Содержание
Как спарсить любой сайт? / Хабр
Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
👀 Ого? Это не очевидно 🤔? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте.
Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
 Пример: http://techcrunch.com/sitemap.xml
Пример: http://techcrunch.com/sitemap.xmlПоищите XHR запросы в консоли разработчика
Кабина моего самолета
Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).
Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Кнопка, которую я искал месяцы
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.И наш любимый (у парсеров) Linkedin!
Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто
requests.get.Вырезаете JSON из HTML любыми костылямии (я использую
html.find("={")).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_source
Selenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver(
enable_vnc=False, browser_name="firefox"
):
capabilities = {
"browserName": browser_name,
"version": "",
"enableVNC": enable_vnc,
"enableVideo": False,
"screenResolution": "1280x1024x24",
"sessionTimeout": "3m",
# Someone used these params too, let's have them as well
"goog:chromeOptions": {"excludeSwitches": ["enable-automation"]},
"prefs": {
"credentials_enable_service": False,
"profile. password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver
password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driverЗаметьте фложок enableVNC. Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из <a href="https://okhlopkov.com">Cool website</a> достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.
Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход 😉
10 инструментов, позволяющих парсить информацию с веб-сайтов, включая цены конкурентов + правовая оценка для России / Хабр
Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.
Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
5 крутых инструментов для сбора данных для вашего следующего проекта!
Новичок
Сбор данных
Список
Программирование
Питон
Technique
Эта статья была опубликована в рамках блога Data Science Blogathon
Введение
Без данных никто не может завершить проект по науке о данных; и вы не можете говорить о науке о данных без данных.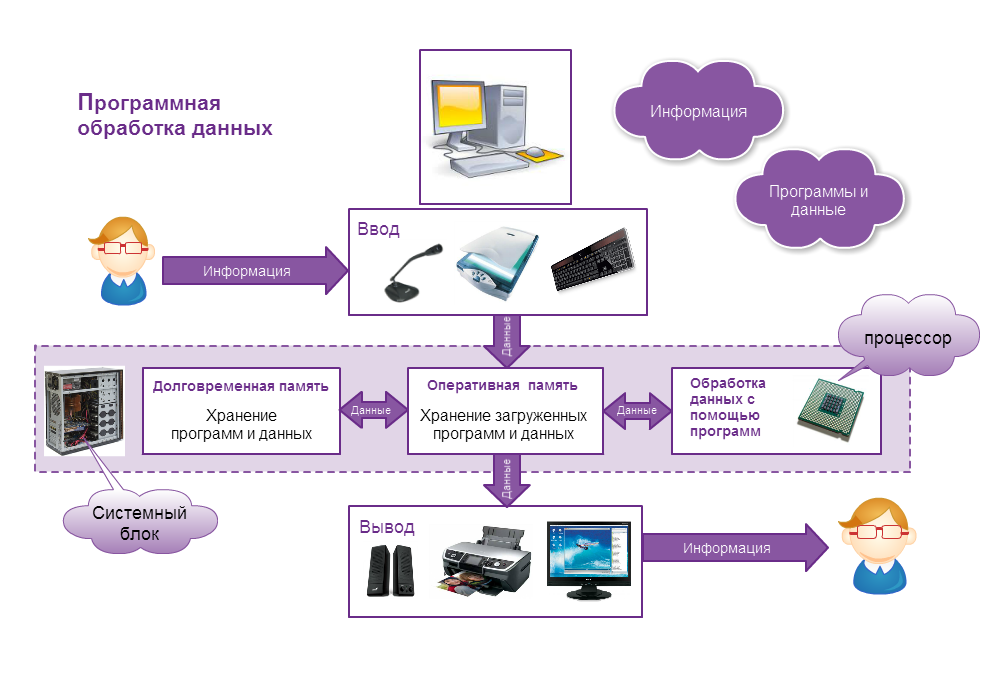 Обычно во многих проектах данные, которые мы используем для анализа и разработки моделей машинного обучения, хранятся в базе данных. Мы можем собирать данные с определенных веб-страниц о конкретном продукте или социальных сетях, чтобы обнаруживать закономерности или выполнять анализ настроений данных. Независимо от того, почему мы собираем данные или как мы собираемся их использовать, сбор информации из Интернета — веб-скрапинг — это задача, которая может быть довольно утомительной, но нам необходимо собирать данные для достижения целей нашего проекта.
