Содержание
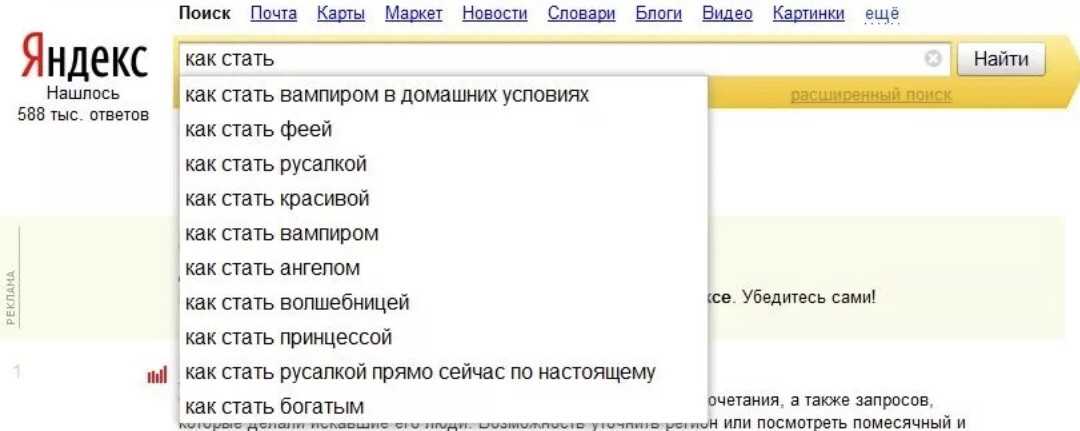
Как просто отследить тренды поисковых запросов в Яндексе и Гугле
Рейтинг: 5 / 5
Пожалуйста, оцените
Оценка 1Оценка 2Оценка 3Оценка 4Оценка 5
Отслеживание поисковых трендов нужно для решения самых разнообразных задач: прогнозирования роста трафика на сайта, оценки перспективности нового направления в бизнесе, выявления сезонных трендов. В статье я расскажу, как это сделать в Яндексе и Гугле легко и быстро.
Содержание:
- Что такое поисковый тренд и зачем он нужен
- Инструменты для оценки трендов
- Яндекс Вордстат
- Google Trends
- Как делать выводы по трендам запросов
- Вопрос-ответ
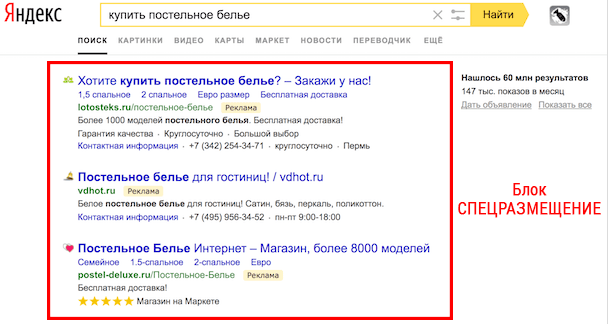
Доли Яндекса и Гугла в Рунете
Что такое поисковой тренд и зачем он нужен?
Поисковой тренд — это тенденция изменения числовых показателей популярности поискового запроса.
Анализ тренда строится на допущении, что поведение в прошлом может прогнозировать поведение в будущем.
 Анализ тренда строится на допущении, что поведение в прошлом может прогнозировать поведение в будущем.
Анализ тренда строится на допущении, что поведение в прошлом может прогнозировать поведение в будущем.Вот некоторые типовые задачи бизнеса, которые решает анализ поисковых трендов в Яндексе и Гугле:
- Узнать интерес к теме в разрезе любого региона
- Прогнозировать, какие запросы наберут популярность, чтобы уже сейчас их учесть в своем ядре и подготовить контент
- Оценить эффективность маркетинговых активностей
- Определить новые ниши или подниши для запуска бизнеса
- Анализировать трафик не по абсолютным значениям, а с учетом годовой сезонности
Инструменты для оценки трендов
Рассмотрим два главных инструмента для оценки поисковых трендов: Яндекс Вебмастер и Google Trends.
Как использовать Яндекс Вебмастер для отслеживания трендов
Заходим на главную страницу Yandex Wordstat и выбираем функцию «история запросов» (1). Нужно будет ввести капчу, а далее выбрать регион (2).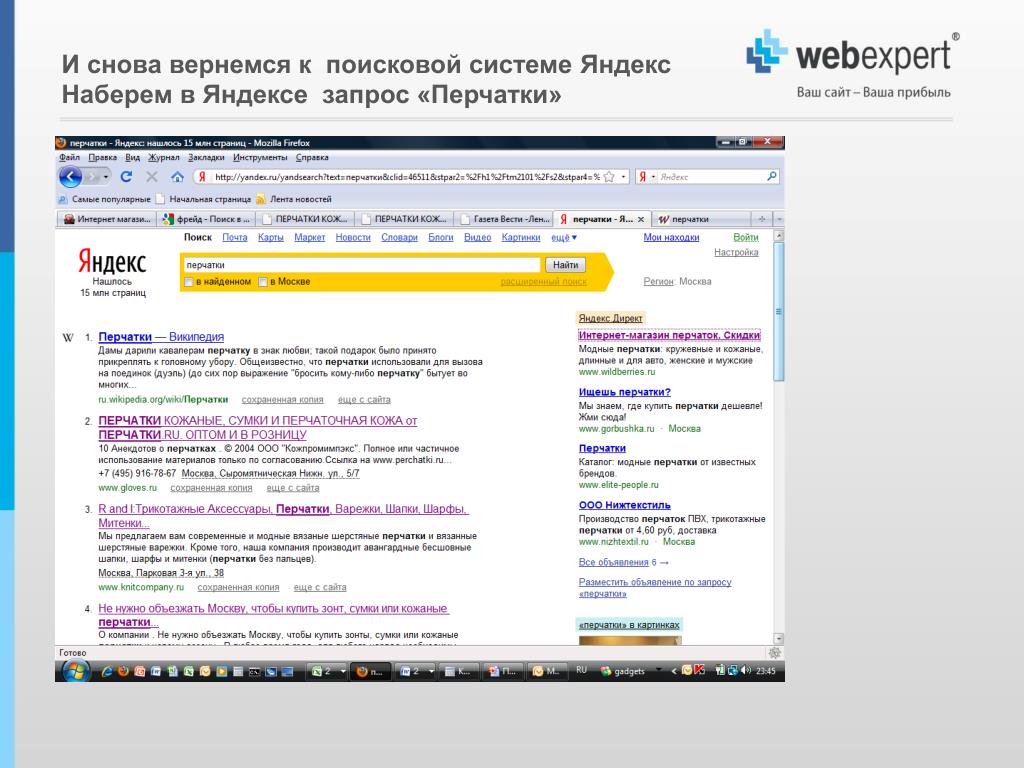 Для работы с вордстатом необходимо авторизоваться на яндексе.
Для работы с вордстатом необходимо авторизоваться на яндексе.
