Содержание
Шардинг, перебалансировка и распределенные транзакции в реляционных базах данных
При разработке нового проекта в качестве основной СУБД нередко выбираются реляционные базы данных, такие, как PostgreSQL или MySQL. В этом действительно есть смысл. Первое время у проекта мало пользователей, и потому все данные помещаются в один сервер. При этом проект активно развивается. Нельзя заранее сказать, какой функционал в нем станет основным, а какой будет выкинут. Есть много историй о том, как мобильный дейтинг в итоге превращался в криптомессанджер, и подобного рода. РСУБД удобны на ранних этапах, потому что они универсальны. Так, PostgreSQL из коробки имеет встроенный полнотекстовый поиск, умеет эффективно работать с геоданными, а также подходит для хранения очередей и рассылки уведомлений. По мере развития проекта и роста нагрузки часть данных может быть перенесена в специализированные NoSQL решения. Также нагрузку можно распределить, поделив базу на несколько совершенно не связанных между собой баз, а также при помощи потоковой репликации. Но что делать в случае, если все это не помогло? В этом посте я постараюсь ответить на данный вопрос.
Но что делать в случае, если все это не помогло? В этом посте я постараюсь ответить на данный вопрос.
Примечание: Хочу поблагодарить gridem, sum3rman и gliush за активное участие в обсуждении поднятых в данном посте вопросов. Многие из озвученных ниже идей были позаимствованы у этих ребят.
Декомпозиция проблемы
Задачу построения горизонтально масштабируемого РСУБД-кластера можно разделить на следующие сравнительно независимые задачи:
- Автофейловер. С ростом числа машин в системе встает проблема автоматической обработки падения этих машин. В рамках сего поста автофейловер не рассматривается, так как ему был посвящен отдельный пост Stolon: создаем кластер PostgreSQL с автофейловером. Далее эта задача считается решенной. Предполагается, что все кусочки данных (vbucket’ы) хранятся на репликасетах с автофейловером (кластерах Stolon’а). Термин репликасет позаимствован у MongoDB.
- Шардинг, или распределение данных по репликасетам.

- Перебалансировка, или перемещение данных между репликасетами.
- Решардинг. Под решардингом далее понимается изменение схемы шардирования или ее параметров. Например, изменения числа частей, на которые нарезаются данные. Важно подчеркнуть, что это совершенно отдельная от перебалансировки задача и их не следует путать. Данная терминология (перебалансировка, решардинг, и что это не одно и то же) позаимствована из документации множества таких NoSQL решений, как Cassandra, CouchDB, Couchbase и Riak.
- Распределенные транзакции. Поскольку данные распределяются по нескольким репликасетам, возникает проблема выполнения транзакций между репликасетами.
- Автоматизация. Переизобретать все описанное выше в каждом новом проекте трудоемко и непрактично. Поэтому возникает закономерное желание как-то решить эту проблему один-единственный раз и потом повторно использовать это решение. Увы, как будет показано ниже, очень сложно представить себе универсальное решение, которое подходило бы всем. Поэтому в рамках данной заметки вопрос автоматизации не рассматривается.

 Поэтому в рамках данной заметки вопрос автоматизации не рассматривается.
Поэтому в рамках данной заметки вопрос автоматизации не рассматривается.Попробуем рассмотреть озвученные проблемы по отдельности.
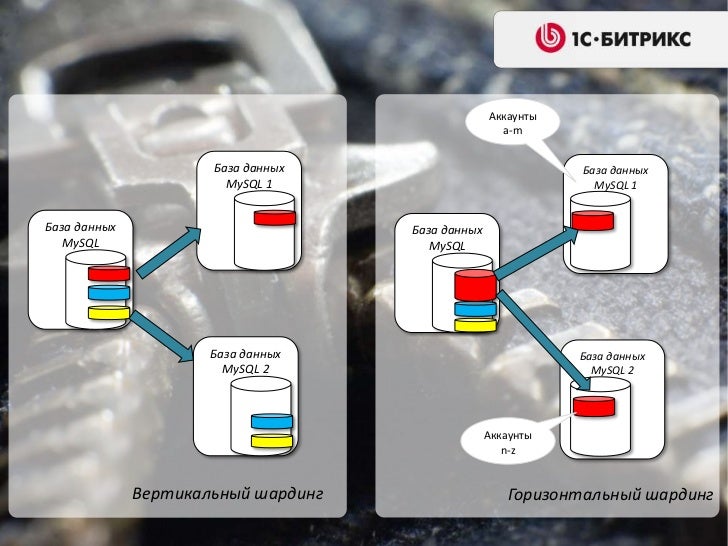
Шардинг
Существует много схем шардирования. С довольно полным списком можно ознакомиться, например, здесь. Насколько мне известно, наиболее практичной и часто используемой схемой (в частности, она используется в Riak и Couchbase) является следующая.
Каждая единица данных относится к определенной «виртуальной корзине», или vbucket. Число vbucket определяется заранее, берется достаточно большим и обычно является степенью двойки. В Couchbase, например, по умолчанию существует 1024 vbucket’а. Для определения, к какому vbucket относится единица данных, выбирается некий ключ, однозначно определяющий единицу данных, и используется формула типа:
vbucket_num = hash(key) % 1024
Couchbase, например, является KV-хранилищем. Поэтому совершенно логично единицей данных в нем является пара ключ-значение, а ключом, определяющим единицу данных, является, собственно, строковый ключ. Но единица данных может быть и более крупной. Например, если мы пишем социальную сеть, то можем создать 1024 баз данных с одинаковой схемой, а в качестве ключа использовать идентификатор пользователя. Самое главное здесь, чтобы данные, попадающие в разные vbucket’ы, были как можно менее связанными друг с другом, а в идеале — вообще никак не связанными.
Но единица данных может быть и более крупной. Например, если мы пишем социальную сеть, то можем создать 1024 баз данных с одинаковой схемой, а в качестве ключа использовать идентификатор пользователя. Самое главное здесь, чтобы данные, попадающие в разные vbucket’ы, были как можно менее связанными друг с другом, а в идеале — вообще никак не связанными.
Описанным выше способом мы получаем отображение (ключ → номер vbucket). Однако это отображение не дает нам ответа на вопрос, где физически следует искать данные, то есть, к какому репликасету они относятся. Для этого используется так называемый словарь, отображающий номер vbucket’а в конкретный репликасет. Поскольку выше было сказано, что задачу автоматического фейловера мы решаем при помощи Stolon, а ему для работы нужен Consul, который, помимо прочего, является KV-хранилищем, вполне логично хранить словарь в Consul. Например, словарем может быть документ вида:
{
«format_version»: 1,
«vbuckets»: [
«cluster1»,
«cluster2»,
. ..
..
«clusterN»
]
}
Здесь format_version нужен на случай изменения формата словаря в будущем. Также нам нужна версия (ревизия) словаря, увеличивающаяся при каждом обновлении словаря. Выше она не приведена, так как в Consul это есть из коробки для всех данных и называется ModifyIndex. Наконец, в массиве vbuckets по i-му индексу хранится имя кластера Stolon, соответствующего i-му vbucket. В случае, если в настоящее время происходит перебалансировка (см далее), вместо одного имени кластера хранится пара ["clusterFrom","clusterTo"] — откуда и куда сейчас переносятся данные.
Вы спросите, зачем так сложно? Во-первых, эта схема очень гибкая. Например, на ранних этапах развития проекта мы можем использовать один репликасет, хранящий все 1024 vbucket’а. В будущем мы можем использовать до 1024-х репликасетов. Если каждый репликасет будет хранить 1 Тб данных (далеко не предел по сегодняшним меркам), это обеспечит хранение петабайта данных во всем кластере. Во-вторых, при добавлении новых репликасетов не возникает необходимости перемещать вообще все данные туда-сюда, как это происходит, например, при использовании формулы
Во-вторых, при добавлении новых репликасетов не возникает необходимости перемещать вообще все данные туда-сюда, как это происходит, например, при использовании формулы hash(key) % num_replicasets. Наконец, мощности машин в кластере могут различаться. Эта схема позволяет распределить данные по ним неравномерно, в соответствии с мощностями.
