Содержание
Возвращаем Яндекс-поиск в Firefox / Информационная безопасность, Законы, Программы, ПО, сайты / iXBT Live
Для работы проектов iXBT.com нужны файлы cookie и сервисы аналитики.
Продолжая посещать сайты проектов вы соглашаетесь с нашей
Политикой в отношении файлов cookie
Вероятно, поддавшись последним веяниям, компания Mozilla, в обновлении 98.0.1 от 14 марта, удалила поиск Yandex и Mail.ru в своем весьма популярном браузере Firefox, сделав активным, по умолчанию, поиск Google. Не то чтобы слишком печально, но неприятно, если привык именно к Яндексу. Однако, совсем немного потыкавшись в менюшках браузера, привычный поиск вполне можно вернуть без всяких сложностей.
Пользователи, у которых Firefox обновляется автоматически до новой версии, при перезагрузке браузера после обновления, под строкой меню, получили сообщение, что Yandex-поиск был заменен на поиск Google. Об этом же можно почитать на официальной странице:
Соответственно, после такого обновления, вбивая текстовый запрос на поиск в строке адреса или в окошке поиска, даже если в браузере ранее по умолчанию был пользователем установлен поиск от Яндекса, теперь стал открываться Google. Также нет возможности выбрать «Яндекс», нажав на лупу в окошке поиска:
Также нет возможности выбрать «Яндекс», нажав на лупу в окошке поиска:
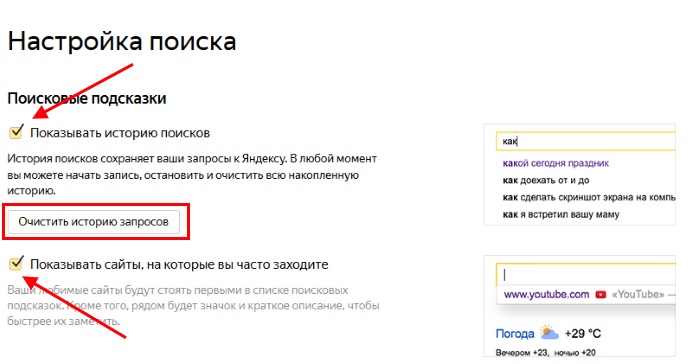
Заходя в «Настройки» -> «Поиск» также нет возможности выбрать Яндекс (или Mail.ru):
И в значках поисковых систем он также пропал:
Таким образом, из настроек фактически его никак ввернуть нельзя. Однако, это можно сделать просто внимательно почитав руководство пользователя на сайте Mozilla. Один из способов оказался не закрыт. Заключается он в добавлении поисковой системы из адресной панели браузера. Чем и воспользуемся.
Просто заходим на Яндекс, кликаем на адресной строке правой кнопкой мышки и, в выпадающем меню, жмем «Добавить „Яндекс“:
Теперь он также появляется в меню выбора поисковика (при нажатии на лупу в строке поиска буква „Я“):
Ну а теперь заходим в „Настройки“-> „Поиск“ и выбираем по умолчанию, в качестве поисковика Яндекс, который опять появился в меню:
Всё! Мы все починили. Теперь по умолчанию снова работает поиск от Яндекса:
Проверяем… При наборе поискового текста в адресной строке или в окошке поиска.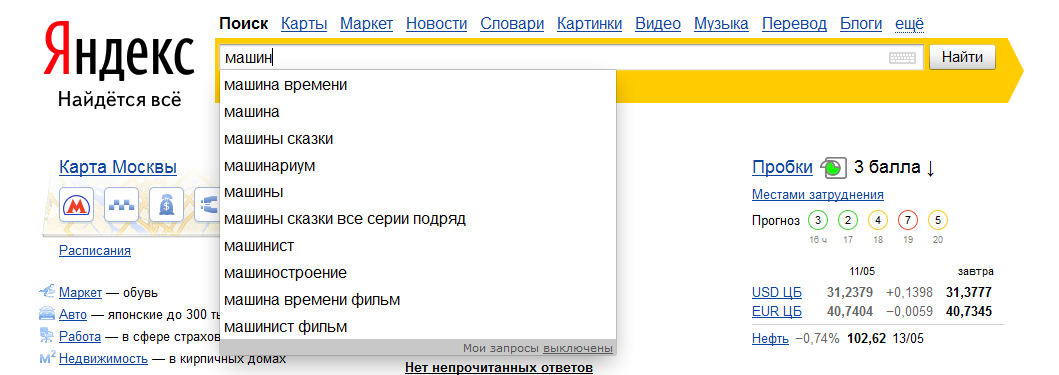 ….
