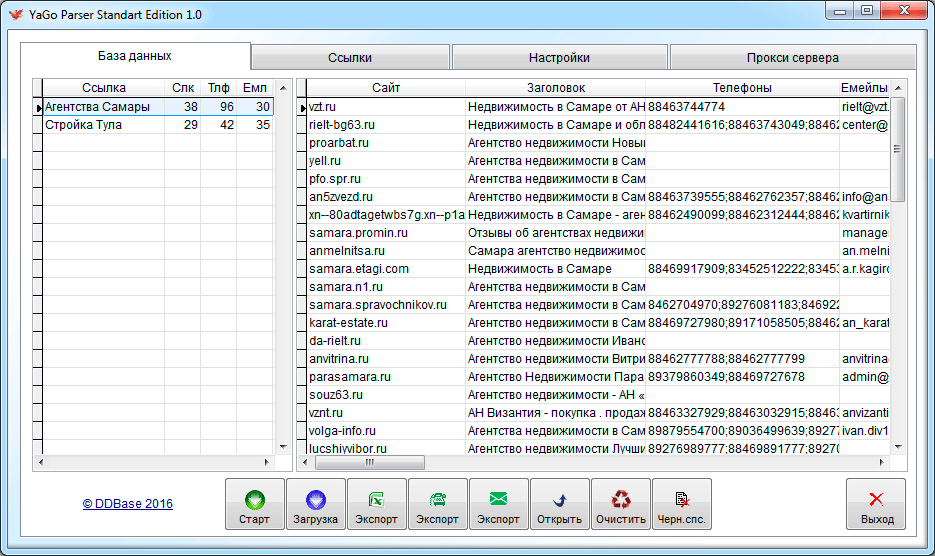
Содержание
Парсер подсказок Яндекс и Google онлайн
Для сбора запросов семантического ядра поисковые подсказки Яндекс и Google являются одним из наиболее качественных источников запросов, потому что:
- В поисковых подсказках содержатся самые свежие данные (реальный поток запросов пользователей).
- Запросы, которые показываются в подсказках, имеют изначально верную словоформу.
- В сервисе есть фильтрация «кривых» запросов и опечаток, например:
В итоге можно получить наибольшее количество качественных запросов, в отличие от Яндекс Wordstat, который отдает гораздо меньше данных.
В сервис Rush Analytics интегрированы мощные парсеры поисковых подсказок Яндекса, Гугла и Ютуб, имеющие гибкие настройки, высокую производительность и низкую стоимость.
Рассмотрим как собрать подсказки Яндекса и Google — парсинг ПС отдельно.
Поисковые подсказки Яндекс
Подсказки в поисковой строке Яндекса являются наиболее мощным источником ключевых слов, имеющих отличную полноту для практических любой тематики. Мы сделали инструмент максимально гибким и настраиваемым под любые цели.
Мы сделали инструмент максимально гибким и настраиваемым под любые цели.
- Для сбора доступен любой регион Яндекса.
В настройках доступные совершенно все регионы, не только Россия, а, например, такие актуальные как Украина и Беларусь.
!NB: Подсказки могут быть сильно региональны – по одним и тем же запросам в разных регионах можно получить совершенно разные подсказки, в зависимости от структуры поискового спроса в выбранном регионе.
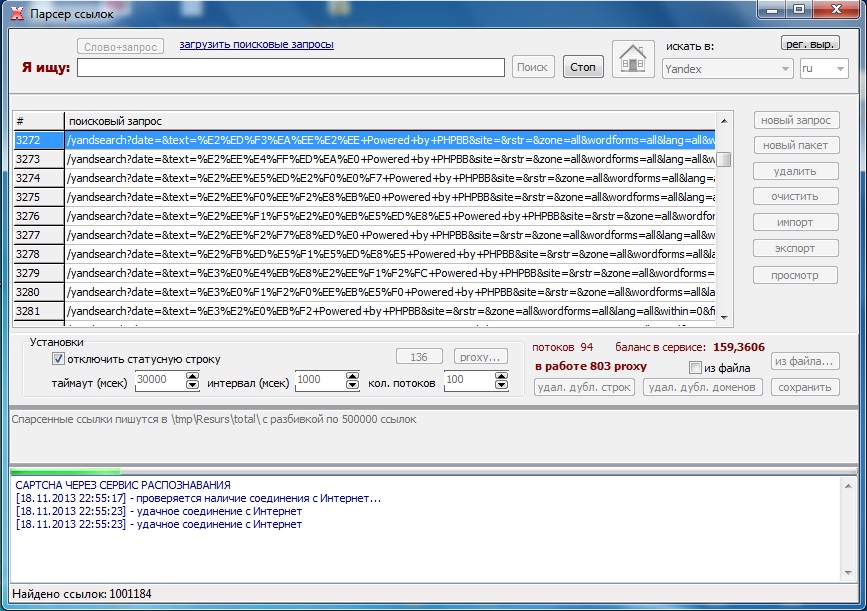
2. Реализованы гибкие настройки перебора и глубины парсинга.
