Содержание
Как просто отследить тренды поисковых запросов в Яндексе и Гугле
Рейтинг: 5 / 5
Пожалуйста, оцените
Оценка 1Оценка 2Оценка 3Оценка 4Оценка 5
Отслеживание поисковых трендов нужно для решения самых разнообразных задач: прогнозирования роста трафика на сайта, оценки перспективности нового направления в бизнесе, выявления сезонных трендов. В статье я расскажу, как это сделать в Яндексе и Гугле легко и быстро.
Содержание:
- Что такое поисковый тренд и зачем он нужен
- Инструменты для оценки трендов
- Яндекс Вордстат
- Google Trends
- Как делать выводы по трендам запросов
- Вопрос-ответ
Доли Яндекса и Гугла в Рунете
Что такое поисковой тренд и зачем он нужен?
Поисковой тренд — это тенденция изменения числовых показателей популярности поискового запроса.
Анализ тренда строится на допущении, что поведение в прошлом может прогнозировать поведение в будущем.
 Анализ тренда строится на допущении, что поведение в прошлом может прогнозировать поведение в будущем.
Анализ тренда строится на допущении, что поведение в прошлом может прогнозировать поведение в будущем.Вот некоторые типовые задачи бизнеса, которые решает анализ поисковых трендов в Яндексе и Гугле:
- Узнать интерес к теме в разрезе любого региона
- Прогнозировать, какие запросы наберут популярность, чтобы уже сейчас их учесть в своем ядре и подготовить контент
- Оценить эффективность маркетинговых активностей
- Определить новые ниши или подниши для запуска бизнеса
- Анализировать трафик не по абсолютным значениям, а с учетом годовой сезонности
Инструменты для оценки трендов
Рассмотрим два главных инструмента для оценки поисковых трендов: Яндекс Вебмастер и Google Trends.
Как использовать Яндекс Вебмастер для отслеживания трендов
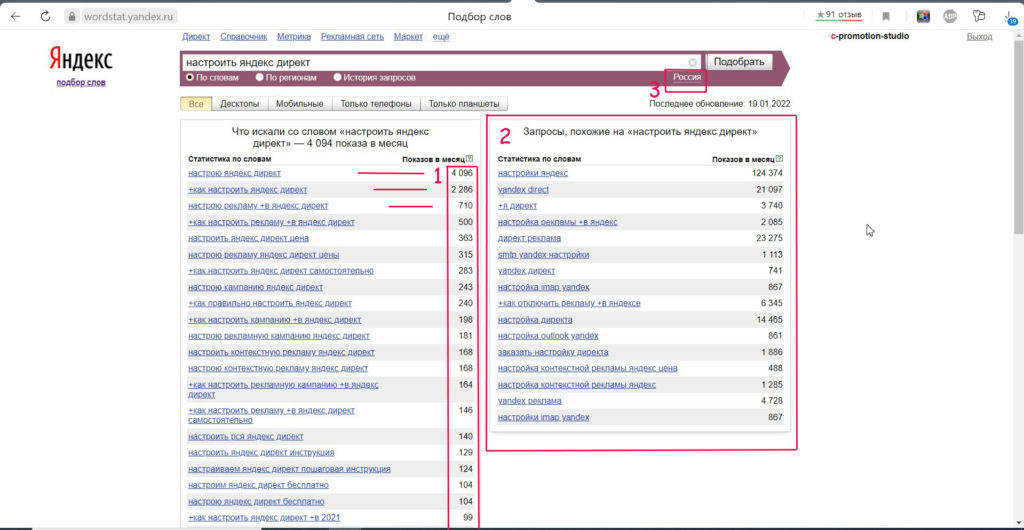
Заходим на главную страницу Yandex Wordstat и выбираем функцию «история запросов» (1). Нужно будет ввести капчу, а далее выбрать регион (2). Для работы с вордстатом необходимо авторизоваться на яндексе.
Для работы с вордстатом необходимо авторизоваться на яндексе.
Оценка трендов в Яндекс Вордстат
Далее вводим интересующий нас поисковой запрос и получаем отчет трендов от вордстата:
Результат оценки трендов в Вордстате
Мы видим тренд запроса за 2 прошедших года. По этому графику можно выявить относительную сезонность запроса (с июля по ноябрь), а также построить тренд. Он получается восходящий (т.е. разность абсолютных значений за один и тот же период времени положительна), пусть и приближающийся к стабильному (разность маленькая).
Приведу расчет. Берем два смежных месяца и вычитаем:
- 15560 (июль 17) — 14503 (июль 16) = 1057 или примерно 6% прироста
- 17597 (август 17) — 14967 (август 16) = 2630 или примерно 14% прироста
В среднем по году мы получим рост в 7%. Исходя из этого мы можем прогнозировать поведение запроса в коридоре +/- 7% в 2018 году.
Google Trends — эффективное прогнозирование трендов
В отношении поисковых трендов гугл дает нам более продвинутый инструмент. Идем в сервис https://trends.google.ru (для полноценной работы нужно авторизоваться на гугле) и видим такую картину
Идем в сервис https://trends.google.ru (для полноценной работы нужно авторизоваться на гугле) и видим такую картину
Главная страница Google Trends
Мы можем отслеживать тренды по разным категориям и регионам. Введем тот же запрос, что и в Яндексе. Далее выберем регион (1), период анализа тренда (2) и получим такую картину:
Результат анализа в Гугл Трендс
Методика оценки популярности в гугле несколько иная. Самый популярный период берется за 100%, и все остальные данные нормализируются на это значение. Если бегло проведем медианный анализ по этому графику, то увидим примерно такой же рост, как и в Яндексе: около 7%.
Интересные данные предлагает Google Trends в нижней части страницы. Попробуем с ними разобраться.
Дополнительные данные анализа трендов в гугле
Здесь мы видим похожие темы (аналог правой колонки в Яндекс Вордстат) и похожие запросы из той же ниши. По похожим темам можно расширять товарную линейку своего бизнеса. Мы видим, что вместе с окнами ищут двери, балконы и шторы. Если мы развернем список тем, то получим ещё и направление подоконников и брендов производителей профиля для окон.
Если мы развернем список тем, то получим ещё и направление подоконников и брендов производителей профиля для окон.
Дополнительные темы
В Гугл Трендс можно сравнить несколько запросов. Сравним, например, нишу окон с нишей натяжных потолков. Нажмем на кнопку «Сравнить» и введем соответствующий поисковой запрос. Вот результат (зелеными линиями я примерно показал результаты медианного анализа):
Сравнение трендов поисковых запросов в Гугле
Опять же, за 100% взята популярность одного из запросов в верхней точке.
Как делать выводы по трендам
Выводы делаются исходя из поставленной задачи. Расскажу несколько типовых ситуаций.
