Содержание
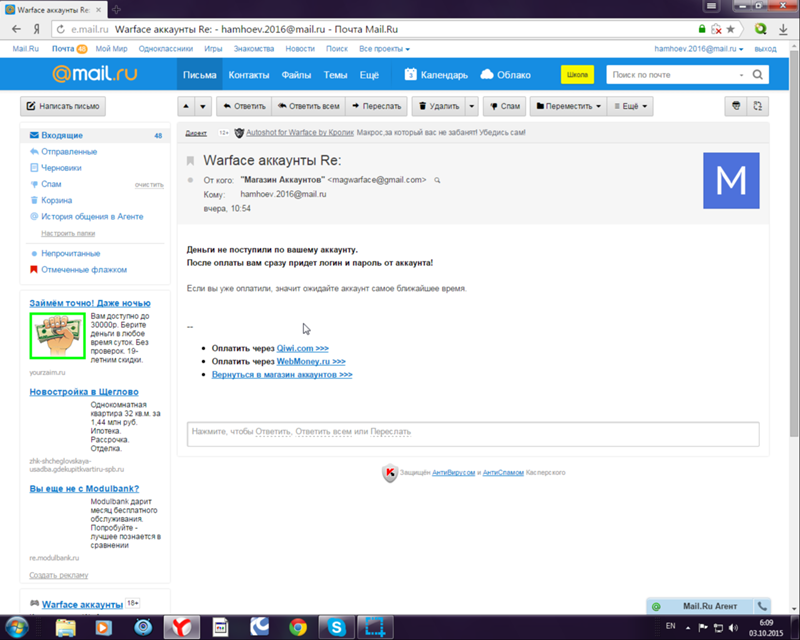
Поиск@Mail.Ru. Часть первая / Хабр
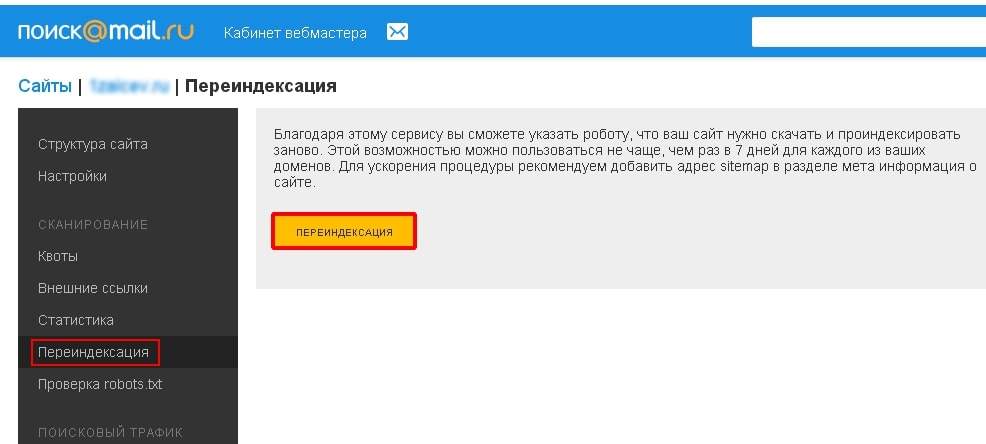
«У нас есть свой поиск!»
Два года подряд все свои выступления на конференциях я начинал этой фразой, ведь даже не все специалисты по поиску знали о том, что их запросы, заданные в поисковой строке Mail.Ru с большой долей вероятности обрабатывались не лицензированным сторонним движком, а внутренней разработкой компании.
Сейчас я вижу, что ситуация изменилась: многие знают и принимают наш поисковик. Однако вопросы или сомнения всё равно остаются – ну как так, Mail.Ru Group и пишет свой поиск? Mail.Ru Group — это почта, это социальные сети, развлечения… Что за поисковик они могут написать? Вот чтобы развеять эти сомнения, я и хочу рассказать о нашем поиске, о том, как мы его делаем, какие технологии используем, что хотим получить в итоге. Я надеюсь, что предлагаемая статья будет познавательной и интересной; более того, мы собираемся продолжить рассказ о наших технологиях уже более детально, и в следующих постах поговорить о машинном обучении, спайдере, антиспаме и т. п.
п.
GoGo.Ru
Поисковая система Mail.Ru начала разрабатываться в 2004 году Михаилом Костиным, бывшим руководителем поисковой системы aport.ru. В 2007 году поисковик был представлен под именем GoGo на домене gogo.ru.
Уже тогда GoGo обладал довольно интересными свойствами: он мог ограничивать область поиска коммерческими и информационными сайтами, а также форумами и блогами. Через некоторое время в нём появился поиск по картинкам и первый в рунете поиск по видео.
Много внимания в нём было уделено ранжированию и оптимизации времени выполнения поисковых запросов. Например, формула текстового ранжирования GoGo участвовала в конкурсе РОМИП (Российского семинара по оценке методов информационного поиска), где показала лучшие результаты среди всех участников (см. www.romip.ru/romip2005/09_mailru.pdf ).
От GoGo — к Go.Mail.Ru
Всё это время запросы, которые вводятся на главной странице портала Mail.Ru, выполнял лицензированный поисковый движок; сначала это был движок Google, потом — Яндекса. Но в 2009 году контракт с Яндексом закончился, и было решено c 1 января 2010 года попробовать свой собственный поисковик.
Но в 2009 году контракт с Яндексом закончился, и было решено c 1 января 2010 года попробовать свой собственный поисковик.
Позже мы заключили партнерство с поисковым движком Google на следующих условиях: часть запросов обрабатывает Google, другую — мы. Но это произошло только в августе 2010 года, и в течение восьми месяцев Поиск работал полностью на собственном движке.
