Содержание
Язык поисковых запросов Google — ITandLife.ru
Содержание
- 1 Операторы языка поисковых запросов Google
- 1.1 Логическое «И»
- 1.2 Логическое «ИЛИ»
- 1.3 Точное совпадение
- 1.4 Выделение важных слов
- 1.5 Исключение нежелательных слов
- 1.6 Поиск по конкретному сайту
- 1.7 Похожие страницы
- 1.8 Ссылающиеся страницы
- 1.9 Использование синонимов
- 1.10 Поиск документов конкретного типа
- 1.11 Числовые диапазоны
- 1.12 Поиск определений
- 1.13 Поиск в Кэше
- 1.14 Поиск ключевых слов в URL
- 1.15 Текст ссылок
- 1.16 Учет заголовка веб-документа
- 1.17 Все ключевые слова запроса в одном документе
- 1.18 Регион поиска
- 1.19 Информация о странице
- 1.20 Составные запросы
- 2 Итоги
Каждый из нас постоянно сталкивается с различными проблемами. Чтобы их решить нужно собрать достаточно информации для принятия дальнейших решений или действий. Иногда поиск нужной информации занимает больше времени, чем последующие физические действия по решению проблемы. Я уже много лет пользуюсь поисковой машиной Google, но до сих пор не использовал его возможности на 100%. Поэтому я решил, что нужно изучить этот инструмент, который почти каждый день приходит мне на помощь (я взял за правило искать информацию по любой проблеме возникающей в моей жизни, будь то выбор зимней обуви или поиск описания WinAPI-функции; это очень помогает).
Иногда поиск нужной информации занимает больше времени, чем последующие физические действия по решению проблемы. Я уже много лет пользуюсь поисковой машиной Google, но до сих пор не использовал его возможности на 100%. Поэтому я решил, что нужно изучить этот инструмент, который почти каждый день приходит мне на помощь (я взял за правило искать информацию по любой проблеме возникающей в моей жизни, будь то выбор зимней обуви или поиск описания WinAPI-функции; это очень помогает).
На первый взгляд такая тривиальная задача как поиск информации в Google не должна представлять проблем. Но не стоит забывать что Google это не простой поисковик, он оснащен специальными сервисами, призванными значительно упростить различные задачи. Также, разработчики, стремясь облегчить поиск, создали специальный язык поисковых запросов Google — специальные операторы и функции обработчика поисковых запросов.
О поисковых машинах и поиске информации я уже писал — правила поиска информации.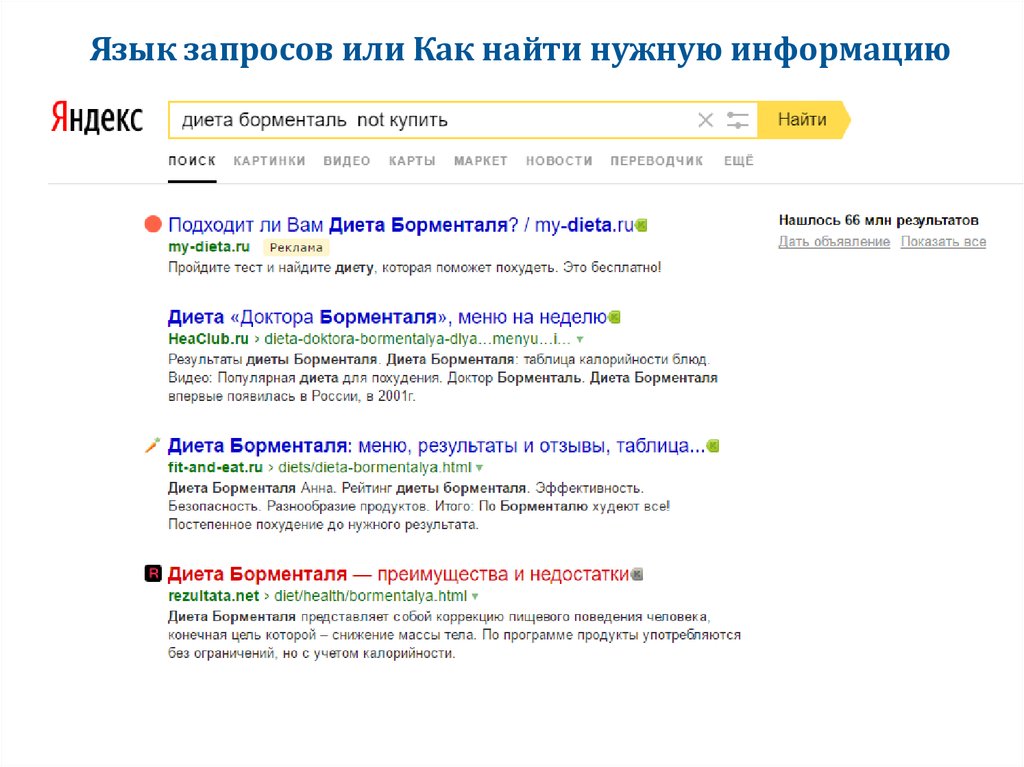
Язык поисковых запросов Google
Операторы языка поисковых запросов Google
Логическое «И»
Оператор AND
По умолчанию к каждому введенному ключевому слову поисковая система применяет операцию логического «И». Это значит, что на запрос «UserandLinux журнал ноябрь» Google выдаст только те страницы, которые одновременно будут содержать и слово «UserandLinux», и «журнал», и «ноябрь». Стоит заметить, что в 90% случаев результат такого запроса приводит к искомой странице (может поэтому рядовые пользователи не заморачиваются с языком поисковых запросов?).
Логическое «ИЛИ»
Оператор OR
Допустим нам необходимо найти журнал UserandLinux или Хакер за ноябрь, то тогда запрос будет выглядеть следующим образом — «UserandLinux or Хакер журнал ноябрь».
Точное совпадение
Оператор «текст запроса«
Сложные алгоритмы поиска Google учитывают морфологию языка, различные особенности построения веб-документа и вовсе не предполагают, что найденные страницы будут содержать в точности ту фразу, которая указана в строке запроса. Слова могут быть разбросаны по всей странице и даже иметь другую форму, что в большинстве случаев очень удобно. Но что если требуется именно точное совпадение? Скажем, нужно найти текст песни по одной известной строке? В этом случае надо заключить нужные слова в кавычки.
Слова могут быть разбросаны по всей странице и даже иметь другую форму, что в большинстве случаев очень удобно. Но что если требуется именно точное совпадение? Скажем, нужно найти текст песни по одной известной строке? В этом случае надо заключить нужные слова в кавычки.
Выделение важных слов
Оператор +
Чтобы сделать акцент на одно или несколько слов нужно использовать «+». Это поможет системе понять, какие из ключевых слов наиболее важные, и сформулировать результаты поиска более точно.
Пример: UserandLinux +журнал
Исключение нежелательных слов
Оператор —
Полученные результаты нередко засоряет какая-то лишняя информация. Чтобы не тратить время на ее просмотр, советую наложить на результаты поиска фильтр. Просто нужно перед нежелательными слова поставить «-«.
Пример UserandLinux журнал +декабрь -ноябрь
Поиск по конкретному сайту
Оператор site:
Очень полезный оператор. Язык поисковых запросов Google и стоит изучать ради таких операторов.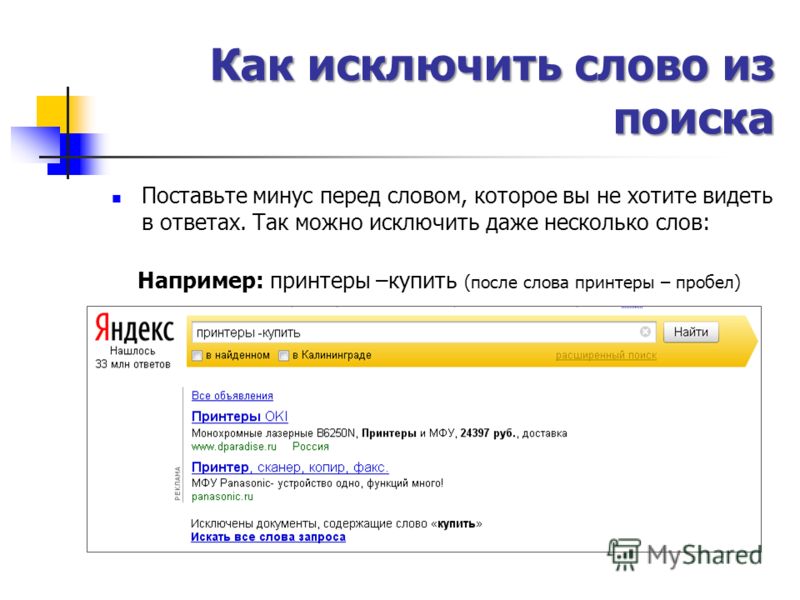 Если известно, что необходимая информация есть на определенном сайте, то можно ограничить поиск рамками только этого сайта. Для это используется модификатор site:somesite.com. Этот прием очень удобен, если нужно найти информацию на каком-то ресурсе у которого плохо или вообще не работает внутренний поиск.
