Содержание
Как группировать семантику для контекстной рекламы: 9 подходов / Хабр
Собрать семантику для контекста — это часть дела. Ее еще нужно упорядочить — чтобы можно было удобно и эффективно управлять кампаниями. Но как группировать ключи? Мы собрали 9 подходов. Здесь нет правильных и неправильных — все они применимы в тех или иных ситуациях, и все имеют как плюсы, так и минусы. Об этих подходах полезно знать, чтобы протестировать их и, возможно, найти точки роста.
Содержание статьи
1. Все ключи — в одну группу объявлений
2. Группировка по продуктовому принципу
3. Группировка на основе морфологической схожести
4. Группировка по намерениям пользователей
5. Группировка по этапам воронки продаж
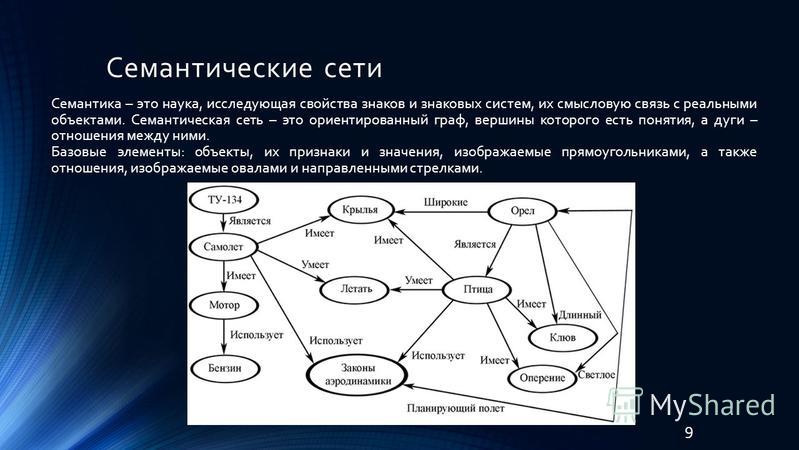
6. Кластеризация ключевых фраз
7. Группировка методом SKAG
8. Группировка методом Альфа/Бета
9. Группировка методом STAG
Так какой способ группировки выбрать?
1. Все ключи — в одну группу объявлений
Самый простой способ — отправляем все ключи в одну группу и пишем для нее одно или несколько объявлений. Хотя такой метод и кажется каким-то неправильным, он имеет право на жизнь.
Хотя такой метод и кажется каким-то неправильным, он имеет право на жизнь.
По всем этим ключам в одной группе может показываться объявление с рекламой онлайн-курсов копирайтеров
Когда подходит
- Вы запускаете рекламу одного оффера с узкой семантикой и одной целевой страницей.
- Ставки по ключевым фразам плюс-минус одинаковые.
- Целевая аудитория однородна и вам нет смысла писать много объявлений, чтобы триггерить разные сегменты.
- Вы хотите расширить семантику в узкой нише и запускаете рекламу в широком соответствии по базовым ключам, а потом собираете запросы, по которым были переходы, и по ним уже расширяете ядро.
В большинстве же случаев такой способ группировки неэффективен. Он приведет к хаосу в аккаунте. Лучше потратить время на систематизацию семантики.
Плюсы:
- Не нужно тратить время на разбивку ключевых фраз на группы и написание объявлений для каждой из них.

- Можно быстро запустить кампанию, чтобы, например, протестировать идею или найти новые запросы.
- Не нужна кросс-минусовка, потому что нет разных групп, а значит, и пересекающихся ключевых слов в них.

Минусы:
- При большом количестве ключей в одной группе чисто физически сложно управлять кампанией.
- Эффективность группы объявлений «размазывается», и вам не с чем будет сравнивать результаты.
- При добавлении в группу разнородных ключей снижается качество и рейтинг объявлений. Вам сложнее будет занять более высокую позицию без повышения ставки.
- Когда ключевых фраз много и они совершенно разные, не получится вписать их в заголовки и тексты объявлений для повышения кликабельности.
- Для разных фраз могут быть разные ставки, и мы переплатим за клики там, где можно было бы сэкономить (или не получим переходов по дорогим запросам).
2. Группировка по продуктовому принципу
Заносим в одну группу ключевые фразы, которые относятся к конкретному товару/услуге/категории. Например, первая группа будет про двигатели, а вторая — про подвеску. Так мы можем показывать релевантные объявления пользователям, которые ищут одни и те же товары или услуги с помощью разных поисковых запросов.
Например, первая группа будет про двигатели, а вторая — про подвеску. Так мы можем показывать релевантные объявления пользователям, которые ищут одни и те же товары или услуги с помощью разных поисковых запросов.
С помощью запросов «ремонт двигателя», «ремонт мотора» и «ремонт движка» пользователи ищут одну и ту же услугу
Когда применять
Метод используется, например, при подборе ключевых слов с помощью Планировщика ключевых слов Google. Вводите название товара/услуги и получаете запросы, в том числе синонимы. Если добавить в одну группу собранные «Планировщиком» слова, получите группировку по продуктовому принципу.
Подбор слов через «Планировщик ключевых слов»
Часто таким способом пользуются рекламодатели, которые настраивают контекст для себя и не имеют большого опыта работы с семантикой. Зашли в Планировщик — сгруппировали руками по продукту — запустили рекламу.
Если же вы собрали семантику в несколько тысяч запросов, то заниматься группировкой синонимов трудозатратно и не имеет смысла. Лучше разнести их по отдельным группам путем группировки по морфологии (см. пункт 3).
Лучше разнести их по отдельным группам путем группировки по морфологии (см. пункт 3).
Также способ не подойдет, если ставки по синонимичным фразам отличаются в разы или много неоднозначных по смыслу запросов, которые важно проработать, чтобы исключить нецелевые показы.
Плюсы:
- Группировка проста для понимания и реализации — есть отдельные группы объявлений под разные товары, услуги и категории.
- При группировке по продуктовому принципу при составлении объявлений удобно использовать генераторы — например, бесплатный генератор из YML (о нем мы рассказывали). Загружаете YML-фид, настраиваете шаблон, получаете объявления и разбрасываете их по группам.
Пример настройки шаблона объявления в генераторе из YML
Минусы:
- С таким подходом в одну группу могут попасть поисковые запросы, которые вводят пользователи с разными намерениями.
- Ставки по синонимичным запросам будут отличаться. В этом случае, объединяя запросы, мы не можем эффективно назначать ставки на уровне группы объявлений.
 В этом случае, объединяя запросы, мы не можем эффективно назначать ставки на уровне группы объявлений.
В этом случае, объединяя запросы, мы не можем эффективно назначать ставки на уровне группы объявлений.
Разная ставка для одинаковых по своей сути запросов
- Если мы объединяем в группе много синонимов, придется составлять много разных объявлений. Как вариант, можно использовать динамическую вставку ключевых слов — это частично решит проблему.
Пример настройки динамической вставки ключевых слов в Google Ads
3. Группировка на основе морфологической схожести
Распределяя ключи этим способом, отправляем в одну группу фразы с одинаковыми или однокоренными словами. В итоге синонимичные запросы с разными словами попадут в разные группы, и мы получим несколько групп объявлений для одних и тех же товаров и посадочных страниц.
