Содержание
Понятия репликации Active Directory | Microsoft Learn
-
Статья -
- Чтение занимает 9 мин
-
Область применения: Windows Server 2022, Windows Server 2019, Windows Server 2016, Windows Server 2012 R2, Windows Server 2012
Прежде чем проектировать топологию сайта, ознакомьтесь с некоторыми Active Directory концепциями репликации.
Объект Connection
NПОПЫТКА
Функции отработки отказа
Подсеть
Сайт
Связь сайтов
Мост связей сайтов
Транзитивность связи сайтов
Сервер глобального каталога
Кэширование членства в универсальных группах
Объект подключения
Объект Connection — это Active Directory объект, представляющий подключение репликации с исходного контроллера домена к целевому контроллеру домена. Контроллер домена является членом одного сайта и представлен на сайте объектом сервера в службах домен Active Directory Services (AD DS). у каждого объекта сервера есть дочерний объект NTDS Параметры, представляющий реплицируемый контроллер домена в сайте.
Контроллер домена является членом одного сайта и представлен на сайте объектом сервера в службах домен Active Directory Services (AD DS). у каждого объекта сервера есть дочерний объект NTDS Параметры, представляющий реплицируемый контроллер домена в сайте.
объект connection является дочерним по отношению к объекту Параметры NTDS на целевом сервере. Чтобы репликация выполнялась между двумя контроллерами домена, объект сервера одного из них должен иметь объект Connection, представляющий входящую репликацию из другого. все подключения репликации для контроллера домена хранятся в виде объектов подключения в объекте NTDS Параметры. Объект Connection определяет исходный сервер репликации, содержит расписание репликации и указывает транспорт репликации.
Средство проверки согласованности знаний (KCC) автоматически создает объекты подключения, но их также можно создать вручную. Объекты подключения, созданные КСС, отображаются в оснастке «Active Directory сайты и службы», которая создается > автоматически и считается достаточной при нормальных условиях работы.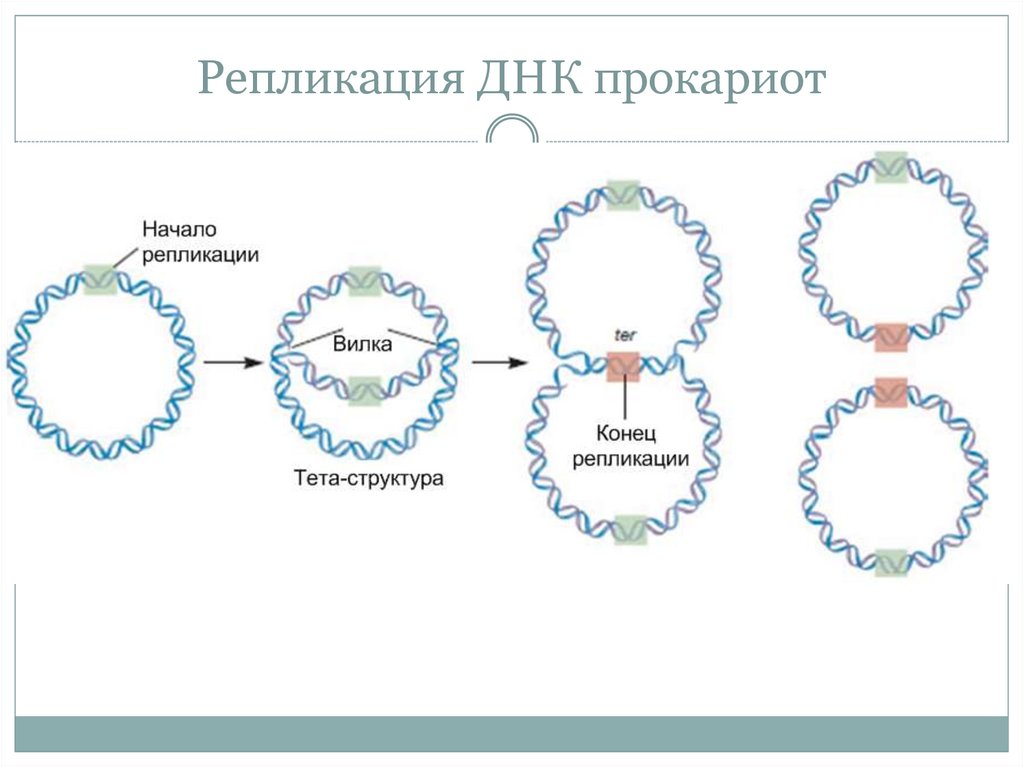 Объекты соединения, созданные администратором, создаются вручную. Объект подключения, созданный вручную, определяется по имени, назначенному администратором при его создании. При изменении автоматически созданного > объекта соединения он преобразуется в административно измененный объект подключения, а объект отображается в виде идентификатора GUID. KCC не вносит изменения в ручные или измененные объекты подключения.
Объекты соединения, созданные администратором, создаются вручную. Объект подключения, созданный вручную, определяется по имени, назначенному администратором при его создании. При изменении автоматически созданного > объекта соединения он преобразуется в административно измененный объект подключения, а объект отображается в виде идентификатора GUID. KCC не вносит изменения в ручные или измененные объекты подключения.
NПОПЫТКА
KCC — это встроенный процесс, который выполняется на всех контроллерах домена и создает топологию репликации для Active Directory леса. KCC создает отдельные топологии репликации в зависимости от того, выполняется ли репликация на сайте (внутрисайтовая) или между сайтами (межсайтовой). KCC также динамически корректирует топологию, чтобы она соответствовала добавлению новых контроллеров домена, удалению существующих контроллеров домена, перемещению контроллеров домена на сайты, изменяющимся затратам и расписаниям, а также к контроллерам домена, которые временно недоступны или находятся в состоянии ошибки.
В пределах сайта подключения между контроллерами домена с возможностью записи всегда упорядочиваются по двунаправленному кругу с дополнительными подключениями для уменьшения задержки на больших сайтах. С другой стороны, межсайтовая топология является слоем распределения деревьев. Это означает, что между двумя сайтами каждого раздела каталога существует одно межсайтическое соединение, которое обычно не содержит ярлыки. Дополнительные сведения о охвате деревьев и Active Directory топологии репликации см. в статье Технический справочник по топологии репликации Active Directory ( https://go.microsoft.com/fwlink/?LinkID=93578 ).