Запуск нового товара
- Если тренд растущий, то имеет смысл товар запускать. Скорость запуска должна зависеть от кривизны графика (чем он круче, тем быстрее нужно выводить товар на рынок)
- Если тренд стабильный — это сигнал насыщения рынка. После насыщения неизбежен спад. Если вывод нового товара не требует больших вложений — это можно делать. Но всегда нужно быть готовым к спаду спроса
- Если тренд падающий — то лучше этот товар на рынок не выводить. Спрос уменьшается, а число предложений в таких случаях намного его превышает, что неизбежно ведет к снижению маржинальности.
 Но всегда нужно быть готовым к спаду спроса
Но всегда нужно быть готовым к спаду спроса
Стоит ли включать рекламу на новый регион
- Опять смотрим на тренд. Если он падающий, то в этом особого смысла нет.
Как использовать сезонность запроса
- Вы узнали, что есть в нише четкая сезонность. Поэтому мы запускаем платную рекламу за месяц до начала сезона. Как правило, цена клика будет низкой, пока конкуренты спят. И вы сможете набрать много предзаказов на сезон, либо уже отгрузить товар, пока остальные только планируют рекламные бюджеты.
Вопрос-ответ
В: Можно ли отследить популярные запросы на ютуб?
О: Да, это можно сделать с помощью Гугл Трендс. В списке видов поиска нужно выбрать Youtube:
Популярные запросы на Ютуб
В: Насколько можно доверять данным поисковых трендов?
О: Это реальные данные поисковых систем.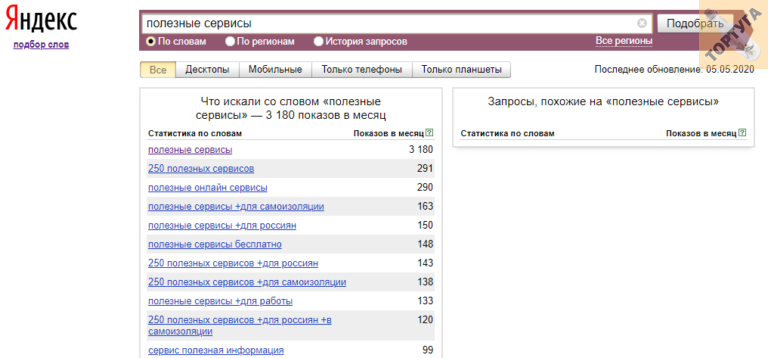 А насчет прогнозирования будущего — никто гарантию не даст.
А насчет прогнозирования будущего — никто гарантию не даст.
Теги::
Google Trends, Яндекс Вордстат
( 1 Rating )
гайд по работе со статистикой запросов и подбору ключевых слов в 2023 году
Содержание
- Что показывает Вордстат
- Операторы в Яндекс Вордстат: что это и как пользоваться ими
- Как автоматизировать работу с ключевыми фразами в Вордстат
- Советы по применению Вордстата в бизнесе и рекламе
Вордстат — бесплатный сервис Яндекса, который показывает статистику запросов в одноименном поисковике. Это ценный инструмент для маркетологов и предпринимателей. Можно изучить потребности аудитории, выявить популярные формулировки запросов по товару или услуге, составить семантику сайта и многое другое. Но не все знают о дополнительных возможностях Вордстата, которые сделают этот инструмент еще полезнее для работы.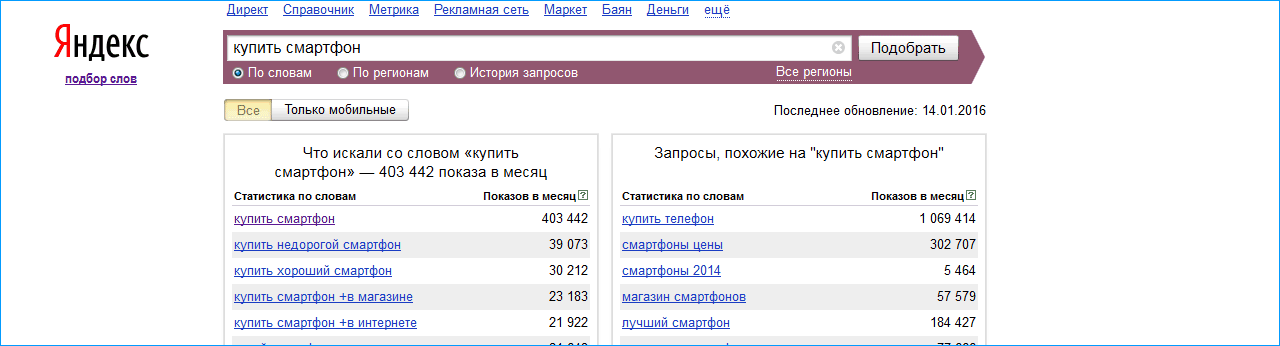 В материале рассказываем, как узнать статистику самых популярных запросов в Яндекс Вордстат по регионам и устройствам, где применять операторы и что поможет автоматизировать поиск ключевиков.
В материале рассказываем, как узнать статистику самых популярных запросов в Яндекс Вордстат по регионам и устройствам, где применять операторы и что поможет автоматизировать поиск ключевиков.
Что показывает Вордстат
Сервис можно открыть по ссылке: wordstat.yandex.ru. Этот официальный сайт доступен с десктопов и мобильных, функционирует в различных браузерах. Для использования не нужно иметь аккаунт в Яндексе и быть авторизованным.
Подбор ключевых слов через сервис Яндекс Wordstat
Главное назначение Вордстата — прогноз частотности, то есть количества показов по запросам. Вы указываете в строке Wordstat ключевое слово, которое вас интересует, например, «сквозная аналитика». Нажимаете кнопку «Подобрать».
Интерфейс Яндекс Вордстат
Сервис за доли секунды извлекает информацию из статистики Яндекса и выдает вам в левом столбце список с цифрами — сколько раз ваш запрос искали за последний месяц.
Также вы увидите список частых запросов, в которых были слова «сквозная аналитика» и что-то еще, например, «настройки». По цифре напротив — частотности — вы можете понять, насколько та или иная формулировка была в тренде.
По цифре напротив — частотности — вы можете понять, насколько та или иная формулировка была в тренде.
В правом столбце показываются запросы, которые похожи на введенный по смыслу. Это то, что ищут вместе с какими-то из тех запросов, которые приведены слева. Благодаря им вы можете подобрать для своей ниши дополнительные запросы для семантики сайта или идей контента. Аналог функционала Вордстата есть в Планировщике ключевых слов в Гугле, если вы работаете через Google Adwords.
Дополнительные функции: статистика по регионам, типам устройств и история запросов
В Вордстате есть и расширенные опции поиска. Вы можете отфильтровать статистику запроса по регионам и по типам устройств пользователей. А еще — изучить историю запросов пользователей в зависимости от времени.
