Содержание
Что происходит, когда вводишь url, или как работает интернет / Хабр
Об этом спрашивают на собеседованиях. Структурированное понимание этого может помочь вам, даже если вы давно строите сложные архитектурные процессы или кодите 20-ый год подряд. Я — программист уже много лет, последние пару из которых пишу на Go в Каруне. Работа работой, а внутренний исследователь не дремлет. И вот я наконец-то решил привести в порядок информацию, разбросанную по разным закоулкам чертогов разума, по добротным книгам и статьям на тему сетевых технологий.
Хочу представить краткую выжимку о работе протоколов. А если тема окажется интересной, могу продолжить работать с ней более детально. Рассмотрим простейший пример: вы ввели некоторый url в адресную строку. Поехали.
The Open Systems Interconnection model (OSI)
Для начала придётся упомянуть семиуровневую модель OSI, с которой, возможно, каждый из вас знаком не понаслышке. Эталонная модель взаимодействия открытых систем является абстракцией, которая связывает и стандартизирует взаимодействие открытых систем. Она не описывает никакие используемые протоколы, а только определяет, какие функции выполняет каждый из её уровней. В основе любого сетевого взаимодействия лежит данная модель. Для привычного нам интернета схема OSI и соответствующие ей протоколы чаще всего имеют следующий вид:
Она не описывает никакие используемые протоколы, а только определяет, какие функции выполняет каждый из её уровней. В основе любого сетевого взаимодействия лежит данная модель. Для привычного нам интернета схема OSI и соответствующие ей протоколы чаще всего имеют следующий вид:
Эталонная модель OSI и соответствие ей протоколов Интернета
Некоторые уровни могут отсутствовать и/или объединяться. Рассматривать работу схемы начнём с верхнего уровня — с того самого ввода адреса в адресную строку.
Прикладной уровень, HTTP
Прикладной уровень в модели OSI нужен для взаимодействия пользовательских приложений с сетью. Единица данных, которой оперирует прикладной уровень, называется сообщением. В описываемой системе уровень представлен протоколом HTTP. При вводе адреса google.com ваш браузер формирует HTTP сообщение, которое состоит из строки запроса, тела сообщения и заголовков со служебной информацией — такой как версия протокола, контрольная сумма сообщения, и т.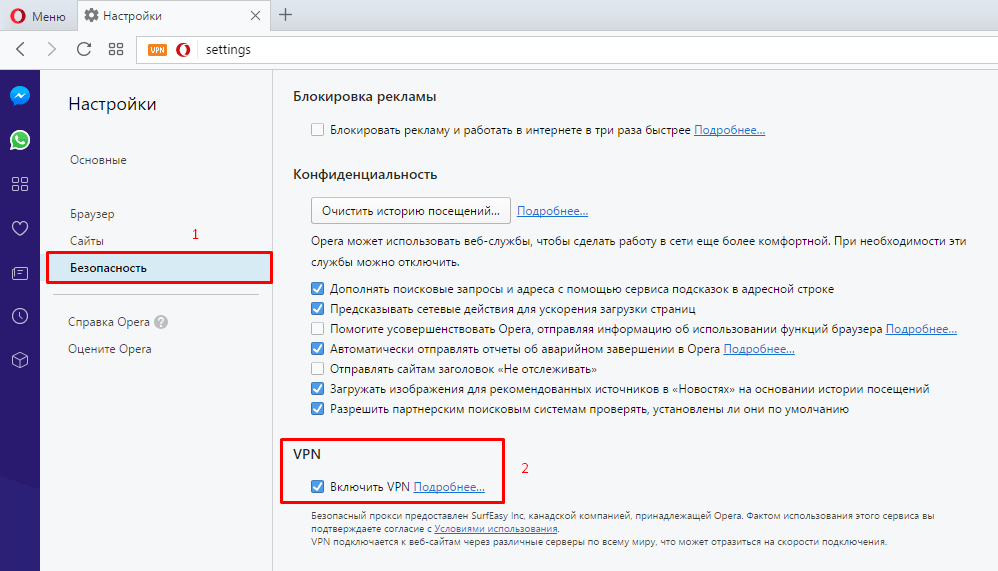 д. Далее задача в том, чтобы передать HTTP-сообщение на следующий уровень — представления, если это HTTPS, или на TCP, если это HTTP.
д. Далее задача в том, чтобы передать HTTP-сообщение на следующий уровень — представления, если это HTTPS, или на TCP, если это HTTP.
Уровень представления, SSL (TLS)
Уровень представления отвечает за кодирование/декодирование, а также за шифрование/дешифрование данных. Благодаря этому уровню информация, передаваемая одной системой, всегда понятна другой системе.
Если сервер, к которому вы посылаете запрос, работает на протоколе HTTPS, то в него включён протокол защиты данных — SSL. SSL развивался до версии 3.0. Потом на основе него был создан TLS, который сейчас используется везде и гарантирует безопасность соединения. Принцип работы протокола базируется на ассиметричном шифровании и для создания безопасного канала связи оперирует такими понятиями как публичный ключ, приватный ключ, сеансовый ключ.
Ваш браузер и сервер заново создают защищённое соединение при каждом открытии сайта. Как же это работает? Для начала браузер создаёт запрос на запрашиваемый адрес, чтобы узнать есть ли у него SSL-сертификат. В ответ на запрос он получает информацию и публичный ключ, с полученной информацией делает запрос в центр сертификации (адреса центров сертификации уже есть в вашем браузере по умолчанию). Если информация подтверждается, ваш браузер генерирует сеансовый ключ, зашифровывает его публичным ключом и отправляет на сервер. Сервер расшифровывает сообщение с помощью приватного ключа и сохраняет сеансовый ключ. После этого соединение можно считать установленным — при общении клиента и сервера используется для шифрования сеансовый ключ. И «общение» между клиентом и сервером переходит на симметричное шифрование с помощью сгенерированного сеансового ключа.
В ответ на запрос он получает информацию и публичный ключ, с полученной информацией делает запрос в центр сертификации (адреса центров сертификации уже есть в вашем браузере по умолчанию). Если информация подтверждается, ваш браузер генерирует сеансовый ключ, зашифровывает его публичным ключом и отправляет на сервер. Сервер расшифровывает сообщение с помощью приватного ключа и сохраняет сеансовый ключ. После этого соединение можно считать установленным — при общении клиента и сервера используется для шифрования сеансовый ключ. И «общение» между клиентом и сервером переходит на симметричное шифрование с помощью сгенерированного сеансового ключа.