3. Вы можете выбрать нужные методы перебора символов в зависимости от вашей задачи:
- Нужно собрать максимальное количество переформулировок названий карточек товаров? – однозначно выбираем перебор латинских символов и цифр, глубина парсинга 3.
- Нужно собрать запросы для сайта, на котором представлены бренды с только кириллическим написанием? – убираем перебор латинских символов.
- Нужно базово прикинуть структуру спроса на конкретной категории интернет магазина и не хочется обрабатывать кучу данных? – оставляем сбор только по «ключевое слово» и «ключевое слово_», а глубину парсинга ставим максимум 2.

- Подробное описание работы с поисковыми подсказками можно найти по ссылке – https://www.rush-analytics.ru/faq/parsing-poiskovyih-podskazok
Наш парсер позволяет решать любые задачи и получать только те данные, которые вам нужны в любом количестве и с максимальной скоростью!
Поисковые подсказки Google (Гугл)
Поисковые подсказки Google — отличный источник ключевых слов для тематик с большой примесью английских названий и брендов, отлично подойдет для сбора семантики под продвижение западных проектов.
Основные преимущества нашего парсера подсказок Google:
- Мультирегиональность – в Rush Analytics поддерживается парсинг всех регионов Google в мире! Можно парсить – от России и Зимбабве до Канады и Кубы!
- Гибкие настройки переборов и глубины. Вы сможете настроить парсинг под любую нужную вам задачу!
- Парсинг блока «Вместе с этим часто ищут» — дополнительный блок поиска Google, который показывает все связанные запросы по заданному ключевому слову:
Подсказки Youtube
Хотите создавать на Youtube видео, которое наберет миллионы просмотров и подписчиков?
Парсинг подсказок видеохостинга Youtube — соберет для вас самые свежие, популярные и релевантные ключевые фразы из поиска Youtube за считанные секунды. Мощный инструмент будет полезен всем, кто продвигает видеоконтент и хочет увеличить трафик в Youtube:
Мощный инструмент будет полезен всем, кто продвигает видеоконтент и хочет увеличить трафик в Youtube:
Собранные ключевые слова можете использовать в названии, описании, тегах и рекламе своего видео, что поможет ему подняться за короткие сроки в тренд Youtube:
- Собирайте подсказки Youtube по разным странам и на разных языках мира.
Воспользовавшись инструментом Сбор подсказок, вы сможете извлечь тысячи подходящих запросов для своих видео и поднять трафик!
- Парсер имеет гибкие настройки перебора:
- сбор с пробелом и без после каждой фразы,
- с перебором кириллического и латинского алфавита,
- с перебором цифр после слова.
2. Есть возможность указать СТОП-СЛОВА, которые не попадут в итоговый отчет, если будут найдены при сборе.
Сбор подсказок в Rush Analytics — лучший инструмент для эффективного продвижения в Ютюб. Без ключевых слов ваше видео никогда не наберет большое количество лайков и комментариев. Читайте как быстро собрать поисковые подсказки Youtube>>
Читайте как быстро собрать поисковые подсказки Youtube>>
Комплексный сбор поисковых подсказок в Rush Analytics
Если перед вами стоит задача собрать максимально полное и качественное семантическое ядро, вам не обойтись без сбора поисковых подсказок Яндекса, Google и Youtube.