Обычно во многих проектах данные, которые мы используем для анализа и разработки моделей машинного обучения, хранятся в базе данных. Мы можем собирать данные с определенных веб-страниц о конкретном продукте или социальных сетях, чтобы обнаруживать закономерности или выполнять анализ настроений данных. Независимо от того, почему мы собираем данные или как мы собираемся их использовать, сбор информации из Интернета — веб-скрапинг — это задача, которая может быть довольно утомительной, но нам необходимо собирать данные для достижения целей нашего проекта.
Как Data Scientist, веб-скрапинг является одним из жизненно важных навыков, которыми вам нужно овладеть, и вы должны искать полезные данные, собирать и предварительно обрабатывать данные, чтобы ваши результаты были значимыми и точными.
Прежде чем мы углубимся в инструменты, которые могут помочь в извлечении данных, давайте подтвердим, что это действие является законным, поскольку парсинг веб-страниц был серой правовой областью. В 2020 году суд США полностью легализовал извлечение общедоступных данных из Интернета. Это означает, что если вы нашли информацию в Интернете (например, статьи в Википедии), то парсинг данных является законным.
В 2020 году суд США полностью легализовал извлечение общедоступных данных из Интернета. Это означает, что если вы нашли информацию в Интернете (например, статьи в Википедии), то парсинг данных является законным.
Тем не менее, когда будете это делать, убедитесь:
- Не использовать повторно и не публиковать данные таким образом, который нарушает авторские права.
- Соблюдение условий обслуживания веб-сайта, который вы парсите.
- Что у вас хорошая скорость сканирования.
- Чтобы вы не пытались извлечь приватные части сайта.
Если вы не нарушаете приведенные выше условия, ваша деятельность по очистке веб-страниц будет законной.
Я думаю, что некоторые из вас могли использовать BeautifulSoup и запросы для сбора данных и pandas для их анализа для ваших проектов. В этом посте вы найдете пять инструментов для парсинга веб-страниц, которые не включают BeautifulSoup, которые можно использовать бесплатно и собирать данные для вашего будущего проекта.
Создатель Common Crawl создал этот инструмент, потому что считает, что каждый должен иметь возможность исследовать и анализировать окружающие его данные и находить полезную информацию. Они бесплатно предоставляют высококачественные данные, которые были открыты только для крупных организаций и исследовательских институтов, для любого любопытного ума, чтобы поддержать их убеждения в открытом исходном коде.
Можно использовать этот инструмент, не беспокоясь о расходах или других финансовых затруднениях. Если вы студент, новичок, который хочет погрузиться в науку о данных, или просто нетерпеливый человек, который любит изучать идеи и открывать новые тенденции, этот инструмент будет вам полезен. Они делают необработанные данные веб-страниц и извлеченные слова доступными в виде открытых наборов данных. Он также предлагает ресурсы для инструкторов, обучающих анализу данных, и помощь в случаях использования, не основанных на коде.
Перейдите на веб-сайт для получения дополнительной информации об использовании наборов данных и способах извлечения данных.
Crawly — еще один выбор, особенно если вам нужно извлечь только простые данные с веб-сайта или если вы хотите извлечь данные в формате CSV, чтобы вы могли изучить их без написания кода. Пользователю необходимо ввести URL-адрес, идентификатор электронной почты для отправки извлеченных данных, формат необходимых данных (выберите между CSV или JSON) и вуаля, очищенные данные находятся в вашем почтовом ящике для использования.
Можно использовать данные JSON и анализировать их с помощью Pandas и Matplotlib или любого другого языка программирования. Если вы новичок в науке о данных и веб-скрапинге, а не программист, это хорошо, но имеет свои ограничения. Можно извлечь ограниченный набор тегов HTML, включая заголовок, автора, URL-адрес изображения и издателя.
Изображение автора
После того, как вы открыли сканируемый веб-сайт, введите URL-адрес для очистки, выберите формат данных и свой идентификатор электронной почты для получения данных. Проверьте свой почтовый ящик на наличие данных.
