Содержание
Директива Clean-param — Вебмастер. Справка
- Обучающее видео
- Как использовать директиву Clean-param
- Синтаксис директивы
- Дополнительные примеры
- Disallow и Clean-param
Примечание. Иногда для закрытия таких страниц используется директива Disallow. Рекомендуем использовать Clean-param, так как эта директива позволяет передавать основному URL или сайту некоторые накопленные показатели.
Как использовать директиву Clean-param. Посмотреть видео |
Заполняйте директиву Clean-param максимально полно и поддерживайте ее актуальность. Новый параметр, не влияющий на контент страницы, может привести к появлению страниц-дублей, которые не должны попасть в поиск. Из-за большого количества таких страниц робот медленнее обходит сайт. А значит, важные изменения дольше не попадут в результаты поиска.
Из-за большого количества таких страниц робот медленнее обходит сайт. А значит, важные изменения дольше не попадут в результаты поиска.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Clean-param: ref /some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123
 example.com/some_dir/get_book.pl?book_id=123
example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex Clean-param: utm
Совет. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла. Если вы указываете другие директивы именно для робота Яндекса, перечислите все предназначенные для него правила в одной секции. При этом строка User-agent: * будет проигнорирована.
Clean-param: p0[&p1&p2&..&pn] [path]
В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots. txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.php
означает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php Clean-param: sid&sort /forum/*.php Clean-param: someTrash&otherTrash
#для адресов вида: www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Clean-param: s /forum/showthread.
 php
php#для адресов вида: www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae #robots.txt будет содержать: User-agent: Yandex Clean-param: sid /index.php
#если таких параметров несколько: www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311 www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896 #robots.txt будет содержать: User-agent: Yandex Clean-param: s&ref /forum*/showthread.php
#если параметр используется в нескольких скриптах: www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.example1.com/forum/index.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Clean-param: s /forum/index.php Clean-param: s /forum/showthread.php
Директива Clean-param не требует обязательного сочетания с директивой Disallow.
User-agent: Yandex Disallow: Clean-param: s&ref /forum*/showthread.php #идентично: User-agent: Yandex Clean-param: s&ref /forum*/showthread.php
Так как директива Clean-param межсекционная, ее можно указывать в любом месте файла, вне зависимости от расположения директив Disallow и Allow. Исполнение Disallow при этом имеет приоритет и, если адрес страницы запрещен к индексированию в Disallow и одновременно ограничен в Clean-param, страница проиндексирована не будет.
User-agent: Yandex Disallow:/forum Clean-param: s&ref /forum*/showthread.php
В этом случае страница https://example.com/forum?ref=page будет считаться запрещенной. Не указывайте директиву Disallow для страниц, если хотите только удалить из поиска варианты ссылок с GET-параметрами.
какие данные нужно скрывать и как проверить работу запрета. — Топвизор
Содержание
 txt
txtВ статье о том, зачем и как закрыть сайт от индексации в robots.txt, что можно скрыть и как проверить, что вы всё сделали правильно.
Эта статья — часть нашего бесплатного курса по SEO для начинающих, с ней помогал главный эксперт курса Александр Сопоев. Если хотите разобраться, как продвигать сайты в ТОП поисковых систем, заходите на курс. В конце — сертификат от Топвизора!
Зачем закрывать сайт от индексации
Когда поисковые роботы просканировали и проиндексировали страницы сайта, они начинают показываться в поисковых системах. Это значит, что пользователи могут находить сайт по конкретным поисковым запросам в Google, Яндексе и других поисковых системах.
При этом сайт может состоять из множества разных страниц, и некоторые из них пользователям и поисковым системам видеть не нужно. Например, служебные страницы, дубли страниц и другой малополезный контент. Страницы с таким контентом поисковые системы могут и сами «выбрасывать» из индекса или понижать их позиции, но тогда это может отразиться на ранжировании всего сайта.
Страницы с таким контентом поисковые системы могут и сами «выбрасывать» из индекса или понижать их позиции, но тогда это может отразиться на ранжировании всего сайта.