Перебалансировка
Что делать в случае, если мы хотим переместить vbucket с одного репликасета на другой?
Начнем со словаря. Каким образом он будет изменяться при перебалансировке, было описано выше. Но перед началом переноса vbucket’ов важно убедиться, что все клиенты увидели новый словарь, в котором отражен процесс переноса. Каким образом это можно сделать? Простейшее решение заключается в том, что для каждой версии словаря раз в определенный интервал времени T (скажем, 15 секунд) клиенты пишут в Consul «словарь такой-то версии последний раз использовался тогда-то». Само собой разумеется, предполагается, что время между клиентами более-менее синхронизировано с помощью ntpd. Если словарь никем не используется уже T*2 времени, можно смело полагать, что все клиенты увидели новую версию словаря. Сами клиенты могут запрашивать последнюю версию словаря просто время от времени, или же воспользоваться механизмом Consul подписки на изменения данных.
Если словарь никем не используется уже T*2 времени, можно смело полагать, что все клиенты увидели новую версию словаря. Сами клиенты могут запрашивать последнюю версию словаря просто время от времени, или же воспользоваться механизмом Consul подписки на изменения данных.
Итак, все клиенты знают о начале перебалансировки. Далее возможны варианты.
- Только чтение. Проще всего запретить изменение переносимых данных. Клиенты могут читать с clusterFrom, но не могут ничего записывать. Для многих проектов такое решение вполне подходит. Например, для переноса можно выбрать время, когда системой пользуется меньше всего людей (4 часа ночи) и тем немногим, что попытаются что-то записать, честно сказать, что у проекта сейчас maintenance. Если vbucket’ы достаточно маленькие, перенос все равно займет лишь несколько минут, после чего пользователь сможет повторить запрос.
- Все данные неизменяемые. На первый взгляд это кажется странным, но многим реальным проектам (социальные сети, почта, IM, и прочее) на самом деле не очень-то нужны изменяемые данные. Все данные можно представить в виде лога событий. Новые данные добавляются с помощью обычного insert. В тех редких случаях, когда нужно что-то изменить, update делается через вставку новой версии данных, а delete — через вставку специальной метки, что данные больше не существуют. При таком подходе при переносе данных можно писать в clusterTo, а читать из clusterFrom и clusterTo. У этого подхода есть и ряд других преимуществ — простота синхронизации мобильных клиентов, версионность всех данных (важно в финансах), предсказуемая производительность (не нужен autovacuum), и прочие.
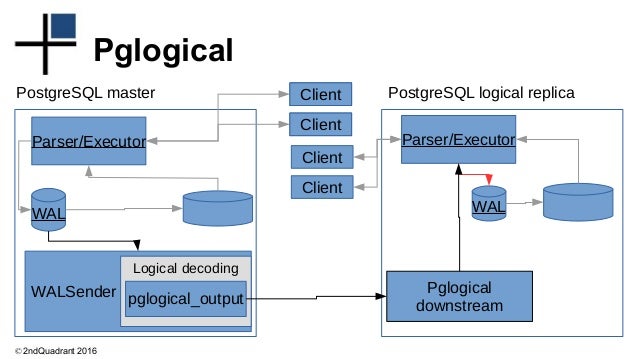
- Логическая репликация между clusterFrom и clusterTo. Ждем полной синхронизации, работая только с clusterFrom. Затем переключаемся на clusterTo и работаем только с ним. Это наиболее универсальное решение, но есть нюансы. Например, в случае с PostgreSQL логическая репликация — это очень болезненная тема. Наиболее многообещающим решением здесь является pglogical, но у него есть ряд существенных ограничений. Кроме того, последний раз, когда я пробовал pglogical, мне попросту не удалось заставить его работать. Вероятно, вам придется написать свою собственную логическую репликацию. Но это сложно и затратно по времени, так как следует корректно обрабатывать несколько транзакций, выполняющихся параллельно, откаты транзакций, и прочее в таком духе.
- Смешанный подход, то есть, использование (1), (2) или (3) на выбор администратора, запустившего перенос. Или же использование разных подходов для разных данных в базе.
 Все данные можно представить в виде лога событий. Новые данные добавляются с помощью обычного insert. В тех редких случаях, когда нужно что-то изменить, update делается через вставку новой версии данных, а delete — через вставку специальной метки, что данные больше не существуют. При таком подходе при переносе данных можно писать в clusterTo, а читать из clusterFrom и clusterTo. У этого подхода есть и ряд других преимуществ — простота синхронизации мобильных клиентов, версионность всех данных (важно в финансах), предсказуемая производительность (не нужен autovacuum), и прочие.
Все данные можно представить в виде лога событий. Новые данные добавляются с помощью обычного insert. В тех редких случаях, когда нужно что-то изменить, update делается через вставку новой версии данных, а delete — через вставку специальной метки, что данные больше не существуют. При таком подходе при переносе данных можно писать в clusterTo, а читать из clusterFrom и clusterTo. У этого подхода есть и ряд других преимуществ — простота синхронизации мобильных клиентов, версионность всех данных (важно в финансах), предсказуемая производительность (не нужен autovacuum), и прочие. Кроме того, последний раз, когда я пробовал pglogical, мне попросту не удалось заставить его работать. Вероятно, вам придется написать свою собственную логическую репликацию. Но это сложно и затратно по времени, так как следует корректно обрабатывать несколько транзакций, выполняющихся параллельно, откаты транзакций, и прочее в таком духе.
Кроме того, последний раз, когда я пробовал pglogical, мне попросту не удалось заставить его работать. Вероятно, вам придется написать свою собственную логическую репликацию. Но это сложно и затратно по времени, так как следует корректно обрабатывать несколько транзакций, выполняющихся параллельно, откаты транзакций, и прочее в таком духе.Дополнение: Вместо pglogical вы, вероятно, захотите использовать логическую репликацию, которая начиная с PostgreSQL 10 теперь есть из коробки.
В случаях (1) и (2) данные можно переносить обычным pg_dump или воспользоваться COPY:
— экспорт таблицы
COPY tname TO PROGRAM ‘gzip > /tmp/data.gz’;
— экспорт данных по запросу
COPY (SELECT * FROM tname WHERE …) TO PROGRAM ‘gzip > /tmp/data.gz’;
— импорт данных
COPY tname FROM PROGRAM ‘zcat /tmp/data.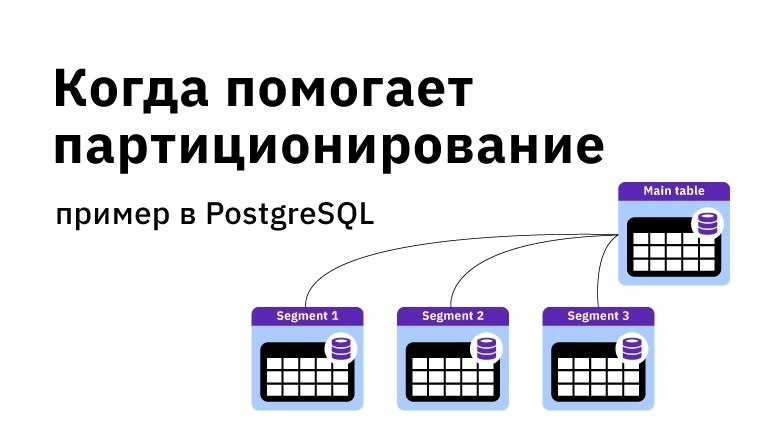 gz’;
gz’;
Следует также отметить, что вместо логической репликации можно использовать обычную потоковую. Для этого нужно, чтобы каждый vbucket жил на отдельном инстансе СУБД. В частности, PostgreSQL позволяет легко запускать много инстансов на одной физической машине безо всякой виртуализации. В этом случае вы, вероятно, захотите выбрать несколько меньшее число vbuckets, чем предложенные ранее 1024. Еще, как альтернативный вариант, можно реплицировать вообще все данные, а потом удалять лишние. Но это дорого и будет работать только при введении в строй совершенного нового репликасета.
