Содержание
Что такое парсинг, зачем он нужен и законно ли парсить данные
Парсинг — это автоматический процесс сбора и систематизации данных в интернете. Для него используют специальные программы — парсеры, которые отбирают с сайтов информацию по заданным критериям.
Личный кабинет сервиса для парсинга постов и профилей в Instagram* в программе Apify
Зачем нужен парсинг
Анализ конкурентов. Парсер поможет собрать информацию о том, какие товары и по каким ценам продают другие компании.
SEO-продвижение. При помощи парсинга вы можете собрать семантическое ядро, найти ошибки на своем сайте, проанализировать поисковую выдачу.
Запуск рекламы. Парсинг позволяет собрать базу целевой аудитории или найти потенциальные рекламные площадки.
Наполнение сайтов. Парсинг помогает наполнить сайты, на которые требуется большой объем информации. Например, распространена схема, когда парсят иностранные сайты и переводят информацию о товарах на нужный язык.
Анализ контента. Вы можете проанализировать посты, комментарии, сообщения, хештэги и другой контент, чтобы лучше понять поведение и потребности аудитории.
Сквозная аналитика. Парсер интегрируется с нужной площадкой, автоматически сводит данные о бюджетах и результатах сделок, подсчитывает окупаемость рекламных кампаний.
Как работает парсинг
Процесс парсинга можно схематично разделить на три шага.
- Вы указываете в программе условия, по которым нужно найти данные.
- Парсер сканирует код указанных сайтов — их называют целевыми — и ищет нужные данные.
- Собранные данные выводятся в отчете или собираются в таблицу.
Например, вы выходите на рынок товаров для животных и хотите узнать, какие цены устанавливают конкуренты на аналогичные продукты. Вы указываете в парсере товары, на которые нужно найти цены, выбираете нужный регион, перечисляете сайты конкурентов и запускаете программу.
Парсер анализирует указанные сайты, находит нужные товары и собирает расценки в единую базу. После окончания анализа программа формирует отчет — и вы можете наглядно увидеть ценовую политику в вашей отрасли.
Отчет о ценовой политике конкурентов на рынке электротранспорта в сервисе uXprice. Источник
Законность парсинга
Несмотря на большое количество плюсов, парсинг часто считают «серым» инструментом продвижения из-за последствий, к которым он может привести. Поэтому нужно учитывать некоторые нюансы.
Сам по себе сбор данных из открытых источников законом не запрещен — программы просто автоматизируют то, что маркетолог может сделать вручную. Право искать общедоступную информацию и использовать ее по своему усмотрению гарантируют статья 29 Конституции и статья 7 Закона об информации. При этом и искать, и использовать информацию нужно с соблюдением законодательства — и тут в силу вступают другие правовые нормы:
- Если при помощи парсеров вы полностью копируете информацию с сайтов конкурентов на собственный ресурс, это может привести к нарушению интеллектуального права.

- Чрезмерно агрессивный парсер может создать большую нагрузку на целевой сайт, которая будет выглядеть как DDOS-атака. Если вы парсите такой программой интернет-магазин, то он может стать недоступным на несколько часов, и владельцы сайта потерпят убытки. Даже если сайт не «приляжет», могут возрасти затраты на обслуживание серверов.
- В 272 статье Уголовного кодекса предусмотрена ответственность за «неправомерный доступ к охраняемой законом информации». Эта формулировка включает в себя персональные данные или коммерческую тайну. Например, нельзя парсить чужие списки клиентов, защищенную от несанкционированного доступа информацию, адреса электронной почты для последующей рассылки.
- Согласно поправкам 2021 года к Закону о персональных данных, для сбора и использования даже находящихся в открытом доступе персональных данных нужно получить согласие пользователя. Строго говоря, один из популярных способов использовать парсеры — собирать данные пользователей для запуска таргетированной рекламы — тоже незаконен. Но установить факт парсинга данных при запуске рекламы сейчас технически невозможно, поэтому многие компании продолжают использовать этот инструмент.
 Но установить факт парсинга данных при запуске рекламы сейчас технически невозможно, поэтому многие компании продолжают использовать этот инструмент.
Но установить факт парсинга данных при запуске рекламы сейчас технически невозможно, поэтому многие компании продолжают использовать этот инструмент.Вывод: парсить можно, главное, чтобы этот процесс не приводил к случаям, когда может возникнуть дополнительная ответственность. В частности нельзя продавать полученные данные, использовать персональные данные для рекламы и рассылок, копировать информацию на собственные ресурсы, создавать чрезмерную нагрузку на целевой сайт.
Плюсы парсинга
- Он ускоряет процесс сбора данных. Все эти действия обычно можно совершить вручную, но программа автоматизирует процесс и позволяет получить результат значительно быстрее.
