Содержание
Топ 11 лучших инструментов для парсинга данных в Интернете в 2021 году — Сервисы на vc.ru
Меня зовут Максим Кульгин и моя компания занимается парсингом сайтов в России порядка четырех лет. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы, как правило, отдаем данные в формате Excel/CSV. Но существуют и другие решения — готовые сервисы (конструкторы, особенно их много на Западе) для запуска парсинга практически без программирования (или с минимальными усилиями). Ниже их список, краткая аннотация и рейтинг к каждому.
4664
просмотров
Инструменты веб-парсинга— это программное обеспечение, разработанное специально для упрощения процесса извлечения данных из веб-сайтов. Извлечение данных считается довольно полезным и используемым повсеместно процессом, однако его также можно легко превратить в сложное и запутанное мероприятие, требующее уйму усилий и времени.
Так чем же занимается веб-парсер, то есть программа для сбора данных в сети Интернет? При извлечении данных такие инструменты выполняют множество процессов и подпроцессов: от предотвращения блокировки вашего IP-адреса до корректного парсинга целевого веб-сайта, генерации данных в удобном формате и очистки данных. К счастью, веб-парсеры и инструменты для сбора данных делают этот процесс простым, быстрым и бесперебойным.
К счастью, веб-парсеры и инструменты для сбора данных делают этот процесс простым, быстрым и бесперебойным.
- Зачастую информацию в Интернете слишком объемная, чтобы извлекать ее вручную. Вот почему компании, использующие инструменты для парсинга, могут собирать данные быстрее и дешевле.
- Кроме того, компании, пользующиеся преимуществами парсинга, находятся на шаг впереди конкурентов в долгосрочной перспективе.
В этом посте вы найдете топ 11 лучших инструментов веб-парсинга, сопоставленных на основе их функций, стоимости и удобства использования.
Лучшие инструменты парсинга данных (бесплатные/платные)
Инструменты веб-парсинга выполняют поиск новых данных вручную или автоматически. Они извлекают измененные или новые данные, а затем сохраняют их, чтобы вы могли легко получить к ним доступ. Эти инструменты полезны любому, кто пытается собирать данные в Интернете.
Например, их можно использовать для сбора данных о недвижимости, об отелях из популярных туристических порталов, о продуктах, о ценах, об отзывах в интернет-магазинах и так далее.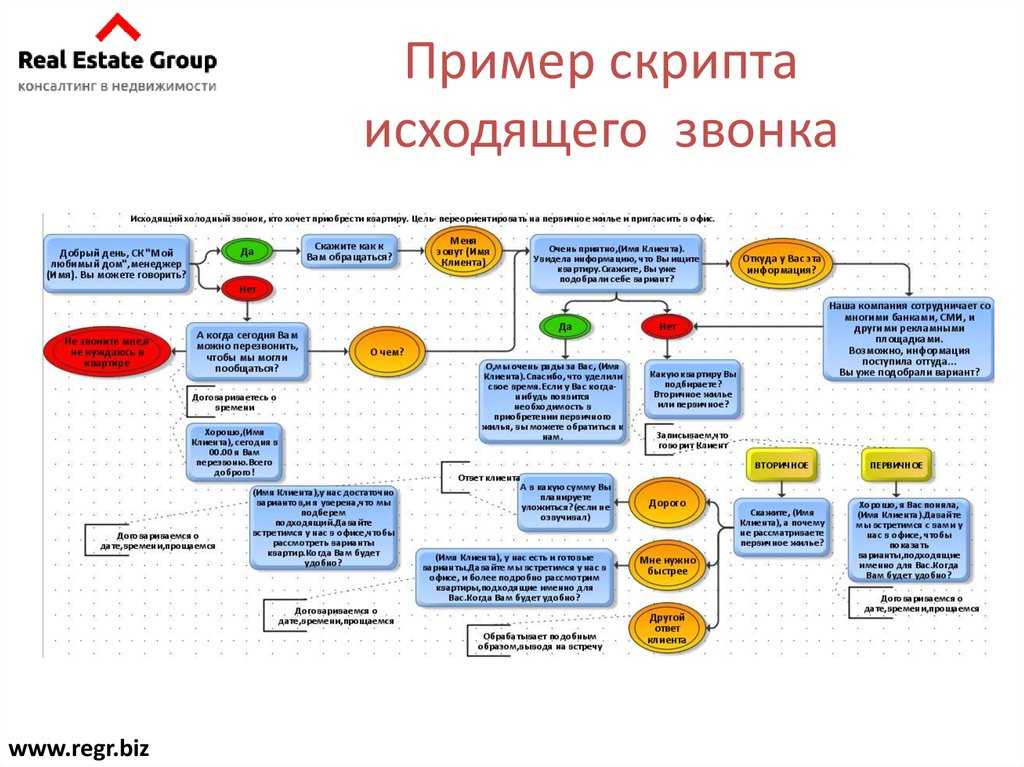 Таким образом, если вы задаете себе вопрос о том, где можно выполнять сбор данных, то ответом на него будут инструменты парсинга данных.