На мой взгляд, наиболее правдоподобным и универсальным вариантом на сегодняшний день является использование потоковой репликации с удалением лишних данных по окончании репликации по сценарию (3). Это работает только при добавлении совершенно нового, пустого репликасета. В случае, если данные нужно слить с нескольких репликасетов в один, следует использовать pg_dump по сценарию (1).
Решардинг
Напомню, что решардингом, в отличие от перебалансировки, называется изменение числа vbucket’ов или же полное изменение схемы шардирования. Последнее по моим представлениям является очень сложной задачей, делается крайне редко, и исключительно в случае, если весь шардинг реализован непосредственно в самом приложении, а не на стороне СУБД или какого-то middleware перед ним. Здесь очень многое зависит от конкретной ситуации, поэтому далее мы будем говорить о решардинге только в контексте изменения числа vbucket’ов.
Последнее по моим представлениям является очень сложной задачей, делается крайне редко, и исключительно в случае, если весь шардинг реализован непосредственно в самом приложении, а не на стороне СУБД или какого-то middleware перед ним. Здесь очень многое зависит от конкретной ситуации, поэтому далее мы будем говорить о решардинге только в контексте изменения числа vbucket’ов.
Простейший подход к решардингу — это не поддерживать его и просто заранее выбирать достаточно большее количество vbucket’ов 🙂
Если же решардинг все-таки требуется поддерживать, многое зависит от того, что было выбрано за единицу данных (см параграф про шардинг). Допустим, ей является строка в таблице. Тогда мы можем очень просто удвоить количество vbucket’ов. Вспомним формулу:
// было
vbucket_num = hash(key) % 1024 [ = hash(key) & 0x3FF ]
// стало
vbucket_num = hash(key) % 2048 [ = hash(key) & 0x7FF ]
После удвоения числа vbucket’ов половина ключей будут соответствовать все тому же номеру бакета, от 0 до 1023. Еще половина ключей будет перенесена в бакеты с 1024 по 2047. Притом ключ, ранее принадлежавший бакету 0, попадет в бакет 1024, ранее принадлежавший бакету 1 — в бакет 1025, и так далее (у номера бакета появится дополнительный старший бит, равный единице). Это означает, что если мы возьмем текущий словарь, и модифицируем его так:
Еще половина ключей будет перенесена в бакеты с 1024 по 2047. Притом ключ, ранее принадлежавший бакету 0, попадет в бакет 1024, ранее принадлежавший бакету 1 — в бакет 1025, и так далее (у номера бакета появится дополнительный старший бит, равный единице). Это означает, что если мы возьмем текущий словарь, и модифицируем его так:
// оператор ++ означает операцию append, присоединение массива с конца
dict.vbuckets = dict.vbuckets ++ dict.vbuckets
… то все ключи автоматически окажутся на нужных репликасетах без какого-либо переноса. Теперь, когда число vbucket’ов удвоилось, бакеты можно переносить с репликасета на репликасет, как обычно. Уменьшение числа vbucket’ов происходит аналогично в обратном порядке — сначала серия переносов, затем обновление словаря. Как и в случае с перебалансировкой, следует проверять, что все клиенты увидели новую версию словаря.
Если единицами данных являются базы данных с одинаковой схемой, все несколько сложнее. В этом случае не очень понятно, как можно быстро и правильно для общего случая разделить каждую базу на две. Похоже, лучшее, что можно сделать при такой схемы шардирования, вместо использования формулы
Похоже, лучшее, что можно сделать при такой схемы шардирования, вместо использования формулы hash(key) % 1024 просто сообщать пользователю количество vbucket’ов. В этом случае определение номера бакета по ключу, а также перенос данных в случае решардинга перекладываются на приложение. Зато число бакетов может в любой момент быть увеличено на произвольное число просто путем создания пустых бакетов. Или уменьшено путем удаления лишних бакетов, в предположении, что пользователь заблаговременно перенес из них все данные.
Распределенные транзакции
Поскольку бакеты могут быть логически связанными и храниться на разных репликасетах, иногда приходится делать транзакции между репликасетами. При правильно выбранной схеме шардирования распределенные транзакции должны выполняться редко, поскольку они всегда недешевы. Если в вашем проекте распределенные транзакции не нужно делать никогда, вам сильно повезло.
Как всегда, в зависимости от ситуации задачу можно решить разными способами. Допустим, вы решили воспользоваться описанной выше идеей с неизменяемыми данными, и каждый пользователь в вашем проекте читает данные только из своего бакета. В этом случае «транзакцию» между бакетами А и Б можно выполнить по предельно простому алгоритму:
Допустим, вы решили воспользоваться описанной выше идеей с неизменяемыми данными, и каждый пользователь в вашем проекте читает данные только из своего бакета. В этом случае «транзакцию» между бакетами А и Б можно выполнить по предельно простому алгоритму:
- Создайте объект «транзакция», хранящий все, что вы хотите записать в бакеты А и Б.
- Произведите запись в бакет А. Запись должна производиться в одну локальную транзакцию, а у записанных объектов должна быть метка, к какой транзакции они относятся. Если объекты с соответствующей меткой уже записаны, ничего не делать.
- Аналогичным образом произведите запись в бакет Б.
- Удалите объект «транзакция»;
Шаги (2) и (3) могут выполняться параллельно. Если выполнение кода прервется на шаге (2), (3) или (4), «транзакцию» всегда можно будет докатить (специально предусмотренным для этого процессом). Это возможно по той причине, что операции (2) и (3) идемпотентны — их повторное выполнение приводит к тому же результату. При этом, поскольку пользователь читает данные только из своего бакета, с его точки зрения данные всегда консистентны.
При этом, поскольку пользователь читает данные только из своего бакета, с его точки зрения данные всегда консистентны.
Само собой разумеется, это не настоящие транзакции, но для многих проектов их будет более, чем достаточно. При определенных условиях этот подход можно применить даже в случае, если данные в бакетах изменяемые.
Описание более универсального подхода можно найти в блоге Дениса Рысцова. Также этот прием описан как минимум в документации к MongoDB и блоге CockroachDB. В общих чертах алгоритм примерно такой:
- Создайте объект «транзакция» с состоянием
committed = false, aborted = false. - При обращении к объектам в вашей базе данных на чтение и на запись указывайте в них ссылку на транзакцию. При обращении на запись в специальное поле допишите, каким станет объект в случае, если транзакция завершится успешно (локальные изменения). Если у объекта уже есть метка, и соответствующая транзакция:
- … закоммичена, примените локальные изменения объекта и запишите свою метку.
- … отменена, очистите локальные изменения и запишите свою метку.
- … все еще выполняется, значит произошел конфликт. Вы можете подождать, отменить свою транзакцию, или отменить чужую транзакцию. Примите во внимание, что процесс, выполнявший другую транзакцию, мог уже умереть. Так что, как минимум при определенных условиях вы должны отменять ту, другую транзакцию (например, если она начала выполнение достаточно давно). Иначе затронутые ею объекты останутся заблокированы навсегда.
- … закоммичена, примените локальные изменения объекта и запишите свою метку.
- Если транзакция все еще не прибита другими процессами, измените ее состояние на
committed = true. Это ключевой момент алгоритма. Так как этот шаг выполняется атомарно, и все транзакции знают, как трактовать локальные изменения, у транзакции нет никаких промежуточных состояний. В любой момент времени она либо применена, либо нет. - Почистите за собой — примените локальные изменения ко всем затронутым объектам, затем удалите объект «транзакция». Этот шаг не обязателен в смысле корректности алгоритма. Он просто освобождает место на диске от данных, которые стали ненужны.
 Он просто освобождает место на диске от данных, которые стали ненужны.