В группы попадают максимально похожие запросы
Когда применять
Группировка на основе морфологической схожести — это системная работа с ключами.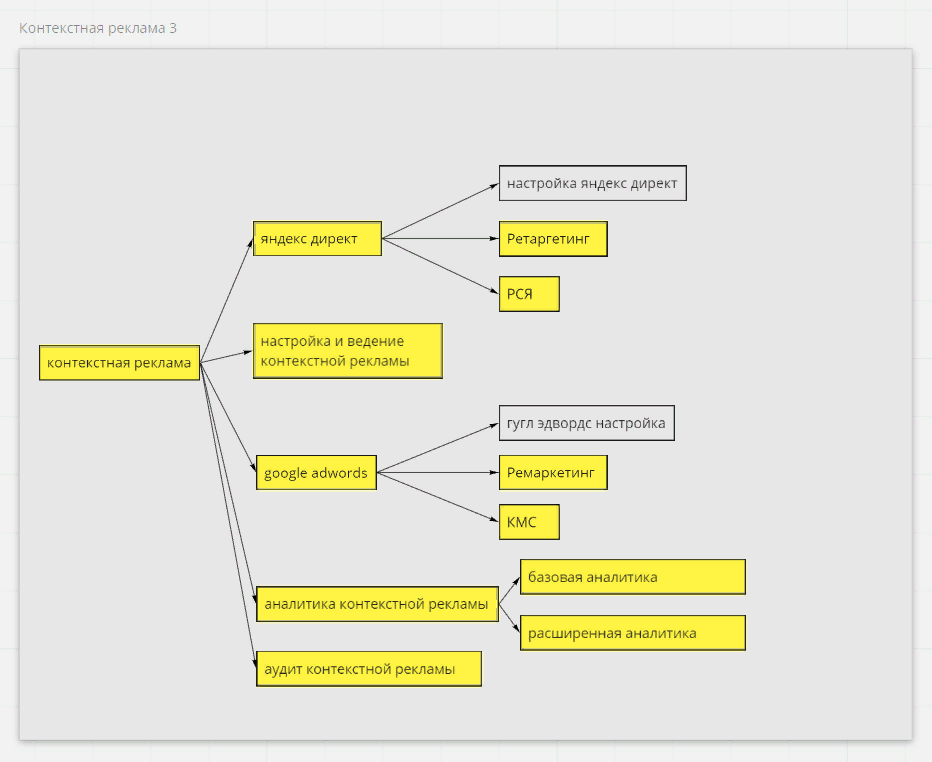 Подходит практически для любых тематик с обширной семантикой, особенно если много однокоренных слов.
Подходит практически для любых тематик с обширной семантикой, особенно если много однокоренных слов.
Создавая релевантные объявления под запросы, мы повышаем кликабельность. Кроме того, одинаковые по своей сути, но разные по морфологии запросы обычно имеют разную цену клика. Разнося их по группам, мы более гибко управляем ставками.
Плюсы:
- Это универсальный способ группировки — подходит для любых ниш.
- Делая отдельную группу для каждой морфемы, мы можем точно вписать ключевые фразы в заголовки и тексты объявлений, что повысит их релевантность и кликабельность.
- Такая группировка позволит получить детальную статистику по группам и гибко управлять рекламой. Например, мы будем знать, какая группа более эффективна: «купить рено» или «купить renault».
- Семантику удобно группировать — это можно сделать в том же Excel. А если использовать, например, Key Collector, то сгруппировать фразы по этому принципу можно еще быстрее.

Минусы:
- В группу могут попасть запросы с однокоренными словами, которые вводят пользователи с разными намерениями. Например, «купить ноутбук» — это запрос розничного покупателя, а «купить ноутбуки» — может быть запросом оптового клиента.
- Из-за того, что синонимы разносятся по разным группам, объявления из разных групп могут показываться по одним и тем же запросам. Чтобы избежать конкуренции между ними, нужно провести кросс-минусовку.
4. Группировка по намерениям (интенту) пользователей
Люди, которые вводят в поиске название вашего товара или услуги, руководствуются разными намерениями — одним нужен товар для личного пользования, другим — оптовая партия, третьим — вообще монтаж.
Так мы получаем три группы объявлений — для тех, кому нужны:
- двери в свою квартиру;
- оптовая партия дверей;
- услуги по установке.
Запросы с разным интентом разносим в разные группы
А если бы мы сгруппировали эти ключи по морфологическому принципу и взяли за основу фразу «межкомнатные двери», то они бы попали в одну группу.
Есть разные механики группировки по интенту. Самый простой вариант — в группы заносятся слова в широком соответствии. Но в этом случае сложно контролировать показ объявлений по нужным словам. Потребуется длительная и тщательная минусовка.
Есть подход IBAGs, который предложили в Store Growers. Суть в том, что каждый ключ заносится в группу в трех типах соответствия: точном, фразовом и с модификатором (для Google Ads). Широкое соответствие не используется. В этом случае уменьшится процент нецелевых показов.
IBAGs является вариацией SKAG-подхода (мы еще остановимся на нем) — с той лишь разницей, что в каждой группе не один ключ в трех типах соответствия, а несколько ключей в тех же трех типах соответствия.
Когда применять
Группировка по поисковому интенту может принести лучший результат, чем по продуктовому или морфологическому принципу. Но она требует больше ресурсов. Поэтому метод целесообразно использовать:
- в сложных нишах с длительным сроком принятия решения о покупке/заказе, высокой конкуренцией и дорогим трафиком;
- в любых нишах — при небольшом объеме семантического ядра, когда не придется тратить недели на группировку.
Плюсы:
- Объединяя ключи по намерениям, мы можем написать для группы более релевантное объявление, чем при группировке по продуктовому принципу. Это повысит CTR, рейтинг объявления и конверсию.
- Анализируя намерения пользователей, мы уделяем больше внимания смыслу поисковых запросов, а значит, не добавим в одну группу похожие морфологически, но разные по смыслу фразы.
Минусы:
- Группировка более затратна по времени и сложнее автоматизируется, чем разделение по морфологическому принципу, потому что нужно просмотреть все запросы и выбрать слова со схожими намерениями. И это основной минус. Частично решить проблему трудоемкости помогает кластеризация — на ней мы остановимся отдельно.
- При таком подходе в группу попадут разные слова. Не все из них получится вписать в заголовки и тексты объявлений. Но при желании можно или увеличить количество объявлений, или использовать динамическую вставку ключевых слов.

Разные по морфологии слова с похожим интентом
5. Группировка по этапам воронки продаж
Этот метод — частный случай группировки по интенту. На разных этапах воронки продаж — потребность, осведомленность, интерес, желание, покупка — люди вводят в поиск разные запросы, и информация им нужна разная. Группируя ключевые фразы по этому принципу, мы отправим в разные группы запросы пользователей, которые:
- осознают потребность, но еще не знают, что ее можно закрыть нашим продуктом;
- только интересуются продуктом;
- уже хотят его купить.
Пользователи, которые вводят запросы из первой группы, пока только хотят узнать, поможет ли им процедура, из второй — уже интересуются ценой, из третьей — близки к заказу
В зависимости от возможностей и бюджета можно охватить потенциальных покупателей на всех этапах воронки продаж или выбрать некоторые из них.
Плюсы:
- Собирая в одну группу запросы пользователей, которые находятся на одном этапе воронки, мы показываем им релевантные объявления и ведем на соответствующую целевую страницу.
- Захватывая верхние этапы воронки, мы можем получить переходы дешевле, чем по коммерческим запросам нижних этапов. А потом подвести пользователей к покупке контентом, рассылками, ремаркетингом.