Таким образом, если вы задаете себе вопрос о том, где можно выполнять сбор данных, то ответом на него будут инструменты парсинга данных.
Теперь давайте посмотрим на список лучших инструментов веб-парсинга и сравним их, чтобы определить лучший.
1. Scrape.do
Scrape.do — удобный инструмент веб-парсинга, предоставляющий масштабируемый, быстрый и проксируемый API веб-парсинг с конечной точкой обработки запросов. Благодаря хорошему соотношению стоимости к результативности и своим возможностям Scrape.do находится на верхней позиции данного списка. Прочитайте этот пост целиком, и вы поймете, что Scrape.do — это один из наиболее дешевых инструментов парсинга.
В отличие от своих конкурентов, Scrape.do не требует дополнительную плату за работу с Google и другими сложными для парсинга сайтами. Этот инструмент предлагает лучшее соотношение цены и производительности на рынке для парсинга Google (5 000 000 страниц поисковой выдачи за $249). Вдобавок средняя скорость Scrape.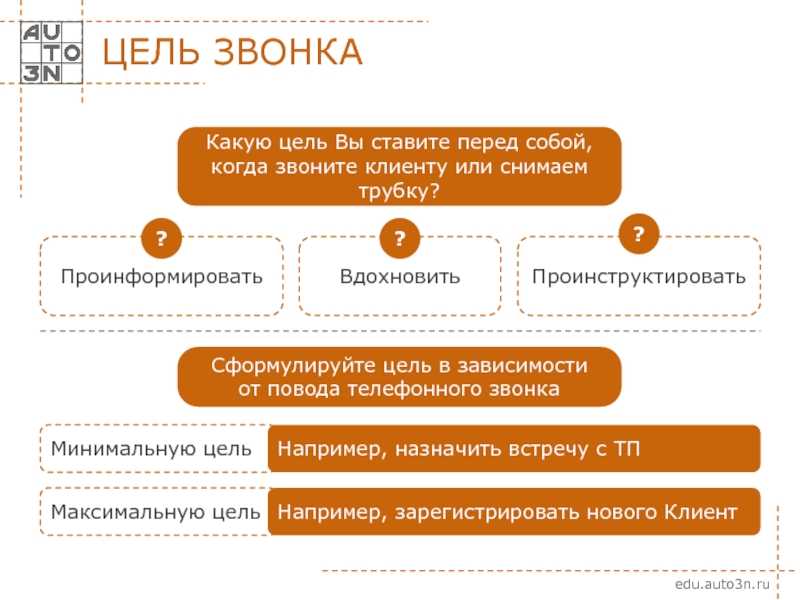 do при сборе анонимных данных из Instagram составляет 2-3 секунды, а вероятность успеха — 99 процентов. Также его скорость шлюза в четыре раза выше скорости конкурентов. Более того, этот инструмент предлагает доступ к резидентным и мобильным прокси в два раза дешевле.
do при сборе анонимных данных из Instagram составляет 2-3 секунды, а вероятность успеха — 99 процентов. Также его скорость шлюза в четыре раза выше скорости конкурентов. Более того, этот инструмент предлагает доступ к резидентным и мобильным прокси в два раза дешевле.
Ниже перечислены некоторые из других возможностей.
Возможности
- Прокси-серверы с ротацией IP-адресов, позволяющие собирать данные на любом веб-сайте. Scrape.do циклически меняет IP-адреса при выполнении каждого запроса к API, используя свой пул прокси-серверов.
- Неограниченная пропускная способность на любом тарифном плане.
- Инструмент можно полностью настроить под ваши нужды.
- Плата взимается только за успешные запросы.
- Возможность геотаргетинга, позволяющая выбирать из более чем 10 стран.
- Выполнение JavaScript кода, что позволяет собирать данные с веб-страниц, на которых для отображения данных используется JavaScript.

- Возможность задействовать функцию «Исключительный прокси» (параметр «super»), что дает возможность собирать данные с веб-сайтов, обладающих защитой на основе списка IP-адресов центров обработки данных.

Стоимость: тарифные планы начинаются со стоимости $29/месяц. Профессиональный план (Pro) стоит $99/месяц за 1 300 000 запросов к API.
