Содержание
Модели атрибуции — подробный обзор и сравнение | by Александр Пономаренко
В этой статье мы рассмотрим основные принципы, плюсы и минусы большинства известных моделей атрибуции: от стандартных моделей из Google Analytics до Цепей Маркова и Вектора Шепли. Вы узнаете, как оценить взаимное влияние кампаний, а не только последний клик, и сможете выбрать модель, максимально подходящую вашему бизнесу.
Узнайте, какие кампании приносят прибыль, а какие не окупаются Автоматически импортируйте расходы из рекламных сервисов в Google Analytics. Сравнивайте затраты, CPC и ROAS разных кампаний в одном отчете.
- Зачем нужна атрибуция
- Какие модели атрибуции доступны на рынке
- Модели атрибуции на основе позиции канала в цепочке
- По первому клику (First Interaction или First Click)
- По последнему клику (Last Interaction или Last Click)
- По последнему непрямому клику (Last Non-Direct Click)
- Линейная модель атрибуции (Linear)
- С учетом давности взаимодействия (Time Decay)
- На основе позиции (Position Based или U-образная)
- В чем проблема стандартных моделей атрибуции
- Алгоритмические модели атрибуции
- Атрибуция на основе данных (Data-Driven Attribution, Вектор Шепли)
- Атрибуция на основе Цепей Маркова (Markov Chains)
- OWOX BI Attribution
- Краткие выводы
- Вебинар по моделям атрибуции
Чтобы ответить на этот вопрос, давайте посмотрим на типичную воронку продаж. Она состоит из четырех основных этапов:
Она состоит из четырех основных этапов:
- Знакомство с брендом.
- Рассмотрение, когда пользователь уже знает о компании, но еще думает, стоит ли покупать — смотрит отзывы, сравнивает цены, выбирает продукт.
- Конверсия, то есть покупка.
- Удержание, то есть повторные покупки.
Большинство из вас наверняка знает, что удерживать клиентов намного дешевле, чем привлекать новых. На привлечение направлены менее персонализированные кампании. У них намного шире охват, их сложнее оценить.
На удержание, наоборот, направлены более целевые кампании, оценить эффективность которых намного легче, потому что мы уже знаем конкретного пользователя и можем связать все его покупки и взаимодействия с компанией.
Как же узнать, какие рекламные каналы и кампании и на каком этапе воронки срабатывают лучше всего? На этот вопрос помогает ответить атрибуция.
Атрибуция — это распределение ценности от конверсии между кампаниями, которые продвигали пользователя по воронке. Она помогает ответить на вопрос, в какой мере каждый из каналов повлиял на ту прибыль, которую вы получили в итоге. Подобрав правильную модель атрибуции для своего бизнеса, вы сможете оптимально распределять рекламный бюджет и, как следствие, снизить расходы и увеличить доход. Давайте разберемся, кому какая модель подходит.
Она помогает ответить на вопрос, в какой мере каждый из каналов повлиял на ту прибыль, которую вы получили в итоге. Подобрав правильную модель атрибуции для своего бизнеса, вы сможете оптимально распределять рекламный бюджет и, как следствие, снизить расходы и увеличить доход. Давайте разберемся, кому какая модель подходит.
бонус для читателей
Сравнительная таблица с моделями атрибуциии
Скачать материал
Существуют десятки возможных моделей атрибуции. Их можно классифицировать разными способами в зависимости от того, какая логика используется при расчете:
- Например, если мы смотрим на то, какое место занимал канал в цепочке перед заказом, то речь про модели атрибуции на основе позиции (Time Decay, Position Based). Если же при расчете учитываются все данные, а не только позиция канала в цепочке, то это алгоритмические модели атрибуции (Data-Driven, Цепи Маркова).
- Если мы отдаем всю ценность только одному каналу, который участвовал в воронке, то такие модели называются одноканальными (Last Click, First Click).
 Если ценность распределятся между всеми каналами в цепочке, то это — многоканальные модели атрибуции (Linear, Time Decay).
Если ценность распределятся между всеми каналами в цепочке, то это — многоканальные модели атрибуции (Linear, Time Decay).
 Если ценность распределятся между всеми каналами в цепочке, то это — многоканальные модели атрибуции (Linear, Time Decay).
Если ценность распределятся между всеми каналами в цепочке, то это — многоканальные модели атрибуции (Linear, Time Decay).Начнем с самых простых моделей атрибуции на основе позиции, которые доступны в бесплатной версии Google Analytics.
Вся ценность, полученная от конверсии, атрибутируется на первый источник, который привел пользователя. Например, если у нас есть цепочка из 4 касаний, как показано ниже, по модели First Click вся ценность от конверсии уйдет CPC каналу.
Плюсы: легко настроить и использовать, так как нет никаких вычислений или аргументов относительно распределения ценности между каналами. Полезна для маркетологов, которые сосредоточены исключительно на формировании спроса и узнаваемости бренда.
Минусы: не показывает всю картину и переоценивает каналы верхнего уровня. В большинстве случаев пользователь делает несколько касаний перед покупкой, которые модель First Interaction полностью игнорирует.
Кому подходит: бизнесам, которые хотят повысить узнаваемость бренда и увеличить охват аудитории, а также понять, где покупать трафик, который потом конвертируется.
По этой модели вся ценность от конверсии достается последнему каналу, с которым соприкоснулся пользователь перед конверсией. Вклад остальных каналов все так же игнорируется. На нашем примере вся ценность достанется каналу Direct.
Плюсы: популярная и привычная многим маркетологам модель. Идеальна для оценки кампаний, направленных на быстрые покупки, например, сезонных товаров.
Минусы: как и все одноканальные модели, игнорирует роль других источников в цепочке перед заказом.
Кому подходит: бизнесам с коротким циклом продаж, которые используют до трех рекламных каналов.
В отчетах Google Analytics эта модель используется по умолчанию. Вся ценность конверсии присваивается последнему каналу в цепочке, НО, если это прямой заход (Direct), то ценность атрибутируется на предыдущий источник. Логика проста — если пользователь перешел к вам из закладок или ввел URL, то он, скорее всего, уже знаком с вашим брендом. То есть это уже привлеченные пользователи, и их не нужно брать в расчет.
