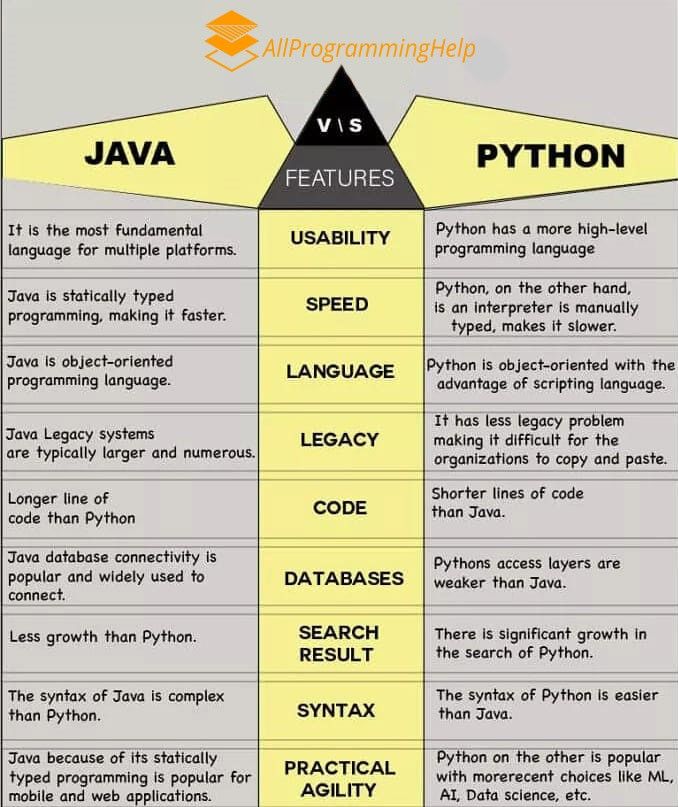
Содержание
Измеряем скорость кода Java правильно (используя JMH) / Хабр
Привет, Хабр!
Это вводная статья про то, как следует делать тесты производительности на JVM языках (java, kotlin, scala и тд.). Она полезна для случая, когда требуется в цифрах показать изменение производительности от использования определенного алгоритма.
Все примеры приведены на языке kotlin и для системы сборки gradle. Исходный код проекта доступен на github.
Подготовка
JMH
В первую очередь остановимся на основной части наших замеров — использовании JMH. Java Microbenchmark Harness — набор библиотек для тестирования производительности небольших функций (то есть тех, где пауза GC увеличивает время работы в разы).
Перед запуском теста JMH перекомпилирует код, так как:
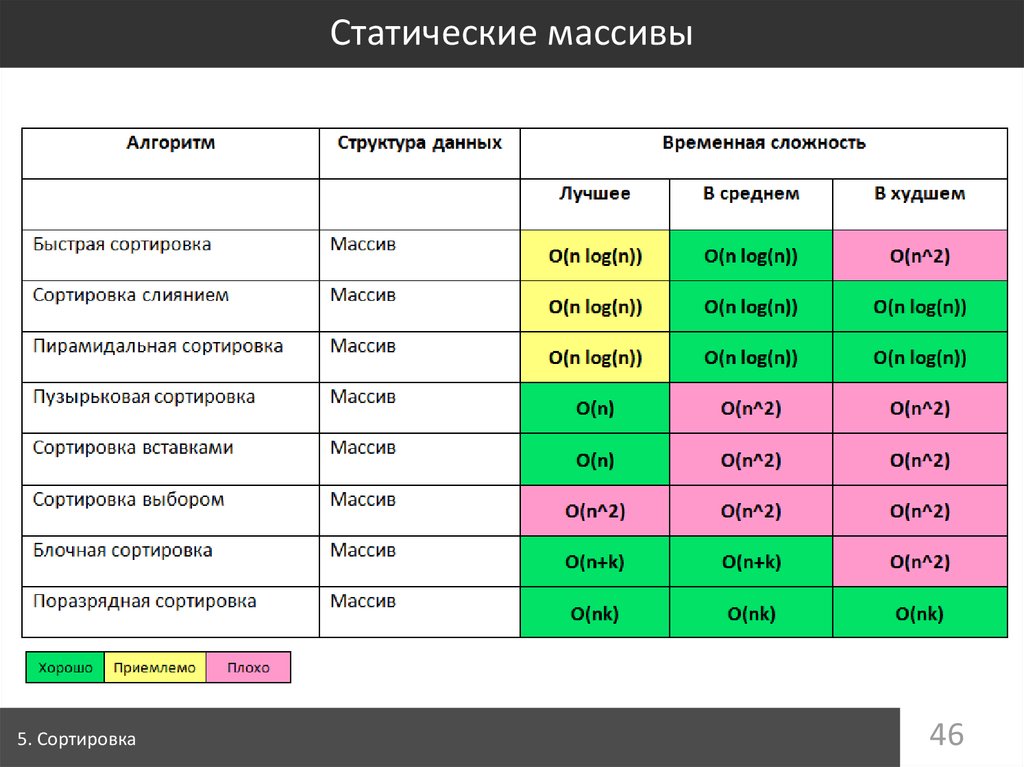
- Для уменьшения погрешности вычисления времени работы функции необходимо запустить её N раз, подсчитать общее время работы, а потом поделить его на N.
- Для этого требуется обернуть запуск в виде цикла и вызова необходимого метода.
 Однако в этом случае на время работы функции повлияет сам цикл, а также сам вызов замеряемой функции. А потому вместо цикла будет вставлен непосредственно код вызова функции, без reflection или генерации методов в runtime.
Однако в этом случае на время работы функции повлияет сам цикл, а также сам вызов замеряемой функции. А потому вместо цикла будет вставлен непосредственно код вызова функции, без reflection или генерации методов в runtime.
 Однако в этом случае на время работы функции повлияет сам цикл, а также сам вызов замеряемой функции. А потому вместо цикла будет вставлен непосредственно код вызова функции, без reflection или генерации методов в runtime.
Однако в этом случае на время работы функции повлияет сам цикл, а также сам вызов замеряемой функции. А потому вместо цикла будет вставлен непосредственно код вызова функции, без reflection или генерации методов в runtime.
После переделки байткода тестирование можно запустить командой вида java -jar benchmarks.jar, так как все необходимые компоненты уже будут запакованы в один jar файл.
JMH Gradle Plugin
Как понятно из описания выше, для тестирования производительности кода недостаточно просто добавить необходимые библиотеки в classpath и запустить тесты в стиле JUnit. А потому, если мы хотим делать дело, а не разбираться в особенности написания билд скриптов, нам не обойтись без плагина к maven/gradle. Для новых проектов преимущество остается за gradle, потому выбираем его.
Для JMH есть полуофициальный плагин для gradle — jmh-gradle-plugin. Добавляем его в проект:
buildscript {
repositories {
mavenCentral()
maven {
url "https://plugins. gradle.org/m2/"
}
}
dependencies {
classpath "me.champeau.gradle:jmh-gradle-plugin:$jmh_gradle_plugin_version"
}
}
apply plugin: "me.champeau.gradle.jmh" gradle.org/m2/"
}
}
dependencies {
classpath "me.champeau.gradle:jmh-gradle-plugin:$jmh_gradle_plugin_version"
}
}
apply plugin: "me.champeau.gradle.jmh"
gradle.org/m2/"
}
}
dependencies {
classpath "me.champeau.gradle:jmh-gradle-plugin:$jmh_gradle_plugin_version"
}
}
apply plugin: "me.champeau.gradle.jmh"Плагин автоматом создаст новый source set (это «набор файлов и ресурсов, которые должны компилироваться и запускаться вместе», прочитать можно или статью на хабре за авторством svartalfar, или же в официальной документации gradle). jmh source set автоматически ссылается на main, то есть получаем короткий алгоритм работы:
- Код, который мы будем изменять, пишем в стандартном main source set, там же, где и всегда.
