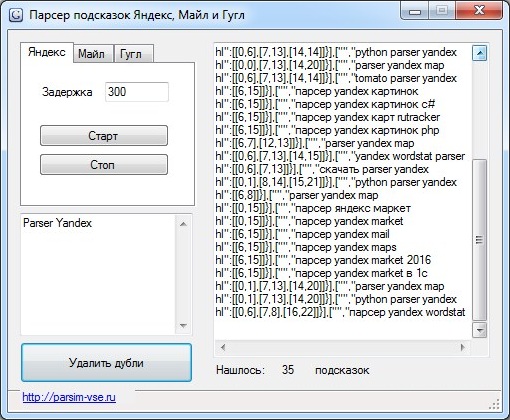
Содержание
Парсер подсказок Яндекс и Google онлайн
Для сбора запросов семантического ядра поисковые подсказки Яндекс и Google являются одним из наиболее качественных источников запросов, потому что:
- В поисковых подсказках содержатся самые свежие данные (реальный поток запросов пользователей).
- Запросы, которые показываются в подсказках, имеют изначально верную словоформу.
- В сервисе есть фильтрация «кривых» запросов и опечаток, например:
В итоге можно получить наибольшее количество качественных запросов, в отличие от Яндекс Wordstat, который отдает гораздо меньше данных.
В сервис Rush Analytics интегрированы мощные парсеры поисковых подсказок Яндекса, Гугла и Ютуб, имеющие гибкие настройки, высокую производительность и низкую стоимость.
Рассмотрим как собрать подсказки Яндекса и Google — парсинг ПС отдельно.
Поисковые подсказки Яндекс
Подсказки в поисковой строке Яндекса являются наиболее мощным источником ключевых слов, имеющих отличную полноту для практических любой тематики. Мы сделали инструмент максимально гибким и настраиваемым под любые цели.
Мы сделали инструмент максимально гибким и настраиваемым под любые цели.
- Для сбора доступен любой регион Яндекса.
В настройках доступные совершенно все регионы, не только Россия, а, например, такие актуальные как Украина и Беларусь.
!NB: Подсказки могут быть сильно региональны – по одним и тем же запросам в разных регионах можно получить совершенно разные подсказки, в зависимости от структуры поискового спроса в выбранном регионе.
2. Реализованы гибкие настройки перебора и глубины парсинга.
3. Вы можете выбрать нужные методы перебора символов в зависимости от вашей задачи:
- Нужно собрать максимальное количество переформулировок названий карточек товаров? – однозначно выбираем перебор латинских символов и цифр, глубина парсинга 3.
- Нужно собрать запросы для сайта, на котором представлены бренды с только кириллическим написанием? – убираем перебор латинских символов.
- Нужно базово прикинуть структуру спроса на конкретной категории интернет магазина и не хочется обрабатывать кучу данных? – оставляем сбор только по «ключевое слово» и «ключевое слово_», а глубину парсинга ставим максимум 2.

- Подробное описание работы с поисковыми подсказками можно найти по ссылке – https://www.rush-analytics.ru/faq/parsing-poiskovyih-podskazok
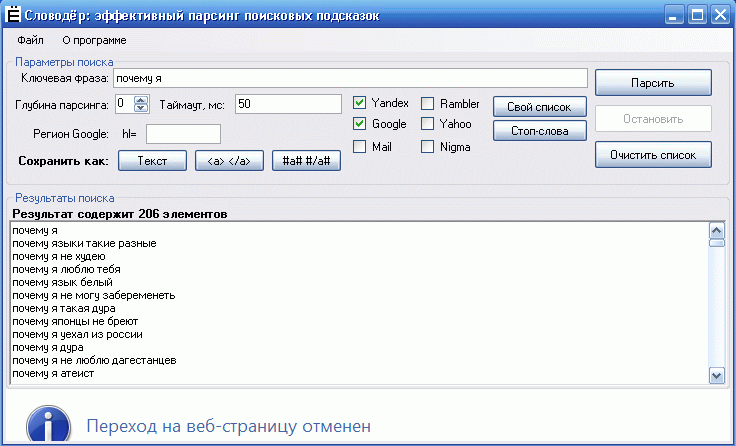
Наш парсер позволяет решать любые задачи и получать только те данные, которые вам нужны в любом количестве и с максимальной скоростью!
