Содержание
Правильный файл robots.txt для сайта на WordPress в 2023
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Пример;
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Пример правильного файла robots.txt для сайта на WordPress
- User-agent: *
- Disallow: /cgi-bin
- Disallow: /wp-admin/
- Disallow: /wp-includes/
- Disallow: /wp-content/plugins/
- Disallow: /wp-content/cache/
- Disallow: /wp-content/themes/
- Disallow: /wp-trackback
- Disallow: /wp-feed
- Disallow: /wp-comments
- Disallow: /author/
- Disallow: */embed*
- Disallow: */wp-json*
- Disallow: */page/*
- Disallow: /*?
- Disallow: */trackback
- Disallow: */comments
- Disallow: /*.php
- Host: https://seopulses.
 ru
ru - Sitemap: https://seopulses.ru/sitemap_index.xml
 ru
ruГде можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
https://ru. wordpress.org/plugins/pc-robotstxt/
wordpress.org/plugins/pc-robotstxt/
- Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.

Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site. ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Правильный robots.txt для WordPress | Как сделать robots.txt
Содержание:
-
Что такое robots.txt
-
Для чего нужен robots.txt
-
Как редактировать robots txt
-
Правильный robots. txt для CMS WordPress
-
Проверка robots.txt
 txt для CMS WordPress
txt для CMS WordPress
Вебмастера и маркетологи знают насколько важна индексация сайта поисковыми системами. Именно поэтому они делают все возможное, чтобы помочь поисковикам типа Google и Yandex правильно сканировать и индексировать свои сайты.
Большое количество времени и ресурсов тратятся на внутреннюю и внешнюю оптимизацию, такую как контент, ссылки, теги, оптимизация изображений и структуры сайта.
Всё это играет огромную роль в продвижении. Однако если вы забыли сделать техническую оптимизацию сайта, если вы не слышали о файлах robots.txt и sitemap.xml могут возникнуть проблемы с правильным сканированием и индексацией вашего сайта.
В этой статье я объясню как правильно настраивать и использовать файл robots.txt и мета-тег robots. Итак, начнем!
к содержанию ↑
Что такое robots.txt
Robots. txt – это текстовый файл, который используется в качестве инструкции для роботов поисковых систем (также известных как сканеры, боты или пауки), как сканировать и индексировать страницы сайта.
txt – это текстовый файл, который используется в качестве инструкции для роботов поисковых систем (также известных как сканеры, боты или пауки), как сканировать и индексировать страницы сайта.
Простыми словами, robots.txt говорит роботам, какие страницы или файлы сайта мы хотим видеть в поиске, а какие нет.
В идеале файл robots.txt размещается в корневом каталоге вашего веб-сайта (https://site.com/robots.txt), чтобы роботы могли сразу получить доступ к его инструкциям.
Если вы используете CMS WordPress, то вы сможете увидеть ваш файл по вышеуказанному адресу, однако вы не найдете сам файл в общей папке с вашим сайтом. Это потому что WordPress автоматически создает виртуальный файл robots.txt (с параметрами по-умолчанию), если не находит данный файл в корневом каталоге сайта.
Виртуальный файл robots.txt CMS WordPress не решает всех необходимых задач, в связи с этим крайне желательно написать свой.
к содержанию ↑
Для чего нужен robots.
 txt
txt
Файл robots.txt нужен, для того чтобы запретить поисковым роботам посещать определенные разделы вашего сайта, например:
- страницы пагинации;
- страницы с результатами поиска на сайте;
- административные файлы;
- служебные страницы;
- ссылки с utm-метками;
- данные о параметрах сортировки, фильтрации, сравнении;
- страница личного кабинета и т.п.
Важно! Файл robots.txt не является обязательным к исполнению поисковыми роботами. В связи с этим, если вы хотите на 100% быть уверенными в том что какая-либо из страниц вашего сайта не появится в поисковой выдаче – используйте мета-тег robots.
Согласно Cправке Google файл robots.txt не предназначен для того, чтобы запрещать показ веб-страниц в результатах поиска Google.
Если вы не хотите чтобы какая-то страница вашего сайта появилась в поиске вставьте в <head> страницы атрибут noindex:
<meta name=“robots” content=“noindex,nofollow”>
к содержанию ↑
Как редактировать robots txt
Редактировать файл robots. txt в CMS WordPress можно двумя способами. Добавить необходимый код в файл functions.php, или при помощи плагина.
txt в CMS WordPress можно двумя способами. Добавить необходимый код в файл functions.php, или при помощи плагина.