Оценка трендов в Яндекс Вордстат
Далее вводим интересующий нас поисковой запрос и получаем отчет трендов от вордстата:
Результат оценки трендов в Вордстате
Мы видим тренд запроса за 2 прошедших года. По этому графику можно выявить относительную сезонность запроса (с июля по ноябрь), а также построить тренд. Он получается восходящий (т.е. разность абсолютных значений за один и тот же период времени положительна), пусть и приближающийся к стабильному (разность маленькая).
Приведу расчет. Берем два смежных месяца и вычитаем:
- 15560 (июль 17) — 14503 (июль 16) = 1057 или примерно 6% прироста
- 17597 (август 17) — 14967 (август 16) = 2630 или примерно 14% прироста
В среднем по году мы получим рост в 7%. Исходя из этого мы можем прогнозировать поведение запроса в коридоре +/- 7% в 2018 году.
Google Trends — эффективное прогнозирование трендов
В отношении поисковых трендов гугл дает нам более продвинутый инструмент. Идем в сервис https://trends.google.ru (для полноценной работы нужно авторизоваться на гугле) и видим такую картину
Идем в сервис https://trends.google.ru (для полноценной работы нужно авторизоваться на гугле) и видим такую картину
Главная страница Google Trends
Мы можем отслеживать тренды по разным категориям и регионам. Введем тот же запрос, что и в Яндексе. Далее выберем регион (1), период анализа тренда (2) и получим такую картину:
Результат анализа в Гугл Трендс
Методика оценки популярности в гугле несколько иная. Самый популярный период берется за 100%, и все остальные данные нормализируются на это значение. Если бегло проведем медианный анализ по этому графику, то увидим примерно такой же рост, как и в Яндексе: около 7%.
Интересные данные предлагает Google Trends в нижней части страницы. Попробуем с ними разобраться.
Дополнительные данные анализа трендов в гугле
Здесь мы видим похожие темы (аналог правой колонки в Яндекс Вордстат) и похожие запросы из той же ниши. По похожим темам можно расширять товарную линейку своего бизнеса. Мы видим, что вместе с окнами ищут двери, балконы и шторы.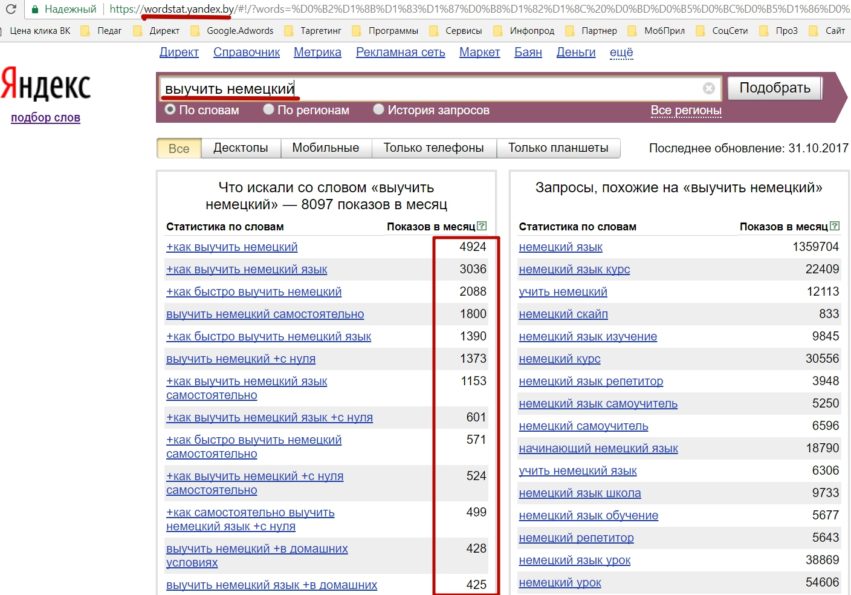 Если мы развернем список тем, то получим ещё и направление подоконников и брендов производителей профиля для окон.
Если мы развернем список тем, то получим ещё и направление подоконников и брендов производителей профиля для окон.
Дополнительные темы
В Гугл Трендс можно сравнить несколько запросов. Сравним, например, нишу окон с нишей натяжных потолков. Нажмем на кнопку «Сравнить» и введем соответствующий поисковой запрос. Вот результат (зелеными линиями я примерно показал результаты медианного анализа):
Сравнение трендов поисковых запросов в Гугле
Опять же, за 100% взята популярность одного из запросов в верхней точке.
Как делать выводы по трендам
Выводы делаются исходя из поставленной задачи. Расскажу несколько типовых ситуаций.
Запуск нового товара
- Если тренд растущий, то имеет смысл товар запускать. Скорость запуска должна зависеть от кривизны графика (чем он круче, тем быстрее нужно выводить товар на рынок)
- Если тренд стабильный — это сигнал насыщения рынка. После насыщения неизбежен спад. Если вывод нового товара не требует больших вложений — это можно делать. Но всегда нужно быть готовым к спаду спроса
- Если тренд падающий — то лучше этот товар на рынок не выводить. Спрос уменьшается, а число предложений в таких случаях намного его превышает, что неизбежно ведет к снижению маржинальности.
 Но всегда нужно быть готовым к спаду спроса
Но всегда нужно быть готовым к спаду спроса
Стоит ли включать рекламу на новый регион
- Опять смотрим на тренд. Если он падающий, то в этом особого смысла нет.
Как использовать сезонность запроса
- Вы узнали, что есть в нише четкая сезонность. Поэтому мы запускаем платную рекламу за месяц до начала сезона. Как правило, цена клика будет низкой, пока конкуренты спят. И вы сможете набрать много предзаказов на сезон, либо уже отгрузить товар, пока остальные только планируют рекламные бюджеты.
Вопрос-ответ
В: Можно ли отследить популярные запросы на ютуб?
О: Да, это можно сделать с помощью Гугл Трендс. В списке видов поиска нужно выбрать Youtube:
Популярные запросы на Ютуб
В: Насколько можно доверять данным поисковых трендов?
О: Это реальные данные поисковых систем.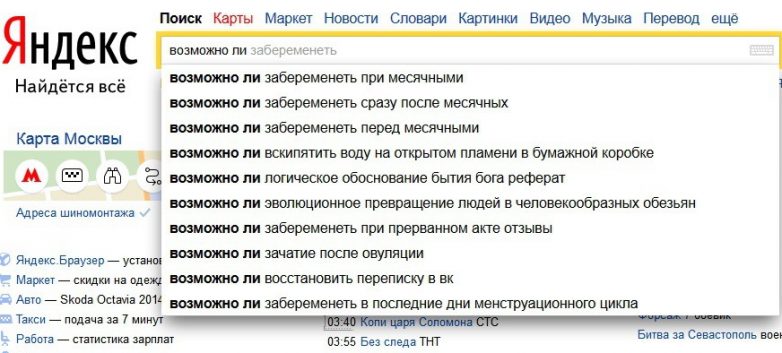 А насчет прогнозирования будущего — никто гарантию не даст.
