Содержание
Как ускорить базу данных при помощи шардирования / Хабр
Шардирование было одним из первых механизмов, позволяющих распределять базы данных для повышения их производительности. Последние инновации превратили шардирование в один из лучших механизмов в своем роде.
Сегодня базам данных уделяется особое внимание, так как через них компания управляет своим самым ценным архивом: информацией. Всего 30 лет назад большинство данных хранилось на бумаге, магнитной ленте или каких-либо дисках. Поскольку мы производили и потребляли гораздо меньше данных на душу населения, даже на таких носителях нам удавалось эффективно хранить их, управлять ими и обращаться к ним.
Но сегодня с данными складывается совершенно иная ситуация. Смартфоны распространились повсеместно и превратились в необходимую вещь. Вместе со смартфонами увеличилось количество мобильных приложений, и сегодня через них производятся и потребляются такие объемы данных, какие были просто немыслимы 15 лет назад. В такой ситуации серьезно возрастает нагрузка на кластеры баз данных, поскольку им приходится обрабатывать все более серьезные объемы трафика. Некоторые из топовых веб-сайтов и веб-сервисов обрабатывают миллиарды посещений в неделю.
Некоторые из топовых веб-сайтов и веб-сервисов обрабатывают миллиарды посещений в неделю.
Как справиться с таким невероятным объемом трафика, поступающим в кластер базы данных?
Можно попробовать шардирование. Возможно, вы никогда и не слышали о таком подходе, либо по-быстрому отбраковывали его как старомодное решение, не отвечающее современным вызовам. Сам феномен «шардирования баз данных» едва ли сулит полный набор примочек, какими могли бы похвастаться другие решения, но этот подход определенно эффективен и практичен.
Не так давно этот подход обогатился существенными инновационными дополнениями, позволившими реализовать продвинутое шардирование с таким набором возможностей, который еще недавно показался бы немыслимым. В частности, стоит упомянуть распределенный SQL, благодаря которому стало гораздо легче выполнять шардирование и управлять шардами. Может быть, именно поэтому так возросла популярность шардирования среди блокчейновых компаний, стремящихся к максимальному масштабированию.
Фрагментация баз данных
Базы данных существуют уже более 50 лет. Может показаться, что к нашему времени в них уже не внести ничего инновационного, однако фрагментация баз данных – одна из самых быстроразвивающихся вертикалей в современной технической индустрии. По-видимому, сложность, присущая имеющимся ныне инфраструктурам данных, в будущем станет только усугубляться.
Многие современные приложения выстраиваются поверх множества баз данных, зачастую – узкоспециализированные. Единственное приложение может быть оснащено реляционной базой данных для хранения содержимого и обращения к нему (напр. PostgreSQL), базу данных в оперативной памяти (напр. Redis) для кэширования контента, собственную базу данных, например, для ведения временных рядов, а также склад данных для аналитики. Теперь попробуйте вообразить, как все это будет реализовано в бизнесе, работающем со множеством приложений, множеством отделов, в каждом из которых есть собственное приложение или, хуже того, взаимодействующем с разными вендорами.
Как упоминалось выше, данные превратились в один из важнейших активов любого бизнеса. В последнее время развитие технологий баз данных существенно ускорилось, и это, пожалуй, коррелирует с развитием искусственного интеллекта, машинного обучения, блокчейна и облачных технологий, которые также развиваются очень быстро.
По данным сайта DB-Engines, существует более 350 систем управления базами данных, но на самом деле их гораздо больше, многие даже не попали в этот список.
Согласно “Базе данных баз данных”, составленной в университете Карнеги-Меллона, в настоящее время существует 792 различных систем управления базами данных, которые заслуживают упоминания.
Такое разнообразие систем управления базами данных (СУБД) демонстрирует, насколько широк спектр возможных требований, которые может предъявлять и должен учитывать бизнес, когда приходится выбирать систему управления базой данных.
Например, банк или финансовая организация может выбрать реляционную СУБД, такую как SQL Server или PostgreSQL, чтобы обеспечить сумму свойств ACID (atomicity, consistency, isolation, durability = атомарность, согласованность, изоляцию, надежность) при транзакциях со структурированными данными. Бизнес, занятый поддержкой крупномасштабной онлайновой многопользовательской игрой или веб-приложениями, работа с которыми требует начинать и завершать сеансы, предпочтет базу данных типа NoSQL, состоящую из ключей и значений – такую как Redis. В свою очередь, бизнес, занимающийся аналитикой в социальных сетях, как правило, пользуются графовыми базами данных. Если же бизнес работает с Интернетом Вещей (IoT), то такой компании подойдет база данных для работы с временными рядами, хорошо поддерживающая данные с сенсоров или сетевые данные.
Бизнес, занятый поддержкой крупномасштабной онлайновой многопользовательской игрой или веб-приложениями, работа с которыми требует начинать и завершать сеансы, предпочтет базу данных типа NoSQL, состоящую из ключей и значений – такую как Redis. В свою очередь, бизнес, занимающийся аналитикой в социальных сетях, как правило, пользуются графовыми базами данных. Если же бизнес работает с Интернетом Вещей (IoT), то такой компании подойдет база данных для работы с временными рядами, хорошо поддерживающая данные с сенсоров или сетевые данные.
Если такой выбор вам по душе, то добро пожаловать к столу, поскольку в ближайшие годы на рынке будут появляться все новые и новые решения. Их будут предлагать как новые инновационные стартапы, так и состоявшиеся вендоры баз данных, выпускающие новые продукты или улучшающие уже обкатанные решения.
В ближайшем будущем рынок баз данных ждет только дальнейшая фрагментация. Такая фрагментация сопряжена с серьезными вызовами, навскидку — с совместимостью технологий от разных вендоров, адаптируемостью унаследованных систем, с восстановительной стоимостью.
Для чего требуется шардирование
Традиционные базы данных порой не справляются с обработкой растущих объемов данных и нарастающего трафика запросов. Сегодня очень популярны концепции NoSQL и NewSQL – соответственно, на рынке баз данных появляется все больше продуктов, вдохновленных этими новыми концепциями. Но их одних недостаточно, чтобы решить все более серьезные проблемы с данными.
Шардирование – это прием, позволяющий разбивать данные на отдельные строки и столбцы, хранимые на отдельных инстансах серверов базы данных. Так удается распределить нагрузку, оказываемую трафиком. Каждая такая малая таблица называется «шард». Некоторые NoSQL-продукты шардируются, таковы, например, Apache HBase или MongoDB. Шардинговая архитектура встроена в NewSQL-системы.
Рассмотрим NewSQL-архитектуру конкретного типа: как в ней применяется шардирование, и как оно соотносится с современными проблемами OLTP (онлайновой обработки транзакций).
Притом, что существует много решений, позволяющих минимизировать нагрузку на базу данных, шардирование отличается следующими серьезными преимуществами:
- Хранение данных распределяется на множестве машин;
- Легко сбалансировать между разными шардами нагрузку, которую оказывает трафик;
- Значительно улучшается производительность запросов;
- Масштабирование баз данных обеспечивается без дополнительной работы;
- Традиционные СУБД легко обновлять и эффективно многократно использовать;
- При шардировании разные пользователи получают совместный доступ к единственному серверу или к ресурсам для облачных вычислений, поскольку, благодаря использованию прокси, в данном случае поддерживается многоарендный подход (multi-tenancy).
Как шардировать базу данных
Ниже представлен базовый рабочий цикл, позволяющий реализовать шардирование в СУБД. Обсудив устройство и основополагающие идеи этой технологии, ниже мы углубленно расскажем о некоторых наиболее существенных аспектах.
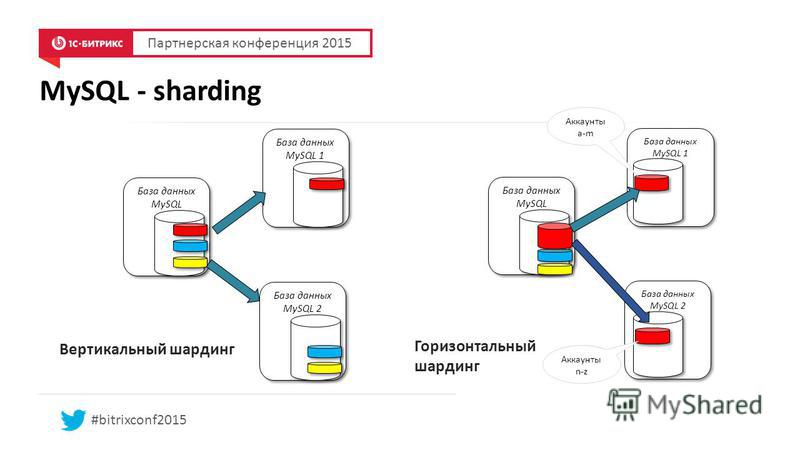
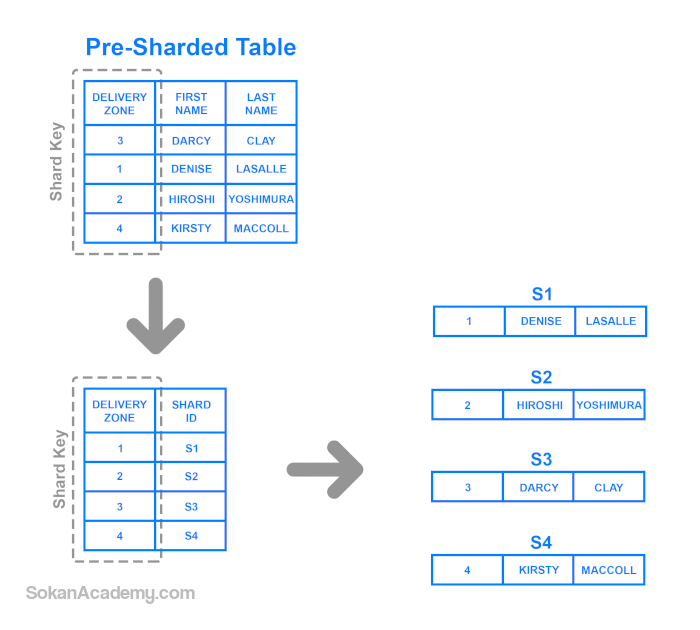
Один из наилучших способов создания шардов таков: данные нужно разделять на множество небольших таблиц. Они также называются «сегментами» (partitions).
Исходную таблицу можно разделить на вертикальные или горизонтальные шарды – то есть, хранить в отдельных таблицах один или более столбцов либо одну или более строк. Эти таблицы можно обозначить ‘VS1’ для вертикальных шардов и ‘HS1’ для плоских шардов. Число соответствует первой таблице или первой схеме. The number represents the first table or the first schema. Then 2, then 3, and so on. When taken together, these subsets of data comprise the table’s original schema.
Вот две ключевые составляющие шардирования:
- Шардинговый ключ: конкретное значение в столбце, указывающее, в каком шарде хранится данная строка.
- Шардинговый алгоритм: алгоритм, согласно которому ваши данные распределяются в одном или нескольких шардах.
