Содержание
Сетевые базы данных.
Главная / Базы данных / Сетевые базы данных.
в Базы данных
14.01.2018
0
11,441 Просмотров
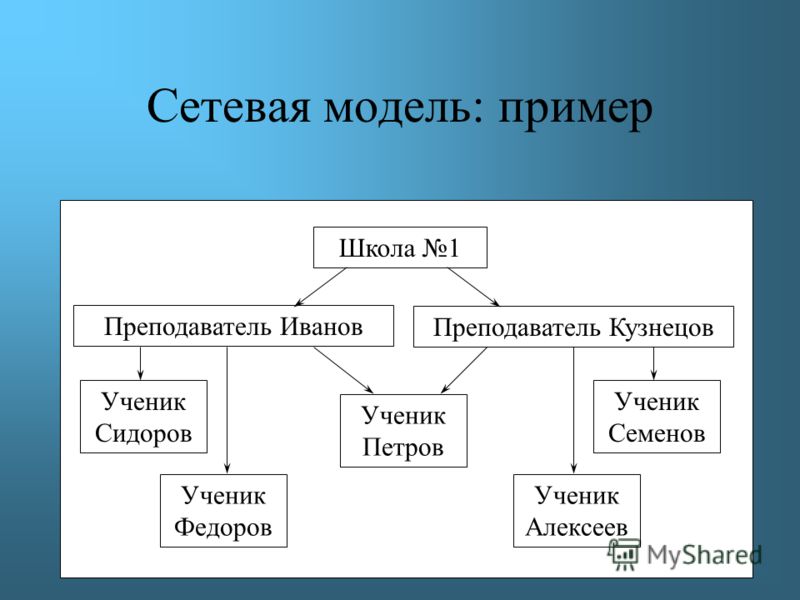
Сетевая база данных – это модель данных, где несколько записей или файлов могут быть связаны с несколькими владельцами файлов и наоборот. Модель может рассматриваться как перевернутое дерево, где каждый член – это отрасли, связанные с владельцем, который находится в нижней части дерева. По сути, это отношения в чистой форме, где один элемент может указывать на множество элементов данных, и само по себе может быть указано несколько элементов данных.
Модель сетевой базы данных позволяет каждой записи иметь несколько родителей и несколько дочерних записей, которые, когда они визуализируются, принимают форму сетевой структуры сетевых записей. В отличие от иерархической модели данных она может иметь только одну родительскую запись, но может иметь много дочерних записей.
Это свойство иметь несколько ссылок применяется двумя способами: схема и сама база данных может рассматриваться как обобщенный график типов записей, которые связаны типами отношений. Основное достоинство базы данных заключается в том, что она позволяет получить более естественное моделирование связей между записями, в отличие от иерархической модели. Но реляционная модель базы данных начала завоевывать всё большую популярность перед сетевой и иерархической моделями из-за её гибкости и производительности, что стало ещё более очевидным, когда аппаратная технология стала ещё быстрее.
Основное достоинство базы данных заключается в том, что она позволяет получить более естественное моделирование связей между записями, в отличие от иерархической модели. Но реляционная модель базы данных начала завоевывать всё большую популярность перед сетевой и иерархической моделями из-за её гибкости и производительности, что стало ещё более очевидным, когда аппаратная технология стала ещё быстрее.
Сетевая модель базы данных
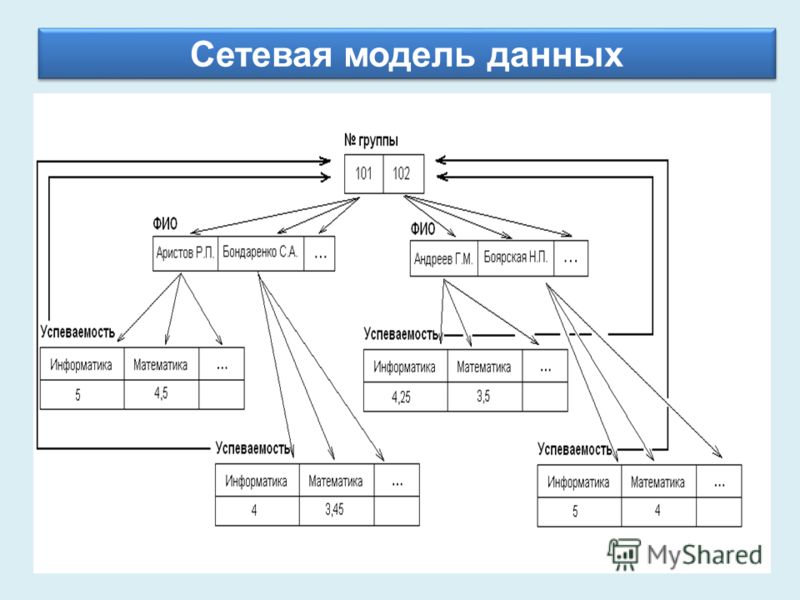
Улучшенная форма иерархической модели данных, сетевая модель представляет данные в виде дерева записей. Связи между таблицами (отчеты) выражаются в виде наборов. В наборе есть одна родительская запись (владелец) и одна или более дочерних записей (члены). Связанные записи в наборе напрямую связаны с указателями, а не путём сопоставления повторяющихся столбцов, как и в случае с реляционной моделью данных.
Записи, связанные с одним владельцем
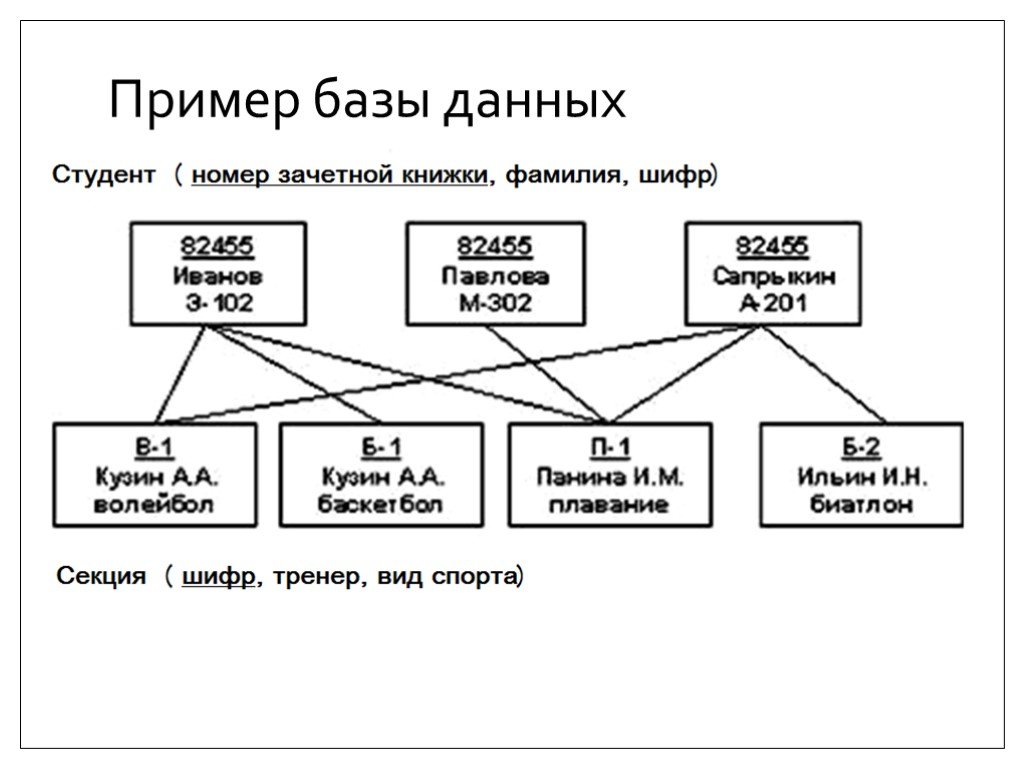
Модель сетевой базы данных позволяет записям из более чем одной таблицы быть связанными с одним владельцем с записями из другой таблицы. Это обеспечивает определенное преимущество над реляционной базой при запросе результатов из нескольких внешних ключей таблиц, связанных с одним первичным ключом таблицы. В базе данных медиа-коллекции, таких как альбом песен и видео записи, все они могут быть членами собственника в одном комплекте, как показано на рисунке 2. Это означает, что оба альбома и фильмы для данного собственника могут быть получены за одну операцию. При этом отпадает необходимость хранить и потенциально изменять порядок временных результатов в середине операции, что приводит к повышению производительности запросов. Без необходимости хранить и сохранять дубликаты столбцы базы данных также помогают уменьшить дисковое пространство и память.
Это обеспечивает определенное преимущество над реляционной базой при запросе результатов из нескольких внешних ключей таблиц, связанных с одним первичным ключом таблицы. В базе данных медиа-коллекции, таких как альбом песен и видео записи, все они могут быть членами собственника в одном комплекте, как показано на рисунке 2. Это означает, что оба альбома и фильмы для данного собственника могут быть получены за одну операцию. При этом отпадает необходимость хранить и потенциально изменять порядок временных результатов в середине операции, что приводит к повышению производительности запросов. Без необходимости хранить и сохранять дубликаты столбцы базы данных также помогают уменьшить дисковое пространство и память.