- Код с настройкой и прогревом тестов пишем в отдельном source set. Именно его byte code и будет перезаписываться, сюда плагин добавит необходимые зависимости, в которых есть определения аннотация и тд.
Получаем следующую иерархию каталогов:
- src
- jmh / kotlin/ <Имя java пакета> / <код, запускающий тесты (и аннотированный JMH аттрибутами)>
- main / kotlin / <Имя java пакета> / <код для тестирования>
Или как это выглядит в IntelliJ Idea:
В итоге, после настройки проекта, можно запускать тесты простым вызовом . (или  \gradlew.bat jmh
\gradlew.bat jmh.\gradlew jmh для Linux, Mac, BSD)
С плагином есть пара интересных особенностей на Windows:
- JMH использует fork java процесса. В случае Windows это сделать так просто нельзя, а потом новый процесс просто запускается с тем же classpath. И весь список jar файлов передается через командную строку, размер которой ограничен. В итоге, если GRADLE_USER_HOME (папка, внутри которой лежит в том числе кеш gradle) находится в глубине файловой структуры, список jar файлов для fork становится настолько большим, что Windows отказывается запускать процесс с таким громадным число аргументов командной строки. Следовательно, если JMH отказывается делать fork — просто переместите кеши Gradle в папку с коротким именем, т.е. запишите в environment variable GRADLE_USER_HOME что-то вроде c:\gradle
- Иногда предыдущий процесс JMH делает lock на файле (возможно, это делает byte code rewrite). В итоге, повторная компиляция может не работать, так как файл с нашим benchmark открыт кем-то на запись. Чтобы исправить эту проблему необходимо просто остановить deamon процессы gradle (которые уже запущены, чтобы ускорить работу компилятора):
.\gradlew.bat --stop - Для чистоты экспериментов, лучше отказаться от инкрементальной сборки для наших тестов. Отсюда, перед тестированием всегда вызываем
.\gradlew.bat clean
 Чтобы исправить эту проблему необходимо просто остановить deamon процессы gradle (которые уже запущены, чтобы ускорить работу компилятора):
Чтобы исправить эту проблему необходимо просто остановить deamon процессы gradle (которые уже запущены, чтобы ускорить работу компилятора):
Тестирование
В качестве примера я возьму вопрос (ранее заданный на kotlin discussions), который мучал меня ранее — зачем в конструкции use используется inline метод?
О конструкции use
В Java есть паттерн — try with resources, который позволяет автоматически вызывать метод close внутри блока, более того — безопасно обрабатывать исключения, не перекрывая уже летящее. Аналог из мира .Net — конструкция using для интерфейсов IDisposable.
Пример java кода:
try (BufferedReader reader = Files.newBufferedReader(file, charset)) { //именно этот try и является озвученной конструкцией
/*читаем из reader'а*/
}В kotlin есть полный аналог, который имеет немного другой синтаксис:
Files.
 newBufferedReader(file, charset)).use { reader ->
/*читаем из reader'а*/
}
newBufferedReader(file, charset)).use { reader ->
/*читаем из reader'а*/
}То есть, как видно:
- Use — это просто метод-расширение, а не отдельная конструкция языка
- Use является inline методом, то есть одни и те же конструкции встраиваются в каждый метод, что увеличивает размер байткода, а значит в теории JIT`у будет сложнее оптимизировать код и т.д. И вот эту теорию мы и будем проверять.
Итак, необходимо сделать два метода:
- Первый будет просто использовать use, который поставляется в библиотеке kotlin
- Второй будет использовать те же методы, однако без inline. В итоге на каждый вызов в куче будет создаваться объект с параметрами для лямбды.
Код с JMH аттрибутами, который будет запускать разные функции:
@BenchmarkMode(Mode.All) // тестируем во всех режимах
@Warmup(iterations = 10) // число итераций для прогрева нашей функции
@Measurement(iterations = 100, batchSize = 10) // число проверочных итераций, причем в каждой из них будет по четыре вызова функции
open class CompareInlineUseVsLambdaUse {
@Benchmark
fun inlineUse(blackhole: Blackhole) {
NoopAutoCloseable(blackhole). use {
blackhole.consume(1)
}
}
@Benchmark
fun lambdaUse(blackhole: Blackhole) {
NoopAutoCloseable(blackhole).useNoInline {
blackhole.consume(1)
}
}
} use {
blackhole.consume(1)
}
}
@Benchmark
fun lambdaUse(blackhole: Blackhole) {
NoopAutoCloseable(blackhole).useNoInline {
blackhole.consume(1)
}
}
}
use {
blackhole.consume(1)
}
}
@Benchmark
fun lambdaUse(blackhole: Blackhole) {
NoopAutoCloseable(blackhole).useNoInline {
blackhole.consume(1)
}
}
}Dead Code Elimination
Java Compiler & JIT довольно умные и имеют ряд оптимизаций, как в compile time, так и в runtime. Метод ниже, например, вполне может свернуться в одну строку (как для kotlin, так и для java):
fun sum() : Unit {
val a = 1
val b = 2
a + b;
}И в итоге мы будем тестировать метод:
fun sum() : Unit {
3;
}Однако результат ведь никак не используется, потому компиляторы (byte code + JIT) в итоге вообще выкинут метод, так как он в принципе не нужен.
Чтобы избежать этого, в JMH существует специальный класс «черная дыра» — Blackhole. В нем есть методы, которые с одной стороны не делают ничего, а с другой стороны — не дают JIT выкинуть ветку с результатом.
А для того, чтобы javac не пытался сложить-таки a и b в процессе компиляции, нам требуется определить объект state, в котором будут храниться наши значения. В итоге в самом тесте мы будем использовать уже подготовленный объект (то есть не тратим время на его создание и не даем компилятору применить оптимизации).
В итоге в самом тесте мы будем использовать уже подготовленный объект (то есть не тратим время на его создание и не даем компилятору применить оптимизации).
В итоге для грамотного тестирования нашей функции требуется её написать вот в таком виде:
fun sum(blackhole: Blackhole) : Unit {
val a = state.a // компилятор не знает заранее значение a
val b = state.b
val result = a + b;
blackhole.consume(result) // JIT не может выкинуть сложение, так как результат кому-то все-таки нужен
}Здесь мы взяли a и b из некоторого state, что помешает компилятору сразу посчитать выражение. А результат мы отправили в черную дыру, что помешает JIT выкинуть последнюю часть функции.
Возвращаясь к моей функции:
- Объект для вызова метода close я создам в самом тесте, так как практически всегда при вызове метода close у нас до этого создавался объект.
- Внутри нашего метода придется вызывть функцию из blackhole, чтобы спровоцировать создание лямбды в куче (и не дать JIT выкинуть потенциально ненужный код).