2. Scrapingdog
Scrapingdog — инструмент веб-парсинга, который облегчает работу с прокси, браузерами и капчами. Этот инструмент за один запрос к API предоставляет данные из HTML-разметки любой веб-страницы. Одна из лучших возможностей Scrapingdog — наличие API LinkedIn. Ниже перечислены некоторые другие основные возможности Scrapingdog.
Возможности
- Выполняет ротацию IP-адресов при каждом запросе и обходит любую капчу, позволяя собирать данные без блокировки.
- Выполнение JavaScript-кода.
- Вебхуки.
- Headless-режим для Chrome.
Для кого этот инструмент? Scrapingdog подходит тем, кому требуется собирать данные в Интернете, — от разработчиков до обычных пользователей.
Стоимость: тарифные планы начинаются со стоимости $20/месяц. Возможность выполнения JavaScript-кода доступна, начиная с плана Standard стоимостью $90/месяц. API LinkedIn доступен только на плане Pro стоимостью $200/месяц.
3. ParseHub
ParseHub — бесплатный инструмент парсинга, разработанный для сбора данных во Всемирной паутине. Этот инструмент предлагается в виде загружаемого приложения для настольных компьютеров. Он предоставляет больше возможностей, чем большинство других парсеров. Например, вы можете собирать и скачивать изображения либо файлы, а также скачивать данные в виде CSV и JSON. Ниже представлен список других его возможностей.
Возможности
- Ротация IP-адресов.
- Реализован в облаке, что позволяет автоматически сохранять данные.
- Сбор данных по расписанию (ежемесячно, еженедельно и так далее).
- Регулярные выражения, позволяющие очищать текст и HTML перед скачиванием данных.
- API и вебхуки для интеграции с другими веб-сервисами.
- REST API.
- Возможность скачивания данных в формате JSON и Excel.
- Извлечение данных из таблиц и карт.
- Бесконечное прокручивание страниц.
- Извлечение данных из под авторизованного пользователя.

Стоимость: да, ParseHub предлагает множество возможностей, но большинство из них не включены в бесплатный тарифный план. Бесплатный план предусматривает возможность сбора данных с 200 страниц в течение 40 минут и пять публичных проектов.
Стоимость платных тарифных планов начинается со $149/месяц. Поэтому можно говорить о том, что за большее количество возможностей придется доплатить. Если у вас небольшая компания, то лучше всего воспользоваться бесплатной версией или одним из более дешевых веб-скрейперов из данного списка.
Если у вас небольшая компания, то лучше всего воспользоваться бесплатной версией или одним из более дешевых веб-скрейперов из данного списка.
4. Diffbot
Diffbot — еще один инструмент веб-парсинга, который предоставляет данные, извлекаемые из веб-страниц. Этот парсер данных — один из лучших инструментов для извлечения контента. Он позволяет автоматически определять тип содержимого веб-страниц благодаря возможности «Analyze API», а также извлекать данные о товарах, статьи, обсуждения, видео и изображения.
Возможности
- Product API (API для автоматического извлечения полных данных со страницы о товаре в любом интернет-магазине).
- «Очищает» текст и HTML-код.
- Структурированный поиск, благодаря которому пользователь видит только те результаты, которые соответствуют его запросу.
- Визуальная обработка данных, позволяющая собирать данные с большинства веб-страниц, написанных не на английском языке.
- Форматы JSON и CSV.
- Различные API для извлечения статей, товаров, обсуждений, видео и изображений.
- Пользовательские параметры обхода веб-страниц.
- Полностью облачное решение.

Стоимость: 14-дневный бесплатный пробный период. Тарифные планы стартуют со стоимости $299/месяц, что довольно дорого и является недостатком инструмента. Тем не менее, вам решать, нужны ли вам дополнительные функции, которые предоставляет данный инструмент. И вам же оценивать его эффективность с учетом стоимости.
5. Octoparse
Octoparse на фоне других инструментов веб-скрейпинга выделяется удобством и отсутствием необходимости писать программный код. Он предоставляет облачные сервисы для хранения извлеченных данных и ротацию IP-адресов для предотвращения их блокировки. Вы можете запланировать парсинг на любое время. Кроме того, Octoparse предлагает возможность бесконечной прокрутки веб-страниц. Можно скачивать результаты в формате CSV, Excel-форматах или в формате API.
Можно скачивать результаты в формате CSV, Excel-форматах или в формате API.
Для кого этот инструмент? Octoparse лучше всего подойдет для тех, кто не является разработчиком и кто ищет дружественный интерфейс для управления процессами извлечения данных.
Рейтинг Capterra: 4.6/5.
Стоимость: доступен бесплатный тарифный план с ограниченными возможностями. Платные тарифные планы стартуют со стоимости $75/месяц.