- Статистика по регионам
Функция позволяет спрогнозировать спрос для своего региона или тех городов, где доступно ваше предложение. Логично, что одну и ту же продукцию могут часто искать в крупных городах и почти не интересоваться ей в небольших населенных пунктах. И что есть особые регионы со специфическими интересами потребителей: текстиль в Иваново, пляжные принадлежности в Краснодаре и так далее.
И что есть особые регионы со специфическими интересами потребителей: текстиль в Иваново, пляжные принадлежности в Краснодаре и так далее.
Чтобы задать конкретную локацию для статистики запросов, нажмите на «Все регионы» и в выпадающем окне отметьте галочками нужные места. Затем нажмите «Выбрать». Можно, например, как посмотреть статистику ключевых запросов в России, так и сузить поиск до отдельного города.
Эта опция полезнее всего для регионального бизнеса — например, небольших местных кафе или магазинов без доставки.
Есть и другая функция — анализ поисковых запросов по популярности в одном регионе по сравнению с другими. Так вы сможете выбрать точку с наибольшим спросом. Это полезно, если вы планируете открывать филиал или запускать рекламу по геолокации.
Выберите под строкой поиска пункт «По регионам». Сервис покажет не только число показов в месяц, но и «Региональную популярность» по сравнению с другими локациями. Если этот параметр больше 100%, то в этом регионе темой интересуются чаще, чем в других.
Из примера видно, что высокий интерес к сквозной аналитике показывают Москва, Краснодар и его округ.
- Статистика по типам устройств
Запускать рекламу через партнерскую сеть или в приложениях? Где люди чаще ищут вашу услугу — дома с компьютера или в дороге с телефона? Какой версии сайта уделять больше внимания — десктопной или мобильной? Если у вас нет однозначного ответа на подобные вопросы, изучите статистику по типам устройств.
Под строкой поиска выберите нужный вариант — десктопы или мобильные.
Чтобы сравнить частоту запросов с десктопов и с мобильных, переключайтесь между этими двумя вкладками и сопоставляйте значения напротив одинаковых фраз.
Обратите внимание: в понятие мобильных устройств включаются телефоны, смартфоны и планшеты. Если вам нужно рассмотреть лишь первые, то выберите вариант «Только телефоны».
На уточнение, что такое десктопы в Яндекс Вордстат, ответить достаточно просто: это персональные компьютеры, ноутбуки, макбуки. В статистике вы увидите количество запросов со всех этих типов устройств.
В статистике вы увидите количество запросов со всех этих типов устройств.
Данная функция полезна не только для непосредственного запуска рекламы, но и для лучшего понимания целевой аудитории. Если ваша ЦА на ходу ищет техники релаксации с телефона, то это совсем другой темп жизни, чем при комфортном поиске дома или на работе с ПК.
- История запросов
Если вам нужно проанализировать, как интерес пользователей к вашему запросу менялся со временем, используйте пункт «История запросов» под строкой Вордстата.
Вы увидите график: число запросов в зависимости от месяца. Статистика приводится за последние два года. Вы можете выбрать более детальную статистику, если отметите под строкой поиска разбивку не по месяцам, а по неделям.
Можно изучить тенденцию спроса на графике, а можно — по численным данным в таблице. В ней, как и на графике, приведены значения для 24 последних месяцев.
В истории запросов приводится абсолютное и относительное значение в Яндекс Вордстат. Первое показывает число запросов, второе — число запросов, деленное на количество показов результатов поиска Яндекса за соответствующий месяц.
Первое показывает число запросов, второе — число запросов, деленное на количество показов результатов поиска Яндекса за соответствующий месяц.
Если вам нужно посмотреть только одну из величин на графике, вы можете выбрать это по кнопке «Абсолютное» или «Относительное» под ним.
Несмотря на то, что сквозная аналитика — запрос достаточно «круглогодичный», в отличие от рассады или дубленок, на графике есть взлеты и падения спроса. Например, недавний пик интереса к этой теме был в феврале, когда рынок трансформировался из-за блокировки привычных рекламных площадок.
Как и для статистики по словам и регионам, вы можете вывести историю запросов только с мобильных или десктопных устройств. Для этого выберите соответствующую кнопку под строкой поиска. В примере выше выбран вариант «Мобильные».
Операторы в Яндекс Вордстат: что это и как пользоваться ими
Операторы — это специальные символы, которые помогают уточнить поисковый запрос, его язык и синтаксис. Разберем инструкцию по работе с шестью операторами, которые помогут вам упростить и расширить поиск статистики в Вордстате.
- Кавычки
Оператор «» фиксирует число слов в запросе и сами слова. Это значит, что по запросу «сквозная аналитика» Вордстат покажет вам данные поиска только этой формулировки. Например, варианты «настройка сквозной аналитики» или «сквозная аналитика ROMI center» в показанную статистику не войдут.
Для точной формулировки нашлось 639 показов за месяц. А в таблице уже приводится статистика для различных словоформ запроса — их более 5000. Это то же самое, как если бы вы искали без оператора кавычек.
- Плюс
Оператор + включает в ваш запрос точные формы предлогов и стоп-слов, то есть местоимений, частиц, междометий.
Если искать просто «сквозная аналитика в маркетинге», то сервис покажет все запросы со словами «сквозная», «аналитика» и «маркетинг». А вариант «сквозная аналитика +в маркетинге» предоставит вам возможность просмотра частотности только этой фразы — именно с предлогом «в».
- Минус
Знак минуса — исключает из результатов запросы, которые не содержали слово, написанное после этого оператора. Например, если вы предлагаете сквозную аналитику без бесплатного пробного периода, то можете исключить нерелевантные запросы через формулировку «сквозная аналитика -бесплатно».
Например, если вы предлагаете сквозную аналитику без бесплатного пробного периода, то можете исключить нерелевантные запросы через формулировку «сквозная аналитика -бесплатно».
4991 показ — это статистика для пользователей, которые искали сквозную аналитику без слова «бесплатно». А если не исключать их из результатов, то получится 5020 запросов.
С помощью оператора минус вы можете исключать те слова, которые не связаны с вашим бизнесом, но часто встречаются в нужных вам ключевиках. Например, «своими руками», «даром», «доставка в день заказа». Такие слова, которые нужно исключить из ключевиков, в рекламе называют минус-словами или минусовками.
- Восклицательный знак
Оператор ! фиксирует форму слова, которое следует за ним. То есть оно будет искаться четко в том же падеже, числе и времени, которое вы ввели.
Например, вам нужно зафиксировать форму слов «курсы» и «аналитике». Тогда используйте запрос «!курсы по !аналитике».
Восклицательный знак можно применить ко всем словам в запросе, а можно только к некоторым.