В нашей компании мы предпочитаем второй способ.
Устанавливаем плагин Virtual Robots.txt из репозитория CMS WordPress, открываем его в админ. панеле во вкладке Настройки. В открывшееся поле плагина вносим необходимый код, жмем кнопку Save и вуаля – ваш файл robots.txt готов.
к содержанию ↑
Правильный robots.txt для CMS WordPress
Взял с сайта seogio.ru и немного подкорректировал. Вот что получилось:
User-agent: * # общие правила для роботов всех поисковых систем
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск по сайту
Disallow: *&s= # поиск по сайту
Disallow: /search/ # поиск по сайту
Disallow: /author/ # архив автора
Disallow: /users/ # архив пользователей
Disallow: */trackback # трекбеки, уведомления в комментариях о ссылке на веб-документ
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Allow: /*/*.js # открываем файлы скриптов js
Allow: /*/*.css # открываем фалы css
Allow: /wp-*.png # разрешаем индексировать изображения
Allow: /wp-*.jpg # разрешаем индексировать изображения
Allow: /wp-*.jpeg # разрешаем индексировать изображения
Allow: /wp-*.gif # разрешаем индексировать гифки
Allow: /wp-admin/admin-ajax.php # разрешаем ajax
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail. RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
 xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Allow: /*/*.js # открываем файлы скриптов js
Allow: /*/*.css # открываем фалы css
Allow: /wp-*.png # разрешаем индексировать изображения
Allow: /wp-*.jpg # разрешаем индексировать изображения
Allow: /wp-*.jpeg # разрешаем индексировать изображения
Allow: /wp-*.gif # разрешаем индексировать гифки
Allow: /wp-admin/admin-ajax.php # разрешаем ajax
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Allow: /*/*.js # открываем файлы скриптов js
Allow: /*/*.css # открываем фалы css
Allow: /wp-*.png # разрешаем индексировать изображения
Allow: /wp-*.jpg # разрешаем индексировать изображения
Allow: /wp-*.jpeg # разрешаем индексировать изображения
Allow: /wp-*.gif # разрешаем индексировать гифки
Allow: /wp-admin/admin-ajax.php # разрешаем ajax
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail. RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
к содержанию ↑
Проверка robots.txt
Если файл robots.txt настроен неправильно это может привести к множественным ошибкам в индексации сайта. Проверить правильность настройки вашего robots.txt можно с помощью бесплатного инструмента Google Robots Testing Tool
Выбираем наш сайт:
Вводим в строку путь к нашему файлу robots.txt и жмем кнопку Проверить:
В результате не должно быть ошибок и предупреждений и файл должен быть Доступен для роботов:
Если файл robots.txt настроен правильно, это значительно ускорит процесс индексации вашего сайта.
шаблон WordPress robots.
 txt · GitHub
txt · GitHub
Этот файл содержит двунаправленный текст Unicode, который может быть интерпретирован или скомпилирован не так, как показано ниже. Для просмотра откройте файл в редакторе, который показывает скрытые символы Unicode.
Подробнее о двунаправленных символах Unicode
Показать скрытые символы
| # Роботы рулят! — Иногда… # | |
| Агент пользователя: * | |
| Разрешить: / | |
| # Запретить эти каталоги, типы URL и типы файлов | |
| Запретить: /trackback/ | |
| Запретить: /wp-admin/ | |
| Запретить: /wp-content/ | |
| Запретить: /wp-includes/ | |
Запретить: /xmlrpc. php php | |
| Запретить: /wp- | |
| Запретить: /cgi-bin | |
| Запретить: /readme.html | |
| Запретить: /license.txt | |
| Запретить: /*?* | |
| Запретить: /*.php$ | |
| Запретить: /*.js$ | |
| Запретить: /*.inc$ | |
| Запретить: /*.css$ | |
| Запретить: /*.gz$ | |
| Запретить: /*.wmv$ | |
Запретить: /*. cgi$ cgi$ | |
| Запретить: /*.xhtml$ | |
| Запретить: /*/wp-* | |
| Запретить: /*/канал/* | |
| Запретить: /*/*?s=* | |
| Запретить: /*/*.js$ | |
| Запретить: /*/*.inc$ | |
| Разрешить: /wp-content/uploads/ | |
| Агент пользователя: ia_archiver* | |
| Запретить: / | |
| Агент пользователя: duggmirror | |
| Запретить: / | |
Карта сайта: http://yourdomain. com/sitemap.xml com/sitemap.xml |
Что это такое и как его использовать
Вы когда-нибудь слышали термин robots.txt и задавались вопросом, как он применим к вашему веб-сайту? На большинстве веб-сайтов есть файл robots.txt, но это не значит, что большинство владельцев сайтов понимают его. В этом посте мы надеемся изменить это, предложив подробно изучить файл robots.txt WordPress, а также то, как он может контролировать и ограничивать доступ к вашему сайту.
