Содержание
основы для новичков – PR-CY Блог
Успешная индексация нового сайта зависит от многих слагаемых. Один из них — файл robots.txt, с правильным заполнением которого должен быть знаком любой начинающий веб-мастер. Обновили материал для новичков.
Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
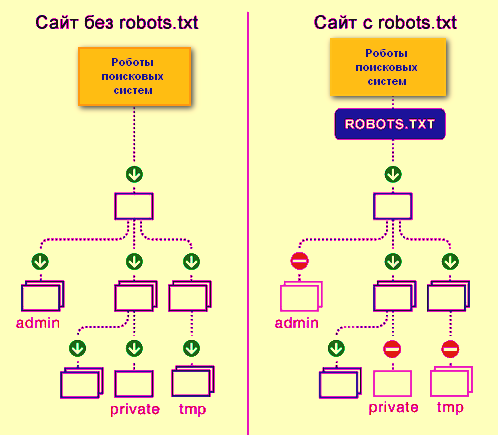
Файл robots.txt — это документ в формате .txt, содержащий инструкции по индексации конкретного сайта для поисковых ботов. Он указывает поисковикам, какие страницы веб-ресурса стоит проиндексировать, а какие не нужно допустить к индексации.
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.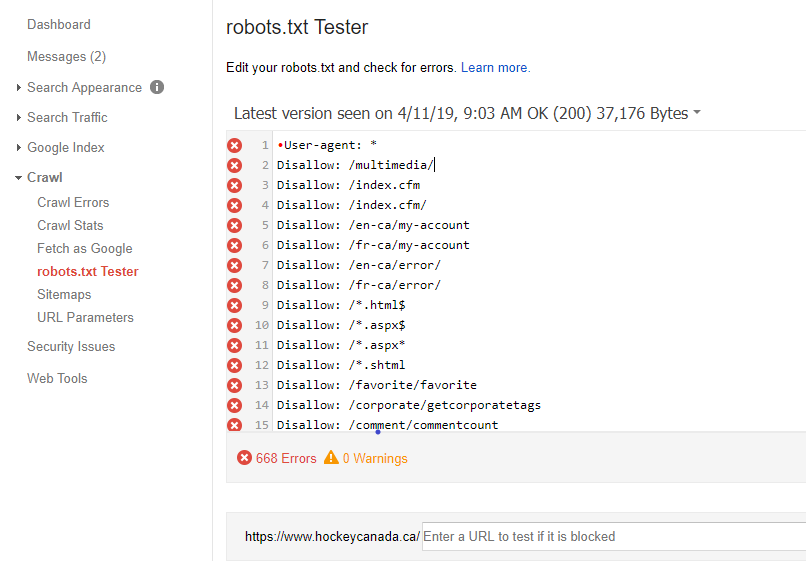 txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Запрет индексирования сайта, Яндекс
Блокировка индексирования, Google
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
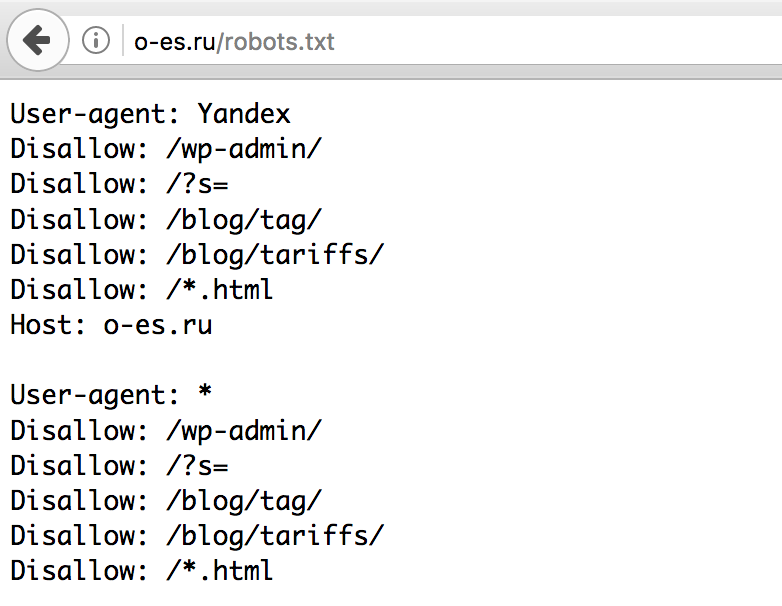
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.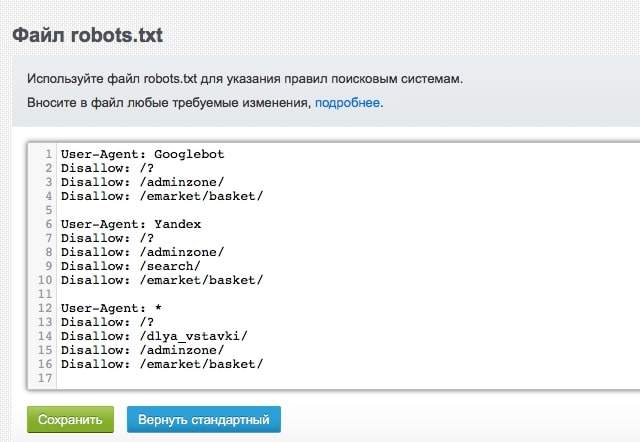 txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
«Sitemap:
» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml
и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.ru/sitemap.xml Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
Что делать дальше:
- проверить корректность созданного документа, например, посредством сервиса Яндекса;
- при помощи FTP-клиента закачать готовый файл в корневую папку своего сайта.