….
… вываливаются поисковые запросы от Яндекс:
Чтобы Firefox больше так не пакостил, можно отменить автоматическую установку обновлений.
Почему производитель „проглядел“ такую возможность простого восстановления поиска не очень понятно, ну и ладно. С mail.ru такой способ не сработал.
Новости
Публикации
Социальная инженерия – это психологическое воздействие на людей, через манипуляции, обман и внушение. Цель: побуждение человека к каким-либо действиям, получение конфиденциальной информации,…
«Горшочек, больше не вари!» — вспомнилась мне сказка братьев Гримм при взгляде на электрическую мультиварку mc-5100 от GOODHELPER. Сегодня в обзоре хочу рассказать о данной мультиварке, отметив…
Электрический
чайник давно вошел в повседневную жизнь каждого человека. Сейчас редко можно
увидеть на кухне обычный эмалированный чайник, даже если у вас газовая плита.
По сути своей они все очень…
Хорошая новость в том, что провисание и связанные с ним проблемы можно легко предотвратить. Источник: www.palit.com Во что в конце концов выльются бесконтрольно растущие размеры…
Источник: www.palit.com Во что в конце концов выльются бесконтрольно растущие размеры…
Человек существо социальное, мы постоянно общаемся с множеством людей, в том числе невербально (жестами и языком тела без слов). Мы все привыкли кивать головой на утверждение (когда говорим «да»)…
Как
уже можно было убедиться ранее, Hoco – достаточно специфический бренд, продукты которого
могут вызывать смешанные впечатления. Достаточно давно было заказано данное
зарядное устройство, но…
Причины удаления страницы из индекса поисковой системы Яндекс?
#Оптимизация сайта
#Индексация
#82
Ноябрь’18
19
Ноябрь’18
19
Анализируя индексацию сайта в поисковой системе Яндекс, можно увидеть, что некоторые страницы сайта были исключены из индекса.
Основные причины удаления страниц из поиска
Ошибки ответа сервера — 3**, 4**, 5**
- Код ответа 3** связан с переадресацией страниц. Наиболее простой пример, когда из индекса удаляется страница — когда она имеет 301 редирект.
- Код ответа 4** связан с недоступностью страницы. Самые популярные ошибки — 404 и 403.
Первый код означает, что страница больше не открывается по данному адресу, и соответственно Яндекс удаляет ее из поиска.
Важно: если вы поменяли адрес странице, но она уже была в индексе, то необходимо настроить 301 редирект на новую страницу.
403 код ответа сервера указывает на то, что отсутствует доступ к данному ресурсу. В таком случае необходимо разобраться с настройками хостинга.
- Из-за проблем с сервером (коды ошибок 5**) страницы также удаляются из индекса.
Запрет к индексации
Страница запрещена к индексации через файл robots.txt или через мета-тег noindex.
Страница имеет атрибут rel=«canonical»
Тег <link> с данным атрибутом указывает, какую ссылку необходимо индексировать ПС.
Дубликаты страницы
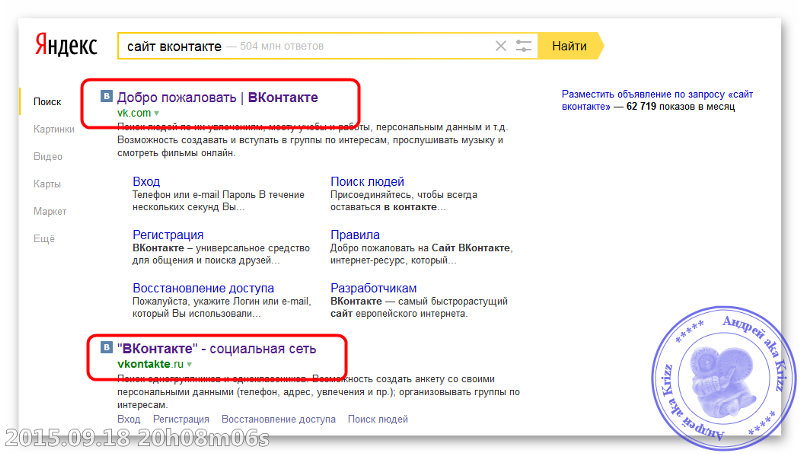
Обычно из индекса удаляются страницы, имеющие одинаковый контент, но открывающиеся по различным адресам. Но на скриншоте выше разные страницы https://tk9.ru/in/maslo_rapsovoe_neraf/ и https://tk9.ru/catalog/ признаны дубликатами. В таких ситуациях рекомендуется сообщать технической поддержке об ошибке и отправлять страницы на переобход.