С точки зрения разработчиков это означало совершенно иные требования к поиску: если раньше gogo.ru обслуживал сотни тысяч запросов в день, то теперь ему нужно было обслуживать десятки миллионов. Предполагаемый рост нагрузки на два порядка требовал новых архитектурных решений. Самым значительным изменением был подъём обратного индекса в оперативную память: раньше он лежал на жёстком диске, что не давало возможности уложиться в требуемое время ответа до 300 миллисекунд на запрос. И на все изменения у команды разработчиков было всего несколько месяцев, 1 января 2010 года новый поисковик должен был работать и обслуживать запросы пользователей портала Mail. Ru.
Ru.
Такая задача относится к классу «mission impossible», но разработчики совершили трудовой подвиг и с ней успешно справились: переключение на новый поисковик произошло в 0:00 1 января 2010 года. Первый коммит в репозиторий Поиска, исправляющий одну из свежеобнаруженных проблем, произошёл уже в три часа новогодней ночи. И после этого, пока большая часть страны находилась на новогодних каникулах, команда Поиска, что называется, «держала небо», постоянно находя и исправляя самые разные баги.
Проблемы со стабильностью Поиска возникали и решались в течение всего года, но первые три месяца были самыми напряжёнными и требующими максимальной отдачи от всех разработчиков поисковой системы. При этом окончательно потушить пожар смогли, наверное, только к августу 2010 года. После этого Поиск наконец-то зажил нормальной жизнью, и разработчики смогли переключаться на более долгосрочные задачи, чем исправление очередной критической проблемы. В частности, можно было задуматься о том, насколько вообще текущая архитектура Поиска соответствует стоящим перед нами задачам.
Что было у нас: историческая справка за 2010 год
В 2010 году внутренняя презентация об архитектуре Поиска схематично показывала его примерно таким образом:
- Спайдер, качает веб. Это 24 сервера, обкачивающие каждый свою часть веба. Какую часть обкачивать, определялось хешем от имени домена. Спайдеры содержали внутри себя базу скачанных страниц, и сами определяли, что нужно качать, а что — нет.
- Индексаторы, создают готовые индексы баз. Их тоже было порядка 30 штук на конец 2010 года. Кроме непосредственно индексации, они выполняли анализ поступающих страниц на спам, порнографию и т.п., выделяли интересующие данные для обсчёта, например, ссылки для последующего построения индекса цитирования.
- Batch-серверы (около 20 штук), выполняющие обсчёты внешних данных, того же ИЦ. Расчёты были самые разнообразные: некоторые — быстрые, некоторые — медленные.
- Поисковый кластер, полторы сотни серверов. Принимали базы от индексаторов и непосредственно выполняли поисковые запросы пользователей.

В 2010 году стало понятно, что в организации хранения и обработки данных есть довольно много архитектурных изъянов: Поиск быстро развился от состояния «несколько десятков серверов» до «несколько сотен серверов», количество обрабатываемых данных и требования к скорости их обработки стали возрастать, и старые методы уже не удовлетворяли насущным требованиям к качеству работы. Например, расчёт индекса цитирования производился на одном сервере и теперь работал месяц. Если сервер за это время перезагружался или процессу не хватало памяти, то приходилось начинать всё заново; таким образом, индекс цитирования в какой-то момент времени просто перестал обновляться.
Множество исходных данных, размещаемых в индексе, рассчитывалось на разных серверах, под разными пользователями и доставлялись в индекс какими-то уникальными для данного вида данных путями. В итоге разработчики путались в том, откуда что берётся: несколько раз мы обнаруживали, что те или иные факторы по какой-то причине «отвалились» от индекса ещё месяц назад, и никто до сих пор этого не замечал.
Разработчики часто решали одни и те же задачи: как «распилить» входные данные таким образом, чтобы можно было бы распараллелить их обсчёт по нескольким дискам, а потом и по нескольким серверам. Все решения были в чём-то похожи, но в чём-то и отличались друг от друга, а кроме того, часто разработчики повторяли один и тот же тернистый путь построения системы распределённых вычислений с нуля, что явно не способствовало эффективной разработке.
Большую проблему составляло наличие двух баз документов: одна — у спайдера, другая – у индексатора. Это приводило к размытию решения относительно судьбы одного и того же документа — например, анализ спамности на индексаторе мог принять решение выкинуть документ из индекса, а спайдер продолжал бы его качать. Или, наоборот, спайдер мог выкинуть документ из своей базы по каким-то причинам, но команда на удаление документа из индекса могла из-за технического сбоя не дойти до индексатора, так что документ оставался в индексе надолго, до очередной чистки мусора.
Стало ясно, что для того, чтобы продолжать разработку поиска, нужен иной, новый подход: нам не хватало единой платформы для распределённого выполнения задач, высокопроизводительной базы данных. Предстояло сделать выбор между самостоятельной разработкой и готовым решением, и, во втором случае — найти вариант, который устраивал бы нас в плане стабильности и быстро работал бы на наших нагрузках.
В следующих постах я расскажу о том, как мы вырабатывали и реализовывали этот подход, а также о том, как работают другие поисковые системы.
Андрей Калинин,
Руководитель разработчиков Поиска Mail.ru
обзор архитектур подготовки данных больших поисковых систем / Хабр
Обзор архитектур подготовки данных больших поисковых систем
В прошлый раз мы с вами вспомнили, как стартовал в 2010 году Go.Mail.Ru, и каким Поиск был до этого. В этом посте мы попробуем нарисовать общую картину — остановимся на том, как работают другие, но сначала расскажем о поисковой дистрибуции.
Как распространяются поисковые системы
Как вы и просили, мы решили подробнее остановиться на основах дистрибуционных стратегий самых популярных поисковых систем.
Бытует мнение, что интернет-поиск – один из тех сервисов, которые большинство пользователей выбирает самостоятельно, и победить в этой битве должен сильнейший. Эта позиция нам крайне симпатична – именно ради этого мы постоянно совершенствуем наши поисковые технологии. Но ситуация на рынке вносит свои корректировки, и в первую очередь сюда вмешиваются так называемые «браузерные войны».