На каждом контроллере домена KCC создает маршруты репликации, создавая односторонние объекты входящих подключений, которые определяют подключения других контроллеров домена. Для контроллеров домена на одном сайте KCC автоматически создает объекты подключения без вмешательства администратора. При наличии нескольких сайтов вы настраиваете связи сайтов между сайтами, а единое средство проверки согласованности знаний на каждом сайте автоматически создает подключения между сайтами.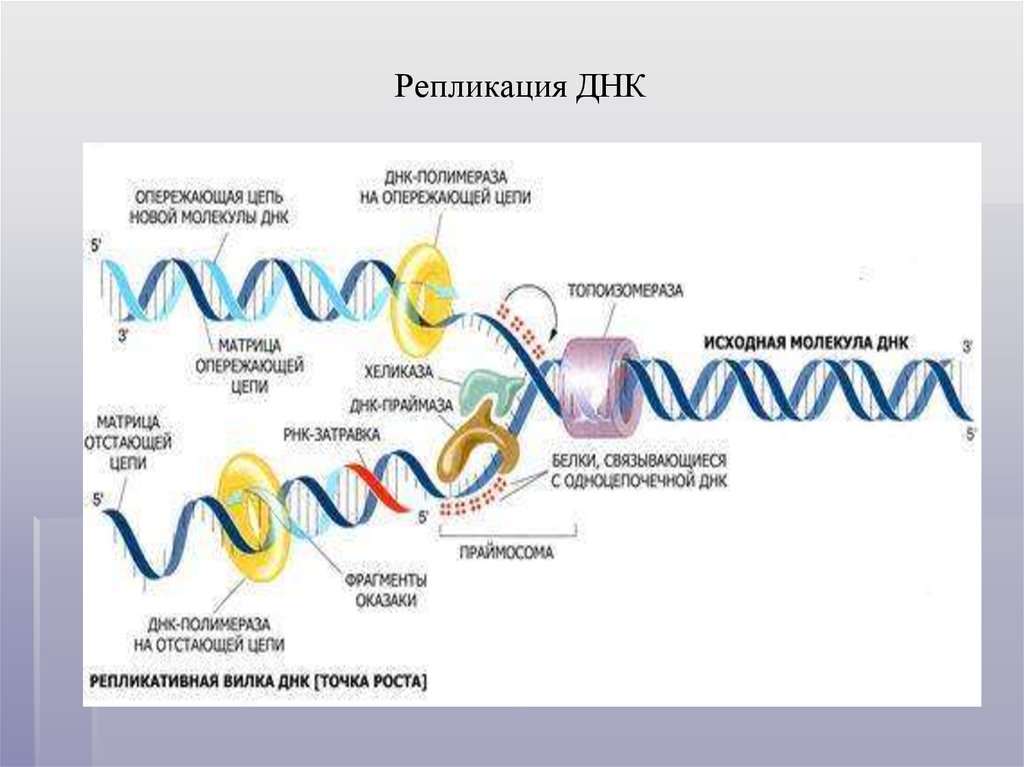
улучшения KCC для Windows Server 2008 rodc
существует ряд улучшений KCC для размещения нового доступного контроллера домена только для чтения (RODC) в Windows Server 2008. Типичным сценарием развертывания для RODC является филиал. Топология репликации Active Directory, наиболее часто развернутая в этом сценарии, основана на конструкции «звезда», где контроллеры домена ветви на нескольких сайтах реплицируются с небольшим количеством серверов-плацдармов на сайте концентратора.
Одним из преимуществ развертывания RODC в этом сценарии является однонаправленная репликация. Серверы-плацдармы не должны реплицироваться с RODC, что снижает нагрузку на администрирование и использование сети.
однако одна из задач администрирования, выделенная топологией hub в предыдущих версиях операционной системы Windows Server, заключается в том, что после добавления нового контроллера домена-плацдарма в концентратор не существует автоматического механизма повторного распределения подключений репликации между контроллерами домена ветви и контроллерами домена концентратора, чтобы воспользоваться преимуществами нового контроллера домена концентратора.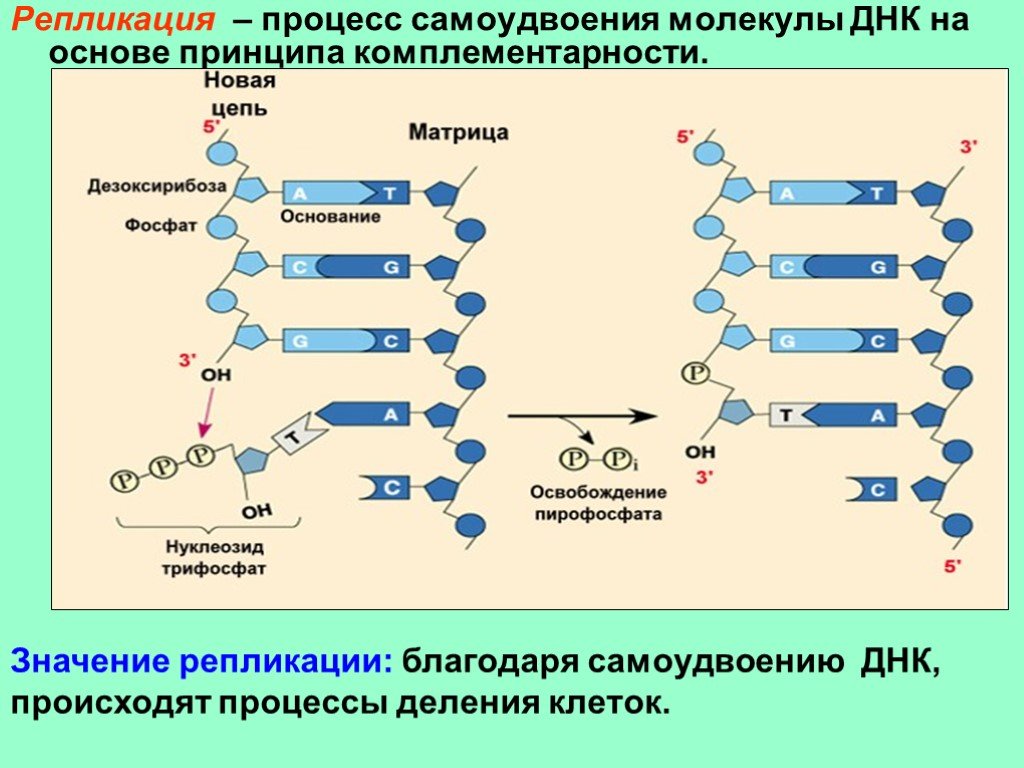
для Windows Server 2008 rodc нормальная работа KCC обеспечивает некоторую перераспределение. Новые функции включены по умолчанию. Его можно отключить, добавив следующий набор разделов реестра на RODC:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Parameters
«Random BH LoadBalancing Allowed»1 = Enabled (по умолчанию), 0 = отключено
Дополнительные сведения о том, как работают эти улучшения KCC, см. в разделе Планирование и развертывание служб домен Active Directory для филиалов ( https://go.microsoft.com/fwlink/?LinkId=107114 ).
Функции отработки отказа
Сайты обеспечивают маршрутизацию репликации по сетевым ошибкам и контроллерам домена вне сети. Проверка согласованности знаний выполняется с указанными интервалами, чтобы настроить топологию репликации для изменений, происходящих в AD DS, например при добавлении новых контроллеров домена и создании новых сайтов. KCC проверяет состояние репликации существующих соединений, чтобы определить, не работают ли какие либо подключения. Если подключение не работает из-за сбоя контроллера домена, KCC автоматически создает временные подключения к другим партнерам репликации (если они доступны), чтобы убедиться в том, что репликация выполняется. Если все контроллеры домена в сайте недоступны, KCC автоматически создает подключения репликации между контроллерами домена с другого сайта.
