Содержание
Виды поисковых роботов — SEO на vc.ru
{«id»:13772,»url»:»\/distributions\/13772\/click?bit=1&hash=93a368816b1e347dfad2882f455fc9bb4606ce94b2370bda4e82b172745bc14e»,»title»:»\u00ab\u041c\u0430\u0440\u043a\u0435\u0442\u00bb \u0437\u0430\u043f\u0443\u0441\u0442\u0438\u043b \u0440\u0435\u0444\u0435\u0440\u0430\u043b\u043a\u0443 \u0434\u043b\u044f \u043f\u0440\u043e\u0434\u0430\u0432\u0446\u043e\u0432″,»buttonText»:»\u0427\u0442\u043e \u0434\u0435\u043b\u0430\u0442\u044c»,»imageUuid»:»d09521f5-ee9c-5e06-8358-733cd4596e9d»,»isPaidAndBannersEnabled»:false}
SEO
SEO блиц
Поисковый робот или паук — это специальная программа, предназначенная для сканирования сайтов. Робот, переходя по ссылкам, индексирует информацию и сохраняет ее в базе поисковых систем.
Робот, переходя по ссылкам, индексирует информацию и сохраняет ее в базе поисковых систем.
5003
просмотров
Поисковые роботы Google
Существует множество видов различных поисковых роботов, каждый из которых выполняет определенную функцию.
- У Google основной поисковый робот называется Googlebot — он находит новые страницы и изменения на старых, после чего добавляет информацию в индекс.
- Googlebot-Image выполняет поиск изображений.
- Googlebot-Video соответственно отвечает за видео-контент.
- Googlebot-News добавляет информацию в Google Новости.
- APIs-Google используется для отправки push-уведомлений.
- AdsBot-Google, AdsBot-Google-Mobile, AdsBot-Google-Mobile-Apps проверяют качество рекламы на компьютерах, мобильных устройствах и в приложениях.
- Mediapartners-Google определяет содержание объявлений в AdSense.


Подробнее узнать о поисковых роботах Google можно в официальной справке компании.
Поисковые роботы Яндекса
- Основной робот Яндекса (YandexBot/3.0) отвечает за поиск новых страниц/сайтов и переиндексацию новых версий ранее известных страниц.
- Робот-зеркальщик (YandexBot/3.0; MirrorDetector) определяет зеркала сайтов.
- Робот Яндекс.Картинок (YandexImages/3.0) отвечает за индексацию изображений.
- Робот Яндекс.Новостей (YandexNews/4.0).
- Робот, индексирующий фавиконки сайтов (YandexFavicons/1.0).
- Робот Рекламной сети Яндекса (YandexDirect/3.0) определяет тематику сайтов для подбора более релевантных объявлений.
Подробнее о поисковых роботах Яндекса можно в официальной справке компании.
Управление поисковыми роботами
При помощи файла robots. txt или мета-тега <meta name=”robots”/> можно запретить поисковым роботам индексацию определенных страниц. Для этого нужно добавить соответствующие правила, и указать к какому роботу они относятся в директиве User-agent файла robots.txt или атрибуте name мета-тега.
txt или мета-тега <meta name=”robots”/> можно запретить поисковым роботам индексацию определенных страниц. Для этого нужно добавить соответствующие правила, и указать к какому роботу они относятся в директиве User-agent файла robots.txt или атрибуте name мета-тега.
Например, нижеприведенный код в файле robots.txt запрещает роботу Яндекс.Картинок индексировать все изображения.
User-agent: YandexImagesDisallow: /
А этот запрещает главному поисковому роботу Google индексировать страницу, на которой размещен данный тег:
<meta name=”googlebot” content=”noindex, follow”/>
О том, как правильно настроить индексирование сайта, можно узнать в статье.
Ждите новые заметки в блоге или ищите на нашем сайте.
