Содержание
Что такое веб-архив и как им пользоваться
Веб-архив — это проект web.archive.org, на котором хранятся разные версии всех сайтов с момента их создания при условии, что нет запрета на сохранение ресурса. Благодаря наличию сохраненных копий в веб-архиве, доступно восстановление сайта даже при отсутствии резервной копии. Также в веб-архиве можно найти интересный контент из закрытых сайтов конкурентов, который активно используют создатели PBN-сеток сайтов.
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
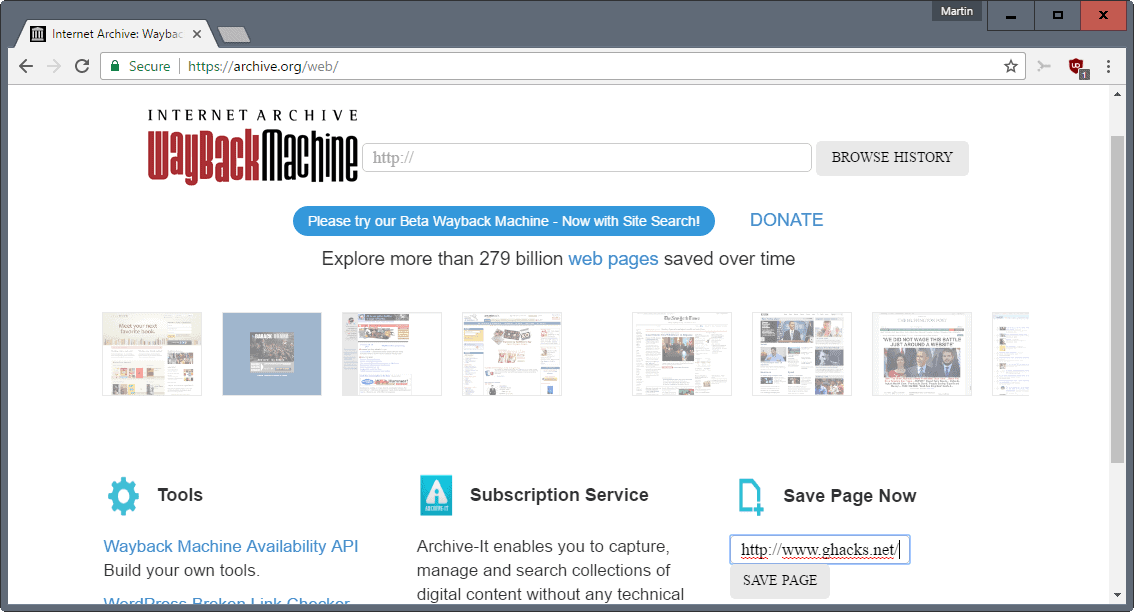
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Как добавить современную версию сайта в веб-архив
Для уверенности в том, что все нужные версии собственного проекта будут сохранены в веб-архиве, желательно самостоятельно инициировать сканирование сайта. Для этого введем в разделе «Save Page Now» домен сайта и нажмем «Save page»:
После этого в архив будет добавлена текущая версия сайта. На всякий случай повторяйте подобную процедуру перед всеми существенными изменениями сайта и после их осуществления.
Как запретить добавление сайта в веб-архив
Чтобы сайт не был доступен в веб-архиве, пропишите запрет в файле robots.txt. Для этого нужно зайти в корневой каталог сайта на панели управления хостинг-провайдера и выбрать редактирование данного файла:
Запрет устанавливается с помощью такого кода:
User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: /
После этого удалятся существующие версии проекта, а также не будет осуществляться копирование сайта в архив пока домен функционирует и в файле robots.txt присутствуют данные настройки. Когда закончится регистрация доменного имени старые версии сайта вновь станут доступны в веб-архиве.
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как парсить веб-архив с помощью Robotools
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в демо-версии, после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
Затем нажимаем «Все ОК, собрать ZIP-архив»:
После этого нажимаем «Скачать архив»:
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
Как скачать сайт из веб-архива с помощью Archivarix
Этот сервис также помогает восстановить старые версии сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта:
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Запомнить
- Веб-архив — масштабный бесплатный проект, созданный для сохранения всего контента, представленного в интернете, даже после его удаления на исходном сайте.
