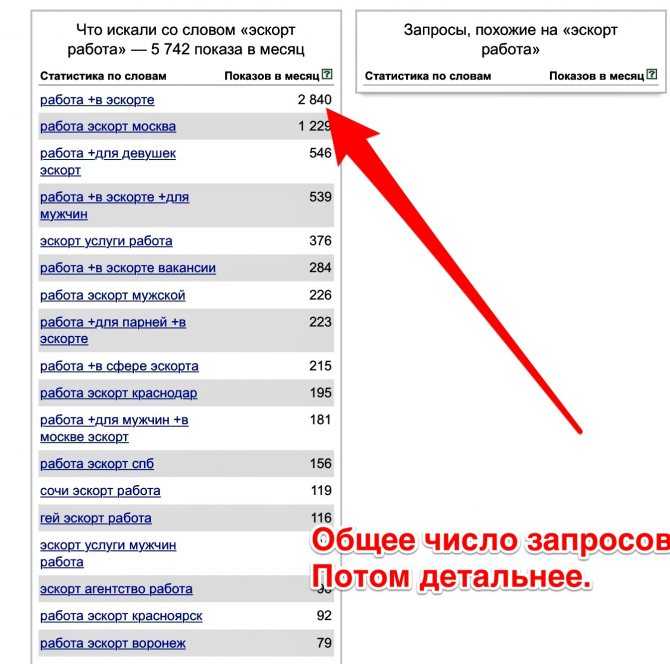
Содержание
Определение требований к производительности и емкости для сред совместной работы отделов (SharePoint Server 2013) — SharePoint Server
-
Статья -
-
ОБЛАСТЬ ПРИМЕНЕНИЯ:2013 2016 2019 Subscription Edition SharePoint в Microsoft 365
В этой статье приведено руководство по планированию производительности и емкости для решения совместной работы отделов, основанного на SharePoint Server 2013. В статье приведены следующие сведения.
Спецификации среды лаборатории тестирования, например оборудование, топология фермы и конфигурация.
Рабочая нагрузка фермы тестирования и набор данных, с помощью которого создается тестовая нагрузка.

Результаты тестов и их анализ, демонстрирующий тенденции пропускной способности, задержки и потребности в оборудовании под нагрузкой при определенных уровнях масштабирования.
Используйте сведения в этой статье, чтобы понять характеристики сценария при обычных и пиковых нагрузках, а также изменения тенденций производительности при горизонтальном масштабировании серверов фермы. С помощью этой статьи можно определить начальные характеристики планируемой архитектуры и факторы, которые необходимо учитывать при разработке плана по поддержанию приемлемых уровней производительности при пиковой нагрузке.
Введение
В этой статье описано, как выполнять горизонтальное масштабирование серверов в решении для совместной работы отделов на основе SharePoint Server 2013. Решение для совместной работы отделов это развертывание SharePoint Server 2013, в котором для совместной работы используется меньшее количество компьютеров, чем в корпоративном решении для совместной работы. В этой статье предполагается, что отдел это организация внутри предприятия, в которой работает от 1000 до 10000 сотрудников.
В этой статье предполагается, что отдел это организация внутри предприятия, в которой работает от 1000 до 10000 сотрудников.
При использовании различных сценариев возникают различные требования. Поэтому необходимо не только использовать сведения, содержащиеся в данном руководстве, но и проводить дополнительное тестирование конкретного оборудования в конкретной среде. Если планируемая структура и рабочие нагрузки аналогичны параметрам описанной в этой статье среды, вы можете определить ожидаемую производительность при горизонтальном и вертикальном масштабировании вашей среды.
Важно!
Результаты тестов, описанные в этой статье, получены в лаборатории тестирования, в которой для имитации рабочей среды в высококонтролируемых условиях использовались рабочая нагрузка, набор данных и архитектура. Несмотря на тщательную разработку этих тестов характеристики производительности лаборатории тестирования никогда не будут такими же, как у рабочей среды. Эти результаты не отражают характеристики производительность и емкость рабочей фермы.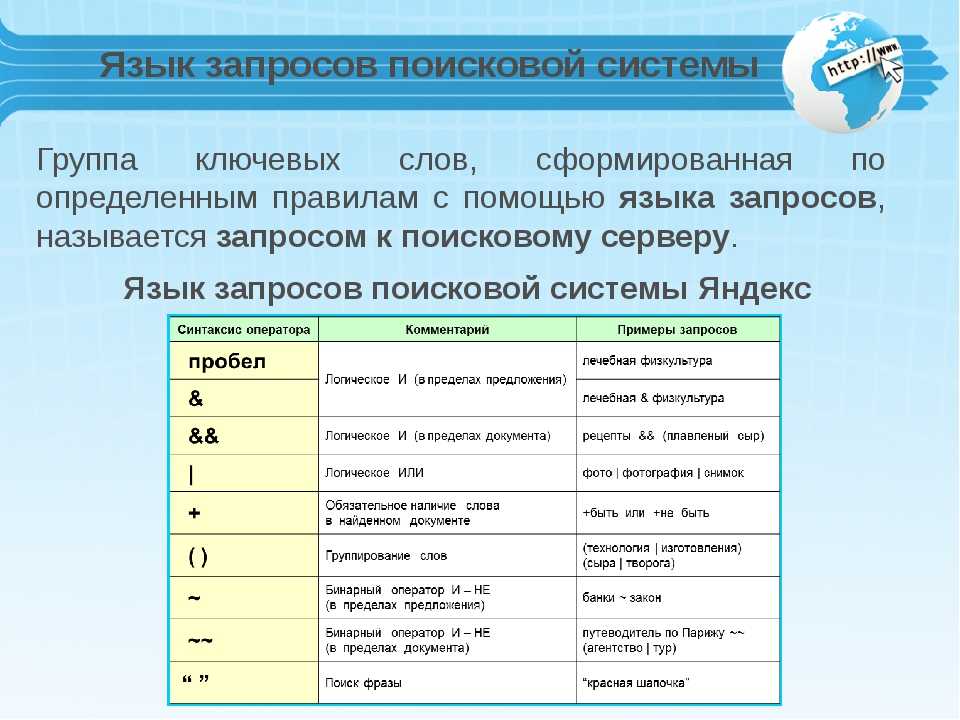 Результаты тестов всего лишь демонстрируют наблюдаемые тенденции в отношении пропускной способности, задержки и потребности в оборудовании. Используйте анализ наблюдаемых данных для планирования емкости и управления собственной фермой.
Результаты тестов всего лишь демонстрируют наблюдаемые тенденции в отношении пропускной способности, задержки и потребности в оборудовании. Используйте анализ наблюдаемых данных для планирования емкости и управления собственной фермой.
В этой статье содержится следующая информация.
Спецификации, включающие сведения об оборудовании, топологии и конфигурации.
Рабочая нагрузка, которая включает анализ потребностей фермы, числа пользователей и характеристик использования
Сведения о наборе данных, например о размерах баз данных и типах контента.
Результаты тестов и их анализ для горизонтального масштабирования веб-серверов.
Прежде чем прочитать эту статью, ознакомьтесь со следующими статьями, чтобы понять основные понятия, связанные с управлением емкостью, в разделе Границы и ограничения программного обеспечения для SharePoint 2013SharePoint Server 2013.
