Содержание
Как почистить семантическое ядро от дублей и мусора
Для максимального охвата целевой аудитории в поиске необходимо собрать исчерпывающее семантическое ядро. Иногда это сотни, иногда тысячи, а иногда и десятки и сотни тысяч запросов — в зависимости от объема сайта и конкуренции в тематике.
Чтобы семантика полностью отражала спрос, нужно использовать разные источники — сервисы поисковых систем, поисковые подсказки, фразы-ассоциации и другие (подробно о сборе запросов мы писали в гайде).
При подборе ключевиков неизбежно прямое или косвенное их дублирование (например, «чай каталог» и «каталог чая»), попадание в список спецсимволов, лишних пробелов, слов с прописными буквами. Собрать полное семантическое ядро и удалить «мусорные» запросы вручную — задача рутинная, но нужная.
Мы покажем, как собрать и почистить семантическое ядро с помощью бесплатных автоматизированных инструментов PromoPult на примере чайного магазина.
Первоначальный сбор и расширение семантического ядра
Ручная очистка ядра от нерелевантных запросов
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Как чистить ядро с помощью «Нормализатора слов»
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Убирайте мусор вовремя
Первоначальный сбор и расширение семантического ядра
Сначала составляется базовый перечень фраз, описывающих бизнес. Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Переключаясь на вкладки, генерируйте запросы и подходящие добавляйте в опорный список для расширения.
Когда опорный список готов, переходите к расширению. Для этого понадобится раздел «Ручной подбор и расширение слов». Включите профессиональный режим:
Далее базовый список расширяйте в ширину с помощью правой колонки Вордстат (смежные по значению запросы) — кнопка «Показать ассоциации». Обязательно ознакомьтесь с рекомендациями по выбору числа страниц для парсинга (они будут во всплывающем окне после клика по ссылке «настройки»).
Найденные слова и фразы, которые отвечают тематике, добавляйте в опорный список к базовым запросам.
Затем опорный список расширяйте в глубину с помощью левой колонки Вордстат (другие фразы с вхождением ключа) – кнопка «Что искали со словами»:
Если слов очень много (более тысячи) и система начинает работать медленно, операцию можно проводить поэтапно. Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Для «ширины» есть еще пара профессиональных инструментов PromoPult, для которых мы написали подробные инструкции:
- парсер поисковых подсказок;
- парсер фраз-ассоциаций (блок выдачи «вместе с запросом ищут»).
Прогоните через них базовый (начальный) список запросов и добавьте спарсенные слова в общий Excel-файл.
Собрать такой список — полдела.
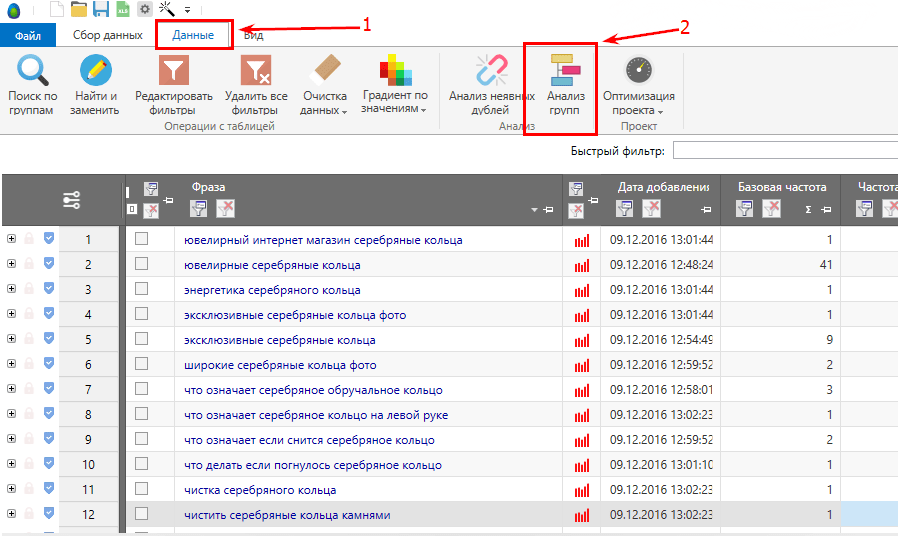
В ядро могут попадать нерелевантные тематике фразы и мусор в виде дублей запросов, лишних символов, фраз с нулевой частотностью. Список обязательно нужно чистить.
Ручная очистка ядра от нерелевантных запросов
Нерелевантные запросы — это те, что не соответствуют тематике сайта. Например, чайной лавке из Тюмени не подойдут для продвижения такие запросы как «песня зеленый чай», «духи зеленый чай», «чайный гриб», «кафе кофе», «чай википедия» и т. д. В этом списке также могут быть фразы с указанием города, где нет представительства магазина, названия конкурирующих компаний.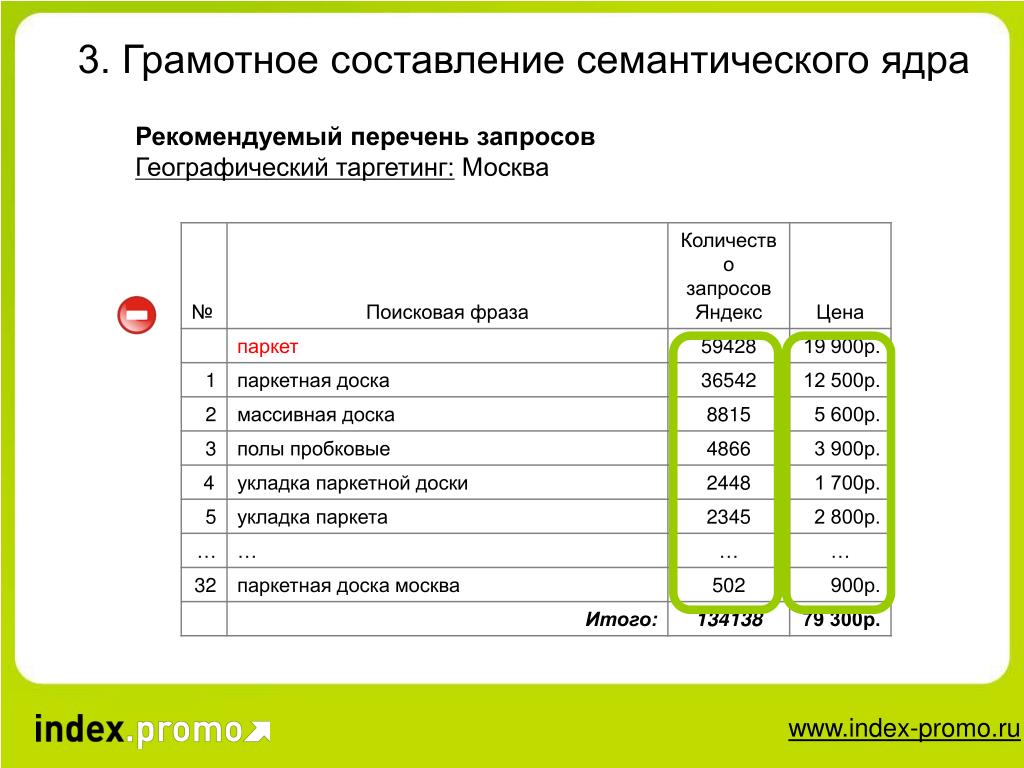
Чтобы они заведомо не попали в список, при парсинге нужно указывать возможные минус-слова. В данном случае к ним относятся «песня», «духи», «гриб», «кафе», «википедия», «спб», «москва» и т. д.
Предусмотреть все минус-слова невозможно, поэтому после каждой операции по расширению ядра нужно визуально проверять список на наличие нерелевантных запросов и удалять их.
Обращайте внимание на фразы с неуточненным интентом и исключайте их из ядра. Например, ключевые слова «золотые брови», «красный халат» (такие сорта чая) применимы также к другим тематикам — продажа косметики, продажа текстиля. Дальнейшее расширение этих фраз спровоцирует появление множества запросов, не имеющих ничего общего с тематикой чая.
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Кроме нерелевантных фраз в списке неминуемо будут присутствовать повторяющиеся фразы и лишние символы. Это мусор, который провоцирует беспорядок в файле и требует удаления.