Шаг 1: Проанализировать сценарий запроса и распределение данных, чтобы найти шардинговый ключ и шардинговый алгоритм
Чтобы определить, в каком шарде будет храниться каждая конкретная строка, шардинговый алгоритм применяется к шардинговому ключу.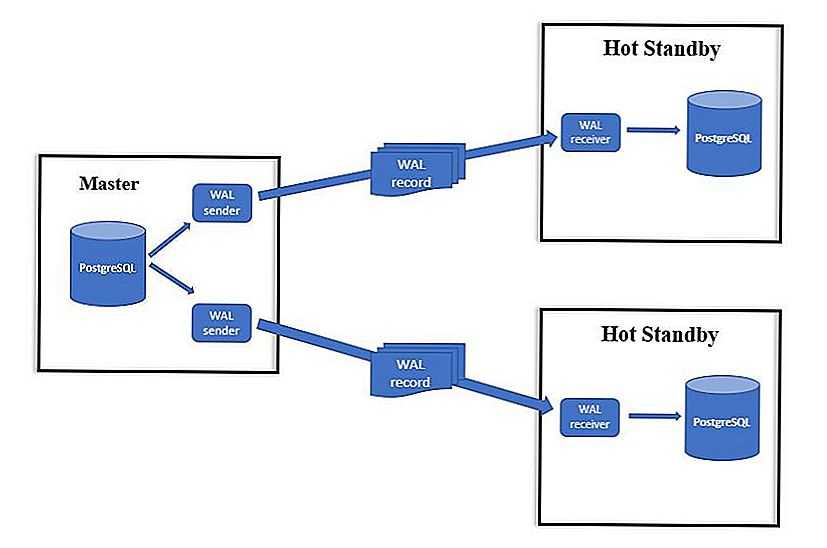 Различные стратегии шардирования вписываются в разные сценарии. Вот распространенные стратегии:
Различные стратегии шардирования вписываются в разные сценарии. Вот распространенные стратегии:
- MOD: сокращенно от «модульный». В данном случае каждая n-ная строка или каждый n-ный столбец отправляются в конкретный шард. Например, алгоритм MOD 3 отправит в первый шард первую, четвертую и седьмую строки, во второй шард – вторую, пятую и восьмую строки, в третий шард – третью, шестую и девятую строки и т. д.
- HASH: При хеш-шардировании данные распределяются по шардам равномерным случайным образом. Каждая строка таблицы попадает в тот или иной шард, согласно вычисленному согласованному хешу значений столбцов шарда для данной строки.
- RANGE: этот алгоритм отправляет конкретные диапазоны строк или столбцов в отдельные шарды.
- TAG: этот алгоритм отправляет в один шард все строки или столбцы, соответствующие конкретному значению.
Например, при шардинговом ключе “ID” и шардинговом алгоритме “ID modulo 2” (который делит все строки на четные и нечетные), строки будут сортироваться примерно так:
Следовательно, ваша задача – спроектировать подходящий алгоритм, использующий шардинговый ключ.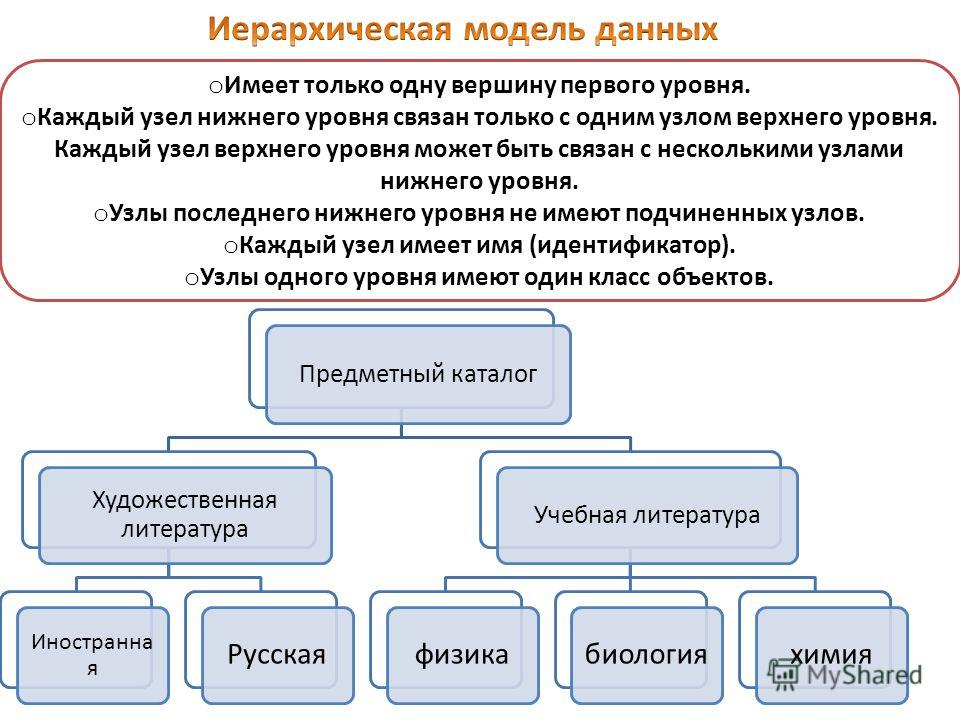 Выбранная вами стратегия шардирования существенно повлияет на эффективность запросов, а в дальнейшем – на горизонтальное масштабирование. Неподходящий или плохой шардинговый алгоритм всегда создает в шардах избыточные данные, которые нужно вычислить, что приводит к общему снижению вычислительной производительности.
Выбранная вами стратегия шардирования существенно повлияет на эффективность запросов, а в дальнейшем – на горизонтальное масштабирование. Неподходящий или плохой шардинговый алгоритм всегда создает в шардах избыточные данные, которые нужно вычислить, что приводит к общему снижению вычислительной производительности.
Ключевыми моментами, которые нужно учитывать, решая, как шардировать базу данных, являются характеристики бизнес-запроса и распределение данных. В каждой базе данных найдутся уникальные факторы, которые повлияют на это решение, но здесь можно рассмотреть для примера несколько сценариев, которые помогут понять, как хороший шардинговый алгоритм эффективно распределяет данные.
RANGE
Например, когда при шардировании таблицы требуется учитывать детальные данные из логов, снабженные метками времени, рекомендуется использовать для шардирования алгоритм RANGE, где шардинговым ключом служит дата создания записи. Причина в том, что традиционно такие подробные записи запрашиваются только в пределах конкретного временного диапазона.
При использовании даты и времени алгоритм RANGE может вызывать другую проблему: обычно сравнительно давние исторические записи обновляются нечасто, а свежие записи и обновляются, и запрашиваются часто. Поэтому большинство запросов будет попадать в шард с самыми свежими записями. Таким образом, большинство запросов будут конкурировать друг с другом за получение исключительных прав на обновление данных.
MOD
Шардинговый алгоритм MOD способен эффективно избегать такой жаркой конкуренции. Он делит строки по принципу ‘shardingKey MOD количество шардов’. Новейшие строки будут распределяться по разным шардам, чтобы за эти строки не разыгрывалась конкуренция. Когда шардинговый ключ – это строковое значение (потенциально не подлежащее раскрытию), можно воспользоваться алгоритмом HASH. Он создает значение, которое алгоритм MOD может использовать для распределения данных по шардам.
TAG
Но случается и так, что данные предпочтительно шардировать по значению ячейки. В таком случае вам подойдет шардинговый алгоритм TAG. Предположим, что, ради соответствия общему регламенту по защите данных (GDPR) вы хотите хранить все данные, относящиеся к ЕС, на сервере, расположенном в ЕС. Как в таком случае шардировать распределенную базу данных?
В таком случае вам подойдет шардинговый алгоритм TAG. Предположим, что, ради соответствия общему регламенту по защите данных (GDPR) вы хотите хранить все данные, относящиеся к ЕС, на сервере, расположенном в ЕС. Как в таком случае шардировать распределенную базу данных?
Если администратор БД использует шардинговый алгоритм TAG, то строки с данными из помеченных стран могут направляться на конкретные шарды, физически расположенные в подходящей стране. Чтобы выяснить, сколько записей будет при этом затронуто, наша щардинговая система базы данных для ответа на такой запрос всего лишь должна вернуть COUNT(*) из шарда, относящегося к ЕС: SELECT COUNT(*) FROM registrant_table WHERE region = "EU". Распределенный запрос, который должен вычислить конечный результат для целой распределенной системы, превращается в простой единичный запрос от одного шарда.
Здесь нет панацеи на все случаи жизни. Чтобы добиться максимально возможной производительности, уделите время тщательному анализу вашего конкретного бизнес-сценария. Если вас интересует быстрый старт, то распределенная шардинговая система БД обычно может подхватить распространенную стратегию, которая подойдет для большинства практических случаев.
Если вас интересует быстрый старт, то распределенная шардинговая система БД обычно может подхватить распространенную стратегию, которая подойдет для большинства практических случаев.
Шаг 2: Миграция имеющихся данных
Если вы решили реализовать шардирование, то необязательно переносить все оригинальные данные в шардинговый кластер. Это совсем не просто, так как вы столкнетесь со следующими проблемами:
- Как шардировать данные, если бизнес работает круглосуточно и без выходных
- Как воспроизвести инкрементные данные в новом шардинговом кластере
- Как сравнить данные между оригинальной базой данных и новым шардинговым кластером
- Как найти наилучший момент, чтобы перенаправить трафик в новый шардинговый кластер
Правда, если вы решите перенести в шарды исторические данные, то традиционно это делается так:
- Во-первых, перед переносом исторических данных в шардинговый кластер новой базы данных их нужно сегментировать при помощи вашего шардингового алгоритма.
 Рекомендую пользоваться программой для автоматического переноса данных, которая автоматически выполнила бы все необходимые SQL-запросы.
Рекомендую пользоваться программой для автоматического переноса данных, которая автоматически выполнила бы все необходимые SQL-запросы. - Во-вторых, запустите платформу или программу, которая вытянет и распарсит лог базы данных – так можно будет понять, какие изменения возникли в процессе сегментирования, и применить эти изменения в новом шардинговом кластере (сделать шарды с инкрементными данными).
- В-третьих, выберите стратегию проверки данных, чтобы сравнить данные в оригинальной базе данных и новом шардинговом кластере. Такие стратегии отличаются гибкостью и обеспечивают любые варианты от «очень точно» до «очень быстро» — либо позволяют уравновесить эти крайности. Именно от вас зависит, хотите ли вы сравнить варианты с точностью до ячейки, либо просто проверить общую сумму. Если нужно подобрать максимально точную стратегию проверки данных, то наиболее ресурсоемкой будет проверка всех строк по порядку, тогда как проверка только суммы по строкам для оригинальных и новых кластеров потребует меньше всего времени – но придется пожертвовать точностью. Другие стратегии, например, CRC32, позволяют соблюсти баланс между точностью и скоростью.
 Рекомендую пользоваться программой для автоматического переноса данных, которая автоматически выполнила бы все необходимые SQL-запросы.
Рекомендую пользоваться программой для автоматического переноса данных, которая автоматически выполнила бы все необходимые SQL-запросы.
 Другие стратегии, например, CRC32, позволяют соблюсти баланс между точностью и скоростью.
Другие стратегии, например, CRC32, позволяют соблюсти баланс между точностью и скоростью.
