Содержание
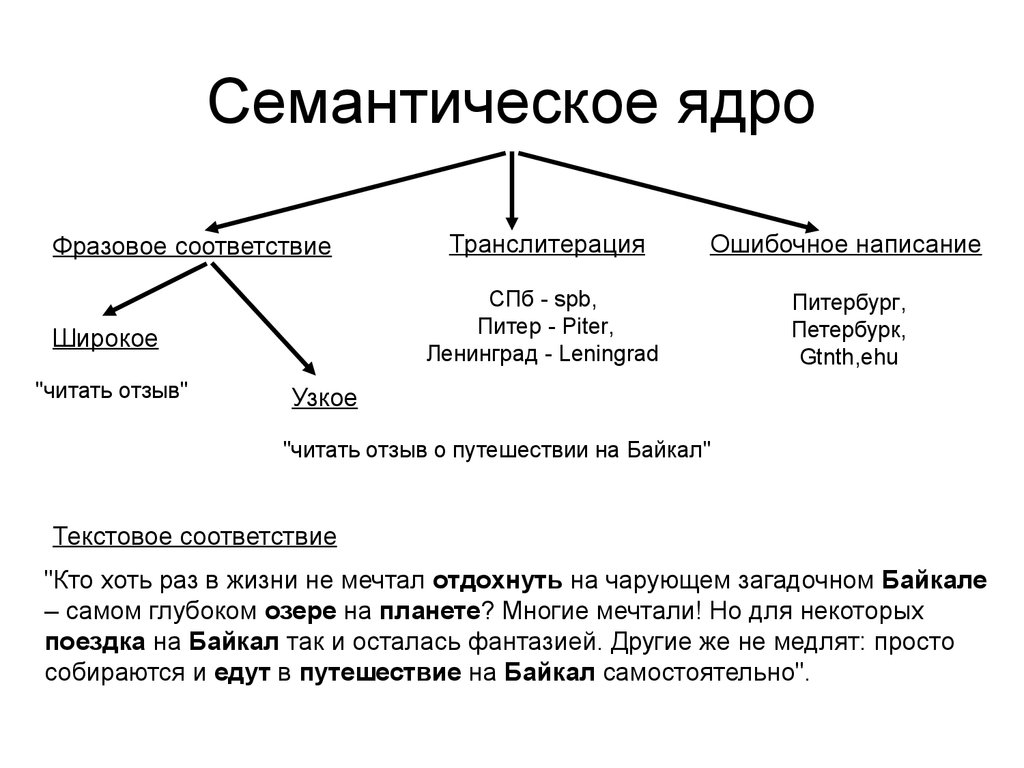
Как почистить семантическое ядро от дублей и мусора
Для максимального охвата целевой аудитории в поиске необходимо собрать исчерпывающее семантическое ядро. Иногда это сотни, иногда тысячи, а иногда и десятки и сотни тысяч запросов — в зависимости от объема сайта и конкуренции в тематике.
Чтобы семантика полностью отражала спрос, нужно использовать разные источники — сервисы поисковых систем, поисковые подсказки, фразы-ассоциации и другие (подробно о сборе запросов мы писали в гайде).
При подборе ключевиков неизбежно прямое или косвенное их дублирование (например, «чай каталог» и «каталог чая»), попадание в список спецсимволов, лишних пробелов, слов с прописными буквами. Собрать полное семантическое ядро и удалить «мусорные» запросы вручную — задача рутинная, но нужная.
Мы покажем, как собрать и почистить семантическое ядро с помощью бесплатных автоматизированных инструментов PromoPult на примере чайного магазина.
Первоначальный сбор и расширение семантического ядра
Ручная очистка ядра от нерелевантных запросов
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Как чистить ядро с помощью «Нормализатора слов»
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Убирайте мусор вовремя
Первоначальный сбор и расширение семантического ядра
Сначала составляется базовый перечень фраз, описывающих бизнес. Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Переключаясь на вкладки, генерируйте запросы и подходящие добавляйте в опорный список для расширения.
Когда опорный список готов, переходите к расширению. Для этого понадобится раздел «Ручной подбор и расширение слов». Включите профессиональный режим:
Далее базовый список расширяйте в ширину с помощью правой колонки Вордстат (смежные по значению запросы) — кнопка «Показать ассоциации». Обязательно ознакомьтесь с рекомендациями по выбору числа страниц для парсинга (они будут во всплывающем окне после клика по ссылке «настройки»).
Найденные слова и фразы, которые отвечают тематике, добавляйте в опорный список к базовым запросам.