Недостаточное качество страницы
Как вовремя реагировать на изменения
Чтобы быть в курсе всех изменений, рекомендуется настроить уведомления в панели вебмастера:
Также рекомендуется добавить целевые страницы в инструмент «Мониторинг важных страниц».
Что делать, если Яндекс удалил нужную страницу из поиска
В таком случае необходимо устранить причину удаления и отправить ее на переобход https://webmaster.yandex.ru/site/indexing/reindex/. Страница вернется в поиск в ближайшие апдейты.
Похожее
Оптимизация сайта
Индексация
Атрибут rel=canonical
Оптимизация сайта
Индексация
Индексация ссылок
Оптимизация сайта
Индексация
#133
Атрибут rel=canonical
Апрель’23
12751
23
Оптимизация сайта
Индексация
#119
Индексация ссылок
Апрель’19
4864
30
Оптимизация сайта
Индексация
#111
Описание и настройка директивы Clean-param
Апрель’19
10221
24
Оптимизация сайта
Индексация
#104
Как привлечь быстроробота Яндекс
Февраль’19
2379
21
Оптимизация сайта
Индексация
#94
Проверка индекса сайта. Как найти мусорные или недостающие страницы
Как найти мусорные или недостающие страницы
Декабрь’18
10184
28
Оптимизация сайта
Индексация
#86
Как закрыть ссылки и текст от поисковых систем
Ноябрь’18
6668
22
Оптимизация сайта
Индексация
#60
Правильная индексация страниц пагинации
Февраль’18
8777
19
Оптимизация сайта
Индексация
#47
Как узнать дату индексации страницы
Ноябрь’17
8427
19
Оптимизация сайта
Индексация
#46
Какие страницы надо закрывать от индексации
Ноябрь’17
11350
19
Оптимизация сайта
Индексация
#38
Как удалить страницу из индекса Яндекса и Google
Ноябрь’17
15043
20
Оптимизация сайта
Индексация
#37
Как добавить страницу в поиск Яндекса и Google
Апрель’17
21025
19
Оптимизация сайта
Индексация
#7
Как закрыть сайт от индексации
Ноябрь’17
10679
18
Оптимизация сайта
Индексация
#2
Как проверить индексацию сайта в поисковых системах
Ноябрь’17
18560
27
Оптимизация сайта
Индексация
#1
Как ускорить индексацию сайта
Ноябрь’17
6743
29
Утечка факторов ранжирования в поиске Яндекса: информация
Сообщество поискового маркетинга пытается разобраться в просочившемся репозитории Яндекса, содержащем файлы, перечисляющие то, что выглядит как факторы ранжирования в поиске.
Некоторые могут искать действенные подсказки SEO, но это, вероятно, не реальная ценность.
По общему мнению, это будет полезно для общего понимания того, как работают поисковые системы.
Если вам нужны хаки или ярлыки, их здесь нет. Но если вы хотите больше узнать о том, как работает поисковая система. Есть золото.
— Райан Джонс (@RyanJones) 29 января 2023 г.
Есть чему поучиться
Райан Джонс (@RyanJones) считает, что эта утечка имеет большое значение.
Он уже загрузил некоторые модели машинного обучения Яндекса на свою машину для тестирования.
Райан убежден, что есть чему поучиться, но для этого потребуется гораздо больше, чем просто изучение списка факторов ранжирования.
Райан объясняет:
«Хотя Яндекс — это не Google, мы можем многому научиться из этого с точки зрения сходства.
Яндекс использует множество технологий, изобретенных Google.
Они ссылаются на PageRank по имени, используют Map Reduce и BERT и многое другое.
Очевидно, что факторы будут различаться, и веса, применяемые к ним, также будут различаться, но методы компьютерной науки того, как они анализируют релевантность текста, связывают текст и выполняют вычисления, будут очень похожи в разных поисковых системах.
Я думаю, что мы можем почерпнуть много информации из факторов ранжирования, но одного лишь просмотра просочившегося списка недостаточно.
Когда вы смотрите на веса по умолчанию (до машинного обучения), вы видите отрицательные веса, которые SEO-специалисты считают положительными, или наоборот.
Кроме того, в коде рассчитывается НАМНОГО больше факторов ранжирования, чем указано в списках факторов ранжирования.