А насчет прогнозирования будущего — никто гарантию не даст.
Теги::
Google Trends, Яндекс Вордстат
( 1 Rating )
Wordstat Яндекс: как использовать в маркетинге
Узнаете, как работать с сервисом Яндекс Wordstat маркетологу, какие задачи помогает решить и почему Вордстат запрашивает капчу.
Что такое Яндекс Вордстат
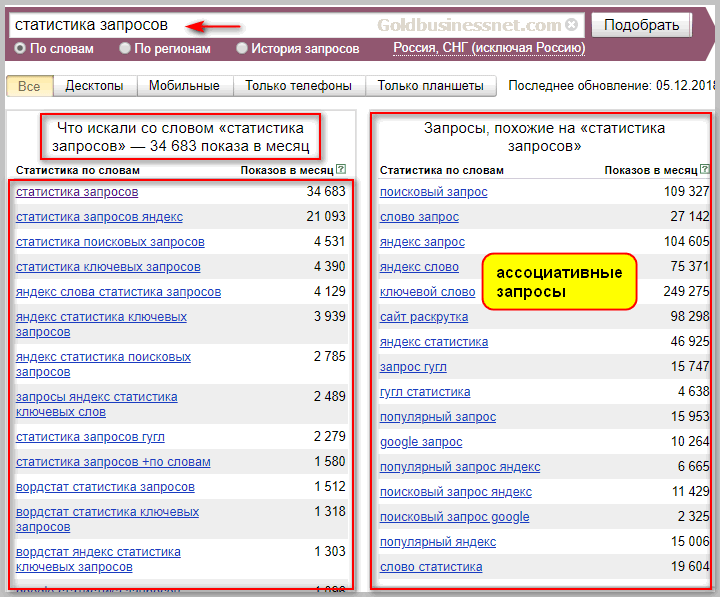
Яндекс.Подбор слов, Яндекс Wordstat или просто Wordstat — бесплатный сервис для определения популярности поисковых запросов. С его помощью можно проанализировать интерес аудитории к теме, проверить спрос на товар или услугу. Сервис подсчитывает количество показов в поисковике Яндекса по заданным ключевым словам за последний месяц, а также показывает историю показов за последние 2 года.
Пример: вводим запрос «купить фен москва» — Вордстат собрал статистику по этому ключевому слову в двух колонках:
Слева — данные по показам, которые включают указанное слово или фразу. Справа — похожие на указанное слово или фразу запросы
Справа — похожие на указанное слово или фразу запросы
Какие задачи помогает решать сервис Яндекс.Подбор слов
1. Собрать семантическое ядро. Первый инструмент, с которого нужно начинать поиск ключевых слов, — Яндекс Вордстат. Семантика нужна для SEO и запуска контекстной рекламы. Изучите популярные запросы — поймёте, какие из них стоит взять на заметку, а какие не понадобятся.
Онлайн-обзор платформы Roistat
В прямом эфире расскажем, как сделать маркетинг эффективным
Подключиться
2. Выбрать тему для публикации. Когда не знаете, о чём написать в первую очередь, проверьте ваши темы в Подборе слов. Статистика ключевых слов подскажет, что интересует пользователей больше, а какие темы «гуглят» реже.
3. Оценить сезонность продукта. Wordstat хранит данные по показам ключевых слов в выдаче Яндекса за последние два года. Можно посмотреть, были ли пики популярности запроса в какие-либо периоды года и узнать, как меняется популярность запросов в зависимости от сезона. Для этого выберите селектор «История запросов» и изучите график. Подробнее о том, как работать с сезонностью в Вордстате, расскажем дальше.
Для этого выберите селектор «История запросов» и изучите график. Подробнее о том, как работать с сезонностью в Вордстате, расскажем дальше.
4. Найти новые регионы для продажи продукта. Чтобы посмотреть, в каких регионах популярен ваш запрос, выберите селектор «По регионам» под поисковой строкой Поиска слов.
Сервис Яндекс.Подбор слов — преимущества и недостатки
| ➕ | ➖ |
| На одном экране Яндекс Вордстат показывает частотность ключей и подсвечивает похожие запросы — не нужно искать отдельно по каждой словоформе | Яндекс.Wordstat не указывает на тренды — сервис ищет похожие запросы, а не показывает, что популярно в поисковике |
| С помощью «Истории запросов» можно оценить сезонность ключей | Результаты поиска ограничены. На одной странице не более 50 запросов, максимум — 40 страниц |
| Сервис покажет статистику по указанным регионам | Сбор ключевых слов из Wordstat основан на ручном добавлении запросов, не учитывает семантику конкурентов. Если вам нужно полноценное семантическое ядро — необходимо использовать дополнительные сервисы Если вам нужно полноценное семантическое ядро — необходимо использовать дополнительные сервисы |
| Можно использовать расширения для Wordstat, чтобы быстро собирать семантику | Перед каждым новым поиском нужно заполнять «капчу» |
Статистика Яндекс Wordstat — что показывает
Основная информация, которую собирает и выдаёт сервис — количество показов в месяц по искомому запросу. Эту цифру также называют поисковым спросом или частотностью. Справа от каждого ключевого слова находится цифра, которая фиксирует частотность:
Информация в Яндекс Вордстат приблизительная: данные по запросу включают все показы в поисковой выдаче с введёнными ключевыми словами. Например, в запрос «фен строительный» входят показы как по запросам «фен строительный купить», так и «ремонт строительного фена», «пайка строительным феном».