Транспортный уровень, TCP
Транспортный уровень по определению обеспечивает передачу данных со степенью надёжности, которая требуется приложениям. В сети Интернет, в рассматриваемом взаимодействии, этот уровень представлен протоколом TCP, задача которого — надёжно доставить HTTP(S)-сообщение в пункт назначения.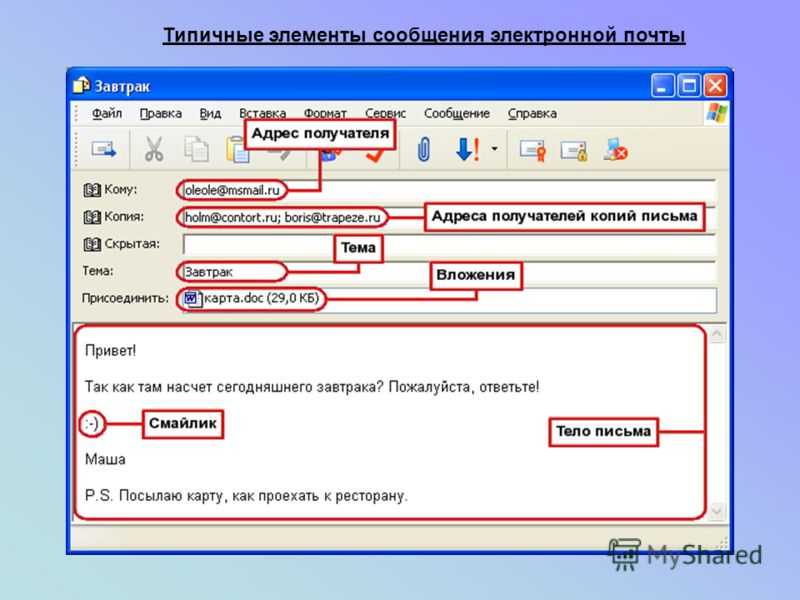 Единица данных как для TCP уровня, так и для следующего (IP) носит название пакет.
Единица данных как для TCP уровня, так и для следующего (IP) носит название пакет.
Операционная система, получив HTTP-сообщение от браузера, должна «встроить» его в пакет протокола нижележащего уровня — TCP. Такой процесс встраивания называется инкапсуляцией. Операция эта осуществляется на каждом уровне: пакеты вышележащего уровня инкапсулируются в пакеты нижележащего. И на самом нижнем уровне мы получаем информационную “матрёшку” с вложенными друг в друга пакетами, со служебной информацией в виде заголовков, добавленных на каждом уровне:
Формируются TCP-пакеты чаще всего в ядре операционной системы. Вся прелесть протокола TCP — в надёжности доставки. Использование этого протокола предусматривает установление так называемого логического соединения между двумя конечными узлами сети (перед этим, естественно, такое соединение нужно согласовать). Надёжную доставку пакетов протокол TCP обеспечивает посредством нумерации пакетов, подтверждения их передачи квитанциями, а также контроля правильного порядка пакетов. Схема установления логического соединения, передачи данных и разрыва соединения представлена на рисунке ниже:
Схема установления логического соединения, передачи данных и разрыва соединения представлена на рисунке ниже:
Работа хостов с помощью логического соединения
Сетевой уровень, IP
Сетевой уровень в общем случае нужен для образования единой транспортной системы, которая объединяет несколько сетей. Сети, кстати, могут иметь разные стеки протоколов. Также на этом уровне определяется маршрут пересылки пакетов от отправителя к получателю.
По ходу перемещения IP-пакета по сети маршрутизаторы передают пакеты от одной сети к другой или же на конечный узел-получатель. Данный протокол не занимается установлением соединения, не контролирует целостность данных, не гарантирует доставку и не отвечает за их достоверность, то есть реализует политику доставки «по возможности». Всё это бремя возложено на вышележащий протокол — TCP. Получив TCP-пакет, ОС инкапсулирует его в IP-пакет, добавляет в него свои параметры и передаёт далее.
DNS
Для того чтобы отправить какие-то данные серверу в IP-пакете, нужно узнать его IP-адрес. Для этого есть специальный протокол DNS, с помощью которого делается отдельный от основного запрос. Запрос этот называется DNS-запросом, и посылается он на специальный DNS сервер — его адрес заведомо известен и прописал в настройках вашей операционной системы. DNS-протокол — это представитель протокола прикладного уровня. Кратко его работу можно описать так:
Для этого есть специальный протокол DNS, с помощью которого делается отдельный от основного запрос. Запрос этот называется DNS-запросом, и посылается он на специальный DNS сервер — его адрес заведомо известен и прописал в настройках вашей операционной системы. DNS-протокол — это представитель протокола прикладного уровня. Кратко его работу можно описать так:
Клиент создает DNS-сообщение, добавляя неизвестный URL в раздел вопроса этого сообщения.
Сообщение DNS инкапсулируется в UDP-дейтаграмму протокола UDP транспортного уровня.
UDP-дейтаграмма инкапсулируется в IP-пакет данных с IP-адресом назначения DNS-сервера и отправляется на DNS-сервер.
DNS-сервер возвращает запись ресурса, в которой указан IP-адрес URL.
Строго говоря, запрос этот выполняется не всегда. Так как вначале браузер проверяет соответствие IP адреса и домена в своем кэше (для chrome это chrome://net-internals/#dns). Затем, если соответствия не найдено, браузер обращается к операционной системе, которая ищет информацию в системном файле hosts. И только в случае, если ничего не найдено в этом файле, посылается запрос DNS. Полученный адрес уже можно указать в формируемом IP-пакете основного запроса.
И только в случае, если ничего не найдено в этом файле, посылается запрос DNS. Полученный адрес уже можно указать в формируемом IP-пакете основного запроса.
Физический и канальный уровни, Ethernet
Канальный уровень (также — уровень передачи данных) необходим для передачи сырых данных физического уровня по надежной линии связи. Основная задача на этом уровне — обнаружение и коррекция ошибок. Также он может исправлять ошибки за счёт повторной передачи поврежденных кадров. Канальный уровень тоже должен проверить доступность среды — можно ли выполнять пересылку данных в конкретный момент. Иногда эту функцию выделяют в отдельный подуровень управления доступом к среде (MAC).
Физический уровень отвечает за передачу потока битов по каналам физической связи (коаксиальные кабеля, оптоволокно, витая пара). Со стороны компьютера функции физического уровня выполняет сетевой адаптер или COM-порт. На этом уровне есть только поток битов и ничего более: протокол «не задумывается» об информации, которую он передаёт.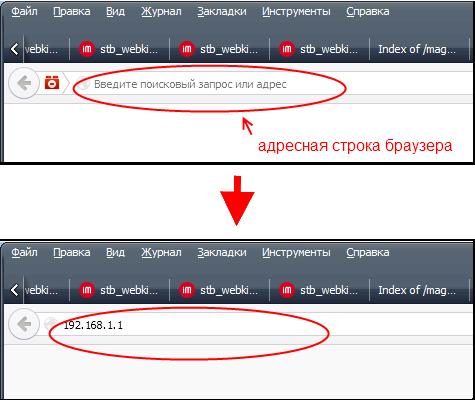
В нашем случае протокол Ethernet объединяет эти два уровня. Ethernet оперирует единицей данных, которая называется кадр. Для физического уровня нет никакого анализа информации, которая передаётся. Для передачи данных между узлами протокол работает по схеме с коммутацией пакетов, то есть сеть ведёт себя менее «ответственно», не создавая для абонентов отдельных каналов связи. Данные могут задерживаться и даже теряться. Поэтому ошибки на этом уровне не исправляются. Это опять же возложено на протокол верхнего уровня — TCP.