Этот список, по-видимому, представляет собой только статические факторы и не учитывает, как они вычисляют релевантность запроса, или многие динамические факторы, связанные с набором результатов для этого запроса».
 Они ссылаются на PageRank по имени, используют Map Reduce и BERT и многое другое.
Они ссылаются на PageRank по имени, используют Map Reduce и BERT и многое другое.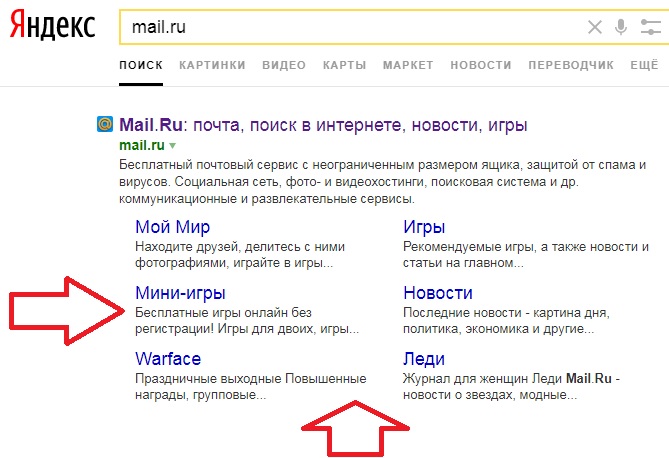
Более 200 факторов ранжирования
На основе утечки часто повторяют, что Яндекс использует 1923 фактора ранжирования (некоторые говорят, что меньше).
Кристоф Цемпер (профиль LinkedIn), основатель Link Research Tools, говорит, что друзья сказали ему, что существует гораздо больше факторов ранжирования.
Кристоф поделился:
«Друзья видели:
- 275 факторов персонализации
- 220 факторов «свежести в Интернете»
- 3186 факторов поиска изображений
- 2 314 факторов поиска видео
Еще многое предстоит нанести на карту.
Наверное, самое удивительное для многих то, что у Яндекса сотни коэффициентов для ссылок».
Дело в том, что это намного больше, чем 200+ факторов ранжирования, которые раньше заявлял Google.
И даже Джон Мюллер из Google сказал, что Google отошел от 200+ факторов ранжирования.
Так что, возможно, это поможет индустрии поиска отойти от того, чтобы думать об алгоритме Google в таких терминах.
Никто не знает весь алгоритм Google?
Что поразительно в утечке данных, так это то, что факторы ранжирования были собраны и организованы таким простым способом.
Утечка ставит под сомнение идею о том, что алгоритм Google тщательно охраняется и что никто, даже в Google, не знает всего алгоритма.
Возможно ли, что в Google есть таблица с более чем тысячей факторов ранжирования?
Кристоф Семпер сомневается в том, что никто не знает алгоритма Google.
Кристоф прокомментировал журнал Search Engine:
«Кто-то сказал в LinkedIn, что не может себе представить, чтобы Google просто так «документировал» факторы ранжирования.
Но именно так нужно строить подобную сложную систему. Эта утечка исходит от очень авторитетного инсайдера.
У Google есть код, который также может стать предметом утечки.
Часто повторяющееся утверждение о том, что даже сотрудники Google не знают факторов ранжирования, всегда казалось абсурдным для такого технического специалиста, как я.
Людей, у которых есть все детали, будет очень мало.
Но это должно быть в коде, потому что код — это то, что запускает поисковую систему.
Какие части Яндекса похожи на Google?
Просочившиеся файлы Яндекса дают представление о том, как работают поисковые системы.
Данные не показывают, как работает Google. Но он дает возможность просмотреть часть того, как поисковая система (Яндекс) ранжирует результаты поиска.
То, что содержится в данных, не следует путать с тем, что может использовать Google.
Тем не менее, между двумя поисковыми системами есть интересные сходства.
MatrixNet — это не RankBrain
Одна из интересных идей, которую некоторые находят, связана с нейронной сетью Яндекса под названием MatrixNet.
MatrixNet — более старая технология, представленная в 2009 году (ссылка на объявление на сайте archive.org).