Нам предстоит многое рассказать, так что давайте начнем!
Мгновенно ускорьте свой сайт WordPress на 20%
Воспользуйтесь преимуществами самых быстрых серверов Google и сети Premium Tier, поддерживаемой более чем 275 CDN Cloudflare по всему миру, для невероятно быстрой загрузки. Входит бесплатно во все планы WordPress.
Начните сегодня
Что такое файл robots.txt WordPress?
Прежде чем мы поговорим о файле robots.txt WordPress, важно определить, что такое «робот» в данном случае. Роботы — это «боты» любого типа, которые посещают веб-сайты в Интернете. Наиболее распространенным примером являются сканеры поисковых систем. Эти боты «ползают» по сети, помогая таким поисковым системам, как Google, индексировать и ранжировать миллиарды страниц в Интернете.
Роботы — это «боты» любого типа, которые посещают веб-сайты в Интернете. Наиболее распространенным примером являются сканеры поисковых систем. Эти боты «ползают» по сети, помогая таким поисковым системам, как Google, индексировать и ранжировать миллиарды страниц в Интернете.
Итак, боты есть, вообще , хорошая штука для интернета… ну или хотя бы нужная вещь. Но это не обязательно означает, что вы или другие владельцы сайтов хотите, чтобы боты свободно бегали. Желание контролировать взаимодействие веб-роботов с веб-сайтами привело к созданию в середине 1990-х годов стандарта исключения роботов . Robots.txt является практической реализацией этого стандарта — , он позволяет вам контролировать, как участвующие боты взаимодействуют с вашим сайтом . Вы можете полностью заблокировать ботов, ограничить их доступ к определенным областям вашего сайта и многое другое.
Однако эта часть «участия» важна. Robots.txt не может заставить бота следовать его указаниям. А вредоносные боты могут и будут игнорировать файл robots.txt. Кроме того, даже авторитетные организации игнорируют некоторые команды, которые вы можете поместить в robots.txt. Например, Google будет игнорировать любые правила, которые вы добавите в файл robots.txt о том, как часто его поисковые роботы посещают ваш сайт. Вы можете настроить скорость, с которой Google сканирует ваш веб-сайт, на странице настроек скорости сканирования вашего ресурса в Google Search Console.
А вредоносные боты могут и будут игнорировать файл robots.txt. Кроме того, даже авторитетные организации игнорируют некоторые команды, которые вы можете поместить в robots.txt. Например, Google будет игнорировать любые правила, которые вы добавите в файл robots.txt о том, как часто его поисковые роботы посещают ваш сайт. Вы можете настроить скорость, с которой Google сканирует ваш веб-сайт, на странице настроек скорости сканирования вашего ресурса в Google Search Console.
Если у вас много проблем с ботами, может пригодиться защитное решение, такое как Cloudflare или Sucuri.
Как найти robots.txt?
Файл robots.txt находится в корне вашего веб-сайта, поэтому добавление /robots.txt после вашего домена должно загрузить файл (если он у вас есть). Например, https://kinsta.com /robots.txt .
Когда следует использовать файл robots.txt?
Для большинства владельцев сайтов преимущества хорошо структурированного файла robots. txt сводятся к двум категориям:
txt сводятся к двум категориям:
- Оптимизация ресурсов сканирования поисковых систем путем указания им не тратить время на страницы, которые вы не хотите индексировать. Это помогает поисковым системам сосредоточиться на сканировании наиболее важных для вас страниц.
- Оптимизация использования сервера путем блокировки ботов, которые тратят ресурсы впустую.
Robots.txt не предназначен конкретно для управления тем, какие страницы индексируются в поисковых системах
Robots.txt не является надежным способом управления тем, какие страницы индексируются поисковыми системами. Если вашей основной целью является предотвращение включения определенных страниц в результаты поисковой системы, правильным подходом является использование мета-тега noindex или защиты паролем.
