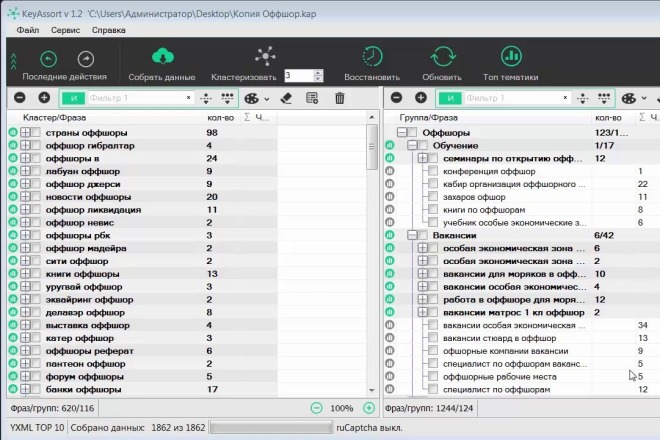
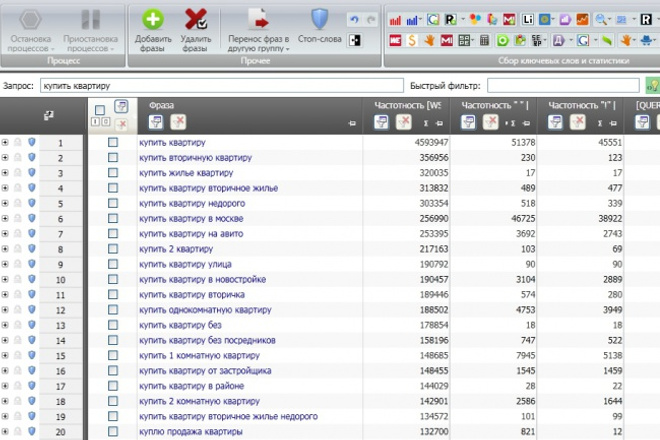
Содержание
Сбор фраз – Key Collector
Инструменты пакетного сбора фраз позволяют расширить семантическое ядро путем сбора идей запросов из различных источников.
В зависимости от конкретного модуля функционал может немного отличаться, но в общем смысле инструменты похожи.
Формирование задания
Для запуска пакетного сбора сперва нужно выбрать режим сбора: добавление в текущую активную группу или сложный сбор в режиме распределения по группам (1).
Далее необходимо ввести запросы для обработки (2) и выбрать режим добавления запросов, задать настройки сбора (3).
Запросы можно вводить вручную или загрузить из внешнего файла. При работе в режиме распределения по группам пакеты для обработки можно сформировать вручную или воспользоваться функцией автоматического распределения по группам .
Образец окна пакетного сбора
Распределение по группам
В режиме распределения по группам вы можете указать целевые группы для добавления результатов по каждому из запросов.
В дереве групп (1) двойным кликом по заголовку или специальными кнопками на панели (3) выберите нужные группы, а затем введите запросы в панели формирования очереди (2).
Изучите подсказки к кнопкам , позволяющим автоматически наполнить выбранные целевые группы фразами из этих групп или их заголовками.
Панель распределения по группам
Автоматическое распределение
Иногда заранее известен набор фраз для обработки, но группы еще не созданы. В этом случае вы можете автоматически создать распределение по группам.
- Шаг 1. Выберите режим добавления фраз «Добавить в текущую группу».
- Шаг 2.
 Введите список запросов.
Введите список запросов. - Шаг 3. Нажмите кнопку для автоматического создания в проекте одноименных групп и распределения по группам.
 Введите список запросов.
Введите список запросов.На шаге 2 запросы можно вводить как в виде плоского списка, так и с поддержкой вложенности (сложной структуры) в режиме Группа:Ключ.
Настройки и параметры
О режиме пропуска дубликатов фраз можно прочитать здесь. Будьте внимательны при выборе режима, т.к. от этого сильно будет зависеть результат сбора фраз.
Например, если вы обрабатываете похожие или пересекающиеся по выдаче запросы, то в режиме пропуска дубликатов в других группах в проект полная выдача попадет только для одного из запросов, который успел оказаться в очереди на обработку раньше (выдача по остальным может обрезаться, т.к. дубликаты фраз согласно выбранному режиму будут пропускаться).
Использовать символ запятой как разделитель между фразами
Использовать режим импортирования «Группа:Ключ»
Принудительно добавлять исходные фразы в таблицу
Некоторые системы не гарантируют наличие исходного запроса в результатах.
Например, по запросу «макароны» может быть выдача «макароны по-флотски», «макароны с сыром» и т.д., но сам исходный запрос «макароны» в выдаче может отсутствовать.
Использование этой опции позволяет принудительно добавлять исходные запросы в результаты сбора.
Принудительно добавляемый запрос подчиняется всем правилам добавления фраз, и может быть пропущен, если таковы требования выбранных режимов и настроек.
Глубина парсинга
При использовании ненулевой глубины парсинга программа автоматически будет подставлять собранные ранее результаты по запросу в качестве исходных запросов на следующей итерации.
Использование глубины > 0 целесообразно, если вы хотите извлечь максимальное количество результатов по исходному запросу.
При этом собранные дополнительные варианты могут незначительно отличаться по теме от исходного введенного вручную запроса.Без явной необходимости рекомендуем использовать глубину парсинга = 0.