Поисковые роботы Яндекс и Google
SEO WikiGoogleАлгоритмы ранжированияАнализ эффективностиВеб разработкаВнутренняя оптимизацияВредоносные технологииЗапросыИндексация сайтаИнтернет рекламаКонтекстная рекламаМета-тегиПоисковые системыПоисковые фильтрыПродвижение сайтовРанжированиеСервисыСоциальные сетиСпециалистыСсылочная оптимизацияСтруктура сайтаТекстовая оптимизацияТехническая оптимизацияЧерное SEOЯндекс
Оглавление
Виды поисковых роботов
 org/ListItem»>
org/ListItem»>Принцип работы
Поисковым роботом называется специальная программа какой-либо поисковой системы, которая предназначена для занесения в базу (индексирования) найденных в Интернете сайтов и их страниц. Также используются названия: краулер, паук, бот, automaticindexer, ant, webcrawler, bot, webscutter, webrobots, webspider.
Принцип работы
Поисковый робот — это программа браузерного типа. Он постоянно сканирует сеть: посещает проиндексированные (уже известные ему) сайты, переходит по ссылкам с них и находит новые ресурсы. При обнаружении нового ресурса робот процедур добавляет его в индекс поисковика. Поисковый робот также индексирует обновления на сайтах, периодичность которых фиксируется. Например, обновляемый раз в неделю сайт будет посещаться пауком с этой частотой, а контент на новостных сайтах может попасть в индекс уже через несколько минут после публикации. Если на сайт не ведет ни одна ссылка с других ресурсов, то для привлечения поисковых роботов ресурс необходимо добавить через специальную форму (Центр вебмастеров Google, панель вебмастера Яндекс и т.д.).
Например, обновляемый раз в неделю сайт будет посещаться пауком с этой частотой, а контент на новостных сайтах может попасть в индекс уже через несколько минут после публикации. Если на сайт не ведет ни одна ссылка с других ресурсов, то для привлечения поисковых роботов ресурс необходимо добавить через специальную форму (Центр вебмастеров Google, панель вебмастера Яндекс и т.д.).
Виды поисковых роботов
Пауки Яндекса:
- Yandex/1.01.001 I — основной бот, занимающийся индексацией,
- Yandex/1.01.001 (P) — индексирует картинки,
- Yandex/1.01.001 (H) — находит зеркала сайтов,
- Yandex/1.03.003 (D) — определяет, соответствует ли страница, добавленная из панели вебмастера, параметрам индексации,
- YaDirectBot/1.0 (I) — индексирует ресурсы из рекламной сети Яндекса,
- Yandex/1.02.000 (F) — индексирует фавиконы сайтов.
Пауки Google:
- Робот Googlebot — основной робот,
- Googlebot News — сканирует и индексирует новости,
- Google Mobile — индексирует сайты для мобильных устройств,
- Googlebot Images — ищет и индексирует изображения,
- Googlebot Video — индексирует видео,
- Google AdsBot — проверяет качество целевой страницы,
- Google Mobile AdSense и Google AdSense — индексирует сайты рекламной сети Google.

Другие поисковики также используют роботов нескольких видов, функционально схожих с перечисленными.
- Индексация сайта
- Поисковые системы
Rookee — простой способ поднять сайт в ТОП поисковых систем
Начать продвижение
Базовая техническая оптимизация
12 090 ₽
Написание метатегов
от 2790 ₽
Наполнение сайта
Популярно
от 13 390 ₽/месяц
Настройка ссылочной стратегии
Популярно
1290 ₽
Настройка целей в Яндекс. Метрике
Метрике
3590 ₽
Общий технический аудит
Популярно
3490 ₽
Оптимизация коммерческих факторов
4090 ₽
Оптимизация сайта под мобильные устройства
7990 ₽
Подбор запросов для продвижения
Популярно
от 3290 ₽
Присвоение региона продвижения
1290 ₽
Техническое задание на тексты
Популярно
от 1290 ₽
Увеличение кликабельности сайта в выдаче
3690 ₽
Установка Яндекс. Метрики
Метрики
1490 ₽
SEO Wiki
Подписывайтесь на «Новости SEO рынка»
Нажимая кнопку, вы подтверждаете свое согласие на
обработку персональных данных.