Логика проста — если пользователь перешел к вам из закладок или ввел URL, то он, скорее всего, уже знаком с вашим брендом. То есть это уже привлеченные пользователи, и их не нужно брать в расчет.
Плюсы: позволяет игнорировать незначительные с точки зрения рекламных расходов каналы и сосредоточиться на платных источниках. К тому же Last Non-Direct Click можно использовать как базовую для сравнения с другими моделями атрибуции.
Минусы: не учитывает вклад других каналов в конверсию. Кроме того, часто предпоследним источником в цепочке оказывается email. Мы понимаем, что этот пользователь откуда-то раньше приходил и оставил нам свой email. Используя Last Non-Direct Click, мы недооцениваем те источники, которые помогли пользователю ознакомиться с брендом, оставить свой email и в конечном итоге решиться на покупку.
Кому подходит: бизнесам, которые хотят оценить эффективность конкретного платного канала и которым уже не так важна узнаваемость бренда.
Еще одна очень простая модель — мы просто делим ценность от транзакции поровну между всеми источниками в цепочке.
Плюсы: простая, но при этом более продвинутая, чем одноканальные модели атрибуции, так как учитывает все сессии перед заказом.
Минусы: бесполезна, если вам нужно перераспределить бюджет — делить его поровну между каналами не самый оптимальный вариант, так как они не могут быть одинаково эффективны.
Кому подходит: бизнесам с длинным циклом продаж, которым важно поддерживать контакт с клиентом на всех этапах воронки, например, B2B компаниям.
Ценность от транзакции распределяется между каналами по нарастающей. То есть источник, который был первым в цепочке, получает меньше всего ценности, а источник который был последним и по времени ближе всех к конверсии, получает больше всего ценности.
Плюсы: все каналы в цепочке не остаются обделенными и получают свой «кусок пирога». Причем больше всего получает тот, который все-таки подтолкнул пользователя к покупке, что справедливо.
Минусы: сильно недооценивается вклад источников, которые привели пользователя в воронку.
Кому подходит: тем, кто хочет оценить эффективность акционных рекламных кампаний, то есть ограниченных во времени.
БОльшую ценность — по 40% — получают два источника: тот, что познакомил пользователя с брендом и тот, что закрыл сделку. Оставшиеся 20% делятся поровну между всеми каналами в середине воронки.
Плюсы: отдает наибольшую ценность каналам, которые в большинстве случаев играют самую важную роль — привлекают клиента и мотивируют совершить конверсию. Минусы: иногда сессии в середине цепочки продвигают пользователя по воронке намного больше, чем кажется на первый взгляд. Например, помогают ему добавить товар в корзину, подписаться на рассылку или нажать «Следить за ценой». Модель Position Based такие сессии и их источники недооценивает. Кому подходит: бизнесам, для которых одинаково важно как привлечь новую аудиторию, так и конвертировать в покупателей уже имеющихся пользователей.
Согласно исследованию Ad Roll за 2017 год, 44% маркетологов в США и Европе используют атрибуцию по последнему клику. По нашему опыту для рынка СНГ этот процент еще больше. В то же время алгоритмические модели атрибуции на основе данных используют лишь 18% маркетологов. При этом 72,4% тех, кто все еще использует Last Click, отмечают, что они не знают, почему это делают — так сложилось исторически. При выборе модели они отдали предпочтение той, которая выглядит самой простой и понятной, несмотря на то, что она недооценивает все сессии в цепочке, кроме последнего клика.
У происходящего, на наш взгляд, есть три основных причины:
- Недопонимание потенциального эффекта от более сложных моделей атрибуции. К примеру, если вам сказать, что при переходе на алгоритмическую модель вы увеличите доход на 20%, вы перейдете? Скорее всего, да.
- Нет одного человека, который бы отвечал за атрибуцию. В итоге разные маркетологи используют разные модели в рамках одной кампании. В итоге общий атрибутированный доход получается больше реального дохода, который заработал бизнес.
- Разрозненные данные. Модели, доступны в Google Analytics, безусловно удобны — все данные в одной системе, можно использовать стандартные отчеты. Однако эти отчеты ничего не скажут вам об офлайн-данных, об исполняемости ваших заказов, о ROPO-эффекте.

Устранив эти причины, решить задачу атрибуции будет намного проще.
У Google Ads, Double Click и некоторых других сервисов тоже есть собственные модели атрибуции. Их общий недостаток в том, что по сути вы можете использовать для расчетов только внутренние данные сервиса.
Представьте, что вы занимаетесь контекстом, настраиваете рекламу в Google Ads или Facebook. Оценка по последнему непрямому клику покажет, работает эта кампания или нет. Как аудитория на нее откликается. Внутри рекламного кабинета или Google Analytics использовать сложные модели атрибуции не имеет смысла.
Но, если вы хотите оценить взаимное влияние друг на друга всех своих источников, то тут уже нужно объединять в одной системе данные из разных рекламных сервисов, Google Analytics, CRM и использовать более сложные модели атрибуции. Благодаря этому вы узнаете, какие связки рекламных каналов хорошо работают вместе и на каких этапах.
Благодаря этому вы узнаете, какие связки рекламных каналов хорошо работают вместе и на каких этапах.
К алгоритмическим моделям атрибуции относятся Data-Driven в Google Analytics 360, Цепи Маркова, OWOX BI Attribution и кастомные алгоритмы.
Пользователям платной версии Google Analytics доступна модель атрибуции на основе данных. Все описанные выше модели атрибуции, используют правила, которые задает система веб-аналитики или вы сами. В отличие от них, у модели Data-Driven нет заранее заданных правил — она рассчитывает ценность каналов, используя ваши данные и Вектор Шепли.
Особенность модели на основе данных в том, что она не учитывает порядок канала в цепочке, а оценивает в общем, как повлияло на конверсию присутствие этого канала. Если вы измените порядок сессий, то ценность каналов по Вектору Шепли никак не поменяется.