Если известно, что необходимая информация есть на определенном сайте, то можно ограничить поиск рамками только этого сайта. Для это используется модификатор site:somesite.com. Этот прием очень удобен, если нужно найти информацию на каком-то ресурсе у которого плохо или вообще не работает внутренний поиск.
Пример: site:rutor.org Тайны Смолвиля 10 Сезон +Smarts Studios
Похожие страницы
Оператор related:
Используя модификатор related: можно находить похожие страницы. Это очень удобно для владельцев сайтов для определения дружественных или конкурирующих сайтов.
Пример related:microsoft.com
Ссылающиеся страницы
Оператор link:
Мощь Google можно использовать для проверки популярности ресурса. Чем больше ссылающихся страниц, тем больше популярность проекта.
Пример link:habrahabr.ru
Использование синонимов
Оператор ~
Если нужно чтобы в поисковую выдачу вошли синонимы определенного слова, то нужно передним поставить символ «~».
Пример почтовые ~клиенты
Поиск документов конкретного типа
Оператор filetype:
Модификатор filetype: позволяет искать только конкретный тип документа по его расширению.
Пример smallville +»season 10″ filetype:torrent
Числовые диапазоны
Оператор 2002..2005
Если поиск нужно производить по определенному периоду (например за определенные годы), то этот оператор очень полезен.
Пример Ария дискография 2000..2006
Поиск определений
Оператор define:
Очень полезный модификатор! Позволяет найти определение неизвестного слова или понятия.Теперь с помощью языка поисковых запросов Google, найти нужное определение не составит труда.
Например define:ДНК
Поиск в Кэше
Оператор cache:
Этот модификатор предназначен для поиска в так называемом кэше, т.е. в сохраненных поисковым роботом страницах. Его использование очень полезно если целевой ресурс, содержащий информацию недоступен. Стоит отметить, что в выдаче есть специальная ссылка, «пройдя» по которой, можно открыть страницу кеша. На ней будут выделены цветом ключевые слова поискового запроса.
На ней будут выделены цветом ключевые слова поискового запроса.
Пример cache:ora.com
Поиск ключевых слов в URL
Оператор allinurl:
Этот модификатор позволяет искать страницы адрес которых содержит все слова поискового запроса.
Пример allinurl: Java Eclipse Userguide
Оператор inurl:
Этот модификатор похож по функциональности с предыдущим, но в выдаче попадут страницы, в URL которых содержатся ключевые слова (в любом порядке, в любом количестве). Посмотрите выдачу, и увидите разницу.
Пример inurl: Java Eclipse Userguide
Текст ссылок
Оператор inanchor:
Ищет ключевые слова в анкорах (тексте) ссылок.
Пример «изучение SQL» inanchor:blog
Учет заголовка веб-документа
Оператор allintitle:
Находит страницы, в заголовках которых есть все искомые ключевые слова (один из самых полезных операторов языка поисковых запросов Google).
Пример allintitle:программирование на ActionScript
Оператор intitle:
Намного большей эффективности поиска удается добиться, если с помощью модификатора intitle указать слова, которые обязательно должны входить в заголовок документа (т. е в тег title).
е в тег title).
Пример: intitle:статьи site:rsdn.ru
Все ключевые слова запроса в одном документе
Оператор allintext:
Поиск страниц с ключевыми словами в теле документа.
Пример allintext:как настроить веб-сервер
Регион поиска
Оператор :
Ищет информацию по регионам
Пример rootkit`s +:ru
Информация о странице
Оператор info:
Интерфейс для нескольких операторов. Показывает информацию о странице
Пример info:securitylab.ru
Составные запросы
Все описанные выше операторы языка поисковых запросов Google можно комбинировать для достижения более релевантных результатов. Вот, например, мне недавно нужно было найти пример практической работы по физике. Вот как я это сделал (первая ссылка — необходимый результат).
Пример allintext:определение ускорения свободного падения с помощью оборотного маятника +»практическая работа»
Итоги
Поисковая система Google это очень мощный инструмент поиска информации. Знание всех возможностей этого инструмента очень облегчает жизнь. Поэтому нужно запомнить эти команды (можно сделать закладку страницы) и начать их применять в повседневной поисковой рутине. Результат не заставит себя долго ждать. Итак, сводная страница наиболее используемых операторов языка поисковых запросов Google:
Знание всех возможностей этого инструмента очень облегчает жизнь. Поэтому нужно запомнить эти команды (можно сделать закладку страницы) и начать их применять в повседневной поисковой рутине. Результат не заставит себя долго ждать. Итак, сводная страница наиболее используемых операторов языка поисковых запросов Google:
| Оператор | Назначение |
| AND | Поиск 1-го, 2-го и N-го слова (логическое «И», используется по умолчанию) |
| OR | Поиск 1-го или 2-го слова (логическое «ИЛИ») |
| » « | Поиск точной фразы, заключенной в » « |
| + | Выделение главных ключевых слов в запросе |
| — | Исключение нежелательных слов в результатах поисковой выдачи |
| site: | Поиск по конкретному сайту |
| related: | Поиск похожих страниц (обычно этот оператор применяется для поиска похожих сайтов) |
| link: | Поиск ссылающихся страниц |
| ~ | Включение в выдачу синонимов выделенного слова |
| filetype: | Поиск документов по расширению |
| define: | Поиск определений |
| cache: | Обращение к странице, сохраненной в кеше поисковой машины |
| allinurl: | Поиск страниц, содержащих в своем адресе все слова из поискового запроса |
| inurl: | Поиск страниц, содержащих в своем адресе слова из поискового запроса в любом порядке и в любом количестве |
| inanchor: | Поиск в тексте ссылок |
| allintitle: | Поиск страниц, содержащих в своем заголовке все слова из поискового запроса |
| intitle: | Поиск страниц, содержащих в своем заголовке слова из поискового запроса в любом порядке и в любом количестве |
| allintext: | Поиск страниц, содержащих все слова поискового запроса |
| : | Задает регион поиска |
| info: | Показывает информацию о странице |
. |
RFID технологии
Работают ли электромобили в зимних условиях?
Сравнение фич и языка запросов Яндекса и Google, таблица поисковых запросов
Поисковые системы уже давно идут к максимальному упрощению работы пользователя. Для этого они придумывают всяческие «штуки», которые помогают пользователям получить качественный результат сразу, не перебирая многочисленные ссылки в выдаче. Проанализировав язык пользовательских запросов, поисковые системы могут определять, что нужно пользователю, когда он набирает определенную последовательность запросов. В Яндексе подобные мгновенные ответы, которые находятся над первым пунктом поисковой выдачи, называются колдунщики. В Google такие ответы тоже имеются и называются они Search Features, говоря по-русски «поисковые фичи». Таким образом, поисковые системы делают пользователю хорошо, не напрягая его.
Но есть в поисковиках и другая сторона: они хотят обучать своих пользователей, раскрывая им специальный язык пользовательских запросов. Это набор операторов, которые изначально ограничивают область поиска информации, уточняют конкретный тип файла, в котором заинтересован пользователь, или позволяют искать тексты, в которых отсутствуют ненужные слова.
