Содержание
10 инструментов, позволяющих парсить информацию с веб-сайтов, включая цены конкурентов + правовая оценка для России / Хабр
Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed. com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂
com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.
Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.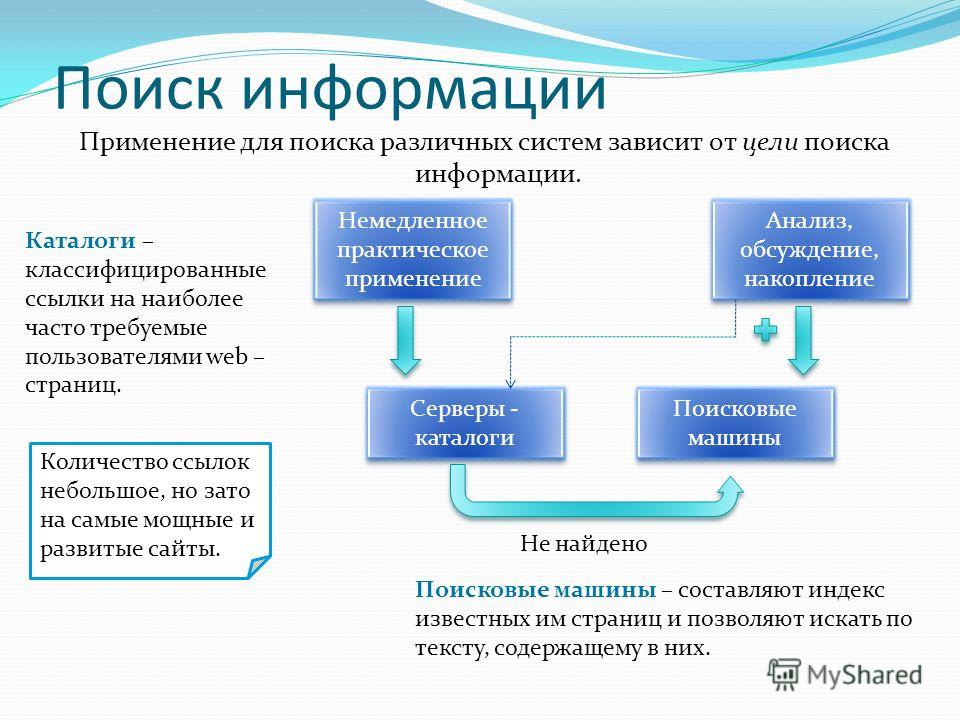
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).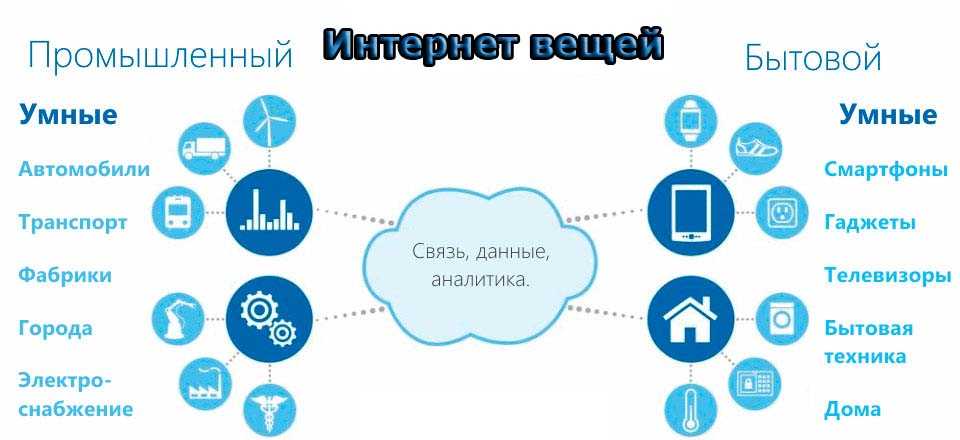
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
Страница не найдена – Блог TRINET
Все лица, заполнившие сведения, являющиеся персональными данными на сайте https://www. trinet.ru/ и его поддоменах, а также разместившие иную информацию на сайте https://www.trinet.ru/ и его поддоменах, подтверждают свое согласие на обработку персональных данных и их передачу Оператору обработки персональных данных – ООО «Комплексный интернет-маркетинг» (Юридический адрес: 197022, г. Санкт-Петербург, пр. Медиков, д. 9, лит. Б, пом. 12-Н, ч. 214.1).
trinet.ru/ и его поддоменах, а также разместившие иную информацию на сайте https://www.trinet.ru/ и его поддоменах, подтверждают свое согласие на обработку персональных данных и их передачу Оператору обработки персональных данных – ООО «Комплексный интернет-маркетинг» (Юридический адрес: 197022, г. Санкт-Петербург, пр. Медиков, д. 9, лит. Б, пом. 12-Н, ч. 214.1).
Пользователь дает свое согласие на обработку его персональных данных, а именно совершение действий, предусмотренных пунктом 3 части 1 статьи 3 Федерального закона от 27.07.2006 № 152-ФЗ «О персональных данных», и подтверждает, что, давая такое согласие, он действует свободно, своей волей и в своем интересе.
- ОПРЕДЕЛЕНИЕ ТЕРМИНОВ
- В настоящей Политике конфиденциальности используются следующие термины:
- «Администрация сайта Компании (далее – Администрация сайта)» – уполномоченные сотрудники на управление сайтом, действующие от имени «ООО «Комплексный интернет-маркетинг», которые организуют и (или) осуществляет обработку персональных данных, а также определяют цели обработки персональных данных, состав персональных данных, подлежащих обработке, действия (операции), совершаемые с персональными данными.

- «Персональные данные» — любая информация, относящаяся к прямо или косвенно определенному или определяемому физическому лицу (субъекту персональных данных).