Поисковые подсказки Google (Гугл)
Поисковые подсказки Google — отличный источник ключевых слов для тематик с большой примесью английских названий и брендов, отлично подойдет для сбора семантики под продвижение западных проектов.
Основные преимущества нашего парсера подсказок Google:
- Мультирегиональность – в Rush Analytics поддерживается парсинг всех регионов Google в мире! Можно парсить – от России и Зимбабве до Канады и Кубы!
- Гибкие настройки переборов и глубины. Вы сможете настроить парсинг под любую нужную вам задачу!
- Парсинг блока «Вместе с этим часто ищут» — дополнительный блок поиска Google, который показывает все связанные запросы по заданному ключевому слову:
Подсказки Youtube
Хотите создавать на Youtube видео, которое наберет миллионы просмотров и подписчиков?
Парсинг подсказок видеохостинга Youtube — соберет для вас самые свежие, популярные и релевантные ключевые фразы из поиска Youtube за считанные секунды. Мощный инструмент будет полезен всем, кто продвигает видеоконтент и хочет увеличить трафик в Youtube:
Мощный инструмент будет полезен всем, кто продвигает видеоконтент и хочет увеличить трафик в Youtube:
Собранные ключевые слова можете использовать в названии, описании, тегах и рекламе своего видео, что поможет ему подняться за короткие сроки в тренд Youtube:
- Собирайте подсказки Youtube по разным странам и на разных языках мира.
Воспользовавшись инструментом Сбор подсказок, вы сможете извлечь тысячи подходящих запросов для своих видео и поднять трафик!
- Парсер имеет гибкие настройки перебора:
- сбор с пробелом и без после каждой фразы,
- с перебором кириллического и латинского алфавита,
- с перебором цифр после слова.
2. Есть возможность указать СТОП-СЛОВА, которые не попадут в итоговый отчет, если будут найдены при сборе.
Сбор подсказок в Rush Analytics — лучший инструмент для эффективного продвижения в Ютюб. Без ключевых слов ваше видео никогда не наберет большое количество лайков и комментариев.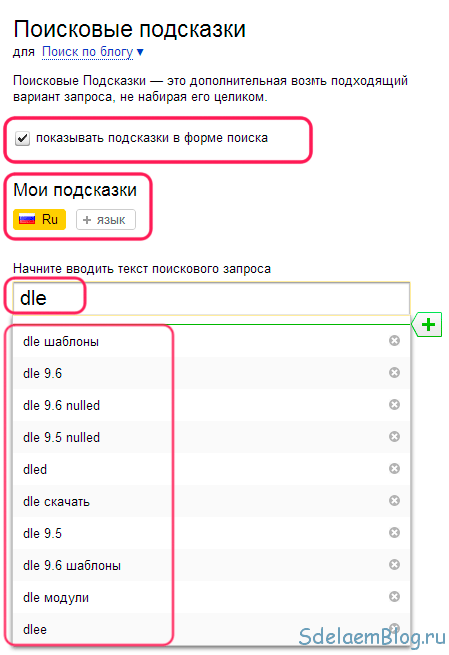 Читайте как быстро собрать поисковые подсказки Youtube>>
Читайте как быстро собрать поисковые подсказки Youtube>>
Комплексный сбор поисковых подсказок в Rush Analytics
Если перед вами стоит задача собрать максимально полное и качественное семантическое ядро, вам не обойтись без сбора поисковых подсказок Яндекса, Google и Youtube.
Уникальность парсинга в сервисе Rush Analytics в том, что он дает возможность собирать подсказки в одном проекте сразу по всем поисковым системам, регионам и языкам, с любым перебором и глубиной.