Кроме того, стоит учитывать и краулинговый бюджет сайта — лимит на количество страниц сайта, которые поисковые роботы смогут обойти за сутки. И этот лимит может тратиться на неважные страницы сайта, в то время как важные целевые страницы могут долго быть непроиндексированными. Подробнее об этом мы писали в статье «Как оптимизировать краулинговый бюджет».
Что можно закрыть от индексации
Дубль
Это страницы сайта, которые отличаются URL‑адресом, но содержат одинаковый или практически одинаковый контент. Дубли могут привести к таким последствиям, как:
снижение скорости индексирования новых страниц. Индексирующий робот может медленнее доходить до новых страниц, из‑за того что будет обходить дубли;
поисковая система «склеит» дубли и сама выберет среди них основную страницу.
При этом есть риск, что эта выбранная страница не будет вашей целевой;в индексе останутся все дубли. Тогда все они могут конкурировать между собой, «моргать» в выдаче и т. д. Это может влиять на положение сайта в поиске.
 При этом есть риск, что эта выбранная страница не будет вашей целевой;
При этом есть риск, что эта выбранная страница не будет вашей целевой;Подробнее про дубли в Яндекс.Справке
Документ для скачивания
В некоторых случаях может быть нужно закрыть от индексации документы, например в формате pdf, docx и т. п. С помощью robots.txt это можно сделать.
С одной стороны, когда документы можно скачать из выдачи, не переходя на сайт, это может приводить к потере трафика, с другой стороны, может, наоборот, положительно повлиять на посещаемость сайта. Исходите из стратегии и пользы для вашего проекта.
Страницы, которые находятся в разработке
Если на странице нет контента или есть, но он дублирует другую страницу, если на странице идёт редизайн или доработка и мы пока не хотим её выкатывать и в других подобных случаях можно запретить её индексацию.
Если оставить такие страницы доступными для индексации, то ПС может сама понизить или исключить их из индекса, что может сказаться на оценке сайта в целом.
Техническая страница
Все служебные, технические страницы не содержат полезного контента для пользователей или вовсе могут быть пустыми. Поэтому их стоит закрыть от индексации.
Такими страницами, в зависимости от конкретного сайта и особенностей проекта, могут быть: страницы регистрации, авторизации, результаты поиска по страницам сайта, Личный кабинет, Корзина, Избранное и т. д.
Папка
Файлы сайта обычно распределяются по папкам, например по категориям, каталогам, разделам, подразделам и т. д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
Картинка
Помимо закрытия страниц сайта, можно также закрыть от индексации отдельный тип контента, например все картинки определённого формата или фотографии.
Если вы размещаете информативные и полезные изображения, закрывать их от индексации нежелательно.
Ссылка
С помощью robots.txt мы не можем запретить индексацию одной ссылки. Чтобы робот не переходил по ссылкам на странице, мы можем закрыть от индексации страницу, на которой размещена ссылка, или страницу, на которую она ведёт.
Чтобы скрыть от индексирования конкретную ссылку, Яндекс рекомендует использовать атрибут rel.
Блок на сайте
Мы не можем закрывать в robots.txt отдельные блоки на странице.
Запретить индексирование части текста в Яндексе можно с помощью тега noindex, но Google данный тег не поддерживает.
Как запретить индексацию в robots.txt
Файл robots.txt — это текстовый документ формата .txt, в котором прописаны специальные правила (директивы) для поисковых роботов. Они помогают управлять индексацией сайта.
С помощью этих правил можно указать поисковым роботам, какие страницы и файлы сайта не должны присутствовать в поисковой выдаче, а какие, наоборот, должны.
В файле robots.txt можно:
разрешить или запретить индексацию страниц или разделов сайта;
указать ссылку на карту сайта Sitemap.
xml;заблокировать показ изображений, видеороликов и аудиофайлов в результатах поиска.
 xml;
xml;В robots.txt мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
Если у сайта есть robots.txt, то обычно он хранится он в корневой папке сайта — там, куда загружаются каталоги и другие файлы.
Кроме того, на некоторых сайтах robots.txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
Если файла нет, значит, скорее всего, сейчас для индексации доступны все страницы сайта и у поисковых роботов нет специальных указаний.