Было время, когда поиск не был связан с браузером. Тогда поисковая система была просто очередным сайтом, на который пользователь заходил по своему усмотрению. Представьте себе —Internet Explorer до 7-й версии, появившейся в 2006-м году, не имел строки поиска; Firefox имел строку поиска с первой версии, но сам он при этом появился только в 2004-м году.
Откуда же взялась строка поиска? Придумали её не авторы браузеров — впервые она появилась в составе Google Toolbar, вышедшего в 2001-м году. Google Toolbar добавлял в браузер функциональность «быстрого доступа к поиску Google» – а именно, поисковую строчку в свою панель:
Google Toolbar добавлял в браузер функциональность «быстрого доступа к поиску Google» – а именно, поисковую строчку в свою панель:
Зачем Google выпустил свой тулбар? Вот как описывает его предназначение Дуглас Эдвардс, бренд-менеджер Гугла в тот момент, в своей книге «I’m Feeling Lucky: The Confessions of Google Employee Number 59»:
«The Toolbar was a secret weapon in our war against Microsoft. By embedding the Toolbar in the browser, Google opened another front in the battle for unfiltered access to users. Bill Gates wanted complete control over the PC experience, and rumors abounded that the next version of Windows would incorporate a search box right on the desktop. We needed to make sure Google’s search box didn’t become an obsolete relic».
«Toolbar был секретным оружием в войне против Microsoft. Интегрировав Toolbar в браузер, Google открыл очередной фронт в битве за прямой доступ к пользователям. Биллу Гейтсу хотелось полностью контролировать то, как пользователи взаимодействуют с ПК: множились слухи, что в следующей версии Windows строка поиска будет устанавливаться прямо на рабочий стол. Необходимо было принять меры, чтобы строка поиска Google не стала пережитком прошлого».
Необходимо было принять меры, чтобы строка поиска Google не стала пережитком прошлого».
Как распространялся тулбар? Да всё так же, вместе с популярным программным обеспечением: RealPlayer, Adobe Macromedia Shockwave Player и т.п.
Понятно, что другие поисковики начали распространять свои тулбары (Yahoo Toolbar, например), а производители браузеров не преминули воспользоваться этой возможностью получения дополнительного источника доходов от поисковых систем и встроили поисковую строчку к себе, введя понятие «поисковик по умолчанию».
Бизнес-департаменты производителей браузеров выбрали очевидную стратегию: браузер — точка входа пользователя в интернет, настройки поиска по умолчанию с высокой вероятностью будут использоваться аудиторий браузера — так почему бы не продать эти настройки? И они были по-своему правы, ведь интернет-поиск — это продукт с практически нулевой «приклеиваемостью».
На этом пункте стоит остановиться подробнее. Многие возмутятся: «нет, человек привыкает к поиску и пользуется только той системой, которой доверяет», но практика доказывает обратное. Если, скажем, ваш почтовый ящик или аккаунт соц. сети по какой-то причине недоступен, вы не переходите тут же в другой почтовый сервис или другую социальную сеть, ведь вы «приклеены» к своим аккаунтам: их знают ваши друзья, коллеги, семья. Смена аккаунта — долгий и болезненный процесс. С поисковиками же всё совсем иначе: пользователь не привязан к той или иной системе. Если поисковик по каким-то причинам недоступен, пользователи не сидят и не ждут, когда он, наконец, заработает — они просто идут в другие системы (например, мы отчётливо видели это по счётчикам LiveInternet год назад, во время сбоев у одного из наших конкурентов). При этом пользователи не сильно страдают от аварии, ведь все поисковики устроены примерно одинаково (поисковая строка, запрос, страница результатов) и даже неопытный юзер не растеряется при работе с любым из них. Более того, примерно в 90% случаев пользователь получит ответ на свой вопрос, в какой бы системе он его ни искал.
Если, скажем, ваш почтовый ящик или аккаунт соц. сети по какой-то причине недоступен, вы не переходите тут же в другой почтовый сервис или другую социальную сеть, ведь вы «приклеены» к своим аккаунтам: их знают ваши друзья, коллеги, семья. Смена аккаунта — долгий и болезненный процесс. С поисковиками же всё совсем иначе: пользователь не привязан к той или иной системе. Если поисковик по каким-то причинам недоступен, пользователи не сидят и не ждут, когда он, наконец, заработает — они просто идут в другие системы (например, мы отчётливо видели это по счётчикам LiveInternet год назад, во время сбоев у одного из наших конкурентов). При этом пользователи не сильно страдают от аварии, ведь все поисковики устроены примерно одинаково (поисковая строка, запрос, страница результатов) и даже неопытный юзер не растеряется при работе с любым из них. Более того, примерно в 90% случаев пользователь получит ответ на свой вопрос, в какой бы системе он его ни искал.
Итак, поиск, с одной стороны имеет практически нулевую «приклеиваемость» (в английском языке есть специальный термин «stickiness»). С другой — какой-то поиск уже предустановлен в браузер по умолчанию, и довольно большое количество людей будет использовать его только по той причине, что им удобно пользоваться именно оттуда. И если поиск, стоящий за поисковой строчкой, удовлетворяет задачам пользователя, то он может продолжить его использовать.
С другой — какой-то поиск уже предустановлен в браузер по умолчанию, и довольно большое количество людей будет использовать его только по той причине, что им удобно пользоваться именно оттуда. И если поиск, стоящий за поисковой строчкой, удовлетворяет задачам пользователя, то он может продолжить его использовать.
К чему мы приходим? У ведущих поисковых систем не осталось другого выхода, кроме как бороться за поисковые строки браузеров, распространяя свои десктопные поисковые продукты — тулбары, которые в процессе инсталляции меняют дефолтный поиск в барузере пользователя. Зачинщиком этой борьбы был Google, остальным пришлось защищаться. Можно, к примеру, прочитать такие слова Аркадия Воложа, создателя и владельца Яндекса, в его интервью:
«Когда в 2006–2007гг. доля Google на российском поисковом рынке стала расти, мы сначала не могли понять, из-за чего. Потом стало очевидно, что Google продвигает себя путем встраивания в браузеры (Opera, Firefox). А с выходом собственного браузера и мобильной операционной системы Google вообще стал разрушать соответствующие рынки».
