Содержание
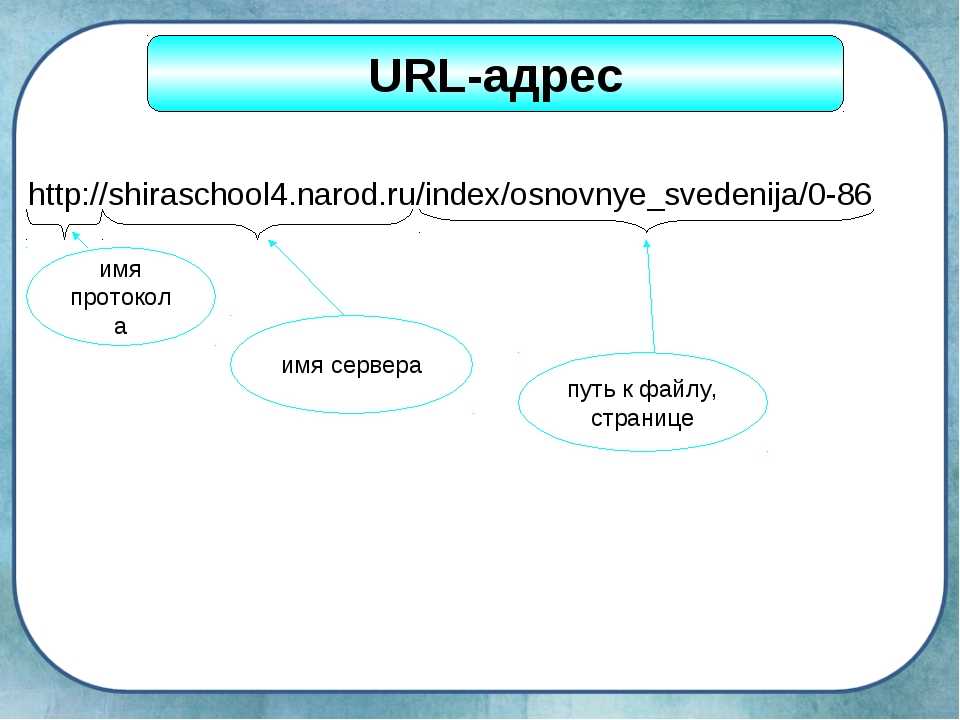
▷ Що таке файл Robots.txt — як створити та налаштувати правила в файлі Robots.txt, приклади використання
Що таке Robots.txt?
Robots.txt — текстовий файл, в якому вказуються правила сканування сайту для пошукових систем. Файл знаходиться в кореневій папці і є звичайним текстовим документом в форматі .txt.
Пошукові системи спочатку сканують вміст файлу Robots.txt і тільки потім інші сторінки сайту. Якщо файл Robots.txt відсутня – пошуковим системам дозволено сканувати всі сторінки сайту.
Содержание
- Що таке Robots.txt?
- Для чого потрібен файл Robots.txt
- Як створити текстовий файл Robots.txt
- Вимоги до файлу Robots.txt
- Обмеження документа Robots.txt
- Позначення і види директив
- У якому порядку виконуються правила
- Приклади використання файлу Robots.txt
- Найбільш поширені помилки
- Довідкові матеріали
Для чого потрібен файл Robots.txt
- Вказати пошуковим системам правила сканування і індексації сторінок сайту.
 Для кожного пошукача можна задати як різні правила, так і однакові.
Для кожного пошукача можна задати як різні правила, так і однакові. - Вказати пошуковим системам посилання на xml-карту сайту, щоб роботи могли без проблем її знайти і просканувати.
 Для кожного пошукача можна задати як різні правила, так і однакові.
Для кожного пошукача можна задати як різні правила, так і однакові.Основним завданням robots.txt є управління доступу до сторінок сайту пошуковим системам і іншим роботам. На сайті може перебувати конфіденційна інформація, наприклад, особисті дані користувачів або внутрішні документи компанії. Завдяки директивам в файлі Robots.txt можна заборонити до них доступ пошуковим системам і їх не знайдуть.
Варто пам’ятати про те, що пошукові системи враховують правила в файлі Robots.txt по-різному. Для Google вміст файлу є рекомендацією по скануванню сайту, а для Яндекса – прямий директивою.
Тобто, якщо сторінка закрита в файлі Robots.txt, вона все одно може потрапити в індекс пошукової системи Google, адже для нього це рекомендації по скануванню, а не індексації.
Щоб не допустити індексації певних сторінок сайту потрібно використовувати метатег robots або X-Robots-Tag.
Яндекс сприймає вміст файлу Robots.txt як директиви і завжди їх виконує.