Результат теста
Запустив ./gradle jmh, а потом подождав два часа, я получил следующие результаты работы на моем mac mini:
# Run complete. Total time: 01:51:54 Benchmark Mode Cnt Score Error Units CompareInlineUseVsLambdaUse.inlineUse thrpt 1000 11689940,039 ± 21367,847 ops/s CompareInlineUseVsLambdaUse.lambdaUse thrpt 1000 11561748,220 ± 44580,699 ops/s CompareInlineUseVsLambdaUse.inlineUse avgt 1000 ≈ 10⁻⁷ s/op CompareInlineUseVsLambdaUse.lambdaUse avgt 1000 ≈ 10⁻⁷ s/op CompareInlineUseVsLambdaUse.inlineUse sample 21976631 ≈ 10⁻⁷ s/op CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.00 sample ≈ 10⁻⁷ s/op CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.
 50 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.90 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.95 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.99 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.9999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p1.00 sample 0,005 s/op
CompareInlineUseVsLambdaUse.lambdaUse sample 21772966 ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.00 sample ≈ 10⁻⁸ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.50 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.
50 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.90 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.95 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.99 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p0.9999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.inlineUse:inlineUse·p1.00 sample 0,005 s/op
CompareInlineUseVsLambdaUse.lambdaUse sample 21772966 ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.00 sample ≈ 10⁻⁸ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.50 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse. lambdaUse:lambdaUse·p0.90 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.95 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.99 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.9999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p1.00 sample 0,010 s/op
CompareInlineUseVsLambdaUse.inlineUse ss 1000 ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.lambdaUse ss 1000 ≈ 10⁻⁵ s/op
Benchmark result is saved to /Users/imanushin/git/use-performance-test/src/build/reports/jmh/results.txt
lambdaUse:lambdaUse·p0.90 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.95 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.99 sample ≈ 10⁻⁷ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p0.9999 sample ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.lambdaUse:lambdaUse·p1.00 sample 0,010 s/op
CompareInlineUseVsLambdaUse.inlineUse ss 1000 ≈ 10⁻⁵ s/op
CompareInlineUseVsLambdaUse.lambdaUse ss 1000 ≈ 10⁻⁵ s/op
Benchmark result is saved to /Users/imanushin/git/use-performance-test/src/build/reports/jmh/results.txtИли, если сократить таблицу:
Benchmark Mode Cnt Score Error Units inlineUse thrpt 1000 11689940,039 ± 21367,847 ops/s lambdaUse thrpt 1000 11561748,220 ± 44580,699 ops/s inlineUse avgt 1000 ≈ 10⁻⁷ s/op lambdaUse avgt 1000 ≈ 10⁻⁷ s/op inlineUse sample 21976631 ≈ 10⁻⁷ s/op lambdaUse sample 21772966 ≈ 10⁻⁷ s/op inlineUse ss 1000 ≈ 10⁻⁵ s/op lambdaUse ss 1000 ≈ 10⁻⁵ s/op
В результате есть две самые важные метрики:
- Inline метод показал производительность
11,6 * 10^6 ± 0,02 * 10^6операций в секунду. 6 операций в секунду. - Inline метод в итоге работает быстрее и стабильнее по скорости. Возможно, увеличенная погрешность для lambdaUse связана с более активной работой с памятью.
- Я таки был неправ на том форуме — в стандартной библиотеке kotlin лучше оставить текущую реализацию метода.
 6 операций в секунду.
6 операций в секунду.
Заключение
При разработке ПО есть два довольно частых способа сравнения производительности:
- Замер скорости работы цикла с N итерациями подопытной функции.
- Философские рассуждения вида «я уверен, что быстрее использовать сдвиг, чем умножение на 2», «сколько я программирую, всегда XML сериализация была самой быстрой» и тд.
Однако, как знает любой технически подкованный специалист, оба этих варианта зачастую приводят к ошибочным суждениям, тормозам в приложениях и пр. Я надеюсь, что эта статья поможет вам делать хорошее и быстрое ПО.
Перевод на английский язык тут.
Java и C++: тест на быстродействие | Java World
В те времена, когда все виртуальные машины Java представляли собой интерпретаторы байт-кода, эта технология вызывала справедливые нарекания за свою низкую производительность. Но по прошествии некоторого времени на рынке появились хорошие компиляторы just-in-time (JIT), и сегодня тесты показывают, что по быстродействию Java во многих областях практически сравнялась с C++. Наметившиеся тенденции позволяют надеяться на то, что уже в самое ближайшее время Java не уступит в скорости C++.
Но по прошествии некоторого времени на рынке появились хорошие компиляторы just-in-time (JIT), и сегодня тесты показывают, что по быстродействию Java во многих областях практически сравнялась с C++. Наметившиеся тенденции позволяют надеяться на то, что уже в самое ближайшее время Java не уступит в скорости C++.
Как соотносится производительность приложений Java и аналогичных программ на C++, максимально оптимизированных по критерию быстродействия? Думаю, что пользователям было бы интересно ознакомиться как с результатами теоретического сравнения, так и с выводами, сделанными на основе анализа тестовых программ и реальных приложений. Большинство аналитиков, не желая углубляться в хитросплетения сложных технологий, с ходу заявляют, что Java всегда будет уступать в производительности другим языкам по причине многоплатформенности Java. Такие утверждения можно встретить во многих статьях, посвященных Java и сетевым компьютерам.
Мы решили провести самостоятельное исследование и выяснить, в чем Java уступает C++ (специалисты любят противопоставлять именно эти два языка). Были изучены компоненты архитектуры Java и определены сравнительные характеристики быстродействия идентичных программ, написанных на Java и на C++.
Были изучены компоненты архитектуры Java и определены сравнительные характеристики быстродействия идентичных программ, написанных на Java и на C++.
Мы готовились к тому, что программы Java будут отставать по всем показателям, хотя и не верили, что C++ окажется в несколько раз быстрее. К большому нашему удивлению, какой-либо разницы в производительности практически не ощущалось. В некоторых случаях скорость приложений Java действительно значительно уступала этому показателю у C++, что, впрочем, легко объясняется наличием строгой модели безопасности и издержками технологии «сборки мусора».
Любое повышение производительности какого-либо языка следует рассматривать в строго определенном контексте. С момента появления Java прошло уже немало времени, и это время не было потрачено впустую. Неслучайно сегодня по уровню быстродействия этогот язык в большинстве случаев сравним с C++ (а C++ славится своей высокой скоростью).
Программное обеспечение: Visual C++ 5.0 и Sun JDK 1.1.5.
В данной статье под платформой понимается комбинация процессора и ОС. Например, платформой можно считать комбинацию ОС Windows NT и процессора Intel, ОС Linux и процессора Intel или же ОС Linux и процессора Digital Alpha.
Например, платформой можно считать комбинацию ОС Windows NT и процессора Intel, ОС Linux и процессора Intel или же ОС Linux и процессора Digital Alpha.
ЗАГРУЗКА ИСПОЛНЯЕМОГО КОДА
При создании нового приложения разработчики сначала записывают программный код в один или несколько исходных файлов. Компилятор/компоновщик транслирует исходный код в исполняемый. В готовом приложении работает именно исполняемый код. На первом этапе необходимо загрузить исполняемый код в память компьютера.
Загрузка исполняемого кода: Java против C++
Если программа находится на локальном диске, загрузка даже сложного приложения не займет много времени. Если же программа хранится на Web-узле в Internet или в корпоративной сети intranet, размер исполняемого кода может существенно повлиять на производительность. Программы и ресурсы Java занимают значительно меньше места на диске по сравнению с программами C++ и загружаются из Internet и intranet гораздо быстрее. При определении скорости загрузки необходимо учитывать размер исполняемого кода и возможность избирательной загрузки.