Шаг 3: Перебросить трафик на новый кластер
Если предположить, что все вышеописанные шаги прошли гладко, то на следующем этапе перебросим онлайновый трафик на ваш новый шардинговый кластер. Это должно быть сделано, пока невозможна запись в кластер баз данных, так, что два множества данных остаются согласованными и поддерживаются опциональные запросы. Как правило, этот шаг выполняется в период минимальной загруженности.
Для обеспечения согласованности распределенных данных все запросы на обновление должны быть запрещены, но запросы при этом разрешаются, поскольку запрос не вносит никаких изменений в распределенную систему.
Этот процесс достаточно прямолинеен, но обработка каждого из его этапов может оказаться нетривиальной. Если переход автоматизирован, то минимизируется длительность простоя; однако, при этом рекомендуется известная осторожность, поскольку вы будете обращаться с ценными данными.
В данном случае отрадно, что не вы первый сталкиваетесь с такими вызовами. Благодаря опенсорсным проектам, мы можем стоять на плечах гигантов.
Среди основных возможностей Apache ShardingSphere (контрибьютором которого является автор поста) – возможность проведения всего шардирования целиком. В этом инструменте предусмотрены различные шардинговые стратегии, обеспечена миграция данных, решардинг и управление имеющимися шардами.
Также здесь предоставляются и более продвинутые функции – они помогают с устранением проблем, рассмотренных в следующем разделе. В качестве бонуса Apache ShardingSphere может похвастаться активным сообществом – а значит, что большинство ваших проблем уже кем-то решались.
В чем заключается качественное шардирование
Теперь вы понимаете, каков поток задач при шардировании, и какие шаги необходимы при шардировании базы данных. Но каковы признаки хорошего шардирования?
Не будем вдаваться в детали сомнительных теорий или в контекст и требования, специфичные для конкретных сценариев. В целом хорошее шардирование обладает шестью качествами.
В целом хорошее шардирование обладает шестью качествами.
Такое шардирование легко настраивается, при нем легко понять, изменился ли администратор БД, выполняющий операции. Хорошее шардирование характеризуется высокой доступностью, возможностью эластичного горизонтального масштабирования, высокой производительностью распределенных систем, отслеживаемостью и низкими издержками при миграции данных.
При наличии всех этих шести характеристик шардирование можно считать идеальным, но в целом его качество зависит и от выбранного вами шардингового клиента.
Используем шардирование и репликацию
Кроме основного потока задач, описанного выше, разберитесь в перечисленных ниже элементах, поскольку сценарии работы с базой данных разнообразны, а по мере масштабирования приложения и ваши потребности будут меняться.
Кроме того, повысить производительность и улучшить масштабируемость базы данных можно путем репликации. Репликация подразумевает дублирование узлов базы данных, причем, такие узлы действуют независимо друг от друга. Данные, записанные на одном узле, затем реплицируются на его узле-дублере.
Данные, записанные на одном узле, затем реплицируются на его узле-дублере.
Вообще, как профессиональные разработчики, так и программисты, ведущие проект для души, выжимают из баз данных максимум, чтобы обеспечить высокую доступность и производительность. Тем не менее, если архитектура предусматривает шардирование и репликацию, это может осложнять как управление базой данных, так и стратегию маршрутизации.
Предположим, у каждого шарда есть узлы-реплики. Получается структура, напоминающая приведенный ниже график. Если у одного узла будет более одной реплики, то для всех приложений, обращающихся к базе данных, ситуация быстро деградирует.
Итак, чем же отличаются шардирование и репликация? Как рассмотрено выше, при шардировании одна таблица дробится на множество более мелких – так получаются многочисленные шарды. При репликации, в свою очередь, создается много реплик исходной таблицы. В каждой реплике будет содержаться полный набор данных с оригинала (ведущего узла).
Шардирование помогает пользователю сбалансировать нагрузку при работе с данными, существующими на множестве серверов – так обеспечивается масштабируемость. Репликация, в свою очередь, позволяет создавать резервные копии основной базы данных, чтобы увеличить доступность системы. Две эти архитектуры разные, и они привносят разные преимущества в распределенную систему. Рассуждая именно так, некоторые пользователи хотят одновременно располагать обеими этими возможностями, поэтому довольно часто встречаются смешанные архитектуры, одновременно опирающиеся как на шардирование, так и на репликацию.
Репликация, в свою очередь, позволяет создавать резервные копии основной базы данных, чтобы увеличить доступность системы. Две эти архитектуры разные, и они привносят разные преимущества в распределенную систему. Рассуждая именно так, некоторые пользователи хотят одновременно располагать обеими этими возможностями, поэтому довольно часто встречаются смешанные архитектуры, одновременно опирающиеся как на шардирование, так и на репликацию.
Как показано на следующей иллюстрации, пользователь, возможно, захочет шардировать по разным серверам (например, P1, P2, P3) одну базу данных, содержащую колоссальный объем информации. Каждый запрос также будет разбиваться по разным шардам, ради улучшения показателей TPS (транзакции в секунду) или QPS (запросы в секунду) данной распределенной системы. Однако, если один из шардов откажет, то доступность системы снизится до 2/3. Более того, понадобится немало времени, чтобы поднять еще одну копию оффлайновой версии, часть данных будет потеряна, и последствия будут тяжелыми. Эффективный способ повысить доступность шардированной системы – организовать репликацию каждого шарда, то есть, вышеупомянутых ведущих узлов P1, P2, P3.
Эффективный способ повысить доступность шардированной системы – организовать репликацию каждого шарда, то есть, вышеупомянутых ведущих узлов P1, P2, P3.
Вышеописанное решение проиллюстрировано ниже, и нужно обратить внимание на R1, R2, R3. Когда P1 недоступен, его реплика R1 будет повышена в правах до ведущего узла, чтобы влиться в полноценное обслуживание бизнеса. Это безопасный вариант, продуманный с учетом того, что, чем меньше продлится отказ, тем меньше будут потери для вашего бизнеса и услуг.
Идея кажется отличной, но топология такой распределенной шардированной системы базы данных осложняет посещение приложения. Допустим, каждому ведущему узлу принадлежит две реплики. В таком случае, сеть, состоящая из P1, P2, P3 и шести их реплик запутает и обременит разработчиков, поставив, например, такие вопросы: какой из ведущих узлов лучше всего подходит для данного запроса? Как посетить одну из реплик? Как сбалансировать нагрузку между разными репликами? Кто поможет мне перенаправить данный запрос, если ведущий узел окажется неработоспособен?
В нашем гипотетическом сценарии ответственность разработчика – в том, чтобы эффективно писать код для бизнеса. У описанной здесь примечательной архитектуры в самом деле есть достоинства, но она слишком сложна в использовании и поддержке.
У описанной здесь примечательной архитектуры в самом деле есть достоинства, но она слишком сложна в использовании и поддержке.
Как вынести эту сложность за пределы приложения?
Обычно существует два типа клиентов или режимов доступа, предоставляемых на выбор пользователям, плюс еще один «бонусный» тип клиента. Стимулом к шардированию может послужить некий фактор, требующий соединения со специализированной базой данных, либо подключение вашего приложения к прокси-приложению, которое маршрутизирует данные.
Среди доступных режимов шардирования есть сравнительно новая концепция «прицеп» (sidecar), впервые возникшая в сервисных сетях. Проще говоря, это прокси-инстанс, развертываемый с целью обработки коммуникации, мониторинга, т.д. – наряду с другими службами. Концептуально такой сервис похож на коляску мотоцикла. Подобно коляске, он подцепляется к главному приложению и обеспечивает для него вспомогательные функции.
Если вместо прицепа воспользоваться выделенным драйвером или прокси, то вся система будет действовать и выглядеть как единый сервер базы данных, который поможет пользователям управлять имеющимся кластером. Таким образом, эти сложные топологии посещения не отразятся на приложениях, и данные топологии не придется рефакторить, чтобы адаптировать их к новому фреймворку.
Таким образом, эти сложные топологии посещения не отразятся на приложениях, и данные топологии не придется рефакторить, чтобы адаптировать их к новому фреймворку.
Заключение и существующие тренды
Шардирование – это один из способов справиться с новыми вызовами, возникающими в ходе эволюции сетевых приложений. Среди других подобных решений – база данных как услуга (DBaaS) или облачная база данных, новые архитектуры базы данных или просто дедовский метод – увеличить количество баз данных, используемых в качестве хранилищ информации.
Итак, мы сделали полный круг и вернулись к началу. Надеюсь, этот опус послужил вам введением в шардинговую архитектуру и помог с ней познакомиться, тем более, если вы уже слышали о таких архитектурах, но отметали их из-за кажущейся старомодности. Возможно, теперь ваше мнение изменилось.
Мне не нравится слово «мода», поскольку мода кажется мне чем-то мимолетным, сегодня она актуальна, а завтра ее нет.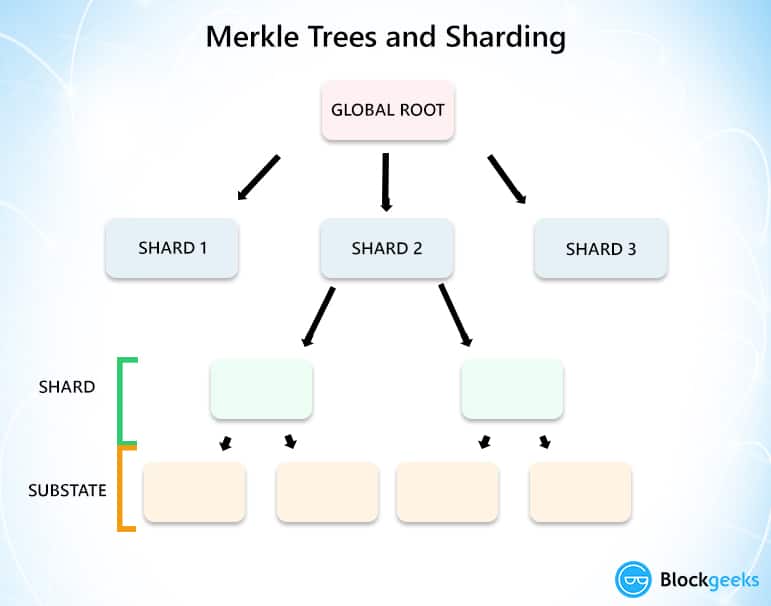 В то время, что именно так и бывает со многими вещами в жизни, и особенно в технологиях, я предпочитаю судить о технологии по ее практичности, эффективности и экономности при конкретном сценарии.
В то время, что именно так и бывает со многими вещами в жизни, и особенно в технологиях, я предпочитаю судить о технологии по ее практичности, эффективности и экономности при конкретном сценарии.
При этом хорошо бы всегда откликаться на новые тенденции, не забывая, что порой уже имеющиеся и зрелые технологии предлагают наилучшее возможное решение.