Тут потрібна картинка, що Яндекс кориться вимогам, а Google ухиляється. Треба намалювати.
Як створити текстовий файл Robots.txt
- Створіть текстовий документ у форматі .txt.
- Поставте йому ім’я robots.txt.
- Вкажіть вміст файлу.
- Додайте його в кореневий каталог сайту, щоб він був доступний за адресою /robots.txt.
- Перевірте коректність файлу через інструмент Яндекса или Google.
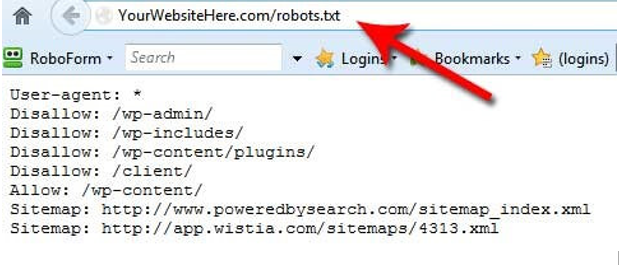
Файл Robots.txt повинен обов’язково знаходитися за адресою robots.txt. Якщо він буде розміщений по іншому url-адресою, пошукова система буде його ігнорувати і вважати, що все дозволено для сканування і індексації.
Вірно:
https://inweb.ua/robots.txt
Невірно:
https://inweb.ua/robots.txt
https://inweb.ua/ua/robots.txt
https://inweb.ua/robot.txt
Для популярних CMS є плагіни для редагування файлу Robots.txt:
- WordPress – Clearfy Pro .
- Opencart – редактор Robots.txt .
- Bitrix – є можливість редагувати через адміністративну панель за замовчуванням. Маркетинг & gt; Пошукова оптимізація & gt; Налаштування robots.txt.

За допомогою зазначених модулів можна легко змінювати директиви через адміністративну панель, без використання ftp.
Вимоги до файлу Robots.txt
Щоб пошукові системи виявили і слідували директивам необхідно дотримуватись наступних правил:
- Розмір файлу не перевищує 500кб;
- Це TXT-файл з назвою robots – robots.txt;
- Файл розміщений в кореневому каталозі сайту;
- Файл доступний для роботів – код відповіді сервера – 200. Перевірити можна за допомогою сервісу або інструментів Google Search Console і Яндекс Вебмастера.
- Якщо файл не відповідає вимогам – сайт вважається відкритим для сканування і індексації.
Якщо ж пошукова система, при запиті файлу /robots.txt, отримала код відповіді сервера відмінний від 200 – сканування сайту припиниться.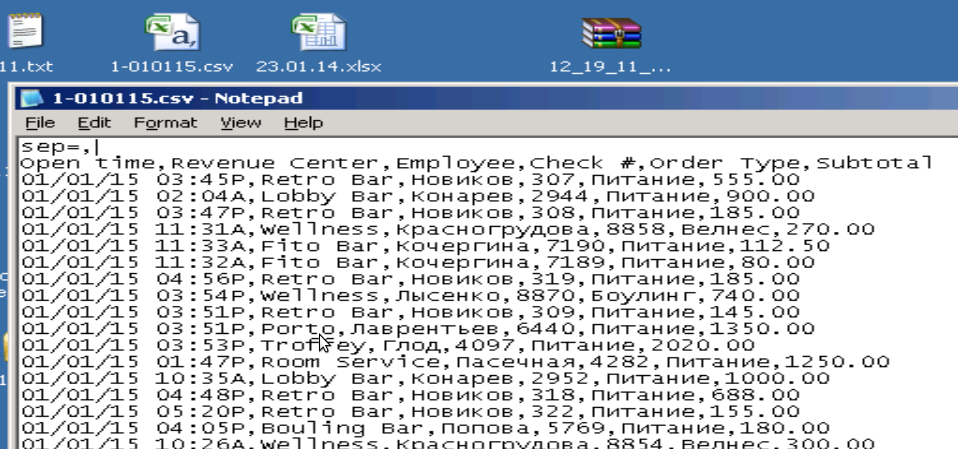 Це може істотно погіршити швидкість сканування сайту.
Це може істотно погіршити швидкість сканування сайту.
Обмеження документа Robots.txt
- Не всі пошукові системи обробляють директиви у файлі Robots.txt однаково. У кожної є своя інтерпретація. При складанні правил слід на це звертати увагу.
- Кожна директива повинна починатися з нового рядка.
- У кожної пошукової системи є кілька роботів, які сканують сайти. Деякі з них інтерпретують правила robots.txt інакше.
- У файлі Robots.txt дозволяється використовувати тільки латинські літери. Якщо у вас кириличні url-адреси або домен – необхідно використовувати punycode.