Сделайте свою работу с запросами простой и удобной вместе с Rush Analytics!
как их собрать и где использовать
Есть много способов расширить семантическое ядро для сайта и привлечь тем самым дополнительный трафик на него. Один из них — работа с поисковыми подсказками. Объясняем, что это, зачем они нужны пользователям и владельцам веб-ресурсов и как их правильно использовать, чтобы получить больше переходов на страницы сайта.
Что такое поисковые подсказки
Когда вы вводите в поисковую строку Яндекса или Google какое-то слово, появляется всплывающее окно. В нем мы видим введенное слово и какие-то дополнения к нему — конкретные запросы, которые можно выбрать и использовать, чтобы добраться до какой-то информации. Эти запросы и есть поисковые подсказки Яндекса и Google.
В нем мы видим введенное слово и какие-то дополнения к нему — конкретные запросы, которые можно выбрать и использовать, чтобы добраться до какой-то информации. Эти запросы и есть поисковые подсказки Яндекса и Google.
Все это — поисковые подсказки Яндекса
Список подсказок свой на каждое слово, на каждую букву и даже на каждого пользователя. Прежде чем «отдать» человеку список релевантных ключей, поисковые системы находят их в несколько этапов:
- ищут все те конкретные ключи, которые начинаются на эту же букву или на это же слово;
- фильтруют их по релевантности и популярности — оставляют самые востребованные и релевантные запросы;
- учитывают местоположение пользователя — если человек из Москвы вводит слово «кафе», ему покажут подсказку «кафе в Москве», а не «кафе в Санкт-Петербурге»;
- учитывают историю запросов — если пользователь искал что-то подобное раньше, ему в первую очередь предложат уже использованный им запрос.
Таким образом в подсказки попадают только те запросы, на которые пользователь нажмет с высокой долей вероятности.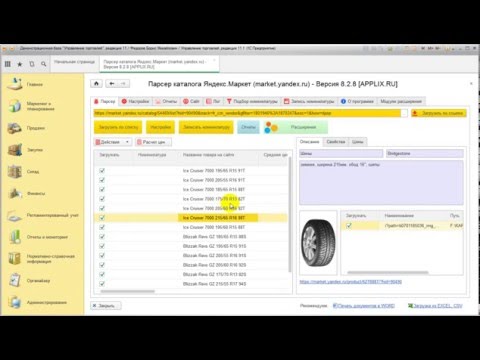
Поисковые подсказки в Google и Яндекс хорошо работают только с высокочастотными ключами — те, которые запрашивают не меньше десяти тысяч раз каждый месяц. Если изначально ввести в строку поиска какой-то низкочастотный запрос, подсказок может вообще не быть.
Здесь только одна поисковая подсказка — Яндекс посчитал ее самой релевантной запросу
Есть еще поисковые подсказки, которые сразу дают ответ на запрос пользователя. Мы видим их, когда хотим узнать, сколько сантиметров в километре или какое расстояние от Солнца до Земли.
Так выглядят поисковые подсказки, которые сразу дают ответ на запрос пользователя
А еще есть подсказки, которые позволяют сразу перейти на конкретный сайт. Чаще всего они появляются, когда вводишь название ресурса или компании в поисковой строке. При этом они сопровождаются стандартными подсказками, по которым можно найти конкретный товар компании или ее услугу. Попасть в такие поисковые подсказки в Яндексе можно просто — если пользователь будет вводить название вашей компании или домен сайта, поисковая система может порекомендовать его.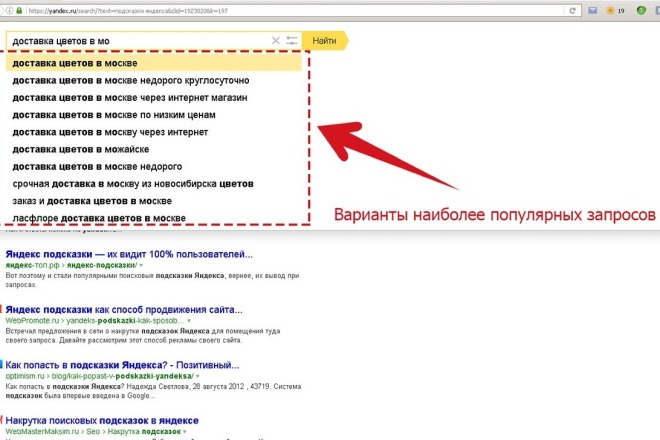
Так выглядит подсказка со ссылкой на сайт
На продвижение могут повлиять только стандартны подсказки — те, которые поисковики отдают после анализа популярности запросов, истории пользователя и его геолокации. Поэтому мы не будем говорить о моментальных ответах или ссылках на конкретные сайты.