Минус:
- Трудоемкость — нужно выстроить воронку, определить намерения и систематизировать ключи.
6. Кластеризация ключевых фраз
В описанных выше способах мы использовали разные критерии группировки: продукт, интент, морфологию. Но можно зайти с другой стороны — довериться алгоритмам поисковых систем и их пониманию схожести поисковых запросов.
Используя этот способ, группируем запросы на основе схожести результатов поисковой выдачи по ним. Логика в том, что если результаты первой страницы органической выдачи по конкретным запросам совпадают, то поисковые системы считают, что они закрывают одну и ту же потребность. А значит, есть смысл определить их в одну группу.
Фрагмент кластеризованного семантического ядра
Когда использовать
Кластеризация удобна, когда нужно быстро сгруппировать огромную семантику.
Этот метод также можно использовать как вспомогательный при группировке по интенту. Вы получите укрупненные кластеры, которые потом вручную разнесете по группам объявлений.
Плюсы:
- Объявления, созданные под кластеры, будут релевантны ключевым словам не только с точки зрения интента и морфологии, но и алгоритмов ПС.
- Этот способ группировки хорошо автоматизируется. Для этого используются кластеризаторы — например, наш. Он группирует фразы для Яндекса и/или Google, можно задать точность числом, диапазоном или выбрать условия кластеризации. В отчете будут не только группы слов, но и их частотности. Как работать с инструментом — читайте в гайде.
Минусы:
- Кластеризаторы ускоряют процесс, но потратить время на «чистку» групп все-таки придется.
- Если хотите запустить рекламу в Яндекс.Директе и Google Ads, кластеризовать запросы нужно для каждой рекламной системы отдельно. В теории можно, конечно, использовать результаты, полученные для Яндекса, для рекламы в Google Ads, но это нарушает логику процесса — выдача в поисковых системах разная.
- Бывает сложно подобрать оптимальную точность кластеризации. При низкой (2–3) получаем слишком широкие кластеры, при высокой (6–7) они будут раздроблены. Оптимальной считается точность 4–5, но все равно нужно смотреть на результаты и подбирать точность.

7. Группировка методом SKAG
При такой группировке в каждую группу объявлений добавляется одна ключевая фраза, которая прописывается в трех типах соответствия: точном, фразовом и с модификатором широкого соответствия. Таким образом, мы можем анализировать CTR и оставлять в группе только то соответствие, которое работает наиболее эффективно.
Пример SKAG-группировки
Правда, после того как Google сделал похожими алгоритмы срабатывания фразового соответствия и модификатора широкого соответствия, позиции SKAG пошатнулись, и мнения PPC-специалистов разделились. Одни считают, что SKAG стал нежизнеспособен и нужно перестраивать кампании, ориентируясь на намерения пользователей, другие — что метод по-прежнему жив, просто требует более детальной и тщательной оптимизации.
Когда применять
Когда важно добиться максимальной релевантности объявлений и эффективности рекламной кампании, чтобы повысить ROI.
Но надо понимать, что затраты на создание и управление SKAG-группами могут превысить эффект от их использования. Поэтому применять подход нужно при условии, что вы точно знаете, что делаете.
Плюсы:
- Способ простой для понимания.
- Для автоматизации есть скрипты — например, вот и вот.
- При SKAG-подходе объявления идеально заточены под ключевые слова. Обычно достигается высокий Quality Score.
- Кампанию проще оптимизировать, видя детальную статистику по каждой фразе.
- Ориентируясь на единственную фразу в группе, удобнее добавлять минус-слова.
- После правильной оптимизации можно добиться высокой эффективности.
Минусы:
- На написание объявлений под каждый ключ уходит много времени. Можно использовать генератор объявлений для Яндекса и Google. Конечно, объявления получаются не идеальными, но могут стать шаблонами для дальнейшей правки.
- Нужна серьезная кросс-минусовка. Автоматизация доступна в бесплатном медиапланере Click.ru — перекрестная минусовка проводится по умолчанию при подборе семантики.
- Сложно тестировать объявления — из-за дробления групп и трафика по ним придется составлять много разных вариантов и долго собирать статистику.
- Такую кампанию придется регулярно и долго оптимизировать руками, чтобы добавить в список минус-слов большинство нецелевых запросов.
- Группы с низкочастотными ключами могут получить статус «мало показов».
- Большим количеством групп сложно управлять.
 Можно использовать генератор объявлений для Яндекса и Google. Конечно, объявления получаются не идеальными, но могут стать шаблонами для дальнейшей правки.
Можно использовать генератор объявлений для Яндекса и Google. Конечно, объявления получаются не идеальными, но могут стать шаблонами для дальнейшей правки.
8. Группировка методом Альфа/Бета
Разновидность SKAG-группировки, которую разработал и описал в своей книге «Контекстная реклама, которая работает» ведущий мировой эксперт по Google Ads Перри Маршалл. Она заключается в том, что из работающей бета-кампании выбираем фразы, которые принесли больше всего конверсий, и переносим их в точном соответствии в новую альфа-кампанию. В бета-кампании такие ключи заносим в список минус-слов.
Она заключается в том, что из работающей бета-кампании выбираем фразы, которые принесли больше всего конверсий, и переносим их в точном соответствии в новую альфа-кампанию. В бета-кампании такие ключи заносим в список минус-слов.
Далее мы делаем это регулярно — выбираем наиболее эффективные ключи из старой кампании и в точном соответствии переносим в новую.
Мы создали 10 групп объявлений, в каждой из которых — один ключ в точном соответствии
Когда применять
Способ подходит для сложных ниш, когда важно искать пути наращивания конверсий при оптимальных расходах.
Плюсы:
- Постоянно пополняя альфа-кампанию высокоэффективными фразами, мы наращиваем общее количество конверсий.
- Выделяя больший бюджет на альфа-кампанию с конверсионными фразами, мы можем максимизировать результат.
Минусы:
- Фраза, которая показала хороший коэффициент конверсии в бета-кампании, может «просесть» в альфа-кампании. С увеличением бюджета и количества кликов коэффициент конверсий может снизиться.
- Нужно регулярно переносить конверсионные фразы в альфа-кампанию и делать минусовку в бета-кампании. При большом количестве ключей это трудоемко.
 С увеличением бюджета и количества кликов коэффициент конверсий может снизиться.
С увеличением бюджета и количества кликов коэффициент конверсий может снизиться.
9. Группировка методом STAG
Способ группировки STAG (Single Theme Ad Groups) позиционируется как противоположный SKAG, более современный. Распределяя ключевые фразы этим методом, формируем группы из ключей, которые относятся к одной узкой теме. Можно добавить столько фраз, сколько есть для конкретной темы в нашей семантике.
Причем для группировки выбирается один четкий критерий (тема) — например, цена, характеристики и т. п.
Пример группировки семантики по методу STAG по критериям «скачать» и «бесплатно»
У метода есть вариация — 20KAG. Особенность в том, что в одну группу объявлений нельзя добавить более 20 фраз. Способ появился с подачи британского агентства One PPC. Логика подхода в том, что ограничение в 20 фраз соответствует рекомендациям Google по работе с ключевыми словами.
Плюсы:
- На создание объявлений уходит меньше времени, чем при создании групп для каждого ключа.
- Если правильно выделить темы и сформировать группы, можно создать релевантные объявления и подобрать максимально подходящие целевые страницы.