Согласно Википедии, Вектор Шепли — это принцип оптимальности распределения выигрыша между игроками в задачах теории кооперативных игр. Представляет собой распределение, в котором выигрыш каждого игрока равен его среднему вкладу в благосостояние тотальной коалиции.
Представляет собой распределение, в котором выигрыш каждого игрока равен его среднему вкладу в благосостояние тотальной коалиции.
Чтобы понять, как работает Data-Driven, рассмотрим конкретный пример. Допустим, у нас есть две цепочки, которые привели к транзакциям:
- Facebook → Direct → Транзакция на $500.
- Direct → Транзакция на $300.
Мы специально взяли для примера короткие цепочки, чтобы не усложнять и без того сложную формулу.
Теперь определим, какую сумму принес каждый канал в отдельности и оба вместе:
V1 (Facebook + Direct) = $500 V2 (Direct) = $300 V3 (Facebook) = 0
Ценность канала по Вектору Шепли рассчитывается с помощью такой формулы:
Где: n — количество игроков (в нашем случае это рекламные каналы). v — ценность, которую принес источник. k — количество участников коалиции K.
Если мы вставим в эту формулу значения из нашего примера, то получим следующее:
Ф1 = (1–1)! * (2–1)! / 2! * (0–0) + (2–1)! * (2–2)! / 2! * ($500 — $300) = 0 + $100 = $100 Ф2 = (1–1)! * (2–1)! / 2! * (300–0) + (2–1)! * (2–2)! * ($500–0) = $150 + $250 = $400
Ф1 — это ценность канала Facebook. Ф2 — ценность канала Direct.
Ф2 — ценность канала Direct.
А теперь простыми словами, для тех кого напугали формулы 🙂 Начнем с Facebook. Этот канал сам по себе нам ничего не принес, поэтому первое слагаемое у нас будет 0.
Facebook вместе с Direct принесли $500, а Direct самостоятельно принес $300. Мы отнимаем от суммы, которую принесла коалиция каналов, деньги, заработанные директом, и делим результат на два. Получается: ($500 — $300) / 2 = $100. Это второе слагаемое.
Теперь складываем: 0 + $100 = 100$ — это ценность канала Facebook.
Теперь считаем ценность канала Direct. Самостоятельно он принес $300, делим это на два и получаем $150. Коалиция Facebook + Direc принесла $500, делим это на два и получаем $250. Складываем эти цифры и получаем $400 — ценность канала Direct.
Подробнее о том, как работает Вектор Шепли, вы можете посмотреть в видеоролике от Coursera.
Плюсы: максимально объективная и достоверная модель, так как для оценки каналов используются ваши собственные данные.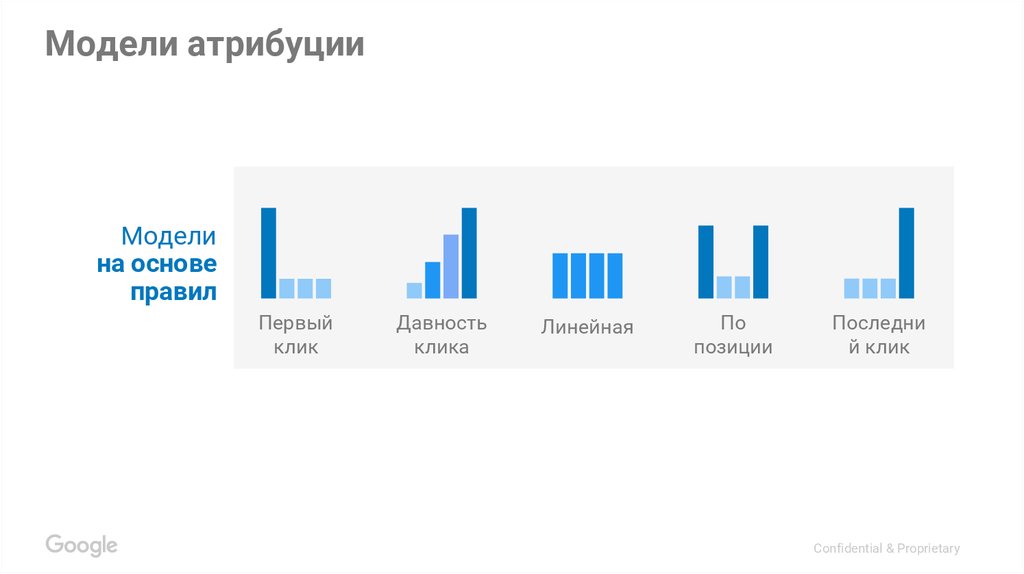
Минусы: для расчета необходимо иметь в Google Analytics достаточный объем данных, поэтому модель подходит не для всех компаний. Не оценивает продвижение по воронке, нельзя подключить офлайн-данные из CRM и посмотреть детальную информацию по каждой транзакции.
Кому подходит: всем, кто хочет узнать, какие кампании и ключевые слова работают максимально эффективно, и использовать эту информацию для распределения маркетингового бюджета. Не подходит для бизнесов, у которых конверсия совершается в одну сессию.
Чем OWOX BI отличается от Google Analytics 360. Атрибуция и маркетинговые отчеты
Согласно Википедии, Цепь Маркова — это последовательность случайных событий с конечным или счетным числом исходов, характеризующаяся тем, что при фиксированном настоящем будущее независимо от прошлого.
Изначально Цепи Маркова использовались, чтобы решать задачи с прогнозированием (погода, букмекерские конторы и т.д.). Использовать их для оценки рекламных кампаний начали относительно недавно — с развитием digital рынка. Атрибуция на основе Цепей Маркова помогает ответить на вопрос, как отсутствие канала повлияет на конверсию.
Атрибуция на основе Цепей Маркова помогает ответить на вопрос, как отсутствие канала повлияет на конверсию.
Чтобы понять, как работают Цепи Маркова, рассмотрим конкретный пример из Ecommerce. Допустим, у нас есть три цепочки:
- С1 → C2 → C3 → Покупка.
- C1 → Неуспешная конверсия.