Опытные пользователи Excel убирают ненужные строки, символы и пробелы с помощью макросов, автозамен и формул.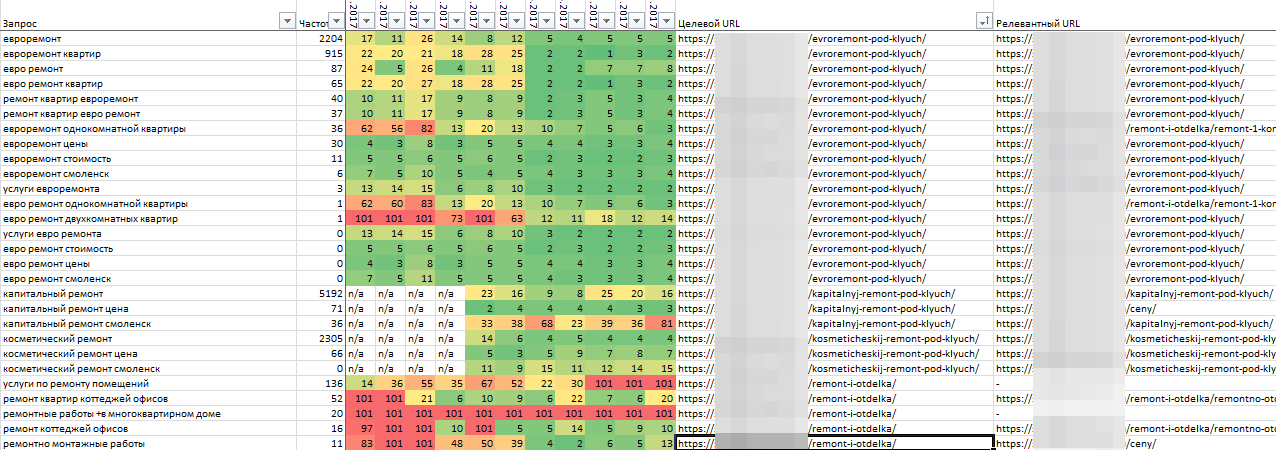 Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Основные возможности инструмента:
- удаление дубликатов в точном вхождении;
- удаление дубликатов с перестановкой слов и учетом морфологии;
- удаление спецсимволов в начале и конце слова;
- удаление лишних пробелов между словами, в начале и конце строки;
- удаление табуляции в начале и конце строки;
- удаление пустых строк;
- преобразование слов в нижний регистр;
- замена ё на е.
Особенности сервиса:
- бесплатное использование;
- неограниченное количество запросов при проверке за один раз;
- работа онлайн — не требует установки софта;
- работа в фоне — не нужно держать страницу открытой;
- не требует разгадывания капчи;
- быстрая скорость обработки данных в облаке;
- результат обработки можно скачать в формате XLSX;
- бессрочное хранение выполненных задач в аккаунте PromoPult.


Как чистить ядро с помощью «Нормализатора слов»
Зарегистрируйтесь или авторизуйтесь в системе PromoPult — так все отчеты сохранятся в вашем личном кабинете.
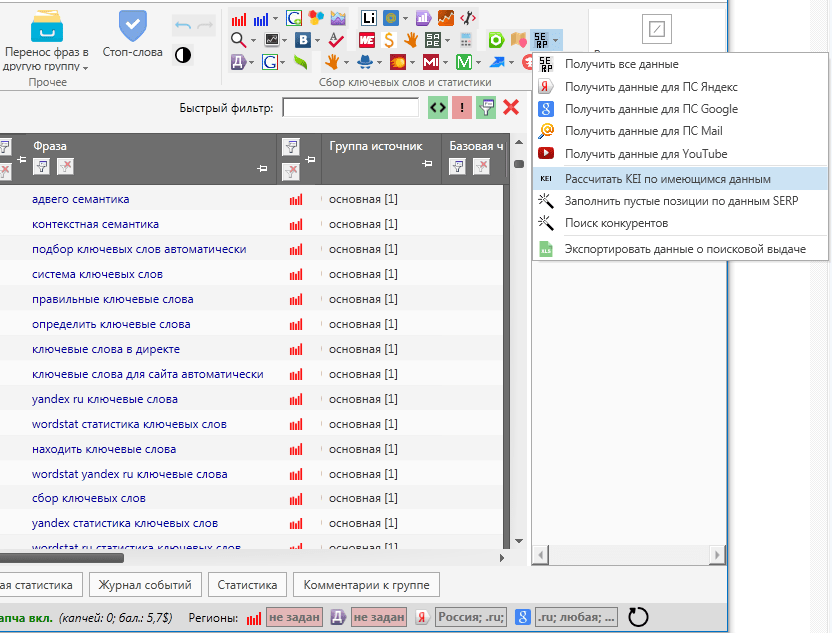
Перейдите на страницу инструмента, нажмите «Добавить задачу» и укажите список запросов, который нужно почистить.
Загрузить запросы можно с помощью файла Excel (собираются данные с первого листа файла) или добавлением списка в окно сервиса (каждый запрос с новой строки).
Обратите внимание, что при загрузке XLSX-файла система считывает данные по принципу «одна ячейка — один запрос», поэтому добавляйте в файл только перечень запросов без другой служебной информации.
Далее необходимо поставить галочки — выбрать действия с ядром.
Удалить дубликаты слов
Система может удалить полностью идентичные строки (дубли словосочетаний) или строки, где слова в словосочетании имеют другой порядок и используются в других словоформах. Например, «виды китайского чая» и «китайский чай виды» будут считаться идентичными — в списке останется только тот запрос, что стоит выше.
Убрать спецсимволы
Иногда запросы для SEO могут мигрировать из контекстных рекламных кампаний и заимствовать спецсимволы. Или же попросту пользователи ставят при наборе запроса знаки препинания, которые вместе с фразами попадают в базы. Парсер поможет убрать их все одним кликом. По умолчанию заданы символы +-?: и при необходимости их можно дополнить.
Убрать лишние пробелы и табуляцию
При наличии лишних пробелов в начале текстовой строки, между словами во фразе и в конце строки система их обнаружит и удалит. Аналогично и с табуляцией — пустое пространство будет удалено в начале и в конце строки.
Удалить пустые строки
Строки без текста будут удалены.
Преобразовать слова в нижний регистр
Опция может быть полезна, когда список содержит спарсенные заголовки — часто слова в них бывают прописаны в верхнем регистре.
Заменить ё на е
На каждой площадке своя редполитика и свои правила написаний слов с буквой ё. Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Можно выставить сразу все галочки или только те, которые отвечают конкретной задаче. Ведь парсер полезен не только для чистки семантического ядра — он удобен для наведения порядка в любых списках.
По факту выполнения задачи будет доступен файл для скачивания. Задаче можно дать свое название, чтобы в будущем ее было проще идентифицировать.
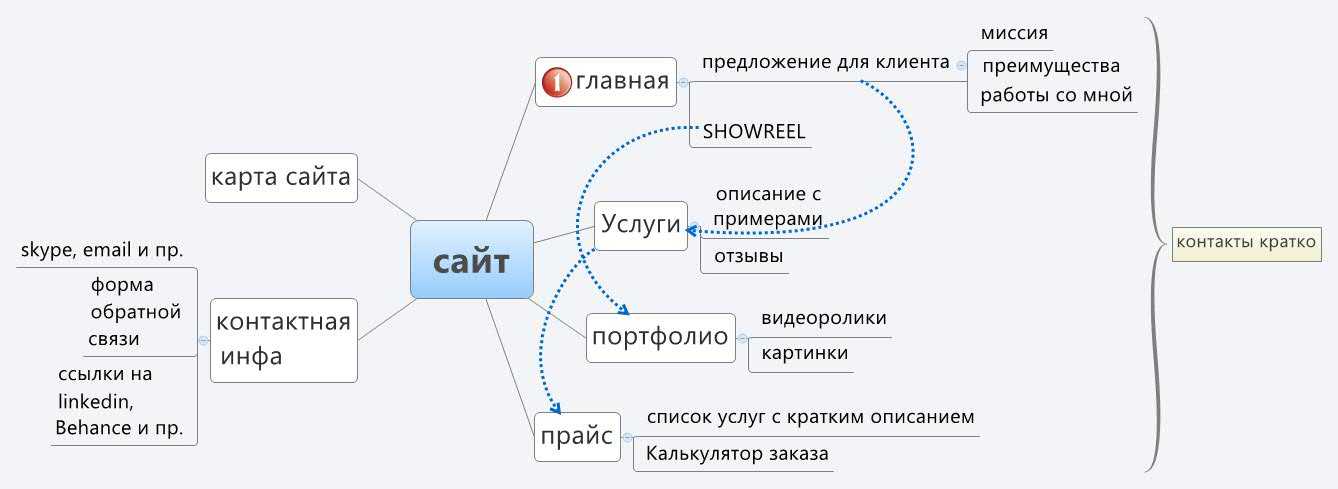
В загруженном файле заполнен один лист с финальным списком запросов.