Контент-граббер — это гибкий инструмент, если вы хотите очистить веб-страницу и не хотите указывать другие параметры, пользователь может выполнить это с помощью своего простого графического интерфейса. Тем не менее, это дает возможность полностью контролировать параметры извлечения для настройки.
Пользователь может автоматически запланировать получение информации из Интернета, что является одним из его преимуществ. В настоящее время все мы знаем, что веб-страницы регулярно обновляются, поэтому частое извлечение контента было бы полезно.
Он предлагает различные форматы извлеченных данных, такие как CSV, JSON для SQL Server или MySQL.
Быстрый пример очистки данных
Этот инструмент можно использовать для визуального просмотра веб-сайта и нажатия на элементы данных в том порядке, в котором вы хотите их собрать. Он автоматически определит правильный тип действия и предоставит имена по умолчанию для каждой команды, поскольку он создает для вас агент на основе указанных элементов содержимого.
Изображение от Content Grabber
Этот инструмент представляет собой набор команд, которые выполняются по порядку до завершения. Порядок выполнения обновляется на панели Agent Explorer. Можно использовать панель команд агента настройки, чтобы настроить команду в соответствии с требованиями конкретных данных. Пользователи также могут добавлять новые команды.
ParseHub — это мощный инструмент для очистки веб-страниц, который каждый может использовать бесплатно. Он предлагает безопасное и точное извлечение данных одним щелчком мыши. Пользователи также могут установить время очистки, чтобы их останки оставались актуальными.
Одной из его сильных сторон является то, что он может без проблем удалять даже самые сложные веб-страницы. Пользователь может указать инструкции, такие как формы поиска, вход на веб-сайты и щелчки по картам или изображениям для последующего сбора данных.
Пользователи также могут вводить различные ссылки и ключевые слова, из которых можно извлечь соответствующую информацию за считанные секунды. Наконец, можно использовать REST API для загрузки извлеченных данных для анализа в форматах CSV или JSON. Пользователи также могут экспортировать собранную информацию в виде Google Sheet или Tableau.
Наконец, можно использовать REST API для загрузки извлеченных данных для анализа в форматах CSV или JSON. Пользователи также могут экспортировать собранную информацию в виде Google Sheet или Tableau.
Пример парсинга веб-сайта электронной коммерции
После завершения установки откройте новый проект в ParseHub, используйте URL-адрес электронной коммерции, и страница отобразится в приложении.
- Нажмите на название продукта в первом результате на странице после загрузки сайта. Когда вы выбираете продукт, он становится зеленым, чтобы показать, что он был выбран.
Изображение от ParseHub
- Желтый цвет будет использоваться для выделения остальных названий продуктов. Выберите второй вариант из списка. Зеленый теперь будет использоваться для выделения всех объектов.
Изображение от ParseHub
- Переименуйте свой выбор в «продукт» на левой боковой панели. Теперь вы можете увидеть название продукта и URL-адрес, извлеченные ParseHub.
