Содержание
Руководство по архитектуре страниц и экстентов — SQL Server
-
Статья -
- Чтение занимает 15 мин
-
Область применения: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр SQL Azure Azure Synapse Analytics Analytics Platform System (PDW)
Страница является основной единицей хранения данных в SQL Server. Экстент — это коллекция из восьми физически смежных страниц. Экстенты помогают эффективно управлять страницами. В этом руководстве описаны структуры данных, используемые для управления страницами и экстентами во всех версиях SQL Server. Понимание архитектуры страниц и экстентов важно для проектирования и разработки эффективных баз данных.
Понимание архитектуры страниц и экстентов важно для проектирования и разработки эффективных баз данных.
Страницы и экстенты
Основной единицей хранилища данных в SQL Server является страница. Место на диске, выделенное файлу данных (MDF или NDF) в базе данных, логически делится на страницы, нумеруемые последовательно от 0 до n. Дисковые операции ввода-вывода выполняются на уровне страницы. Это означает, что SQL Server считывает или записывает целые страницы данных.
Экстент — это коллекция, состоящая из восьми физически непрерывных страниц; они используются для эффективного управления страницами. Все страницы организуются в экстенты.
Страницы
В обычной книге все материалы написаны на страницах. Как и в книге, SQL Server записывает все строки данных на страницах, и все страницы данных имеют одинаковый размер: 8 КБ. В книге большинство страниц содержат данные — основное содержимое книги, а некоторые страницы содержат метаданные о содержимом (например, оглавление и индекс). Опять же, SQL Server не отличается: большинство страниц содержат фактические строки данных, которые хранились пользователями; они называются страницами данных и текстовыми и графическими страницами (в особых случаях). Страницы индекса содержат ссылки на индексы о расположении данных. Наконец, существуют системные страницы , в которых хранятся различные метаданные о организации данных.
Опять же, SQL Server не отличается: большинство страниц содержат фактические строки данных, которые хранились пользователями; они называются страницами данных и текстовыми и графическими страницами (в особых случаях). Страницы индекса содержат ссылки на индексы о расположении данных. Наконец, существуют системные страницы , в которых хранятся различные метаданные о организации данных.
Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница.
В следующей таблице представлены типы страниц, используемые в файлах данных базы данных SQL Server.
| Тип страницы | Содержимое |
|---|---|
| Данные | Строки данных со всеми данными, за исключением текста, ntext, image, nvarchar(max), varchar(max), varbinary(max)и xml , если для текста в строке задано значение ON. |
| Индекс | Содержимое индекса. |
| Текст или изображение | Типы данных больших объектов: text, ntext, image, nvarchar(max), varchar(max), varbinary(max)и xml-данные . Столбцы переменной длины, если строка данных превышает 8 КБ: varchar, nvarchar, varbinary и sql_variant. |
| Глобальная карта распределения (GAM) Общая глобальная карта распределения (SGAM) | Сведения о том, размещены ли экстенты. |
| Свободное место на страницах (PFS) | Сведения о размещении страниц и доступном на них свободном месте. |
| Карта распределения индекса (IAM) | Сведения об экстентах, используемых таблицей или индексом для единицы распределения. |
| Схема массовой замены (BCM) | Сведения об экстентах, измененных массовыми операциями со времени последнего выполнения инструкции BACKUP LOG для единицы распределения. |
| Схема дифференциальной замены (DCM) | Сведения об экстентах, измененных с момента последнего выполнения инструкции BACKUP DATABASE для единицы распределения. |
Примечание
Файлы журнала не содержат страницы. Они содержат ряд записей журнала, которые не имеют фиксированного размера.
Строки данных хранятся на странице последовательно, начиная с заголовка. Таблица смещения строк начинается в конце страницы; каждая таблица смещения строк содержит одну запись для каждой строки на странице. Каждая запись смещения строки хранит байт первой строки от начала страницы. Таким образом, функция таблицы смещения строк заключается в том, чтобы SQL Server быстро находить строки на странице. Записи в таблице смещения строк находятся в обратном порядке относительно последовательности строк на странице.
Поддержка больших строк
Строки не могут охватывать страницы; однако части строки могут быть перемещены со страницы строки, поэтому строка может быть очень большой. Максимальный объем данных и дополнительных затрат, содержащихся в одной строке на странице, составляет 8060 байт. Это не включает данные, хранящиеся в типе страницы текста или изображения.
Максимальный объем данных и дополнительных затрат, содержащихся в одной строке на странице, составляет 8060 байт. Это не включает данные, хранящиеся в типе страницы текста или изображения.
Это ограничение смягчается для таблиц, содержащих столбцы varchar, nvarchar, varbinary или sql_variant . Когда общий размер строк всех фиксированных и переменных столбцов в таблице превышает предел в 8060 байт, SQL Server динамически перемещает один или более столбцов переменной длины на страницы в единице распределения ROW_OVERFLOW_DATA, начиная со столбца с наибольшей шириной.
Это действие выполняется всегда, когда в результате операций вставки или обновления общий размер строки выходит за предел в 8060 байт. Когда происходит перемещение столбца на страницу в единице распределения ROW_OVERFLOW_DATA, 24-байтовый указатель на исходной странице в единице распределения IN_ROW_DATA сохраняется. Если при последующей выполняемой операции размер строки уменьшается, SQL Server динамически перемещает столбцы обратно на исходную страницу данных.
Рекомендации по переполнению строк
Строка не может находиться на нескольких страницах и может переполнение, если совокупный размер полей типа данных переменной длины превышает ограничение в 8060 байт. Чтобы проиллюстрировать, можно создать таблицу с двумя столбцами: одной varchar(7000) и другой varchar (2000). По отдельности ни один столбец не превышает 8060 байт, но вместе они могут сделать это, если заполнена вся ширина каждого столбца. SQL Server может динамически перемещать столбец переменной длины varchar(7000) на страницы в единице распределения ROW_OVERFLOW_DATA. При объединении столбцов типа varchar, nvarchar, varbinary или sql_variant или CLR, которые превышают 8060 байт на строку, учитывайте следующее:
Перемещение больших записей на другую страницу осуществляется динамически, по мере удлинения записей при операциях обновления. Операции обновления, которые укорачивают записи, могут привести к возвращению записей на исходную страницу в единице распределения IN_ROW_DATA.