Управление мощностью и масштабирование в SharePoint Server 2013
Оценка требований к производительности и емкости для сред совместной работы в корпоративной интрасети (SharePoint Server 2013)
Глоссарий
В списке ниже представлены определения ключевых терминов, используемых в этой статье.
RPS: Запросы в секунду. RPS — это количество запросов, получаемых фермой или сервером за одну секунду. Это общепринятая единица измерения нагрузки на сервер или ферму.
Примечание.
Запросы и загрузки страниц это не одно и то же. Страница содержит несколько компонентов, каждый из которых создает один или несколько запросов при загрузке страницы браузером. При загрузке одной страницы создается несколько запросов. Обычно процедуры проверки подлинности и события, использующие незначительное количество ресурсов, не учитываются при измерениях RPS.
Зеленая зона: Зеленая зона представляет определенный набор характеристик нагрузки при нормальных условиях эксплуатации, вплоть до ожидаемых ежедневных пиковых нагрузок.
Ферма, работающая в этом диапазоне, должна быть способна поддерживать время ответа и задержки в рамках допустимых параметров.Это состояние, в котором сервер удовлетворяет указанным ниже условиям.
Задержка на стороне сервера для не менее чем 75 % запросов составляет менее одной секунды.
Уровень использования ЦП на всех серверах фермы не превышает 60 %.
Примечание.
Наша лабораторная среда не выполняла активное сканирование поиска. Таким образом, мы сохранили сервер базы данных на 50 % загрузки ЦП или ниже, чтобы зарезервировать 10 % для загрузки обхода поиска. При этом предполагается, что для ограничения нагрузки обхода контента при поиске на уровне 10 % в рабочей среде используется регулятор ресурсов SQL Server.
Процент сбоев составляет менее 0,01 %.
Красная зона (макс.) Красная зона представляет определенный набор характеристик нагрузки в пиковых условиях работы. В красной зоне для фермы характерна временная повышенная потребность в ресурсах, при которой работа может поддерживаться только в течение ограниченного периода, пока не наступит отказ или не возникнут иные проблемы, связанные с производительностью и надежностью.
Это состояние, в котором сервер удовлетворяет указанным ниже условиям в течение ограниченного периода времени:
Компонент регулирования запросов HTTP включен, но ошибки 503 (сервер занят) отсутствуют.
Частота сбоев меньше 0. 1%.
Задержка на стороне сервера для не менее чем 75 % запросов составляет менее 3 секунд.
Уровень использования ЦП на всех серверах фермы (кроме серверов баз данных) не превышает примерно 90 %.
Использование ЦП сервера базы данных не превышает примерно 50 %, что позволяет иметь достаточный резерв для нагрузки обхода контента при поиске.
AxBxC (графовая нотация): Количество веб-серверов, серверов приложений и серверов баз данных в ферме соответственно. Например, значение 10x1x1 указывает на то, что в данной среде имеется 10 веб-серверов, 1 сервер приложений и 1 сервер базы данных.
MDF и LDF: SQL Server физические файлы.
Дополнительные сведения см. в статье Архитектура файлов и файловых групп.
 Ферма, работающая в этом диапазоне, должна быть способна поддерживать время ответа и задержки в рамках допустимых параметров.
Ферма, работающая в этом диапазоне, должна быть способна поддерживать время ответа и задержки в рамках допустимых параметров.
 Дополнительные сведения см. в статье Архитектура файлов и файловых групп.
Дополнительные сведения см. в статье Архитектура файлов и файловых групп.Обзор
В этом разделе приведен обзор способа масштабирования и методики тестирования.
Способ масштабирования
В этом разделе описывается способ, который использовался нами для масштабирования лабораторной среды. Этот способ позволяет найти оптимальную конфигурацию для рабочей нагрузки.
Мы выполнили горизонтальное масштабирование веб-серверов, пока не получили четыре используемых веб-сервера. На каждом сервере работает служба распределенного кэша.
Мы добавили выделенный сервер, на котором работает служба распределенного кэша.
Мы отключили службу распределенного кэша на веб-серверах.
Мы выполнили горизонтальное масштабирование дополнительных веб-серверов в максимально допустимом для тестирования объеме.
Методика и замечания по тестированию
Так как в этой статье представлены результаты, полученные в среде лаборатории тестирования, мы могли контролировать определенные факторы, чтобы продемонстрировать конкретные аспекты производительности для данной рабочей нагрузки. Кроме того, некоторые перечисленные ниже элементы рабочей среды не были включены в лабораторную среду для упрощения тестирования.
Кроме того, некоторые перечисленные ниже элементы рабочей среды не были включены в лабораторную среду для упрощения тестирования.
Примечание.
В рабочих средах исключать эти элементы не рекомендуется.
Между тестовыми запусками мы изменяли только по одной переменной за раз, чтобы упростить сравнение полученных результатов.
Серверы баз данных не входили в кластер, поскольку избыточность для такого тестирования не требовалась.
Обход поиска не выполнялся во время тестов. Конечно, он может выполняться в рабочей среде. Чтобы учесть это, мы снизили SQL Server использования ЦП в определениях «зеленая зона» и «красная зона», чтобы разместить ресурсы, которые обход поиска обычно будет использовать во время тестирования.
Спецификации
В этом разделе приведены подробные сведения об оборудовании, программном обеспечении, топологии и конфигурации тестовой лабораторной среды.
Оборудование
В следующих разделах описано оборудование, которое использовалось в среде лаборатории тестирования.
Важно!
Мы использовали узлы Hyper-V для виртуализации всех веб-серверов и серверов приложений в тестовой лаборатории. Серверы баз данных не были виртуализированы. В этом разделе физическое оборудование узла и виртуальное оборудование виртуальной машины описаны раздельно.
Узлы Hyper-V
Для наших тестов мы использовали шесть идентично сконфигурированных узлов Hyper-V. На каждом узле работает одна или две виртуальные машины.
| Оборудование узла | Value (Значение) |
|---|---|
| Процессоры | 2 четырехъядерных процессора с тактовой частотой 2,49 ГГц |
| ОЗУ | 32 ГБ |
| Операционная система | Windows Server 2008 R2 с пакетом обновления 1 (SP1) |
| Количество сетевых адаптеров | 2 |
| Скорость сетевого адаптера | 1 гигабит |
Виртуальные веб-серверы и серверы приложений
В нашей тестовой ферме используются восемь виртуальных веб-серверов. Мы также использовали выделенный виртуальный сервер, на котором работает служба распределенного кэша.
Мы также использовали выделенный виртуальный сервер, на котором работает служба распределенного кэша.
Примечание.