Уникальность парсинга в сервисе Rush Analytics в том, что он дает возможность собирать подсказки в одном проекте сразу по всем поисковым системам, регионам и языкам, с любым перебором и глубиной.
Сделайте свою работу с запросами простой и удобной вместе с Rush Analytics!
Парсер WordStat — быстрый сбор частотности запросов онлайн, парсинг выдачи и подсказок Яндекс — Пиксель Тулс
Онлайн-сервис помогает составить семантическое ядро с использованием поисковых подсказок Яндекса, а так же определить вид фразы и проверить запросы на их корректность (присутствие в search suggestions).
Как осуществить наиболее эффективный сбор?
Пользоваться инструментом несложно благодаря интуитивно понятному интерфейсу.
В первую форму вводятся поисковые фразы, для которых необходимо спарсить подсказки. В случае ошибки, можно нажать на крестик в правом верхнем углу и очистить форму. Кроме того, если фраз достаточно много, для удобства можно увеличить поле, потянув значок в правом нижнем углу.
После ввода фраз, из выпадающего меню требуется задать необходимый регион продвижения.
Дальнейшие настройки — зависят от решаемых задач.
Параметр «Глубина парсинга» отвечает за итерационный сбор.
Если указана цифра 1, сбор подсказок будет осуществляться только для фраз, введенных в поле «Список поисковых запросов». Если же нужна более широкая семантика, то имеет смысл сначала собрать подсказки к имеющимся ключевым фразам, а затем — подсказки к уже полученным. Этот последовательный сбор можно выполнить за одну операцию, просто выставив глубину парсинга, равную двум.
Например, если требуется сначала спарсить поисковые подсказки по слову [мебель], а затем дополнить их теми подсказками, которые были собраны, например, к [мебель для ванной], то сервис «Пиксель Тулс» окажется крайне полезен для этой задачи.
Кроме того, инструмент позволяет воспользоваться словами-исключениями для того, чтобы не собирать подсказки, содержащие ненужные слова, например, [бесплатно] или [своими руками].
Видео с обзором функционала
Какие еще функции доступны в сервисе?
Кроме возможности собирать поисковые подсказки по нужной фразе и с нужной глубиной, можно добавлять дополнительные условия сбора: с пробелом или без пробела в конце фразы, с перебором букв кириллического или английского алфавита, а также с перебором цифр.
В этом случае, сервис автоматически переберет возможные добавления к поисковому запросу, начинающиеся на какую-либо букву или цифру, что еще более расширяет возможности для сбора широкой целевой семантики для продвижения сайта.
При выборе чек-бокса «Скачать результаты в виде CSV-файла», результаты выгружаются сразу для дальнейшей работы в формате CSV. Имеется возможность работать с результатами и прямо в интерфейсе инструмента и сортировать результаты по любой из колонок.
Имеется возможность работать с результатами и прямо в интерфейсе инструмента и сортировать результаты по любой из колонок.
История парсинга сохраняется в таблице, откуда можно в любой момент скачать необходимый файл (до 30 последних сборов), переименовать его для большего удобства или удалить, если он потерял актуальность.
Какие типы подсказок бывают?
Это только кажется на первый взгляд, что все поисковые подсказки одинаковые. Если посмотреть на них более пристально, то окажется, что их можно разбить на типы, вот и «Пиксель Тулс» теперь может отделить по меньшей мере 6 видов:
-
Навигационная. Ссылка на сам результат есть в колдунщике. Продвигаться по такой фразе, как правило, смысла нет.
-
Новостная. Подсказка появилась недавно и, скорее всего, скоро пропадёт. Имеет смысл продвигаться по данному типу если у вас новостной / информационный проект.
-
Есть в подсказках.
Обычный тип. Для большинства проектов (коммерческих) важно удостовериться, что запросы из продвигаемой вами семантики — относятся к этому типу. -
Автосгенерированная. Фактически, такой подсказки нет, но она выдается Яндексом для придания пользователю уверенности. Как правило, это мусорные запросы и продвижение по ним нецелесообразно. Важно проверить семантику и убедиться, то таких запросов в ядре нет или что по ним хотя бы не расходуется приличный бюджет.
-
Перестановка слов — тип, когда она получена с перестановкой слов из пользовательского запроса.
