Содержание
Составление семантического ядра сайта: статистика поисковых запросов и SeoPult
Составление семантического ядра – это один из важнейших этапов не только продвижения существующего сайта, но и разработки нового ресурса. От характера подобранных поисковых запросов зависит, будут ли они в ТОПе поисковых систем.
Семантическое ядро и статистика поисковых запросов
Семантическое ядро – это совокупность слов и словосочетаний, которые наиболее точно определяют вид бизнеса, товары, услуги или размещенную на сайте информацию. Проще говоря, это те ключевые запросы, которые могут набирать в поисковых системах люди при поиске информации о соответствующих вашему бизнесу товарах, услугах и др.
Составление семантического ядра является одним из самых важных этапов при продвижении сайта с использованием следующие методов:
- Поисковое продвижение сайта. Процесс подготовки семантического ядра заключается в подборе запросов, по которым ваш сайт будет показываться в результатах органической выдачи поисковых систем.

- Реклама в социальных сетях. В социальных сетях при подаче платных таргетированных рекламных сообщений используется набор ключевых слов, в соответствии с которыми и будет показываться сообщение пользователям, чьи персональные данные соответствуют настройкам рекламного объявления.
- Контекстная реклама с помощью Яндекс.Директ, Google AdWords и других систем, в которых основой является показ рекламных объявлений в соответствии с поисковыми запросами.
В качестве основных источников ключевых слов используют статистические сервисы поисковых систем:
- Яндекс.Вордстат (https://wordstat.yandex.ru/) — предоставляет данные о том, сколько раз в месяц пользователи вводят тот или иной запрос в поисковую систему Яндекс.
- Планировщик ключевых слов для Google Adwords (http://adwords.google.com/keywordplanner). С его помощью вы сможете узнать прогноз показов определенного запроса.
- Статистика запросов в Рамблере (http://wordstat.rambler.ru/wrds/). Данный сервис позволяет собирать данные по запросам, которые пользователи вводят в поисковой системе Рамблер, и их словоформам.

Составление семантического ядра с помощью атоматизированной рекламной системы SeoPult
В автоматизированной рекламной системе SeoPult для быстрой и максимально автоматизированной работы с ключевыми запросами предусмотрены широкие возможности. К примеру, пользователь может воспользоваться следующими шестью способами составления списка ключевых слов:
1. Ручное добавление ключевых слов
2. Расширение списка ключевых слов, добавленных вручную
3. Автоматический подбор слов на основе анализа сайта
4. Автоматический подбор слов на основе анализа конкурентов
5. Автоматический подбор слов, близких к ТОП-10
6. Автоматический подбор слов из данных счетчика статистики
Для начала работы по подбору семантического ядра в SeoPult требуется в разделе «Проекты в системе» добавить новый проект (рис. 1).
1).
Рис. 1. Добавление проекта для SEO-продвижения
1. Ручное добавление ключевых слов
После добавления проекта во вкладке «Шаге 1. Слова» можно самим вписать заранее известные или предполагаемые ключевые слова (поисковые запросы). К примеру, мы ввели запросы «эколог» и «экология» (см. рис. 2), которые предположительно могут набирать в строке запроса в поисковых системах наши потенциальные посетители при поиске общей информации по соответствующей профессии или области знаний.
Рис. 2. Форма добавления ключевых слов
Далее можно расширять список ключевых слов с помощью нижеописанных инструментов, формируя тем самым эффективное семантическое ядро для продвижения сайта.
2. Расширение списка ключевых слов, добавленных вручную
Добавленные в ручную слова можно расширить за счет подбора слов на основе собранных статистических данных, используя инструменты подбора слов по статистике Wordstat.Яндекс, по семантике, а также подбор низкочастотных и среднечастотных запросов по собственным методикам Seopult (см. Рис. 3).
Рис. 3).
Рис. 3. Инструменты и списки слов для расширения семантического ядра
Используя данные инструменты можно быстро сформировать эффективное семантическое ядро из предлагаемого системой списка подобранных запросов.
3. Подбор слов на основе анализа сайта
При автоматическом анализе контента страниц сайта и подборе запросов, подборщик автоматически сгенерирует список ключевых слов при нажатии на кнопку «Авто» (см. рис. 2).
4. Автоматический подбор слов на основе анализа конкурентов
Во вкладке «Слова Ваших конкурентов» можно увидеть список сайтов конкурентов и их ключевые слова из ТОП-50 Яндекса.
5. Автоматический подбор слов, близких к ТОП-10
Во вкладке «Близкие к ТОПу» доступен сформированный список найденных запросов и их позиций, которые можно добавить в семантическое ядро.
6. Автоматический подбор слов из данных счетчика статистики
Во вкладке «Из счетчика статистики» показаны запросы, по которым в течение прошлых месяцев были переходы из поисковых систем на продвигаемый сайт. Данные система может получить из счетчиков сайта систем Яндекс.Метрика или Google Analytics (пароли от счетчиков необходимо будет ввести).
Данные система может получить из счетчиков сайта систем Яндекс.Метрика или Google Analytics (пароли от счетчиков необходимо будет ввести).
В заключении следует отметить, что технологии поисковой оптимизации эволюционируют и максимально автоматизируются, переходя к полностью автоматическому формированию семантического ядра. Можно экспериментировать и использовать всевозможные методы поиска эффективных запросов для привлечения посетителей и покупателей.
Список использованных источников:
1. Штарёв А. Создание семантического ядра в SeoPult, 2015 — https://seopult.ru/subscribe.html?id=257
2. Семантическое ядро: 6 адовых ошибок (от Ingate) — http://digital.ingate.ru/#books-show-494
Автор:
директор компании АУП-Консалтинг
Катаев А.В.