Розглянемо на прикладі, як Robots.txt використовує систему кодування:
Вірно:
User-agent: *
Disallow: /корзина
Sitemap: сайт.рф/sitemap.xml
Не вірно:
User-agent: *
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap:http://xn--80aswg.xn--p1ai/sitemap.xml
Позначення і види директив
Нижче розглянемо які є директиви у файлі Robots. txt
txt
- User-agent — вказівка пошукового бота, до якого застосовуються правила. Щоб вибрати всіх роботів – вкажіть “*”. Директива є обов’язковою для використання, без вказівки User-gent не можна використовувати будь-які правила.
Наприклад:
User-agent: * # правила для всіх.
User-agent: Googlebot # правила тільки для Google.
User-agent: Yandex # правила тільки для Яндекса
. - Disallow — директива, яка забороняє сканування певних сторінок або розділів.
Наприклад:
Disallow: / order / # закриває всі сторінки, які починаються з / order /.
Disallow: / * sort-order # закриває всі сторінки, які містять фрагмент “sort-order”.
Disallow: / secretiki / # закриває всі сторінки, які починаються з / secretiki /. - Sitemap — вказівка посилання на xml-карту сайту. Якщо xml-карт сайту кілька – можна вказати їх все.
Наприклад:
Sitemap: https://inweb.ua/sitemap.xml
Sitemap: https://inweb. ua/sitemap-images.xml - Allow — дозволяє відкрити для робота сторінку або групу сторінок.
Наприклад:
Disallow: /category/
Allo: /category/phones/
Ми закриваємо всі сторінки, які починаються з / category /, але відкриваємо /category/phones/ - Clean-param — повідомляє Яндексу, що в адресі є параметри і мітки, необов’язкові при скануванні. Працює тільки з роботами в Yandex.
- Crawl-delay — з 22 лютого 2018 року не враховується. Раніше враховувалася тільки пошуковою системою Яндекс і впливала на затримку між зверненнями до сайту.
- Host — вказівка головного дзеркала для Яндекса. Не враховується з 12 березня 2018 року. Тепер все пошукові системи ігнорують цю директиву.
- Спецсимволи:* – позначає будь-яку кількість символів.
Наприклад:
Disallow: * # забороняє сканування всього сайту.
Disallow: * limit # Забороняє сканування всіх сторінок, які містять “limit”.
Disallow: / order / * / success / # забороняє сканування всіх сторінок, які починаються з / order /, потім містять будь-яку кількість символів, а потім / success /. - $ – позначає кінець рядка.
Наприклад:
Disallow: /*order$ #забороняє сканування всіх сторінок, які закінчуються на order.
 ua/sitemap-images.xml
ua/sitemap-images.xml
У якому порядку виконуються правила
Yandex і Google обробляє директиви Allow і Disallow не по порядку, в якому вони вказані, а спочатку сортує їх від короткого правила до довгого, а потім обробляє останнім відповідне правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
Буде прочитана як:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким чином, якщо перевіряється посилання виду: /wp-content/uploads/file.jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
У разі, якщо директиви рівнозначні або суперечать один одному:
User-agent: *
Disallow: /admin
Allow: /admin
Пріоритет віддається директиві Allow.
Приклади використання файлу Robots.txt
Приклад №1 – повністю закрити сайт від індексації.
User-agent: *
Disallow: /
Приклад №2 – блокуємо доступ до папки для Google, іншим пошуковим системам відкриваємо.
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /papka/
Приклад №3 – сайт повністю відкритий для індексації.
User-agent: *
Disallow:
Приклад №4 – закриваємо всі сторінки сайту, які містять фрагмент url-адреси “secret”.
User-agent: *
Disallow: *secret
Приклад №5 – закриємо повністю сайт для Яндекса, а для Google відкриємо тільки папку /for-google/
User-agent: Yandex
Disallow: /
User-agent: Googlebot
Disallow: /
Allow: /for-google/
Найбільш поширені помилки
Розглянемо найбільш поширені помилки, які допускають SEO-фахівці при складанні директив.
- Відсутність на самому початку директиви зірочки. Варто пам’ятати, що обов’язково потрібно додавати * перед фрагментом url-адреси, якщо директива містить фрагмент, який знаходиться не на початку url-адреси.
Наприклад, потрібно закрити від сканування url-адреса
https://inweb.ua/catalog/cateogory/?sort=name
Невірно: Disallow: ?sort=
Вірно: Disallow: /*sort= - Директива, крім неякісних url-адрес, забороняє сканування якісних сторінок. При написанні директив варто вказувати їх максимально чітко, щоб навіть теоретично якісні url-адреси не потрапили під заборону.