Это связано с тем, что файл robots.txt прямо не указывает поисковым системам не индексировать контент — он просто говорит им не сканировать его. Хотя Google не будет сканировать отмеченные области внутри вашего сайта, сам Google заявляет, что если внешний сайт ссылается на страницу, которую вы исключаете с помощью файла robots. txt, Google все равно может проиндексировать эту страницу.
txt, Google все равно может проиндексировать эту страницу.
Джон Мюллер, аналитик Google для веб-мастеров, также подтвердил, что если на страницу есть ссылки, указывающие на нее, даже если она заблокирована файлом robots.txt, она все равно может быть проиндексирована. Ниже приводится то, что он сказал в видеовстрече Webmaster Central:
Здесь следует иметь в виду одну вещь: если эти страницы заблокированы robots.txt, то теоретически может случиться так, что кто-то случайно свяжется с одной из этих страниц. И если они это сделают, то может случиться так, что мы проиндексируем этот URL без какого-либо контента, потому что он заблокирован robots.txt. Таким образом, мы не знали бы, что вы не хотите, чтобы эти страницы действительно индексировались.
Принимая во внимание, что если они не заблокированы robots.txt, вы можете поместить на эти страницы метатег noindex. И если кто-то ссылается на них, и мы случайно просканируем эту ссылку и подумаем, что, может быть, здесь есть что-то полезное, тогда мы будем знать, что эти страницы не нужно индексировать, и мы можем просто полностью исключить их из индексации.
Итак, в этом отношении, если на этих страницах есть что-то, что вы не хотите индексировать, не запрещайте их, вместо этого используйте noindex .

Нужен ли мне файл robots.txt?
Важно помнить, что у вас нет файла robots.txt на вашем сайте. Если у вас нет проблем с тем, что все боты могут свободно сканировать все ваши страницы, вы можете не добавлять их, поскольку у вас нет реальных инструкций для сканеров.
В некоторых случаях вы даже не сможете добавить файл robots.txt из-за ограничений используемой вами CMS. Это нормально, но есть и другие способы проинструктировать ботов о том, как сканировать ваши страницы без использования файла robots.txt.
Какой код состояния HTTP должен быть возвращен для файла robots.txt?
Файл robots.txt должен возвращать код состояния HTTP 200 OK, чтобы поисковые роботы могли получить к нему доступ.
Если у вас возникли проблемы с индексацией ваших страниц поисковыми системами, стоит дважды проверить код состояния, возвращенный для вашего файла robots. txt. Все, кроме кода состояния 200, может помешать поисковым роботам получить доступ к вашему сайту.
txt. Все, кроме кода состояния 200, может помешать поисковым роботам получить доступ к вашему сайту.
Некоторые владельцы сайтов сообщают о деиндексации страниц из-за того, что их файл robots.txt возвращает статус, отличный от 200. В марте 2022 года владелец веб-сайта спросил о проблеме с индексацией во время встречи Google SEO в рабочее время, и Джон Мюллер объяснил, что файл robots.txt должен либо возвращать статус 200, если они присутствуют, либо статус 4XX, если файл не существовать. В этом случае возвращалась внутренняя ошибка сервера 500, которая, по словам Мюллера, могла привести к тому, что робот Googlebot исключил сайт из индексации.
То же самое можно увидеть в этом твите, где владелец сайта сообщил, что весь его сайт деиндексирован из-за того, что файл robots.txt возвращает ошибку 500.
[Совет по поисковой оптимизации]
Если у вас возникли проблемы с индексированием, убедитесь, что ваш файл robots.
Если ваш файл возвращает 500, Google в конечном итоге деиндексирует ваш веб-сайт, как я видел в этом проекте. pic.twitter.com/8KiYLgDVRo
— Антуан Эрипрет (@antoineripret) 14 ноября 2022 г.
 txt возвращает либо 200, либо 404.
txt возвращает либо 200, либо 404.Можно ли использовать метатег Robots вместо файла robots.txt?
Нет. Метатег robots позволяет вам контролировать, какие страницы индексируются, а файл robots.txt позволяет вам контролировать, какие страницы сканируются. Боты должны сначала просканировать страницы, чтобы увидеть метатеги, поэтому вам следует избегать попыток использовать метатеги disallow и noindex, так как noindex не будет обнаружен.
Если ваша цель — исключить страницу из поисковых систем, метатег noindex обычно является лучшим вариантом.