Статистика поисковых запросов Яндекса, Google и Рамблера, зачем нужен Вордстат
Доброго времени суток, дорогие читатели. Рассмотрим статистику поисковых запросов от Google, Яндекс и Рамблер. Стоит отметить, что тема достаточно скучная, однако предоставить необходимые знания для продвижения проекта с помощью уникального контента.
Стоит отметить, что тема достаточно скучная, однако предоставить необходимые знания для продвижения проекта с помощью уникального контента.
В связи с этим и получается, что самостоятельное написание статей гарантирует высокую посещаемость и успешность проекта. Однако, к большому сожалению, в реальности это совершенно не так и всему виной та самая вездесущая статистика запросов поиска.
Содержание статьи:
Для чего необходима статистика поисковых запросов
Статистика Яндекса, Google или Рамблера запросов может свести к нулю все старания привлечь пользователей с систем поиска, путем написания познавательных и в полной мере уникальных статей, однако оптимизированных под на авось выбранных запросов.
Именно это и происходит с большинством статей, которые опубликованы без предварительного формирования и анализа актуальных ключевых слов из запросов, непосредственно связанных с тематикой ресурса.
Как результат, это испорченное настроение, поскольку статьи могли быть годными и способными привлекать посетителей с разных систем поиска одновременно по большому количеству ключевых слов и фраз, имеющий огромную частотность. Именно поэтому так важно разобраться с проблемой учета данных информации запросов поиска.
Именно поэтому так важно разобраться с проблемой учета данных информации запросов поиска.
Загвоздка заключается в слепой работе, то есть без предварительного формирования семантического ядра для текста определенной статьи, что значительно повлияет на промах в оптимизации и внутренней перелинковке совершенно не под нужные запросы поиска, которые в свою очередь отвечают за привлечение большого количества посетителей.
Зачастую, промах в таком деле – не редкое явление, поскольку он основан на интуитивном формировании многообещающих запросов, которые позже огорчат своими значениями в статистике Яндекса или Google, поскольку они оказались просто пустышками, то есть запросами, ключами которых пользователи достаточно редко используют в запросах.
Скорей всего, такой проблемы бы не было, если бы все вебмастера были в равных условиях и не имели доступа к статистике для просмотра и анализа запросов. Но, это не так, поэтому не воспользоваться такой возможностью – глупость.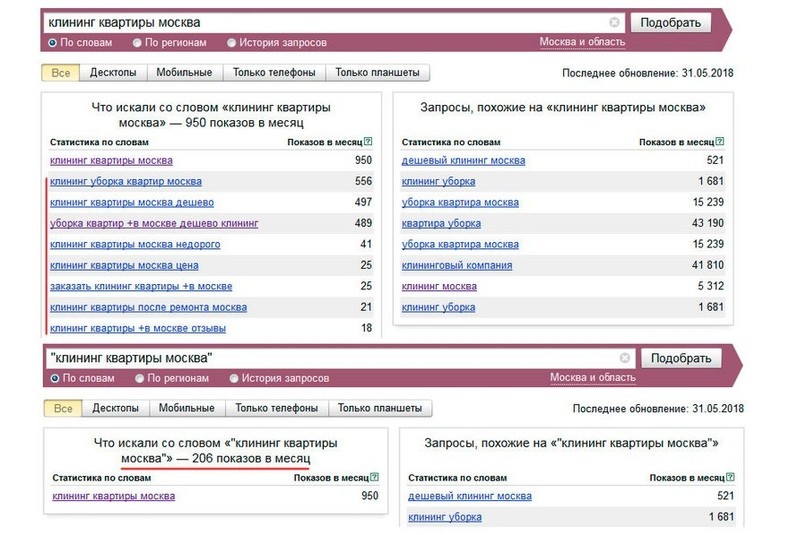
Нужно научится не обращать внимание на “троллей”, которые что только и делают так это кричат о опущении проекта для людей до уровня проектов, нацеленных на заработок, составив изначально небольшое семантическое ядро для будущего текста статьи, использовав при этом онлайн сервисы статистики запросов поиска Яндекса или Google и Рамблер. Не нужно заспамливать ключевыми словами текст статьи, поскольку все можно изменить лишь в худшую сторону.
Сначала рассмотрим фактическую информацию, а далее сведения, основанные на опыте вебмастеров. Так что приступим. Начнем с того, зачем Яндекс, Google или Рамблер предоставляют нам возможность смотреть их статистику?
Поскольку оптимизаторы, а они же Seo-шники, всегда находились совершенно в другой стороне по отношению к системам поиска. Ответ достаточно банальный. Все заключается в деньгах так, как оптимизаторы получают часть прибыли у поисковиков от контекстной рекламы. А клиенты Директа или Adwords привлекают посетителей за счёт услуг оптимизаторов.
Все действительно достаточно странно, что Гугл и Яндекс позволяют оптимизаторам следить за статистикой запросов поиска. Но снова же таки, ответ в том, что навязан некий способ заработка поисковиков. Все упирается в то, что рекламодатели контекста требуют эту информацию для формирования наиболее оптимизированных объявлений для Яндекс директа или же Google Adwords. Благодаря этому статистика запросов доступна и для нас, что мы свою очередь используем, для собственных интересов.
Ресурсы статистики поисковых запросов в Яндексе, Google и Rambler
К наиболее оптимальным и удобным сервисам, предназначенными для получения непосредственной статистики запросов поиска относятся:
статистика запросов Яндекса – главное орудие вебмастеров. Вордстат предоставляет данные в немного упрощенной форме. Однако, используя специальные операторы можно конкретизировать статистику Яндекса по необходимым словоформам не поискового запроса. Достаточно лишь заключить нужную фразу в кавычки или перед каждым словом фразы без пробелов поставить восклицательные знаки и заключить все в кавычки.

Замечательно, что на данном ресурсе отображаются расширенные варианты запросов с приставкой других слов, что в свою очередь влияет на расширение семантического ядра.