Альтернативой глубинному исследованию запросов является полуавтоматическая обработка, когда сперва вы получаете результаты при глубине = 0, затем выполняете предварительную фильтрацию данных (опционально можно удалить заведомо ненужные фразы), затем копируете оставшиеся фразы и используете их в качестве входных на следующей итерации.
В таком случае вы получаете полный контроль на прогрессом выполнения задачи, возможность без потерь приостанавливать и возобновлять сбор данных, возможность сократить время обработки за счет удаления заведомо ненужных запросов.
Парсить страниц
Многие сервисы отображают результаты в постраничном режиме.
Данный параметр отвечает за кол-во просматриваемых программой страниц.В зависимости от задач (экспресс-анализ или полный сбор) можно устанавливать небольшие или максимальные значения параметра.
Обновлять статистику для существующих в таблице фраз
В процессе сбора фраз в результатах сбора может встретиться фраза, которая уже присутствует в целевой группе фраз.
Если вы хотите, чтобы программа принудительно обновила ранее записанные для такой фразы данные статистики на только что полученные свежие, то включите эту опцию.
 При этом собранные дополнительные варианты могут незначительно отличаться по теме от исходного введенного вручную запроса.
При этом собранные дополнительные варианты могут незначительно отличаться по теме от исходного введенного вручную запроса. Данный параметр отвечает за кол-во просматриваемых программой страниц.
Данный параметр отвечает за кол-во просматриваемых программой страниц.Автоматическое назначение региона
В некоторых инструментах, поддерживающих выбор региона при сборе данных, может присутствовать функция автоматического назначения региона для одноименных с названием региона групп.
Эта функция может пригодится, если структура проекта содержит подгруппы регионов для некоторых категорий структуры. Например, это может встретиться при составлении семантического ядра интернет-магазинов.
Нажмите кнопку автоматического задания регионов, и программа выполнит поиск групп в проекте, заголовки которых совпадают с поддерживаемыми названиями регионов.
Сбор статистики
Можно не только собирать новые фразы, но и получать статистику для существующих в проекте фраз без добавления новых. Причем данные можно периодически обновлять.
Узнать больше
Пример составления семантического ядра в Key Collector – пошаговое руководство
Пошаговое руководство как сделать семантическое ядро сайта в программе Key Collector. В статье приводим технологию сбора и парсинга семантического ядра, кластеризацию, анализ конкурентов и составление структуры сайта.
Зачем нужен экспресс-метода сбора семантики
Что такое семантическое ядро, из чего оно состоит и зачем его делают — подробно рассмотрено в материале здесь.
Рассмотрим составление семантического ядра сайта на примере, как его сделать в Кей Коллекторе в режиме «Экспресс-метода». Маркетологи студии DIUS его делают в случаях:
- При разработке нового сайта, когда планируется его продвижение в поиске. Таким образом задается SEO-адаптированная структура.
- При заказе SEO аудита сайта. Выявляются конкуренты на поиске и проводится сравнительный анализ сайта заказчика.
- На начальном этапе переговоров с потенциальным заказчиком, чтобы определить потенциал поискового продвижения и объем работ.
Экспресс-метод составления семантического ядра в Key Collector отличается от полноценной разработки СЯ тем, что не производится дополнительных итераций по сбору фраз. Если при упрощенном методе оптимизатор по маскам собирает из вордстата фразы одним прогоном, то при рабочем проекте дополнительно производятся:
- Повторный сбор фраз из вордстата по очищенной выборке;
- Сбор подсказок из Яндекс и Гугл;
- Добавление фраз конкурентов, собранных по сервисам;
- Добавление фраз по основным маскам из базы Букварикс;
- Сбор из Вордстат фраз с предлогами.
В результате количество полученных фраз на порядок превышает объем, созданный при экспресс-методе. Таким образом, проект прорабатывается гораздо глубже, учитывается больше факторов.
