Содержание
Бесплатный онлайн “текст в речь” — Бесплатная начитка текста голосом
Как вы можете использовать наш онлайн-читатель текста?
- Вставьте ваш текст
- Выберите язык
- Нажмите на кнопку “Начать говорить”
Почему вам стоит использовать наш онлайн-читатель для преобразования текста в речь?
Он точен, прост в использовании и абсолютно бесплатен. Наш онлайн-читатель может читать вслух то, что вы напечатаете на самых разных языках с естественными голосами.
Кроме того, наш бесплатный онлайн инструмент позволяет вам контролировать громкость, скорость и высоту произносимого текста и даже сохранять его в виде файла.
Учитывая простоту использования, это отличное решение для тех, кто хочет слушать тексты на ходу. Мы также очень рады помочь многим людям с нарушениями зрения.
Какие функции предлагает наш онлайн синтезатор речи?
- Бесплатно и в режиме онлайн
- Без скачиваний, установок и регистрации.
- Поддержка разных языков.

- Естественно звучащая речь
- Озвучка мужскими и женскими голосами.
- Способность читать очень длинные фрагменты текста.
- Вы можете сделать паузу или прекратить говорить.
- Вы можете менять параметры громкости, скорости и высоты тона.
- Возможность сохранить текст в виде аудиофайла (для этого вам нужно будет включить ваш микрофон: система будет считывать текст и захватывать аудио), качество будет среднее.
Каковы преимущества начитки текста голосом?
Существует бесчисленное множество интуитивных преимуществ для преобразования текста в голосовые записи.Однако, есть некоторые удивительные преимущества, которые вы, возможно, еще не рассматривали.
Сколько книг, статей или даже рабочих документов вы откладывали на потом из-за нехватки времени?
С очень занятым и тесным расписанием у вас может быть очень ограниченное свободное время, и вполне естественно, если вы захотите провести его сидя, расслабленно и без напряжения глаз.
Благодаря высокой лингвистической точности вы сможете слушать ваши любимые тексты находясь в дороге, занимаясь спортом, выполняя другие задачи или просто расслабляясь. Вы также можете преобразовать любой текст в аудиофайл независимо от его длины.
Вы также можете преобразовать любой текст в аудиофайл независимо от его длины.
Поскольку все показания являются беглыми и естественными, наш инструмент может помочь тем, кто изучает новый язык, улучшить свое произношение и навыки аудирования.
С помощью простых и интуитивных элементов управления нашего онлайн-читателя вы сможете ускорять или замедлять тексты, для лучшего понимания их смысла.
Онлайн-читатель текста в речь также может стать отличным инструментом редактирования, помогая писателям и профессионалам улучшать свои тексты.
Прослушивая то, что вы написали может дать новые, осмысленные представления о том, как редактировать ваши предложения или создавать лучшие аргументы в поддержку ваших идей.
Мало того, наш продвинутый онлайн-читатель может помочь людям с нарушением зрения и помочь им получить доступ к знаниям, которые они иначе не смогли бы получить.
С большим выбором естественных человеческих голосов и множеством вариантов языков, акцента и пола каждый может настроить свой опыт прослушивания в соответствии со своими потребностями.
Что же такое инструмент “текст в речь”?
Инструмент преобразования текста в речь, также известный как произношение текста голосом или приложение преобразования текста в голос — это технология, которая читает вслух цифровые тексты.
Эти инструменты не требуют никаких усилий со стороны пользователя, кроме как копировать/вставить текст, который они хотят произнести. Затем с помощью интеллектуального алгоритма программа чтения текста предоставляет аудиоверсию этого текста.
В то время как каждый инструмент преобразования текста в речь работает по разному, самые передовые технологии поддерживают широкий спектр языков и предлагает множество естественно звучащих голосов, как мужских, так и женских.
Кто использует инструмент “текст в речь”?
Начитка текстов голосами не только экономично по времени, но также и изобретательно. Произношение текстов голосами может обеспечить широкий спектр преимуществ для людей из всех слоев общества. Он может работать для студентов, занятых профессионалов, писателей, слабовидящих или для всех, кто хочет дать свои глазам отдохнуть и расслабиться изучая что-то новое.
Зрелые читатели или слабовидящие люди могут использовать инструмент “текст в голос”, чтобы наслаждаться текстами, которые они иначе не смогли бы сделать. Поскольку наша программа интуитивна и доступна для всех категорий, вы можете быстро прочитать свой текст вслух или преобразовать любой написанный текст в аудиофайлы.
В то время как чтение предполагает пребывание на месте, прослушивание может происходить на ходу, позволяя вам выполнять многозадачность. Например, сколько раз ваш почтовый ящик был заполнен электронными письмами, но у вас не было времени прочитать их всех? Теперь же, вы можете преобразовывать различные тексты в mp3-файлы и слушать их во время вождения, тренировок или выполнения других задач.
Или давайте скажем, что вы писатель. Затем, прослушивание вашего текста вслух может выявить для вас, какие изменения вам стоит внести. Ошибки, которые ваши глаза возможно не смогли увидеть, могут стать очевидными для ваших ушей и вы сможете легко найти недостатки, которые могут исказить структуру вашего текста.
Учитывая его точность, приложение синтезатор речи также является креативным способом для студентов изучающих второй язык, которые хотят улучшить свое произношение или понимание текста. Они могут играть со скоростью текста, чтобы развить свои навыки аудирования и стать более беглыми в разговорной речи.
Наше приложение синтезатор речи также является полезным решением для людей с ограниченными возможностями в обучении такими, как дислексия. Прослушивание текстов, а не их чтение, снижает стресс, позволяя каждому получить доступ к информации без границ.
Интернет должен быть местом для всех, и приложение синтезатор речи помогает обеспечить доступность для всех групп людей, независимо от возраста, образования или проблем.
Устранение неполадок
- Нет речи. Прежде всего проверьте ваши динамики громкость.Также голос может быть недоступен для заданной громкости/скорости/высоты тона. Просто отрегулируйте ваши параметры.
- Браузер не поддерживает распознавание речи: поддерживает последняя версия Chrome.
- Есть проблемы с микрофоном (при сохранении в виде аудиофайла):
- Аппаратная проблема с микрофоном: убедитесь, что ваш компьютер обнаружил ваш микрофон.
- Не предоставляется разрешение на доступ к микрофону. Позвольте нашему синтезатору речи иметь доступ к вашему микрофону.
- Браузер прослушивает неправильный/другой микрофон.
Чтобы решить проблемы с доступом микрофона, нажмите на небольшой значок камеры в адресной строке браузера (появится после нажатия кнопки воспроизведения), установите там разрешение на использование микрофона и выберите соответствующий микрофон из выпадающего списка.
Если у вас есть другие проблемы, пожалуйста свяжитесь с нами, чтобы подробнее описать проблему.
Что такое инструмент “текст в речь”?
“Текст в речь” — это инструмент, который читает текст вслух. Вам просто нужно скопировать и вставить текст, включить динамики и нажать кнопку “Начать говорить”. У вас также есть возможность поставить на паузу или приостановить аудио, когда вы захотите и сохранить речь в виде файла. Попробуйте прямо сейчас, это бесплатно!
Попробуйте прямо сейчас, это бесплатно!
Как включить инструмент “текст в речь”?
Включить инструмент очень просто. После того, как вы набрали или вставили текст, который хотите быть прочитанным вслух, просто нажмите “Начать говорить”. Наш онлайн-читатель текста прочитает ваш текст вслух. Никакой регистрации или оплаты не требуется, это совершенно бесплатно. Попробуйте прямо сейчас!
Как задействовать инструмент “текст в речь”?
Онлайн инструмент “текст в речь” очень прост в использовании. Выберите язык вашего текста, включите ваши динамики, введите или скопируйте текст, который вы хотите услышать вслух из приложения и нажмите на кнопку “Начать говорить”. Попробуйте прямо сейчас, это бесплатно!
Записывайте и загружайте любой звук бесплатно, используя ваш микрофон и наш онлайн диктофон.
Нажмите на значок микрофона, чтобы начать запись
Как записать звук используя наш онлайн диктофон?
- Нажмите на значок микрофона, чтобы начать запись
- Разрешите вашему браузеру доступ к вашему микрофону
- Начинайте говорить или издайте какой нибудь звук.