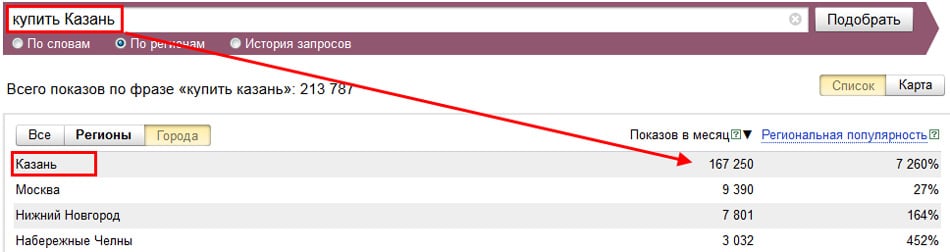
Первая вкладка “По словам” статистики Яндекса отображает число введенных слов, а на вкладке “По регионам” приводится информация запросов с нужным ключом по регионах.
Вкладка “Карта” дает возможность узнать о частотности употребления конкретного слова пользователями в поисковых запросах. Эту же частоту можно отслеживать за определенный период с помощью вкладки “по месяцах” и “по неделях”.
статистика запросов Рамблера – статистика, которая в последнее время стремительно теряет свою востребованность по причине малой доли самой системы поиска. Данная статистика отличается от Яндекса тем, что в ней не результаты не объединяются относительно словоформ. То есть частотность отображается только в заданном падеже без склонений.
Данный ресурс уникален тем, что с него можно узнавать количество просмотров первой страницы поисковой выдачи и количество просмотров прочих страниц.
Сервис для подбора ключевых слов. Хороший инструмент для расширения семантического ядра статьи или сайта. Гугл, в отличие от Яндекс, самостоятельно идентифицирует регион, а нам остается только, при работе с ним вводить стартовые наборы ключей, после чего будут отображены фразы с ключами и частотностью употребления при поиске за один месяц.
Статистика поиска Google – ресурс, который позволяет сравнивать популярность определенных двух ключевых фраз. Динамика популярности за некий период времени отображается виде диаграмм.
Как правильно работать со статистикой Яндекс?
Не стоит путать между собой поисковые запросы и ключевые слова. Первое является набором слов, вводимых в поисковую строку любым пользователем. Есть некие определенные комбинации слов, которые запрашивают у поисковика очень часто (ВЧ – высокочастотные, более 10 000 показов за один месяц), а есть менее востребованные (СЧ – среднечастотные, между 1 000 – 10 000 показов в один месяц), а также встречаются редкие наборы слов (НЧ – низкочастотные, менее 1 000 показов за один месяц).
Разумеется, что для формирования семантического ядра лучше всего выбирать запросы с высокой частотой показов, поскольку в результате завоевания позиции на первой странице гарантировано можно получить огромный приток посетителей. Следовательно, продвигаться, опираясь на ВЧ и СЧ будет достаточно непростой задачей.
По этой причине подбирая поисковые запросы для формирования семантического ядра для сайта или статьи лучше предварительно объективно оценить соответственные возможности, поскольку в противном случае не получится занять позицию в ТОП-10, если есть возможность получить аж целых ничего по ВЧ. Бывают исключения, когда эффективнее продвигать проект по НЧ. Это непосредственно зависит от специфики и тематики сайта.
И вот, мы наконец-то подошли к оптимизации с помощью ключевых слов, которые дают возможность продвигать проект по определённых запросах. Достаточно часто первая десятка ключей для семантического ядра состоит из одного и того же самого слова или фразы, которое надо включить в текст статьи N раз. Title нужно формировать из основных ключей, то есть тех, которые имеют самую высокую частотность.
Title нужно формировать из основных ключей, то есть тех, которые имеют самую высокую частотность.
Попробуйте поэкспериментировать в Вордстате и вы убедитесь, что на самом деле при всем количестве фраз из семантического ядра статьи, подходящих ключевиков не так уж и много для оптимизации текста. Для страницы со статьей требуется всегда и обязательно грамотно составленный Title, который должен содержать ключи из самых частых поисковых запросов, а в самой статье надо минимум по 1 – 2 % употребить каждый ключ от объема всего текста статьи. При этом следите за заспамленностью. Не рекомендуется употреблять один ключ в прямом вхождении более 3 %, поскольку возникнет угроза исключения теста из индекса системы поиска. Оптимальнее всего ключевики включать в разных словоформах, не теряя при этом логики содержимого. При проверке текста не обращайте внимание на тошноту, поскольку ее показатель – это корень квадратный из наиболее часто употребляемого слова в тексте. А, следовательно, чем больше статья, тем выше показатель тошноты, что совершенно не отвечает никакой логике.
Подведем итог. Предварительно сформировав список часто вводимых запросов пользователями, которые необходимы для расчёта притока посещаемости, надо четко определить ключевые слова, которые дальше включить в Title (основные, то есть с самой высокой частотностью), продвигаемого сайта, и включить ключи не более 1 – 2 % в текст статьи от общего количества слов.
Благодаря Вордстату вы сможете подвергать анализу содержимое вашего проекта и корректировать направление его развития. Более того, данный сервис позволяет определится с тематикой будущих статей, основываясь на часто набираемые запросы в поисковики пользователями. Все это в результате принесет высокие результаты и успех проекту, поскольку заранее предугадывать интересы потенциальных пользователей – это преимущество над конкурентами.