Подбор масок (маркеров)
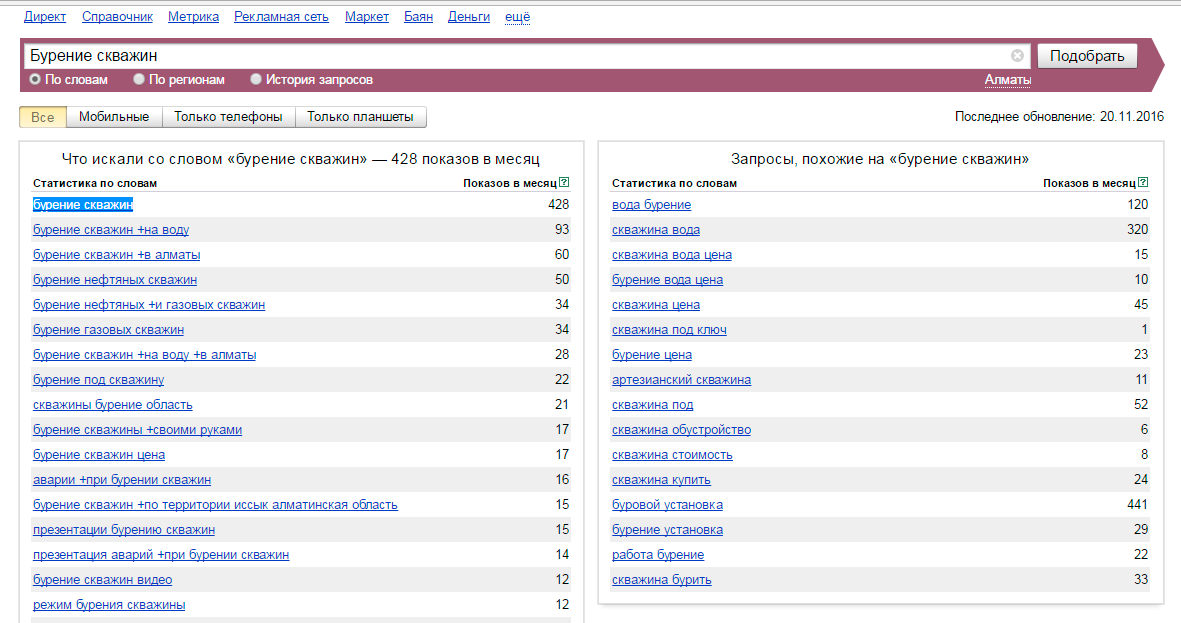
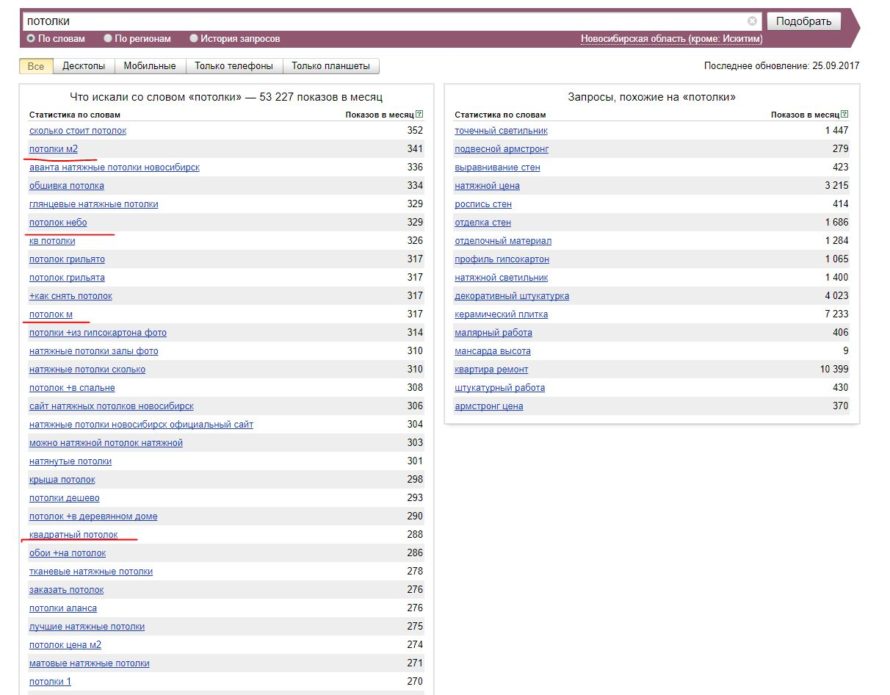
Рассмотрим процесс составления семантики по направлению «рольставни», в продолжение темы, начатой здесь. В первую очередь необходимо подобрать маркеры. Для этого оптимизаторы DIUS используют популярный ресурс Википедия. Набираем в поисковике Яндекс «рольставни википедия» и читаем материал:
И дальше:
Выписываем разные названия: | Также интересны склонения слова: |
|
|

Собираем фразы из Вордстат в Кей Коллекторе
Создаем новый проект в Кей Коллекторе и добавляем списком разные названия. А к словам в склонении добавляем вначале восклицательный знак:
Итого получилось 18 фраз, по которым производится сбор фраз из Wordstat (Что такое Яндекс.Вордстат и как им пользоваться). При сборе общей частоты регион выставляем выше целевого, если это Москва, то берем «Центр». Это позволяет собрать больше фраз. А уточненную или точную частоту собираем по целевому региону (подробнее про частотность здесь). В данном случае сбор фраз сделали без выбора региона.