Почему вам стоит использовать наш онлайн диктофон?
Он точен, прост в использовании и абсолютно бесплатен. Наш диктофон может записывать любой тип звука: одиночный голос, разговор, музыку или звук, сделанный на заказ. Как только вы записали звук и выбрали ту часть, которую хотели сохранить, просто экспортируйте ваш аудио файл и скачайте бесплатно в формате WAV.
Он так прост в использовании. Это делает его отличным решением для тех, кто хочет записать разговор и впоследствии прослушать аудиофайл.
Какие функции предлагает это онлайн программное обеспечение для записи звука?
- Бесплатно и онлайн
- Без регистрации и установки программного обеспечения
- Легко обрезать и сохранять ту часть записи, которая вам нужна
- Сохраняйте ваш аудиофайл в формате WAV легко и бесплатно
- Ставить на паузу или останавливать запись по необходимости
Какие есть преимущества у онлайн диктофона?
Есть бесчисленные преимущества для записи и сохранения аудио. К примеру:
К примеру:
Сколько разговоров, телефонных звонков, курсов или встреч вы хотели бы прослушать заново? Разве не было бы здорово иметь возможность легко записывать их в будущем? Затем вы можете прослушать их снова используя экспортированные аудиофайлы.
Делать заметки во время разговора может быть сложным и неэффективным. Ваша концентрация разделяется между написанием, слушанием и разговором одновременно, что может привести к ошибкам.
Использование диктофона онлайн позволяет вам сосредоточиться на вашем разговоре или встрече, зная, что вы можете прослушать аудио в любое удобное для вас время. Быть в моменте и сосредоточиться на разговоре может помочь избежать недопониманий.
Вам в голову приходит отличная идея. У вас нет времени, чтобы изучить её и у вас нет ручки и бумаги, чтобы записать. Онлайн диктофон позволит вам записывать ваши мысли и сохранить WAV файл, чтобы вернуться к нему позже.
Что же именно такое онлайн диктофон?
Онлайн диктофон, также известный как аудио/звукозаписывающее устройство — это технология, которая записывает любой произведенный звук.
Эти инструменты очень просты в использовании. Просто нажмите на значок микрофона, разрешите вашему браузеру доступ к микрофону устройства, которое вы используете и начинайте говорить, петь или издавать звук. Благодаря функции экспорта вы можете быстро сохранять и скачивать аудио, которое можно сохранить в виде WAV-файла.
Кто использует онлайн диктофон?
Инструменты аудио диктофона идеально подходит для тех, кто хочет легко записывать аудио без необходимости покупать или устанавливать программное обеспечение. Он может быть использован студентами, занятыми профессионалами, музыкантами и многими другими.
Онлайн диктофон или также известный как, онлайн-устройство записи может облегчить жизнь тем, хочет записывать важные разговоры или избегает многозадачности при записи заметок. Он также может помочь тем, кто просто наслаждается удобством, когда не нужно печатать или записывать свои мысли.
Поскольку наше программное обеспечение интуитивно понятное в использовании и доступно для всех, вы можете с легкостью сохранить вашу аудиозапись и прослушивать ее в любое удобное вам время.
Устранение неисправностей
Могут возникнуть следующие проблемы:
- Неспособность уловить звук: Убедитесь, что ваш компьютер определил микрофон, который вы хотите использовать.
- Разрешение на доступ к микрофону не предоставляется: Нажмите на маленький значок микрофона в адресной строке браузера (он появится после того, как вы нажмете на значок, чтобы начать диктовку). Здесь вы можете изменить разрешение, чтобы позволить использование микрофона.
- Браузер выбирает неправильный микрофон: Откройте настройки разрешений (смотреть выше) и выберите правильный микрофон из выпадающего списка.
Если у вас появились другие неполадки с нашим онлайн диктофоном, пожалуйста свяжитесь с нами описав вашу проблему в деталях.
Безопасность & конфиденциальность
Безопасность вашей информации и защита вашей конфиденциальности являются нашим абсолютным приоритетом. Записанный вами звук доступен только вам и не сохраняется на наших серверах.
Как включить онлайн диктофон?
Включение аудио диктофона очень простое. Просто нажмите на значок микрофона и начните воспроизводить звук, который вы хотите записать. Нажмите кнопку “Стоп”, как только закончите. Наш онлайн диктофон позволит вам загрузить файл WAV. Регистрация и оплата не требуется, это абсолютно бесплатно. Попробуйте прямо сейчас!
Просто нажмите на значок микрофона и начните воспроизводить звук, который вы хотите записать. Нажмите кнопку “Стоп”, как только закончите. Наш онлайн диктофон позволит вам загрузить файл WAV. Регистрация и оплата не требуется, это абсолютно бесплатно. Попробуйте прямо сейчас!
Как включить онлайн диктофон?
Онлайн диктофон очень прост в использовании. Нажмите на значок микрофона. При появлении запроса разрешите нашему диктофону получить доступ к вашему микрофону и начните говорить. Попробуйте прямо сейчас, это бесплатно!
Могу ли я сохранить онлайн аудиозапись в виде файла?
Сохранить вашу онлайн аудиозапись очень просто. Как только вы закончите записывать ваше аудио, выберите раздел аудио, который вы хотите экспортировать. Затем нажмите кнопку “Сохранить”, чтобы загрузить файл на свое устройство.
Могу ли обрезать и загрузить нужную часть онлайн записи?
Да. Как только вы закончите запись, выберите нужную вам часть аудио, которую вы хотите сохранить, переместив курсор на звуковые волны. Затем нажмите кнопку “Сохранить”, чтобы загрузить файл на свое устройство.
Как только вы закончите запись, выберите нужную вам часть аудио, которую вы хотите сохранить, переместив курсор на звуковые волны. Затем нажмите кнопку “Сохранить”, чтобы загрузить файл на свое устройство.
Преобразование данных оцифровки речи
: за кулисами
Джули Клементс | Последнее обновление: 29 сентября 2022 г. | Опубликовано 17 августа 2015 г. | Блог, Аутсорсинговые услуги | 0 комментариев
Эффективная оцифровка речи, часть преобразования данных , которая включает преобразование речи из ее аналоговой формы сигнала, требует правильных инструментов, технических знаний и терпения.