В рабочих средах обычно развертывают выделенные серверы, на которых работает служба распределенного кэша в конфигурации высокой доступности. В нашей среде лаборатории тестирования мы использовали один выделенный сервер для распределенного кэша, потому что высокая доступность не является важным фактором.
| Оборудование виртуальной машины | WFE1-8 и DC1 |
|---|---|
| Процессоры | 4 виртуальных процессора |
| ОЗУ | 12 ГБ |
| Операционная система | Windows Server 2008 R2 с пакетом обновления 1 (SP1) |
| Размер диска для SharePoint | 100 ГБ |
| Количество сетевых адаптеров | 2 |
| Скорость сетевого адаптера | 10 гигабит (трафик между узлами ограничен в соответствии со скоростью сетевых адаптеров узлов) |
| Проверка подлинности | Windows NTLM |
| Тип подсистемы балансировки нагрузки | F5 Big IP |
| Запускаемые локально службы | WFE 1-8: базовые федеративные службы. Сюда входит служба таймера SharePoint, служба трассировки, службы Word Automation Services, службы Службы Excel и служба изолированного кода Microsoft SharePoint Foundation. Сюда входит служба таймера SharePoint, служба трассировки, службы Word Automation Services, службы Службы Excel и служба изолированного кода Microsoft SharePoint Foundation. DC1: служба распределенного кэша. |
Серверы баз данных
В своих тестах мы используем один физический сервер баз данных и запускаем экземпляр SQL Server по умолчанию, в котором хранятся базы данных SharePoint. В этой статье мы не отслеживаем базу данных журналов.
Примечание.
Если включено ведение отчетов об использовании, рекомендуется хранить базу данных журналов с отдельным логическим номером устройства (LUN). Для крупных развертываний и некоторых развертываний среднего размера может потребоваться выделенный сервер базы данных журналов, чтобы справиться с нагрузкой на ЦП, создаваемой большим количеством регистрируемых событий.
В нашей лабораторной среде мы ограничили функции ведения журналов и хранили базу данных журналов в отдельном экземпляре SQL Server.
| Сервер базы данных экземпляр по умолчанию | SQL Server |
|---|---|
| Процессоры | 4 четырехъядерных процессора с тактовой частотой 2,4 ГГц |
| ОЗУ | 32 ГБ |
| Операционная система | Windows Server 2008 R2 с пакетом обновления 1 (SP1) |
| Хранилище и геометрия | Непосредственно подключенное хранилище (DAS) 1 системный том (RAID0, 1 шпиндель, 300 ГБ) 2 тома для данных контента (RAID0, 4 шпинделя, по 450 ГБ) 2 тома для журналов контента (RAID0, 2 шпинделя, по 450 ГБ) 1 том для временных данных (RAID0, 2 шпинделя, по 300 ГБ) 1 том для временных журналов (RAID0, 2 шпинделя, по 300 ГБ) |
| Количество сетевых адаптеров | 1 |
| Скорость сетевого адаптера | 1 гигабит |
| Проверка подлинности | Windows NTLM |
| Версия программного обеспечения | SQL Server 2008 R2 |
Топология
На следующей схеме показана топология нашей среды лаборатории тестирования.
Конфигурация
В следующей таблице перечислены значительные изменения конфигурации сервера баз данных, сделанные в нашей лабораторной среде. Они позволяют оптимизировать тестовую производительность и прояснить связи между параметрами и результатами тестов. Обратите внимание, что для SharePoint Server 2013 необходим параметр MAXDOP. Другие изменения параметров касаются только нашей среды лаборатории тестирования и могут не повлиять на вашу рабочую среду.
| Параметр | Значение | Примечания |
|---|---|---|
| Семейство веб-сайтов | 179 (общее количество в среде) | Для семейств веб-сайтов в нашей тестовой среде используются параметры по умолчанию и проверка подлинности на основе утверждений Windows. |
| Кэширование больших двоичных объектов | Вкл. | По умолчанию выключено.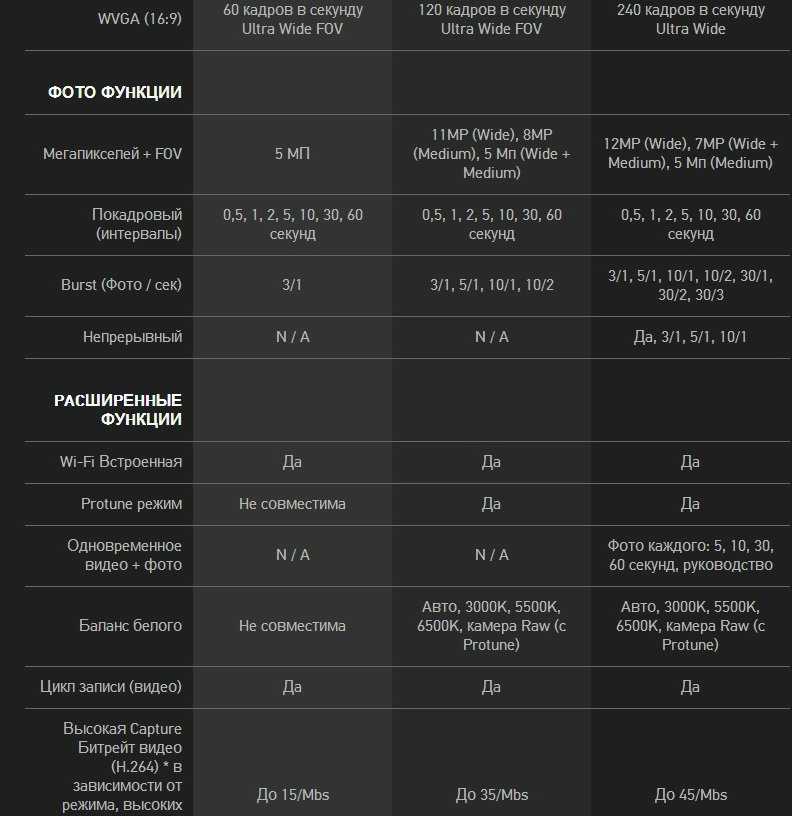 Включение кэширования больших двоичных объектов повышает эффективность работы сервера благодаря сокращению количества вызовов к серверу базы данных для статических ресурсов страниц, часто запрашиваемых браузером. Включение кэширования больших двоичных объектов повышает эффективность работы сервера благодаря сокращению количества вызовов к серверу базы данных для статических ресурсов страниц, часто запрашиваемых браузером. |
| Максимальная степень параллелизма (MAXDOP) | 1 | Этот параметр задается для экземпляра SQL Server или экземпляров, содержащих базы данных контента SharePoint Server 2013. По умолчанию используется значение, которое позволяет SQL Server самостоятельно определять максимальную степень параллелизма. В SharePoint Server 2013 параметр MAXDOP должен иметь значение 1 для экземпляров SQL Server, содержащих базы данных SharePoint Server 2013. Дополнительные сведения о настройке параметра MAXDOP для SQL Server 2008 R2 см. в статье Параметр max degree of parallelism. Сведения о настройке параметра MAXDOP для SQL Server 2012 см. в статье Настройка параметра конфигурации сервера max degree of parallelism. |
Workload
В этом разделе разъясняются лабораторные тесты, проведенные для SharePoint Server 2013. Параметры теста типичны для среды совместной работы отделов.
Параметры теста типичны для среды совместной работы отделов.
Набор данных
Набор данных, использованный в среде лаборатории тестирования, отражает типичную среду совместной работы отделов. Этот набор данных содержит различные семейства веб-сайтов, сайтов, списков, библиотек, типов и размеров файлов.
| Характеристики набора данных | Значение |
|---|---|
| Размер базы данных (общий) | 174 ГБ |
| Размер MDF | 154 ГБ |
| Размер LDF | 20 ГБ |
| Размер большого двоичного объекта | 152 ГБ |
| Число баз данных контента | 2 |
| Число семейств веб-сайтов | 179 |
| Число веб-приложений | 1 |
| Число сайтов | 1,471 |
Результаты и анализ
Следующие результаты упорядочены в соответствии со способом масштабирования, описанным в разделе Обзор.