Поэтому файл нужно создать самостоятельно. Сделать это можно в Блокноте или другом текстовом редакторе. В файле нужно прописать специальные директивы, о которых расскажем ниже.
После этого сохраняем документ в формате .txt с названием robots и загружаем в корневую папку сайта.
Основные директивы robots.txt
User‑Agent — обязательная директива, которая говорит, какому именно поисковому роботу адресуются указанные ниже правила. В документе эта директива может повторяться несколько раз — с неё начинается каждая новая группа правил для конкретного бота.
В файле эта строка будет выглядеть так:
User‑agent:
После двоеточия мы прописываем название бота, к которому будут обращены последующие правила.
Чаще всего используем такие:
- * — когда обращаемся ко всем поисковым роботам;
- Googlebot — когда обращаемся к роботам Google;
- Yandex — когда обращаемся к роботам Яндекса.
Записи в файле будут выглядеть так:
User‑agent: * или: User‑agent: Yandex или: User‑agent: Googlebot
Список User‑agent поисковых роботов Google
Список User‑agent поисковых роботов Яндекса
Перед каждой новой директивой User‑agent, которую вы прописываете в документе, необходимо ставить дополнительный пропуск строки.
Например, если бы нам нужно было закрыть весь сайт от индексации для Яндекса и Google, мы бы написали так:
User‑agent: Googlebot Disallow: / User‑agent: Yandex Disallow: /
Disallow — этой директивой мы можем запретить роботу индексировать определённые разделы сайта, страницы или файлы. Здесь могут закрываться от индексации, например:
технические страницы: страницы регистрации, авторизации и др., у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
страницы сортировок, которые изменяют вид отображения информации;
страницы внутреннего поиска и т. д.
Правила указания директивы такие:
Сначала указываем саму директиву и двоеточие. Например: Disallow:
После этого указываем раздел или страницу в корневой папке текущего сайта без указания самого домена.
Например: /ru/marketing/.
 Например: /ru/marketing/.
Например: /ru/marketing/.Например, чтобы запретить роботам Яндекса индексацию всего раздела «Маркетинг» в Топвизор‑Журнале, мы бы написали в robots.txt так:
User‑agent: Yandex Disallow: /ru/marketing/
Allow — директива указывает поисковому роботу, какие разделы сайта можно индексировать. Обычно используется для указания подправила директивы Disallow, например, когда мы хотим разрешить сканирование какой‑то страницы или каталога внутри закрытого директивой Disallow раздела.
User‑agent: Yandex Disallow: /catalog/ Allow: /catalog/auto/ # запрещает скачивать страницы, начинающиеся с '/catalog/', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto/'
Если в документе одновременно указаны директивы Allow и Disallow для одного и того же элемента, то предпочтение отдаётся директиве Allow — элемент будет проиндексирован.
О директиве Disallow и Allow у Яндекса
О директиве Disallow и Allow у Google
Дополнительно
При указании пути к разделу, странице или файлам может использоваться спецсимвол «*».
Он означает любую (в том числе пустую) последовательность символов. Может ставиться как префикс в начале адреса или как суффикс в конце.
Например:
Disallow: /catalog/*/shopinfo — запрещает индексацию любых страниц в разделе catalog, в URL которых есть shopinfo.
Disallow: *shopinfo — запрещает индексацию всех страниц, содержащих в URL “shopinfo”, например: /ru/marketing/shopinfo.
Подробнее о спецсимволах и правилах их использования в Яндексе
Спецсимволы работают в том числе и с директивой Allow.
Путь указывается через директиву Sitemap, а сам путь должен быть полным, с указанием домена, как в браузере:
Sitemap: https://site.com/sitemaps1.xml
Если карт сайта несколько, директиву можно повторять несколько раз с новой строки.
Директива считается межсекционной: поисковые роботы увидят путь к карте сайта вне зависимости от места в файле robots.txt, где он указан.