Выполнение запросов и других операций выборки, например сортировки и соединения, в отношении больших записей с превышающими размер страницы данными строки, увеличивает время обработки, поскольку эти записи обрабатываются синхронно, а не асинхронно.
Поэтому при проектировании таблицы с несколькими столбцами типа varchar, nvarchar, varbinary или sql_variant или clR, определяемым пользователем, учитывайте процент строк, которые, скорее всего, будут перетекать и частоту, с которой эти данные переполнения, скорее всего, будут запрашиваться. Если ожидаются частые запросы по многим превышающим размер страницы данным строки, рекомендуется нормализовать таблицу таким образом, чтобы некоторые столбцы переместились в другую таблицу. После этого запросы по таблице можно будет выполнять с помощью асинхронной операции JOIN.
Длина отдельных столбцов по-прежнему должна превышать 8000 байт для столбцов типа varchar, nvarchar, varbinary или sql_variant и CLR.
И только общая их длина может выходить за предел в 8 060 байт на строку таблицы.Сумма других столбцов типа данных, включая данные char и nchar , должна соответствовать ограничению строк в 8060 байт. Данные больших объектов также могут выходить за предел в 8 060 байт на строку.
Ключ кластеризованного индекса не может включать в себя столбцы varchar, для которых существуют данные в единице размещения ROW_OVERFLOW_DATA. Если кластеризованный индекс создается для столбца типа varchar и существующие данные располагаются в единице размещения IN_ROW_DATA, то все последующие операции вставки или обновления для данного столбца, выталкивающие данные за пределы строки, будут завершаться ошибкой. Дополнительные сведения об единицах распределения см. в руководстве по архитектуре индекса и проектированию.
Пользователь может включить столбцы, которые содержат превышающие размер страницы данные строки, в качестве ключевых или неключевых столбцов некластеризованного индекса.
Максимальный размер записи в таблицах, в которых используются разреженные столбцы, составляет 8 018 байт. Если суммарная величина преобразуемых данных и существующих данных записи превышает 8 018 байт, то возвращается ошибка MSSQLSERVER ERROR 576. При преобразовании столбцов между разреженными и непарспарными типами ядро СУБД сохраняет копию текущих данных записи. В связи с этим удваивается количества места, которое требуется для хранения записи.
Для получения сведений о таблицах или индексах, которые могут содержать превышающие размер страницы данные строки, используется функция динамического управления sys.dm_db_index_physical_stats.

 И только общая их длина может выходить за предел в 8 060 байт на строку таблицы.
И только общая их длина может выходить за предел в 8 060 байт на строку таблицы.
Экстенты
Экстенты являются основными единицами организации пространства. Экстент состоит из восьми непрерывных страниц или 64 КБ. Это означает, что SQL Server базы данных имеют 16 экстентов на мегабайт.
В SQL Server есть два типа экстентов.
- Однородные экстенты принадлежат одному объекту, и все восемь страниц экстента может использовать только этот владеющий объект.
- Смешанные экстенты могут находиться в общем пользовании максимум у восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
До и, в том числе, SQL Server 2014 (12.x), ядро СУБД не выделяет целые экстенты для таблиц с небольшим объемом данных. Новая таблица или индекс обычно выделяет страницы из смешанных экстентов. При увеличении размера таблицы или индекса до восьми страниц эти таблица или индекс переходят на использование однородных экстентов для последовательных единиц распределения. При создании индекса для существующей таблицы, в которой содержится достаточно строк, чтобы сформировать восемь страниц в индексе, все единицы распределения для индекса находятся в однородных экстентах.
Начиная с SQL Server 2016 (13.x) по умолчанию для большинства выделений в пользовательской базе данных и tempdb используется однородные экстенты, за исключением выделения, принадлежащих первым восьми страницам цепочки IAM. Выделения для
Выделения для masterбаз msdbmodel данных и баз данных по-прежнему сохраняют предыдущее поведение.
Примечание
В SQL Server до SQL Server 2014 (12.x) можно использовать флаг трассировки (TF) 1118, чтобы изменить выделение по умолчанию так, чтобы всегда использовать однородные экстенты. Дополнительные сведения об этом флаге трассировки см. в статье DBCC TRACEON — флаги трассировки (Transact-SQL).
Начиная с SQL Server 2016 (13.x), функции, предоставляемые TF 1118, автоматически включаются для tempdb всех пользовательских баз данных. Для пользовательских баз данных это поведение управляется параметром SET MIXED_PAGE_ALLOCATIONALTER DATABASE, при этом значение по умолчанию имеет значение OFF, а TF 1118 не действует. Дополнительные сведения см. в статье Параметры ALTER DATABASE SET (Transact-SQL).
Начиная с SQL Server 2012 (11.x), системная функция sys.dm_db_database_page_allocations может передавать сведения о распределении страниц для базы данных, таблицы, индекса и секции.
Важно!
Системная функция sys.dm_db_database_page_allocations не задокументирована и может быть изменена. Совместимость не гарантируется.
Начиная с SQL Server 2019 (15.x), доступна системная функция sys.dm_db_page_info, которая возвращает сведения о странице в базе данных. Функция возвращает одну строку, содержащую сведения о заголовке со страницы, включая object_id, index_idи partition_id. В большинстве случаев эта функция заменяет потребность в использовании DBCC PAGE.
Управление выделением экстентов и свободным пространством
Структуры данных SQL Server, управляющие размещением экстента и отслеживанием свободного места, обладают относительно простой структурой. Учтите следующие преимущества:
Сведения о свободном месте плотно упакованы, поэтому эти данные содержат относительно небольшое количество страниц.
Это повышает скорость, уменьшая количество операций чтения диска, необходимых для получения сведений о выделении.