- Квадратные скобки
Оператор [] фиксирует порядок слов в запросе, учитывая словоформу и стоп-слова. Когда вы заключаете фразу полностью в квадратные скобки, то можете узнать, сколько запросов получит именно такая постановка фразы.
В примере ниже формулировка «курсы по аналитике» получила всего 735 запросов за месяц.
- Круглые скобки и разделитель
Оператор (|) помогает найти статистику по нескольким фразам одновременно. Если вы предлагаете услуги, которые можно искать с близкими формулировками, то можно искать сразу обе и смотреть общую частотность.
Например, фразы «курсы по маркетингу» и «курсы по рекламе» можно найти разом, если ввести «курсы по (маркетингу|рекламе)». Те слова, которые вы разделяете символом |, считаются для сервиса синонимами и ищутся вместе с теми, которые стоят за скобками.
Вы можете комбинировать операторы, чтобы где-то зафиксировать форму слова, а где-то — допустить вольность в выборе синонима. Пример: «курсы по (маркетингу|рекламе) -бесплатно».
Пример: «курсы по (маркетингу|рекламе) -бесплатно».
С такой формулировкой вы допускаете взаимозаменяемость слов «маркетинг» и «реклама», но исключаете запросы, содержащие слово «бесплатно».
Эти операторы действуют так же, как и в Яндекс.Директ, где вы настраиваете объявления на определенные формулировки ключевиков.
Как автоматизировать работу с ключевыми фразами в Вордстат
Из предыдущих разделов вы узнали, как получить от Вордстата нужную статистику. Но что делать, если нужно таким образом проработать сотню или тысячу разных ключевиков? Работу упростят и ускорят специальные программы.
- Плагин Yandex Wordstat Helper
Скачайте бесплатный плагин по указанной ссылке, чтобы он появился в вашем браузере. Его виджет появится слева на странице Вордстата.
Теперь при поиске на сервисе около слов в списке будет отображаться значок плюса. По клику на + вы можете сохранить запрос в группе. Для удаления нужно нажать на минус.
В итоге у вас сформируются удобные списки запросов, которые релевантны вашему предложению.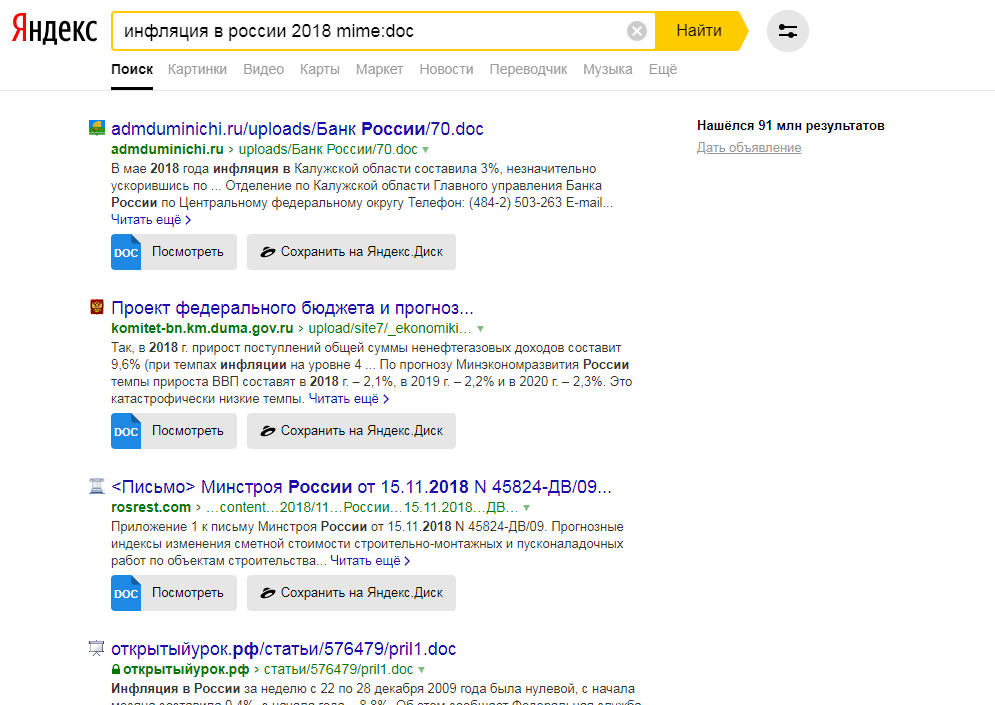 Вы можете сортировать сохраненные ключевики по алфавиту или частотности. В парсере доступна также проверка запросов на дубли и массовое удаление слов онлайн.
Вы можете сортировать сохраненные ключевики по алфавиту или частотности. В парсере доступна также проверка запросов на дубли и массовое удаление слов онлайн.
Плагин автоматически открывается, когда вы заходите на страницу Вордстата. Чтобы прекратить работу с плагином, удалите его в настройках браузера — раздел «Расширения» или «Дополнения».
- Плагин Yandex Wordstat Assistant — YWA
Этот вариант автоматизации похож на предыдущий — можно сохранять запросы в свой список, если нажать на плюс рядом с ними. Отличие в том, что вы можете скопировать полученные запросы и их частотность и перенести в другое приложение. Например, в Excel или Блокнот.
Для начала работы с этим бесплатным плагином его тоже нужно скачать из интернет-магазина Chrome и установить в браузере. Виджет Ассистента будет появляться слева на странице Вордстата.
Ваши списки сохранятся даже после закрытия вкладки Вордстата. Можно выбрать способ сортировки ключевиков, проверить дубли, смотреть разные данные в отдельных вкладках браузера. Для удаления плагина, как и в предыдущем случае, нужно зайти в настройки расширений.
Для удаления плагина, как и в предыдущем случае, нужно зайти в настройки расширений.
Существуют более сложные способы автоматизации, например, создание собственного приложения. Метод называют API Wordstat, и для его применения потребуются базовые навыки работы с кодами и регистрация приложения на OAuth-сервере Яндекса. Для этого лучше обратиться к разработчику или вебмастеру.
Советы по применению Вордстата в бизнесе и рекламе
Мы разобрали основные возможности Яндекс Вордстата. Теперь перейдем к частностям и советам — как эффективнее применить этот инструмент в 2022 году для конкретных процессов.
Для запуска контекстной рекламы
Сначала проведите в отделе маркетинга и контента мозговой штурм: какие слова и фразы ассоциируются у покупателей с вашим предложением. Особое внимание уделите глаголам, намерению: в запросе должно быть выражение желания приобрести ваш продукт, а не просто изучить тему.
Примеры запросов на тему курсов аналитики:
- обучение аналитике;
- аналитика курсы с нуля;
- научиться аналитике;
- как стать аналитиком.