6. ScrapingBee
ScrapingBee — еще один популярный инструмент для извлечения данных. Он выводит вашу веб-страницу так, как если бы использовался настоящий браузер, давая возможность управлять тысячами экземпляров Chrome последней версии, которые работают в headless-режиме. Таким образом, разработчики утверждают, что другие веб-парсеры при работе с браузерами в headless-режиме затрачивают много времени, «съедают» вашу оперативную память и нагружают процессор. Что еще предлагает ScrapingBee?
Возможности
- Выполнение JavaScript-кода.
- Прокси-серверы с ротацией IP-адресов.
- Типичные задачи веб-парсинга, такие как сбор данных о недвижимости, отслеживание цен и извлечение отзывов. При этом нет опасности нарваться на блокировку в процессе сбора данных.
- Сбор данных из поисковой выдачи.
- Гроузхакинг (лидогенерация, сбор контактных данных или данных из социальных сетей).

Стоимость: тарифные планы ScrapingBee стартуют со стоимости $29/месяц.
7. Luminati
Luminati — веб-парсер с открытым исходным кодом для извлечения данных. Это сборщик данных, предоставляющий автоматический и настраиваемый поток данных.
Возможности
- Разблокировщик данных.
- Управление прокси-серверами с открытым исходным кодом, не требующее от пользователей заниматься программированием.
- Сканер поисковых систем (search engine crawler).
- API прокси-серверов (Proxy API).
- Расширение браузера.

Рейтинг Capterra: 4.9/5.
Стоимость: цены варьируются в зависимости от выбранных решений: инфраструктуры прокси-серверов, разблокировщика и сборщика данных, а также от дополнительных возможностей. Зайдите на веб-сайт Luminati.io для получения подробных сведений.
8. Grepsr
Разработанный для создания решений для парсинга данных, Grepsr может помочь вам с программами по лидогенерации, сбором данных конкурентов, агрегацией новостей и сбором финансовых данных. Веб-парсинг для генерации или сбора лидов позволяет извлекать адреса электронной почты. Вернемся к Grepsr. Давайте посмотрим на основные возможности этого инструмента.
Возможности
- Сбор данных для генерации лидов.
- Сбор данных о конкурентах и ценах.
- Сбор маркетинговых и финансовых данных.
- Отслеживание цепочки сбыта.
- Любые индивидуальные требования к сбору данных.
- Готовый к использованию API.
- Сбор данных из социальных сетей и многое другое.
Стоимость: тарифные планы начинаются со стоимости $199 за один источник данных. Цена немного завышена, и это может быть недостатком данного инструмента. Тем не менее всё зависит от потребностей вашей компании.
9. Scraper API
Scraper API — это проксируемый API для веб-парсинга. Этот инструмент позволяет вам управлять прокси-серверами, браузерами и капчами, чтобы вы могли получать HTML-разметку любой веб-страницы с помощью запроса к API.
Возможности
- Ротация IP-адресов.
- Полная настройка под ваши потребности: заголовки запросов, тип запроса, IP-геолокация и браузер в headless-режиме.
- Выполнение JavaScript-кода.
- Неограниченная пропускная способность со скоростью до 100 Мб/с.
- Более 40 миллионов IP-адресов.
- Более 12 географических местоположений.

Стоимость: платные тарифные планы начинаются со стоимости $29/месяц, однако наиболее дешевый из них ограничен в возможностях. Например, он не предусматривает геотаргетинг и выполнение JavaScript-кода.
Геолокация на тарифном плане Startup ($99/месяц) ограничивается только США. Также на этом плане отсутствует выполнение JavaScript-кода. Чтобы воспользоваться всеми преимуществами геолокации и выполнения JavaScript-кода, вам нужно приобрести план Business стоимостью $249/месяц.
10. Scrapy
Еще один фигурант нашего списка лучших инструментов веб-парсинга — это Scrapy. Scrapy — фреймворк с открытым исходным кодом, созданный коллективными усилиями и предназначенный для извлечения данных с веб-сайтов. Это библиотека веб-парсинга для Python-разработчиков, которые хотят создавать масштабируемых роботов для сбора данных в сети Интернет.
Данный инструмент абсолютно бесплатен.
11. Import.io
Этот инструмент веб-парсинга позволяет собирать данные с большим размахом. Он предлагает оперативное управление всеми вашими веб-данными, обеспечивая при этом точность, полноту и надежность.
Import.io предлагает конструктор для формирования ваших собственных наборов данных путем импорта данных из определенной веб-страницы и экспорта извлеченных данных в CSV. Также он позволяет создавать более тысячи API, соответствующих вашим требованиям.
Import.io предлагается в виде инструмента, доступного в Интернете. Также имеются бесплатные приложения для Mac OS X, Linux и Windows.