- В программе можно тонко настроить параметры для сбора данных.
Парсер TargetHunter позволяет найти слушателей конкретного музыканта
- Парсинг защищает от ошибок, вызванных человеческим фактором.
- Парсер позволяет сэкономить бюджет как на сборе данных (вместо большого количества сотрудников процесс выполняет одна программа), так и на оптимизации рекламных кампаний. Например, парсеры социальных сетей позволяют более тонко настроить таргетированную рекламу, а значит, сэкономить на продвижении.
 Например, парсеры социальных сетей позволяют более тонко настроить таргетированную рекламу, а значит, сэкономить на продвижении.
Например, парсеры социальных сетей позволяют более тонко настроить таргетированную рекламу, а значит, сэкономить на продвижении.Парсинг можно проводить регулярно и автоматически: например, еженедельно отслеживать изменение цен конкурентов.
Виды парсинга
Парсинг товаров. Программа собирает информацию из каталога интернет-магазинов. На основе этих данных можно анализировать ассортимент конкурентов, заполнять страницы собственного сайта.
Парсинг цен. Позволяет проанализировать цены конкурентов и отслеживать изменения в ценовой политике.
Парсинг для SEO. Программа анализирует семантическое ядро целевых сайтов. Данные можно использовать как для наполнения собственного сайта ключевыми словами, так и для контекстной рекламы. Также этот вид парсинга используют, чтобы найти ошибки в мета-тегах, дублирующие элементы, битые ссылки и другие недочеты на собственном сайте.
Парсинг контактов. При этом виде парсинга программа собирает адреса электронной почты, номера телефонов и другую контактную информацию, которая находится в открытом доступе.
Парсинг аудитории. Помогает найти потенциальных клиентов, как правило, среди пользователей социальных сетей. Этот вид парсинга обычно используют для настройки таргетированной рекламы.
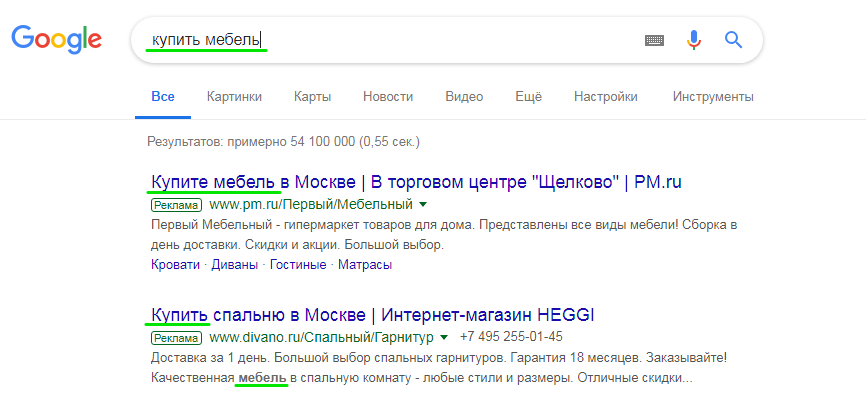
Парсинг выдачи. Выявляет лидеров поисковой выдачи по заданным ключевым словам и предоставляет дополнительную информацию — тип сниппета, заголовок, описание, анкоры, связанные ключевые слова. Можно использовать для анализа конкурентов или поиска подходящих рекламных площадок — это позволит размещать рекламу на ресурсах, которые лучше всего индексируются по нужным ключевым словам.
Результатом парсинга выдачи может быть Excel-таблица со всеми интересующими данными: запросом, ссылкой, заголовком, сниппетом. Источник
Программы для парсинга
Программу для парсинга можно разработать самостоятельно, а можно воспользоваться уже готовыми решениями. Вот несколько вариантов:
- Облачные парсеры сайтов: Диггернаут, Import.io, Apify, Mozenda (есть и десктопная версия).
- Десктопные парсеры сайтов: ParserOK, Neatpeak Spider, ComparseR, Parsehub (бесплатный)
- Парсеры социальных сетей: Церебро Таргет, TargetHunter, Pepper.Ninja.
- Парсеры email-адресов: Scrapp.io, Scrapebox Email Scraper.
Как правило, большинство парсеров предоставляют бесплатную версию, но она ограничена либо по времени, либо по возможностям.
Главные мысли
- Это автоматический сбор и систематизация нужных данных в интернете, которые производят при помощи специальных программ — парсеров.
- Программы анализируют выбранные сайты по заданным условиям: ищут цены конкурентов, контакты аудитории, ошибки в мета-тегах сайта, ключевые слова.
- Парсинг используют для SEO-продвижения, таргетированной рекламы, наполнения сайтов, анализа конкурентов, поиска рекламных площадок, создания ценовой политики.