Исследование эффективности
Реальные данные показывают, что прирост производительности и экономия ресурсов с использованием сетевых баз данных может быть довольно значительной. В структуре данных, используются трехсторонние отношения между художником, альбомом и таблицами песни, наши разработчики сравнили изменения данных и выполнение запросов в реляционной модели и сетевой базе данных с помощью настольных систем и небольших, потребительских устройств.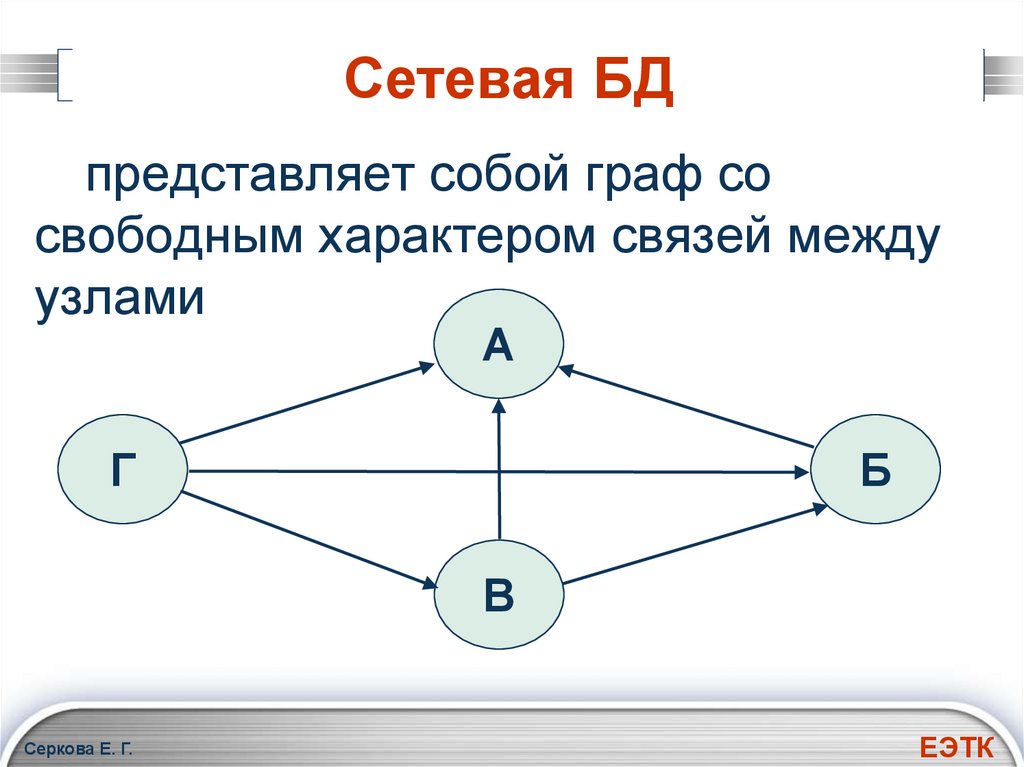 Они обнаружили, что сетевая модель использует на 29% меньше дискового пространства для хранения одинакового количества записей и связей, чем реляционная модель данных. Все сбережения при хранении можно отнести к замене ключевых показателей артист-альбом и альбом-песни зарубежные на установленные указатели.
Они обнаружили, что сетевая модель использует на 29% меньше дискового пространства для хранения одинакового количества записей и связей, чем реляционная модель данных. Все сбережения при хранении можно отнести к замене ключевых показателей артист-альбом и альбом-песни зарубежные на установленные указатели.
Удаление этих структур данных, оказало огромное влияние на требования к хранению, поскольку типичный индекс B-дерева требует примерно в 1,3 раза больше пространства, чем индексы. Они также обнаружили, что сетевая модель базы данных увеличила до 23 раз лучше производительность вставки и выросла в 123 раза быстрее производительность запросов, как показано в таблице 1.
Сетевая база данных против реляционной базы данных
Различные требования управления означают разные структуры данных и различные методы хранения и доступа к данным. В результате система может состоять из нескольких таблиц без связей или сотни таблиц, связанных со сложными взаимосвязями. В то время как реляционная модель данных является стандартом де-факто, теперь мы знаем, что она не всегда обеспечивает оптимальные решения для более сложных задач управления данными. Выбор подходящей модели данных, или даже объединение нескольких моделей, может дать гораздо более эффективный результат, чем реляционная модель данных работающая в одиночку. В результате достигается значительная экономия затрат, повышение качества и увеличение пользовательского опыта.
Выбор подходящей модели данных, или даже объединение нескольких моделей, может дать гораздо более эффективный результат, чем реляционная модель данных работающая в одиночку. В результате достигается значительная экономия затрат, повышение качества и увеличение пользовательского опыта.
Вывод
В то время как реляционная модель данных является очень популярной из-за её простоты использования, она не требует ключа и индексов таблицы, что существенно замедляет работу приложения. Сетевая модель базы данных обеспечивает более быстрый доступ к данным и является оптимальным методом для быстрого применения. Так что если Вы нажмете на любимого артиста, а также если хотите посмотреть список для поиска лишних альбомов и просмотреть названия фильмов на вашем медиа-плеере, это может быть создано сетевыми моделями СУБД.
2018-01-14
Предыдущий: Иерархическая база данных.
Следующий: Объектно-ориентированная база данных (ООСУБД).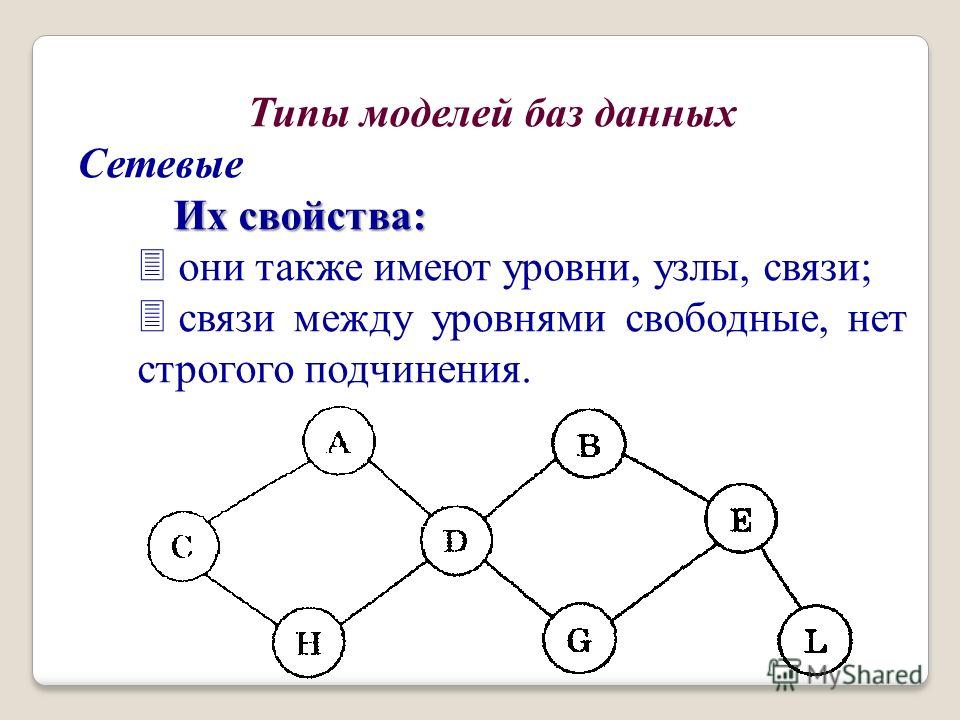
Модели баз данных
- Основные виды баз данных и их модели
- Модели баз данных — иерархическая база данных
- Иерархическая база данных — пример
- Сетевая модель базы данных
- Реляционная модель базы данных
- Сравниваем три модели баз данных
- «Один к одному»
- «Один ко многим»
- «Многие ко многим»
- Другие модели баз данных (ООСУБД)
СУБД используют различные модели баз данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
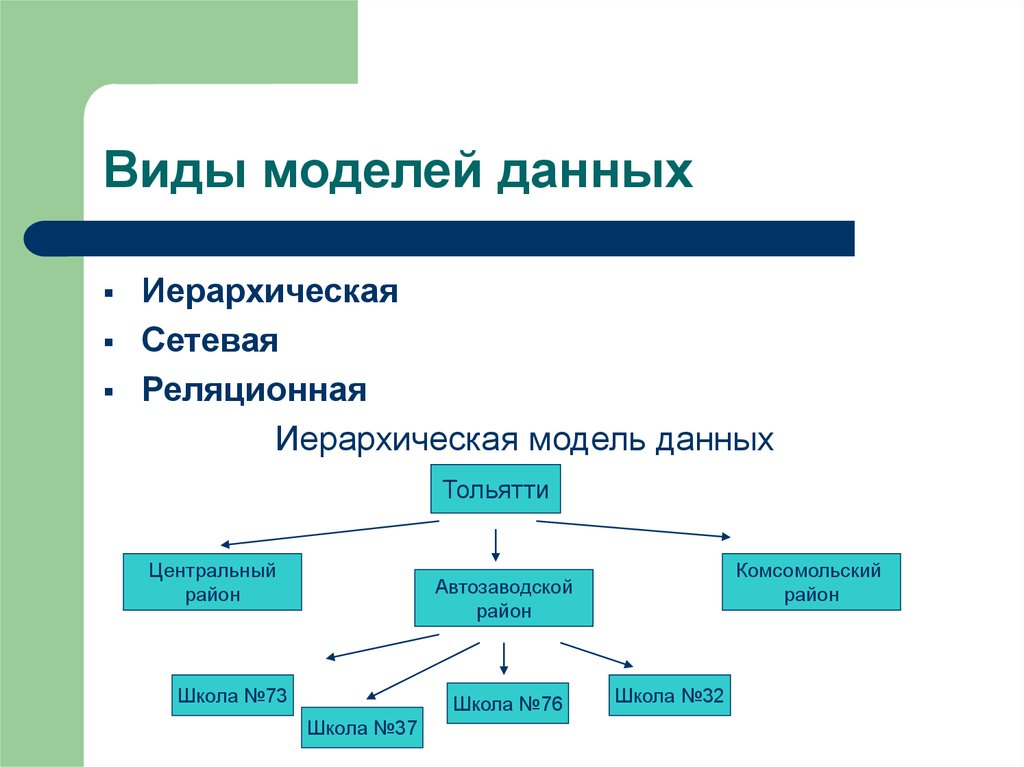
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов.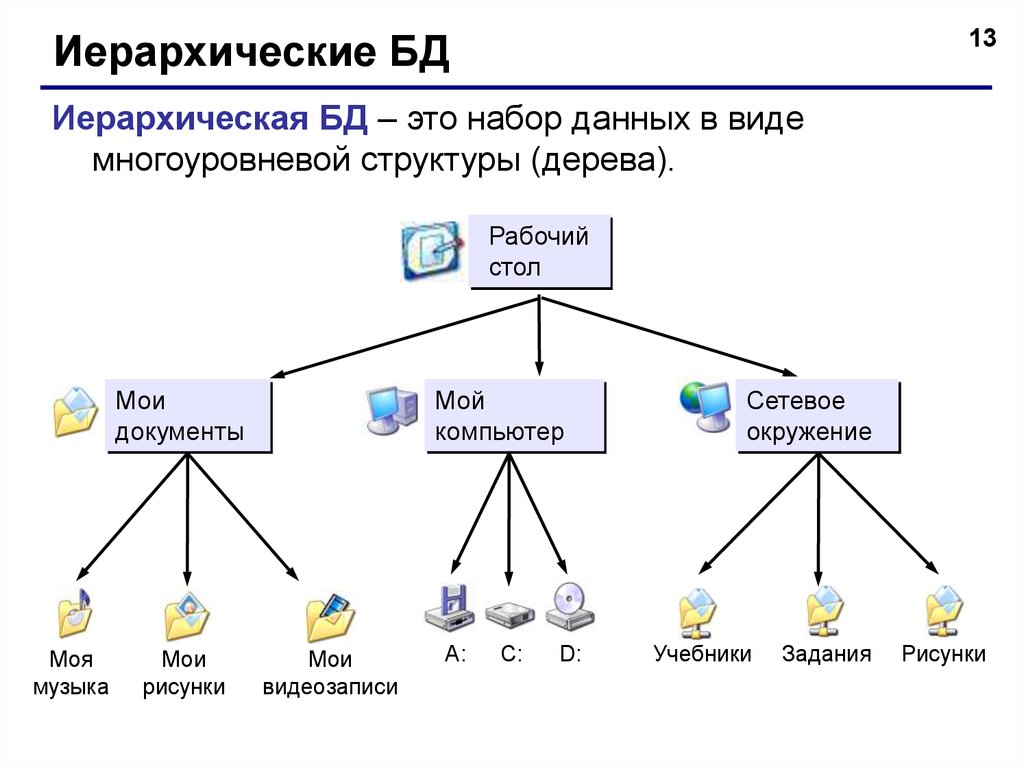 Но у дочернего элемента может быть только один предок.
Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату.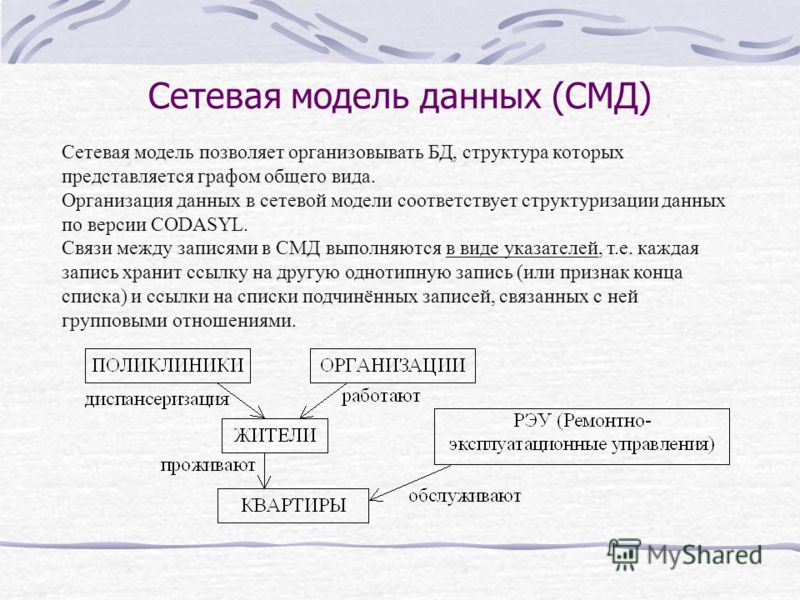 Организация также может хранить информацию о его детях, их имена и даты рождения.
Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.

Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.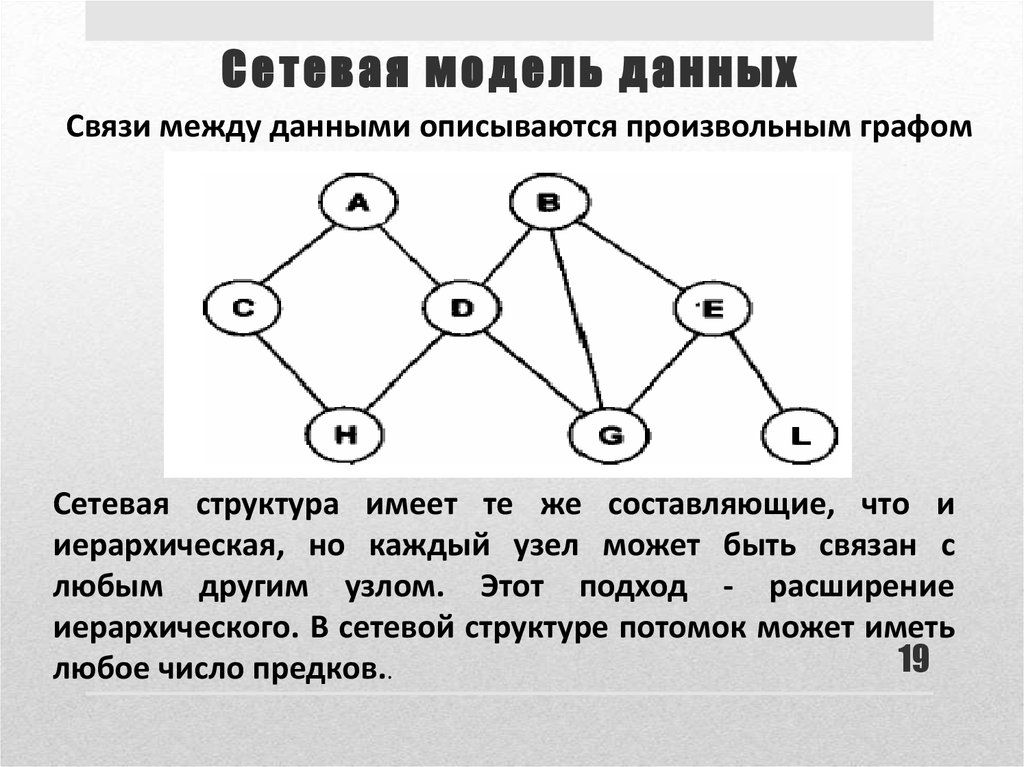
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.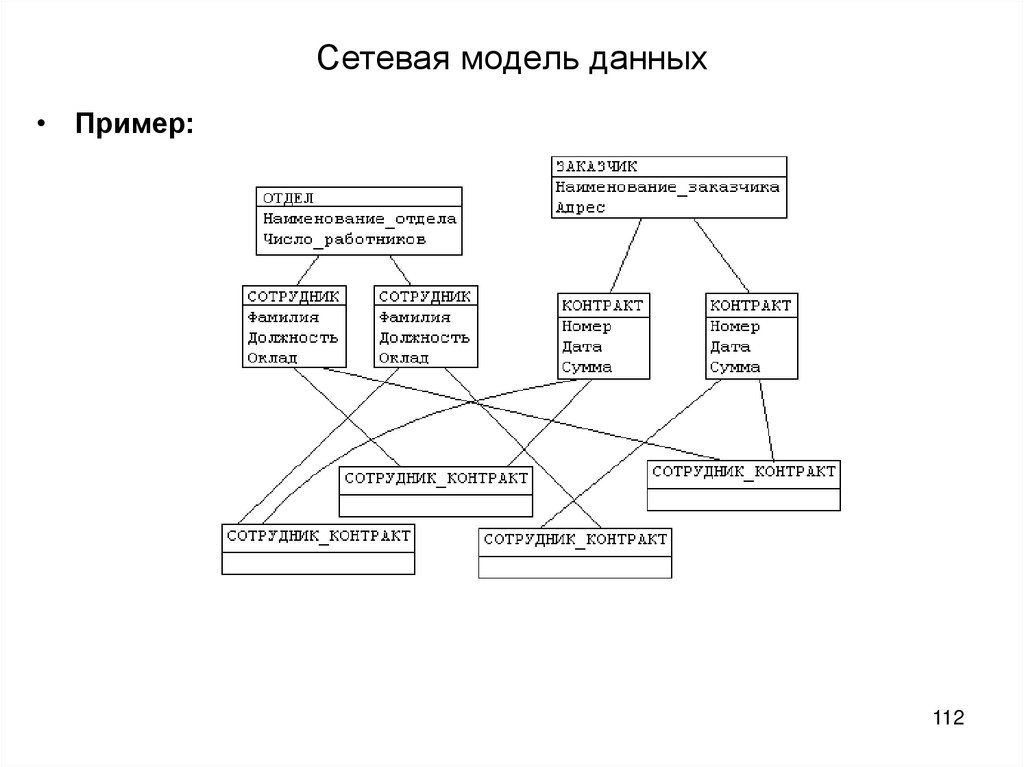
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД.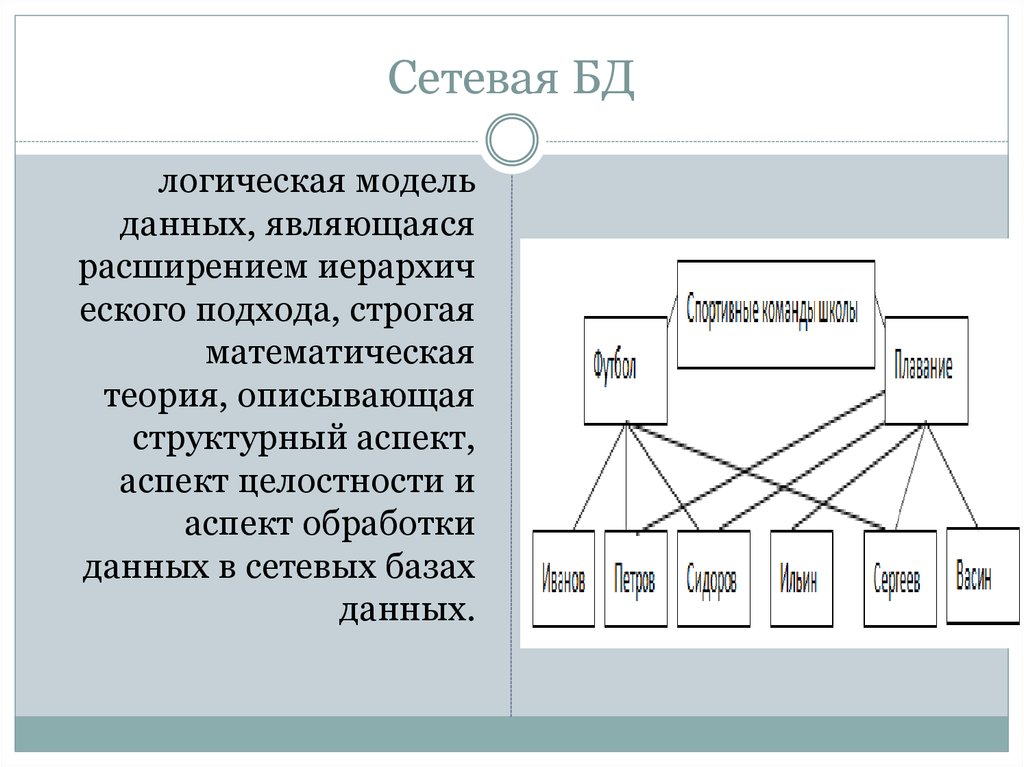 Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.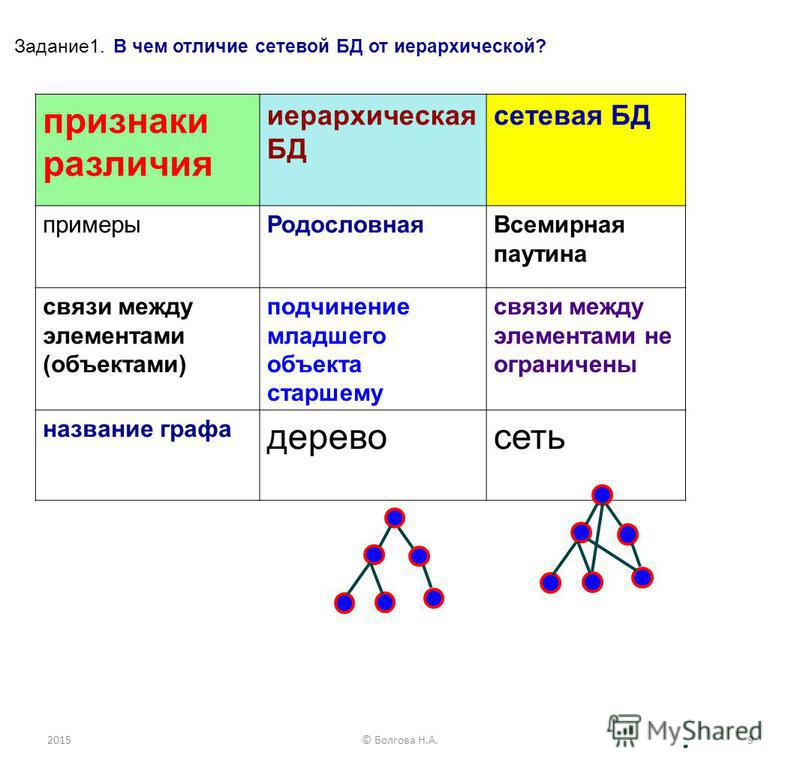
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
 То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.

Пожалуйста, опубликуйте свои отзывы по текущей теме материала. За комментарии, лайки, дизлайки, подписки, отклики огромное вам спасибо!
МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
Сетевая модель в СУБД — Темы масштабирования
Обзор
Модель базы данных — это логическое представление базы данных, т. е. ограничения и отношения между хранимыми данными. Сетевая модель в СУБД — это иерархическая модель, которая используется для представления отношения «многие ко многим» между ограничениями базы данных. Он представлен в виде графика, следовательно, это простая и легкая в построении модель базы данных. Сетевая модель в СУБД позволяет 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) отношения между сущностями или членами.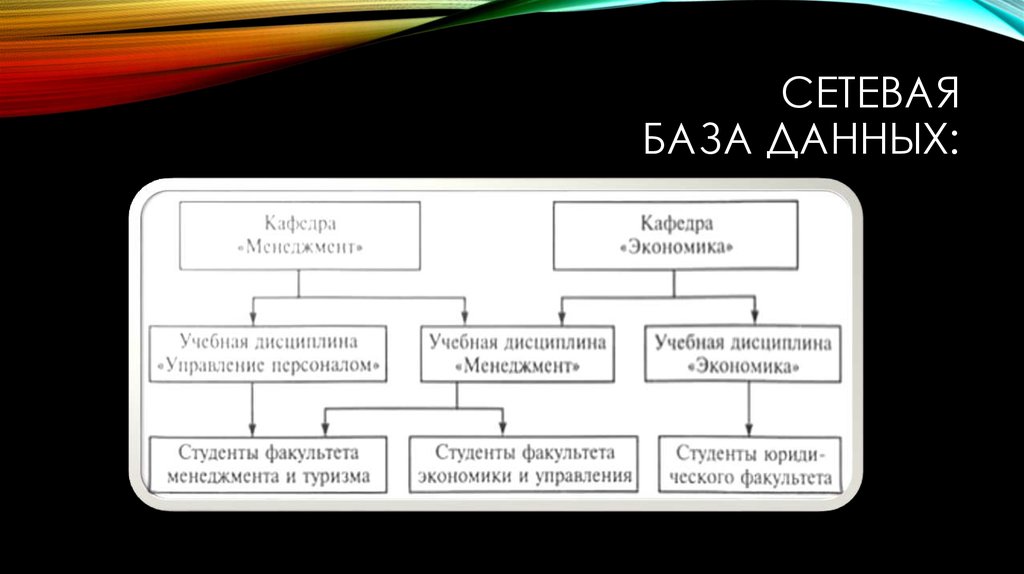 Щелкните здесь, чтобы узнать больше об отношениях в СУБД.
Щелкните здесь, чтобы узнать больше об отношениях в СУБД.
Область применения статьи
В статье рассматриваются такие темы, как
- Введение в сетевую модель в СУБД.
- Структура сетевой модели в СУБД.
- Характеристики сетевой модели в СУБД.
- Примеры сетевой модели в СУБД и сетевых базах данных.
- Операции над сетевой моделью в СУБД.
- Преимущества и недостатки сетевой модели в СУБД.