Чистка фраз в Key Collector
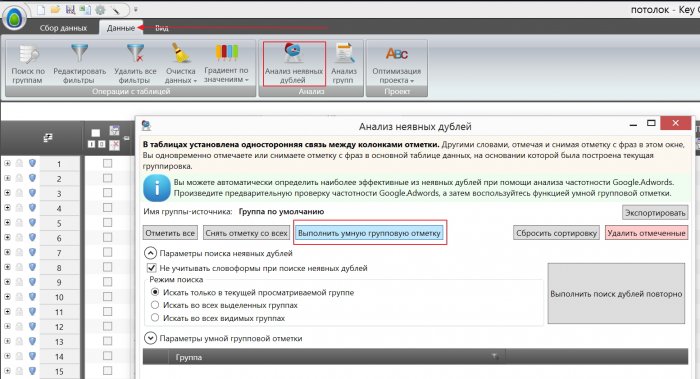
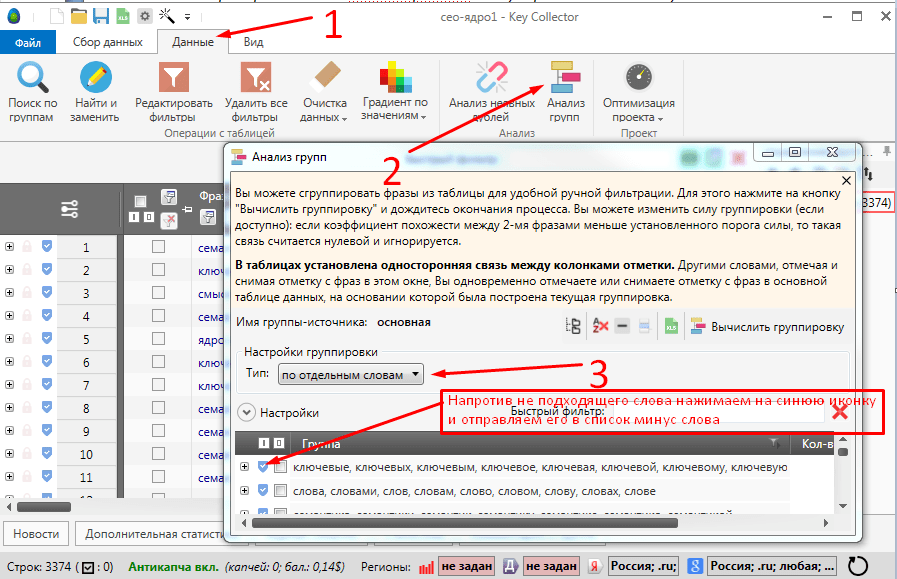
Для этого во вкладке «Данные» запускаем инструмент «Анализ групп» и получаем группировку фраз по словам. В ней отмечаем нецелевые слова и кликом правой клавиши мыши на одном из них отправляем их в список «Стоп-слов». На будущее это пригодится, т.к. экспресс-ядро потом разворачивается в рабочий проект, который потом дополняется, и есть готовый список для минусов.
Стоит отметить, что в примере работу проводим по коммерческим запросам и информационные ключевики отправляем в корзину, а в рабочем проекте для них создается отдельная папка «Инфо». С ними также происходит работа по аналогии с дальнейшими этапами. Чем отличаются информационные запросы от коммерческих смотрите здесь, а также «Как продвигать сайт по информационным запросам».
Также в студии есть готовые списки слов по городам России и Подмосковья, которые добавляются в список «Стоп-слов», что ускоряет чистку. И еще предусмотрены списки слов для создания отдельной группы информационных запросов.
В результате чистки в «Корзину» отправлено 1367 запросов. Их не удаляют, т.к. в будущем эти фразы могут пригодится для работы, и при повторном сборе они не будут добавлены.
Сбор точной частоты
Рассмотрим, как собрать частотность в Кей Коллекторе. По оставшимся 2958 фразам определяем точную частоту при помощи инструмента «Сбор статистики Yandex.Direct». Выставляем целевой регион «Москва и область» и отмечаем следующие опции:
Все фразы, где точная частота равно 0, отправляем в корзину или в отдельную папку «0».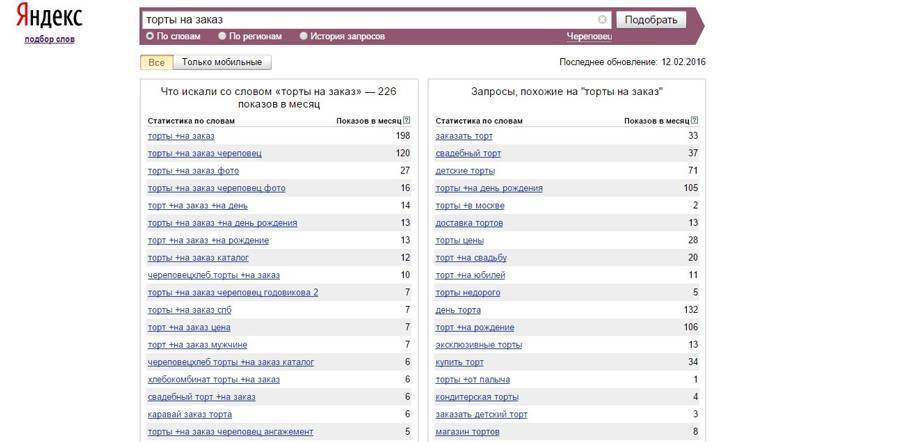 Из 2958 оставленных фраз получилось 1598 нулевых. Оставшиеся слова сортируем по частоте:
Из 2958 оставленных фраз получилось 1598 нулевых. Оставшиеся слова сортируем по частоте:
И дополнительно проводим анализ групп или глазами пробегаемся по фразам, чтобы убрать нецелевые фразы, которые не увидели при первой чистке. Тут можно использовать следующий алгоритм:
- Нажимаем и держим букву «S» на клавиатуре и кликаем по слову, которое не целевое.
- Оно отмечается, и так далее делаем со всеми словами ниже.
- Когда просмотрели пару сотен фраз и отметили ненужные, дополнительно нажимаем «Shift» и делаем двойной клик на любом отмеченном слове.
- Появится окно, где все выделенные слова буду добавлены в список для «Стоп-слов»:
Жмем кнопку «Добавить в стоп-слова» и переносим их в папку «Корзина».
При повторной чистке в «Анализ групп» — отсортируйте слова по сумме точной частоты, достаточно просмотреть до суммы 5:
В результате чистки осталось 1035 фраз.