Вопреки утверждениям некоторых, MatrixNet не является Яндекс-версией Google RankBrain.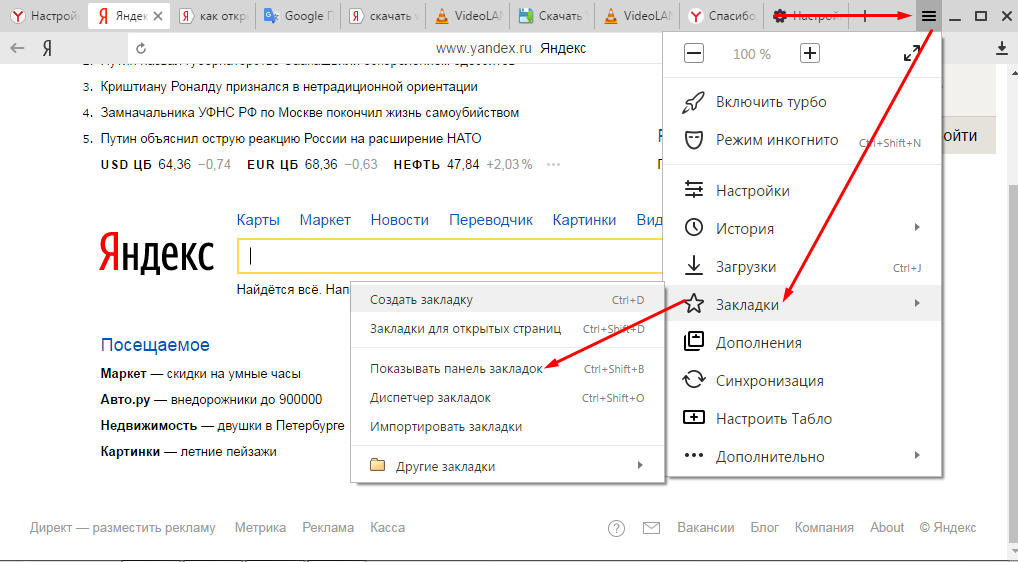
Google RankBrain — это ограниченный алгоритм, ориентированный на понимание 15% поисковых запросов, которые Google раньше не видел.
Статья в Bloomberg раскрыла информацию о RankBrain в 2015 году. В статье говорится, что RankBrain был добавлен в алгоритм Google в том же году, через шесть лет после появления Yandex MatrixNet (снимок статьи на Archive.org).
В статье Bloomberg описывается ограниченное назначение RankBrain:
«Если RankBrain увидит слово или фразу, с которыми он не знаком, машина может предположить, какие слова или фразы могут иметь похожее значение, и соответствующим образом отфильтровать результат, что сделает его более эффективным при обработке невиданных ранее поисковых запросов».
MatrixNet, с другой стороны, представляет собой алгоритм машинного обучения, который делает множество вещей.
Одной из его задач является классификация поискового запроса и последующее применение к этому запросу соответствующих алгоритмов ранжирования.
Это часть того, что говорится в анонсе алгоритма 2009 года на английском языке за 2016 год:
«MatrixNet позволяет создать очень длинную и сложную формулу ранжирования, которая учитывает множество различных факторов и их комбинаций.
Еще одной важной особенностью MatrixNet является возможность настройки формулы ранжирования для определенного класса поисковых запросов.
Кстати, настройка алгоритма ранжирования, скажем, для поиска музыки не повлияет на качество ранжирования для других типов запросов.
Алгоритм ранжирования похож на сложный механизм с десятками кнопок, переключателей, рычагов и датчиков. Обычно любой поворот любого отдельного переключателя в механизме приводит к глобальным изменениям во всей машине.
Однако
MatrixNet позволяет настраивать определенные параметры для конкретных классов запросов, не вызывая капитального ремонта всей системы.
Кроме того, MatrixNet может автоматически выбирать чувствительность для определенных диапазонов факторов ранжирования».

MatrixNet делает гораздо больше, чем RankBrain, но очевидно, что это не одно и то же.
Но что классно в MatrixNet, так это то, что факторы ранжирования являются динамическими, поскольку он классифицирует поисковые запросы и применяет к ним различные факторы.
MatrixNet упоминается в некоторых документах по факторам ранжирования, поэтому важно поместить MatrixNet в правильный контекст, чтобы факторы ранжирования рассматривались в правильном свете и имели больше смысла.
Возможно, будет полезно узнать больше об алгоритме Яндекса, чтобы разобраться в утечке Яндекса.
Прочтите: Искусственный интеллект и алгоритмы машинного обучения Яндекса
Некоторые факторы Яндекса соответствуют практике SEO
У Доминика Вудмана (@dom_woodman) есть несколько интересных наблюдений об утечке.
Некоторые из просочившихся факторов ранжирования совпадают с некоторыми методами SEO, такими как изменение анкорного текста:
Меняй якорный текст, детка!
4/х pic.