Перейти в блог
Пауки и роботы поисковых систем
Поисковые системы по большей части являются объектами, которые полагаются на автоматизированных программных агентов, называемых пауками, сканерами, роботами и ботами. Эти боты ищут контент в Интернете и на отдельных веб-страницах. Эти инструменты являются ключевыми элементами работы поисковых систем.
(Пожалуйста, ознакомьтесь с маркетинговыми услугами Metamend в поисковых системах).
Чтобы иметь возможность индексировать Интернет, поисковым системам нужен инструмент, который может посещать веб-сайты; перемещаться по веб-сайтам; различать информацию о веб-сайте; решить, о чем сайт; и добавьте эти данные в его index.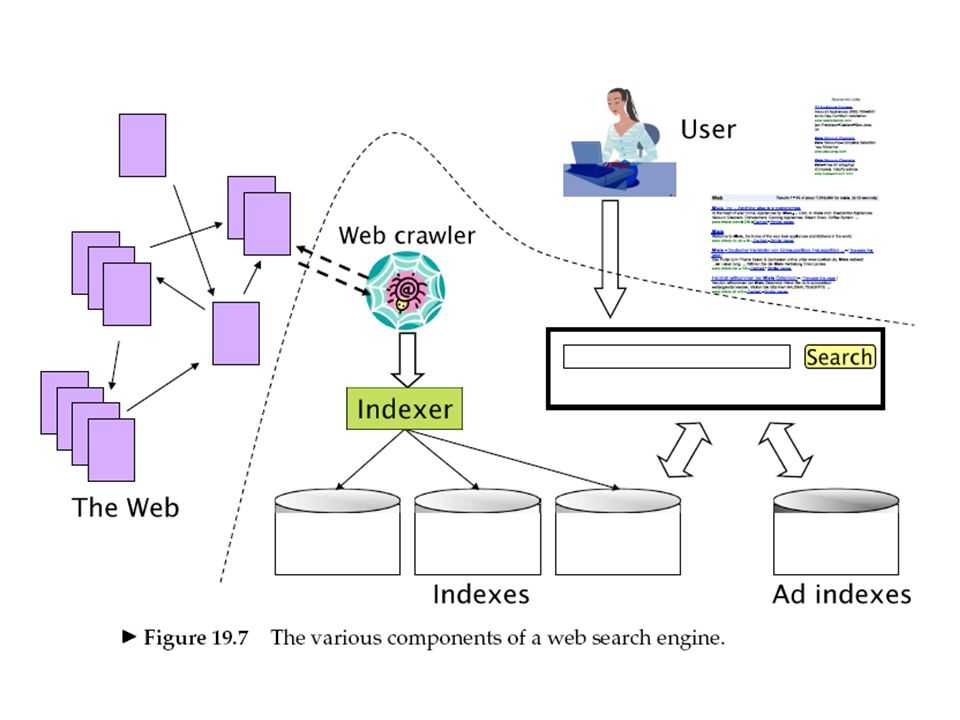 Этот инструмент также должен иметь возможность следить за лидами или ссылками с одного веб-сайта на другой, чтобы он мог бесконечно продолжать собирать информацию и узнавать об Интернете. Если он выполняет свою работу должным образом, то поисковая система имеет хорошую, ценную базу данных или индекс и будет предоставлять релевантные результаты по запросу посетителей.
Этот инструмент также должен иметь возможность следить за лидами или ссылками с одного веб-сайта на другой, чтобы он мог бесконечно продолжать собирать информацию и узнавать об Интернете. Если он выполняет свою работу должным образом, то поисковая система имеет хорошую, ценную базу данных или индекс и будет предоставлять релевантные результаты по запросу посетителей.