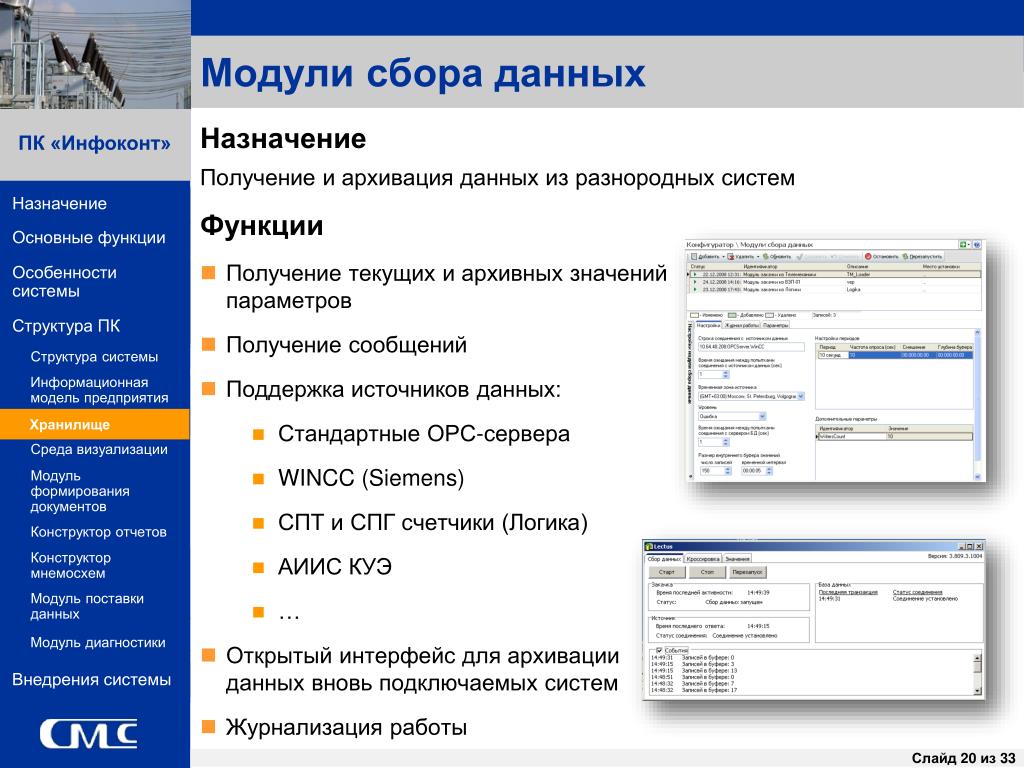
Изображение Parse Hub
- Щелкните знак ПЛЮС (+) рядом с выбором продукта на левой боковой панели и выберите команду Относительный выбор.
- Щелкните первое название продукта на странице, а затем цену продукта, используя команду Относительный выбор. Появится стрелка, соединяющая два варианта. Этот шаг необходимо повторить несколько раз, чтобы обучить Parsehub тому, что вы хотите извлечь.
Изображение Parse Hub
- Повторите предыдущий шаг, чтобы извлечь стиль посадки и изображение продукта. Не забудьте правильно переименовать новые варианты.
Запуск и экспорт вашего проекта
Теперь, когда мы закончили настройку проекта, пришло время запустить задание очистки.
Чтобы запустить очистку, нажмите кнопку «Получить данные» на левой боковой панели, а затем кнопку «Выполнить». Для более крупных проектов мы рекомендуем запустить тестовый прогон, чтобы убедиться, что ваши данные правильно отформатированы.
Изображение Parse Hub
Это последний инструмент для очистки в списке. Он имеет API веб-скрейпинга, который может обрабатывать даже самые сложные страницы Javascript и преобразовывать их в необработанный HTML для использования пользователями. Он также предлагает специальный API для очистки веб-сайтов с помощью поиска Google.
Мы можем использовать этот инструмент одним из трех способов:
- Общий просмотр веб-страниц, например, получение отзывов клиентов или цен на акции.
- Страница результатов поисковой системы, используемая для мониторинга ключевых слов или SEO.
- Извлечение контактной информации или данных из социальных сетей включает в себя Growth Hacking.
Этот инструмент предлагает бесплатный план, который включает 1000 кредитов и платные планы для неограниченного использования.