Горизонтальное масштабирование веб-серверов
В следующих разделах описываются результаты теста, полученные при горизонтальном масштабировании количества веб-серверов в нашей среде лаборатории тестирования.
Методология тестирования
Добавьте веб-серверы с аналогичными характеристиками оборудования и выполните тест еще раз, не изменяя параметры фермы или теста.
Измерьте количество запросов в секунду, задержку и использование ресурсов на каждом сервере в тестовой ферме.
Анализ
Во время тестирования мы обнаружили следующее.
Было выполнено масштабирование среды до десяти веб-серверов на сервер базы данных. Увеличение пропускной способности было относительно линейным.
Даже при максимальном протестированном количестве веб-серверов, равном 10, добавление серверов баз данных не приводило к увеличению пропускной способности. Узким местом, как правило, являются ресурсы веб-серверов.
Средняя задержка в «зеленой зоне» была практически постоянной в течение всего тестирования.
Количество веб-серверов и пропускная способность не оказывали на нее влияние. Данные по задержке в «красной зоне» соответствуют ожидаемой тенденции. На одиночном веб-сервере задержка очень высока. Кривая в пределах от 2 до 8 веб-серверов находится в рамках условий «красной зоны».Примечание.
Некоторое влияние на задержку может оказать перемещение службы распределенного кэша с веб-серверов фермы на выделенный сервер. Это связано с тем, что трафик распределенного кэша, который ранее был внутренним для каждого веб-сервера, начинает передаваться через сеть. Протестируйте горизонтальное масштабирование в собственной среде, чтобы определить, является ли это снижение производительности существенным. Обратите внимание, что задержка в нашей тестовой среде увеличилась незначительно при переносе службы распределенного кэша на выделенный сервер. Задержка снижалась при добавлении каждого веб-сервера, так как номинальное увеличение задержки компенсировалось уменьшением нагрузки на процессоры и память веб-серверов.
> Дополнительные сведения о планировании емкости распределенного кэша см. в статье Планирование веб-каналов и службы распределенного кэша в SharePoint Server.Из-за улучшения характеристик кэширования и использования баз данных в SharePoint Server 2013 средняя нагрузка на слой серверов баз данных низка. Мы обнаружили, что во время наших тестов не было необходимости в горизонтальном масштабировании серверов баз данных.
При добавлении виртуальных веб-серверов прирост производительности частично зависит от аппаратных ресурсов узла и от использования ресурсов другими виртуальными компьютерами, работающими на этом же узле. Для виртуальных серверов необходимы дополнительные стратегии планирования и управления, специально предназначенные для виртуализации.
Дополнительные сведения о планировании производительности и емкости Hyper-V см. в разделах Требования к виртуализации Hyper-V для SharePoint 2013 и Использование лучших конфигураций для виртуальных машин SharePoint 2013 и среды Hyper-V.
 Количество веб-серверов и пропускная способность не оказывали на нее влияние. Данные по задержке в «красной зоне» соответствуют ожидаемой тенденции. На одиночном веб-сервере задержка очень высока. Кривая в пределах от 2 до 8 веб-серверов находится в рамках условий «красной зоны».
Количество веб-серверов и пропускная способность не оказывали на нее влияние. Данные по задержке в «красной зоне» соответствуют ожидаемой тенденции. На одиночном веб-сервере задержка очень высока. Кривая в пределах от 2 до 8 веб-серверов находится в рамках условий «красной зоны».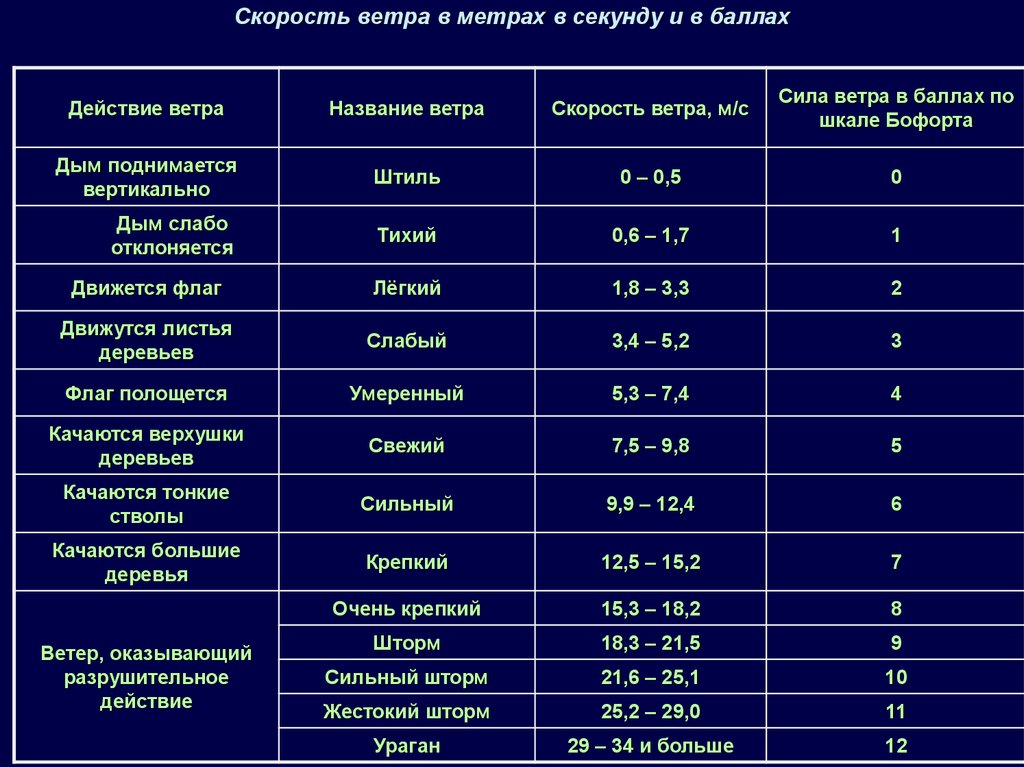 > Дополнительные сведения о планировании емкости распределенного кэша см. в статье Планирование веб-каналов и службы распределенного кэша в SharePoint Server.
> Дополнительные сведения о планировании емкости распределенного кэша см. в статье Планирование веб-каналов и службы распределенного кэша в SharePoint Server.
Примечание.
Выводы, изложенные в этом разделе, зависят от оборудования, формирующего среду. В этой среде можно достичь такой же пропускной способности, если использовать большее количество менее мощных серверов узлов Hyper-V или меньшее количество более мощных серверов узлов Hyper-V. Наращивание аппаратных ресурсов на сервере баз данных не окажет значительного влияния на результаты.
Результаты, графики и диаграммы
На графиках ниже по оси x отображается изменение количества веб-серверов в ферме. Шкала начинается с одного виртуального веб-сервера и одного физического сервера баз данных (1×1). Максимальная конфигурация состоит из восьми виртуальных веб-серверов, одного выделенного сервера распределенного кэша (добавленного к четырем веб-серверам) и одного физического сервера баз данных (8x1x1).
Примечание.