- Веб-архив полезен для анализа сайтов клиентов и конкурентов, отслеживания изменений на собственном проекте, проверки доменов перед покупкой.

- Используя данные веб-архива, полученные с помощью онлайн-сервисов, доступно восстановление сайта без бэкапа.
- В веб-архиве много контента, в том числе уникальные статьи почти на любую тематику.
Что такое Web Archive и как им пользоваться
2 июня 2020ЛикбезТехнологии
Сервис пригодится, если нужно будет просмотреть неработающую или удалённую веб-страницу.
Поделиться
0
Что такое Web Archive
В 1996 году американский предприниматель и активист Брюстер Кейл основал некоммерческую организацию Internet Archive («Архив интернета»). С тех пор она создаёт и хранит копии сайтов, а также книг, изображений и другого контента, который публикуется на открытых ресурсах Сети. Таким образом учредитель намерен сберечь международное культурное наследие.
Архив пополняют боты, сканирующие веб. Им помогают сотрудники и партнёры организации, среди которых множество библиотек и университетов. Кроме того, любой пользователь может загружать контент на серверы через официальный сайт организации. Содержимое архива доступно здесь же — бесплатно и для всех желающих.
Содержимое архива доступно здесь же — бесплатно и для всех желающих.
Web Archive, также известный как Wayback Machine («Машина времени»), — это один из разделов на сайте Internet Archive. Здесь можно добавить новые или просмотреть уже загруженные копии веб-страниц.
Боты периодически обновляют данные. Но каждая очередная копия страницы не перезаписывает предыдущую, а сохраняется отдельно с указанием даты добавления. Поэтому с помощью Internet Archive можно посмотреть, как со временем менялись дизайн и наполнение выбранного сайта.
Копия сайта Google, созданная 3 декабря 2000 года
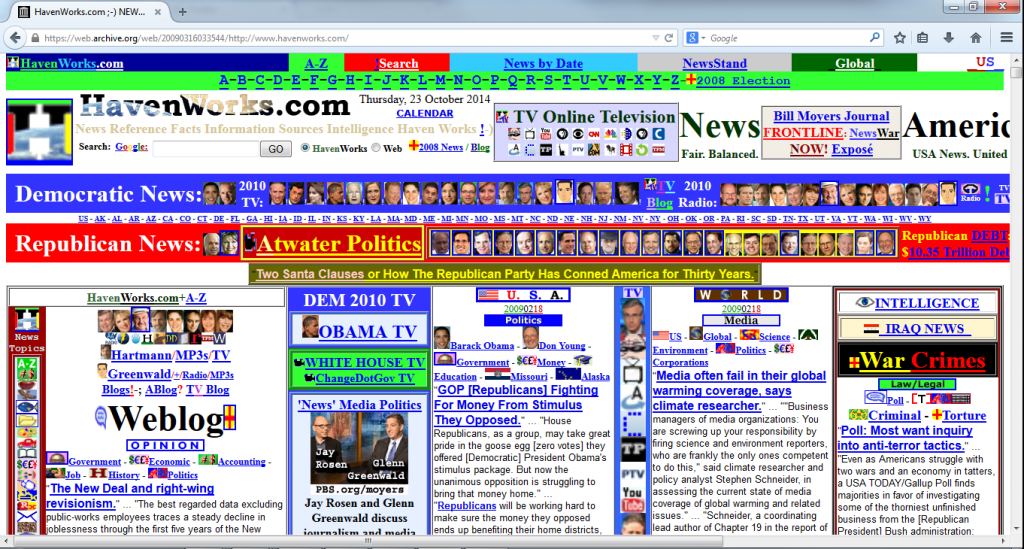
Более того, сохранённые копии остаются доступными, даже если оригинал исчезает из Сети. По этой причине Web Archive часто используют, чтобы просмотреть опубликованную информацию, которую пытаются стереть, или получить доступ к старым и уже неработающим сайтам.
С сервисом можно работать через сайт и официальное приложение Wayback Machine для iOS и Android.
Сейчас читают 🔥
- Как скачать видео с YouTube на любое устройство
Как посмотреть архивные копии страницы в Web Archive
Откройте сайт Web Archive или приложение сервиса. Если используете последнее, сразу после запуска создайте аккаунт.
Если используете последнее, сразу после запуска создайте аккаунт.