- Разница между сетевой моделью, иерархической моделью и реляционной моделью.
Каждая из тем четко объяснена с диаграммами и примерами, где это необходимо.
Введение в сетевую модель в СУБД
СУБД означает систему управления базами данных. СУБД — это компьютерное программное обеспечение, которое используется для организации, управления и манипулирования базами данных. СУБД предоставляет интерфейс для выполнения таких операций, как создание данных, обновление данных, создание таблицы в базе данных и многое другое.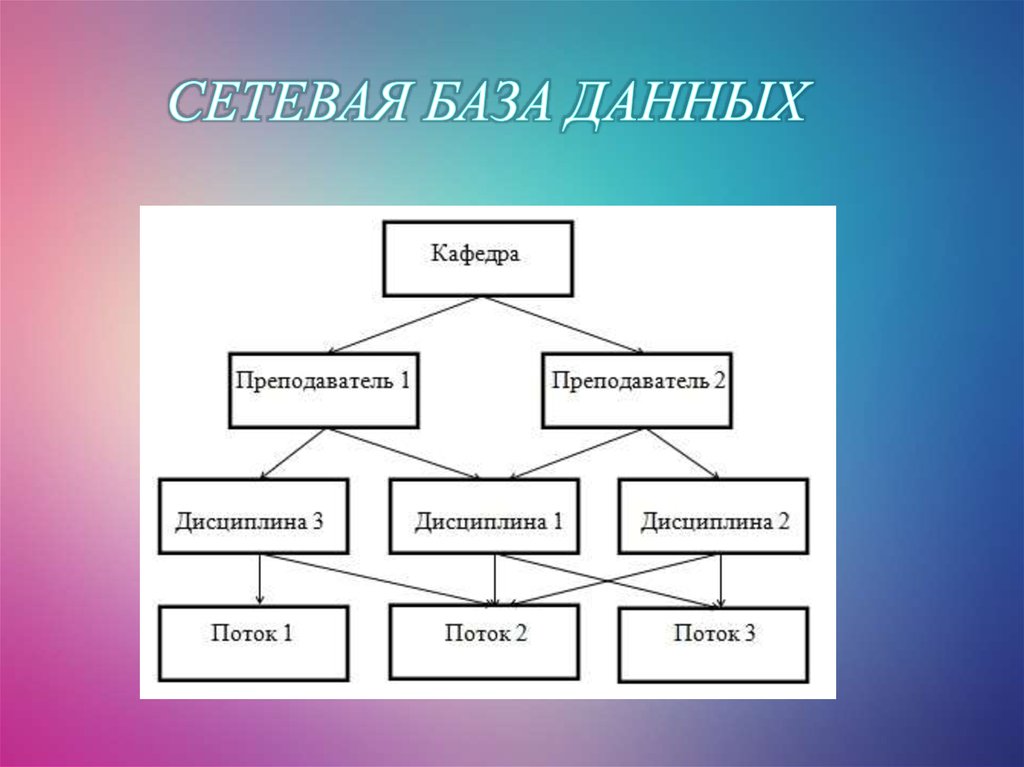
Модель базы данных — это логическое представление базы данных, т. е. ограничений и отношений между хранимыми данными. Модель базы данных обычно представлена в виде блок-схем, называемых диаграммой базы данных . Существуют различные типы моделей баз данных, такие как:
- Реляционная модель
- Иерархическая модель
- Сетевая модель
- Модель объектно-ориентированной базы данных
- Объектно-реляционная модель
- Модель отношения сущности
- Другие модели баз данных
- Модели баз данных NoSQL
- Базы данных в Интернете
Сетевая модель в СУБД представляет собой иерархическую модель, которая используется для представления отношения «многие ко многим» между ограничениями базы данных. Это простая и легкая в построении модель базы данных. Сетевая модель в СУБД основана на теории множеств (математической теории множеств), поэтому модель базы данных строится с набором связанных записей (данных).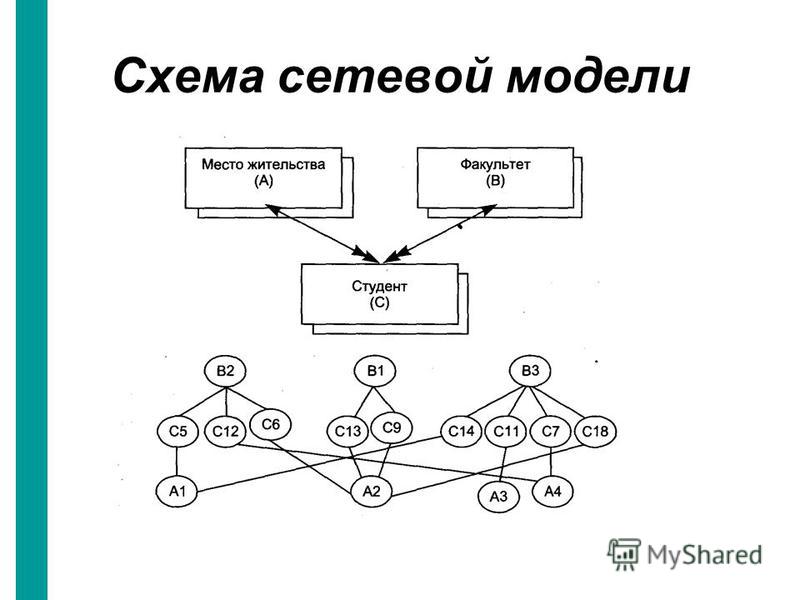
Сетевая модель в СУБД была одной из самых популярных моделей до появления реляционной модели, поскольку ее легко создавать и визуализировать. Он представлен в виде графика. Давайте возьмем пример простой базы данных колледжа, в которой есть два отдела или секции, а именно: отдел CSE и библиотека. Все студенты колледжа могут поступать на оба факультета. Итак, давайте попробуем представить эту иерархическую связь (обратитесь к диаграмме ниже для лучшей визуализации).