Невірно: Disallow: *sort
Вірно: Disallow: /*?sort=
У першому випадку, випадково можуть бути сторінки виду:
https://inweb.ua/kak-zakryt-ot-indeksacii-sortirovki/ Адже, теоретично, деякі сторінки можуть містити в url-адресу фрагмент “sort”. - Сторінки одночасно закриті в файлі Robots.txt і через метатег robots.Еслі неякісний документ закритий від сканування в файлі Robots.txt і від індексування через метатег robots – сторінка ніколи не випаде з індексу, оскільки робот пошукової системи Google не побачить noindex, адже не може її просканувати.
- Використання кириличних символів. Варто завжди пам’ятати, що кирилиця не розпізнає пошуковими системами в файлі Robots. txt, обов’язково потрібно замінити на punycode. Посилання на конвертер.

 txt, обов’язково потрібно замінити на punycode. Посилання на конвертер.
txt, обов’язково потрібно замінити на punycode. Посилання на конвертер.Довідкові матеріали
- Довідка Яндекс по Robots.txt.
- Довідка Google по Robots.txt.
- Види пошукових роботів Google.
- Види пошукових роботів Яндекс.
- Інструмент перевірки файлу Robots.txt.
Тест на знання файлу Robots.txt
Коли-небудь настане день і знамення олдові «Термінатора» стане реальністю – роботи заполонять світ і візьмуть верх над людством. І тільки вправні знавці машин зможуть лавірувати в смертельній сутичці. Як добре ви вмієте спілкуватися з роботами? Чи зможете очолити повстання проти машин? Давайте перевіримо!
Что такое файл robots.txt? – iSEO
Файл robots.txt («роботс тэ-экс-тэ») – текстовый файл, который представляет собой основной способ управления сканированием и индексацией сайта поисковыми системами. Размещается строго в корневой папке сайта. Имя файла должно быть прописано в нижнем регистре.
Зачем нужен robots.
 txt?
txt?
Поисковый робот, попадая на сайт обращается к файлу robots.txt, чтобы получить информацию о том, какие разделы и страницы сайта нужно игнорировать, а также информацию о расположении XML-карты сайта и другие параметры.
Данный файл позволяет убрать из поиска дубли страниц и служебные страницы, на которые не должны попадать посетители из поисковых систем. Помогает улучшить позиции сайта в поиске и комфортность для посетителей в использовании сайта.
Для создания robots.txt достаточно воспользоваться любым текстовым редактором. Его необходимо заполнить в соответствии с определенными правилами (о них расскажем далее) и загрузить в корневой каталог сайта.
Если файла robots.txt на сайте нет или он пустой – поисковые системы могут пытаться сканировать и индексировать весь сайт.
Основные директивы в robots.txt
Комментарии
В файле robots.txt можно оставлять комментарии – они будут игнорироваться поисковыми системами. Комментарии помогают структурировать файл, указывать какие-то важные пометки и т. п. Строка с комментарием должна начинаться с символа решетки – #.
п. Строка с комментарием должна начинаться с символа решетки – #.
Пример:
# Это комментарий
User-agent
Указывает для какого робота предназначены следующие за ней инструкции. Файл robots.txt может состоять из нескольких блоков инструкций, каждая из которых предназначена для определенной поисковой системы. Каждый блок начинается с директивы User-agent и состоит из следующих за ней инструкций. Каждая инструкция – с новой строки.
Наименования роботов для User-agent можно найти, например, в справке поисковых систем. В Рунете чаще всего используются три:
- * – указывает, что следующие инструкции предназначены для всех роботов. Если робот не найдет в файле robots.txt секции конкретно для него, то будет учитывать эту секцию.
- Yandex – робот Яндекса.
- Googlebot – робот Google.
Примеры:
# Секция для всех роботов, которая разрешает индексировать весь сайт User-agent: * Disallow: # Секция для Google, которая запрещает индексировать папку /secret/ User-agent: Googlebot Disallow: /secret/
Disallow и Allow
Основные директивы, которые указывают, что можно и что нельзя индексировать:
- Disallow – запрещает индексацию
- Allow – разрешает
Поскольку, изначальная стандартная функция robots. txt это именно запрещать индексацию, то чаще используются директивы Disallow. Директива Allow появилась позднее и её могут поддерживать не все поисковые системы. Но Яндекс и Google – поддерживают.
txt это именно запрещать индексацию, то чаще используются директивы Disallow. Директива Allow появилась позднее и её могут поддерживать не все поисковые системы. Но Яндекс и Google – поддерживают.