Это набор операторов, которые изначально ограничивают область поиска информации, уточняют конкретный тип файла, в котором заинтересован пользователь, или позволяют искать тексты, в которых отсутствуют ненужные слова.
Мы решили составить сравнительную таблицу операторов и быстрых запросов к поисковым системам, по которым можно сразу получить интересующую вас информацию. Таблица разбита на несколько блоков:
- Базовые операторы, уточняющие запрос
- Информация
- Определения и перевод
- Конвертация и калькулятор
- Ссылки
- Поиск с ограничениями
- Время
- Развлекательные фичи
Сразу отметим, что мы рассматривали как международный Google, так и русскоязычный. Но в ходе работы почти все операторы и фичи этих поисковиков за небольшими исключениями совпали. Поэтому в итоговой таблице сравниваются Яндекс и Goоgle. com
com
Базовые операторы, уточняющие запрос
И Google, и Яндекс предоставляют пользователю возможность искать документ, в котором не содержится определенного слова; документ в котором присутствует любое из слов запроса, и документ, в котором встречается абсолютно точное вхождение запроса. В каждой из поисковых систем за это отвечают различные операторы. Уникальными для Яндекса являются операторы:
- /N, в котором N заменяется на число, обозначающее количество слов, которое может разделять в документе слова запроса;
- ! осуществляет поиск без учета морфологии запроса. В американском поисковике Google такой оператор не нужен из-за природы английского языка, слова которого практически не содержат окончаний;
- & и && осуществляют поиск слов, встречающихся в одном предложении и на одной странице соответственно.
Google может похвастаться операторами поиска в определенном числовом интервале (. .) и оператор, заменяющий любое слово (*).
.) и оператор, заменяющий любое слово (*).
|
Действие
|
Яндекс
|
|
|
Строго все слова запрос
|
оптимизация + продвижение + интернет-реклама
|
keyword +content +SEO
|
|
Поиск документа, в котором не содержится слов после знака
|
карта памяти ~~купить
|
keyword content -SEO
|
|
Ищет любое из слов запроса
|
оптимизация | продвижение | интернет-реклама
|
keyword content OR phrase
|
|
Ищет точное вхождение запроса
|
«контент провайдеры обеспечивают»
|
«keywords in the content»
|
|
Замена любого слова
|
—
|
google *
|
|
Числовой интервал поиска
|
—
|
google 10.
|
|
Слова запроса встречаются в одном предложении
|
ключевик & контент
|
—
|
|
Слова запроса находятся на одной странице
|
ключевик && контент
|
—
|
|
Слова на расстояние указанного числа слов
|
ключевик /2 контент
|
—
|
|
Поиск без учета морфологии
|
!контент
|
—
|
 .100
.100По информационным запросам Яндекс и Google выглядят примерно одинаково. У российского поисковика есть преимущество в том, что он показывает пресс-портреты по имени и фамилии персоны, IP пользователя и погоду по однословному запросу [погода]. Западный поисковик не обладает ни одной из этих функций. Google ведет себя адекватнее при запросе, содержащем слово «новости», выдавая вверху выдачи новостной блок. Яндекс чаще не выделяет отдельным блоком новости на подобные запросы.
У российского поисковика есть преимущество в том, что он показывает пресс-портреты по имени и фамилии персоны, IP пользователя и погоду по однословному запросу [погода]. Западный поисковик не обладает ни одной из этих функций. Google ведет себя адекватнее при запросе, содержащем слово «новости», выдавая вверху выдачи новостной блок. Яндекс чаще не выделяет отдельным блоком новости на подобные запросы.
|
Действие
|
Яндекс
|
|
|
Погода в своем городе
|
погода
|
—
|
|
Погода в каком-либо городе
|
погода тула
|
weather tula
|
|
Пресс-портреты
|
сергей брин
|
—
|
|
Новости
|
—
|
news obama
|
|
Маркет
|
glofiish x600
|
—
|
|
Финансовые и биржевые показатели
|
—
|
goog
|
|
Адрес собственного IP
|
мой ip
|
—
|
|
|
мой айпи
|
—
|
|
Карта по адресу
|
тула проспект ленина 125
|
875 n Michigan ave Chicago il
|
|
Карта города
|
москва карта
|
moscow
|
Определения и перевод
Google не предоставляет пользователю быстрого доступа к переводу слова как с иностранного, так и на иностранный язык. Яндекс выдает на запросы, содержащие слова «перевод», «по-английски», «по-испански» и им подобным, быстрый перевод слов из встроенных двуязычных словарей.
Яндекс выдает на запросы, содержащие слова «перевод», «по-английски», «по-испански» и им подобным, быстрый перевод слов из встроенных двуязычных словарей.
|
Действие
|
Яндекс
|
|
|
Словарное определение
|
интернет это
|
—
|
|
|
что такое интернет
|
what is internet
|
|
|
—
|
define:internet
|
|
Перевод
|
медведь по-английски
|
—
|
|
|
blue water перевод
|
—
|
Для определений у западного поисковика есть специальный оператор define:, от Яндекса можно добиться словарного определения слова, если ввести, например, «что такое интернет» или «интернет это».
Конвертация и калькулятор
Наиболее серьезные различия между поисковыми системами наблюдаются в подсчитывании математических выражений и конвертации из одной меры измерения в другую. Начнем с того, что Яндекс выполняет 4 математических действия сразу в поисковой строке. Как только пользователь ввел, запрос, состоящий из чисел и математических знаков, поисковая строка раскрывается вниз, показывая результат. Google показывает результаты над выдачей.
Кроме четырех математических действий Яндекс не может вычислять ничего: ни корней, ни процентов, ни логарифмов, ни факториалов, ни тригонометрических функций. Это с успехом делает Google. К тому же западный поисковик способен переводить из римских цифр в арабские; из одной системы счисления в другую (например, в десятичную).
Примерно одинаково поисковые системы справляются с задачами конвертации: из одной системы мер длины, массы, объема в другую. Яндекс не поддерживает функции конвертации температур из системы Фаренгейта в Цельсиус, или наоборот, и из одной валюты в другую.
|
Действие
|
Яндекс
|
|
|
Конвертация меры длины
|
3 дюйма
|
3 miles
|
|
Конвертация меры веса
|
5 фунтов
|
5 pounds
|
|
Конвертация меры объема
|
2 галлона
|
2 gallons
|
|
Конвертация температуры
|
—
|
86 fahrenheit in celsius
|
|
Конвертация в другую систему счисления
|
—
|
16 in binary
|
|
|
—
|
16 in octal
|
|
|
—
|
0×11 in decimal
|
|
|
—
|
16 in hex
|
|
Конвертация из арабских цифр в римские
|
—
|
2009 in roman
|
|
Конвертация валюты
|
—
|
150 GBP in USD
|
|
Курс валют
|
доллар евро курс
|
dollar euro rate
|
|
Корень квадратный
|
—
|
square root 4 and sqrt 4
|
|
Корень большей степени
|
—
|
5th root of 32
|
|
Процент
|
—
|
45% of 39
|
|
Синус, косинус, тангенс, катангенс
|
—
|
sin 45
|
|
|
—
|
cos 0
|
|
|
—
|
tan 90
|
|
|
—
|
ctan 45
|
|
Факториал
|
—
|
5!
|
|
Логарифм
|
—
|
ln(15)
|
|
Десятичный логарифм
|
—
|
log(500)
|
Ссылки и поиск с ограничениями
Еще в середине 2007 года Яндекс отменил операторы link и anchor, которыми пользовались SEOшники. Но Google сохранил возможность искать бэклинки и ссылки, анкоры которых содержат определенные слова.
Но Google сохранил возможность искать бэклинки и ссылки, анкоры которых содержат определенные слова.