Затем опорный список расширяйте в глубину с помощью левой колонки Вордстат (другие фразы с вхождением ключа) – кнопка «Что искали со словами»:
Если слов очень много (более тысячи) и система начинает работать медленно, операцию можно проводить поэтапно.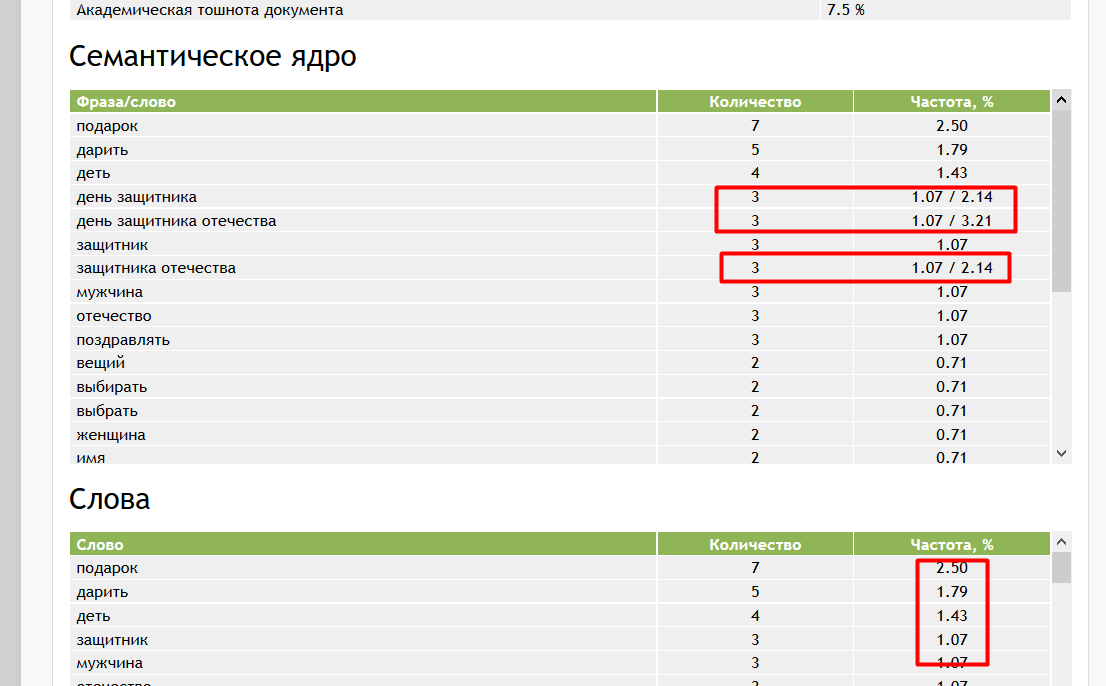 Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Для «ширины» есть еще пара профессиональных инструментов PromoPult, для которых мы написали подробные инструкции:
- парсер поисковых подсказок;
- парсер фраз-ассоциаций (блок выдачи «вместе с запросом ищут»).
Прогоните через них базовый (начальный) список запросов и добавьте спарсенные слова в общий Excel-файл.
Собрать такой список — полдела.
В ядро могут попадать нерелевантные тематике фразы и мусор в виде дублей запросов, лишних символов, фраз с нулевой частотностью. Список обязательно нужно чистить.
Ручная очистка ядра от нерелевантных запросов
Нерелевантные запросы — это те, что не соответствуют тематике сайта. Например, чайной лавке из Тюмени не подойдут для продвижения такие запросы как «песня зеленый чай», «духи зеленый чай», «чайный гриб», «кафе кофе», «чай википедия» и т. д. В этом списке также могут быть фразы с указанием города, где нет представительства магазина, названия конкурирующих компаний.
Чтобы они заведомо не попали в список, при парсинге нужно указывать возможные минус-слова. В данном случае к ним относятся «песня», «духи», «гриб», «кафе», «википедия», «спб», «москва» и т. д.
Предусмотреть все минус-слова невозможно, поэтому после каждой операции по расширению ядра нужно визуально проверять список на наличие нерелевантных запросов и удалять их.
Обращайте внимание на фразы с неуточненным интентом и исключайте их из ядра. Например, ключевые слова «золотые брови», «красный халат» (такие сорта чая) применимы также к другим тематикам — продажа косметики, продажа текстиля. Дальнейшее расширение этих фраз спровоцирует появление множества запросов, не имеющих ничего общего с тематикой чая.
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Кроме нерелевантных фраз в списке неминуемо будут присутствовать повторяющиеся фразы и лишние символы. Это мусор, который провоцирует беспорядок в файле и требует удаления.
Опытные пользователи Excel убирают ненужные строки, символы и пробелы с помощью макросов, автозамен и формул. Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Основные возможности инструмента:
- удаление дубликатов в точном вхождении;
- удаление дубликатов с перестановкой слов и учетом морфологии;
- удаление спецсимволов в начале и конце слова;
- удаление лишних пробелов между словами, в начале и конце строки;
- удаление табуляции в начале и конце строки;
- удаление пустых строк;
- преобразование слов в нижний регистр;
- замена ё на е.
Особенности сервиса:
- бесплатное использование;
- неограниченное количество запросов при проверке за один раз;
- работа онлайн — не требует установки софта;
- работа в фоне — не нужно держать страницу открытой;
- не требует разгадывания капчи;
- быстрая скорость обработки данных в облаке;
- результат обработки можно скачать в формате XLSX;
- бессрочное хранение выполненных задач в аккаунте PromoPult.

Как чистить ядро с помощью «Нормализатора слов»
Зарегистрируйтесь или авторизуйтесь в системе PromoPult — так все отчеты сохранятся в вашем личном кабинете.
Перейдите на страницу инструмента, нажмите «Добавить задачу» и укажите список запросов, который нужно почистить.
Загрузить запросы можно с помощью файла Excel (собираются данные с первого листа файла) или добавлением списка в окно сервиса (каждый запрос с новой строки).
Обратите внимание, что при загрузке XLSX-файла система считывает данные по принципу «одна ячейка — один запрос», поэтому добавляйте в файл только перечень запросов без другой служебной информации.
Далее необходимо поставить галочки — выбрать действия с ядром.
Удалить дубликаты слов
Система может удалить полностью идентичные строки (дубли словосочетаний) или строки, где слова в словосочетании имеют другой порядок и используются в других словоформах. Например, «виды китайского чая» и «китайский чай виды» будут считаться идентичными — в списке останется только тот запрос, что стоит выше.
Убрать спецсимволы
Иногда запросы для SEO могут мигрировать из контекстных рекламных кампаний и заимствовать спецсимволы. Или же попросту пользователи ставят при наборе запроса знаки препинания, которые вместе с фразами попадают в базы. Парсер поможет убрать их все одним кликом. По умолчанию заданы символы +-?: и при необходимости их можно дополнить.
Убрать лишние пробелы и табуляцию
При наличии лишних пробелов в начале текстовой строки, между словами во фразе и в конце строки система их обнаружит и удалит. Аналогично и с табуляцией — пустое пространство будет удалено в начале и в конце строки.
Удалить пустые строки
Строки без текста будут удалены.
Преобразовать слова в нижний регистр
Опция может быть полезна, когда список содержит спарсенные заголовки — часто слова в них бывают прописаны в верхнем регистре.