Если подключение не работает из-за сбоя контроллера домена, KCC автоматически создает временные подключения к другим партнерам репликации (если они доступны), чтобы убедиться в том, что репликация выполняется. Если все контроллеры домена в сайте недоступны, KCC автоматически создает подключения репликации между контроллерами домена с другого сайта.
Подсеть
Подсеть — это сегмент сети TCP/IP, к которому назначаются наборы логических IP-адресов. Подсети группируют компьютеры таким образом, чтобы определить их физическое сходство в сети. Объекты подсети в AD DS определяют сетевые адреса, используемые для подключения компьютеров к сайтам.
Сайт
Сайты — это Active Directory объекты, представляющие одну или несколько подсетей TCP/IP с высокой надежностью и быстрыми сетевыми подключениями. Сведения о сайте позволяют администраторам настраивать Active Directory доступ и репликацию для оптимизации использования физической сети. Объекты сайта связаны с набором подсетей, и каждый контроллер домена в лесу связан с Active Directory сайтом в соответствии с его IP-адресом. Сайты могут размещать контроллеры домена из нескольких доменов, а домен может быть представлен более чем одним сайтом.
Сайты могут размещать контроллеры домена из нескольких доменов, а домен может быть представлен более чем одним сайтом.
Связь сайтов
Связи сайтов — это Active Directory объекты, которые представляют логические пути, используемые КСС для установления соединения для репликации Active Directory. Объект связи сайтов представляет собой набор сайтов, которые могут обмениваться данными с одинаковыми затратами через указанный межсайтовый транспорт.
Все сайты, содержащиеся в связи сайтов, считаются подключенными посредством одного типа сети. Сайты должны быть связаны с другими сайтами вручную с помощью связей сайтов, чтобы контроллеры домена на одном сайте могли реплицировать изменения каталога с контроллеров домена на другом сайте. Поскольку связи сайтов не соответствуют фактическому пути, принятому сетевыми пакетами в физической сети во время репликации, вам не нужно создавать избыточные связи сайтов для повышения эффективности репликации Active Directory.
При соединении двух сайтов с помощью связи сайтов система репликации автоматически создает подключения между конкретными контроллерами домена на каждом сайте, который называется серверами-плацдармами. в Windows Server 2008 все контроллеры домена на сайте, где размещается один и тот же раздел каталога, являются кандидатами для выбора в качестве серверов-плацдармов. Подключения репликации, созданные KCC, случайным образом распределяются между всеми потенциальными серверами-плацдармами на сайте для совместного использования рабочей нагрузки репликации. По умолчанию процесс случайного выбора выполняется только один раз, когда объекты соединения впервые добавляются на сайт.
в Windows Server 2008 все контроллеры домена на сайте, где размещается один и тот же раздел каталога, являются кандидатами для выбора в качестве серверов-плацдармов. Подключения репликации, созданные KCC, случайным образом распределяются между всеми потенциальными серверами-плацдармами на сайте для совместного использования рабочей нагрузки репликации. По умолчанию процесс случайного выбора выполняется только один раз, когда объекты соединения впервые добавляются на сайт.
Мост связей сайтов
Мост связи сайтов — это объект Active Directory, представляющий набор связей сайтов, все сайты которых могут обмениваться данными с помощью общего транспорта. Мосты связей сайтов позволяют подключать контроллеры домена, которые не соединены напрямую через канал связи для репликации друг с другом. Как правило, мост связей сайтов соответствует маршрутизатору (или набору маршрутизаторов) в IP-сети.
По умолчанию KCC может формировать транзитный маршрут через все связи сайтов, на которых имеются общие сайты. Если такое поведение отключено, каждая связь сайтов представляет собственную отдельную и изолированную сеть. Наборы связей сайтов, которые можно рассматривать как один маршрут, выражаются через мост связей сайтов. Каждый мост представляет среду изолированного взаимодействия для сетевого трафика.
Если такое поведение отключено, каждая связь сайтов представляет собственную отдельную и изолированную сеть. Наборы связей сайтов, которые можно рассматривать как один маршрут, выражаются через мост связей сайтов. Каждый мост представляет среду изолированного взаимодействия для сетевого трафика.
Мосты связей сайтов — это механизм, логически отражающий транзитивное физическое подключение между сайтами. Мост связей сайтов позволяет KCC использовать любое сочетание входящих в него связей сайтов, чтобы определить наименее дорогостоящий маршрут к разделам каталога Interconnect, которые хранятся на этих сайтах. Мост связей сайтов не обеспечивает фактическое подключение к контроллерам домена. Если мост связей сайтов удален, репликация по Объединенным связям сайтов будет продолжаться до тех пор, пока не будут удалены ссылки.
Мосты связей сайтов необходимы только в том случае, если сайт содержит контроллер домена, на котором размещается раздел каталога, который также не размещается на контроллере домена соседнего сайта, но контроллер домена, на котором размещается этот раздел каталога, находится на одном или нескольких сайтах в лесу. Смежные сайты определяются как любые два или больше сайтов, входящих в одну связь сайтов.
Смежные сайты определяются как любые два или больше сайтов, входящих в одну связь сайтов.
Мост связей сайтов создает логическое подключение между двумя связями сайтов, предоставляя транзитный путь между двумя отключенными сайтами с помощью промежуточного сайта. В целях создания межсайтовых топологий (ISTG) мост подразумевает физическое подключение с использованием промежуточного сайта. Мост не подразумевает, что контроллер домена на промежуточном сайте предоставит путь репликации. Тем не менее, если промежуточный сайт содержал контроллер домена, на котором размещен раздел каталога для репликации, в этом случае мост связей сайтов не требуется.
