Содержание
Ранжирование текстов по похожести на опорные тексты при помощи модели TF-IDF в реализации GENSM / Хабр
Бывает так, что критерии поиска текстов слишком сложны, чтобы обойтись регулярными выражениями. В таких случаях на помощь приходит ML. Если из списка текстов выбрать самый подходящий для нас, можно выяснить похожесть всех остальных текстов на этот. Похожесть(similarity) это численная мера, чем выше – тем более текст похож, поэтому при сортировке по убыванию по этому параметру мы увидим наиболее подходящие нам тексты из выборки.
В качестве примера возьмем любой набор текстов. Здесь http://study.mokoron.com/ можно скачать небольшое csv с твитами. В реальной работе это могут быть разного рода комментарии, ответы от техподдержки, запросы пользователей. Так или иначе, импортировав все нужные библиотеки, загрузим в pandas наш список текстов и взглянем на первые из них:
import pandas as pd import re from gensim import corpora,models,similarities from gensim.utils import tokenize df = pd.а-яА-Я] означает «любой символ, который не является русской буквой». Вообще для создания регулярных выражений удобно использовать сайт regex. Метод str.count библиотеки pandas применяет регулярное выражение массово на весь датасет, выдавая количество найденных регулярок. Флаг re.IGNORECASE это часть конфигурации библиотеки регулярных выражений regex, заставляющая ее искать вне зависимости от того, заглавные в тексте буквы или строчные.
Результат выполнения выглядит так:
Этого иногда бывает достаточно, но даже если нет, такую предварительную работу всегда стоит проводить для облегчения фильтрации. Если мы точно знаем, что в тексте встретятся слова «бумажный носитель», но нам точно не подойдет «платежный документ», мы добавим «бума.*носит» и «платежн.*документ» и в дальнейшем отфильтруем их так, как нам надо.
Для непосредственного поиска похожих текстов стоит использовать реализацию doc2bow из библиотеки genism, поскольку помимо нужных нам моделей она предоставляет множество других полезных функций, например токенизацию со встроенной лемматизацией, что может быть полезно в случае, если предварительно обученные модели для лемматизации использовать нельзя.
Первым делом выделим тексты, по которым будет проводиться сравнение, далее называя их «опорные тексты». Скорее всего, после первого этапа поисков этот список расширится, поскольку модель предложит дополнительные варианты подходящих текстов. В качестве примера просто возьмем первые 5 твитов, главное помнить, что эти тексты так же должны быть в общем наборе.
texts_to_compare = list(df.head(5)["text"]) ['@first_timee хоть я и школота, но поверь, у нас то же самое :D общество профилирующий предмет типа)', 'Да, все-таки он немного похож на него. Но мой мальчик все равно лучше:D', 'RT @KatiaCheh: Ну ты идиотка) я испугалась за тебя!!!', 'RT @digger2912: "Кто то в углу сидит и погибает от голода, а мы ещё 2 порции взяли, хотя уже и так жрать не хотим" :DD http://t.co/GqG6iuE2…', '@irina_dyshkant Вот что значит страшилка :D\nНо блин,посмотрев все части,у тебя создастся ощущение,что авторы курили что-то :D']Теперь токенизируем все тексты в нашем датасете. На этом этапе осуществляется обработка текстов, который можно провести множеством способов при помощи множества библиотек.
 а-яА-Я] означает «любой символ, который не является русской буквой». Вообще для создания регулярных выражений удобно использовать сайт regex. Метод str.count библиотеки pandas применяет регулярное выражение массово на весь датасет, выдавая количество найденных регулярок. Флаг re.IGNORECASE это часть конфигурации библиотеки регулярных выражений regex, заставляющая ее искать вне зависимости от того, заглавные в тексте буквы или строчные.
а-яА-Я] означает «любой символ, который не является русской буквой». Вообще для создания регулярных выражений удобно использовать сайт regex. Метод str.count библиотеки pandas применяет регулярное выражение массово на весь датасет, выдавая количество найденных регулярок. Флаг re.IGNORECASE это часть конфигурации библиотеки регулярных выражений regex, заставляющая ее искать вне зависимости от того, заглавные в тексте буквы или строчные.
 Самые распространённые способы включают в себя:
Самые распространённые способы включают в себя:Удаление стоп слов, таких как «а», «и», «но» и прочее. Обычно для этого используются заранее собранные словари. Можно выполнить библиотекой NLTK
Понижение регистра слов до строчных. Большинство библиотек и чистый python сам по себе могут это делать. Некоторые, могут еще и удалить диакритические знаки, например gensim.
Лемматизация, то есть приведение слова к словарной форме. Сложность этого действия зависит от языка, для русского языка этот процесс не прост и требует специальных библиотек. pymystem3 подойдет, но важно всегда контролировать качество.
Стемминг, или обрезка слов до корня. Это более экстремальный вариант лемматизации, который «чайник» может превратить в «чай». Выполняется если потеря смысла не страшна. Подходящая библиотека pymorphy и написанные под нее скрипты для русского языка в духе Стеммера Портера.
def tokenize_in_df(strin):
try:
return list(tokenize(strin,lowercase=True, deacc=True,))
except:
return ""
df["tokens"] = df["text"]. apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
 apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
В нашем примере мы применили только приведение к строчным буквам и удаление ударений в параметрах функции gensim. tokenize: lowercase=True, deacc=True.
tokenize: lowercase=True, deacc=True.