Минусы:
- Четко разделить семантику на тематические группы получается не всегда.
- Если не учесть намерения пользователей и этап воронки продаж, есть риск показать объявления пользователям, которые ищут совсем другое.
Так какой способ группировки выбрать?
Выбрать какой-то один способ группировки ключевых слов для контекстной рекламы и сказать, что он наиболее эффективный, сложно. Все зависит от цели кампании, количества ключевых слов, специфики ниши, поведения ЦА, бюджета и т. п.
Например, если семантика небольшая, можно руками разнести ключи по интенту или поэкспериментировать со SKAGами. Если же имеете дело с тысячами запросов, тут нужна автоматизация — например, группировка по морфологии или кластеризация.
Также можно комбинировать несколько способов, тестировать и находить эффективные решения.
3 способа собрать семантическое ядро для контекстной рекламы
Сбор семантического ядра — один из самых важных этапов в создании контекстной рекламной кампании, проектировании сайта, SEO и создании контент-плана для блога. Принцип сбора у всех этих задач похож, но в статье я расскажу про то, как эффективно собрать семантическое ядро именно для контекста. И рассмотрю для этого три способа (чтобы перейти к одному из способов, воспользуйтесь меню справа):
- Key Collector и таблицы — платный инструмент для сбора семантики на 1000 ключей и более.
- «Вордстат» и таблицы — бесплатный способ для ядра размером меньше 1000 ключей.
- Интерфейс «Яндекс.Директ» — бесплатный способ, но сложно обрабатывать больше 10 ключей.
Но прежде чем мы начнем, давайте разберемся с терминами, которые будут встречаться в статье.
Семантическое ядро = семантика — это слова или словосочетания, по которым пользователь увидит вашу рекламу.
Ключевые фразы = ключевые слова = ключи — это слова или словосочетания, по которым пользователи ищут материал в интернете. Из ключевых слов состоит семантическое ядро.
Низкочастотные запросы = НЧ запросы = низкочастотные ключи = НЧ Ключи — запросы, которые ищут менее 100 раз в месяц.
Высокочастотные запросы = ВЧ запросы = высокочастотные ключи = ВЧ ключи — запросы, которые ищут более 1000 раз в месяц
Маска — это самый ВЧ ключ, обычно состоит из 1-3 слов.
Хвосты — это слова, которые добавляются к маске, уменьшая частотность запроса.
Минус-фразы = минус-слова — это слова, по которым ваши объявления не должны показываться.
Но собранное семантическое ядро — это не готовый продукт. Готовый продукт — это семантика разбитая на группы, потому что для групп вы можете писать объявления, сделать посадочную страницу, оптимизировать текст.
Поэтому мы с вами поэтапно разберем процесс сбора, очистки и группировки семантического ядра.
Способ 1. Key Collector и таблицы
Преимущества способа: быстро, можно без проблем обработать более 1000 ключей.
Недостатки способа: платный Key Collector.
Этап 1. Сбор основных масок
Перед тем, как начать собирать семантику, нужно составить таблицу, в которую вы будете заносить ключевые запросы, по которым клиенты могут искать ваш продукт. Пример таблицы приведен ниже.
Первый столбец определяет товар или услугу (ответ на вопрос «Что вы предлагаете?»). Для примера возьмем токарные станки. Как люди могут искать токарные станки? Они могут вбивать запрос «токарные станки», могут искать на сленге — «токарка».
Второй столбец определяет характеристику вашего продукта. Какие токарные станки вы предлагаете? По дереву? По металлу?
Третий столбец содержит название марки.
Четвертый столбец определяет действие, которое с вашим товаром или услугой можно совершить. Для чего нужен токарный станок? Для точения конусов? Для нарезки пазов? все возможные синонимы заносите в таблицу.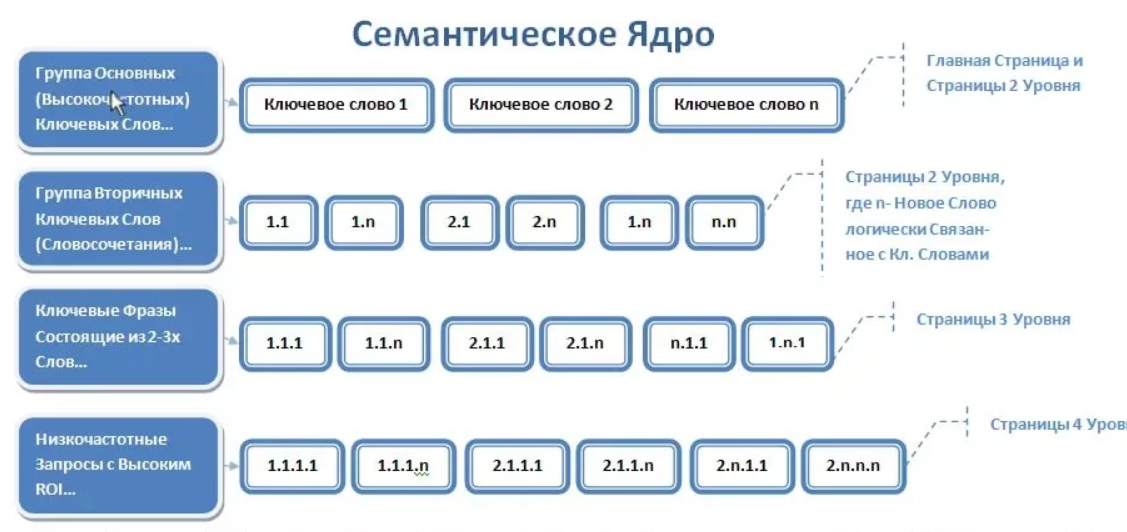
Пятый столбец содержит дополнительные преимущества вашего продукта.
Шестой столбец содержит слова, которые показывают заинтересованность пользователя в покупке. Как пользователь может выражать желание купить ваш продукт? К примеру, пытается узнать стоимость.
Седьмой столбец также несет дополнительную информацию о продукте. Факты, которые для некоторых пользователей будут решающими. Какие это могут быть факты? Доставка? От производителя?
Столбцы, в зависимости от продукта, могут совпадать, а могут и различаться. Главное — понимать: чтобы собрать максимально широкое семантическое ядро, нужно продумать все возможные варианты того, как ваш продукт могут искать разные люди.
Откуда брать все эти варианты запросов? Во-первых, из головы. Устройте мозговой штурм, придумайте различные варианты, по которым пользователи могут вас искать. Когда идеи закончатся, вам может помочь «Яндекс.Метрика» со своим отчетом «Поисковые фразы».
.
Этап 2. Составляем список ключевых запросов
Из получившейся таблицы мы будем составлять семантическое ядро. Нам нужно по очереди скомпоновать между собой ключевики из разных столбцов, «перемножить» их друг с другом, чтобы получить все возможные комбинации. Через таблицы выполнять эту работу слишком долго, поэтому мы пользуемся сервисами — компоновщиками ключевых фраз. Существует их большое количество, вы обязательно найдете удобный для вас. Мы чаще всего используем генератор от Key.so.
Пользоваться генераторами просто: вы поочередно заносите ключевики в соответствующие ячейки и система автоматически выдает вам все возможные комбинации.
Скопируйте их на отдельный лист таблицы. После того как вы прогоните через программу все столбцы из таблички, у вас должен получиться большой список, состоящий из нескольких тысяч ключевых запросов. Безусловно, некоторая часть этих запросов будет «мусорной». От них мы и будем избавляться на следующем этапе.