-
Дополнение / исправление начала запроса — тип, когда Яндекс дополнил фразу с её начала, а не в конце.
-
Если же подсказки вообще нет по запросу, то он будет скрыт / убран из итоговой таблицы. Такие фразы также следует исключать из продвижения.
 Обычный тип. Для большинства проектов (коммерческих) важно удостовериться, что запросы из продвигаемой вами семантики — относятся к этому типу.
Обычный тип. Для большинства проектов (коммерческих) важно удостовериться, что запросы из продвигаемой вами семантики — относятся к этому типу.

К методу существует API, то есть пользователи, которые хотят интегрировать инструмент с каким-то своим сервисом или забирать данные по API — могут это сделать.
Удаче в сборе широкой и целевой семантики для сайта.
Google Translate API и App Inventor: альтернатива Яндексу. привел к связанным людям. Инфраструктура, которая поддерживает все коммуникации между устройствами, также известна как Интернет вещей (IoT).
Этот блог не предназначен для рекламы Google API, а также для того, чтобы преуменьшить замечательные функции и возможности Яндекса. Только авторы хотят поделиться с читателями своим опытом, который, по его мнению, может послужить определенной цели, поскольку кто-то может захотеть узнать, как перевести что-то на язык, которого еще нет в репертуаре Яндекса, или создать приложение с множеством разных API-интерфейсы машинного переводчика для анализа и сравнения.
Наша цель в этом блоге — предоставить пользователю лучшее понимание того, как фильтровать результаты из Интернета с помощью блока синтаксического анализатора JSON или текстовых функций App Inventor. Конечно, при использовании Яндекса App Inventor уже позаботился об этих проблемах, поэтому пользователям не нужно о них беспокоиться. Но с API, отличными от Яндекса, вы должны знать, как манипулировать строками, чтобы получить желаемый результат; это то, что мы собираемся показать вам.
Конечно, при использовании Яндекса App Inventor уже позаботился об этих проблемах, поэтому пользователям не нужно о них беспокоиться. Но с API, отличными от Яндекса, вы должны знать, как манипулировать строками, чтобы получить желаемый результат; это то, что мы собираемся показать вам.
Для этого мы создаем приложение со следующими компонентами для графического интерфейса:
- Кнопка-счетчик, которая будет использоваться для выбора нужного языка из раскрывающегося списка. Но для целей этого блога в список включены только 4 языка (французский, испанский, английский и гаитянский креольский)
- Текстовое поле, используемое для приема пользовательского ввода для перевода. Подсказка для этого текстового поля содержит шаги, с помощью которых пользователь может начать работу.
- Две метки используются для отображения вывода переведенного текста с каждого сервера (Google и Яндекс).
.
Чтобы начать использовать API машинного переводчика, нам необходимо настроить учетную запись для службы, если только мы не используем встроенную процедуру Яндекса или метод, созданный для этой цели в App Inventor. Поскольку мы используем Google Translate API и Яндекс, нам нужна как минимум учетная запись для Google, которая у нас уже есть. После создания учетной записи нам нужно перейти в консоль API, чтобы создать проект и включить API для этого проекта. При получении учетных данных API для проекта выберите ключ API браузера. Если в этом процессе требуется помощь, следуйте документации по API, доступной на пользовательской консоли. Теперь, когда ключ API создан, как нам его использовать? Это вопрос, на который мы обещаем ответить дальше.
Поскольку мы используем Google Translate API и Яндекс, нам нужна как минимум учетная запись для Google, которая у нас уже есть. После создания учетной записи нам нужно перейти в консоль API, чтобы создать проект и включить API для этого проекта. При получении учетных данных API для проекта выберите ключ API браузера. Если в этом процессе требуется помощь, следуйте документации по API, доступной на пользовательской консоли. Теперь, когда ключ API создан, как нам его использовать? Это вопрос, на который мы обещаем ответить дальше.
Как упоминалось ранее, одним из преимуществ использования Яндекса является то, что App Inventor уже учел метод, используемый для выполнения запроса к веб-API, и способ обработки ответа, и, кроме того, не нужно беспокоиться о создании учетной записи. Но когда дело доходит до пользовательского API, вам нужно знать, как с ним обращаться, и это то, что мы собираемся показать вам сейчас. Прежде чем мы это сделаем, давайте взглянем на компоненты, задействованные в этом приложении, взглянув на список в интерфейсе разработки.