К слову, с помощью анализа можно не только предугадать актуальность тем, но и актуальность содержимого уже на существующем сайте, что позволит узнать какие позиции занимает ваш ресурс по интересующему ключу или словосочетанию.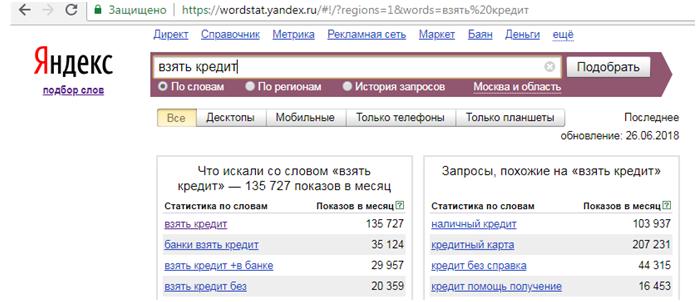
Успешные оптимизаторы дополнительно используют программу “Site Auditor”, которая определяет видимость сайта по определённому запросу. Все что нужно, так это в вкладке “Подбор” программы ввести интересующие слова и начать проверку, после которой программа перекидывает на вкладку “Видимость сайта”, где спрашивает URL ресурса.
В результате проделанных манипуляций с программой, отобразятся позиции сайта в поисковых системах Яндекс и Гугл по заданному ключевому слову или фразе. Если ваш ресурс не отображается, значит он ниже пятидесятой позиции в поисковой выдаче.
Смотрите так же на нашем сайте:
последние новые функции интеллектуального анализа текста
Что нового в версии 2022?
Мы рады представить WordStat 2022. Переход с WordStat 9 на новую версию WordStat 2022 (и новую схему нумерации версий) означает более быстрое введение новых функций, выпускаемых каждый год, а не каждые 2 или 3 года, и, вероятно, даже более одного раза в год.
В новом WordStat 2022 реализовано несколько важных функций, которые, хотя и не так многочисленны, как в предыдущих основных выпусках, но, по нашему мнению, имеют большое значение, особенно для разработки моделей классификации, таксономий или словарей.
1. Высокооптимизированное тематическое моделирование с факторным анализом
В WordStat 2022 мы внедрили новую процедуру многопоточного факторного анализа, которая работает до 65 раз быстрее, чем в предыдущих версиях. Это означает, что большие задачи, на вычисление которых ушел бы час, теперь могут быть получены менее чем за минуту. Мы также смогли увеличить емкость факторного анализа до 10 000 слов (с 3 000 в предыдущих версиях).
Наши собственные исследования показали, что тематическое моделирование с использованием факторного анализа дает тематические решения, которые являются более последовательными, а также более разнообразными, чем методы тематического моделирования, основанные на методах LDA и нейронных сетей (Peladeau & Davoodi, 2018; Peladeau, 2022). Он также имеет дополнительное преимущество, заключающееся в том, что он стабилен и каждый раз дает одинаковые результаты. Однако главными его неудобствами всегда были скорость и вместительность. Это привело нас к реализации в WordStat 8 специальной процедуры извлечения темы с использованием неотрицательной матричной факторизации (или NMF). Этот метод гораздо быстрее дает результаты, очень похожие на результаты, полученные с помощью факторного анализа. Однако его вероятностная реализация приводит к тому, что результаты немного отличаются от одного прогона к другому, что некоторые исследователи находят несколько тревожным. Важно отметить, что почти все другие популярные методы тематического моделирования в компьютерных науках дают тематические решения, которые еще более нестабильны, чем наша собственная реализация NMF. Те, кто ищет оптимальные и стабильные тематические решения, вероятно, оценят значительно улучшенную скорость и возможности новой процедуры тематического моделирования факторного анализа.
Он также имеет дополнительное преимущество, заключающееся в том, что он стабилен и каждый раз дает одинаковые результаты. Однако главными его неудобствами всегда были скорость и вместительность. Это привело нас к реализации в WordStat 8 специальной процедуры извлечения темы с использованием неотрицательной матричной факторизации (или NMF). Этот метод гораздо быстрее дает результаты, очень похожие на результаты, полученные с помощью факторного анализа. Однако его вероятностная реализация приводит к тому, что результаты немного отличаются от одного прогона к другому, что некоторые исследователи находят несколько тревожным. Важно отметить, что почти все другие популярные методы тематического моделирования в компьютерных науках дают тематические решения, которые еще более нестабильны, чем наша собственная реализация NMF. Те, кто ищет оптимальные и стабильные тематические решения, вероятно, оценят значительно улучшенную скорость и возможности новой процедуры тематического моделирования факторного анализа.
2. Улучшенные предложения на странице Частоты