Тем не менее, статистика Вордстат может стать хорошим ориентиром для оценки спроса или планирования рекламной кампании. Сервис делает прогноз показов, оценивая данные по каждому запросу за последние 30 дней.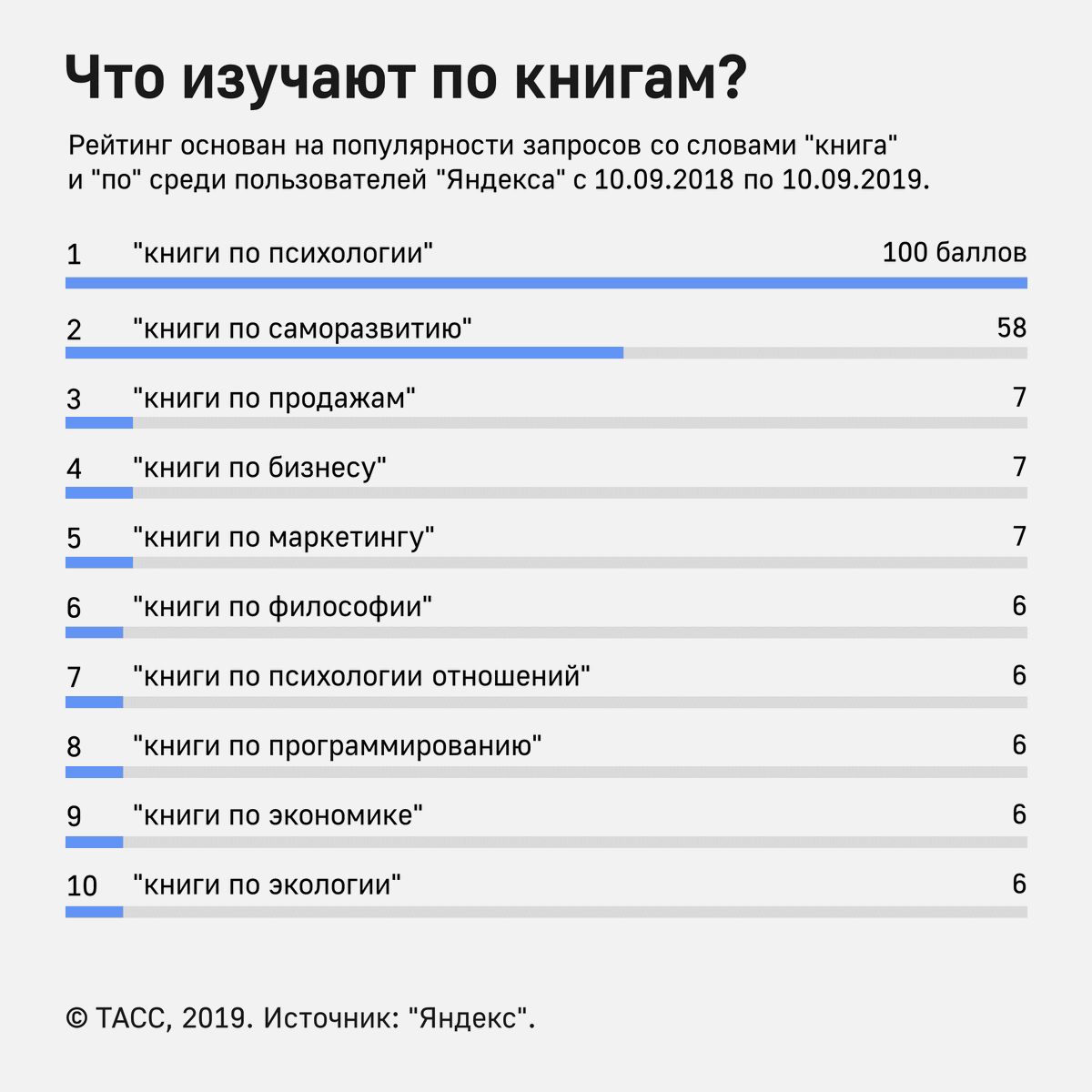 Данные собираются только с поиска Яндекса — запросы в других поисковых системах и не учитываются в Яндекс Вордстат. Статистика по запросам — это предварительный прогноз показов в месяц.
Данные собираются только с поиска Яндекса — запросы в других поисковых системах и не учитываются в Яндекс Вордстат. Статистика по запросам — это предварительный прогноз показов в месяц.
Виды частотностей Wordstat
Базовая частотность
Базовая частотность Wordstat — это показы по всем возможным вариантам указанного запроса. Базовая частотность — самая неточная. Например, в запрос «купить машину» попадёт множество смежных запросов — «стиральная машина купить», «посудомоечная машина купить», «швейная машина купить», «купить машину автомат». Если вы продаёте автомобили, вам не нужны данные по другим запросам, потому ключевое слово нужно уточнить.
У базовых запросов высокие просмотры — их используют, чтобы оценить заинтересованность аудитории в продукте или теме
Фразовая частотность
Фразовая частотность показывает статистику только по конкретным запросам, когда пользователи вводили их в поиск без лишних слов. Чтобы посмотреть частотность выбранной фразы, нужно использовать оператор кавычки (‟”).
Оператор Wordstat кавычки (‟”) фиксирует поисковую фразу при сборе статистики в Подборе слов. Так можно отсеять все дополнительные слова. При этом в статистике Wordstat по выбранному запросу будет учтён любой порядок слов и все склонения фразы.
Введём запрос в кавычках (‟”) — «купить машину». Число показов сократилось почти в 100 раз, потому что во фразовой частотности не учитываются дополнительные слова, указывающие на регион — «купить машину Москва» или «купить машину Казань», тип покупки — «купить машину бу» и другие.
Для поиска по фразовой частотности нужно вводить кавычки лапки (‟”), а не ёлочки («»)
Точная частотность
Яндекс.Подбор слов покажет точное вхождение по запросу, если ввести ключевые слова, сохранив склонения, спряжения, число. Точное вхождение — когда в тексте на веб-странице ключевая фраза встречается с заданным порядком слов, в выбранной грамматической форме.
Чтобы посмотреть точную частотность по выбранному запросу, нужно взять его в кавычки (‟”) и добавить оператор восклицательный знак (!) перед каждым словом.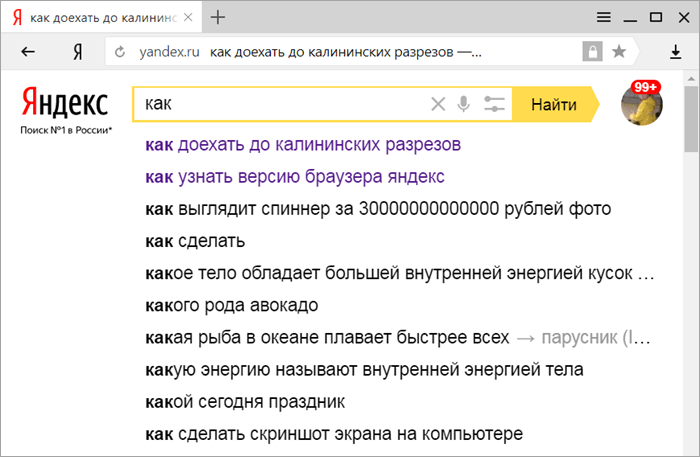
Оператор Wordstat восклицательный знак (!) фиксирует форму слова. Так в статистике можно увидеть показы поискового запроса в выдаче Яндекса в конкретной словоформе без учёта склонений и множественного числа.
В примере с запросом «купить машину» используем оба оператора и видим, что точное вхождение использовали 23 500 раз при базовой частотности 2,6 млн.
Точный запрос в Вордстат указывает на высокочастотный ключ
Важно: для упрощения работы с ключами, их делят на три категории:
- высокочастотные — от 5 000 запросов в месяц;
- среднечастотные — 5 000-10 000;
- низкочастотные — меньше 1 000.
Высокочастотные запросы приводят больше трафика. Низкочастотные ключи могут приводить целевой трафик и положительно влиять на конверсию.
Все операторы Подбора слов Яндекса и их назначения
Чтобы понимать, как правильно искать в Wordstat, нужно научиться пользоваться операторами. Это символы, с помощью которых сервис меняет характер запроса. Всего в Вордстат их 5.
Всего в Вордстат их 5.
- Оператор «минус» ( — ). Убирает из поиска слово, перед которым расположен оператор. Нужно добавлять минус в начале слова без пробела. Запрос «автомобиль -бу» покажет запросы, где есть первое слово, но нет второго.