- Парсить можно, но важно знать ситуации, в которых это может привести к нарушению закона. Например, нельзя использовать полученные адреса для рассылок без согласия пользователей.
 Например, нельзя использовать полученные адреса для рассылок без согласия пользователей.
Например, нельзя использовать полученные адреса для рассылок без согласия пользователей.Парсинг ключевых слов в Key Collector
После прочтения статей вы научитесь: оптимизировать кампании в Excel методами, которые используются в оптимизаторах конверсий; автоматически собирать семантику, сегментировать и создавать объявления; прогнозировать конверсию на базе истории и многое другое.
Темы статей:
- Выгрузка данных из Google Analytics и Яндекс Метрики по API
- Парсинг ключевых слов в Key Collector
- Кластеризация запросов
- Агрегирование данных
- Прогнозирование конверсии для ключевых слов
- Расчет ставок
- Разработка заголовков
- Разработка рекламных кампаний
- Анализ эффективности
Материал сложный и раскрывает только базовые подходы к автоматизации, чтобы задать вам вектор развития.
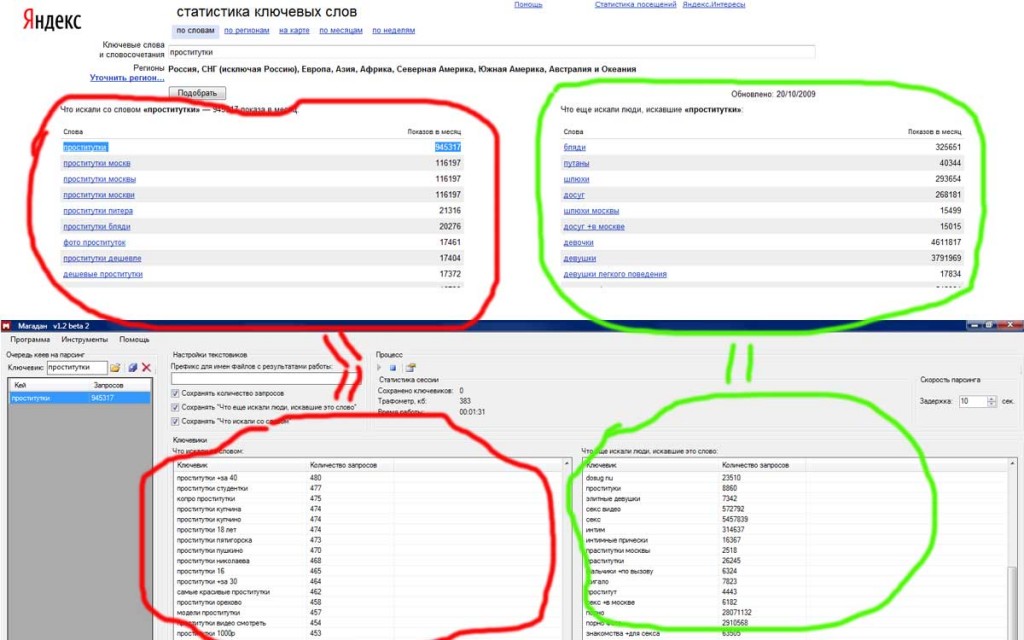
В прошлой статье мы получили список запросов с конверсиями из Яндекс Метрики, которые теперь нам предстоит распарсить входящие запросы. Парсить будем входящие ключевые слова с частотностью менее 2000, но более 30 запросов в месяц по России.
Парсить будем входящие ключевые слова с частотностью менее 2000, но более 30 запросов в месяц по России.
Что мы делаем?
1) У нас есть запросы с конверсиями, которые нам нужно расширить
2) Мы берем запросы с конверсиями и парсим их входящие запросы, которыми мы их потом и расширим 3) То есть мы создаем базу входящих ключевых слов, из которой подтянем похожие слова к словам с конверсиями. Если слово будет входить в одну группу с фразой с конверсией, то мы его «подтягиваем». 4) На практике можно использовать не только входящие слова, но и любые другие, базу слов можно «расширять» бесконечно, вы ограничены только ресурсами кластеризации. В рамках статьи мы взяли только входящие запросы, чтобы не усложнять ее.