Для физического уровня Ethernet описывается стандартом группы IEEE 802.3, который определяет физические характеристики канала связи. Например, какой кабель будет использоваться для передачи данных: витая пара, коаксиальный кабель или оптоволокно. Тут же определяется вид кодирования и модуляции сигнала. Технические характеристики каждого стандарта хорошо описаны в данной статье. Например, спецификация 100Base-T определяет в качестве используемого кабеля витую пару, с максимальной длинной физического сегмента 100 метров и манчестерским кодом для данных в кабеле.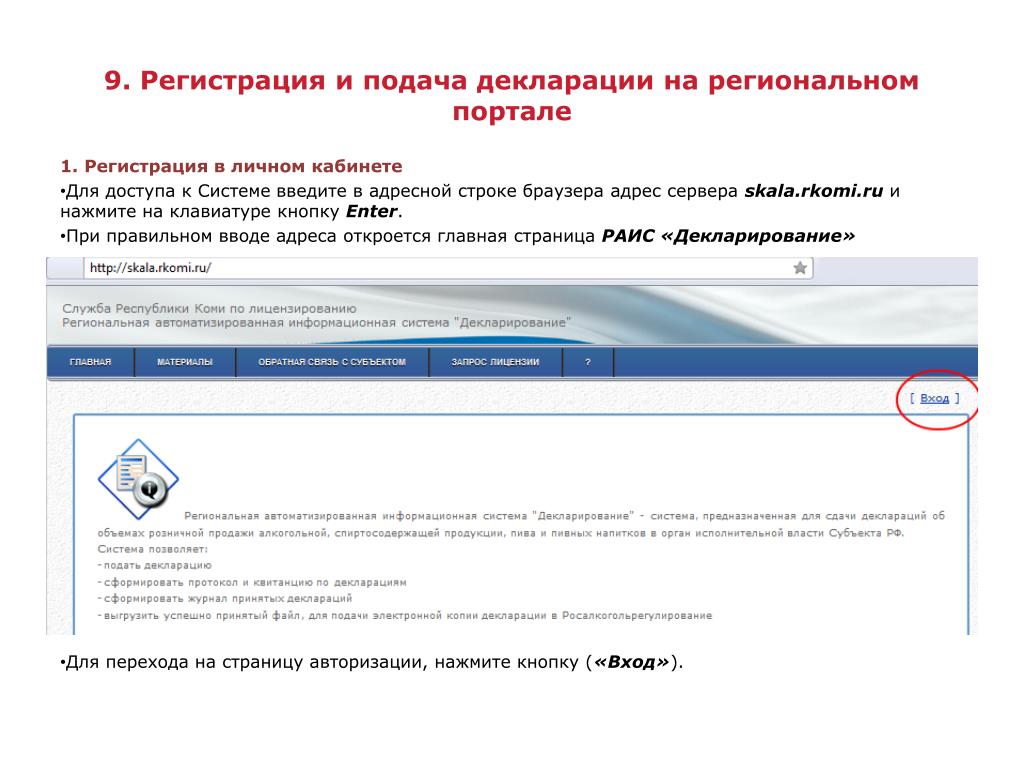
Путь пакета
На следующей схеме представлена схема взаимодействия узлов сети. Наш пакет выходит из конечного узла слева, проходя через концентраторы, коммутаторы (работающие на канальном уровне) и маршрутизаторы, работающие на сетевом уровне:
Общая схема взаимодействия узлов сети
Как видно из схемы, концентратор работает с данными на физическом уровне, но в настоящее время они вытеснены сетевыми коммутаторами, умеющими работать на канальном и физическом уровнях.
Совершив путь от одного конечного узла до другого, он распаковывается в обратном порядке: из Ethernet-кадра вытаскивается IP-пакет, из него, в свою очередь, TCP-пакет. Получив в конечном счёте HTTP-сообщение и считав с него нужную информацию, сервер формирует и посылает ответное HTTP-сообщение. Оно, в свою очередь, также проходит через каждый уровень и возвращается в виде ответа клиенту, распаковывается каждым уровнем, и мы видим заветную информацию на экране.
Конечно, это краткий обзор того, что происходит в сети Интернет на примере HTTP-запроса. Существует много деталей, которые не вошли в эту статью, дабы не растягивать её до бесконечности, но, надеюсь, войдут в будущие мои обзоры.
Существует много деталей, которые не вошли в эту статью, дабы не растягивать её до бесконечности, но, надеюсь, войдут в будущие мои обзоры.
Книги, которые помогли мне. Рекомендую и вам:
Олифер В.Г., Олифер Н.А. Компьютерные сети. Принципы, технологии, протоколы — СПб.: Питер, 2018. — 992
Таненбаум Э., Уэзеролл Д. Компьютерные сет — СПб.: Питер, 2020. — 960 с.: ил.
Что стоит за простой загрузкой веб-странички в браузере | by Viacheslav Odynokov | Genesis Media
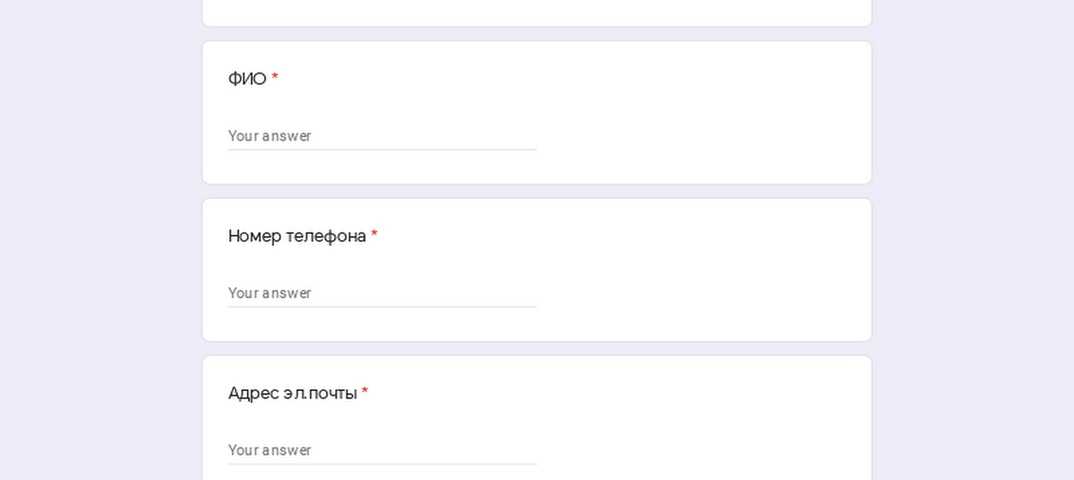
На собеседованиях мы часто просим кандидата рассказать настолько подробно, насколько он может, что происходит, когда вводишь в адресной строке браузера адрес сайта и нажимаешь кнопку “Ввод”. В зависимости от того, кого собеседуем — фронтендщика или бекендщика — мы ожидаем разные ответы. А как бы выглядел идеальный ответ на этот вопрос? Ниже мой вариант ответа.
Итак, пользователь вводит в адресной строке браузера адрес сайта и нажимает кнопку “Ввод”.
Браузер состоит из нескольких компонентов, одним из которых является User Interface. Адресная строка как раз является одной из частей этого компонента.
Адресная строка как раз является одной из частей этого компонента.
User Interface после ввода URL в адресной строке передаёт управление компоненту Browser Engine, который отвечает за взаимодействие различных компонентов браузера.
Чтобы сделать запрос по указанному URL, браузеру нужно знать IP сервера. Первым делом он смотрим в свой локальный кэш DNS.Компонент Browser Engine как раз имеет доступ к этому кэшу.
В браузере Chrome локальный кэш DNS . доступен по ссылке chrome://net-internals/#dns
Если там нет соответствующей записи, то браузер передаёт управление операционной системе, которая проверяет свой кэш DNS. Если и там отсутствует соответствующая запись, то ОС смотрит в локальные хосты (файл /etc/hosts в Unix-системах). Если запись о хосте отсутствует, то операционная система обращается к интернет провайдеру, у которого тоже есть свой кэш DNS на своих рекурсивных серверах DNS. В случае отсутствия записи в кэше на серверах DNS провайдера, запрос идёт на корневой DNS. У корневого DNS тоже есть кэш. Если соответствующей записи в кэше корневого DNS нет, запрос идёт дальше по цепочке серверов DNS.