- «Обработка персональных данных» — любое действие (операция) или совокупность действий (операций), совершаемых с использованием средств автоматизации или без использования таких средств с персональными данными, включая сбор, запись, систематизацию, накопление, хранение, уточнение (обновление, изменение), извлечение, использование, передачу (распространение, предоставление, доступ), обезличивание, блокирование, удаление, уничтожение персональных данных.
- «Конфиденциальность персональных данных» — обязательное для соблюдения Оператором или иным получившим доступ к персональным данным лицом требование не допускать их распространения без согласия субъекта персональных данных или наличия иного законного основания.
- «Пользователь сайта (далее Пользователь)» – лицо, имеющее доступ к Сайту, посредством сети Интернет и использующее Сайт Компании.
- «Cookies» — небольшой фрагмент данных, отправленный веб-сервером и хранимый на компьютере пользователя, который веб-клиент или веб-браузер каждый раз пересылает веб-серверу в HTTP/HTTPS-запросе при попытке открыть страницу соответствующего сайта.
- «IP-адрес» — уникальный сетевой адрес узла в компьютерной сети, построенной по протоколу IP.
- «Администрация сайта Компании (далее – Администрация сайта)» – уполномоченные сотрудники на управление сайтом, действующие от имени «ООО «Комплексный интернет-маркетинг», которые организуют и (или) осуществляет обработку персональных данных, а также определяют цели обработки персональных данных, состав персональных данных, подлежащих обработке, действия (операции), совершаемые с персональными данными.
- В настоящей Политике конфиденциальности используются следующие термины:
- ОБЩИЕ ПОЛОЖЕНИЯ
- Использование Пользователем сайта https://www.trinet.ru/ и его поддоменов означает согласие с настоящей Политикой конфиденциальности и условиями обработки персональных данных Пользователя.
- В случае несогласия с условиями Политики конфиденциальности Пользователь должен прекратить использование сайта https://www.trinet.ru/ и его поддоменов.
- Настоящая Политика конфиденциальности применяется только к сайту https://www.trinet.ru/ и его поддоменов. Компания не контролирует и не несет ответственность за сайты третьих лиц, на которые Пользователь может перейти по ссылкам, доступным на сайте Компании.
- Администрация сайта не проверяет достоверность персональных данных, предоставляемых Пользователем сайта.
- ПРЕДМЕТ ПОЛИТИКИ КОНФИДЕНЦИАЛЬНОСТИ
- Настоящая Политика конфиденциальности устанавливает обязательства Администрации сайта Компании по неразглашению и обеспечению режима защиты конфиденциальности персональных данных, которые Пользователь предоставляет по запросу Администрации сайта при вводе данных в формы обратной связи на сайте https://www.trinet.ru/ и его поддоменов или при оформлении заказа на приобретение услуг Компании.
Персональные данные, разрешённые к обработке в рамках настоящей Политики конфиденциальности, предоставляются Пользователем путём заполнения форм обратной связи на сайте ООО «Комплексный интернет-маркетинг» и включают в себя следующую информацию:
- фамилию, имя, отчество Пользователя;
- контактный телефон Пользователя;
- адрес электронной почты (e-mail) Пользователя;
- ЦЕЛИ СБОРА ПЕРСОНАЛЬНОЙ ИНФОРМАЦИИ ПОЛЬЗОВАТЕЛЯ
- Персональные данные Пользователя Администрация сайта Компании может использовать в целях:
- Для оформления заказа и (или) заключения Договора оказания услуги дистанционным способом с ООО «Комплексный интернет-маркетинг».
- Предоставления Пользователю доступа к персонализированным ресурсам Сайта.
- Установления с Пользователем обратной связи, включая направление уведомлений, запросов, касающихся использования Сайта, оказания услуг, обработка запросов и заявок от Пользователя.
- Определения места нахождения Пользователя для обеспечения безопасности, предотвращения мошенничества.
- Подтверждения достоверности и полноты персональных данных, предоставленных Пользователем.
- Уведомления Пользователя Сайта о состоянии Заказа.
- Обработки и получения платежей, подтверждения налога или налоговых льгот, оспаривания платежа, определения права на получение кредитной линии Пользователем.
- Предоставления Пользователю эффективной клиентской и технической поддержки при возникновении проблем связанных с использованием Сайта.
- Предоставления Пользователю с его согласия, обновлений продукции, специальных предложений, информации о ценах, новостной рассылки и иных сведений от имени Веб-студии или от имени партнеров Веб-студии.
- Осуществления рекламной деятельности с согласия Пользователя.
- Предоставления доступа Пользователю на сайты или сервисы партнеров с целью получения продуктов, обновлений и услуг.
- Для оформления заказа и (или) заключения Договора оказания услуги дистанционным способом с ООО «Комплексный интернет-маркетинг».
- Персональные данные Пользователя Администрация сайта Компании может использовать в целях:
- СПОСОБЫ И СРОКИ ОБРАБОТКИ ПЕРСОНАЛЬНОЙ
- Обработка персональных данных Пользователя осуществляется без ограничения срока, любым законным способом, в том числе в информационных системах персональных данных с использованием средств автоматизации или без использования таких средств.
- Пользователь соглашается с тем, что Администрация сайта вправе передавать персональные данные третьим лицам, в частности, курьерским службам, организациями почтовой связи, операторам электросвязи, исключительно в целях выполнения заказа Пользователя, оформленного на Сайте ООО «Комплексный интернет-маркетинг».
- Персональные данные Пользователя могут быть переданы уполномоченным органам государственной власти Российской Федерации только по основаниям и в порядке, установленным законодательством Российской Федерации.
- При утрате или разглашении персональных данных Администрация сайта информирует Пользователя об утрате или разглашении персональных данных.