К сожалению, инструменты, от которых зависят поисковые системы при добавлении контента в свои базы данных, не являются ни передовыми, ни невероятно мощными. Роботы поисковых систем имеют очень ограниченную функциональность, аналогичную возможностям ранних веб-браузеров с точки зрения того, что они могут понять на веб-странице. Из видимой им информации эти пауки извлекают такую информацию, как заголовки страниц, метатеги и метаданные, а также текстовый контент для включения в индекс или базу данных поисковой системы.
Если вы хотите получить представление о том, что видят веб-сайты поисковые системы, возьмите в руки браузер Internet Explorer версии 3 или Netscape Navigator. Это не всегда красиво. Но, как и ранние браузеры, боты поисковых систем просто не знают, как делать определенные вещи. Эти боты не понимают фреймы, флэш-ролики, изображения или JavaScript. Они не могут нажимать какие-либо кнопки на веб-сайте, поэтому, если нет статической ссылки, по которой они могли бы перейти, они не перейдут по ней. Они не могут перемещаться по раскрывающимся меню и не могут выполнить поиск на вашем веб-сайте, чтобы найти контент. Они также, вероятно, будут остановлены на своем пути при попытке проиндексировать динамически сгенерированный веб-сайт или веб-сайт, использующий навигацию JavaScript.
Это не всегда красиво. Но, как и ранние браузеры, боты поисковых систем просто не знают, как делать определенные вещи. Эти боты не понимают фреймы, флэш-ролики, изображения или JavaScript. Они не могут нажимать какие-либо кнопки на веб-сайте, поэтому, если нет статической ссылки, по которой они могли бы перейти, они не перейдут по ней. Они не могут перемещаться по раскрывающимся меню и не могут выполнить поиск на вашем веб-сайте, чтобы найти контент. Они также, вероятно, будут остановлены на своем пути при попытке проиндексировать динамически сгенерированный веб-сайт или веб-сайт, использующий навигацию JavaScript.
Как работают роботы поисковых систем?
Думайте о роботах поисковых систем как об очень простых и автоматизированных программах поиска данных, путешествующих по сети в поисках информации и ссылок. Они поглощают только то, что видят, и хотя картинка стоит тысячи слов для человека, она ничего не стоит для поисковой системы. Они могут только читать и понимать текст, и то только в том случае, если он изложен в формате, адаптированном к их потребностям. Обеспечение того, чтобы они могли получить доступ и прочитать все содержимое веб-сайта, должно быть основной частью любого стратегия поисковой оптимизации .
Обеспечение того, чтобы они могли получить доступ и прочитать все содержимое веб-сайта, должно быть основной частью любого стратегия поисковой оптимизации .
Когда веб-страница отправляется в поисковую систему, URL-адрес добавляется в очередь веб-сайтов для посещения ботами поисковой системы. Даже если вы не отправляете напрямую веб-сайт или веб-страницы на веб-сайте, большинство роботов найдут контент на вашем веб-сайте , если на него ссылаются других веб-сайтов. Это часть процесса, называемого построением взаимных ссылок. Это одна из причин, почему так важно повысить ссылочную популярность веб-сайта и получить ссылки с других тематических сайтов на ваш. Это должно быть частью любой маркетинговой стратегии веб-сайта, которую вы выбираете.
Когда бот поисковой системы заходит на веб-сайт, он должен проверить, есть ли у вас файл robots.txt. Этот файл используется, чтобы сообщить роботам, какие области вашего сайта им недоступны. Как правило, это могут быть каталоги, содержащие файлы, с которыми роботу не нужно иметь дело. Некоторые боты будут игнорировать эти файлы. Однако все поисковые роботы ищут файл. Он должен быть на каждом сайте, даже если он пустой. Это всего лишь одна из вещей, которые ищут поисковые системы.