Создадим словарь слов, которые есть во всем нашем наборе текстов:
dictionary = corpora.Dictionary(df["tokens"])
feature_cnt = len(dictionary.token2id)
dictionary.token2id
{'d': 0,
'first_timee': 1,
'же': 2,
'и': 3,
'нас': 4,
'но': 5,
'общество': 6,
'поверь': 7,
'предмет': 8,
'профилирующии': 9,
'самое': 10,
'типа': 11,
'то': 12,
'у': 13,
'хоть': 14,
'школота': 15,
'я': 16,
'все': 17,
'да': 18,
'лучше': 19,
…
Каждое новое слово получает свой номер. Для дальнейшего использования номера слов в словаре походят намного лучше, чем сами слова. Теперь нужно создать корпус, превратив наши токенизированные тексты в векторы (называются bow – bag of words – мешок слов). Вектор в данном случае — список пар значений «номер слова в словаре : количество таких слов в отдельном тексте».
corpus = [dictionary.doc2bow(text) for text in df["tokens"]] corpus [[(0, 1), (1, 1), (2, 1), (3, 3), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 2), (10, 1), (11, 1), (12, 1), (13, 1), (14, 2), (15, 1), (16, 1), …
Прелесть такого вектора в том, что, в отличие от текстов, с ним можно проводить операции матричного умножения, под которые идеально заточены вычислительные мощности процессора и видеокарты, что делает обработку даже самых огромных наборов текстов очень быстрой.
Именно этим займется модель tf-idf. Сама по себе аббревиатура TF-IDF расшифровывается как TF — term frequency, IDF — inverse document frequency, то есть отношение частоты употребления слова в отдельном тексте к частоте употребления слова во всех документах. Построенная на основе такой меры модель прекрасно подходит для поиска похожих текстов, поскольку позволяет сравнивать совокупные меры текстов между собой, строя матрицу похожести.
tfidf = models.TfidfModel(corpus) index = similarities.SparseMatrixSimilarity(tfidf[corpus],num_features = feature_cnt)
Как именно отработала эта модель мы сможем увидеть на примере, построив векторы наших опорных текстов и получив значения их похожестей из матрицы.
for text in texts_to_compare:
kw_vector = dictionary.doc2bow(tokenize(text))
df[text] = index[tfidf[kw_vector]]Теперь мы можем избавиться от заведомо непохожих текстов, посчитав сумму весов и оставив тексты с самыми высокими суммами. Результаты поиска слов при помощи регулярных выражений, между прочим, тоже можно включить в эту сумму, уменьшив их значимость.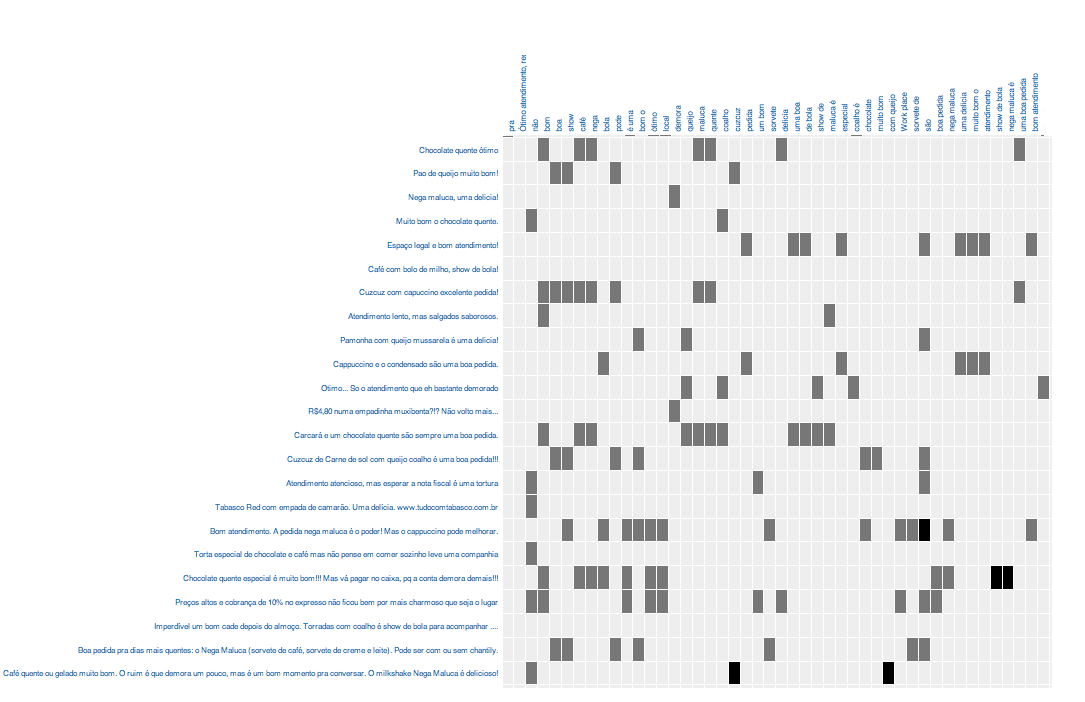
df["sum"] = 0
for text in texts_to_compare:
df["sum"] = df["sum"]+df[text]
for word in regex_queries:
df["sum"] = df["sum"]+df[word]/5 Избавляться от лишних текстов можно обрезав по порогу суммы, или отсортировав по сумме и обрезав датасет по количеству текстов.
df["sum"].value_counts(bins=5) (-0.0022700000000000003, 0.254] 113040 (0.254, 0.508] 1829 (0.508, 0.762] 31 (0.762, 1.016] 7 (1.016, 1.269] 4
На этом этапе python уже не нужен, продолжать работать удобнее в excel:
df[df["sum"]>0.250].to_excel("похожие тексты.xlsx")Проверка результата и поиск дополнительных текстов и слов для улучшения алгоритма комфортно проходит в Excel, за счет использования фильтров и сортировок.
Вот пример, отсортируем результат по похожести на самый первый опорный текст (он, разумеется, окажется на самом первом месте при сортировке):
Видно, что хоть мы и не указывали модели явно такие слова как «школота», «общество» и «предмет», она нашла по ним остальные тексты, поскольку эти слова оказались самыми значимыми.