Если вы посмотрите на рис. 1а слева вверху, внизу есть два невидимых компонента. Один из них — это веб-компонент, который будет использоваться для доступа к API Google через URL-адрес, а другой — компонент Яндекса, доступный в App Inventor для решения этих задач. Если мы посмотрим на документацию Google Translate API, то увидим, что для отправки запроса на перевод текста через Google Translate API мы должны использовать следующий URL-адрес: https://www.googleapis.com/language/translate. /v2?параметры
Где параметры:
- Ключ API: используйте ключевой параметр для идентификации вашего приложения.
- Целевой язык: используйте целевой параметр, чтобы указать язык, на который вы хотите перевести.
- Исходная текстовая строка: используйте параметр q, чтобы указать текст для перевода.
Здесь наступает момент, когда нам нужно вернуться к тому, на чем мы остановились, когда говорили о создании ключа API браузера, и получить учетные данные для этого ключа.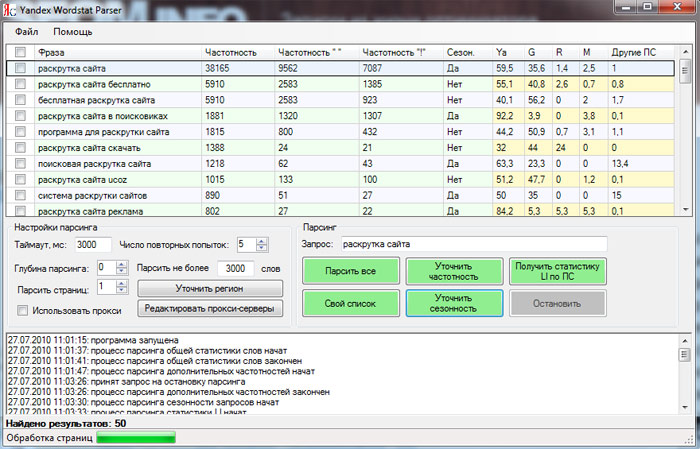
На этом этапе нам нужно создать три переменные, которые будут объединены конкатенацией, чтобы составить URL-адрес Google API, необходимый для обеспечения успешного ответа (код 200).
Из соображений безопасности ключ API, показанный выше, был изменен и поэтому не будет работать, если его использовать как есть.
Давайте взглянем на этот блок кода, прежде чем говорить о том, как мы делаем запрос к обоим API.
Этот блок кодов сообщает App Inventor, что после выбора пользователем языка из списка:
- Назначьте соответствующий код переменной languagecode.
- Скрыть клавиатуру.
- Задайте URL-адрес API Google для объединенного текста в блоке соединения.
- Получить ответ.
- Запросить такой же перевод у яндекса.
Вот разница между запросами к обоим серверам с использованием их API.
Как они отвечают на запрос? Мы сосредоточимся только на том, как ответил сервер Google, поскольку наша цель — показать, как отфильтровать целевой ответ из возвращенных метаданных.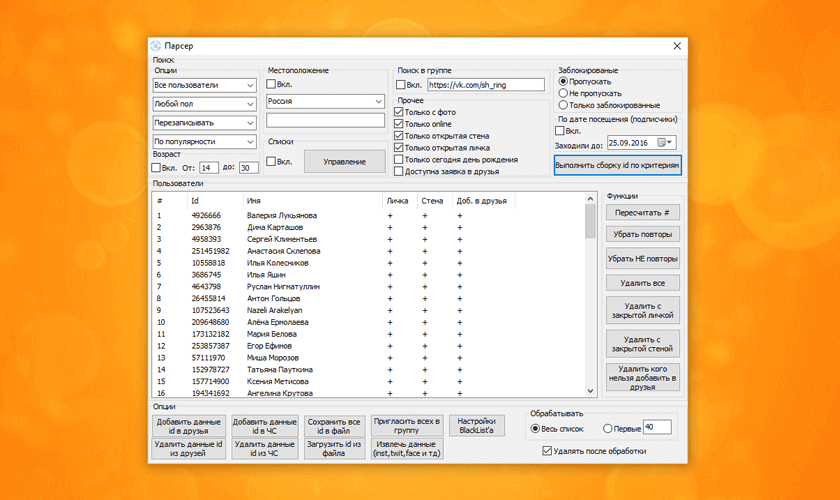
App Inventor уже обработал результат, возвращенный Яндексом в этом событии:
Теперь давайте предположим, что ответ от Google отображается примерно без анализа, форматирования или фильтрации. Как бы это выглядело?