- Оператор «плюс» ( + ). Добавляет предлоги и союзы, запросы с которыми сервис самостоятельно не учитывает. Например, «автомобиль +в Воронеже».
- Оператор «или» ( | ). Помогает находить запросы с несколькими вариантами слов. Такие слова нужно обязательно указывать в скобках — символ | выполняет роль союза «или». Например, по запросу «автомобиль (купить|арендовать)» Вордстат покажет статистику по обеим фразам — «автомобиль купить» и «автомобиль арендовать».
- Оператор «восклицательный знак» ( ! ). Показывает точное соответствие запросу. Например, по запросу «!автомобиль !купить» в результатах будет частотность показов по ключам с точным вхождением — только в именительном падеже, единственном числе и инфинитиве. Другие словоформы не будут учтены в статистике.
- Оператор квадратные скобки ( [ ] ). Закрепляет порядок слов в ключе. Например, для запроса «[автомобиль купить]» Wordstat не учтёт показы фразы «купить автомобиль».
- Оператор кавычки ( ‟” ). Сохранит соответствие словам из запроса, но не учтёт их порядок и окончания. Например, по запросу «недорогой автомобиль купить» сервис может показать ключ «купить автомобиль недорого».
 Другие словоформы не будут учтены в статистике.
Другие словоформы не будут учтены в статистике.Как маркетологу или владельцу бизнеса работать с Яндекс Wordstat
Как смотреть сезонность
Спрос на продукты и информацию взлетает в пик сезона и падает, когда сезон проходит. Перед праздниками люди ищут подарки, а в августе закупают канцелярию перед стартом учебного года. Важно отслеживать сезонность, чтобы грамотно расходовать деньги на рекламу. Например, снижать стоимость клика CPC по запускам в несезон и подогревать интерес перед стартом сезона.
Wordstat поможет оценить сезонность с помощью истории запросов. Для этого укажите запрос и под строчкой поиска выберите «История запросов». Сервис покажет результаты за последние 2 года. Например, проверяем запрос «конструктор лего». На графике выделяются 2 пиковых периода с наибольшим спросом — декабрь 2020 и декабрь 2021. Этот товар покупали в качестве подарков на Новый год.
Для этого укажите запрос и под строчкой поиска выберите «История запросов». Сервис покажет результаты за последние 2 года. Например, проверяем запрос «конструктор лего». На графике выделяются 2 пиковых периода с наибольшим спросом — декабрь 2020 и декабрь 2021. Этот товар покупали в качестве подарков на Новый год.
Летом спрос на конструктор самый низкий
С помощью истории запросов можно находить ключи-пустышки. Это запросы, которые выстрелили в один момент, а потом не давали никакого охвата. В таком случае показы искусственно накрутили или товар был популярен некоторое время, а потом о нём забыли.
Важно: история запросов показывает динамику по базовой частотности и не учитывает операторы — кавычки и восклицательные знаки.
Онлайн-обзор платформы Roistat
В прямом эфире расскажем, как сделать маркетинг эффективным
Подключиться
Как разделить показы по регионам
Полезно знать статистику по регионам, если запускаете новый продукт или ищете перспективный рынок для расширения бизнеса. Для запуска рекламной кампании данные по регионам тоже пригодятся — сможете оценить целесообразность рекламы в выбранных регионах.
Для запуска рекламной кампании данные по регионам тоже пригодятся — сможете оценить целесообразность рекламы в выбранных регионах.
Чтобы посмотреть запросы Яндекс.Подбор слов по регионам, укажите запрос и под строчкой поиска выберите «По регионам». Сервис предоставит 3 списка:
- по регионам — например, Центральный федеральный округ;
- города;
- все — регионы + города.
Вордстат Яндекс — статистика по ключевому запросу «пластиковые окна» в России и СНГ по регионам
Результаты поиска можно посмотреть в виде географической карты. Регионы, где запрос очень популярен, окрашены в красный цвет, а где непопулярен — в жёлтый.
Как оценить популярность запросов Wordstat по типу устройств
Если продвигаете сервисы только с десктопов или со смартфонов, важно отслеживать данные по просмотрам с этих устройств. Например, не всегда выгодно продвигать приложение на телефон по запросам с наибольшим охватом для пользователей ПК. Лучше изучить запросы для смартфонов или запускать отдельную рекламу для десктопов, мотивируя пользователей переходить в приложение.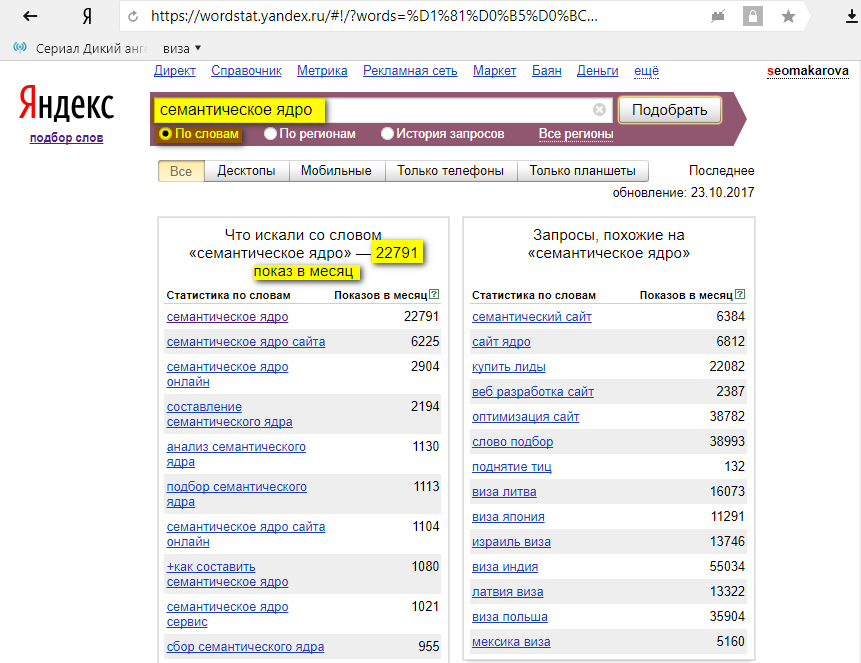
Чтобы посмотреть запросы по типу устройств, укажите запрос и после того, как сервис подгрузит результаты, выберите один из пяти вариантов:
- все — Вордстат по умолчанию покажет охват по всем устройствам;
- десктопы;
- мобильные — смартфоны + планшеты;
- только телефоны;
- только планшеты.
Например, с помощью разделения статистики по запросам с десктоп и мобильных устройств, видим, что Вордстат чаще ищут с компьютеров. Можно предположить, что сервисом пользуются чаще всего с десктопных устройств.
Как собрать семантическое ядро сайта в Wordstat
Семантика нужна для анализа конкурентов, запуска контекстной рекламы, SEO-продвижения сайта. Это список отобранных ключевых слов, которые можно брать в работу. Вордстат поможет собрать основу семантического ядра — самые очевидные запросы, актуальные фразы и похожие ключи.