Заменить ё на е
На каждой площадке своя редполитика и свои правила написаний слов с буквой ё. Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Можно выставить сразу все галочки или только те, которые отвечают конкретной задаче. Ведь парсер полезен не только для чистки семантического ядра — он удобен для наведения порядка в любых списках.
По факту выполнения задачи будет доступен файл для скачивания. Задаче можно дать свое название, чтобы в будущем ее было проще идентифицировать.
В загруженном файле заполнен один лист с финальным списком запросов.
В нашем примере исходный список из 1103 запросов был обработан за 10 секунд. После чистки был удален мусор — дубликаты, занимающие порядка 11% ядра.
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Отсеяв мусор и дубли, необходимо также почистить ядро от запросов, частотность которых стремится к нулю. Они не способны генерировать трафик, поэтому нет смысла тратить время и деньги на создание и оптимизацию посадочных страниц.
Собрать частотности Wordstat можно вручную, но это долго и неудобно. Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Убирайте мусор вовремя
Если раньше было достаточно оптимизировать сайт под сотню базовых запросов, то сегодня требуются тысячи НЧ и длиннохвостых запросов, которые вручную собрать невозможно. Благодаря парсерам эта задача решается быстро и просто, однако побочным эффектом выступает огромное наличие мусора.
Техническая чистка ядра — необходимая процедура, позволяющая исключить неэффективные для продвижения слова. Сделать проверку быстрой и точной можно с помощью инструментов PromoPult.
«Нормализатор слов» доступен бесплатно. Парсер Wordstat — от двух копеек за сбор частотностей для одного запроса. Первые 50 проверок — бесплатно.
Попробовать инструменты PromoPult
Как удалить из семантического ядра неэффективные запросы? Как и написать текст для «кривых» ключевых фраз?
Данный вопрос — приоритетный!
Евгений:
Здравствуйте. В работе интернет-магазин и в данный момент подбирается семантическое ядро для одного из разделов.
Собрано около 300 запросов после чистки: минимальная частота «!» не менее 30 (не видим смысла в разделах продвигать запросы которые даже спрашивают меньше 30 раз в месяц, после была чистка по формуле: [точная_частота/общая_частота < 0.05–0.07 (≈ 5%–7%)], после чистка на минус-слова и неподходящие).
Все запросы распределены по релевантным страницам, так же дополнительно будут созданы ещё страницы на различные комбинации фильтров релевантно запросам.
Но при этом, после распределения запросов, выходит ситуация, что на некоторых страницах по 30 или более фраз. Интересует, каким ещё методами (более автоматизированными) можно почистить семантическое ядро от неэффективных запросов, например, которые не принесут трафик вообще?
Делали попытку собрать данные (прогноз переходов) SeoPult, Rookee, ВебЭффектор и даже средние показатели. Но данные не внушают доверия, что бы им доверять, так как они слишком разные, в РАЗЫ!
Так же интересует понимание правильных словоформ и порядка слов. Как быть в случае, если запрос звучит явно не так как он мог бы быть использован в тексте (SEO)?
Как быть в случае, если запрос звучит явно не так как он мог бы быть использован в тексте (SEO)?
Например: [офисное кресло купить в москве], хотя логичнее если запрос в тексте будет [купить офисное кресло в москве], возможно не самый лучший пример, но всё же главная загвоздка в том, что не всегда ключи выглядят достаточно хорошо, что бы входить в содержание сайта и возникает ощущение, что так не ищут и незачем такой запрос продвигать?
Работа проводится в Key Collector.
Евгений, приветствую! Если резюмировать, то у вас три вопроса:
Как удалить из семантического ядра неэффективные запросы?
Как сгруппировать фразы? Можно ли продвинуть условные 30 запросов на документе?
Как правильно написать текст, если исходная фраза звучит «криво»?
Разберём их в этом порядке.
1. Неэффективные фразы
Давайте называть эффективной не ту фразу, которая имеет точную частоту более 30, а ту, которая удовлетворяет следующим критериям:
Она целевая.
То есть, та, по которой интент пользователя преимущественно совпадает с тем, который вы можете удовлетворить на документе.Стоимость совершения целевого действия по которой — является рентабельной для проекта.
 То есть, та, по которой интент пользователя преимущественно совпадает с тем, который вы можете удовлетворить на документе.
То есть, та, по которой интент пользователя преимущественно совпадает с тем, который вы можете удовлетворить на документе.
Как правило, рассчитать CPA по фразе на этапе сбора семантики — сложно и следует опираться на стоимость одного показа, метрика CPV = Стоимость продвижения / Точная частота в регионе.
Если вы достаточно хорошо умеете оценивать стоимость продвижения, то опираться лучше именно на это соотношение, а не на точную частоту. Число показов может быть и менее 30, но если они вам не будут почти ничего стоить и будут целевыми, то это эффективные фразы.
Можно прокачать формулу оценки и добавить к числу показов (точная частота) множитель, который отвечает за долю целевых показов. Если рассматривать коммерческий проект, то в данным коэффициентом будет степень коммерциализации выдачи по «Пиксель Тулс». Ниже приведена оценка, после выгрузки из инструмента.
Следует ориентироваться на соотношение: стоимость продвижения / эффективные показы.
Дополнительно лучше оценить, что запрос входит / есть в поисковых подсказках и она не сгенерирована, это позволит очистить ядро от накрученных запросов.