- Администрация сайта принимает необходимые организационные и технические меры для защиты персональной информации Пользователя от неправомерного или случайного доступа, уничтожения, изменения, блокирования, копирования, распространения, а также от иных неправомерных действий третьих лиц.
- Администрация сайта совместно с Пользователем принимает все необходимые меры по предотвращению убытков или иных отрицательных последствий, вызванных утратой или разглашением персональных данных Пользователя.
- ОБЯЗАТЕЛЬСТВА СТОРОН
- Пользователь обязан:
- Предоставить информацию о персональных данных, необходимую для пользования Сайтом.
- Обновить, дополнить предоставленную информацию о персональных данных в случае изменения данной информации.
- Администрация сайта обязана:
- Использовать полученную информацию исключительно для целей, указанных в п. 4 настоящей Политики конфиденциальности.
- Обеспечить хранение конфиденциальной информации в тайне, не разглашать без предварительного письменного разрешения Пользователя, а также не осуществлять продажу, обмен, опубликование, либо разглашение иными возможными способами переданных персональных данных Пользователя, за исключением п.п. 5.2. и 5.3. настоящей Политики Конфиденциальности.
- Принимать меры предосторожности для защиты конфиденциальности персональных данных Пользователя согласно порядку, обычно используемого для защиты такого рода информации в существующем деловом обороте.
- Осуществить блокирование персональных данных, относящихся к соответствующему Пользователю, с момента обращения или запроса Пользователя или его законного представителя либо уполномоченного органа по защите прав субъектов персональных данных на период проверки, в случае выявления недостоверных персональных данных или неправомерных действий.
- Использовать полученную информацию исключительно для целей, указанных в п.
- Пользователь обязан:
- ДОПОЛНИТЕЛЬНЫЕ УСЛОВИЯ
- Администрация сайта вправе вносить изменения в настоящую Политику конфиденциальности без согласия Пользователя.
- Новая Политика конфиденциальности вступает в силу с момента ее размещения на Сайте, если иное не предусмотрено новой редакцией Политики конфиденциальности.
- Все предложения или вопросы по настоящей Политике конфиденциальности следует сообщать по адресу [email protected]
- Действующая Политика конфиденциальности размещена на странице по адресу https://www.trinet.ru/politika_konfidencialnosti/
- Администрация сайта вправе вносить изменения в настоящую Политику конфиденциальности без согласия Пользователя.
- ОФЕРТА ВИДЕОХОСТИНГА
- Передаваемые права третьим лицам
- Размещая пользовательский контент посредством использования наших услуг, вы предоставляете каждому пользователю Сервиса неисключительную, безвозмездную, действующую во всем мире лицензию на доступ к вашему Контенту и его использование в пределах, допускаемых функционалом Сервиса, в том числе на отображение его с помощью плеера Сервиса на сайтах третьих лиц посредством технологии embed (iframe), а также разрешаете создание временных технических копий контента и видео-превью такого контента.





 4 настоящей Политики конфиденциальности.
4 настоящей Политики конфиденциальности.

Что такое парсинг веб-страниц? Как собирать данные с веб-сайтов
Веб-скребки автоматически собирают информацию и данные, которые обычно доступны только при посещении веб-сайта в браузере. Выполняя это автономно, скрипты парсинга веб-страниц открывают мир возможностей для интеллектуального анализа данных, анализа данных, статистического анализа и многого другого.
Чем полезен просмотр веб-страниц
Мы живем в такое время, когда информация более доступна, чем в любое другое время. Существующая инфраструктура, используемая для доставки этих самых слов, которые вы читаете, является проводником к большему количеству знаний, мнений и новостей, чем когда-либо было доступно людям в истории человечества.
На самом деле настолько, что мозг самого умного человека, усиленный до 100% эффективности (кто-то должен снять об этом фильм), все равно не сможет хранить 1/1000 данных, хранящихся в Интернете в Соединенных Штатах. Штаты одни.
По оценкам Cisco, в 2016 году трафик в Интернете превысил один зеттабайт, что составляет 1 000 000 000 000 000 000 000 байт, или один секстиллион байт (вперед, хихикайте над секстиллионом). Один зеттабайт — это примерно четыре тысячи лет потоковой передачи Netflix. Это было бы равносильно тому, если бы вы, бесстрашный читатель, просматривали «Офис» от начала до конца без остановки 500 000 раз.
Изображение предоставлено: Cisco/The Dawn of the Zettabyte
Все эти данные и информация очень пугают. Не все верно. Немногое из этого имеет отношение к повседневной жизни, но все больше и больше устройств доставляют эту информацию с серверов по всему миру прямо к нашим глазам и в наш мозг.
Поскольку наши глаза и мозг не могут обрабатывать всю эту информацию, веб-скрапинг стал полезным методом для программного сбора данных из Интернета. Веб-скрапинг — это абстрактный термин, обозначающий процесс извлечения данных с веб-сайтов для их локального сохранения.
Подумайте о типе данных, и вы, вероятно, сможете собрать их, просканировав Интернет. Списки недвижимости, спортивные данные, адреса электронной почты предприятий в вашем районе и даже тексты песен вашего любимого исполнителя можно найти и сохранить, написав небольшой сценарий.
Списки недвижимости, спортивные данные, адреса электронной почты предприятий в вашем районе и даже тексты песен вашего любимого исполнителя можно найти и сохранить, написав небольшой сценарий.
Связано: что такое интеллектуальный анализ данных и является ли он незаконным?
Как браузер получает веб-данные?
Чтобы разобраться в парсерах, нам нужно сначала понять, как работает сеть. Чтобы попасть на этот веб-сайт, вы либо набрали «makeuseof.com» в своем веб-браузере, либо щелкнули ссылку с другой веб-страницы (скажите нам, где, серьезно, мы хотим знать). В любом случае, следующие несколько шагов одинаковы.