Вставьте ссылку на нужную страницу и нажмите Enter (на сайте) или Overview of All Archives (в приложении).
Пролистайте календарь, чтобы найти подходящие копии. Дни, в которые бот создавал дубликаты страницы, отмечены кружками.
Нажмите на подходящую дату, чтобы просмотреть архивную копию.
Сайт также позволяет сравнивать две копии. Для этого на странице с календарём нажмите Changes, отметьте две даты и кликните Compare.
В результате Web Archive отобразит копии рядом и выделит несовпадения.
Как удалить копии ваших страниц из Web Archive или запретить их добавление
Если вы не желаете, чтобы копии вашего ресурса были в архиве, сообщите об этом администрации Internet Archive. Согласно официальной справке, для этого нужно отправить письмо на ящик [email protected], указав ссылку на свой сайт.
Скорее всего, вас попросят доказать факт владения ресурсом и объяснить причину удаления или запрета на добавление в архив. И да, писать лучше на английском.
И да, писать лучше на английском.
Как добавить копию страницы в Web Archive
Чтобы не дожидаться, пока бот найдёт и сохранит нужную вам страницу, можете добавить её вручную.
Если используете сайт, перейдите в специальный подраздел. Вставьте ссылку на сохраняемую страницу и нажмите Save Page. Отметьте пункт Save error pages, если хотите, чтобы система архивировала в том числе страницы, которые не открываются из-за ошибок.
Если используете приложение, вставьте ссылку на нужную страницу и нажмите Archive Page Now.
Для быстрого добавления страниц можно также использовать расширения для десктопных браузеров. После установки достаточно открыть в браузере нужную ссылку, нажать на кнопку плагина и выбрать Save Page Now.
Загрузить
Цена: Бесплатно
Загрузить
Цена: Бесплатно
Загрузить
Цена: 0
Загрузить
Цена: Бесплатно
Читайте также 🌐🖥🌐
- Как на Android сделать резервную копию данных в Google Drive
- Что такое кража цифровой личности и как защитить свои данные в интернете
- 6 причин не сохранять пароли в браузере
- Как восстановить файлы в Excel, если вы забыли их сохранить
- 10 лучших программ для восстановления данных с жёсткого диска
7 Альтернатива Wayback Machine (веб-сайт Интернет-архива) 2022
АвторAlyssa Walker
Часы
Обновлено
Информация об архивах Wayback Machine доступна в WWW (World Wide Web). Он широко используется исследователями и историками для сохранения цифровых артефактов. Однако у Wayback Machine есть некоторые ограничения, например, он очень медленный и не отвечает на многих сканируемых веб-сайтах.
Вот список лучших приложений, которые могут заменить Wayback Machine. Список содержит как открытое (бесплатное), так и коммерческое (платное) программное обеспечение.
#1) Archive.fo
Archive.fo — это онлайн-инструмент, который поможет вам создать копию веб-страницы. Эта копия останется в сети, даже если исходная страница будет удалена.
Особенности:
- Это приложение сохраняет текстовую и графическую копии страницы для большей точности.
- Это одна из лучших альтернатив Wayback Machine, которая дает короткую ссылку на неизменяемую запись любой веб-страницы.
- Этот инструмент позволяет отслеживать изменения веб-сайта, содержащего предложение о работе, прайс-лист, сообщение в блоге, список недвижимости и т. д.
- Сохраненные страницы не содержат вредоносных программ или всплывающих окон.
 д.
д.Ссылка: https://archive.fo/
#2) Stillio
Stillio — это инструмент, который автоматически делает снимки веб-сайтов, архивирует их и предоставляет другим пользователям. Вы можете управлять историей своего сайта и сэкономить много времени.
Особенности:
- Вы можете установить частоту создания скриншотов в соответствии с настроенной продолжительностью
- Вы можете добавить сразу несколько URL.
- Вы можете сохранить снимок экрана в Dropbox.
- Поддерживает совместное использование URL.
- Это один из лучших сайтов веб-архивов, который позволяет фильтровать URL-адреса по домену.
- Вы можете использовать собственные заголовки, чтобы все было организовано.
- Машина времени веб-сайта Stillio поможет вам сделать снимок экрана с географическим местоположением веб-сайта, определив его IP-адрес.