Теперь вы можете изучать статистику по этим запросам в Вордстате. Если ваш бизнес работает в конкретном регионе, обязательно укажите это.
Исследуйте запросы, которые похожи на заданные вами. Сравните, какие формулировки наиболее популярны в нужном регионе. Если нужно расширить семантику по конкретному варианту, просто кликните по нему. Например, вы нажали на запрос «аналитик +с нуля курсы».
Так вы постепенно наберете самые подходящие запросы, пользующиеся популярностью. Можно сохранять их через плагины Wordstat Helper или Wordstat Assistant и делить их на удобные группы.
Обратите внимание на частотность собранных запросов:
- для рекламы в РСЯ достаточно набрать основные запросы — высокочастотные, короткие, которые ассоциируются с вашим предложением у большинства людей, например, «сквозная аналитика»;
- для рекламы на поиске используйте подбор более узких запросов, чтобы по точным ключевикам ваше объявление получило высокие позиции в выдаче и релевантные клики, пример — «сквозная аналитика ROMI center пробный период подключить».

Для продвижения сайта в поисковой выдаче
Сайты, особенно крупные, нуждаются в широком и подробном семантическом ядре. Так называют набор ключевиков, которые отражают суть вашего предложения клиентам. По словам из семантического ядра поисковые алгоритмы смогут найти ваш сайт и предложить его пользователям, которые ищут ваш товар или услугу.
Вордстат помогает собрать идеи и широкие ключевые запросы. Если вам нужно больше вариаций, то пользуйтесь сервисами вроде Key Collector. Там вам высветятся все возможные вариации фраз по вашему широкому запросу.
Чтобы собрать все запросы с высоким рейтингом, которые вы потом используете в Key Collector, отработайте идеи из мозгового штурма. Просто вводите ваши варианты и смотрите, какие еще запросы можно взять на заметку. Сохранять их можно через те же плагины Wordstat Helper или Wordstat Assistant.
Обязательно обратите внимание на правый столбец. Там вы можете найти идеи похожих запросов, которые тоже подходят вашему бизнесу и помогут продвинуть сайт в топ выдачи.
Собранные ключевики нужно распределить по структуре сайта. Самые широкие высокочастотные запросы используются на главной странице, в оглавлении каталогов, а более конкретные — в карточках товара, например, «кондиционер для дома LG белого цвета».
При поиске идей для контента
Через Вордстат вы можете не только собрать запросы для рекламы или оптимизации сайта, но почерпнуть идеи для контента. Это важно для компаний, которые ведут блог или корпоративные соцсети.
Введите ключевые фразы, которые по вашему предположению интересуют целевую аудиторию. В правом столбце вы увидите близкие по смыслу запросы, а в левом — дополнительные уточнения, которые популярны в поиске.
Система поиска формулировок из левого и правого столбца поможет вам собрать новые темы для блога или даже полноценный контент-план. В материале мы рассказали, как проверить частотность поисковых запросов в Яндекс через Вордстат, какие возможности есть у этого сервиса и как их эффективно применять. Вам же осталось лишь изучить запросы в своей нише и получать больше трафика по самым популярным из них.
Вам же осталось лишь изучить запросы в своей нише и получать больше трафика по самым популярным из них.
Частые вопросы
Что такое Вордстат?
Это бесплатный сервис Яндекса, в котором можно узнать частотность запросов. Вордстат берет данные из статистики поисковика и отображает, сколько раз пользователи искали вашу фразу. Можно рассмотреть историю запросов в зависимости от времени, сделать выборку по конкретному региону или типу устройств.
Зачем бизнесу использовать Вордстат?
Если вы продвигаетесь в Интернете, нужно понимать, какие из ваших ключевиков популярнее других. Так вы подберете самые эффективные формулировки для объявлений, соцсетей, контента. Еще при изучении различных ключевиков вы лучше узнаете потребности своей целевой аудитории.
Можно ли не искать ключевики вручную?
Для упрощения работы в Вордстате есть два популярных плагина: Yandex Wordstat Helper и Yandex Wordstat Assistant. Они помогут вам как выгрузить, так и сохранить собранные ключевики вместе с актуальной частотностью. Для продвинутой автоматизации поиска вы можете создать свое приложение через API Wordstat. Также есть другие сервисы поиска запросов, например, Key Collector. Однако они чаще всего платные.
Для продвинутой автоматизации поиска вы можете создать свое приложение через API Wordstat. Также есть другие сервисы поиска запросов, например, Key Collector. Однако они чаще всего платные.
Следующая статья: « Фиды в Яндекс.Директ: как создать и добавить
Содержание
- Что показывает Вордстат
- Операторы в Яндекс Вордстат: что это и как пользоваться ими
- Как автоматизировать работу с ключевыми фразами в Вордстат
- Советы по применению Вордстата в бизнесе и рекламе
Оцените статью:
Средняя оценка: 4.6 Количество оценок: 76
Понравилась статья? Поделитесь ей:
Подпишитесь на рассылку ROMI center: Получайте советы и лайфхаки, дайджесты интересных статей и новости об интернет-маркетинге и веб-аналитике:
Вы успешно подписались на рассылку. Адрес почты:
Читать также
Как увеличить продажи в несколько раз с помощью ROMI center?
Закажите презентацию с нашим экспертом. Он просканирует состояние вашего маркетинга, продаж и даст реальные рекомендации по её улучшению и повышению продаж с помощью решений от ROMI center.
Он просканирует состояние вашего маркетинга, продаж и даст реальные рекомендации по её улучшению и повышению продаж с помощью решений от ROMI center.
Запланировать презентацию сервиса
Попробуйте наши сервисы:
Импорт рекламных расходов и доходов с продаж в Google Analytics
Настройте сквозную аналитику в Google Analytics и анализируйте эффективность рекламы, подключая Яндекс Директ, Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистов
Попробовать бесплатно
Импорт рекламных расходов и доходов с продаж в Яндекс Метрику
Настройте сквозную аналитику в Яндекс.Метрику и анализируйте эффективность рекламы, подключая Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистов
Попробовать бесплатно
Система сквозной аналитики для вашего бизнеса от ROMI center
Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Попробовать бесплатно
 Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Сквозная аналитика для Google Analytics позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Подробнее → Попробовать бесплатно
Сквозная аналитика для Яндекс.Метрики позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Подробнее → Попробовать бесплатно
Сквозная аналитика от ROMI позволит высчитывать ROMI для любой модели аттрибуции Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Подробнее → Попробовать бесплатно
 Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.GET-запросов. Руководство разработчика
Внимание. Специальные символы, которые передаются как значения параметров, должны быть заменены соответствующими управляющими последовательностями для процентного кодирования. Например, вместо знака равенства («=») необходимо использовать управляющую последовательность «%3D».
https://yandex.<домен>/search/xml ? [\nИмя пользователя. Должен совпадать с логином для Яндекс.Паспорта, который был указан при регистрации.