Во-первых, ваш браузер возьмет URL-адрес, который вы ввели или на который нажали (совет для профессионалов: наведите указатель мыши на ссылку, чтобы увидеть URL-адрес в нижней части браузера, прежде чем щелкнуть по ней, чтобы избежать панка) и сформировать «запрос» отправить на сервер. Затем сервер обработает запрос и отправит ответ.
Ответ сервера содержит HTML, JavaScript, CSS, JSON и другие данные, необходимые для того, чтобы ваш веб-браузер мог сформировать веб-страницу для вашего удовольствия.![]()
Проверка веб-элементов
Современные браузеры позволяют нам кое-что узнать об этом процессе. В Google Chrome для Windows вы можете нажать Ctrl + Shift + I или щелкнуть правой кнопкой мыши и выбрать Проверить . Затем в окне появится экран, который выглядит следующим образом.
Список опций с вкладками расположен в верхней части окна. Сейчас интерес представляет вкладка Network . Это даст подробную информацию о HTTP-трафике, как показано ниже.
В правом нижнем углу видим информацию о HTTP-запросе. URL — это то, что мы ожидаем, а «метод» — это HTTP-запрос «GET». Код состояния из ответа указан как 200, что означает, что сервер посчитал запрос действительным.
Под кодом состояния находится удаленный адрес, который является общедоступным IP-адресом сервера makeuseof.com. Клиент получает этот адрес по протоколу DNS.
В следующем разделе перечислены сведения об ответе. Заголовок ответа содержит не только код состояния, но и тип данных или содержимого, которые содержит ответ. В данном случае мы смотрим на «text/html» со стандартной кодировкой. Это говорит нам о том, что ответ — это буквально HTML-код для отображения веб-сайта.
В данном случае мы смотрим на «text/html» со стандартной кодировкой. Это говорит нам о том, что ответ — это буквально HTML-код для отображения веб-сайта.
Другие типы ответов
Кроме того, серверы могут возвращать объекты данных в качестве ответа на запрос GET, а не только HTML для отображения веб-страницы. Интерфейс прикладного программирования веб-сайта (или API) обычно использует этот тип обмена.
Просматривая вкладку «Сеть», как показано выше, вы можете увидеть, существует ли этот тип обмена. При исследовании таблицы лидеров CrossFit Open отображается запрос на заполнение таблицы данными.
При нажатии на ответ отображаются данные JSON вместо HTML-кода для отображения веб-сайта. Данные в формате JSON представляют собой серию меток и значений в многоуровневом структурированном списке.
Вручную анализировать HTML-код или просматривать тысячи пар ключ/значение JSON очень похоже на чтение Матрицы. На первый взгляд это похоже на тарабарщину. Информации может быть слишком много, чтобы расшифровать ее вручную.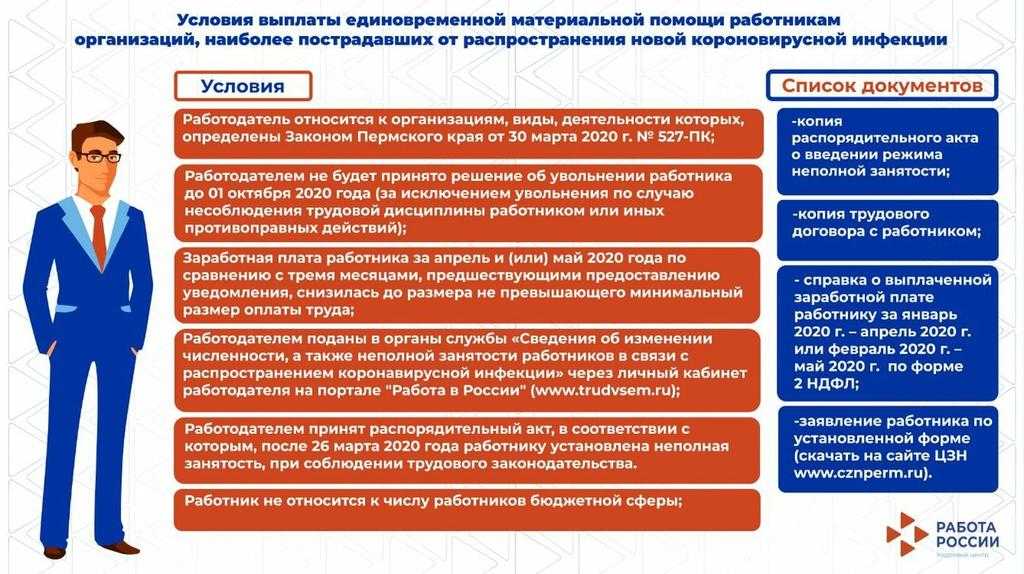
Веб-скребки спешат на помощь!
Теперь, прежде чем вы пойдете просить синюю таблетку, чтобы убраться отсюда, вы должны знать, что нам не нужно вручную декодировать HTML-код! Невежество не есть блаженство, а этот стейк вкусен.
Парсер может выполнить эти сложные задачи за вас. Фреймворки для парсинга доступны на Python, JavaScript, Node и других языках. Один из самых простых способов начать парсинг — использовать Python и Beautiful Soup.