С этим блоком кода:
У нас будет что-то вроде этого на выходе:
Как вы можете видеть слева, перевод Яндекса был выполнен, как и ожидалось, в то время как сервер Google вернул больше, чем мы ожидали в качестве ответа, и нам нужно найти метод, чтобы отфильтровать желаемый ответ от того, что было возвращено. Но хорошая новость заключается в том, что независимо от того, являетесь ли вы программистом или нет, App Inventor позволяет обойти все проблемы программирования, которые могут помешать нам получить желаемый результат. Вот почему мы сначала обратимся к проблемам людей, не знающих JavaScript или какого-либо языка программирования.
Наша цель — получить строку символов между двойными кавычками включительно Me gustaria ver un cambio de technologia la forma de pensar. Для этого мы исследовали и обнаружили, что открывающая кавычка перед Me находится на позиции 61 в строке. Мы также обнаружили, что длина оставшейся строки, которая следует за закрывающей кавычкой, равна 111. При этом давайте используем текстовый блок сегмента для извлечения целевой строки следующим образом:
Для этого мы исследовали и обнаружили, что открывающая кавычка перед Me находится на позиции 61 в строке. Мы также обнаружили, что длина оставшейся строки, которая следует за закрывающей кавычкой, равна 111. При этом давайте используем текстовый блок сегмента для извлечения целевой строки следующим образом:
Чтобы избавиться от кавычек, мы присоединили предыдущий блок. на заменить весь текстовый блок, как показано ниже:
Давайте посмотрим на вывод, если этот блок подключен к событию googleAPI.GotText.
Окончательный код App Inventor для этой версии
Мы только что показали вам, как получить предполагаемый ответ после перевода с сервера, используя простые арифметические вычисления и функции обработки текста в App Inventor. Возможно, есть люди на другой стороне мира пользователей App Inventor, которые все еще хотят знать, как справиться с ответом. Я предполагаю, что эти люди могут иметь некоторое знание языка JavaScript или, возможно, они слышали о JSON (обозначение объектов JavaScript), предназначенном для использования в этой практике в качестве альтернативы тому, что мы только что сделали. Если у нас есть веб-компонент, добавленный в пользовательский интерфейс, который в нашем случае называется googleAPI, при нажатии на этот компонент в редакторе блоков вы увидите блок, подобный этому:
Если у нас есть веб-компонент, добавленный в пользовательский интерфейс, который в нашем случае называется googleAPI, при нажатии на этот компонент в редакторе блоков вы увидите блок, подобный этому:
Если мы продолжим наше исследование так же, как начали ранее, мы можем прикрепить содержимое ответа к этому блоку, чтобы увидеть, как будут выглядеть выходные данные:
Декодер JSON App Inventor изменил содержимое ответа на выходные данные, показанные фиолетовым цветом . Этот вывод привел к карте, показанной ниже:
Эта карта говорит нам, что если мы используем список списка, то мы можем иметь прямой доступ к последнему элементу, создав эту цепочку списка выбора ниже:
Если мы используем цикл, мы можем довести эту цепочку до определенного уровня абстракции, как показано ниже:
Вот результат, который следует за блоком кода выше:
Окончательный код App Inventor для этой версии
Вкратце, это может быть долгое упражнение, но мы рассмотрели наши основные цели, которые заключались в том, чтобы предоставить пользователям альтернативу API Яндекса как средство для перевода текста и различные стратегии или методы, которые можно использовать для конкретного ответа из содержания ответа. Среди используемых методов использовались текстовые функции App Inventor и блок JSON веб-компонента. Приложение, созданное для этого блога, может дать читателю возможность сравнить точность Google Translation и Yandex Translation.