Хотя Import.io предоставляет полезные функции, у этого инструмента веб-скрейпинга есть некоторые недостатки.
Рейтинг Capterra: 3.6/5. Причина такого низкого рейтинга заключается в недостатках инструмента. Большинство пользователей жалуются на недостаточно качественную поддержку и на слишком высокую стоимость.
Стоимость: запишитесь на консультацию, чтобы получить сведения о стоимости.
Итоги
Мы попытались составить список лучших инструментов веб-парсинга, которые уменьшат трудоемкость сбора данных в Интернете. Надеемся, что эта публикация будет для вас полезной при выборе парсера данных.
8 инструментов для парсинга сайтов
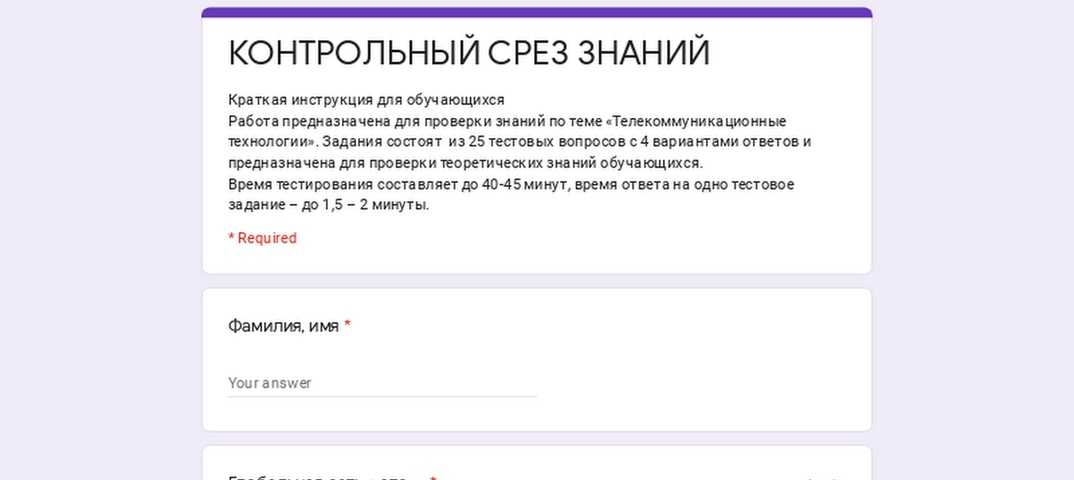
Google выдает пользователю релевантные ссылки благодаря мониторингу сети и парсингу сайтов. Программы парсинга используют не только для поиска близких к запросу ссылок, но и для сбора данных.
Рассказываем, как просканировать интернет и какое ПО вам понадобится.
Как устроен парсинг сайтов
Это автоматический сбор и систематизация информации с помощью ПО. Парсеры применяют, работая с большими объемами информации, которые сложно отсортировать вручную.
Парсингом сайтов часто занимаются роботы поисковиков. Инструмент также используют для анализа ценовой политики на сайтах-конкурентах и наполнения своих онлайн-ресурсов. Например, парсят сайты спортивной аналитики, чтобы обновлять информацию о ходе матчей, или мониторят комментарии в социальных сетях. Кроме того, платформы, которые отслеживают информацию о компаниях, применяют парсеры, чтобы автоматически добавлять новые сведения из госреестров.
Кроме того, платформы, которые отслеживают информацию о компаниях, применяют парсеры, чтобы автоматически добавлять новые сведения из госреестров.
Возможен и самопарсинг — поиск багов на своем сайте (продублированных или несуществующих страниц, а также неполных описаний продуктов).
Как противодействуют парсингу
Парсить и потом использовать можно только те данные, которые не защищены авторским правом или содержатся в открытых источниках. Иногда владельцы сайтов устанавливают защиту — за большую нагрузку на серверы нужно платить, а слишком интенсивный парсинг может вызвать DoS-атаку.
Способы защиты:
#1. Временная задержка между запросами (ограничивает доступ к информации для программы-парсера).
#2. Защита от роботов (установка капчи, подтверждение регистрации).
#3. Ограничения прав доступа.
#4. Блокировка IP-адресов.
#5. Honeypot — ссылки на пустые файлы или эмуляторы сервера, которые используют для обнаружения взломщиков или парсеров.
Honeypot — ссылки на пустые файлы или эмуляторы сервера, которые используют для обнаружения взломщиков или парсеров.
Как обойти защиту
Основная проблема парсера в том, что сайт видит признаки нетипичного поведения и блокирует доступ. Пользователи не открывают тысячи страниц за минуты. Поэтому задача парсера — выдать себя за обычного пользователя. Один из этапов — применение эмуляторов пользовательских инструментов. Они отправляют серверу HTTP-запросы с заголовком User Agent, то есть таким же, как у обычного пользователя.