- Вы можете скрыть нежелательные элементы, такие как оверлеи, баннеры или всплывающие окна с файлами cookie.

#3) Perma.cc
Perma.cc — это приложение для веб-архивирования, разработанное и поддерживаемое библиотекой Гарвардской школы права. Это поможет вам создавать постоянные записи веб-сайтов.
Особенности:
- Вы можете удалить ссылки в течение 24 часов после создания.
- Помогает просматривать архивные записи через ссылку Perma.cc
- URL-адресов могут быть вставлены через блог или бумажные статьи.
- Эта альтернатива Wayback Machine позволяет создать Parma, которая посещает веб-сайт, и создать запись содержимого этого веб-сайта.
- Если сохранение не удалось, это приложение предложит вам загрузить PDF-файл или изображение.
- Физические лица могут получить доступ к постоянным ссылкам через многоуровневую подписку.
- Вы можете назначать пользователей любой организации, просто отправив адрес электронной почты пользователя в эту облачную программу.

Ссылка: https://perma.cc
#4) Pagefreezer
PageFreezer — это сервис SaaS, который обеспечивает архивирование блогов, веб-сайтов и социальных сетей. Это помогает фирмам и предприятиям, предоставляющим финансовые услуги, фиксировать онлайн-разговоры, обеспечивает мониторинг рисков.
Особенности:
- Это онлайн-приложение проверяет подлинность и целостность ваших записей.
- Эта альтернатива Wayback Machine может собирать динамический веб-контент в режиме реального времени.
- PageFreezer может захватывать внутренние социальные сети.
- Он может записывать разговоры в корпоративном чате и отслеживать активность на предмет потенциальных рисков.
- Вы можете архивировать SMS или текстовые сообщения.
- Помогает собирать онлайн-контент и управлять им.
- Вы можете получить доступ к прошлой сети по запросу.
Ссылка: https://www.pagefreezer.com
#5) Actiance
Приложение Actiance помогает организациям собирать и архивировать электронные сообщения. Это один из таких сайтов, как Wayback Machine, который поддерживает более 80 каналов.
Характеристики:
- Захватите все важные сообщения.
- Вы можете выявлять риски и управлять ими, а также извлекать коммерческую ценность ваших данных.
- Позволяет создавать, упаковывать и доставлять контент по требованию.
- Это облачное приложение предоставляет аналитическую панель для лучшей визуализации данных.
- Это один из лучших архивных веб-сайтов, который включает в себя расширенный поиск, а также поиск по всем каналам.
- Предлагает комплексные и настраиваемые отчеты.
Ссылка: https://www.smarsh.com
#6) Веб-архив Великобритании
Веб-архив Великобритании ежегодно собирает сведения о многочисленных сайтах и сохраняет их на будущее. Это один из лучших сайтов веб-архивов, который фокусируется на предмете, событии или интересующей области, а также на социальных сетях для архивирования.
Это один из лучших сайтов веб-архивов, который фокусируется на предмете, событии или интересующей области, а также на социальных сетях для архивирования.
Характеристики:
- Вы можете использовать этот веб-сайт для поиска веб-архивов Великобритании.
- Позволяет открыть для себя веб-сайт на различные темы и темы.
- Это приложение для сбора истории Интернета собирает изображения, видео, HTML-страницы, PDF-файлы и т. д.
- Это один из лучших сайтов-архивов в Интернете, который выполняет автоматизированный сбор ассортимента веб-сайтов Великобритании за один год.
Ссылка: https://www.webarchive.org.uk/ukwa/
#7) Путешествие во времени Memento
Путешествие во времени Memento помогает вам искать и просматривать версии веб-страниц, которые существовали в прошлом. Это один из лучших сайтов-архивов веб-сайтов, который поддерживает поиск Mementos в веб-архивах.
Особенности:
- Проверяет весь спектр серверов для поиска веб-страниц.
- Этот веб-сайт архива истории Интернета отображает компоненты веб-страницы в зависимости от запрошенного вами времени.
- Самоархивирует содержимое веб-сервера.
- Он фокусируется на различных компонентах, таких как HTML, таблицы стилей, изображения и т. д.
- Вы можете увидеть распределение архивного DateTime с помощью временной шкалы.
- Эта интернет-машина времени предоставляет гистограмму, показывающую отмеченные и отсутствующие компоненты.