Панель Предложений в предыдущих версиях WordStat отображала синонимы, антонимы и родственные слова для языков, для которых был доступен тезаурус. В нем также представлены слова, начинающиеся с одних и тех же начальных букв, что позволяет определить некоторые орфографические ошибки, а также родственные слова. Новый раздел Associated Words теперь извлекает из корпуса текстов другие слова, семантически, синтаксически и статистически связанные с выбранными словами в частотной таблице. Эта новая функция должна работать на любом языке. Записи будут перечислены по умолчанию в порядке убывания релевантности. Синонимы, антонимы и родственные слова также будут отсортированы в порядке убывания релевантности, что облегчит определение подходящих предложений. Можно по-прежнему сортировать эти записи в алфавитном порядке или в порядке убывания частоты. Кроме того, новая опция частотной фильтрации позволяет отфильтровывать низкочастотные предложения, позволяя сосредоточиться на более частых предложениях.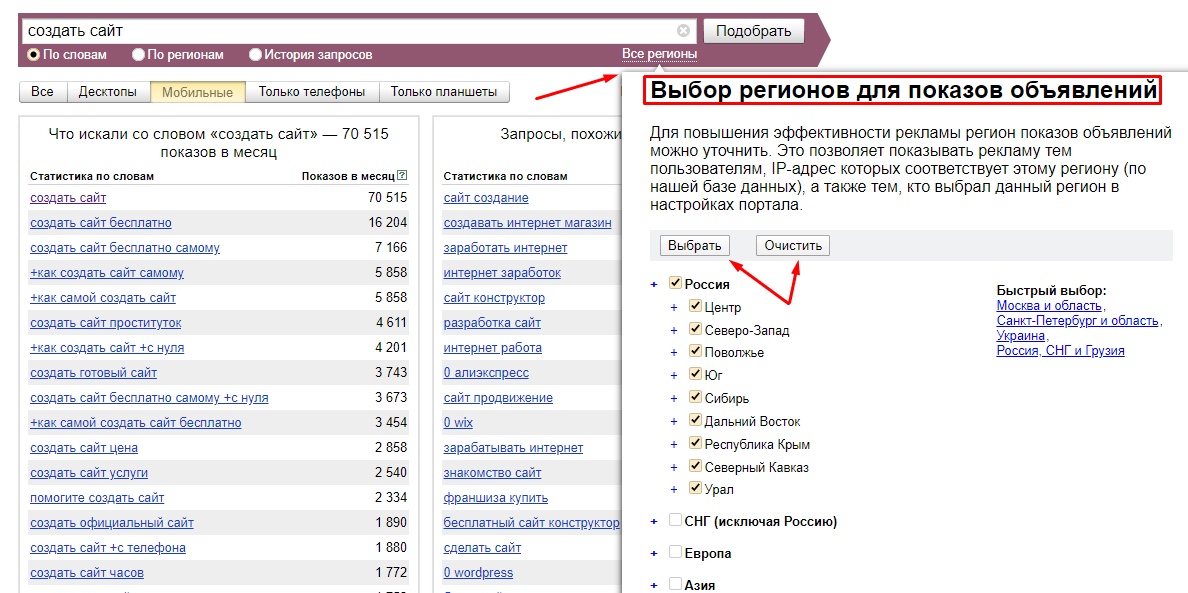
Поскольку этот новый способ извлечения связанных слов и упорядочивания предложений не зависит от языка, он будет особенно полезен для людей, анализирующих языки, для которых нет тезауруса. Тем не менее, мы обнаружили, что даже когда такие лингвистические ресурсы доступны, дополнительные предложения, основанные на контекстуальном использовании слов и сортировке существующих синонимов и связанных слов по релевантности, должны значительно облегчить идентификацию соответствующих элементов.
3. Новая вкладка предложений для процедуры извлечения фраз.
Панель Overlap была заменена панелью Suggestions , отображающей фразы, семантически, синтаксически или статистически связанные с выбранными строками в таблице частоты фраз, в дополнение к перекрывающимся фразам. Эта функция также не зависит от языка.
4. Улучшение распознавания именованных объектов.
На страницу Распознавание именованных объектов добавлена новая панель Related .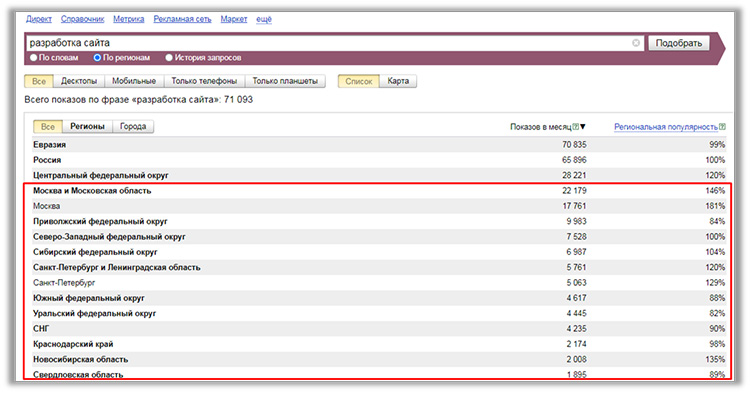 При выборе одного именованного объекта появятся связанные именованные объекты, а также объекты, принадлежащие к одному и тому же классу (люди, место, организация и т. д.). При выборе нескольких примеров определенного класса (например, нескольких городов) также будет получено больше элементов, принадлежащих этому классу. Контекстное меню также позволяет переместить любой элемент в словарь категорий или в список исключений. По выбранным предложениям также может быть выполнен поиск по ключевым словам в контексте.
При выборе одного именованного объекта появятся связанные именованные объекты, а также объекты, принадлежащие к одному и тому же классу (люди, место, организация и т. д.). При выборе нескольких примеров определенного класса (например, нескольких городов) также будет получено больше элементов, принадлежащих этому классу. Контекстное меню также позволяет переместить любой элемент в словарь категорий или в список исключений. По выбранным предложениям также может быть выполнен поиск по ключевым словам в контексте.
5. Выделение контекстных слов в таблицах ключевых слов в контексте.
При оценке слов в категоризационном словаре или кандидатов на включение часто необходимо смотреть на наличие дополнительных ключевых слов в контексте появления целевого слова или фразы. Новая функция выделения позволяет указать список слов и фраз для поиска в окружающем контексте слова. Этот список заполняется автоматически, когда список KWIC вызывается из моделирования темы или из дендрограммы, или при оценке элементов в категории содержимого, содержащей несколько записей.
6. Фильтрация элементов в графиках соответствий по частоте или расстоянию от исходной точки.
Графики соответствия из более чем нескольких сотен элементов могут создавать темную массу перекрывающихся элементов в центре графика (начало). Добавлен новый ползунок для скрытия элементов, которые встречаются реже или близки к этому происхождению. Если кто-то не хочет определить, что является общим для всех классов независимой переменной, наиболее интересными являются те элементы, которые далеки от начала, поскольку они характеризовали разные классы. Фильтрация этих элементов позволяет легче идентифицировать дифференцирующие элементы.
7. Улучшенный поиск по ключевым словам
Результаты поиска по ключевым словам теперь сортируются в порядке убывания релевантности с учетом как частоты, так и разнообразия совпадающих элементов в зависимости от длины полученного текстового сегмента. Новый столбец частоты также можно использовать для сортировки только по частотам.
8. Вычисление строковой переменной конкатенацией
Новая команда преобразования данных позволяет вычислять строковую переменную путем конкатенации значений нескольких существующих переменных (числа, строки, даты и т.д.), а также печатного текста. Такую процедуру также можно использовать для инициализации строковой переменной постоянным строковым значением.