— Доминик Вудман (@dom_woodman) 27 января 2023 г.
 twitter.com/qSGh5xF5UQ
twitter.com/qSGh5xF5UQАлекс Буракс (@alex_buraks) опубликовал в Твиттере мегатред на эту тему, которая имеет отголоски практики SEO.
Один из таких факторов, который выделяет Алекс, относится к оптимизации внутренних ссылок для минимизации глубины сканирования важных страниц.
Джон Мюллер из Google уже давно призывает издателей делать ссылки на важные страницы заметными.
Мюллер не рекомендует закапывать важные страницы глубоко в архитектуру сайта.
Джон Мюллер поделился в 2020 году:
«Итак, мы увидим, что домашняя страница действительно важна, вещи, связанные с домашней страницей, как правило, также очень важны.
А потом… по мере того, как он будет удаляться от главной страницы, мы подумаем, что это менее критично».
Очень важно, чтобы важные страницы находились рядом с главными страницами, на которые заходят посетители сайта.
Таким образом, если ссылки ведут на домашнюю страницу, то страницы, на которые есть ссылки с домашней страницы, считаются более важными.
Джон Мюллер не говорил, что глубина сканирования является фактором ранжирования. Он просто сказал, что это сигнализирует Google, какие страницы важны.
Правило Яндекса, на которое ссылается Алекс, использует глубину сканирования с главной страницы в качестве правила ранжирования.
#1 Глубина сканирования является фактором ранжирования.
Держите важные страницы ближе к главной странице:
– главные страницы: 1 клик от главной страницы
– важные страницы: <3 клика pic.twitter.com/BB1YPT9Egk— Алекс Буракс (@alex_buraks) 28 января 2023 г.
Имеет смысл рассматривать домашнюю страницу как отправную точку важности, а затем вычислять меньшую важность, чем дальше от нее щелкают вглубь сайта.
Есть также исследовательские работы Google, в которых есть похожие идеи (модель разумного пользователя, модель случайного пользователя), которые рассчитывают вероятность того, что случайный посетитель может оказаться на данной веб-странице, просто перейдя по ссылкам.
Алекс обнаружил фактор, определяющий приоритет важных главных страниц:
#3 Обратные ссылки с главных страниц важнее, чем с внутренних страниц.
Имеет смысл. pic.twitter.com/Mts9jHsRjE
— Алекс Буракс (@alex_buraks) 28 января 2023 г.
Эмпирическое правило для SEO уже давно заключается в том, чтобы держать важный контент на расстоянии не более нескольких кликов от главной страницы (или от внутренних страниц, которые привлекают внешние ссылки).
Яндекс Update Vega… Связано с экспертизой и авторитетностью?
Яндекс обновил свою поисковую систему в 2019 году обновлением Vega.
В обновлении Яндекс Вега появились нейронные сети, обученные с экспертами по теме.
Целью этого обновления 2019 года было добавление в результаты поиска экспертных и авторитетных страниц.
Но специалисты по поисковому маркетингу, изучающие документы, еще не нашли ничего, что соответствовало бы таким вещам, как биографии авторов, которые, по мнению некоторых, связаны с опытом и авторитетом, которые ищет Google.
Учись, учись, учись
Мы находимся на первых этапах утечки, и я подозреваю, что это приведет к лучшему пониманию того, как в целом работают поисковые системы.
Рекомендуемое изображение: Shutterstock/san4ezz
Категория
Новости
SEO
Российская поисковая система Яндекс добавляет криптовалюты в свой конвертер – Биткойн Новости
Яндекс, крупнейший российский поисковик, обновил свой конвертер валют, добавив криптовалюты. Виджет теперь показывает курсы этих монет в ряде фиатных валют, и в будущем планируется ввести пары крипто-крипто.
Пользователи ведущей поисковой системы России «Яндекс» могут просматривать информацию о более чем 140 самых популярных криптовалютах, помимо данных о национальных валютах разных стран. Криптовалютные курсы были добавлены в последнюю версию конвертера валют, объявила компания.
Виджет с ценовым графиком и инструментом быстрой конвертации расположен прямо над результатами поиска, сообщает российское новостное издание Rb. ru со ссылкой на Яндекс. Программное обеспечение распознает стандартные ключевые слова и даже сленг или неточные формулировки в запросе.
ru со ссылкой на Яндекс. Программное обеспечение распознает стандартные ключевые слова и даже сленг или неточные формулировки в запросе.
Стоимость интересующих монет и токенов может отображаться в российских рублях, долларах США, евро и других фиатных валютах. В будущем будет добавлено больше пар, а также возможность увидеть цену данного цифрового актива в другой криптовалюте.