Пошаговое руководство по использованию Scrapingbee API
Подпишитесь на бесплатный план на сайте ScrapingBee, и вы получите 1000 бесплатных запросов к API, которых должно быть достаточно для изучения и тестирования этого API.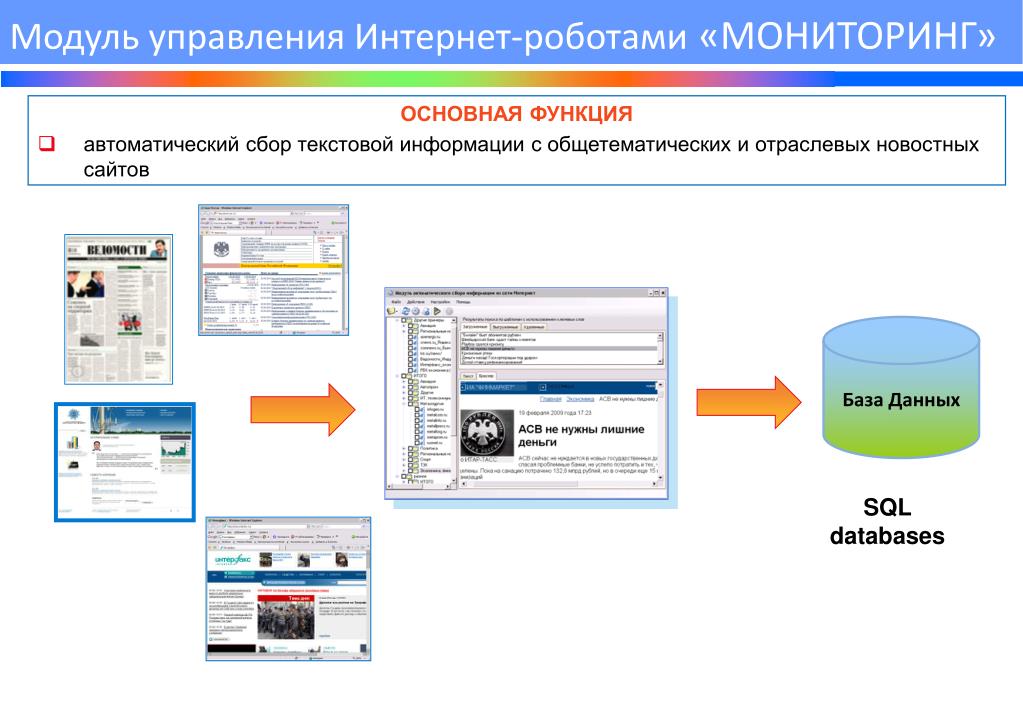
Теперь перейдите на панель инструментов и скопируйте ключ API, который нам понадобится позже в этом руководстве. ScrapingBee теперь обеспечивает многоязычную поддержку, позволяя вам использовать ключ API непосредственно в ваших приложениях.
Поскольку Scaping Bee поддерживает REST API, он подходит для любого языка программирования, включая CURL, Python, NodeJS, Java, PHP и Go. Для большего парсинга мы будем использовать Python и фреймворк Request, а также BeautifulSoup. Установите их с помощью PIP следующим образом:
# Чтобы установить библиотеку запросов Python: запросы на установку pip # Дополнительные модули, которые нам понадобились: pip установить BeautifulSoup
Используйте приведенный ниже код для запуска веб-API ScrapingBee. Мы делаем вызов запроса с URL-адресом параметров и ключом API, и API ответит HTML-содержимым целевого URL-адреса.
запросов на импорт
защита get_data():
ответ = запросы.получить(
URL="https://app. scrapingbee.com/api/v1/",
параметры = {
"api_key": "ВСТАВЬТЕ-ВАШ-API-КЛЮЧ",
"url": "https://example.com/", #сайт для очистки
},
)
print('Код состояния HTTP: ', response.status_code)
print('Тело ответа HTTP: ', response.content)
получить_данные()  scrapingbee.com/api/v1/",
параметры = {
"api_key": "ВСТАВЬТЕ-ВАШ-API-КЛЮЧ",
"url": "https://example.com/", #сайт для очистки
},
)
print('Код состояния HTTP: ', response.status_code)
print('Тело ответа HTTP: ', response.content)
получить_данные()
scrapingbee.com/api/v1/",
параметры = {
"api_key": "ВСТАВЬТЕ-ВАШ-API-КЛЮЧ",
"url": "https://example.com/", #сайт для очистки
},
)
print('Код состояния HTTP: ', response.status_code)
print('Тело ответа HTTP: ', response.content)
получить_данные() Нажмите «Выполнить», чтобы увидеть вывод:
Добавив код prettify, мы можем сделать этот вывод более читабельным с помощью BeautifulSoup.