Ссылка: http://timetravel.mementoweb.org/
Часто задаваемые вопросы
❓ Что такое Wayback Machine?
Wayback Machine — это служба, которая архивирует информацию, доступную в WWW (World Wide Web). Это позволяет пользователям увидеть, как веб-сайты выглядели в прошлом. Многие исследователи и историки широко используют его для сохранения цифровых артефактов. Однако у Wayback Machine есть некоторые ограничения, например, он очень медленный и не отвечает на многих сканируемых веб-сайтах.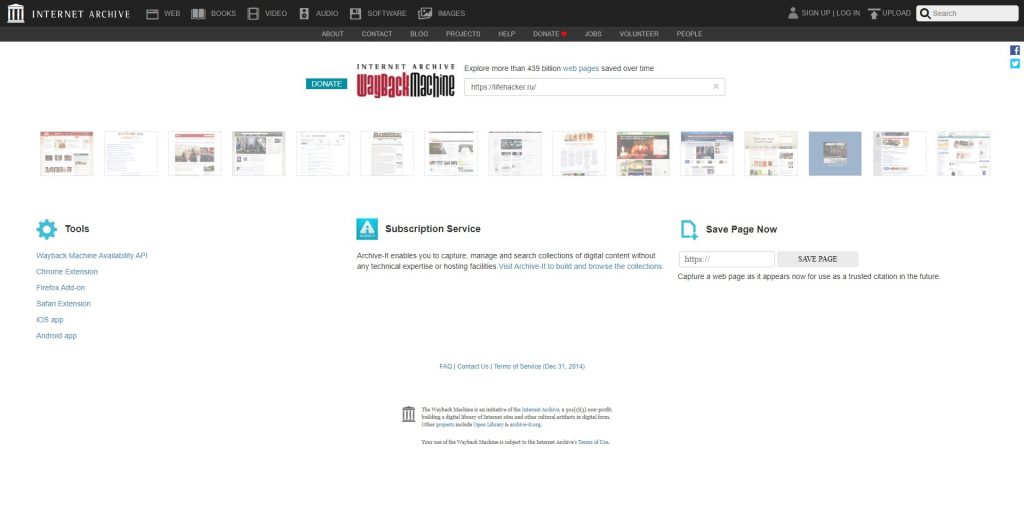
❗ Какие сайты лучше всего похожи на Wayback Machine?
Ниже приведены некоторые из лучших сайтов, таких как Wayback Machine:
- archive.today
- Стиллио
- Perma.cc
- Замораживатель страниц
- Действие
- Веб-архив Великобритании
- Память о путешествии во времени
🏅 Как использовать Wayback Machine?
Вы можете выполнить следующие шаги, чтобы использовать Wayback Machine для просмотра архива веб-сайта:
- Шаг 1) Откройте эту ссылку в веб-браузере
- Шаг 2) Введите URL-адрес сайта, который вы хотите сохранить, в поле «Введите URL-адрес или слова, относящиеся к домашней странице сайта»
- Шаг 3) Нажмите кнопку «Ввод»
- Шаг 4) Выберите год на гистограмме
- Шаг 5) Выберите дату
- Шаг 6) Просмотр различных архивных версий сайта
Использование Archive.
 org для расследований OSINT — мы OSINTCurio.us
org для расследований OSINT — мы OSINTCurio.us
OSINT
Интернет-архив, широко известный как Wayback Machine, позволяет пользователям посещать архивные версии веб-сайтов. Интернет-архив архивирует сайты с 1996 года и насчитывает 514 миллиардов заархивированных веб-страниц!