- C2 → C3 → Неуспешная конверсия.
С1, C2 и C3 — это сессии с тремя разными источниками, например, Google CPC, Facebook и Email.
Заполняем такую таблицу:
В первом столбце у нас путь клиента — три цепочки из примера. Во втором столбце — то, как путь клиента будет выглядеть внутри модели. Мы добавили вход в воронку (нулевой этап Старт) и выход из воронки (Конверсия или null — неудачная конверсия). В третьем столбце мы разбили каналы попарно, так как нужно оценить все возможные переходы с одного шага на следующий. Затем нам нужно рассчитать вероятности для каждого из возможных вариантов перехода и занести их в отдельную таблицу. Эти цифры считаются эмпирически, то есть анализируются реальные данные о действиях пользователей, например из вашего Google Analytics. Делается это при помощи программирования, например, через R или Python.
Делается это при помощи программирования, например, через R или Python.
Цифры в таблице выше приведены для примера. Чтобы было понятно, что это за цифры, отобразим их на графике:
Итак, мы видим все возможные варианты перехода для нашего примера. Все начинается с этапа Старт (start). Затем треть пользователей идет на канал С2, а две трети — на C1. Дальше половина пользователей с канала C1 покидает воронку, а другая половина идет на C2, потом на C3 и наконец совершает покупку. И еще несколько вариантов — перечислять их не будем, думаем, вам понятен принцип.
Обратите внимание, что в нашем примере, путей к конверсии по сути всего два и оба они проходят через канал C2.
Как оцениваются такие сессии? При помощи эффекта удаления. То есть мы удаляем по очереди каждый из источников и смотрим, как его отсутствие скажется на количестве конверсий:
Например, если мы уберем из нашего примера источник C1, то потеряем 50% конверсий. Как получилась эта цифра?
Расчет ценность каналов проводится в три этапа:
1. Сначала нам нужно посчитать вероятность совершения конверсий для каждого из каналов. Точнее, сколько конверсий мы получим, если убрать из цепочки, конкретный канал.
Сначала нам нужно посчитать вероятность совершения конверсий для каждого из каналов. Точнее, сколько конверсий мы получим, если убрать из цепочки, конкретный канал.
Вероятности конверсии (Р) для каждого канала считаются по следующей формуле:
P1 = (0,33 * 1 * 0,5) = 0,167 P2 = (0,33 * 0 * 0,5) = 0 P3 = (0,33 * 1 * 0) = 0
Давайте разберем подробнее первую формулу — это у нас вероятность конверсии для канала C1. Мы убрали из модели канал C1 и перемножили все оставшиеся вероятности перехода из цепочек, которые ведут к покупке. То есть умножили 33,3% на 100% и на 50%, только не в процентном, а в числовом формате. В результате у нас получилось 0,167 или 16,7% — столько конверсий мы получим, если убрать из воронки источник С1.
Если мы уберем каналы C2 и C3, то у нас вообще не будет конверсий.
2. Затем определяем эффект удаления (R) для каждого канала. Этот коэффициент показывает, сколько конверсий мы потеряем, если удалим канал из воронки, и считается так: от единицы (т. е.100%) отнимается вероятность конверсии (P), деленная на количество пользователей в начале цепочки (вероятность перехода).
е.100%) отнимается вероятность конверсии (P), деленная на количество пользователей в начале цепочки (вероятность перехода).
R1 = 1–0,167/0,33 = 0,5 R2 = 1–0 = 1 R3 = 1–0 = 1
3. И наконец считаем ценность (V) каждого канала. Берем процент потерянных конверсий (R) и делим его на сумму всех коэффициентов (R1, R2 и R3)
V1 = 0,5 / (0,5 + 1 + 1) = 0,2 V2 = 1 / (0,5 + 1 + 1) = 0,4 V3 = 1 / (0,5 + 1 + 1) = 0,4
Плюсы: модель атрибуции на основе Цепей Маркова позволяет оценить взаимное влияние каналов на конверсию и узнать, какой канал самый значимый.
Минусы: недооценивает первый канал в цепочке, требует навыков программирования.
Кому подходит: бизнесам, у которых все данные собраны в единой системе.
OWOX BI Attribution помогает оценить взаимное влияние каналов на конверсию и продвижение пользователя по воронке.
Раньше ценность каналов рассчитывалась по собственному алгоритму OWOX BI. А с недавнего времени мы начали использовать в расчетах атрибуции Цепи Маркова. Скоро мы опубликуем подробную статью на эту тему, где опишем все изменения и преимущества нового алгоритма. А пока вы можете попробовать, как работает наша обновленная атрибуция, подписавшись на бесплатный trial-период.
В модели OWOX BI Attribution вы можете использовать следующую информацию:
- Данные о поведении пользователей из Google Analytics, собранные в Google BigQuery с помощью стандартного экспорта из GA 360 или с помощью OWOX BI Pipeline.
- Данные из любых рекламных сервисов, которые вы используете.
- Данные из вашей внутренней CRM-системы.
Все эти данные можно анализировать в комплексе и использовать для настройки шагов воронки (по умолчанию используется воронка Enhanced Ecommerce). Вы можете добавить любые шаги, например, транзакции из СRM и любые другие онлайн- и офлайн-события (звонки, встречи и т. д).
д).
Кроме того мы используем данные из CRM, чтобы сделать аналитику сквозной. То есть мы с помощью одного идентификатора связываем действия пользователя в мобильном приложении, на десктопе, на любых других устройствах, чтобы понимать, что это был один конкретный пользователь. В результате вы получите полную картину взаимодействия пользователя с вашим бизнесом и учтете влияние всех рекламных каналов на конверсию.
Плюсы: позволяет найти эффективный канал и сказать, где именно он эффективен. Нет ограничений на минимальный объем данных. Определяет новых и вернувшихся пользователей и показывает детальную информацию по каждой транзакции: какая сессия, source/medium и действия пользователя на воронке к ней привели. Может учитывать маржу и исполняемость заказов из CRM.