В приведенном выше примере у объекта Student есть два родителя, а именно — отдел CSE и библиотека. Отдел CSE и библиотека имеют один и тот же родительский колледж
Примечание . Сетевая модель в СУБД была формализована рабочей группой по базам данных в 1960-х годах.
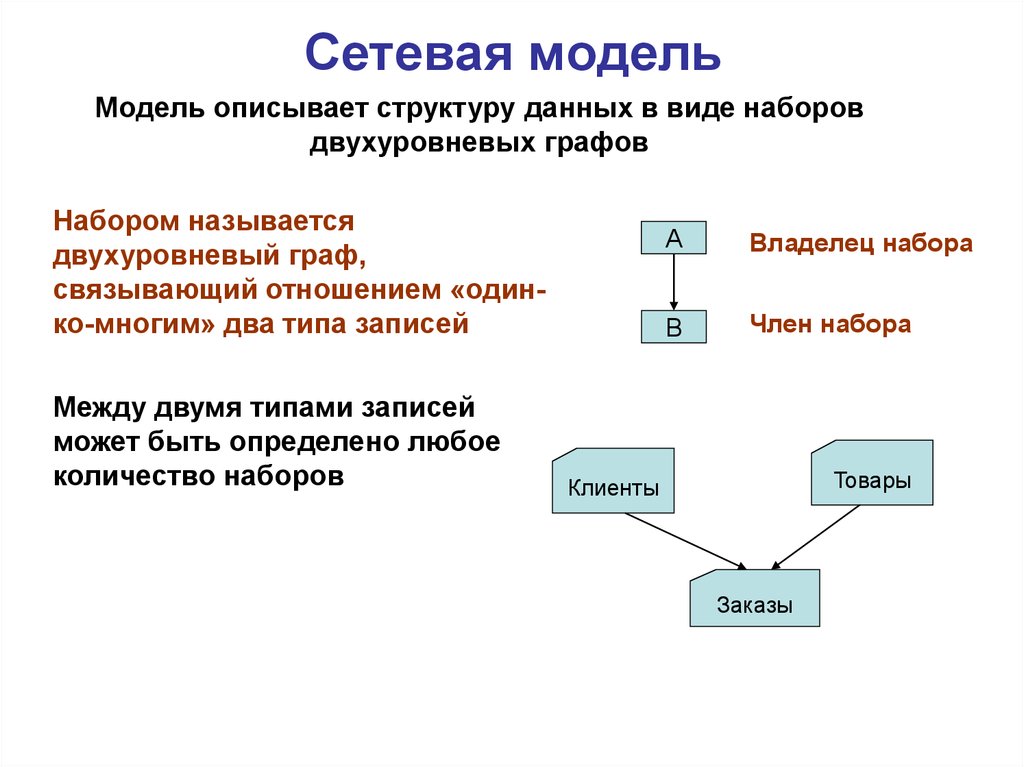
Структура сетевой модели в СУБД
Хотя сетевая модель в СУБД представляет собой иерархическую структуру, она отличается от иерархической модели базы данных тем, что у члена может быть множество родителей.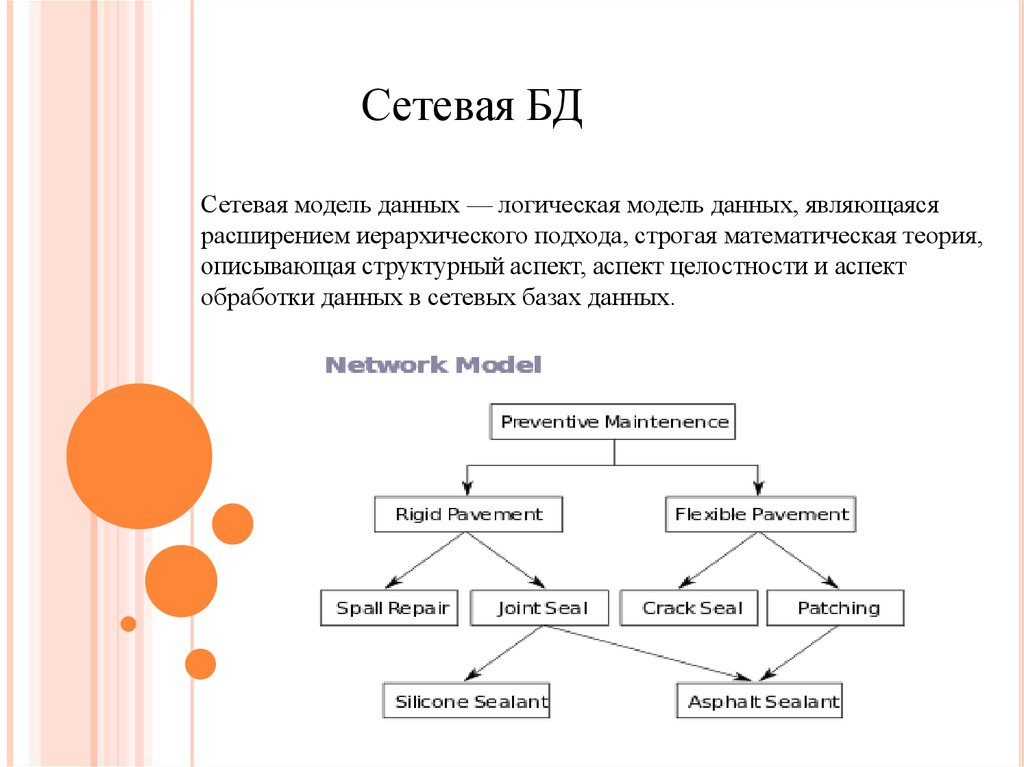
Возьмем базовую иерархическую структуру для визуализации структуры сетевой модели в СУБД.
Приведенная выше структура представляет сетевую модель, в которой ОДИН является основным владельцем модели (проще говоря, мы можем сказать, что остальные члены зависят от ОДНОГО). Аналогично, член ПЯТЬ имеет двух владельцев, а именно — ДВА и ТРИ. Модель сетевой базы данных допускает отношения 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) между объектами или элементами. Смоделированная иерархическая структура помогает избежать проблем с избыточностью данных, поскольку существует несколько путей к одной и той же записи.
Обратитесь к разделу «Примеры сетевой модели в СУБД», чтобы лучше понять пример из реальной жизни.
Характеристики сетевой модели
Давайте обсудим различные характеристики модели сетевой базы данных.
- Сетевая модель в СУБД лучше иерархической, так как больше взаимосвязей между сущностями.
- Поддерживает различные отношения, такие как «один к одному», «один ко многим» и «многие ко многим».
- Сущность может иметь разных родителей или владельцев.
- Связанная структура обеспечивает высокую производительность.
- Все объекты взаимосвязаны друг с другом как связанная сеть.
- Связанная сеть сущностей базы данных представлена в виде графика для лучшего представления, рабочего процесса и визуализации.
- Сетевая модель в СУБД не очень гибкая.
- Это также довольно сложная структура.
- К определенной записи в СУБД может быть несколько путей, что делает поиск данных более быстрым и простым.
- Операции, выполняемые в сетевой модели базы данных с использованием кругового связанного списка (дополнительные сведения см. в разделе «Операции в сетевой модели в СУБД»).
- Сетевая модель в СУБД не поддерживает средство запросов.
- Программы 3GL используются программистами для представления отношений между различными объектами сетевой модели в СУБД.