После нахождения нужных текстов самые подходящие из них можно отправить в начало скрипта, добавив в список texts_to_compare, уточняя или углубляя поиск.
Ссылка на код
Что такое TF-IDF в машинном обучении?
Введение в векторизацию TF-IDF в машинном обучении и его реализация с использованием Python.
Одним из важнейших способов изменения размера данных в процессе машинного обучения является использование термина "частота документа с инвертированной частотой", также известная как метод TF-IDF. В этой статье я расскажу, что такое метод TF-IDF в машинном обучении и как его реализовать с помощью языка программирования Python.
Что такое TF-IDF?
Идея метода TF-IDF заключается в том, чтобы придавать большое значение любому термину, который часто встречается в конкретном документе, но не во многих документах в корпусе. Если слово часто встречается в конкретном документе, но не во многих документах, оно, вероятно, удачно описывает содержание этого документа.
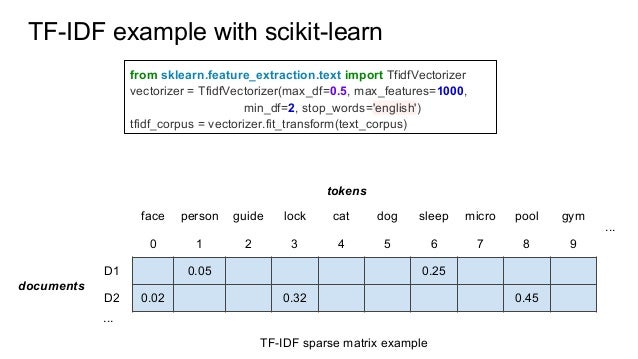
Scikit-Learn реализует метод TF-IDF в двух классах: TfidfTransformer, который принимает выходные данные разреженной матрицы, созданные CountVectorizer, и преобразует их, и TfidfVectorizer, который принимает текстовые данные и выполняет как извлечение функций из пакета слов, так и преобразование TF-IDF.
Зачем нужна векторизация TF-IDF?
Предположим, у поисковой системы есть база данных с тысячами описаний кошек, и пользователь хочет найти пушистых кошек, а затем вводит запрос «The furry cat». Поисковой системе необходимо решить, какой результат должен быть возвращен из базы данных.
Если в поисковой системе есть документы, которые соответствуют точному запросу, не будет никаких сомнений, но что, если ей нужно выбрать между частичными совпадениями? Чтобы упростить, скажем, он должен выбрать между этими двумя описаниями:
- «The pretty cat»
- «A furry kitten»
Первое описание содержит 2 из 3 слов запроса, а второе соответствует только 1 из 3, тогда поисковая система выберет первое описание.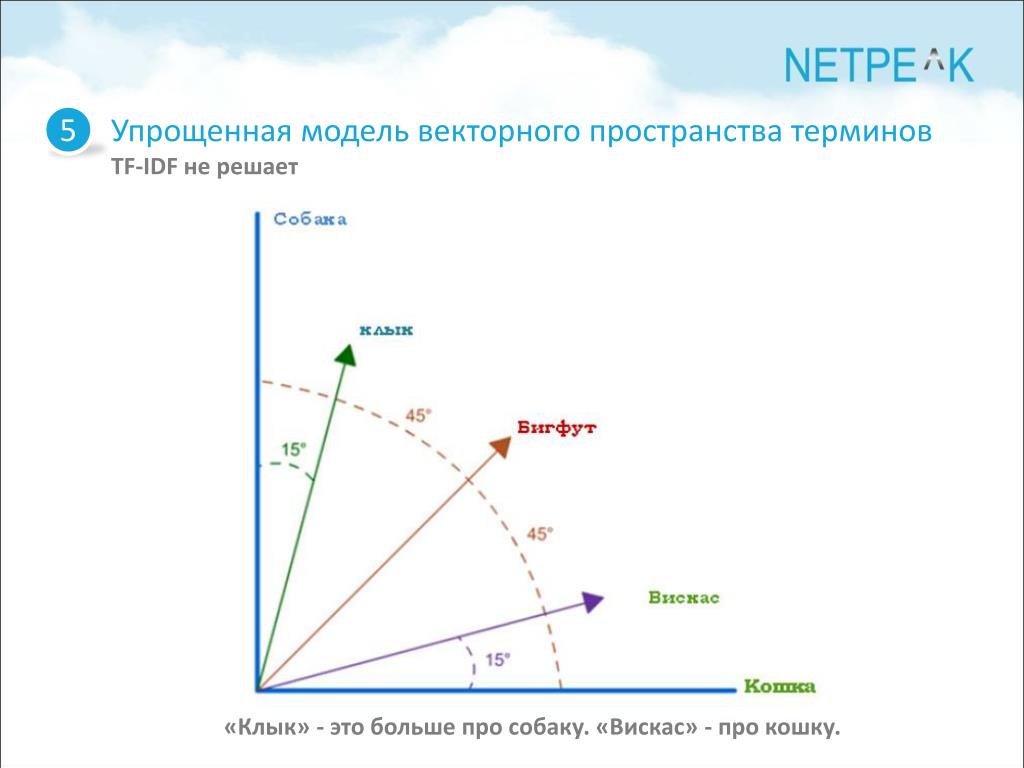 Как TF-IDF может помочь ему выбрать второе описание вместо первого?
Как TF-IDF может помочь ему выбрать второе описание вместо первого?
TF одинаков для каждого слова, здесь никакой разницы. Однако можно было бы ожидать, что термины «cat» и «kitten» будут представлены во многих документах (высокая частота документов означает низкий IDF), а вот термин «furry» будет встречаться в меньшем количестве документов (IDF выше). Таким образом, TF-IDF для «cat» и «kitten» имеет низкое значение, а TF-IDF будет больше для «hairy», то есть в нашей базе данных слово «hairy» имеет большую силу. Различение как «cat» и «kitten».
