тема "керамика")
-- /topic/collage ==> Просто (Тема "коллаж")
-- /topic/ ==> Ничего
-- /blog/42 ==> Просто (Блог 42)
-- /blog/123 ==> Просто (Блог 123)
-- /blog/mosaic ==> Ничего
-- /user/tom/ ==> Just (Пользователь "tom")
-- /user/sue/ ==> Просто (пользователь "sue")
-- /user/bob/comment/42 ==> Just (Комментарий "bob" 42)
-- /user/sam/comment/35 ==> Just (Комментарий "sam" 35)
-- /user/sam/comment/ ==> Ничего
-- /user/ ==> Ничего
Модуль Url. позволяет достаточно просто полностью преобразовать действительные URL-адреса в качественные данные Elm! Parser
Parser
Пример 2
Теперь предположим, что у нас есть личный блог, где допустимы такие адреса:
-
/блог/12/история стульев -
/блог/13/бесконечный-сентябрь -
/блог/14/кит-факты -
/блог/ -
/блог?q=киты -
/блог?q=seiza
В этом случае у нас есть отдельные сообщения в блоге и обзор блога с необязательным параметром запроса. Нам нужно добавить модуль Url.Parser.Query , чтобы написать наш парсер URL на этот раз:
import Url.Parser, раскрывающий (Parser, (), (), int, map, oneOf, s, string)
импортировать Url.Parser.Query как запрос
тип Маршрут
= BlogPost Целая строка
| BlogQuery (возможно, строка)
routeParser : Парсер (Маршрут -> а) а
парсер маршрута =
один из
[ map BlogPost (s "blog" int string)
, map BlogQuery (s "blog" Query. string "q")
]
-- /blog/14/whale-facts ==> Just (BlogPost 14 "whale-facts")
-- /blog/14 ==> Ничего
-- /blog/whale-facts ==> Ничего
-- /blog/ ==> Просто (BlogQuery Ничего)
-- /blog ==> Просто (BlogQuery Ничего)
-- /blog?q=chabudai ==> Просто (BlogQuery (Просто "чабудай"))
-- /blog/?q=whales ==> Просто (BlogQuery (Просто "киты"))
-- /blog/?query=whales ==> Просто (BlogQuery Ничего)
 string "q")
]
-- /blog/14/whale-facts ==> Just (BlogPost 14 "whale-facts")
-- /blog/14 ==> Ничего
-- /blog/whale-facts ==> Ничего
-- /blog/ ==> Просто (BlogQuery Ничего)
-- /blog ==> Просто (BlogQuery Ничего)
-- /blog?q=chabudai ==> Просто (BlogQuery (Просто "чабудай"))
-- /blog/?q=whales ==> Просто (BlogQuery (Просто "киты"))
-- /blog/?query=whales ==> Просто (BlogQuery Ничего)
string "q")
]
-- /blog/14/whale-facts ==> Just (BlogPost 14 "whale-facts")
-- /blog/14 ==> Ничего
-- /blog/whale-facts ==> Ничего
-- /blog/ ==> Просто (BlogQuery Ничего)
-- /blog ==> Просто (BlogQuery Ничего)
-- /blog?q=chabudai ==> Просто (BlogQuery (Просто "чабудай"))
-- /blog/?q=whales ==> Просто (BlogQuery (Просто "киты"))
-- /blog/?query=whales ==> Просто (BlogQuery Ничего)
Операторы и позволяют нам писать синтаксические анализаторы, которые очень похожи на фактические URL-адреса, которые мы хотим анализировать. А добавление Url.Parser.Query позволило нам обрабатывать такие параметры запроса, как ?q=seiza .
Пример 3
Хорошо, теперь у нас есть веб-сайт документации с такими адресами:
-
/Основы -
/Возможно -
/Список -
/Список#карта -
/Список#фильтр -
/List#foldl
Мы можем использовать синтаксический анализатор фрагмента из Url. для обработки этих адресов следующим образом: Parser
Parser
введите псевдоним Документы =
(Струна, может быть, струна)
docsParser : Парсер (Документы -> а) а
docsParser =
map Tuple.pair (строка идентификатор фрагмента)
-- /Basics ==> Просто ("Основы", Ничего)
-- /Maybe ==> Just ("Может быть", Ничего)
-- /List ==> Just ("Список", Ничего)
-- /List#map ==> Просто ("Список", Просто "карта")
-- /List# ==> Просто ("Список", Просто "")
-- /List/map ==> Ничего
-- / ==> Ничего
Итак, теперь мы можем работать и с фрагментами URL!
Синтез
Теперь, когда мы рассмотрели несколько синтаксических анализаторов, мы должны посмотреть, как они вписываются в программу Browser.application . Вместо того, чтобы просто сохранять текущий URL-адрес, как в прошлый раз, можем ли мы разобрать его на полезные данные и показать вместо этого?
ДЕЛАТЬ
Основные новинки:
- Наше обновление
UrlChanged.