\n "}}">=<имя пользователя>] & [\nЗначение ключа API, выданного при регистрации.
\n "}}">=<ключ API>] & [\n \nТекст поискового запроса. Вместо специальных символов необходимо использовать соответствующие управляющие последовательности.
\n \nЗапрос имеет следующие ограничения: максимальная длина запроса — 400 символов; максимальное количество слов — 40.
\n "}}">=<текст поискового запроса>] & [\nПоддерживается только для типов поиска «Русский» и «Турецкий».
\nID страны или региона для поиска. Определяет правила ранжирования документов. Например, если мы передаем в этот параметр значение «11316» (Новосибирская область), при формировании результатов поиска используется формула, определенная для Новосибирской области.
\nСписок идентификаторов общих стран и регионов приведен в приложении.
\n "}}">=] & [\n Язык уведомления для ответа на поиск. Это влияет на текст, который передается в
\nfound-docs-human, а также в сообщениях об ошибках.Допустимые значения зависят от используемого типа поиска:
\n
- \n
«Русский (yandex.ru)» — «ru» (русский), «uk» (украинский), «be» ( белорусский), «кк» (казахский).
Если не указано, уведомления отправляются на русском языке.«Турецкий (yandex.com.tr)» — Поддерживает только значение «tr» (турецкий).
«Worldwide (yandex.com)» — Поддерживает только значение «en» (англ.).
 Если не указано, уведомления отправляются на русском языке.
Если не указано, уведомления отправляются на русском языке.\n
\n
\n
\n «}}»>=<язык уведомлений>]
& [\n
Правила сортировки результатов поиска. Возможные значения:
\n
- \n
«rlv» — По релевантности.
«tm» — По времени изменения документа.
\n
\n
\n
Если опущено, результаты сортируются по релевантности.
\n
При сортировке по времени изменения параметр может содержать атрибут порядка , который является порядком сортировки документов. Возможные значения:
\n
- \n
«по убыванию» — Вперед (от самого последнего к самому старому).
Используется по умолчанию.«по возрастанию» — в обратном порядке (от самого старого к самому последнему).
 Используется по умолчанию.
Используется по умолчанию.\n
\n
\n
Формат: sortby=<тип сортировки>.order%3D<порядок сортировки> . Например, для обратной сортировки по дате используйте следующее: sortby=tm.order%3По возрастанию .
\n «}}»>=<тип сортировки>]
& [\n
Правила фильтрации результатов поиска (исключение документов из результатов поиска по одному из правил). Возможные значения:
\n
- \n
«нет» — фильтрация отключена. Вывод включает любые документы, независимо от их содержания.
«умеренный» — умеренная фильтрация.
Вывод исключает документы, попадающие в категорию «только для взрослых», если поиск явно не направлен на поиск этих типов ресурсов.«строгий» — Семейный фильтр. Независимо от поискового запроса, документы, предназначенные «только для взрослых» или содержащие ненормативную лексику, удаляются из результатов поиска.
\n
 Вывод исключает документы, попадающие в категорию «только для взрослых», если поиск явно не направлен на поиск этих типов ресурсов.
Вывод исключает документы, попадающие в категорию «только для взрослых», если поиск явно не направлен на поиск этих типов ресурсов.\n
\n
\n
Если параметр опущен, используется умеренная фильтрация.
\n «}}»>=<тип фильтра>]
& [\n
Максимальное количество пассажей, которые можно использовать при создании сниппета для документа. Отрывок — это отрывок из найденного документа, содержащий слова запроса. Пассажи используются для создания сниппетов, которые представляют собой текстовые аннотации к найденным документам.
\n
Допустимые значения — от 1 до 5. Результат поиска может содержать меньше отрывков, чем значение, установленное для этого параметра.
\n
Если параметр не указан, для каждого документа возвращается не более четырех пассажей с текстом запроса.
\n «}}»>=<количество проходов>]
& [\n
Набор параметров, определяющих правила группировки результатов. Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в разделе 9.0020 сортировка по параметру . Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.
\n
Параметры разделяются запятыми и задаются в формате:
attr%3D<вспомогательный атрибут>.mode%3D<тип группировки>.groups-on-page%3D<количество групп на странице>.docs -in-group%3D<количество документов в группе>
\n
Параметры:
- \n
\n
режим— Метод группировки. Возможные значения:\n
- \n
«flat» — Плоская группировка. Каждая группа содержит один документ. Передано с пустым значением параметра
attr.«deep» — Группировка по домену. Каждая группа содержит документы из одного домена. Передается со значением «d» для параметра
attr.
\n
\n
\n
Если параметр не определен, используется плоская группировка по доменам.
\n
\n
attr— Служебный атрибут. Зависит от значения атрибута режима.\n
групп-на-странице— Максимальное количество групп, которое может быть возвращено на странице результатов поиска. Допустимые значения — от 1 до 100.docs-in-group— Максимальное количество документов, которые могут быть возвращены на группу. Допустимые значения — от 1 до 3.
 Возможные значения:
Возможные значения:\n
 Зависит от значения атрибута
Зависит от значения атрибута \n
\n
\n
\n «}}»>=<параметры группировки результатов>]
& [\n
Номер запрашиваемой страницы в результатах поиска. Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»).
Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»).
\n
Например, если количество возвращаемых документов на странице равно «n», а в параметре передано значение «p», в результаты поиска будут включены документы, попадающие в диапазон выходных позиций от p* n+1 от до p*n+n включительно.
\n
Если параметр опущен, возвращается первая страница результатов поиска.
\n «}}»>=<номер страницы>]
& [\n
Инициирует проверку пользователя на предмет возможной защиты от роботов.
\n
Используется только значение «да».