Если мы используем TF-IDF для взвешивания различных слов, соответствующих запросу, слово «furry» будет более релевантным, чем слово «cat», и поэтому мы могли бы выбрать «A furry kitten» как лучшее соответствие.
Реализация алгоритма с помощью Python
А теперь давайте посмотрим, как реализовать метод TF-IDF с машинным обучением и использованием языка программирования Python. В приведенном ниже примере показана реализация векторизации TF-IDF с использованием Scikit-learn:
from sklearn.
 feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.shape)
feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.shape)
Результат:
(4, 9)
Имейте в виду, что масштабирование TF-IDF предназначено для поиска слов, которые различают документы, но это неконтролируемый метод. Возможности с низким TF-IDF – это те, которые либо очень часто используются в документах, либо используются редко и только в очень длинных документах.
Надеюсь, вам понравилась эта статья о векторизации TF-IDF в машинном обучении.
Понимание TF-IDF для машинного обучения
машинное обучение
6 октября 2021 г.
Нежное введение в термин частотно-обратная частота документа
6 октября 2021 г.
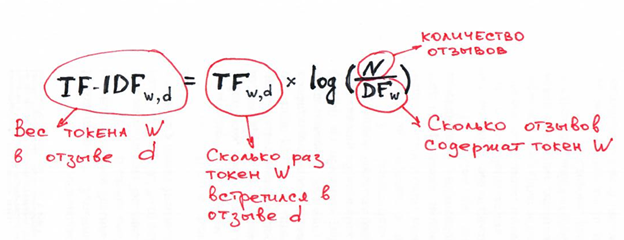
90 002 TF-IDF означает частоту термина - обратная частота документа 90 015, и это мера, используемая в области поиска информации (IR) и машинного обучения, которая может количественно оценить важность или релевантность строковых представлений (слов, фраз, лемм и т. д.) в документе среди набора документы (также известные как корпус).
Обзор TF-IDF
TF-IDF можно разбить на две части: TF (частота термина), и IDF (обратная частота документа).
Что такое TF (термин частота)?
Частота термина работает, глядя на частоту конкретного термина , который вас интересует по отношению к документу. Существует несколько мер или способов определения частоты:
- Количество раз, когда слово появляется в документе (необработанное количество).
- Частота терминов с поправкой на длину документа (необработанное количество вхождений, деленное на количество слов в документе).
- Частота в логарифмическом масштабе (например, log(1 + необработанный счет)).
- Логическая частота (например, 1, если термин встречается в документе, или 0, если термин не встречается в документе).

Что такое IDF (обратная частота документа)?
Инверсия частоты документа показывает, насколько часто (или редко) встречается слово в корпусе. IDF рассчитывается следующим образом, где t — это термин (слово), общность которого мы хотим измерить, а N — это количество документов (d) в корпусе (D). Знаменатель — это просто количество документов в в котором появляется термин t .
Источник изображения: https://monkeylearn.com/blog/what-is-tf-idf/
вообще не появляются в корпусе, что может привести к ошибке деления на ноль. Один из способов справиться с этим - взять существующий счетчик и добавить 1. Таким образом, получается знаменатель (1 + счетчик). Пример того, как с этим справляется популярная библиотека scikit-learn, можно увидеть ниже.
Пример того, как с этим справляется популярная библиотека scikit-learn, можно увидеть ниже.
Источник изображения: https://towardsdatascience.com/how-sklearns-tf-idf-is-different-from-the-standard-tf-idf-275fa582e73d
Причина, по которой нам нужен IDF, заключается в том, чтобы помочь исправить слова like «of», «as», «the» и т. д., поскольку они часто встречаются в английском корпусе. Таким образом, применяя инверсию частоты документов, мы можем свести к минимуму вес частых терминов, в то время как нечастые термины будут иметь большее влияние.
Наконец, IDF также можно получить либо из фонового корпуса, который корректирует систематическую ошибку выборки, либо из набора данных, используемого в данном эксперименте.
Собираем вместе: TF-IDF
Подводя итог ключевой интуиции, мотивирующей TF-IDF, можно сказать, что важность термина обратно пропорциональна его частоте в документах. TF дает нам информацию о том, как часто термин появляется в документе и IDF дает нам информацию об относительной редкости термина в коллекции документов. Перемножив эти значения вместе, мы можем получить окончательное значение TF-IDF.
Перемножив эти значения вместе, мы можем получить окончательное значение TF-IDF.
Источник изображения: https://monkeylearn.com/blog/what-is-tf-idf/
Чем выше балл TF-IDF, тем важнее или релевантнее термин; по мере того, как термин становится менее релевантным, его оценка TF-IDF приближается к 0,9.0003
Где использовать TF-IDF
Как мы видим, TF-IDF может быть очень удобной метрикой для определения того, насколько важен термин в документе. Но как используется TF-IDF? Есть три основных приложения для TF-IDF. Это машинное обучение , поиск информации, и обобщение текста/извлечение ключевых слов.
Использование TF-IDF в машинном обучении и обработке естественного языка
Алгоритмы машинного обучения часто используют числовые данные, поэтому при работе с текстовыми данными или любой задачей обработки естественного языка (NLP) подобласть ML/AI, связанная с текст, эти данные сначала необходимо преобразовать в вектор числовых данных с помощью процесса, известного как векторизация. Векторизация TF-IDF включает в себя вычисление оценки TF-IDF для каждого слова в вашем корпусе относительно этого документа, а затем помещение этой информации в вектор (см. изображение ниже с примерами документов «A» и «B»). Таким образом, каждый документ в вашем корпусе будет иметь свой собственный вектор, и вектор будет иметь оценку TF-IDF для каждого отдельного слова во всей коллекции документов. Когда у вас есть эти векторы, вы можете применить их к различным вариантам использования, например, посмотреть, похожи ли два документа, сравнивая их вектор TF-IDF с использованием косинусного сходства.