В нашем примере исходный список из 1103 запросов был обработан за 10 секунд. После чистки был удален мусор — дубликаты, занимающие порядка 11% ядра.
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Отсеяв мусор и дубли, необходимо также почистить ядро от запросов, частотность которых стремится к нулю. Они не способны генерировать трафик, поэтому нет смысла тратить время и деньги на создание и оптимизацию посадочных страниц.
Собрать частотности Wordstat можно вручную, но это долго и неудобно. Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Убирайте мусор вовремя
Если раньше было достаточно оптимизировать сайт под сотню базовых запросов, то сегодня требуются тысячи НЧ и длиннохвостых запросов, которые вручную собрать невозможно. Благодаря парсерам эта задача решается быстро и просто, однако побочным эффектом выступает огромное наличие мусора.
Техническая чистка ядра — необходимая процедура, позволяющая исключить неэффективные для продвижения слова. Сделать проверку быстрой и точной можно с помощью инструментов PromoPult.
«Нормализатор слов» доступен бесплатно. Парсер Wordstat — от двух копеек за сбор частотностей для одного запроса. Первые 50 проверок — бесплатно.
Попробовать инструменты PromoPult
Семантическое ядро – что это и как правильно составить семантику сайта.
В этой статье подробно разберем, как собрать семантику для молодого веб-сайта, как сделать семантическое ядро максимально эффективным и как не допустить ошибок на данном этапе SEO.
Что такое семантическое ядро сайта?
Семантическое ядро сайта (семантика) — это список ключевых слов и словосочетаний, приводящих на сайт целевых посетителей, используются для продвижения сайта в поисковых системах. Запросы в семантическом ядре (СЯ) разделяется по частотности, конкуренции и коммерческой составляющей, семантика позволяет понять распределение поискового спроса и сформировать правильную для продвижения структуру сайта.
Для чего нужно семантическое ядро?
-
Проработка структуры сайта — ядро позволяет определить иерархию страниц и сформировать структуру, которая необходима для упрощения работы с сайтом пользователям и поисковым роботам.
-
Продвижение страниц в топ поиска — семантическое ядро позволяет оптимизировать каждую страницу под конкретный поисковый запрос, что требуется для корректного ранжирования сайта в поисковой сети.
-
Составление контент-плана — собранные ключи используются для создания матрицы контента, что позволяет определить направленность, тему и задачи, представляемые к контенту на сайте.
-
Создание перелинковки на сайте — семантическая база после кластеризации упрощает настройку перелинковки страниц, которая необходима для распределения ссылочного веса и создания удобной навигации.
-
Настройка контекстной рекламы — в дальнейшем оптимизированное семантическое ядро веб-сайта может использоваться для запуска РРС-рекламы, позволяющей получить дополнительный охват и трафик.
Ключевые фразы в семантическом ядре сегментируются по частотности:
-
Высокочастотные (от 10 000 показов в мес.) — одно или два слова, которые определяют тематику страницы. Пример: “наушники” — алгоритмы определяют предмет поиска и предложит смесь информационных и коммерческих страниц в выдаче.
-
Среднечастотные (500–10 000 показов в мес.) — включают несколько слов и приставки, и используются для уточнения задачи поиска. Пример: “купить наушники водостойкие” — в браузере будут отображаться только коммерческие страницы, цель которых продать наушники, устойчивые к влаге.
-
Низкочастотные (до 500 показов в мес.) — состоят из нескольких слов и конкретизируют саму потребность пользователя. Пример: “где купить водоустойчивые наушники в Москве” — поиск выведет топ лучших интернет-магазинов в черте города, реализующих наушники для спорта, которые можно погружать в воду.
 Пример: “купить наушники водостойкие” — в браузере будут отображаться только коммерческие страницы, цель которых продать наушники, устойчивые к влаге.
Пример: “купить наушники водостойкие” — в браузере будут отображаться только коммерческие страницы, цель которых продать наушники, устойчивые к влаге.
В семантическое ядро включаются запросы всех типов, которые в дальнейшем сегментируются по целям и задачам. Таким образом, сбор семантики — важный этап оптимизации сайта, без которого невозможно повысить видимость сайта в поисковых системах и получить стабильный органический трафик.
Как подобрать ключевые слова для семантического ядра
Сейчас подробно разберем, как правильно собрать семантику для молодого сайта. Опишем на что нужно обращать внимание при работе с ключами, чтобы получить максимальный прирост органического трафика из поисковых сетей Яндекс и Google.
Шаг 1. Проанализировать сайты конкурентов
Анализ конкурентов позволяет определить основные категории и направления при формировании семантического ядра.
Для понимания структуры и распределения будущего ядра ключевых слов, необходимо выбрать 2–3 лидеров тематики и проанализировать структуру их сайта.
Провести анализ структуры сайта-конкурента можно через профильные программы — Screaming Frog SEO Spider или Netpeak Spider, либо визуальным осмотром навигационного меню, категорий и карты сайта.
Пример анализа структуры сайта-конкурента в виде графа
Анализ конкурентов необходим для понимания объема семантики и сложности структуры сайтов-конкурентов.
На данном этапе необходимо определить крупные сайты-конкуренты и выявить специфику их семантики — примерный объем семантического ядра, количество высоко-, средне и низкочастотных ключевых слов, упор на коммерческий или информационный трафик, т. д.
д.
Шаг 2. Собрать базовые ключевые слова для семантического ядра
Определив вектор SEO-продвижения, можно переходить к формированию костяка семантического ядра. Сбор базовых ключевых слов необходим для корректного проектирования структуры будущего сайта и не позволит увести сайт от основной тематики.
Обычно костяк собирается в формате списка или таблицы, в которые забиваются основные ключи, определяющую тематику сайта. В костяк входят все ключи, характеризующие специфику и направленность компании. Например, для сайта, продающего акустические колонки, в костяк войдут следующие ключи:
Сбор основных ключевых слов для категории “Акустические системы”
На данном этапе главное сформировать костяк, из которого дальше будут формироваться семантика сайта, его структура и контент-план.
Практически все ключи отличаются низкой специфичностью и высокой частотностью — продвижение сайта только по этим запросам получится дорогим и неэффективной. Поэтому требуется расширить и сегментировать собранное ядро.
Поэтому требуется расширить и сегментировать собранное ядро.
Шаг 3. Сбор семантического ядра
Для сбора семантики сайта чаще всего используется Яндекс.Wordstat или Планировщик ключевых слов Google, обладающий схожим функционалом. Сначала разберем, как собрать семантическое ядро сайта с помощью сервиса от Яндекс.
Для этого переходим в Яндекс.Wordstat и поочередно проводим подбор слов по ранее собранному костяку ключевых слов. Таким образом из 20–150 ключевых запросов удастся собрать в районе 1000–1500 вхождений, что уже считается неплохой базой для структуры молодого сайта.
Например, вбиваем один из базовых ключевых слов — «колонки» в Wordstat. Сервис отобразит такой результат.
Сбор запросов и частотностей в «Яндекс.Вордстат» по ключевому слову “Колонки”
Ключи можно отсортировать по частотности или полностью скопировать в новую таблицу. Аналогичная ситуация проводится со всеми базовыми ключами, что позволяет бесплатно расширить семантику в несколько раз.
Важно! По коммерческим запросам нужно выбирать точный регион оказания услуг, поскольку поисковый спрос напрямую привязан к геолокации, по информационным — указать всю страну, так как такие запросы ранжируются без привязки к местоположению.
Читайте также:
Яндекс.Вордстат: руководство по работе со статистикой поисковых запросов
Шаг 4. Расширение семантического ядра
Для того, чтобы семантика вашего сайта была максимально полной, необходимо использовать все возможные инструменты для сбора.
Расширение семантического ядра с помощью поисковых подсказок
Также стоит добавить в таблицу поисковые подсказки. Преимуществом подсказок считается отображение релевантных запросов — поисковая система выводит подсказки, которые используют пользователи при поиске, что позволяет расширить семантическое ядро актуальными запросами.