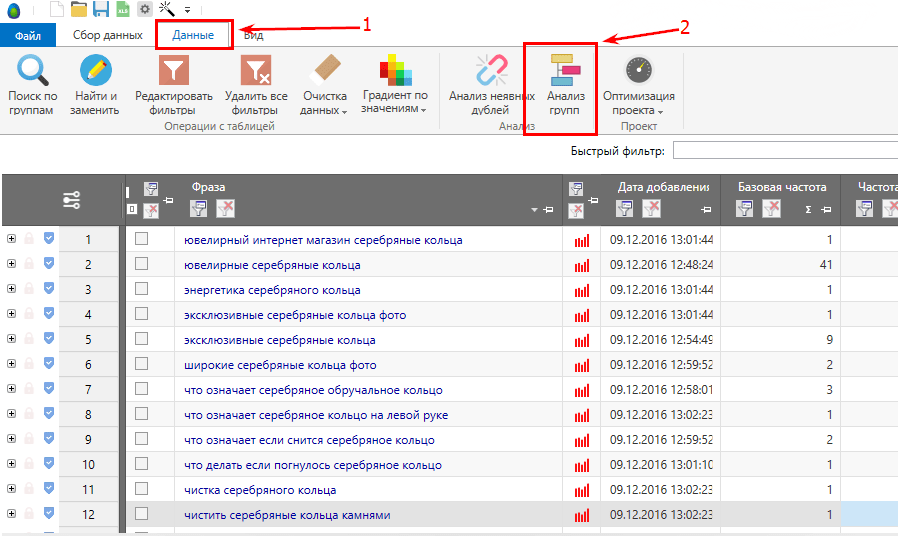
2. Группировка и финальная чистка
Финальную чистку семантического ядра рекомендуется производить уже после его группировки и распределения по посадочным страницам. Почему это важно? Это связано с тем, что решение удалять или не удалять запрос будет зависеть от того, если ли у вас в группе на URL другие фразы.
Поясним: если на URL ведёт всего 1 запрос, то лучше оставить его (если он целевой) и наоборот, можно удалить запрос с высоким значением CPV, если в группе много других, более эффективных фраз.
Первичную группировку/кластеризацию лучше производить с помощью инструментов автоматизации — «Онлайн кластеризация семантического ядра сайта». Сервис поможет в пару кликов определить частоты фраз, релевантные URL и текущую позицию сайта, а также, что самое важное, опираясь на ТОП-10 скомпонует запросы так, как их можно будет продвинуть.
Если после кластеризации и оценки CPV у вас остались эффективные фразы, которые нормально продвинутся на одном URL, то их может быть и 10-15 и 30 штук (редко, но такое бывает, да). Бояться этого не стоит, переходите к этапу внутренней оптимизации.
ТОП — не врёт!
3. Работа с «кривыми» ключами
Да, часто запросы звучат не так, как их можно использовать в тексте. Самый базовый пример: [мебель москва].
Совет очень простой: используйте в тексте наиболее приближенные фразы, корректные с точки зрения русского языка. Несколько примеров:
- [мебель москва] -> …мебель в Москве…
- [мебель цена] -> …цена на мебель…
- [офисное кресло купить в москве] -> …купить офисное кресло в Москве…
Это позволит удовлетворить большинство текстовых факторов ранжирования и не попасть под санкции за переоптимизацию. Стоить также избегать точных вхождений в тексте для очень длинных фраз, они, в последнее время, не очень хорошо воспринимаются поисковой системой Яндекс.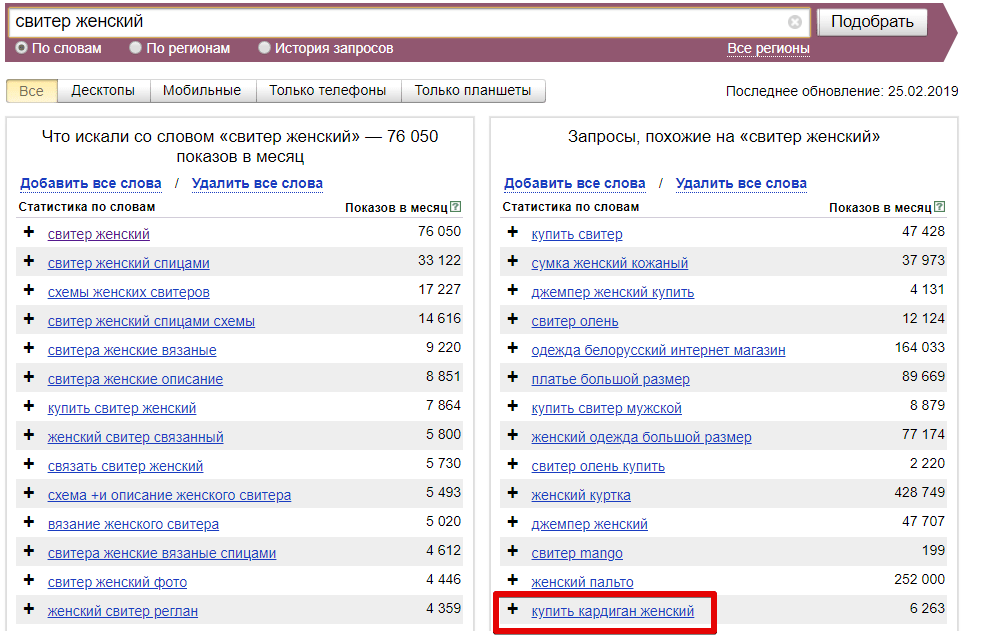 Разбейте запрос на 2 более коротких фрагмента с частичным вхождением.
Разбейте запрос на 2 более коротких фрагмента с частичным вхождением.
Итоговая последовательность действия
Если резюмировать, то итоговая последовательность действий следующая:
Проверяете точную частоту фраз.
Удаляете запросы, которые не подходят вам по интенту / потребности.
Удаляете запросы, которые отсутствуют в поисковых подсказках или подсказки автосгенерированные.
Определяете стоимость продвижения.
Определяете коммерциализацию выдачи (коммерческий проект).
Вычисляете CPV по эффективным показам = Стоимость продвижения / (Точная частота × Степень коммерциализации).
Группируете запросы и распределяете их по посадочным URL.
Удаляете фразы с завышенным значением CPV, если в группе уже достаточное число запросов (5-10).
Для технических заданий на тексты и тегов — приводите фразы к корректному написанию с точки зрения русского языка.
Проводите оптимизацию. В помощь — критерии, которым требуется удовлетворить.