Парсинг веб-сайта с помощью Python
Чтобы начать работу, нужно написать всего несколько строк кода, если у вас установлены Python и BeautifulSoup. Вот небольшой скрипт, чтобы получить исходный код веб-сайта и позволить BeautifulSoup оценить его.
from bs4 import BeautifulSoup
import requesturl = "http://www.athleticvolume.com/programming/"
content = request.get(url)
суп = BeautifulSoup(content.text)print(soup )
Очень просто, мы делаем запрос GET к URL-адресу, а затем помещаем ответ в объект.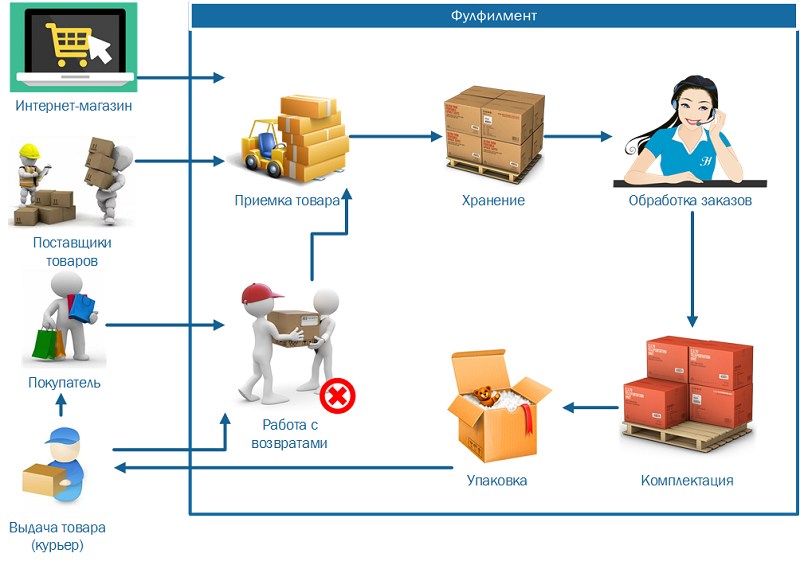 При печати объекта отображается исходный HTML-код URL-адреса. Процесс такой же, как если бы мы вручную зашли на сайт и нажали Просмотр исходного кода .
При печати объекта отображается исходный HTML-код URL-адреса. Процесс такой же, как если бы мы вручную зашли на сайт и нажали Просмотр исходного кода .
В частности, это веб-сайт, который публикует тренировки в стиле кроссфита каждый день, но только по одной в день. Мы можем создать наш парсер, чтобы получать тренировки каждый день, а затем добавить их в агрегированный список тренировок. По сути, мы можем создать текстовую историческую базу данных тренировок, в которой можно легко искать.
Волшебство BeaufiulSoup заключается в возможности поиска по всему коду HTML с помощью встроенной функции findAll(). В этом конкретном случае веб-сайт использует несколько тегов «sqs-block-content». Следовательно, скрипт должен перебрать все эти теги и найти тот, который нам интересен.
Кроме того, в разделе есть несколько тегов
. Скрипт может добавить весь текст из каждого из этих тегов в локальную переменную. Для этого добавьте в сценарий простой цикл:
для div_class в супе.
If 'Program' в p.text.upper ():
recordthis = true
, если recordthis:
Program += P.Text
program += '\n'
 findall ('p'):
findall ('p'): Готово! Родился парсер.
Увеличение масштаба Очистка
Существуют два пути продвижения вперед.
Один из способов исследовать веб-скрапинг — использовать уже созданные инструменты. Web Scraper (отличное имя!) насчитывает 200 000 пользователей и прост в использовании. Кроме того, Parse Hub позволяет пользователям экспортировать очищенные данные в Excel и Google Таблицы.
Кроме того, Web Scraper предоставляет подключаемый модуль Chrome, который помогает визуализировать создание веб-сайта. Лучше всего, судя по названию, OctoParse — мощный парсер с интуитивно понятным интерфейсом.
Наконец, теперь, когда вы знакомы с основами парсинга веб-страниц, создание собственного маленького парсера, способного сканировать и работать самостоятельно, — это увлекательное занятие.
16 Инструменты для извлечения данных с веб-сайта
В современном деловом мире умные решения, основанные на данных, являются приоритетом номер один. По этой причине компании отслеживают, контролируют и записывают информацию круглосуточно и без выходных. Хорошей новостью является то, что на серверах есть много общедоступных данных, которые могут помочь компаниям оставаться конкурентоспособными.
По этой причине компании отслеживают, контролируют и записывают информацию круглосуточно и без выходных. Хорошей новостью является то, что на серверах есть много общедоступных данных, которые могут помочь компаниям оставаться конкурентоспособными.
Процесс извлечения данных с веб-страниц вручную может быть утомительным, трудоемким, подверженным ошибкам, а иногда даже невозможным. Вот почему в большинстве усилий по анализу веб-данных используются автоматизированные инструменты.
Веб-скрапинг — это автоматизированный метод сбора данных с веб-страниц. Данные извлекаются с веб-страниц с помощью программного обеспечения, называемого веб-скраперами, которые в основном представляют собой веб-ботов.