На графиках в этом разделе отображены средние значения для каждой точки данных в ходе всего теста. Все графики включают базовые показатели RPS для «зеленой» и «красной» зон для демонстрации связи между RPS и такими факторами как задержка, использование ресурсов сервера и использование дисков SQL Server.
1. Количество запросов в секунду
На следующем графике показано, как горизонтальное масштабирование влияет на базовый показатель количества запросов в секунду.
2. Задержка
На следующем графике показано, как горизонтальное масштабирование влияет на задержку. Обратите внимание, что график задержки в «зеленой зоне» остается почти плоским, а в «красной зоне» он растет в допустимых пределах.
3. Использование процессоров и памяти веб-серверов
На следующем графике показано, как горизонтальное масштабирование влияет на средние показатели использования ЦП и памяти на веб-серверах. Обратите внимание, что в «зеленой зоне» показатели использования ЦП и среднего использования памяти остаются относительно постоянными, а RPS растет.
Показатель использования процессора в «красной зоне» имеет тенденцию к понижению. Эта тенденция отражает тот факт, что средняя потребность в ЦП веб-сервера при максимальной нагрузке постепенно снижается по мере увеличения количества серверов.
4. SQL Server Количество операций ввода-вывода в секунду и использование ЦП
На следующих графиках показано, как изменяется среднее количество дисковых операций ввода-вывода в секунду (общих, чтения и записи) и показатели использования ЦП при горизонтальном масштабировании количества веб-серверов. Для измерения количества операций ввода-вывода в секунду мы используем следующие счетчики производительности.
Значения каждого счетчика, полученные на протяжении всего теста, были усреднены и просуммированы для получения общего количества операций ввода-вывода в секунду.
Примечание.
Поскольку данные об использовании памяти для SQL Server были недоступны во время наших тестов, они не включены в этот график.
Важно!
Эти результаты тестов на количество операций ввода-вывода в секунду не являются показателем для рабочей среды, поскольку наш набор данных был намного меньше тех, которые используются в рабочей ферме. Это позволило выполнить кэширование большего процента данных на веб-серверах, чем это возможно в рабочей среде. Поэтому в этом разделе были вычислены усредненные результаты для показателей количества операций ввода-вывода в секунду на основании доступных данных тестов. Мы ожидаем, что наши показатели количества операций ввода-вывода в секунду в общем будут ниже, чем такие же показатели для рабочей среды. Тщательное тестирование нашей фермы в пилотной среде может дать различные результаты.
Поэтому в этом разделе были вычислены усредненные результаты для показателей количества операций ввода-вывода в секунду на основании доступных данных тестов. Мы ожидаем, что наши показатели количества операций ввода-вывода в секунду в общем будут ниже, чем такие же показатели для рабочей среды. Тщательное тестирование нашей фермы в пилотной среде может дать различные результаты.
Обратите внимание, что на графиках в этом разделе и количество операций ввода-вывода в секунду, и показатель использования процессора сервера баз данных уменьшаются на шести интерфейсных веб-серверах, в то время как RPS продолжает расти. Это изменение также отражено в показателе использования ЦП веб-сервера, как показано на предыдущем графике.
Это указывает на то, что масштабирование фермы достигло такой степени, при которой оказывается максимальная нагрузка на ресурсы серверов фермы с помощью базовой рабочей нагрузки и набора данных. Для выполнения рабочей нагрузки в ферме требуется снизить загрузку ресурсов серверов.
На основании этой тенденции можно сделать следующие предположения.
Если бы тестовая нагрузка была увеличена при добавлении шестого веб-сервера, можно было бы достичь большего количество запросов в секунду. При этом использование ресурсов серверов осталось бы на том же уровне.
При дальнейшем масштабировании количества веб-серверов и той же тестовой нагрузке количество запросов в секунду продолжило бы увеличиваться, а нагрузка на ресурсы серверов продолжила бы снижаться.
Общее количество операций ввода-вывода в секунду для SQL Server
На следующем графике показано, как горизонтальное масштабирование влияет на общее число операций ввода-вывода в секунду.
Количество операций ввода-вывода в секунду для SQL Server, разбитое по числу операций чтения и записи
На следующем графике показано, как горизонтальное масштабирование влияет на количество операций чтения и записи в секунду.
Загрузка процессоров SQL Server
На следующем графике показано, как горизонтальное масштабирование влияет на загрузку процессоров SQL Server.

См. также
Понятия
Планирование производительности в SharePoint Server 2013
Результаты тестирования производительности и емкости и рекомендации (SharePoint Server 2013)
Оценка требований к производительности и емкости для сред совместной работы в корпоративной интрасети (SharePoint Server 2013)
Балансировка 70 тысяч запросов в секунду на HighLoad++ / Хабр
Библиотека докладов
Это не просто статья — это целая библиотека докладов про внутреннее устройство тех или иных крупных и высоконагруженных проектов. Все эти доклады звучали на конференциях HighLoad++ и РИТ++ за последние несколько лет.
И еще:
Секция «Архитектуры»
Ключевая секция конференции разработчиков высоконагруженных систем HighLoad++, которая пройдет уже через две недели в Москве, это, конечно, Архитектуры. Доклады в этой секции меняются — если три-четыре года назад мы слушали общие слова о том, сколько серверов в Фейсбуке и где хранятся файлы у ВКонтакте, то сейчас в Программу такие доклады уже не проходят. Сейчас время деталей, микросервисов, подробных разборов того или иного архитектурного паттерна.
Доклады в этой секции меняются — если три-четыре года назад мы слушали общие слова о том, сколько серверов в Фейсбуке и где хранятся файлы у ВКонтакте, то сейчас в Программу такие доклады уже не проходят. Сейчас время деталей, микросервисов, подробных разборов того или иного архитектурного паттерна.
Итак, архитектурные паттерны. На этой конференции подробно разберем пару из них, и первый — это, конечно, микросервисы.
Единое приложение строится как набор небольших микросервисов, каждый из которых работает в собственном процессе, максимально независим от других микросервисов, реализует, как правило, одну бизнес-функцию и коммуницирует с остальными, используя легковесные механизмы, тот же http.
Антон Резников и Владимир Перепелица расскажут не только о микросервисной архитектуре Облака@Mail.ru, но и конкретной реализации паттерна на NoSQL-базе данных Tarantool. Да, Tarantool — это еще одна NoSQL база данных, но еще это полноценный сервер приложений. Приложений, расположенных рядом с данными!
Приложений, расположенных рядом с данными!
Денис Иванов (2Gis) продолжит тему в докладе «Путь от монолита на PHP к микросервисам на Scala». Так и хочется воскликнуть: «Денис, остановись, что ты делаешь, зачем?!». И Денис отвечает на этот вопрос просто — 6 нод с приложениями вместо 18. Ответ достойный, надеемся услышать на конференции детали.
Еще один паттерн, часто используемый в высоконагруженных проектах — это очереди. Тему раскрывает Павел Филонов (Positive Technologies) в докладе «101 способ приготовления RabbitMQ и немного о pipeline-архитектуре».
В докладе обсуждаются варианты использования системы обмена сообщениями RabbitMQ в качестве связующего программного обеспечения (middleware) для построения конвейерной архитектуры. Рассматриваются вопросы производительности и масштабирования как stateless, так и statefull фильтров.