Ссылки:
- db.cs.cmu.edu/papers/2016/pavlo-newsql-sigmodrec2016.pdf
- github.com/apache/shardingsphere
- opensource.com/article/21/9/distsql
Шардирование | это… Что такое Шардирование?
| Возможно, эта статья содержит оригинальное исследование. Добавьте ссылки на источники, в противном случае она может быть выставлена на удаление. |
Шардирование это горизонтальное партиционирование баз данных в компьютерном кластере.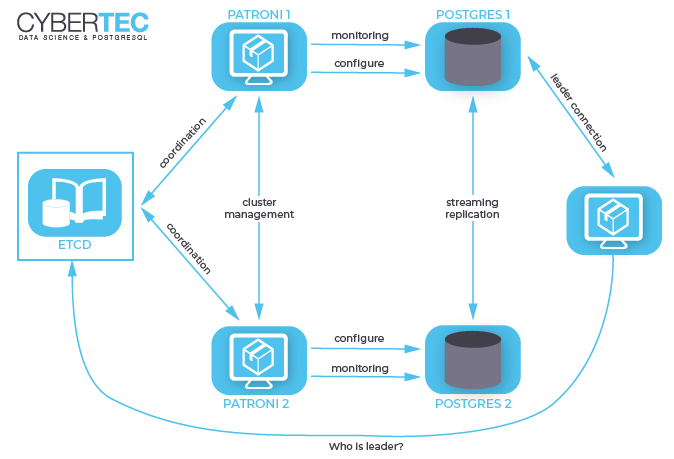
Архитектура базы данных
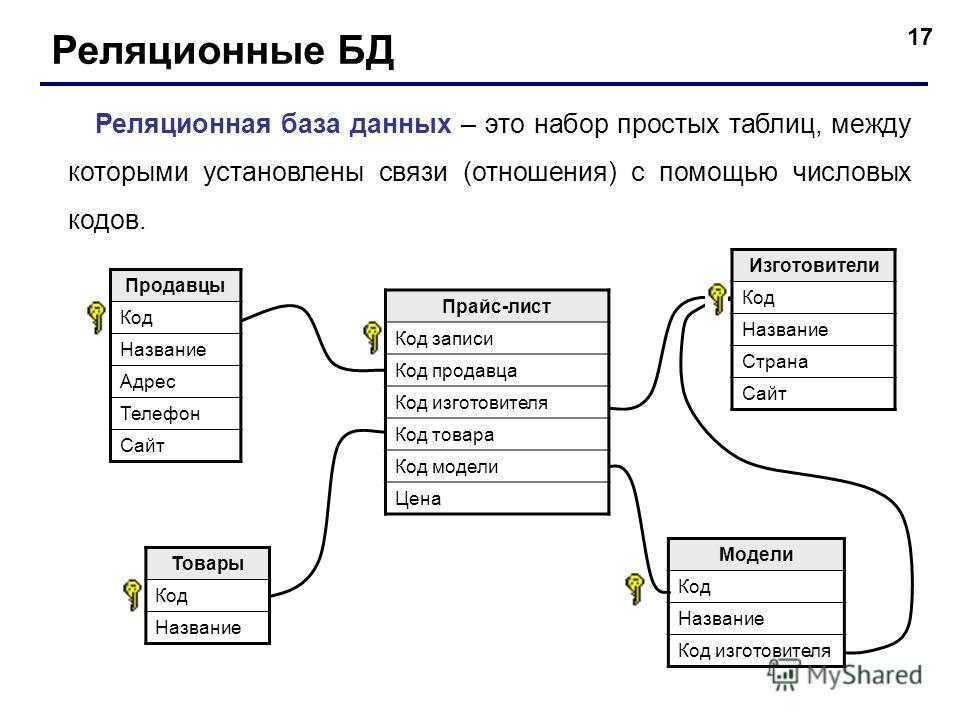
Горизонтальное партиционирование — это принцип проектирования базы данных, при котором логически независимые строки таблицы базы данных хранятся раздельно, заранее сгруппированные в секции, которые, в свою очередь, размещаются на разных, физически и логически независимых серверах базы данных, при этом один физический узел кластера может содержать несколько серверов баз данных. Наиболее типовым методом горизонтального партицирования является применение хеш функции от идентификационных данных клиента, которая позволяет однозначно привязать заданного клиента и все его данные к отдельному и заранее известному экземпляру баз данных («шарду»), тем самым обеспечив практически неограниченную от количества клиентов горизонтальную масштабируемость.
Этот подход принципиально отличается от вертикального масштабирования, которое при росте нагрузки и объёма данных предусматривает наращивание вычислительных возможностей и объёма носителей информации одного сервера баз данных, имеющее объективные физические пределы — максимальное количество поддерживаемых CPU на один сервер, максимальный поддерживаемый объем памяти, пропускная способность шины и т.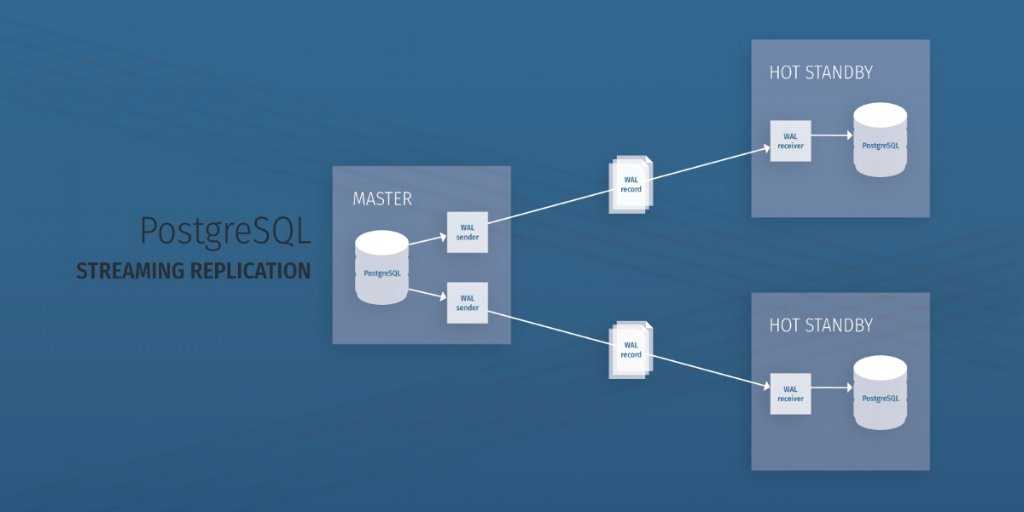 д.
д.
Шардирование обеспечивает несколько преимуществ, главное из которых — снижение издержек на обеспечение согласованного чтения (которое для ряда низкоуровневых операций требует монополизации ресурсов сервера баз данных, внося ограничения на количество одновременно обрабатываемых пользовательских запросов, вне зависимости от вычислительной мощности используемого оборудования). В случае шардинга логически независимые серверы баз данных не требуют взаимной монопольной блокировки для обеспечения согласованного чтения, тем самым снимая ограничения на количество одновременно обрабатываемых пользовательских запросов в кластере в целом.
Серверы баз данных, поддерживающие шардирование
MongoDB
MongoDB поддерживает шардирование с версии 1.6.
Plugin for Grails
Grails поддерживает шардирование путем Grails Sharding Plugin.
Redis
Redis база данных с поддержкой шардирования на стороне клиента.
SQL Azure
Microsoft поддерживает шардирование в SQL Azure через «федерации».
Практически любой сервер баз данных может быть использован по схеме шардинга, при реализации соответствующего уровня абстракции на стороне клиента. К примеру eBay применяет серверы Oracle в режиме шардинга[1], Facebook[2] и Twitter[3] применяют шардирование поверх MySQL и т. д.
Примечания
- ↑ Scalability Best Practices: Lessons from eBay
- ↑ Facebook shares some secrets on making MySQL scale — Cloud Computing News
- ↑ Twitter Engineering: Introducing Gizzard, a framework for creating distributed datastores
Что такое разделение базы данных? — Объяснение базы данных Shard
Что такое сегментирование базы данных?
Разделение базы данных — это процесс хранения большой базы данных на нескольких компьютерах. Одна машина или сервер базы данных может хранить и обрабатывать только ограниченный объем данных. Разделение базы данных преодолевает это ограничение, разбивая данные на более мелкие фрагменты, называемые сегментами, и сохраняя их на нескольких серверах баз данных.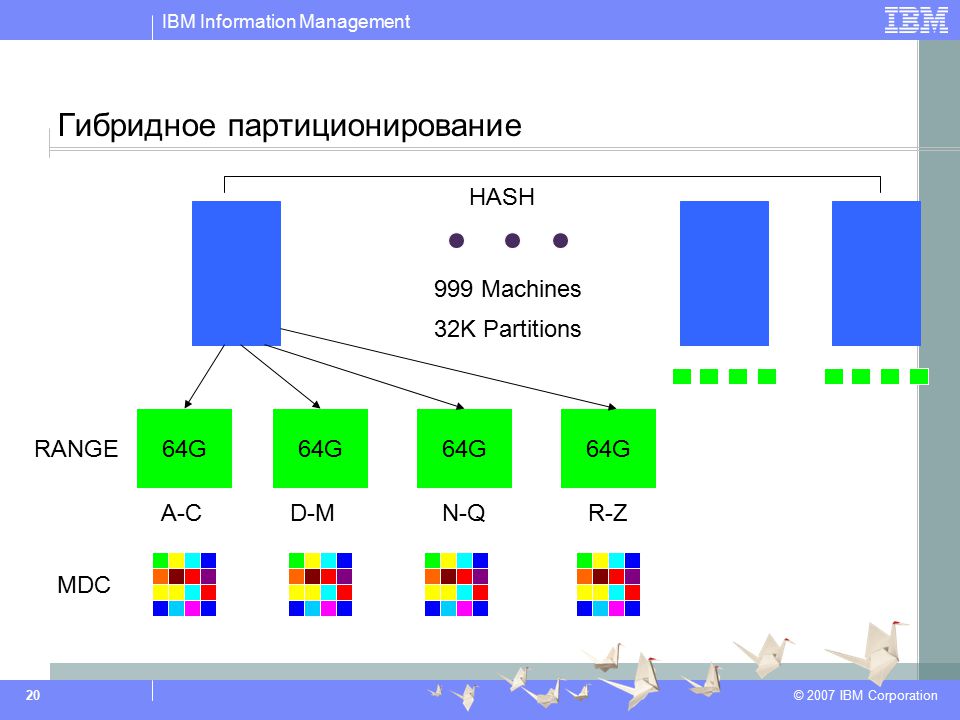 Все серверы баз данных обычно используют одни и те же базовые технологии и работают вместе для хранения и обработки больших объемов данных.
Все серверы баз данных обычно используют одни и те же базовые технологии и работают вместе для хранения и обработки больших объемов данных.
Почему важно сегментировать базу данных?
По мере роста приложения количество пользователей приложения и объем данных, которые оно хранит, со временем увеличиваются. База данных становится узким местом, если объем данных становится слишком большим и слишком много пользователей пытаются использовать приложение для одновременного чтения или сохранения информации. Приложение замедляет работу и влияет на качество обслуживания клиентов. Сегментирование базы данных — один из методов решения этой проблемы, поскольку он обеспечивает параллельную обработку небольших наборов данных между сегментами.
Каковы преимущества сегментирования базы данных?
Организации используют сегментирование базы данных, чтобы получить следующие преимущества:
Сокращение времени отклика
Извлечение данных занимает больше времени в одной большой базе данных. Системе управления базой данных необходимо просмотреть множество строк, чтобы получить правильные данные. Напротив, в осколках данных меньше строк, чем во всей базе данных. Таким образом, получение определенной информации или выполнение запроса из сегментированной базы данных занимает меньше времени.