У корневого DNS тоже есть кэш. Если соответствующей записи в кэше корневого DNS нет, запрос идёт дальше по цепочке серверов DNS.
К примеру, если адрес нашего сайта site.com.ua, то запросы к DNS выглядят так: site.com.ua.: . (корневой DNS) -> ua (DNS зоны “ua”) -> com (DNS зоны “com”)-> site.
Если на любом из этапов находится нужная запись, то она сохраняется во всех кэшах и управление возвращается браузеру, который уже знает IP нужного сервера.
Процесс получения IP адреса называется DNS lookup.
Далее Browser Engine смотрит в локальном кэше, нет ли запрашиваемой страницы. Если страницы в кэше нет, то Browser Engine передаёт управление компоненту Rendering Engine, который обращается к компоненту Networking Component, чтобы тот сделал запрос GET на указанный IP на порт 80 по протоколу HTTP или на порт 443 по протоколу HTTPS (в зависимости от указанного протокола в URL) со своими стандартными HTTP заголовками. Среди стандартных заголовков есть заголовок host, в котором передаётся хост запрашиваемого сайта (в нашем примере site.com.ua). Если в браузере хранятся куки к этому домену, то он отправляет их в заголовке cookie. Запрос будет выполнен, если соответствующий порт на пользовательском компьютере открыт.
Среди стандартных заголовков есть заголовок host, в котором передаётся хост запрашиваемого сайта (в нашем примере site.com.ua). Если в браузере хранятся куки к этому домену, то он отправляет их в заголовке cookie. Запрос будет выполнен, если соответствующий порт на пользовательском компьютере открыт.
На сервере запрос принимает веб-сервер (например, nginx или apache).
В конфигурационных файлах веб-сервера прописаны обслуживаемые хосты. Веб-сервер достаёт хост из заголовка запроса host и сопоставляет с теми, которые указаны в конфигурации. Если есть совпадение, то веб-сервер находит в конфигурационном файле правила обработки такого запроса и выполняет их. Дальнейшее поведение сервера зависит от технологии и особенностей приложения. Здесь может происходить работа с базами данных, кэшами, запросы к другим серверам и сервисам, выполнение различных скриптов. Для простоты представим, что приложение сгенерировало файл HTML, и веб-сервер отдал его браузеру.
Браузер получил файл HTML с соответствующими HTTP заголовками от сервера, в которых указана длина контента (заголовок Content-Length), тип контента (заголовок Content-Type со значением “text/html; charset=UTF-8” для файлов HTML), заголовки для кэширования. Если присутствуют кэширующие заголовки, то браузер сохраняет файл в локальный кэш.
Заголовки ответа сервера можно увидеть в Chrome DevTools на вкладке Networking, выбрав нужный запрос
Если длина контента больше нуля и тип контента поддерживается браузером, то браузер пытается его обработать. В нашем случае браузер получает файл HTML с соответствующим заголовком Content-Type. Браузер начинает разбор (parsing) этого файла с первой инструкции, которой является инструкция <!DOCTYPE>. DOCTYPE указывает на версию HTML, чтобы браузер понимал, каким правилам следовать во время разбора (какие теги как обрабатывать).
Если DOCTYPE отсутствует, то браузер переключится в режим quirks mode и попытается разобрать документ HTML, однако многие элементы будут проигнорированы. Если указан корректный DOCTYPE, то браузер будет работать в standards mode и будет разбирать документ в соответствии с правилами той версии, которая указана в DOCTYPE.
Если указан корректный DOCTYPE, то браузер будет работать в standards mode и будет разбирать документ в соответствии с правилами той версии, которая указана в DOCTYPE.
Rendering Engine начинает разбор документа HTML.
Создаётся DOM (Document Object Model). В браузере этот объект доступен по ссылке, которая хранится в переменной document. У документа есть несколько состояний. Первое состояние — loading. Оно означает, что документ только начал формироваться.
Состояние документа хранится в переменной document.readyState.
Также создаётся объект styleSheets, который будет хранить все стили.
Все стили на странице доступны по ссылке, которая хранится в переменной document.styleSheets.
Любой файл — это набор байтов. Браузер берёт полученный набор байтов и преобразует их в символы по таблице символов в соответствии с кодировкой, которая была передана в заголовке Content-Type. В нашем примере это кодировка UTF-8.
В нашем примере это кодировка UTF-8.
Следующий процесс —разбивание текста на смысловые блоки (tokenization). Так браузер распознаёт теги <html>, <head> и проч., а также понимает, какие правила к какому тегу применять (например, поддерживаемые атрибуты).
Далее токены собираются в узлы (nodes). Эти узлы и сохраняются в DOM со всеми взаимными связями.
Во время разбора, если Rendering Engine встречает ссылку на внешний ресурс, то он передаёт команду загрузить этот ресурс компоненту Networking Component. Это может быть ссылка на стили, скрипты, картинки и т.п. Networking Component ставит все ресурсы в очередь на загрузку. Каждому ресурсу Networking Component присваивает приоритет.
Приоритеты ресурсов можно посмотреть в Chrome DevTools на вкладке Networking в колонке Priority.
Так, у HTML, CSS и шрифтов самый высокий приоритет. У изображений приоритет изначально низкий, но если Rendering Engine обнаружит, что изображение попадает в поле видимости (view port) пользователя, то повысит приоритет до среднего. Приоритет скрипта зависит от положения на странице и способа загрузки. У асинхронных скриптов (async/defer) низкий приоритет. У скриптов, которые в документе перед изображениями — высокий, у тех, что после хотя бы одного изображение — средний.
Приоритет скрипта зависит от положения на странице и способа загрузки. У асинхронных скриптов (async/defer) низкий приоритет. У скриптов, которые в документе перед изображениями — высокий, у тех, что после хотя бы одного изображение — средний.
По возможности браузер пытается загружать ресурсы параллельно. Однако, он не может загружать параллельно более 6 ресурсов с одного домена.
Кроме того, когда Rendering Engine отдаёт команду компоненту Networking Component на синхронную загрузку стиля или скрипта, он останавливает разбор документа.
С загрузкой стилей происходит подобный процесс преобразования из байтов в Object Model (CSSOM): байты -> символы -> токены -> узлы -> CSSOM.
Немного иначе происходит загрузка скрипта. Вместо того, чтобы вернуть управление Rendering Engine’у, Networking Component . передаёт управление JavaScript Interpreter, который преобразует байты в исполняемый код: байты -> символы -> токены -> Abstract Syntax Tree (evaluating). Далее в работу вступает компилятор, который оптимизирует AST, кэширует некоторые участки кода, компилирует его на лету (JIT compilation) в исполняемый код и исполняет (executing). Однако исполняется скрипт только, когда готова CSSOM. До тех пор скрипт стоит в очереди на исполнение.
Далее в работу вступает компилятор, который оптимизирует AST, кэширует некоторые участки кода, компилирует его на лету (JIT compilation) в исполняемый код и исполняет (executing). Однако исполняется скрипт только, когда готова CSSOM. До тех пор скрипт стоит в очереди на исполнение.