Также вы можете сравнить эффективность рекламы по вашей текущей модели атрибуции и по модели OWOX BI Attribution и увидеть недооцененные или переоцененные кампании.
Минусы: недооценивает первый шаг воронки.
Кому подходит: всем, кто хочет учитывать каждый шаг пользователя в воронке и честно оценивать рекламные каналы.
Согласно все тому же исследованию Ad Roll за 2017, 70% маркетологов затрудняются применять результаты атрибуции. Но без применения результатов атрибуция не имеет смысла!
Неважно, какие у вас есть отчеты в Google Sheets или Google Data Studio — если вы не распределяете бюджет на основе этих данных и ничего не меняете в своей стратегии, то толку от этих отчетов немного.
Всем, кто хочет узнать реальную эффективность своего маркетинга, мы рекомендуем:
- Поставить перед собой четкую задачу: по каким KPI вы хотите оценивать, как должны выглядеть отчеты и дашборды.
- Определить, кто отвечает за оценку рекламных кампаний в вашей компании.
- Определить путь ваших пользователей.
- Учитывать не только онлайн-, но и офлайн-данные
- Убедиться в качестве входящих данных: проверить нет ли на сайте задвоенных транзакций, отслеживается ли каждый шаг, который вы хотите учитывать в воронке.
- Попробовать и сравнить разные модели атрибуции и найти гибкое решение, оптимальное для вашего бизнеса.
- Принимать решения на основе данных.

Если вы не нашли в этой статье модель атрибуции, подходящую для вашего проекта, вы можете настроить кастомную модель, например, как это сделала компания Answear. Пишите нам на [email protected] — с радостью поможем вам настроить атрибуцию. Если у вас остались вопросы, вы можете задать их в комментариях.
Модель атрибуции в маркетинге: что это такое и какую модель выбрать
Модель атрибуции — это правило, по которому распределяется ценность между каналами взаимодействия с потребителем.
В редких случаях пользователь видит рекламу и сразу оформляет заказ. Путь клиента к покупке сложный и запутанный. Впервые он узнает о продукте из ролика на YouTube, переходит на сайт, но ничего не покупает. Потом видит таргетированную рекламу в социальных сетях, кликает по ссылке и подписывается на рассылку. Через несколько дней пользователь получает письмо с купоном на скидку, заходит на сайт и покупает товар.
Каждый шаг приближает клиента к целевому действию. Важность или размер этого шага помогает определить модель атрибуции. Весь путь конверсии берется за 100%, а каждая точка взаимодействия получает значение от 0 до 100.
Модель атрибуции учитывает действия клиента в определенном отрезке времени. Длительность принятия решения о покупке зависит от продукта. Квартиру или машину клиент выбирает несколько месяцев, а с моделью нового чайника определится за 1-2 дня. Период между первым касанием и продажей называется окном конверсии.
Зачем использовать модель атрибуции в маркетинге
Атрибуция в маркетинге помогает:
- распределить бюджет между каналами продвижения;
- оптимизировать расходы на рекламу при оплате за конверсии;
- повысить рентабельность инвестиций в рекламу;
- оптимизировать стратегию продвижения, выявить наиболее эффективные каналы, отказаться от бесполезных.

Модели атрибуции позволяют понять ценность касания в пути конверсии. Важные каналы взаимодействия могут иметь низкую конверсию, но большую ценность.
Например, в точке первого касания аудитория узнает о продукте, заходит на сайт, но доверия еще недостаточно, чтобы совершить покупку. Конверсия на этом этапе может составить менее 1%, но благодаря широкому охвату, который приводит новых клиентов, канал получит от 20% до 100% ценности в зависимости от модели атрибуции.
Виды моделей атрибуции
Ценность каждой точки взаимодействия определяется по выбранной модели. Большинство маркетологов используют простые правила атрибуции: по первому или последнему клику, линейную, с учетом давности. Они доступны в сервисах Google Analytics и Яндекс.Метрика.
Если компания располагает достаточными ресурсами и собирает большой объем данных, она может самостоятельно разработать алгоритм для анализа ценности каналов. Рассмотрим модели, которые чаще всего встречаются в системах аналитики.
Атрибуция по первому взаимодействию
100% ценности присваивается первой точке взаимодействия.
Клиент не знает о продукте и впервые знакомится с компанией через таргетированную рекламу или рекламу в блоге. Данный канал формирует спрос и запускает цепочку событий, которые приведут к покупке. Поэтому его вес составляет 100%.
Плюсы: простая в настройке и использовании, подходит для оценки кампаний по повышению узнаваемости бренда.
Минусы: субъективная, вся ценность присваивается одному каналу, не учитывает вес других касаний.
Атрибуция по последнему взаимодействию
100% ценности присваивается последнему каналу взаимодействия, последнему клику.
Модель выделяет событие, которое напрямую ведет к покупке. Пользователь увидел рекламу или ввел поисковый запрос, кликнул по ссылке и совершил целевое действие. Предыдущие контакты с брендом не учитываются. Используется для продвижения товаров импульсивного или сформированного спроса.
Плюсы: простая в настройке и использовании, выявляет точки контакта с высокой конверсией в продажи.
Минусы: субъективная, вся ценность присваивается одному каналу, не учитывает вес других касаний и историю посещения сайта.
Атрибуция по последнему непрямому взаимодействию
100% ценности присваивается последнему непрямому переходу на сайт, последнему платному клику.
Непрямой переход — это переход по ссылке из внешнего источника трафика: рекламы, поиска, социальных сетей, сайта другой компании.
Пользователь зашел на сайт напрямую, то есть ввел название в строке браузера или открыл из закладок. Затем оставил заявку или купил товар. Но перед этим он заходил на сайт из контекстной или таргетированной рекламы. Модель по последнему непрямому взаимодействию учитывает данный переход и присваивает ему максимальный вес.
Плюсы: среди прямых переходов выделяет те, что получены с помощью рекламной кампании.
Минусы: вся ценность присваивается одному каналу, не учитывает вес других касаний.
Линейная модель атрибуции
Ценность распределяется между точками касания в равных долях.