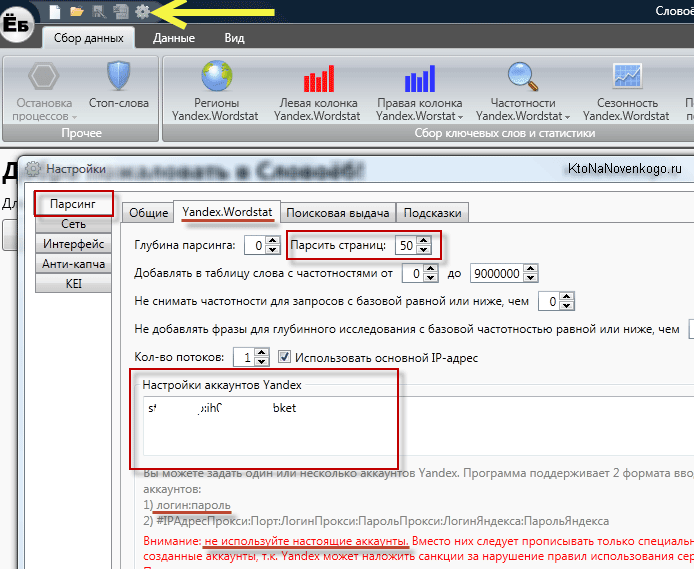
Парсим частотность запросов в Key Collector. Используем прокси с сайта primeproxy.net . Сайт проверенный, вы нам поверьте, мы парсим в промышленных масштабах!
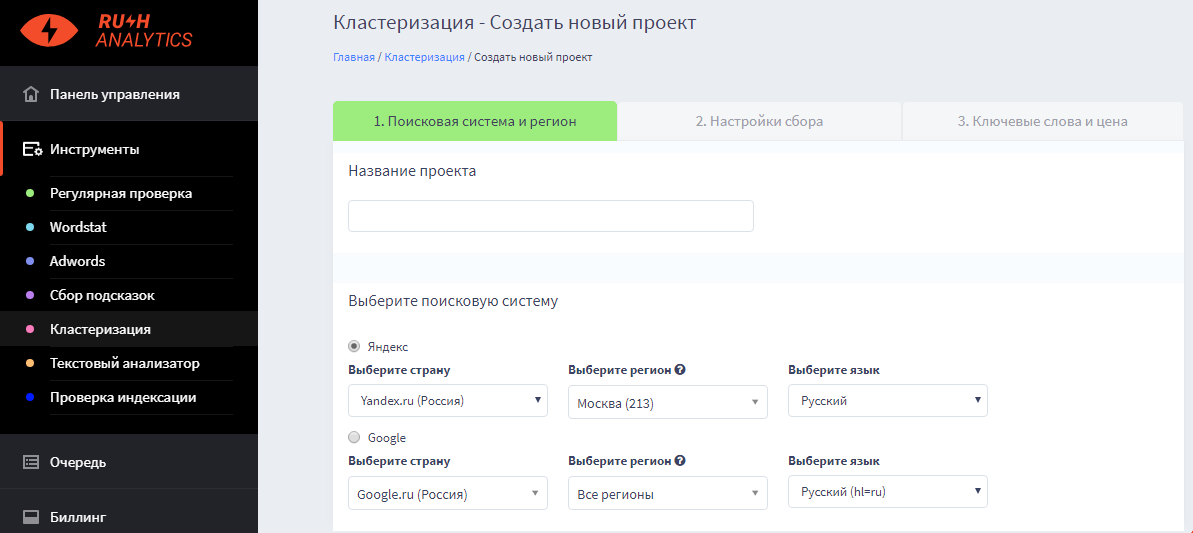
Цены
Вставляем полученные прокси в настройки, как на скринах. К каждому IP нужно закрепить аккаунт в Яндекс Директе. В нашем случае мы купили 5 прокси и сможем парсить в 5 потоков. Вставляем адреса в соответствующие поля.
В нашем случае мы купили 5 прокси и сможем парсить в 5 потоков. Вставляем адреса в соответствующие поля.
И сюда.
Ссылки
Если у вас много посадочных страниц >1000, то лучше импортировать фразы вместе с ссылками, по которым была конверсия, так как она может пригодиться.
Вставляем слова в Key Collector
Запускаем парсинг
Фильтруем список ключевых слов от 50 до 2000, чтобы распарсить их в вордстате.
Почему именно такие цифры? — Меньше 30 собирать слова нет смысла, их там очень мало — легче просто охватить их задав широкое соответствие, а свыше 2000 слишком много, потребуется много ресурсов на кластеризацию и немного другой подход, который усложнит статью.
Тут одна проблема, у нас 1500 ключевых слов, которые включают входящие запросы и получается так, что мы будем парсить один и тот же массив несколько раз, например, у нас есть слова «купить игрушку танк» и «купить игрушку». Нам не смысла парсить «купить игрушку танк», так как она находится внутри «купить игрушку».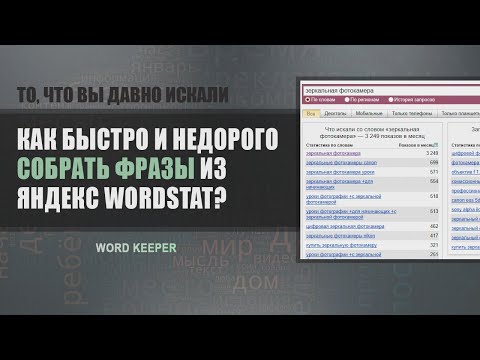
Но как из массива 1500 удалить входящие слова? Готовых решений нет, поэтому пришлось написать свой код на Python.