Разберем популярные сервисы для сбора поисковых подсказок:
-
arsenkin.ru — удобный бесплатный сервис с возможностью парсинга подсказок сразу по 100 ключевым словам. Программа позволяет настроить многоуровневый парсинг и выгрузить готовую базу подсказок таблицей CSV.
-
click.ru — недорогой сервис с возможностью парсинга подсказок из Яндекс, Google и YouTube. Все данные выводятся в формате экспортируемой таблицы.
-
serpstat.com — сложный, но функциональный сервис, позволяющий провести парсинг поисковых подсказок или вопросов, а также отсортировать полученные данные по популярности запросов, их коммерческости и т. д.
Воспользуемся бесплатным сервисом сбора поисковых подсказок https://arsenkin.ru/tools/suggest/ .
Указываем список наиболее релевантных ключевых слов, после чего выбираем и заполняем раздел стоп-слов, исключающий ненужные слова при парсинге.
Сбор поисковых подсказок с помощью сервиса Arsenkin.ru
Далее выбираем нужную поисковую систему для сбора подсказок, а также регион и глубину парсинга. При выборе 2 или более уровня глубины парсинга сервис дополнительно соберет поисковые подсказки, полученные на 1 уровне.
Настройка сбора поисковых подсказок
Сервис работает в фоновом режиме и после парсинга выведет все собранные подсказки в формате таблички. Количество нецелевых вхождений в таблице напрямую зависит от списка стоп-слов — важно максимально полно указать все ключи, которые не относятся к ядру собираемой семантики.
Результаты сбора поисковых подсказок
С помощью сервиса можно быстро собрать подсказки с сайтов из ТОП 10–50 выдачи и выгрузить таблицей CSV.
Расширение семантического ядра спецификаторами
Напоследок остается уделить внимание спецификаторам. Спецификаторы — слова-приставки, которые характеризуют потребность, цель пользователя, осуществляющего поиск в сети. По большей части спецификаторы определяются спецификой бизнеса и будут идентичны на нескольких тематических сайтах. К основным спецификаторам относят 3 группы приставок:
Спецификаторы — слова-приставки, которые характеризуют потребность, цель пользователя, осуществляющего поиск в сети. По большей части спецификаторы определяются спецификой бизнеса и будут идентичны на нескольких тематических сайтах. К основным спецификаторам относят 3 группы приставок:
-
Коммерческие — слова: купить, заказать, в рассрочку, цена, стоимость и т. д.
-
Региональные — в Москве, вблизи, рядом со мной, в городе и т. п.
-
Сервисные — с доставкой, гарантия, отзывы.
В ядро следует добавлять только целевые спецификаторы, например, “бесплатная доставка” и “купить в рассрочку”, если на вашем сайте предоставляются подобные услуги.
Добавление спецификаторов к запросам
Расширять семантическое ядро можно, добавляя к собранным ключам от 1 до 3 спецификаторов, что позволит более тонко оптимизировать страницы сайта под точные запросы пользователей.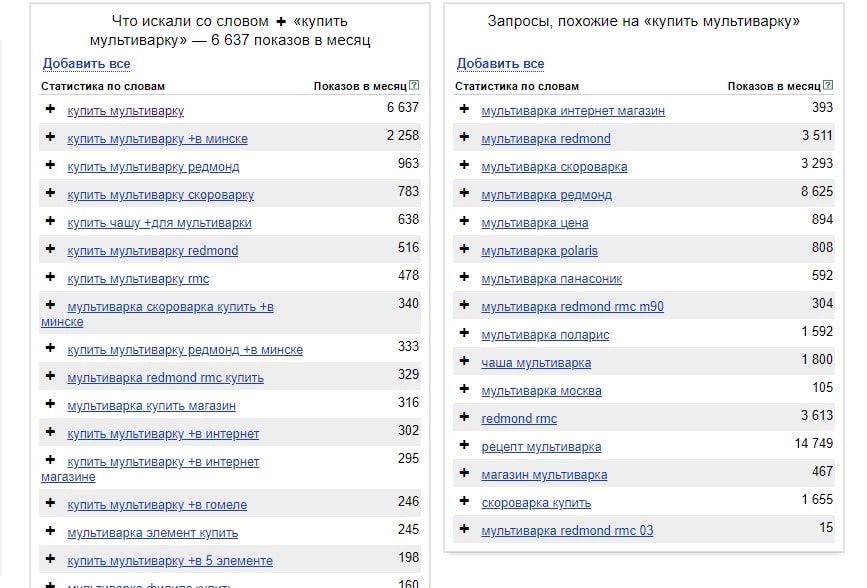 Продвижение по низкочастотным словам оказывается дешевле раскрутки по перегретым ключам и способно приносить релевантный целевой трафик.
Продвижение по низкочастотным словам оказывается дешевле раскрутки по перегретым ключам и способно приносить релевантный целевой трафик.
Расширение семантического ядра с помощью конкурентов
Для расширения семантики с помощью конкурентных сайтов можно воспользоваться сервисами:
-
SEMrush — удобный детализированный сервис для сравнения семантики сразу до 5 сайтов-конкурентов. Сервис платный, но есть бесплатный демо период за подписку.
-
Keys.so — быстрый, ориентированный на Рунет сервис, обладает самой большой базой ключевых слов – более 100 млн, имеет функционал групповых отчетов, в котором можно анализировать сразу и 20 и 50 сайтов конкурентов. Тарифы на использование начинаются от 1500 руб/мес.
-
SpyWords — сравнение конкурентов по регионам в нише и ключевым словам в семантическом ядре. В бесплатном тарифе есть ограничения по географии и возможность сравнения до 5000 ключевых слов.
-
«Топвизор» — гибкий инструментарий для анализа конкурентов по нескольким параметрам, есть бесплатный тестовый период для ознакомления с функционалом.

На примере сервиса SEMrush покажем, как определить и проанализировать конкурентов в нише.
Выбираем «Анализ по домену» и вставляем адрес сайта-конкурента и запускаем сервис.
Анализ сайта-конкурента с помощью сервиса Semrush
Сервис определит количество и геолокацию трафика, приходящего на сайт, а также покажет ключевые слова, по которым приходят посетители из поисковых систем. Кроме того, сервис отобразит других конкурентов вашего сайта, по которым также можно провести анализ и собрать ключи для семантического ядра.
Сводка данных сайта-конкурента
Используя данные о ключевых запросах конкурентов, можем добавить направления, которые мы могли упустить, или расширить уже имеющиеся.
Шаг 5. Удалить мусорные и нецелевые запросы из семантического ядра
Собрав обширное семантическое ядро, остается заняться его качеством. В первую очередь необходимо удалить все нецелевые вхождения, которые попали в ядро при парсинге.
Ручная фильтрация и чистка семантического ядра
Качественно проработать семантику на данном этапе позволяет только ручной труд. Необходимо просмотреть все ядро и удалить мусорные ключи. Смело можно удалять ключи, в которых:
-
Упоминаются конкуренты и сторонние брендовые запросы.
-
Указываются услуги, которые не оказывает компания. В ядре должны включаться только реальные целевые ключи: например, не стоит добавлять приставки “дешево” и “от производителя”, если компания — посредник.
-
Нарушена география запросов — название населенных пунктов, входящих в ключевые фразы, должны ограничиваться зоной доставки компании и концентрироваться в городе или области, где находится главный офис/производство.
-
Указываются дублирующие запросы. Например: “купить колонки” и “ колонки купить” — один ключ, который будет оптимизирован под одну страницу.
-
Упоминаются с ошибками и опечатками.

Цель этапа: отсеять все мусорные вхождения. После чистки в семантике остаются только релевантные запросы, которые соответствуют костяку собранных ключевых слов и полностью отражают специфику самой компании. Теперь можно приступать к кластеризации ключевых слов.
Кластеризация семантического ядра
Кластеризация — это группировка нескольких запросов в один сегмент на основании их смысла, логики. Таким образом удается навести порядок в ядре и создать многоуровневую структуру, в которой ключи будут разделены на тематические кластеры. Количество сегментов в ядре зависит от обширности тематики и специфики бизнеса — для многостраничных интернет-магазинов с большой товарной матрицей ядро может быть разбито на более чем 10 000 кластеров.