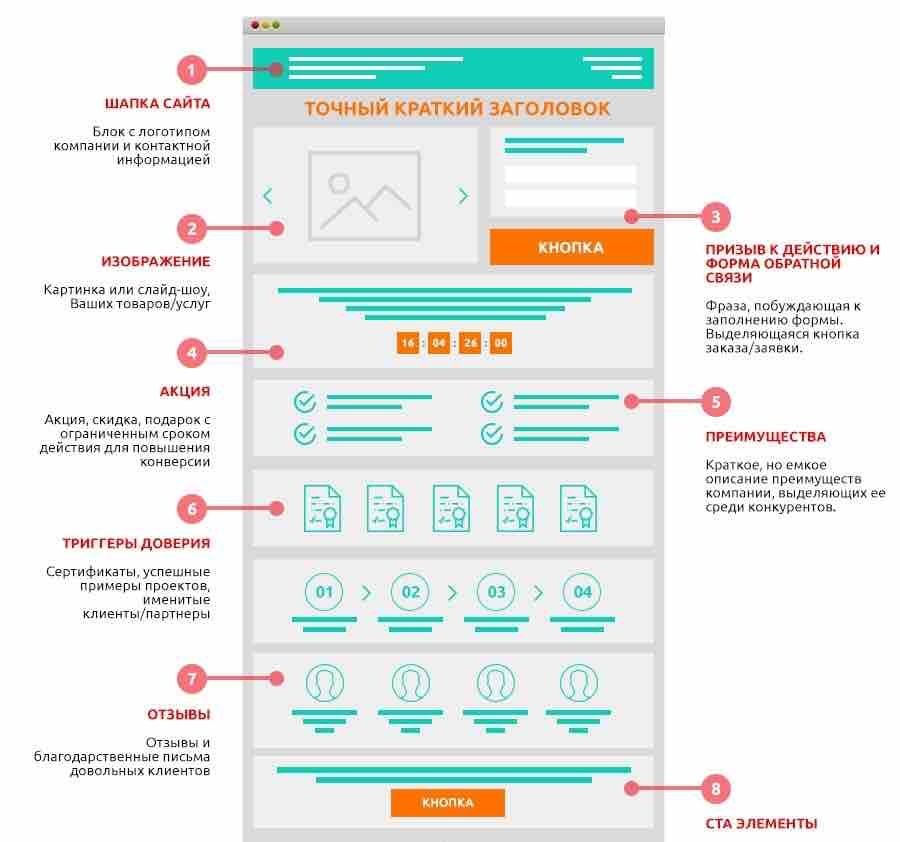
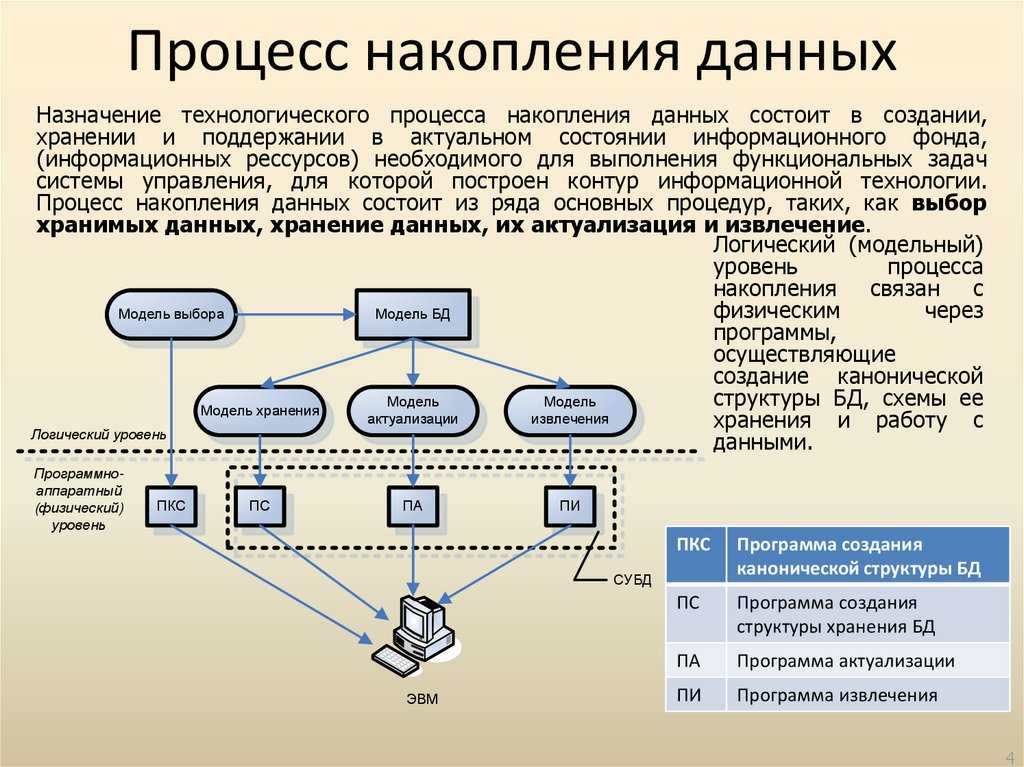
Что такое извлечение данных и как оно работает?
Извлечение данных или просмотр веб-страниц преследует цель извлечь информацию из источника, обработать и отфильтровать ее для последующего использования для построения стратегии и принятия решений. Это может быть частью усилий в области цифрового маркетинга, науки о данных и анализа данных. Извлеченные данные проходят процесс ETL (извлечение, преобразование, загрузка), а затем используются для бизнес-аналитики (BI). Это поле сложное, многослойное и информативное. Все начинается с веб-скрапинга и тактики его эффективного извлечения.
Извлеченные данные проходят процесс ETL (извлечение, преобразование, загрузка), а затем используются для бизнес-аналитики (BI). Это поле сложное, многослойное и информативное. Все начинается с веб-скрапинга и тактики его эффективного извлечения.
До средств автоматизации извлечение данных выполнялось на уровне кода, но это было непрактично для повседневного извлечения данных. Сегодня нет надежных инструментов извлечения данных без кода или с низким кодом, которые значительно упрощают весь процесс.
Каковы варианты использования для извлечения данных?
Чтобы помочь извлечению данных достичь бизнес-целей, извлеченные данные должны использоваться для определенной цели. Общие варианты использования веб-скрапинга могут включать, но не ограничиваться:
- Онлайн-мониторинг цен: для динамического изменения цен и сохранения конкурентоспособности.
- Недвижимость: данные для составления списков недвижимости.
- Агрегация новостей: в качестве альтернативных данных для финансов/хедж-фондов.
- Социальные сети: парсинга, чтобы получить информацию и показатели для стратегии социальных сетей.
- Агрегация отзывов: парсинг собирает отзывы из предопределенных источников управления брендом и репутацией.
- Лидогенерация: список целевых веб-сайтов очищается для сбора контактной информации.
- Результаты поисковой системы: для поддержки стратегии SEO и мониторинга поисковой выдачи.
Законно ли извлечение данных с веб-сайтов?