 В ситуации с WordPress речь обычно идет о системной папке Public_html.
В ситуации с WordPress речь обычно идет о системной папке Public_html.
 В ситуации с WordPress речь обычно идет о системной папке Public_html.
В ситуации с WordPress речь обычно идет о системной папке Public_html.Дальше остается только ждать, когда появятся поисковые роботы, изучат ваш robots.txt, а после возьмутся за индексацию вашего сайта.
Как посмотреть robots.txt чужого сайта
Если вам интересно сперва посмотреть на готовые примеры файла robots.txt в исполнении других, то нет ничего проще. Для этого в адресной строке браузера достаточно ввести site.ru/robots.txt. Вместо «site.ru» — название интересующего вас ресурса.
Файл Robots txt — настройка, как создать и проверить: пример robots txt на сайте, директивы
Текстовый файл, записывающий специальные инструкции для поискового робота, ограничивающие доступ к содержимому на http сервере, находящийся в корневой директории веб-сайта и имеющий путь относительно имени самого сайта (/robots.txt ).
Robots.txt — как создать правильный файл robots.txt
Файл robots.txt позволяет управлять индексацией вашего сайта. Закрыть какой-либо раздел можно директивой disallow, открыть — allow. Проверка и анализ robots.txt.
Проверка и анализ robots.txt.
Выгрузить в xls, файл, индексация, сайт, директива, яндекс, настройка, запрет, проверка, пример, генератор, анализ, страница, правильный, закрыть, создать, добавить, проверить, задать, запретить, сделать, robots, txt, host, закрытый, где, disallow
Robots.txt — текстовый файл, содержащий инструкции для поисковых роботов, как нужно индексировать сайт.
Почему важно создавать файл robots.txt для сайта
В 2011 году случилось сразу несколько громких скандалов, связанных с нахождением в поиске Яндекса нежелательной информации.
Сначала в выдаче Яндекса оказалось более 8 тысяч SMS-сообщений, отправленных пользователями через сайт компании «МегаФон». В результатах поиска отображались тексты сообщений и телефонные номера, на которые они были отправлены.
Заместитель генерального директора «МегаФона» Валерий Ермаков заявил, что причиной публичного доступа к данным могло стать наличие у клиентов «Яндекс.Бара», который считывал информацию и отправлял поисковому роботу Яндекса.
У Яндекса было другое объяснение:
«Еще раз можем подтвердить, что страницы с SMS с сайта МегаФона были публично доступны всем поисковым системам… Ответственность за размещение информации в открытом доступе лежит на том, кто её разместил или не защитил должным образом…
Особо хотим отметить, что никакие сервисы Яндекса не виноваты в утечке данных с сайта МегаФона. Ни Яндекс.Бар, ни Яндекс.Метрика не скачивают содержимое веб-страниц. Если страница закрыта для индексации в файле robots.txt или защищена логином и паролем, то она недоступна и поисковым роботам, то есть информация, размещенная на ней, никогда не окажется в какой-либо поисковой системе».
Вскоре после этого пользователи нашли в Яндексе несколько тысяч страниц со статусами заказов в онлайн-магазинах книг, игр, секс-товаров и т.д. По ссылкам с результатов поиска можно было увидеть ФИО, адрес и контактные данные клиента магазина, IP-адрес, наименование его покупки, дату и время заказа.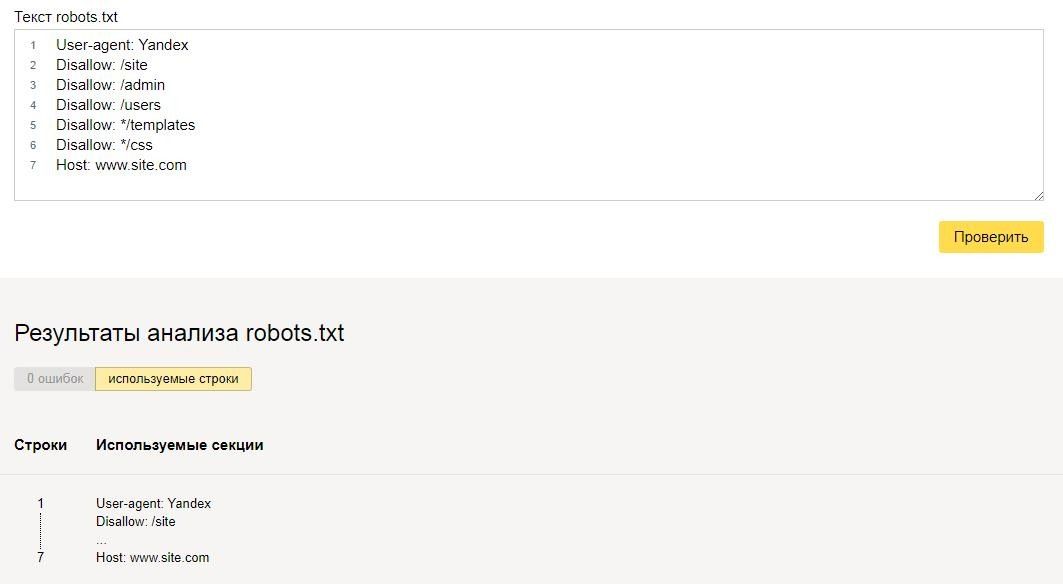 И снова причиной утечки стал некорректно составленный (или вообще отсутствующий) файл robots.txt.