Векторизация TF-IDF включает в себя вычисление оценки TF-IDF для каждого слова в вашем корпусе относительно этого документа, а затем помещение этой информации в вектор (см. изображение ниже с примерами документов «A» и «B»). Таким образом, каждый документ в вашем корпусе будет иметь свой собственный вектор, и вектор будет иметь оценку TF-IDF для каждого отдельного слова во всей коллекции документов. Когда у вас есть эти векторы, вы можете применить их к различным вариантам использования, например, посмотреть, похожи ли два документа, сравнивая их вектор TF-IDF с использованием косинусного сходства.
A = «Автомобиль движется по дороге»; B = «Грузовик едет по шоссе» Изображение из freeCodeCamp — Как обрабатывать текстовые данные с помощью TF-IDF в Python (https://www.freecodecamp.org/news/how-to-process-textual-data-using -tf-idf-in-python-cd2bbc0a94a3/)
Использование TF-IDF в поиске информации
TF-IDF также имеет варианты использования в области поиска информации, одним из распространенных примеров являются поисковые системы. Поскольку TF-IDF может сообщить вам о значимости термина на основе документа, поисковая система может использовать TF-IDF, чтобы помочь ранжировать результаты поиска на основе релевантности, с результатами, которые более релевантны пользователю с более высоким TF-IDF. баллы.
Поскольку TF-IDF может сообщить вам о значимости термина на основе документа, поисковая система может использовать TF-IDF, чтобы помочь ранжировать результаты поиска на основе релевантности, с результатами, которые более релевантны пользователю с более высоким TF-IDF. баллы.
Использование TF-IDF для суммирования текста и извлечения ключевых слов
Поскольку TF-IDF взвешивает слова на основе релевантности, можно использовать этот метод, чтобы определить, что слова с наивысшей релевантностью являются наиболее важными. Это можно использовать для более эффективного обобщения статей или просто для определения ключевых слов (или даже тегов) для документа.
Векторы и вложения слов: TF-IDF, Word2Vec, Bag-of-words, BERT
Как обсуждалось выше, TF-IDF можно использовать для векторизации текста в формат, более подходящий для методов ML и NLP. Однако, хотя это популярный алгоритм НЛП, он не единственный.
Bag of Words
Bag of Words (BoW) просто подсчитывает частоту слов в документе. Таким образом, вектор для документа имеет частоту каждого слова в корпусе для этого документа. Ключевое различие между пакетом слов и TF-IDF заключается в том, что первый не включает в себя какую-либо обратную частоту документа (IDF) и представляет собой только подсчет частоты (TF).
Таким образом, вектор для документа имеет частоту каждого слова в корпусе для этого документа. Ключевое различие между пакетом слов и TF-IDF заключается в том, что первый не включает в себя какую-либо обратную частоту документа (IDF) и представляет собой только подсчет частоты (TF).
Word2Vec
Word2Vec — это алгоритм, который использует поверхностные двухслойные, а не глубокие нейронные сети для обработки корпуса и создания наборов векторов. Некоторые ключевые различия между TF-IDF и word2vec заключаются в том, что TF-IDF — это статистическая мера, которую мы можем применить к терминам в документе, а затем использовать ее для формирования вектора, тогда как word2vec создаст вектор для термина, а затем может потребоваться дополнительная работа. нужно сделать, чтобы преобразовать этот набор векторов в единичный вектор или другой формат. Кроме того, TF-IDF не учитывает контекст слов в корпусе, в отличие от word2vec.
BERT — представления двунаправленного кодировщика от преобразователей
BERT — это метод ML/NLP, разработанный Google, в котором используется модель ML на основе преобразователя для преобразования фраз, слов и т. д. в векторы. Ключевые различия между TF-IDF и BERT заключаются в следующем: TF-IDF не принимает во внимание семантическое значение или контекст слов, в отличие от BERT. Кроме того, BERT использует глубокие нейронные сети как часть своей архитектуры, а это означает, что он может быть намного более затратным в вычислительном отношении, чем TF-IDF, который не имеет таких требований.
д. в векторы. Ключевые различия между TF-IDF и BERT заключаются в следующем: TF-IDF не принимает во внимание семантическое значение или контекст слов, в отличие от BERT. Кроме того, BERT использует глубокие нейронные сети как часть своей архитектуры, а это означает, что он может быть намного более затратным в вычислительном отношении, чем TF-IDF, который не имеет таких требований.
Плюсы и минусы использования TF-IDF
Плюсы использования TF-IDF
Самые большие преимущества TF-IDF заключаются в том, насколько он прост и удобен в использовании. Это просто вычислить, это дешево в вычислительном отношении, и это простая отправная точка для вычислений подобия (через векторизацию TF-IDF + косинусное сходство).
Минусы использования TF-IDF
Следует помнить, что TF-IDF не может помочь передать семантическое значение. Он учитывает важность слов из-за того, как он их взвешивает, но он не может обязательно выводить контексты слов и понимать важность таким образом.
Также, как упоминалось выше, как и BoW, TF-IDF игнорирует порядок слов, поэтому составные существительные, такие как «Королева Англии», не будут рассматриваться как «единая единица». Это также распространяется на такие ситуации, как отрицание с «не оплачивать счет» и «оплачивать счет», где порядок имеет большое значение. В обоих случаях с использованием инструментов NER и символов подчеркивания «queen_of_england» или «not_pay» — это способы обработки фразы как единой единицы.
Другим недостатком является то, что он может страдать от неэффективного использования памяти, поскольку TF-IDF может страдать от проклятия размерности. Напомним, что длина векторов TF-IDF равна размеру словаря. В некоторых контекстах классификации это может не быть проблемой, но в других контекстах, таких как кластеризация, это может быть громоздким по мере увеличения количества документов. Таким образом, может потребоваться изучение некоторых из названных выше альтернатив (BERT, Word2Vec).