Если вам интересно, как вы можете использовать Интернет-архив в своих исследованиях OSINT, вы пришли в нужное место. Есть много способов извлечь важную информацию из Wayback Machine для дальнейшего расследования OSINT. Если вы хотите увидеть исторические версии веб-сайта из-за того, что сайт был удален или заменен новым контентом, Wayback Machine может помочь. Возможно, вам потребуется убедиться, что цель ранее работала в компании, но в текущем состоянии сайта нет информации о цели. Иногда цель может намеренно скрывать информацию со своего нынешнего веб-сайта, просмотр более старых дат сайта может выявить новую информацию. Иногда вы можете собирать соответствующие данные, такие как имена, номера телефонов, адреса электронной почты и даже метаданные из старых версий веб-сайта. Давайте рассмотрим методы поиска…
Давайте рассмотрим методы поиска…
Методы быстрого поиска:
- Самый быстрый способ увидеть все файлы, заархивированные на определенном сайте, — это перейти по URL-адресу https://web.archive.org/*/www.example.com и заменить http: //www.example.com с интересующим вас сайтом. Пример: https://web.archive.org/web/*/www.osinttechniques.com
Если сайт был заархивирован, появится календарь с цветными точками, имеющими разные значения. Синие точки — это то, на что вам нужно нажать, поскольку они указывают на захват веб-страницы. Зеленый цвет указывает на перенаправление, оранжевые точки указывают на то, что сканер получил ошибку клиента, а красный цвет означает, что произошла ошибка сервера. Навигация по временной шкале отобразит даты, когда сайт был заархивирован.
Пример временной шкалы
- Если вы хотите просмотреть все архивы определенного домена, используйте ссылку https://web.archive.org/*/www.example.com/* и замените http://www . example.com с интересующим вас сайтом. Как указано ниже, вы можете видеть, что для www.osinttechiques.com было захвачено 117 URL-адресов. Пример: https://web.archive.org/web/*/www.osinttechniques.com/*
 example.com с интересующим вас сайтом. Как указано ниже, вы можете видеть, что для www.osinttechiques.com было захвачено 117 URL-адресов. Пример: https://web.archive.org/web/*/www.osinttechniques.com/*
example.com с интересующим вас сайтом. Как указано ниже, вы можете видеть, что для www.osinttechiques.com было захвачено 117 URL-адресов. Пример: https://web.archive.org/web/*/www.osinttechniques.com/*Пример всех URL-адресов, заархивированных с Osinttechniques.com
Другие методы поиска:
- Если у вас есть интересующий URL-адрес, вы можете выполнить поиск здесь https://archive.org/web.
Пример: выполните поиск по адресу www.myspace.com, чтобы увидеть, как сайт изменился с течением времени.
Синие точки наиболее интересны для просмотра
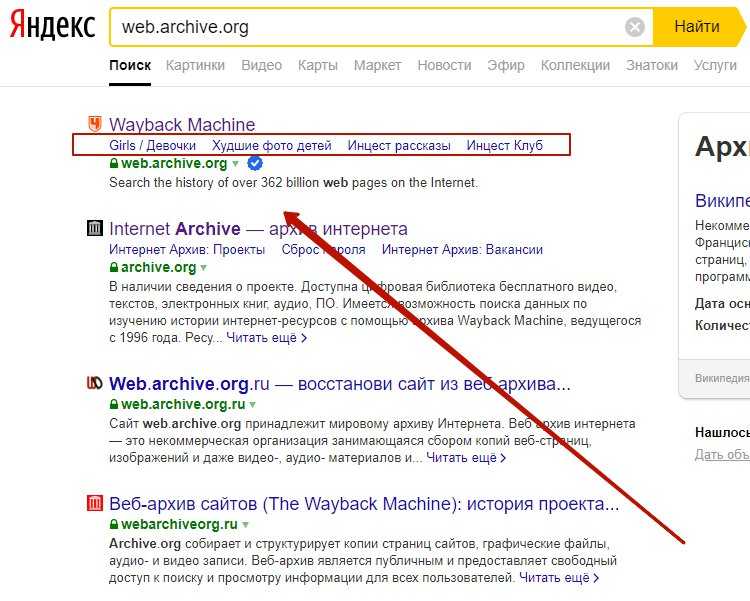
- Выполняйте поиск по ключевым словам здесь https://web.archive.org
Пример: выполните поиск по запросу «осама бен ладен», чтобы увидеть, какие результаты были обнаружены, или выполните поиск в социальных сетях пользователей, таких как профиль Facebook Марка Цукерберга. https://web.archive.org/web/*/www.facebook.com/zuck
- Используйте функцию расширенного поиска здесь https://archive. org или напрямую посетив https://archive.org/advancedsearch.php, чтобы выполнить более целенаправленный поиск и иногда найти адрес электронной почты, связанный с пользователем, загрузившим файл .