Декодирование речи Оцифровка
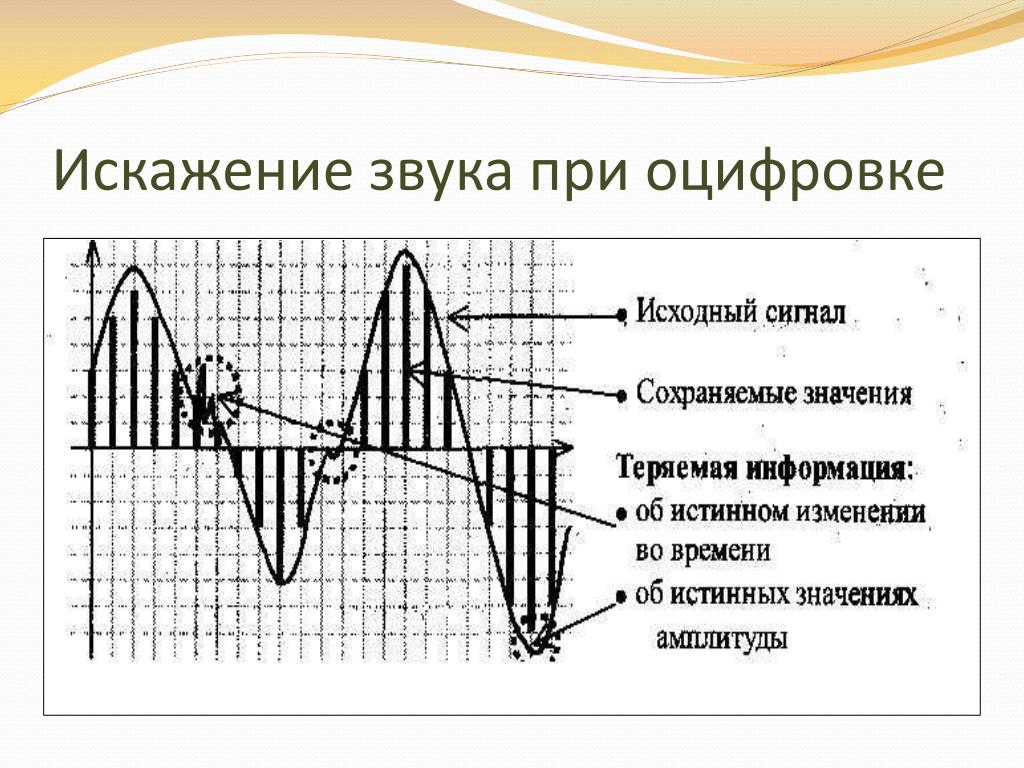
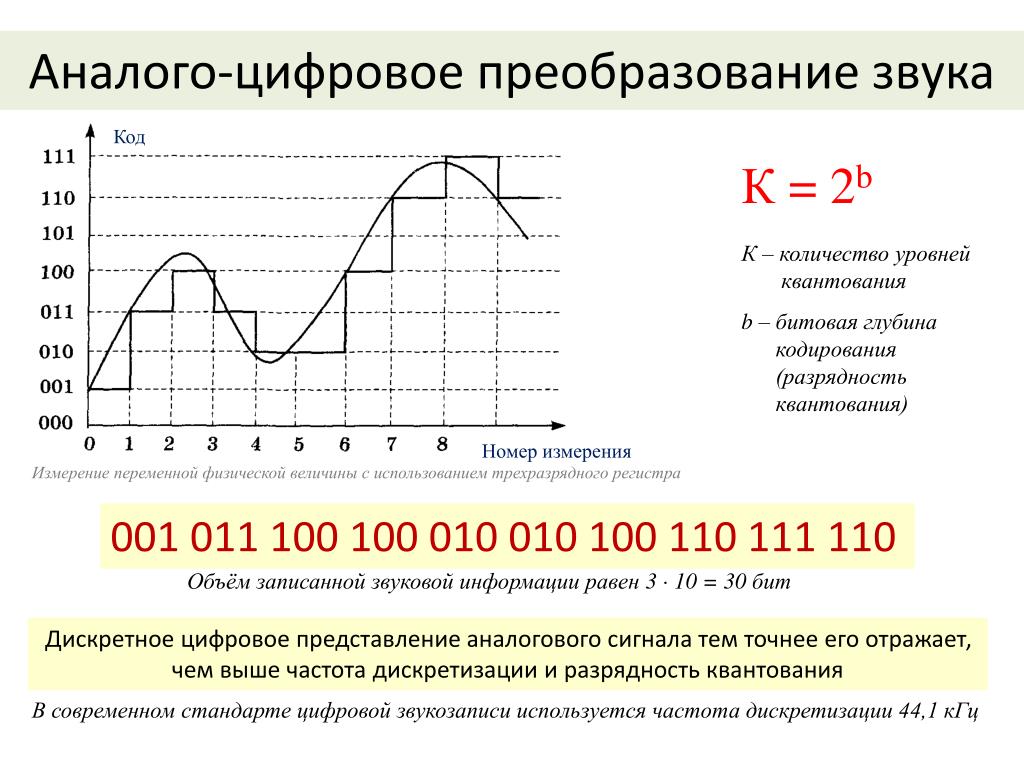
Преобразование речи из аналогового в цифровой формат в основном состоит из дискретизации и квантования. Это включает преобразование аналогового или бесступенчатого сигнала в цифровой или многоуровневый сигнал без изменения основного содержания. В процессе дискретизации измеряется уровень сигнала или амплитуда аналогового сигнала на равномерно распределенных временных маркерах и представляются в виде числовых значений (единиц и нулей), которые добавляются в виде цифровых данных.
Методы оцифровки
Когда дело доходит до оцифровки телефонных разговоров, речь передатчика преобразуется из аналогового сигнала в числовые значения. Для этого существует множество методов, которые можно разделить на кодирование формы сигнала, параметрическое кодирование или кодирование источника и гибридное кодирование.
Кодирование формы волны включает использование фактической формы волны для получения числовых значений, представляющих эту форму волны, на основе определенных правил. Параметрическое или исходное кодирование включает обнаружение некоторых речевых характеристик, включая амплитуду и высоту тона, и создание числовых значений на основе правил, описывающих эти речевые характеристики. Гибридное кодирование включает использование формы сигнала, а также параметрических принципов для создания цифровой версии речи.
Преобразование виниловых пластинок
По мере роста популярности виниловых пластинок растет и потребность в их оцифровке. Людям, у которых есть проигрыватели без возможности подключения через USB, оцифровка потребует подбора подходящего оборудования (включая кабели RCA и предусилитель) и программного обеспечения.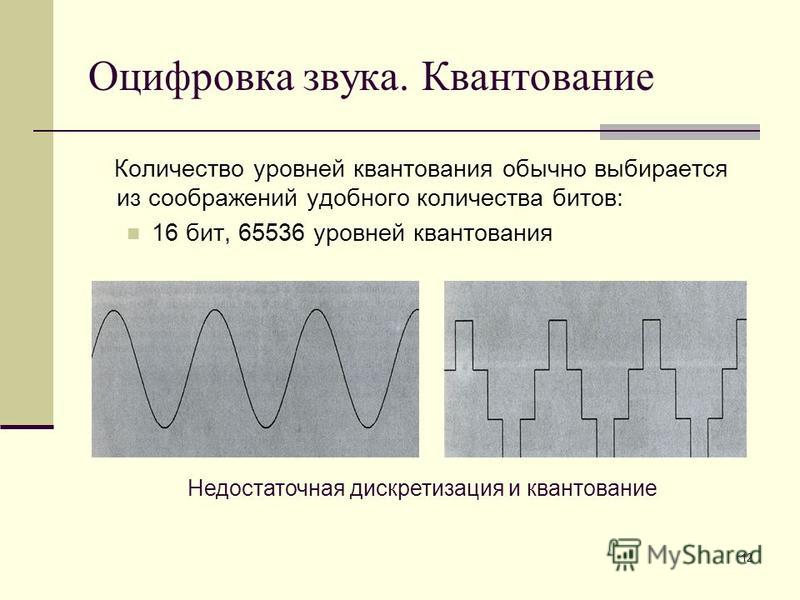
Знаменитая речь императора Хирохито во время Второй мировой войны
Знаменитая речь императора Хирохито о капитуляции во время Второй мировой войны — одна из тех знаменитых речей, которые оцифрованы с виниловых пластинок. Это 15, 19 августа45 радиовыступление, которое изначально было записано на виниловые пластинки, было нечетким и низкого качества, скопировано в 1946 году американскими войсками. Однако Агентству императорского двора японской королевской семьи удалось в цифровом виде переработать речь, которую многие японцы услышали впервые.
Император Хирохито был культовой и очень уважаемой фигурой, и по иронии судьбы его знаменитая речь была до сих пор забыта даже японцами. Цифровой релиз уместен, учитывая, что 2 сентября 2015 года исполнилось бы 70 лет с момента окончания Второй мировой войны, чему способствовала речь Императора о капитуляции.
Аутсорсинг преобразования данных , который включает такие инициативы по оцифровке, действительно помогает в таких случаях, когда важная речь, тесно связанная с эмоциями людей, воплощается в жизнь. Это помогает обеспечить эффективное преобразование опытными профессионалами, использующими передовые инструменты.
Это помогает обеспечить эффективное преобразование опытными профессионалами, использующими передовые инструменты.
Распознавание голоса и оцифровка речи | Арнас Синкявичюс
Распознавание голоса
Подробная статья о распознавании голоса и оцифровке речевой системы.
Распознавание голоса — это технология, которая позволяет автоматически распознавать акустический сигнал, исходящий от человеческого голоса, как определенные слова, активируя программу, соответствующую этим словам. Его можно использовать во многих областях, например, в средствах доступности для немых или людей с ограниченными физическими возможностями, в видеоиграх или других компьютерных программах в качестве автоматизированного устройства ввода. Более того, голос становится одним из самых популярных устройств ввода для смартфонов и планшетов.
Он широко используется в общественных местах, таких как аэропорты или больницы, для размещения объявлений и решения запросов клиентов о конкретных услугах. Многие компании также используют распознавание голоса как способ улучшить обслуживание клиентов.