Обе поисковые системы предлагают пользователю использовать специальный язык запросов для того, чтобы осуществить поиск на определенном сайте; поиск конкретного типа документа; поиск слов запроса в тайтле страницы. У Яндекса есть функция поиска документа только на определенном пользователем языке. У Google есть несколько операторов, которыми не располагает российский поисковик: просмотр закешированной страницы и поиск слов запроса в тексте урла.
|
Действия
|
Яндекс
|
|
|
Поиск определенного типа файла
|
ключевые слова mime=»pdf»
|
keyword filetype:pdf
|
|
Поиск по сайту
|
google url=»www.
|
finance site:www.google.com
|
|
Поиск всех слов запроса в тайтле
|
title[ключевое слово]
|
allintitle:keyword
|
|
Поиск первого слова запроса в тайтле, остальных — в документе
|
—
|
intitle:keyword content
|
|
Поиск документов на определенном языке
|
keyword
|
—
|
|
Поиск закешированной версии страницы
|
—
|
cache:www.
|
|
Поиск всех слов запроса в тексте урла
|
—
|
allinurl:keyword content
|
|
Поиск первого слова запроса в тексте урла, остальных — необязательно
|
—
|
inurl:keyword content
|
 seonews.ru/*»
seonews.ru/*»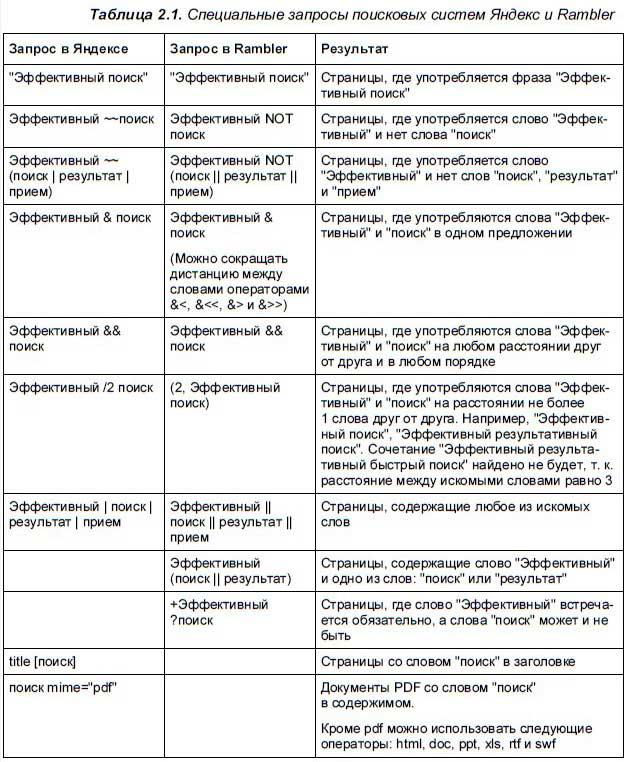 seonews.ru
seonews.ruПомимо вышеперечисленных функций у Яндекса есть несколько интересных фич. Цветовой спектр, с которым можно провести несколько приятных минут, выясняя, как выгляди «цвет детской неожиданности», «гуммигут» или «циннвальдитовый». На запрос, содержащий название праздника, Яндекс предложит перейти к Открыткам, чтобы пользователь поздравил своих друзей.
|
Действия
|
Яндекс
|
|
|
Точное время в своем городе
|
точное время
|
time
|
|
|
скока время
|
—
|
|
Время в каком-либо городе
|
время париж
|
time paris
|
|
Разница во времени
|
разница во времени париж москва
|
—
|
|
Открытки
|
святой валентин
|
—
|
|
Цвет на цветовом спектре
|
цвет детской неожиданности
|
—
|
Update: Полную таблицу исследования вы можете посмотреть здесь (Excel).
| Редакционная информация предоставлена DB-Engines | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Описание | Служба крупномасштабного хранилища данных с таблицами только для добавления и ACID, а также предоставление совместимого с Amazon DynamoDB API 9.0007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Модель первичной базы данных | Реляционные DBMS | Store Store Реляционные DBMS | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Веб -сайт | Cloud.comyy.com/bigquery | Cloud.yandex.com/sers.com/sers.com/sers.com/sers.com/sers.com/sers.com/sers.com/sers.com/sers.com/sers.com/sersex. github.com/ydb-platform/ydb ydb.tech | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Техническая документация | cloud.google.com/bigquery/docs | cloud.yandex.com/en/docs/managed-ydb ydb.  tech /ru/документы tech /ru/документы | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Developer | Yandex | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Первоначальный выпуск | 2010 | 2019 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Лицензия Коммерческий или открытый исходный код | Коммерческий | Open Source Apache 2.0; доступна коммерческая лицензия | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Только облачная версия Доступна только как облачная служба | да | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Предложения DBaaS (рекламные ссылки) База данных как услуга Поставщики предложений DBaaS, пожалуйста, свяжитесь с нами, чтобы получить список. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Серверные операционные системы | размещенные | Linux | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Схема данных | Да | ГИБКА или дата | да | да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поддержка XML Некоторая форма обработки данных в формате XML, например. поддержка структур данных XML и/или поддержка XPath, XQuery или XSLT. | NO | NO | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Вторичные индексы | NO | Да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SQL Поддержка SQL | Да | SQL-подобные Язы RESTful HTTP/JSON API | RESTful HTTP API (совместимый с DynamoDB) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поддерживаемые языки программирования | .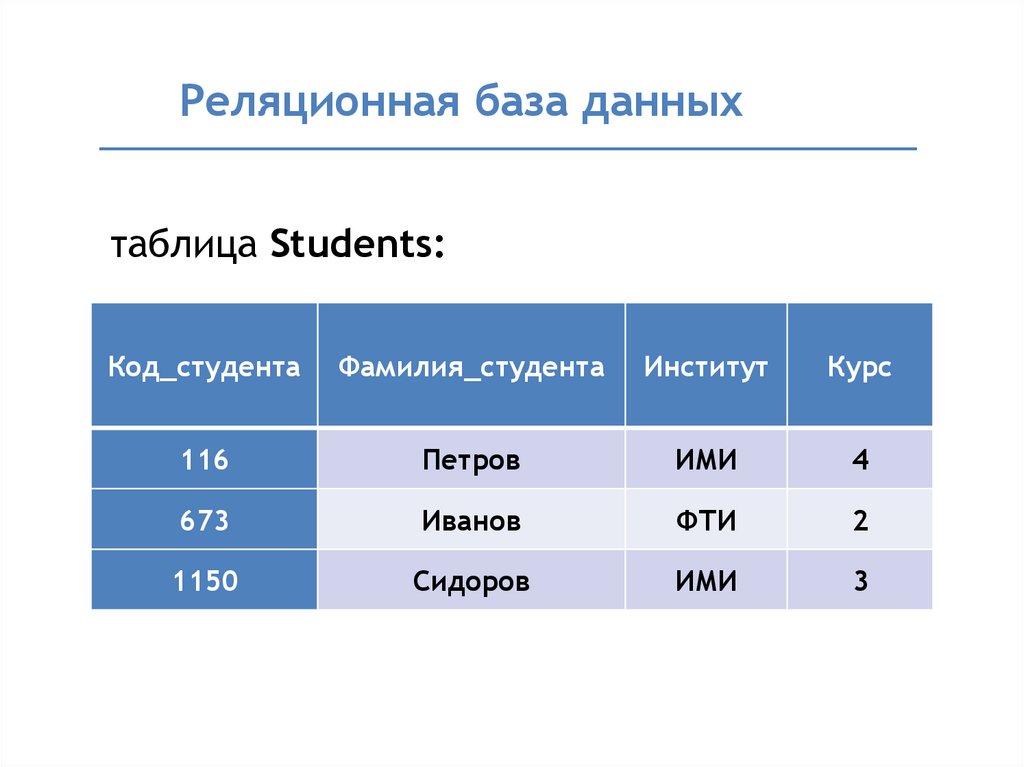 Net Net Java JavaScript Objective-C PHP Python Ruby | Go Java JavaScript (Node.js) PHP Python | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Server-side scripts Stored procedures | user defined functions in JavaScript | no | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Triggers | no | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Методы секционирования Методы хранения различных данных на разных узлах | Нет | Разделение | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Методы репликации Методы избыточного хранения данных на нескольких узлах | Активно-пассивная репликация осколка | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MapReduce предлагает API для пользовательского определенного карты/снижение методов | NO | NO | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции концепции | . Немедленная согласованность | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Внешние ключи Ссылочная целостность | нет | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции транзакций Поддержка обеспечения целостности данных после неатомарных манипуляций с данными | no Since BigQuery is designed for querying data | ACID | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Concurrency Support for concurrent manipulation of data | yes | yes | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Durability Support for making data persistent | yes | yes | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Возможности в памяти Есть ли возможность определить некоторые или все структуры, которые будут храниться только в памяти. | нет | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции пользователя Контроль доступа | Права доступа (владелец, писатель, читатель) на уровне набора данных, таблицы или представления Google Cloud Identity & Access Management (IAM) | Права доступа, определенные для пользователей Yandex Cloud | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Приглашаем представителей поставщиков систем связаться с нами для обновления и расширения системной информации, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Сопутствующие товары и услуги | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| третьи лица | SQLFlow: обеспечивает визуальное представление общего потока данных. Автоматизированный анализ происхождения данных SQL в базах данных, ETL, бизнес-аналитике, облачных средах и средах Hadoop путем анализа сценария SQL и хранимой процедуры. » подробнее CData: подключение к большим данным и NoSQL через стандартные драйверы. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Мы приглашаем представителей поставщиков сопутствующих товаров связаться с нами для предоставления информации о своих предложениях здесь. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Подробнее ресурсы | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DB-инженерные посты в блогах | Популярность DBMS на основе облачных сред за четыре года Рост популярности использования услуг СУБД из облака показать все | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Недавние цитаты в новостях | Google Cloud начинают принимать криптографические платежи посредством партнерства с Coinbase Google’s Logica Language Adders Sql’s Dlaws Win Thricks 2020 Google Cloots. Партнер года – Премия за модернизацию инфраструктуры предоставлено Google News | Узнать, что думают россияне, не спрашивая их Утечка данных приложения по доставке еды раскрыла данные российской тайной полиции предоставлено Google News Вице-президент по науке о данных job by | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 , Lawfare
, LawfareПочему Clickhouse — следующая база данных, которую следует изучить такие предложения, как Greenplum, Vertica, Teradata, Paraccel и т. д. В то время развертывание баз данных OLAP обходится очень дорого, и доступ к ним есть только у компаний с огромным бюджетом. Небольшие организации не получат возможности использовать базы данных OLAP. Что ж, теперь все изменилось.