Так как Mail.Ru – это ещё и поиск, то он не может стоять в стороне от «браузерных войн». Мы просто вышли на рынок немного позже других. Сейчас качество нашего Поиска заметно выросло, и наша дистрибуция является реакцией на ту самую борьбу тулбаров, которая ведётся на рынке. При этом для нас действительно важно, что всё большее количество людей, которые пробуют пользоваться нашим Поиском, остаются довольны результатами.
К слову, наша дистрибуционная политика в несколько раз менее активна, чем у ближайшего конкурента. Мы видим это по счётчику top.mail.ru, который установлен на большей части сайтов рунета. Если пользователь переходит на сайт по запросу через один из дистрибуционных продуктов (тулбар, собственный браузер, сёрчбокс браузера-партнёра), в URL присутствует параметр clid=… Таким образом, мы можем оценить ёмкость дистрибуционных запросов: у конкурента она почти в 4 раза больше, чем у нас.
Но давайте от дистрибуции перейдем к тому, как устроены другие поисковые системы. Ведь внутренние обсуждения архитектуры мы, естественно, начинали с изучения архитектурных решений других поисковиков. Я не буду подробно описывать их архитектуры — вместо этого я дам ссылки на открытые материалы и выделю те особенности их решений, которые мне кажутся важными.
Ведь внутренние обсуждения архитектуры мы, естественно, начинали с изучения архитектурных решений других поисковиков. Я не буду подробно описывать их архитектуры — вместо этого я дам ссылки на открытые материалы и выделю те особенности их решений, которые мне кажутся важными.
Подготовка данных в крупных поисковых системах
Рамблер
Поисковая система Рамблер, ныне закрытая, обладала рядом интересных архитектурных идей. Например, было известно об их собственной системе хранения данных (NoSQL, как сейчас модно называть подобные системы) и распределённых вычислений HICS (или HCS), использовавшейся, в частности, для вычислений на графе ссылок. Так же HICS позволял стандартизировать представление данных внутри поиска единым универсальным форматом.
Архитектура Рамблера довольно сильно отличалась от нашей в организации спайдера. У нас спайдер был выполнен как отдельный сервер, со своей, самописной, базой адресов скачанных страниц. Для выкачки каждого сайта запускался отдельный процесс, который одновременно качал страницы, парсил их, выделял новые ссылки и мог сразу же по ним пойти. Спайдер Рамблера был сделан значительно проще.
Для выкачки каждого сайта запускался отдельный процесс, который одновременно качал страницы, парсил их, выделял новые ссылки и мог сразу же по ним пойти. Спайдер Рамблера был сделан значительно проще.
На одном сервере был расположен большой текстовый файл со всеми известными Рамблеру адресами документов, по одному на строку, отсортированный в лексикографическом порядке. Раз в сутки этот файл обходился и генерировались другие текстовые файлы-задания на выкачку, которые выполнялись специальными программами, умеющими только скачивать документы по списку адресов. Затем документы парсились, извлекались ссылки и клались рядом с этим большим файлом-списком всех известных документов, сортировались, после чего списки сливались в новый большой файл, и цикл повторялся снова.
Достоинства такого подхода были в простоте, наличии единого реестра всех известных документов. Недостатки заключались в невозможности пройти по свежеизвлечённым адресам документов сразу же, так как скачивание новых документов могло случиться только на следующей итерации спайдера. Кроме того, размер базы и скорость её обработки была ограничена одним сервером.
Кроме того, размер базы и скорость её обработки была ограничена одним сервером.
Наш же спайдер, наоборот, мог быстро пройти по всем новым ссылкам с сайта, но очень плохо управлялся снаружи. В него было тяжело «влить» дополнительные данные к адресам (необходимые для ранжирования документов внутри сайта, определяющие приоритетность выкачки), трудно было сделать дамп базы.
Яндекс
О внутреннем устройстве поиска Яндекса было известно не так много до тех пор, пока Ден Расковалов не рассказал о нём в своём курсе лекций.
Оттуда можно узнать, что поиск Яндекса состоит из двух разных кластеров:
- пакетной обработки данных
- обработки данных в реальном времени (это не совсем уж «реальное время» в том смысле, в котором этот термин используется в системах управления, где просрочка времени выполнения задач может быть критичной. Скорее, это возможность попадания документа в индекс максимально быстро и независимо от других документов или задач; этакий «мягкий» вариант реального времени)
Первый используется для штатной обкачки интернета, второй – для доставки в индекс самых лучших и интересных документов, появившихся только что. Будем рассматривать пока что только пакетную обработку, потому что до обновления индекса в реальном времени нам тогда было довольно далеко, мы хотели выйти на обновление индекса раз в один-два дня.
Будем рассматривать пока что только пакетную обработку, потому что до обновления индекса в реальном времени нам тогда было довольно далеко, мы хотели выйти на обновление индекса раз в один-два дня.
При этом, несмотря на то, что внешне кластер пакетной обработки данных Яндекса был в чём-то похож на нашу пару качающих и индексирующих кластеров, в нём было и несколько серьёзных отличий:
- База адресов страниц одна, хранится на индексирующих узлах. Как следствие, нет проблем с синхронизацией двух баз.
- Управление логикой выкачки перенесено на индексирующие узлы, т.е. узлы спайдера очень простые, качают то, что им указывают индексаторы. У нас спайдер сам определял, что ему и когда скачать.
- И, очень важное отличие, — внутри все данные представлены в виде реляционных таблиц документов, сайтов, ссылок. У нас же все данные были разнесены по разным хостам, хранились в разных форматах. Табличное представление данных значительно упрощает доступ к ним, позволяет делать различные выборки и получать самую разнообразную аналитику индекса. Всего этого мы были лишены, и на тот момент только лишь синхронизация двух наших баз документов (спайдера и индексатора) занимала неделю, причём нам приходилось останавливать на это время оба кластера.