Заключение
TF-IDF (частота терминов — обратная частота документа) — это удобный алгоритм, который использует частоту слов для определения того, насколько релевантны эти слова для данного документа. Это относительно простой, но интуитивно понятный подход к взвешиванию слов, что позволяет использовать его в качестве отличной отправной точки для множества задач. Это включает в себя создание поисковых систем, обобщение документов или другие задачи в области поиска информации и машинного обучения.
Это относительно простой, но интуитивно понятный подход к взвешиванию слов, что позволяет использовать его в качестве отличной отправной точки для множества задач. Это включает в себя создание поисковых систем, обобщение документов или другие задачи в области поиска информации и машинного обучения.
ЗАЯВЛЕНИЕ О РАСКРЫТИИ ИНФОРМАЦИИ: © 2021 Capital One. Мнения принадлежат конкретному автору. Если в этом посте не указано иное, Capital One не связана и не поддерживается ни одной из упомянутых компаний. Все товарные знаки и другая интеллектуальная собственность, используемая или отображаемая, являются собственностью их соответствующих владельцев.
Понимание TF-ID: простое введение
TF-IDF (термин частотно-обратная частота документа) — это статистическая мера, которая оценивает, насколько релевантно слово документу в наборе документов.
Это делается путем умножения двух показателей: сколько раз слово встречается в документе и обратная частота встречаемости слова в наборе документов.
Он имеет множество применений, в первую очередь для автоматизированного анализа текста, и очень полезен для подсчета слов в алгоритмах машинного обучения для обработки естественного языка (NLP).
TF-IDF был изобретен для поиска документов и поиска информации. Он работает, увеличиваясь пропорционально количеству раз, которое слово встречается в документе, но компенсируется количеством документов, содержащих это слово. Таким образом, слова, которые являются общими в каждом документе, такие как это, что и если, имеют низкий рейтинг, даже если они могут встречаться много раз, поскольку они не имеют большого значения для этого документа в частности.
Однако, если слово Ошибка много раз встречается в одном документе, но редко встречается в других, это, вероятно, означает, что оно очень важно. Например, если мы пытаемся выяснить, к каким темам относятся некоторые ответы NPS, слово Bug , вероятно, окажется связанным с темой «Надежность», поскольку большинство ответов, содержащих это слово, будут посвящены этой теме.
Как рассчитывается TF-IDF?
TF-IDF для слова в документе вычисляется путем умножения двух разных показателей:
- Частота терминов слова в документе. Есть несколько способов подсчета этой частоты, самый простой из которых — это необработанный подсчет случаев появления слова в документе. Кроме того, есть способы настроить частоту по длине документа или по необработанной частоте наиболее часто встречающегося слова в документе.
- обратная частота документа слова в наборе документов. Это означает, насколько часто или редко встречается слово во всем наборе документов. Чем он ближе к 0, тем слово встречается чаще. Этот показатель можно рассчитать, взяв общее количество документов, разделив его на количество документов, содержащих слово, и вычислив логарифм.
- Итак, если слово очень распространено и появляется во многих документах, это число будет приближаться к 0. В противном случае оно будет приближаться к 1.

Умножение этих двух чисел дает оценку TF-IDF для слова в документе. Чем выше оценка, тем более релевантным является это слово в данном конкретном документе.
Говоря более формально математически, оценка TF-IDF для слова t в документе d из набора документов D рассчитывается следующим образом:
Где:
Почему TF-IDF используется в машинном обучении?
Машинное обучение с использованием естественного языка сталкивается с одним серьезным препятствием — его алгоритмы обычно имеют дело с числами, а естественный язык — это текст. Поэтому нам нужно преобразовать этот текст в числа, также известный как векторизация текста. Это фундаментальный шаг в процессе машинного обучения для анализа данных, и различные алгоритмы векторизации сильно повлияют на конечные результаты, поэтому вам нужно выбрать тот, который даст ожидаемые результаты.
После того, как вы преобразовали слова в числа способом, понятным алгоритмам машинного обучения, оценку TF-IDF можно передать алгоритмам, таким как наивный байесовский метод и метод опорных векторов, что значительно улучшает результаты более простых методов, таких как слово считает.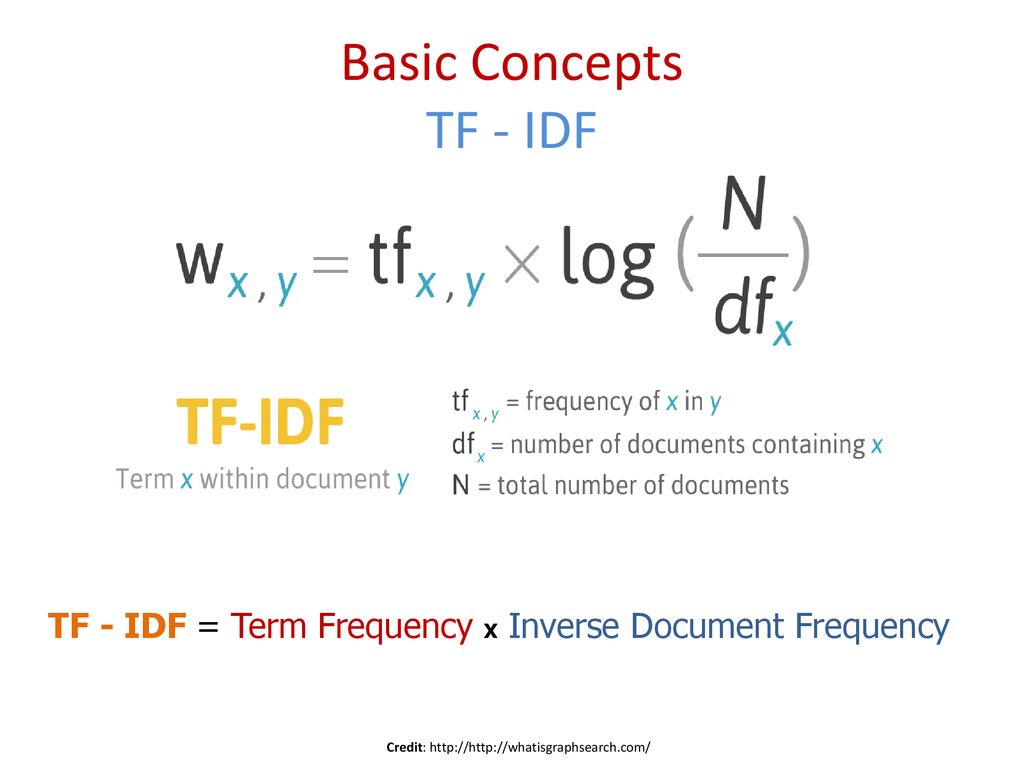
Почему это работает? Проще говоря, вектор слов представляет документ в виде списка чисел, по одному для каждого возможного слова корпуса. Векторизация документа берет текст и создает один из этих векторов, а номера векторов каким-то образом представляют содержимое текста. TF-IDF позволяет нам связать каждое слово в документе с числом, которое представляет, насколько релевантно каждое слово в этом документе. Тогда документы с похожими релевантными словами будут иметь похожие векторы, что мы и ищем в алгоритме машинного обучения.