Clickhouse — это быстрая система управления базой данных OLAP с открытым исходным кодом, ориентированная на столбцы, разработанная Яндексом для своего сервиса веб-аналитики Яндекс.Метрика, аналогичного Google Analytics. Он создан для обработки триллионов строк и петабайт данных и быстрого выполнения аналитических запросов.
Обновление, сентябрь 2021 г.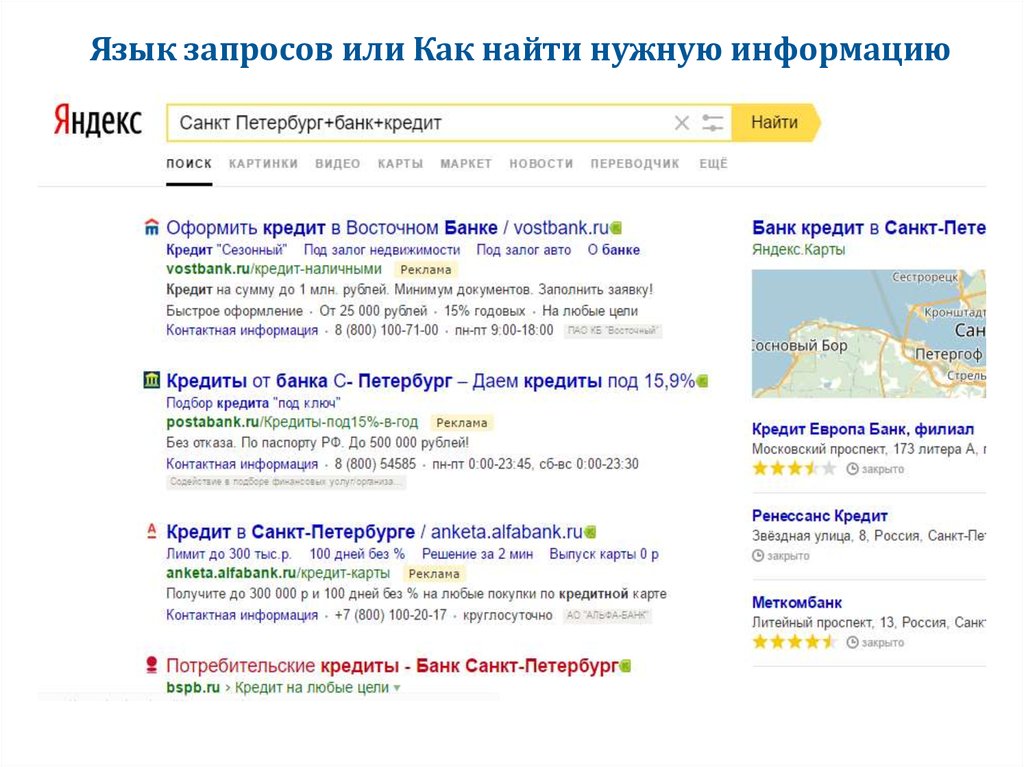 : Clickhouse Inc.
: Clickhouse Inc.
была выделена из Яндекса и недавно получила финансирование серии А в размере 50 миллионов долларов во главе с Index Ventures и Benchmark при участии Yandex N.V. и других компаний.
Базы данных Clickhouse и OLAP обычно используются для ответов на такие бизнес-вопросы, как «Сколько людей посетило www.fadhil-blog.dev
вчера пришли из Малайзии и использовали браузер Google Chrome?» . В традиционной базе данных онлайн-обработки транзакций (OLTP) для обработки такого запроса могут потребоваться минуты или даже часы, в зависимости от размера набора данных. С помощью базы данных OLAP вы можете получить результат в миллисекундах.Огромная разница в скорости между OLTP и OLAP обусловлена природой самой базы данных, базы данных, ориентированной на столбцы, и базы данных, ориентированной на строки.