Директива Allow применяется если вам нужно разрешить к индексированию что-то, что было запрещено директивами Disallow. Например, если какая-то папка запрещена к индексированию, но определенный файл/страницу в ней нужно разрешить.
В каждой из директив указывается префикс URL (т. е. начало адреса страницы), для которого должно применяться это правило. Также есть специальные символы:
- * – любая последовательность символов (в том числе, пустая). В конце инструкций ставить этот символ не нужно, т. к. по умолчанию директивы интерпретируются так, что как будто он там уже есть.
- $ – конец строки. Отменяет подразумеваемый символ * на конце строки.
Если в файле используются одновременно директивы Allow и Disallow, то приоритет будет иметь та, префикс URL у которой длиннее. Правила применяются по возрастанию длины префикса.
Правила применяются по возрастанию длины префикса.
Пример:
# Секция для Яндекса, которая запрещает индексировать папку /secret/ # но разрешает индексировать страницу /secret/not-really/ # при этом не разрешает индексировать всё остальное в папке /secret/not-really/ User-agent: Yandex Disallow: /secret/ Allow: /secret/not-really/$ # Секция для всех роботов, которая запрещает индексировать весь сайт User-agent: * Disallow: / # Секция для Google, которому можно индексировать только страницы с параметрами в URL User-agent: Googlebot Disallow: / Allow: /*?*=
Clean-param
Директива, которую поддерживает Яндекс. Используется для указания параметров в URL, которые следует игнорировать (т. е. считать страницы с такими параметрами одной и той же страницей).
Синтаксис:
Clean-param: param1[¶m2¶m3&..¶mN] [path]
Где param1…paramN это список параметров, разделенных символом &, а [path] это опциональный префикс URL для которого нужно применять это правило (по аналогии с Allow/Disallow).
Директив может быть несколько. Длина правила – не более 500 символов.
Пример:
# Разрешить Яндексу индексировать всё # кроме страниц с параметром session_id в папке /catalog/ User-agent: Yandex Disallow: Clean-param: session_id /catalog/
Sitemap
Указывает на расположение XML-карт сайта. Таких директив может быть несколько.
Директива Sitemap является межсекционной – не важно в каком блоке User-agent или месте файла она будет указана. Все роботы будут учитывать все директивы Sitemap в вашем файле robots.txt.
Пример:
Sitemap: https://www.site.ru/sitemap_index.xml
Host
Межсекционная директива для указания основного хоста. Раньше поддерживалась Яндексом. Теперь поддерживается только роботом поиска Mail.ru. Ее наличие в файле не является какой-то ошибкой, но и пользы от нее немного, т. к. доля органического трафика с поиска Mail.ru обычно очень низкая (порядка 1%).
Пример:
Host: https://www.site.ru
Crawl-delay
Устаревшая директива, которая использовалась для указания задержки между обращениями робота к сайту. Теперь управлять нагрузкой робота на сайте можно в Яндекс Вебмастере и Google Search Console. Директиву Crawl-delay не поддерживает ни Яндекс, ни Google.
Что еще важно знать про robots.txt
- Регистр букв имеет значение. Папки /aaa/ и /AAA/ это разные папки и для них нужны разные директивы.
- Кириллица – не поддерживается. Как она не поддерживается в URL и в названиях доменов. В файле robots.txt кириллические папки/файлы и названия доменов должны быть указаны в закодированном виде.
- Google считает, что файл robots.txt управляет сканированием, а не индексацией. На практике это значит, что если какие-то страницы сайта Google уже нашел и проиндексировал (например, на них были ссылки с других сайтов), то запрет их индексации в robots. txt не поможет исключить их из индекса. Для этого нужно применять метатег robots на самой странице. При этом, чтобы Google это тег увидел и учёл – страница не должна быть закрыта в robots.txt. Звучит это довольно абсурдно, но работает именно так, к сожалению.
- Прежде чем залить файл на «боевой» домен – проверьте его правильность с помощью соответствующих инструментов в Яндекс Вебмастере и Google Search Console.
 txt не поможет исключить их из индекса. Для этого нужно применять метатег robots на самой странице. При этом, чтобы Google это тег увидел и учёл – страница не должна быть закрыта в robots.txt. Звучит это довольно абсурдно, но работает именно так, к сожалению.
txt не поможет исключить их из индекса. Для этого нужно применять метатег robots на самой странице. При этом, чтобы Google это тег увидел и учёл – страница не должна быть закрыта в robots.txt. Звучит это довольно абсурдно, но работает именно так, к сожалению.Подробнее о файле robots.txt в справке поисковых систем:
- https://yandex.ru/support/webmaster/controlling-robot/robots-txt.html
- https://developers.google.com/search/docs/advanced/robots/intro?hl=ru
Ubuntu Manpage: urls.txt — база данных URL для регрессионного тестирования
Предоставлено: siege_3.0.8-1_amd64
ИМЯ
urls.txt — база данных URL для регрессионного тестирования
ВВЕДЕНИЕ
Файл urls. txt по умолчанию устанавливается в /etc/siege/urls.txt. Когда вызывается осада
без ссылки командной строки на URL-адрес, то по умолчанию он ищет URL-адреса в этом файле.