Чтобы собрать семантику, введите самые простые ключевые слова, которые первыми приходят на ум. Например, для интернет-магазина цветов подойдёт запросы «цветы», «цветы москва», «розы», «цветы доставка».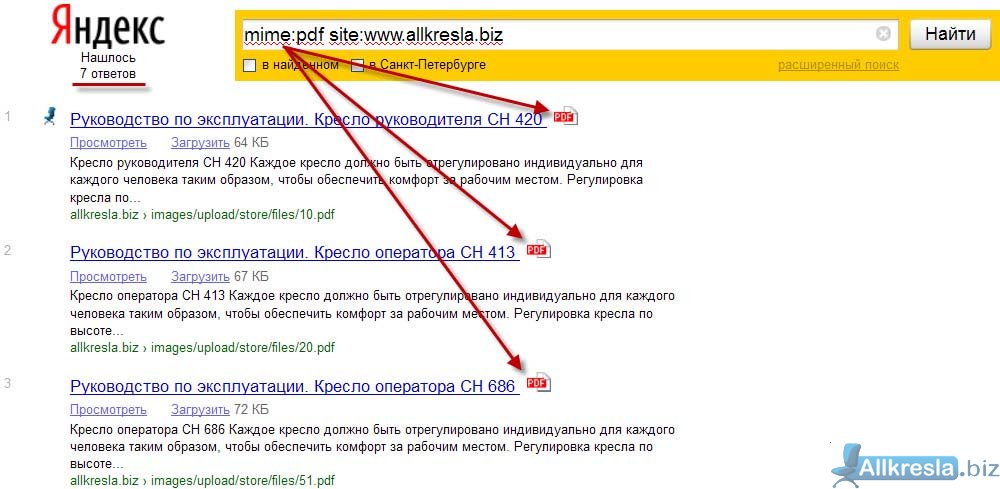 Этого хватит для начала — сервис покажет похожие и близкие по тематике запросы.
Этого хватит для начала — сервис покажет похожие и близкие по тематике запросы.
Копируйте запросы Яндекс Вордстат в отдельный документ — например, в Google Таблицу. Указывайте частотность — пригодится, чтобы поделить запросы на высокочастотные и низкочастотные.
Вордстат — первый шаг для сбора семантики. Ключи нужно отсортировать и почистить, добавить минус-слова. Подробнее о том, как довести семантическое ядро до ума и в каких сервисах это сделать, рассказали в блоге Roistat.
Расширения для браузера при работе с Wordstat
Удобнее собирать семантику в Вордстат с помощью расширений для браузера. Например, для Google Chrome можно использовать расширение Wordstater. Оно умеет собирать не только запросы, но и минус-фразы, стоп-слова. Можно настроить работу вручную или запустить автоматически сбор слов по параметрам. Wordstater поможет спрогнозировать приблизительную цену клика для каждой фразы.
При установке расширения в сервисе Подбор слов Яндекса вы увидите кнопку плюса у каждого запроса. С помощью неё удобно копировать запросы в окно расширения, чтобы дальше с ними работать. После сбора семантики можно будет забрать из этого окна семантику в выбранном виде:
С помощью неё удобно копировать запросы в окно расширения, чтобы дальше с ними работать. После сбора семантики можно будет забрать из этого окна семантику в выбранном виде:
- через запятую или столбиком;
- с частотностью или без неё;
- с операторами или без них.
Также при использовании расширения для Вордстат под поисковой строкой появляются операторы Wordstat: можно подставлять их в проверяемый запрос одним кликом.
Другие расширения для Вордстат
Yandex Wordstat Helper. Помогает копировать запросы в один клик, узнавать частотность, добавлять и удалять ключи из таблицы.
Yandex Wordstat Assistant. Более продвинутый сервис — поможет добавить слова в Word или Excel, автоматически очистит ключи от дублей, отфильтрует по нужным параметрам.
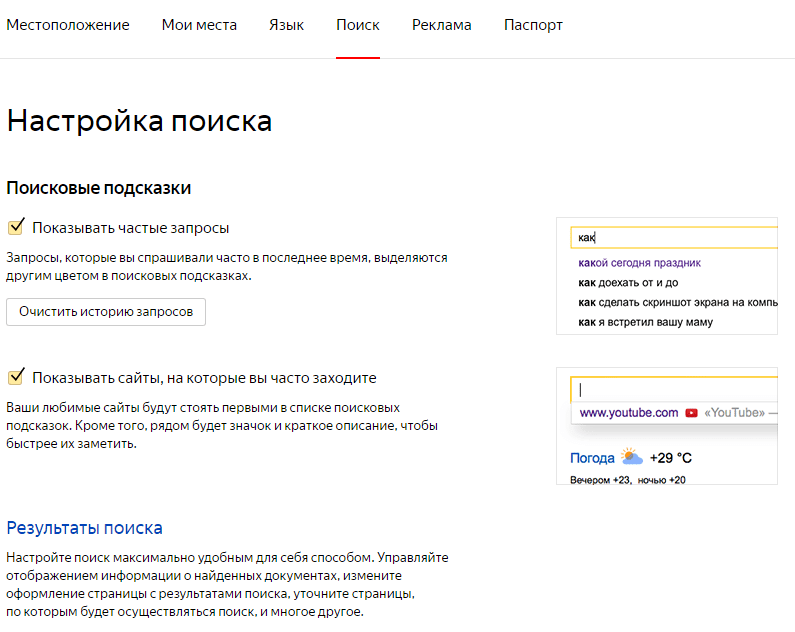
Как отключить капчу в Вордстате
Капча нужна, чтобы Яндекс Wordstat убедился, что вы человек, а не робот. Её придётся вводить перед запросом. Иногда сервис реже показывает капчу, если отключить плагины и расширения браузера — например, блокировщик рекламы, который мешает получать cookie.
Когда Яндекс Wordstat считает запросы похожими
- Когда в одном месте использовали букву «ё», а в другом — «е».
- Когда использовали единственное или множественное числа — ёжик, ёжики.
- Когда употребили различные падежи и степени сравнения — вовлеку, вовлечёшь.
- Когда слова ввели с опечатками — купить, кпуить.
GET-запросов. Руководство разработчика
Внимание. Специальные символы, которые передаются как значения параметров, должны быть заменены соответствующими управляющими последовательностями для процентного кодирования. Например, вместо знака равенства («=») необходимо использовать управляющую последовательность «%3D».
https://yandex.<домен>/search/xml ? [\nИмя пользователя. Должен совпадать с логином для Яндекс.Паспорта, который был указан при регистрации.
\n "}}">=<имя пользователя>] & [\nЗначение ключа API, выданного при регистрации.
\n "}}">=<ключ API>] & [\n \nТекст поискового запроса.
\n \nЗапрос имеет следующие ограничения: максимальная длина запроса — 400 символов; максимальное количество слов — 40.