Многие компании также используют распознавание голоса как способ улучшить обслуживание клиентов.
Оцифровка голоса — это процесс преобразования голоса в цифровой сигнал с помощью аналого-цифрового преобразователя, чтобы компьютер мог управлять им. Распознавание речи — это процесс анализа и преобразования речевого сигнала в текст.
В этом смысле первое, что нужно сделать, это записать чей-то голос с помощью микрофона. Запись может производиться с использованием звукозаписывающего устройства любого типа, выход которого проходит через аналого-цифровой преобразователь (АЦП), и он всегда должен быть в стереофоническом 16-битном формате ACM. Для прямого доступа к микрофону код должен быть написан для этой конкретной операционной системы (ОС) и аппаратного обеспечения.
Обычно основная часть программы распознавания голоса состоит из трех этапов: распознавание речи, синтез текста и преобразование текста в речь (TTS). Первый этап заключается в получении числового значения входного сигнала, представляющего его энергию, с использованием адаптивной фильтрации. Затем, используя скрытую марковскую модель (HMM), он преобразует эту энергию в последовательность фонем, которые можно интерпретировать с помощью конечного автомата. Как только эти фонемы получены, они преобразуются в слова с использованием статистических языковых моделей.
Затем, используя скрытую марковскую модель (HMM), он преобразует эту энергию в последовательность фонем, которые можно интерпретировать с помощью конечного автомата. Как только эти фонемы получены, они преобразуются в слова с использованием статистических языковых моделей.
При распознавании речи первым этапом является получение числового значения входного сигнала, представляющего его энергию. По полученной таким образом информации можно определить, что это за звук: голос, музыка или шум. Адаптивная фильтрация и скрытая марковская модель (HMM) используются для преобразования этой энергии в последовательность фонем, которые могут быть интерпретированы конечным автоматом. По этой причине процессор распознавателя речи должен иметь достаточную информацию о характере звуков, используемых для их точной интерпретации. После этого фонемы преобразуются в слова с использованием статистических языковых моделей. Этот этап известен как распознавание речи, и он очень похож на распознавание языка, которое не является специфичным для голоса.
Основные различия между ними:
На этапе распознавания слов можно использовать несколько подходов:
Более простой способ получить некоторые результаты — использовать модель «n»-грамм. В этой модели он работает с пользовательскими словарями для получения статистических данных о словах в них, таких как их частоты и вероятности перехода телефон/слово. Эти вероятности хранятся в таблице, называемой моделью n-грамм.
Распознавание голоса имеет несколько приложений, некоторые более продвинутые, чем другие. Например, в случае ADR (автоматическая замена диалогов) цель состоит в том, чтобы сопоставить каждое слово, произнесенное персонажем в фильме или сериале, с транскрипцией, которая может быть текстом из сценария или сгенерирована вручную с помощью автоматической транскрипции диалога. система. Это позволяет редактировать новое аудио и автоматически синхронизировать его с видеозаписью.
Для редактирования ADR требуется только запись голоса актера и исходный видеофайл редактируемой сцены. Распознавание голоса также можно использовать для оцифровки различных бизнес-процессов и статистики, таких как финансовые транзакции, записи о клиентах, цены на продукты и запасы.
Распознавание голоса также можно использовать для оцифровки различных бизнес-процессов и статистики, таких как финансовые транзакции, записи о клиентах, цены на продукты и запасы.
Распознавание голоса может сыграть важную роль в будущем домашней автоматизации. Основная цель систем распознавания голоса — позволить пользователям управлять бытовой техникой с помощью голоса, чтобы они могли пользоваться преимуществами этой технологии без необходимости использовать дистанционное управление.
Системы распознавания голоса были впервые разработаны для использования в приложениях для диктовки. В этих системах оцифровки речи пользователь говорит в микрофон, чтобы записать исходный аналоговый аудиопоток в цифровом виде на компьютер. Затем он преобразуется в текст, чтобы его можно было редактировать или обрабатывать другими программами. Этот тип системы оцифровки речи имеет много преимуществ по сравнению с обычными системами транскрипции:
В прошлом было несколько систем распознавания речи, разработанных разными исследователями. В 19В 60-х годах появилась машина под названием «Механический мозг». Он использовал структуру, похожую на шахматную доску, с магнитами для передачи битов информации и был запрограммирован на 1000 слов. В 1970-х годах IBM изобрела DART (Digital Automated Receiver Transcriber), а в 1998 году японская компания Lernout & Hauspie создала голосовую систему Kurzweil. Другие системы были разработаны в Германии, Франции и Великобритании. В 2000 году стала доступна первая коммерчески доступная система распознавания речи, когда Microsoft выпустила программу «Totem Speech».
В 19В 60-х годах появилась машина под названием «Механический мозг». Он использовал структуру, похожую на шахматную доску, с магнитами для передачи битов информации и был запрограммирован на 1000 слов. В 1970-х годах IBM изобрела DART (Digital Automated Receiver Transcriber), а в 1998 году японская компания Lernout & Hauspie создала голосовую систему Kurzweil. Другие системы были разработаны в Германии, Франции и Великобритании. В 2000 году стала доступна первая коммерчески доступная система распознавания речи, когда Microsoft выпустила программу «Totem Speech».
Технология распознавания голоса продвинулась вперед за последнее десятилетие и сейчас становится все более сложной. Простая система с ограниченными возможностями, такая как та, которая ранее использовалась операторами мобильной связи для проверки телефонных счетов, теперь может быть улучшена, чтобы пользователи могли диктовать или управлять своими бытовыми приборами с помощью голосовых команд. Поскольку последние достижения в области технологий позволили компьютерам воспроизводить человеческие голоса с помощью созданных компьютером механизмов синтеза речи, домовладельцы получили возможность использовать персональный компьютер без необходимости изучать использование специальных интерфейсов или клавиатур.
Ранние системы распознавания голоса использовали небольшой набор предварительно запрограммированных слов. Однако недавно разработчики смогли использовать методы машинного обучения для создания систем распознавания речи, способных распознавать слова, используемые реальными людьми. Наиболее распространенными методами, используемыми в системах распознавания речи, являются:
Чтобы система распознавания голоса работала, она должна фиксировать последовательность слов в определенные моменты времени, иначе ее вывод будет непредсказуемым и ненадежным. Обычно ключом к захвату этих слов является их покадровая запись, но некоторые распознаватели речи также могут работать со звуковыми волнами непосредственно с микрофона, которые анализируются специальным программным обеспечением.
Ключ к проблеме распознавания речи заключается в том, что распознаватель речи должен быть в состоянии точно распознавать слово в присутствии любого фонового шума. Фоновый шум представляет собой серьезную проблему для распознавателей речи, потому что люди не придавали ему никакого символического значения, поэтому люди не знают о нем и, следовательно, не могут говорить о нем.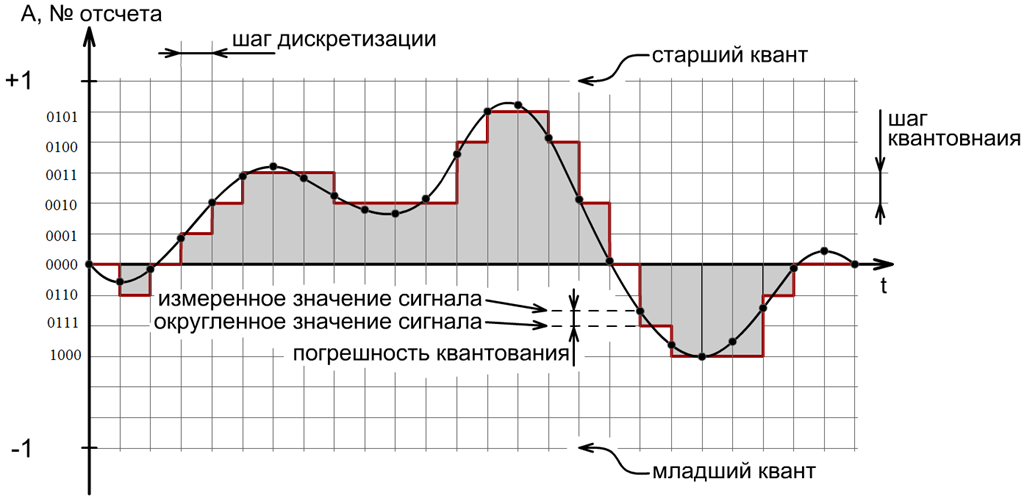 С этой целью должна быть возможность распознавать слова в присутствии фонового шума, репрезентативного для того, что человек сказал бы в обычном разговоре. Для успешной работы распознавателя речи точность его распознавания должна быть выше 70 %, а оптимальный размер словарного запаса, т. е. количество слов, необходимых для точной работы, не должен превышать приблизительно 1000.