Он просто освобождает место на диске от данных, которые стали ненужны.Важно! Приведенное описание предполагает, что каждая операция чтения или записи выполняется в отдельной транзакции при уровне изоляции serializable. Или, в более общем случае, если СУБД не поддерживает транзакций, в одну CAS-операцию. Однако выполнение нескольких операций в одной транзакции не влияет на корректность алгоритма.
Этот алгоритм довольно неприятно применять по той причине, что абсолютно все транзакции, включая локальные, должны понимать, как трактовать локальные изменения. Алгоритм обеспечивает уровень изоляции repeatable read. Это уровень изоляции менее строгий, чем snapshot isolation и serializable, и на нем возможны некоторые аномалии (phantom read, write skew). Тем не менее, он подходит для многих приложений, если знать об его ограничениях.
Хочу еще раз подчеркнуть важность проставления метки транзакции на шаге (2) не только при записи, но и при чтении. Если этого не делать, другая транзакция может изменить объект, который вы читаете, и при повторном его прочтении вы увидите что-то другое. Если вы точно знаете, что не станете ничего писать в него, то можете просто закэшировать объект в памяти.
Если вы точно знаете, что не станете ничего писать в него, то можете просто закэшировать объект в памяти.
Заключение
Горизонтальное масштабирование РСУБД — задача решаемая. Несмотря на сложность некоторых описанных выше моментов, это ничто по сравнению со сложностями, которые вас ждут при использовании в проекте исключительно NoSQL решений. В частности, для обеспечения какой-либо консистентности придется делать распределенные транзакции, как было описано выше, практически на все.
Как вы могли убедиться, тут довольно сложно представить универсальное решение, подходящее абсолютно всем и всегда. И это мы еще упустили из виду, например, такие важные вопросы, как репликация между несколькими ДЦ и снятие консистентных бэкапов с множества репликасетов! Именно ввиду существования огромного количества возможных решений мы не рассматривали вопрос автоматизации всего описанного выше.
Надеюсь, что вы нашли представленный выше материал интересным. Как обычно, если у вас есть вопросы или дополнения, не стесняйтесь оставлять их в комментариях!
Дополнение: В этом контексте вас также может заинтересовать статья Поднимаем кластер CockroachDB из трех нод.
Метки: Распределенные системы, СУБД.
Принципы шардинга реляционных баз данных | by Igor Olemskoi | Southbridge
Когда ваша база данных небольшая (10 ГБ), вы можете легко добавить больше ресурсов и таким образом масштабировать ее. Однако, поскольку таблицы растут, нужно подумать и о других способах масштабирования базы данных.
С одной стороны шардинг — лучший способ масштабирования. Он позволяет линейно масштабировать ресурсы базы данных, памяти и диска, дробя базу данных на более мелкие части. С другой стороны целесообразность использования шаринга — спорная тема. Интернет полон советов по шардингу, от «масштабирования инфраструктуры базы данных» до «почему вы никогда не используете шардинг». Итак, вопрос в том, какую сторону принять.
Всегда, когда возникал вопрос шардинга, ответ был «раз на раз не приходится». Теория шардинга проста: выберите один ключ (столбец), который равномерно распределяет данные. Убедитесь, что большинство запросов могут быть решены с помощью этого ключа. Эта теория проста, но только до того момента, пока вы не приступите к практике.
Эта теория проста, но только до того момента, пока вы не приступите к практике.
В Citus мы помогли сотням команд, когда они обращались к шардингу баз данных. С получением опыта мы обнаружили, что имеются ключевые шаблоны.
В этой статье мы сначала рассмотрим ключевые параметры, которые влияют на успех шардинга, а затем раскроем основную причину, по которой мнения о шардинге столь разные. Когда дело доходит до шардинга базы данных, на успех в большей степени влияет тип приложения, которое вы создаете.
На успех шардинга базы данных влияют 3 ключевых параметра. На диаграмме они показаны на трех осях, а также приведены примеры известных компаний.
Ось X на диаграмме показывает тип рабочей нагрузки. Эта ось начинается с транзакционных нагрузок слева и продолжается организацией хранилищ данных. Изменения этой оси более заметны при шардинге.
Ось Z демонстрирует еще один важный параметр — нахождение в жизненном цикле приложения. Сколько таблиц у вас есть в базе данных (10, 100, 1000) или как долго приложение находится в производстве? Приложение, запущенное на PostgreSQL в течение нескольких месяцев, будет легче шардироваться, чем приложение, которое было в производстве в течение многих лет.
В Citus мы обнаружили, что большинство пользователей имеют достаточно развитые приложения. Когда приложение развито, ось У становится критической. К сожалению, изменения этой оси не так заметны, как изменения остальных осей. Фактически большинство статей, которые противоречат выводам о фрагментации, предоставляют свои рекомендации в контексте одного типа приложения.
Ось У на диаграмме показывает наиболее важный параметр при шардинге баз данных — тип приложения. В верхней части этой оси находятся приложения B2B, модели данных которых более удобны для фрагментации. В нижней части этой оси — приложения B2C, такие как Amazon и Facebook, которые требуют больше работы. Далее мы расскажем о различиях трех известных компаний.
Хорошим примером приложения для B2B является программное обеспечение CRM. Когда вы создаете CRM-приложение, такое как Salesforce, ваше приложение будет обслуживать других клиентов. Например, компания GE Aviation будет одним из ваших клиентов, использующих Salesforce.
В GE Aviation есть пользователи, которые входят в свою панель мониторинга компании. GE также фиксирует:
потенциальных клиентов, с которыми они могут вести бизнес,
контакты/людей, которые уже известны и с которыми установлены деловые отношения,
счета, которые представляют бизнес-единицы и у которых есть работающие на них контакты,
возможности, которые являются событиями продаж, связанными с учетной записью и одного или нескольких контактов.
Сопоставление этих сложных соотношений выглядит следующим образом:
График выглядит сложным. Но изучив график, можно заметить, что большинство таблиц происходит из таблицы клиентов. Графы можно преобразовать, добавив столбец customer_id ко всем таблицам.
С помощью этого простого преобразования у базы данных теперь есть хороший ключ оглавления: customer_id. Он равномерно распределяет данные, и большинство запросов к базе данных будут включать ключ клиента. Кроме того, вы можете размещать таблицы в client_id и продолжать использовать ключевые функции реляционной базы данных, такие как транзакция, объединение таблиц и ограничение внешнего ключа.
Другими словами, если у вас есть приложение B2B, характер ваших данных дает вам фундаментальное преимущество при шардинге.
Amazon.com — хороший пример расширенного приложения B2C. Если бы вы строили сайт Amazon.com сегодня, у вас было бы несколько концепций для рассмотрения. Во-первых, пользователь приходит на ваш сайт и начинает смотреть продукты: книги, электронику. Когда пользователь посещает страницу продукта, скажем, Harry Potter 7, он видит информацию каталога, связанную с этим продуктом. Пример информации о каталоге включает автора, цену, обложку и другие изображения.
Когда пользователь регистрируется на веб-сайте, он получает доступ к данным, связанным с пользователем. Пользователь должен быть аутентифицирован, может писать отзывы о любимых продуктах и добавлять элементы в корзину покупок. В какой-то момент пользователь решает сделать покупку и размещает заказ. Заказ обрабатывается, забирается со склада и отправляется.
При сопоставлении отношений в реляционнной базе данных вы обнаружите, что они отличаются от примера Salesforce одной важной чертой. У вас нет единого измерения, которое является центром всех отношений, а есть как минимум три: каталог, пользователь и данные заказа.
У вас нет единого измерения, которое является центром всех отношений, а есть как минимум три: каталог, пользователь и данные заказа.
При фрагментации данных типа B2C один из вариантов заключается в преобразовании приложения в микросервисы. Например, есть связанные службы каталога, которые владеют каталогом и предлагают данные, а также связанные с пользователем службы, которые владеют данными корзины проверки подлинности и покупок. API-интерфейсы между службами определяют границы доступа к базам данным.
При создании такого разделения между данными можно шардировать данные, которые предоставляют каждую услугу или группу услуг отдельно. Фактически Amazon.com использовал аналогичный подход к шардингу, когда перешел на сервис-ориентированную архитектуру.