Размер исполняемого кода
Исполняемые модули Windows NT, написанные на C++, занимают на диске значительно больше места, чем исполняемые модули Java. На размеры исполняемого кода оказывают влияние три фактора:
Во-первых, двоичный формат исполняемого кода C++ увеличивает его размеры по сравнению с кодом Java почти в два раза.
Во-вторых, технология Java предусматривает активное использование ряда библиотек, содержащих математические и сетевые функции, классы для работы с составными элементами и графикой и так далее. В виртуальные машины Java (JVM) встроена поддержка этих библиотек. В C++ же, напротив, определяются интерфейсы прикладных программ (API), позволяющие разработчику унифицировать доступ к большинству функций. К сожалению, если программист захочет использовать какие-либо специальные функции, не имея доступа к базовому API C++, ему придется самому реализовывать поддержку библиотек для своей программы. Включение в программу библиотечных функций может удвоить или даже утроить размеры конечного кода.
В третьих, в комплект Java входят специальные библиотеки, позволяющие работать с графическими и звуковыми файлами, записанными в сжатом формате. Поддерживаются, в частности, графические форматы Joint Photographic Expert Group (JPEG) и Graphics Interchange Format (GIF), а также аудиоформат AU. Средства разработки программ на C++ для Windows NT поддерживают только несжатые форматы: bitmap (BMP) для изображений и wave (WAV) для аудиофайлов. Сжатие дает возможность на порядок уменьшить размеры графических файлов, и приблизительно в три раза — размеры аудиофайлов. Если вы хотите работать с другими форматами графических и звуковых файлов, можно воспользоваться дополнительными библиотеками классов.
Избирательная загрузка
Загрузчики программ, написанных на C++, перед началом выполнения должны полностью загрузить исполняемый файл. В среде Win32 имеется два способа связи с библиотеками DLL: статический и динамический. Статически связанные DLL (используемые в большинстве случаев) загружаются до начала выполнения программы. В случае динамического связывания библиотеки DLL загружаются по запросу. Однако такой вариант гораздо менее популярен, поскольку написание кода динамической загрузки и обращения к библиотечным функциям требует от разработчика значительных усилий.
В случае динамического связывания библиотеки DLL загружаются по запросу. Однако такой вариант гораздо менее популярен, поскольку написание кода динамической загрузки и обращения к библиотечным функциям требует от разработчика значительных усилий.
Кроме того, не существует способов проверки целостности динамически связанной DLL на этапе выполнения. Это означает, что без аварийного завершения нельзя выяснить, изменялась ли DLL в процессе выполнения программы. Наконец, если программа будет загружаться с удаленного диска, необходимо предварительно скопировать библиотеки на локальный носитель. Реализация такой процедуры в автоматическом режиме потребует дополнительных затрат на программирование.
В свою очередь загрузчик Java способен выборочно загружать классы по мере необходимости. Рассмотрим, к примеру, полнофункциональный текстовый процессор со встроенным тезаурусом, орфографическим корректором и средствами создания и экспорта почты. Реализация данных возможностей обычно приводит к генерации многомегабайтного кода.
Средний пользователь в любой конкретный момент времени использует лишь малую часть потенциала средств разработки. Если программа была написана на C++, перед началом обработки пользователь обязан загрузить файл полностью. В случае, когда программа написана на Java, на первом этапе в памяти размещается только самое необходимое (например, главное окно), а дополнительные модули подгружаются по мере необходимости.
Загрузка исполняемого кода реальных программ
В таблице 1 представлены размеры протестированных программ и их ресурсов. Огромная разница между размерами кода C++ и Java объясняется наличием библиотек, необходимых для выполнения программы C++. Объемы ресурсов отличаются вследствие того, что приложения Java работают со сжатыми файлами (в формате GIF), а программы C++ — с обычными файлами bitmap.
Таблица 1
| Имя программы | Размеры программы, Кбайт (C++/Java) | Ресурсы, Кбайт (C++/Java) |
| Simple Loop | 46/3,9 | -/- |
| Memory Allocation | 34/1,4 | -/- |
| Bouncing Globes | 103/21 | 485/13 |
ВЫПОЛНЕНИЕ ПРОГРАММНЫХ ИНТСТРУКЦИЙ
После загрузки исполняемого кода процессор начинает выполнять программные инструкции. При традиционном программировании на C++ исполняемый файл содержит двоичные инструкции процессора выбранной платформы. Для переноса приложения на другую платформу разработчику потребуется создать новый исполняемый файл путем перекомпиляции исходного кода. Кроме того, особенности конкретной платформы каждый раз заставляют вносить определенные изменения в исходный код. Исполняемые же файлы, получаемые на выходе компилятора Java, представляют собой совокупность байт-кодов, которые не могут выполняться процессором без дополнительного преобразования в двоичный код. Это преобразование возлагается на JVM. Виртуальная машина Java может осуществлять преобразование двумя способами: с помощью интерпретатора байт-кода или посредством компилятора just-in-time (JIT).
При традиционном программировании на C++ исполняемый файл содержит двоичные инструкции процессора выбранной платформы. Для переноса приложения на другую платформу разработчику потребуется создать новый исполняемый файл путем перекомпиляции исходного кода. Кроме того, особенности конкретной платформы каждый раз заставляют вносить определенные изменения в исходный код. Исполняемые же файлы, получаемые на выходе компилятора Java, представляют собой совокупность байт-кодов, которые не могут выполняться процессором без дополнительного преобразования в двоичный код. Это преобразование возлагается на JVM. Виртуальная машина Java может осуществлять преобразование двумя способами: с помощью интерпретатора байт-кода или посредством компилятора just-in-time (JIT).
Выполнение программных инструкций: Java против C++
У программ, написанных на Java, не слишком хорошая репутация. Их производительность заставляет вспомнит о старых JVM, для которых интерпретация байт-кода была единственным способом выполнения программных инструкций.
Интерпретаторы байт-кода работали в несколько раз медленнее исполняемого кода программ C++, поскольку каждую инструкцию в ходе выполнения необходимо было преобразовать в двоичный код. Это, в свою очередь, приводило к неоправданным расходам. Приведем простейший пример. Каждый цикл состоит из набора многократно повторяющихся инструкций. При выполнении очередной итерации JVM снова и снова интерпретирует один и тот же байт-код, при этом на процедуру интерпретации уходит довольно много процессорного времени.
Но методы, на которых базировалась работа старых JVM, уже уходят в прошлое. Большинство современных виртуальных машин Java оснащается JIT-компиляторами. Эти компиляторы транслируют и преобразуют в двоичный код сразу весь исходный файл. Таким образом, отпадает необходимость повторной трансляции каждой инструкции байт-кода.