С этой целью должна быть возможность распознавать слова в присутствии фонового шума, репрезентативного для того, что человек сказал бы в обычном разговоре. Для успешной работы распознавателя речи точность его распознавания должна быть выше 70 %, а оптимальный размер словарного запаса, т. е. количество слов, необходимых для точной работы, не должен превышать приблизительно 1000.
До распознавания речи было просто невозможно сделать вывод о том, что кто-то сказал компьютеру, используя только записи, сделанные по телефону. Например, пользователь не мог вести интерактивный разговор с компьютером, используя только записанные телефонные звонки, которые он сделал или получил. Технология транскрипции голоса была представлена в 1940-х годах, а к 1960-м годам, когда технологии ПК стали доступными и доступными, они позволили пользователям взаимодействовать с компьютерами без необходимости говорить в микрофон. Синтез речи — это процесс преобразования человеческой речи в цифровые сигналы для использования на электронных устройствах (например, компьютерах). Этот процесс обычно осуществляется путем преобразования аудиосигналов в дискретные цифровые образцы, называемые «кодовыми словами», которые затем произносятся вслух через динамик.
Этот процесс обычно осуществляется путем преобразования аудиосигналов в дискретные цифровые образцы, называемые «кодовыми словами», которые затем произносятся вслух через динамик.
Таким образом, технология распознавания речи развивалась параллельно технологии синтеза речи. Некоторые системы распознавания речи можно даже обучить распознавать любой голос, если пользователь готов потратить время на запись своего голоса для создания модели речи. Этот процесс аналогичен созданию сообщения голосовой почты по телефону: нужно только записать краткое введение, а затем система автоматически записывает для вас все будущие входящие сообщения, чтобы вы могли прослушать их позже и ответить по телефону.
В большинстве случаев записанный голос пользователя должен быть проанализирован автоматизированной системой для преобразования его в текст. Если от пользователя требуется расшифровать слова вручную, это может стать утомительным и может занять довольно много времени. Вот почему технология автоматического распознавания речи полезна и для операторов мобильной связи. Пользователь мобильного телефона может набрать номер своего телефона и говорить прямо в аппарат без необходимости расшифровывать то, что он говорит на клавиатуре. Затем телефонный оператор слушает разговор и проверяет, совпадает ли голос звонящего с записанным голосом клиента.
Пользователь мобильного телефона может набрать номер своего телефона и говорить прямо в аппарат без необходимости расшифровывать то, что он говорит на клавиатуре. Затем телефонный оператор слушает разговор и проверяет, совпадает ли голос звонящего с записанным голосом клиента.
Системы распознавания голоса в настоящее время используются в различных отраслях, таких как банковское дело, здравоохранение, юриспруденция, управление бытовой техникой и образование. Они также используются во многих новых продуктах, таких как смарт-часы, бытовая техника с голосовым управлением, персональные компьютеры и смартфоны. Системы распознавания голоса также могут быть полезны слепым и слабовидящим людям для доступа к компьютерным услугам.
Многие компании разработали альтернативное программное обеспечение для распознавания речи, которое позволяет пользователям вводить слово или фразу так, как они произносятся, и в большинстве случаев точно транскрибирует слово или фразу. В 2011 году стартап Vocera получил финансирование в размере 17 миллионов долларов от венчурной компании Accel Partners. Было объявлено, что приложение будет доступно для iPhone к концу 2011 года. За этим последовало аналогичное объявление от Apple Inc. относительно приложения под названием VoiceOver для устройств iOS от 30 января 2012 года9.0003
Было объявлено, что приложение будет доступно для iPhone к концу 2011 года. За этим последовало аналогичное объявление от Apple Inc. относительно приложения под названием VoiceOver для устройств iOS от 30 января 2012 года9.0003
Google Inc. также предлагает систему под названием Voice Recognition от Google, которая преобразует произносимые слова в текст, используя алгоритмы для понимания произнесенных слов. Google также предоставил разработчикам API (интерфейс программирования приложений) для доступа к своим инструментам распознавания голоса. Среди этих инструментов есть специальные языковые модели, которые могут обрабатывать различные языки и диалекты и включать данные разговорного языка из Интернета, а также собранные в ходе частных исследований продуктов Google. Другой метод основан на исследованиях, проведенных в Центре образования и рабочей силы Джорджтаунского университета. Эта система, известная как «Система распознавания жестов», была интегрирована в Android 4.2 на Nexus 5 в конце 2013 года.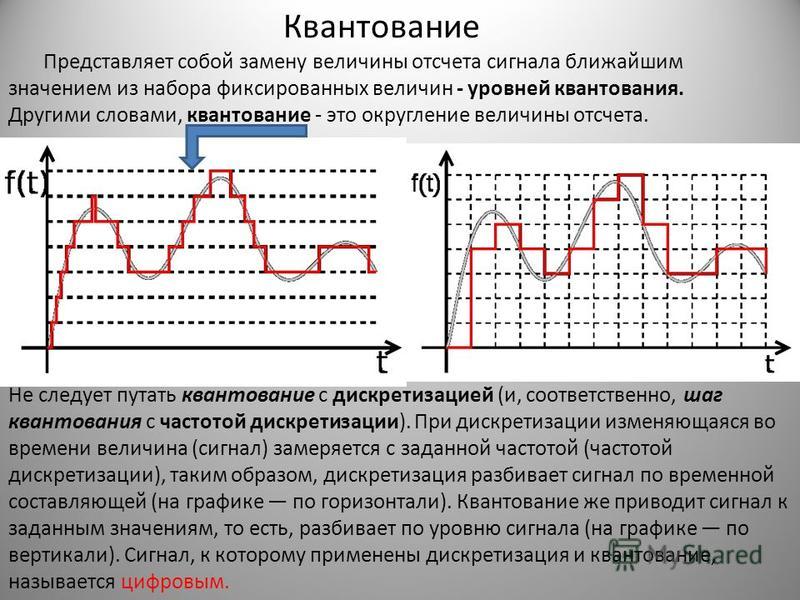 Ее также можно использовать при разработке веб-приложений с программой чтения с экрана JAWS для чтения информации вслух, когда зрячий пользователь не смотрит на нее. Это.
Ее также можно использовать при разработке веб-приложений с программой чтения с экрана JAWS для чтения информации вслух, когда зрячий пользователь не смотрит на нее. Это.
В 2011 году Microsoft представила технологию под названием «Cortana», которая представляет собой попытку предоставить личного помощника в режиме реального времени, о чем в том же году объявил генеральный директор Microsoft Стив Балмер. В 2012 году Microsoft приобрела компанию по распознаванию речи SpeechSynch, что позволит интегрировать эту технологию в Skype.
Сегодня доступно несколько других продуктов и технологий распознавания голоса. В 2013 году Samsung представила функцию распознавания голоса на своем смартфоне Galaxy S4, которую можно было использовать для таких функций, как телефонные звонки или текстовые сообщения, хотя в то время только на корейском языке. За этим последовала функция их новых моделей Galaxy S5.
Известные примеры транскрипции голоса, распознавания речи и технологий распознавания голоса можно найти в современных средствах массовой информации, таких как телевидение и кино:
И телешоу «Баффи — истребительница вампиров», и фильм «Матрица» использовали расширенные каналы для распознавания голосов пользователей. В «Особом мнении» с Томом Крузом в главной роли использовалась система под названием «предвидение». Сцена из фильма «ВАЛЛ-И» показывает автоматический пресс для мусора, который реагирует на человеческие голоса. В пилотном эпизоде также использовалась система распознавания речи в Лос-Аламосской национальной лаборатории; это также использовалось в «Западном крыле».