В отчете отмечается, что
Яндекс получает рыночные данные от Coingecko, одного из крупнейших порталов агрегации в криптопространстве. Согласно собственной статистике российской поисковой системы, биткойн, эфириум, лайткоин, доджкоин и солана были самыми популярными криптовалютами по количеству поисковых запросов в 2022 году9.0003
Глобальные онлайн-платформы поддерживают аналогичные функции, но доступ к некоторым из них ограничен для россиян. Как отмечает РБК Крипто, функция, позволяющая отслеживать курсы криптовалют, была запущена Twitter еще в декабре прошлого года, но платформа соцсети заблокирована в России.
Закон «О цифровых финансовых активах» вступил в силу в России в январе 2021 года, но правительству еще предстоит должным образом регулировать операции с децентрализованными криптовалютами, такими как биткойн. По заявлениям официальных лиц, это должно произойти в 2023 году9.0003
Законопроект, направленный на легализацию майнинга криптовалют, был внесен в российский парламент в ноябре 2022 года. Закон также направлен на регулирование обмена добытых криптовалют на торговых площадках за рубежом или в рамках особых правовых режимов в России.
Теги в этой истории
Крипто, Крипто актив, крипто активы, Цены крипто, крипто курсы, Криптовалюты, Криптовалюта, Цифровые активы, Цифровая валюта, Курсы валют, Функция, функция, вариант, Цены, ставки, Россия, русский, поиск, поисковая система, Twitter, виджет, яндекс
Как вы думаете, Яндекс представит в будущем больше функций, связанных с криптографией? Расскажите нам в разделе комментариев ниже.
Любомир Тасев
Любомир Тасев — журналист из технически подкованной Восточной Европы, которому нравится цитата Хитченса: «Быть писателем — это то, чем я являюсь, а не то, что я делаю». Помимо криптографии, блокчейна и финтеха, международная политика и экономика являются двумя другими источниками вдохновения.
Кредиты изображений : Shutterstock, Pixabay, Wiki Commons, Trismegist san / Shutterstock.com
Отказ от ответственности : Эта статья предназначена только для информационных целей. Это не прямое предложение или ходатайство о покупке или продаже, а также рекомендация или одобрение каких-либо продуктов, услуг или компаний. Bitcoin.com не предоставляет инвестиционных, налоговых, юридических или бухгалтерских консультаций. Ни компания, ни автор не несут прямой или косвенной ответственности за любой ущерб или убытки, вызванные или предположительно вызванные использованием или доверием к любому контенту, товарам или услугам, упомянутым в этой статье.
 Что значит «лучше отвечает»? Предположили, что это означает более полезный документ (так мы называем страницы в интернете) в топ-1 результатов выдачи. Мы взяли около 30 программистских запросов и документы в топ-1 Яндекса и Google. Перемешали, чтобы никто не знал, какие ответы откуда. Участникам нужно было сказать, какой из двух документов лучше решает задачу из запроса, или отметить, что они одинаково полезны. Три десятка попарных оценок показали, что Яндекс как минимум не выигрывает. Статистически значимой такую выборку, конечно, не назвать, но этого было достаточно, чтобы начать копать по-крупному.
Что значит «лучше отвечает»? Предположили, что это означает более полезный документ (так мы называем страницы в интернете) в топ-1 результатов выдачи. Мы взяли около 30 программистских запросов и документы в топ-1 Яндекса и Google. Перемешали, чтобы никто не знал, какие ответы откуда. Участникам нужно было сказать, какой из двух документов лучше решает задачу из запроса, или отметить, что они одинаково полезны. Три десятка попарных оценок показали, что Яндекс как минимум не выигрывает. Статистически значимой такую выборку, конечно, не назвать, но этого было достаточно, чтобы начать копать по-крупному.  Так нам удалось за несколько недель собрать уже не 30, а 1500 попарных оценок! К сожалению, выводы остались теми же: мы отвечаем существенно хуже, чем говорят нам метрики. Почему? Чтобы понять причину, нужно немного рассказать, как именно оцениваются результаты поиска.
Так нам удалось за несколько недель собрать уже не 30, а 1500 попарных оценок! К сожалению, выводы остались теми же: мы отвечаем существенно хуже, чем говорят нам метрики. Почему? Чтобы понять причину, нужно немного рассказать, как именно оцениваются результаты поиска.  Он видит, что в документе вполне себе есть и C++, и find, и даже if. Этот документ будет отмечен как хороший.