Этап 3.
 Удаляем мусорные запросы
Удаляем мусорные запросы
Чтобы избавиться от нерелевантных запросов и собрать частоты по целевым, воспользуйтесь программой Key Collector. Сервис платный, но у него огромный функционал. Если вы собираетесь заниматься рекламой или SEO на профессиональном уровне, не пожалейте денег. Лицензия отработает себя в первый же месяц.
Настройка Key Collector
Прежде всего нужно купить лицензию на официальном сайте. Далее по инструкции установить программу.
Установили — переходим в настройки и в разделе «Парсинг → Общие ». Выставляем сбор слов с частотностью более 10. Так как по словам с частотностью менее 10 объявления не будут показываться.
После этого переходим в подраздел «Парсинг → Антикапча» и настраиваем антикапчу. Мы используем этот сервис антикапчи, самый дешевый тариф.
После этого переходим в раздел «Yandex → Аккаунты» и вводим почту от «Яндекса» и пароль. Рекомендуем для Key Collector завести отдельный аккаунт — основной могут заблокировать, так как вы используете автоматическую систему сбора.
Но это еще не все. Нужен прокси-сервер. Его можно купить тут.
Сбор частотности
После этого переходим к сбору частотности семантики. Создайте новый проект, перейдите на вкладку «Парсинг» и выберите иконку Wordstat.
Выберите регион, вставьте список масок, которые вам выдал генератор, и нажмите «Начать сбор».
Можно идти пить чай. Инструмент соберет частотности запросов самостоятельно.
Когда KeyCollector закончит собирать ключи, перейдите на вкладку «Данные», нажмите кнопку «Анализ групп».
В настройках выберите тип группировки «по отдельным словам». Этот тип нам нужен, чтобы сформировать список минус-фраз.
Программа создаст группы слов, из которых состоит ваше семантическое ядро.
Пометьте флажками слова, по которым Яндекс не должен показывать рекламу.
Google тоже не будет показывать по ним объявления, но рекламы в Google в России больше нет 🙁
После того как выберете всё, кликните правой кнопкой мыши по отмеченному слову и нажмите «Отправить все слова из заголовков помеченных групп в минус-слова»
Добавьте выделенные слова в список минус-слов.
Переходим на основную вкладку с данными.
Переходим во вкладку «Главная → Минус-слова».
Выделите минус-слова, которые добавили, и отметьте фразы из семантического ядра, которые содержат эти слова.
И удалите отмеченные фразы.
Этап 4. Группировка ключевых запросов.
Чтобы сгруппировать ключевые запросы, в строку поиска вводите слово, которое характеризовало бы группу. Это могут быть коммерческие слова «купить/ цена» или слова, которые характеризуют группу качественно — «красный/ стационарный».
Главное правило: объединяйте ключевые фразы так, чтобы вы могли написать под них объявление, которое подходило бы для каждой фразы в группе.
После того, как отметили фразы, выбираем на вкладке «Главная → Коп./перенести фразы»
И создаём новую группу либо подгруппу.
В настройках группы выбираем «Перенос», задаём название и кликаем «Выполнить перенос».
Если в группе слишком много ключей, можно её открыть и разбить на подгруппы.
Способ 2. «Вордстат» и таблицы
Преимущества способа: Быстро, бесплатно.
Недостатки способа: Сложно обрабатывать более 1000 ключей, риск собрать не все.
Этап 1. Сбор основных масок
Он заключается в том, что мы выбираем самую ВЧ маску и собираем все ключи по ней.
В нашем случае мы возьмем маски «Токарный станок» и «Токарка».
Обратите внимание на то, что мы не берем маску «Станок», потому что это очень широкая маска и нам придется очень много чистить мусора. А если возьмем маску «Токарно-винторезный станок», то пропустим много целевых запросов. Поэтому используйте самую широкую подходящую маску.
Этап 2.Сбор основных масок
Чтобы собрать семантику этим способом, нужно установить расширение Yandex Wordstat Assistant. Это расширение поможет скопировать фразы и их частотность из списка. Копировать можно как по одной фразе, так и по 50 фраз со страницы.
Не забудьте указать регион, по которому вы хотите собрать семантику. Это важно! Если вы соберете семантику по всей России, а показывать рекламу будете для жителей небольшого городка, то можете получить статус «мало показов» и пользователи вашу рекламу не увидят. Да и много лишнего придется минусовать. Поэтому собирайте семантику в том регионе, где хотите показывать рекламу.
Это важно! Если вы соберете семантику по всей России, а показывать рекламу будете для жителей небольшого городка, то можете получить статус «мало показов» и пользователи вашу рекламу не увидят. Да и много лишнего придется минусовать. Поэтому собирайте семантику в том регионе, где хотите показывать рекламу.
Теперь, когда все настроено, вы можете собрать семантические ядро.
Если вы собираете по нескольким широким маскам, то просто вводите запрос и добавляете все запросы из левого столбца. Вносите со всех страниц, пока частотность не будет меньше 10 запросов.
Но если ключей много, вы можете недолистать до запросов с частотностью менее 10, потому что статистика показов ограничена 41 страницей.
Чтобы собрать всевозможные хвосты, на первых 10-20 страницах кликайте на запрос, чтобы Wordstat показал его хвосты.
И обращайте внимание на запросы из правой колонки. В этой колонке содержатся запросы, которые ищут вместе с тем, который вы ввели. Поэтому там могут быть широкие маски, которые мы могли не учесть.
После того как закончили сбор семантического ядра, скопируйте в буфер обмена запросы с их частотностью и вставьте на лист таблицы.
Этап 3. Удаляем мусорные запросы.
Теперь вам нужно, прочитывая каждую фразу, искать нерелевантные слова и выписывать их в соседний столбец.
По окончании выделите все столбцы и отсортируйте по столбцу с минус-словами.
После скопируйте очищенную семантику на отдельный лист, а в столбце с минус-словами удалите дубли. В итоге у вас должен остаться лист с минус-словами и лист с чистой семантикой.
Этап 4. Группировка ключевых запросов.
Чтобы разгруппировать вручную, вам придется просматривать все очищенные запросы в таблице и окрашивать их в цвет группы. Чтобы ускорить этот процесс, я через фильтр по условию «Текст содержит» ввожу слова, которые бы характеризовали всю группу, и окрашиваю их в цвет группы.
После сортирую по цветам, а оставшиеся незакрашенные группы сортирую вручную.
Способ 3.
 Интерфейс «Яндекс.Директ»
Интерфейс «Яндекс.Директ»
Преимущества способа: Интуитивно понятно
Недостатки способа: Сложно обрабатывать больше 10 ключей
Этап 4. Группировка ключевых запросов.
Это не ошибка. Этот способ начинается с группировки.
Если вы решили воспользоваться инструментом сбора семантики через интерфейс директа, то вы уже должны создать кампанию и внутри кампании группу. И семантику собирать под созданную группу.
Этап 1. Сбор основных масок
Полностью повторяет Этап 1. Сбор основных масок
Этап 2. Составляем список ключевых запросов
Если вы собираете ключи через встроенный функционал «Яндекс.Директ», то вам не нужны сторонние генераторы фраз. На этом хорошие новости для этого способа заканчиваются.
При добавлении новой группы, в условиях показа выберите «Подобрать фразы».