В «Особом мнении» с Томом Крузом в главной роли использовалась система под названием «предвидение». Сцена из фильма «ВАЛЛ-И» показывает автоматический пресс для мусора, который реагирует на человеческие голоса. В пилотном эпизоде также использовалась система распознавания речи в Лос-Аламосской национальной лаборатории; это также использовалось в «Западном крыле».
Будущие разработки программного обеспечения для расшифровки голоса в конечном итоге облегчат пользователям технологий взаимодействие с окружающей средой. Это включает в себя способность компьютера понимать смысл того, что говорит пользователь, чтобы его можно было использовать более осмысленным образом. Например, Siri от Apple действует как личный помощник, помогая пользователям управлять электронной почтой и организовывать календари, в которых человек взаимодействует с помощью распознавания речи. В 2014 году Microsoft представила Cortana, интеллектуального личного помощника, который записывает электронные письма и информацию, связанную с встречами. Компания Google Inc. теперь также предоставляет персональную помощь на основе распознавания речи пользователям своих смартфонов на ОС Android.
Компания Google Inc. теперь также предоставляет персональную помощь на основе распознавания речи пользователям своих смартфонов на ОС Android.
На многих веб-сайтах есть технология распознавания речи, например, на Amazon, где пользователь может искать элемент, произнося название того, что он ищет. Нет необходимости использовать физическую клавиатуру на компьютере, чтобы говорить в микрофон, чтобы компьютер понял, что вы говорите. Это особенно полезно для слепых пользователей, у которых нет доступа к физической клавиатуре. Распознавание голоса также широко используется для онлайн-банкинга и онлайн-покупок.
Прослушивание записанной или произнесенной голосовой информации или текста может быть очень трудоемким, особенно при использовании программного обеспечения для распознавания речи. Процесс анализа сказанного необходимо изменить, чтобы сделать его проще и эффективнее. Есть возможность сделать это с помощью глубокой нейронной сети, которую можно научить прослушивать речь пользователя. Это делается путем чтения диалога вслух, чтобы его можно было проанализировать таким образом. Идеальным методом была бы разработка гибридной системы, сочетающей в себе распознавание речи и машинное обучение (глубокая нейронная сеть). Это позволит пользователям взаимодействовать с окружающей средой без необходимости использовать физическую клавиатуру или мышь, что может быть очень утомительно. Глубокие нейронные сети состоят из множества слоев взаимосвязанных узлов, которые соединены между собой с помощью односторонних ссылок. Алгоритмы глубокого обучения были разработаны для распознавания речи, что делает распознавание голоса более распространенным сегодня.
Это делается путем чтения диалога вслух, чтобы его можно было проанализировать таким образом. Идеальным методом была бы разработка гибридной системы, сочетающей в себе распознавание речи и машинное обучение (глубокая нейронная сеть). Это позволит пользователям взаимодействовать с окружающей средой без необходимости использовать физическую клавиатуру или мышь, что может быть очень утомительно. Глубокие нейронные сети состоят из множества слоев взаимосвязанных узлов, которые соединены между собой с помощью односторонних ссылок. Алгоритмы глубокого обучения были разработаны для распознавания речи, что делает распознавание голоса более распространенным сегодня.
Распознавание голоса подвергалось критике за ненадежность и неточность, особенно в автоответчиках, для которых от него не ожидается хорошей работы. В 2010 году журнал Scientific American отметил, что «типичная система распознавания речи… будет автоматически транскрибировать произносимое предложение в компьютер со скоростью около 25 слов в минуту», и что она лучше «в некоторых ситуациях» и «менее точна в других». ».
».
Тем не менее, есть много задач, с которыми программное обеспечение для распознавания голоса справляется достаточно хорошо. Если задание включает в себя прослушивание коротких вопросов/ответов (например, ПИН-кода) или даже корректуру текста, то можно добиться хороших результатов. Распознавание речи также используется для обработки разговорной речи в больших базах данных, которые не расшифровываются. Программное обеспечение для распознавания речи часто используется в колл-центрах, где основной задачей является ввод информации с помощью голосового ввода.
Обычная критика голосового общения между «водителем и автомобилем» заключается в том, что оно может отвлекать водителя от дороги. По данным Общества автомобильных инженеров (SAE), «использование во время вождения любого устройства громкой связи, независимо от того, является ли оно ручным или громким, увеличивает риск аварии как минимум в два с половиной раза». Кроме того, «голосовые команды, на которые опирается технология Drive-by-Wire, могут подвергнуть водителя риску в случае отказа систем автомобиля».
Программное обеспечение для распознавания голоса также может быть проблематичным для пожилых людей. Большая часть пожилых людей хочет выполнять задачи на своих компьютерах, не используя физическую клавиатуру или мышь. Исследование показало, что наличие громкой связи было полезно для улучшения их способности пользоваться компьютером, но не обязательно обеспечивало такую же поддержку для задач, которые было просто легче набирать. Это может включать поиск информации и навигацию по сети, что обычно делается путем ввода URL-адресов или ключевых слов.
Основной проблемой распознавания речи является его неточность при использовании в среде с фоновыми шумами. Фоновый шум является большой проблемой для точности процесса распознавания. Частично это можно решить, используя два микрофона (по одному на каждый динамик) для захвата речи. Второе решение может быть более эффективным, поскольку оно позволяет микрофону использовать оба уха одновременно, а не только одно.
Распознавание речи также имеет проблемы в шумной обстановке, а также с акцентами и качеством голоса. Если присутствует шумная среда, то для улучшения распознавания речи необходимо использовать подавление акустического эха. Подавление акустического эха включает в себя использование различных фильтров для блокировки звука эха, что может обеспечить лучшие результаты, чем простое его игнорирование.
Основная проблема с системой распознавания голоса заключается в том, что если человек говорит что-то, что программа не распознала, ему будет предложено сказать это еще раз, когда программа должна услышать это более точно. Это может привести к большим ошибкам ввода данных. Чтобы избежать этой ошибки, система должна быть очень точной. Один из способов сделать это — использовать нейронную сеть со скрытыми слоями узлов. Нейронную сеть можно обучить, дав ей много примеров хорошей речи и один пример плохой или отсутствующей речи пользователя.
Точность распознавания голоса зависит от многих факторов, включая качество голоса и акцент, а также фоновый шум, который может повлиять на обнаружение или понимание того, что говорится.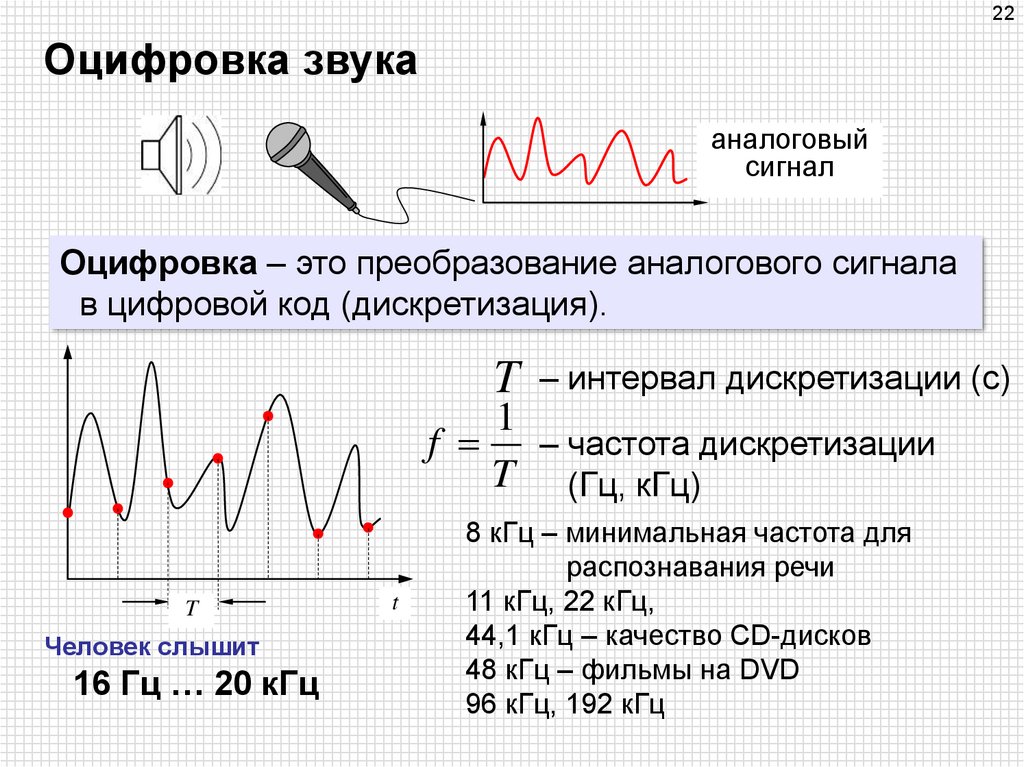 На точность распознавания голоса также влияет процесс обучения используемой нейронной сети. Программное обеспечение для распознавания речи можно протестировать, чтобы увидеть, насколько хорошо оно может различать слова, а также как быстро оно может распознавать их после того, как услышит их только один раз.