И снова причиной утечки стал некорректно составленный (или вообще отсутствующий) файл robots.txt.
Чтобы не оказаться в подобных ситуациях, лучше заранее составить правильный robots.txt файл для сайта. Как сделать robots.txt в соответствии с рекомендациями поисковых систем, расскажем ниже.
Как создать robots.txt для сайта
Настройка robots.txt начинается с создания текстового файла с именем «robots.txt». После заполнения этот файл нужно будет сохранить в корневом каталоге сайта, поэтому лучше заранее проверить, есть ли к нему доступ.
Основные директивы robots.txt
В простейшем файле robots.txt используются следующие директивы:
- User-agent
DisallowAllow
Директива User-agent
Здесь указываются роботы, которые должны следовать указанным инструкциям. Например, User-agent: Yandex означает, что команды будут распространяться на всех роботов Яндекса. User-agent: YandexBot – только на основного индексирующего робота. Если в данном пункте мы поставим *, правило будет распространяться на всех роботов.
User-agent: YandexBot – только на основного индексирующего робота. Если в данном пункте мы поставим *, правило будет распространяться на всех роботов.
Директива Disallow
Эта команда сообщает роботу user-agent, какие URL не нужно сканировать. При составлении файла robots.txt важно помнить, что эта директива будет относиться только к тем роботам, которые были перед этим указаны в директиве user-agent. Если подразумеваются разные запреты для разных роботов, то в файле нужно указать отдельно каждого робота и директиву disallow для него.
Как закрыть части сайта с помощью директивы Disallow:
- Если нужно закрыть от сканирования весь сайт, необходимо использовать косую черту (
/):Disallow: / -
Если нужно закрыть от сканирования каталог со всем его содержимым, необходимо ввести его название и косую черту в конце:Disallow: /events/ -
Если нужно закрыть страницу, необходимо указать название страницы после косой черты:Disallow: /file. html
 html
html
Директива Allow
Разрешает роботу сканировать сайт или отдельные URL.
В примере ниже robots.txt запрещает роботам Яндекса сканировать весь сайт за исключением страниц, начинающихся с «events»:
User-agent: Yandex
Allow: /events
Disallow: /
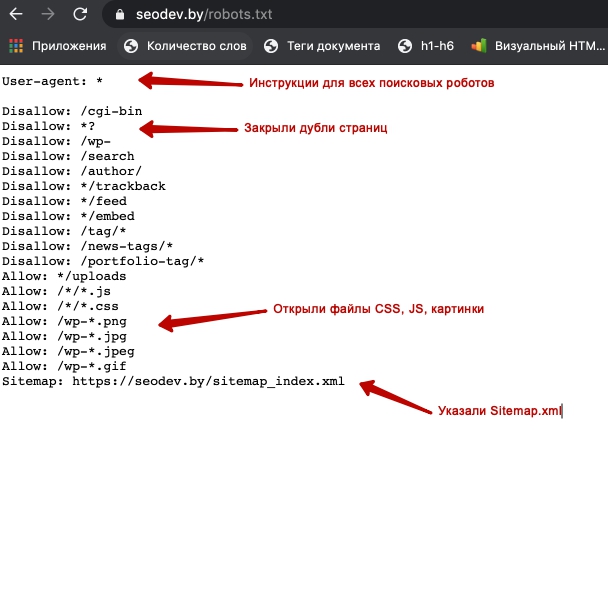
Спецсимволы в директивах
Для директив Allow и Disallow используются спецсимволы «*» и «$».
Звездочка (*) подразумевает собой любую последовательность символов. Например, если нужно закрыть подкаталоги, начинающиеся с определенных символов:Disallow: /example*/-
По умолчанию символ * ставится в конце каждой строки. Если нужно закончить строку определенным символом, используется спецсимвол $. Например, если нужно закрытьURL, заканчивающиеся наdoc:Disallow: /*. doc$ -
Спецсимвол # используется для написания комментариев и не учитывается роботами.