Добавляется стоимость каждой связи сайтов, что приводит к созданию суммированных затрат для итогового пути. Мост связей сайтов будет использоваться, если промежуточный сайт не содержит контроллер домена, на котором размещается раздел каталога, а ссылка с более низкими затратами не существует. Если промежуточный сайт содержал контроллер домена, на котором размещается раздел каталога, два отключенных сайта настроили подключения репликации к промежуточному контроллеру домена и не используют мост.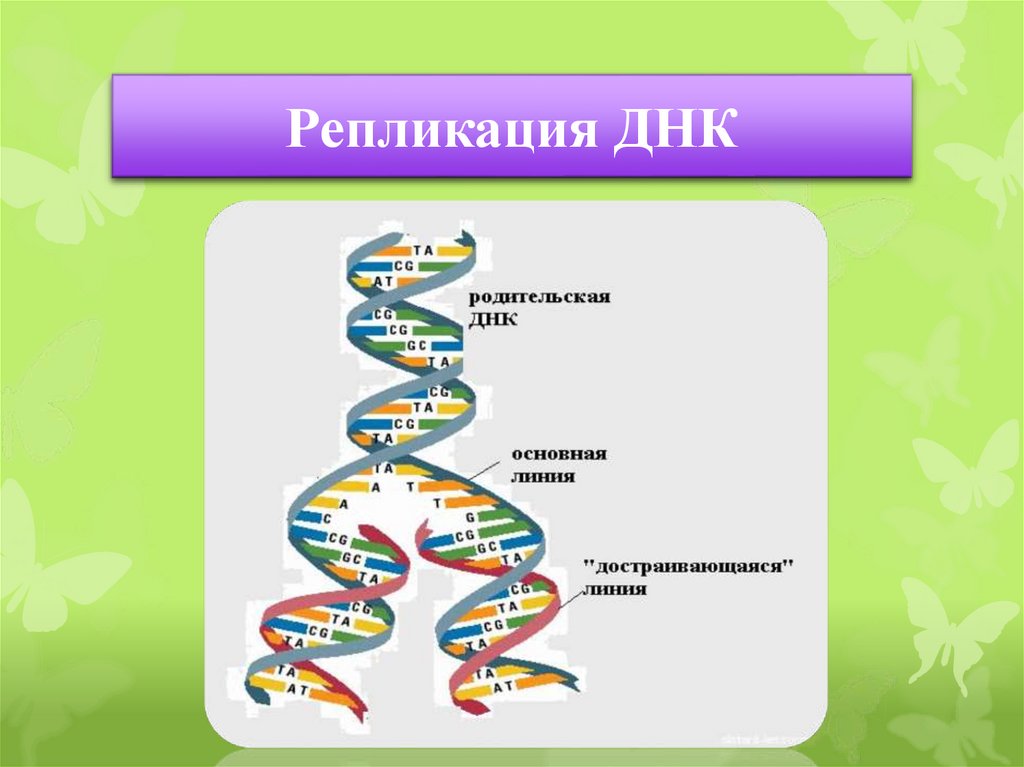
Транзитивность связи сайтов
По умолчанию все связи сайтов являются транзитивными или «моста». Если связи сайтов проходят мост и расписания перекрываются, KCC создает подключения репликации, которые определяют партнеров по репликации контроллеров домена между сайтами, где сайты не подключаются напрямую с помощью связей сайтов, но соединяются через набор общих сайтов. Это означает, что можно подключить любой сайт к любому другому сайту, используя сочетание связей сайтов.
Как правило, для полностью перенаправленной сети нет необходимости создавать мосты связей сайтов, если не требуется управлять потоком изменений репликации. Если сеть не была полностью направляться, необходимо создать мосты связей сайтов, чтобы избежать невозможности попыток репликации. Все связи сайтов для определенного транспорта неявно принадлежат одному мосту связей сайтов для этого транспорта. Мост по умолчанию для связей сайтов происходит автоматически, и ни один объект Active Directory не представляет этот мост. Параметр мост все связи сайтов , который находится в свойствах межсайтовых транспортных контейнеров (IP и SMTP), реализует автоматическую маршрутизацию связей сайтов.
Параметр мост все связи сайтов , который находится в свойствах межсайтовых транспортных контейнеров (IP и SMTP), реализует автоматическую маршрутизацию связей сайтов.
Примечание
Репликация SMTP не будет поддерживаться в будущих версиях AD DS; Поэтому не рекомендуется создавать объекты связей сайтов в контейнере SMTP.
Сервер глобального каталога
Сервер глобального каталога — это контроллер домена, в котором хранятся сведения обо всех объектах в лесу, чтобы приложения могли выполнять поиск AD DS, не ссылаясь на конкретные контроллеры домена, в которых хранятся запрошенные данные. Как и все контроллеры домена, сервер глобального каталога хранит полные, доступные для записи реплики и разделы каталога конфигурации, а также полную доступную для записи реплику раздела каталога домена для домена, в котором он размещен. Кроме того, сервер глобального каталога сохраняет частичную реплику, доступную только для чтения, для каждого домена в лесу. Частичные реплики домена только для чтения содержат каждый объект в домене, но только подмножество атрибутов (эти атрибуты чаще всего используются для поиска объекта).
Кэширование членства в универсальных группах
Кэширование членства в универсальных группах позволяет контроллеру домена кэшировать сведения о членстве в универсальных группах для пользователей. контроллеры домена, работающие под управлением Windows Server 2008, можно включить для кэширования членства в универсальных группах с помощью оснастки «сайты и службы Active Directory».
Включение кэширования членства в универсальных группах устраняет потребность в сервере глобального каталога на каждом сайте в домене, что сводит к минимуму использование полосы пропускания сети, поскольку контроллеру домена не требуется реплицировать все объекты, расположенные в лесу. Это также сокращает время входа в систему, так как контроллерам домена, выполняющим аутентификацию, не всегда требуется доступ к глобальному каталогу для получения сведений о членстве в универсальных группах. Дополнительные сведения об использовании кэширования членства в универсальных группах см. в разделе Планирование размещения сервера глобального каталога.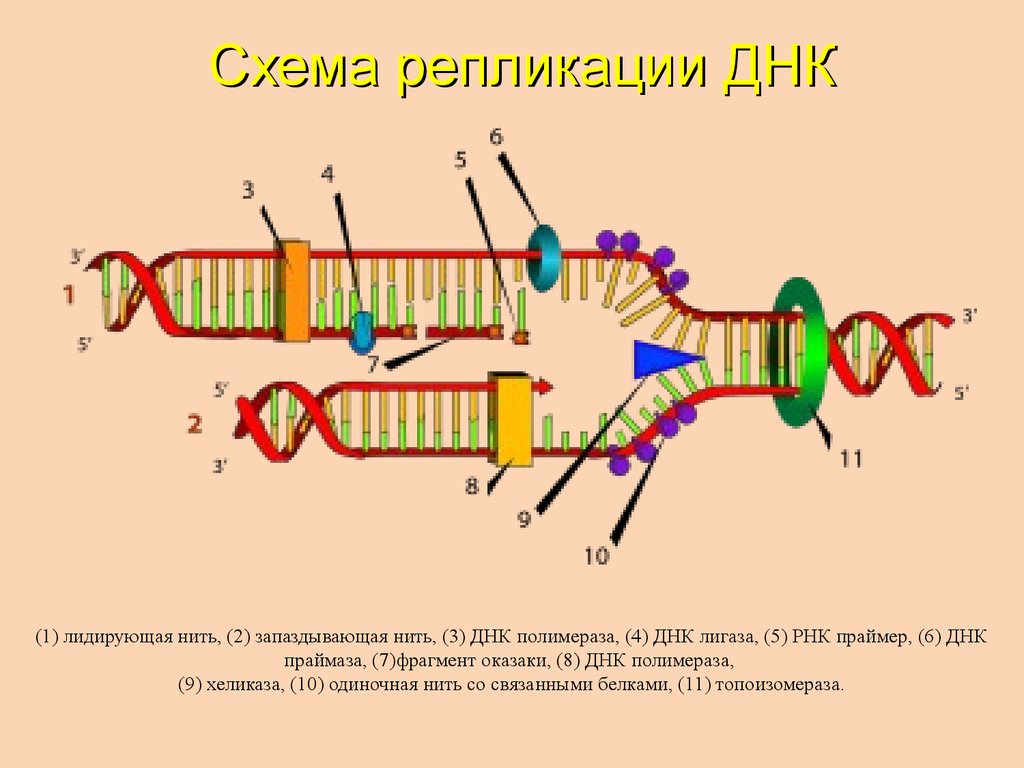
Скорость и надежность обработки данных: синхронная репликация в in-memory
Несмотря на сложную экономическую обстановку, крупные компании продолжают курс цифровизации бизнеса. Мобильные приложения и онлайн-кабинеты стали обязательным каналом коммуникации и обслуживания, что кратно увеличивает нагрузку на ИТ-инфраструктуру. Проблему производительности действующих систем можно решить несколькими путями, один из них — технологии in-memory. Но способны ли они гарантировать достаточный уровень надежности?