Здесь, как в комбинаторе, добавьте фразы в столбцы и создайте комбинации. Но помните, что вы генерируете фразы, которые должны попасть в одну группу. Поэтому для примера мы взяли один тип станка и коммерческие фразы.
Поэтому для примера мы взяли один тип станка и коммерческие фразы.
Чтобы избавиться от лишней работы включите функцию «Исключить фразы с нулевыми показами» и создайте комбинации.
Здесь вы можете посмотреть частотность, глубину запроса, добавить фразу в список ключевых или минус-слово.
Окошко для работы очень маленькое, поэтому мне пользоваться сервисом неудобно.
Также вы можете создать комбинации фраз в стороннем сервисе и загрузить их в тот же раздел «Условия показа», но выбрать там «Прогноз и уточнение». И помните, что фразы должны быть уже сгруппированы.
Этап 3. Удаляем мусорные запросы.
После того, как добавили ключи, в разделе «Прогноз и уточнение» вы можете посмотреть частотность, хвосты и добавить минус-фразы. Но мне этот функционал не нравится, он требует много лишних кликов, которые отнимают время.
Этап 4. Группировка ключевых запросов.
Если вы решили воспользоваться инструментом сбора семантики через интерфейс директа, то вы уже должны создать кампанию и внутри кампании группу. И семантику собирать под созданную группу.
И семантику собирать под созданную группу.
Вывод
Мы предложили вам три способа сбора семантического ядра. Выбирайте любой в зависимости от задачи.
Если задача большая, то используйте Key Collector.
Если нужно настроить рекламу по новому продукту, то используйте Wordstat и таблицы.
Если нужно точечно добавить ключи в группы, то используйте интерфейс «Директа».
Но также вы можете и комбинировать различные способы в зависимости от этапа. Лично я люблю собрать семантику по ВЧ маскам и почистить её в Key Collector, а группирую уже в Google таблицах.
Семантическая реклама: 4 вида
Что такое «семантическая реклама»? (Или рекламные встречи семантического типа.)
Короткий ответ: конечно, реклама, использующая технологию семантической паутины. Но, как оказалось, это определение сильно зависит от того, как вы определяете понятия «реклама» и «семантическая сеть».
В связи с потоком инноваций, происходящим в обеих этих областях — и на их пересечении — теперь существует несколько разных значений семантической рекламы, в зависимости от того, кого вы спрашиваете.
Вот 4 различных вида семантической рекламы:
#1: Контекстная реклама с семантикой
Несколько рекламных сетей — Google AdSense на сегодняшний день является самой популярной — автоматически анализируют содержание веб-страниц, чтобы динамически определять, какие объявления являются наиболее популярными. актуально там служить. Если я читаю на сайте о ЖК-телевизорах, они показывают мне рекламу розничных продавцов, которые их продают – без необходимости издателя или рекламодателя (или даже рекламной сети) что-либо явно указывать. На самом деле это просто контекстная реклама, но когда она использует семантическую технологию для определения контекста, это называется семантической рекламой.
Это, пожалуй, самая распространенная сегодня интерпретация смысловой рекламы.
Рекламные сети, такие как Peer39 и iSense от adpepper, под этим лозунгом семантической рекламы действительно подчеркивают использование семантической технологии в качестве конкурентного преимущества. По большей части их семантическая технология состоит из собственных алгоритмов обработки естественного языка. Это не имеет ничего общего с Семантической сетью, как ее описал бы Тим Бернерс-Ли, хотя можно привести аргумент, что она действительно реализует подход семантической сети сверху вниз.
По большей части их семантическая технология состоит из собственных алгоритмов обработки естественного языка. Это не имеет ничего общего с Семантической сетью, как ее описал бы Тим Бернерс-Ли, хотя можно привести аргумент, что она действительно реализует подход семантической сети сверху вниз.
[Обновление: в ответ на этот пост Ян Сондерс, один из соавторов iSense, опубликовал отличный комментарий ниже с более подробным объяснением своего подхода.]
Теперь, если бы издатели сайта добавили семантические данные на свои сайты с помощью RDF-тегов и/или микроформатов — что произойдет, когда бизнес-стимулы для этого станут достаточно убедительными – тогда эти метаданные можно будет использовать для еще большего повышения точности контекстной рекламы. Это имело бы преимущество (и некоторые потенциальные проблемы), поскольку издатели могли бы давать семантическим рекламным сетям подсказки о семантическом значении контента на странице, используя истинные семантические веб-стандарты.
№2: реклама в семантическом поиске
Новое поколение семантических поисковых систем, таких как Powerset и Hakia, пытается использовать семантическую технологию, чтобы предоставить людям лучший опыт поиска. Это, кажется, набирает обороты, особенно в вертикальном поиске, где значения слов и отношений могут быть относительно легко устранены — например, сайт поиска работы Trovix.
Конечно, бизнес-модель этих семантических поисковых систем почти наверняка заканчивается рекламой. А если вы размещаете рекламу в семантической поисковой системе, это семантическая реклама, верно?
Возможно. Интересным моментом является то, что рекламодатели в семантическом поиске могут в конечном итоге делать ставки на понятия и отношения, а не на ключевые слова или фразы. На самом деле это довольно крутая концепция семантической рекламы.
#3: Динамический рекламный контент
Одной из целей собственно семантического веба является облегчение программного обмена данными через Интернет.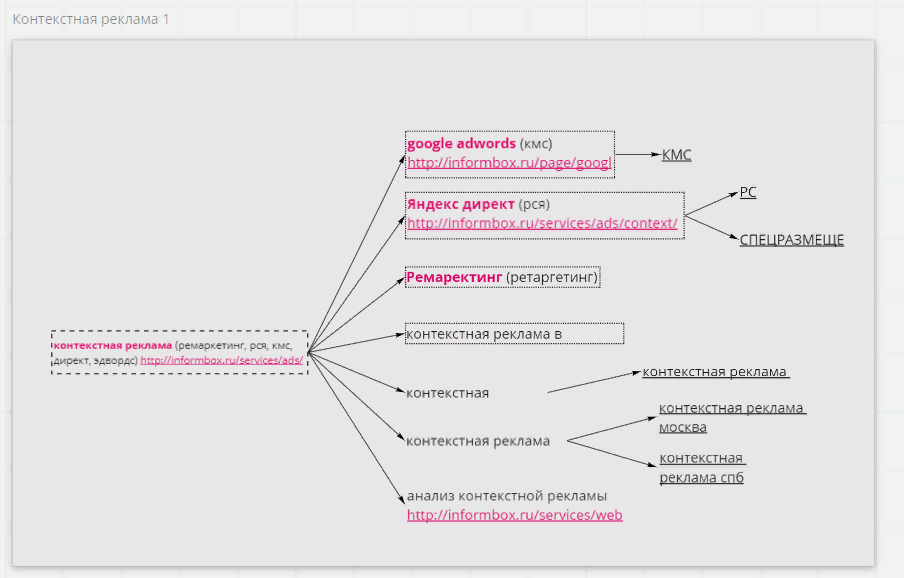 Делая Интернет более «машиночитаемым» — выше и выше удобочитаемого контента Интернета, который мы любим сегодня – можно открыть новую эру интеллектуальных, подключенных программных приложений.
Делая Интернет более «машиночитаемым» — выше и выше удобочитаемого контента Интернета, который мы любим сегодня – можно открыть новую эру интеллектуальных, подключенных программных приложений.