Он видит, что в документе вполне себе есть и C++, и find, и даже if. Этот документ будет отмечен как хороший.  Дальше наш взор устремился на модель, которая и отвечает за ранжирование документов.
Дальше наш взор устремился на модель, которая и отвечает за ранжирование документов. Если убрать все-все остальные факторы, то качество поиска хоть и ухудшится, но не фатально. Ни один другой фактор в одиночку удержать качество не сможет.
Если убрать все-все остальные факторы, то качество поиска хоть и ухудшится, но не фатально. Ни один другой фактор в одиночку удержать качество не сможет.
 Благодаря тем же самым асессорам-программистам мы собрали датасет и с его помощью обучили CS YATI работать ещё и в режиме классификатора запросов — отличать программистские от всех остальных. Но главную проблему это всё равно никак не решало: модель была слишком тяжёлой, чтобы применять её на каждом запросе.
Благодаря тем же самым асессорам-программистам мы собрали датасет и с его помощью обучили CS YATI работать ещё и в режиме классификатора запросов — отличать программистские от всех остальных. Но главную проблему это всё равно никак не решало: модель была слишком тяжёлой, чтобы применять её на каждом запросе.  Но давайте обо всём по порядку.
Но давайте обо всём по порядку.  Это запросы, ответы на которые появились в интернете совсем недавно — от нескольких минут до нескольких дней назад. Чтобы правильно отвечать на них, недостаточно быстро индексировать интернет. Необходимо обучать модель на примерах запросов, по которым пользователи хотят видеть свежие документы, и на самих свежих документах, которые хорошо на такие запросы отвечают. Если этого не делать, то модель на подобных документах будет вести себя неадекватно. Свежие ответы либо вовсе пропадут из топа выдачи, либо будут нерелевантными.
Это запросы, ответы на которые появились в интернете совсем недавно — от нескольких минут до нескольких дней назад. Чтобы правильно отвечать на них, недостаточно быстро индексировать интернет. Необходимо обучать модель на примерах запросов, по которым пользователи хотят видеть свежие документы, и на самих свежих документах, которые хорошо на такие запросы отвечают. Если этого не делать, то модель на подобных документах будет вести себя неадекватно. Свежие ответы либо вовсе пропадут из топа выдачи, либо будут нерелевантными. Сейчас это так и работает в проде.
Сейчас это так и работает в проде. Это поможет быстрее сделать правильный выбор.
Это поможет быстрее сделать правильный выбор. rbc.ru
rbc.ru rbc.ru
rbc.ru Главные интриги тура РПЛ
Главные интриги тура РПЛ Реклама. 0+
Реклама. 0+ РБК направил запрос в пресс-службу Mozilla.
РБК направил запрос в пресс-службу Mozilla.
 0a1 x64????
0a1 x64???? yandex.ru/ и обратите внимание на зеленый кружок со знаком + на панели поиска Firefox. Нажмите на нее, а затем найдите строку в раскрывающемся списке, чтобы добавить сайт в качестве поисковой системы.
yandex.ru/ и обратите внимание на зеленый кружок со знаком + на панели поиска Firefox. Нажмите на нее, а затем найдите строку в раскрывающемся списке, чтобы добавить сайт в качестве поисковой системы. yandex.ru (нажать на большую желтую полосу), но я не уверен в совместимости с бета-версиями и ночными сборками (и работает ли на английском, если это так). (Я предлагаю отключить подсказку для покупок, потому что это довольно раздражает)
yandex.ru (нажать на большую желтую полосу), но я не уверен в совместимости с бета-версиями и ночными сборками (и работает ли на английском, если это так). (Я предлагаю отключить подсказку для покупок, потому что это довольно раздражает) 0.1 предоставляет подробную информацию, но до сих пор неясно, какие службы поиска были затронуты в выпуске Firefox 98.0.
0.1 предоставляет подробную информацию, но до сих пор неясно, какие службы поиска были затронуты в выпуске Firefox 98.0. ru, предлагаемую через партнерские каналы распространения, в этом выпуске эти настройки удаляются, включая надстройки и закладки по умолчанию. Там, где это применимо, ваш браузер вернется к настройкам по умолчанию, предлагаемым Mozilla. Все другие выпуски Firefox не затронуты этим изменением.
ru, предлагаемую через партнерские каналы распространения, в этом выпуске эти настройки удаляются, включая надстройки и закладки по умолчанию. Там, где это применимо, ваш браузер вернется к настройкам по умолчанию, предлагаемым Mozilla. Все другие выпуски Firefox не затронуты этим изменением.