На точность распознавания голоса также влияет процесс обучения используемой нейронной сети. Программное обеспечение для распознавания речи можно протестировать, чтобы увидеть, насколько хорошо оно может различать слова, а также как быстро оно может распознавать их после того, как услышит их только один раз.
Основная проблема с распознаванием речи и обучением заключается в том, что нейронной сети требуется значительное количество времени для изучения новых акцентов и слов в языке. Это может вызвать проблемы, если много разных пользователей говорят одновременно. Другим последствием этой неточности от пользователей, которые говорят так, что программное обеспечение не распознает, может быть предложено повторить то, что было сказано дважды, прежде чем оно правильно распознает то, что было сказано.
Одна из проблем гибридной системы заключается в том, что может быть трудно распознать, говорит пользователь или слушает. Если пользователю не нравится система, он, вероятно, попытается ее избежать. Чтобы решить эту проблему, необходимо провести оценку того, насколько хорошо система может распознавать все типы голосов, а не распознавать только голос одного человека. Система, которая позволяет пользователям переводить телефон в беззвучный режим, звучит по-разному, когда к нему не прикасаются, и, вероятно, будет лучше различать режимы прослушивания и разговора. Способность программного обеспечения для распознавания голоса слышать разницу между пользователем, который тихо говорит и ест, и тем, кто ест только тихо, также может быть важна для повышения точности системы.
Чтобы решить эту проблему, необходимо провести оценку того, насколько хорошо система может распознавать все типы голосов, а не распознавать только голос одного человека. Система, которая позволяет пользователям переводить телефон в беззвучный режим, звучит по-разному, когда к нему не прикасаются, и, вероятно, будет лучше различать режимы прослушивания и разговора. Способность программного обеспечения для распознавания голоса слышать разницу между пользователем, который тихо говорит и ест, и тем, кто ест только тихо, также может быть важна для повышения точности системы.
Еще одна проблема с гибридной системой заключается в том, что может быть трудно различать голоса разных людей и то, как они произносят слова. Некоторые из основных проблем, связанных с распознаванием голоса, заключаются в том, что оно плохо понимает акценты и язык, а монотонных пользователей не так легко отличить друг от друга.
Одной из наиболее важных особенностей гибридных систем является обеспечение того, чтобы телефонное приложение всегда прослушивало речь пользователя, а не только его прикосновения.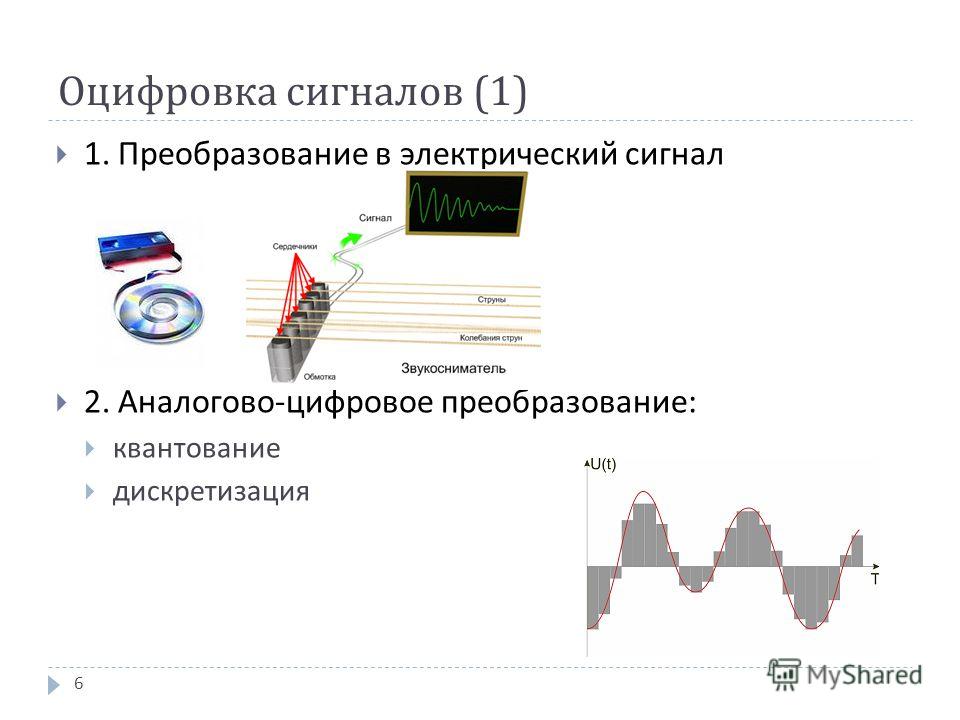 В идеале было бы одновременное прослушивание с обеих сторон, но это редко возможно. Большинство программ для распознавания голоса могут переключать телефон из режима прослушивания в режим прослушивания в зависимости от того, кто говорит или касается его. Однако это не так точно, как одновременный режим, потому что может быть трудно определить, кто касается или говорит.
В идеале было бы одновременное прослушивание с обеих сторон, но это редко возможно. Большинство программ для распознавания голоса могут переключать телефон из режима прослушивания в режим прослушивания в зависимости от того, кто говорит или касается его. Однако это не так точно, как одновременный режим, потому что может быть трудно определить, кто касается или говорит.
Основная проблема с системами распознавания голоса для телефонов заключается в том, что встроенный в телефон микрофон может плохо улавливать голос пользователя. Внешние микрофоны могут гораздо лучше улавливать голос пользователя и их легче понять пользователям.
Одним из преимуществ программного обеспечения для распознавания речи является то, что оно понимает, что говорят люди, независимо от того, сколько разных акцентов и языков. Еще одним преимуществом является то, что он позволяет человеку контролировать свои задачи, не используя руки, что может помочь ему избежать синдрома запястного канала, повторяющихся травм от перенапряжения или других подобных состояний.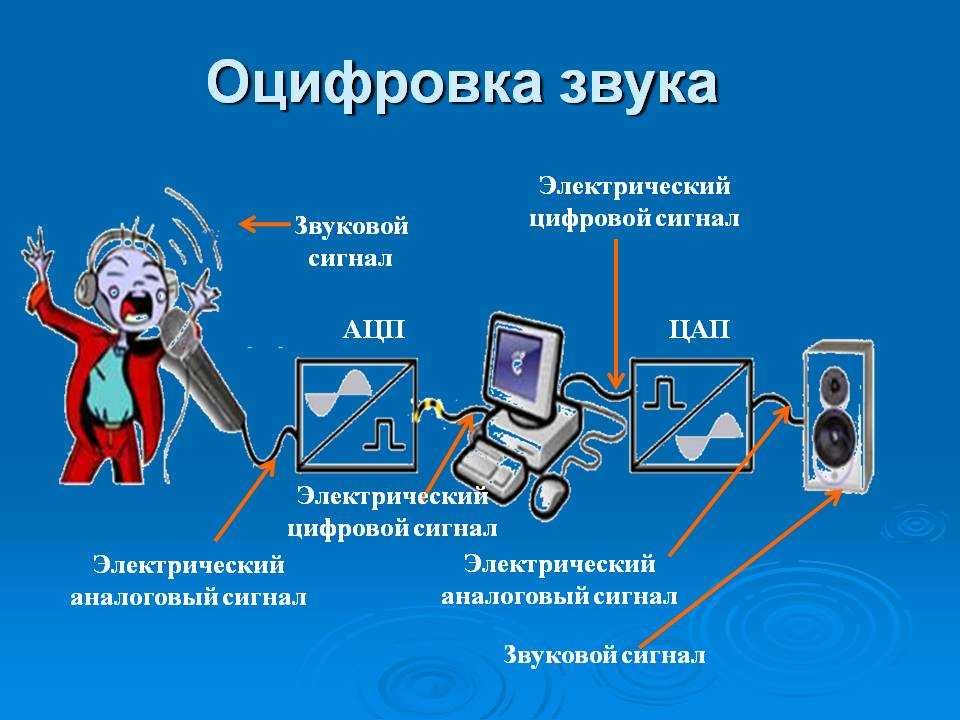 Некоторые из других преимуществ систем распознавания речи заключаются в том, что они изучают языки и акценты, что снижает вероятность того, что их потребуется переобучить, как только новый пользователь начнет их использовать. Они также обычно более удобны, чем набор текста, потому что для этого не требуются руки и нет клавиш, которые нужно нажимать, что делает их более быстрыми и простыми в использовании.