Кодирование
Вы также можете использовать urllib.parse для шифрования URL-адреса, который вы хотите очистить, как показано ниже:
импорт urllib.parse
encoded_url = urllib.parse.quote("URL для очистки") Заключение
Сбор данных для ваших проектов — самый утомительный и наименее увлекательный шаг. Эта задача может отнимать много времени, и если вы работаете в компании или фрилансером, вы знаете, что время — деньги, и если есть самый важный способ выполнить задачу, вам лучше использовать его. Хорошей новостью является то, что просмотр веб-страниц не должен быть утомительным, а использование правильного инструмента может помочь вам сэкономить много времени, денег и усилий. Эти инструменты могут быть полезны для аналитиков или людей, не имеющих знаний в области кодирования. Прежде чем выбрать инструмент для парсинга, необходимо учесть несколько факторов, таких как интеграция с API и масштабируемость парсинга. В этой статье представлены некоторые полезные инструменты для различных задач сбора данных, из которых вы можете выбрать тот, который упрощает сбор данных.
Хорошей новостью является то, что просмотр веб-страниц не должен быть утомительным, а использование правильного инструмента может помочь вам сэкономить много времени, денег и усилий. Эти инструменты могут быть полезны для аналитиков или людей, не имеющих знаний в области кодирования. Прежде чем выбрать инструмент для парсинга, необходимо учесть несколько факторов, таких как интеграция с API и масштабируемость парсинга. В этой статье представлены некоторые полезные инструменты для различных задач сбора данных, из которых вы можете выбрать тот, который упрощает сбор данных.
Надеюсь, эта статья окажется полезной. Спасибо.
Медиафайлы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
blogathondata miningpythonвеб-скрапинг
Содержание
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте.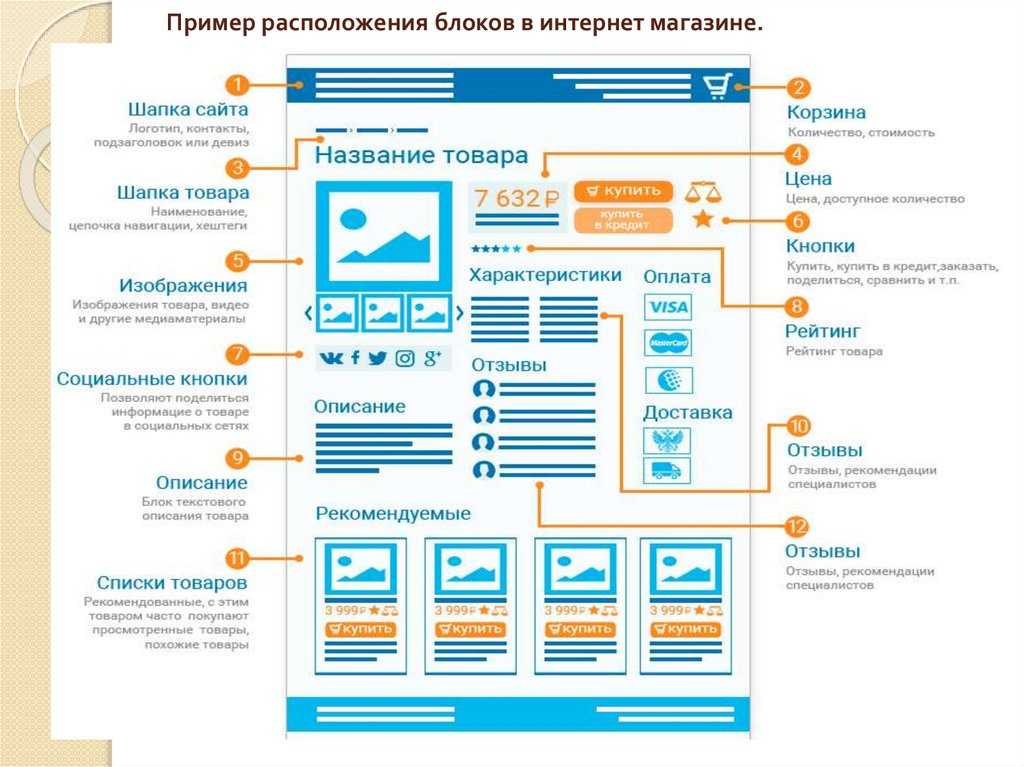 Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Политика конфиденциальности и использования файлов cookie
Более 100 вакансий в сфере Data Science
Lenovo, TVS, Convergytics, Ripik.AI и многие другие нанимают сотрудников | Открыто для всех энтузиастов науки о данных. Зарегистрируйтесь сейчас
Что такое Web Scraping? Как собирать данные с веб-сайтов
Веб-скребки автоматически собирают информацию и данные, которые обычно доступны только при посещении веб-сайта в браузере. Выполняя это автономно, скрипты парсинга веб-страниц открывают мир возможностей для интеллектуального анализа данных, анализа данных, статистического анализа и многого другого.