Такой подход к очертаниям имеет более выгодное соотношение затрат и стоимости, чем шардинг приложения B2B. Что касается преимуществ, при разделении данных на группы таким образом можно полагаться на базу данных для объединения данных из разных источников или обеспечения транзакций и ограничений для групп данных. Со стороны затрат теперь нужно очертить не одну, а несколько групп данных.
Со стороны затрат теперь нужно очертить не одну, а несколько групп данных.
Подкатегория, которая находится между B2B и B2C, включает такие приложения, как Postmates, Instacart или Lyft. Например, Instacart доставляет продукты пользователям из местных магазинов. В некотором смысле Instacart похож на пример Amazon.com. Instacart имеет три основных габаритных поля: местные магазины (предлагают продукты), пользователи (заказывают продукты) и водители (доставляют продукты). Таким образом, трудно выбрать один ключ, на котором можно очертить базу данных.
Если у вас есть расширенные приложения B2C2C, такие как Instacart, вы можете следовать другой стратегии. Большинство таблиц базы данных имеют другое измерение: география. В этом случае вы можете выбрать город или местоположение в качестве своего ключа и очертить таблицы по ключу географии.
В общем, шардинг приложений B2B2C / B2C2C находится в середине спектра. Шардинг для B2B2C имеет тенденцию к более высокому соотношению выгод и затрат, чем шардинг приложений B2C, и более низкое, чем приложения B2B.
Интернет полон мнений о шардинге. Мы обнаружили, что большинство этих мнений формируются с учетом одного типа приложения. Фактически тип приложения (B2B или B2C) влияет на успех более всего. В частности, если у вас приложение для B2B, то вам будет легче шардировать реляционную базу данных.
При планировании масштабирования базы данных нужно иметь полное представление об этом процесcе и оценить все параметры с учетом требований проекта.
Оригинал: Principles of Sharding for Relational Databases.
Уроки, извлеченные из сегментирования Postgres в Notion
Ранее в этом году мы закрыли Notion на пять минут планового обслуживания. В то время как наше объявление указывало на «повышенную стабильность и производительность», за кулисами была кульминация месяцев целенаправленной, срочной командной работы: разделение монолита PostgreSQL Notion на парк баз данных с горизонтальными разделами.
Считается, что номенклатура осколков возникла из MMORPG Ultima Online, когда разработчикам игры понадобилось объяснение во вселенной существования нескольких игровых серверов, на которых запущены параллельные копии мира.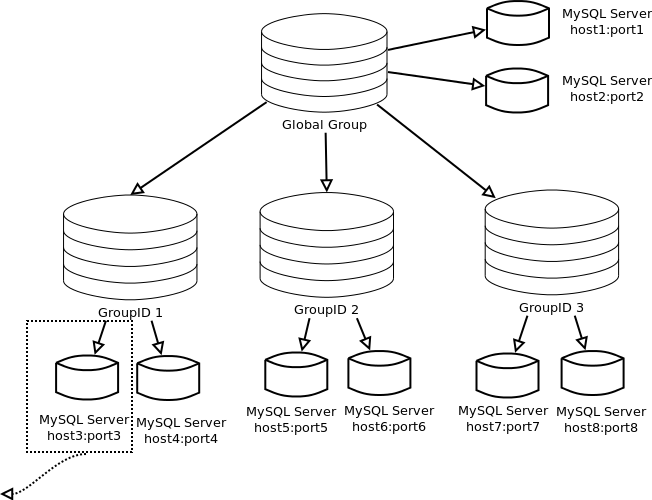 В частности, каждый осколок появился из разбитого кристалла, через который злой волшебник Мондейн ранее пытался захватить контроль над миром.
В частности, каждый осколок появился из разбитого кристалла, через который злой волшебник Мондейн ранее пытался захватить контроль над миром.
Несмотря на то, что переключение прошло с большим ликованием, мы хранили молчание на случай каких-либо проблем после миграции. К нашей радости, пользователи быстро начали замечать улучшения:
Guillermo Rauch
rauchg
Удивительно, насколько быстрее работает @notionhq в последнее время. Принцип «показывай, а не рассказывай» здесь очень силен.
Но одно окно обслуживания не говорит всей истории. Наша команда потратила месяцы на разработку этой миграции, чтобы сделать Notion быстрее и надежнее на долгие годы.
Позвольте мне рассказать вам историю о том, как мы разделялись и чему научились на этом пути.
Принятие решения о том, когда выполнять сегментирование
Разделение стало важной вехой в наших постоянных усилиях по повышению производительности приложений. За последние несколько лет было приятно и унизительно видеть, как все больше и больше людей внедряют Notion во все аспекты своей жизни. И неудивительно, что все новые вики компании, трекеры проектов и покедексы означают миллиарды новых блоков, файлов и пространств для хранения. К середине 2020 года стало ясно, что использование продукта превзойдет возможности нашего надежного монолита Postgres, который верно служил нам в течение пяти лет и четырех порядков роста. Дежурные инженеры часто просыпались из-за всплесков ЦП базы данных, а простые миграции только каталогов становились небезопасными и ненадежными.
За последние несколько лет было приятно и унизительно видеть, как все больше и больше людей внедряют Notion во все аспекты своей жизни. И неудивительно, что все новые вики компании, трекеры проектов и покедексы означают миллиарды новых блоков, файлов и пространств для хранения. К середине 2020 года стало ясно, что использование продукта превзойдет возможности нашего надежного монолита Postgres, который верно служил нам в течение пяти лет и четырех порядков роста. Дежурные инженеры часто просыпались из-за всплесков ЦП базы данных, а простые миграции только каталогов становились небезопасными и ненадежными.
Когда дело доходит до сегментирования, быстрорастущие стартапы должны найти деликатный компромисс. В течение нулевых число сообщений в блогах преждевременно излагало опасности сегментирования: увеличение нагрузки на обслуживание, новые ограничения в коде на уровне приложений и зависимость от архитектурного пути.¹ Конечно, в наших масштабах сегментирование было неизбежным. Вопрос был только в том, когда.
Для нас переломный момент наступил, когда процесс Postgres VACUUM начал постоянно останавливаться, не позволяя базе данных освобождать дисковое пространство от мертвых кортежей. В то время как емкость диска может быть увеличена, более тревожной была перспектива переноса идентификатора транзакции (TXID) — механизма безопасности, при котором Postgres прекращает обработку всех операций записи, чтобы избежать затирания существующих данных. Понимая, что циклический перенос TXID создаст экзистенциальную угрозу для продукта, наша команда по инфраструктуре удвоила усилия и приступила к работе.
Разработка схемы сегментирования
Если вы никогда раньше не шардировали базу данных, вот вам идея: вместо вертикального масштабирования базы данных с увеличением количества экземпляров, горизонтальное масштабирование путем разделения данных по нескольким базам данных. Теперь вы можете легко развернуть дополнительные хосты для обеспечения роста. К сожалению, теперь ваши данные находятся в нескольких местах, поэтому вам необходимо разработать систему, обеспечивающую максимальную производительность и согласованность в распределенной среде.
Почему бы просто не масштабировать по вертикали? Как мы обнаружили, игра в Cookie Clicker с кнопкой RDS «Изменить размер экземпляра» не является жизнеспособной долгосрочной стратегией, даже если у вас есть на это бюджет. Производительность запросов и процессы обслуживания часто начинают ухудшаться задолго до того, как таблица достигает максимального размера, связанного с аппаратным обеспечением; наша зависшая автоочистка Postgres была примером этого мягкого ограничения.