Также увеличивается вероятность того, что страницы размещения будут оставаться в памяти и повторных операций чтения не потребуется.Большая часть сведений о выделении не объединяется. Это упрощает управление сведениями о размещении.
Каждое действие по размещению или освобождению страницы может выполняться быстро. Это сокращает состязание между одновременными задачами размещения и освобождения страниц.
 Также увеличивается вероятность того, что страницы размещения будут оставаться в памяти и повторных операций чтения не потребуется.
Также увеличивается вероятность того, что страницы размещения будут оставаться в памяти и повторных операций чтения не потребуется.Управление выделением экстентов
SQL Server использует два типа карт распределения для записи размещения экстентов.
Глобальная карта распределения (GAM)
На GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. GAM имеет 1 бит для каждого экстента в интервале, который он охватывает. Если бит имеет значение
1, экстент свободен; если бит равен0, экстент выделяется.Общая глобальная карта распределения (SGAM)
На SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу.
В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. SGAM имеет 1 бит для каждого экстента в интервале, который он охватывает. Если бит имеет значение 1, экстент используется как смешанный экстент и имеет бесплатную страницу. Если бит имеет значение0, экстент не используется как смешанный экстент или является смешанным экстентом и используются все его страницы.
 В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. SGAM имеет 1 бит для каждого экстента в интервале, который он охватывает. Если бит имеет значение
В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. SGAM имеет 1 бит для каждого экстента в интервале, который он охватывает. Если бит имеет значение Каждый экстент обладает следующими наборами битовых шаблонов в картах GAM и SGAM, основанными на его текущем использовании.
| Текущее использование экстента | Настройка битов карты GAM | Настройка битов карты SGAM |
|---|---|---|
| Свободно, в текущий момент не используется | 1 | 0 |
| Однородный экстент или заполненный смешанный экстент | 0 | 0 |
| Смешанный экстент со свободными страницами | 0 | 1 |
Это дает простые алгоритмы управления экстентами страниц.
- Чтобы выделить единообразный экстент, ядро СУБД выполняет поиск GAM для бита
1и задает для него0значение . - Чтобы найти смешанный экстент с бесплатными страницами, ядро СУБД ищет SGAM немного
1. - Чтобы выделить смешанный экстент, ядро СУБД выполняет поиск GAM для
1бита, устанавливает для него0значение, а затем задает соответствующий бит в SGAM в значение1. - Чтобы освободить экстент, компонент Database Engine гарантирует, что для бита GAM задано значение
1, а для бита SGAM задано значение0.
Алгоритмы, которые используются ядром СУБД, являются более сложными, чем описано в этой статье, так как ядро СУБД равномерно распределяет данные в базе данных. Однако даже настоящие алгоритмы упрощаются из-за того, что отпадает необходимость управления цепочками сведений о размещении экстентов.
Отслеживание свободного места
Страницы Page Free Space (PFS) записывают состояние размещения каждой страницы, информацию о том, была ли размещена конкретная страница, а также количество свободного места на каждой странице. PFS имеет 1 байт для каждой страницы, записывая, выделена ли страница, и если да, то является ли она пустой, от 1 до 50 процентов заполнена, от 51 до 80 процентов заполнена, от 81 до 95 процентов заполнена, или от 96 до 100 процентов заполнено.
PFS имеет 1 байт для каждой страницы, записывая, выделена ли страница, и если да, то является ли она пустой, от 1 до 50 процентов заполнена, от 51 до 80 процентов заполнена, от 81 до 95 процентов заполнена, или от 96 до 100 процентов заполнено.
После размещения экстента на объект ядро СУБД использует PFS-страницы для записи информации о том, какие страницы в экстенте размещены, а какие свободны. Эти сведения используются ядром СУБД при размещении новой страницы. Объем свободного места на странице поддерживается только для страниц кучи и текста или изображения. Это используется при поиске ядром СУБД страницы, имеющей свободное место, которого достаточно для сохранения в ней новой добавляемой строки. Индексы не требуют отслеживания свободного места на странице, так как точка вставки новой строки задается значениями ключа индекса.
В файл данных добавляется новая страница PFS, GAM или SGAM для каждого дополнительного диапазона, который отслеживается. Таким образом, после первой PFS-страницы находится новая PFS-страница с 8088 страницами, а также дополнительные PFS-страницы с последующими интервалами в 8088 страниц. Допустим, страница с идентификатором 1 является PFS-страницей, страница с идентификатором 8088 является PFS-страницей, страница с идентификатором 16176 является PFS-страницей и т. д.
Допустим, страница с идентификатором 1 является PFS-страницей, страница с идентификатором 8088 является PFS-страницей, страница с идентификатором 16176 является PFS-страницей и т. д.
После первой GAM-страницы имеется новая GAM-страница с 64 000 экстентов, которая отслеживает 64 000 экстентов за ней. Последовательность продолжится с интервалом в 64 000. Аналогичным образом после первой SGAM-страницы стоит новая SGAM-страница с 64 000 экстентов, и SGAM-страницы добавляются каждые 64 000 экстентов.
На иллюстрации ниже показана последовательность страниц, используемая ядром СУБД для выделения экстентов и управления ими.
Управление пространством, используемым объектами
Страница карты распределения индекса (Index Allocation Map, IAM) сопоставляет экстенты в 4-гигабайтном фрагменте файла базы данных с единицей размещения, использующей этот фрагмент. Единица распределения может иметь один из трех типов.
IN_ROW_DATA
Содержит секцию кучи или индекса.
LOB_DATA
Содержит типы данных больших объектов (LOB), такие как xml, varbinary(max)и varchar(max).
ROW_OVERFLOW_DATA
Содержит данные переменной длины, хранящиеся в столбцах varchar, nvarchar, varbinary или sql_variant столбцах, превышающих ограничение в 8 060 байтов строк.

В каждой секции кучи или индекса содержится по крайней мере одна единица распределения IN_ROW_DATA. Кроме того, в зависимости от схемы кучи или индекса, там могут содержаться единицы распределения LOB_DATA или ROW_OVERFLOW_DATA.