Бесплатные сервисы для кластеризации ключевых слов:
-
coolakov — удобный кластеризатор семантического ядра, способный бесплатно сгруппировать небольшое семантическое ядро объемом до 500 слов (от 1000 до 100000 запросов стоимость 20 копеек за запрос). Результат выгружается в таблице Excel, параллельно прилагается сразу список конкурентов.
-
semantist — сервис позволяет бесплатно кластеризовать ядро объемом до 2000 слов с порогом группировки равным 10. Это оптимальный вариант для сбора семантики молодого сайта или расширения ядра при добавлении отдельной товарной группы в каталог.
-
seoquick — программа поддерживает загрузку файлов из любой программы по сбору семантики и может сгруппировать до 40 000 запросов единоразово. Инструментарий позволяет сразу заполнить список стоп-слов и обязательные слова для кластеризации. Сервис бесплатно позволяет кластеризовать до 1000 запросов 1 раз в сутки.
 Сервис бесплатно позволяет кластеризовать до 1000 запросов 1 раз в сутки.
Сервис бесплатно позволяет кластеризовать до 1000 запросов 1 раз в сутки.
Разбивка семантики на кластеры
Кластеризация ключевых слов — сложный процесс, который лучше доверить профильному ПО. Для этого воспользуемся любым из сервисов выше — вставим собранные ключи и получить группировку запросов по их логике, тематике. В качестве примера — сервис coolakov, который дополнительно отображает страницы конкурентов в поисковой выдаче, продвигаемых по данному кластеру запросов.
Порог кластеризации определяет наименьшее количество URL в поисковой выдаче, при которой будут создаваться кластеры семантического ядра. На примере сервиса coolakov порог кластеризации представляет минимальное количество URL, при котором ключевые фразы будут объединяться одну в группу, кластер. Чем выше порог кластеризации, тем меньше групп будет создано, однако ключи в одном кластере окажутся более связанными. Для коммерческих запросов оптимальным будет порог в 3 URL на топ-выдачу, для информационных — 2 порог.
Итог кластеризации: проработанное семантическое ядро, которое может использоваться для создания структуры страниц сайта и составления контент-плана. После дополнительной оптимизации и чистки от информационных запросов данное ядро может подойти и для запуска контекстной рекламы.
Читайте также:
Продвижение сайтов в Яндексе в ТОП
Проверка «коммерческости» запроса в семантическом ядре
Интент ключевого слова обозначает желание пользователя, который вбивает фразу в строку поисковых систем. Он позволяет определить к какому типу — информационному или коммерческому — относится поисковая фраза.
Интент ключа используется поисковыми системами для отображения релевантной выдачи пользовательскому запросу. Яндекс и Google опираются не только на смысл и тематику фразы, но и цель пользователя, таким образом — ключи с различным интентом нужно продвигать на разных страницах.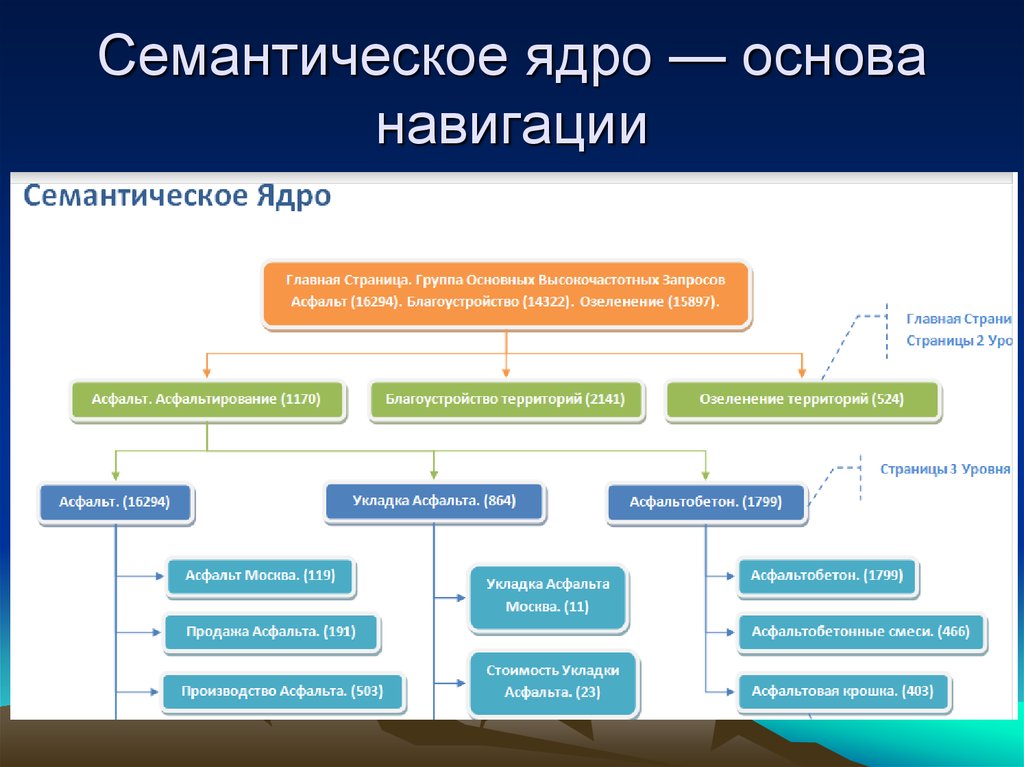
Интент может меняться в зависимости от спроса пользователей на товары — так один и тот же ключ может быть в разное время и коммерческим, и информационным. Разберем это на примере с помощью сервиса majento.ru — вбиваем ключевые слова и нажимаем проверить:
Определение «коммерческости» запросов
Таким образом ключ “купить акустическую колонку” должен не использоваться для продвижения информационной страницы, а смешанные ключи “заказать колонки” и “колонки с доставкой на дом” — могут. Наличие коммерческого ключа на информационной странице может привести к снижению страницы в поисковой выдаче, использование же смешанных запросов допускается.
Определение коммерческости запросов позволяет сегментировать семантическое ядро на информационную и коммерческую группу.
Как не допустить ошибок при сборе семантического ядра
Качество семантического ядра напрямую влияет на продажи сайта. Разберем все популярные ошибки при сборе семантики для сайта, которые негативно влияют на трафик и продажи.
Разберем все популярные ошибки при сборе семантики для сайта, которые негативно влияют на трафик и продажи.
|
Ошибочное мнение клиентов |
Мнение эксперта |
|
«Мне не нужны низкоконкурентные ключи» Большой вклад в ранжирование сайта вносят внешние ссылки. Линкбилдинг с использованием НЧ-запросов стоит недорого, однако по мнению маркетологов, не обладает достаточным конверсионным эффектом.
|
Продвижение по низкочастотным ключам позволяет получить органичный трафик даже в высококонкурентных тематиках. Выйти в топ-выдачи НЧ-запросов гораздо проще, чем при использовании перегретых ключевых слов, при этом есть шанс получить сразу подогретых клиентов — тех, кто уже ищет и готов купить конкретный товар. 
Именно поэтому конверсия по НЧ запросам сильно выше чем по ВЧ. |
|
«Под каждый запрос требуется своя страница» Каждая ключевая фраза должна приносить профит веб-сайту — для этого требуется оптимизация одной страницы под отдельный запрос.
|
Для корректного ранжирования семантика должна пройти кластеризацию, что позволит объединить схожие по задачам, потребностям ключи в одну группу. Пример: “Купить наушники” и “Заказать наушники” — разные ключи, по которым должна продвигаться одна страница. |
|
«Нужно больше ключевых слов для обхода конкурентов» Конкуренты тратят тонну средств на анализ и аудит, и выходят в ТОП.
|
Молодым сайтам нет смысла постоянно мониторить конкурентов для корректировки семантики. Анализ конкурентов необходим для понимания вектора развития семантического ядра, а также при дефиците идей для контент-плана. |
|
«Семантическое ядро можно собрать автоматически» Зачем платить seo-специалисту или собирать семантику самому, если есть профильные сервисы? Можно же купить лицензию на Key Collector и получить семантику под ключ.
|
Профильный софт позволяет оптимизировать ручной труд и упростить сложные задачи — сбор ключевых слов, парсинг конкурентов, сегментирование запросов. Однако для корректного составления семантического ядра требуется вручную составить костяк семантики и провести чистку от мусорных вхождений. 
|
|
«Мне не нужны высокочастотные запросы» Продвижение в SEO и PPC по ВЧ-запросов обходиться довольно дорого, при этом не позволяет выйти в топ молодым сайтам из-за небольшого траст-фактора — здесь уже сказываются слабые коммерческие и поведенческие факторы.
|
Высокочастотные запросы необходимы в семантике сайта для корректной разработки структуры и контента плана. В начале продвижения данные запросы не являются основным приоритетом, однако, в дальнейшем при комплексном подходе к продвижению и проработки всего запросного индекса сайт может занять почетное место в ТОП-10 по ВЧ-запросам. |
 Составление ядра по их примеру позволит сэкономить личный бюджет и сразу выйти в топ-выдачи, избежав собственных ошибок.