Системе управления базой данных необходимо просмотреть множество строк, чтобы получить правильные данные. Напротив, в осколках данных меньше строк, чем во всей базе данных. Таким образом, получение определенной информации или выполнение запроса из сегментированной базы данных занимает меньше времени.
Избегайте полного отключения службы
Если компьютер, на котором размещена база данных, выходит из строя, приложение, зависящее от базы данных, также выходит из строя. Разделение базы данных предотвращает это, распределяя части базы данных по разным компьютерам. Выход из строя одного из компьютеров не останавливает работу приложения, поскольку оно может работать с другими функциональными сегментами. Разделение также часто выполняется в сочетании с репликацией данных между сегментами. Таким образом, если один сегмент становится недоступным, данные можно получить и восстановить из другого сегмента.
Эффективное масштабирование
Растущая база данных потребляет больше вычислительных ресурсов и в конечном итоге достигает емкости хранилища. Организации могут использовать сегментирование базы данных, чтобы добавить дополнительные вычислительные ресурсы для поддержки масштабирования базы данных. Они могут добавлять новые сегменты во время выполнения, не закрывая приложение для обслуживания.
Организации могут использовать сегментирование базы данных, чтобы добавить дополнительные вычислительные ресурсы для поддержки масштабирования базы данных. Они могут добавлять новые сегменты во время выполнения, не закрывая приложение для обслуживания.
Как работает сегментация базы данных?
База данных хранит информацию в нескольких наборах данных, состоящих из столбцов и строк. Разделение базы данных разбивает один набор данных на разделы или сегменты. Каждый сегмент содержит уникальные строки данных, которые можно хранить отдельно на нескольких компьютерах, называемых узлами. Все сегменты работают на отдельных узлах, но имеют общую схему или структуру исходной базы данных.
Например, нераспределенная база данных, содержащая набор данных для записей клиентов, может выглядеть так.
Идентификатор клиента | Имя | Государственный |
1 | Джон | Калифорния |
2 | Джейн | Вашингтон |
3 | Пауло | Аризона |
4 | Ван | Грузия |
Разделение включает в себя выделение различных строк информации из таблицы и их хранение на разных компьютерах, как показано ниже.
Компьютер А
Идентификатор клиента | Имя | Государственный |
1 | Джон | Калифорния |
2 | Джейн | Вашингтон |
Компьютер B
Идентификатор клиента | Имя | Государственный |
3 | Пауло | Аризона |
4 | Ван | Грузия |
Осколки
Разделенные фрагменты данных называются логическими осколками. Компьютер, на котором хранится логический сегмент, называется физическим сегментом или узлом базы данных. Физический сегмент может содержать несколько логических сегментов.
Компьютер, на котором хранится логический сегмент, называется физическим сегментом или узлом базы данных. Физический сегмент может содержать несколько логических сегментов.
Ключ сегмента
Разработчики программного обеспечения используют ключ сегмента, чтобы определить, как разделить набор данных. Столбец в наборе данных определяет, какие строки данных объединяются в сегмент. Разработчики баз данных выбирают ключ сегмента из существующего столбца или создают новый.
Архитектура без общего доступа
Сегментация базы данных работает на архитектуре без общего доступа. Каждый физический сегмент работает независимо и не знает о других сегментах. Только физические сегменты, содержащие запрашиваемые вами данные, будут обрабатывать данные параллельно для вас.
Программный уровень координирует хранение данных и доступ к этим множественным сегментам. Например, некоторые типы технологий баз данных имеют встроенные функции автоматического сегментирования. Разработчики программного обеспечения также могут писать код сегментирования в своем приложении для хранения или извлечения информации из нужного сегмента или сегментов.
Разработчики программного обеспечения также могут писать код сегментирования в своем приложении для хранения или извлечения информации из нужного сегмента или сегментов.
Какие существуют методы сегментирования базы данных?
Методы сегментирования базы данных применяют разные правила к ключу сегмента, чтобы определить правильный узел для конкретной строки данных. Ниже приведены распространенные архитектуры сегментирования.
Сегментация на основе диапазона
Сегментация на основе диапазона или динамическая сегментация разбивает строки базы данных на основе диапазона значений. Затем разработчик базы данных назначает ключ сегмента соответствующему диапазону. Например, разработчик базы данных разделяет данные по первому алфавиту в имени клиента следующим образом.
Имя | Общий ключ |
Начинается с A до I | А |
Начинается с J до S | Б |
Начинается с T до Z | С |
При записи записи клиента в базу данных приложение определяет правильный ключ сегмента, проверяя имя клиента.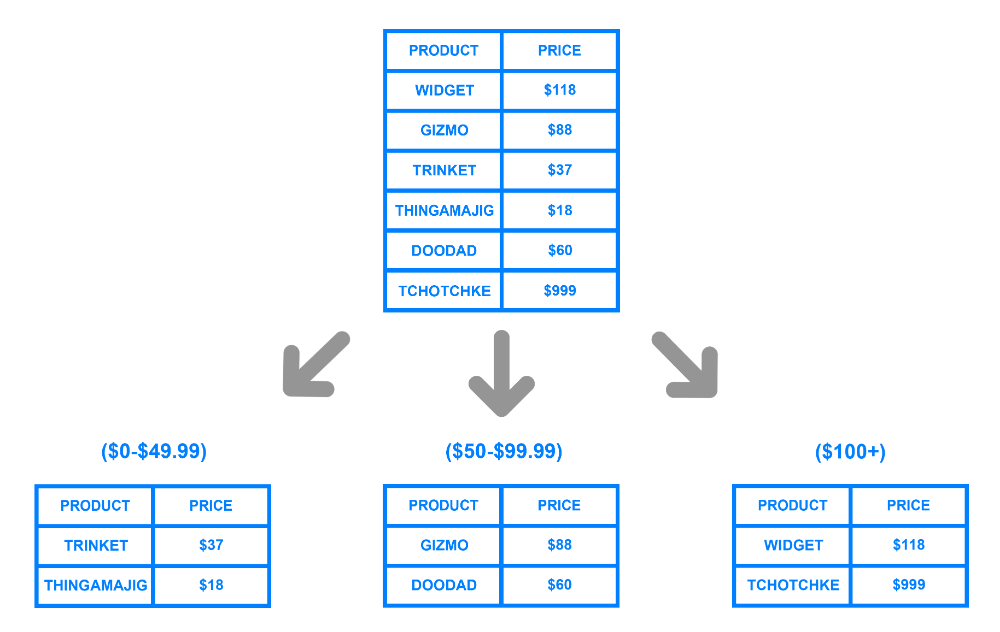 Затем приложение сопоставляет ключ со своим физическим узлом и сохраняет строку на этом компьютере. Точно так же приложение выполняет обратное сопоставление при поиске конкретной записи.
Затем приложение сопоставляет ключ со своим физическим узлом и сохраняет строку на этом компьютере. Точно так же приложение выполняет обратное сопоставление при поиске конкретной записи.
Плюсы и минусы
В зависимости от значений данных сегментирование на основе диапазона может привести к перегрузке данных на одном физическом узле. В нашем примере сегмент A (содержащий имена, начинающиеся с букв от A до I) может содержать гораздо большее количество строк данных, чем сегмент C (содержащий имена, начинающиеся с букв от T до Z). Однако его проще реализовать.
Хеширование сегментирования
Хэширование сегментирования назначает ключ сегмента каждой строке базы данных с помощью математической формулы, называемой хеш-функцией. Хеш-функция берет информацию из строки и создает хэш-значение. Приложение использует хеш-значение в качестве ключа сегмента и сохраняет информацию в соответствующем физическом сегменте.![]()
Разработчики программного обеспечения используют хэширование для равномерного распределения информации в базе данных между несколькими сегментами. Например, программное обеспечение разделяет записи о клиентах на две части с альтернативными хеш-значениями 1 и 2.
Хэш-значение
Джон
1
Джейн
2
Пауло
1
Ван
2
Плюсы и минусы
Хотя хэширование обеспечивает равномерное распределение данных между физическими сегментами, оно не разделяет базу данных на основе значения информации. Поэтому разработчики программного обеспечения могут столкнуться с трудностями при переназначении значения хеш-функции при добавлении дополнительных физических сегментов в вычислительную среду.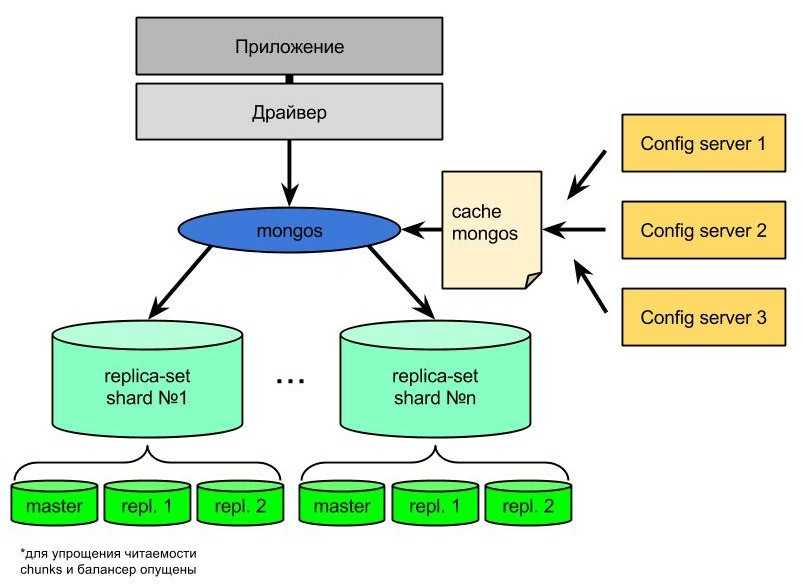
Разделение каталога
Разделение каталога использует таблицу поиска для сопоставления информации базы данных с соответствующим физическим сегментом. Таблица поиска похожа на таблицу в электронной таблице, которая связывает столбец базы данных с ключом сегмента. Например, на следующей диаграмме показана таблица поиска цветов одежды.
Цвет | Общий ключ |
Синий | А |
Красный | Б |
Желтый | С |
Черный | Д |
Когда приложение сохраняет информацию об одежде в базе данных, оно обращается к таблице поиска.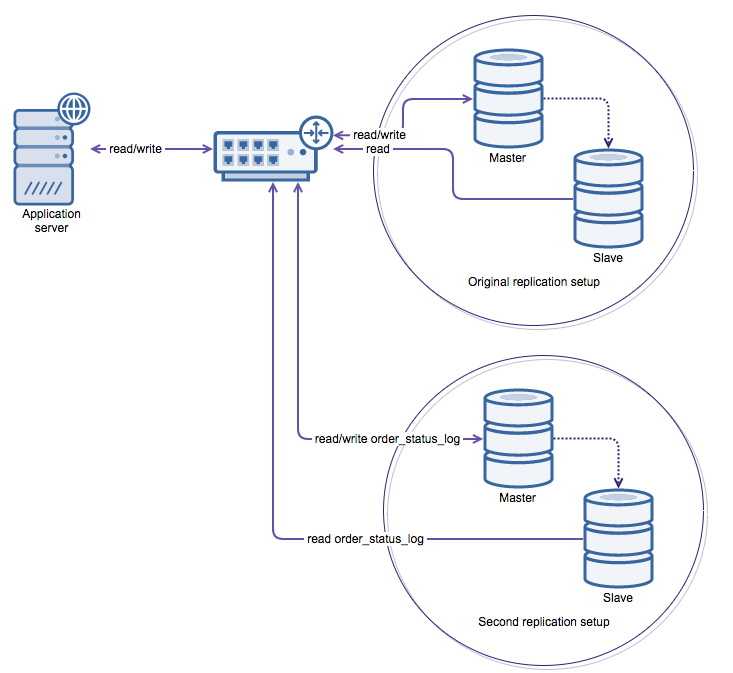 Если платье синее, приложение сохраняет информацию в соответствующем осколке.