 Всего этого мы были лишены, и на тот момент только лишь синхронизация двух наших баз документов (спайдера и индексатора) занимала неделю, причём нам приходилось останавливать на это время оба кластера.
Всего этого мы были лишены, и на тот момент только лишь синхронизация двух наших баз документов (спайдера и индексатора) занимала неделю, причём нам приходилось останавливать на это время оба кластера.
Google, без сомнений, является мировым технологическим лидером, поэтому на него всегда обращают внимание, анализируют что он сделал, когда и зачем. А архитектура поиска Google, естественно, была для нас самой интересной. К сожалению, свои архитектурные особенности Google открывает редко, каждая статья – большое событие и практически моментально порождает параллельный OpenSource-проект (иногда и не один) реализующий описываемые технологии.
Тем, кому интересны особенности поиска Google, можно с уверенностью посоветовать изучить практически все презентации и выступления одного из самых главных специалистов в компании по внутренней инфраструктуре — Джеффри Дина (Jeffrey Dean), например:
- «Challenges in Building Large-Scale Information Retrieval Systems» (слайды) благодаря которым можно узнать, как развивался Google, начиная с самой первой версии, которая ещё была сделана студентами и аспирантами Стэнфордского университета и до 2008-го года, до внедрения Universal Search. Есть видеозапись этого выступления и аналогичное выступление в Стэндфорде, «Building Software Systems At Google and Lessons Learned»
- «MapReduce: Simplified Data Processing on Large Clusters». В статье описывается вычислительная модель, позволяющая легко распараллелить вычисления на большом количестве серверов. Сразу же после этой публикации появилась опенсорсная платформа Hadoop.
- «BigTable: A Distributed Structured Storage System», рассказ о NoSQL-базе данных BigTable, по мотивам которой были сделаны HBase и Cassandra (видео можно найти тут, слайды — здесь)
- «MapReduce, BigTable, and Other Distributed System Abstractions for Handling Large Datasets» — описание cамых известных технологий Google.
 Есть видеозапись этого выступления и аналогичное выступление в Стэндфорде, «Building Software Systems At Google and Lessons Learned»
Есть видеозапись этого выступления и аналогичное выступление в Стэндфорде, «Building Software Systems At Google and Lessons Learned»
Основываясь на этих выступлениях, можно выделить следуюшие особенности архитектуры поиска Google:
- Табличная структура для подготовки данных. Вся база поиска хранится в огромной таблице, где ключом является адрес документа, а метаинформация сохраняется в отдельных колонках, объединённых в семейства. Причём таблица изначально сделана таким образом, чтобы эффективно работать с разреженными данными( т.е. когда значения в колонках есть далеко не у всех документов).
- Единая система распределённых вычислений MapReduce. Подготовка данных (включая создание поискового индекса) является последовательностью mapreduce-задач, выполняемых над таблицами BigTable или файлами в распределённой файловой системе GFS.
 Причём таблица изначально сделана таким образом, чтобы эффективно работать с разреженными данными( т.е. когда значения в колонках есть далеко не у всех документов).
Причём таблица изначально сделана таким образом, чтобы эффективно работать с разреженными данными( т.е. когда значения в колонках есть далеко не у всех документов).
Всё это выглядит довольно разумно: все известные адреса документов сохраняются в одной большой таблице, по ней выполняется их приоритезация, вычисления над ссылочным графом и т.п., в неё приносит содержимое выкачанных страниц паук поиска, по ней в итоге строится индекс.
Есть ещё одно интересное выступление уже другого специалиста Google, Дэниела Пенга (Daniel Peng) про новшества в BigTable, позволившие реализовать быстрое, в течение нескольких минут, добавление новых документов в индекс. Эта технология «снаружи» Google была разрекламирована под названием Caffeine, а в публикациях получила название Percolator. Видео выступления на OSDI’2010 можно посмотреть здесь.
Видео выступления на OSDI’2010 можно посмотреть здесь.
Если говорить очень грубо, то это тот же самый BigTable, но в котором реализованы т.н. триггеры, — возможность загрузить свои кусочки кода, которые срабатывают на изменения внутри таблицы. Если до сих пор я описывал пакетную обработку данных, т.е. когда данные по возможности объединяются и обрабатываются вместе, то реализация того же на триггерах получается совершенно иной. Допустим, спайдер что-то скачал, поместил в таблицу новое содержимое; сработал триггер, сигнализирующий «появился новый контент, его нужно проиндексировать». Немедленно запустился процесс индексации. Получается, что все задачи поисковика в итоге могут быть разбиты на подзадачи, каждая из которых запускается по своему щелчку. Имея большое количество техники, ресурсов и отлаженный код, можно решать задачу добавления новых документов быстро, буквально за минуту — что и продемонстрировал Google.
Отличие архитектуры Google от архитектуры Яндекса, где тоже была указана система обновления индекса в режиме реального времени, в том, что в Google, как утверждается, вся процедура построения индекса выполнена на триггерах, а у Яндекса она есть только для небольшого подмножества самых лучших, самых ценных документов.
Lucene
Стоит упомянуть и ещё об одном поисковике – Lucene. Это свободно распространяемый поисковик, написанный на Java. В некотором смысле, Lucene является платформой для создания поисковиков, например, от него отпочковался поисковик по вебу под названием Nutch. По сути, Lucene — это поисковое ядро для создания индекса и поискового движка, а Nutch — это то же самое плюс спайдер, который обкачивает страницы, потому что поисковик не обязательно ищет по документам, которые находится в вебе.
На самом деле, в самом Lucene реализовано не так много интересных решений, которые могла бы позаимствовать большая поисковая система по вебу, рассчитанная на миллиарды документов. С другой стороны, не стоит забывать, что именно разработчики Lucene запустили проекты Hadoop и HBase (каждый раз, когда появлялась новая интересная статья от Google, авторы Lucene пытались применить озвученные решения у себя. Так, например, возник HВase, который является клоном BigTable). Однако эти проекты давно уже существуют сами по себе.