Составление ядра по их примеру позволит сэкономить личный бюджет и сразу выйти в топ-выдачи, избежав собственных ошибок.
Грамотное семантическое ядро представляет коктейль из релевантных ключевых слов, необходимый для продвижения в поиске, а также маркетинговых запросов, отражающих потребности и боли реальных клиентов.
Придерживаясь наших рекомендаций, можно собрать релевантное семантическое ядро, позволяющее улучшить ранжирование молодого сайта и привлечь органичный целевой трафик.
Формирование семантического ядра сайта.
Ключи к ТОПу!
25 долларов США в час
45 долларов США в час
ЗАКАЗАТЬ СЕЙЧАС
Продажа
-45%
Подберем ключи для вашего сайта, которые откроют дверь в ТОП!
Аналитика семантики бизнес-ниши.
Поиск по всем похожим ключевым фразам из ТОП-20.
Аналитика сложности семантики.
Проверенная система сбора семантики.
Очистка семантического ядра от стоп-слов.
Кластеризация поисковых фраз.
Рекомендации по распределению ключевых слов на сайте.
Заказать сбор семантики
Свяжитесь мгновенно через мессенджер!
Выбери свой любимый мессенджер на
Бесплатная консультация по твоему проекту.
Связаться с Viber
Свяжитесь с WhatsApp
Связаться с Telegram
Для чего необходимо формирование семантического ядра сайта?
Семантическое ядро — это слова, описывающие деятельность компании, ее продукты и услуги. По ним поисковик определяет, что сайт соответствует запросу пользователя. Это основные части фраз, которые пользователи вводят при поиске в браузере. Google и Яндекс показывают сайты, содержащие ключевые слова на первых двух страницах. Это означает, что они удовлетворяют потребности людей, которые ищут продукт, услугу или информацию. Если не использовать такие «маркеры» для программ, попасть в Топ невозможно. Это основа SEO-продвижения.
Что важно учитывать при формировании семантического ядра?
Эти основные фразы отражают интересы потенциальных покупателей. Чем разнообразнее и точнее они будут, тем шире охват интернет-пользователей. Если собрать все реалистичные варианты, система покажет сайт большей целевой аудитории. Используя все формулировки, которые могут ввести пользователи, можно будет максимально увеличить охват по ключевым запросам.
Если собрать все реалистичные варианты, система покажет сайт большей целевой аудитории. Используя все формулировки, которые могут ввести пользователи, можно будет максимально увеличить охват по ключевым запросам.
Очистка семантического ядра от «мусорных» слов, не относящихся к системе, способствует продвижению. Сайт показывается только по целевым запросам. Кластеризация семантики — это распределение слов по смысловым группам и основа для создания seo-контента.
Как построить семантическое ядро?
Подберем ключевые слова, чтобы Ваш сайт был впереди конкурентов в ТОПе. Это увеличит органический поисковый трафик и увеличит продажи. TopUser.PRO гарантирует такие результаты, потому что наши специалисты:
- знакомятся с особенностями бизнеса клиента, согласовывают с ним задачу;
- проанализировать нишу, изучить страницы конкурентов заказчика;
- маркеры формы, выделение слов и словосочетаний, характеризующих сферу деятельности клиента;
- владеют инструментами для разбора запросов, поэтому собирают все подходящие варианты;
- избавиться от лишних слов и словосочетаний, не способствующих продвижению в поисковой выдаче;
- сгруппировать результаты по категориям в соответствии с намерениями или потребностями тех, для кого предназначены веб-страницы;
- доработка структуры семантического ядра вручную;
- формировать отчеты по этапам работ и предоставлять их заказчику;
- дать совет, как оптимизировать ваш сайт, используя полученный список ключевых слов и предложить такую услугу.

Комплексный подход гарантирует, что семантическое ядро покроет все возможные запросы и не будет отягощено стоп-словами, которые снижают ранжирование и отнимают ресурсы на нецелевые показы. Такая основа позволит создавать контент, который будет не только отвечать интересам целевой аудитории6, но и хорошо ранжироваться поисковыми роботами. Это первое, что необходимо для успешного SEO-продвижения. Быстрый путь в ТОП вашего сайта!
Заказывайте и обгоняйте конкурентов уже сегодня
Часто задаваемые вопросы (FAQ)
✔️ Почему при формировании семантического ядра сайта иногда требуется использование вопросительных слов?
Google оценивает слова «как», «где» и другие как признак интереса аудитории. Особенно важно использовать их в вопросах вместе с основными ключевыми словами.
✔️ Как по результатам, которые дали формирование семантического ядра сайта, оптимизировать ваш контент на вопросы?
Используйте их в тексте как риторические. Создайте блок «Вопрос – Ответ».
✔️ Какой самый простой инструмент для формирования семантического ядра сайта?
Google Планировщик ключевых слов. Все подобные сервисы просты в использовании.
✔️ Включаются ли длинные ключевые слова при формировании семантического ядра сайта?
Краткие формулировки являются основными. Ключевые слова с длинным хвостом — это дополнительные фразы. Они реже используются в поиске. Конкуренция для них ниже. Они также используются.
✔️ Как аналитика влияет на формирование семантического ядра сайта?
Исследование ключевых слов может помочь вам «заглянуть в головы ваших клиентов», найдя темы для включения в вашу контент-стратегию. Как только вы узнаете, что ищет ваша целевая аудитория, вы сможете оптимизировать свой контент, чтобы предоставить ответы, которые ей нужны.
✔️ Как правильно дополнить ключевые слова контекстом, применяя формирование семантического ядра сайта?
Есть несколько полезных советов. Посмотрите на результаты автозаполнения, когда вы вводите слово или фразу в поле поиска Google. Этот список меняется по мере добавления слов для предоставления контекста.
Посмотрите на результаты автозаполнения, когда вы вводите слово или фразу в поле поиска Google. Этот список меняется по мере добавления слов для предоставления контекста.
✔️ В чем ошибка использования ключевых слов после того, как выполнено формирование семантического ядра сайта?
Перенасыщение ключевыми словами и неестественное использование. Они должны применяться к людям, а не поисковым системам.
Задавай вопрос
Как построить семантическое ядро для вашего приложения: пошаговое руководство
Создание семантического ядра — важнейшая часть оптимизации App Store, от которой зависит эффективность дальнейшего продвижения. Вам нужно найти конкретные ключевые слова, которые принесут вам установки из поиска. В этой статье мы подробно расскажем, как правильно построить семантическое ядро.
Это серия статей, основанных на материалах лекций Академии ASOdesk, где мы рассмотрели все аспекты оптимизации App Store. Мы уже отмечали, как конкурентный анализ помогает в оптимизации App Store, как работать с итерациями в ASO и что важно учитывать при оптимизации приложения для иностранных языков. Оригинал лекции можно посмотреть здесь:
Мы уже отмечали, как конкурентный анализ помогает в оптимизации App Store, как работать с итерациями в ASO и что важно учитывать при оптимизации приложения для иностранных языков. Оригинал лекции можно посмотреть здесь:
Прежде чем строить ядро, проанализируйте рынок и убедитесь, что вам нужен ASO. Чтобы проверить, нужно ли вам это, используйте эту статью. Вы найдете процент поискового трафика в разных категориях и получите инструкции, как проверить процент брендированного трафика в вашей нише. После того, как вы определили, насколько ваше приложение нуждается в ASO, вы можете переходить к построению семантического ядра.
Результатом анализа поисковых запросов будет семантическое ядро; вы будете использовать запросы ядра в текстовых метаданных. Выделяем следующие этапы построения семантического ядра:
Процесс построения семантического ядра
Обычно ASO-специалист вносит изменения в семантическое ядро перед каждой итерацией (циклом оптимизации). Чтобы вывести приложение в топ, требуется не менее 6-8 итераций. Подробнее о работе с итерациями читайте в этой статье.