Некоторые из других преимуществ систем распознавания речи заключаются в том, что они изучают языки и акценты, что снижает вероятность того, что их потребуется переобучить, как только новый пользователь начнет их использовать. Они также обычно более удобны, чем набор текста, потому что для этого не требуются руки и нет клавиш, которые нужно нажимать, что делает их более быстрыми и простыми в использовании.
Одним из преимуществ для людей с ограниченными физическими возможностями, которые не могут пользоваться клавиатурой или мышью, является то, что программное обеспечение для распознавания речи не требует для своей работы движения руки или кисти, в отличие от других известных альтернатив. Кроме того, пользователи с ограниченными физическими возможностями могут найти беспроводную технологию более простой в использовании, чем проводную, поскольку нет проводов, соединяющих вычислительное устройство с устройством ввода (клавиатурой). Благодаря беспроводной технологии пользователь может легко перемещаться, пока он печатает или слушает. Им также нужно меньше беспокоиться о потере устройства, потому что к нему нет шнура, соединяющего их. Это означает, что пользователи могут использовать программное обеспечение для распознавания речи самостоятельно, а не прибегать к помощи кого-то другого.
Им также нужно меньше беспокоиться о потере устройства, потому что к нему нет шнура, соединяющего их. Это означает, что пользователи могут использовать программное обеспечение для распознавания речи самостоятельно, а не прибегать к помощи кого-то другого.
Недостатком программного обеспечения для распознавания речи является то, что оно может быть не в состоянии достаточно хорошо понимать направления только по речи. Люди с ограниченными физическими возможностями могут плохо видеть экран своего компьютера и могут запутаться в письменных или устных указаниях, если они не видят их достаточно хорошо, чтобы понять их.
Одним из преимуществ программ распознавания голоса является то, что они не используют клавиатуру или мышь, что упрощает доступ для людей с ограниченными физическими возможностями. Однако программы распознавания голоса труднее использовать, чем другие альтернативы, для людей с когнитивными нарушениями. Это потому, что требуется больше внимания и умственных усилий, чтобы помнить, что и когда говорить.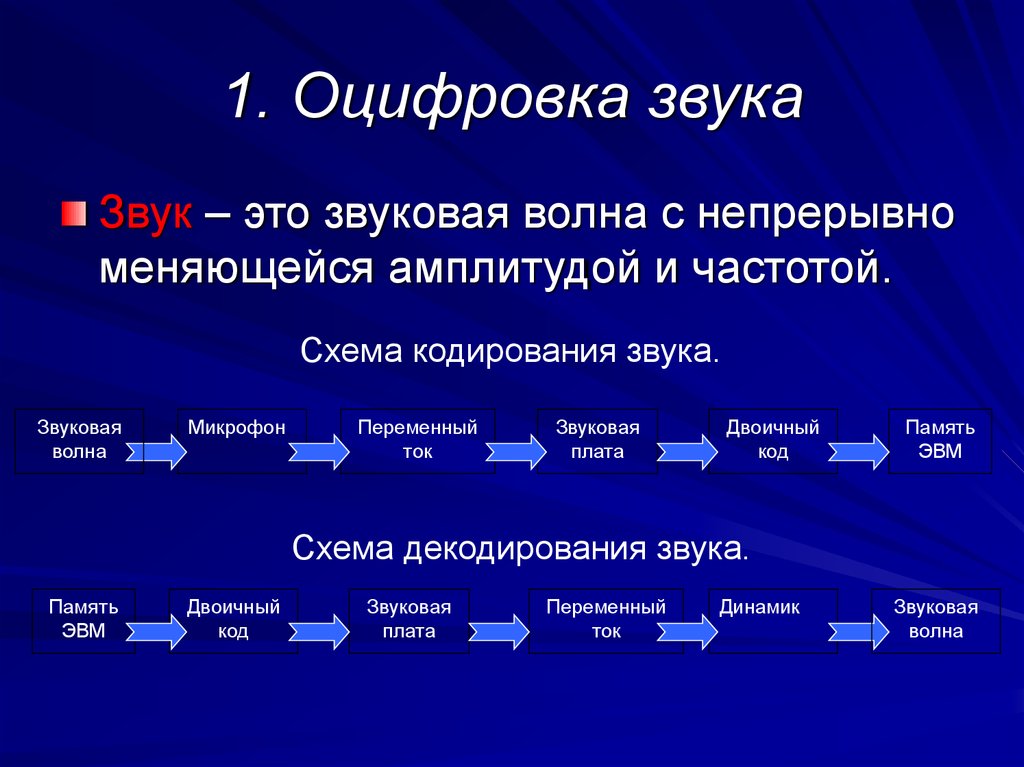 Если у пользователя проблемы с обучаемостью, ему может быть трудно использовать этот тип программного обеспечения, поскольку он зависит от памяти и навыков концентрации пользователя. Если пользователь легко отвлекается на фоновый шум или не знает, как попросить о помощи, то этот тип программного обеспечения может быть не идеальным для него.
Если у пользователя проблемы с обучаемостью, ему может быть трудно использовать этот тип программного обеспечения, поскольку он зависит от памяти и навыков концентрации пользователя. Если пользователь легко отвлекается на фоновый шум или не знает, как попросить о помощи, то этот тип программного обеспечения может быть не идеальным для него.
Программное обеспечение для распознавания голоса потенциально может привести пользователей к проблемам, потому что, если пользователи делают что-то не так (например, нарушают политику использования Интернета), им может быть запрещено использовать устройство. Если им запретят использовать устройство, им может стать труднее общаться с семьей, друзьями и коллегами.
Одним из недостатков программ распознавания голоса является то, что люди с ограниченными возможностями верхних конечностей не могут пользоваться ими без особых трудностей. Это потому, что это требует хорошего зрения и контроля движений рук и рук. Чтобы использовать этот тип программного обеспечения, кто-то должен иметь возможность четко видеть экран и иметь хорошие навыки мелкой моторики, чтобы иметь возможность двигать мышь или касаться экрана так, чтобы управлять программой. В некоторых случаях для этого требуется участие другого пользователя или лица, осуществляющего уход. Люди, которые не знают, как просить о помощи, могут не знать, как использовать программное обеспечение для распознавания голоса.
В некоторых случаях для этого требуется участие другого пользователя или лица, осуществляющего уход. Люди, которые не знают, как просить о помощи, могут не знать, как использовать программное обеспечение для распознавания голоса.
Другим недостатком программного обеспечения для распознавания голоса является то, что оно требует определенных умственных усилий и концентрации для управления, а это означает, что люди с когнитивными нарушениями могут испытывать трудности с его использованием.
Одним из недостатков распознавания речи по сравнению с другими формами является то, что пользователь должен направить свою энергию на речь, а не думать о том, что он хочет сказать. Этот метод также требует, чтобы они могли говорить четко и отчетливо, чтобы микрофон мог улавливать их голос. Если кто-то не может говорить громко, ему может быть трудно или невозможно общаться с помощью этого типа программного обеспечения.
Другим недостатком является то, что использование программного обеспечения для распознавания голоса может нанести вред здоровью пользователя, в зависимости от того, как часто он им пользуется.