Если платье синее, приложение сохраняет информацию в соответствующем осколке.
Плюсы и минусы
Разработчики программного обеспечения используют сегментирование каталогов, потому что оно гибкое. Каждый сегмент представляет собой осмысленное представление базы данных и не ограничен диапазонами. Однако сегментирование каталога завершается ошибкой, если таблица поиска содержит неверную информацию.
Геошардинг
Геошардинг разделяет и хранит информацию базы данных в соответствии с географическим положением. Например, веб-сайт службы знакомств использует базу данных для хранения информации о клиентах из разных городов следующим образом.
Имя | Общий ключ |
Джон | Калифорния |
Джейн | Вашингтон |
Пауло | Аризона |
Разработчики программного обеспечения используют города в качестве осколочных ключей. Они хранят информацию о каждом клиенте в физических шардах, географически расположенных в соответствующих городах.
Они хранят информацию о каждом клиенте в физических шардах, географически расположенных в соответствующих городах.
Плюсы и минусы
Геошардинг позволяет приложениям быстрее извлекать информацию из-за более короткого расстояния между сегментом и клиентом, делающим запрос. Если шаблоны доступа к данным преимущественно основаны на географии, то это работает хорошо. Однако геошардинг также может привести к неравномерному распределению данных.
Как оптимизировать сегментирование базы данных для равномерного распределения данных
Когда происходит перегрузка данных на определенных физических сегментах, хотя другие остаются недогруженными, это приводит к возникновению горячих точек в базе данных. Горячие точки замедляют процесс поиска в базе данных, сводя на нет цель сегментирования данных.
Правильный выбор ключа сегмента может равномерно распределить данные по нескольким сегментам. При выборе ключа сегмента проектировщики баз данных должны учитывать следующие факторы.
Мощность
Кардинальность описывает возможные значения ключа сегмента. Он определяет максимальное количество возможных сегментов в отдельных базах данных, ориентированных на столбцы. Например, если разработчик базы данных выбирает поле данных «да/нет» в качестве ключа сегмента, количество сегментов ограничивается двумя.
Частота
Частота — это вероятность хранения конкретной информации в конкретном шарде. Например, разработчик базы данных выбирает возраст в качестве ключа сегмента для фитнес-сайта. Большая часть записей может попасть в узлы для подписчиков в возрасте 30–45 лет, что приведет к появлению горячих точек в базе данных.
Монотонное изменение
Монотонное изменение — это скорость изменения ключа сегмента. Монотонно увеличивающийся или уменьшающийся ключ сегмента приводит к несбалансированности сегментов. Например, база данных отзывов разделена на три разных физических сегмента следующим образом:
- Раздел A хранит отзывы клиентов, совершивших от 0 до 10 покупок.
- Shard B хранит отзывы покупателей, совершивших 11–20 покупок.
- Shard C хранит отзывы клиентов, совершивших 21 или более покупок.
По мере роста бизнеса клиенты будут совершать более 21 или более покупок. Приложение сохраняет их отзывы в сегменте C. Это приводит к несбалансированному сегменту, поскольку сегмент C содержит больше записей отзывов, чем другие сегменты.
Какие есть альтернативы сегментированию базы данных?
Сегментирование базы данных — это стратегия горизонтального масштабирования, которая выделяет дополнительные узлы или компьютеры для разделения рабочей нагрузки приложения. Организации выигрывают от горизонтального масштабирования благодаря его отказоустойчивой архитектуре. Когда один компьютер выходит из строя, остальные продолжают работать без сбоев. Разработчики баз данных сокращают время простоя, распределяя логические фрагменты по нескольким серверам.
Однако сегментирование является одной из нескольких других стратегий масштабирования базы данных.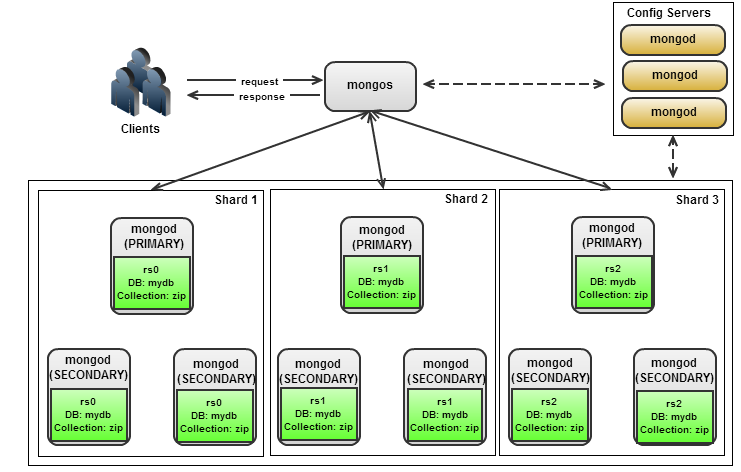 Изучите некоторые другие методы и поймите, как они сравниваются.
Изучите некоторые другие методы и поймите, как они сравниваются.
Вертикальное масштабирование
Вертикальное масштабирование увеличивает вычислительную мощность одной машины. Например, ИТ-группа добавляет ЦП, ОЗУ и жесткий диск к серверу базы данных для обработки растущего трафика.
Сравнение сегментирования базы данных и вертикального масштабирования
Вертикальное масштабирование менее затратно, но существует ограничение на вычислительные ресурсы, которые можно масштабировать по вертикали. Между тем, сегментирование, стратегию горизонтального масштабирования, проще реализовать. Например, ИТ-команда устанавливает несколько компьютеров вместо обновления старого компьютерного оборудования.
Репликация
Репликация — это метод создания точных копий базы данных и их хранения на разных компьютерах. Разработчики баз данных используют репликацию для разработки отказоустойчивой системы управления реляционными базами данных. Когда один из компьютеров, на которых размещена база данных, выходит из строя, другие реплики остаются в рабочем состоянии. Репликация является обычной практикой в распределенных вычислительных системах.
Когда один из компьютеров, на которых размещена база данных, выходит из строя, другие реплики остаются в рабочем состоянии. Репликация является обычной практикой в распределенных вычислительных системах.
Сравнение сегментирования базы данных и репликации
Сегментирование базы данных не создает копии одной и той же информации. Вместо этого он разбивает одну базу данных на несколько частей и хранит их на разных компьютерах. В отличие от репликации, сегментирование базы данных не обеспечивает высокой доступности. Шардинг можно использовать в сочетании с репликацией для достижения масштабируемости и высокой доступности.
В некоторых случаях сегментирование базы данных может состоять из репликации определенных наборов данных. Например, розничный магазин, который продает товары клиентам из США и Европы, может хранить копии таблиц преобразования размеров в разных осколках для обоих регионов. Приложение может использовать дублированные копии таблицы преобразования для преобразования размера измерения без доступа к другим серверам базы данных.
Секционирование
Секционирование — это процесс разделения таблицы базы данных на несколько групп. Разделение подразделяется на два типа:
- Горизонтальное разделение базы данных разбивает базу данных по строкам.
- Вертикальное разделение создает разные разделы столбцов базы данных.
Сравнение сегментирования и секционирования базы данных
Сегментирование базы данных похоже на горизонтальное секционирование. Оба процесса разбивают базу данных на несколько групп уникальных строк. При секционировании все группы данных хранятся на одном компьютере, а при сегментировании базы данных они распределяются по разным компьютерам.
Какие проблемы возникают при сегментировании базы данных?
Организации могут столкнуться с этими проблемами при реализации сегментирования базы данных.
Точки доступа к данным
Некоторые сегменты становятся несбалансированными из-за неравномерного распределения данных.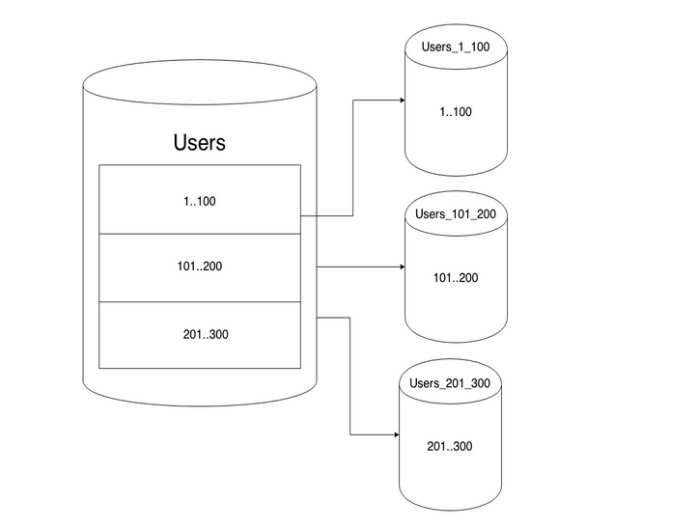 Например, один физический сегмент, содержащий имена клиентов, начинающиеся с буквы A, получает больше данных, чем другие. Этот физический осколок будет использовать больше вычислительных ресурсов, чем другие.
Например, один физический сегмент, содержащий имена клиентов, начинающиеся с буквы A, получает больше данных, чем другие. Этот физический осколок будет использовать больше вычислительных ресурсов, чем другие.
Решение
Вы можете равномерно распределить данные, используя оптимальные ключи сегментов. Некоторые наборы данных лучше подходят для сегментирования, чем другие.
Операционная сложность
Сегментация базы данных создает операционную сложность. Вместо управления одной базой данных разработчикам приходится управлять несколькими узлами базы данных. Когда они извлекают информацию, разработчики должны запрашивать несколько сегментов и объединять фрагменты информации вместе. Эти операции поиска могут усложнить аналитику.
Решение
В линейке баз данных AWS настройка базы данных и операции с ней в значительной степени автоматизированы. Это упрощает работу с сегментированной архитектурой базы данных.
Это упрощает работу с сегментированной архитектурой базы данных.
Расходы на инфраструктуру
Организации платят больше за расходы на инфраструктуру, когда они добавляют больше компьютеров в виде физических сегментов. Затраты на обслуживание могут возрасти, если вы увеличите количество компьютеров в локальном центре обработки данных.
Решение
Разработчики используют Amazon Elastic Compute Cloud (Amazon EC2) для размещения и масштабирования сегментов в облаке. Вы можете сэкономить деньги, используя виртуальную инфраструктуру, которой полностью управляет AWS.
Сложность приложения
Большинство систем управления базами данных не имеют встроенных функций сегментирования. Это означает, что проектировщики баз данных и разработчики программного обеспечения должны вручную разделять, распределять и управлять базой данных.
Решение
Вы можете перенести свои данные в соответствующие специализированные базы данных AWS, которые имеют несколько встроенных функций, поддерживающих горизонтальное масштабирование.