Производительность кода различных компиляторов
Компиляторы C++ могут повысить скорость выполнения отдельных частей кода путем выявления неэффективных участков и их соответствующего преобразования.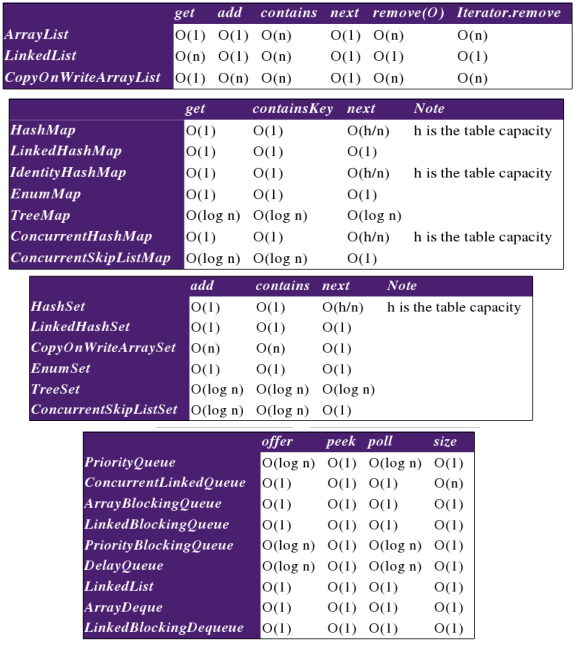 Этот процесс носит название оптимизации. К примеру, хороший компилятор способен распознать небрежность программиста и исключить из цикла «статические» вычисления. Под «статическими» вычислениями понимается выполнение в цикле определенной операции, результатом которой независимо от итерации всегда является константа.
Этот процесс носит название оптимизации. К примеру, хороший компилятор способен распознать небрежность программиста и исключить из цикла «статические» вычисления. Под «статическими» вычислениями понимается выполнение в цикле определенной операции, результатом которой независимо от итерации всегда является константа.
Распознав такую конструкцию, компилятор выводит ее за рамки цикла. Таким образом, значение константы вычисляется еще до входа в цикл и может использоваться внутри него, сокращая время выполнения и не изменяя логики программы. Этот тип оптимизации называется перемещением выражений. Для его выполнения компилятору необходимо сделать несколько проходов и изучить все инструкции цикла. В приведенном выше примере перемещения выражения все команды цикла должны быть тщательно проверены, и компилятор обязан убедиться в том, что при любой итерации значением выражения является константа.
Виртуальная машина Java, не имеющая JIT-компилятора, последовательно интерпретирует каждую инструкцию и не может проводить подобную оптимизацию «на лету».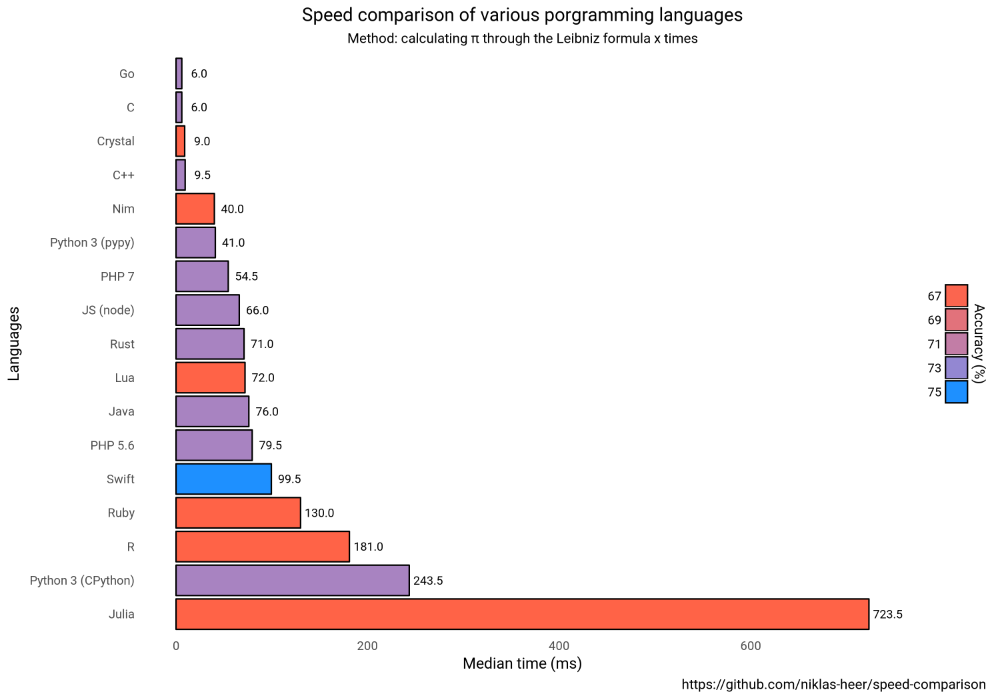 Технология JIT-компилятора позволяет оптимизировать файл классов целиком.
Технология JIT-компилятора позволяет оптимизировать файл классов целиком.
Таким образом, единственная причина, по которой обрабатываемая JIT-компилятором программа Java и приложение C++ работают с разной скоростью, — это необходимость первоначальной трансляции файла классов; она же, в свою очередь, зависит от типа проводимой оптимизации.
Общее время выполнения программы, включающей в себя большое количество классов, складывается из времени, которое требуется на компиляцию этих классов, и времени обработки процессором двоичного кода. В реальных программах многократно встречаются одни и те же классы, поэтому на практике затраты на компиляцию всегда оказываются значительно ниже затрат на непосредственное выполнение двоичного кода.
На начальном этапе большинство компаний, разрабатывавших компиляторы JIT, пытались определять, какие классы следует компилировать, а какие — нет. Это зависело от того, как часто появляются классы в программе. Впоследствии многие производители отказались от такого решения, и компиляторы стали транслировать весь исходный код, поскольку общее время выполнения при этом практически не изменялось.
Теория и практика
Теоретически скорости выполнения байт-кода Java, обрабатываемого JIT-компилятором, и двоичного кода С++ не должны существенно различаться. На практикеже необходимо учитывать два фактора, оказывающих существенное влияние на производительность.
Во-первых, одной и той же инструкции байт-кода могут соответствовать несколько различных последовательностей команд конкретного процессора. В результате выполнения этих последовательностей вы получите один и тот же результат, но время обработки при этом будет заметно отличаться. Если команды, получаемые на выходе JIT-компилятора и компилятора C++, требуют одинакового количества тактов процессора, быстродействие программ Java и C++ оказывается практически одинаковым. (В данном случае все зависит от того, насколько хорошо компилятор оптимизирует исполняемый код по критерию быстродействия.)
Во-вторых, имеет смысл оценивать количество проходов компилятора, необходимое для оптимизации отдельных участков кода. В рассмотренном выше примере «статических» вычислений, чтобы определить, изменяется значение выражения или нет, компилятору, возможно, потребуется проверить все итерации цикла.
В рассмотренном выше примере «статических» вычислений, чтобы определить, изменяется значение выражения или нет, компилятору, возможно, потребуется проверить все итерации цикла.
Один из видов более сложной оптимизации — это устранение неиспользуемого кода. В данном случае компилятор должен найти операторы, которые не выполняются ни при каких условиях. Если такие операторы существуют, они не включаются в исполняемый код.
Устранение неиспользуемого кода может привести к существенному повышению быстродействия программы, однако при этом значительно увеличивается и время компиляции. Необходимо учитывать, что появление неиспользуемого кода — это результат ошибок программиста. Опытные разработчики обязательно проверяют текст программы на наличие неиспользуемого кода, облегчая тем самым задачу компилятора.
В общем случае в зависимости от выигрыша в производительности и временных затрат все виды оптимизации можно разделить на несколько уровней.
Первый и второй уровень оптимизации как правило повышают быстродействие на 10-15 % при минимальных затратах.