Дополнительные директивы robots.txt
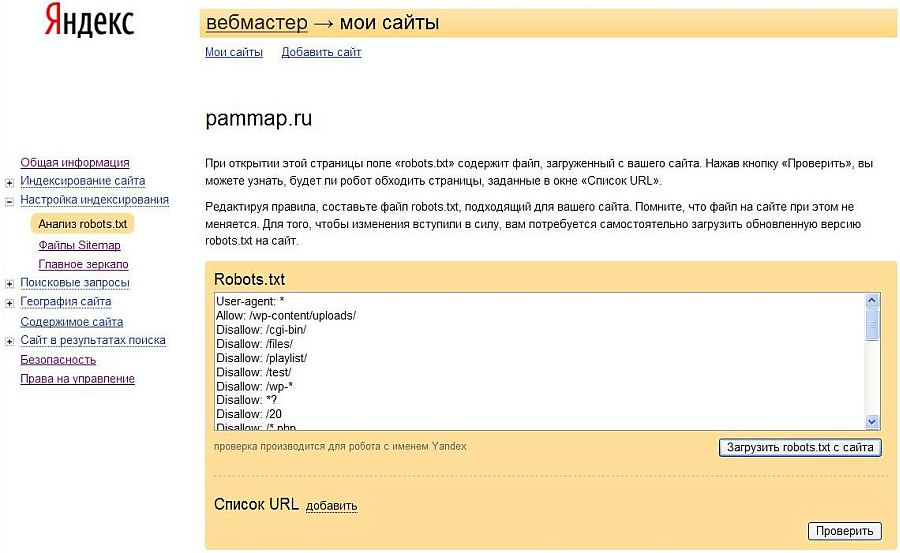
Директива Host
Директива Host в robots.txt используется, чтобы указать роботу на главное зеркало сайта.
Пример:
https://www.glavnoye-zerkalo.ru является главным зеркалом сайта, и для всех сайтов из группы зеркал необходимо прописать в robots.txt:
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: https://www.glavnoye-zerkalo.ru
Правила использования директивы Host:
- В файле robots.txt может быть только одна директива
Host. Робот всегда ориентируется на первую директиву, даже если их указано несколько. - Если зеркало доступно по защищенному каналу, нужно добавить протокол HTTPS,
- Должно быть указано одно доменное имя и номер порта в случае необходимости.
Если директива Host прописана неправильно, роботы ее проигнорируют.
Директива Crawl-delay
Директива Crawl-delay задает для робота промежуток времени, с которым он должен загружать страницы. Пригодится в случае сильной нагрузки на сервер.
Например, если нужно задать промежуток в 3 секунды между загрузкой страниц:
User-agent: *
Disallow: /search
Crawl-delay: 3
Директива Clean-param
Пригодится для сайтов, страницы которых содержат динамические параметры, которые не влияют на их содержимое (например, идентификаторы сессий). Директива позволяет роботам не перезагружать дублирующуюся информацию, что положительно сказывается на нагрузке на сервер.
Использование кириллицы
При составлении файла robots. txt нельзя использовать кириллические символы. Допускается использование Punycode для доменов.
txt нельзя использовать кириллические символы. Допускается использование Punycode для доменов.
Как проверить robots.txt
Для проверки файла robots.txt можно использовать Яндекс.Вебмастер (Анализ robots.txt) или Google Search Console (Инструмент проверки файла Robots.txt).
Как добавить файл robots.txt на сайт
Как только файл robots.txt написан и проверен, его нужно сохранить в виде текстового файла с названием robots.txt и загрузить в каталог верхнего уровня сайта или в корневой каталог.
Полное руководство по robots.txt • Yoast
Файл robots.txt является одним из основных способов указать поисковой системе, где она может и не может находиться на вашем сайте. Все основные поисковые системы поддерживают основные функции, которые они предлагают, но некоторые из них реагируют на некоторые дополнительные правила, которые также могут быть полезны. В этом руководстве описаны все способы использования robots.![]() txt на вашем веб-сайте.
txt на вашем веб-сайте.
Внимание!
Любые ошибки, допущенные вами в файле robots.txt, могут серьезно повредить вашему сайту, поэтому убедитесь, что вы прочитали и поняли всю эту статью, прежде чем погрузиться в нее.
Содержание
- Что такое файл robots.txt?
- Для чего нужен файл robots.txt?
- Куда мне поместить файл robots.txt?
- Плюсы и минусы использования robots.txt
- Синтаксис файла robots.txt
- Не блокировать файлы CSS и JS в robots.txt
- Проверка и исправление в Google Search Console
- Подтвердите файл robots.txt
- См. код
Что такое файл robots.txt?
Директивы сканирования
Файл robots.txt является одной из нескольких директив сканирования. У нас есть руководства по всем из них, и вы найдете их здесь.
Файл robots.txt — это текстовый файл, читаемый поисковыми системами (и другими системами). Файл robots.txt, также называемый протоколом исключения роботов, является результатом консенсуса среди первых разработчиков поисковых систем. Это не официальный стандарт, установленный какой-либо организацией по стандартизации, хотя его придерживаются все основные поисковые системы.