Во многих современных браузерах во время исполнения JavaScript в отдельном потоке продолжается сканирование документа на наличие ссылок на другие ресурсы и постановка ресурсов в очередь на скачивание (Speculative parsing).
Каждый этап разбора HTML, CSS и JS можно увидеть в Chrome DevTools во вкладке Performance
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут async, то он не останавливает разбор документа во время загрузки скрипта. Скрипт также станет в очередь на исполнение, дожидаясь, когда CSSOM будет готова.
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут defer, то он не останавливает разбор документа во время загрузки скрипта, но когда скрипт загрузится, он станет в очередь на исполнение, которая заработает при возникновении события DOMContentLoaded. К этому моменту CSSOM будет уже готова.
К этому моменту CSSOM будет уже готова.
Когда Rendering Engine заканчивает разбор документа, он вызывает событие DOMContentLoaded, и состояние документа меняется на interactive. При этом ресурсы (например, картинки) могут продолжать загружаться.
Когда все ресурсы загрузились, вызывается событие load, а состояние документа меняется на complete.
После того, как документ полностью разобран и сформированы DOM и CSSOM, Rendering Engine начинает построение Render Tree. В него попадут все элементы, которые нужно отрисовать. Некоторые элементы изначально могут быть невидимыми — их не нужно рисовать. Для каждого элемента, который “выпадает” из потока (например, используется position: absolute), будет создаваться отдельная ветка в Render Tree.
Во время Rendering Tree происходит сопоставление узлов из DOM и узлов CSSOM.
Свойства узла можно получить с помощью функции window.getComputedStyles(узел).

Когда Rendering Tree готов, Rendering Engine запускает процесс layout. Он заключается в вычислении размеров и позиций каждого элемента на странице.
Следующий этап — paint. Rendering Engine вычисляет цвет каждого пикселя.
И, наконец, последний этап — composite. Компонент UI Backend слой за слоем отрисовывает элементы на странице. При этом, если требуется отрисовать изображение, которое ещё не загрузилось, во время процесса layout, Rendering Engine зарезервирует место для изображения, если у него указаны ширина и высота. Rendering Engine вынесет на отдельный слой те элементы, стили которых содержат правила opacity, transform или will-change. Более того, эти слои Rendering Engine передаст для обработки GPU.
Если требуется отобразить текст, для которого используется нестандартный шрифт, то современные браузеры скроют текст до момента загрузки шрифта (flash of invisible text).
В современных браузерах скачивание документа, его разбор и отрисовка происходят по кускам, частями.
В документе HTML могут присутствовать некоторые мета-теги, которые могут менять порядок загрузки ресурсов, а также их приоритет.
К примеру, мета-тег dns-prefetch вынуждает Rendering Engine обратиться к Networking Component и получить IP нужного домена ещё до того, как Rendering Engine встретить его в документе.
Мета-тег prefetch вынудит Networking Component поставить указанный ресурс в очередь на загрузку с низким приоритетом.
Мета-тег preload вынудит Networking Component поставить указанный ресурс в очередь на загрузку с высоким приоритетом.
Мета-тег preconnect вынудит Networking Component заранее подключиться к другом хосту, то есть пройти нужные этапы: DNS lookup, redirects, hand shakes.
Время, которое затрачивается на каждый этап, происходящий во время запроса и разбора документа HTML, хранится в объекте performance.timing.
Полезные ссылки
How Browsers Work: Behind the scenes of modern web browsers
How JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time
Notes on “How Browsers Work”
Introductory HTTP — книга по HTTP для начинающих
Создать HTTP-запрос очень просто.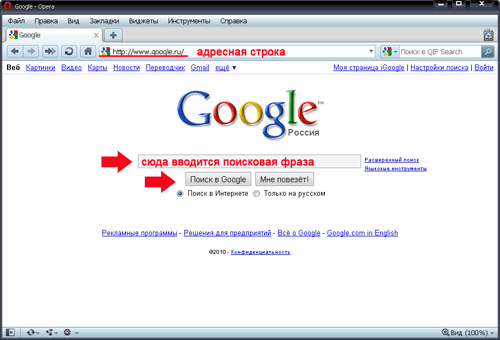 Скажем, вы хотите посетить Reddit в своем браузере. Все, что вам нужно сделать, это запустить браузер и ввести адрес https://www.reddit.com, и это снимок того, что вы можете увидеть:
Скажем, вы хотите посетить Reddit в своем браузере. Все, что вам нужно сделать, это запустить браузер и ввести адрес https://www.reddit.com, и это снимок того, что вы можете увидеть:
Сервер, на котором размещен основной веб-сайт Reddit, обрабатывает ваши запросы и вопросы. ответ вашему браузеру. Ваш браузер достаточно умен, чтобы обработать отправленный ответ и отобразить сайт, который вы видите на скриншоте, со всеми его цветами, изображениями, текстом и презентацией.
Поскольку браузеры показывают нам обработанную версию ответа, мы не можем видеть необработанный ответ, отправленный сервером. Как мы видим необработанные данные ответа HTTP?
Для этого мы можем использовать инструмент HTTP, и так же, как это делал браузер, когда мы вводили URL-адрес в адресную строку, мы можем сделать так, чтобы наш инструмент HTTP выдавал запрос на https://www.reddit.com. Наш HTTP-инструмент Paw не обрабатывает ответ и позволяет нам увидеть необработанные данные ответа, которые выглядят примерно так:
Какая огромная разница между необработанным ответом и отображением в вашем браузере! Если вы никогда раньше не видели необработанных данных HTTP-ответа, это может вас шокировать. То, что вы видите здесь, фактически является тем, что ваш браузер также получает, за исключением того, что он анализирует и обрабатывает этот огромный блок данных в удобном для пользователя формате.
То, что вы видите здесь, фактически является тем, что ваш браузер также получает, за исключением того, что он анализирует и обрабатывает этот огромный блок данных в удобном для пользователя формате.
Если вы изучаете HTTP, чтобы стать веб-разработчиком, вам нужно научиться читать и обрабатывать необработанные данные ответа HTTP, просто сканируя их. Конечно, у вас не получится преобразовать его в картинку высокого разрешения в голове, но вы должны иметь общее представление о том, о чем идет речь. Имея достаточный опыт, вы можете копаться в необработанных данных, выполнять некоторую отладку и точно видеть, что содержится в ответе.
В каждом современном браузере есть способ просмотра HTTP-запросов и ответов, и обычно он называется инспектором . Мы собираемся использовать Chrome Inspector, чтобы продемонстрировать, как анализировать HTTP-связь вашего браузера.
- Запустите браузер Chrome и откройте Инспектор, перейдя в меню Chrome в правом верхнем углу браузера.
 Выберите Инструменты > Дополнительные инструменты > Инструменты разработчика . Существуют и другие способы доступа к инспектору, например, щелчок правой кнопкой мыши и выбор параметра «Инспектор» или использование сочетания клавиш
Выберите Инструменты > Дополнительные инструменты > Инструменты разработчика . Существуют и другие способы доступа к инспектору, например, щелчок правой кнопкой мыши и выбор параметра «Инспектор» или использование сочетания клавиш Ctrl+Shift+I(илиOption+Command+Iна Mac). - Отправьте новый запрос в Reddit, введя адрес https://www.reddit.com в браузере.