Третий уровень оптимизации позволяет увеличить производительность еще на 5 %, однако это обойдется значительно дороже.
Примеры реальных программ
В таблице 2 сравниваются результаты выполнения нескольких процедур Java и аналогичных программ, написанных на C++. Нетрудно заметить, что при отсутствии JIT-компилятора производительность Java в три-четыре раза уступает этому показателю для C++.
Таблица 2
| Тест | Описание | Время выполнения программы C++, сек. | Время выполнения программы Java (JIT- компилятор), сек. | Время выполнения программы Java (интер- претатор байт-кода), сек. |
| Целочисленное деление | В цикле 10 тыс. раз выполнялась операция целочисленного деления. | 1,8 | 1,8 | 4,8 |
| Неиспользуемый код | В цикле 10 млн. раз встречалось неиспользуемое выражение | 3,7 | 3,7 | 9,5 |
| Комбинация неиспользуемого кода и целочисленного деления | В цикл была встроена одна исполняемая команда и 10 млн. раз неиспользуемых выражений раз неиспользуемых выражений | 5,4 | 5,7 | 20 |
| Деление с плавающей точкой | В цикле 10 млн. раз выполнялось деление с плавающей точкой | 1,6 | 1,6 | 8,7 |
| Статический метод | В цикле 10 млн. раз вызывался статический метод, реализующий целочисленное деление | 1,8 | 1,8 | 6,0 |
| Компонентный метод | В цикле 10 млн. раз вызывался компонентный метод, реализующий целочисленное деление | 1,8 | 1,8 | 10 |
| Виртуальный компонентный метод* | В данном тесте 10 млн. раз вызывался виртуальный компонентный метод, реализующий целочисленное деление | 1,8 | 1,8 | 10 |
| Виртуальный компонентный метод с приведением типов и идентификацией типа в момент выполнения (RTTI) | В данном тесте 10 млн. раз вызывался виртуальный метод класса, в котором выполнялась операция приведения типов | 11 | 4,3 | 12 |
| Виртуальный компонентный метод с неправильным приведением типа и идентификацией типа в момент выполнения (RTTI) | В данном тесте 10 млн. раз вызывался виртуальный метод класса, в котором выполнялась операция приведения типов раз вызывался виртуальный метод класса, в котором выполнялась операция приведения типов | -** | -** | -** |
** Аварийное завершение
В полном соответствии с теоретическими исследованиями быстродействие программ Java, обрабатываемых JIT-компилятором, практически не отличается от этого показателя для процедур C++. Единственное исключение — выполнение операции приведения типов, где скорость C++ значительно превосходит скорость Java.
Сложные объектно-ориентированные программы имеют сложную иерархию, вследствие чего часто приходится выполнять операцию преобразования родительского класса в дочерний. Данная операция называется приведением типов.
В момент выполнения программы проверяется правильность преобразования родительского класса в дочерний (идентификация типа в момент выполнения — run-time type identification, RTTI). При эксплуатации сложных систем, в которых не реализованы методы RTTI, часто возникают ошибки. Это значительно снижает эффективность всей системы и подрывает доверие пользователей.
При эксплуатации сложных систем, в которых не реализованы методы RTTI, часто возникают ошибки. Это значительно снижает эффективность всей системы и подрывает доверие пользователей.
Большинство программистов, пишущих на C++, отключают RTTI, чтобы повысить быстродействие. Технология Java не позволяет воспользоваться таким приемом, поскольку это может привести к нарушению системы безопасности. Наши тесты еще раз продемонстрировали, насколько методы RTTI замедляют скорость выполнения программы.
РАСПРЕДЕЛЕНИЕ ПАМЯТИ
Для хранения информации и выполнения вычислений программы должны эффективно управлять имеющейся памятью. После того как потребность в ранее выделенной области памяти отпадает, эта память должна быть освобождена и возвращена системе. Механизмы выделения памяти C++ и Java очень похожи. Что касается освобождения, здесь имеются принципиальные отличия. Программы C++ обязаны явно освобождать память. Очень часто при выполнении программ C++ возникают ошибки, вызванные тем, что программист забыл явно освободить память. Эта память «блокируется» и становится недоступной до завершения работы приложения.
Эта память «блокируется» и становится недоступной до завершения работы приложения.
В среде Java реализован встроенный механизм освобождения памяти, называемый «сборкой мусора». Этот механизм автоматически определяет момент, когда конкретная область памяти больше не нужна программе, после чего память возвращается системе.
Распределение памяти: Java против C++
Поскольку «сборщик мусора» Java должен автоматически выявить незадействованные программой области памяти, общие расходы Java на распределение памяти значительно превышают соответствующие расходы C++. Но при этом механизм освобождения памяти Java обеспечивает два очень важных преимущества.
Во-первых, программы фактически гарантированы от утери памяти. Поскольку ошибки, связанные с потерей областей памяти, очень часто встречаются в сложных системах, отпадает необходимость поиска таких ошибок и длительного изучения кода с помощью отладчика, а следовательно значительно сокращается цикл разработки.
Еще один недостаток сложных систем — фрагментация памяти, возникающая в результате многочисленных операций выделения и освобождения памяти и существенно снижающая скорость выполнения приложения. Хорошо написанный «сборщик мусора» Java способен, эффективно перераспределяя память, предотвратить фрагментацию.
Хорошо написанный «сборщик мусора» Java способен, эффективно перераспределяя память, предотвратить фрагментацию.
Таким образом, Java и C++ используют различные механизмы управления памятью. Эффективность распределения памяти, характерная для Java, достигается за счет снижения производительности.
Сложность реализации стратегии «сборки мусора» заключается в том, что механизм освобождения памяти должен самостоятельно выявить неиспользуемые объекты. Если программист твердо придерживается принципов объектно-ориентированной философии, процесс «сборки мусора» обойдется сравнительно недорого. В случае же использования процедурного подхода, сложность взаимосвязей значительно затруднит поиск неиспользуемых объектов.
Примеры программ
На выделение и освобождение памяти для 10 млн. 32-разрядных целых чисел программе на C++ потребовалось 0,812 сек., а программе на Java — 1,592 сек. На основании данного примера хорошо прослеживается снижение быстродействия Java. И все же несмотря на огромную дополнительную работу, выполненную «сборщиком мусора», производительность Java вполне соизмерима с производительностью C++.
ДОСТУП К СИСТЕМНЫМ РЕСУРСАМ
Помимо распределения памяти программе необходим доступ к другим системным службам, таким как вывод графических примитивов, обработка звука и управление окнами. Традиционные программы на C++ обращаются к системным функциям при помощи интерфейсов прикладных программ (API). Каждой платформе соответствует свой API, поэтому при переносе программы с одной платформы на другую разработчику приходится порой проводить существенные модификации.
Программы Java обращаются к системным службам любой платформы при помощи единственного API. Каждая платформа имеет сходные интерфейсы, которые в ответ на обращения Java выделяют программе необходимые ресурсы.
Доступ к системным ресурсам: Java против C++
В общем случае преимущества, которые дает однотипное обращение к системным службам, оправдывают стоимость разработки специальных интерфейсов Java. Программы Java, вызывающие системные функции, работают так же быстро, как программы C++.
Единственным исключением из этого правила является то, что средства, эквивалентные функциям API Java, имеются не на всех платформах. В частности, операционные системы компьютеров Macintosh не поддерживают потоки, поэтому соответствующие функции API Java невозможно задействовать на платформе Macintosh.