Видео с чек-листом чистки фраз
Удачи в самостоятельном продвижении в ТОП!
Дата ответа:
Автор ответа:
Дмитрий Севальнев
Формирование семантического ядра сайта.
Ключи к ТОПу!
25 долларов США в час
45 долларов США в час
ЗАКАЗАТЬ СЕЙЧАС
Продажа
-45%
Подберем ключи для вашего сайта, которые откроют дверь в ТОП!
Аналитика семантики бизнес-ниши.
Поиск по всем похожим ключевым фразам из ТОП-20.

Аналитика сложности семантики.
Проверенная система сбора семантики.
Очистка семантического ядра от стоп-слов.
Кластеризация поисковых фраз.
Рекомендации по распределению ключевых слов на сайте.
Заказать сбор семантики
Свяжитесь мгновенно через мессенджер!
Выбери свой любимый мессенджер на
Бесплатная консультация по твоему проекту.
Связаться с Viber
Свяжитесь с WhatsApp
Связаться с Telegram
Для чего необходимо формирование семантического ядра сайта?
Семантическое ядро — это слова, описывающие деятельность компании, ее продукты и услуги. По ним поисковик определяет, что сайт соответствует запросу пользователя. Это основные части фраз, которые пользователи вводят при поиске в браузере. Google и Яндекс показывают сайты, содержащие ключевые слова на первых двух страницах. Это означает, что они удовлетворяют потребности людей, которые ищут продукт, услугу или информацию. Если не использовать такие «маркеры» для программ, попасть в Топ невозможно. Это основа SEO-продвижения.
Google и Яндекс показывают сайты, содержащие ключевые слова на первых двух страницах. Это означает, что они удовлетворяют потребности людей, которые ищут продукт, услугу или информацию. Если не использовать такие «маркеры» для программ, попасть в Топ невозможно. Это основа SEO-продвижения.
Что важно учитывать при формировании семантического ядра?
Эти основные фразы отражают интересы потенциальных покупателей. Чем разнообразнее и точнее они будут, тем шире охват интернет-пользователей. Если собрать все реалистичные варианты, система покажет сайт большей целевой аудитории. Используя все формулировки, которые могут ввести пользователи, можно будет максимально увеличить охват по ключевым запросам.
Очистка семантического ядра от «мусорных» слов, не относящихся к системе, способствует продвижению. Сайт показывается только по целевым запросам. Кластеризация семантики — это распределение слов по смысловым группам и основа для создания seo-контента.
Как построить семантическое ядро?
Подберем ключевые слова, чтобы Ваш сайт был впереди конкурентов в ТОПе. Это увеличит органический поисковый трафик и увеличит продажи. TopUser.PRO гарантирует такие результаты, потому что наши специалисты:
Это увеличит органический поисковый трафик и увеличит продажи. TopUser.PRO гарантирует такие результаты, потому что наши специалисты:
- знакомятся с особенностями бизнеса клиента, согласовывают с ним задачу;
- проанализировать нишу, изучить страницы конкурентов заказчика;
- маркеры формы, выделение слов и словосочетаний, характеризующих сферу деятельности клиента;
- владеют инструментами для разбора запросов, поэтому собирают все подходящие варианты;
- избавиться от лишних слов и словосочетаний, не способствующих продвижению в поисковой выдаче;
- сгруппировать результаты по категориям в соответствии с намерениями или потребностями тех, для кого предназначены веб-страницы;
- доработка структуры семантического ядра вручную;
- формировать отчеты по этапам работ и предоставлять их заказчику;
- дать совет, как оптимизировать ваш сайт, используя полученный список ключевых слов и предложить такую услугу.
Комплексный подход гарантирует, что семантическое ядро покроет все возможные запросы и не будет отягощено стоп-словами, которые снижают ранжирование и отнимают ресурсы на нецелевые показы. Такая основа позволит создавать контент, который будет не только отвечать интересам целевой аудитории6, но и хорошо ранжироваться поисковыми роботами. Это первое, что необходимо для успешного SEO-продвижения. Быстрый путь в ТОП вашего сайта!
Такая основа позволит создавать контент, который будет не только отвечать интересам целевой аудитории6, но и хорошо ранжироваться поисковыми роботами. Это первое, что необходимо для успешного SEO-продвижения. Быстрый путь в ТОП вашего сайта!
Заказывайте и обгоняйте конкурентов уже сегодня
Часто задаваемые вопросы (FAQ)
✔️ Почему при формировании семантического ядра сайта иногда требуется использование вопросительных слов?
Google оценивает слова «как», «где» и другие как признак интереса аудитории. Особенно важно использовать их в вопросах вместе с основными ключевыми словами.
✔️ Как по результатам, которые дали формирование семантического ядра сайта, оптимизировать ваш контент на вопросы?
Используйте их в тексте как риторические. Создайте блок «Вопрос – Ответ».
✔️ Какой самый простой инструмент для формирования семантического ядра сайта?
Google Планировщик ключевых слов. Все подобные сервисы просты в использовании.
Все подобные сервисы просты в использовании.
✔️ Включаются ли длинные ключевые слова при формировании семантического ядра сайта?
Краткие формулировки являются основными. Ключевые слова с длинным хвостом — это дополнительные фразы. Они реже используются в поиске. Конкуренция для них ниже. Они также используются.
✔️ Как аналитика влияет на формирование семантического ядра сайта?
Исследование ключевых слов может помочь вам «заглянуть в головы ваших клиентов», найдя темы для включения в вашу контент-стратегию. Как только вы узнаете, что ищет ваша целевая аудитория, вы сможете оптимизировать свой контент, чтобы предоставить ответы, которые ей нужны.
✔️ Как правильно дополнить ключевые слова контекстом, применяя формирование семантического ядра сайта?