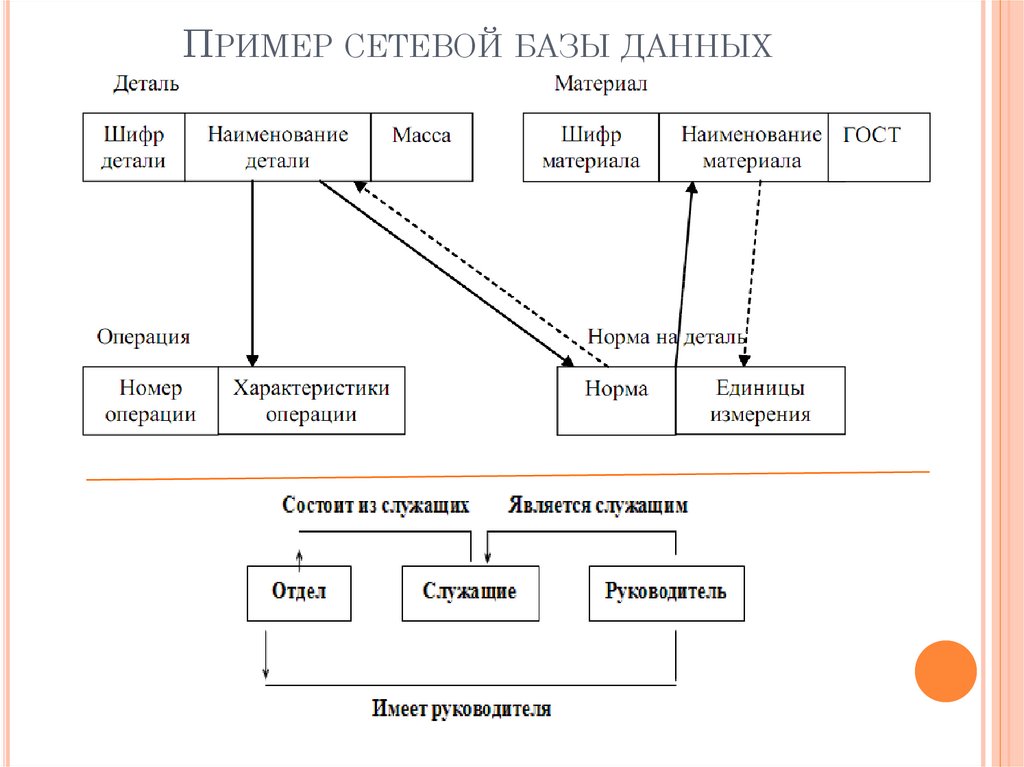
Примеры сетевой модели в СУБД
Возьмем базовый пример для визуализации структуры сетевой модели в СУБД.
Предположим, мы разрабатываем сетевую модель для базы данных Студенты. Как мы видим, сущность Subject имеет отношения как с сущностью Student, так и с сущностью Degree. Таким образом, существует грань, соединяющая сущность Subject со студентом и степенью.
Объект Subject имеет двух родительских объектов, а два других объекта имеют по одному дочернему объекту.
Другими примерами сетевой модели в СУБД могут быть: —
- База данных магазина (имеющая связь между клиентами, менеджером, продавцом, заказом, товарами и т. д.).
- База данных финансового отдела (имеющая связь между клиентами, продуктами, счетами, платежами и т. д.).
Примеры сетевых баз данных
Некоторые из известных сетевых баз данных могут быть:-
- TurboIMAGE
- Интегрированное хранилище данных (IDS)
- Диспетчер баз данных Raima
- Юнивак DMS-1100
- IDMS (интегрированная система управления базами данных) и т. д.
 д.
д.Операции с сетевой моделью в СУБД
Давайте обсудим различные операции, которые можно выполнять с сетевой моделью в СУБД.
Операция вставки — Мы можем вставить или добавить новую запись в модель сетевой базы данных, но перед добавлением любой новой записи администратор базы данных или пользователь должны понять всю структуру.
Операция обновления — Мы можем обновить записи данных. Если определенные данные обновляются, это также влияет на все его дочерние объекты.
Операция удаления — Мы можем удалить запись(и) данных, но удаление является очень важной операцией. Прежде чем удалять какую-либо запись, мы должны сначала проверить различные связанные объекты, чтобы удаление не повлияло на соответствующие объекты.
Операция извлечения — Извлечение записей в сетевой модели в СУБД достаточно сложно запрограммировать, но очень быстро, так как объекты взаимосвязаны и к определенным записям ведут различные пути.
Преимущества сетевой модели в СУБД
Теперь обсудим некоторые преимущества сетевой модели в СУБД:
- Это простая и легкая в построении иерархическая модель базы данных.
- Модель сети в СУБД допускает 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) отношения между сущностями или членами.
- В сетевой модели СУБД существует несколько путей к одной и той же записи, что помогает избежать проблем с избыточностью данных.
- В сетевой модели СУБД существует целостность данных, так как у каждой сущности-члена есть один или несколько владельцев. Только главный родитель не имеет владельца, но имеет различные взаимосвязанные дочерние элементы.
- Извлечение данных происходит быстрее в случае сетевой модели в СУБД, поскольку сущности и данные более взаимосвязаны.
- Из-за отношения родитель-потомок, если есть изменение в родительском объекте, оно также отражается в дочернем объекте. Это также экономит время, поскольку нам не нужно обновлять все связанные дочерние объекты.
 Это также экономит время, поскольку нам не нужно обновлять все связанные дочерние объекты.
Это также экономит время, поскольку нам не нужно обновлять все связанные дочерние объекты.Недостатки сетевой модели в СУБД
Давайте теперь обсудим некоторые недостатки сетевой модели в СУБД:
- Модель сетевой базы данных очень сложна из-за нескольких объектов, взаимосвязанных друг с другом. Так что управлять тоже довольно сложно.
- В случае добавления новых сущностей администратор базы данных или пользователь должны понимать всю структуру.
- Из-за сложной взаимосвязанной структуры добавление, обновление, а также удаление очень затруднены.
- Автоматическая оптимизация запросов в СУБД не предусмотрена.
- Нам нужно использовать указатель для навигации, поэтому существуют операционные аномалии.
Сетевая модель VS Иерархическая модель VS Реляционная модель
Как мы уже видели, сетевая модель, иерархическая модель и реляционная модель несколько связаны друг с другом. Давайте теперь обсудим разницу между ними.
Давайте теперь обсудим разницу между ними.
| Модель сетевых данных | Модель иерархических данных | Модель реляционных данных |
|---|---|---|
| В иерархической модели данных представление выполняется в виде отношения родитель-потомок. | В реляционной модели данных мы используем ключи для представления отношений между записями. | |
| Отношение между сущностями может быть в форме отношения «многие ко многим». | Отношение между сущностями не может быть в форме отношения «многие ко многим». | Отношение между сущностями может быть проще в форме отношения «многие ко многим». |
Нет проблем с несогласованностью данных.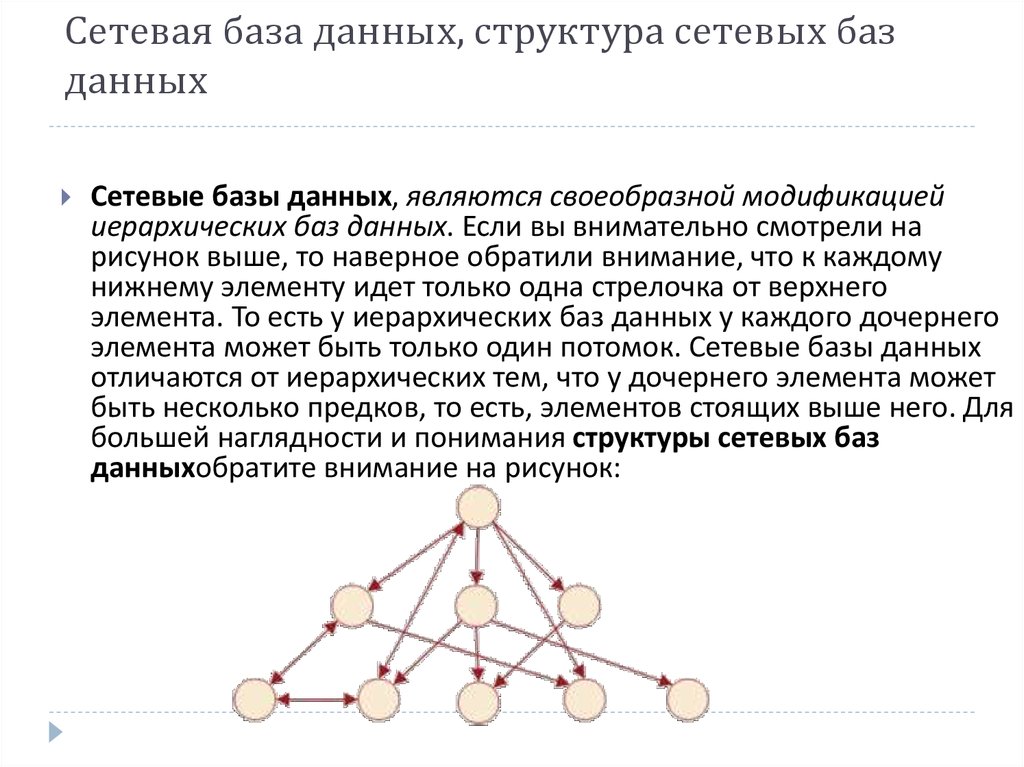 | Существует вероятность несогласованности данных при обновлении и удалении данных. | Поддерживает целостность и согласованность данных с помощью метода нормализации. |
| Отношения между записями довольно сложны из-за использования указателей. | Существуют различные методы реализации связи между сущностями, такие как простой, естественный и прямой. | Мы используем ключи (такие как первичные ключи, внешние ключи, составные ключи и т. д.) для представления отношений между различными сущностями. |
| Поиск записи очень прост, так как существует множество путей к определенной записи. | Поиск записи очень сложен, поскольку дочернюю запись можно найти только после просмотра родительской записи. | Мы используем уникальный ключ (ключ-идентификатор) для поиска записей. |
| Очень полезно представлять записи, имеющие отношение «многие ко многим». | Это очень полезно в тех случаях, когда между сущностями существует некоторая иерархическая связь. | Очень полезно представлять объекты реального мира и отношения между различными объектами. |
Заключение
- Модель базы данных — это логическое представление базы данных, т. е. ограничений и отношений между хранимыми данными.
- Сетевая модель в СУБД — это иерархическая модель, которая используется для представления отношения «многие ко многим» между ограничениями базы данных.
- Сетевая модель в СУБД представляет собой иерархическую структуру, но отличается от иерархической модели базы данных тем, что у члена может быть множество родителей.