IAM-страница охватывает в файле диапазон 4 ГБ, то есть столько же, сколько и GAM- или SGAM-страница. Если в единице распределения содержатся экстенты из более чем одного файла или фрагмент файла размером более 4 ГБ, то несколько IAM-страниц будут объединены в IAM-цепочку. Таким образом, каждая единица распределения содержит как минимум одну IAM-страницу для каждого из файлов, в которых содержатся ее экстенты. Для файла может существовать несколько IAM-страниц, если размер экстентов файла, назначенного единице распределения, превышает объем, который может быть записан в одной IAM-странице.
Для файла может существовать несколько IAM-страниц, если размер экстентов файла, назначенного единице распределения, превышает объем, который может быть записан в одной IAM-странице.
IAM-страницы для каждой единицы распределения выделяются по необходимости и располагаются в файле в случайном порядке. Системное представление sys.system_internals_allocation_units указывает на первую страницу IAM единицы размещения. Все страницы IAM, относящиеся к одной единице размещения, объединяются в цепочку IAM.
Важно!
Системное представление sys.system_internals_allocation_units предназначено только для внутреннего использования и может быть изменено. Совместимость не гарантируется. Это представление недоступно в База данных SQL Azure.
IIAM-страница имеет заголовок, отражающий первый экстент из диапазона, сопоставленного с данной IAM-страницей. IAM-страница также имеет большую битовую карту, в которой каждый бит представляет экстент. Первый бит схемы представляет первый экстент диапазона, второй бит — второй экстент и т.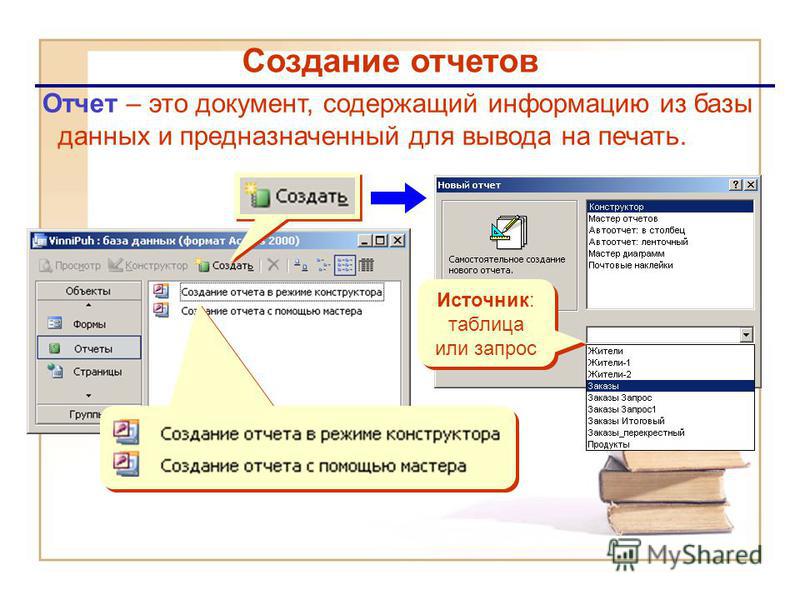 д. Если бит,
д. Если бит, 0то экстент, который он представляет, не выделяется единице распределения, принадлежащей IAM. Если бит равен 1, экстент, который он представляет, выделяется единице распределения, принадлежащей странице IAM.
Если ядро СУБД должно вставить новую строку и на текущей странице не будет свободного места, она использует страницы IAM и PFS, чтобы найти страницу для выделения, или для кучи или страницы текста или изображения, страницы с достаточным пространством для хранения строки. Ядро СУБД использует IAM-страницы для поиска экстентов, привязанных к единице распределения. Для каждого экстента ядро СУБД просматривает PFS-страницы, чтобы определить наличие страниц, которые можно использовать. Каждая страница IAM и PFS охватывает много страниц данных, поэтому в базе данных есть несколько страниц IAM и PFS. Поэтому обычно IAM- и PFS-страницы находятся в памяти буферного пула SQL Server, и поиск в них осуществляется очень быстро. Для индексов точка вставки новой строки определяется ключом индекса, но если нужна новая страница, происходит описанный выше процесс.
Ядро СУБД выделяет новый экстент для единицы выделения только в том случае, если она не может быстро найти страницу в существующем экстенте с достаточным пространством для размещения вставленной строки.
Пропорциональное выделение заливки
Ядро СУБД выделяет экстенты из доступных в файловой группе с помощью алгоритма распределения пропорционального заполнения . В одной файловой группе с двумя файлами, если один файл имеет двойное свободное пространство, как и другой, две страницы будут выделены из файла с доступным пространством для каждой страницы, выделенной из другого файла. Это означает, что процент заполнения для каждого из файлов в группе будет примерно одинаковым.
Отслеживание измененных экстентов
SQL Server использует две внутренние структуры данных для отслеживания экстентов, измененных операциями массового копирования, и экстентов, измененных с момента последней полной резервной копии. Эти структуры данных существенно ускоряют разностные резервные копии. Они также ускоряют операции записи в журнал массового копирования, если база данных использует модель восстановления с неполным протоколированием. Как и страницы GAM и SGAM, эти структуры представляют собой растровые изображения, в которых каждый бит представляет один экстент.
Они также ускоряют операции записи в журнал массового копирования, если база данных использует модель восстановления с неполным протоколированием. Как и страницы GAM и SGAM, эти структуры представляют собой растровые изображения, в которых каждый бит представляет один экстент.