Сбор данных SERP
Включаем фильтр группы «Частота “!”», оставляем фразы больше 4 — в итоге в группе остается 448 фраз:
Включаем сбор данных по SERP:
Программа собирает данные ТОП-20 в Яндекс по каждой фразе. Параметры сбора этого инструмента выставляются в общих настройках:
Параметры сбора этого инструмента выставляются в общих настройках:
В результате сбора в программе по каждой фразе с частотой «!» от 5 и выше будет список сайтов, которые находятся в ТОП-20. Кей Коллектор автоматически сведет данные на уровне доменов, чтобы можно было увидеть сайт и количество фраз, по которым он в ТОП.
Анализ конкурентов
После сбора данных СЕРП включаем инструмент «Поиск конкурентов»:
Получаем следующую сводку:
Указаны сайты и количество фраз по которым они в ТОП-20 (или ТОП-10, зависит от настроек). Нажимаем «Ctrl» и кликаем по этим сайтам – они откроются в браузере. Внимательно изучаем меню разделов «Рольставни», какие там есть подразделы:
- luxrol.ru
- rolstavni-prom.ru
- zhaluzi-rolstavni.ru
При клике на каждый домен в общей группе отмечаются фразы, по которым сайт ранжируется в ТОП-20. Так, например, если выделить первые 5 сайтов от luxrol.ru до rusroll.ru, в группе будет отмечено 420 фраз из 1035, это фразы, по которым был осуществлен съем SERP. Для более детального анализ производится съем SERP по всем фразам.
Для более детального анализ производится съем SERP по всем фразам.
Семантическое проектирование структуры сайта
Создаем табличку в Эксель или проект в МайндМап, в который выписываем разделы из меню сайтов с высокой видимостью, и создаем структуру:
[скачать файл Эксель]
Таким же образом можно сделать кластеризацию запросов в Key Collector:
Распределили слова по группам. Смотрим по «Анализ групп», что осталось:
Судя по группировкам, еще можно создать кластеры: в проем, с электроприводом, стеклянные, пластиковые и т.д. Это уже на усмотрение оптимизатора, т.к. сбор был не полный, а основные группы, генерирующие трафик, созданы на основе структур сайтов конкурентов.
[скачать исходник – семантическое ядро в формате key collector]
Результат
В результате сбора фраз и анализа конкурентов за пару-тройку часов оптимизатор получает:
- сгруппированное семантическое ядро по направлениям;
- список из конкурентов с высокой видимостью для проведения сравнительного анализа по коммерческим факторам, содержанию и т. д.;
- получены данные для оценки потенциала продвижения – планируемый трафик, объем предстоящих работ по доработке сайта и т.д.;
- есть список минус-слов для будущей чистки фраз при дополнительном сборе фраз.
 д.;
д.;Кей Коллектор сокращает временные затраты на рутинные операции в разы, т.к. если это делать вручную – понадобилось бы несколько дней.
Комиксы
Key Collector — Что за—?!
Очистить все фильтры ([[checkedAggCount]])
Что за—?! (1988)
Загрузка…
[[agg.name]]
[[agg.key_as_string || агг.ключ]]
Показать варианты
7 результатов
Низкий $1
Средний $2
Высокий $3
Собственный
Хочу
eBay
Двухстраничный рассказ Тодда Макфарлейна «Рождение героя»
Пародия на «Бэтмена» о том, как он выбрал себе имя
Камея Джокера
Двухстраничный рассказ Тодда Макфарлейна «Рождение героя»
Пародия на «Бэтмена» о том, как он выбрал себе имя
Камея Джокера
Низкий $1
Средний $2
Высокий $8
Собственный
Хочу
eBay
Первое появление Росомахи, женской пародии на Росомаху
Первое появление Росомахи, женской пародии на Росомаху
Низкий $2
Средний $8
Высокий $20
Собственный
Хочу
eBay
Первое эпизодическое появление Барта Симпсона в комиксе
Первое эпизодическое появление Барта Симпсона в комиксе
Низкий $1
Средний $2
Высокий $9
Собственный
Хочу
eBay
Пародия на Росомаху
Пародия на Росомаху
Низкий $1
Средний $5
Высокий $18
Собственный
Хочу
eBay
Первое появление Pork Grind, версии Venom
из вселенной Spider-Ham.
Первое появление Pork Grind, версии Venom
из вселенной Spider-Ham.
Низкий $2
Средний $4
Высокий $12
Собственный
Хочу
eBay
Пародийное издание Marvel с «Перчаткой бесконечности»
Пародийное издание Marvel с «Перчаткой бесконечности»
Низкий $2
Средний $8
Высокий $20
Собственный
Хочу
eBay
Первое появление Свин-Паука 2099, Пигель О’Хара
Окончательный выпуск
Первое появление Свин-паука 2099, Пигеля О’Хара
Окончательный выпуск
Сбор полного семантического ядра: почему это так важно для проекта на любой стадии разработки
05. 06.2022
06.2022
seo.boutique.com
0 комментариев
Семантик-ядро-сайт, что это такое
Часто на старте сео продвижения сайта многие сталкиваются с таким понятием, как семантическое ядро сайта (далее просто КЛ), в этой статье мы подробно разберем, как правильно и качественно подготовить ЦЛ, на какие нюансы обратить внимание, чтобы не допустить ошибок.