Когда инспектор все еще открыт, щелкните вкладку Network :
Первое, что вы должны заметить, это то, что там много записей. Каждая запись представляет собой отдельный запрос, что означает, что при посещении URL-адреса ваш браузер делает несколько запросов, по одному для каждого ресурса (изображения, файла и т. д.). Нажмите на первый запрос на главную страницу,
www.reddit.comзапись:Отсюда вы сможете увидеть конкретные заголовки запросов, файлы cookie, а также необработанные данные ответа:
 Выберите Инструменты > Дополнительные инструменты > Инструменты разработчика . Существуют и другие способы доступа к инспектору, например, щелчок правой кнопкой мыши и выбор параметра «Инспектор» или использование сочетания клавиш
Выберите Инструменты > Дополнительные инструменты > Инструменты разработчика . Существуют и другие способы доступа к инспектору, например, щелчок правой кнопкой мыши и выбор параметра «Инспектор» или использование сочетания клавиш Вложенная вкладка по умолчанию, Заголовки , показывает заголовки запросов, отправленных на сервер, а также заголовки ответов, полученные от сервера.
Щелкните подвкладку Response , чтобы просмотреть необработанные данные ответа.
Данные ответа должны выглядеть так же, как мы видели ранее, используя наш инструмент HTTP.
Еще одна вещь, на которую следует обратить внимание при использовании вкладки Сеть инспектора, это то, что помимо первого запроса возвращается множество других запросов:
Почему эти дополнительные ответы отправляются обратно, кто инициировал запросы? Что происходит, так это то, что запрошенный нами ресурс, первоначальная запись www.reddit.com , вернул некоторый HTML. И в этом теле HTML есть ссылки на другие ресурсы, такие как изображения, таблицы стилей css, файлы javascript и многое другое. Ваш браузер, будучи умным и полезным, понимает, что для создания визуально привлекательной презентации он должен пойти и захватить все эти ресурсы, на которые есть ссылки. Следовательно, браузер будет делать отдельные запросы для каждого ресурса, указанного в исходном ответе. Когда вы прокручиваете вниз Сеть , вы сможете увидеть все ресурсы, на которые есть ссылки. Эти другие запросы, среди прочего, должны убедиться, что страница правильно отображается на вашем экране. В целом вы видите, что инспектор браузера дает вам хорошее представление об этих ресурсах, на которые есть ссылки. С другой стороны, чисто HTTP-инструмент возвращает один огромный фрагмент ответа, не заботясь об автоматическом извлечении ресурсов, на которые ссылаются. Запрос
Когда вы прокручиваете вниз Сеть , вы сможете увидеть все ресурсы, на которые есть ссылки. Эти другие запросы, среди прочего, должны убедиться, что страница правильно отображается на вашем экране. В целом вы видите, что инспектор браузера дает вам хорошее представление об этих ресурсах, на которые есть ссылки. С другой стороны, чисто HTTP-инструмент возвращает один огромный фрагмент ответа, не заботясь об автоматическом извлечении ресурсов, на которые ссылаются. Запрос curl продемонстрирует следующее:
$ curl -X GET "https://www.reddit.com/" -m 30 -v
Вы должны увидеть только один запрос и ответ, содержащий HTML, но никаких дополнительных запросов, автоматически выдаваемых, как вы видите в браузере.
Давайте вернемся к диаграмме из шага 3 выше, когда мы рассмотрели ответы на вкладке Сеть . Вы могли заметить два столбца с именами Method и Status . Если столбец Method не отображается, возможно, он скрыт по умолчанию. Чтобы отобразить столбец Method , щелкните правой кнопкой мыши Статус и выберите Метод . Столбец Method теперь должен отображаться рядом со столбцом Status .
Чтобы отобразить столбец Method , щелкните правой кнопкой мыши Статус и выберите Метод . Столбец Method теперь должен отображаться рядом со столбцом Status .
В этом разделе мы рассмотрим, что означает информация, отображаемая в этих столбцах.
Информация, отображаемая в столбце Method , называется HTTP Request Method . Вы можете думать об этом как о глаголе, который сообщает серверу, какое действие нужно выполнить с ресурсом. Два наиболее распространенных метода HTTP-запроса, которые вы увидите, — это 9.0032 ПОЛУЧИТЬ и ОТПРАВИТЬ . Когда вы думаете о получении информации, подумайте о GET , который является наиболее часто используемым методом HTTP-запроса. На приведенной выше диаграмме вы заметите, что почти все запросы используют GET для получения ресурсов, необходимых для отображения веб-страницы.
Столбец Статус показывает статус ответа на каждый запрос. Подробнее об ответах мы поговорим позже в этой книге. Важно понимать, что каждый запрос получает ответ, даже если ответ является ошибкой — это все равно ответ. (Технически это не на 100% верно, так как некоторые запросы могут time out , но мы пока отложим эти редкие случаи.)
GET Запросы инициируются щелчком по ссылке или через адресную строку браузера. Когда вы вводите адрес типа https://www.reddit.com в адресную строку браузера, вы делаете запрос GET . Вы просите веб-браузер получить ресурс по этому адресу, а это значит, что мы сделали запроса GET на протяжении всей книги. То же самое касается взаимодействия со ссылками в веб-приложениях. По умолчанию ссылка выдает GET запрос на URL. Давайте сделаем простой запрос GET на https://www.reddit.com с помощью инструмента HTTP. Обязательно выберите GET и введите адрес:
Вы можете просмотреть необработанный HTTP-ответ и другую информацию, отправленную с веб-сервера, на правой панели.![]()
curl пользователи могут ввести следующую команду на своем терминале:
$ curl -X GET "https://www.reddit.com/" -m 30 -v
Мы также можем отправлять строки запроса с помощью инструмента HTTP. Давайте рассмотрим еще один быстрый пример, отправив запрос на поиск всех вещей Майкл Джексон по телефону https://itunes.apple.com/ со строками запроса. Конечный URL будет выглядеть так:
https://itunes.apple.com/search?term=Michael%20Jackson.
перед отправкой запроса обязательно выберите GET .
Здесь мы просто отправляем запрос HTTP GET на сервер по адресу https://itunes.apple.com/ с параметром term=Michael%20Jackson , где %20 — это URL-кодированный символ ПРОСТРАНСТВА.
Команда curl для этого примера:
$ curl -X GET "https://itunes.apple.com/search?term=Michael%20Jackson" -m 30 -v
Это все, что вам нужно знать о выдаче запросов HTTP GET на данный момент. Основные понятия:
Основные понятия:
- Запросы GET используются для извлечения ресурса, и большинство ссылок являются GET.
- Ответ на запрос GET может быть любым, но если это HTML и этот HTML ссылается на другие ресурсы, ваш браузер автоматически запросит эти ресурсы. Инструмент чистого HTTP не будет.