Подходит для ниш, где внимание клиента нужно удерживать, и поэтому каждый контакт важен и ценен. Модель отражает все каналы, которые участвовали в привлечении клиента.
Плюсы: учитывает все точки контакта с клиентом.
Минусы: нельзя выявить наиболее эффективные касания.
Атрибуция «временной спад» — с учетом давности взаимодействий
Чем ближе во времени точка контакта к целевому действию, тем большая ценность ей присваивается. Вес последних двух каналов обычно составляет от 50% (в Google Analytics) до 80% (в CRM-системах или сервисах аналитики, например Roistat).
Плюсы: учитывает все каналы продвижения, которые участвовали в привлечении покупателя, присваивает больший вес последнему контакту перед покупкой.
Минусы: низкий вес у первых точек касания, которые познакомили клиента с брендом.
Атрибуция по обратной давности работает аналогично. Большая ценность отдается каналам, которые приводят новых клиентов.
Атрибуция с привязкой к позиции
Наибольшая ценность определяется для первой и последней точки контакта — по 40%. Оставшиеся 20% делят между другими касаниями.
Оставшиеся 20% делят между другими касаниями.
U-образная модель используется в рекламных кампаниях, когда первое знакомство с брендом так же важно, как и покупка. Например, компания выпускает на рынок новый бренд. На первом этапе она ставит задачу охватить большую часть целевой аудитории. А на последнем — выявить каналы с наибольшей конверсией в продажи.
Плюсы: отражает все точки взаимодействия, больший вес получают наиболее значимые касания — первое и последнее.
Минусы: не учитывает влияние каналов в середине воронки продаж.
W-образная атрибуция
Распределяет по 30% веса на первое, последнее и ключевое взаимодействие в середине воронки продаж. Оставшиеся 10% делятся между другими каналами продвижения.
Взаимодействие в середине пути подталкивает клиента к покупке. Это может быть рассылка, звонок менеджера, вебинар, таргетированная реклама.
Плюсы: можно добавлять и убирать точки контакта, отслеживать влияние на конверсию в продажу.
Минусы: сложно настроить и не всегда понятно, как каналы в середине воронки продаж повлияли на решение о покупке.
Модель атрибуции полного пути
Если в W-образную схему добавить точку, где пользователь превратился в лида, получится Z-образная модель.
Лид — это потенциальный клиент, который отреагировал на рекламу: оставил заявку или контактные данные, подписался на рассылку, зарегистрировался на мероприятие. Атрибуция полного пути полно и точно отражает все взаимодействия с клиентом от первого контакта до продажи.
Плюсы: позволяет выявить наиболее эффективную стратегию продвижения.
Минусы: сложно настроить и реализовать, нужен большой объем синхронизированных данных.
Атрибуция на основе данных (data-driven)
Оценивает реальную значимость каждого касания независимо от расположения в цепочке продаж. Сложная алгоритмическая модель выявляет закономерности, которые повлияли на решение о покупке.
Существует два способа рассчитать ценность взаимодействия:
- модель по Вектору Шепли оценивает, как присутствие канала повлияло на результат;
- атрибуция на основе цепей Маркова определяет, какое воздействие на конверсию оказывает отсутствие канала.

Плюсы: достоверная и объективная оценка, позволяет оценить взаимное влияние каналов взаимодействия.
Минусы: нужен большой объем данных для корректной работы алгоритмов.
Какую модель атрибуции выбрать для бизнеса
Протестируйте разные модели атрибуции, чтобы найти наиболее результативную и подходящую под текущие цели. На выбор влияют такие параметры, как размер окна конверсии, количество каналов продвижения, объем собираемых данных, маркетинговые задачи.
Окно конверсии. Для ниш с коротким циклом сделки подойдет модель по последнему клику. Если между первым касанием и продажей проходит несколько месяцев или недель, важно определить источник, который впервые привел клиента, и применить правило атрибуции по первому клику или с привязкой к позиции.
Количество каналов продвижения. Чем больше точек взаимодействия с потребителем, тем сложнее модель атрибуции.
Объем собираемых данных. Небольшим компаниям подойдут простые стандартные модели внутри сервисов веб-аналитики. Средние и крупные фирмы, которые собирают и хранят большие объемы данных по рекламным компаниям, могут использовать сложно настраиваемые и алгоритмические модели.
Средние и крупные фирмы, которые собирают и хранят большие объемы данных по рекламным компаниям, могут использовать сложно настраиваемые и алгоритмические модели.
Маркетинговая задача. При выводе нового бренда или продукта важны охваты рекламной кампании. В этом случае предпочтительна атрибуция по первому клику, обратная временная, с привязкой к позиции. Если фирма работает со сформированным спросом и ключевая задача повысить конверсию в продажи, стоит выбрать модель по последнему клику, последнему платному взаимодействию, временной спад, с привязкой к позиции.
Главные мысли
Ценностный подход Shapley к модели мультисенсорной атрибуции
Какой из них подходит для вашего бизнеса?
В области интернет-рекламы, средства массовой информации эффективной оценки является важной частью процесса принятия решений. Поскольку стоимость рекламы зависит от количества кликов или показов, очень важно понимать медиаэффективность каждого действия. Из-за различной природы каждого канала необходимо понимать маркетинговый эффект каждого канала. Поэтому, чтобы понять влияние онлайн-маркетинга, необходимо рассмотреть многоканальную модель атрибуции.
Поэтому, чтобы понять влияние онлайн-маркетинга, необходимо рассмотреть многоканальную модель атрибуции.
Путь клиента
Общие модели анализа атрибуции включают:
- Последний щелчок: последняя точка взаимодействия перед тем, как пользователь приобретет все значения вклада
- Первый щелчок: первая точка взаимодействия на пути доступа пользователя получает все значения вклада
- Линейная модель: все значения вклада точки взаимодействия на пути доступа пользователя в равной степени распределяют значение вклада
- Модель временного распада: более ранние точки взаимодействия на пути доступа пользователя получают большее значение вклада
Модели на основе правил
Multi-Touch Attribution — очень популярный метод маркетинговой науки в цифровом маркетинге. Традиционные модели, основанные на правилах, такие как модель последнего касания (клика) или модель на основе позиции, имеют укоренившиеся предубеждения, которые делают их неэффективными.