Семантическое ядро (SN) — это база ключевых слов и словосочетаний, которые помогают пользователям находить ваш сайт в результатах поиска. Сбор семантического ядра по праву считается одним из важнейших этапов SEO-оптимизации сайта, ведь от качества его подготовки зависит дальнейшая судьба и позиции сайта в поисковой выдаче. Если правильно собирать СА, то после ряда работ ваш сайт получит увеличение целевого трафика, увеличение количества целевых действий, а также увеличение прибыли.
В этой статье мы подробно разберем, как правильно и качественно подготовить СА, на какие нюансы обратить внимание, чтобы не допустить ошибок.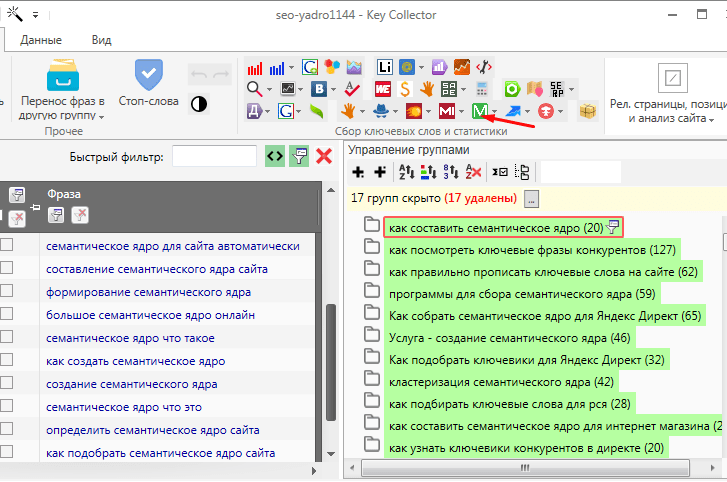
Что такое семантическое ядро для
При проектировании сайта многие веб-мастера игнорируют такое понятие как семантическое ядро и оформляют сайт условно по своему усмотрению, что приводит к грубым ошибкам и мешает пользователям находить сайт в поиске Результаты. Давайте разберемся, зачем нужно строить семантическое ядро:
- Качественная проработка структуры сайта – SL позволяет спроектировать максимально полную структуру сайта, которая будет охватывать все запросы клиентов.
- Продвижение страниц по топам поисковой выдачи — это позволяет оптимизировать каждую страницу в отдельности под определенный набор поисковых запросов, чтобы страница занимала высокие позиции в поисковой выдаче.
- Составить план наполнения страниц — собранные ключевые фразы позволяют понять, по каким запросам ранжируется страница. Все эти ключи в прямом вхождении, в виде словоформ обязательно должны присутствовать на сайте. На основе приоритета страниц формируются технические задания для написания текстов на страницах.
- Создание автоматической перелинковки на сайте – все анкоры, которые добавляются на сайт, должны быть сформированы из словесной базы семантического ядра.
- В некоторых случаях собранное семантическое ядро используется для настройки контекстной рекламы.
- Четко понимать, по каким запросам нужно продвигать сайт, какие из этих запросов высокочастотные, какие среднечастотные, а какие низкочастотные.

Типы ключевых слов
Прежде чем перейти к числовым значениям каждого типа запроса, стоит отметить, что необходимо правильно ранжировать по частоте внутри каждой ниши в отдельности, т.к. на этот показатель влияет сезонность. Каждая ниша имеет свой потенциал, например для продвижения ниши шин высокочастотные запросы будут стартовать с частотой от 5 000 запросов в месяц, а например в нише паркетной укладки высокочастотные запросы будут начинаться с 500 человек в месяц.
Высокочастотные ключевые слова (ВЧ) — это запросы, которые пользователи чаще всего вводят в поиске.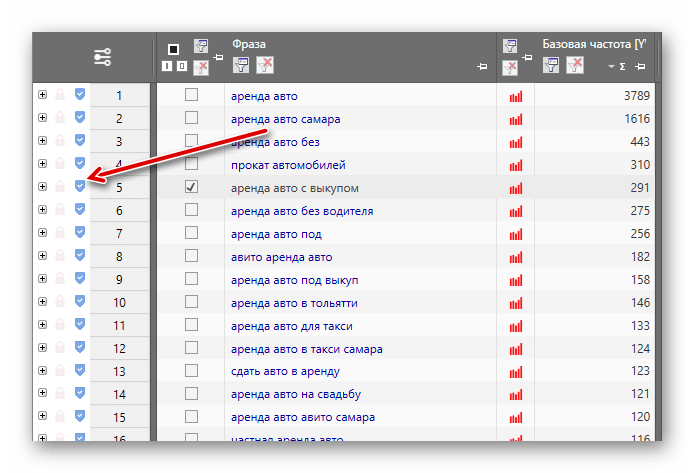 Как показывает практика, это достаточно короткие запросы, зачастую они состоят из 1 или 2 слов.
Как показывает практика, это достаточно короткие запросы, зачастую они состоят из 1 или 2 слов.
Плюсы продвижения вверх по тройке:
- Эти ключевые слова дают возможность увеличить количество органического трафика на сайте.
- ВЧ-запросы предоставляют возможность автоматического роста средне- и низкочастотных запросов.
- Такие запросы дают возможность узнаваемости бренда в Интернете.