Как создать и отредактировать файл robots.txt в WordPress
По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Так что, даже если вы и пальцем не пошевелите, на вашем сайте уже должен быть файл robots. txt по умолчанию. Вы можете проверить, так ли это, добавив «/robots.txt» в конец вашего доменного имени. Например, «https://kinsta.com/robots.txt» открывает файл robots.txt, который мы используем здесь, в Kinsta.
txt по умолчанию. Вы можете проверить, так ли это, добавив «/robots.txt» в конец вашего доменного имени. Например, «https://kinsta.com/robots.txt» открывает файл robots.txt, который мы используем здесь, в Kinsta.
Пример файла robots.txt
Вот пример файла robots.txt от Kinsta:
Пример файла robots.txt
Это дает всем роботам инструкции о том, какие пути игнорировать (например, путь wp-admin) с любыми исключениями (например, admin-ajax. php), а также расположение XML-карты сайта Kinsta.
Поскольку этот файл виртуальный, вы не можете его редактировать. Если вы хотите отредактировать файл robots.txt, вам нужно фактически создать физический файл на своем сервере, которым вы сможете манипулировать по мере необходимости. Вот три простых способа сделать это:
Как создать и отредактировать файл robots.txt в WordPress с помощью Yoast SEO
Если вы используете популярный плагин Yoast SEO, вы можете создать (а затем отредактировать) файл robots.txt прямо из интерфейса Yoast. Однако, прежде чем вы сможете получить к нему доступ, вам нужно добраться до SEO → Инструменты и нажать Редактор файлов
Однако, прежде чем вы сможете получить к нему доступ, вам нужно добраться до SEO → Инструменты и нажать Редактор файлов
Перейдите в редактор файлов в Yoast SEO
И как только вы нажмете эту кнопку, вы сможете редактировать содержимое вашего файла robots.txt непосредственно из того же интерфейса, а затем сохраните все внесенные изменения.
Отредактируйте и сохраните изменения в файле robots.txt
Если у вас еще нет физического файла robots.txt, Yoast предложит вам вариант Создать файл robots.txt :
Создать файл robots.txt
Как вы читаете дальше, мы углубимся в то, какие типы директив следует помещать в файл robots.txt WordPress.
Как создать и отредактировать файл robots.txt с помощью All-in-One SEO
Если вы используете почти такой же популярный плагин Yoast All-in-One SEO Pack , вы также можете создавать и редактировать ваш файл WordPress robots.txt прямо из интерфейса плагина. Все, что вам нужно сделать, это перейти к All-in-One SEO → Инструменты :
Все, что вам нужно сделать, это перейти к All-in-One SEO → Инструменты :
Как перейти к robots.txt в All-in-One SEO
Затем переключите переключатель Enable Custom robots.txt , чтобы он был включен. Это позволит вам создавать настраиваемые правила и добавлять их в файл robots.txt:
Как добавить настраиваемые правила в robots.txt в All-in-One SEO
Как создать и отредактировать файл robots.txt через FTP
Если вы не используете SEO-плагин, предлагающий функциональность robots.txt, вы все равно можете создавать файл robots.txt и управлять им через SFTP. Сначала с помощью любого текстового редактора создайте пустой файл с именем «robots.txt»:
Как создать собственный файл Robots.txt
Затем подключитесь к своему сайту через SFTP и загрузите этот файл в корневую папку вашего сайта. Вы можете внести дополнительные изменения в файл robots.txt, отредактировав его через SFTP или загрузив новые версии файла.
Что поместить в файл robots.
 txt
txt
Хорошо, теперь у вас есть физический файл robots.txt на вашем сервере, который вы можете редактировать по мере необходимости. Но что вы на самом деле делаете с этим файлом? Что ж, как вы узнали из первого раздела, robots.txt позволяет вам контролировать, как роботы взаимодействуют с вашим сайтом. Вы делаете это с помощью двух основных команд:
- User-agent — позволяет настроить таргетинг на определенных ботов. Пользовательские агенты — это то, что боты используют для идентификации себя. С ними можно было бы, например, создать правило, применимое к Bing, но не к Google.
- Запретить — позволяет запретить роботам доступ к определенным областям вашего сайта.