Преимущество использования файла urls.txt состоит из двух частей: во-первых, вы освобождаете вас от повторного ввода
URL при каждом вызове. Во-вторых, это позволяет провести полную регрессию сайта.
тестирование.
Когда используется файл urls.txt, siege считывает все URL-адреса в этом файле в память и запускается
через список одним из двух способов, последовательно или случайным образом. Запуск по умолчанию
последовательно от начала до конца и обратно до тех пор, пока параметр --reps или --time не будет
был удовлетворен. Если выбрана опция -i/--internet, осада проходит через файл
случайным образом имитируя стресс, применяемый сообществом пользователей Интернета.
Параметр -f/--file позволяет вам выбрать файл, отличный от файла urls.txt по умолчанию. Ты
также может указать Siege использовать другой файл с директивой «file» в . siegerc,
т. е. «файл = /usr/local/etc/urls.txt»
Вы можете устанавливать и ссылаться на переменные внутри файла urls.txt. Все переменные должны быть
объявляются ДО того, как на них ссылаются. Переменные объявляются с помощью оператора "=",
ПЕРЕМЕННАЯ = ЗНАЧЕНИЕ. Затем на них ссылаются внутри $() или ${}, например: $(HOST), ${HOST}
ХОСТ=joey.joedog.org
http://${HOST}/browse.jsp?size=5
http://${HOST}/admin.jsp?name=ralph
 txt по умолчанию устанавливается в /etc/siege/urls.txt. Когда вызывается осада
без ссылки командной строки на URL-адрес, то по умолчанию он ищет URL-адреса в этом файле.
Преимущество использования файла urls.txt состоит из двух частей: во-первых, вы освобождаете вас от повторного ввода
URL при каждом вызове. Во-вторых, это позволяет провести полную регрессию сайта.
тестирование.
Когда используется файл urls.txt, siege считывает все URL-адреса в этом файле в память и запускается
через список одним из двух способов, последовательно или случайным образом. Запуск по умолчанию
последовательно от начала до конца и обратно до тех пор, пока параметр --reps или --time не будет
был удовлетворен. Если выбрана опция -i/--internet, осада проходит через файл
случайным образом имитируя стресс, применяемый сообществом пользователей Интернета.
Параметр -f/--file позволяет вам выбрать файл, отличный от файла urls.txt по умолчанию. Ты
также может указать Siege использовать другой файл с директивой «file» в .
txt по умолчанию устанавливается в /etc/siege/urls.txt. Когда вызывается осада
без ссылки командной строки на URL-адрес, то по умолчанию он ищет URL-адреса в этом файле.
Преимущество использования файла urls.txt состоит из двух частей: во-первых, вы освобождаете вас от повторного ввода
URL при каждом вызове. Во-вторых, это позволяет провести полную регрессию сайта.
тестирование.
Когда используется файл urls.txt, siege считывает все URL-адреса в этом файле в память и запускается
через список одним из двух способов, последовательно или случайным образом. Запуск по умолчанию
последовательно от начала до конца и обратно до тех пор, пока параметр --reps или --time не будет
был удовлетворен. Если выбрана опция -i/--internet, осада проходит через файл
случайным образом имитируя стресс, применяемый сообществом пользователей Интернета.