В частности, операционные системы компьютеров Macintosh не поддерживают потоки, поэтому соответствующие функции API Java невозможно задействовать на платформе Macintosh.
Примеры программ
Мы протестировали программу, разработанную известным специалистом в области анимации и мультимедиа Джеем Бартотом. Быстродействие реализующего ее алгоритм апплета Java ничем не отличалось от этого показателя программы, написанной при помощи средств Win32 SDK.
Данный пример поможет служить подтверждением двух важнейших постулатов.
Во-первых, производительность Java зависит от производительности JVM. Тестовая программа, работавшая под управлением Internet Explorer 4.0 и Netscape Communicator в среде Windows NT, не отличалась высокой скоростью выполнения. Объекты перемещались на экране неестественно, с высокой дискретностью. Однако стоило запустить браузеры в среде Windows 95, как скорость анимации стала вполне приемлемой.
Разница в производительности объясняется огромной работой, проделанной с тем, чтобы оптимизировать быстродействие браузеров в среде Windows 95. Принципиальные архитектурные различия не позволяют обеспечить одинаковую производительность браузера в обеих операционных системах.
Принципиальные архитектурные различия не позволяют обеспечить одинаковую производительность браузера в обеих операционных системах.
Во-вторых, пакет JDK for Win32, разработанный корпорацией Sun, является общепринятым стандартом, который обязаны поддерживать все браузеры и JVM.
КОМПЕТЕНТНОСТЬ РАЗРАБОТЧИКА — ГАРАНТИЯ ВЫСОКОЙ ПРОИЗВОДИТЕЛЬНОСТИ
Создается впечатление, что аналитики, упрекающие Java в недостаточной производительности, никогда не переведутся. Впрочем, то же самое наблюдалось при появлении языков второго поколения, структурного и объектно-ориентированного программирования. Каждая новая технология повышает эффективность разработки, но и заставляет соблюдать определенную дисциплину. Поскольку Java — это объектно-ориентированный язык, наиболее активное его неприятие ощущается со стороны тех, кто до сих пор не осознал преимуществ новой парадигмы.
Проведенный нами анализ показал, что как с теоретической, так и с практической точки зрения значительной разницы в производительности приложений C++ и Java не наблюдается. А если такая разница и существует, программист, пишущий на Java, оказывается в гораздо более выгодном положении по сравнению с тем, кто работает на C++.
А если такая разница и существует, программист, пишущий на Java, оказывается в гораздо более выгодном положении по сравнению с тем, кто работает на C++.
Если сравнивать программирование на Java и на C++, оказывается, что у первого, безусловно, есть три основных преимущества, позволяющих сократить время разработки и повысить быстродействие сложных приложений.
Остается лишь перечислить эти преимущества:
Производительность
. Действительно ли Java работает медленно?
Кажется, вы задаете два разных вопроса:
- Действительно ли Java работает медленно, и если да, то почему?
- Почему Java считается медленной, хотя она быстрее многих альтернатив?
Первый из них более или менее похож на вопрос «длинной ли веревки». Это сводится к вашему определению «медленно». По сравнению с чистым интерпретатором Java чрезвычайно быстр. По сравнению с другими языками, которые (обычно) компилируются в какой-то байт-код, а затем динамически компилируются в машинный код (например, C# или что-то еще в .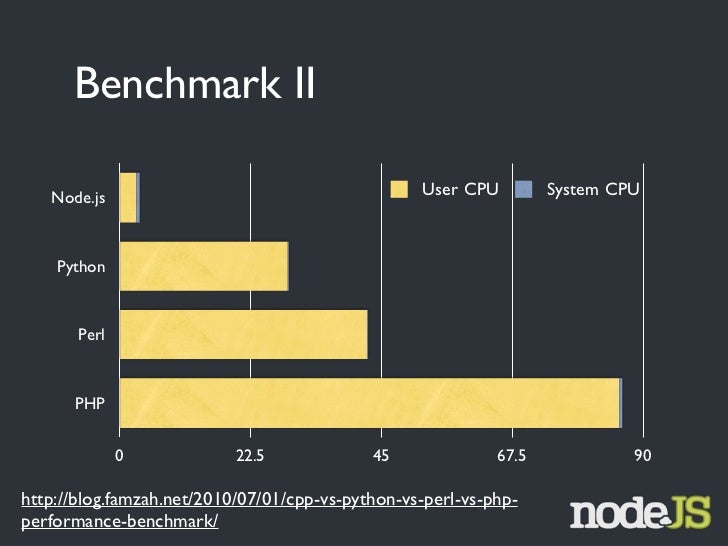 NET), Java находится примерно на одном уровне. По сравнению с языками, которые обычно компилируются в чистый машинный код и имеют (часто большие) группы людей, работающие только над улучшением своих оптимизаторов (например, C, C++, Fortran, Ada), Java довольно хорошо справляется с несколько вещей , но в целом, как минимум, несколько медленнее.
NET), Java находится примерно на одном уровне. По сравнению с языками, которые обычно компилируются в чистый машинный код и имеют (часто большие) группы людей, работающие только над улучшением своих оптимизаторов (например, C, C++, Fortran, Ada), Java довольно хорошо справляется с несколько вещей , но в целом, как минимум, несколько медленнее.
Многое из этого связано в первую очередь с реализацией — в основном, это сводится к тому факту, что пользователь ожидает, пока работает динамический/JIT-компилятор, поэтому, если у вас нет программы, которая выполняется довольно долго, чтобы начать с , трудно оправдать то, что компилятор тратит много времени на сложную оптимизацию. Поэтому большинство компиляторов Java (и C# и т. д.) не прилагают много усилий для действительно сложной оптимизации. Во многих случаях дело не столько в том, какие оптимизации выполняются, сколько в том, где они применяются. Многие задачи оптимизации являются NP-полными, поэтому время, которое они занимают, быстро растет с размером атакуемой проблемы. Один из способов сохранить время в пределах разумного — применять оптимизацию только к чему-то вроде одной функции за раз. Когда компилятор ждет только разработчик, вы можете позволить себе потратить гораздо больше времени и применить ту же самую оптимизацию к гораздо большим частям программы. Точно так же код для некоторых оптимизаций довольно громоздкий (и поэтому может быть довольно большим). Опять же, поскольку пользователь ждет, пока загрузится этот код (а время запуска JVM часто является важным фактором в общем времени), реализация должна сбалансировать время, сэкономленное в одном месте, и потерянное в другом — и учитывая, как мало кода извлекает выгоду из сложной оптимизации, сохранение небольшого размера JVM обычно более выгодно.
Один из способов сохранить время в пределах разумного — применять оптимизацию только к чему-то вроде одной функции за раз. Когда компилятор ждет только разработчик, вы можете позволить себе потратить гораздо больше времени и применить ту же самую оптимизацию к гораздо большим частям программы. Точно так же код для некоторых оптимизаций довольно громоздкий (и поэтому может быть довольно большим). Опять же, поскольку пользователь ждет, пока загрузится этот код (а время запуска JVM часто является важным фактором в общем времени), реализация должна сбалансировать время, сэкономленное в одном месте, и потерянное в другом — и учитывая, как мало кода извлекает выгоду из сложной оптимизации, сохранение небольшого размера JVM обычно более выгодно.