Чем полезен просмотр веб-страниц
Мы живем в такое время, когда информация более доступна, чем в любое другое время. Существующая инфраструктура, используемая для доставки этих самых слов, которые вы читаете, является проводником к большему количеству знаний, мнений и новостей, чем когда-либо было доступно людям в истории человечества.
На самом деле настолько, что мозг самого умного человека, усиленный до 100% эффективности (кто-то должен снять об этом фильм), все равно не сможет вместить 1/1000 данных, хранящихся в Интернете в Соединенных Штатах. один.
По оценкам Cisco, в 2016 году трафик в Интернете превысил один зеттабайт, что составляет 1 000 000 000 000 000 000 000 байт, или один секстиллион байт (вперед, хихикайте над секстиллионом). Один зеттабайт — это примерно четыре тысячи лет потоковой передачи Netflix. Это было бы равносильно тому, если бы вы, бесстрашный читатель, просматривали «Офис» от начала до конца без остановки 500 000 раз.
Изображение предоставлено: Cisco/The Dawn of the Zettabyte.
Все эти данные и информация очень пугают. Не все верно. Немногое из этого имеет отношение к повседневной жизни, но все больше и больше устройств доставляют эту информацию с серверов по всему миру прямо к нашим глазам и в наш мозг.
Поскольку наши глаза и мозг не могут обрабатывать всю эту информацию, веб-скрапинг стал полезным методом для программного сбора данных из Интернета. Веб-скрапинг — это абстрактный термин, обозначающий процесс извлечения данных с веб-сайтов для их локального сохранения.
Веб-скрапинг — это абстрактный термин, обозначающий процесс извлечения данных с веб-сайтов для их локального сохранения.
Подумайте о типе данных, и вы, вероятно, сможете собрать их, просканировав веб-страницы. Списки недвижимости, спортивные данные, адреса электронной почты предприятий в вашем районе и даже тексты песен вашего любимого исполнителя можно найти и сохранить, написав небольшой сценарий.
Связано: Что такое интеллектуальный анализ данных и является ли он незаконным?
Как браузер получает веб-данные?
Чтобы понять веб-скраперы, нам нужно сначала понять, как работает сеть. Чтобы попасть на этот веб-сайт, вы либо набрали «makeuseof.com» в своем веб-браузере, либо щелкнули ссылку с другой веб-страницы (скажите нам, где, серьезно, мы хотим знать). В любом случае, следующие несколько шагов одинаковы.
Во-первых, ваш браузер возьмет URL-адрес, который вы ввели или на который нажали (совет для профессионалов: наведите указатель мыши на ссылку, чтобы увидеть URL-адрес в нижней части браузера, прежде чем щелкнуть ее, чтобы избежать панка) и сформирует «запрос» на отправить на сервер. Затем сервер обработает запрос и отправит ответ.
Затем сервер обработает запрос и отправит ответ.
Ответ сервера содержит HTML, JavaScript, CSS, JSON и другие данные, необходимые для того, чтобы ваш веб-браузер мог сформировать веб-страницу для вашего удовольствия.
Проверка веб-элементов
Современные браузеры позволяют нам кое-что узнать об этом процессе. В Google Chrome для Windows вы можете нажать Ctrl + Shift + I или щелкнуть правой кнопкой мыши и выбрать Проверить . Затем в окне появится экран, который выглядит следующим образом.
В верхней части окна находится список опций с вкладками. Сейчас интересует Сеть вкладка. Это даст подробную информацию о HTTP-трафике, как показано ниже.
В правом нижнем углу видим информацию о HTTP-запросе. URL — это то, что мы ожидаем, а «метод» — это HTTP-запрос «GET». Код состояния из ответа указан как 200, что означает, что сервер посчитал запрос действительным.