Есть несколько полезных советов. Посмотрите на результаты автозаполнения, когда вы вводите слово или фразу в поле поиска Google. Этот список меняется по мере добавления слов для предоставления контекста.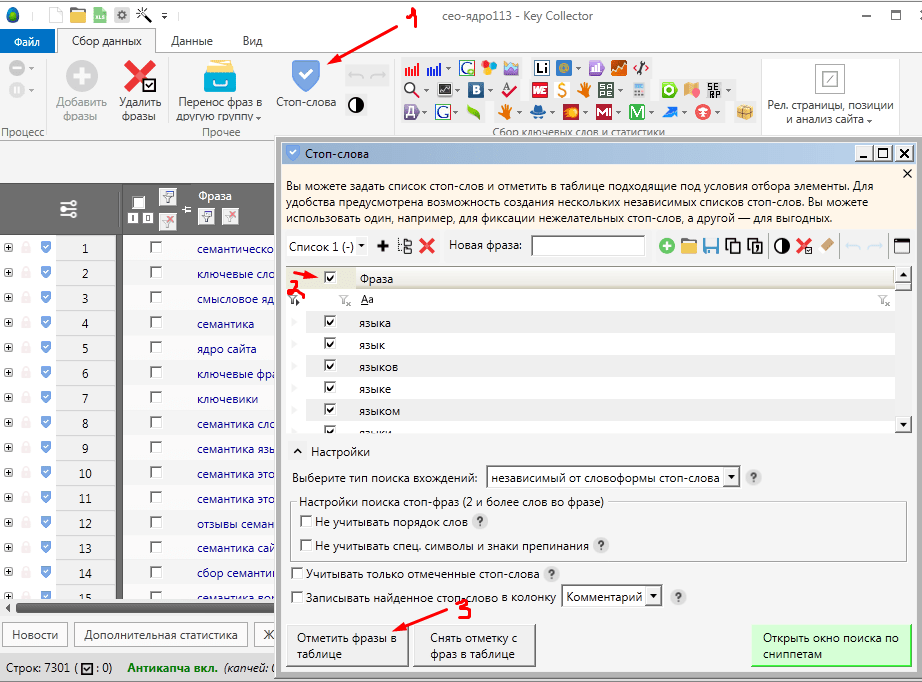
✔️ В чем ошибка использования ключевых слов после того, как выполнено формирование семантического ядра сайта?
Перенасыщение ключевыми словами и неестественное использование. Они должны применяться к людям, а не поисковым системам.
Задавай вопрос
ASO: Как создать семантическое ядро для вашего приложения | Анатолий Шарифулин | AppFollow
Оптимизация App Store — это процесс оптимизации метаданных, направленный на улучшение видимости приложения в результатах поиска.
Семантическое ядро — это набор ключевых слов и фраз, наиболее точно и понятно описывающих приложение.
Прежде всего, важно подчеркнуть, что семантическое ядро и процесс его создания — одна из самых ответственных и трудоемких задач в ASO. Далее на основе семантического ядра выбираем, какие ключевые слова использовать.
Ключевые слова могут иметь:
- высокая частота,
- средняя частота,
- низкая частота.

В отличие от веб-разработчиков, команды разработчиков мобильных приложений не могут точно знать, какую частоту получают те или иные ключевые слова. Даже Apple Search Ads не дает доступа к такой информации в абсолютных значениях. Поэтому мы можем только предполагать, насколько частым является тот или иной поисковый запрос.
Для большей наглядности рассмотрим каждый шаг создания семантического ядра на примере реального приложения. Наш хороший друг любезно согласился предоставить нам всю необходимую информацию о своем новом приложении Travel Quests (на момент публикации приложение еще не было запущено в App Store).
Перед построением семантического ядра задайте себе несколько вопросов.
Кто ваша целевая аудитория?
Вы должны четко понимать, кто ваши пользователи. Например, ваше приложение — это игра, в которой пользователи должны выбирать наряды для кукол. Скорее всего, ваша основная аудитория — девочки в возрасте до 12 лет.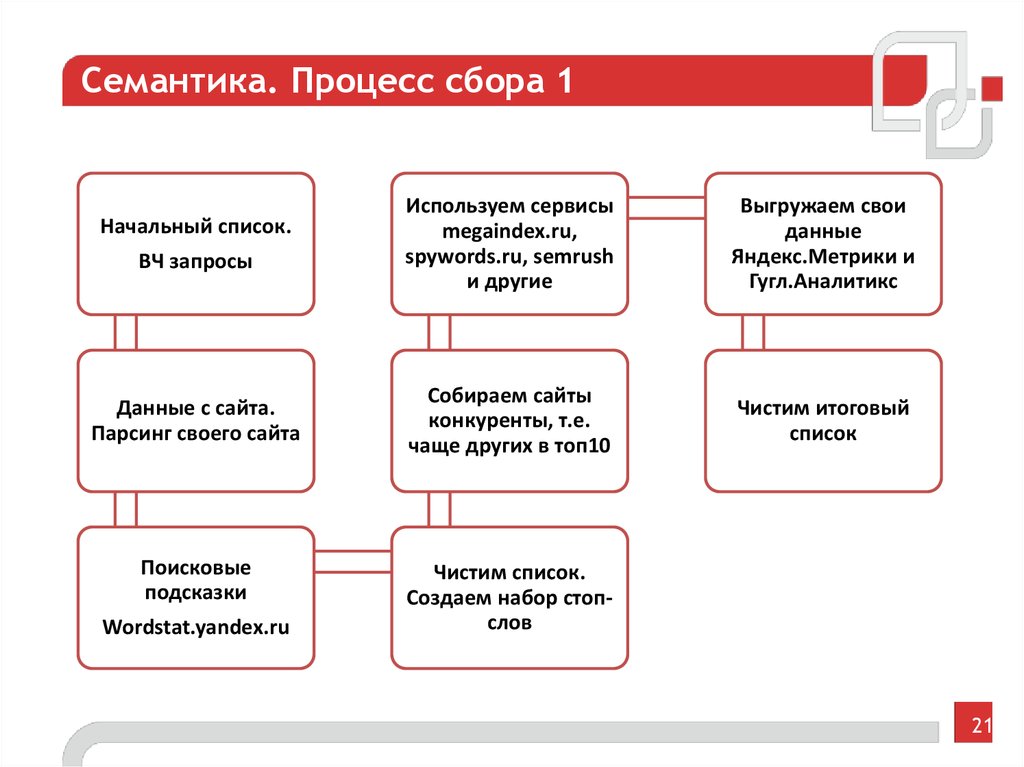 Девочек или мальчиков постарше это вряд ли заинтересует. Прежде чем приступить к созданию семантического ядра, попробуйте определить свой потребительский сегмент.