О директиве Sitemap в Яндекс.Справке
О директиве Sitemap в Google Справке
Яндекс предупреждает, что если не закрыть страницы с параметрами через Clean‑param, то в поиске могут появиться многочисленные дубли страниц, что может негативно отразиться на ранжировании.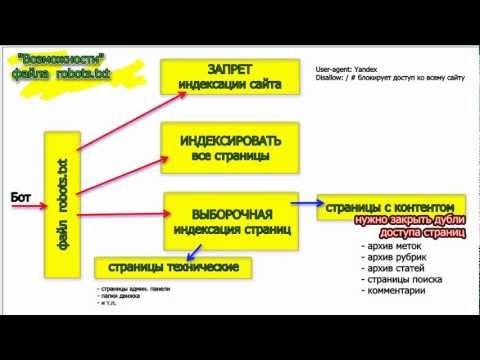
Синтаксис и правила оформления:
файл должен называться robots.txt;
размер файла не больше 500 КБ;
на сайте должен быть только один такой файл;
файл размещён в корневом каталоге сайта, но не в подкаталоге. Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;
файл отдаёт ответ сервера 200 OK.
Подробные правила оформления robots.txt у Яндекса.
Подробные правила оформления robots.txt у Google.
Дополнительно про файл robots.txt:
есть директивы, которые одни ПС воспринимают, а другие нет. Например, Clean‑param для Яндекса;
те страницы, которые вы запретили в файле, всё равно могут быть проиндексированы. Например, Google говорит, что страницы могут попасть в индекс, если поисковый робот нашёл их по ссылке с других сайтов или страниц.
Чтобы полностью скрыть информацию от краулеров, стоит использовать другие способы, например метатег robots и HTTP‑заголовок X‑Robots‑Tag и др.
 Чтобы полностью скрыть информацию от краулеров, стоит использовать другие способы, например метатег robots и HTTP‑заголовок X‑Robots‑Tag и др.
Чтобы полностью скрыть информацию от краулеров, стоит использовать другие способы, например метатег robots и HTTP‑заголовок X‑Robots‑Tag и др.Как проверить запрет
После создания из загрузки файла на сайт убедитесь, что он существует, размещён в корневом каталоге сайта и без проблем открывается. Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
После этого можно проверить файл в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Яндекс.Вебмастер
В Вебмастере открываем «Инструменты» → «Анализ robots.txt». Обычно содержимое файла сразу будет отображаться в строке. Если нет, копируем из браузера и вставляем сюда. Затем нажимаем кнопку «Проверить»:
Проверка файла в Вебмастере
Если в файле будут ошибки, Вебмастер подскажет, как их исправить.
Google Search Console
Для того чтобы проверить файл robots.txt с помощью валидатора Google, необходимо:
1. Зайти в аккаунт Google Search Console.
Зайти в аккаунт Google Search Console.
2. Перейти в инструмент проверки robots.txt.
3. В открывшемся окне вы увидите уже подгруженную информацию из файла. Если нет, вставьте её из браузера.
GSC покажет, есть ли в файле ошибки и как их исправить.
Проверка файла в GSC
Краткий конспект
На сайте может быть необходимо скрыть некоторые страницы, например:
Закрывать от индексации можно как сайт полностью, так и отдельные страницы, файлы, изображения.
В robots.txt с помощью специальных директив мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
После создания правил для индексирования сайта в robots.txt важно его проверить. Сделать это можно бесплатно в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Директивы Disallow и Allow — Webmaster. Справка
- Запретить
- Разрешить
- Объединение директив
- Использовать директивы Разрешить и Запретить без параметров
- Использование специальных символов * и $
- Примеры того, как директивы интерпретируются для индексирования отдельных разделов данной директивы или запрета на индексирование отдельных разделов сайта
Страницы, содержащие конфиденциальные данные.
Страницы с результатами поиска по сайту.
Статистика посещаемости сайта.
Дублирование страниц.
Различные журналы.
Сервисные страницы базы данных.
- web-crawlers
- yandex
страницы. Примеры:
Примеры:
Примечание. При выборе директивы для страниц, которые необходимо исключить из поиска, если их адреса содержат GET-параметры, рекомендуется использовать директиву Clean-param, а не Disallow. Если вы используете Disallow, вы не сможете идентифицировать повторяющиеся URL-адреса ссылок без параметра и отправить некоторые метрики запрещенных страниц.