\n "}}">=<текст поискового запроса>] & [\nПоддерживается только для типов поиска «Русский» и «Турецкий».
\nID страны или региона для поиска. Определяет правила ранжирования документов. Например, если мы передаем в этот параметр значение «11316» (Новосибирская область), при формировании результатов поиска используется формула, определенная для Новосибирской области.
\nСписок идентификаторов общих стран и регионов приведен в приложении.
\n "}}">=] & [\n Язык уведомления для ответа на поиск. Это влияет на текст, который передается в
\nfound-docs-human, а также в сообщениях об ошибках.Допустимые значения зависят от используемого типа поиска:
\n
 Вместо специальных символов необходимо использовать соответствующие управляющие последовательности.
Вместо специальных символов необходимо использовать соответствующие управляющие последовательности. 
- \n
«Русский (yandex.ru)» — «ru» (русский), «uk» (украинский), «be» ( белорусский), «кк» (казахский). Если не указано, уведомления отправляются на русском языке.
«Турецкий (yandex.com.tr)» — Поддерживает только значение «tr» (турецкий).
«Worldwide (yandex.com)» — Поддерживает только значение «en» (англ.).
\n
\n
\n
\n «}}»>=<язык уведомлений>]
& [\n
Правила сортировки результатов поиска. Возможные значения:
\n
- \n
«rlv» — По релевантности.
«tm» — По времени изменения документа.
\n
\n
\n
Если опущено, результаты сортируются по релевантности.
\n
При сортировке по времени изменения параметр может содержать атрибут порядка , который является порядком сортировки документов. Возможные значения:
Возможные значения:
\n
- \n
«по убыванию» — Вперед (от самого последнего к самому старому). Используется по умолчанию.
«по возрастанию» — в обратном порядке (от самого старого к самому последнему).
\n
\n
\n
Формат: sortby=<тип сортировки>.order%3D<порядок сортировки> . Например, для обратной сортировки по дате используйте следующее: sortby=tm.order%3По возрастанию .
\n «}}»>=<тип сортировки>]
& [\n
Правила фильтрации результатов поиска (исключение документов из результатов поиска по одному из правил). Возможные значения:
\n
- \n
«нет» — фильтрация отключена.
Вывод включает любые документы, независимо от их содержания.«умеренный» — умеренная фильтрация. Вывод исключает документы, попадающие в категорию «только для взрослых», если поиск явно не направлен на поиск этих типов ресурсов.
«строгий» — Семейный фильтр. Независимо от поискового запроса, документы, предназначенные «только для взрослых» или содержащие ненормативную лексику, удаляются из результатов поиска.
 Вывод включает любые документы, независимо от их содержания.
Вывод включает любые документы, независимо от их содержания.\n
\n
\n
\n
Если параметр опущен, используется умеренная фильтрация.
\n «}}»>=<тип фильтра>]
& [\n
Максимальное количество пассажей, которые можно использовать при создании сниппета для документа. Отрывок — это отрывок из найденного документа, содержащий слова запроса. Пассажи используются для создания сниппетов, которые представляют собой текстовые аннотации к найденным документам.
\n
Допустимые значения — от 1 до 5. Результат поиска может содержать меньше отрывков, чем значение, установленное для этого параметра.
\n
Если параметр не указан, для каждого документа возвращается не более четырех пассажей с текстом запроса.
\n «}}»>=<количество проходов>]
& [\n
Набор параметров, определяющих правила группировки результатов. Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в разделе 9.0020 сортировка по параметру . Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.
\n
Параметры разделяются запятыми и задаются в формате:
attr%3D<вспомогательный атрибут>.mode%3D<тип группировки>.groups-on-page%3D<количество групп на странице>.docs -in-group%3D<количество документов в группе>
\n
Параметры:
- \n
\n
режим— Метод группировки. Возможные значения:\n
- \n
«flat» — Плоская группировка. Каждая группа содержит один документ. Передано с пустым значением параметра
attr.«deep» — Группировка по домену. Каждая группа содержит документы из одного домена. Передается со значением «d» для параметра
attr.
\n
\n
\n
Если параметр не определен, используется плоская группировка по доменам.
\n
\n
attr— Служебный атрибут. Зависит от значения атрибута режима.\n
групп-на-странице— Максимальное количество групп, которое может быть возвращено на странице результатов поиска. Допустимые значения — от 1 до 100.docs-in-group— Максимальное количество документов, которые могут быть возвращены на группу. Допустимые значения — от 1 до 3.
 Возможные значения:
Возможные значения:\n
 Зависит от значения атрибута
Зависит от значения атрибута \n
\n
\n
\n «}}»>=<параметры группировки результатов>]
& [\n
Номер запрашиваемой страницы в результатах поиска. Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»).
Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»).
\n
Например, если количество возвращаемых документов на странице равно «n», а в параметре передано значение «p», в результаты поиска будут включены документы, попадающие в диапазон выходных позиций от p* n+1 от до p*n+n включительно.
\n
Если параметр опущен, возвращается первая страница результатов поиска.
\n «}}»>=<номер страницы>]
& [\n
Инициирует проверку пользователя на предмет возможной защиты от роботов.
\n
Используется только значение «да».
\n «}}»>=<да>]
пользователь | Имя пользователя. Должен совпадать с логином для Яндекс. |
ключ | Значение ключа API, выданного при регистрации. |
запрос | Текст поискового запроса. Вместо специальных символов необходимо использовать соответствующие управляющие последовательности. Запрос имеет следующие ограничения: максимальная длина запроса — 400 символов; максимальное количество слов — 40. |
lr | Поддерживается только для типов поиска «Русский» и «Турецкий». Идентификатор страны или региона для поиска. Определяет правила ранжирования документов. Например, если мы передаем в этот параметр значение «11316» (Новосибирская область), при формировании результатов поиска используется формула, определенная для Новосибирской области. Список идентификаторов общих стран и регионов приведен в приложении. |
l10n | Язык уведомления для ответа на поиск. Допустимые значения зависят от используемого типа поиска:
|
sortby | Правила сортировки результатов поиска. Возможные значения:
Если не указано, результаты сортируются по релевантности. При сортировке по времени изменения параметр может содержать атрибут
Формат: |
filter | Правила фильтрации результатов поиска (исключение документов из результатов поиска по одному из правил). Возможные значения:
Если параметр опущен, используется умеренная фильтрация. |
maxpassages | Максимальное количество пассажей, которые можно использовать при создании сниппета для документа. Отрывок — это отрывок из найденного документа, содержащий слова запроса. Пассажи используются для создания сниппетов, которые представляют собой текстовые аннотации к найденным документам. Допустимые значения — от 1 до 5. Результат поиска может содержать меньше отрывков, чем значение, установленное для этого параметра. Если параметр опущен, для каждого документа возвращается не более четырех пассажей с текстом запроса. |
groupby | Набор параметров, определяющих правила группировки результатов. Параметры разделяются запятыми и задаются в формате: attr%3D<вспомогательный атрибут>.mode%3D<тип группировки>.groups-on-page%3D<количество групп на странице>.docs-in -group%3D<количество документов в группе> Параметры:
|
страница | Номер запрашиваемой страницы в поисковой выдаче. Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»). Например, если количество документов, возвращаемых на странице, равно «n», а в параметре передано значение «p», в результаты поиска будут включены документы, попадающие в диапазон выходных позиций от Если параметр опущен, возвращается первая страница результатов поиска. |
showmecaptcha | Инициирует проверку пользователя на предмет возможной защиты от роботов. Используется только значение «да». |
 Паспорта, который был указан при регистрации.