#!/usr/bin/env python # -*- coding: UTF-8 -*- # импортируем библиотеки import pandas as pd import re # открываем таблицу df = pd.read_excel('Слова для парсинга в вордстате.xlsx', header=0) # в столбике delete пишем delete для входящих ключевых слов df.loc[:,'delete'] = 0 for i in range(len(df)): temp = df.loc[i,'delete'] t = df.copy() for word in df.loc[i,'Keyword'].split(' '): t = t[t['Keyword'].str.contains(word)] for idx in t.index: df.loc[idx,'delete'] = 'delete' df.loc[i,'delete'] = temp # сохраняем таблицу в файл df.to_excel('Слова для парсинга в вордстате.xlsx')
На выходе получаем новый столбик «delete», в котором значение «0» значит верхний запрос, а «delete» входящий — все входящие запросы мы удаляем, а верхние распарсиваем в wordstat’е
Фильтруем слова со значением «0» и копируем их в кей коллектор, получилось 1000 слов из 1500.
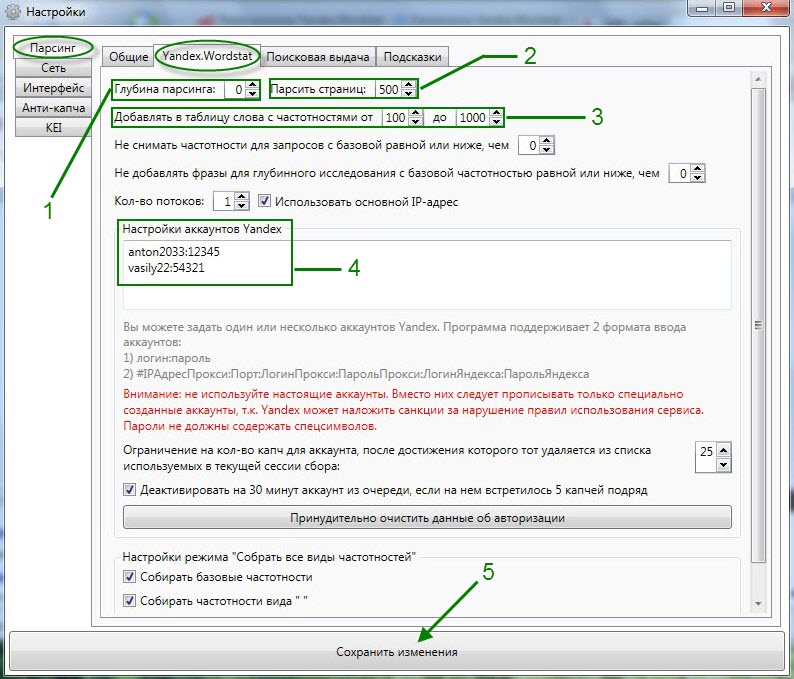
Вставляем в KeyCollector
Для парсинга используем настройки, которые на скрине — мы изменили кол-во потоков на 5, так как у нас 5 прокси и для каждого свой аккаунт в Яндекс Директе.
Все, парсинг запущен, в следующем этапе поговорим о прогнозировании.
Пишите вопросы в комментариях, какие темы было бы интересно раскрыть подробнее? Если у вас есть идеи или советы, то делитесь!