Чем больше маркетинговых каналов и более сложных путей поведения клиентов, тем более проницательные модели атрибуции необходимы для определения ценности канала, оптимизации набора каналов и распределения ресурсов. Тонкая разница в каналах может помочь компаниям победить в рыночной конкуренции.
Итак, в чем же заключается маркетинговая модель мультисенсорной атрибуции? К счастью, модель атрибуции на основе данных может обнаруживать изменения канала и корректировать значения веса канала, поэтому в большинстве случаев она будет более точной.
Было предложено несколько моделей, управляемых данными, основанных на различных математических теориях: Марковские модели , теория игр модели, модели анализа выживания и т. д. В этом посте мы рассмотрим только модель теории игр и значение Шепли. Ценность Шепли также применялась в качестве подхода к модели атрибуции на основе данных Google Analytics.
Значение Шепли было разработано лауреатом Нобелевской премии по экономике Ллойдом С. Шепли как подход к справедливому распределению результатов работы команды между ее членами.
В теории игр значение Шепли является концепцией решения справедливого распределения как выгод, так и затрат между несколькими участниками, работающими в коалиции. Значение Шепли применяется в первую очередь в ситуациях, когда вклады каждого участника неравны, но они работают в сотрудничестве друг с другом для получения выигрыша.
Фото Anne Nygård
Маркетинговые каналы — это игроки в совместной игре, и каждый из них можно рассматривать как работающий вместе для увеличения числа конверсий. Другими словами, этот подход справедливо определяет вклад каждой точки взаимодействия в конверсию.
Прежде чем мы начнем, я хотел бы представить ключевые понятия сервала, которые мы будем использовать в последующих вычислениях. Обратите внимание, что я определяю характеристическую функцию просто как сумму конверсий, созданных коалицией.
Обратите внимание, что я определяю характеристическую функцию просто как сумму конверсий, созданных коалицией.
- N = Каналы {Домашняя реклама, Facebook, Электронная почта, Google и т. д.} Это набор игроков
- S = Коалиция, подмножество игроков, каналы работали вместе, где сформировались коалиции.
- |𝑆| является мощностью коалиции 𝑆, и сумма распространяется на все подмножества 𝑆 числа n, не содержащие канал i.
- n = количество N
- v(S) = функция v с действительным знаком, называемая характеристической функцией. Вклад S, который обозначает коалицию N (каналов). Это вес каждого канала после расчета.
- Вес = |S|!(n-|S|-1)!/n!
- Предельный вклад = v(SU {i})-v(S) Приростная взвешенная сумма минус коалиция без v(S)
Значение Шепли можно рассчитать по следующей формуле post, я не собираюсь смущать вас, чтобы объяснить целостную методологию, чтобы показать здесь доказательство. См. здесь для доказательства. Но вам нужно знать, что основная идея метода ценности Шепли заключается в том, что он берет средневзвешенное значение его предельного вклада по всем возможным коалициям для каждого канала.
См. здесь для доказательства. Но вам нужно знать, что основная идея метода ценности Шепли заключается в том, что он берет средневзвешенное значение его предельного вклада по всем возможным коалициям для каждого канала.
Здесь мы будем использовать пример набора маркетинговых данных от Kaggle.
После того, как мы загрузим данные, нам нужно будет сделать некоторые манипуляции. Здесь нам нужны только четыре переменные: user_id, дата, канал, конверсия . Пожалуйста, пометьте преобразование как 1, иначе как 0. И удалите нулевые данные.
Вот код Python для справки.
Вы должны получить подобные результаты.
Следующим шагом мы хотим получить подмножество каналов S, коалиции и сумму их преобразований.
Вывод может выглядеть примерно так:
Код MySQL для ссылки
ВЫБЕРИТЕ подмножество_каналов, сумма (b.conversion) как сумма_конверсии
ОТ(
ВЫБЕРИТЕ user_id, GROUP_CONCAT(DISTINCT(канал)) как подмножество_каналов, макс.
FROM(
SELECT user_id,channel,conversion
FROM demo.simulated_data
ORDER BY user_id,channel
) a
GROUP BY user_id)
b
GROUP BY channels_subset;
 (конверсия) как преобразование
(конверсия) как преобразование Затем мы будем использовать Python для расчета веса и предельного вклада.
Во-первых, нам нужно импортировать модули в Python
import pandas as pd
import itertools
from collections import defaultdict
from itertools import permutations,combinations
import numpy as np
Создайте функцию, которая возвращает все возможные комбинации канал
def power_set(List):
PS = [список(j) для i в диапазоне(len(List)) для j в itertools.combinations(List, i+1)]
return PS
Вернуть все возможные подмножества набора каналов
def subset(s):
'''
Эта функция возвращает все возможные подмножества набора каналов.
input :
- s: набор каналов.
'''
if len(s)==1:
return s
else:
sub_channels=[]
for i in range(1,len(s)+1):
sub_channels.
return list(map(",".join,map(sorted,sub_channels)))
 extend(map(list, itertools.combinations(s, i)))
extend(map(list, itertools.combinations(s, i))) Вычисляет ценность каждой коалиции.
по определению v_function (A, C_values):
'''
Эта функция вычисляет ценность каждой коалиции.
входы:
- A : объединение каналов.
- C_values : словарь, содержащий количество конверсий, полученных каждым подмножеством каналов.
'''
subsets_of_A = subsets(A)
#print(subsets_of_A)
#exit()
value_of_A=0
для подмножества в subsets_of_A:
#print("subset:", subset)
если подмножество в C_values:
#print("подмножество:", подмножество, "; Значение:", C_values[подмножество])
value_of_A += C_values[подмножество]
вернуть value_of_A
Вычислить факториал числа (неотрицательное целое)
def factorial(n):
если n == 0:
вернуть 1
иначе:
вернуть n * factorial(n-1)
Конечный код здесь
def calculate_shapley(df, col_name):
'''
Эта функция возвращает значения Shapley
- df: кадр данных с двумя столбцами: ['channels_subset', 'conversion_sum'].