Применение TF-IDF
Определение степени релевантности слова документу или TD-IDF полезно во многих отношениях, например:
- Поиск информации
поиска и может использоваться для предоставления результатов, которые наиболее соответствуют тому, что вы ищете. Представьте, что у вас есть поисковая система, и кто-то ищет Леброна. Результаты будут отображаться в порядке релевантности. То есть наиболее релевантные спортивные статьи будут иметь более высокий рейтинг, потому что TF-IDF дает слову Леброн более высокий балл.
Вполне вероятно, что каждая поисковая система, с которой вы когда-либо сталкивались, использует в своем алгоритме оценки TF-IDF.
- Извлечение ключевых слов
TF-IDF также полезен для извлечения ключевых слов из текста. Как? Слова с наивысшим баллом в документе являются наиболее релевантными для этого документа, и поэтому их можно считать ключевыми словами для этого документа. Довольно просто.
Заключительные слова
Полезно понять, как работает TF-IDF, чтобы вы могли лучше понять, как работают алгоритмы машинного обучения. В то время как алгоритмы машинного обучения традиционно лучше работают с числами, алгоритмы TF-IDF помогают им расшифровывать слова, выделяя им числовое значение или вектор. Это было революционно для машинного обучения, особенно в областях, связанных с НЛП, таких как анализ текста.
При анализе текста с помощью машинного обучения алгоритмы TF-IDF помогают сортировать данные по категориям, а также извлекать ключевые слова.

 Самые распространённые способы включают в себя:
Самые распространённые способы включают в себя: apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
 tokenize: lowercase=True, deacc=True.
tokenize: lowercase=True, deacc=True.
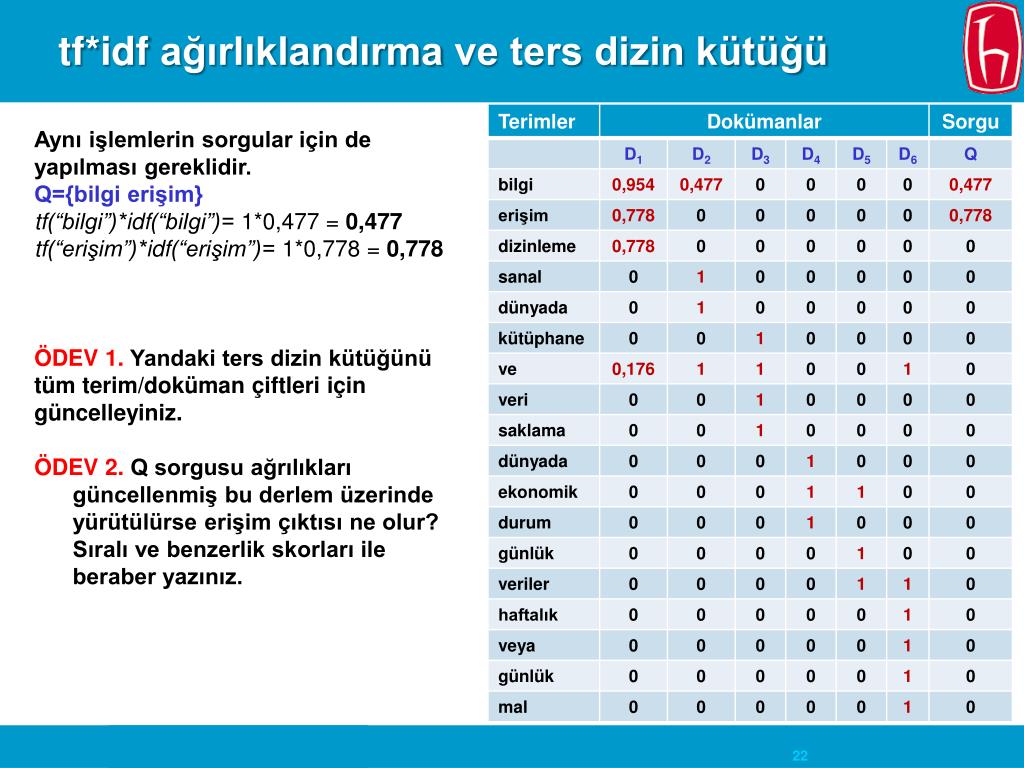
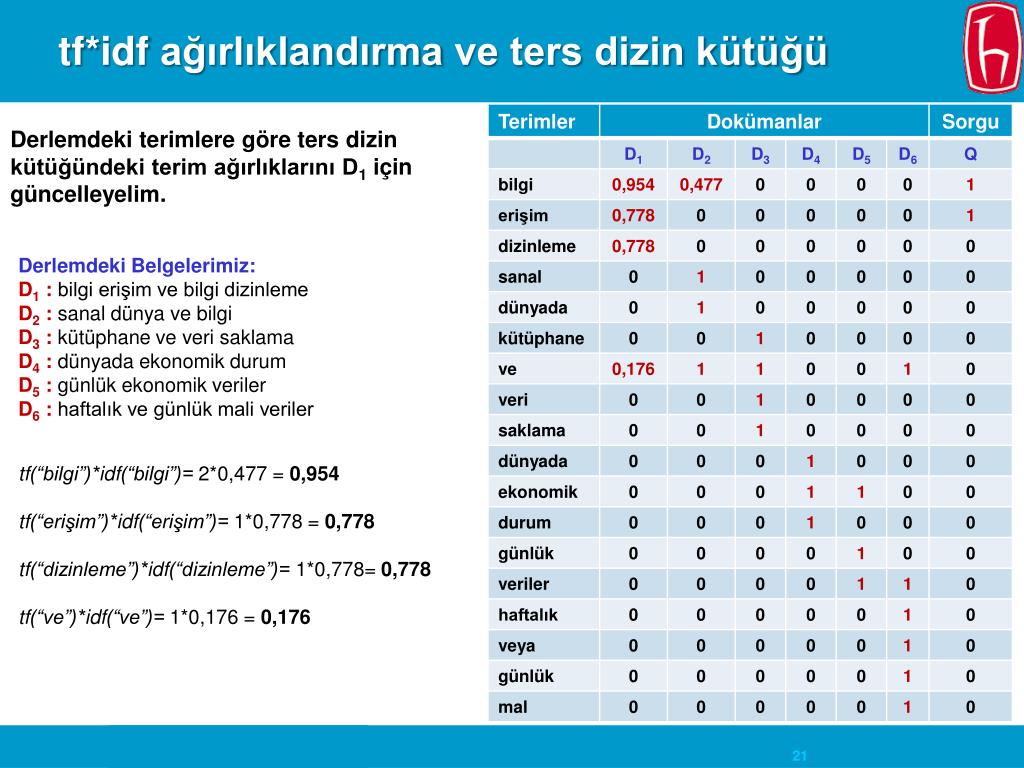
 \pL\p{Space}]', '', j.strip().lower()).replace(' ',' ')