Схема разностных изменений (Differential Changed Map, DCM)
Эта схема отслеживает экстенты, которые были изменены со времени последнего выполнения инструкции
BACKUP DATABASE. Если бит для экстента равен1, экстент был изменен с момента последнегоBACKUP DATABASEоператора. Если бит равен0, экстент не был изменен.Чтобы определить, какие экстенты были изменены, разностные резервные копии считывают только страницы DCM. Это существенно сокращает количество страниц, которые должна просмотреть разностная резервная копия. Продолжительность выполнения разностной резервной копии пропорциональна количеству экстентов, измененных с момента последней
BACKUP DATABASEинструкции, а не общему размеру базы данных.Схема массовых изменений (Bulk Changed Map, BCM)
Это отслеживает экстенты, которые были изменены операциями с неполным протоколированием с момента последнего
BACKUP LOGоператора. Если бит для экстента равен1, экстент был изменен операцией с неполным протоколированием после последнейBACKUP LOGинструкции. Если бит равен0, экстент не был изменен операциями с неполным протоколированием.Несмотря на то, что страницы BCM существуют во всех базах данных, они соответствуют только в том случае, если база данных использует модель восстановления с неполным протоколированием. В этой модели восстановления при выполнении инструкции
BACKUP LOGпроцесс резервного копирования проверяет схемы BCM на наличие измененных экстентов. Затем она включает в себя экстенты из резервной копии журнала. Это восстанавливает операции с неполным протоколированием, если база данных восстанавливается из резервной копии базы данных и последовательности резервных копий журналов транзакций. Страницы BCM не относятся к базе данных, использующую простую модель восстановления, так как операции массового ведения журнала не регистрируются. Они не актуальны в базе данных, использующую модель полного восстановления, так как эта модель восстановления обрабатывает операции с неполным протоколированием как полностью зарегистрированные операции.

 Страницы BCM не относятся к базе данных, использующую простую модель восстановления, так как операции массового ведения журнала не регистрируются. Они не актуальны в базе данных, использующую модель полного восстановления, так как эта модель восстановления обрабатывает операции с неполным протоколированием как полностью зарегистрированные операции.
Страницы BCM не относятся к базе данных, использующую простую модель восстановления, так как операции массового ведения журнала не регистрируются. Они не актуальны в базе данных, использующую модель полного восстановления, так как эта модель восстановления обрабатывает операции с неполным протоколированием как полностью зарегистрированные операции.Интервал между DCM- и BCM-страницами равен интервалу между GAM- и SGAM-страницами — 64 000 экстентов. Страницы DCM и BCM находятся за страницами GAM и SGAM в физическом файле следующим образом:
См. также раздел
- sys.allocation_units (Transact-SQL)
- Кучи (таблицы без кластеризованных индексов)
- sys.dm_db_page_info
- Считывание страниц
- Запись страниц
Что такое база данных веб-сайта и зачем это нужно.
Любой человек, который занимается веб-разработкой рано или поздно сталкивается с таким понятием как база данных веб-сайта.
Давайте будем разбираться, что такое база данных и зачем это нужно.
Предположим, что мы решили создать какой-то свой веб-сайт. Мы создали одну страницу. Предположим, что это будет страница page.html. На этой странице находится какое-то содержимое.
С течением времени сайт начинает разрастаться. На нем начинают появляться все новые и новые материалы и страниц, на которых будут храниться эти материалы становиться все больше и больше.
Возникает вопрос, как хранить все данные, которые будут отображаться на этих веб-страницах. Какую структуру организации этих данных выбрать.
1 способ. Каждый материал (страница) — отдельный html-файл.
Как вариант, это будет работать. Но, при этом возникает ряд проблем.
Что если в этой структуре файлов, нам нужно будет добавить или изменить какой-то общий элемент? Например, нужно поменять изображение в шапке сайта.
Нужно будет открывать каждый из этих файлов и в каждом из них менять путь до картинки.
Конечно, если файлов всего 3 — это сделать довольно просто. Но, если этих файлов сотни и тысячи, могут возникнуть трудности.
А что если у нас будет стоять задача получить какую-то статистику по этим страницам? Например, нам нужно узнать сколько всего у нас есть веб-страниц и вывести это в каком-то месте веб-сайта.
Если каждая страница у нас отдельный файл, сделать это может быть трудно.
Что если нам нужно будет организовать поиск по этим файлам?
С этим тоже могут быть трудности.
Наконец, как дать доступ на редактирование созданных html-страниц человеку, который в веб-разработке ничего не понимает. Для него это тоже будут некоторые трудности.
Из-за этих проблем, что трудно обслуживать такую структуру организации данных веб-сайта, есть другой подход как можно хранить информацию, которая будет отображаться на всех этих страницах.
В этом подходе мы исходим из того, что у нас есть только один файл. Предположим, это файл page.php.
Предположим, это файл page.php.
Именно этот файл будет главным для всех страниц нашего сайта. А текст всех страниц, которые будут на этом сайте. Ссылки, даты и.т.д. мы выносим в отдельную сущность, которая называется база данных.
Т.е. мы разделяем структуру веб-страницы. Разметка документа отдельно и содержимое страницы тоже отдельно.
По сути, база данных — это простые таблицы, которые содержат строки и столбцы. На пересечении этих строк и столбцов содержится какая-то информация. Каждый элемент, который будет на сайте, храниться в отдельном поле базы данных.
Каждая строка соответствует каждой странице.
При такой структуре мы можем настроить веб-сервер, чтобы при обращении по определенному url-адресу ему показывается каждый раз какая-то уникальная страница из базы данных.
Главное преимущество такой структуры в том, что нам теперь не нужно хранить на сервере огромное количество файлов.
Теперь у нас контент отдельно и разметка страницы тоже отдельно.
Какие мы теперь получаем преимущества:
1) Мы можем просто вносить изменения в содержимое страниц сайта за счет того, что контент размещается отдельно от структуры и логики.
2) Скорость и простота обработки информации в базе данных. Статистика, поиск и.т.д.
3) Возможность создания панели управления для людей, которые не знакомы с веб-разработкой.
В итоге, база данных — это то место, где храниться содержимое какой-то определенной сущности. Например, мы выбрали сущности «страница» и храним информацию в базе данных, которая к этой сущности относится.
Надеюсь, что стало понятнее что такое база данных и для чего они нужны.
Не во всех случаях оправдано их использование. Если вам приходится работать с большим объемом каких-то данных, тот первый вопрос, который вам нужно себе задать: не логичнее ли будет всю эту информацию хранить в базе данных.