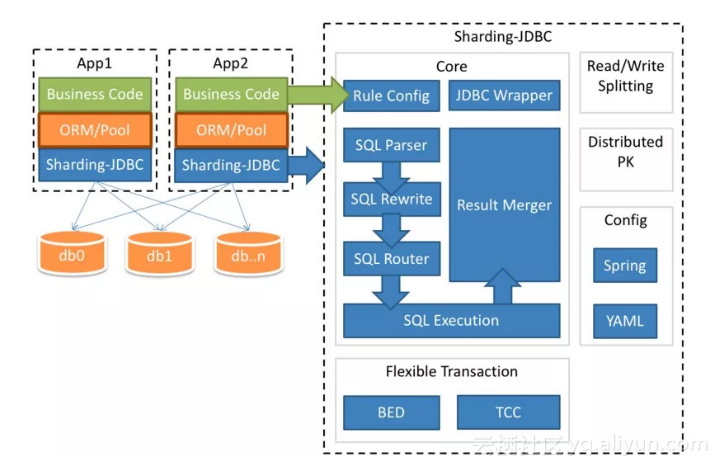
Разделение на уровне приложения
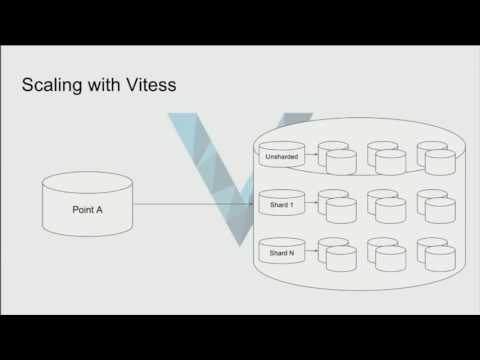
Мы решили реализовать собственную схему секционирования и маршрутизировать запросы из логики приложения, подход, известный как сегментирование на уровне приложения . Во время нашего первоначального исследования мы также рассматривали пакетные решения для сегментирования/кластеризации, такие как Citus для Postgres или Vitess для MySQL. Хотя эти решения привлекают своей простотой и готовыми инструментами для перекрестных сегментов, фактическая логика кластеризации непрозрачна, и мы хотели контролировать распределение наших данных². решения:
решения:
Какие данные мы должны шардировать? Часть того, что делает наш набор данных уникальным, заключается в том, что таблица
блокаотражает деревья пользовательского контента, которые могут сильно различаться по размеру, глубине и коэффициенту ветвления. Например, один крупный корпоративный клиент создает больше нагрузки, чем многие средние личные рабочие места вместе взятые. Мы хотели сегментировать только необходимые таблицы, сохраняя при этом локальность связанных данных.Как мы должны разделить данные? Хорошие ключи секций обеспечивают равномерное распределение кортежей по осколкам. Выбор ключа секции также зависит от структуры приложения, поскольку распределенные соединения обходятся дорого, а гарантии транзакционности обычно ограничиваются одним хостом.
Сколько осколков мы должны создать? Как должны быть организованы эти осколки? Это соображение касается как количества логических сегментов на таблицу, так и конкретного сопоставления между логическими сегментами и физическими хостами.
Поскольку модель данных Notion вращается вокруг концепции блока, каждый из которых занимает строку в нашей базе данных, таблица блока имела наивысший приоритет для сегментирования. Однако блок может ссылаться на другие таблицы, например 9.0029 пробел (рабочие области) или обсуждение (обсуждения на уровне страницы и встроенные потоки обсуждения). В свою очередь, обсуждение может ссылаться на строки в таблице комментариев и так далее.
Мы решили разбить все таблицы, доступные из таблицы блока , через какое-то отношение внешнего ключа. Не все эти таблицы нужно было сегментировать, но если запись хранилась в основной базе данных, а связанный с ней блок хранился в другом физическом сегменте, мы могли вызвать несоответствия при записи в разные хранилища данных.
Например, рассмотрим блок, хранящийся в одной базе данных, с соответствующими комментариями в другой базе данных. Если блок удаляется, комментарии должны быть обновлены, но, поскольку гарантии транзакционности применяются только в каждом хранилище данных, удаление блока может завершиться успешно, а обновление комментариев не удастся.
Если блок удаляется, комментарии должны быть обновлены, но, поскольку гарантии транзакционности применяются только в каждом хранилище данных, удаление блока может завершиться успешно, а обновление комментариев не удастся.
Решение 2: Разделение данных блока по идентификатору рабочей области
После того, как мы решили, какие таблицы следует сегментировать, нам пришлось их разделить. Выбор хорошей схемы секционирования сильно зависит от распределения и связности данных; поскольку Notion — это командный продукт, нашим следующим решением было разбить данные по идентификатору рабочей области .³
Каждой рабочей области при создании назначается UUID, поэтому мы можем разделить пространство UUID на одинаковые сегменты. Поскольку каждая строка в сегментированной таблице является либо блоком, либо связана с ним, и каждый блок принадлежит ровно одной рабочей области , мы использовали идентификатор рабочей области в качестве ключа раздела .![]() Поскольку пользователи обычно одновременно запрашивают данные в пределах одной рабочей области, мы избегаем большинства объединений между сегментами.
Поскольку пользователи обычно одновременно запрашивают данные в пределах одной рабочей области, мы избегаем большинства объединений между сегментами.
Решение 3: Планирование мощности
Nintendo .DS_Store
sliminality
sharding postgres: «вы бы предпочли бороться с 1 пользователем, делающим 1 млн запросов, или с 1 млн пользователей, делающих по 1 запросу» установка, которая будет обрабатывать наши существующие данные и в масштабе, чтобы соответствовать нашему двухлетнему прогнозу использования с минимальными усилиями. Вот некоторые из наших ограничений:
Тип экземпляра: Пропускная способность дискового ввода-вывода, выраженная в IOPS, ограничена как типом экземпляра AWS, так и объемом диска. Нам требовалось не менее 60 000 операций ввода-вывода в секунду для удовлетворения существующего спроса с возможностью дальнейшего масштабирования при необходимости.
Количество физических и логических сегментов: Чтобы Postgres продолжала работать и сохранить гарантии репликации RDS, мы установили верхний предел в 500 ГБ на таблицу и 10 ТБ на физическую базу данных.
Количество экземпляров: Большее количество экземпляров означает более высокую стоимость обслуживания, но более надежную систему.
Стоимость: Мы хотели, чтобы наш счет линейно масштабировался с настройкой нашей базы данных, и нам нужна была гибкость для раздельного масштабирования вычислительных ресурсов и дискового пространства.
После подсчетов мы остановились на архитектуре, состоящей из 480 логических сегментов , равномерно распределенных по 32 физическим базам данных . Иерархия выглядела так:
Вам может быть интересно: « Почему 480 осколков? Я думал, что вся компьютерная наука делается в степени двойки, и я не знаю такого размера диска!»
There were many factors that led to the choice of 480:
2
3
4
5
6
8
10, 12, 15, 16, 20, 24, 30, 32, 40, 48, 60, 80, 96, 120, 160, 240
Дело в том, что 480 делится на множество чисел, что обеспечивает гибкость добавлять или удалять физические хосты, сохраняя единообразное распределение сегментов.
Предположим, что у нас есть 512 логических осколков. Все множители 512 являются степенями двойки, то есть мы бы перескочили с 32 до 64 хостов, если бы хотели сохранить осколки равными. Любая степень числа 2 потребует от нас удвоить количества физических хостов для повышения масштаба. Выберите значения с большим количеством факторов!
Мы перешли от одной базы данных, содержащей каждую таблицу, к группе из 32 физических баз данных, каждая из которых содержит 15 логических сегментов, каждый из которых содержит одну из каждой сегментированной таблицы. Всего у нас было 480 логических шардов.
Мы решили построить
schema001.block,schema002.blockи т. д. как отдельных таблиц , а не поддерживать одну секционированную таблицуblockдля каждой базы данных с 15 дочерними таблицами.
Код приложения: идентификатор рабочей области → физическая база данных.
Таблица разделов: идентификатор рабочей области → логическая схема.
Сохранение отдельных таблиц позволило нам направлять данные непосредственно из приложения к определенной базе данных и логическому сегменту.
Нам нужен был единый источник достоверной информации для маршрутизации от идентификатора рабочей области к логическому сегменту, поэтому мы решили создавать таблицы отдельно и выполнять всю маршрутизацию в приложении.