Это не официальный стандарт, установленный какой-либо организацией по стандартизации, хотя его придерживаются все основные поисковые системы.
Базовый файл robots.txt может выглядеть примерно так:
Агент пользователя: * Запретить: Карта сайта: https://www.example.com/sitemap_index.xml
Что делает файл robots.txt?
Кэширование
Поисковые системы обычно кэшируют содержимое файла robots.txt, поэтому им не нужно его постоянно загружать, но обычно они обновляют его несколько раз в день. Это означает, что изменения в инструкциях обычно отражаются довольно быстро.
Поисковые системы обнаруживают и индексируют Интернет, просматривая страницы. По мере сканирования они обнаруживают ссылки и переходят по ним. Это занимает их от сайт A до сайт B до сайт C и так далее. Но прежде чем поисковая система посетит любую страницу в домене, с которым она раньше не сталкивалась, она откроет файл robots.txt этого домена. Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие нет).
Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие нет).
Подробнее: Бот-трафик: что это такое и почему вы должны о нем заботиться »
Куда мне поместить файл robots.txt?
Файл robots.txt всегда должен находиться в корне вашего домена. Итак, если ваш домен www.example.com , сканер должен найти его по адресу https://www.example.com/robots.txt .
Также важно, чтобы ваш файл robots.txt назывался robots.txt. Имя чувствительно к регистру, поэтому сделайте это правильно, иначе оно не будет работать.
Плюсы и минусы использования robots.txt
Плюсы: управление краулинговым бюджетом
Общеизвестно, что поисковый паук заходит на веб-сайт с заранее определенным «допуском» на то, сколько страниц он будет сканировать (или сколько ресурс/время, которое он потратит, в зависимости от авторитета/размера/репутации сайта и того, насколько эффективно отвечает сервер). SEO-специалисты называют это краулинговый бюджет .
Если вы считаете, что у вашего веб-сайта проблемы с краулинговым бюджетом, то запрет поисковым системам «тратить» энергию на несущественные части вашего сайта может означать, что вместо этого они сосредоточатся на тех разделах, которые действительно важны. Используйте настройки очистки сканирования в Yoast SEO Premium, чтобы помочь Google сканировать то, что важно.
Иногда может быть полезно запретить поисковым системам сканировать проблемные разделы вашего сайта, особенно на сайтах, где необходимо выполнить большую SEO-очистку. После того, как вы прибрали вещи, вы можете впустить их обратно.
Примечание о блокировке параметров запроса
Одной из ситуаций, когда краулинговый бюджет имеет решающее значение, является ситуация, когда ваш сайт использует множество параметров строки запроса для фильтрации или сортировки списков. Допустим, у вас есть десять различных параметров запроса, каждый из которых имеет разные значения, которые можно использовать в любой комбинации (например, футболки разных цветов и размеров). Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы.
Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы.
Против: не удалять страницу из результатов поиска
Несмотря на то, что вы можете использовать файл robots.txt, чтобы сообщить сканеру, куда он не может попасть на вашем сайте, вы не можете использовать его, чтобы сказать поиску движок, URL-адреса которого не показывать в результатах поиска – другими словами, его блокировка не остановит его индексацию. Если поисковая система найдет достаточное количество ссылок на этот URL, она включит его; он просто не будет знать, что находится на этой странице. Таким образом, ваш результат будет выглядеть так:
Если вы хотите надежно заблокировать страницу от появления в результатах поиска, вам нужно использовать мета-роботы тег noindex . Это означает, что для того, чтобы найти тег
Это означает, что для того, чтобы найти тег noindex , поисковая система должна иметь доступ к этой странице, поэтому не блокируйте ее с помощью robots.txt.
Директивы Noindex
Раньше можно было добавить директивы noindex в файл robots.txt, чтобы удалить URL-адреса из результатов поиска Google и избежать появления этих «фрагментов». Это больше не поддерживается (и технически никогда не было).
Con: не распространяется значение ссылки
Если поисковая система не может просканировать страницу, она не может распределить значение ссылки по ссылкам на этой странице. Это тупик, когда вы заблокировали страницу в robots.txt. Любое значение ссылки, которое могло пройти на эту страницу (и через нее), теряется.
Синтаксис robots.txt
WordPress robots.txt
У нас есть целая статья о том, как лучше настроить файл robots.txt для WordPress. Не забывайте, что вы можете редактировать файл robots.txt вашего сайта в разделе Инструменты Yoast SEO → Редактор файлов.
Файл robots.txt состоит из одного или нескольких блоков директив, каждая из которых начинается со строки пользовательского агента. «User-agent» — это имя конкретного паука, к которому он обращается. У вас может быть либо один блок для всех поисковых систем, используя подстановочный знак для пользовательского агента, либо отдельные блоки для определенных поисковых систем. Поисковый паук всегда выберет блок, который лучше всего соответствует его названию.