Другой способ защиты — встроенный фрагмент JavaScript. Запуск фрагмента с браузера произойдет успешно, но при парсинге код HTML-страницы будет нечитаемым. Платформа node.js, которая позволяет запускать JS вне браузера, решает проблему.
Еще один вариант — использовать «безголовый» браузер. Это программа, которая копирует функции обычного браузера, но не имеет графического интерфейса. Она использует программное управление и может работать в фоновом режиме.
При большом количестве запросов с одного IP-адреса сайт может потребовать верификацию с помощью капчи. Некоторые из них можно расшифровать оптическим распознаванием символов, но лучше менять IP. Для этого используют прокси-серверы, которые запрашивают информацию с разных адресов.
XPath — язык запросов для доступа к частям документа XML, который используют для поиска элементов с определенным атрибутом. C его помощью реализуют навигацию в DOM (Document Object Model) — программном интерфейсе, который содержит информацию о структуре сайта, HTML и XML-документах.
Программы для парсинга
Расширения для браузера
Веб-приложения используют для простых задач. Такие расширения есть в каждом браузере. Они удобны для анализа маленького объема данных (до нескольких страниц).
- Data Scraper
Этот инструмент используют для извлечения данных из таблиц или информации со страницы в форматах XLS, CSV и TSV. Платный доступ добавляет новые функции. Например, API и анонимные IP.
Платный доступ добавляет новые функции. Например, API и анонимные IP.
Стоимость: бесплатно при просмотре до 500 страниц.
- Scraper.AI
Расширение предназначено для импорта данных с сайтов. Есть возможность кликнуть на элемент страницы и выбрать все элементы такого типа на сайте.
В Scraper.AI доступна функция регулярного мониторинга изменений на веб-странице. Собранная информация экспортируется в форматы JSON, CSV и XLSX.
Стоимость: бесплатно первые 3 месяца, пакеты — от $49 до $249 в месяц.
Облачные сервисы
По сравнению с расширениями, у этих программ больше функций. Работа проходит в «облаке» через веб-интерфейс или API, а на компьютере сохраняются только результаты.
- Scraper API
Этот сервис применяют для парсинга сайтов с высокой степенью защиты. Его использование требует навыков программирования.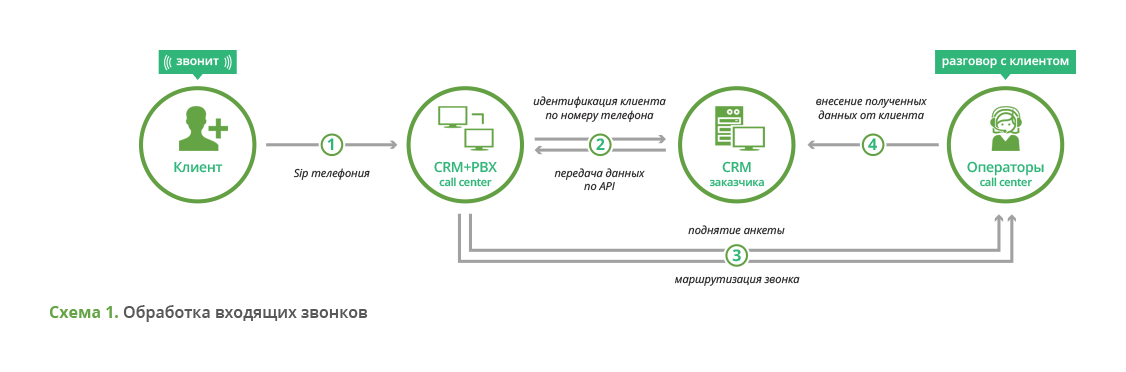
Программа самостоятельно повторяет неуспешные запросы и обрабатывает капчу. А также приложение может визуализировать элементы, которые требуют рендеринга Javascript. Scraper API работает с Python, Ruby и PHP.
Стоимость: 1 тыс. бесплатных запросов API, пакеты от $29 до $249 в месяц.
- Diffbot
Он использует ML-алгоритмы и computer vision при парсинге, а также работает с API и может автоматически определить тип URL-адресов. Diffbot регулярно парсит сеть и сохраняет результаты. Компания строит самый большой граф знаний — она соединяет факты о созданных продуктах, новостных событиях, результатах отчетов. Узнать больше о Diffbot можно здесь.
Стоимость: бесплатно первые 14 дней, пакеты Start и Plus — $299 и $899 в месяц.