\n «}}»>=<да>]
пользователь | Имя пользователя. Должен совпадать с логином для Яндекс. |
ключ | Значение ключа API, выданного при регистрации. |
запрос | Текст поискового запроса. Вместо специальных символов необходимо использовать соответствующие управляющие последовательности. Запрос имеет следующие ограничения: максимальная длина запроса — 400 символов; максимальное количество слов — 40. |
lr | Поддерживается только для типов поиска «Русский» и «Турецкий». Идентификатор страны или региона для поиска. Определяет правила ранжирования документов. Например, если мы передаем в этот параметр значение «11316» (Новосибирская область), при формировании результатов поиска используется формула, определенная для Новосибирской области. Список идентификаторов общих стран и регионов приведен в приложении. |
l10n | Язык уведомления для ответа на поиск. Допустимые значения зависят от используемого типа поиска:
|
sortby | Правила сортировки результатов поиска. Возможные значения:
Если не указано, результаты сортируются по релевантности. При сортировке по времени изменения параметр может содержать атрибут
Формат: |
filter | Правила фильтрации результатов поиска (исключение документов из результатов поиска по одному из правил). Возможные значения:
Если параметр опущен, используется умеренная фильтрация. |
maxpassages | Максимальное количество пассажей, которые можно использовать при создании сниппета для документа. Отрывок — это отрывок из найденного документа, содержащий слова запроса. Пассажи используются для создания сниппетов, которые представляют собой текстовые аннотации к найденным документам. Допустимые значения — от 1 до 5. Результат поиска может содержать меньше отрывков, чем значение, установленное для этого параметра. Если параметр опущен, для каждого документа возвращается не более четырех пассажей с текстом запроса. |
groupby | Набор параметров, определяющих правила группировки результатов. Параметры разделяются запятыми и задаются в формате: attr%3D<вспомогательный атрибут>.mode%3D<тип группировки>.groups-on-page%3D<количество групп на странице>.docs-in -group%3D<количество документов в группе> Параметры:
|
страница | Номер запрашиваемой страницы в поисковой выдаче. Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»). Например, если количество документов, возвращаемых на странице, равно «n», а в параметре передано значение «p», в результаты поиска будут включены документы, попадающие в диапазон выходных позиций от Если параметр опущен, возвращается первая страница результатов поиска. |
showmecaptcha | Инициирует проверку пользователя на предмет возможной защиты от роботов. Используется только значение «да». |
 Паспорта, который был указан при регистрации.
Паспорта, который был указан при регистрации. Он влияет на текст, который передается в теге
Он влияет на текст, который передается в теге  Возможные значения:
Возможные значения:
 Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в разделе 9.0233 сортировка по параметру . Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.
Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в разделе 9.0233 сортировка по параметру . Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.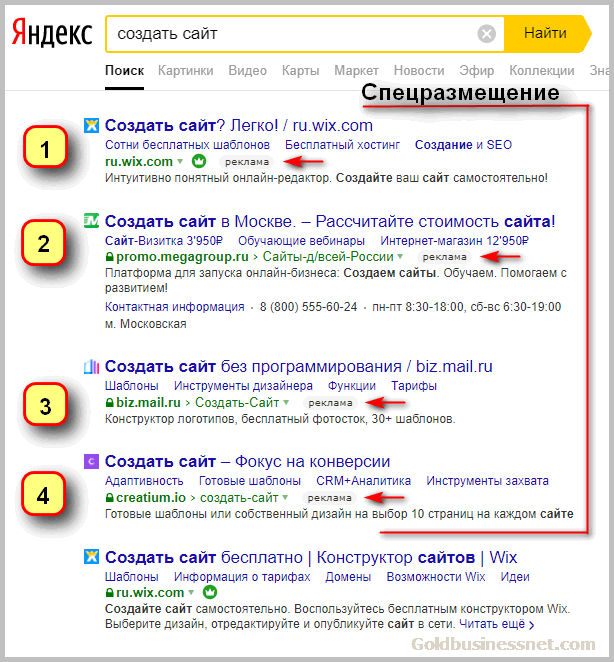
 Допустимые значения — от 1 до 3.
Допустимые значения — от 1 до 3.Следующий запрос возвращает вторую страницу результатов поиска по запросу «
 Тип поиска: Русский (yandex.ru). Результаты сгруппированы по доменам. Каждая группа содержит три документа, и на странице может быть возвращено пять групп.
Тип поиска: Русский (yandex.ru). Результаты сгруппированы по доменам. Каждая группа содержит три документа, и на странице может быть возвращено пять групп. Паспорта, который был указан при регистрации.
Паспорта, который был указан при регистрации. 
 ). Если не указано, уведомления отправляются на русском языке.
). Если не указано, уведомления отправляются на русском языке. пользователь | Имя пользователя. Должен совпадать с логином для Яндекс.Паспорта, который был указан при регистрации. |
ключ | Значение ключа API, выданного при регистрации. |
filter | Правила фильтрации результатов поиска (исключение документов из результатов поиска по одному из правил). Возможные значения:
Если параметр опущен, используется умеренная фильтрация. |
lr | Поддерживается только для типов поиска «Русский» и «Турецкий». Идентификатор страны или региона для поиска. Определяет правила ранжирования документов. Например, если мы передаем в этот параметр значение «11316» (Новосибирская область), при формировании результатов поиска используется формула, определенная для Новосибирской области. Список идентификаторов общих стран и регионов приведен в приложении. |
l10n | Язык уведомления для ответа на поиск. Он влияет на текст, который передается в теге Допустимые значения зависят от используемого типа поиска:
|
showmecaptcha | Инициирует проверку пользователя на предмет возможной защиты от роботов. Используется только значение «да». |
 Вывод включает любые документы, независимо от их содержания.
Вывод включает любые документы, независимо от их содержания.
0" encoding="Кодировка файла XML"?> < Описание
Тег группировки. Дочерние теги содержат параметры поискового запроса.
"}}">> < Описание\n \n
Текст поискового запроса. Вместо специальных символов необходимо использовать соответствующие управляющие последовательности.
\n \nЗапрос имеет следующие ограничения: максимальная длина запроса — 400 символов; максимальное количество слов — 40.
\n "}}">> < Описание\n
Правила сортировки результатов поиска. Возможные значения:
\n
- \n
«rlv» — По релевантности.
«tm» — По времени изменения документа.
\n
\n
\n
Если опущено, результаты сортируются по релевантности.
\n
При сортировке по времени изменения параметр может содержать атрибут порядок , который является порядком сортировки документов.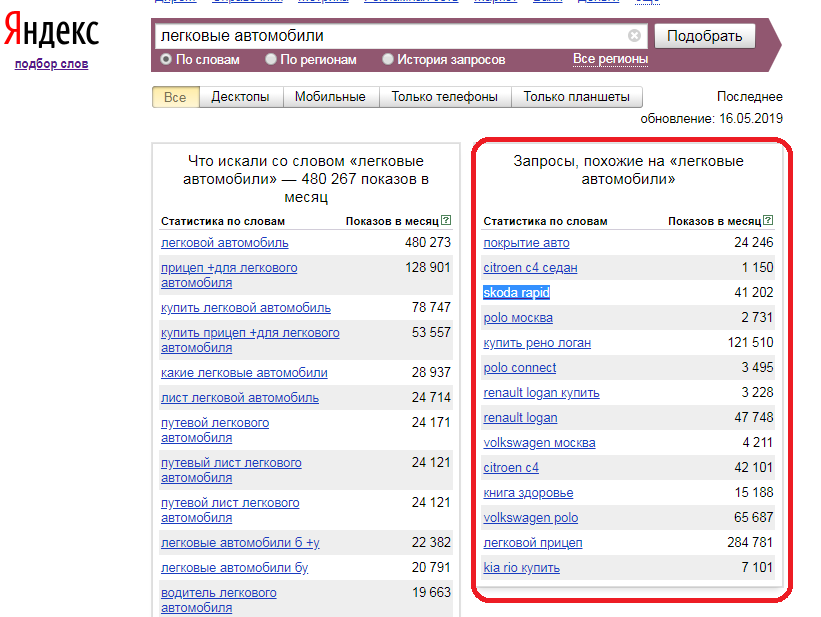 Возможные значения:
Возможные значения:
\n
- \n
«по убыванию» — Вперед (от самого последнего к самому старому). Используется по умолчанию.