Параметр -f/--file позволяет вам выбрать файл, отличный от файла urls.txt по умолчанию. Ты
также может указать Siege использовать другой файл с директивой «file» в .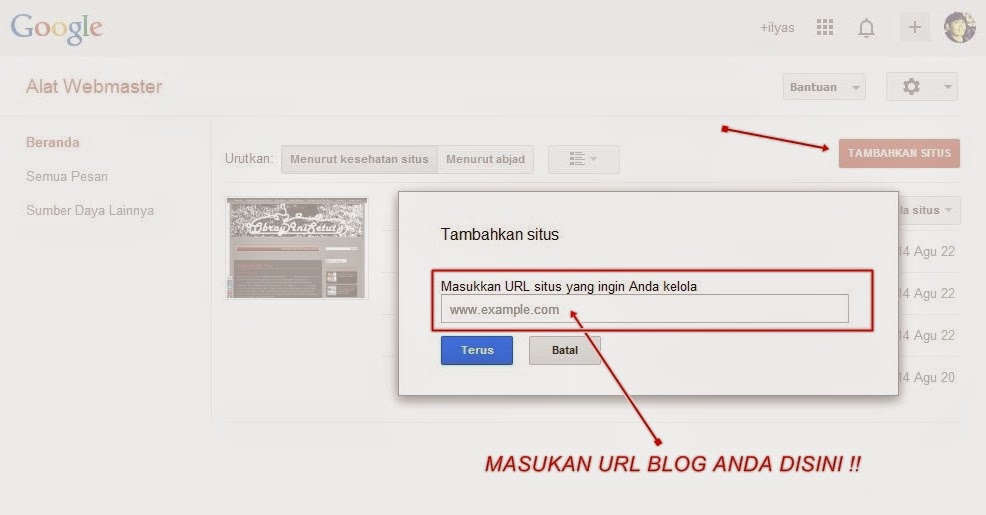 siegerc,
т. е. «файл = /usr/local/etc/urls.txt»
Вы можете устанавливать и ссылаться на переменные внутри файла urls.txt. Все переменные должны быть
объявляются ДО того, как на них ссылаются. Переменные объявляются с помощью оператора "=",
ПЕРЕМЕННАЯ = ЗНАЧЕНИЕ. Затем на них ссылаются внутри $() или ${}, например: $(HOST), ${HOST}
ХОСТ=joey.joedog.org
http://${HOST}/browse.jsp?size=5
http://${HOST}/admin.jsp?name=ralph
siegerc,
т. е. «файл = /usr/local/etc/urls.txt»
Вы можете устанавливать и ссылаться на переменные внутри файла urls.txt. Все переменные должны быть
объявляются ДО того, как на них ссылаются. Переменные объявляются с помощью оператора "=",
ПЕРЕМЕННАЯ = ЗНАЧЕНИЕ. Затем на них ссылаются внутри $() или ${}, например: $(HOST), ${HOST}
ХОСТ=joey.joedog.org
http://${HOST}/browse.jsp?size=5
http://${HOST}/admin.jsp?name=ralph
ПРИМЕР ФАЙЛ
Это пример файла urls.txt. Строки, начинающиеся с решётки (#), являются комментариями и игнорируются.
осадой.
#
# Пример файла urls.txt
# база данных URL для осады
#
http://www.хаха.com/index.html
http://www.haha.com/howto/index.html
http://www.haha.com/cgi-bin/howto/display.cgi?1013
www.haha.com/cgi-bin/fm.cgi?first=j.&last=fulmer
https://www.haha.com/index.shtml
https://www.whoohoo.com/my_whoohoo. jsp
# Данные POST требуют директивы POST
www.haha.com/cgi-bin/foo.cgi POST first=bart&last=simpson
www.haha.com/hoho.jsp POST name=jeff&pass=secret
# POST содержимое файла с помощью
# символ ввода строки "<"
http://www.haha.com/my.jsp ОТПРАВИТЬ АВТОР
Джеффри Фулмер и др.
ОШИБКИ
Сообщайте об ошибках по адресу [email protected]. Дайте подробное описание проблемы и сообщите
версия осады, которую вы используете.
АВТОРСКОЕ ПРАВО
Copyright © 2007 Джеффри Фулмер и др.
Эта программа является бесплатным программным обеспечением; вы можете распространять его и/или изменять в соответствии с условиями
Стандартная общественная лицензия GNU, опубликованная Free Software Foundation; либо
версии 2 Лицензии или (по вашему выбору) любой более поздней версии.
Эта программа распространяется в надежде, что она будет полезна, но БЕЗ КАКИХ-ЛИБО ГАРАНТИЙ;
даже без подразумеваемой гарантии КОММЕРЧЕСКОЙ ПРИГОДНОСТИ или ПРИГОДНОСТИ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ.
Дополнительные сведения см. в Стандартной общественной лицензии GNU.
Вы должны были получить копию Стандартной общественной лицензии GNU вместе с этой программой;
если нет, напишите в Free Software Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139.,
США.
НАЛИЧИЕ
Самая последняя выпущенная версия siege доступна по анонимному FTP с
ftp.joedog.org в каталоге pub/siege.
СМ. ТАКЖЕ
осада(1) siege.config(1) закладкаосада(7)
windows 7 - wget - много URL-адресов в файле .txt - скачать и сохранить как
спросил
Изменено
9 лет, 9 месяцев назад
Просмотрено
8к раз
У меня есть 2000 URL-адресов в файле Excel. URL-адреса находятся в первом столбце, а во втором столбце — имена файлов, загруженных с URL-адреса в первом столбце. Я могу скопировать это и вставить в файл .txt, если это необходимо, без проблем.