Столбец channel_subset — это каналы, связанные с конверсией, а количество — это сумма конверсий. 9(n) где n — количество каналов. Если у вас 30 каналов
это 1 073 741 824 комбинации.'''
c_values = df.set_index("channels_subset").to_dict()[col_name]
df['channels'] = df['channels_subset'].apply(lambda x: x if len(x.split( ",")) == 1 else np.nan)
каналов = список (df['channels'].dropna().unique())v_values = {}
для A в power_set (каналы):
v_values [','.join(sorted(A))] = v_function(A,c_values)
#print(v_values)
n=len(каналы)
shapley_values = defaultdict(int)для канала в каналах:
для A в v_values.keys():
#print(A)
если канал не в A.split(","):
#print(channel)
cardinal_A =len(A.split(","))
A_with_channel = A.split(",")
A_with_channel.append(channel)
A_with_channel=",".join(sorted(A_with_channel))
# Weight = |S |!(n-|S|-1)!/n!
вес = (factorial(cardinal_A)*factorial(n-cardinal_A-1)/factorial(n))
# Предельный вклад = v(SU {i})-v(S)
contrib = (v_values[A_with_channel]-v_values[A])
shapley_values[канал] += вес * contrib
# Добавить термин, соответствующий пустому набору
shapley_values[канал]+= v_values[канал]/nreturn shapley_values

Примерные данные, которые мы использовали в этом посте, мы получили результаты ниже
DefaultDict (int,
{'Facebook': 198,50000000000003,
'Instagram': 168.
'Ads' Ads ': 427.83333333333333333333333333333333333333333333333333333333333333333333333333333н3н3н3н3н',
'. Толчок: 74.16666666666669,
'Электронная почта': 146.5})
 0,
0, Наконец-то мы можем это представить.
#visualizations
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
%matplotlib inline
import seaborn as snsresult = DataFrame(list(dict(calculate_shapley(data, "conversion_sum")).items()),columns = ['Канал','Вклады'])# Визуализация
plt.subplots(figsize=(18, 6))
sns.barplot(x='Канал', y='Вклады', данные=результат)
plt. show()
Попробуйте сами!
В этом посте мы рассмотрим, как использовать необработанные данные для создания модели атрибуции на основе данных. Реальные данные еще сложнее, но, по крайней мере, вы понимаете, как это работает.
Я также планирую написать еще один пост о методе цепей Маркова для мультитач-модели атрибуции с использованием R и Python. Следите за обновлениями!
Следите за обновлениями!
Хорошо, дайте мне знать, что вы думаете ниже. Если вам нравится этот пост, нажмите кнопку хлопков ниже и не забудьте поставить поделитесь им в социальных сетях .
Размещение истории университетского письма
Натан Шепли
Копия отредактирована Джулией Смит. Дизайн Майк Палмквист.
В Размещение истории письма в колледже Натан Шепли утверждает, что история композиции до 1950-х годов, если ее анализировать с помощью правильных концептуальных инструментов, может расширить и прояснить наше понимание взаимосвязи между письмом студентов колледжа и физическим, социальное и дискурсивное окружение. Шепли показывает, что даже если непосредственным результатом студенческого письма является получение академического кредита, письмо выполняет более сложную риторическую работу. Это дает учащимся возможность поддерживать или корректировать институциональные кодексы поведения учащихся, позволяет учащимся и их спонсорам грамотности реагировать на социально-политические проблемы в городе или штате, позволяет преподавателям и администраторам создавать стратегические представления институциональной или программной идентичности и связывает людей из разных дисциплин. , занятия и географическое положение. Шепли утверждает, что даже если многие из сегодняшних ученых и преподавателей композиции работают в учреждениях, в которых отсутствуют обширные исторические записи, которые обычно предпочитают историки композиции, эти ученые и преподаватели могут копаться в своих институциональных коллекциях в поисках признаков различных контекстов, с которыми имел дело студенческое письмо.
, занятия и географическое положение. Шепли утверждает, что даже если многие из сегодняшних ученых и преподавателей композиции работают в учреждениях, в которых отсутствуют обширные исторические записи, которые обычно предпочитают историки композиции, эти ученые и преподаватели могут копаться в своих институциональных коллекциях в поисках признаков различных контекстов, с которыми имел дело студенческое письмо.
Содержание
Открыть всю книгу: В формате PDF В формате ePub
Вступительная часть
Благодарности
Третья: Отслеживание линий коммуникации: Письмо учащихся как ответ на гражданские вопросы
Глава четвертая: Демонстрационная композиция: Учащиеся, демонстрирующие компетенцию колледжа
Глава пятая: Переосмысление связей между историями композиции
Глава шестая: Композиция как грамотность, дискурс и риторика
Процитированные работы
Глоссарий
Об авторе
Натан Шепли — доцент Хьюстонского университета английского языка , где он преподает курсы бакалавриата и магистратуры по риторике и композиции. Помимо истории композиции, его области специализации включают педагогику композиции, а также экологические и неоософские теории письма. Его статьи появились в Изучение композиции , Инкультурация , Форум композиции и Open Words: Access and English Studies .
Помимо истории композиции, его области специализации включают педагогику композиции, а также экологические и неоософские теории письма. Его статьи появились в Изучение композиции , Инкультурация , Форум композиции и Open Words: Access and English Studies .
Информация о публикации: Шепли, Натан. (2015). Размещение истории студенческой письменности: рассказы из неполного архива . Информационная служба ВААК; Салон Пресс. https://doi.org/10.37514/PER-B.2015.0711
Дата публикации в Интернете: 25 октября 2015 г.
Дата публикации в печати: 21 марта 2016 г.
ISBN: 9781642150711 (pdf) | 9781642150728 (epub) | 9781602358010 (pbk.)
DOI: 10.37514/PER-B.2015.0711
Контактная информация:
Nathan Shepley: [email protected]
Perspectives on Writing
Редакторы серии: Susan H.