Десктопные программы
Большинство десктоп-парсеров работают с Windows, но на macOS их можно запустить с виртуальных машин. Есть и кроссплатформенные решения.
Десктопные парсеры могут быть эффективнее облачных. Минус в том, что они используют операционную мощность компьютера.
- ParseHub
Программа позволяет интегрировать и визуализировать собранные данные с помощью BI-системы Tableau. Поддерживает графический интерфейс обработки данных point-and-click. У ParseHub есть функция запланированного сбора датасета в установленный интервал времени. Сервис работает с Windows, Mac и Linux. Доступен в облачной и десктопной версии.
Стоимость: бесплатно при обработке до 200 страниц, пакеты Standard и Professional — $149 и $499 в месяц.
Библиотеки для создания собственного парсера
- Jaunt
Библиотека на Java, которую используют для парсинга и автоматизации запросов в формате JSON. Это формат обмена данных в веб-приложениях, например, для отправки информации с сервера клиенту и отображения на сайте. Jaunt работает как браузер без графического интерфейса, что ускоряет его. В Jaunt обрабатывают выборочные HTTP-запросы и ответы, а еще есть доступ в DOM.
Jaunt работает как браузер без графического интерфейса, что ускоряет его. В Jaunt обрабатывают выборочные HTTP-запросы и ответы, а еще есть доступ в DOM.
Стоимость: бесплатно
- Scrapy
Библиотека для Python с открытым кодом. Фреймворк используют для парсинга. Особенность Scrapy — обработка запросов в асинхронном порядке: можно задавать команду, не дожидаясь завершения предыдущей. Также следующие запросы будут выполняться, даже если в обработке одного из них возникла ошибка.
В библиотеке можно установить паузу между запросами, а также регулировать число запросов с одного IP или домена.
Стоимость: бесплатно
- Beautiful Soup
Тоже библиотека на языке Python, но более простая. Обычно фреймворк используют для данных из HTML- и XML-документов. Чтобы открывать ссылки и сохранять собранные результаты, к Beautiful Soup необходимо подключить дополнительные библиотеки.
Стоимость: бесплатно
Сбор данных с помощью скрипта сбора данных
Сбор данных с помощью скрипта сбора данных
< Предыдущий | оглавление | Индекс | Далее > |
Сбор данных с помощью скрипта сбора данных
Для сбора выборочных данных для анализа с помощью VRAdvisor вам не нужно устанавливать VRAdvisor в системе. Используйте сценарий сбора данных для сбора данных для AIX,
Системы HP-UX, Linux или Solaris.
Скрипт сбора данных:
- собирает образцы данных, используя метод, подходящий для хоста. Если VxVM установлен, сценарий использует команду
vxstatдля сбора данных. Если VxVM не установлен, сценарий использует соответствующую команду операционной системы для сбора данных:- AIX: использует
lvmstatдля сбора данных для всех логических томов. - HP-UX, Linux: использует
sarдля сбора данных для всех дисков. - Solaris: использует
iostatдля сбора данных для всех дисков.
- AIX: использует
- хранит собранные данные и связанные с ними метаданные в формате, который может быть проанализирован VRAdvisor.
- отправляет уведомления по электронной почте при возникновении ошибки или успешном завершении сбора данных.
 Если VxVM не установлен, сценарий использует соответствующую команду операционной системы для сбора данных:
Если VxVM не установлен, сценарий использует соответствующую команду операционной системы для сбора данных:Для сбора данных с помощью скрипта
- Установите языковой стандарт на поддерживаемый языковой стандарт. Например:
# экспорт LC_ALL=C
- Скопируйте сценарий сбора данных и все необходимые файлы в систему, в которой вы планируете собирать данные, из одного из следующих мест:
-
Volume_replicator/tools/vradvisor/scripts/каталог диска продукта Veritas -
scriptsкаталог системы Solaris, в которой установлен VRAdvisor. По умолчанию каталог /opt/VRTSvradv/scripts. -
scriptsпапка системы Windows, в которой установлен VRAdvisor. По умолчанию папкаProgram Files/VERITAS/Volume Replicator Advisor/scripts - Примечание. Обязательно скопируйте все файлы в каталоге.
-
- Для сбора данных в нужном для анализа формате используйте следующий скрипт:
 По умолчанию каталог
По умолчанию каталог # sh vra_data_collection.sh [ -g dgname ] [ -i interval ] \
[ -t длительность ] .
[ -m список рассылки ]
где:
dgname — разделенный запятыми список групп дисков, для которых необходимо собрать данные, если установлена VxVM. По умолчанию все группы дисков на хосте.
По умолчанию все группы дисков на хосте.
interval — интервал сбора данных в секундах. По умолчанию 120 секунд.