- Модель сети в СУБД допускает 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) отношения между сущностями или члены.
- В сетевой модели СУБД существует несколько путей к одной и той же записи, что помогает избежать проблем с избыточностью данных.
- В сетевой модели СУБД существует целостность данных, так как у каждой сущности-члена есть один или несколько владельцев. Только главный родитель не имеет владельца, но имеет различные взаимосвязанные дочерние элементы.
- Модель сетевой базы данных очень сложна из-за нескольких объектов, взаимосвязанных друг с другом. Так что управлять тоже довольно сложно.

Подробнее:
- Кортеж в СУБД.
- Аномалии в СУБД.
- Структура СУБД.
- Типы баз данных.
- Недостатки СУБД.
Сравнение сетевой базы данных, реляционной базы данных и графической базы данных
Что такое сетевая база данных?
Система управления сетевой базой данных (сетевая СУБД) основана на сетевой модели данных, которая позволяет каждой записи быть связанной с несколькими первичными записями и несколькими вторичными записями. Сетевые базы данных позволяют создавать гибкие модели отношений между сущностями.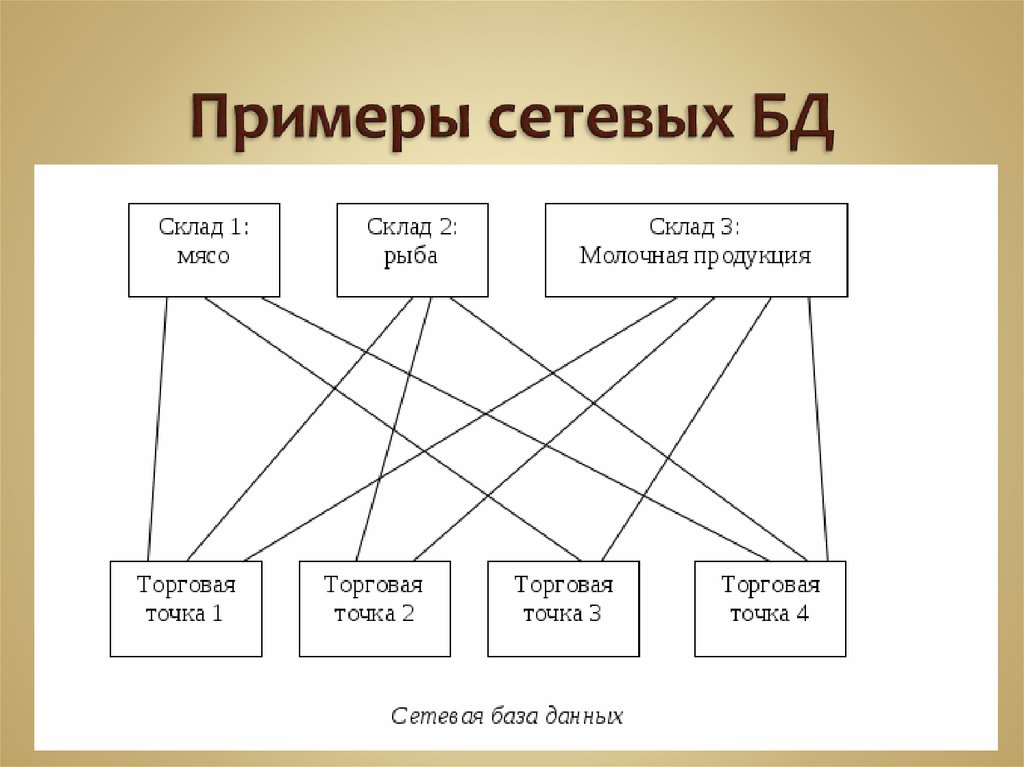 Сетевая модель была предложена в 1969 Чарльза Бахмана, как расширение иерархической модели базы данных.
Сетевая модель была предложена в 1969 Чарльза Бахмана, как расширение иерархической модели базы данных.
Слово «сеть» в сетевых базах данных относится не к соединениям между различными компьютерами и программным обеспечением (известным как сеть), а скорее к отношениям между различными объектами данных.
- Как работает сетевая база данных?
- Плюсы и минусы сетевой модели данных
- Профи
- Минусы
- Иерархическая модель, сетевая модель и модель реляционной базы данных
- Сетевая база данных и графическая база данных
- Системы баз данных, использующие сетевую модель
- Интегрированное хранилище данных
- ИДМС
- Диспетчер баз данных Raima
Как работает сетевая база данных?
Сетевая база данных основана на традиционной иерархической базе данных, за исключением того, что она позволяет каждому объекту иметь несколько родителей вместо одного родителя. Это позволяет моделировать более сложные отношения.
Это позволяет моделировать более сложные отношения.
Сетевые базы данных могут быть представлены в виде графа вместо древовидной структуры. Граф определяется схемой, которая представляет собой список узлов данных и отношений между ними. Это обеспечивает структуру данных, к которой в обычной реляционной базе данных можно получить доступ только путем логического вывода.
Сетевые базы данных обеспечивают большую гибкость, но по-прежнему ограничены шаблонами доступа и архитектурными ограничениями иерархических баз данных. Позднее эти ограничения были преодолены системами управления реляционными базами данных.
Плюсы и минусы сетевой модели данных
Плюсы
- Простая концепция — подобно иерархической базе данных, сетевые базы данных концептуально просты и легко проектируются.
- Несколько типов отношений — Сетевые модели могут поддерживать отношения один-ко-многим и многие-ко-многим, что полезно для фиксации реальных отношений между объектами.
- Целостность данных — модель сети не позволяет членам существовать без владельца.
- Независимость от данных — сетевая модель превосходит иерархическую модель в отделении обработки данных от деталей физического хранения.
- Доступ к данным -доступ к данным быстрее и проще, чем в иерархической базе данных.
Минусы
- Сложная реализация — все записи должны храниться с использованием указателей, что делает структуру базы данных намного более сложной, чем в иерархической базе данных.
- Неэффективное управление операциями — операции вставки, удаления и обновления требуют множества корректировок указателя, что может снизить производительность.
- Негибкая структура — сложно изменить структуру базы данных, если она уже заполнена.
Иерархическая модель, сетевая модель и модель реляционной базы данных
Ниже приводится сводка различий между традиционной иерархической моделью данных, сетевой моделью данных и современной реляционной моделью данных.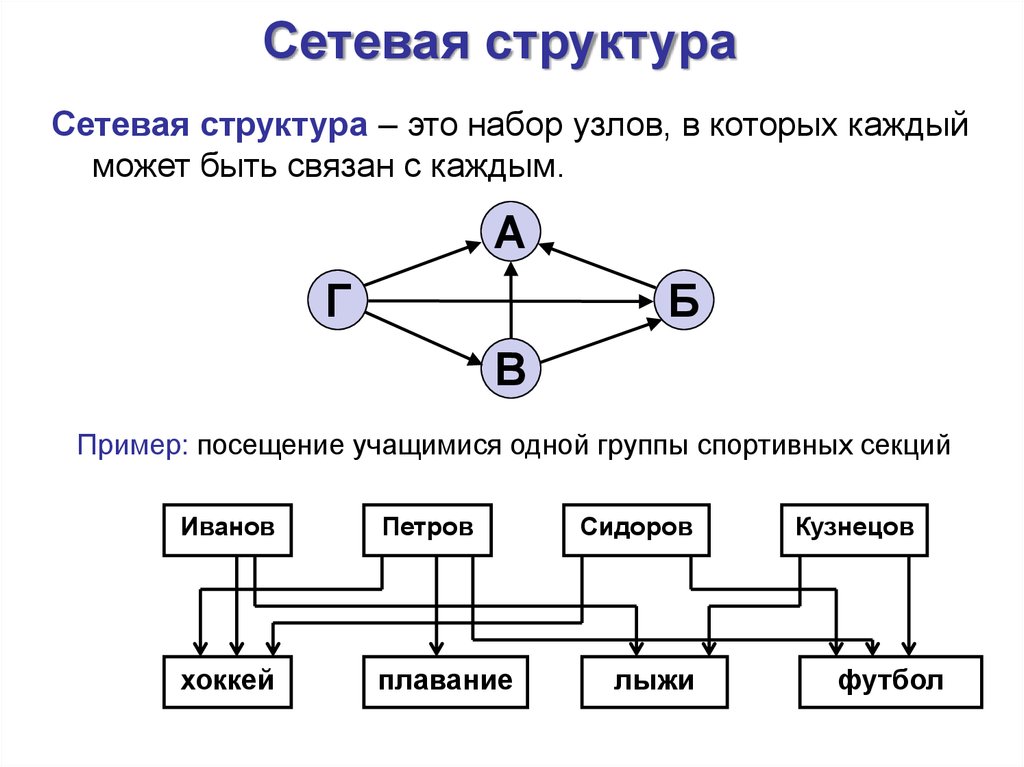
| Иерархическая модель | Сетевая модель | Реляционная модель |
| Организует данные в виде древовидной структуры | Организация данных в графическую структуру | Сохраняет данные в таблицах |
| Представляет отношения «один ко многим» | Представляет отношения «многие ко многим» | Поддерживает отношения «один ко многим» и «многие ко многим» |
| Неэффективный доступ к данным | Эффективный доступ к данным | Эффективный доступ к данным |
| Негибкий | Гибкость при проектировании базы данных, менее гибкая после заполнения данными | Гибкость как во время проектирования, так и после загрузки данных |
Сетевая база данных и графовая база данных
Сетевые базы данных похожи на новый тип нереляционной базы данных — графовую базу данных.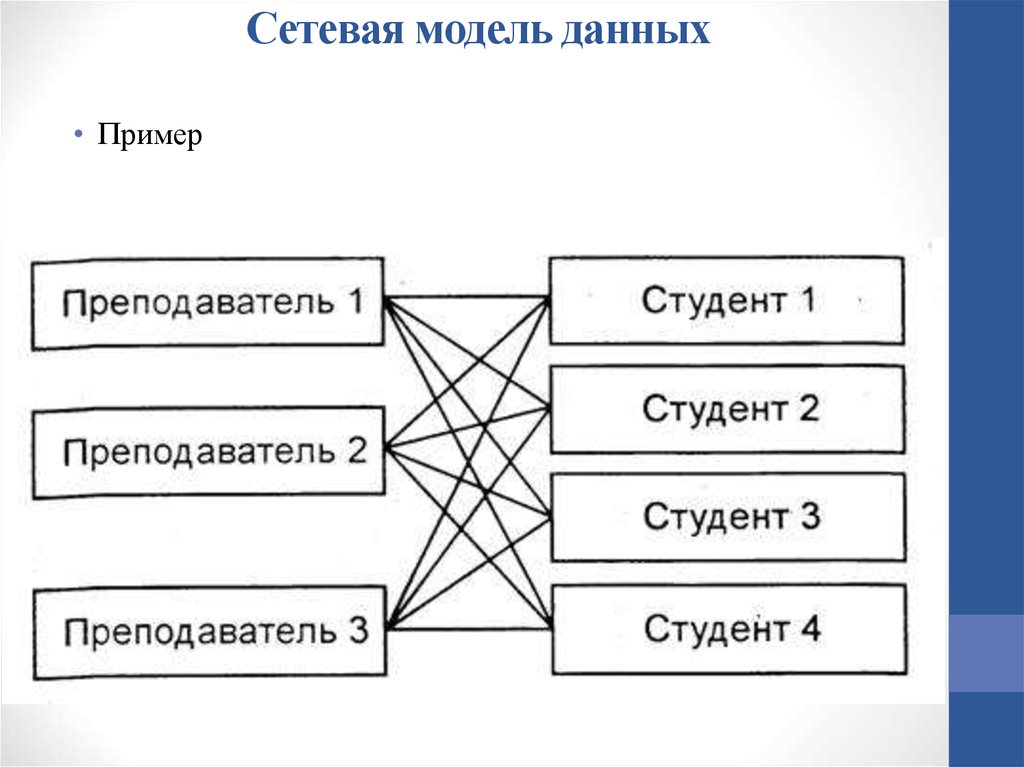 Вот некоторые различия между сетевыми базами данных и графовыми базами данных.