Среди используемых методов использовались текстовые функции App Inventor и блок JSON веб-компонента. Приложение, созданное для этого блога, может дать читателю возможность сравнить точность Google Translation и Yandex Translation.
Используйте этот QR-код, если хотите попробовать приложение:
A-Parser и мобильные прокси
Содержание статьи
- Возможности A-parser
- Мобильные прокси для a-parser: зачем они нужны и где их купить ?
- Пошаговая настройка мобильных прокси в а-парсере
В работе SEO компаний, фрилансеров, SaaS сервисов много рутинной и однотипной работы. Для построения семантического ядра нужно собрать много информации с сайтов конкурентов и структурировать ее. Это требует много времени и усилий. Но этот процесс можно автоматизировать с помощью специальных программ для парсинга. С их помощью данные загружаются и структурируются с сайтов конкурентов или поисковых систем с минимальным участием человека. И один из таких программных продуктов, широко используемый профессионалами, — приложение A-Parser.
И один из таких программных продуктов, широко используемый профессионалами, — приложение A-Parser.
Познакомимся подробнее с возможностями этого ПО. Мы расскажем, зачем нужно подключать мобильные прокси для работы и где купить подходящий продукт. Рассмотрим пошагово процесс настройки серверов в программе A-Parser.
Возможности A-Parser
A-Parser — программа, предоставляющая пользователям доступ к неограниченным ресурсам и позволяющая парсить данные в любом объеме. Что отличает его от конкурентов, так это непревзойденная скорость: приложение может обрабатывать тысячи запросов за одну минуту. Есть более 90 встроенных парсеров, которые постоянно обновляются и дополняются. К преимуществам софта также можно отнести бесплатную техническую поддержку, наличие телеграм-чата с огромным количеством участников. В A-Parser пользователи получают множество готовых решений, которые станут залогом стабильного и эффективного продвижения сайта.
Оценить преимущества использования этого парсера смогут следующие категории пользователей:
- SEO-специалисты, студии. А-Парсер собирает ссылки, проверяет позиции во всех без исключения поисковых системах, составляет семантическое ядро на основе парсеров подсказок, Яндекс.ВордСтат, Планировщик ключевых слов, проверяет цену за клик, частоту. Его также можно использовать для построения ссылок, PBN, охвата, используя более сотни параметров с разных сайтов, включая Alexa, SEMRush, MajesticSEO, SerpStat, MOZ, Ahrefs.
- Фрилансеры и представители бизнеса. A-Parser обеспечивает ощутимую экономию времени и материальных затрат на разработку и поддержку продукта. Это обеспечивается за счет автоматизации задач разного уровня сложности, создания собственных SaaS-сервисов, детально учитывающих специфику продвигаемого продукта.
- Разработчики программного обеспечения. A-Parser реализует многозадачность, многопоточность, обеспечивает простую и удобную работу с мобильными прокси. Программа способна выполнять коды в тысячи потоков, предоставляет возможность подключать модули NodeJS, управлять Chrome в консольном или графическом режиме через puppeteer в Linux или Windows.
- Маркетологи. Парсинг рекламных блоков и исследование конкурентной среды еще никогда не было таким простым, удобным и быстрым. A-Parser собирает и автоматически анализирует рекламные хайлайты конкурентов, собирает данные с сайтов, форумов, досок объявлений, включая адреса электронной почты, номера телефонов. Программа также предоставляет инструменты для работы с социальными сетями.
- Торговые площадки, интернет-магазины. Цены конкурентов автоматически отслеживаются и сравниваются с вашими. Возможен разбор карточек товаров вместе с их описанием, ценами, рубриками, картинками. Все это позволяет наполнять интернет-магазин автоматически.
- Для арбитров. A-Parser умеет собирать целевую аудиторию через социальные сети, мессенджеры (Instagram, Telegram). Для построения семантического ядра, получения дополнительной информации о конкурентах многие пользователи используют парсинг сайта, они могут перевести сайт на любой из языков мира, чтобы расширить семантическое ядро, увеличить географию продвижения. Собранный материал может быть автоматически опубликован на вашем ресурсе.