Существует также команда Разрешить , которую вы будете использовать в определенных ситуациях. По умолчанию все на вашем сайте отмечено цифрой 9.0217 Разрешить , поэтому нет необходимости использовать команду Разрешить в 99% ситуаций.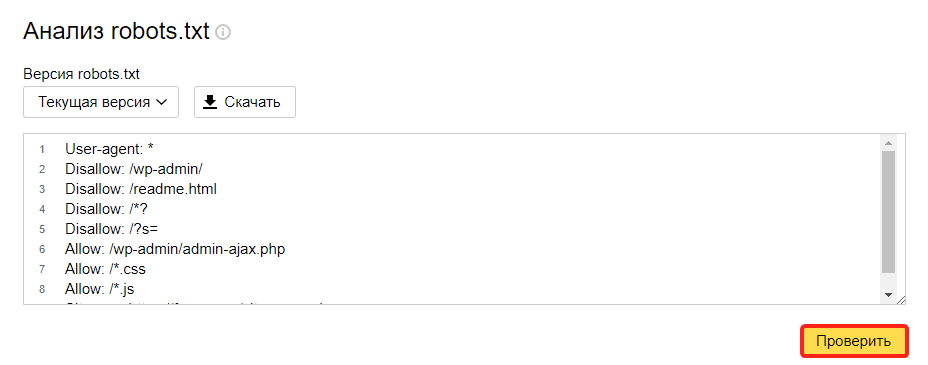 Но это удобно, когда вы хотите запретить доступ к папке и ее дочерним папкам, но разрешить доступ к одной конкретной дочерней папке.
Но это удобно, когда вы хотите запретить доступ к папке и ее дочерним папкам, но разрешить доступ к одной конкретной дочерней папке.
Чтобы добавить правила, сначала укажите, к какому User-agent должно применяться правило, а затем укажите, какие правила следует применять, используя Disallow и Allow . Есть также некоторые другие команды, такие как Задержка сканирования и Карта сайта , но это либо:
- Игнорируется большинством основных поисковых роботов, либо интерпретируется совершенно по-разному (в случае задержки сканирования)
- Излишне использовать такие инструменты, как Google Search Console (для карт сайта)
Давайте рассмотрим некоторые конкретные варианты использования, чтобы показать вам, как все это сочетается.
Как использовать Robots.txt Запретить все, чтобы заблокировать доступ ко всему вашему сайту
Допустим, вы хотите заблокировать все поисковых роботов получают доступ к вашему сайту. Это вряд ли произойдет на живом сайте, но пригодится для сайта разработки. Для этого вы должны добавить код robots.txt, запрещающий весь код, в файл robots.txt WordPress:
Это вряд ли произойдет на живом сайте, но пригодится для сайта разработки. Для этого вы должны добавить код robots.txt, запрещающий весь код, в файл robots.txt WordPress:
User-agent: * Disallow: /
Что происходит в этом коде?
Звездочка * рядом с User-agent означает «все пользовательские агенты». Звездочка — это подстановочный знак, означающий, что он применяется к каждому отдельному пользовательскому агенту. / косая черта рядом с Запретить говорит, что вы хотите запретить доступ к всем страницам, которые содержат «yourdomain.com/» (то есть каждая отдельная страница на вашем сайте).
Как использовать robots.txt, чтобы заблокировать доступ одного бота к вашему сайту
Давайте изменим ситуацию. В этом примере мы притворимся, что вам не нравится тот факт, что Bing сканирует ваши страницы. Вы все время являетесь командой Google и даже не хотите, чтобы Bing просматривал ваш сайт. Чтобы заблокировать только Bing от сканирования вашего сайта, вы должны заменить подстановочный знак *звездочка с Bingbot:
Чтобы заблокировать только Bing от сканирования вашего сайта, вы должны заменить подстановочный знак *звездочка с Bingbot:
Агент пользователя: Bingbot Disallow: /
По сути, приведенный выше код сообщает , что только применяют правило Disallow к ботам с агентом пользователя «Bingbot» . Теперь вы вряд ли захотите заблокировать доступ к Bing, но этот сценарий пригодится, если есть конкретный бот, которому вы не хотите получать доступ к своему сайту. На этом сайте есть хороший список имен большинства известных пользовательских агентов службы.
Как использовать robots.txt для блокировки доступа к определенной папке или файлу
В этом примере предположим, что вы хотите заблокировать доступ только к определенному файлу или папке (и ко всем подпапкам этой папки). Чтобы применить это к WordPress, допустим, вы хотите заблокировать:
- Всю папку wp-admin
- WP-логин. php
 php
phpВы можете использовать следующие команды:
User-agent: * Запретить: /wp-admin/ Disallow: /wp-login.php
Как использовать robots.txt Разрешить все, чтобы предоставить роботам полный доступ к вашему сайту
Если в настоящее время у вас нет причин блокировать доступ сканеров к любой из ваших страниц, вы можете добавить следующую команду.