На этом все, желаю вам удачно проектировать структуру своего веб-сайта и удачной работы.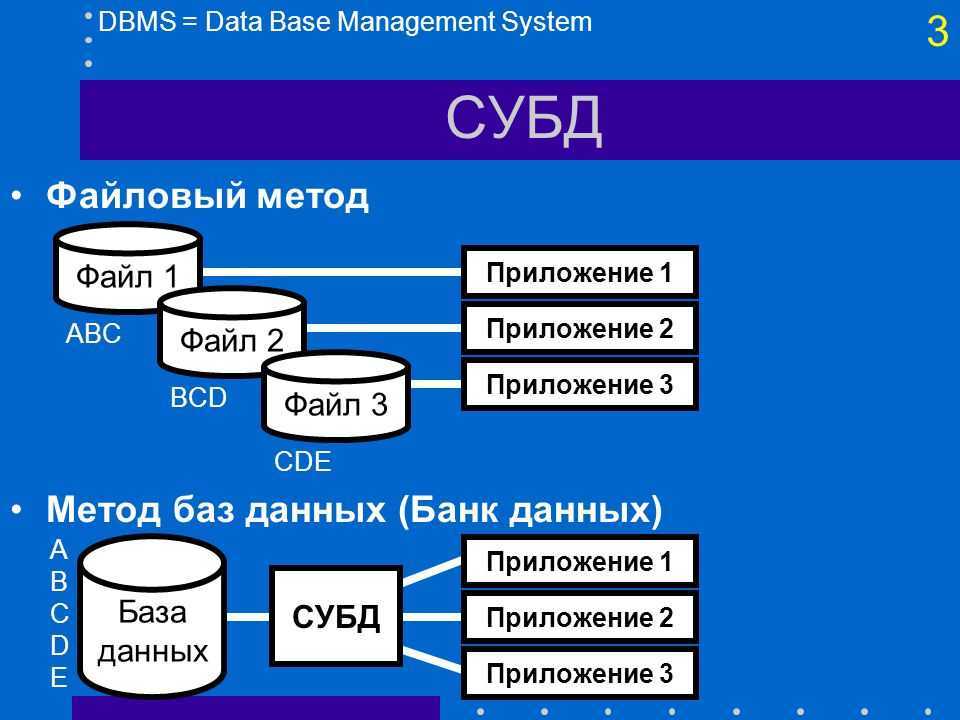
PostgreSQL: Документация: 15: 73.6. Макет страницы базы данных
- 73.6.1. Макет строки таблицы
В этом разделе представлен обзор формата страницы, используемого в таблицах и индексах PostgreSQL. [17] Последовательности и таблицы TOAST форматируются так же, как и обычные таблицы.
В следующем объяснении предполагается, что байт содержит 8 бит. Кроме того, термин элемент относится к отдельному значению данных, которое хранится на странице. В таблице элемент — это строка; в указателе элемент является элементом указателя.
Каждая таблица и индекс хранятся в виде массива из страниц фиксированного размера (обычно 8 КБ, хотя при компиляции сервера можно выбрать другой размер страницы). В таблице все страницы логически эквивалентны, поэтому конкретный элемент (строка) может храниться на любой странице. В индексах первая страница обычно зарезервирована как метастраница , содержащая управляющую информацию, и в индексе могут быть разные типы страниц, в зависимости от метода доступа к индексу.
В таблице 73.2 показан общий макет страницы. На каждой странице пять частей.
Таблица 73.2. Общий макет страницы
| Элемент | Описание |
|---|---|
| Данные заголовка страницы | Длина 24 байта. Содержит общую информацию о странице, включая указатели свободного места. |
| ItemIdData | Массив идентификаторов элементов, указывающих на фактические элементы. Каждая запись представляет собой пару (смещение, длина). 4 байта на элемент. |
| Свободное место | Нераспределенное пространство. Идентификаторы новых элементов выделяются с начала этой области, новые элементы — с конца. |
| Предметы | Сами предметы. |
| Специальное место | Специфические данные метода доступа к индексу. Разные методы хранят разные данные. Пусто в обычных столах. Разные методы хранят разные данные. Пусто в обычных столах. |
Первые 24 байта каждой страницы состоят из заголовка страницы ( PageHeaderData ). Его формат подробно описан в таблице 73.3. Первое поле отслеживает самую последнюю запись WAL, связанную с этой страницей. Второе поле содержит контрольную сумму страницы, если включены контрольные суммы данных. Далее идет 2-байтовое поле, содержащее флаговые биты. Далее следуют три 2-байтовых целочисленных поля ( pd_lower , pd_upper и pd_special ).). Они содержат смещения в байтах от начала страницы до начала нераспределенного пространства, до конца нераспределенного пространства и до начала специального пространства. Следующие 2 байта заголовка страницы, pd_pagesize_version , хранят как размер страницы, так и индикатор версии. Начиная с PostgreSQL 8.3 номер версии — 4; PostgreSQL 8.1 и 8.2 использовали версию номер 3; PostgreSQL 8. 0 использовал версию номер 2; PostgreSQL 7.3 и 7.4 использовали версию номер 1; в предыдущих выпусках использовалась версия номер 0. (Базовый макет страницы и формат заголовка не изменились в большинстве этих версий, но изменился макет заголовков строк в куче.) Размер страницы в основном присутствует только как перекрестная проверка; нет поддержки наличия более одного размера страницы в установке. Последнее поле — это подсказка, которая показывает, будет ли прибыльным сокращение страницы: оно отслеживает самый старый несокращенный XMAX на странице.
0 использовал версию номер 2; PostgreSQL 7.3 и 7.4 использовали версию номер 1; в предыдущих выпусках использовалась версия номер 0. (Базовый макет страницы и формат заголовка не изменились в большинстве этих версий, но изменился макет заголовков строк в куче.) Размер страницы в основном присутствует только как перекрестная проверка; нет поддержки наличия более одного размера страницы в установке. Последнее поле — это подсказка, которая показывает, будет ли прибыльным сокращение страницы: оно отслеживает самый старый несокращенный XMAX на странице.