Имена файлов содержат пробелы. Мне нужно сделать это на Windows 7.
Не могли бы вы помочь мне?
@Редактировать:
Что ж, извините, если моя проблема неясна. Я не носитель английского языка. У меня есть URL-адрес в первом столбце, и я хочу сохранить файл, загруженный с этого URL-адреса, с именем из второго столбца. Я хочу, чтобы эти места были там. Я хочу загрузить все файлы одной командой или пакетным файлом с помощью инструмента «wget».
 jsp
# Данные POST требуют директивы POST
www.haha.com/cgi-bin/foo.cgi POST first=bart&last=simpson
www.haha.com/hoho.jsp POST name=jeff&pass=secret
# POST содержимое файла с помощью
# символ ввода строки "<"
http://www.haha.com/my.jsp ОТПРАВИТЬ
jsp
# Данные POST требуют директивы POST
www.haha.com/cgi-bin/foo.cgi POST first=bart&last=simpson
www.haha.com/hoho.jsp POST name=jeff&pass=secret
# POST содержимое файла с помощью
# символ ввода строки "<"
http://www.haha.com/my.jsp ОТПРАВИТЬ  Дополнительные сведения см. в Стандартной общественной лицензии GNU.
Вы должны были получить копию Стандартной общественной лицензии GNU вместе с этой программой;
если нет, напишите в Free Software Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139.,
США.
Дополнительные сведения см. в Стандартной общественной лицензии GNU.
Вы должны были получить копию Стандартной общественной лицензии GNU вместе с этой программой;
если нет, напишите в Free Software Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139.,
США.
 URL-адреса находятся в первом столбце, а во втором столбце — имена файлов, загруженных с URL-адреса в первом столбце. Я могу скопировать это и вставить в файл .txt, если это необходимо, без проблем.
URL-адреса находятся в первом столбце, а во втором столбце — имена файлов, загруженных с URL-адреса в первом столбце. Я могу скопировать это и вставить в файл .txt, если это необходимо, без проблем.- windows-7
- скачать
- wget
- url
- сохранить как
1
Шаги
Откройте лист в Excel и нажмите Файл → Сохранить как .
Закройте Excel, чтобы разблокировать файл.
Выберите CSV (значения, разделенные запятыми) в качестве типа и тот же файл, что и
urls.csv.Откройте командную строку, выполните
введите urls.csv
и определите разделитель значений (символ, помещенный между URL-адресом и именем файла.
Если это, например, точка с запятой, выполните следующую команду:
для /f "delims=; tokens=1,2" %a в (urls.csv) do @wget -O "%b" "%a"
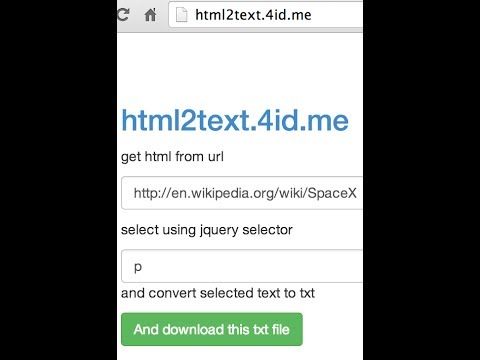
Как это работает
Excel сохраняет URL-адреса и соответствующие имена в виде значений, разделенных запятой (или точкой с запятой).
Пример:
http://foo;бар http://foo-бар;foobar
for /f ... %a (urls.csv)проходит по всем строкам и сохраняет первое значение в%aи второй в%b.Здесь
разделителей=;указывает точку с запятой в качестве разделителя значений, аtoken=1,2указывает, что будет два токена.wget -O "%b" "%a"сохраняет%aв%b. Поскольку URL-адрес заключен в кавычки, Wget автоматически позаботится о пробелах и других специальных символах.@перед@wgetпредотвращает печать команд.

См. также: For /f — циклический просмотр текста | SS64.com
10
Мы можем вам помочь?
Возможно, если бы вы действительно сказали, что именно вам нужно сделать.
Что вы имеете в виду под «именами файлов»?
Вот общий ответ.
1) В программе для работы с электронными таблицами скопируйте столбец, содержащий данные, из которых вы хотите удалить пробелы.
2) Сохраните это в файл .txt.
3) Откройте этот .txt файл в любой программе с работающим поиском и заменой.
4) Найдите пробелы и замените на _
5) Сохраните этот файл .txt.
6) Откройте его в программе для работы с электронными таблицами.
7) У вас должен быть столбец с data_data_data.