\pL\p{Space}]', '', j.strip().lower()).replace(' ',' ')
 values.tolist()
df_tfidfvect2['combine'] = df_tfidfvect2.values.tolist()
values.tolist()
df_tfidfvect2['combine'] = df_tfidfvect2.values.tolist()


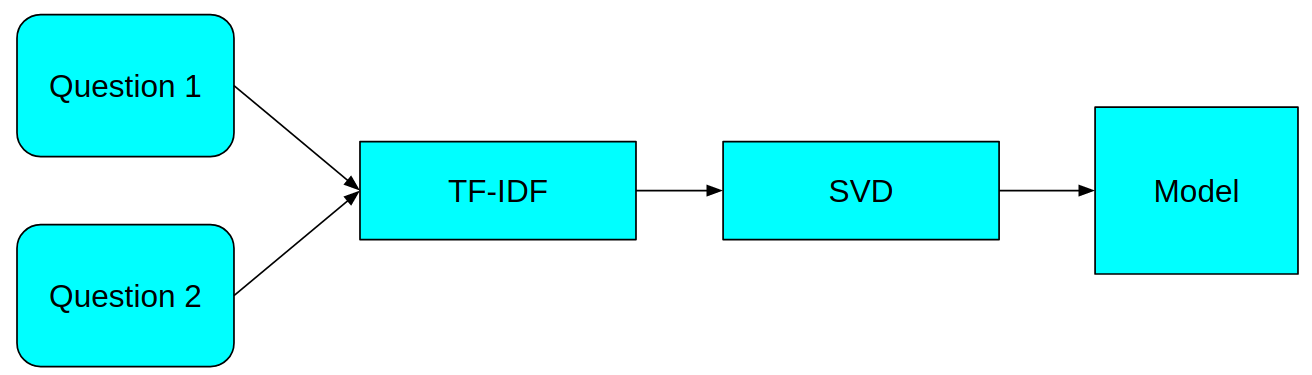
 Это означает, что простые монотонные задачи, такие как пометка заявок в службу поддержки или ряды отзывов и ввод данных, могут быть выполнены за считанные секунды.
Это означает, что простые монотонные задачи, такие как пометка заявок в службу поддержки или ряды отзывов и ввод данных, могут быть выполнены за считанные секунды. д.) в документе среди набора документов (также называется корпусом).
д.) в документе среди набора документов (также называется корпусом). IDF рассчитывается следующим образом, где t — термин (слово), общность которого мы хотим измерить, а N — количество документов (d) в корпусе (D). Знаменатель равен просто количество документов, в которых встречается термин t .
IDF рассчитывается следующим образом, где t — термин (слово), общность которого мы хотим измерить, а N — количество документов (d) в корпусе (D). Знаменатель равен просто количество документов, в которых встречается термин t .  д., поскольку они часто встречаются в английском корпусе. Таким образом, применяя инверсию частоты документов, мы можем свести к минимуму вес частых терминов, в то время как нечастые термины будут иметь большее влияние.
д., поскольку они часто встречаются в английском корпусе. Таким образом, применяя инверсию частоты документов, мы можем свести к минимуму вес частых терминов, в то время как нечастые термины будут иметь большее влияние.
 Это можно использовать для более эффективного обобщения статей или просто для определения ключевых слов (или даже тегов) для документа.
Это можно использовать для более эффективного обобщения статей или просто для определения ключевых слов (или даже тегов) для документа.