Зачем пользователям нужны поисковые подсказки
Поисковые системы создавали подсказки, чтобы пользователи могли проще и быстрее находить нужную информацию. Сам Яндекс заявляет, что они нужны, «чтобы сэкономить время».
Цитата из материала Яндекса о поисковых подсказках
Пользоваться поиском, который сам предлагает релевантные запросы, действительно проще. Можно не вводить запрос целиком, а напечатать только первое его слово и выбрать подходящий вариант. Или быстро сформулировать вопрос — если не знаешь, как именно его задать, Google и Яндекс покажут самые распространенные варианты.
Зачем собирать поисковые подсказки
Сбор поисковых подсказок в Яндексе и Google поможет расширить семантическое ядро сайта и найти популярные ключевые фразы, под которые пока не оптимизированы страницы. То есть с их помощью вы можете найти дополнительные ключи, оптимизировать сайт под них, а значит — выйти в топ по ним и получить дополнительный трафик.
То есть с их помощью вы можете найти дополнительные ключи, оптимизировать сайт под них, а значит — выйти в топ по ним и получить дополнительный трафик.
Как это работает:
- находите основные ключевые запросы — отправную точку, от которой будете искать подсказки: например, если ваш сайт о животных — «кошка», «собака», «волнистый попугай»;
- ищете поисковые подсказки вручную или разными сервисами, записываете их в отдельный файл: проще всего работать с данными в таблице;
- смотрите, какие ключевые фразы уже есть в семантическом ядре, и удаляете их — оставляете только новые запросы;
- добавляете запросы на релевантные страницы, если они есть, или создаете новые специально под них.
Таким образом все больше охватываете выдачу, и в результате получаете все больше органического трафика.
Сервисы для сбора поисковых подсказок
Пару подсказок можно найти вручную. Но если нужно спарсить много фраз, лучше использовать специальные сервисы по трем причинам:
- ручной сбор займет слишком много времени;
- можно что-то упустить;
- поисковики ориентируются на историю запросов и геолокацию, поэтому могут не показать вам подсказки, которые покажут другим пользователям — вы упустите часть ключей.

Сервисы позволяют автоматизировать парсинг: вы просто задаете основные ключевые слова и получаете список релевантных ключей. Подобный функционал есть у многих сервисов. Самые популярные из них:
Arsenkin. Онлайн-сервис, позволяющий собирать поисковые подсказки с глубиной до 3. Это значит, что он возьмет все подсказки, полученные по первому ключевому слову, и найдет по каждой из них еще подсказки. И так же — по подсказкам, полученным на втором уровне.
За один раз можно задать до 100 ключевых слов, минус-слова, регион. Доступен выбор источника — Google, Яндекс или YouTube. Чтобы воспользоваться инструментом, нужно зарегистрироваться на сайте. Есть бесплатный тариф, но он позволяет работать только с Яндексом. Платные тарифы стоят от 549 ₽ ежемесячно.
Так выглядят тарифы на Arsenkin
«Топвизор». Еще один онлайн-сервис, который умеет собирать ключевые подсказки в Яндексе, Google, Bing, Yahoo, Mail.ru и YouTube. Тоже может находить их на трех уровнях.