Доклад похож на учебный, но тема-то уж больно хороша!
Следующий доклад о балансировке от Юрия Насретдинова из компании Badoo — серьезная заявка на победу. Пользуясь случаем, мы попробовали задать Юрию несколько вопросов, чтобы пролить свет на один из самых захватывающих докладов, ожидающихся на конференции:
Пользуясь случаем, мы попробовали задать Юрию несколько вопросов, чтобы пролить свет на один из самых захватывающих докладов, ожидающихся на конференции:
— Юра, как вы подошли к уровню нагрузки в 70к запросов в секунду?
К такому уровню нагрузки мы подходили весьма плавно, в течение уже почти 10 лет. В последние годы у нас также начало сильно расти количество пользователей на мобильных устройствах, что тоже вызвало рост количества запросов в секунду — наше мобильное приложение отправляет больше мелких запросов на сервер, чем веб-сайт. Хотелось бы отметить, что 70к запросов в секунду приходится на PHP-FPM, общее число HTTP-запросов на наш сайт составляет до 250к в секунду.
— Что, кроме яиц, нужно для того, чтобы держать такие нагрузки?
В целом нет никакой проблемы с тем, чтобы обслуживать 250 000 HTTP-запросов в секунду. Вы можете обслуживать такую нагрузку с помощью банального nginx и DNS round-robin. Мы используем «хардварные» решения для обработки входящего трафика — GTM и LTM от компании F5.
Грубо говоря, распределение запросов по серверам — это не архисложная задача, и для PHP масштабирование заключается просто в добавлении серверов в backend с соответствующими весами.
Намного сложнее не просто держать такую нагрузку, но и создать архитектуру для хранения пользовательских данных, которая бы могла хранить и отдавать сотни терабайт и даже петабайты фотографий и текстовых данных. О нашей архитектуре было много докладов, например мастер-класс от Алексея Рыбака на DevConf в 2012 году или мой доклад про архитектуру хранения фотографий в 2015 году. К сожалению, кратко рассказать об архитектуре в рамках интервью не представляется возможным, поэтому я бы рекомендовал посмотреть на наши презентации для деталей.
 Они позволяют обрабатывать все запросы на одном IP-адресе, то есть без использования DNS round-robin. На входном маршрутизаторе задаются правила, по которым запросы попадают на тот или иной кластер, задаются веса машин при необходимости, и остальное делает за вас эта железка (или nginx, который мы используем для проксирования запросов на мобильный кластер).
Они позволяют обрабатывать все запросы на одном IP-адресе, то есть без использования DNS round-robin. На входном маршрутизаторе задаются правила, по которым запросы попадают на тот или иной кластер, задаются веса машин при необходимости, и остальное делает за вас эта железка (или nginx, который мы используем для проксирования запросов на мобильный кластер).
— Каким образом достигается подобная пропускная способность архитектуры, какие есть отдельные интересные места?
Опять же – подобная пропускная способность не является чем-то выдающимся, и тот же LTM с нагрузкой справляется даже без дополнительных «подпорок» с нашей стороны.
Если говорить про архитектуру хранения данных пользователей, то здесь всё немного интереснее. Мы храним данные каждого пользователя на одном сервере, то есть шардим данные по пользователям, а не по ID или другим синтетическим величинам. Это позволяет нам делать достаточно сложные выборки при работе с данными пользователей, использовать JOIN и сложные сортировки. При этом пользователи не «прибиваются гвоздями» к своему серверу, а могут перемещаться по кластеру при необходимости. Это достигается за счёт того, что мы храним «spot_id» и «place_id» пользователя (идентификаторы, из которых можно определить имя сервера и имя таблицы на сервере) в центральном сервисе, называемом «authorizer».
 К этому сервису делаются запросы каждый раз, когда нужно установить соединение с базой данных пользователя. На сервис приходится около 40к запросов на чтение в секунду, и обслуживаются они по протоколу HandlerSocket одним инстансом MySQL. Этот сервис является, пожалуй, самым высоконагруженным внутренним сервисом, который обслуживает один сервер, и в данный момент у нас есть запас по производительности минимум в 2 раза. Даже если мы упремся в масштабируемость MySQL + handlersocket, всегда можно попробовать, к примеру, Tarantool для этой задачи — этот демон может выдавать 100к запросов/сек на _ядро_ (ср. с 100к запросов на _сервер_ в случае с MySQL+handlersocket).
К этому сервису делаются запросы каждый раз, когда нужно установить соединение с базой данных пользователя. На сервис приходится около 40к запросов на чтение в секунду, и обслуживаются они по протоколу HandlerSocket одним инстансом MySQL. Этот сервис является, пожалуй, самым высоконагруженным внутренним сервисом, который обслуживает один сервер, и в данный момент у нас есть запас по производительности минимум в 2 раза. Даже если мы упремся в масштабируемость MySQL + handlersocket, всегда можно попробовать, к примеру, Tarantool для этой задачи — этот демон может выдавать 100к запросов/сек на _ядро_ (ср. с 100к запросов на _сервер_ в случае с MySQL+handlersocket).– И пару слов о твоём докладе на HighLoad++
В докладе я расскажу о системе, которая выставляет веса для серверов на наших балансировщиках (LTM для веб-нагрузки и nginx для мобильного кластера). Система нужна для того, чтобы достичь намного более равномерного распределения нагрузки по кластеру, чем получается сделать «руками».
Я расскажу о существующих подходах к автоматическому распределению весов для машин, о том, какие подходы мы попробовали, и на чём в результате установились. Написанное нами решение будет выложено в open-source, чтобы вы могли использовать его в своем проекте при необходимости.
 С ростом нагрузки и количества запросов нам начало требоваться всё большее число серверов, и помимо добавления новых серверов мы решили потратить некоторые усилия на то, чтобы обеспечить более равномерную загрузку существующих. До того, как мы начали что-то делать, разброс между CPU usage на самом нагруженном сервере и на самом свободном составлял около 20-30%, а после — всего 2,5%. На наших объемах это позволило нам сэкономить до сотни серверов, и оно, безусловно, стоило того.
С ростом нагрузки и количества запросов нам начало требоваться всё большее число серверов, и помимо добавления новых серверов мы решили потратить некоторые усилия на то, чтобы обеспечить более равномерную загрузку существующих. До того, как мы начали что-то делать, разброс между CPU usage на самом нагруженном сервере и на самом свободном составлял около 20-30%, а после — всего 2,5%. На наших объемах это позволило нам сэкономить до сотни серверов, и оно, безусловно, стоило того.И напоследок, классический доклад об архитектуре крупного проекта, правда очень крупного, самого крупного сервиса объявлений в Рунете — Avito.ru. Михаил Тюрин, главный системный архитектор Avito, расскажет о том, «Где живут ваши объявления?»
Одинаковых высоконагруженных проектов не бывает, дьявол кроется в мелочах, в нюансах работы той или иной функции, хранения и использования того или иного блока данных.
 Именно поэтому свой курс лекций о высоконагруженных системах в МФТИ я начинаю с рассказа и демонстрации важности аналитической части работы над высоконагруженных проектом. И именно поэтому я рекомендую сходить на доклад Михаила — крупнейший классифайд в Европе, 600 миллионов объявлений – как это все работает?