Девочек или мальчиков постарше это вряд ли заинтересует. Прежде чем приступить к созданию семантического ядра, попробуйте определить свой потребительский сегмент.
Какую ценность представляет ваше приложение для пользователей?
О чем ваше приложение? Какова его цель? Зачем пользователю устанавливать его? Ответы на эти вопросы — ваши первые релевантные ключевые слова.
Чем ваше приложение отличается от конкурентов?
Попробуйте сформулировать, что делает ваше приложение особенным. Ваши идеи — это средне- или низкочастотные поисковые запросы, которые могут использовать клиенты. Они могут быть не самыми популярными, но здесь скрыта ценность. В то время как ваши конкуренты сосредотачиваются на наиболее часто используемых ключевых словах, вы можете достичь более высоких позиций, применяя менее популярные, но хорошо нацеленные запросы.
Кто ваши конкуренты?
На этом этапе не полагайтесь только на имена, которые первыми приходят вам в голову.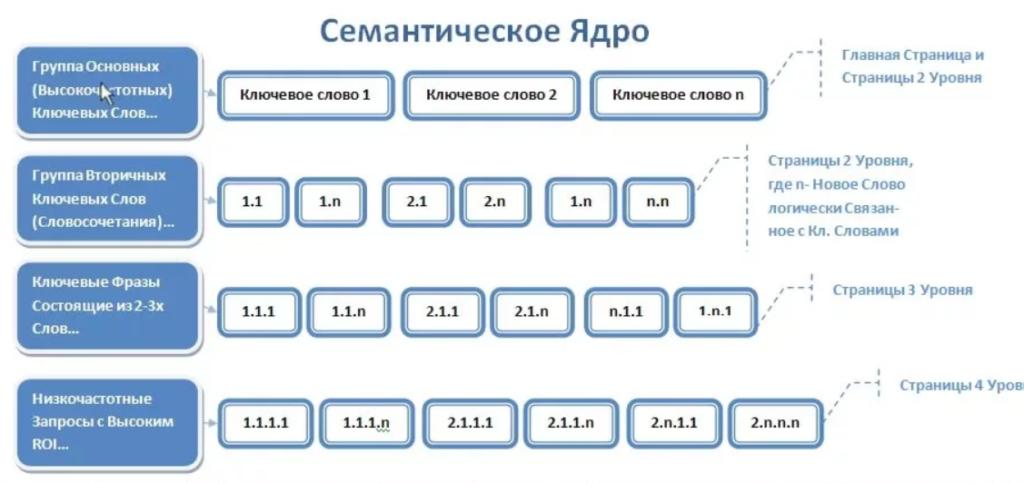 Проведите хорошее исследование и выясните, кто ваши прямые и косвенные конкуренты. После проверки каждого из них составьте список ключевых слов, которые они используют чаще всего. Вы можете «позаимствовать» некоторые из них и генерировать собственные идеи.
Проведите хорошее исследование и выясните, кто ваши прямые и косвенные конкуренты. После проверки каждого из них составьте список ключевых слов, которые они используют чаще всего. Вы можете «позаимствовать» некоторые из них и генерировать собственные идеи.
Каков основной рынок для вашего приложения?
Возможно, вы удивитесь, но ключевые слова, используемые в британском и австралийском App Store, могут подойти и для российского рынка. Как вы можете это использовать? Даже если ваша основная клиентская база находится в России, вы можете добавить ключевые слова, которые не подошли в русской версии (из-за ограничений символов) для магазинов приложений Великобритании и Австралии. Более подробная информация о дополнительных локалях и индексации в Google Play будет доступна в одной из следующих статей.
Возможно, вы уже ответили на все выделенные вопросы ранее. Скорее всего, вы сделали это еще до создания приложения. Даже лучше! Эта информация необходима для создания семантического ядра и подбора правильных ключевых слов.
Подбор ключевых слов является основой создания семантического ядра, поэтому важно выбрать наиболее релевантные для дальнейшего продвижения. Вернемся к нашему примеру — приложению Travel Quests. По названию приложения легко понять, что оно связано с путешествиями и квестами. Это означает, что мы должны сосредоточить наши ASO-усилия на людях, которые любят путешествовать и ищут интересные и активные способы провести время за границей.
В данном случае релевантными запросами являются: «путешествие», «гид», «советы» и т.д. Кроме того, стоит обратить внимание на похожие запросы, т.е. слова, которые не описывают напрямую основные функции приложения, но все же имеют потенциал для привлечения трафика . Для туристических квестов это могут быть следующие ключевые слова: «музеи», «экскурсии», «достопримечательности». Анализируемое приложение не является туристическим агентством, однако его клиентами могут стать люди, планирующие поездку. Актуальность запроса очень субъективна, поэтому чем больше альтернатив вы проверите, тем выше шансы, что вы создадите качественное семантическое ядро.