К сервису можно получить бесплатный тестовый доступ. Когда он кончится, стоимость будет от 0,7 ₽ за один найденный запрос.
Когда он кончится, стоимость будет от 0,7 ₽ за один найденный запрос.
Serpstat. Сервис для комплексной оптимизации сайтов в выдаче поисковых систем. В нем нет отдельного инструмента для сбора поисковых подсказок, но их можно увидеть в отчетах при анализе конкретных ключевых фраз.
Примерно так будет выглядеть анализ конкретного ключевого словосочетания
Serpstat платный, стоимость тарифов начинается от 55 $ в месяц. Можно запросить бесплатную демонстрацию возможностей, но тестового периода нет.
«Словоеб». Бесплатная программа, которую нужно установить на компьютер. Она позволяет работать с ключевыми словами: находить релевантные, в том числе с помощью поисковых подсказок.
Key Collector. Это тоже программа, которую нужно устанавливать на ПК. Она подбирает релевантные ключевые фразы, в том числе используя поисковые подсказки. Работает с Google, YouTube, Mail.ru и Яндексом. Стоимость — 2 200 ₽ за бессрочную лицензию, которую можно переносить с одного компьютера на другой.
Используя специальные сервисы, вы автоматизируете сбор поисковых подсказок Яндекса и Google и быстро найдете новые ключевые фразы, под которые можно оптимизировать страницы. Легкой вам оптимизации!
python — ошибка при установке pycuda ModuleNotFound: нет модуля с именем «distutils.command.sdist»
Я пытаюсь установить pycuda с помощью pip install pycuda в виртуальной среде. Я установил python3.10-distutils, но ошибка остается. Моя система Ubuntu22.04, python3.10. Я также пробовал ручную установку с инструкциями с https://wiki.tiker.net/PyCuda/Installation/Linux/. Это также не удалось с ModuleNotFoundError: нет модуля с именем «setuptools.command.build_ext» .
Какие-либо предложения?
Сбор пикуды Использование кэшированного файла pycuda-2022.1.tar.gz (1,7 МБ) Установка зависимостей сборки... сделано Получение требований для сборки колеса... сделано Подготовка метаданных (pyproject.toml)... сделано Сбор pytools>=2011.2 Использование кэшированного pytools-2022.", строка 2, в Файл " ", строка 34, в Файл "/tmp/pip-install-s4dqljda/pytools_9b2a0e1beabb402e9d87af0960b817ca/setup.py", строка 14, в установка (имя = "pytools", Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/__init__.py", строка 87, в настройках вернуть distutils.core.setup(**attrs) Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/_distutils/core.py", строка 172, в настройках ок = dist.parse_command_line() Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/_distutils/dist.py", строка 474, в строке parse_command_line аргументы = self. ", строка 1050, в _gcd_import Файл " _bootstrap>", строка 1027, в _find_and_load Файл "
", строка 1006, в _find_and_load_unlocked Файл " ", строка 688, в _load_unlocked Файл " ", строка 883, в exec_module Файл " ", строка 241, в _call_with_frames_removed Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/command/egg_info.py", строка 24, в из setuptools.command.sdist импортировать sdist Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/command/sdist.py", строка 2, в импортировать distutils.command.sdist как оригинал ModuleNotFoundError: нет модуля с именем «distutils.command.sdist» [конец вывода] примечание: эта ошибка возникает из-за подпроцесса и, скорее всего, не связана с pip. ошибка: сбой генерации метаданных × Обнаружена ошибка при создании метаданных пакета.
 1.12.tar.gz (70 КБ)
Подготовка метаданных (setup.py)... ошибка
ошибка: подпроцесс-выход-с-ошибкой
× python setup.py egg_info не запустился успешно.
│ код выхода: 1
╰─> [32 строки вывода]
Traceback (последний последний вызов):
Файл "
1.12.tar.gz (70 КБ)
Подготовка метаданных (setup.py)... ошибка
ошибка: подпроцесс-выход-с-ошибкой
× python setup.py egg_info не запустился успешно.