Чтобы вывести приложение в топ, требуется не менее 6-8 итераций. Подробнее о работе с итерациями читайте в этой статье.
Как построить семантическое ядро мы рассмотрим на примере приложения «Тренировки для женщин: Фитнес дома».
Разработчик и специалист по мобильному маркетингу должны хорошо знать свое приложение и задачи, которые оно решает. Перед началом продвижения ASO-специалист также должен разбираться в продукте и знать, кому он нужен и зачем.
Поисковые запросы исходят от задач, с которыми может помочь приложение. Поэтому, прежде чем прибегать к поисковым подсказкам, запишите все запросы, которые, по вашему мнению, используют пользователи для поиска похожих приложений.
Перейдите в ASOdesk Keyword Analytics и введите запросы, относящиеся к вашему приложению, в поле Добавить ключевые слова.
Если у вас фирменное приложение, начните с фирменных ключевых слов. А затем введите все общие запросы. На первом этапе мы получили 43 ключевых слова.![]()
Добавить ключевые слова в аналитику ключевых слов
Самостоятельно можно найти от 20 до 100 поисковых запросов. Но самостоятельно придумать все комбинации ключевых слов невозможно. Автоматические сервисы увеличат количество ключевых слов в 3-10 раз.
Автопредложения в Keyword Analytics
Инструмент Автопредложения в ASOdesk находит все поисковые запросы, относящиеся к приложению. Лента поисковых предложений бесконечно обновляется, и если вы добавили все перечисленные запросы, система предложит новые.
Благодаря поисковым подсказкам мы нашли еще 265 слов для нашего приложения.
Автопредложения в аналитике ключевых слов
Отсутствует ранжированное ключевое слово
Этот инструмент показывает поисковые запросы, которых еще нет в семантическом ядре, но приложение уже ранжируется по ним. Если популярность поисковых объявлений и ежедневные показы высоки, есть смысл добавить их в семантическое ядро.
Search Ads Popularity (SAP) — показатель популярности запросов, который Apple предоставляет при настройке рекламных кампаний в Apple Search Ads. Низкочастотные запросы с SAP меньше 5 лучше не использовать.
Низкочастотные запросы с SAP меньше 5 лучше не использовать.
Daily Impressions — количество пользователей, которые ищут приложение по определенному запросу.
С помощью инструмента «Отсутствующие ключевые слова» мы нашли 39 слов.
Отсутствующие ключевые слова в аналитике ключевых слов
Ключевые слова с длинным хвостом
Около 70% поискового трафика приходится на запросы с длинным хвостом. Здесь вы найдете те самые целевые запросы, по которым у приложения будет низкая конкуренция.
Из этого инструмента мы добавили еще 29 ключевых слов для приложения для тренировок.
Ключевые слова с длинным хвостом в автоматических предложениях ключевых слов
Шаг 3. Анализ предложений поиска в магазине приложений
При поиске приложения пользователь не вводит весь запрос, а нажимает на предложение поиска, которое предлагает магазин приложений .
Наша задача попытаться восстановить весь путь поиска приложения.
Этот способ очень полезен для 2-4 итераций, когда вы уже используете основную массу запросов, но продолжаете искать точки роста.
С предложениями магазина приложений вы можете увидеть картину глазами пользователей и сузить ядро.
Например, вы работали на охват и используете широкие запросы («фитнес», «тренировки», «похудеть»). Тогда стоит найти более узкие поисковые запросы, подходящие под специфику приложения: «фитнес для женщин», «тренировки для начинающих», «похудеть за 30 дней» и т. д.
что вам предлагает магазин приложений.
Более подробно и вводить слова посимвольно можно в App Store или Google Play.
ASOdesk также поможет вам найти подсказки для поиска по вашим запросам. Они отображаются в таблице ключевых слов, столбец «Предложения». Мы добавили 25 слов из предложений для нашего приложения.
Таблица ключевых слов в Keyword Analytics Предложения по ключевым словам для «похудения»
Вы также можете проверить предложения с помощью инструмента Keyword Explorer.
Результаты поиска по запросу «тренировка» в Keyword Explorer
Лучшие конкуренты предоставляют информацию о ключевых словах и метаданных. Вы можете увидеть прогноз количества установок, которые получают конкуренты по различным ключевым словам. А также оценить, какие слова и фразы проходят модерацию.
Для анализа необходимо найти конкурентов по поисковым запросам из вашей ниши. Это можно сделать через Keyword Explorer в ASOdesk.
Результаты поиска по запросу «тренировка» в Keyword Explorer
На этом этапе мы также проверяем релевантность ваших поисковых запросов. Если при вводе запроса в поиск вы видите похожие заявки конкурентов, это ключевое слово можно добавить в семантическое ядро. Если по этому запросу ранжируются совершенно разные приложения, не следует использовать этот запрос.
Например, в результатах поиска по запросу «тело» много приложений и игр для редактирования фотографий, а не приложений для фитнеса. Поэтому нам необходимо убрать это ключевое слово из семантического ядра или использовать его только в сочетании с другими словами (идеальное тело, здоровое тело).
Результаты поиска по запросу «тело» в Keyword Explorer
В ASOdesk вы можете найти и проанализировать до 9 конкурентов одновременно, используя следующие инструменты:
Органический отчет
Показывает прогноз установок по поисковым запросам приложение конкурента ранжируется (Estimate Installs).
Мы проанализировали конкурента и нашли поисковые запросы. Теперь добавим в семантическое ядро наиболее релевантные.
Органический отчет конкурента
Отсутствующие ключевые слова конкурентов
Инструмент, основанный на приложениях конкурентов, показывает запросы, которых нет в нашем ядре. По этим запросам похожие приложения входят в топ 1, топ 2–5 и т. д.
В ходе анализа мы добавили 73 запроса для приложения тренировки.
Отсутствующие ключевые слова конкурентов в аналитике ключевых слов
Лучшие ключевые слова конкурентов
Находит самые популярные запросы, которые приносят установки вашим конкурентам.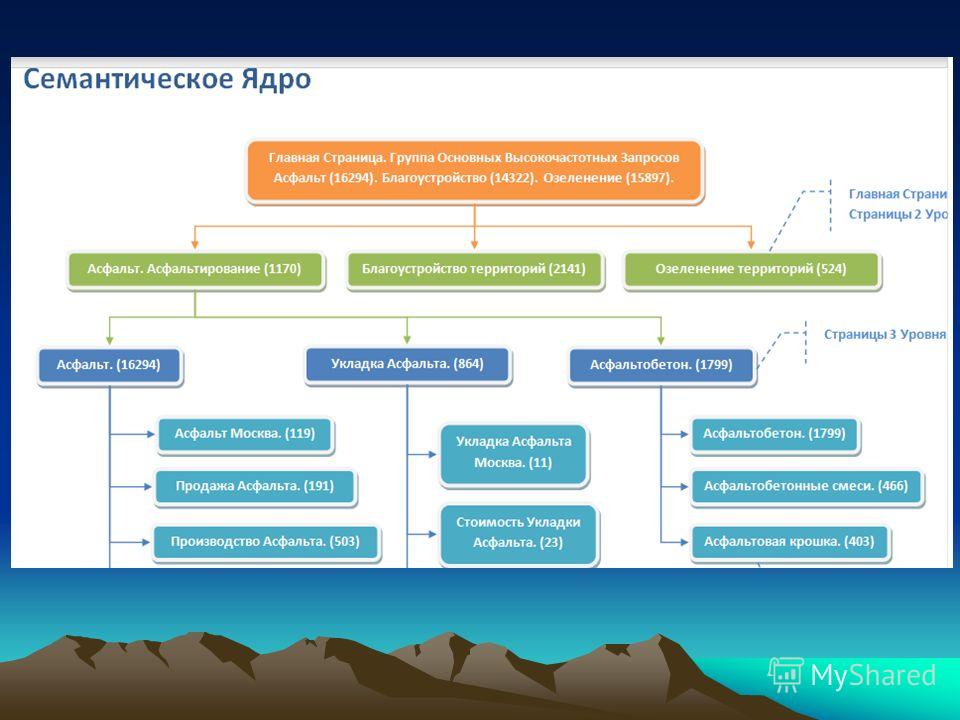 Вы можете добавить эти запросы в свое семантическое ядро. Мы добавили 24 ключевых слова для нашего приложения.