Однако эти проекты давно уже существуют сами по себе.
Для меня в Lucene/Nutch было интересно то, как они использовали Hadoop. Например, в Nutch для обкачки веба был написан специальный спайдер, выполненный целиком в виде задач для Hadoop. Т.е. весь спайдер – это просто процессы, которые запускаются в Hadoop в парадигме MapReduce. Это довольно необычное решение, выбивающееся за рамки того, как Hadoop используется. Ведь это платформа для обработки больших объёмов данных, а это предполагает, что данные уже имеются. А здесь эта задача ничего не вычисляет или обрабатывает, а, наоборот, скачивает.
С одной стороны, такое решение подкупает своей простотой. Ведь спайдеру необходимо получить все адреса одного сайта для обкачки, обходить их друг за другом, сам спайдер тоже должен быть распределённым и запускаться на нескольких серверах. Вот мы и делаем мэппер в виде разделителя адресов по сайтам, а каждый индивидуальный процесс выкачки реализуем в виде редьюсера.
С другой стороны, это довольно смелое решение, потому что сайты обкачивать тяжело — не каждый сайт отвечает за гарантированное время, и вычислительные ресурсы кластера тратятся на то, чтобы он просто ждал ответа от чужого веб-сервера. Причём проблема «медленных» сайтов всегда есть при наличии достаточно большого количества адресов на выкачку. Спайдер за 20% времени обкачивает 80% документов с быстрых сайтов, потом тратит 80% времени в попытках обкачать медленные сайты – и практически никогда не может их обкачать целиком, всегда приходится что-то бросать и оставлять «на следующий раз».
Причём проблема «медленных» сайтов всегда есть при наличии достаточно большого количества адресов на выкачку. Спайдер за 20% времени обкачивает 80% документов с быстрых сайтов, потом тратит 80% времени в попытках обкачать медленные сайты – и практически никогда не может их обкачать целиком, всегда приходится что-то бросать и оставлять «на следующий раз».
Мы некоторое время анализировали такое решение, и в результате отказались от него. Пожалуй, для нас архитектура этого спайдера была интересна как, своего рода, «отрицательный пример».
Подробнее о структуре нашего поисковика, о том, как мы строили поисковую систему, я расскажу в следующем посте.
Удалить вирус поисковой системы go.mail.ru из Chrome, Firefox и IE
Содержание
Очень неприятно сталкиваться с компьютерной инфекцией, такой как вирус go.mail.ru , который без разрешения перенаправляет браузер на нежелательный сайт.
Что такое вирус go.mail.ru?
Многие веб-службы сталкиваются с этической дилеммой в какой-то момент своего развития. Все сводится к выбору механизма продвижения: агрессивного или совсем ненавязчивого. Некоторым провайдерам удается найти баланс, но многие в конечном итоге буквально заставляют людей использовать все, что они могут предложить. Вирус go.mail.ru — яркий пример чересчур прямолинейного маркетинга, набирающего обороты в наши дни. Это вредоносное приложение использует функцию поиска в Интернете, связанную с mail.ru, одним из самых популярных почтовых веб-сервисов в России. Проблема в том, что многие пользователи из-за пределов этой страны сообщают о случаях взлома браузера, где целевой страницей является go.mail.ru. Даже в случае русскоязычной аудитории онлайн-серфинг многочисленных жертв перенаправляется на указанный сайт без какой-либо явной авторизации.
Все сводится к выбору механизма продвижения: агрессивного или совсем ненавязчивого. Некоторым провайдерам удается найти баланс, но многие в конечном итоге буквально заставляют людей использовать все, что они могут предложить. Вирус go.mail.ru — яркий пример чересчур прямолинейного маркетинга, набирающего обороты в наши дни. Это вредоносное приложение использует функцию поиска в Интернете, связанную с mail.ru, одним из самых популярных почтовых веб-сервисов в России. Проблема в том, что многие пользователи из-за пределов этой страны сообщают о случаях взлома браузера, где целевой страницей является go.mail.ru. Даже в случае русскоязычной аудитории онлайн-серфинг многочисленных жертв перенаправляется на указанный сайт без какой-либо явной авторизации.
Жертвы продолжают посещать go.mail.ru в результате перенаправления браузера
Вот в чем дело: данная поисковая система легальна, и, вероятно, ее не следует обвинять в демонстративном захвате веб-браузеров. Тем не менее, есть люди, направляющие трафик на него теневым образом. Зачем? Скорее всего, деньги получат заинтересованные стороны, возможно, в том числе и сам go.mail.ru. Когда происходит «классический» захват браузера, подобный этому, веб-навигация зараженного пользователя сначала направляется через ряд промежуточных доменов и только затем достигает якобы безопасного и уважаемого места. Каждое такое незаметное попадание фиксируется в хитрых рамках монетизации, и авторы вируса загребают прибыль, уменьшая при этом возможности просмотра для жертв.
Зачем? Скорее всего, деньги получат заинтересованные стороны, возможно, в том числе и сам go.mail.ru. Когда происходит «классический» захват браузера, подобный этому, веб-навигация зараженного пользователя сначала направляется через ряд промежуточных доменов и только затем достигает якобы безопасного и уважаемого места. Каждое такое незаметное попадание фиксируется в хитрых рамках монетизации, и авторы вируса загребают прибыль, уменьшая при этом возможности просмотра для жертв.