Около десяти лет назад для всех карточных операций банку было достаточно информационной системы с пропускной способностью 1000 запросов в секунду. Для сравнения, сегодня обработка только инвестиционных сделок банка из топ-10 — это более 5000 ежесекундных обращений. Традиционные базы данных, которые многие компании и банки используют в качестве основного хранилища, не справляются с потоком запросов от пользователей мобильных приложений. Чтобы избежать финансовых и репутационных убытков, ИТ-департаменты ищут способы ускорить существующие системы.
Для многих компаний решением стали in-memory-технологии. Этот подход подразумевает, что хранение и обработка данных происходит в оперативной памяти, а запись на диски ведется для большей надежности. Таким образом, удается достигнуть кратно лучшей пропускной способности и обработки в секунду сотен тысяч запросов против в лучшем случае 10-15 тысяч в традиционных базах данных. Но если вычисления в оперативной памяти настолько производительнее, почему мы не наблюдаем повального перехода с традиционных баз данных? Ответ связан с ресурсами — смена технологий требует денег и времени.
ИТ-ландшафт большинства крупных компаний формировался задолго до появления in-memory в современном представлении. Многие бизнес-процессы «завязаны» на устаревших системах. Перенос критических систем на другой стек технологий в данном случае неразрывно связан с большими финансовыми затратами. Порой дешевле создать новую компанию, чем мигрировать с устаревающей инфраструктуры. Каждая компания сама выбирает, создавать ли новую архитектуру с нуля или усовершенствовать то, что есть.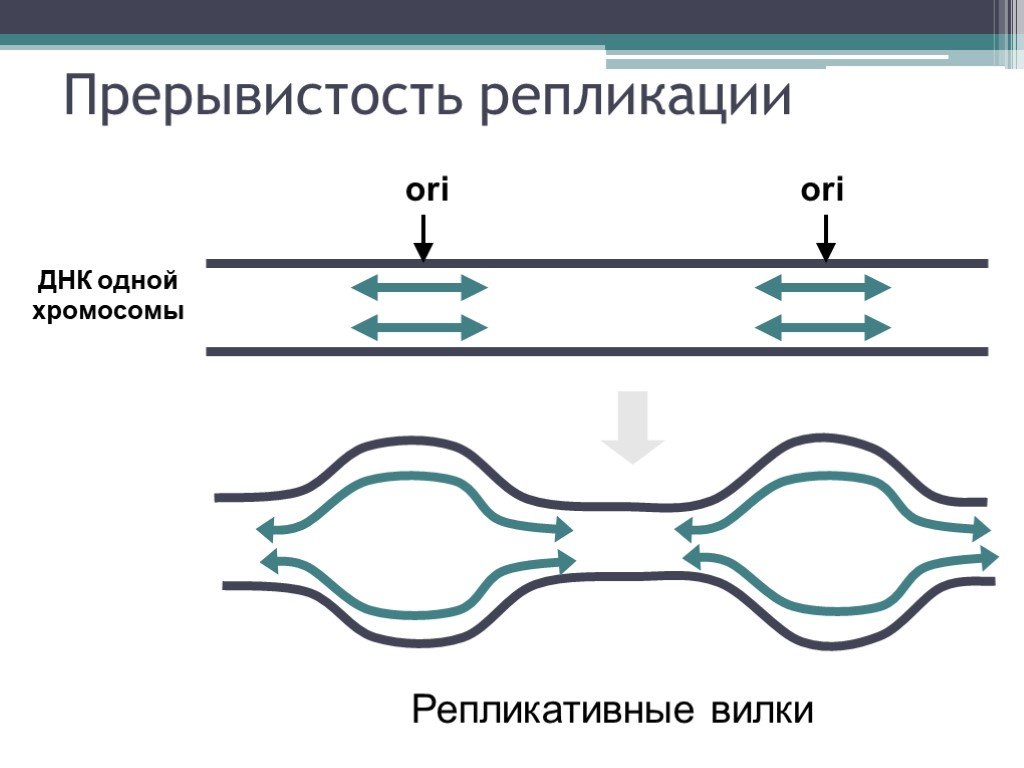
В обоих случаях решение не только должно работать достаточно быстро, но соответствовать требованиям отказоустойчивости, масштабируемости и гибкости. На вопросы отказоустойчивости отвечает репликация, и дальше речь пойдет именно о ней. С масштабируемостью и даже частично с гибкостью можно разобраться на уровне приложения или сервиса, а репликация встроена в архитектуру базы данных, ее реализация влияет на надежность и пропускную способность всей системы. При выборе вендора важно обратить внимание на реализацию репликации.
Зачем нужна репликация базы данных
В упрощенном виде, репликация подразумевает дублирование данных с одного экземпляра на несколько — реплики. Она повышает отказоустойчивость решения и снижает нагрузку на основную базу. Поскольку одинаковые данные содержатся в нескольких копиях, то если основной сервер выходит из строя, приложение или сервис быстро переключается на копию и продолжает работу.
Реплики можно делать на технологиях одного производителя или разных вендоров. Например, для Oracle часто используют GoldenGate с другими базами. Такое же решение можно собрать с использованием in-memory, и оно будет дешевле. Репликация между базами разных вендоров позволяет повысить надежность решения. Благодаря такому подходу можно не переписывать основную логику приложения, и все равно его ускорить.
Например, для Oracle часто используют GoldenGate с другими базами. Такое же решение можно собрать с использованием in-memory, и оно будет дешевле. Репликация между базами разных вендоров позволяет повысить надежность решения. Благодаря такому подходу можно не переписывать основную логику приложения, и все равно его ускорить.
Синхронная и асинхронная репликация
Репликация делится на два типа – асинхронная и синхронная. In-memory решения часто используют асинхронную репликацию, так как она не влияет на скорость ответа пользователю. Задержка между появлением изменений и их отображением в приложении составляет менее миллисекунды, что едва ли может быть заметно для человека. Ключевой показатель, который достигается с помощью асинхронной репликации — скорость восстановления базы данных (RTO).