Агент пользователя: * Позволять: /
Или альтернативно:
User-agent: * Запретить:
Как использовать Robots.txt, чтобы разрешить доступ к определенному файлу в запрещенной папке
Хорошо, теперь предположим, что вы хотите заблокировать всю папку, но при этом хотите разрешить доступ к определенному файлу внутри этой папки. Вот где 9Команда 0217 Разрешить пригодится. И это на самом деле очень применимо к WordPress. Фактически, виртуальный файл robots.txt WordPress прекрасно иллюстрирует этот пример:
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.
 php
php Этот фрагмент блокирует доступ ко всей папке /wp-admin/ , кроме файла /wp-admin/admin-ajax.php .
Как использовать robots.txt, чтобы запретить ботам сканировать результаты поиска WordPress
Одна из настроек WordPress, которую вы, возможно, захотите сделать, — запретить поисковым роботам сканировать ваши страницы результатов поиска. По умолчанию WordPress использует параметр запроса «?s=». Итак, чтобы заблокировать доступ, все, что вам нужно сделать, это добавить следующее правило:
User-agent: * Запретить: /?s= Disallow: /search/
Это также может быть эффективным способом предотвращения программных ошибок 404, если вы их получаете. Обязательно прочитайте наше подробное руководство о том, как ускорить поиск в WordPress.
Как создать разные правила для разных ботов в robots.txt
До сих пор все примеры касались одного правила за раз. Но что, если вы хотите применить разные правила к разным ботам? Вам просто нужно добавить каждый набор правил в объявление User-agent для каждого бота. Например, если вы хотите создать одно правило, которое применяется к всем ботам , а другое правило, которое применяется к , только к Bingbot , вы можете сделать это следующим образом:
Например, если вы хотите создать одно правило, которое применяется к всем ботам , а другое правило, которое применяется к , только к Bingbot , вы можете сделать это следующим образом:
User-agent: * Запретить: /wp-admin/ Агент пользователя: Bingbot Запретить: /
В этом примере всем ботам будет заблокирован доступ к /wp-admin/, но Bingbot будет заблокирован доступ ко всему вашему сайту.
Проверка файла robots.txt
Чтобы убедиться, что файл robots.txt настроен правильно и работает должным образом, его следует тщательно протестировать. Один неуместный символ может иметь катастрофические последствия для производительности сайта в поисковых системах, поэтому тестирование может помочь избежать потенциальных проблем.
Тестер Google robots.txt
Инструмент Google robots.txt Tester (ранее входивший в состав Google Search Console) прост в использовании и выявляет потенциальные проблемы в вашем файле robots.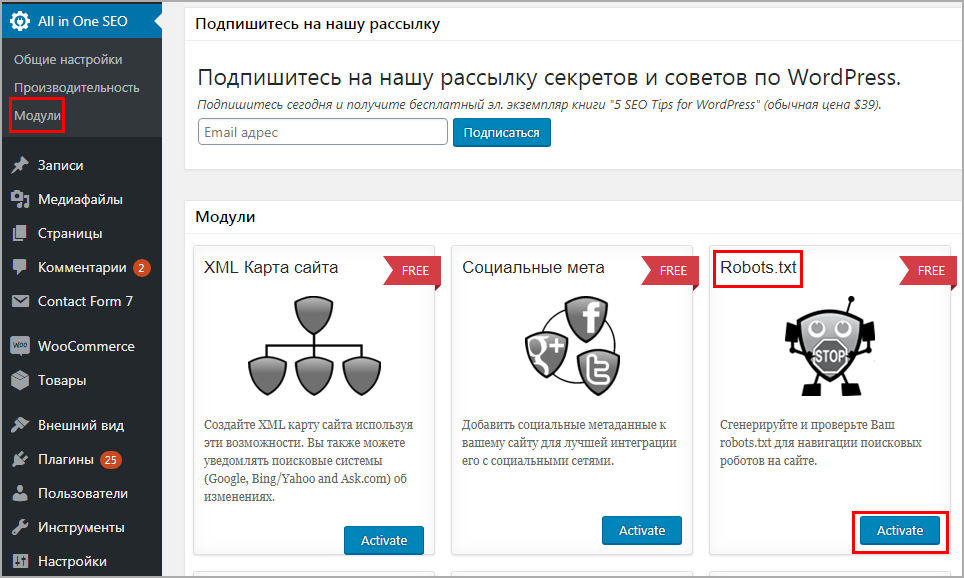 txt.
txt.