Несмотря на то, что вирус go.mail.ru обходит согласие пользователей на изменение определенных системных настроек, его проникновение в компьютер всегда зависит от того, что потенциальная жертва выбирает. Однако решение, как правило, является необдуманным. Типичный сценарий заражения связан с маневром связывания, когда часть безопасного программного обеспечения устанавливается вместе с виновником. Никаких подробностей о комбо не упоминается на экранах настройки по умолчанию, что объясняет, почему многие люди не знают о вредоносном ПО.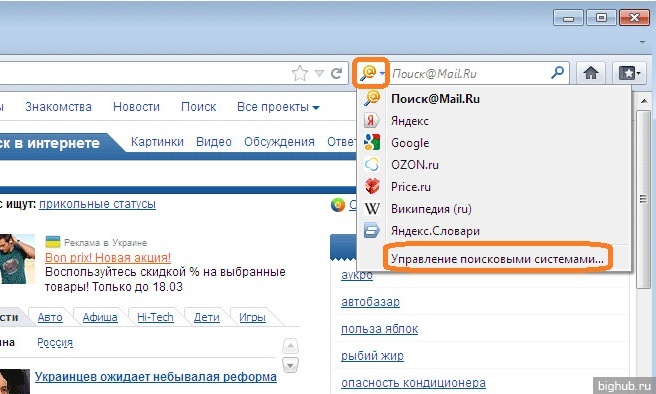 Находясь внутри и работая, нежелательный код становится упорным на хосте, добавляя запланированную задачу, которая повторно выполняет плохой двоичный файл, если пользователь завершает работу. Активная фаза атаки предполагает замену настроек браузера на go.mail.ru. Настройки, которые подлежат этой настройке, включают предпочтительную поисковую систему и домашнюю страницу по умолчанию.
Находясь внутри и работая, нежелательный код становится упорным на хосте, добавляя запланированную задачу, которая повторно выполняет плохой двоичный файл, если пользователь завершает работу. Активная фаза атаки предполагает замену настроек браузера на go.mail.ru. Настройки, которые подлежат этой настройке, включают предпочтительную поисковую систему и домашнюю страницу по умолчанию.
Таким образом, жертва будет заходить на российский сайт всякий раз, когда вводит ключевые слова в омнибоксе или просто запускает Chrome, Firefox или Internet Explorer. Это явно не тот способ, которым должен работать веб-серфинг, поэтому удаление вредоносного ПО стоит на повестке дня любого зараженного. К счастью, процесс очистки не слишком сложен — подробности см. Ниже.
Автоматическое удаление вируса поисковой системы go.mail.ru
Когда дело доходит до борьбы с подобными инфекциями, следует начать с использования надежного инструмента очистки. Придерживаясь этого рабочего процесса, каждый компонент рекламного ПО будет обнаружен и удален с зараженного компьютера.
1 . Загрузите и установите средство очистки и нажмите кнопку Start Computer Scan .
Скачать утилиту для удаления Go.mail.ru
2 . Ожидание того стоит. После завершения сканирования вы увидите отчет со списком всех вредоносных или потенциально нежелательных объектов, обнаруженных на вашем ПК. Нажмите на опцию Fix Threats , чтобы автоматически удалить перенаправление Go.mail.ru с вашего компьютера вместе со всеми его модулями. Когда это будет сделано, вы должны быть готовы идти.
Удаление Go.mail.ru через панель управления
- В меню Windows перейдите к Панель управления . Выберите Установка и удаление программ (для Windows XP/Windows 8) или Удаление программы (Windows Vista/Windows 7)
- Найдите в списке Go.mail.ru . Если его нигде нет, поищите программы, связанные с мультимедиа (например, Flash Enhancer ) или другие странные приложения, которые вы недавно устанавливали.
Выберите подозрительный и нажмите Удалить/Изменить

Удаление вируса перенаправления go.mail.ru из веб-браузеров вручную
Рабочий процесс, описанный ниже, предназначен для отмены всех изменений, внесенных вирусом Go.mail.ru в Chrome, Firefox и Internet Explorer. Исправление включает в себя несколько шагов: удаление вредоносного расширения; и (если предыдущее действие оказалось неэффективным) сброс браузера. Имейте в виду, что в последнем случае вы столкнетесь с некоторыми сопутствующими неудобствами, а именно с потерей всех установленных надстроек и персонализированной информации (сохраненных паролей, кэшированных данных, закладок и другого контента).
Удалить Go.mail.ru в Chrome
1. Удалите расширение Go.mail.ru
- Щелкните значок меню Chrome и выберите Дополнительные инструменты > Расширения
- Найдите надстройку, связанную с Go. mail.ru , и нажмите на корзину рядом с плохой записью.
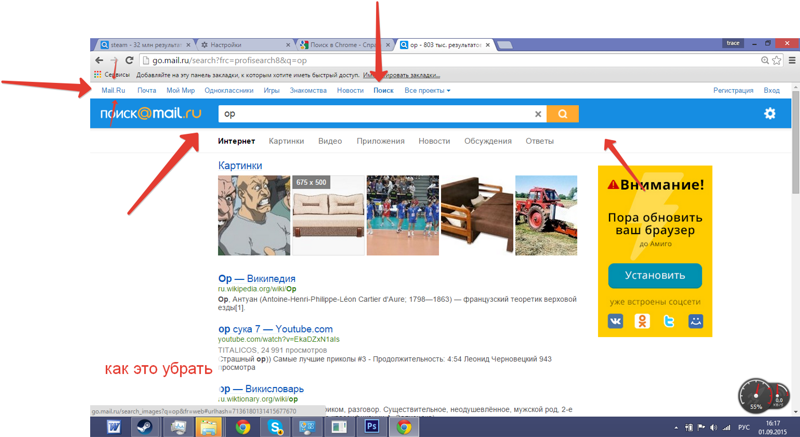 mail.ru , и нажмите на корзину рядом с плохой записью.
mail.ru , и нажмите на корзину рядом с плохой записью.2. Восстановить настройки домашней страницы по умолчанию
- Вернитесь в меню Chrome и выберите Настройки
- Перейдите в подраздел При запуске и активируйте опцию Открыть определенную страницу или набор страниц . Также нажмите Задать страницы
- Найдите Go.mail.ru введите под Startup pages и нажмите кнопку X рядом с ним
3. Восстановить правильные параметры поиска
- Перейдите к Управление поисковыми системами и выберите услугу, которую вы предпочитаете использовать.