Недостатки тройного продвижения:
- Пока процесс продвижения ВЧ запросов достаточно затратный, т.к. как правило Топ 5 по таким запросам занимают крупные сайты, сайты-агрегаторы, с которыми сложно конкурировать.
- Продвижение по высокочастотным запросам требует достаточно больших вложений: как финансовых, так и временных.
- Большая конкуренция по высокочастотным запросам заставляет постоянно быть в курсе, следить за позициями конкурентов и следить за всеми изменениями, которые они вносят на сайт.
Среднечастотные (СЧ) – это запросы, которые считаются не самыми узкими, но и не узконаправленными, они занимают нишу между высокочастотными и низкочастотными запросами. Как правило, средние запросы содержат специфику (например, регион, цвет, размер и т. д.). МФ-запросы продвигать гораздо сложнее, чем НЧ-запросы, здесь без проектирования структуры и контента не обойтись, для продвижения таких запросов необходимо наращивать внешнюю ссылочную массу и при этом использовать не только прямые входы, но и также различные анкоры, максимально полно описывающие страницу.
Как правило, средние запросы содержат специфику (например, регион, цвет, размер и т. д.). МФ-запросы продвигать гораздо сложнее, чем НЧ-запросы, здесь без проектирования структуры и контента не обойтись, для продвижения таких запросов необходимо наращивать внешнюю ссылочную массу и при этом использовать не только прямые входы, но и также различные анкоры, максимально полно описывающие страницу.
Плюсы среднесрочного продвижения:
- Имеют потенциал стать высокочастотными запросами, если их хорошо проработать, то
- Продвижение по среднесрочным запросам дает возможность подтянуть позиции по высокочастотным запросам в результаты поиска.
- Дайте возможность потенциальным клиентам ознакомиться с сайтом, его ассортиментом, структурой сайта.
Минусы среднего продвижения:
- Они не всегда хорошо конвертируются и не всегда заканчиваются покупкой.
- Иногда средние частоты могут стать низкочастотными запросами.
- Не привлекать много трафика на сайт.
- li>

Низкочастотные ключевые запросы (LF) – часто такие запросы еще называют long-tail запросы, так как содержат довольно много уточнений. Низкочастотные запросы обычно вводят пользователи, точно знающие, что ищут, готовые совершить целевое действие — совершить покупку или заказать услугу. Для продвижения в ЛФ достаточно проработать структуру сайта, ссылки между страницами и написать контент на каждой странице с нужными записями.
Плюсы движения по басу:
- Высокая конверсия — как правило, клиенты, которые приходят на сайт по таким запросам, уже четко обозначили свою потребность и готовы совершить покупку.
- Низкая конкуренция – как правило, владельцы бизнеса не ориентируются на такого рода запросы, по ним легко двигаться.
- Продвижение среднечастотных и высокочастотных запросов – низкочастотные запросы дают возможность проработать страницы, что в дальнейшем положительно скажется на продвижении высокочастотных и среднечастотных запросов.
- Стабильный результат – попав в топ результатов по низким частотам, они сохранят результаты довольно долго.
Недостатки перемещения по басу:
- Постоянная работа на сайте.
- Невозможность оценить финансовые затраты.
- Дать небольшое количество трафика на сайт.
Как правильно собрать семантическое ядро
Прежде чем приступить к формированию СА необходимо:
- Проанализируйте конкурентов, см. Top SERPs, чтобы определить, какие конкуренты лидируют в поисковой выдаче.
- Подумайте, какие ключевые слова вас интересуют, как клиенты могут найти вас в результатах поиска.
Далее начинается самый трудоемкий процесс – сбор ключевых запросов, из которых в дальнейшем будет формироваться семантическое ядро сайта, по которому и будет происходить продвижение.
Есть два способа сбора SP, мы рассмотрим их более подробно ниже.
Сбор СЛ конкурентами
Для такого подхода нужно выбрать 2-3 конкурентов, собрать с помощью внешних инструментов, таких как Serpstat или Ahrefs (больше ресурсов для сбора длинного списка запросов мы разберем в статье «Полезные инструменты для SEO-продвижения сайтов»), всю базу ключевых слов, по которым эти сайты ранжируются.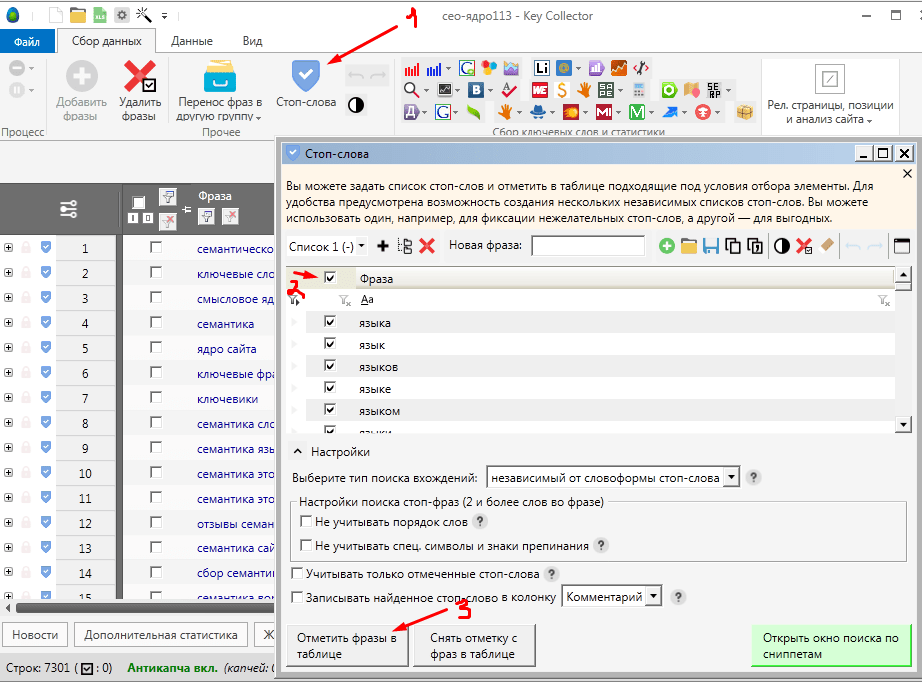 Ключи на продвижение рекомендуется брать начиная с частоты 9. На ключи с частотой меньше 9 не стоит обращать особого внимания. после базовой оптимизации под СЧ, ВЧ и НЧ клавиши с частотой 1-9будут автоматически подтягиваться к началу результатов поиска.