Просто перейдите к инструменту и выберите свойство для сайта, который вы хотите протестировать, затем прокрутите страницу вниз и введите любой URL-адрес в поле, затем нажмите красную кнопку TEST :
Testing robots.txt files
Если все доступно для сканирования, вы увидите зеленый ответ Разрешено .
Вы также можете выбрать, с какой версией Googlebot вы хотите провести тест: Googlebot, Googlebot-News, Googlebot-Image, Googlebot-Video, Googlebot-Mobile, Mediapartners-Google или Adsbot-Google.
Вы также можете проверить каждый отдельный URL-адрес, который вы заблокировали, чтобы убедиться, что они действительно заблокированы и/или запрещены .
Остерегайтесь спецификации UTF-8
Спецификация означает метку порядка следования байтов и в основном является невидимым символом, который иногда добавляется в файлы старыми текстовыми редакторами и т.п. Если это произойдет с вашим файлом robots. txt, Google может неправильно его прочитать. Вот почему важно проверить файл на наличие ошибок. Например, как показано ниже, наш файл имел невидимый символ, и Google жалуется на непонимание синтаксиса. По сути, это делает первую строку нашего файла robots.txt недействительной, что нехорошо! У Гленна Гейба есть отличная статья о том, как UTF-8 Bom может убить ваш SEO.
txt, Google может неправильно его прочитать. Вот почему важно проверить файл на наличие ошибок. Например, как показано ниже, наш файл имел невидимый символ, и Google жалуется на непонимание синтаксиса. По сути, это делает первую строку нашего файла robots.txt недействительной, что нехорошо! У Гленна Гейба есть отличная статья о том, как UTF-8 Bom может убить ваш SEO.
Робот Google в основном базируется в США
Также важно не блокировать робота Googlebot из США, даже если вы ориентируетесь на локальный регион за пределами США. Иногда они выполняют локальное сканирование, но Googlebot в основном базируется в США .
Робот Google в основном базируется в США, но иногда мы сканируем и локально. https://t.co/9KnmN4yXpe
— Google Search Central (@googlesearchc) 13 ноября 2017 г.
Что популярные сайты WordPress помещают в свой файл robots.txt
Чтобы на самом деле представить некоторый контекст для пунктов, перечисленных выше, вот как некоторые из самых популярных сайтов WordPress используют свои файлы robots.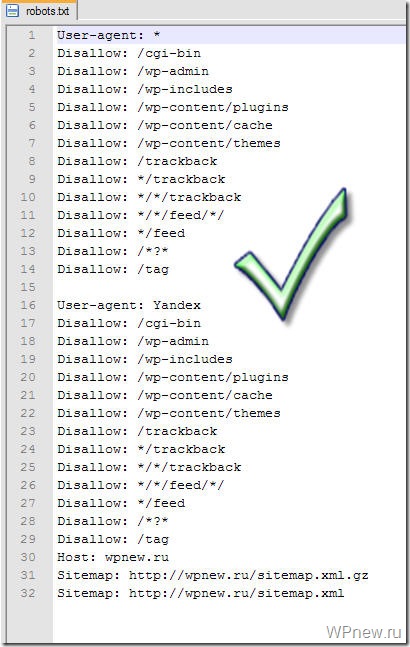 txt.
txt.
TechCrunch
TechCrunch Robots.txt File
Помимо ограничения доступа к ряду уникальных страниц, TechCrunch, в частности, запрещает поисковым роботам доступ к:
- /wp-admin/
- /wp-логин.php
Также установлены специальные ограничения на двух ботов:
- Swiftbot
- ИРЛбот
Если вам интересно, IRLbot — это поисковый робот из исследовательского проекта Техасского университета A&M. Странно!
Фонд Обамы
Фонд Обамы Файл Robots.txt
Фонд Обамы не вносил особых дополнений, ограничивая доступ исключительно к /wp-admin/.
Angry Birds
Angry Birds Файл Robots.txt
Angry Birds имеет те же настройки по умолчанию, что и Фонд Обамы. Ничего особенного не добавляется.
Дрифт
Дрифт Robots.txt Файл
Наконец, Drift решает определить свои карты сайта в файле Robots.txt, но в остальном оставляет те же ограничения по умолчанию, что и The Obama Foundation и Angry Birds.