Вы можете добавить эти запросы в свое семантическое ядро. Мы добавили 24 ключевых слова для нашего приложения.
Конкуренты Лучшие ключевые слова в ключевых словах Автопредложения
Наименее конкурентные ключевые слова
Если приложение еще не популярно, выйти в топ по высокочастотным запросам будет невозможно. Поэтому ранжироваться нужно по запросам с низкой конкуренцией.
В результате анализа мы нашли 30 ключевых слов для приложения для тренировок.
Наименее ключевые слова конкурентов в автопредложениях ключевых слов
Сравнительный отчет ASO
Этот инструмент позволяет увидеть ключевые слова, по которым конкуренты поднимаются или опускаются в поисковых позициях, а также недавно добавленные ключевые слова.
Ключевые слова можно фильтровать с помощью движения. Мы добавили 27 ключевых слов.
ASO Сравнительный отчет конкурента конкурентов приложение
Начните развивать свое приложение бесплатно
Шаг 5: очистите ядро от нерелевантных и низкочастотных запросов
Все запросы, которые мы собрали в ходе анализа, отображаются в таблице ключевых слов. В результате построения семантического ядра приложения для тренировки мы получили 439 ключевых слов.
В результате построения семантического ядра приложения для тренировки мы получили 439 ключевых слов.
Таблица ключевых слов в Keyword Analytics
Количество метаданных ограничено. Поэтому мы не можем включить все указанные запросы в заголовок, описание и ключевые слова. Вам нужно выбрать именно те ключевые слова, которые принесут установки. Поэтому важно очистить ядро от неактуальных и низкочастотных запросов.
Удаление неактуальных запросов из семантического ядра
Ваше приложение должны найти только те, кто заинтересован в его использовании.
Например, в вашем приложении есть только упражнения для похудения и набора мышечной массы, но в нем нет функций диеты и подсчета калорий.
В этом случае не следует добавлять в семантическое ядро ключевые слова «диета», «кетодиета» или «подсчет калорий». Если пользователи скачают приложение, а потом поймут, что искали совсем другое, вы получите негативные отзывы.
Количество удалений будет расти, а жизненный цикл и коэффициент удержания пользователей будут падать. Поэтому выбирайте только релевантные запросы, чтобы приложение находили те пользователи, которым оно действительно нужно.
Поэтому выбирайте только релевантные запросы, чтобы приложение находили те пользователи, которым оно действительно нужно.
Оцените, использовать ли брендированные запросы конкурентов
Например, модерацию не пройдут запросы «Тренировки Nike», «GetFit», «BetterMe», для приложения «Тренировки для женщин: Fit at Home».
Но мы можем добавить ошибочный брендовый запрос: «подойди», «бетерме» и т. д. По таким запросам иногда возможно проиндексироваться.
В iOS 14 добавлена функция автокоррекции, которая автоматически исправляет опечатки. Чтобы узнать, следует ли нам использовать брендированный запрос с ошибкой, попробуйте ввести его в строку поиска App Store и посмотрите, исправит ли его магазин приложений.
Используйте бренд, если приложение связано с другим приложением. Например, мы можем вставить в заголовок «WhatsApp», если будем делать стикеры для этого мессенджера.
Анализ имен конкурентов
Оставшиеся запросы разбить на группы
После декитинга всех нерелевантных ключевых слов у нас осталось 411 ключевых слов. С помощью умного флажка вы можете сортировать ключевые слова по популярности поисковых приложений, ежедневным показам и другим параметрам. Вы можете установить нужные значения или просто нажать на нужный показатель, и система автоматически покажет ключевые слова для максимального или минимального значения. Например, на скриншоте мы отфильтровали ключевые слова в порядке возрастания: от самого низкого SAP к самому высокому.
С помощью умного флажка вы можете сортировать ключевые слова по популярности поисковых приложений, ежедневным показам и другим параметрам. Вы можете установить нужные значения или просто нажать на нужный показатель, и система автоматически покажет ключевые слова для максимального или минимального значения. Например, на скриншоте мы отфильтровали ключевые слова в порядке возрастания: от самого низкого SAP к самому высокому.
Для удобства анализа запросов разделим их на 4 группы:
Низкочастотные поисковые запросы: Search Ads Популярность от 5 до 15
Мы не будем включать запросы с SAP 5 в метаданные. Они будут занимать много места, но установок мы с них не получим, так как их практически не ищут в любой день.
Запросы от SAP выше 5 будут направляться на дополнительную локаль. Например, если дополнительный языковой стандарт предназначен только для Испании, поле ключевых слов может содержать запросы на испанском языке, которые не соответствуют основному языковому стандарту.
Мы также добавим их в отдельную категорию и посмотрим, как изменится популярность поисковых объявлений и ежедневные показы по этим ключевым словам. Давайте отфильтруем запросы по популярности поисковых приложений и выделим их синим цветом.
Мы также удалили ключевые слова, ежедневный показ которых равен 0. Теперь у нас осталось 319 слов.
Низкочастотные запросы в таблице ключевых слов
Запросы, по которым в данный момент система рассчитывает трафик: Search Ads Popularity Calculation
Если вы видите слово «Расчет», значит, вы нашли новый запрос. Ранее пользователи ASOdesk не искали такие запросы, поэтому у нас пока нет данных об их популярности.
Добавьте их в отдельную группу. Вам нужно дождаться, пока система рассчитает популярность поисковых объявлений и ежедневные показы для этих запросов, а затем решить, оставить их или удалить.
Запросы, по которым учитывается трафик
Высокочастотные поисковые запросы: Search Ads Популярность более 40
Популярные запросы не будут работать для приложений, которые только выходят на рынок.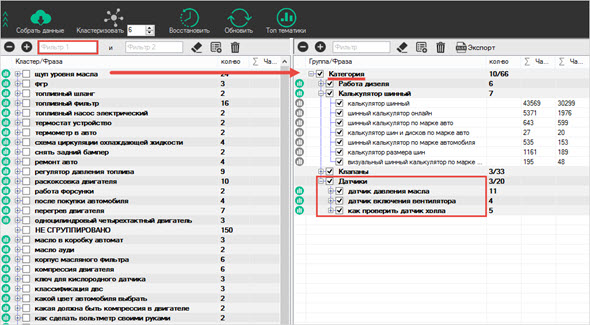 Конкуренция за них уже высока и позиций вы не наберете. Поэтому не сосредотачивайтесь исключительно на топовых поисковых запросах. Лучше не использовать ключевые слова с Search Ads Popularity более 40 в первых итерациях.
Конкуренция за них уже высока и позиций вы не наберете. Поэтому не сосредотачивайтесь исключительно на топовых поисковых запросах. Лучше не использовать ключевые слова с Search Ads Popularity более 40 в первых итерациях.
Кроме того, высокочастотные запросы все равно будут отображаться в ваших метаданных. Например, метаданные нашего приложения будут включать запросы «тренировка», «домашняя тренировка». Вам просто нужно отслеживать такие запросы в процессе оптимизации.
Высокочастотные поисковые запросы в Таблице ключевых слов
Среднечастотные запросы: Search Ads Популярность от 15 до 40
Если ваше приложение только выходит на рынок, добавьте в семантическое ядро поисковые запросы с популярностью от 16 до 40.
Среднечастотные запросы в таблице ключевых слов
Перед каждой итерацией необходимо изучить поисковые запросы и включить их в семантические когорты. Например, в ходе итерации по сужению ядра мы видим, что запросы со словом «похудение» набирают популярность в поиске. Тогда стоит добавить в метаданные больше похожих ключевых слов.
Тогда стоит добавить в метаданные больше похожих ключевых слов.
Для построения семантического ядра необходимо выполнить 5 простых шагов:
1. Добавить все поисковые запросы, относящиеся к приложению, исходя из вашего мнения.
2. Расширьте семантическое ядро с помощью автоматических предложений услуг ASO.
3. Добавьте ключевые слова из автоматических предложений магазина приложений.
4. Проанализируйте своих конкурентов. Найдите запросы, по которым приложения конкурентов: поднимаются в поиске, получают наибольшее количество установок, находятся в топе поисковой выдачи.
5. Очистить ядро от низкоконкурентных и нерелевантных запросов. Мы должны оставить только те ключевые слова, которые принесут нам установки.
На основе построенного семантического ядра подготовить метаданные. При этом помните о правилах App Store и Google Play, а также о факторах ранжирования приложений в магазине. Подробнее об этих факторах читайте в нашей статье.