Ключи на продвижение рекомендуется брать начиная с частоты 9. На ключи с частотой меньше 9 не стоит обращать особого внимания. после базовой оптимизации под СЧ, ВЧ и НЧ клавиши с частотой 1-9будут автоматически подтягиваться к началу результатов поиска.
Собрав исходное семантическое ядро конкурентов, необходимо дополнительно оценить его качество. В первую очередь нужно избавиться от мусорных и нецелевых ключевых слов, попавших в CL при сборе.
К нежелательным запросам относятся:
- Упоминание названия компании, бренда конкурента.
- Указание услуг, товаров, на которых компания не специализируется.
- Нецелевые географические запросы (города других стран, города, в которых компания не работает).
- Запросы с ошибками.
- Повторяющиеся запросы.
После того, как CL для сайта собран, его необходимо кластеризовать, т.к. прорабатывать документы такого объема вручную нецелесообразно и неэффективно с точки зрения затрат времени и бюджетов.
Сбор ключевых слов по ключевым словам
При таком подходе необходимо определить, какие запросы наиболее интересны для продвижения и какие запросы вообще присутствуют в нише. Далее необходимо с помощью любого внешнего инструмента, например Serpstat, собрать все ключевые фразы, содержащие интересующую нас для продвижения фразу/слово.
После того, как длинные списки запросов собраны, очищены от нежелательных запросов, начинается этап кластеризации.
Кластеризация семантического ядра, что это такое?
Кластеризация — это процесс, при котором запросы, имеющие общую тему и ведущие на одну и ту же страницу в результатах поиска, группируются в кластерные группы.
Каждый из полученных кластеров ключевых слов будет использован для продвижения и оптимизации одной страницы.
Существует несколько методов кластеризации: Жесткий, Мягкий и Средний. Ниже мы подробно разберем каждый из них.
Мягкая кластеризация – для этого метода используется наиболее частый ключ и на его основе выбираются все остальные, т. е. все ключи связываются между собой по наиболее частому ключу. Этот метод кластеризации подходит для новостных порталов, информационных сайтов, небольших сайтов, потому что в этом методе есть ошибки и ошибки.
е. все ключи связываются между собой по наиболее частому ключу. Этот метод кластеризации подходит для новостных порталов, информационных сайтов, небольших сайтов, потому что в этом методе есть ошибки и ошибки.
Средняя кластеризация — это нечто среднее между мягкой и жесткой кластеризацией. Все начинается с того, что берется самая частотная фраза и с ней сравниваются остальные ключи по количеству общих URL, при этом существует определенный порог добавления ключей в кластер (обычно не более 10), после чего формируется новый сегмент кластера.
Жесткая кластеризация — это кластеризация, при которой сам частотный ключ сравнивается со следующими ключами по количеству общих URL в ТОП-10 результатов поиска. Этот способ подходит для крупных сайтов, ниш, где большая конкуренция и где большое количество слов-синонимов. В итоге после этой кластеризации мы получаем меньшую SA, чем после SOFT и Middle, но более точную.
В Интернете есть много бесплатных ресурсов, позволяющих быстро и эффективно создавать кластеры. Давайте посмотрим на некоторые из них:
Давайте посмотрим на некоторые из них:
- Coolakov — довольно удобный сервис, который может бесплатно кластеризовать до 500 слов. Этот сервис удобен еще и тем, что сразу выводит список конкурентов.
- Semantist — с помощью этого сервиса можно кластеризовать SL до 2 000 слов. Этот ресурс идеально подходит для кластеризации добавления новой категории на сайт.
- Seoquick — с помощью этого сервиса можно кластеризовать до 40 000 запросов, но следует учитывать один момент, если использовать бесплатную версию приложения в сутки, можно кластеризовать не более 1 000 запросов.
Сбор СА в ручном режиме
При таком способе сбора ключевых слов специалист вручную прорабатывает каждую страницу сайта, собирает семантику по конкуренту и по целевым запросам, а затем «рассаживает» собранные ключи по страницам. Этот метод требует очень много времени. Из минусов также можно отметить, что при таком варианте проработки семантики специалист не имеет возможности качественно проработать и спроектировать структуру сайта, что лишает сайт шансов иметь наиболее полная и расширенная структура, отвечающая спросу.