Под кодом состояния находится удаленный адрес, который является общедоступным IP-адресом сервера makeuseof. com. Клиент получает этот адрес по протоколу DNS.
com. Клиент получает этот адрес по протоколу DNS.
В следующем разделе перечислены сведения об ответе. Заголовок ответа содержит не только код состояния, но и тип данных или содержимого, которые содержит ответ. В данном случае мы смотрим на «text/html» со стандартной кодировкой. Это говорит нам о том, что ответ — это буквально HTML-код для отображения веб-сайта.
Другие типы ответов
Кроме того, серверы могут возвращать объекты данных в ответ на запрос GET, а не только HTML для отображения веб-страницы. Интерфейс прикладного программирования веб-сайта (или API) обычно использует этот тип обмена.
Просматривая вкладку «Сеть», как показано выше, вы можете увидеть, существует ли этот тип обмена. При исследовании таблицы лидеров CrossFit Open отображается запрос на заполнение таблицы данными.
При нажатии на ответ отображаются данные JSON вместо HTML-кода для отображения веб-сайта. Данные в формате JSON представляют собой серию меток и значений в многоуровневом структурированном списке.
Вручную анализировать HTML-код или просматривать тысячи пар ключ/значение JSON очень похоже на чтение Матрицы. На первый взгляд это похоже на тарабарщину. Информации может быть слишком много, чтобы расшифровать ее вручную.
Веб-скребки спешат на помощь!
Теперь, прежде чем вы попросите синюю таблетку, чтобы убраться отсюда, вы должны знать, что нам не нужно вручную декодировать HTML-код! Невежество не есть блаженство, а этот стейк вкусен.
Веб-скрейпер может выполнить эти сложные задачи за вас. Фреймворки для парсинга доступны на Python, JavaScript, Node и других языках. Один из самых простых способов начать парсинг — использовать Python и Beautiful Soup.
Парсинг веб-сайта с помощью Python
Чтобы начать работу, нужно написать всего несколько строк кода, если у вас установлены Python и BeautifulSoup. Вот небольшой скрипт, чтобы получить исходный код веб-сайта и позволить BeautifulSoup оценить его.
from bs4 import BeautifulSoup
import request
url = "http://www.
content = request.get(url)
soap = BeautifulSoup(content.text)
print(soup)
 athleticvolume.com/programming/"
athleticvolume.com/programming/" Очень просто, мы делаем запрос GET к URL-адресу, а затем помещаем ответ в объект. При печати объекта отображается исходный HTML-код URL-адреса. Процесс такой же, как если бы мы вручную зашли на сайт и нажали Просмотр исходного кода .
В частности, это веб-сайт, который публикует тренировки в стиле кроссфита каждый день, но только по одной в день. Мы можем создать наш парсер, чтобы получать тренировки каждый день, а затем добавить их в агрегированный список тренировок. По сути, мы можем создать текстовую историческую базу данных тренировок, в которой можно легко искать.
Магия BeaufiulSoup заключается в возможности поиска по всему коду HTML с помощью встроенной функции findAll(). В этом конкретном случае веб-сайт использует несколько тегов «sqs-block-content». Следовательно, скрипт должен перебрать все эти теги и найти тот, который нам интересен.
Кроме того, в разделе есть несколько тегов
. Скрипт может добавить весь текст из каждого из этих тегов в локальную переменную. Для этого добавьте в скрипт простой цикл:
для div_class в супе.findAll('div', {'class': 'sqs-block-content'}):
recordThis = False
для p в div_class.findAll('p'):
, если 'PROGRAM' в p.text.upper():
recordThis = True
if recordThis:
программа += p.text
программа += '
'
Вуаля! Родился парсер.
Масштабирование очистки
Существует два пути продвижения вперед.
Один из способов исследовать веб-скрапинг — использовать уже созданные инструменты. Web Scraper (отличное имя!) насчитывает 200 000 пользователей и прост в использовании. Кроме того, Parse Hub позволяет пользователям экспортировать очищенные данные в Excel и Google Таблицы.
Кроме того, Web Scraper предоставляет подключаемый модуль Chrome, который помогает визуализировать создание веб-сайта.