Эти блоки выглядят так (не пугайтесь, ниже мы объясним):
User-agent: *
Disallow: /User-agent: Googlebot
Disallow:User-agent: bingbot
Disallow: /not-for-bing/
Такие директивы, как Allow и Disallow , не должны учитывать регистр, поэтому вам решать писать их строчными буквами или заглавными буквами. Значения чувствительны к регистру, поэтому /photo/ не совпадает с /Photo/ . Нам нравится писать директивы с большой буквы, потому что это облегчает чтение файла (для людей).
Директива агента пользователя
Первый бит каждого блока директив — это агент пользователя, который идентифицирует конкретного паука. Поле user-agent соответствует пользовательскому агенту этого конкретного паука (обычно более длинному), поэтому, например, наиболее распространенный паук от Google имеет следующий пользовательский агент:
Mozilla/5.0 (совместимый; Googlebot/2.1; +http ://www.google.com/bot.html)
Если вы хотите указать этому сканеру, что делать, относительно простой User-agent: Googlebot 9Строка 0066 сделает свое дело.
Большинство поисковых систем имеют несколько пауков. Они будут использовать определенный паук для своего обычного индекса, рекламных программ, изображений, видео и т. д.
Поисковые системы всегда выбирают наиболее конкретный блок директив, который они могут найти. Допустим, у вас есть три набора директив: один для * , один для Googlebot и один для Googlebot-News . Если приходит бот, чей пользовательский агент
Если приходит бот, чей пользовательский агент Googlebot-Video , он будет следовать ограничениям Googlebot 9.0066 . Бот с пользовательским агентом Googlebot-News будет использовать более конкретные директивы Googlebot-News .
Наиболее распространенные пользовательские агенты для поисковых роботов
Вот список пользовательских агентов, которые вы можете использовать в файле robots.txt для соответствия наиболее часто используемым поисковым системам:
| Поисковая система | Поле | Агент пользователя | ||
|---|---|---|---|---|
| Baidu | Общие | Baiduspider | ||
| Baidu | Изображения | Baiduspider-image | ||
| Baidu | Мобильный | 65 baiduspider-mobile | ||
| Baidu | Новости | baiduspider-news | ||
| Baidu | Видео | baiduspider-video | ||
| Bing | Общие | bingbot | ||
| Bing | Общие | msnbot | ||
| Bing | Изображения и видео | |||
| Bing | Реклама | adidxbot | ||
| Общие | Googlebot | |||
| Изображения | Googlebot-Image | |||
| Мобильный | Googlebot-Mobile | |||
| Новости | Googlebot-Новости | |||
Googlebot-Video | ||||
| AdSense | Mediapartners-Google | |||
| AdWords | AdsBot-Google | |||
| Yahoo! | Общие | slurp | ||
| Яндекс | Общие | yandex |
Директива disallow во второй строке2 блоком директив является строка Disallow . У вас может быть одна или несколько таких строк, указывающих, к каким частям сайта не может получить доступ указанный паук. Пустая строка
У вас может быть одна или несколько таких строк, указывающих, к каким частям сайта не может получить доступ указанный паук. Пустая строка Disallow означает, что вы ничего не запрещаете, чтобы паук мог получить доступ ко всем разделам вашего сайта.
В приведенном ниже примере блокируются все поисковые системы, которые «прослушивают» файл robots.txt, и не могут сканировать ваш сайт.
User-agent: *
Disallow: /
В приведенном ниже примере все поисковые системы могут сканировать весь ваш сайт, пропуская один символ.
User-agent: *
Disallow:
В приведенном ниже примере Google не сможет сканировать каталог Photo на вашем сайте и все, что в нем содержится.
Агент пользователя: googlebot
Запретить: /Фото
Это означает, что все подкаталоги каталога /Photo также не будут сканироваться. Это , а не , заблокирует Google от сканирования каталога /photo , так как эти строки чувствительны к регистру.
Это и заблокирует доступ Google к URL-адресам, содержащим /Photo , например /Photography/ .
Как использовать подстановочные знаки/регулярные выражения
«Официально» стандарт robots.txt не поддерживает регулярные выражения или подстановочные знаки; однако все основные поисковые системы это понимают. Это означает, что вы можете использовать такие строки для блокировки групп файлов:
Disallow: /*.php
Disallow: /copyrighted-images/*.jpg
В приведенном выше примере * расширяется до любого имени файла, которому оно соответствует. Обратите внимание, что остальная часть строки по-прежнему чувствительна к регистру, поэтому вторая строка выше не блокирует сканирование файла с именем /copyrighted-images/example.JPG .
Некоторые поисковые системы, такие как Google, позволяют использовать более сложные регулярные выражения, но имейте в виду, что другие поисковые системы могут не понимать эту логику. Самая полезная функция, которую это добавляет, - это
Самая полезная функция, которую это добавляет, - это $ , что указывает на конец URL-адреса. В следующем примере вы можете увидеть, что это делает:
Disallow: /*.php$
Это означает, что /index.php нельзя индексировать, но /index.php?p=1 можно. быть. Конечно, это полезно только в очень специфических обстоятельствах и довольно опасно: легко разблокировать то, чего вы не хотели.