продолжительность — продолжительность сбора данных в часах или днях. Укажите суффикс «h» для часов, «d» для дней. По умолчанию 14 дней.
volume_list — список имен томов, разделенных запятыми, для которых необходимо собрать данные, если установлена VxVM. По умолчанию все тома на хосте.
имя_каталога — это каталог, в котором хранятся файлы собранных данных. Если каталог не указан, файлы сохраняются в текущем рабочем каталоге.
список рассылки — это разделенный запятыми список адресов электронной почты для получения уведомлений. По умолчанию сценарий отправляет уведомление по электронной почте привилегированному пользователю хоста.
После завершения сбора данных файл собранных данных содержит образец данных в формате, который может использоваться для анализа с помощью VRAdvisor. Имена файлов следующие:
Имена файлов следующие:
-
hostname_dgname_timestamp.vxstatУказывает, что файл содержит вывод
vxstat. Это значение по умолчанию, если VxVM установлена в системе, где собираются данные. Любые связанные метаданные находятся в файле с тем же именем и расширением.meta. -
hostname_dgname_timestamp.vraУказывает, что данные представлены в формате VRAdvisor CSV. Сценарий преобразует данные в этот формат, если для сбора данных использовалась команда, отличная от
vxstat. Любые связанные метаданные находятся в файле с тем же именем и расширением.meta.
Чтобы продолжить, см. Анализ выборки данных.
Чтобы показать справку по параметрам скрипта
-
#ш vra_data_collection.sh -h
Примеры
Пример 1
Собирайте данные каждую минуту в течение 30 часов.
# sh vra_data_collection.sh -i 60 -t 30h
Пример 2
Храните собранные данные в каталоге образцов и уведомить [email protected] .
# sh vra_data_collection.sh -d образцы -m [email protected]
Пример 3
Соберите данные для групп дисков VxVM dg1 и dg2 .
# sh vra_data_collection.sh -g dg1,dg2
Пример 4
Соберите данные для томов VxVM vol1 , vol2 и vol3 в группе дисков dg1 .
# sh vra_data_collection.sh -g dg1 -v vol1,vol2,vol3
Пример 5
Соберите данные для томов VxVM vol1 и vol2 в группе дисков dg1 9Наверх
< Предыдущий | оглавление | Индекс | Далее >
Сбор данных по сценарию Обзор | LogicMonitor
Введение
Как правило, предопределенных методов сбора, таких как SNMP, WMI, WEBPAGE и т. д., достаточно для расширения LogicMonitor вашими собственными источниками данных. Однако в некоторых случаях вам может понадобиться использовать механизм SCRIPT для получения показателей производительности из труднодоступных мест. Вот несколько распространенных вариантов использования метода сбора SCRIPT:
д., достаточно для расширения LogicMonitor вашими собственными источниками данных. Однако в некоторых случаях вам может понадобиться использовать механизм SCRIPT для получения показателей производительности из труднодоступных мест. Вот несколько распространенных вариантов использования метода сбора SCRIPT:
- Выполнение произвольной программы и захват ее вывода
- Использование HTTP API, требующего проверки подлинности на основе сеанса перед опросом
- Объединение данных из нескольких узлов SNMP или классов WMI в один источник данных
- Измерение времени выполнения или кода выхода процесса
Подход с набором сценариев
Создать настраиваемый мониторинг с помощью сценария несложно. Вот общий обзор того, как это работает:
- Напишите код, который извлекает интересующие вас числовые показатели. Если у вас есть текстовые данные мониторинга, вы можете рассмотреть сценарий Scripted EventSource.
- Вывести метрики в стандартный вывод, как правило, в виде пар ключ-значение (например, имя = значение), по одной на строку.
- Создайте точку данных, соответствующую каждой метрике, и используйте постпроцессор точки данных, чтобы зафиксировать значение для каждого ключа.
- Установите пороги предупреждений и/или создайте графики на основе точек данных.
Режимы сбора данных на основе сценариев
Сбор данных на основе сценариев может работать либо в «атомарном», либо в «агрегированном» режиме. Мы называем эти режимы типами коллекций SCRIPT и BATCHSCRIPT соответственно.
В стандартном режиме SCRIPT сценарий сбора запускается для каждого экземпляра DataSource в каждом интервале сбора. Значение: для источника данных с несколькими экземплярами, который обнаружил пять экземпляров, скрипт сбора будет запускаться пять раз через каждый интервал сбора. Каждая из этих «задач» по сбору данных независима друг от друга. Таким образом, скрипт сбора данных будет выдавать следующие строки:
ключ1: значение1 ключ2: значение2 key3: value3
Затем необходимо создать три точки данных: по одной для каждой пары ключ-значение.