Как AWS может помочь в сегментировании базы данных?
AWS — это глобальная платформа управления данными, которую можно использовать для построения современной стратегии обработки данных. С AWS вы можете выбрать подходящую специализированную базу данных, добиться масштабируемой производительности, запустить полностью управляемые базы данных и положиться на высокую доступность и безопасность.
Начните управление данными в AWS, создав учетную запись AWS уже сегодня.
Разделение базы данных: концепции и примеры
Ваше приложение растет. У него больше активных пользователей, больше функций и он генерирует больше данных каждый день. Теперь ваша база данных становится узким местом для остальной части вашего приложения. Разделение базы данных могло бы стать решением ваших проблем, но многие не имеют четкого представления о том, что это такое и, особенно, когда его использовать. В этой статье мы рассмотрим основы сегментирования базы данных, его лучшие варианты использования и различные способы его реализации.
Перейти к:
- Что такое сегментирование базы данных?
- Оценка альтернатив
- Преимущества и недостатки сегментирования
- Как работает сегментирование базы данных?
- Архитектура и типы сегментирования
- Часто задаваемые вопросы
Что такое сегментирование базы данных?
Разделение — это метод распределения одного набора данных по нескольким базам данных, который затем может храниться на нескольких компьютерах. Это позволяет разбивать большие наборы данных на более мелкие фрагменты и хранить их на нескольких узлах данных, увеличивая общую емкость системы хранения.
Подробнее об основах шардинга читайте здесь.
Точно так же, распределяя данные между несколькими машинами, сегментированная база данных может обрабатывать больше запросов, чем одна машина.
Шардинг — это форма масштабирования, известная как горизонтальное масштабирование или горизонтальное масштабирование , поскольку для распределения нагрузки подключаются дополнительные узлы. Горизонтальное масштабирование обеспечивает почти безграничную масштабируемость для обработки больших данных и интенсивных рабочих нагрузок. Напротив, вертикальное масштабирование относится к увеличению мощности одной машины или одного сервера за счет более мощного ЦП, увеличения объема ОЗУ или увеличения емкости хранилища.
Горизонтальное масштабирование обеспечивает почти безграничную масштабируемость для обработки больших данных и интенсивных рабочих нагрузок. Напротив, вертикальное масштабирование относится к увеличению мощности одной машины или одного сервера за счет более мощного ЦП, увеличения объема ОЗУ или увеличения емкости хранилища.
Вам нужно сегментирование базы данных?
Сегментирование базы данных, как и любая распределенная архитектура, не предоставляется бесплатно. Существуют накладные расходы и сложности при настройке сегментов, обслуживании данных в каждом сегменте и правильной маршрутизации запросов между этими сегментами. Прежде чем приступить к сегментированию, подумайте, подойдет ли вам одно из следующих альтернативных решений.
Вертикальное масштабирование
Просто обновив компьютер, вы сможете масштабировать его по вертикали без сложностей сегментирования. Добавление оперативной памяти, модернизация вашего компьютера (ЦП) или увеличение объема хранилища, доступного для вашей базы данных, — это простые решения, которые не требуют от вас изменения архитектуры вашей базы данных или вашего приложения.
Специализированные службы или базы данных
В зависимости от вашего варианта использования может иметь смысл просто переложить часть нагрузки на других поставщиков или даже на отдельную базу данных. Например, хранилище BLOB-объектов или файлов можно перенести непосредственно к облачному провайдеру, такому как Amazon S3. Аналитикой или полнотекстовым поиском могут заниматься специализированные сервисы или хранилище данных. Разгрузка этой конкретной функции может иметь больше смысла, чем попытка сегментировать всю базу данных.
Репликация
Если ваша рабочая нагрузка данных в основном ориентирована на чтение, репликация повышает доступность и производительность чтения, избегая некоторых сложностей сегментирования базы данных. Просто развернув дополнительные копии базы данных, можно повысить производительность чтения либо за счет балансировки нагрузки, либо за счет маршрутизации запросов с географической привязкой. Однако репликация усложняет рабочие нагрузки, ориентированные на запись, поскольку каждая запись должна быть скопирована на каждый реплицированный узел.
С другой стороны, если основная база данных приложения содержит большие объемы данных, требует больших объемов чтения и записи и/или у вас есть особые требования к доступности, сегментированная база данных может оказаться выходом из положения. Рассмотрим преимущества и недостатки шардинга.
Преимущества сегментирования
Шардинг позволяет масштабировать базу данных для обработки возросшей нагрузки практически до неограниченной степени, обеспечивая повышенную пропускную способность чтения/записи , емкость хранилища и высокую доступность . Давайте рассмотрим каждый из них немного подробнее.
- Увеличение пропускной способности при чтении/записи — за счет распределения набора данных по нескольким сегментам увеличивается производительность операций чтения и записи, если операции чтения и записи ограничены одним сегментом.
- Увеличение емкости хранилища — Точно так же, увеличивая количество осколков, вы также можете увеличить общую емкость хранилища, обеспечивая почти бесконечную масштабируемость.
- Высокая доступность — Наконец, осколки обеспечивают высокую доступность двумя способами. Во-первых, поскольку каждый сегмент представляет собой набор реплик, каждая часть данных реплицируется. Во-вторых, даже если весь сегмент становится недоступным после распределения данных, база данных в целом все равно остается частично функциональной, поскольку часть схемы находится в разных сегментах.

Недостатки сегментирования
Разделение имеет несколько недостатков, а именно накладные расходы при компиляции результатов запроса, сложность администрирования, и увеличение затрат на инфраструктуру.
- Накладные расходы на запрос — Каждая сегментированная база данных должна иметь отдельный компьютер или службу, которая понимает, как направить операцию запроса на соответствующий сегмент. Это вводит дополнительную задержку для каждой операции. Кроме того, если данные, необходимые для запроса, горизонтально разделены на несколько сегментов, маршрутизатор должен затем запросить каждый сегмент и объединить результаты вместе. Это может сделать простую операцию довольно дорогой и замедлить время отклика.
- Сложность администрирования — При наличии одной нераспределенной базы данных обслуживание и обслуживание требует только сам сервер базы данных. В каждой сегментированной базе данных помимо управления самими сегментами необходимо поддерживать дополнительные сервисные узлы. Кроме того, в случаях, когда используется репликация , любые обновления данных должны отражаться на каждом реплицированном узле. В целом, сегментированная база данных — более сложная система, требующая большего администрирования.
- Увеличение затрат на инфраструктуру — Шардинг по своей природе требует дополнительных машин и вычислительной мощности по сравнению с одним сервером базы данных. Хотя это позволяет вашей базе данных выйти за пределы одной машины, каждый дополнительный сегмент обходится дороже. Стоимость системы распределенной базы данных, особенно если в ней отсутствует надлежащая оптимизация, может быть значительной.
 Это может сделать простую операцию довольно дорогой и замедлить время отклика.
Это может сделать простую операцию довольно дорогой и замедлить время отклика.
Взвесив все за и против, давайте двигаться дальше и обсуждать реализацию.
Как работает шардинг?
Чтобы разделить базу данных, мы должны ответить на несколько фундаментальных вопросов. Ответы определят вашу реализацию.
Во-первых, как данные будут распределяться по осколкам? Это фундаментальный вопрос любой сегментированной базы данных. Ответ на этот вопрос повлияет как на производительность, так и на техническое обслуживание. Подробнее об этом можно узнать в разделе «Архитектуры и типы шардинга».
Во-вторых, какие типы запросов будут маршрутизироваться между осколками? Если рабочая нагрузка в основном состоит из операций чтения, репликация данных будет очень эффективной для повышения производительности, и вам может вообще не понадобиться сегментирование. Напротив, смешанная рабочая нагрузка чтения-записи или даже рабочая нагрузка, основанная преимущественно на записи, потребует другой архитектуры.
Наконец, как будут поддерживаться эти осколки? После сегментации базы данных со временем данные необходимо будет перераспределить между различными сегментами и, возможно, потребуется создать новые сегменты.![]() В зависимости от распределения данных это может быть дорогостоящим процессом, и его следует рассмотреть заранее.
В зависимости от распределения данных это может быть дорогостоящим процессом, и его следует рассмотреть заранее.
Имея в виду эти вопросы, давайте рассмотрим некоторые архитектуры сегментирования.
Архитектуры и типы сегментирования
Хотя существует множество различных методов сегментирования, мы рассмотрим четыре основных типа: ранжированное/динамическое сегментирование, алгоритмическое/хешированное сегментирование, сегментирование на основе сущностей/связей и сегментирование на основе географии.
Ранжированное/динамическое сегментирование
Ранжированное сегментирование или динамическое сегментирование берет поле в записи в качестве входных данных и на основе предопределенного диапазона выделяет эту запись соответствующему сегменту. Для сегментирования с диапазоном требуется наличие таблицы поиска или службы, доступной для всех запросов или операций записи. Например, рассмотрим набор данных с идентификаторами в диапазоне от 0 до 50. Простая таблица поиска может выглядеть следующим образом:
Простая таблица поиска может выглядеть следующим образом:
| Диапазон | Идентификатор сегмента |
| [0, 20) | А |
| [20, 40] | Б |
| [40, 50] | С |
Поле, на котором основан диапазон, также известно как ключ сегмента. Естественно, выбор ключа сегмента, а также диапазонов имеют решающее значение для обеспечения эффективности сегментирования на основе диапазонов. Неправильный выбор ключа сегмента приведет к несбалансированности сегментов, что приведет к снижению производительности. Эффективный ключ сегмента позволит нацеливать запросы на минимальное количество сегментов. В нашем примере выше, если мы запрашиваем все записи с идентификаторами 10-30, то нужно будет запрашивать только осколки A и B.
Двумя ключевыми атрибутами эффективного ключа сегмента являются высокая мощность и хорошо распределенная частота . Кардинальность относится к количеству возможных значений этого ключа. Если ключ сегмента имеет только три возможных значения, то может быть максимум три сегмента. Частота относится к распределению данных по возможным значениям. Если 95% записей встречаются с одним значением ключа сегмента, то из-за этой точки доступа 95% записей будут размещены в одном сегменте. Учитывайте оба эти атрибута при выборе ключа сегмента.
Кардинальность относится к количеству возможных значений этого ключа. Если ключ сегмента имеет только три возможных значения, то может быть максимум три сегмента. Частота относится к распределению данных по возможным значениям. Если 95% записей встречаются с одним значением ключа сегмента, то из-за этой точки доступа 95% записей будут размещены в одном сегменте. Учитывайте оба эти атрибута при выборе ключа сегмента.
Сегментирование на основе диапазона — это простой для понимания метод горизонтального разделения, но его эффективность будет сильно зависеть от наличия подходящего ключа сегмента и выбора соответствующих диапазонов. Кроме того, служба поиска может стать узким местом, хотя объем данных достаточно мал, поэтому обычно это не проблема.
Алгоритмическое/хэширование
Алгоритмическое сегментирование или хеширование, берет запись в качестве входных данных и применяет к ней хэш-функцию или алгоритм, который генерирует выходное значение или хеш-значение. Затем этот вывод используется для размещения каждой записи в соответствующем сегменте.
Затем этот вывод используется для размещения каждой записи в соответствующем сегменте.