Мы видели, как получить или запросить информацию с сервера с помощью GET , но что, если вам нужно отправить или отправить данные на сервер? Вот тут-то и появляется еще один важный метод HTTP-запроса: POST . POST используется, когда вы хотите инициировать какое-либо действие на сервере или отправить данные на сервер. Давайте рассмотрим пример с нашим инструментом HTTP:
Вот команда curl:
$ curl -X POST "https://echo.epa.gov" -m 30 -v
На приведенном выше снимке экрана показан запрос POST на https://echo.epa.gov и ответ от сервера. Обычно в браузере вы используете POST при отправке формы.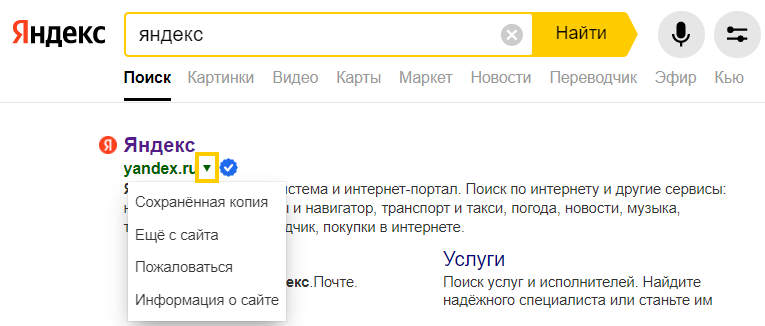
Запросы POST позволяют нам отправлять на сервер гораздо большие и конфиденциальные данные, такие как изображения или видео. Например, предположим, что нам нужно отправить имя пользователя и пароль на сервер для аутентификации. Мы могли бы использовать запрос GET и отправить его через строки запроса. Недостаток этого подхода очевиден: наши учетные данные мгновенно отображаются в URL-адресе; это не то, что мы хотим. Использование Запрос POST в форме устраняет эту проблему. Запросы POST также помогают обойти ограничение размера строки запроса, которое у вас есть с запросами GET . С помощью запросов POST мы можем отправлять на сервер значительно большие формы информации.
Давайте рассмотрим еще один пример выполнения запроса POST путем заполнения веб-формы. Наш пример формы выглядит в браузере так:
После заполнения формы вы будете перенаправлены на страницу, которая выглядит так:
Теперь давайте переключимся на наш инструмент HTTP и смоделируем то, что мы только что сделали в браузере. Вместо заполнения формы в браузере мы отправим запрос
Вместо заполнения формы в браузере мы отправим запрос POST на http://al-blackjack.herokuapp.com/new_player . Это URL-адрес, который отправляет первая форма (та, где мы вводим имя):
Или вы можете использовать curl:
$ curl -X POST "http://al-blackjack.herokuapp.com/ новый_игрок" -d "имя_игрока=Альберт" -m 30 -v
Обратите внимание, что на снимке экрана и в команде curl мы указываем дополнительный параметр player_name=albert . Это имеет тот же эффект, что и ввод имени в первое поле «Как тебя зовут?» форму и отправить ее.
Мы можем проверить содержимое с помощью инспектора (щелкните правой кнопкой мыши и выберите Inspect ). Вы увидите, что параметр player_name , который мы отправляем как часть запроса POST , встроен в форму через имя 9Атрибут 0033 элемента input :
Но загадка в том, как данные, которые мы отправляем, отправляются на сервер, если они не отправляются через URL? Ответом на это является тело HTTP . Тело содержит данные, которые передаются в HTTP-сообщении, и является необязательным. Другими словами, HTTP-сообщение может быть отправлено с пустым телом. При использовании тело может содержать HTML, изображения, аудио и так далее. Вы можете думать о теле как о письме, вложенном в конверт, которое нужно отправить.
Тело содержит данные, которые передаются в HTTP-сообщении, и является необязательным. Другими словами, HTTP-сообщение может быть отправлено с пустым телом. При использовании тело может содержать HTML, изображения, аудио и так далее. Вы можете думать о теле как о письме, вложенном в конверт, которое нужно отправить.
Запрос POST , сгенерированный инструментом HTTP или curl, аналогичен заполнению формы в браузере, отправке этой формы и последующему перенаправлению на следующую страницу. Внимательно посмотрите на необработанный ответ на снимке экрана инструмента HTTP. Ключевая информация, которая перенаправляет нас на следующую страницу, указана в поле Location: http://al-blackjack.herokuapp.com/bet . Заголовок Location — это заголовок ответа HTTP (да, запросы тоже имеют заголовки, но в данном случае это заголовок ответа). Пока не слишком беспокойтесь об этом, так как мы обсудим заголовки в следующем разделе. Ваш браузер видит Location и автоматически отправляет новый запрос на указанный URL-адрес, тем самым инициируя новый, несвязанный запрос. Форма «Сделать ставку», которую вы видите, является ответом на этот второй запрос.
Форма «Сделать ставку», которую вы видите, является ответом на этот второй запрос.
Примечание: Если вы используете какой-либо другой инструмент HTTP, например Insomnia или Postman, вам может потребоваться снять флажок «автоматически следовать перенаправлениям», чтобы увидеть заголовок ответа Location .
Если вы не поняли предыдущий абзац, прочтите его еще раз. Очень важно понимать, что при использовании браузера браузер скрывает от вас большую часть лежащего в основе цикла HTTP-запроса/ответа. Ваш браузер выдал начальные Запрос POST , получил ответ с заголовком Location , затем выдал другой запрос без каких-либо действий с вашей стороны, а затем отобразил ответ на этот второй запрос. Опять же, если бы вы использовали чистый HTTP-инструмент, вы бы увидели заголовок ответа Location из первого запроса POST , но инструмент не выдал бы вам второй запрос автоматически. (Некоторые инструменты HTTP имеют эту возможность, если вы отметите опцию «автоматически следовать перенаправлениям». )
)
9Заголовки HTTP 0002 позволяют клиенту и серверу отправлять дополнительную информацию во время цикла запроса/ответа HTTP. Заголовки представляют собой пары "имя-значение", разделенные двоеточиями, которые отправляются в виде обычного текста. Используя инспектор , мы можем увидеть эти заголовки. Ниже вы можете видеть как заголовки запроса, так и заголовки ответа:
Выше показаны различные заголовки, передаваемые во время цикла запроса/ответа. Далее мы видим, что запрос и ответ содержат разный набор заголовков до 9.0032 Заголовки запроса :
Заголовки запроса содержат дополнительную информацию о клиенте и ресурсе, который необходимо получить. Некоторые полезные заголовки запросов:
| Имя поля | Описание | Пример |
|---|---|---|
| Хост | Доменное имя сервера. | Хост: www.reddit.com |
| Принять язык | Список допустимых языков. | Accept-Language: en-US,en;q=0.8 |
| Агент пользователя | Строка, идентифицирующая клиента. | User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/38.0.2125.101 Safari/537.36 |
| Соединение | Тип подключения, который предпочитает клиент. | Соединение: поддержка активности |
Не утруждайте себя запоминанием каких-либо заголовков запроса, просто знайте, что это часть запроса, отправляемого на сервер. Мы поговорим о заголовках ответов в следующей главе.
Это было краткое введение в выполнение HTTP-запросов. После прохождения этого раздела вы должны научиться:
- использовать инспектор для просмотра HTTP-запросов
- выполнение запросов GET/POST с помощью инструмента HTTP
Наиболее важные компоненты для понимания HTTP-запроса:
- HTTP-метод
- путь (имя ресурса и любые параметры запроса)
- заголовков
- тело сообщения (для
POSTзапросов)
В следующей главе мы продолжим изучение HTTP, рассматривая ответы HTTP.
Сообщения HTTP — HTTP | MDN
HTTP-сообщения — это способ обмена данными между сервером и клиентом. Существует два типа сообщений: запросы , отправленные клиентом для запуска действия на сервере, и ответы , ответ от сервера.
Сообщения HTTP состоят из текстовой информации, закодированной в ASCII, и занимают несколько строк. В HTTP/1.1 и более ранних версиях протокола эти сообщения открыто отправлялись по соединению. В HTTP/2 сообщение, которое когда-то можно было прочитать человеку, теперь разделено на кадры HTTP, что обеспечивает оптимизацию и повышение производительности.