Именно поэтому свой курс лекций о высоконагруженных системах в МФТИ я начинаю с рассказа и демонстрации важности аналитической части работы над высоконагруженных проектом. И именно поэтому я рекомендую сходить на доклад Михаила — крупнейший классифайд в Европе, 600 миллионов объявлений – как это все работает?До встречи на конференции!
P.S. Учебник
Кстати, вот уже несколько недель мы обкатываем новый учебник по проектированию высоконагруженных систем. Это серия писем, построенных на лекциях лучших в России специалистов. Где-то мы расшифровываем лекции, где-то предоставляем видео, но важно следующее – каждый из материалов перепроверен нами, на нём стоит печать качества конференции HighLoad++.
Если интересно – подписывайтесь, это бесплатно: http://highload.guide/
И последнее: Для пользователей «Хабрахабра» конференция предлагает специальную скидку в 15%, всё что нужно сделать — это воспользоваться кодом «IAmHabr» при бронировании билетов.
Оптимизация
. Каков «средний» запрос в секунду для производственного веб-приложения?
спросил
Изменено
8 месяцев назад
Просмотрено
155 тысяч раз
У меня нет системы отсчета с точки зрения того, что считается «быстрым»; Я всегда задавался этим вопросом, но никогда не находил прямого ответа…
- оптимизация
2
OpenStreetMap, кажется, имеет 10-20 изображений в секунду
Википедия, кажется, составляет от 30000 до 70000 изображений в секунду, распределенных по 300 серверам (от 100 до 200 запросов в секунду на машину, большая часть которых является кэшем)
Geograph получает 7000 изображений в секунду неделя (1 загрузка за 95 секунд)
4
Не уверен, что кому-то это еще интересно, но эта информация была размещена в Твиттере (и здесь тоже):
- Более 350 000 пользователей.
- 600 запросов в секунду.
- В среднем 200-300 подключений в секунду. Всплески до 800 подключений в секунду.
- MySQL обрабатывал 2400 запросов в секунду.
- 180 экземпляров Rails. Использует Mongrel в качестве «веб-сервера».
- 1 сервер MySQL (один большой 8-ядерный блок) и 1 ведомое устройство. Слейв читается только для статистики и отчетности.
- Более 30 процессов для обработки случайных заданий.
- 8 Sun X4100s.
- Обработать запрос за 200 миллисекунд в Rails.
- Среднее время пребывания в базе данных составляет 50-100 миллисекунд.
- Более 16 ГБ памяти.
 Фактические цифры, как всегда, очень супер-суперсекретно.
Фактические цифры, как всегда, очень супер-суперсекретно.3
Когда я захожу в панель управления своего веб-хостинга, открываю phpMyAdmin и нажимаю «Показать информацию о времени выполнения MySQL», я получаю:
Этот сервер MySQL работает 53 дня, 15 часов, 28 минут и 53 секунды.
Статистика запросов: с момента запуска на сервер было отправлено 3 444 378 344 запросов.
Всего 3 444 млн
в час 2,68 млн
в минуту 44,59 тыс.
в секунду 743,13
 Он начался 24 октября 2008 года в 04:03.
Он начался 24 октября 2008 года в 04:03.Это в среднем 743 запроса MySQL каждую секунду за последние 53 дня!
Не знаю, как у вас, а у меня это быстро! Очень быстро!!
3
лично мне нравятся оба анализа, выполняемые каждый раз….запросы/секунда и среднее время/запрос, а также мне нравится видеть максимальное время запроса. легко перевернуть, если у вас 61 запрос в секунду, вы можете просто перевернуть его на 1000 мс / 61 запрос.
Чтобы ответить на ваш вопрос, мы сами провели огромный тест нагрузки и обнаружили, что он колеблется на различном оборудовании Amazon, которое мы используем (лучшим значением был 32-битный средний процессор, когда он дошел до $$ / событие / секунду) и наши запросы / секунды варьировались от 29 запросов в секунду на узел до 150 запросов в секунду на узел.
Предоставление лучшего оборудования, конечно, дает лучшие результаты, но не лучшую рентабельность инвестиций. В любом случае, этот пост был великолепен, так как я искал некоторые параллели, чтобы увидеть, где мои цифры на приблизительном уровне, и поделился ли я своими, на случай, если кто-то еще ищет. Мой загружен настолько высоко, насколько я могу.
ПРИМЕЧАНИЕ: благодаря запросам/второму анализу (не ms/request) мы обнаружили серьезную проблему Linux, которую мы пытаемся решить, когда Linux (мы протестировали сервер на C и Java) замораживает все вызовы в библиотеки сокетов, когда слишком много нагрузки, что кажется очень странным. Полный пост можно найти здесь на самом деле ….
http://ubuntuforums.org/showthread.php?p=11202389
Мы все еще пытаемся решить эту проблему, так как это дает нам огромный прирост производительности, поскольку наш тест идет с 2 минут 42 секунд до 1 минуты 35 секунд, когда это исправлено, поэтому мы видим улучшение производительности на 33% . … не говоря уже о том, что чем хуже DoS-атака, тем длиннее эти паузы, так что все процессоры падают до нуля и прекращают обработку … по моему мнению, обработка сервера должна продолжаться в лицо доса но почему то зависает время от времени во время доса иногда до 30 секунд!!!
… не говоря уже о том, что чем хуже DoS-атака, тем длиннее эти паузы, так что все процессоры падают до нуля и прекращают обработку … по моему мнению, обработка сервера должна продолжаться в лицо доса но почему то зависает время от времени во время доса иногда до 30 секунд!!!
ДОПОЛНЕНИЕ: мы обнаружили, что на самом деле это была ошибка состояния гонки jdk …. трудно изолировать на больших кластерах, но когда мы запускали 1 сервер 1 узел данных, но 10 из них, мы могли воспроизводить его каждый раз тогда и просто смотрели на сервер/узел данных, на котором это произошло. Переключение jdk на более раннюю версию устранило проблему. Я думаю, мы были на jdk1.6.0_26.
Это очень открытый вопрос типа «яблоки к апельсинам».
Вы спрашиваете
1. средняя нагрузка запросов для производственного приложения
2. что считается быстрым
Это не обязательно связано.
Среднее количество запросов в секунду определяется
a. количество одновременных пользователей
b. среднее количество запросов страниц, которые они делают в секунду
среднее количество запросов страниц, которые они делают в секунду
c. количество дополнительных запросов (т. е. ajax-вызовов и т. д.)
Что считается быстрым. Вы имеете в виду, сколько запросов может принять сайт? Или если аппаратное обеспечение считается быстрым, если оно может обрабатывать xyz # запросов в секунду?
Обратите внимание, что графики посещаемости будут представлять собой синусоидальные модели с «часами пиковой нагрузки», возможно, в 2 или 3 раза больше, чем вы получаете, когда пользователи спят. (Может быть полезно, когда вы планируете ежедневную пакетную обработку данных на серверах). т.е. пользователи, которые видят более медленные ответы, чем это, думают, что система работает медленно.
Теперь скажите, сколько пользователей вы подключили.
Вы можете выполнить поиск по запросу «анализ эффекта косой черты» для получения графиков того, что вы увидите, если какой-либо аспект сайта внезапно станет популярным в новостях, например. этот график на вики.