│ код выхода: 1
╰─> [32 строки вывода]
Traceback (последний последний вызов):
Файл " _parse_command_opts (парсер, аргументы)
Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/dist.py", строка 1107, в _parse_command_opts
nargs = _Distribution._parse_command_opts(self, parser, args)
Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/_distutils/dist.py", строка 533, в _parse_command_opts
cmd_class = self.get_command_class(команда)
Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/dist.py", строка 954, в get_command_class
self.cmdclass[команда] = cmdclass = ep.load()
Файл "/usr/lib/python3.10/importlib/metadata/__init__.py", строка 171, загружается
модуль = import_module(match.group('module'))
Файл "/usr/lib/python3.10/importlib/__init__.py", строка 126, в import_module
вернуть _bootstrap._gcd_import (имя [уровень:], пакет, уровень)
Файл "
_parse_command_opts (парсер, аргументы)
Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/dist.py", строка 1107, в _parse_command_opts
nargs = _Distribution._parse_command_opts(self, parser, args)
Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/_distutils/dist.py", строка 533, в _parse_command_opts
cmd_class = self.get_command_class(команда)
Файл "/home/konstantin/Яндекс.Диск/code/env/lib/python3.10/site-packages/setuptools/dist.py", строка 954, в get_command_class
self.cmdclass[команда] = cmdclass = ep.load()
Файл "/usr/lib/python3.10/importlib/metadata/__init__.py", строка 171, загружается
модуль = import_module(match.group('module'))
Файл "/usr/lib/python3.10/importlib/__init__.py", строка 126, в import_module
вернуть _bootstrap._gcd_import (имя [уровень:], пакет, уровень)
Файл " ╰─> Выходные данные см. выше.
примечание: это проблема с упомянутым выше пакетом, а не с pip.
подсказка: подробности см. выше.
╰─> Выходные данные см. выше.
примечание: это проблема с упомянутым выше пакетом, а не с pip.
подсказка: подробности см. выше.
Имя атрибута быстрого синтаксического анализа для заданного elementName
Создание словаря [city:id] может быть решением для вас.
Я реализовал простое решение на основе статьи о жизненном цикле NSXMLParser по адресу http://www.codeproject.com/Articles/248883/Objective-C-Fundamentals-NSXMLParser.
Следующий метод вызывается при запуске элемента.
Вы можете получить атрибут идентификатора города и сохранить его в переменной уровня экземпляра, чтобы использовать его в следующем методе.
func parser (parser: NSXMLParser, didStartElement elementName: String, namespaceURI: String?,qualName qName: String?, атрибуты attributeDict: [NSObject: AnyObject])
Затем вызывается следующий метод, когда синтаксический анализатор видит что-то между началом и концом.
анализатор функций (анализатор: NSXMLParser!, строка foundCharacters: String!)
Итак, вы можете получить название города отсюда.
Теперь у нас есть идентификатор города и название города, чтобы добавить новый элемент в словарь [city:id].
Как только вы создадите словарь, поиск станет очень простым.
вот мой рабочий тестовый код.
класс ViewController: UIViewController, NSXMLParserDelegate{
парсер var: NSXMLParser!
вар город: String = String()
вар ifDirOK = ложь
вар ifCityNameOK = ложь
элемент var: строка?
значение переменной: String=String()
var dic = словарь<строка,строка>()
переменная currentCityId:String?
@IBOutlet слабый результат var: UILabel!
@IBOutlet слабый поиск var: UITextField! // ищем текст
Функция @IBAction ActionGoGetIt (отправитель: AnyObject) {
self.result.text=dic[self.search.text]
}
переопределить функцию viewDidLoad() {
super.viewDidLoad()
пусть url: NSURL = NSURL(строка: "https://pogoda.yandex.ru/static/cities.xml")!
синтаксический анализатор = NSXMLParser (contentsOfURL: URL-адрес)
parser.