Как правило, это могут быть каталоги, содержащие файлы, с которыми роботу не нужно иметь дело. Некоторые боты будут игнорировать эти файлы. Однако все поисковые роботы ищут файл. Он должен быть на каждом сайте, даже если он пустой. Это всего лишь одна из вещей, которые ищут поисковые системы.
Роботы хранят список всех ссылок, которые они находят на каждой посещаемой ими странице, и переходят по этим ссылкам на другие веб-сайты. Первоначальная концепция Интернета заключалась в том, что все будет органично связано друг с другом, подобно гигантской модели отношений. Этот принцип до сих пор является частью кода, определяющего, как передвигаются роботы.
Умная часть поисковых систем начинается на следующем этапе. Сбор всех данных, полученных ботами, является частью построения индекса поисковой системы или базы данных. Эта часть индексации веб-сайтов и веб-страниц исходит от инженеров поисковых систем, которые разрабатывают правила и алгоритмы, используемые для оценки и оценки информации, полученной ботами поисковых систем. После того, как веб-сайт добавлен в базу данных поисковой системы, информация становится доступной для клиентов, которые запрашивают поисковую систему. Когда пользователь поисковой системы вводит запрос в поисковую систему, поисковая система выполняет множество шагов, чтобы убедиться, что она предоставляет то, что, по ее оценке, является лучшим, наиболее релевантным ответом на вопрос.
После того, как веб-сайт добавлен в базу данных поисковой системы, информация становится доступной для клиентов, которые запрашивают поисковую систему. Когда пользователь поисковой системы вводит запрос в поисковую систему, поисковая система выполняет множество шагов, чтобы убедиться, что она предоставляет то, что, по ее оценке, является лучшим, наиболее релевантным ответом на вопрос.
Как поисковые системы читают ваш сайт?
Когда бот поисковой системы посещает веб-сайт, он читает весь видимый текст на веб-странице, содержимое различных тегов в исходном коде (тег заголовка, метатеги, теги Dublin Core, теги комментариев, теги alt , теги атрибутов, содержимое и т. д.), а также текст гиперссылок на веб-странице. Из контента, который он извлекает, поисковая система решает, о чем веб-сайт и веб-страница. Есть много факторов, используемых для выяснения того, что имеет ценность, а что имеет значение. Каждая поисковая система имеет свой собственный набор правил, стандартов и алгоритмов для оценки и обработки информации. В зависимости от того, как бот был настроен поисковой системой, различные фрагменты информации собираются, взвешиваются, индексируются, а затем добавляются в базу данных поисковой системы.
В зависимости от того, как бот был настроен поисковой системой, различные фрагменты информации собираются, взвешиваются, индексируются, а затем добавляются в базу данных поисковой системы.
Манипулирование ключевыми словами в этих элементах веб-страницы является частью так называемой поисковой оптимизации .
После добавления информация становится частью процесса ранжирования поисковой системы и каталога. Когда посетитель поисковой системы отправляет свой запрос, поисковая система просматривает свою базу данных, чтобы предоставить окончательный список, который отображается на странице результатов.
Базы данных поисковых систем обновляются в разное время. Как только веб-сайт находится в базе данных поисковой системы, боты будут продолжать посещать его регулярно, чтобы отслеживать любые изменения, внесенные на страницы веб-сайтов, и обеспечивать наличие самых последних данных. Количество посещений веб-сайта будет зависеть от того, как поисковая система настраивает свои посещения, которые могут различаться в зависимости от поисковой системы. Однако чем активнее веб-сайт, тем чаще его посещают. Если веб-сайт часто меняется, поисковая система будет чаще отправлять ботов. Это также верно, если веб-сайт чрезвычайно популярен или имеет большой трафик.
Однако чем активнее веб-сайт, тем чаще его посещают. Если веб-сайт часто меняется, поисковая система будет чаще отправлять ботов. Это также верно, если веб-сайт чрезвычайно популярен или имеет большой трафик.