9. Постоянные настройки сравнительных диаграмм
Тип диаграммы и статистика, а также цветовая палитра этих сравнительных диаграмм теперь связаны с именем переменной и хранятся в настройках проекта. Эти параметры должны оставаться постоянными на всех страницах (частоты, фразы, моделирование тем, дендрограмма и т. д.) и между сеансами, что снижает необходимость постоянной корректировки этих параметров.
Что нового в версии 9.0?
1. Полная поддержка Unicode
Мы всегда стараемся выбирать методы анализа текста, не зависящие от языка. Это позволило пользователям анализировать текстовые данные на более чем 50 языках. Однако для анализа языков, не поддерживаемых установкой Windows по умолчанию, пользователю необходимо изменить некоторые параметры Windows. И хотя можно было анализировать наборы данных на нескольких языках, некоторые комбинации языков были просто невозможны. Новая версия Unicode WordStat позволяет анализировать любой из них без каких-либо изменений настроек, а также новые языки, ранее не поддерживаемые, такие как китайский, японский или тайский. Также были добавлены процедуры сегментации слов для трех предыдущих азиатских языков.
2. Интеграция сценариев предварительной и последующей обработки R и Python
В 2018 г. мы представили возможность создания сценариев предварительной обработки Python в WordStat 8. Версия 9.0 расширяет эту возможность, предлагая возможность создавать сценарии предварительной обработки в Р тоже. Что еще более важно, теперь можно создавать сценарии постобработки на этих двух языках программирования, что позволяет выполнять пользовательский анализ исходных или преобразованных текстовых данных или количественных результатов, полученных в результате анализа содержимого этих документов. Такая функция предлагает бесконечные возможности для расширения функций WordStat, таких как внедрение новых алгоритмов машинного обучения, передовых методов статистического моделирования или преобразования пользовательских данных. Были включены примеры сценариев для вычисления показателей удобочитаемости текста, определения языков, применения других методов тематического моделирования (LDA или STM) или создания прогностических моделей с использованием машинного обучения (SVM, kNN и т. д.).
3. Автоматическая коррекция орфографии
Новый механизм проверки орфографии был написан с нуля для достижения гораздо более быстрой и точной коррекции орфографии, что позволяет реализовать функцию автоматической коррекции орфографии с минимальным влиянием на существующую скорость обработки текста. из WordStat. Интеллектуальная коррекция орфографии может даже исправить написание неизвестных терминов, таких как технические словари, имена собственные и т. д. Результаты могут быть автоматически сохранены в списке замен для пересмотра и исправления.
4. Кросс-таблица с панелями диаграмм и фильтрацией
Страница кросс-таблицы теперь включает панель диаграммы, позволяющую быстро построить распределение выбранных строк таблицы кросс-таблицы для значений текущей выбранной переменной или любой другой переменной. Список фильтрации также позволяет анализировать такие распределения для одного значения или набора значений выбранной переменной.
5.
Интерактивная матрица совпадений
На страницу совпадений добавлена новая функция интерактивной матрицы, позволяющая сосредоточиться на определенных совпадениях. Основные результаты состоят из таблицы, отображающей выбор из различных статистических данных о совпадениях. Такая матрица также очень интерактивна, позволяя преобразовывать определенные строки в новые столбцы или наоборот, используя простые операции перетаскивания. Панель диаграмм слева также позволяет оценить распределение конкретного совпадения по другим переменным. Можно также получить быстрый просмотр всех текстовых сегментов, связанных с определенным совпадением. Эту новую функцию WordStat также можно вызвать из списка частот, выбрав целевые элементы (слова или категории контента), которые должны отображаться в виде столбцов, щелкнув правой кнопкой мыши и выбрав Матрица совпадений.
Эту новую функцию WordStat также можно вызвать из списка частот, выбрав целевые элементы (слова или категории контента), которые должны отображаться в виде столбцов, щелкнув правой кнопкой мыши и выбрав Матрица совпадений.
6. Импорт файлов Nexis UNI и Factiva
Представленный в QDA Miner 6.0 в 2020 году, WordStat теперь также может импортировать стенограммы новостей из выходных файлов LexisNexis и Factiva. После выбора одного или нескольких файлов .DOCX или RTF, полученных от этих служб, WordStat извлечет и сохранит в отдельных переменных название и основную часть стенограммы новостей, ее источник, дату публикации и другую соответствующую информацию. Такая функция должна оказаться полезной для управления репутацией, управления брендом, кризисной коммуникации, анализа медиа-фрейминга, сравнительных медиа-исследований и т. д.
7. Пакетная обработка тематических моделей
Выбор количества тем для извлечения с использованием методов тематического моделирования остается вопросом, на который, насколько нам известно, нет однозначного ответа. Мы можем даже усомниться в существовании такого оптимального числа. На самом деле можно даже предположить, что информация, полученная в разных условиях, вполне может служить разным целям или раскрывать разные аспекты реальности. В таком контексте неопределенности исследователи часто хотят сравнить различные решения. Новая функция пакетной обработки позволяет вычислять несколько тематических моделей путем систематического изменения количества тем для извлечения, а для вероятностного метода (например, NNMF) выполнять несколько прогонов с использованием одних и тех же настроек для оценки стабильности результатов. Все решения тематических моделей временно агрегируются в менеджере отчетов, что позволяет сравнивать решения, полученные в нескольких прогонах с разными настройками.
Мы можем даже усомниться в существовании такого оптимального числа. На самом деле можно даже предположить, что информация, полученная в разных условиях, вполне может служить разным целям или раскрывать разные аспекты реальности. В таком контексте неопределенности исследователи часто хотят сравнить различные решения. Новая функция пакетной обработки позволяет вычислять несколько тематических моделей путем систематического изменения количества тем для извлечения, а для вероятностного метода (например, NNMF) выполнять несколько прогонов с использованием одних и тех же настроек для оценки стабильности результатов. Все решения тематических моделей временно агрегируются в менеджере отчетов, что позволяет сравнивать решения, полученные в нескольких прогонах с разными настройками.