С асинхронной репликацией транзакции отправляются на реплику независимо от ответа пользователю. Поэтому, если произойдет авария на сервере, данные могут быть потеряны в момент, когда пользователь получает ответ об успешной записи.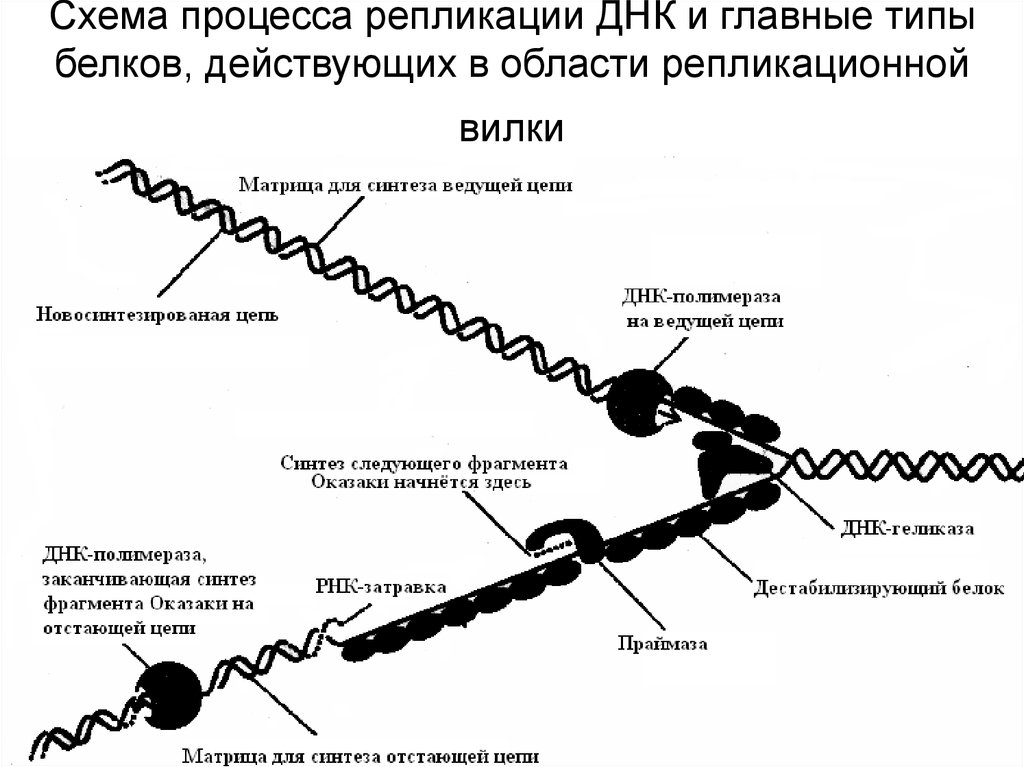 Из-за этого асинхронная репликация не подходит для работы с критической информацией, например, финансовыми операциями или клиентскими заказами.
Из-за этого асинхронная репликация не подходит для работы с критической информацией, например, финансовыми операциями или клиентскими заказами.
При синхронной репликации основная база данных сразу отправляет информацию о транзакции во все реплики, и считает операцию завершенной только когда получает от них подтверждение о выполнении. Таким образом, достигается минимальная целевая точка восстановления (RPO). На практике это означает, что данные во всех репликах будут абсолютно идентичны, и в случае аварии ни одна транзакция не будет утрачена.
Синхронный подход также имеет свои недостатки. Ожидание ответа от реплик вызывает задержку, которая кратна количеству подтверждений: если база данных ждет одну реплику, операция выполняется в два раза дольше, если две – в три и так далее.
Синхронная репликация в In-memory
Любая in-memory технология рассчитана на большую пропускную способность. А подход синхронной репликации, когда от реплик нужно получать подтверждение по сети влечет рост latency — задержки отклика — примерно в два раза. То есть по логике вещей синхронная репликация привносит latency в угоду надежности. Может поэтому не так много вендоров реализуют ее в своих продуктах.
То есть по логике вещей синхронная репликация привносит latency в угоду надежности. Может поэтому не так много вендоров реализуют ее в своих продуктах.
Тем не менее, правильно сделанная синхронная репликация влияет в основном на задержку, но мало влияет на количество операций в секунду. В то время, как один запрос ожидает синхронизации, параллельно могут выполняться другие. Если база данных имеет изоляцию запросов, то она выглядит консистентно, и пользователю не видно промежуточных состояний.
В асинхронной репликации запросы завершаются сразу, поэтому у них очень небольшие требования. А когда мы изолируем запросы друг от друга в синхронной репликации, на каждый из них нужно тратить вычислительные ресурсы и место в памяти. Для тысячи в секунду использовать эти ресурсы — не проблема. Но когда количество запросов начинает увеличиваться до десятков тысяч, эти небольшие расходы заметно нагружают память и требуют больших затрат. Поэтому синхронная репликация для in-memory это особая работа, которую мы в Tarantool проделали.
В поисках баланса
В конечном итоге выбор вендора зависит от потребностей компании. Асинхронный подход позволяет быстрее восстановить работу приложения при отказе основной базы данных. То есть, если сервис отображает статичную информацию, которая не зависит от действий пользователя, асинхронная репликация будет предпочтительнее.
Если же пользователь может внести какие-либо критичные изменения, ключевым показателем становится однородность данных во всех репликах. Так, в случае аварии на основном сервере, приложение восстановит работу без потери транзакций.
Несмотря на то, что синхронная репликация позволяет повысить надежность in-memory до уровня традиционных баз данных, среди подобных решений такой подход встречается достаточно редко.
репликаций | Learn Science at Scitable
Репликация ДНК — это процесс, посредством которого двухцепочечная
Молекула ДНК копируется с образованием двух идентичных молекул ДНК. Репликация
важный процесс, потому что всякий раз, когда клетка делится, две новые дочери
клетки должны содержать ту же генетическую информацию или ДНК, что и родительская клетка.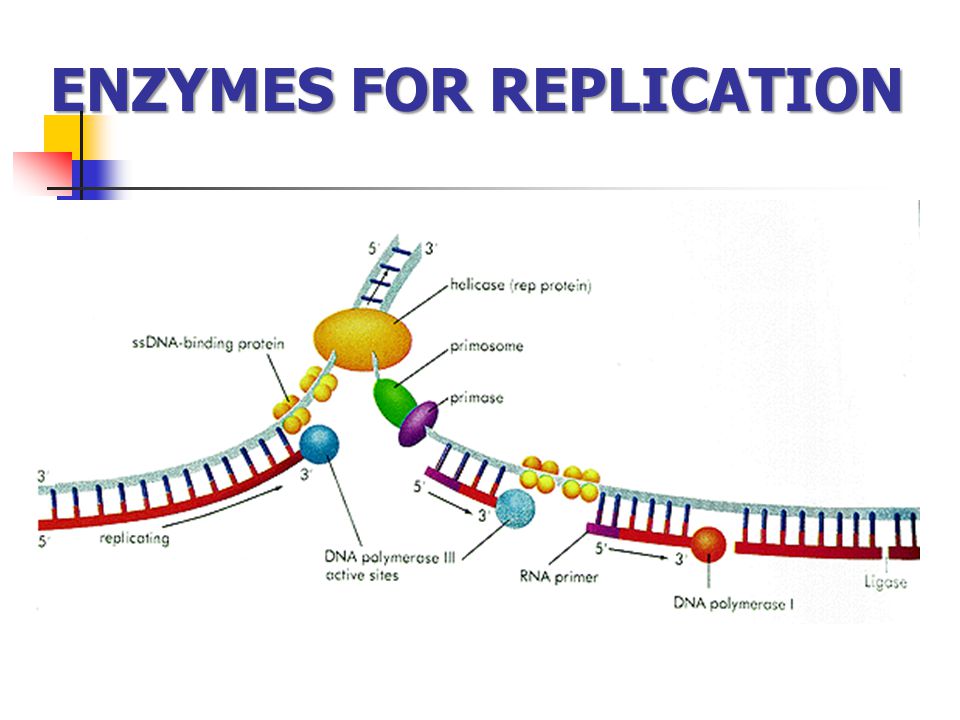
Процесс репликации основан на том факте, что каждая цепь
ДНК может служить матрицей для дупликации. Репликация ДНК начинается в
определенные точки, называемые началами, в которых раскручивается двойная спираль ДНК. Короткая
Затем синтезируется сегмент РНК, называемый праймером, который действует как стартовая
точку для нового синтеза ДНК. Далее начинается фермент, называемый ДНК-полимеразой.