Чтобы получить доступ к некоторым файлам, вам необходимо войти в систему. Здесь вы создаете фальшивую исследовательскую учетную запись для дальнейшего расследования https://archive.org/account/signup
 org или напрямую посетив https://archive.org/advancedsearch.php, чтобы выполнить более целенаправленный поиск и иногда найти адрес электронной почты, связанный с пользователем, загрузившим файл .
org или напрямую посетив https://archive.org/advancedsearch.php, чтобы выполнить более целенаправленный поиск и иногда найти адрес электронной почты, связанный с пользователем, загрузившим файл . - Используйте приведенные ниже шаги, чтобы понять, как найти адрес электронной почты. связанные с загруженными файлами. Для исследования OSINT, если вы идентифицируете адрес электронной почты, это еще один момент, который вы можете использовать и искать этот адрес электронной почты в других местах, таких как поисковые системы или сайты социальных сетей.
Пример: https://archive.org/details/FlintstonesWinstonCigaretteCommericals
- Прокрутите ниже, чтобы найти «варианты загрузки»
- Нажмите «показать все», чтобы отобразить все файлы.
- Нажмите на файл, оканчивающийся на «meta. xml»
- Ctrl+f для слова «загрузчик», и вы увидите адрес электронной почты: [email protected]
 xml»
xml»Нажмите кнопку «Показать все», отображаемую в светло-серое поле справа. Нажмите на …meta.xml-файл в результатах.
Использование коллекций и изменений (бета):
- Коллекции — это способ узнать, почему URL-адрес был заархивирован в Wayback Machine.
Пример: https://web.archive.org/web/collections/2020*/osinttechniques.com
- Изменения позволяют пользователям выбрать 2 разные версии URL-адреса и сравнить их рядом друг с другом.
Пример: https://web.archive.org/web/changes/osinttechniques.com
Узнайте больше о коллекциях и изменениях здесь: https://blog.archive.org/2019/10/18/the-wayback-machine-fighting-digital-extinction-in-new-ways
Сохранение страниц:
- Используйте https://archive.org/web/, чтобы запросить архивирование страницы , кнопку сохранения можно увидеть в правом нижнем углу экрана или перейти непосредственно на https://web. archive.org/save. Этот параметр «Сохранить страницу сейчас» захватывает только эту конкретную страницу, а не весь веб-сайт, и работает только для сайтов, на которых разрешены поисковые роботы. На скриншоте ниже показано сохранение статьи из OSINT Curious в архив.
 archive.org/save. Этот параметр «Сохранить страницу сейчас» захватывает только эту конкретную страницу, а не весь веб-сайт, и работает только для сайтов, на которых разрешены поисковые роботы. На скриншоте ниже показано сохранение статьи из OSINT Curious в архив.
archive.org/save. Этот параметр «Сохранить страницу сейчас» захватывает только эту конкретную страницу, а не весь веб-сайт, и работает только для сайтов, на которых разрешены поисковые роботы. На скриншоте ниже показано сохранение статьи из OSINT Curious в архив.Для целей поиска может быть важно понять, когда что-то было сохранено Интернет-архивом. Давайте посмотрим на ссылку ниже:
https://web.archive.org/web/20180214034336/http://www.osinttechniques.com
Формат чисел в середине: ггггммддччммсс, поэтому дата сайта проползла 14 февраля 2018 года в 03:43 и 36 секунд.
Что делать, если исследуемого вами сайта нет в Интернет-архиве? Некоторые сайты не будут включены в Archive.org из-за файлов robots.txt или из-за того, что владелец веб-сайта попросил не помещать их сайт в архив.
Однако у вас есть другие параметры поиска, такие как поиск содержимого кеша, как указано в этом сообщении в блоге https://osintcurio.us/2019/02/12/osint-on-deleted-content, или проверка других онлайн-архивов, таких как архив . Cегодня.
Cегодня.
Нравится:
Нравится Загрузка…
Риту ГИЛЛ @ OSINTtechniques архив
Прямая трансляция
Присоединяйтесь к нашим прямым трансляциям на YouTube, Twitch и Twitter.
Дискорд-сервер
Пообщайтесь с нами на сервере The OSINT Curious Discord.