Вторая проблема заключается в том, что с Java вы часто получаете более или менее универсальное решение. Например, для многих Java-разработчиков Swing, по сути, является единственной доступной библиотекой окон . В чем-то вроде C++ есть буквально десятки оконных библиотек, фреймворков приложений и т. д., каждая из которых имеет свой собственный набор компромиссов между простотой использования и быстрым выполнением, согласованным внешним видом и родным внешним видом и так далее. Единственным камнем преткновения является то, что некоторые из них (например, Qt) могут быть довольно дорогими (по крайней мере, для коммерческого использования).
д., каждая из которых имеет свой собственный набор компромиссов между простотой использования и быстрым выполнением, согласованным внешним видом и родным внешним видом и так далее. Единственным камнем преткновения является то, что некоторые из них (например, Qt) могут быть довольно дорогими (по крайней мере, для коммерческого использования).
В-третьих, большая часть кода, написанного на C++ (и тем более на C), просто устарела и стала более зрелой. Многие из них содержат ядро подпрограмм, написанных десятилетия назад, когда дополнительное время на оптимизацию кода было нормальным, ожидаемым поведением. Это часто имеет реальное преимущество в коде, который меньше и быстрее. C++ (или C) получает признание за небольшой и быстрый код, но на самом деле это в большей степени продукт разработчика и ограничения времени, когда код был написан. В какой-то степени это приводит к самоисполняющемуся пророчеству: когда люди заботятся о скорости, они часто выбирают C++, потому что у него такая репутация. Они тратят дополнительное время и усилия на оптимизацию, и пишется новое поколение быстрого кода на C++.
Они тратят дополнительное время и усилия на оптимизацию, и пишется новое поколение быстрого кода на C++.
Подводя итог, можно сказать, что нормальная реализация Java делает максимальную оптимизацию в лучшем случае проблематичной. Хуже того, там, где Java видна , такие вещи, как оконные инструменты и время запуска JVM, в любом случае часто играют большую роль, чем скорость выполнения самого языка. Во многих случаях C и C++ также получают признание за то, что на самом деле является результатом просто усердной работы над оптимизацией.
Что касается второго вопроса, я думаю, что это во многом вопрос человеческой природы в действии. Несколько фанатиков делают довольно преувеличенные заявления о том, что Java ослепительно быстр. Кто-нибудь попробует и обнаружит, что запуск даже тривиальной программы занимает несколько секунд, а при запуске она кажется медленной и неуклюжей. Немногие, вероятно, утруждают себя анализом вещей, чтобы понять, что во многом это время запуска JVM и тот факт, что, когда они впервые пробуют что-то, код еще не скомпилирован — часть кода интерпретируется, а некоторые компилируются, пока они ждут. Хуже того, даже когда он работает достаточно быстро, внешний вид обычно кажется большинству пользователей странным и неуклюжим, поэтому даже если бы объективные измерения показывали быстрое время отклика, он все равно казался бы неуклюжим.
Хуже того, даже когда он работает достаточно быстро, внешний вид обычно кажется большинству пользователей странным и неуклюжим, поэтому даже если бы объективные измерения показывали быстрое время отклика, он все равно казался бы неуклюжим.
Если их сложить, то получится довольно простая и естественная реакция: Java медленная, уродливая и неповоротливая. Учитывая шумиху о том, что это действительно быстро, существует тенденция слишком остро реагировать и думать о нем как о ужасно медленном вместо (более точного) «немного медленнее, и это в основном при определенных обстоятельствах». Как правило, это самое худшее для разработчика, пишущего первые несколько программ на этом языке. Выполнение программы «hello world» на большинстве языков кажется мгновенным, но в Java есть легко заметная пауза при запуске JVM. Даже чистый интерпретатор, который работает гораздо медленнее в узких циклах и тому подобном, все равно часто будет казаться быстрее для такого кода просто потому, что он может загрузиться и начать выполняться немного раньше.
Может ли кто-нибудь количественно оценить разницу в производительности между C++ и Java?
У языков нет скорости. Ни в спецификациях языка Java, ни в C++ не указано, что «и программы должны быть скомпилированы, чтобы быть на эффективными».
Каждый язык определяет список вещей, которые программа должна делать, или, по крайней мере, кажется, что делает , что в некоторых случаях устанавливает верхнюю границу того, насколько эффективной может быть программа, но часто умный компилятор может игнорировать эти правила. в отдельных программах, потому что все, что имеет значение, это то, что программа ведет себя , как если бы спецификация была соблюдена. Функции могут быть встроены, данные кучи могут быть перемещены в стек и так далее.
Производительность программы зависит от трех факторов: компилятора, базовой платформы/оборудования и самого программного кода.
Не «язык». Самое близкое, что вы получаете, это компилятор.
Есть веские причины, по которым один язык может быть быстрее другого. C++ дает меньше обещаний, которые потенциально могут замедлить выполнение программы, но Java обрабатывается JIT, что означает, что он потенциально может использовать информацию времени выполнения для оптимизации кода, что C++ не может легко сделать… И опять же, нигде в в спецификации сказано, что C++ должен быть , а не . Точно так же, как я считаю, есть также компиляторы Java, которые генерируют собственный код вместо байт-кода JVM.
C++ дает меньше обещаний, которые потенциально могут замедлить выполнение программы, но Java обрабатывается JIT, что означает, что он потенциально может использовать информацию времени выполнения для оптимизации кода, что C++ не может легко сделать… И опять же, нигде в в спецификации сказано, что C++ должен быть , а не . Точно так же, как я считаю, есть также компиляторы Java, которые генерируют собственный код вместо байт-кода JVM.
Ваш вопрос имеет смысл только в том случае, если у вас есть конкретный компьютер, на котором вы работаете, определенный компилятор для каждого языка и конкретная реализация вашей программы на каждом языке, , и в этом случае вы можете просто запустить оба, чтобы увидеть, какой из них самый быстрый .
Сборка мусора — еще один замечательный пример. Конечно, сборка мусора связана с некоторыми накладными расходами, но также позволяет использовать некоторые важные сокращения. Выделение кучи смехотворно дешево в управляемых языках, таких как Java или . NET, , потому что управляется сборщиком мусора. В С++ это… не указано, конечно, но на практике, как правило, очень медленно, потому что ОС должна пройти через кучу, чтобы найти свободный блок памяти в более или менее фрагментированном пространстве памяти. Какой самый быстрый? Зависит от ОС. Зависит от компилятора. Зависит от исходного кода.
NET, , потому что управляется сборщиком мусора. В С++ это… не указано, конечно, но на практике, как правило, очень медленно, потому что ОС должна пройти через кучу, чтобы найти свободный блок памяти в более или менее фрагментированном пространстве памяти. Какой самый быстрый? Зависит от ОС. Зависит от компилятора. Зависит от исходного кода.
Исходный код также имеет большое значение. Если вы возьмете программу на Java и наивно перенесете ее на C++, она будет работать как дерьмо. C++ не очень хорошо работает с виртуальными функциями и обычно имеет лучшие альтернативы, которые вы могли бы использовать вместо них. Выделение кучи может быть очень медленным в C++, так что повторная реализация программы на Java будет крайне неэффективной. То же самое и при движении в обратном направлении. Многие идиомы C++ будут излишне медленными, если их портировать непосредственно на Java. Итак, даже если вы остановились на одной платформе и одном компиляторе, как вы сравниваете производительность вашей программы? Чтобы даже передать его компилятору, вам нужно написать две его реализации, и тогда это уже не одна и та же программа.