Таблица 73.3. Макет PageHeaderData
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| pd_lsn | Пажекслогрекптр | 8 байт | LSN: следующий байт после последнего байта записи WAL для последнего изменения этой страницы |
| pd_checksum | uint16 | 2 байта | Контрольная сумма страницы |
| pd_flags | uint16 | 2 байта | Флаговые биты |
| пд_нижний | Индекс местоположения | 2 байта | Смещение до начала свободного места |
| pd_upper | Индекс местоположения | 2 байта | Смещение до конца свободного места |
| pd_special | Индекс местоположения | 2 байта | Смещение до начала специального пространства |
| pd_pagesize_version | uint16 | 2 байта | Информация о размере страницы и номере версии макета |
| pd_prune_xid | Идентификатор транзакции | 4 байта | Самый старый несокращенный XMAX на странице или ноль, если нет |
Все подробности можно найти в src/include/storage/bufpage. . h
h
За заголовком страницы следуют идентификаторы элементов ( ItemIdData ), каждый из которых требует четырех байтов. Идентификатор элемента содержит смещение в байтах до начала элемента, его длину в байтах и несколько битов атрибута, влияющих на его интерпретацию. Идентификаторы новых элементов выделяются по мере необходимости с начала нераспределенного пространства. Количество присутствующих идентификаторов предметов можно определить, посмотрев на pd_lower , который увеличивается для выделения нового идентификатора. Поскольку идентификатор элемента никогда не перемещается до тех пор, пока он не будет освобожден, его индекс можно использовать на долгосрочной основе для ссылки на элемент, даже если сам элемент перемещается по странице для сжатия свободного места. Фактически каждый указатель на элемент ( ItemPointer , также известный как CTID ), созданный PostgreSQL, состоит из номера страницы и индекса идентификатора элемента.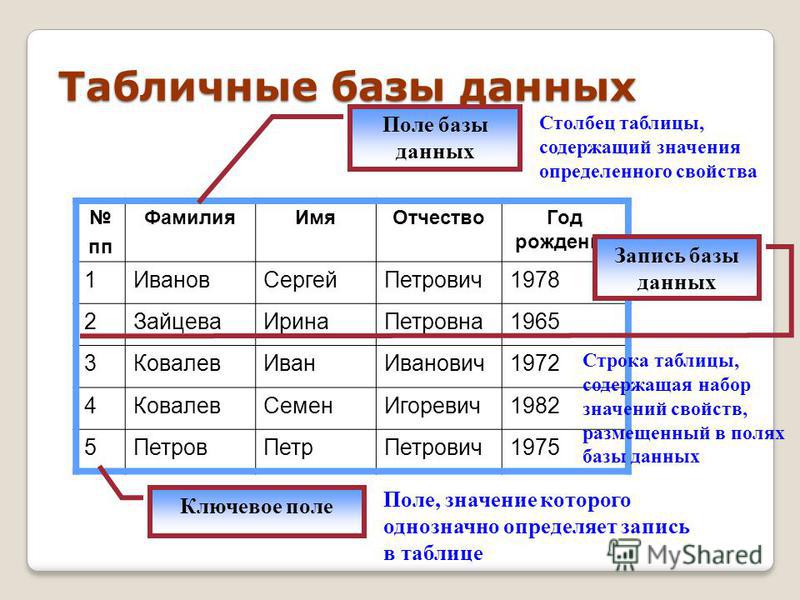
Сами элементы хранятся в пространстве, выделенном в обратном направлении от конца нераспределенного пространства. Точная структура зависит от того, что должна содержать таблица. Таблицы и последовательности используют структуру с именем 9.0078 HeapTupleHeaderData , описанный ниже.
Последний раздел — это «специальный раздел», который может содержать все, что хочет сохранить метод доступа. Например, индексы b-tree хранят ссылки на левый и правый одноуровневые элементы страницы, а также некоторые другие данные, относящиеся к структуре индекса. Обычные таблицы вообще не используют специальный раздел (на это указывает установка pd_special , равная размеру страницы).
На рис. 73.1 показано, как эти части расположены на странице.
Рисунок 73.1. Макет страницы
73.6.1. Структура строк таблицы
Все строки таблицы имеют одинаковую структуру. Существует заголовок фиксированного размера (занимающий 23 байта на большинстве машин), за которым следует необязательный нулевой битовый массив, необязательное поле идентификатора объекта и пользовательские данные.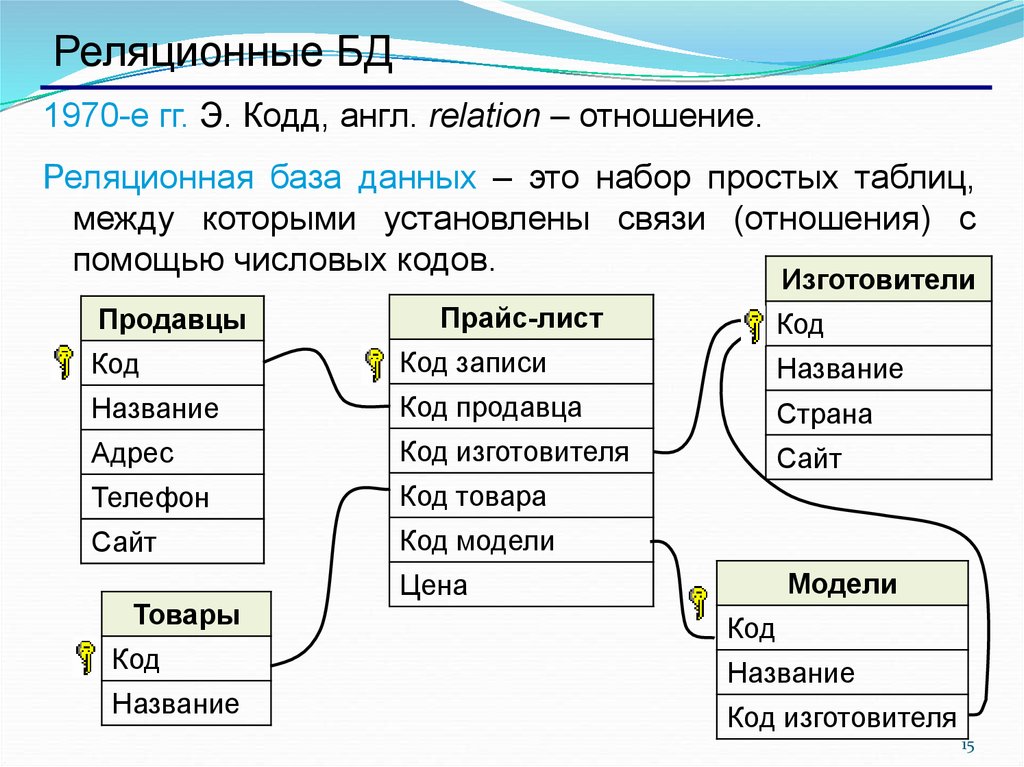 Заголовок подробно описан в таблице 73.4. Фактические пользовательские данные (столбцы строки) начинаются со смещения, указанного
Заголовок подробно описан в таблице 73.4. Фактические пользовательские данные (столбцы строки) начинаются со смещения, указанного t_hoff , которое всегда должно быть кратно расстоянию MAXALIGN для платформы. Нулевое растровое изображение присутствует только в том случае, если HEAP_HASNULL бит установлен в t_infomask . Если он присутствует, он начинается сразу после фиксированного заголовка и занимает достаточно байтов, чтобы иметь один бит на столбец данных (то есть количество битов, равное количеству атрибутов в t_infomask2 ). В этом списке битов бит 1 означает ненулевое значение, а бит 0 означает нуль. Когда растровое изображение отсутствует, все столбцы считаются ненулевыми. Идентификатор объекта присутствует только в том случае, если бит HEAP_HASOID_OLD установлен в t_infomask 9.0079 . Если он присутствует, он появляется непосредственно перед границей t_hoff . Любое заполнение, необходимое для того, чтобы сделать t_hoff множителем MAXALIGN, появится между нулевым растровым изображением и идентификатором объекта. (Это, в свою очередь, обеспечивает правильное выравнивание идентификатора объекта.)