Паспорта, который был указан при регистрации. Он влияет на текст, который передается в теге
Он влияет на текст, который передается в теге 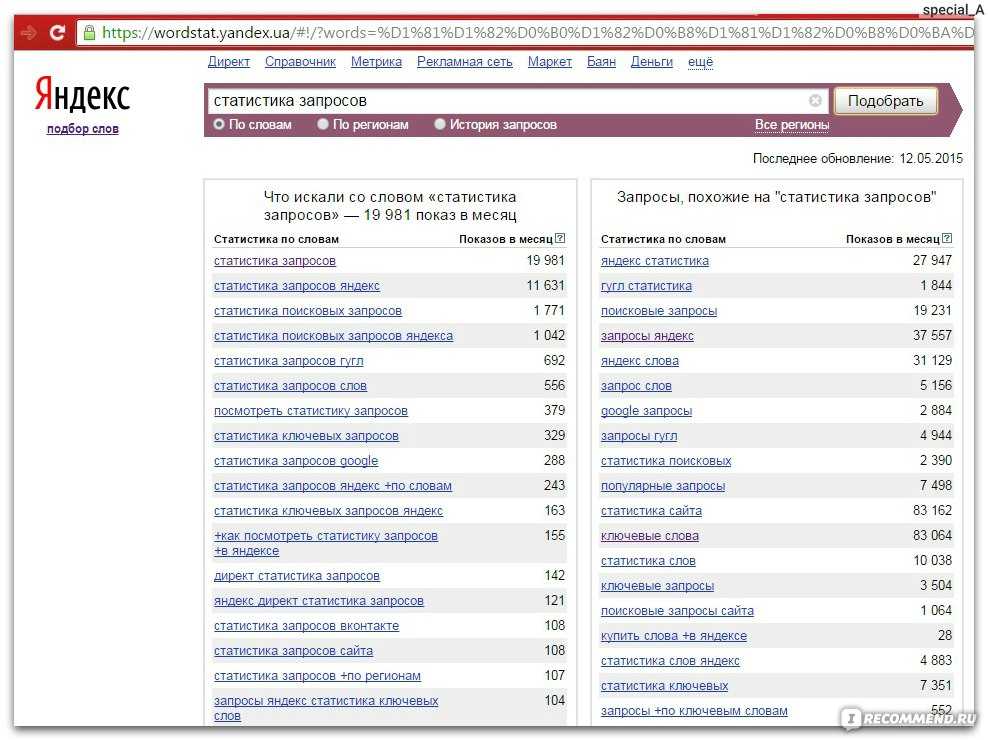 Возможные значения:
Возможные значения: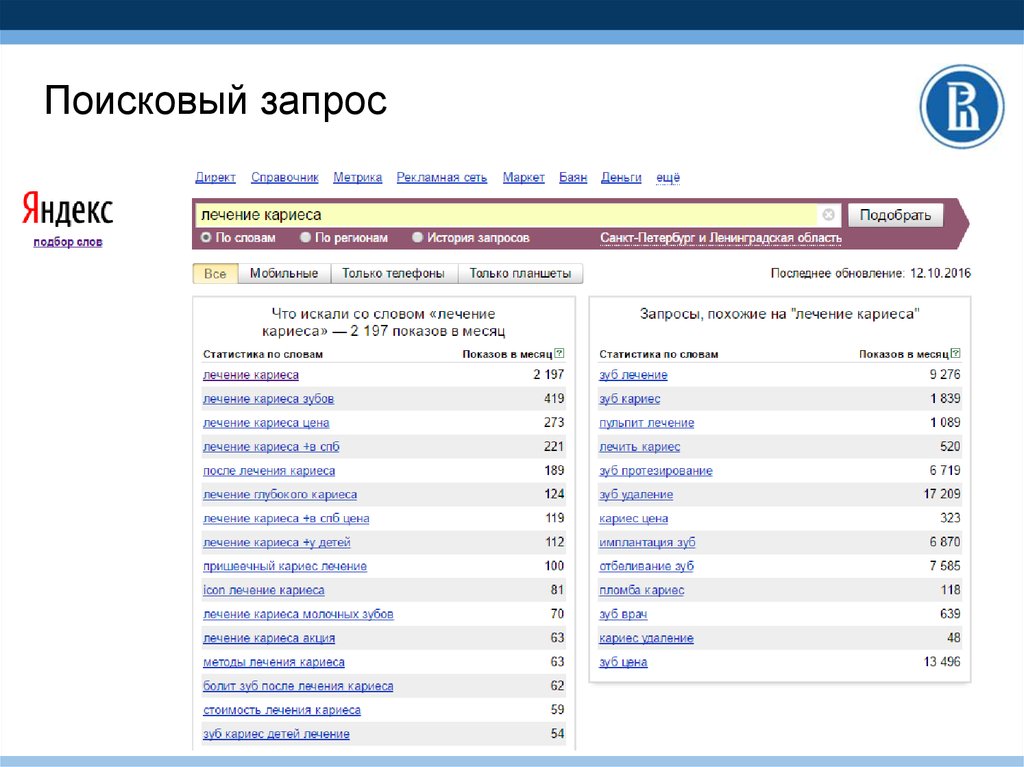
 Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в разделе 9.0233 сортировка по параметру . Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.
Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в разделе 9.0233 сортировка по параметру . Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.
 Допустимые значения — от 1 до 3.
Допустимые значения — от 1 до 3.Следующий запрос возвращает вторую страницу результатов поиска по запросу «
 Тип поиска: Русский (yandex.ru). Результаты сгруппированы по доменам. Каждая группа содержит три документа, и на странице может быть возвращено пять групп.
Тип поиска: Русский (yandex.ru). Результаты сгруппированы по доменам. Каждая группа содержит три документа, и на странице может быть возвращено пять групп. Для выполнения запросов API требуется утвержденный запрос. Получив ваш запрос, мы внесем ваше приложение в реестр приложений, обращающихся к Яндекс Директу, и свяжемся с вами как с его разработчиком, чтобы уведомить вас о важных новостях, попросить настроить работу вашего приложения и т.д.
Для выполнения запросов API требуется утвержденный запрос. Получив ваш запрос, мы внесем ваше приложение в реестр приложений, обращающихся к Яндекс Директу, и свяжемся с вами как с его разработчиком, чтобы уведомить вас о важных новостях, попросить настроить работу вашего приложения и т.д.