 А-Парсер собирает ссылки, проверяет позиции во всех без исключения поисковых системах, составляет семантическое ядро на основе парсеров подсказок, Яндекс.ВордСтат, Планировщик ключевых слов, проверяет цену за клик, частоту. Его также можно использовать для построения ссылок, PBN, охвата, используя более сотни параметров с разных сайтов, включая Alexa, SEMRush, MajesticSEO, SerpStat, MOZ, Ahrefs.
А-Парсер собирает ссылки, проверяет позиции во всех без исключения поисковых системах, составляет семантическое ядро на основе парсеров подсказок, Яндекс.ВордСтат, Планировщик ключевых слов, проверяет цену за клик, частоту. Его также можно использовать для построения ссылок, PBN, охвата, используя более сотни параметров с разных сайтов, включая Alexa, SEMRush, MajesticSEO, SerpStat, MOZ, Ahrefs.
 Собранный материал может быть автоматически опубликован на вашем ресурсе.
Собранный материал может быть автоматически опубликован на вашем ресурсе.A-Parser также поможет обходить капчи, поддерживает протоколы подключения HTTP, SOCKS4 и SOCKS5, контролирует позицию сайта в результатах поиска.
Мобильные прокси для A-Parser: зачем нужны и где купить?
Но прежде чем скачивать программу A-Parser, нужно понимать, что любые многопоточные и многозадачные действия, исходящие с одного IP-адреса, будут идентифицированы поисковыми системами и риск блокирования санкциями очень высок. Чтобы этого избежать, вы подключаетесь к программе мобильного прокси. Это одно из самых простых и надежных решений для обеспечения анонимности и безопасности работы в сети, обхода региональной блокировки, а также бана в поисковых системах.
Но для работы необходимо использовать качественные и функциональные мобильные прокси. Такой продукт по выгодной цене предлагает сервис MobileProxy.Space. За вполне разумные деньги вы получаете:
- приватный канал с неограниченным трафиком: им будете пользоваться только вы;
- возможность автоматической смены IP адреса по таймеру: пользователь самостоятельно устанавливает периодичность смены в диапазоне от 2 минут до 1 часа;
- возможность самостоятельно менять IP-адреса по мере необходимости с помощью GET-запросов к API;
- одновременная работа с протоколами HTTP(S) и Socks5 на двух параллельно подключенных портах;
- возможность быстрой смены ГЕО и оператора сотовой связи;
- возможность привязать IP без обязательной авторизации.
С такими мобильными прокси ваши возможности парсинга с программой A-Parser будут безграничны. Воспользуйтесь предложением и убедитесь в этом сами.
Пошаговая настройка мобильных прокси в A-Parser
A-Parser уже имеет встроенные прокси. Но прежде чем использовать этот вариант, нужно понимать, что эти серверы будут доступны другим пользователям. А это значительно снизит их эффективность и надежность. Поэтому стоит использовать персональные мобильные прокси. Это полностью исключит риски и обеспечит максимально стабильную и продуктивную работу. Теперь подробно опишем последовательность действий по настройке данного продукта:
- Запускаем программу A-Parser. В левом вертикальном меню находим вкладку «Настройки», заходим в нее. Откроется новое окно с горизонтальными вкладками. Находим среди них «Настройки проверки прокси», заходим в нее. В левой части рабочего окна появится синяя кнопка с надписью «Добавить новый парсет». Нажмите на него и дайте ему имя.
- Как только вы сгенерируете новый парсер, соответствующий каталог будет автоматически создан в папке, где находится приложение A-Parser. В него нужно зайти, чтобы добавить ссылку на мобильные прокси. Он будет доступен вам в личном кабинете после покупки товара. Найдите файл sites.txt. Откройте его и вставьте ссылку из личного кабинета. Сохраните изменения.
- Возврат в главное меню программы. В том же вертикальном левом списке инструментов, где мы нашли «Настройки»; на этот раз выберите вкладку «Proxychecker». Найдите только что добавленный парсет и поставьте напротив него галочку — «Включено». Нажмите рядом с синей кнопкой «Перезагрузить».
- Для использования собственных мобильных прокси необходимо создать пресет. Это будет текстовый файл с техническими данными вашего прокси-сервера — proxy.txt Информация может быть введена в любом из следующих форматов: «ip:port», «login:password@ip:port», «domain:port» , «логин:пароль@домен:порт». Все изменения должны быть сохранены.