Типы синтаксических анализаторов и принцип их работы
В общем, существует три типа подходов к анализу резюме/резюме:
o Анализаторы на основе ключевых слов
o Анализаторы на основе грамматики
o Статистические анализаторы
Анализаторы на основе ключевых слов
Определение.- Парсер CV на основе ключевых слов работает, идентифицируя слова, фразы и простые шаблоны в тексте CV/резюме, а затем применяя простые эвристические алгоритмы к тексту, который они находят вокруг этих слов. Это самый простой и наименее точный анализатор резюме.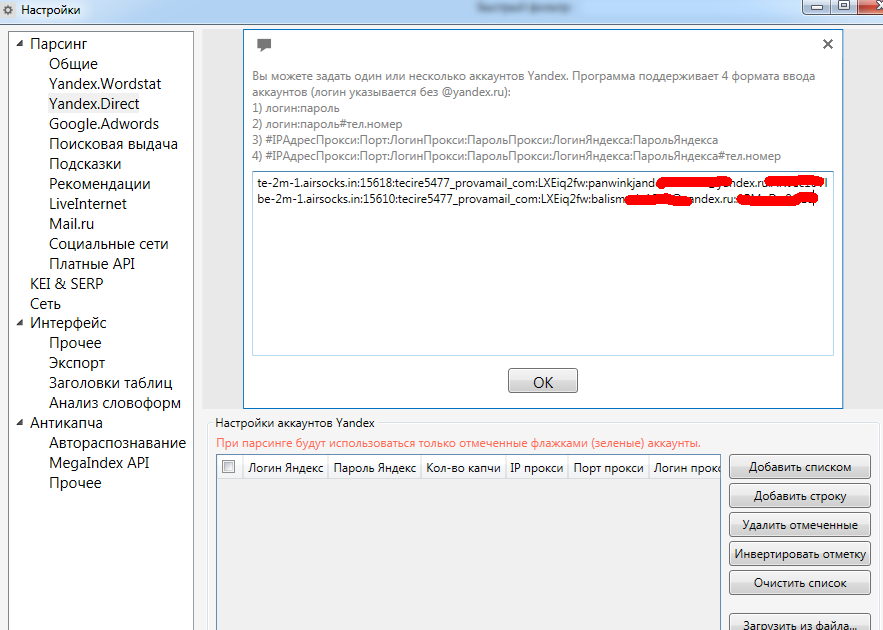
Особенности.- Эти инструменты могут искать что-то похожее на почтовый индекс, а затем пытаться интерпретировать окружающие слова как адрес, или они могут искать шаблоны, которые выглядят как диапазоны дат и предполагают, что окружающий текст является график занятости.
Точность.- трудно превысить 70% точности . Этот тип синтаксического анализа резюме наименее точен, потому что они не могут извлечь информацию, которая не окружает одно из их ключевых слов, а если их ключевые слова неоднозначны (например, навык «Директор»), они часто делают неверные предположения о его интерпретации. .
Анализаторы на основе грамматики
Определение.- Анализаторы на основе грамматики содержат огромное количество грамматических правил, которые направлены на понимание контекста каждого слова в резюме/резюме. Эти же грамматики также объединяют слова и фразы вместе, создавая сложные структуры, отражающие значение каждого предложения в резюме.
Особенности.- Эти синтаксические анализаторы намного сложнее, чем синтаксические анализаторы на основе ключевых слов, и обычно захватывают гораздо больше деталей, а также способны различать различные значения, которые одно слово или фраза могут иметь в разных контекстах.
Точность.- Можно достичь точности намного выше 90% (человеческая точность редко превышает 96%). Недостатком является то, что этот тип синтаксического анализатора резюме требует большого количества ручного кодирования квалифицированными языковыми инженерами и большого количества тестов, чтобы убедиться, что улучшения в одной области не ухудшают производительность в другой.
Статистические синтаксические анализаторы
Определение.- Этот тип синтаксического анализатора пытается применить числовые модели текста для определения структуры резюме/резюме. Как и синтаксические анализаторы на основе грамматики, они могут различать разные контексты одного и того же слова или фразы, а также могут захватывать самые разные структуры, такие как адреса, временные шкалы и т. п.
п.
Характеристики.- Чтобы быть максимально точным, им требуется в качестве входных данных огромное количество резюме/резюме, которые вручную размечаются со всей информацией, необходимой для извлечения.
Точность.- Этот тип анализатора обычно работает лучше, чем анализатор на основе ключевых слов, но не так хорошо, как анализатор на основе грамматики на данных, на которых анализатор не был обучен. Таким образом, чтобы статистический синтаксический анализатор был точным, он должен быть предварительно обучен на данных, которые он должен обрабатывать.
Итак, каковы ключевые параметры хорошего анализатора резюме ?
Выбор метода анализа
В этом разделе рассказывается, как выбрать подходящий метод анализа при определении анализатора.
▪Ключевое слово
▪Параграф
▪Таблица
▪Фильтр
▪Скрипт
Ключевое слово
Пример.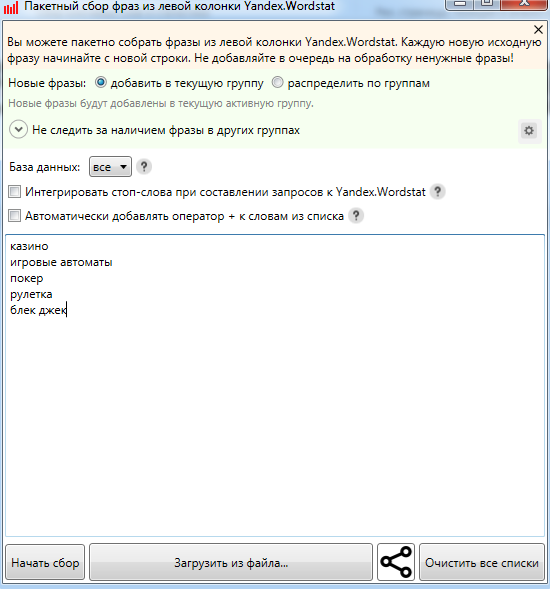 Используйте метод Keyword для анализа номера версии.