Функция может принимать любое подмножество значений в записи в качестве входных данных. Возможно, самым простым примером хэш-функции является использование оператора модуля с количеством осколков, как показано ниже:
Значение хэша=ID % Количество осколков
Это похоже на сегментирование на основе диапазона — набор полей определяет отнесение записи к данному осколку. Хеширование входных данных обеспечивает более равномерное распределение по сегментам, даже если нет подходящего ключа сегмента и нет необходимости поддерживать таблицу поиска. Однако есть несколько недостатков.
Во-первых, операции запроса для нескольких записей с большей вероятностью будут распределены по нескольким сегментам. В то время как ранжированное сегментирование отражает естественную структуру данных в сегментах, хэшированное сегментирование обычно игнорирует смысл данных. Это отражается в увеличении числа операций широковещательной передачи.
Во-вторых, повторное использование может быть дорогостоящим. Любое обновление количества сегментов, скорее всего, потребует перебалансировки всех сегментов для перемещения записей. Сделать это, избежав отключения системы, будет сложно.
Сегментация на основе сущностей/связей
Сегментация на основе сущностей объединяет связанные данные в одном физическом сегменте. В реляционной базе данных (например, PostgreSQL, MySQL или SQL Server) связанные данные часто распределяются по нескольким различным таблицам.
Например, рассмотрим случай базы данных покупок с пользователями и способами оплаты. У каждого пользователя есть набор способов оплаты, который тесно связан с этим пользователем. Таким образом, совместное хранение связанных данных в одном сегменте может снизить потребность в широковещательных операциях и повысить производительность.
Сегментация на основе географии
Сегментация на основе географии или геошардинг также хранит связанные данные вместе на одном сегменте, но в этом случае данные связаны по географии.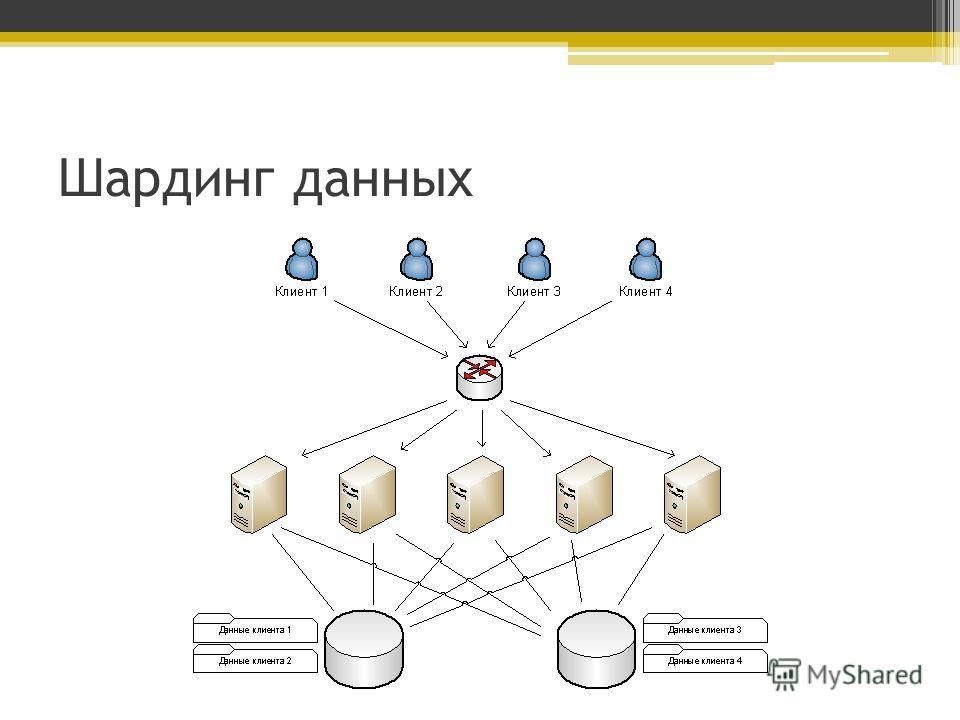 По сути, это ранжированное сегментирование, при котором ключ сегмента содержит географическую информацию, а сами сегменты имеют географическую привязку.
По сути, это ранжированное сегментирование, при котором ключ сегмента содержит географическую информацию, а сами сегменты имеют географическую привязку.
Например, рассмотрим набор данных, в котором каждая запись содержит поле «страна». В этом случае мы можем повысить общую производительность и уменьшить задержку системы, создав сегмент для каждой страны или региона и сохранив соответствующие данные в этом сегменте. Это простой пример, и есть много других способов размещения ваших геошардов, которые выходят за рамки этой статьи.
Резюме
Мы определили, что такое сегментирование, обсудили, когда его использовать, и изучили различные архитектуры сегментирования. Разделение — отличное решение для приложений с большими требованиями к данным и большими объемами операций чтения/записи, но оно сопряжено с дополнительной сложностью. Подумайте, перевешивают ли преимущества затраты или есть более простое решение, прежде чем приступать к реализации.
Готовы начать?
Запустите новый кластер или перейдите на MongoDB Atlas без простоев.

Что подразумевается под шардингом?
Разделение — это метод распределения одного набора данных по нескольким базам данных, который затем может храниться на нескольких компьютерах.
В чем разница между шардингом и секционированием?
Разделение — это форма разделения, при которой каждый сегмент располагается на отдельном физическом узле. Разделы могут сосуществовать на одной машине, тогда как осколки обычно этого не делают.
Что такое шардинг блокчейна?
Шардинг также используется блокчейн-компаниями для масштабирования вычислений и хранения, увеличивая общую производительность обработки транзакций. Концепция, по сути, та же.
Как выполняется шардинг?
Разделение можно выполнить несколькими различными способами. См. выше раздел «Архитектуры и типы сегментирования». Кроме того, см. Разделение: рекомендации по повышению производительности.
Что такое сегментирование в NoSQL?
Хотя базы данных SQL могут быть сегментированы (см.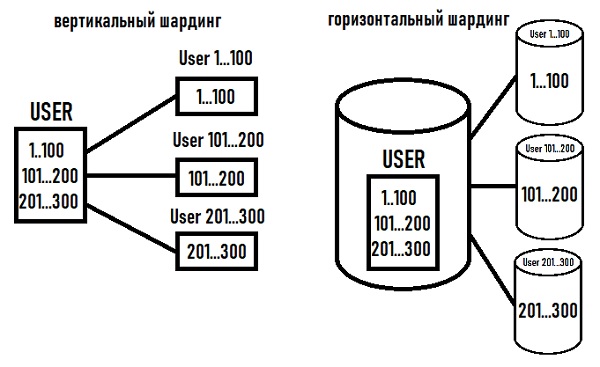 Разделение на основе сущностей/связей выше), отношения между схемами делают его более сложным. NoSQL/нереляционные базы данных были разработаны с учетом сегментации, и их значительно проще сегментировать, чем традиционные реляционные базы данных.
Разделение на основе сущностей/связей выше), отношения между схемами делают его более сложным. NoSQL/нереляционные базы данных были разработаны с учетом сегментации, и их значительно проще сегментировать, чем традиционные реляционные базы данных.
Когда следует сегментировать базу данных?
Если основная база данных приложения содержит большие объемы данных, требует больших объемов чтения и записи и/или у вас есть особые требования к доступности, сегментированная база данных может быть правильным вариантом.
Является ли сегментирование горизонтальным масштабированием?
Да! Разделение — это форма масштабирования, известная как горизонтальное масштабирование или горизонтальное масштабирование , поскольку для распределения нагрузки подключаются дополнительные узлы.
Почему используется шардинг?
Разделение позволяет хранить большие наборы данных в одной базе данных. Точно так же сегментированный набор данных, в котором запросы правильно распределены по машинам, может обрабатывать больше запросов, чем одна машина.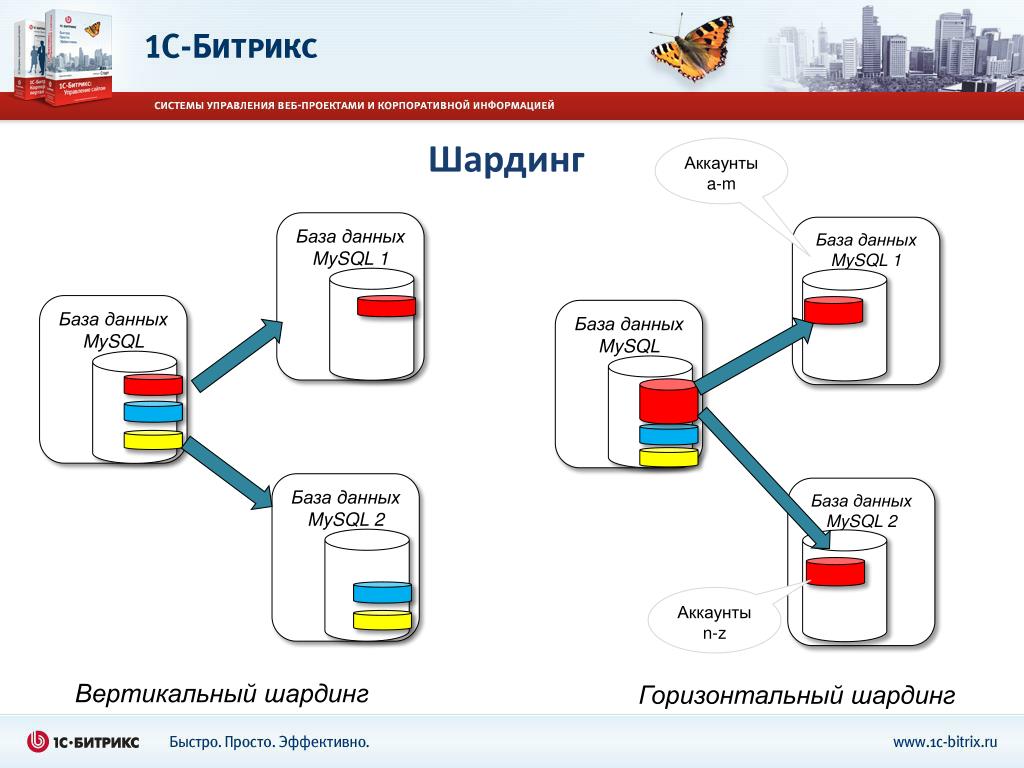
Как работает сегментация MongoDB?
В MongoDB сегментация выполняется с помощью сегментированных кластеров, которые состоят из сегментов, маршрутизаторов/балансировщиков и серверов конфигурации для метаданных. Хотя для ручной настройки потребуется изрядная часть настройки и настройки инфраструктуры, MongoDB Atlas — предложение «база данных как услуга» — делает это довольно просто. Просто включите эту опцию для своего кластера MongoDB и выберите количество осколков.
Настройка по умолчанию реплицирует и сегментирует данные. Это обеспечивает высокую доступность, избыточность и повышенную производительность чтения и записи за счет использования обоих типов горизонтального масштабирования. Также включены маршрутизаторы, распределяющие запросы и данные. Для получения дополнительной информации перейдите по ссылке, чтобы узнать больше о MongoDB Atlas.
Другие вопросы? Ознакомьтесь с часто задаваемыми вопросами о шардинге.
Готовы начать?
Запустите новый кластер или перейдите на MongoDB Atlas без простоев.