Миграция на сегменты
После того, как мы установили нашу схему сегментирования, пришло время ее реализовать. Для любой миграции наша общая структура выглядит примерно так:
Двойная запись: Входящие записи применяются как к старой, так и к новой базе данных.
Заполнение: После начала двойной записи перенесите старые данные в новую базу данных.
Проверка: Обеспечьте целостность данных в новой базе данных.
Переключение: Фактический переход на новую базу данных. Это можно сделать постепенно, например. двойное чтение, а затем перенести все чтения.
Двойная запись с помощью журнала аудита
Фаза двойной записи гарантирует, что новые данные будут заполнять как старую, так и новую базы данных, даже если новая база данных еще не используется. Есть несколько вариантов двойного написания:
Запись напрямую в обе базы данных: Вроде бы все просто, но любая проблема с записью может быстро привести к несогласованности между базами данных, что делает этот подход слишком ненадежным для производственных хранилищ данных критического пути.
Логическая репликация: Встроенная функция Postgres, которая использует модель публикации/подписки для передачи команд нескольким базам данных.
Журнал аудита и сценарий наверстывания: Создайте таблицу журнала аудита, чтобы отслеживать все записи в переносимые таблицы. Наверстывающий процесс перебирает журнал аудита и применяет каждое обновление к новым базам данных, внося необходимые изменения.
Мы выбрали стратегию журнала аудита вместо логической репликации, так как последняя изо всех сил старалась не отставать от объема записи таблицы
блокана начальном этапе моментального снимка.Мы также подготовили и протестировали журнал обратного аудита и сценарий на тот случай, если нам потребуется переключить обратно с осколков на монолит. Этот сценарий будет фиксировать любые входящие записи в сегментированную базу данных и позволит нам воспроизвести эти изменения в монолите. В конце концов, нам не нужно было отступать, но это была важная часть нашего плана на случай непредвиденных обстоятельств.
Обратная загрузка старых данных
После того, как входящие записи успешно распространились на новые базы данных, мы инициировали процесс обратной засыпки для переноса всех существующих данных. Со всеми 96 ЦП (!) на экземпляре
m5.24xlarge, который мы подготовили, нашему окончательному сценарию потребовалось около трех дней для заполнения рабочей среды.Любая достойная обратная засыпка должна сравнивать версии записей перед записью старых данных, пропуская записи с более поздними обновлениями. При запуске сценария наверстывания и обратной засыпки в любом порядке новые базы данных в конечном итоге сойдутся для репликации монолита.
Проверка целостности данных
Миграция хороша настолько, насколько хороша целостность базовых данных, поэтому после того, как осколки были обновлены с помощью монолита, мы начали процесс проверка правильности .
Сценарий проверки: Наш сценарий проверил непрерывный диапазон пространства UUID, начиная с заданного значения, сравнивая каждую запись в монолите с соответствующей записью в сегменте.
«Темное» чтение: Перед переносом запросов на чтение мы добавили флаг для извлечения данных как из старой, так и из новой базы данных (известный как «темное чтение»). Мы сравнили эти записи и отбросили сегментированную копию, зафиксировав при этом несоответствия. Внедрение темного чтения увеличило задержку API, но обеспечило уверенность в том, что переключение будет плавным.
В качестве меры предосторожности логика миграции и проверки была реализована разными людьми . В противном случае была большая вероятность того, что кто-то совершит одну и ту же ошибку на обоих этапах, что ослабит предпосылку проверки.
Извлеченные трудные уроки
Несмотря на то, что большая часть проекта шардинга привлекла внимание команды инженеров Notion, было много решений, которые мы пересмотрели задним числом.
Осколок ранее. Как небольшая команда, мы хорошо знали о компромиссах, связанных с преждевременной оптимизацией. Однако мы ждали, пока наша существующая база данных не станет сильно перегруженной, а это означало, что мы должны были быть очень экономными с миграциями, чтобы не добавить еще больше нагрузки. Это ограничение не позволяло нам использовать логическую репликацию для двойной записи. Идентификатор рабочей области — наш ключ раздела — еще не был заполнен в старой базе данных, и заполнение этого столбца усугубило бы нагрузку на нашем монолите. Вместо этого мы заполнили каждую строку на лету при записи в сегменты, что потребовало специального сценария наверстывания.
Стремитесь к миграции без простоев. Пропускная способность двойной записи была основным узким местом в нашем последнем переключении: после того, как мы отключили сервер, нам нужно было дать сценарию догоняющего завершить распространение операций записи на сегменты.
Ввести комбинированный первичный ключ вместо отдельного ключа раздела. Сегодня строки в сегментированных таблицах используют составной ключ:
id, первичный ключ в старой базе данных; иspace_id, ключ раздела в текущем расположении. Поскольку нам все равно нужно было выполнить полное сканирование таблицы, мы могли бы объединить оба ключа в один новый столбец, избавив от необходимости передаватьspace_idsпо всему приложению.Несмотря на все эти предположения, шардинг имел огромный успех. Для пользователей Notion несколько минут простоя сделали продукт ощутимо быстрее. Внутри мы продемонстрировали скоординированную командную работу и решительное исполнение поставленной цели.
Если срочные сроки не мешают вам серьезно подумать о долгосрочных технических последствиях, мы будем рады пообщаться — присоединяйтесь к нам!
Share this post
Footnotes
[1] Помимо излишней сложности недооцененная опасность преждевременного сегментирования заключается в том, что оно может ограничить модель продукта до того, как она будет четко определена с точки зрения бизнеса. Например, если команда выполняет сегментацию по пользователям, а затем переходит к стратегии продукта, ориентированной на команду, несоответствие архитектурного импеданса может привести к значительным техническим проблемам и даже ограничить определенные функции.
[2] В дополнение к пакетным решениям мы рассмотрели ряд альтернатив: переход на другую систему баз данных, такую как DynamoDB (считается слишком рискованной для нашего варианта использования), и запуск Postgres на жестких экземплярах NVMe без операционной системы для увеличения пропускной способности диска.
[3] Помимо разбиения на основе ключей, которое разделяет данные на основе некоторого атрибута, существуют и другие подходы: вертикальное разбиение по сервису и разделение на основе каталогов с использованием промежуточной таблицы поиска для маршрутизации всех операций чтения и записи.
Попробуйте сейчас
Приступайте к работе в Интернете или на рабочем столе
У нас также есть приложения для Mac и Windows, которые подходят друг другу.
У нас также есть соответствующие приложения для iOS и Android.
Веб-приложение
Настольное приложение
Windows
Apple App Store
Google App Store
Используете Notion на работе? Связаться с отделом продаж
Загрузить из App Store
Продолжить чтение
Все сообщения →
Создание Notion API
Возможность доступа к контенту Notion через API — одна из наиболее востребованных функций нашими пользователями.
Alicia Liu
Engineering
Миграция маркетингового сайта Notion на Next.js
Повышение производительности и удобства пользователей путем перехода с маркетингового сайта, отображаемого клиентом, на статический сайт, созданный Next.js.
Кори Эцкорн
Проектирование и разработка, Notion
Распределенные данные — Azure Cosmos DB для PostgreSQL
Редактировать
Твиттер
Фейсбук
Электронное письмо
- Статья
- 3 минуты на чтение
ПРИМЕНЯЕТСЯ К:
PostgreSQL
В этой статье описаны три типа таблиц в Azure Cosmos DB для PostgreSQL.
Он показывает, как распределенные таблицы хранятся в виде осколков и как осколки размещаются на узлах.Типы таблиц
В кластере есть три типа таблиц, каждая
используются для разных целей.Тип 1: распределенные таблицы
Первый и наиболее распространенный тип — это распределенные таблицы. Они
кажутся обычными таблицами для операторов SQL, но они расположены горизонтально
разделены между рабочими узлами. Это означает, что строки
таблицы хранятся на разных узлах, в таблицах фрагментов, называемых
осколки.Azure Cosmos DB для PostgreSQL выполняет не только операторы SQL, но и операторы DDL во всем кластере.