Лучшие публикации и страницы
Как отслеживать пользователей социальных сетей на разных платформах
Поиск с помощью Shodan
5 основных адресов электронной почты Риту Ресурсы OSINT
10-минутные советы
Отслеживание всего, что связано с WiFi
Категории
КатегорииВыбрать категориюаудио (1)браузер (3)даркнет (3)Facebook (9)судебная экспертиза (3)геолокация (6)изображения (9)инстаграм (2)интернет-устройства (2)расследование (5)право (3)карты/спутник (3)новички в OSINT (1)оперативная безопасность (6)OSINT (54) конфиденциальность (1)python (2)безопасность (4)социальные сети (12) Bitmoji (1) Discord (1) LinkedIn (2) Snapchat (3)sock puppet (1)инструменты (1)без категорий (3)видео (1) беспроводной (1)
Стать покровителем
Поддержите нас, пожертвовав на Patreon.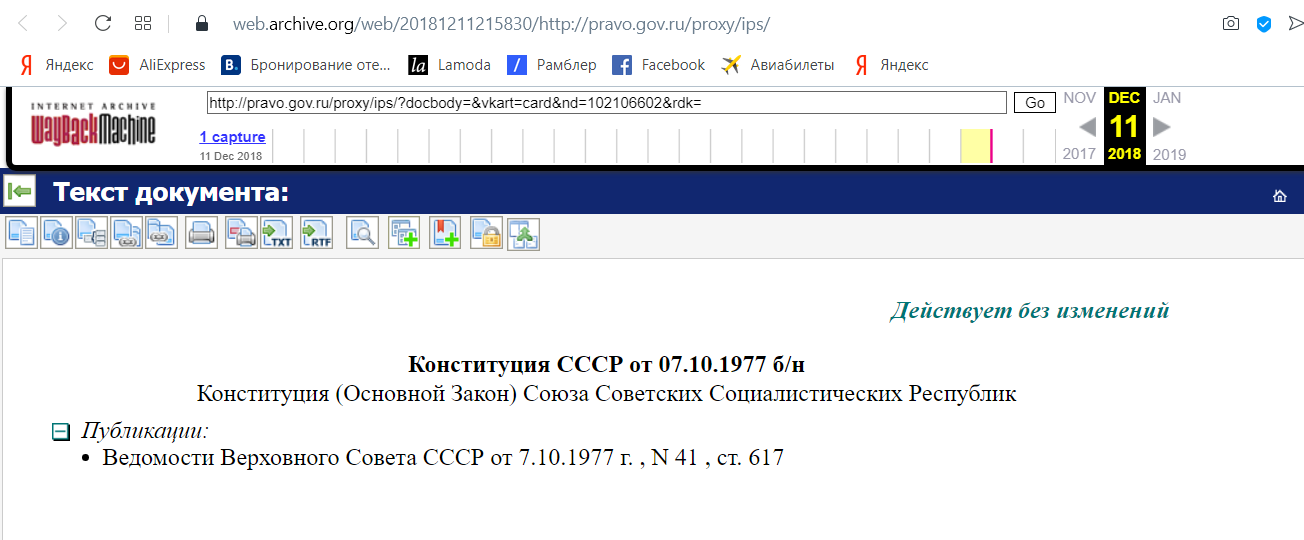 com!
com!
Amazon Smile
Когда вы совершаете покупки на сайте smile.amazon.com, Amazon делает пожертвование в пользу The Osint Curious Project.
«Любопытное» снаряжение!
Зайдите в наш магазин на RedBubble, чтобы получить свой собственный OSINT Любопытные предметы!
Следите за блогом по электронной почте
Введите свой адрес электронной почты, чтобы следить за этим блогом и получать уведомления о новых сообщениях по электронной почте.
Адрес электронной почты
Архивы
Архивы
Выберите месяц ноябрь 2022 (4) октябрь 2022 (3) сентябрь 2022 (1) август 2022 (2) июнь 2022 (1) май 2022 (1) апрель 2022 (2) март 2022 (1) февраль 2022 (1) январь 2022 ( 1) декабрь 2021 (1) ноябрь 2021 (1) сентябрь 2021 (2) июль 2021 (2) июнь 2021 (1) май 2021 (3) апрель 2021 (2) март 2021 (1) февраль 2021 (3) декабрь 2020 ( 1) ноябрь 2020 г. (1) октябрь 2020 г. (2) сентябрь 2020 г. (2) август 2020 г. (2) июнь 2020 г.