8. Создание облаков слов на основе поиска ключевых слов и результатов KWIC
Интерактивные облака слов и таблицы частотности слов теперь могут быть получены непосредственно в результатах поиска ключевых слов и ключевых слов в контексте (KWIC), что позволяет быстро идентифицировать слова, связанные с конкретным содержанием. категории или те, которые появляются до и после определенного целевого элемента.
категории или те, которые появляются до и после определенного целевого элемента.
9. Более мощные правила близости
Количество условий в правилах близости увеличено с четырех до максимум двадцати условий. Если вы считаете, что этого недостаточно, сообщите нам об этом.
10. Предварительный просмотр эффекта подстановочных знаков и взаимодействий со словарем
Использование подстановочных знаков в словаре весьма полезно, но потенциально проблематично, поскольку оно может сопоставлять элементы, о которых вы, возможно, и не подозревали. Например, такая запись, как НАЛОГ*, может позволить вам сопоставить НАЛОГ, НАЛОГИ, НАЛОГООБЛОЖЕНИЕ, но также будет соответствовать таким словам, как ТАКСИ, ТАКСОНОМИЯ, ТАКСИДЕРМИЯ и т. д. Кроме того, правила WordStat для сопоставления элементов и предотвращения двойного подсчета также могут привести к неожиданным результатам. результаты, вызванные другими записями в вашей модели категоризации. Новая панель справа от страниц исключения и категоризации позволяет вам легко идентифицировать новые записи, которые будут сопоставляться с использованием подстановочного знака * в конце слова, а также возможные конфликты с другими записями в вашем словаре.
Новая панель справа от страниц исключения и категоризации позволяет вам легко идентифицировать новые записи, которые будут сопоставляться с использованием подстановочного знака * в конце слова, а также возможные конфликты с другими записями в вашем словаре.
11. Защита паролем файлов проекта
WordStat 9.0 теперь предлагает возможность защиты паролем файлов проекта, ограничивая доступ к определенным проектам только авторизованным пользователям. Диалоговое окно позволяет администратору проекта создавать новые учетные записи пользователей и указывать, какую операцию может выполнять каждый пользователь. Можно ограничить редактирование данных, импорт или преобразование данных, а также экспорт данных проекта, таблиц и графики. В качестве альтернативы вы можете позволить пользователям выполнять любое преобразование, которое они хотят, но запретить им сохранять файл проекта.
12.
Новые параметры очистки данных
Страница предварительной обработки теперь включает параметры для автоматического удаления URL-адресов из текстовых сообщений, а также обозначений выступающих в новостях и расшифровках интервью.
13. Новые диаграммы с областями с накоплением
Функция построения диаграмм на странице кросс-таблицы добавляет возможность создания двух типов диаграмм с областями с накоплением.
14. Цветные элементы на графике соответствия
Цветовые градиенты теперь можно использовать для представления положения конкретных элементов или классов переменных в третьем (глубинном) измерении или на графике соответствия 2D и 3D. Для создания этих градиентов можно выбрать до четырех цветов.
15. Улучшенная пузырьковая диаграмма
Теперь можно переставлять строки и столбцы пузырьковых диаграмм.
16. Буфер анализа каналов
Буфер анализа каналов позволяет вернуться к предыдущим диаграммам каналов, а затем перейти вперед.
17. Более быстрое и точное обогащение тем
WordStat выходит за рамки обычного моделирования тем, предлагая «уникальную функцию обогащения тем, которая идентифицирует связанные фразы, возможные исключения и орфографические ошибки. Он также автоматически генерирует соответствующие названия тем. С версией 9, эта функция обогащения темы теперь работает в два раза быстрее, чем раньше, и обеспечивает лучшее устранение неоднозначности слов для более точного списка исключений. Он также предоставляет лучшие предложения по исправлению орфографии.
Он также автоматически генерирует соответствующие названия тем. С версией 9, эта функция обогащения темы теперь работает в два раза быстрее, чем раньше, и обеспечивает лучшее устранение неоднозначности слов для более точного списка исключений. Он также предоставляет лучшие предложения по исправлению орфографии.
18. Повышенная скорость и точность существующих исправлений орфографии
Существующая функция исправления орфографии теперь работает до 30 раз быстрее, и требуется всего одна или две секунды, чтобы предложить исправления для десятков тысяч неизвестных слов.
19. Новый формат файла .PPRJ
Создан новый формат файла с новым расширением файла (.pprj), обеспечивающий улучшенную поддержку данных Unicode. Тем не менее, WordStat 9 сохраняет обратную совместимость с предыдущими версиями всего нашего программного обеспечения и может открывать и анализировать текущие файлы проекта (.ppj), созданные QDA Miner, SimStat или более ранними версиями WordStat.
20.
 Многочисленные дополнительные улучшения
Многочисленные дополнительные улучшения
В существующие диалоговые окна, графику, управление данными и функции анализа данных было внесено несколько дополнительных опций и улучшений интерфейса.
Новые возможности WordStat 8 можно посмотреть здесь
Программное обеспечение для анализа текста и майнинга | Простой в использовании контент-анализ
WordStat — это гибкое и простое в использовании программное обеспечение для анализа текста — нужны ли вам инструменты анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента. WordStat может использоваться всеми, кому необходимо быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и интеллектуального анализа текста можно использовать во многих приложениях, таких как анализ открытых ответов, бизнес-аналитика, контент-анализ новостей, обнаружение мошенничества и многое другое. Полная интеграция WordStat с SimStat — наш инструмент для анализа статистических данных — QDA Miner — наше программное обеспечение для качественного анализа данных — и Stata — комплексное статистическое программное обеспечение от StataCorp, обеспечивающее беспрецедентную гибкость при анализе текста и сопоставлении его содержимого со структурированной информацией, включая числовую. и категориальные данные.