Веб-разработчики или веб-мастера редко создают эти текстовые HTTP-сообщения самостоятельно: это действие выполняется программным обеспечением, веб-браузером, прокси-сервером или веб-сервером. Они предоставляют HTTP-сообщения через файлы конфигурации (для прокси-серверов или серверов), API-интерфейсы (для браузеров) или другие интерфейсы.
Механизм формирования двоичных файлов HTTP/2 был разработан таким образом, чтобы не требовать каких-либо изменений API-интерфейсов или применяемых файлов конфигурации: он практически прозрачен для пользователя.
HTTP-запросы и ответы имеют схожую структуру и состоят из:
- Стартовая строка , описывающая запросы, которые должны быть реализованы, или ее состояние: успешное или неудачное. Эта стартовая линия всегда представляет собой одну линию.
- Необязательный набор заголовков HTTP , определяющих запрос или описывающих тело, включенное в сообщение.
- Была отправлена пустая строка, указывающая на то, что вся метаинформация для запроса отправлена.
- Необязательное тело , содержащее данные, связанные с запросом (например, содержимое HTML-формы), или документ, связанный с ответом. Наличие тела и его размер определяется стартовой строкой и HTTP-заголовком.
Начальная строка и заголовки HTTP сообщения HTTP вместе известны как заголовок запросов, тогда как его полезная нагрузка известна как тело .
Стартовая строка
HTTP-запросы — это сообщения, отправляемые клиентом для инициирования действия на сервере. Их стартовая строка содержит три элемента:
Их стартовая строка содержит три элемента:
- HTTP-метод , глагол (например,
GET,PUTилиPOST) или существительное (например,HEADилиOPTIONS), описывающее действие, которое необходимо выполнить. Например,GETуказывает, что ресурс должен быть извлечен, илиPOSTозначает, что данные передаются на сервер (создание или изменение ресурса или создание временного документа для отправки обратно). - Цель запроса , обычно URL-адрес или абсолютный путь протокола, порта и домена, обычно характеризуются контекстом запроса. Формат этой цели запроса зависит от разных методов HTTP. Это может быть
- Абсолютный путь, за которым следует
'?'и строка запроса. Это наиболее распространенная форма, известная как исходная форма , и используется с методамиGET,POST,HEADиOPTIONS.-
POST/HTTP/1.1 -
ПОЛУЧИТЬ /background.png HTTP/1.0 -
ГОЛОВА /test.html?query=alibaba HTTP/1.1 -
ВАРИАНТЫ /anypage.html HTTP/1.0
-
- Полный URL-адрес, известный как абсолютная форма , в основном используется с
GETпри подключении к прокси-серверу.
ПОЛУЧИТЬ https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 - Компонент полномочий URL-адреса, состоящий из имени домена и, возможно, порта (с префиксом
':'), называется формой полномочий . Используется только сCONNECTпри настройке HTTP-туннеля.
ПОДКЛЮЧЕНИЕ developer.mozilla.org:80 HTTP/1.1 - Звездочка форма , простая звездочка (
'*') используется сOPTIONS, представляя сервер в целом.
ОПЦИИ * HTTP/1.1
- Абсолютный путь, за которым следует
- Версия HTTP , определяющая структуру оставшегося сообщения, действующая как индикатор ожидаемой версии для использования в ответе.

Заголовки HTTP из запроса следуют той же базовой структуре заголовка HTTP: строка без учета регистра, за которой следует двоеточие ( ':' ) и значение, структура которого зависит от заголовка. Весь заголовок, включая значение, состоит из одной строки, которая может быть довольно длинной.
В запросах может появляться много разных заголовков. Их можно разделить на несколько групп:
- Общие заголовки, такие как
Via, относятся к сообщению в целом. - Заголовки запроса, такие как
User-AgentилиAccept, изменяют запрос, уточняя его (например,Accept-Language), предоставляя контекст (например,Referer) или ограничивая его условно (например,If -Нет). - Заголовки представления, такие как
Content-Type, которые описывают исходный формат данных сообщения и любое примененное кодирование (присутствует, только если сообщение имеет тело).

Body
Заключительной частью запроса является его тело. Не все запросы имеют его: запросы на выборку ресурсов, такие как GET , HEAD , DELETE или OPTIONS , обычно не нуждаются в нем. Некоторые запросы отправляют данные на сервер для их обновления: как это часто бывает с запросами POST (содержащими данные HTML-формы).
Тела можно разделить на две категории:
- Тела с одним ресурсом, состоящие из одного файла, определяемого двумя заголовками:
Тип содержимогоиДлина содержимого. - Тела с несколькими ресурсами, состоящие из составных частей, каждая из которых содержит различный бит информации. Обычно это связано с HTML-формами.
Строка состояния
Начальная строка ответа HTTP, называемая строкой состояния , содержит следующую информацию:
- Версия протокола , обычно
HTTP/1.1. - A код состояния , указывающий на успех или неудачу запроса. Общие коды состояния:
200,404или302 - A текст состояния . Краткое, чисто информационное, текстовое описание кода состояния, помогающее человеку понять HTTP-сообщение.
.
Типичная строка состояния выглядит так: HTTP/1.1 404 Not Found .
Заголовки HTTP для ответов имеют ту же структуру, что и любой другой заголовок: строка без учета регистра, за которой следует двоеточие ( ':' ) и значение, структура которого зависит от типа заголовка. Весь заголовок, включая его значение, представлен в виде одной строки.
В ответах могут появляться разные заголовки. Их можно разделить на несколько групп:
- Общие заголовки, такие как
Через, относятся ко всему сообщению. - Заголовки ответов, такие как
VaryиAccept-Ranges, предоставляют дополнительную информацию о сервере, которая не помещается в строке состояния. - Заголовки представления, такие как
Content-Type, которые описывают исходный формат данных сообщения и любое примененное кодирование (присутствует, только если сообщение имеет тело).
Тело
Последней частью ответа является тело. Не все ответы имеют один: ответы с кодом состояния, который в достаточной степени отвечает на запрос без необходимости соответствующей полезной нагрузки (например, 201 Created или 204 Нет содержимого ) обычно нет.
Тела можно условно разделить на три категории:
- Тела с одним ресурсом, состоящие из одного файла известной длины, определяемой двумя заголовками:
Content-TypeиContent-Length. - Тела с одним ресурсом, состоящие из одного файла неизвестной длины, закодированные фрагментами с
Transfer-Encoding, установленным наchunked. - Тела с несколькими ресурсами, состоящие из составных частей, каждая из которых содержит отдельный раздел информации. Это относительно редко.

Сообщения HTTP/1.x имеют несколько недостатков в плане производительности:
- Заголовки, в отличие от тела, не сжимаются.
- Заголовки часто очень похожи от одного сообщения к другому, но все же повторяются при разных соединениях.
- Мультиплексирование невозможно. На одном сервере необходимо открывать несколько соединений: теплые TCP-соединения более эффективны, чем холодные.
HTTP/2 вводит дополнительный шаг: он делит сообщения HTTP/1.x на кадры, которые встраиваются в поток. Кадры данных и заголовков разделены, что позволяет сжимать заголовки. Несколько потоков могут быть объединены вместе, процесс называется мультиплексирует , что позволяет более эффективно использовать базовые соединения TCP.