Веб-скрапинг стал основным методом типичного сбора данных, но законно ли использовать эти данные? Однозначного ответа и жесткой регламентации нет, но извлечение данных может быть признано незаконным, если вы используете непубличную информацию. Каждый совет, описанный ниже, нацелен на общедоступные данные, извлечение которых является законным. Однако использование удаленных данных в коммерческих целях по-прежнему является незаконным.
Как извлечь данные с веб-сайта
Ручное извлечение данных с веб-сайта (копирование/вставка информации в электронную таблицу) требует много времени и является сложным при работе с большими данными. Если в компании есть штатные разработчики, можно построить конвейер парсинга веб-страниц. Существует несколько способов ручного парсинга веб-страниц.
1. Создайте веб-скрапер с помощью Python
Можно быстро создать программное обеспечение с помощью любого языка программирования общего назначения, такого как Java, JavaScript, PHP, C, C# и т. д. Тем не менее, Python — лучший выбор из-за его простоты и доступности библиотек для разработки парсера.
2. Используйте службу данных
Служба данных — это профессиональный веб-сервис, предоставляющий исследования и извлечение данных в соответствии с бизнес-требованиями. Подобные сервисы могут быть хорошим вариантом, если есть бюджет на извлечение данных.
3. Использование Excel для извлечения данных
Этот метод может вас удивить, но программное обеспечение Microsoft Excel может оказаться полезным инструментом для обработки данных. С помощью парсинга веб-страниц вы можете легко получить информацию, сохраненную на листе Excel. Единственная проблема заключается в том, что этот метод можно использовать только для извлечения таблиц.
С помощью парсинга веб-страниц вы можете легко получить информацию, сохраненную на листе Excel. Единственная проблема заключается в том, что этот метод можно использовать только для извлечения таблиц.
4. Инструменты веб-скрапинга
Современные инструменты извлечения данных являются лучшими надежными решениями без кода/минимального кода для поддержки бизнес-процессов. С тремя типами инструментов извлечения данных — пакетной обработкой, открытым исходным кодом и облачными инструментами — вы можете создать цикл веб-скрапинга и анализа данных. Итак, давайте рассмотрим лучшие инструменты, доступные на рынке.
1.
Import.io
SaaS (программное обеспечение как услуга) Инструмент интеграции веб-данных охватывает весь цикл веб-извлечения на своей платформе. Для известного роста электронной коммерции, анализа рынка и конкурентов этот инструмент может стать неотъемлемой частью рабочего процесса, чтобы быть в курсе развития рынка.
Тип данных
- Подробности продукта
- Octoparse
Octoparse — это эффективный способ сделать все с помощью одного решения, предоставляющего инструмент для извлечения информации для малого бизнеса и крупных предприятий.
Платформа совместима с Windows и Mac OS, обеспечивая извлечение данных в три простых шага.Data type
- Social media
- eCommerce
- Marketing
- Real estate
- Listings
Function : static and dynamic website scraping, data extraction from complex websites, processing information not showing on the website
3.
Parsehub
Бесплатный инструмент для парсинга веб-страниц предлагает расширенные функции, поддерживающие любой формат для анализа. Он помогает собирать данные с помощью файлов cookie, JavaScript, технологий AJAX и т. д. Всего за несколько кликов инструмент может считывать, анализировать и преобразовывать большие данные на основе машинного обучения. Parsehub доступен для Mac OS X, Linux и Windows. Для мгновенного парсинга инструмент имеет расширение для браузера.
Тип данных
- Электронная коммерция
- Агрегаторы и торговые площадки
- Социальные сети
Функция : загрузка данных в любом формате.
4.
Web Scraper
Web Scraper обещает доступное и простое извлечение данных и дублирование всего содержимого веб-сайта, если это необходимо. Инструмент предлагает облачное расширение для обширных объемных данных и расширение Chrome, которое работает с предопределенной картой сайта для навигации и извлечения данных.
Функция : извлечение данных с динамических веб-сайтов, модульной системы выбора, exCSV, XLSX и JSON.
5.
Hevo Data
Инструмент для извлечения данных без кода предлагает простой веб-скрапинг с упрощенными процессами ETL из любого источника. Трехступенчатое извлечение данных загружает информацию в готовую для анализа форму, что облегчает дальнейшие процессы.
Тип данных
- Приложения SaaS
- SDK
- Базы данных
- Потоковые сервисы
Функция : отказоустойчивая архитектура для безопасного последовательного извлечения, горизонтальное масштабирование для обработки миллионов записей с небольшой задержкой.
6.
Phantom Buster
Не требующие кода средства автоматизации и извлечения данных упрощают поиск потенциальных клиентов для поддержки маркетинга и общего роста. Извлеченные данные сохраняются в форматах CSV и JSON.
Тип данных
- Социальные сети
- Извлечение потенциальных клиентов
Функция : Автоматизация цепочки для создания расширенных рабочих процессов.
7. Bardeen
Вы можете собирать данные с любого веб-сайта и передавать их непосредственно в ваши любимые приложения с помощью парсера Bardeen. Вы можете использовать парсер, чтобы делать такие вещи, как копирование данных профиля LinkedIn в вашу базу данных Notion одним щелчком мыши, сохранение заслуживающих внимания твитов в Документе Google и многое другое. У Bardeen также есть шаблон парсера, который мы настоятельно рекомендуем вам проверить.
Тип данных
- Изображения
- Meta Image
- Ссылка
- СТРАНИЦА
Функция : .
Простой облачный инструмент для парсинга веб-страниц помогает извлекать информацию с веб-страниц и получать структурированные данные, используемые в системе BI. Данные можно экспортировать в несколько форматов: JSON, CSV, XML, TSV, XLSX.
Тип данных
- Изображения
- Текст
- Содержимое PDF
Функция : сбор и очистка данных.
9.