Что такое столбцовая база данных#
Представьте, что у вас есть данные, как показано ниже:
------------------------------------------------------------- | отметка времени | домен | посетить | ------------------------------------------------------------- | 2021-09-05 12:00 | fadhil-blog.dev | 20 | | 2021-09-05 12:00 | среда.com | 300 | | 2021-09-05 12:01 | fadhil-blog.dev | 15 | | 2021-09-05 12:02 | fadhil-blog.dev | 21 | -------------------------------------------------------------
 dev | 20 |
| 2021-09-05 12:00 | среда.com | 300 |
| 2021-09-05 12:01 | fadhil-blog.dev | 15 |
| 2021-09-05 12:02 | fadhil-blog.dev | 21 |
-------------------------------------------------------------
dev | 20 |
| 2021-09-05 12:00 | среда.com | 300 |
| 2021-09-05 12:01 | fadhil-blog.dev | 15 |
| 2021-09-05 12:02 | fadhil-blog.dev | 21 |
-------------------------------------------------------------
Когда вы сохраняете данные в базе данных OLTP, ориентированной на строки, такой как PostgreSQL и MySQL, данные будут логически храниться, как показано ниже:
строкаX -> столбец1, столбец2, столбец3;пример: row1 -> 2021-09-05 12:00, fadhil-blog.dev, 20; row2 -> 2021-09-05 12:00, medium.com, 300; row3 -> 2021-09-05 12:01, fadhil-blog.dev, 15; row4 -> 2021-09-05 12:02, fadhil-blog.dev, 21;
Данные для каждого столбца в строке записываются рядом друг с другом. Это ускоряет поиск данных для отдельных строк. Операции обновления и удаления данных также выполняются быстро, поскольку вы можете быстро обновлять или удалять строки, теоретически удаляя эту 1 строку. Но когда вы суммируете группу строк, например количество посещений для fadhil-blog.dev , база данных должна прочитать каждую строку одну за другой, получить соответствующий столбец (и отбросить нерелевантные столбцы), а затем только подвести итог.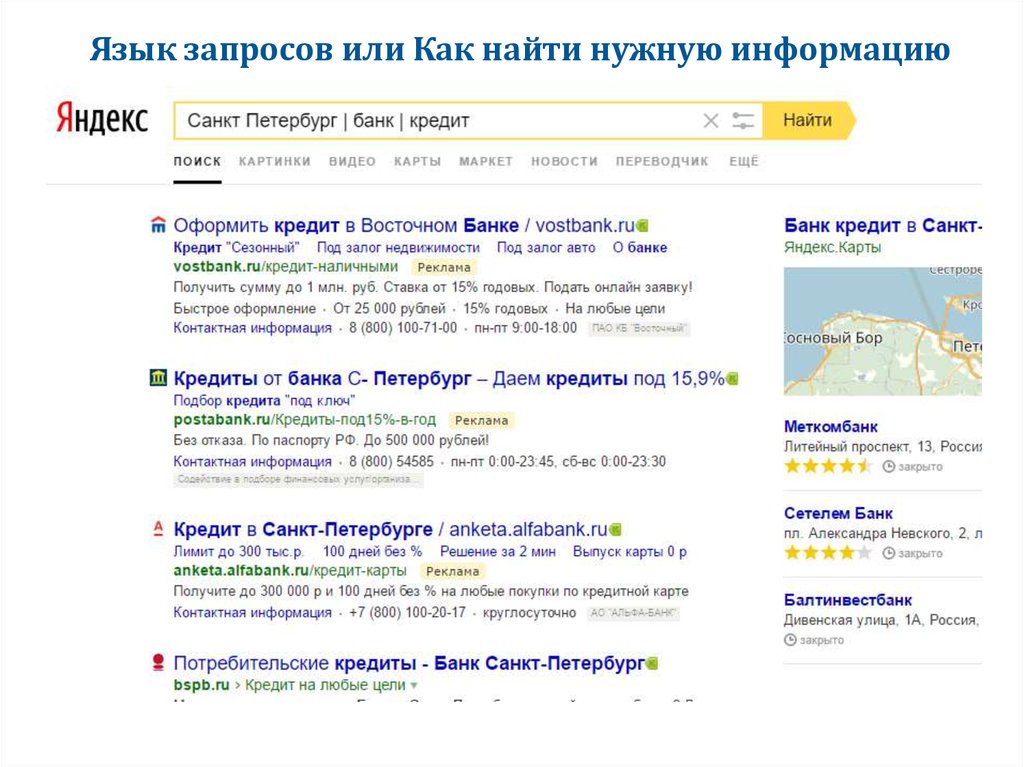 Это пустая трата операций ввода-вывода, и это дорого, что отражает более длительное время обработки этого запроса.
Это пустая трата операций ввода-вывода, и это дорого, что отражает более длительное время обработки этого запроса.
Однако в столбцах данные будут храниться, как показано ниже:
columnX -> row1:id, row2:id, row3:ideexample: столбец отметки времени -> 2021-09-05 12:00:001,2021-09-05 12:00:002,2021-09-05 12:01:003,2021-09-05 12:02:004; столбец домена -> fadhil-blog.dev:001,medium.com:002,fadhil-blog.dev:003,fadhil-blog.dev:004; посетить столбец -> 20:001,300:002,15:003,21:004;
Обратите внимание, что данные для каждой строки в столбце хранятся рядом. Если вы суммируете количество посещений для сайта www.fadhil-blog.dev , в базе данных сначала нужно найти id для fadhil-blog.dev из столбца домен , получить посещение столбец данных для соответствующего полученного идентификатора и, наконец, суммировать их. Базе данных не нужно выполнять множество дорогостоящих операций ввода-вывода для извлечения всей строки, поскольку в первую очередь она получает только соответствующие столбцы. Это главная причина, почему база данных, ориентированная на столбцы, настолько надежна для этого запроса 9.0004
Это главная причина, почему база данных, ориентированная на столбцы, настолько надежна для этого запроса 9.0004
Мое объяснение сильно упрощено. Я рекомендую вам посмотреть это видео, чтобы лучше понять, как это работает, а также плюсы и минусы каждого из них.
Основные цели баз данных Clickhouse или OLAP в целом, но не ограничиваясь ими:
- Анализ данных
- Интеллектуальный анализ данных
- Бизнес-аналитика
- Анализ журнала
По праву вы можете выполнять эти анализы в базе данных OLTP. Общие методы оптимизации, используемые в базе данных OLTP, — это материализованные представления.
, многократная запись в таблицы с несколькими таймфреймами, периодическое агрегирование и сведение данных в почасовые и дневные таблицы с использованием cronjob, использование увеличения и уменьшения счетчика (обычно встречается в сообществе Firebase
) и т. д. Эти методы работают для большинства организаций, но они не являются гибкими. Представьте, что вы продавец в сфере электронной коммерции и храните записи о продажах в таблице базы данных 9.0387 продажи . Чтобы ускорить анализ, вы агрегируете (используя метод, который я упоминал ранее) общие продажи в таблице
д. Эти методы работают для большинства организаций, но они не являются гибкими. Представьте, что вы продавец в сфере электронной коммерции и храните записи о продажах в таблице базы данных 9.0387 продажи . Чтобы ускорить анализ, вы агрегируете (используя метод, который я упоминал ранее) общие продажи в таблице totalSalesDaily со столбцами дата, totalSales . Вы можете легко запросить средние продажи за каждый день или сумму продаж за год из таблицы totalSalesDaily . Но вы не можете быстро просмотреть свою базу данных и выяснить, например, в какое время пользователи активно покупают на сайте (поскольку наилучшая степень детализации — ежедневная), какой продукт является самым популярным и т. д. Конечно, вы можете запросить вашу таблицу продаж с необработанными данными, но это займет минуты или часы, и это большое нет.
Здесь на помощь приходит Clickhouse. С Clickhouse вы можете хранить необработанные данные в своей базе данных и быстро и гибко выполнять анализ детализации.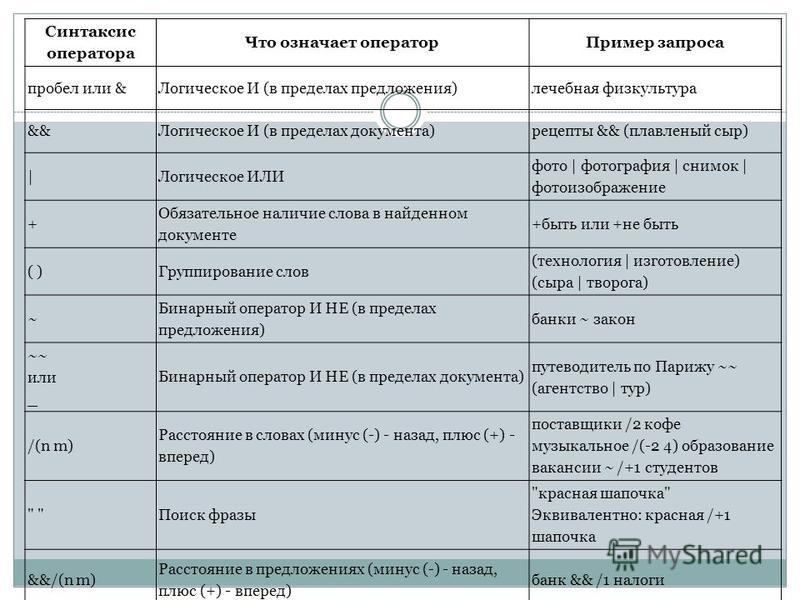 Тем не менее, вы можете вставить практически любые данные в базу данных. Некоторые компании, такие как Cloudflare
Тем не менее, вы можете вставить практически любые данные в базу данных. Некоторые компании, такие как Cloudflare
, мультиплексор
, Правдоподобный
, GraphCDN
и Panelbear получают и сохраняют данные о трафике в Clickhouse и представляют отчет пользователю на своей панели инструментов. Сеть отелей
использует Clickhouse для хранения, анализа и предоставления информации о бронированиях своим клиентам. Перкона
использует Clickhouse для хранения и анализа показателей производительности базы данных. Вы можете узнать больше о последователях Clickhouse
.