репликация ДНК путем сопоставления оснований с исходной цепью. Как только синтез
завершены, РНК-праймеры заменяются ДНК, а любые промежутки между новыми
синтезированные сегменты ДНК запечатываются ферментами.
Репликация ДНК является важным процессом; следовательно,
чтобы гарантировать, что ошибки или мутации не будут внесены, ячейка корректирует
только что синтезированной ДНК. Как только ДНК в клетке реплицируется, клетка может
делятся на две клетки, каждая из которых имеет идентичную копию исходной ДНК.
Дальнейшее исследование
Концептуальные ссылки для дальнейшего изучения
полимеразной цепной реакции
|
S-фаза
|
ДНК
|
РНК
|
мейоз
|
РНК-полимераза
|
хромосома
|
мутация
|
геликаза
|
фосфатный остов
|
грунтовка
|
примас
|
вирус
|
гамета
|
двойная спираль
|
клеточное деление
|
ДНК-полимераза
|
восстановление ДНК
Связанные понятия (18)
Генетика
Клеточная биология
Научная коммуникация
Планирование карьеры
Что такое репликация данных и почему она важна?
Вашей компании требуется репликация данных для аналитики, повышения производительности и аварийного восстановления.
Марк Ван де Виль
14 апреля 2022 г.
Насколько быстро ваша компания использует данные для улучшения бизнес-процессов? Минуты, часы, дни или месяцы после появления данных? В нашем все более быстро меняющемся мире скорость, с которой потребители совершают транзакции, подписываются на услуги и получают доступ к контенту, только увеличивается. Поэтому компании ищут более быстрые способы использования данных, чтобы быстрее принимать бизнес-решения и получать конкурентные преимущества.
Чтобы эффективно использовать данные, компаниям необходимо перемещать данные из нескольких изолированных систем в большие хранилища данных для целей консолидированной отчетности и аналитики, и именно здесь помогает репликация данных. Методы репликации данных обеспечивают быстрый и надежный доступ к данным для пользователей, которые полагаются на них при принятии решений, и клиентов, которым они нужны для выполнения транзакций.
Этот пост будет посвящен логической репликации данных базы данных, при которой операции базы данных из источника воспроизводятся в цели.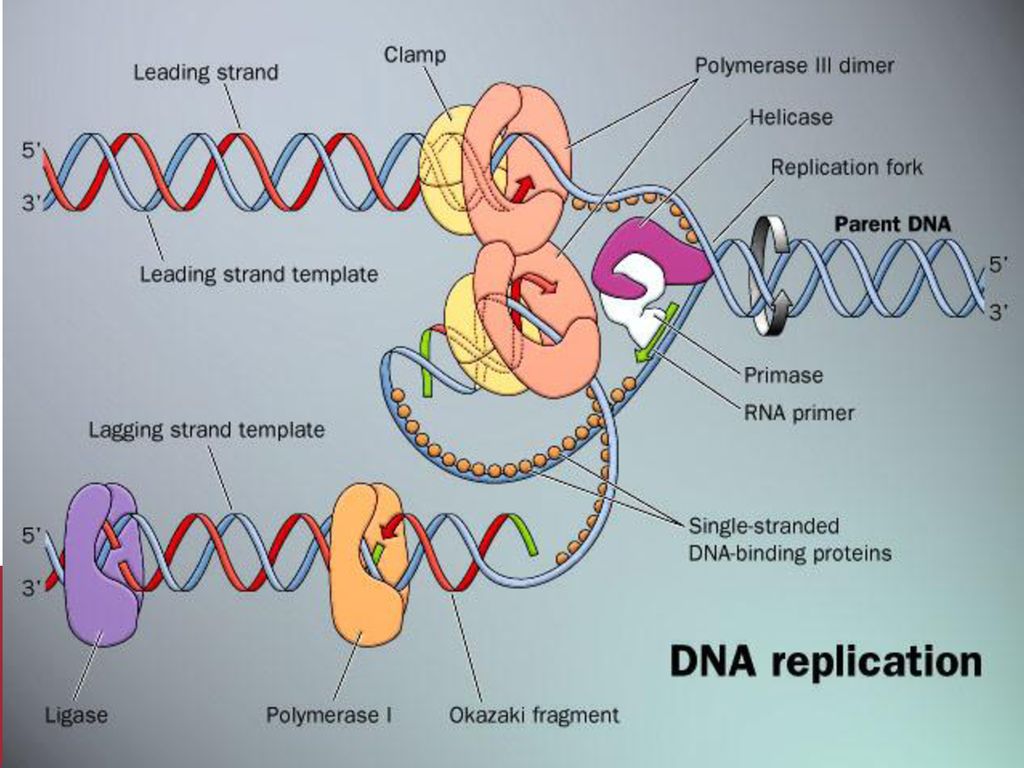 Существует множество других типов репликации данных, таких как репликация физической базы данных, репликация файлов и репликация данных из приложений SaaS.
Существует множество других типов репликации данных, таких как репликация физической базы данных, репликация файлов и репликация данных из приложений SaaS.
Содержание
Глава 1. Что такое репликация данных?
Глава 2. Преимущества репликации данных
Глава 3. Реализация репликации данных
Глава 4. Обеспечение доступности и надежности данных с помощью репликации данных
Что такое репликация данных?
Репликация данных — это процесс копирования или обновления данных из одного места в другое, часто в реальном или близком к реальному времени. Репликация данных может быть однородной, между идентичными технологиями, или гетерогенной, между разными технологиями. Целью репликации данных является непрерывность бизнеса — обеспечение доступности данных для множества пользователей (и вариантов использования), которым они требуются.
Например, данные можно копировать из локальных систем в облачные среды для поддержки аналитики практически в реальном времени. Данные также можно копировать между операционными системами для обеспечения бесперебойной работы и восстановления критически важных и клиентских приложений и данных в случае утечки данных или сбоя системы.