Каскадное изменение схемы распределенной таблицы для обновления
все осколки таблицы через воркеров.Столбец распределения
Azure Cosmos DB для PostgreSQL использует алгоритмическое сегментирование для назначения строк сегментам. Присвоение производится детерминировано на основе значения
столбца таблицы, называемого столбцом распределения.
администратор должен указать этот столбец при распространении таблицы.
Правильный выбор важен для производительности и функциональности.Тип 2: Справочные таблицы
Справочная таблица — это тип распределенной таблицы, все содержимое которой
сконцентрированы в одном осколе. Шард реплицируется на каждого рабочего и
координатор. Запросы на любого работника могут получить доступ к справочной информации
локально, без сетевых накладных расходов на запрос строк с другого узла.
Справочные таблицы не имеют столбца распределения, потому что нет необходимости
различать отдельные осколки в строке.Справочные таблицы обычно имеют небольшой размер и используются для хранения данных,
относящиеся к запросам, выполняемым на любом рабочем узле. Пример указан
такие значения, как статусы заказов или категории продуктов.Тип 3: локальные таблицы
При использовании Azure Cosmos DB для PostgreSQL узел координатора, к которому вы подключаетесь, является обычной базой данных PostgreSQL.
Хорошим кандидатом для локальных таблиц могут быть небольшие административные таблицы, которые не участвуют в запросах на соединение. Примером может служить таблица пользователей для входа в приложение и проверки подлинности.
Осколки
В предыдущем разделе описано, как распределенные таблицы хранятся в виде осколков на
рабочие узлы. В этом разделе обсуждаются более технические детали.Таблица метаданных
pg_dist_shardкоординатора содержит
строка для каждого сегмента каждой распределенной таблицы в системе. Ряд
сопоставляет идентификатор осколка с диапазоном целых чисел в хеш-пространстве
(минимальное значение осколка, максимальное значение осколка).SELECT * из pg_dist_shard; логическая надежность | шардид | осколки | осколочное значение | максимальное значение осколка ---------------+---------+---------------+--------- ------+--------------- гитхаб_события | 102026 | т | 268435456 | 402653183 гитхаб_события | 102027 | т | 402653184 | 536870911 гитхаб_события | 102028 | т | 536870912 | 671088639 гитхаб_события | 102029 | т | 671088640 | 805306367 (4 ряда)Если узел-координатор хочет определить, какой сегмент содержит строку
github_events, он хеширует значение столбца распределения в
строка.
диапазоны определены так, что образ хэш-функции является их
несвязный союз.Размещение осколков
Предположим, что сегмент 102027 связан с рассматриваемой строкой. Ряд
читается или записывается в таблицу с именемgithub_events_102027в одном из
рабочие. Какой рабочий? Это полностью определяется метаданными
столы. Сопоставление шарда с рабочим называется размещением шарда.Координатор узла
переписывает запросы на фрагменты, которые ссылаются на определенные таблицы
напримерgithub_events_102027и запускает эти фрагменты на
соответствующих работников. Вот пример запроса, выполняемого за кулисами, чтобы найти узел, содержащий идентификатор осколка 102027.ВЫБОР шардид, узел.имя узла, node.nodeport ИЗ размещения pg_dist_placement ПРИСОЕДИНЯЙТЕСЬ к узлу pg_dist_node ON размещение.groupid = node.groupid И node.noderole = 'основной'::noderole ГДЕ шардид = 102027;┌─────────┬───────────┬──────────┐ │ shardid │ имя узла │ порт узла │ ├─────────┼───────────┼──────────┤ │ 102027 │ локальный хост │ 5433 │ └─────────┴───────────┴──────────┘Следующие шаги
- Узнайте, как выбрать столбец распределения для распределенных таблиц.
 Нам нужно было выбрать количество логических сегментов и количество физических баз данных, чтобы сегменты можно было равномерно разделить между базами данных.
Нам нужно было выбрать количество логических сегментов и количество физических баз данных, чтобы сегменты можно было равномерно разделить между базами данных. Например, в будущем мы могли бы масштабироваться с 32 до 40 и до 48 хостов, каждый раз делая инкрементальные скачки.
Например, в будущем мы могли бы масштабироваться с 32 до 40 и до 48 хостов, каждый раз делая инкрементальные скачки.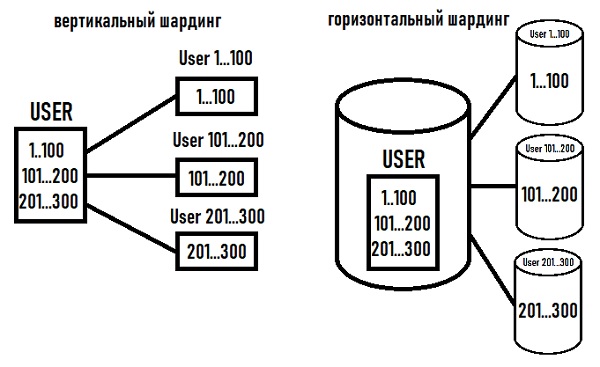 Таблицы с собственным разделением представляют собой еще одну часть логики маршрутизации:
Таблицы с собственным разделением представляют собой еще одну часть логики маршрутизации:
 Ограниченная возможность изменять данные между исходной и целевой базами данных.
Ограниченная возможность изменять данные между исходной и целевой базами данных.
 Поскольку полное сканирование таблицы было бы непомерно дорогим, мы случайным образом выбрали UUID и проверили их смежные диапазоны.
Поскольку полное сканирование таблицы было бы непомерно дорогим, мы случайным образом выбрали UUID и проверили их смежные диапазоны. Вот несколько примеров:
Вот несколько примеров: Если бы мы потратили еще неделю на оптимизацию скрипта, чтобы тратить менее 30 секунд на догонку осколков во время переключения, возможно, можно было бы выполнить горячую замену на уровне балансировщика нагрузки без простоев.
Если бы мы потратили еще неделю на оптимизацию скрипта, чтобы тратить менее 30 секунд на догонку осколков во время переключения, возможно, можно было бы выполнить горячую замену на уровне балансировщика нагрузки без простоев.
 (отклонено из-за стоимости обслуживания резервных копий и репликации).
(отклонено из-за стоимости обслуживания резервных копий и репликации).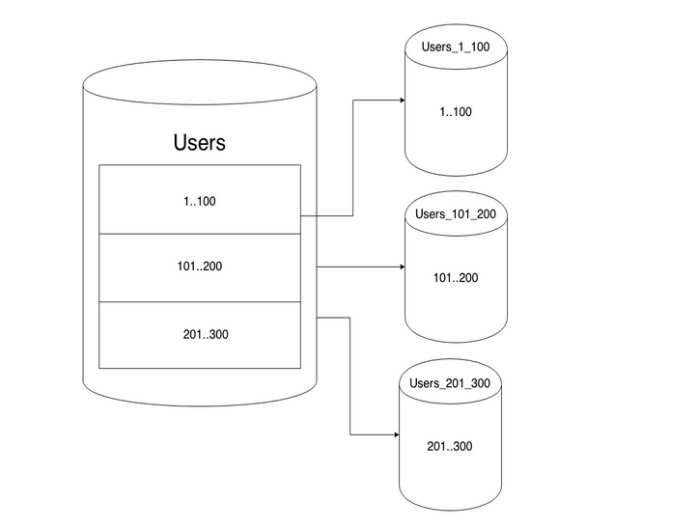 Узнайте о том, как мы разработали наш REST API, чтобы решить задачу сохранения гибкости и выразительности модели данных Notion.
Узнайте о том, как мы разработали наш REST API, чтобы решить задачу сохранения гибкости и выразительности модели данных Notion.
 Кластер
Кластер Вы можете создавать обычные таблицы на координаторе и не разделять их.
Вы можете создавать обычные таблицы на координаторе и не разделять их. Затем узел проверяет, диапазон какого сегмента содержит хешированное значение.
Затем узел проверяет, диапазон какого сегмента содержит хешированное значение.