Нестандартные директивы сканирования robots.txt
А также Disallow и Директивы User-agent , есть пара других директив сканирования, которые вы можете использовать. Все сканеры поисковых систем не поддерживают эти директивы, поэтому убедитесь, что вы знаете их ограничения.
Директива allow
Хотя в исходной «спецификации» ее не было, в самом начале речь шла о директиве allow. Похоже, что большинство поисковых систем его понимают, и он позволяет использовать простые и очень читаемые директивы, такие как:
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.
 php
php Единственным другим способом достижения того же результата без директивы allow было бы конкретно запретить каждый файл в папке wp-admin .
Директива Crawl-delay
Crawl-delay является неофициальным дополнением к стандарту, и не многие поисковые системы придерживаются его. По крайней мере, Google и Яндекс им не пользуются, а с Bing непонятно. Теоретически, поскольку поисковые роботы могут быть довольно прожорливыми, вы можете попробовать .0065 crawl-delay направление, чтобы замедлить их.
Строка, подобная приведенной ниже, указывает этим поисковым системам изменить частоту запросов страниц на вашем сайте.
crawl-delay: 10
Будьте осторожны при использовании директивы crawl-delay . Установив задержку сканирования в десять секунд, вы разрешаете этим поисковым системам доступ только к 8640 страницам в день. Это может показаться достаточным для небольшого сайта, но не очень для больших сайтов. С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик.
С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик.
Директива карты сайта для XML-карты сайта
Используя директиву для карты сайта , вы можете указать поисковым системам — Bing, Yandex и Google — где найти вашу XML-карту сайта. Конечно, вы можете отправить свои XML-карты сайта в каждую поисковую систему, используя их инструменты для веб-мастеров. Мы настоятельно рекомендуем вам это сделать, потому что инструменты для веб-мастеров предоставят вам массу информации о вашем сайте. Если вы не хотите этого делать, добавление строки карты сайта в файл robots.txt является хорошей быстрой альтернативой. Yoast SEO автоматически добавит ссылку на вашу карту сайта, если вы позволите ему сгенерировать файл robots.txt. В существующий файл robots.txt вы можете добавить правило вручную через редактор файлов в разделе «Инструменты».
Карта сайта: https://www.example.com/my-sitemap.
 xml
xml Не блокировать файлы CSS и JS в robots.txt
С 2015 года Google Search Console предупреждает владельцев сайтов не блокировать CSS и JS файлы. Мы давно говорим вам одно и то же: не блокируйте файлы CSS и JS в файле robots.txt. Объясним, почему не следует блокировать эти файлы от робота Googlebot.
Блокируя файлы CSS и JavaScript, вы запрещаете Google проверять правильность работы вашего веб-сайта. Если вы заблокируете файлы CSS и JavaScript в своем robots.txt , Google не может отобразить ваш веб-сайт должным образом. Теперь Google не может понять ваш сайт, что может привести к снижению рейтинга. Более того, даже такие инструменты, как Ahrefs, отображают веб-страницы и выполняют JavaScript. Поэтому не блокируйте JavaScript, если хотите, чтобы ваши любимые SEO-инструменты работали.
Это идеально согласуется с общим предположением, что Google стал более «человечным». Google хочет видеть ваш сайт таким, каким его видит посетитель, поэтому он может отличить основные элементы от дополнительных. Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его.
Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его.
Проверка и исправление в Google Search Console
Google поможет вам найти и исправить проблемы с файлом robots.txt, например, в разделе «Индексирование страниц» в Google Search Console. Просто выберите параметр «Заблокировано robots.txt»:
Проверьте в Search Console, какие URL-адреса заблокированы вашим файлом robots.txt
Чтобы разблокировать заблокированные ресурсы, нужно изменить файл robots.txt . Вам нужно настроить этот файл так, чтобы он больше не запрещал Google доступ к файлам CSS и JavaScript вашего сайта. Если вы работаете на WordPress и используете Yoast SEO, вы можете сделать это напрямую с нашим плагином Yoast SEO.
Проверьте файл robots.txt
Различные инструменты могут помочь вам проверить файл robots.txt, но когда дело доходит до проверки директив сканирования, мы всегда предпочитаем обращаться к источнику. У Google есть инструмент тестирования robots. txt в консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его:
txt в консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его:
Тестирование файла robots.txt в консоли поиска Google
Обязательно проверьте свои изменения. тщательно, прежде чем поставить их жить! Вы не будете первым, кто случайно использует robots.txt, чтобы заблокировать весь ваш сайт и попасть в забвение поисковой системы!
За кулисами синтаксического анализатора robots.txt
В июле 2019 года Google объявил, что делает свой синтаксический анализатор robots.txt открытым исходным кодом. Если вы хотите разобраться в гайках и болтах, вы можете увидеть, как работает их код (и даже использовать его самостоятельно или предложить его модификации).
Йоост де Валк
Йоост де Валк — интернет-предприниматель и основатель Yoast. После продажи Yoast он перестал работать на постоянной основе и выступать в качестве советника компании, но вернулся в качестве временного технического директора. Он также является руководителем стратегии WordPress для материнской компании Yoast Newfold Digital.