Полная интеграция WordStat с SimStat — наш инструмент для анализа статистических данных — QDA Miner — наше программное обеспечение для качественного анализа данных — и Stata — комплексное статистическое программное обеспечение от StataCorp, обеспечивающее беспрецедентную гибкость при анализе текста и сопоставлении его содержимого со структурированной информацией, включая числовую. и категориальные данные.
СКАЧАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ ЗАПРОСИТЬ ВЕБ-ДЕМО
ИССЛЕДОВАНИЕ СОДЕРЖИМОГО ДОКУМЕНТА С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИИ ТЕКСТОВ
• Анализ больших объемов неструктурированной информации с помощью WordStat. Программное обеспечение может обрабатывать 25 миллионов слов в минуту, быстро извлекать темы и автоматически определять закономерности, используя кластеризацию, многомерное масштабирование, диаграммы близости и многое другое.
БЫСТРОЕ ИЗВЛЕЧЕНИЕ ЗНАЧЕНИЯ, ИСПОЛЬЗУЯ РЕЖИМ ПРОВОДНИКА
• Быстро и легко извлекайте смысл из больших объемов текстовых данных, используя режим Проводника, специально созданный для тех, у кого мало опыта анализа текста. Одним щелчком мыши вы можете извлечь наиболее часто встречающиеся слова, фразы и самые важные темы в ваших документах.
Одним щелчком мыши вы можете извлечь наиболее часто встречающиеся слова, фразы и самые важные темы в ваших документах.
ИМПОРТ ИЗ МНОГИХ ИСТОЧНИКОВ
• Импорт Word, Excel, HTML, XML, SPSS, Stata, NVivo, PDF-файлов, а также изображений. Подключайтесь и напрямую импортируйте данные из социальных сетей, электронной почты, платформ веб-опросов и инструментов управления ссылками.
ИЗВЛЕЧЕНИЕ НАИБОЛЕЕ ЗНАЧИТЕЛЬНЫХ ТЕМ С ПОМОЩЬЮ ТЕМАТИЧЕСКОГО МОДЕЛИРОВАНИЯ
• Получите краткий обзор наиболее важных тем из очень больших текстовых коллекций, используя современное автоматическое извлечение тем на основе слов, фраз и родственных слов (включая орфографические ошибки).
ИССЛЕДУЙТЕ СОЕДИНЕНИЯ
• Исследуйте отношения между словами или понятиями и извлекайте текстовые сегменты, связанные с определенными соединениями.
СВЯЗАТЬ ТЕКСТ СО СТРУКТУРИРОВАННЫМИ ДАННЫМИ
• Исследовать отношения между неструктурированным текстом и структурированными данными, такими как даты, числа или категориальные данные, для выявления временных тенденций или различий между подгруппами или для оценки отношений с рейтингом или другими видами категориальных или числовых данных со статистическими и графические инструменты (анализ соответствия, тепловые карты, пузырьковые диаграммы и др.).
КАТЕГОРИЗАЦИЯ ТЕКСТОВЫХ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ СЛОВАРОВ
• Автоматизируйте полнотекстовый анализ с помощью существующих словарей или создайте собственную модель категоризации со словами, фразами, правилами близости и т. д.
ПОЛУЧИТЕ УНИКАЛЬНУЮ ПОДДЕРЖКУ ДЛЯ СОЗДАНИЯ СЛОВАРОВ
• Создавайте свой словарь быстрее с помощью инструментов для извлечения общих фраз и технических терминов, а также для быстрого выявления в вашей текстовой коллекции орфографических ошибок, синонимов, антонимов и родственных слов.
КАТЕГОРИЗАЦИЯ ТЕКСТОВЫХ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ МАШИННОГО ОБУЧЕНИЯ
• Разрабатывайте и оптимизируйте модели автоматической классификации документов с использованием наивного байесовского метода и метода K-ближайших соседей.
ВОЗВРАТ К ИСХОДНОМУ ДОКУМЕНТУ В ОДИН ЩЕЛЧОК
• Проверяйте или углубляйтесь в свой анализ, возвращаясь к тексту почти любой функции, диаграммы или графика. Вы можете использовать функции поиска ключевых слов или ключевых слов в контексте для поиска предложений, абзацев или целых документов. Это особенно полезно при построении таксономий или для устранения неоднозначности смысла слов. Вы также можете прикрепить коды QDA Miner к извлеченным сегментам.
ВЫПОЛНЕНИЕ КАЧЕСТВЕННОГО КОДИРОВАНИЯ
• Объедините WordStat с современным инструментом качественного кодирования (QDA Miner) для более точного исследования данных или более глубокого анализа конкретных документов или извлеченных текстовых сегментов, когда это необходимо.
ПРЕОБРАЗОВАНИЕ НЕСТРУКТУРИРОВАННОГО ТЕКСТА В ИНТЕРАКТИВНЫЕ КАРТЫ (ОТОБРАЖЕНИЕ ГИС)
• Связывайте неструктурированные текстовые данные с географической информацией и создавайте интерактивные графики точек данных, тематических карт и тепловых карт, а также веб-службу геокодирования для преобразования названий местоположений, почтовых индексов и IP-адресов в широту и долготу.
АВТОМАТИЧЕСКОЕ ИЗВЛЕЧЕНИЕ ИМЕНОВАННЫХ ОБЪЕКТОВ
• Автоматическое извлечение именованных объектов, которые можно добавить в словарь категорий с помощью простой операции перетаскивания.
ЭКСПОРТ РЕЗУЛЬТАТОВ
• Простой экспорт результатов анализа текста в распространенные отраслевые форматы файлов, такие как Excel, SPSS, ASCII, HTML, XML, MS Word, а также графики, такие как PNG, BMP и JPEG.