Выжившие веб-приложения, как правило, могут генерировать статические страницы вместо того, чтобы обрабатывать каждый запрос через язык обработки.
Было отличное видео (думаю, оно могло быть на ted.com? Я думаю, оно могло быть снято веб-командой flickr? Кто-нибудь знает ссылку?) с идеями о том, как масштабировать веб-сайты за пределы одного сервера, например. как распределить соединения между серверами только для чтения и чтения-записи, чтобы получить наилучший эффект для различных типов пользователей.
У меня есть клиент, который использует наше программное обеспечение на серверах коммерческих веб-приложений. Программное обеспечение работает на 40 серверах. Программное обеспечение представляет собой Java API 10-летней давности.
4000 ТПС.
Сколько запросов в минуту считается «тяжелой нагрузкой»? (приблизительно)
спросил
Изменено
4 года, 4 месяца назад
Просмотрено
70 тысяч раз
Часто люди говорят в своих (связанных с оптимизацией и производительностью) вопросах и ответах о «большой нагрузке».
Я пытаюсь количественно оценить это в контексте обычного веб-приложения на типичном сервере (в качестве примера возьмем SO и его довольно небольшую инфраструктуру) в количестве запросов в минуту, предполагая, что они возвращаются немедленно (чтобы упростить и принять скорости базы данных и т. д. вне уравнения).
Я ищу номинальное число/диапазон, а не «где ЦП работает максимально» или что-то подобное. Грубое приближение было бы отличным (например,> 5000 / мин). Спасибо!
- server-load
Я думаю, что правильный ответ на этот вопрос, учитывая, что вам не нужна аппаратная загрузка (ЦП, память, использование ввода-вывода), состоит в том, что большая нагрузка — это количество запросов за раз единица на уровне или выше требуемого максимального количества запросов в единицу времени.
Требуемое максимальное количество запросов определяется заказчиком или лицом, ответственным за общую архитектуру.
Скажем, X — это требуемая максимальная нагрузка для приложения. Я думаю, что что-то вроде этого приблизилось бы к ответу:
Я думаю, что что-то вроде этого приблизилось бы к ответу:
0 < Легкая нагрузка < X/2 < Обычная нагрузка < 2X/3 < Высокая нагрузка < X <= Тяжелая нагрузка
Проблема с одним номером из воздуха заключается в том, что он не имеет никакого отношения к вашему приложению. И то, что такое тяжелая нагрузка, полностью, абсолютно, неуловимо связано с тем, что приложение должно делать.
Хотя 200 запросов в секунду — это нагрузка, которая заставит небольшие веб-серверы быть загруженными (~ 12000 в минуту).
0
Несколько сотен запросов в секунду.
Стандартное количество открытых соединений для большинства серверов обычно составляет около 256 или меньше, следовательно, 256 запросов в секунду. Вы можете увеличить его до 2000-5000 для запросов ping или до 500-1000 для облегченных запросов. Сделать его еще выше очень сложно и требует изменений в сети, оборудовании, ОС, серверном приложении и пользовательском приложении (см. задачу 10k).
задачу 10k).
Скорость поиска + задержка для жестких дисков составляет около 1-10 мс, для твердотельных накопителей - 0,1-1 мс . Итак, это 100-100 000 IOPS. Возьмем 100 000 в качестве верхнего значения (последующая запись на SSD)
Обычно соединение остается открытым не менее 1 x значение задержки мс. Задержка от клиента к серверу редко бывает ниже 50-100 мс , поэтому только 100 000/50 = 2000 IOPS могут создавать новые подключения.
Таким образом, 2000 запросов ping в секунду от разных клиентов — это базовый верхний предел для обычного сервера. Его можно улучшить за счет использования RAM-диска или добавления дополнительных твердотельных накопителей для увеличения количества операций ввода-вывода в секунду, маршрутизации запросов для уменьшения пинга, изменения/модификации ОС для уменьшения накладных расходов ядра и т. д. Обычно это также выше из-за того, что многие запросы поступают от одного и того же клиента (соединения) и вообще ограниченное количество клиентов. В хороших условиях она может доходить до сотен тысяч
С другой стороны, более высокий пинг, время выполнения приложения, несовершенство ОС и оборудования могут легко снизить базовое значение до нескольких сотен запросов в секунду. Кроме того, типичные веб-серверы и приложения обычно не очень хорошо подходят для высокоуровневой оптимизации, поэтому предложение Винко Врсаловича о 200 вполне реалистично.
Это не прямой вопрос, на который можно ответить простым числом запросов/минут.
В телекоммуникационном секторе мы часто проводим тестирование производительности и имитируем выполнение большого количества вызовов в секунду, чтобы попытаться выяснить предел. Мы продолжаем повышать скорость вызовов до тех пор, пока сервер не перестанет справляться.
Итак, это зависит от вашего сервера и того, что он может обрабатывать. Это также зависит от вашей точки зрения. Например, старый 386-й может обрабатывать лишь жалкие 50 запросов в минуту. Я бы назвал это легкой нагрузкой. Но сервер с высокими техническими характеристиками может обрабатывать 60 000 запросов в минуту. Это только предположение. Я понятия не имею, может ли Apache это сделать. Наше телекоммуникационное программное обеспечение, безусловно, может.
Но сервер с высокими техническими характеристиками может обрабатывать 60 000 запросов в минуту. Это только предположение. Я понятия не имею, может ли Apache это сделать. Наше телекоммуникационное программное обеспечение, безусловно, может.
Думаю, лучше всего ответить на этот вопрос с точки зрения сервера. Я бы сказал, что очень большая нагрузка — это когда вы приближаетесь к 10% от того, что ваш сервер способен обрабатывать в течение нескольких минут или десятков минут. Тяжелая нагрузка в пределах 15%.
Трудно ответить, потому что нагрузка — это не просто количество запросов в единицу времени. Это зависит от того, что делают эти запросы и как они реализуются.
Например, больше операций чтения, чем операций записи может означать меньшую нагрузку.
Асинхронная обработка записей может означать меньшую нагрузку, чем ожидание завершения синхронной обработки.
Одной крайностью могут быть системы торговли акциями, которые обрабатывают миллиарды транзакций каждый торговый день. Посмотрите на типичный объем на NYSE или NASDAQ и используйте его для оценки высокой стоимости в минуту.
Посмотрите на типичный объем на NYSE или NASDAQ и используйте его для оценки высокой стоимости в минуту.
Предположим, что 2 миллиарда транзакций в торговый день являются репрезентативными для NASDAQ. Рынки открываются в 9 утра и закрываются в 16:00, так что 7 часов * 3600 секунд/час = 25200 секунд. Это даст в среднем 2 млрд транзакций/25200 секунд = 79 365 транзакций в секунду — действительно очень высокая нагрузка. Очевидно, они используют много серверов, поэтому вам понадобится это число, чтобы выяснить, какой должна быть нагрузка на сервер.
Если SO можно считать хорошим эталоном, вы можете спросить о его объеме в мете.
2
Тяжелая нагрузка — это все, что превышает указанное в требованиях. Вам нужно знать, как будет использоваться ваше приложение, чтобы определить, что может представлять собой большую нагрузку. В противном случае вы можете в конечном итоге построить Феррари, который будет использоваться только для доставки продуктов.