«по возрастанию» — в обратном порядке (от самого старого к самому последнему).
\n
\n
\n «}}»>>
< Описание
Тег группировки. Дочерний тег содержит параметры для группировки результатов.
«}}»>>
< Описание
\n
Набор параметров, определяющих правила группировки результатов. Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в параметре sortby . Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.
Результаты, переданные в контейнер, могут быть использованы для включения в результаты поиска нескольких документов из одного домена.
\n
Параметры:
- \n
\n
режим— Метод группировки. Возможные значения:\n
- \n
«flat» — Плоская группировка. Каждая группа содержит один документ. Передано с пустым значением параметра
attr.«deep» — Группировка по домену.
Каждая группа содержит документы из одного домена. Передается со значением «d» для параметра attr.
\n
\n
\n
Если параметр не определен, используется плоская группировка по доменам.
\n
\n
attr— Служебный атрибут. Зависит от значения атрибутарежима.\n
групп-на-странице— Максимальное количество групп, которое может быть возвращено на странице результатов поиска. Допустимые значения — от 1 до 100.docs-in-group— Максимальное количество документов, которые могут быть возвращены на группу. Допустимые значения — от 1 до 3.
 Каждая группа содержит документы из одного домена. Передается со значением «d» для параметра
Каждая группа содержит документы из одного домена. Передается со значением «d» для параметра \n
\n
 Допустимые значения — от 1 до 100.
Допустимые значения — от 1 до 100.\n
\n
\n «}}»> attr=»d» mode=»deep» groups-on-page=»10″ docs-in-group=»1″ />
< Описание
\n
Номер запрашиваемой страницы в результатах поиска. Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»).
\n
Например, если количество возвращаемых документов на странице равно «n», а в параметре передано значение «p», в результаты поиска будут включены документы, попадающие в диапазон выходных позиций из p*n+1 от до p*n+n включительно.
\n
Если параметр опущен, возвращается первая страница результатов поиска.
\n «}}»>>
| Параметр | Описание |
|---|---|
запрос | Группировка 907tag. Дочерние теги содержат параметры поискового запроса. |
| Текст поискового запроса. Вместо специальных символов необходимо использовать соответствующие управляющие последовательности. Запрос имеет следующие ограничения: максимальная длина запроса — 400 символов; максимальное количество слов — 40. |
| Правила сортировки результатов поиска.
Если не указано, результаты сортируются по релевантности. При сортировке по времени изменения параметр может содержать атрибут
|
| Максимальное количество пассажей, которое можно использовать при создании сниппета для документа. Отрывок — это отрывок из найденного документа, содержащий слова запроса. Пассажи используются для создания сниппетов, которые представляют собой текстовые аннотации к найденным документам. Допустимые значения — от 1 до 5. Результат поиска может содержать меньше отрывков, чем значение, установленное для этого параметра. Если параметр опущен, для каждого документа возвращается не более четырех пассажей с текстом запроса. |
страница | Номер запрашиваемой страницы в выдаче поиска. Это определяет диапазон позиций документа, возвращаемых по запросу. Нумерация начинается с нуля (первой странице соответствует значение «0»). Например, если количество документов, возвращаемых на странице, равно «n», а в параметре передано значение «p», в результаты поиска будут включены документы, попадающие в диапазон выходных позиций от Если параметр опущен, возвращается первая страница результатов поиска. |
группировки | Тег группировки. Дочерний тег содержит параметры для группировки результатов. Дочерний тег содержит параметры для группировки результатов. |
| Набор параметров, определяющих правила группировки результатов. Группировка используется для помещения документов из одного домена в контейнер. Внутри контейнера документы ранжируются с использованием правил сортировки, определенных в параметре Параметры:
|
 Возможные значения:
Возможные значения: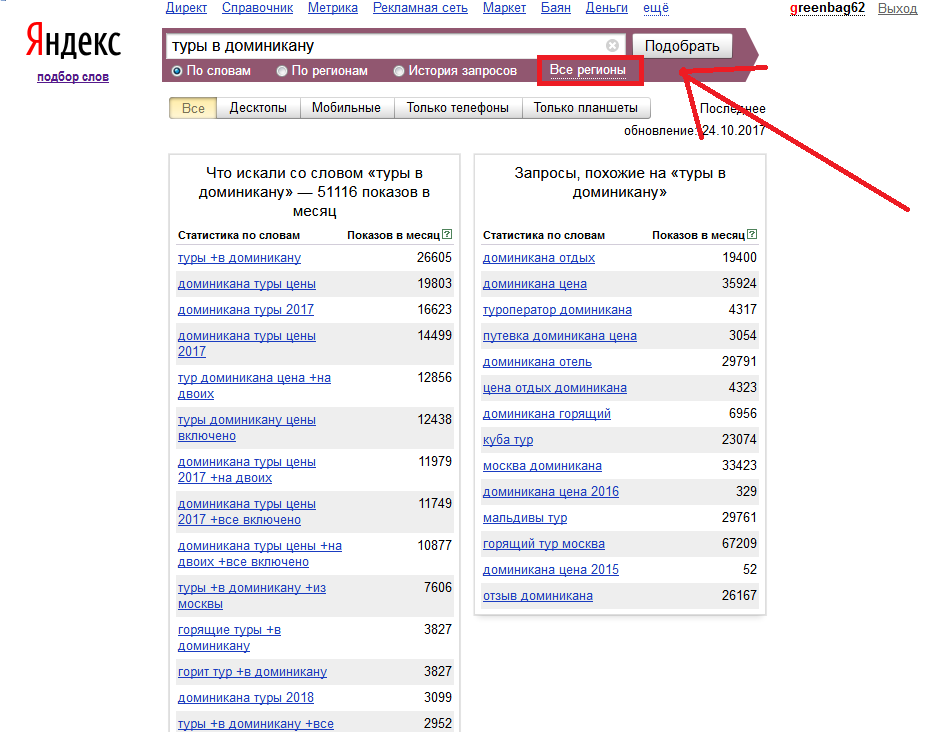
 Каждая группа содержит документы из одного домена. Передается со значением «d» для параметра
Каждая группа содержит документы из одного домена. Передается со значением «d» для параметра Совет.