Примеры:
User-agent: Яндекс Disallow: / # запрещает сканирование всего сайта User-agent: Яндекс Disallow: /catalogue # запрещает сканирование страниц, начинающихся с /catalogue User-agent: Яндекс Запретить: /страница? # Запрещает сканирование страниц с URL-адресом, содержащим параметры
Эта директива позволяет индексировать разделы сайта или отдельные страницы.
Примеры:
User-agent: Яндекс Разрешить: /cgi-bin Запретить: / # запрещает загрузку всего, кроме страниц, # начинающихся с '/cgi-bin'
User-agent: Яндекс Разрешить: /file.xml # позволяет загрузить файл file.xml
Примечание. Пустые разрывы строк не допускаются между директивами User-agent , Disallow и Allow .
Директивы Allow и Disallow из соответствующего блока User-agent сортируются по длине префикса URL (от самого короткого до самого длинного) и применяются по порядку. Если определенной странице сайта соответствует несколько директив, робот выбирает последнюю в отсортированном списке. Таким образом, порядок директив в файле robots.txt не влияет на то, как они используются роботом.
Если определенной странице сайта соответствует несколько директив, робот выбирает последнюю в отсортированном списке. Таким образом, порядок директив в файле robots.txt не влияет на то, как они используются роботом.
Примечание. В случае конфликта между двумя директивами с префиксами одинаковой длины приоритет имеет директива Allow .
# Источник robots.txt: User-agent: Яндекс Позволять: / Разрешить: /каталог/авто Запретить: /каталог # Отсортированный файл robots.txt: User-agent: Яндекс Позволять: / Запретить: /каталог Разрешить: /каталог/авто # запрещает загрузку страниц, начинающихся с '/catalog', # но позволяет загружать страницы, начинающиеся с '/catalog/auto'.
Общий пример:
User-agent: Яндекс Разрешить: /архив Запретить: / # разрешает все, что содержит '/archive', все остальное запрещено User-agent: Яндекс Разрешить: /obsolete/private/*.
 html$ # разрешает файлы HTML # в пути '/obsolete/private/...'
Disallow: /*.php$ # запрещает все '*.php' на сайте
Disallow: /*/private/ # запрещает все вложенные пути, содержащие
# '/private/', но Разрешить выше отрицает
# часть этого запрета Disallow: /*/old/*.zip$ # запрещает все файлы '*.zip', содержащие
# по пути '/старый/'
User-agent: Яндекс
Запретить: /add.php?*user=
# запрещает все 'add.php?' скрипты с опцией 'user'
html$ # разрешает файлы HTML # в пути '/obsolete/private/...'
Disallow: /*.php$ # запрещает все '*.php' на сайте
Disallow: /*/private/ # запрещает все вложенные пути, содержащие
# '/private/', но Разрешить выше отрицает
# часть этого запрета Disallow: /*/old/*.zip$ # запрещает все файлы '*.zip', содержащие
# по пути '/старый/'
User-agent: Яндекс
Запретить: /add.php?*user=
# запрещает все 'add.php?' скрипты с опцией 'user' Если директивы не содержат параметров, робот обрабатывает данные следующим образом:
User-agent: Яндекс Запретить: # то же, что и Разрешить: / User-agent: Яндекс Разрешить: # не учитывается роботом
Вы можете использовать специальные символы при указании путей директив Allow и Disallow * и $ для установки определенных регулярных выражений.
Символ * указывает на любую последовательность символов (или ни на одну). Примеры:
User-agent: Яндекс Disallow: /cgi-bin/*.