Вот некоторые различия между сетевыми базами данных и графовыми базами данных.
| Сетевая база данных | Графическая база данных |
| Использует схему, указывающую, какой тип записи может быть вложен в какой другой тип записи | Нет ограничений, любая вершина может иметь ребро с любой другой вершиной |
| Доступ к записи возможен только через один из путей доступа к этой записи | Можно напрямую обращаться ко всем вершинам с уникальными идентификаторами или использовать индекс для поиска вершин с определенным значением |
| Дочерние элементы каждой записи имеют предустановленный порядок, и база данных должна поддерживать этот порядок. | Вершины и ребра не сортируются, сортируются только результаты при выполнении запроса. |
| Использует язык запросов SQL | Поддерживает декларативные языки запросов, такие как Cypher и SparQL |
Системы баз данных, использующие сетевую модель
К хорошо известным системам баз данных, использующим сетевую модель, относятся;
Интегрированное хранилище данных
Интегрированное хранилище данных (IDS) было ранней системой управления сетевыми базами данных, известной своей высокой производительностью.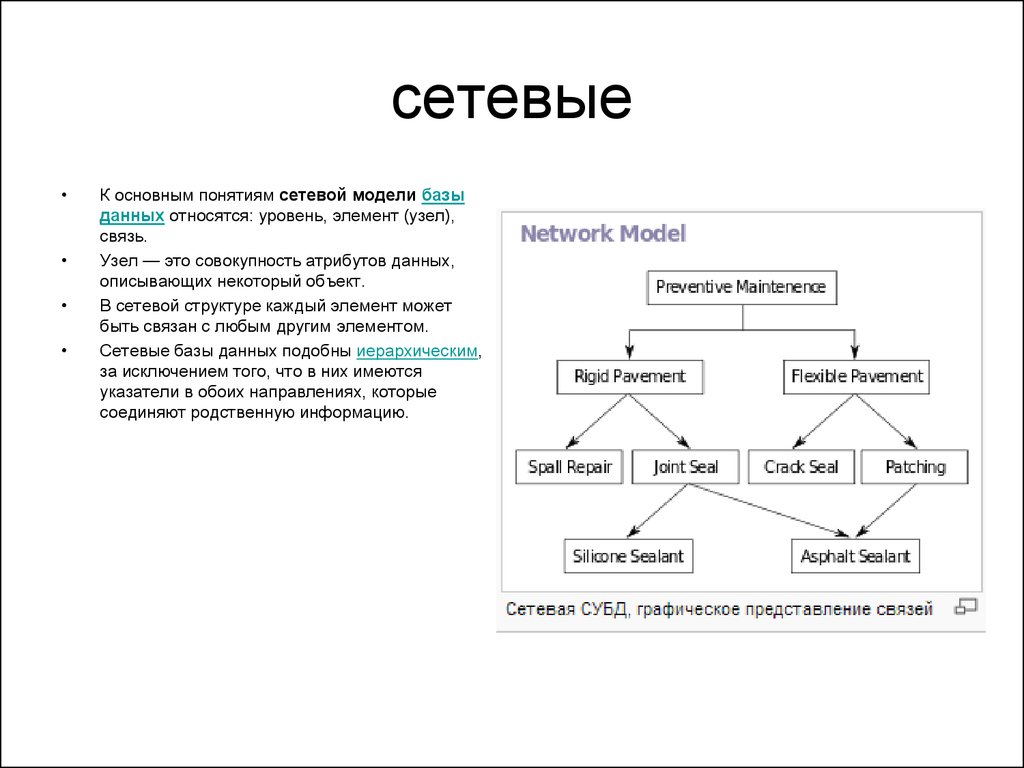
IDS был разработан Чарльзом Бахманом из General Electric и получил премию Тьюринга Компьютерного общества в 1973 году. с помощью ИДС. Однако разумная реализация баз данных типа IDS (например, крупный проект CSS компании British Telecom) продемонстрировала уровень производительности при работе с терабайтными данными, не имеющий себе равных в любой современной реализации реляционной базы данных.
IDMS
Интегрированная система управления базами данных (IDMS) использовала сетевую модель CODASYL. Первоначально разработанный BF Goodrich, с 1989 года он принадлежал Computer Associates, которая переименовала его в CA IDMS.
Сегодня CA IDMS используется как часть IBM z Systems в качестве высокопроизводительной системы управления базами данных и используется сотнями крупных предприятий и государственных учреждений по всему миру. CAI IDMS/DB — это мощное ядро базы данных, которое обеспечивает как сетевой, так и реляционный доступ и использует новейшее оборудование для достижения высокой производительности, включая интегрированный информационный процессор IBM z Systems (zIIP).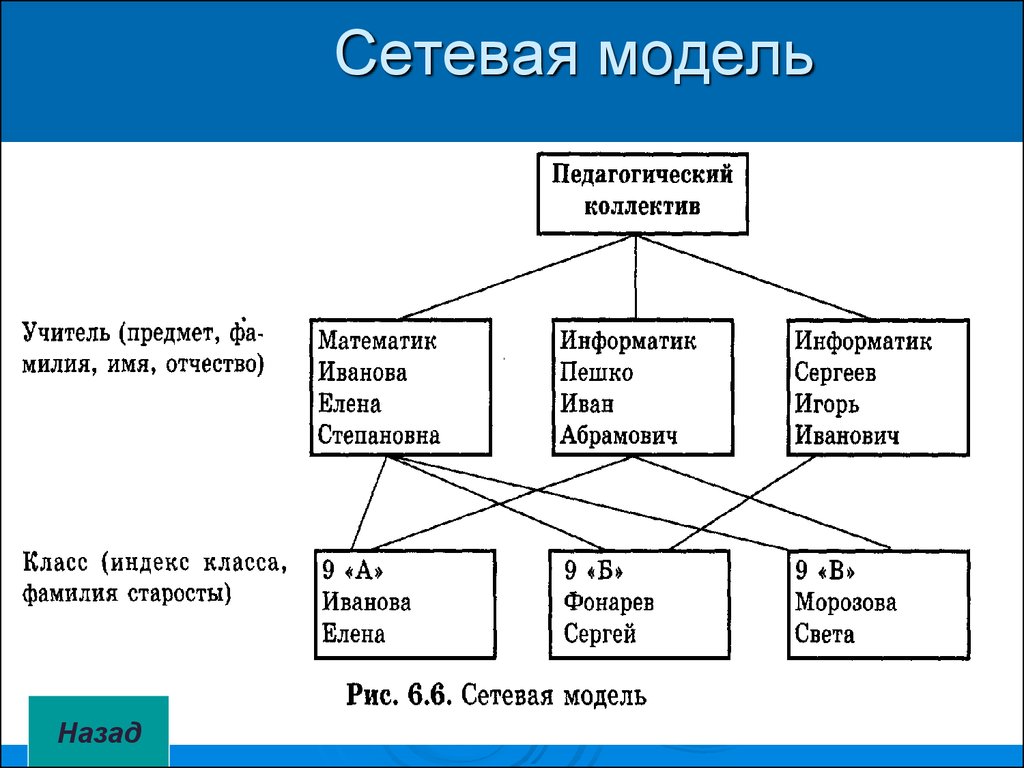
Raima Database Manager
Raima Database Manager (RDM) — это встроенная реляционная база данных, оптимизированная для работы на периферийных устройствах IoT с ограниченными ресурсами, требующих ответов в режиме реального времени.
RDM поддерживает noSQL (доступ к базе данных на уровне записей и курсоров), структуру базы данных SQL и манипуляции с данными, подобные SQL. Функции, отличные от SQL, очень важны во встроенной системной среде с крайне ограниченными ресурсами. В такой среде на первое место выходят высокая производительность и очень малые габариты. SQL важен для предоставления стандартных методов доступа к базе данных.
Сетевая база данных с Raima
Диспетчер базы данных Raima, также называемый RDM, представляет собой СУБД (систему управления реляционными базами данных), разработанную для вариантов использования IoT Edge. Объединяя технологии сети и реляционной модели в одной системе, RDM позволяет эффективно организовывать информацию и получать к ней доступ, независимо от сложности данных.