ScrapingBot
ScrapingBot — это безопасный инструмент для извлечения данных из URL. Он в основном используется для сбора данных о продуктах и оптимизации маркетинговых усилий и присутствия на рынке. Инструмент также обеспечивает интеграцию API для сбора данных в социальных сетях и результатах поиска Google.
Тип данных
- Изображение
- Информация о продукте (название, цена, описание, акции и т. д.)
Функция : парсинг больших данных, парсинг с помощью безголовых браузеров.
10.
Automatio
Automatio — это расширение Chrome без кода, которое помогает выполнять задачи в Интернете. Automatio позволяет создать бота для извлечения данных с любой веб-страницы и даже для мониторинга веб-сайтов. Данные можно экспортировать в CSV, Excel, JSON или XML.
Функция : сбор данных при выходе из системы, работа со сложными сценариями и сбор больших данных.
11.
ScrapeStorm
ScrapeStorm — наш следующий инструмент для извлечения данных. ScrapeStorm — лучший инструмент для начинающих, поскольку он используется для сбора данных с любого веб-сайта и поддерживает все операционные системы. Инструмент даже бесплатный и не требует каких-либо технических знаний
Тип данных
- Списки,
- Формы,
- Ссылки,
- Изображения,
Функция : визуальное нажатие, несколько вариантов экспорта данных, учетная запись в облаке тратить меньше времени на извлечение данных.
Вы можете извлекать контент с любой веб-страницы, управлять скопированными данными и даже восстанавливать очистку данных по очищенным ссылкам.Функция : несколько типов файлов, автоматическое определение содержимого.
13.
Docparser
Docparser позволяет извлекать данные из Word, изображений и PDF. У Docpasers даже есть набор шаблонов, пригодных для любых целей извлечения данных. Вы даже можете структурировать и редактировать свои очищенные данные.
Тип данных
- Изображения
Функция : поддержка распознавания отсканированных документов, обнаружение штрих-кода, QR-кода, получение документов из облачных хранилищ
5
0030 15. Scrapex.ai
Scrapex — наш следующий инструмент для извлечения данных без кода. Он имеет все функции и функции, которые приходят на ум, когда вы думаете о очистке данных. Scrapex может работать с любым веб-сайтом, позволяет экспортировать данные в Excel, CSV, JSON.
Тип данных
- Электронная коммерция
- Недвижимость
- Продажи и маркетинг
API функций0005
16.
ProWebScraper
ProWebScraper — это наш последний инструмент для очистки данных, который поможет вывести вашу автоматизацию на новый уровень благодаря надежным функциям, позволяющим очищать 90% веб-страниц в Интернете. Инструмент позволяет одновременно извлекать данные с нескольких страниц, автоматически генерировать URL-адреса и многое другое.
Функция: Доступ к данным через API, пользовательский селектор
Подведение итогов: как хранить извлеченные данные
Внедрение извлечения данных может облегчить рабочий процесс и разгрузить группы исследователей данных. Кроме того, регулярное извлечение данных поможет вам отслеживать колебания рынка и оптимизировать процессы, чтобы оставаться конкурентоспособными.
Извлечение данных само по себе прекрасно, но не меньшее значение имеют организованное хранение и легкий доступ.
 Платформа совместима с Windows и Mac OS, обеспечивая извлечение данных в три простых шага.
Платформа совместима с Windows и Mac OS, обеспечивая извлечение данных в три простых шага.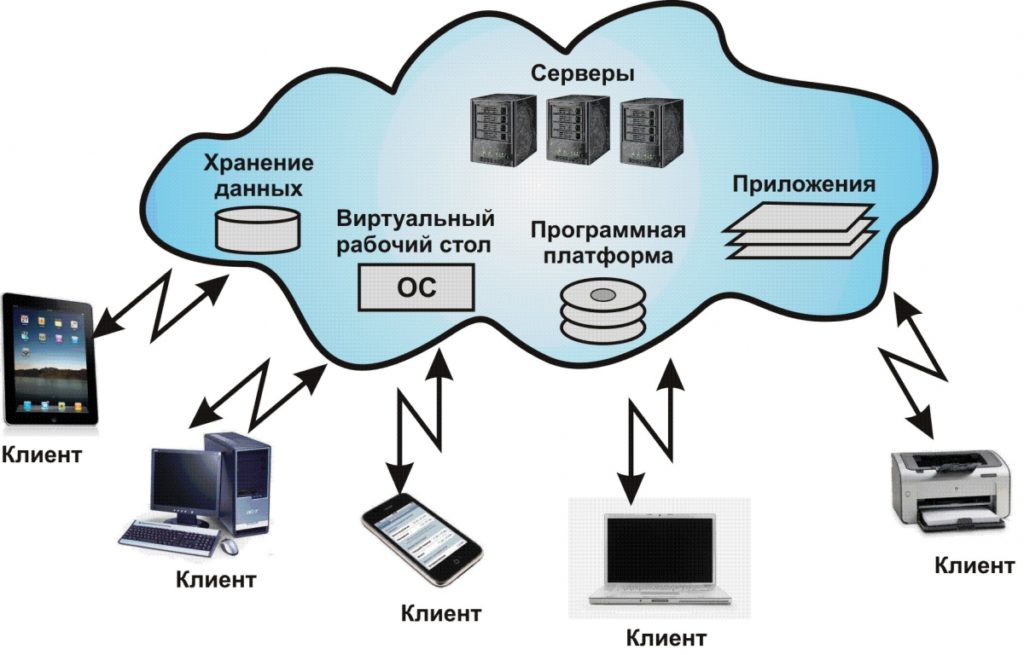


 Вы можете извлекать контент с любой веб-страницы, управлять скопированными данными и даже восстанавливать очистку данных по очищенным ссылкам.
Вы можете извлекать контент с любой веб-страницы, управлять скопированными данными и даже восстанавливать очистку данных по очищенным ссылкам.