 aspx # запрещает '/cgi-bin/example.aspx'
# и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает оба '/private'
# и '/cgi-bin/private'
aspx # запрещает '/cgi-bin/example.aspx'
# и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает оба '/private'
# и '/cgi-bin/private' По умолчанию символ * добавляется в конец каждого правила, описанного в файле robots.txt. Пример:
User-agent: Яндекс
Disallow: /cgi-bin* # блокирует доступ к страницам
# начиная с '/cgi-bin'
Disallow: /cgi-bin # то же самое Для отмены * в конце правила используйте символ $, например:
User-agent: Yandex
Disallow: /example$ # запрещает '/example',
# но разрешает '/example.html' Агент пользователя: Яндекс
Disallow: /example # запрещает оба '/example'
# и '/example.html' Символ $ не запрещает * в конце, то есть:
User-agent: Яндекс
Disallow: /example$ # запрещает только '/example'
Disallow: /example*$ # аналогично 'Disallow: /example'
# запрещает и /example. html, и /example  html, и /example
html, и /example User-agent: Yandex Позволять: / Запретить: / # все позволено User-agent: Яндекс Разрешить: /$ Запретить: / # запрещено все, кроме главной страницы User-agent: Яндекс Запретить: /private*html # запрещает '/private*html', # '/private/test.html', '/private/html/test.aspx' и т.д. User-agent: Яндекс Запретить: /private$ # запрещает только '/private' Пользовательский агент: * Запретить: / User-agent: Яндекс Позволять: / # поскольку робот Яндекса # выбирает записи, содержащие 'User-agent:', # все разрешено
Заблокировать сканер Яндекса — Webmasters Stack Exchange
Задай вопрос
спросил
Изменено
5 лет, 11 месяцев назад
Просмотрено
1к раз
Последние несколько дней наш сайт ведет себя очень странно, много тайм-аутов и т. д. Наконец-то я нашел причину, бот Яндекса сканирует около 10000 страниц в час! Мне нужно остановить это как можно скорее, я думаю, что это создает около 50-100 ГБ пропускной способности в день.
д. Наконец-то я нашел причину, бот Яндекса сканирует около 10000 страниц в час! Мне нужно остановить это как можно скорее, я думаю, что это создает около 50-100 ГБ пропускной способности в день.
Заблокированные IP-адреса (через https://myip.ms/info/bots/Google_Bing_Yahoo_Facebook_etc_Bot_IP_Addresses.html):
100.43.90.0/24, 37.9.115.0/24, 37.140.165.0/24, 77.88.22.0/25, 77.88.29.0/24, 77.88.31.0/24, 77.88.59.0/24, 84.201.204,148,0 .148.0/24, 84.201.149.0/24, 87.250.243.0/24, 87.250.253.0/24, 93.158.147.0/24, 93.158.148.0/24, 93.158.151.0/24, 90.158.319,153.0 /24, 95.108.138.0/24, 95.108.150.0/23, 95.108.158.0/24, 95.108.156.0/24, 95.108.188.128/25, 95.108.234.0/24, 95.108.248.0/24, 100.43.80.0/24, 130.193.62.0/24, 141.8.153.0/24, 178.154.165.0/24, 178.154.166.128/25, 178.154.173.29.154.166.128. 178.154.202.0/24, 178.154.205.0/24, 178.154.239.0/24, 178.154.243.0/24, 37.9.84.253, 199.21.99.99, 178.154.162.29, 178.154.203.251, 178.154.211.
 250, 95.108.246.252, 5.45. 254.0/24, 5.255.253.0/24, 37.140.141.0/24, 37.140.188.0/24, 100.43.81.0/24, 100.43.85.0/24, 100.43.91.0/24, 199.21.99.0/24 9000
250, 95.108.246.252, 5.45. 254.0/24, 5.255.253.0/24, 37.140.141.0/24, 37.140.188.0/24, 100.43.81.0/24, 100.43.85.0/24, 100.43.91.0/24, 199.21.99.0/24 9000Мой robots.txt:
User-agent: Яндекс Запретить: / Пользовательский агент: * Запретить: ... и т. д.
Но, судя по сообщению Cloudflare, он все еще ползает.
Что еще я могу сделать, чтобы остановить это?
Прямо с сайта Яндекса
User-Agent Mozilla/5.0 (совместимый; Яндекс...) строка идентифицирует роботов Яндекса. Роботы
может отправлять запросы GET (например, ЯндексБот/3.0) и HEAD (ЯндексВебмастер/2.0) к
сервер. Обратный просмотр DNS можно использовать для проверки подлинности роботов Яндекса. Более
информацию можно найти в разделе Как проверить принадлежность робота Яндексу
помощь веб-мастера.
Если у вас есть какие-либо вопросы о наших роботах, пожалуйста, свяжитесь с нашей службой поддержки:
support@search.