Иногда боты не могут получить доступ к веб-сайту, который они посещают. Если веб-сайт не работает, бот может не получить к нему доступ. Когда это происходит, веб-сайт может не быть переиндексирован, а если это происходит неоднократно, веб-сайт может упасть в рейтинге.
Файлы robots.txt | Search.gov
Файл /robots.txt — это текстовый файл, который дает автоматическим веб-ботам инструкции о том, как сканировать и/или индексировать веб-сайт. Веб-команды используют их для предоставления информации о том, какие каталоги сайта следует или не следует сканировать, как быстро следует получать доступ к контенту и какие боты приветствуются на сайте.
Как должен выглядеть мой файл robots.txt?
Подробную информацию о том, как и где создать файл robots. txt, см. в протоколе robots.txt. Ключевые моменты, о которых следует помнить:
txt, см. в протоколе robots.txt. Ключевые моменты, о которых следует помнить:
- Файл должен находиться в корне домена, и для каждого поддомена нужен свой файл.
- Протокол robots.txt чувствителен к регистру.
- Легко случайно заблокировать сканирование всего:
-
Запретить: /означает запретить все. -
Disallow:означает ничего не запрещать, то есть разрешать все. -
Разрешить: /означает разрешить все. -
Разрешить:означает ничего не разрешать, что запрещает все.
-
- Инструкции в файле robots.txt являются руководством для ботов, а не обязательными требованиями — вредоносные боты могут игнорировать ваши настройки.
Как оптимизировать файл robots.txt для Search.gov?
Задержка сканирования
В файле robots.txt может быть указана директива «задержка сканирования» для одного или нескольких пользовательских агентов, которая сообщает боту, как быстро он может запрашивать страницы с веб-сайта.![]() Например, задержка сканирования, равная 10, означает, что сканер не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
Например, задержка сканирования, равная 10, означает, что сканер не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
500 000 URL-адресов
x 10 секунд между запросами
5 000 000 секунд на все запросы
5 000 000 секунд = 58 дней, чтобы проиндексировать сайт один раз.
Мы рекомендуем задержку сканирования в 2 секунды для нашего ussearch и установить более высокую задержку сканирования для всех остальных ботов. Чем меньше задержка сканирования, тем быстрее Search.gov сможет проиндексировать ваш сайт. В файле robots.txt это будет выглядеть так:
.
Агент пользователя: usasearch Задержка сканирования: 2 Пользовательский агент: * Задержка сканирования: 10
XML-файлы Sitemap
В файле robots.txt также должны быть перечислены одна или несколько ваших XML-карт сайта. Например:
Карта сайта: https://www.example.gov/sitemap.xml Карта сайта: https://www.example.gov/independent-subsection-sitemap.xml
- Список карт сайта только для домена, в котором находится файл robots. txt. Карта сайта другого субдомена должна быть указана в файле robots.txt этого субдомена.
 txt. Карта сайта другого субдомена должна быть указана в файле robots.txt этого субдомена.
txt. Карта сайта другого субдомена должна быть указана в файле robots.txt этого субдомена.Разрешить только тот контент, который вы хотите найти
Мы рекомендуем запретить любые каталоги или файлы, которые не должны быть доступны для поиска. Например:
Запретить: /архив/ Запретить: /news-1997/ Запретить: /reports/duplicative-page.html
- Обратите внимание: если вы запретите каталог после того, как он был проиндексирован поисковой системой, это может не привести к удалению этого содержимого из индекса. Вам нужно будет зайти в инструменты поисковой системы для веб-мастеров, чтобы запросить удаление.
- Также обратите внимание, что поисковые системы могут индексировать отдельные страницы в запрещенной папке, если поисковая система узнает об URL-адресе из метода, не связанного со сканированием, например, по ссылке с другого сайта или из вашей карты сайта. Чтобы данная страница не была доступна для поиска, установите на этой странице метатег robots.