Используйте метод Keyword для анализа номера версии.
1.Введите команду show version и получите образцы данных на странице редактора парсера.
2.Выделите номер версии точно в образце данных и щелкните Определить ключевое слово в плавающем меню.
3. В диалоговом окне синтаксического анализатора ключевых слов будут автоматически определены как шаблон синтаксического анализатора, так и тип переменной. Переименуйте переменную с var1 на Version.
4.Нажмите Сохранить переменную. Эта переменная будет отображаться в дереве переменных.
Paragraph
Метод Paragraph используется для анализа данных с несколькими экземплярами, таких как коллизии и ошибки CRC для каждого интерфейса в возвращаемых выходных данных команды show interface.
Пример: Используйте метод Paragraph для анализа MTU интерфейса.
1.Введите команду show interface и получите образцы данных на странице редактора анализатора. Пример вывода выглядит следующим образом:
Bos-Core1-Tr>show interface
.
Vlan1 работает, протокол линии работает
Аппаратное обеспечение — EtherSVI, адрес — 0024.1358.1540 (bia 0024.1358.1540)
.
MTU 1500 байт, BW 1000000 Кбит, DLY 10 мкс,
………….
Vlan10 работает, протокол линии работает
Аппаратное обеспечение — EtherSVI, адрес — 0024.1358.1542 (bia 0024.1358.1542)
.
Интернет-адрес: 10.83.10.254/24
.
MTU 1500 байт, BW 1000000 Кбит, DLY 10 мкс,
…………
2.Выделите значение MTU 1500 в образце данных и нажмите «Определить ключевое слово» в плавающем меню. Появится диалоговое окно анализатора ключевых слов.
3. Нажмите «Определить переменную» в разделе «Абзацы» во всплывающем диалоговом окне, чтобы перейти в диалоговое окно «Синтаксический анализ абзацев».
Совет. Анализатор абзацев используется, когда выходные данные команды соответствуют ключевому слову несколько раз, и каждое ключевое слово имеет одинаковое форматирование абзаца, например, начиная с …is…, line protocol is.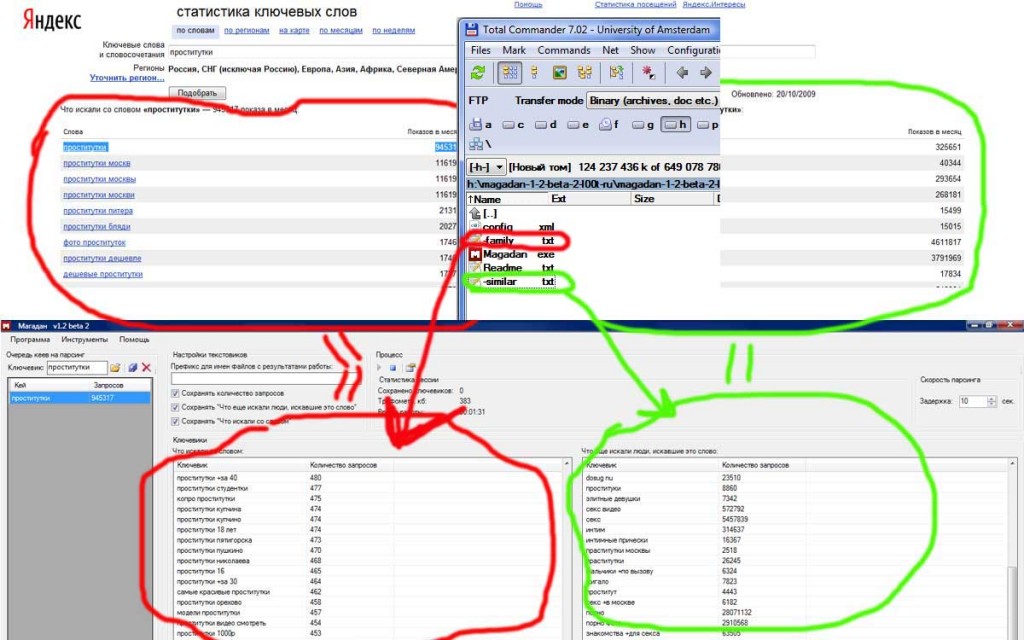
4.Укажите идентификатор абзаца, чтобы определить начало нового абзаца для каждой переменной.
1)Выделите Vlan 1 включен, протокол линии и щелкните Set Paragraph Identifier в плавающем меню.