Джонатан Мендес из RAMP Digital применил эту концепцию к динамической подаче контента в интерактивную Flash-рекламу и назвал ее семантической рекламой. Идея заключается в том, что рекламодатель – особенно розничный продавец – может представить свои последние предложения и инвентарь в виде семантических данных XML, а затем творческий человек или агентство, создающее интерактивную рекламу, может считывать эти данные за кулисами, чтобы динамически изменять содержание рекламы. соответственно.
Это рекламное воплощение проверенного принципа веб-разработки: разделение представления и данных. По мере того, как рекламные объявления становятся все более информативными, работа по их обслуживанию становится более управляемой.
Кто-то из ИТ-отдела рекламодателя берет на себя ответственность за публикацию последних данных. Кто-то из маркетинговой/креативной команды берет на себя ответственность за отображение этих данных в самом крутом виде. Как только обе стороны согласуют формат данных, требуется относительно небольшая координация для обновления с обеих сторон.
Кто-то из маркетинговой/креативной команды берет на себя ответственность за отображение этих данных в самом крутом виде. Как только обе стороны согласуют формат данных, требуется относительно небольшая координация для обновления с обеих сторон.
Это могло бы быть еще более эффективным, если бы формат семантических данных для этих объявлений был стандартизирован для нескольких рекламодателей, возможно, даже для нескольких отраслей. Таким образом, маркетолог может создавать потрясающую рекламу с большим объемом данных, даже не координируя свои действия с ИТ-отделом компании. Это также может позволить использовать эффектные «мэшап-объявления», в которых используются данные из нескольких источников – например, от розничного продавца и брендов различных производителей, которые он продает.
Платформа Dapper MashupAds – одно из возможных воплощений этого с более стандартизированным подходом. На ReadWriteWeb есть хорошая статья об их стратегии, заключающейся в том, чтобы реклама способствовала внедрению семантической сети.
#4: Реклама внутри семантических данных
Когда я писал свою статью о семантическом маркетинге ранее в этом году, мое видение семантической рекламы заключалось в платном размещении данных в авторитетных источниках семантических данных:
Возможно, это приведет к новому виду смысловой рекламы? Люди платят за то, чтобы их семантические данные распространялись через определенные сети, помеченные определенными метаданными под руководством владельца сети. Я считаю, что здесь есть огромные предпринимательские возможности для вертикальных рыночных сетей.
Это совершенно новый канал рекламы, поэтому его сложно представить абстрактно. Итак, вот несколько примеров.
Yahoo! недавно выпущенный SearchMonkey, который позволяет поисковой системе иметь более контекстно-зависимую структуру. Например, результат ресторана от Yelp может содержать рейтинги, адрес и номер телефона, эскиз, ссылки непосредственно на отзывы пользователей и т. д. Эта более структурированная информация предоставляется Yelp Yahoo! как семантические веб-данные.
д. Эта более структурированная информация предоставляется Yelp Yahoo! как семантические веб-данные.
В этом сценарии Yelp стал мощным авторитетом семантических данных о ресторанах. Семантические данные, которые они предоставляют Yahoo! в конечном итоге оказывает значительное влияние на то, как пользователи получают первое впечатление о ресторане в результатах поиска.
А что, если Yelp взимает с ресторанов плату за включение дополнительных элементов данных в эти списки? Например, представьте необязательную ссылку «веб-купон», которая могла бы появиться в этих результатах поиска, если бы за нее заплатил ресторан. Это помогло бы ресторану выделиться еще больше и, надеюсь, побудило бы пользователей воспользоваться возможностью воспользоваться специальным предложением.
Теперь Yelp может хотеть или не хотеть делать именно это, и Yahoo! может разрешать, а может и не допускать, но это иллюстрирует новый вид семантической рекламы. Информация о купоне на самом деле представляет собой машиночитаемые семантические данные, публикуемые Yelp — Yahoo! затем в конечном итоге отображается для конечных пользователей. Но другие сайты также могут использовать семантические данные Yelp, распространяя ценность этого встроенного купона.
Но другие сайты также могут использовать семантические данные Yelp, распространяя ценность этого встроенного купона.
В качестве другого примера рассмотрим проект OpenCalais компании Thomson Reuters. OpenCalais — это приложение, которое берет простые HTML-страницы — например, страницу блога — и создает семантические веб-метаданные для именованных объектов (например, людей, компаний, регионов), фактов и событий, которые оно идентифицирует.
Семантическая реклама в этом контексте будет разрешать рекламодателям включать спонсируемые метаданные в эти результаты. Так, например, если семантическая ссылка на компанию должна была быть включена в результаты метаданных, сгенерированные OpenCalais, эта компания могла заплатить OpenCalais за включение дополнительных метаданных. Или, что более интригующе, рекламодатели могли бы предложить связать дополнительные метаданные с другими фактами или событиями — представьте, что спортивные мероприятия могут стать отличной возможностью для кого-то вроде Nike предоставить семантические ссылки на лицензионные товары.
Опять же, Thomson Reuters может сделать это или нет. Но вполне возможно, что они могли бы. И нет никаких сомнений в том, что это сделают другие органы, занимающиеся семантическими данными.
Во многих отношениях я считаю, что этот тип рекламы является наиболее точным определением «семантической рекламы», поскольку сама реклама представляет собой семантические данные, встроенные в потоки семантических данных.
Но все 4 из этих типов семантической рекламы будет интересно наблюдать за их развитием.
Получите сайт Chiefmartec.com прямо в свой почтовый ящик!
Подпишитесь на мой информационный бюллетень, чтобы получать последние новости о martech, как только они попадут в сеть. Обычно я публикую статью раз в неделю или две — стремясь к качеству, а не количеству.
Как семантика может преобразовать рекламу
Сегодня, когда люди думают о рекламе, они обычно думают о цифровой рекламе. Цифровая реклама перевернула рекламу с ног на голову: в старые времена реклама была креативной, о концепциях, визуальных эффектах и идеях; теперь речь идет о цифрах: показателях эффективности, алгоритмах, KPI или цифрах, связанных с кампаниями бренда.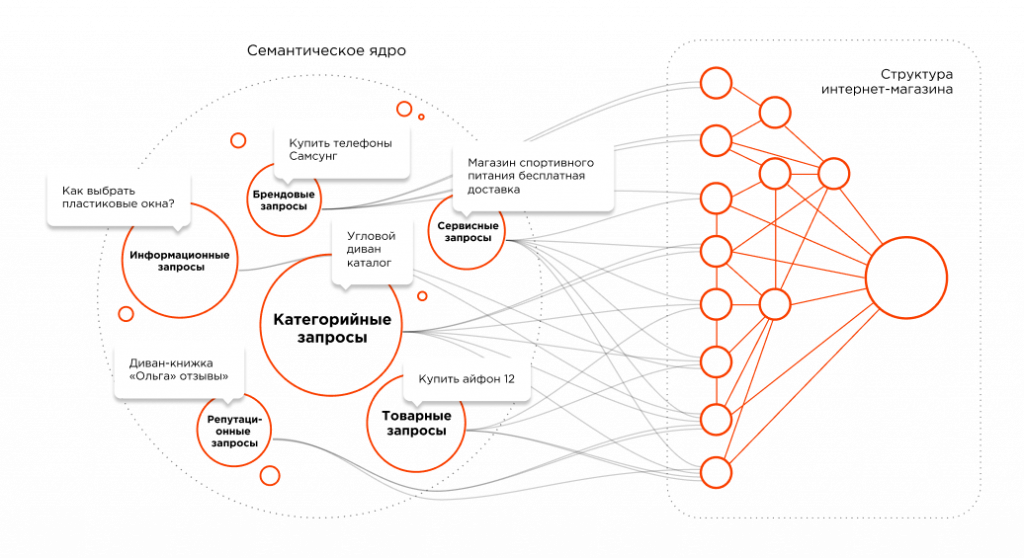
Винсент Потье
Если развитие цифровых технологий сделало бюджеты более подотчетными, на что тратятся эти подотчетные бюджеты? Как мы можем быть уверены, что реклама влияет на поведение потребителей? Часто кажется, что метрики заменяют цель: неужели мы потеряли смысл того, что на самом деле означает реклама? И помогло ли расточительство метрик и цифр понять, чего на самом деле хотят потребители?