Данные также можно копировать между операционными системами для обеспечения бесперебойной работы и восстановления критически важных и клиентских приложений и данных в случае утечки данных или сбоя системы.
Преимущества репликации данных
Репликация данных позволяет повысить доступность и надежность данных путем их копирования в несколько местоположений. Это дает несколько преимуществ, в том числе:
Поддержка аналитики в реальном времени
Репликация данных поддерживает расширенную аналитику за счет синхронизации облачных отчетов и обеспечения перемещения данных из многочисленных источников в хранилища данных, такие как хранилища данных или озера данных, для подпитки бизнес-аналитика и машинное обучение. Кроме того, поскольку репликация данных представляет собой непрерывный процесс в режиме реального времени, она позволяет компаниям мгновенно получать ценную информацию из своих данных. Простой пример — заполнение информационной панели. Более сложный пример — использование репликации данных для извлечения данных о поведении пользователей из различных источников данных в аналитические хранилища данных, а затем запуск прогнозной модели для предоставления персонализированных рекомендаций в реальном времени для улучшения качества обслуживания клиентов.
Более быстрый доступ к данным
Поскольку данные хранятся в нескольких местах, пользователи могут получать данные с ближайших к ним серверов и получать выгоду от сокращения задержки. Например, пользователи в Африке могут столкнуться с задержкой при доступе к данным, хранящимся на серверах в Северной Америке. Но задержка уменьшится, если реплика этих данных будет храниться ближе к их местоположению.
Оптимизированная производительность сервера
Репликация данных позволяет компаниям распределять трафик между несколькими серверами, что приводит к повышению производительности серверов и снижению нагрузки на отдельные серверы. Например, компании могут перемещать сложные аналитические запросы в хранилища данных и озера данных, тем самым снижая нагрузку на операционные базы данных и повышая общую производительность системы.
Аварийное восстановление
Репликация данных обеспечивает эффективную защиту данных и восстановление в случае аварии. Остановки критически важных источников данных могут стоить миллионы долларов в час недоступности данных. Нарушение работы бизнеса может быть еще хуже, если данные безвозвратно потеряны из-за сбоев системы и процессов. Репликация данных — это проверенный подход к уменьшению непредвиденных потерь данных. Например, в случае сбоев в работе сети в одном облачном регионе компания может быстро переключиться на другой регион и продолжить нормальную работу.
Остановки критически важных источников данных могут стоить миллионы долларов в час недоступности данных. Нарушение работы бизнеса может быть еще хуже, если данные безвозвратно потеряны из-за сбоев системы и процессов. Репликация данных — это проверенный подход к уменьшению непредвиденных потерь данных. Например, в случае сбоев в работе сети в одном облачном регионе компания может быстро переключиться на другой регион и продолжить нормальную работу.
Как реализовать репликацию данных
Компании могут использовать несколько методов репликации данных, в зависимости от варианта использования и существующей инфраструктуры данных. Некоторые распространенные стратегии репликации данных включают:
Сбор данных об изменениях на основе журнала
Сбор данных об изменениях (CDC) — это метод репликации данных, который идентифицирует изменения, внесенные в данные в базе данных, а затем доставляет эти изменения в режиме реального времени в целевые системы. CDC на основе журнала, в котором изменения фиксируются асинхронно из журнала транзакций базы данных, широко считается предпочтительным методом. В подходе CDC на основе журнала технология репликации данных идентифицирует модификации записей, такие как вставки, обновления и удаления, из журнала транзакций базы данных. Затем он распространяет эти изменения в режиме реального времени в место назначения данных.
В подходе CDC на основе журнала технология репликации данных идентифицирует модификации записей, такие как вставки, обновления и удаления, из журнала транзакций базы данных. Затем он распространяет эти изменения в режиме реального времени в место назначения данных.
CDC на основе журнала может подойти, если:
- Исходная база данных часто обрабатывает большие объемы изменений, и вы хотите свести к минимуму накладные расходы на обработку в исходной базе данных.
- Транзакционные данные необходимы для потоковой передачи и аналитики в реальном времени. CDC на основе журналов хорошо подходит для перемещения данных в решения для потоковой обработки, такие как Apache Kafka, Amazon Kinesis, Azure Event Hubs или Google PubSub.
- Существует потребность в миграции баз данных без простоев с минимальной задержкой, особенно в географически разделенных системах.
Сбор данных об изменениях на основе триггера
Этот метод репликации данных определяет функции триггера с использованием синтаксиса SQL, такого как «ДО ОБНОВЛЕНИЯ» или «ПОСЛЕ ВСТАВКИ», для захвата изменений на основе событий. Триггеры срабатывают для всех команд INSERT, UPDATE или DELETE (указывающих на изменение) и являются частью транзакции, используемой для создания журнала изменений, хранящегося в теневой таблице. Теневые таблицы могут содержать записи о каждом изменении столбца или только о первичном ключе и типе его операции (вставка, обновление или удаление). Некоторые пользователи предпочитают этот подход, поскольку он работает на уровне SQL, а некоторые базы данных изначально поддерживают функции на основе триггеров.
Триггеры срабатывают для всех команд INSERT, UPDATE или DELETE (указывающих на изменение) и являются частью транзакции, используемой для создания журнала изменений, хранящегося в теневой таблице. Теневые таблицы могут содержать записи о каждом изменении столбца или только о первичном ключе и типе его операции (вставка, обновление или удаление). Некоторые пользователи предпочитают этот подход, поскольку он работает на уровне SQL, а некоторые базы данных изначально поддерживают функции на основе триггеров.
Однако, поскольку триггеры срабатывают как часть транзакции и выполняют дополнительную работу, захват на основе триггера всегда замедляет транзакции. Кроме того, при извлечении изменений, записанных с помощью захвата на основе триггера, отдельные запросы попадают в базу данных, вызывая дополнительную нагрузку. Эти запросы могут потребовать объединения таблиц и не следовать порядку согласованности, которому следовали исходные транзакции.
CDC на основе триггера может подойти, если:
- Исходная база данных изначально поддерживает функции триггера, такие как Oracle, PostgreSQL, SQL Server и MySQL.

- Вам требуется поддержка для отслеживания операций и информации в пользовательской базе данных.
- Производительность отдельных транзакций не критична, и в системе достаточно ресурсов, чтобы справиться с дополнительной нагрузкой.
Репликация моментальных снимков
Репликация моментальных снимков — это процесс создания моментального снимка исходной базы данных в статические моменты времени и репликации данных в целевых системах. Репликация моментальных снимков может потребовать высокой вычислительной мощности, если источник имеет очень большой набор данных.
Репликация данных моментального снимка подходит, если:
- Объем данных ограничен.
- Нет необходимости воспроизводить добавочные изменения практически в режиме реального времени.
- Имеется удобное временное окно для обновления снимка; он подходит для ночного резервного копирования данных, пакетной отчетности и аналитических сценариев использования, когда нагрузка на системы низкая.