НИКОГДА не используйте Clickhouse в качестве замены реляционной базы данных. Clickhouse не предназначен для эффективной обработки обновлений и удалений строк. Clickhouse должен дополнять вашу базу данных OLTP, а не заменять их.
Это может относиться не ко всем, но вам также следует избегать использования Clickhouse в качестве копии ваших баз данных OLTP. Несмотря на то, что технически вы можете сделать это путем потоковой передачи изменений данных из вашей транзакционной базы данных в Clickhouse, рекомендуется использовать Clickhouse в качестве единственного источника достоверных данных для ваших данных, а не в качестве зеркала вашей базы данных OLTP. В любом случае, это зависит от вашей ситуации.
В любом случае, это зависит от вашей ситуации.
Ты в хорошей компании#
При оценке программного обеспечения с открытым исходным кодом важно убедиться, что оно хорошо поддерживается. Вы не хотите перенимать софт/технологию, но через несколько лет проект ушел на кладбище. Такая ситуация не редкость в мире открытого исходного кода. Хорошим признаком здорового проекта с открытым исходным кодом является то, что его принимают интернет-гиганты. Это связано с тем, что они обычно много раздумывают, прежде чем принять решение об использовании программного обеспечения, потому что им очень дорого обходится изменение или переход на другой стек программного обеспечения в будущем, если они сделали неправильный выбор.
Clickhouse используется Cloudflare, Bloomberg, eBay, Spotify, CERN и еще сотней действующих компаний. У Яндекса, например, есть несколько кластеров Clickhouse с данными более 120 триллионов строк и объемом более 100 ПиБ. Это показывает, насколько серьезно компании относятся к внедрению этого программного обеспечения.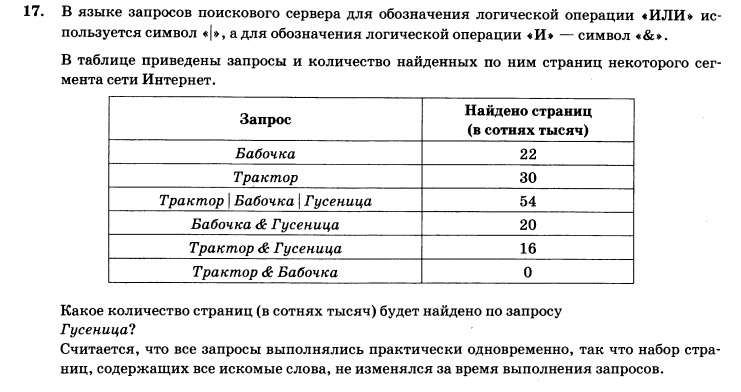
Молниеносные запросы#
По словам Марко Медоевича
, Clickhouse примерно в 260 раз быстрее, чем MySQL, при выполнении аналитического запроса к набору данных с 11 миллионами записей. Тем не менее, это не сравнение Apple с Apple, поскольку MySQL является базой данных OLTP, а Clickhouse — базой данных OLAP, но это демонстрирует, где сияет база данных OLAP.
Предоставлено Марко Медоевичем
Невероятная производительность, достигнутая Clickhouse, обеспечивается уникальным механизмом базы данных MergeTree.
. Clickhouse создан для использования всех доступных аппаратных ресурсов для обеспечения максимальной скорости запросов.
Для сравнения между яблоками Марк Литвинчик
сравнивает различные базы данных OLAP, доступные на рынке. Судя по результатам эталонного теста, Clickhouse является самой быстрой базой данных OLAP с открытым исходным кодом. BrytlytDB, OmniSci (ранее известная как MapD) и kdb+ — это коммерческие базы данных, которые работают быстрее, чем Clickhouse. Тем не менее, и BrytlytDB, и OmniSci используют графические процессоры для ускорения своих вычислений, в то время как Clickhouse использует только стандартное оборудование.
Тем не менее, и BrytlytDB, и OmniSci используют графические процессоры для ускорения своих вычислений, в то время как Clickhouse использует только стандартное оборудование.
Обзор 1,1 миллиарда поездок на такси
Малый индекс (Разреженный индекс)#
Всем известно, что ключом к быстрому поиску данных в базе данных является индекс. Индексы лучше хранить в памяти для быстрого доступа. В базе данных OLTP индексы обычно хранятся в структурах данных B-Tree или B-Tree+, как показано ниже.
Предоставлено Джаватпойнт
Это хорошо подходит для баз данных OLTP, поскольку первичные ключи важны по своей природе. В базе данных OLTP вы обычно запрашиваете базу данных по ее идентификатору, например запрос ВЫБЕРИТЕ имя пользователя, дату_рождения, адрес электронной почты ОТ пользователя, ГДЕ id = 1234 или запрос типа ОБНОВЛЕНИЕ пользователя УСТАНОВИТЕ адрес электронной почты = "[email protected]" ГДЕ id = 1234 .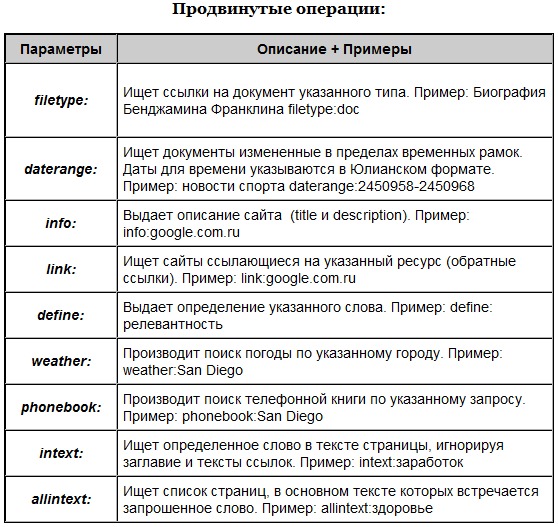 Индекс имеет смысл хранить в B-Tree, так как шаблоны доступа обычно определяются по его идентификатору. Но эти индексы не будут хорошо масштабироваться, когда данные вырастут до миллиардов строк и больше не смогут помещаться в ОЗУ.
Индекс имеет смысл хранить в B-Tree, так как шаблоны доступа обычно определяются по его идентификатору. Но эти индексы не будут хорошо масштабироваться, когда данные вырастут до миллиардов строк и больше не смогут помещаться в ОЗУ.
Цель разреженного индекса — гарантировать, что индекс всегда умещается в памяти, даже если размер данных огромен. В Clickhouse разреженный индекс строится, как показано ниже.
Предоставлено Fatalerrors.org
Clickhouse хранит только подмножество данных своего индекса и действует как «контрольная точка» в большом наборе данных. При этом размер индекса относительно невелик, и он может поддерживать огромные таблицы, но при этом помещаться в памяти. Представьте такие запросы, как SELECT SUM(visit) FROM visit WHERE date BETWEEN '2021-07-01' AND '2021-07-31' , для базы данных имеет смысл хранить индекс в виде разреженного индекса в соответствии с шаблонами доступа. по диапазону дат, а НЕ по идентификатору. Вот почему разреженный индекс отлично подходит для базы данных OLAP. Откровенно говоря, разреженный индекс ужасен для поиска одной строки.
Откровенно говоря, разреженный индекс ужасен для поиска одной строки.
Лучшие данные — это данные, которые можно пропустить
Сжатие данных#
Поскольку данные хранятся по столбцам, а не по строкам, Clickhouse может сжимать данные намного лучше, чем база данных, ориентированная на строки. В PostHog на 70 % сократилось дисковое пространство, необходимое для хранения тех же данных в PostgreSQL. В Clickhouse вы можете указать, какой кодек сжатия данных и уровень сжатия для какого столбца в вашей таблице. Высокие уровни сжатия полезны для асимметричных сценариев, таких как однократное сжатие, многократное распаковывание. Более высокие уровни означают лучшее сжатие, меньший размер дискового пространства и более высокую загрузку ЦП.