Мы считаем, что семантика, применяемая к рекламе, укрепит смысл и поможет лучше понять намерение. Мы верим, что всплеск семантики в области рекламы на самом деле произойдет из-за этой сложной числовой дисциплины, цифровой рекламы.
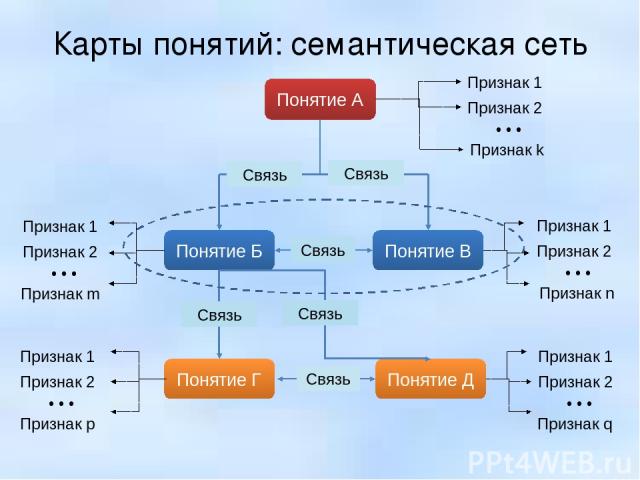
Что такое семантика?
Семантика — это область лингвистики (науки о языке), которая посвящена изучению значения.
Семантика — это не слова, а то, как мы их используем. Можно подумать, что специалисты по поисковому маркетингу являются экспертами в семантике. Но поисковый маркетинг — это программная текстовая прямая реклама. Поисковые маркетологи не ищут смысла; они хотят показывать свои текстовые объявления пользователям, которые, скорее всего, будут на рынке. Большинство рекламных данных — это данные, полученные в результате навигации (контекстной, поведенческой…), а не из намерений, ведущих к навигации. Данные поиска, если их правильно использовать, могут дать смысл.
Поисковые маркетологи не ищут смысла; они хотят показывать свои текстовые объявления пользователям, которые, скорее всего, будут на рынке. Большинство рекламных данных — это данные, полученные в результате навигации (контекстной, поведенческой…), а не из намерений, ведущих к навигации. Данные поиска, если их правильно использовать, могут дать смысл.
Итак, если поисковые данные лучше указывают на намерение, чем любая другая форма данных, где их найти?
Где вы находите данные поиска в Интернете?
Поиск не ограничивается Google. Очень далеко от этого. Большинство исследований показывают, что на поисковые системы премиум-класса приходится около 60% всех поисковых запросов (для настольных компьютеров, для мобильных эта цифра значительно ниже). Если объединить поисковые запросы на настольных компьютерах, планшетах и мобильных устройствах (где поисковая система не является наиболее часто используемой точкой входа в навигацию), то поисковые системы премиум-класса представляют собой лишь один крупный источник поиска. Пользователи, выполняющие поиск на сайтах издателей (специализированные, специализированные и т. д.), часто более вовлечены и продвигаются дальше по воронке продаж. Что очень интересно, когда кто-то сравнивает данные поисковых систем премиум-класса с другими поисковыми данными, так это то, насколько они различаются и дополняют друг друга. Люди ищут во многих разных местах, но они также ищут по-разному.
Пользователи, выполняющие поиск на сайтах издателей (специализированные, специализированные и т. д.), часто более вовлечены и продвигаются дальше по воронке продаж. Что очень интересно, когда кто-то сравнивает данные поисковых систем премиум-класса с другими поисковыми данными, так это то, насколько они различаются и дополняют друг друга. Люди ищут во многих разных местах, но они также ищут по-разному.
Сложность и привлекательность неструктурированных данных
Любая наука о языке занимается структурой. Сегодня проблема раскрытия богатства доступных поисковых данных заключается в возможности привнести структуру в неструктурированное.
Captify — поисковая разведывательная компания. Мы используем данные поиска, чтобы распознать намерение, а затем используем это намерение, чтобы применить таргетинг на уровне пользователя и показывать релевантную рекламу пользователям, которые находятся на рынке для бренда. Мы применяем те же методы к кампаниям брендов и даем уникальную и дифференцированную информацию, которую клиенты брендов не могут найти нигде.
Вначале мы собирали огромные объемы поисковых данных через обширную, многоуровневую и в основном эксклюзивную сеть данных. И мы получим намерение, глядя на эти неструктурированные данные. Вдохновленные поисковым маркетингом на ранних этапах, мы использовали разные типы соответствия, пока не поняли, что нам нужно найти компромисс между точностью (и, следовательно, производительностью) и масштабом. Слишком ограничив тип соответствия, мы получим отличную производительность, но ограниченный масштаб; заходя слишком широко, мы будем масштабироваться, но производительность снизится. И у нас все еще были те огромные объемы неструктурированных данных, которые мы не могли использовать. Это когда копейка упала…
Нам пришлось перевернуть проблему с ног на голову. Люди не могут себе представить, сколько различных поисковых путей будут использовать другие люди, чтобы выразить свои намерения. Таким образом, выяснение наиболее очевидных путей поиска должно было быть ограничено и позволило бы нам лишь коснуться поверхности золотого рудника неструктурированных данных. Нам пришлось создать семантический движок, стремящийся динамически понимать значение миллиардов поисковых ключевых слов и фраз в режиме реального времени, одновременно определяя миллиарды связей между этими ключевыми словами, т.е. мы должны были приступить к чему-то очень амбициозному: созданию динамической онтологии.
Нам пришлось создать семантический движок, стремящийся динамически понимать значение миллиардов поисковых ключевых слов и фраз в режиме реального времени, одновременно определяя миллиарды связей между этими ключевыми словами, т.е. мы должны были приступить к чему-то очень амбициозному: созданию динамической онтологии.
Преимущества структурирования неструктурированного
Понимание намерения миллиардов ключевых слов и фраз вместе с их миллиардами связей имеет огромную ценность, поскольку оно не только позволяет повысить релевантность рекламы, но и меняет характер реклама. Мы больше не проводим кампании. Благодаря технологии, основанной на поисковых данных, теперь можно проводить кампании по брендам, в то же время понимая эффективность и влияние кампании. Данные поиска помогают определить аудиторию, а данные поиска помогают понять влияние на ключевые показатели бренда, такие как узнаваемость бренда, запоминаемость бренда, отношение к бренду, атрибуты бренда, а также выявить неинтуитивные корреляции между параметрами бренда и другими отношениями, интересами и поведением.