Он также является руководителем стратегии WordPress для материнской компании Yoast Newfold Digital.
Йоост вместе со своей женой Марике активно инвестирует и консультирует несколько стартапов через свою компанию Emilia Capital.
Далее!
Файлы robots.txt | Search.gov
Файл /robots.txt — это текстовый файл, в котором автоматизированные веб-боты инструктируются о том, как сканировать и/или индексировать веб-сайт. Веб-команды используют их для предоставления информации о том, какие каталоги сайта следует или не следует сканировать, как быстро следует получать доступ к контенту и какие боты приветствуются на сайте.
Как должен выглядеть мой файл robots.txt?
Подробную информацию о том, как и где создать файл robots.txt, см. в протоколе robots.txt. Основные моменты, на которые следует обратить внимание:
- Файл должен находиться в корне домена, и для каждого поддомена нужен свой файл.
- Протокол robots. txt чувствителен к регистру.
- Легко случайно заблокировать сканирование всего:
-
Запретить: /означает запретить все. -
Disallow:означает ничего не запрещать, то есть разрешать все. -
Разрешить: /означает разрешить все. -
Разрешить:означает ничего не разрешать, что запрещает все.
-
- Инструкции в файле robots.txt являются руководством для ботов, а не обязательными требованиями — вредоносные боты могут игнорировать ваши настройки.
 txt чувствителен к регистру.
txt чувствителен к регистру.Как оптимизировать файл robots.txt для Search.gov?
Задержка сканирования
В файле robots.txt может быть указана директива «задержка сканирования» для одного или нескольких пользовательских агентов, которая сообщает боту, как быстро он может запрашивать страницы с веб-сайта. Например, задержка сканирования, равная 10, означает, что сканер не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
500 000 URL-адресов
x 10 секунд между запросами
5 000 000 секунд на все запросы
5 000 000 секунд = 58 дней, чтобы проиндексировать сайт один раз.
Мы рекомендуем установить задержку сканирования в 2 секунды для нашего пользовательского агента usasearch и установить более высокую задержку сканирования для всех остальных ботов. Чем меньше задержка сканирования, тем быстрее Search.gov сможет проиндексировать ваш сайт. В файле robots.txt это будет выглядеть так:
.
Агент пользователя: usasearch Задержка сканирования: 2 Пользовательский агент: * Задержка сканирования: 10
XML-файлы Sitemap
В файле robots.txt также должны быть перечислены одна или несколько ваших XML-карт сайта. Например:
Карта сайта: https://www.example.gov/sitemap.xml Карта сайта: https://www.example.gov/independent-subsection-sitemap.xml Карта сайта: https://www.example.gov/rss-feed-of-uploaded-files.xml Карта сайта: https://other.example.
 gov/cross-submitted-sitemap.xml
gov/cross-submitted-sitemap.xml
- Список всех карт сайта для домена, в котором находится файл robots.txt. Карта сайта другого субдомена должна быть указана в файле robots.txt этого субдомена.
- Мы также поддерживаем каналы RSS 2.0 и Atom 2.0 в качестве карт сайта. Если вы перечислите эти фиды в файле robots.txt как карты сайта, наша система автоматически проиндексирует URL-адреса фидов.
- При необходимости вы можете «перекрестно отправить» карту сайта для URL-адресов этого домена, используя карту сайта, размещенную в другом домене. Прочтите протокол карты сайта XML, чтобы обеспечить правильную реализацию.
Разрешить только тот контент, который вы хотите найти
Мы рекомендуем запретить любые каталоги или файлы, которые не должны быть доступны для поиска. Например:
Запретить: /архив/ Запретить: /news-1997/ Запретить: /reports/duplicative-page.html
- Обратите внимание: если вы запретите каталог после того, как он был проиндексирован поисковой системой, это может не привести к удалению этого содержимого из индекса. Вам нужно будет зайти в инструменты поисковой системы для веб-мастеров, чтобы запросить удаление.
- Также обратите внимание, что поисковые системы могут индексировать отдельные страницы в запрещенной папке, если поисковая система узнает об URL-адресе из метода, не связанного со сканированием, например, по ссылке с другого сайта или из вашей карты сайта. Чтобы данная страница не была доступна для поиска, установите на этой странице метатег robots.
 Вам нужно будет зайти в инструменты поисковой системы для веб-мастеров, чтобы запросить удаление.
Вам нужно будет зайти в инструменты поисковой системы для веб-мастеров, чтобы запросить удаление.Настройка параметров для разных ботов
Вы можете установить разные разрешения для разных ботов. Например, если вы хотите, чтобы мы проиндексировали ваш заархивированный контент, но не хотите, чтобы Google или Bing индексировали его, вы можете указать следующее:
Агент пользователя: usasearch Задержка сканирования: 2 Разрешить: /архив/ Пользовательский агент: * Задержка сканирования: 10 Запретить: /архив/
Контрольный список robots.txt
1. В корневом каталоге сайта создан файл robots.