Данные TTL#
Хранить данные бесконечно — не всегда хорошая идея; в противном случае в какой-то момент у вас закончится место на диске. В большинстве случаев вы хотите установить разумный срок хранения данных для ваших данных. В Clickhouse вы можете установить политику удаления строк через определенный период. Вы можете легко сделать это, установив TTL данных при создании таблицы, как показано ниже:
В Clickhouse вы можете установить политику удаления строк через определенный период. Вы можете легко сделать это, установив TTL данных при создании таблицы, как показано ниже:
Пример
СОЗДАТЬ ТАБЛИЦУ
(
дата DateTime,
международный
)
ДВИГАТЕЛЬ = дерево слияния
РАЗДЕЛ ПО доГГГГММ(дата)
ЗАКАЗАТЬ
TTL д + ИНТЕРВАЛ 1 МЕСЯЦ
Оператор DDL, приведенный выше, создаст таблицу «пример» и автоматически удалит данные, если «дата» будет более одного месяца от текущей даты.
Драйверы/адаптеры для основных языков программирования#
Сообщество Clickhouse очень активно. Есть драйверы, написанные на Go
, Питон
, Эликсир
, Рубин
и т. п. Существуют также адаптеры, написанные для таких фреймворков, как Ruby on Rails Active Record.
, Феникс/Экто
, Джанго ORM
и многое другое. Это означает, что вы можете легко подключить Clickhouse к вашей существующей системе.
Clickhouse также имеет встроенный интерфейс HTTP.
. Если вы хотите использовать Clickhouse на своем экзотическом языке программирования, вы можете напрямую использовать его HTTP-интерфейс и напрямую вызывать его конечную точку. Фактически, некоторые драйверы, упомянутые выше, на самом деле построены на этом HTTP-интерфейсе. Он также поставляется с функцией проверки активности HTTP, и я полагаю, что он поддерживает пул соединений внутри.
Фактически, некоторые драйверы, упомянутые выше, на самом деле построены на этом HTTP-интерфейсе. Он также поставляется с функцией проверки активности HTTP, и я полагаю, что он поддерживает пул соединений внутри.
Горизонтальная масштабируемость и отказоустойчивость#
Clickhouse создан с учетом как горизонтальной масштабируемости, так и высокой доступности. Вы можете разделить свои данные на несколько узлов и реплицировать данные на другой набор серверов. Преимущества:
- Вы можете хранить данные, превышающие размер одного сервера
- Повышение производительности запросов, так как запросы обрабатываются несколькими узлами параллельно
- Повышение отказоустойчивости и предотвращение единой точки отказа
Как и в других системах, функция горизонтального масштабирования и высокой доступности не предоставляется бесплатно. Сложность может возникнуть при настройке кластера, особенно кластера с отслеживанием состояния. Вы можете использовать Clickhouse Kubernetes Operator
Вы можете использовать Clickhouse Kubernetes Operator
чтобы настроить это, если вы используете Kubernetes.
Дублирование первичных ключей#
Это может показаться вам странным, но да, Clickhouse поддерживает дублирование первичных ключей. В зависимости от ваших вариантов использования это может быть хорошо или плохо для вас. Если вы не хотите дублировать первичные ключи в своей таблице, вы можете использовать ReplacingMergeTree
table engine для автоматической очистки и удаления дублирующихся ключей в вашей базе данных. Однако помните, что операция очистки/слияния базы данных происходит в неизвестное время в фоновом режиме, поэтому вы будете видеть дублирующиеся первичные ключи в течение некоторого времени, прежде чем они будут очищены.
Предпочитает пакетную вставку данных#
Из-за особенностей работы механизма MergeTree он работает лучше всего, если вы вставляете данные большими пакетами, а не небольшими частыми вставками. В обычных условиях Clickhouse может обрабатывать тысячи записей за одну операцию пакетной вставки.
За кулисами каждая вставка в Clickhouse будет создавать одну часть файла в /var/lib/clickhouse/data/ . Затем Clickhouse объединит части в неизвестное время в фоновом режиме. Если вы делаете много небольших вставок, в каталоге будет создано много частей, которые движок должен объединить. Вот почему Clickhouse предпочитает вставку больших пакетов.
Вы можете обратиться к другому моему сообщению о том, как создать пакетную обработку в Python.
.
Обновление и удаление строк требует больших затрат#
Нет простого способа обновить или удалить строки таблицы. Вот несколько способов обновить или удалить строки данных:
- Используйте ИЗМЕНИТЬ ТАБЛИЦУ
в Clickhouse для обновления или удаления данных. Они вступают в силу только после объединения данных в неизвестное время в фоновом режиме. Вы не можете полагаться на эту команду для обновления/удаления строк данных. - Использовать РАЗДЕЛ DROP
команда для удаления всего раздела - Используйте CollapsingMergeTree
движок таблицы для удаления данных. Это работает следующим образом: когда вы хотите удалить строку, вы записываете другую строку, которая «отменяет» существующие данные - Используйте ReplacingMergeTree
табличный движок для обновления данных. Как это работает, вы пишете другую строку с тем же идентификатором. Однако, как и команда ALTER TABLE, это вступает в силу только после выполнения задания слияния в фоновом режиме в неизвестное время.
 Это работает следующим образом: когда вы хотите удалить строку, вы записываете другую строку, которая «отменяет» существующие данные
Это работает следующим образом: когда вы хотите удалить строку, вы записываете другую строку, которая «отменяет» существующие данные.
Несмотря на то, что существует несколько способов обновления или удаления строк данных, ни один из них не является таким удобным, как UPDATE table SET x = y или DELETE table WHERE id = x в MySQL. Вы должны приспособиться к этому.
Специальные настольные двигатели#
Clickhouse бесспорно имеет множество табличных движков, которые поначалу могут сбить вас с толку. Каждый из них служит своей цели. Например, когда вы хотите:
- Получение данных из Kafka; вы можете использовать специальную таблицу Kafka
движок для приема сообщений Kafka - Объединить данные между таблицами; вы можете использовать специальную таблицу Join
движок для ускорения операции JOIN - Материализация данных; вы можете использовать механизм материализованных таблиц
за это - Репликация данных в вашем кластере; вы должны использовать ReplicatedMergeTree
стол двигателя для этого - Многие другие механизмы баз данных и таблиц
Clickhouse работает по-своему. Однако вам, вероятно, они не понадобятся при первом запуске Clickhouse.
Однако вам, вероятно, они не понадобятся при первом запуске Clickhouse.
Развертывание базы данных#
Крупные облачные провайдеры еще официально не предлагают управляемый сервис Clickhouse. Облачные провайдеры, предоставляющие управляемые услуги Clickhouse, — это Яндекс.
, Алибаба
и Тенсент
. Если вы настаиваете на использовании управляемого сервиса Clickhouse в собственном облаке VPC в среде AWS, вы можете использовать Altinity.
.
Если вы только начинаете работать с Clickhouse, можно использовать одноузловой сервер Clickhouse для базы данных. Вы можете использовать такие инструменты, как clickhouse-backup
чтобы помочь вам управлять процессом резервного копирования и автоматизировать его. Кроме того, вам потребуются базовые знания Linux для настройки и защиты сервера (настройка брандмауэра, настройка резервного задания cron и т. д.). Сложности могут возникнуть при масштабировании на несколько машин, где вам понадобится кластер Zookeeper или Clickhouse Keeper для координации нескольких серверов баз данных. На тот момент имело смысл использовать управляемый сервис Clickhouse.
На тот момент имело смысл использовать управляемый сервис Clickhouse.
Для справки, в июне 2020 года правдоподобно
был * (я думаю, что они все еще) *самостоятельно управляли своей базой данных Clickhouse в единой капле DigitalOcean за 80 долларов в месяц.
Правдоподобный отчет за июнь 2020 г.
Я продан этой базе данных. Использование Clickhouse или любой другой базы данных OLAP откроет новые возможности для вас и вашей организации. Я настоятельно рекомендую вам попробовать Clickhouse и посмотреть, какую пользу он может принести вашей организации. В любом случае, это открытый исходный код, вы можете быстро развернуть док-контейнер Clickhouse на своем компьютере с помощью этих простых команд:0004
$ docker run -d --name clickhouse-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 yandex/clickhouse-server\ $ docker exec -it clickhouse-server clickhouse-client
Настройка таблицы базы данных в контейнере Clickhouse
В конечном счете, вы должны знать, когда использовать и когда НЕ использовать базу данных OLAP.