4. Перезапустите Google Chrome
Удалить Go.mail.ru в Firefox
1. Удалите соответствующую надстройку
- В Firefox перейдите в Инструменты > Дополнения
- Перейдите на вкладку Extensions и найдите в списке Go.mail.ru . Нажмите Удалить , чтобы избавиться от него
2. Исправить настройки домашней страницы
- Перейти к Инструменты > Опции
- Перейдите на вкладку General и нажмите Restore to Default (см. изображение ниже).
3. Установите предпочтительного поставщика поиска
Установите предпочтительного поставщика поиска
- Щелкните значок лупы в окне поиска Firefox и выберите Изменить настройки поиска .
- Выберите поисковую систему для использования по умолчанию и нажмите OK , чтобы сохранить изменения.
4. Перезапустите Mozilla Firefox
удаление из Internet Explorer
- Откройте ИЕ. Перейдите к Инструменты > Управление надстройками
- Выберите Панели инструментов и расширения на панели навигации найдите элементы, относящиеся к Go.mail.ru , включая Go.mail.ru API , щелкните правой кнопкой мыши каждый из них, выберите
Удалить в контекстном меню - Перезапустите IE и проверьте наличие симптомов заражения. Если реклама Go.mail.ru больше не появляется, то никаких дальнейших действий не требуется. Если рекламное ПО все еще там, перейдите к шагам ниже
- Перейдите к Инструменты > Свойства обозревателя
- Перейдите на вкладку Advanced и нажмите Reset .
- Убедитесь, что опция Удалить личные настройки в диалоговом окне Сброс настроек Internet Explorer отмечена галочкой, и нажмите Сброс
- Перезапустите Internet Explorer, чтобы изменения вступили в силу
 Если реклама Go.mail.ru больше не появляется, то никаких дальнейших действий не требуется. Если рекламное ПО все еще там, перейдите к шагам ниже
Если реклама Go.mail.ru больше не появляется, то никаких дальнейших действий не требуется. Если рекламное ПО все еще там, перейдите к шагам ниже.
Проблема ушла? Проверьте и посмотрите
Компьютерные угрозы, такие как вирус Go.mail.ru, могут быть скрытнее, чем вы можете себе представить, умело скрывая свои компоненты внутри зараженного компьютера, чтобы избежать удаления. Поэтому, запустив дополнительное сканирование безопасности, вы расставите все точки над i и перечеркнете t в плане очистки.
Поэтому, запустив дополнительное сканирование безопасности, вы расставите все точки над i и перечеркнете t в плане очистки.
Скачать Go.mail.ru антивирусный сканер и удаление
Домены, IP-адреса и информация о приложении
Приложение Mail.Ru
Информация о приложении
На следующей странице представлена подробная информация о доменах, платформах, сетях и
IP-адреса, используемые Mail.Ru .
Описание
Mail.Ru — очень популярный в России веб-сайт. Интернет-портал компании предоставляет электронную почту, поиск, онлайн-игры и другие потребительские услуги.
| Категория | Портал |
| Веб-ссылка | Mail.Ru — Домашняя страница |
Управление полосой пропускания
Вы знаете, сколько трафика Mail.Ru проходит через вашу сеть?
Обнаружение приложений Netify
движок и отчеты предоставляют информацию, помогающую управлять вашей сетью.
Что измеряется, тем можно управлять.
Подробнее
Домены
Основные домены
- mail.ru
Сводка по использованию платформы
| Облачные хосты | # IP-адресов |
|---|---|
| Амазон АВС | 1 |
Сведения об IP
Основные сети
| ИП | Категория | Владелец сети | Сеть | Местоположение | Общий |
|---|---|---|---|---|---|
217. 69.140.36 69.140.36 | Бизнес | ВК | Базовая сеть | Российская Федерация | |
195. 211.21.5 211.21.5 | Бизнес | ВК | Базовая сеть | Российская Федерация | |
128. 140.169.128 140.169.128 | Бизнес | ВК | Базовая сеть | Российская Федерация | |
94. 100.191.28 100.191.28 | Бизнес | ВК | Базовая сеть | Российская Федерация | |
94. 100.180.197 100.180.197 | Бизнес | ВК | Базовая сеть | Российская Федерация | |
94. 100.180.59 100.180.59 | Бизнес | ВК | Базовая сеть | Российская Федерация | |
| и еще 276 | |||||
Другие сети
| IP | Описание ASN | АСН | Маршрут | Местоположение | Общий |
|---|---|---|---|---|---|
| 64:ff9б::5fa3:38c7 | |||||
45. 132.92.2 132.92.2 | Цифровые коммуникации ПП | AS39862 | 45.132.92,0/24 | Украина | |
| 79.137.156.161 | МРГрупп Инвестментс Лимитед | AS205830 | 79. 137.156.0/24 137.156.0/24 | Российская Федерация | |
| 95.163.144.217 | МРГрупп Инвестментс Лимитед | AS205830 | 95.163.144.0/24 | Российская Федерация | |
95. 163.144.218 163.144.218 | МРГрупп Инвестментс Лимитед | AS205830 | 95.163.144.0/24 | Российская Федерация | |
| и еще 4 | |||||
Сведения о платформе
Сети облачного хостинга
| ИП | Платформа | Владелец сети | Сеть | Местоположение | Общий |
|---|---|---|---|---|---|
3. 120.25.179 120.25.179 | Амазон АВС | Амазон АВС | Европа (Франкфурт) | Германия |
API потока данных
Показанные здесь данные также доступны через наш API потока данных.
Дополнительную информацию можно найти на странице информации о фиде данных.
"данные": {
"тег": "netify.twitter",
"метка": "Твиттер",
"shared_ip_detected": правда,
"категория": {
"идентификатор": 24,
"тег": "социальные сети",
"label": "Социальные сети"
},
...
"сетевой_список": [
{
"сеть": "104.