(Это, в свою очередь, обеспечивает правильное выравнивание идентификатора объекта.)
Все подробности можно найти в src/include/access/htup_details.h .
Интерпретировать фактические данные можно только с помощью информации, полученной из других таблиц, в основном pg_attribute . Ключевыми значениями, необходимыми для определения местоположения полей, являются 9.0078 на и на . Невозможно напрямую получить конкретный атрибут, за исключением случаев, когда есть только поля фиксированной ширины и нет пустых значений. Вся эта хитрость заключена в функциях heap_getattr , fastgetattr и heap_getsysattr .
Чтобы прочитать данные, вам нужно проверить каждый атрибут по очереди. Сначала проверьте, является ли поле NULL в соответствии с нулевым растровым изображением. Если это так, перейдите к следующему. Затем убедитесь, что у вас правильное выравнивание. Если поле имеет фиксированную ширину, то все байты просто размещаются. Если это поле переменной длины (attlen = -1), то это немного сложнее. Все типы данных переменной длины имеют общую структуру заголовка
Если это поле переменной длины (attlen = -1), то это немного сложнее. Все типы данных переменной длины имеют общую структуру заголовка struct varlena , которая включает в себя общую длину хранимого значения и некоторые биты флага. В зависимости от флагов данные могут быть либо встроенными, либо в таблице TOAST; он также может быть сжат (см. Раздел 73.2).
[17] Фактически, использование этого формата страницы не требуется ни для табличных, ни для индексных методов доступа. Метод доступа к таблице кучи всегда использует этот формат. Все существующие методы индексирования также используют базовый формат, но данные, хранящиеся на метастраницах индекса, обычно не соответствуют правилам размещения элементов.
Что такое страница в SQL Server и нужно ли мне беспокоиться?
спросил
Изменено
8 лет, 5 месяцев назад
Просмотрено
31к раз
Я столкнулся со страницей в SQL Server 2008 и несколько сбит с толку. В настоящее время я читаю комплект для самостоятельного обучения MCTS (экзамен 70-433): Microsoft SQL Server 2008-Database Development, где авторы обсуждают эту концепцию, но в ограниченном виде.
В настоящее время я читаю комплект для самостоятельного обучения MCTS (экзамен 70-433): Microsoft SQL Server 2008-Database Development, где авторы обсуждают эту концепцию, но в ограниченном виде.
Из MSDN «Понимание страниц и экстентов» я получаю ответ, который на самом деле не помогает. Веб-страница описывает размер (8 КБ) страницы и то, как строки хранятся на странице, и как столбцы будут автоматически перемещаться (SQL Server), если строки не помещаются на странице.
Но все же интересно, стоит ли обращать внимание на уровень страницы при проектировании базы данных с ER-диаграммами, таблицами и типами данных? Или я должен просто полагаться на то, что SQL Server обрабатывает страницы автоматически и наилучшим образом?
Спасибо за внимание!
- sql-сервер
1
ДА ! Страница — это основной элемент хранилища в SQL Server.
Из 8192 байт на странице прибл. 8060 доступны вам как пользователю. Если вам удастся правильно разместить строки данных на странице, они будут занимать гораздо меньше места.
8060 доступны вам как пользователю. Если вам удастся правильно разместить строки данных на странице, они будут занимать гораздо меньше места.
Если ваша строка данных, например. имеет длину 4100 байт, на странице будет храниться только одна строка (остальная часть страницы — 3960 байт — пустое место). Важный момент: эти страницы важны не только на диске, но и в основной памяти SQL Server —> вы хотите попытаться избежать больших областей пространства, которые не могут содержать какую-либо полезную информацию на странице.
Если вам удастся уменьшить размер строки до 4000 байт, то внезапно вы сможете хранить две строки на странице и, таким образом, значительно сократить неиспользуемое пространство (до 60 байт на страницу).
9
Вам не нужно беспокоиться о структуре страницы размером 8 КБ, пока вы не столкнетесь с проблемами производительности. Но если вы хотите узнать, как устроена страница размером 8 КБ, вот видео на YouTube http://www.