Если у вас закончились идеи, используйте следующие методы для поиска релевантных ключевых слов:
- Спросите текущих и потенциальных клиентов, как они нашли ваше приложение, какие слова и фразы они использовали. Небольшой опрос среди ваших друзей и коллег также может дать вам много полезной информации;
- ознакомьтесь с названиями и описаниями приложений конкурентов. Это очень важный шаг, уделите ему достаточно времени;
- использовать аналитические и статистические инструменты, ориентированные на мобильные рынки: App Annie, Mobile Action, Sensor Tower и т. д. Там вы можете найти некоторые ключевые слова, которые ваши конкуренты используют для получения высоких результатов поиска;
- если ваше приложение уже есть в магазине, изучите комментарии пользователей;
- попробуйте инструменты для исследования ключевых слов: Google Keyword Planner, Google Trends, Яндекс.Wordstat. Последнее очень полезно, если ваш основной рынок — Россия. Однако не обращайте особого внимания на значения частоты. Из опыта мы знаем, что между веб и мобильными устройствами есть большая разница;
- используйте синонимы и языковые словари, если вам нужно подобрать ключевые слова для иностранных рынков. Multitran, например, хороший инструмент, чтобы попробовать.
 Однако не обращайте особого внимания на значения частоты. Из опыта мы знаем, что между веб и мобильными устройствами есть большая разница;
Однако не обращайте особого внимания на значения частоты. Из опыта мы знаем, что между веб и мобильными устройствами есть большая разница;Расчетная частота
Как было сказано выше, App Store и Google Play не предоставляют общедоступных данных о частоте поисковых запросов. Однако это не значит, что мы не можем его оценить.
Основным инструментом для этого является список поисковых предложений. Когда вы начинаете вводить запрос в строке поиска, список формируется магазином автоматически. Самые популярные ключевые слова и фразы размещаются вверху. Если запросы, которые вы планируете использовать, не отображаются там, скорее всего, они не будут привлекать трафик в ваше приложение.
Есть еще один инструмент для App Store — Search Ads, недавно представленный Apple для улучшения видимости приложения в поиске.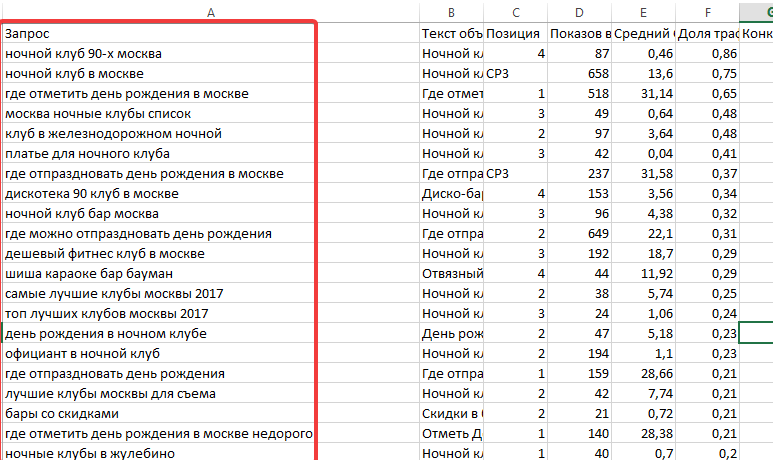 Используя его, становится возможным дать приблизительные оценки того, сколько трафика могут генерировать разные ключевые слова. В настоящее время инструмент доступен только для рынка США. Если ваше приложение нацелено на США, у вас есть преимущество. Таким образом, получите доступ к Search Ads как можно скорее!
Используя его, становится возможным дать приблизительные оценки того, сколько трафика могут генерировать разные ключевые слова. В настоящее время инструмент доступен только для рынка США. Если ваше приложение нацелено на США, у вас есть преимущество. Таким образом, получите доступ к Search Ads как можно скорее!
Собирать поисковые подсказки вручную, проверяя каждый запрос на планшете или смартфоне, очень трудоемко. AppFollow упрощает этот процесс. Этот инструмент может программно генерировать список предложений для вашего приложения, если вы подписаны на план Premium. На этом примере мы проиллюстрируем, как оценить частоту и построить семантическое ядро.
Сбор подсказок — наиболее правильный способ построения семантического ядра.
Если вы еще не там, зарегистрируйтесь на AppFollow.io . В верхней панели выберите «Инструменты ASO», затем «Предложить и найти». Вы увидите следующую страницу:
Выберите необходимое устройство: iPhone/iPad или Android . В поле за ним введите интересующие вас ключевые слова. Выберите нужную локаль в списке справа.
В поле за ним введите интересующие вас ключевые слова. Выберите нужную локаль в списке справа.
В результате вы увидите список предложений в левой колонке. Если вы сравните его со списком на своем смартфоне, вы обнаружите, что они идентичны. В правой колонке вы можете увидеть результаты поиска по введенному ключевому слову в выбранной стране. Мы вернемся к этой части позже в статье.
Стоит заметить, что если вы просматриваете предложения для Android, Google Play корректирует их в соответствии с вашим IP-адресом. Это означает, что если вы находитесь в России и вам нужно увидеть предложения для США, вам нужно изменить свой IP на американский. Бесплатные инструменты VPN могут помочь вам в этом. В противном случае вы увидите данные поиска для страны, в которой вы сейчас находитесь.
Все запросы с разумной частотой будут отображаться в предложениях. Они показаны в порядке убывания. Ключевое слово или фраза на первом месте имеют наибольшую частотность, а нижние — наименьшую.
AppFollow предлагает простой и удобный способ экспорта предложений — через надстройку Google Sheets , доступную для всех пользователей Google Docs.
Надстройка AppFollow для Google Таблиц
Чтобы просмотреть список предложений, добавьте в любую ячейку следующую формулу: =getSuggest(«запрос»). Вместо «запрос» введите интересующее вас ключевое слово или фразу. Не забудьте добавить кавычки.
Как описано выше, вы можете собирать предложения либо вручную, либо с помощью AppFollow и Google Sheets. В итоге у вас будет таблица со списками различных подсказок по каждому поисковому запросу. Важно отметить, к какому рынку или региону относятся эти списки. Примерно так должно получиться:
После того, как вы соберете подсказки для каждого ключевого слова, отметьте их разными цветами. В нашем примере наиболее релевантные предложения выделены синим цветом, а менее релевантные — желтым.
Не учитывать заголовки с «-» , «:» или «&».