2) Идентификатор абзаца включает в себя ключевые слова, которые всегда одинаковы, и выборочные значения, которые изменяются. Замените его на $intf is $status, протокол линии.
3) Нажмите клавишу Enter на клавиатуре, чтобы применить идентификатор абзаца.
5. Переименуйте переменную с var1 на MTU.
6.Необязательно: Настройте дополнительные параметры.
Нажмите «Дополнительно», чтобы настроить дополнительные параметры: 1) Чтобы дополнительно разделить абзац вручную, используйте один из следующих двух способов: ▪Введите конечное ключевое слово абзаца и выберите, следует ли Исключить завершающую строку в абзаце. ▪Отметьте флажок Задать _ строк как абзац и введите количество строк, которые вы хотите включить после строки переменной. 2)Чтобы заполнить пустую переменную, скопировав значение последней переменной, вы можете включить последний флажок и выбрать применяемую переменную из выпадающего меню. 3)Нажмите OK. |
|---|
7.Нажмите Сохранить переменную.
Эта переменная MTU будет отображаться под синтаксическим анализатором абзаца в дереве переменных.
Таблица
Метод таблицы используется для анализа данных в табличном формате, таких как таблица NDP.
Пример. Используйте метод Table для анализа соседей OSPF устройства.
1.Введите команду show ip ospf Neighbour и получите образцы данных на странице редактора парсера. Пример вывода выглядит следующим образом:
BST,POP1>show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
172.24.255.9 1 FULL/ — 00:00:32 172.24.33.140 Serial0
172.24.255.10 1 FULL/DR 00:00:32 172.24.32.6 Ethernet1
172. 24.31.2 1 FULL/ — 00:00:39 172.24.32.1 Serial1
24.31.2 1 FULL/ — 00:00:39 172.24.32.1 Serial1
2.Выделите таблицу в образце данных и нажмите «Определить таблицу» в плавающем меню. Диалоговое окно Table Parser предлагает заголовки таблиц, идентифицированные как переменные.
3.Необязательно: Настройте дополнительные параметры.
Нажмите «Дополнительно», чтобы настроить дополнительные параметры: 1)Выберите способ выравнивания данных таблицы или способ разделения столбца, если он не отформатирован в виде таблицы: ▪Выравнивание по левому краю — выравнивание данных таблицы по левому краю. ▪Выравнивание по правому краю — выравнивание данных таблицы по правому краю. ▪Диапазон символов — адресуйте заголовок таблицы, считая символы от 0, например 0;5;13. ▪Количество слов — обращение к заголовку таблицы путем подсчета количества слов, например 1;2;1. 9$. 3) Чтобы игнорировать несколько первых строк данных таблицы, вы можете установить флажок Пропустить _ строки из заголовка и ввести количество строк. 4)Чтобы заполнить пустое значение переменной, скопировав значение последней переменной, вы можете включить последний флажок и выбрать применяемую переменную из выпадающего меню. |
|---|

4.Нажмите Сохранить переменную. Переменные будут отображаться под синтаксическим анализатором таблицы в дереве переменных.
Фильтр
Метод Filter используется для фильтрации данных на основе условий.
Пример. Используйте метод Filter для анализа пассивных интерфейсов протокола маршрутизации.
1.Введите команду show ip protocols и получите образцы данных на странице редактора парсера.
2. Определите начальную и конечную строки содержимого, которое нужно отфильтровать, выделите интересующее вас содержимое (информация о начальной и конечной строках должна быть включена) и нажмите «Определить фильтр» в плавающем меню.
3. В диалоговом окне Filter Parser автоматически определяются и заполняются начальная и конечная строки. Переименуйте переменную с filter1 на eigrp_passive.
Переименуйте переменную с filter1 на eigrp_passive.
4.Необязательно: Настройте дополнительные параметры.
Нажмите Дополнительно, чтобы настроить условия для фильтра: 1) Выберите «Содержит» или «Не содержит» в раскрывающемся меню и введите ниже ключевое слово. 2)Выберите метод фильтрации: ▪Отфильтровать все совпадающие строки — адресовать все совпадения в пределах области фильтра; если флажок не установлен, фильтр остановится, как только будет найдено первое совпадение. ▪Исключить начальную строку — убрать начальную строку из области фильтра. ▪Исключить конечную строку — убрать конечную строку из области действия фильтра. 3)Нажмите OK. |
|---|
5.Нажмите Сохранить переменную.
Этот синтаксический анализатор фильтров будет отображаться под деревом переменных.
6.Добавьте синтаксический анализатор вложенных таблиц под синтаксический анализатор фильтров:
1) Выберите узел Фильтр($eigrp_passive) в дереве синтаксических анализаторов и выберите Таблица.