Содержание
Сообщения HTTP — HTTP | MDN
HTTP сообщения — это обмен данными между сервером и клиентом. Есть два типа сообщений: запросы, отправляемые клиентом, чтобы инициировать реакцию со стороны сервера, и ответы от сервера.
Сообщения HTTP состоят из текстовой информации в кодировке ASCII, записанной в несколько строк. В HTTP/1.1 и более ранних версиях они пересылались в качестве обычного текста. В HTTP/2 текстовое сообщение разделяется на фреймы, что позволяет выполнить оптимизацию и повысить производительность.
Веб разработчики не создают текстовые сообщения HTTP самостоятельно — это делает программа, браузер, прокси или веб-сервер. Они обеспечивают создание HTTP сообщений через конфигурационные файлы (для прокси и серверов), APIs (для браузеров) или другие интерфейсы.
Механизм бинарного фрагментирования в HTTP/2 разработан так, чтобы не потребовалось вносить изменения в имеющиеся APIs и конфигурационные файлы: он вполне прозрачен для пользователя.
HTTP запросы и ответы имеют близкую структуру. Они состоят из:
- Стартовой строки, описывающей запрос, или статус (успех или сбой). Это всегда одна строка.
- Произвольного набора HTTP заголовков, определяющих запрос или описывающих тело сообщения.
- Пустой строки, указывающей, что вся мета информация отправлена.
- Произвольного тела, содержащего пересылаемые с запросом данные (например, содержимое HTML-формы ) или отправляемый в ответ документ. Наличие тела и его размер определяется стартовой строкой и заголовками HTTP.
Стартовую строку вместе с заголовками сообщения HTTP называют головой запроса, а его данные — телом.
Стартовая строка
HTTP запросы — это сообщения, отправляемые клиентом, чтобы инициировать реакцию со стороны сервера. Их стартовая строка состоит из трёх элементов:
- Метод HTTP, глагол (например,
GET,PUTилиPOST) или существительное (например,HEADилиOPTIONS), описывающие требуемое действие. Например,
Например, GETуказывает, что нужно доставить некоторый ресурс, аPOSTозначает отправку данных на сервер (для создания или модификации ресурса, или генерации возвращаемого документа). - Цель запроса, обычно URL, или абсолютный путь протокола, порт и домен обычно характеризуются контекстом запроса. Формат цели запроса зависит от используемого HTTP-метода. Это может быть
- Абсолютный путь, за которым следует
'?'и строка запроса. Это самая распространённая форма, называемая исходной формой (origin form) . Используется с методамиGET,POST,HEAD, иOPTIONS.
POST / HTTP 1.1 GET /background.png HTTP/1.0 HEAD /test.html?query=alibaba HTTP/1.1 OPTIONS /anypage.html HTTP/1.0 - Полный URL — абсолютная форма (absolute form) , обычно используется с
GETпри подключении к прокси.
GET http://developer.mozilla.org/ru/docs/Web/HTTP/Messages HTTP/1.1 - Компонента URL «authority», состоящая из имени домена и (необязательно) порта (предваряемого символом
':'), называется authority form. Используется только с методомCONNECTпри установке туннеля HTTP.
CONNECT developer.mozilla.org:80 HTTP/1.1 - Форма звёздочки (asterisk form), просто «звёздочка» (
'*') используетсяс методом OPTIONSи представляет сервер.
OPTIONS * HTTP/1.1
- Абсолютный путь, за которым следует
- Версия HTTP, определяющая структуру оставшегося сообщения, указывая, какую версию предполагается использовать для ответа.
 Например,
Например, 
Заголовки
Заголовки запроса HTTP имеют стандартную для заголовка HTTP структуру: не зависящая от регистра строка, завершаемая (':') и значение, структура которого определяется заголовком. Весь заголовок, включая значение, представляет собой одну строку, которая может быть довольно длинной.
Весь заголовок, включая значение, представляет собой одну строку, которая может быть довольно длинной.
Существует множество заголовков запроса. Их можно разделить на несколько групп:
- Основные заголовки (General headers), например,
Via(en-US), относящиеся к сообщению в целом - Заголовки запроса (Request headers), например,
User-Agent,Accept-Type, уточняющие запрос (как, например,Accept-Language), придающие контекст (какReferer), или накладывающие ограничения на условия (likeIf-None). - Заголовки сущности, например
Content-Length, относящиеся к телу сообщения. Как легко понять, они отсутствуют, если у запроса нет тела.
Тело
Последней частью запроса является его тело. Оно бывает не у всех запросов: запросы, собирающие (fetching) ресурсы, такие как GET, HEAD, DELETE, или OPTIONS, в нем обычно не нуждаются.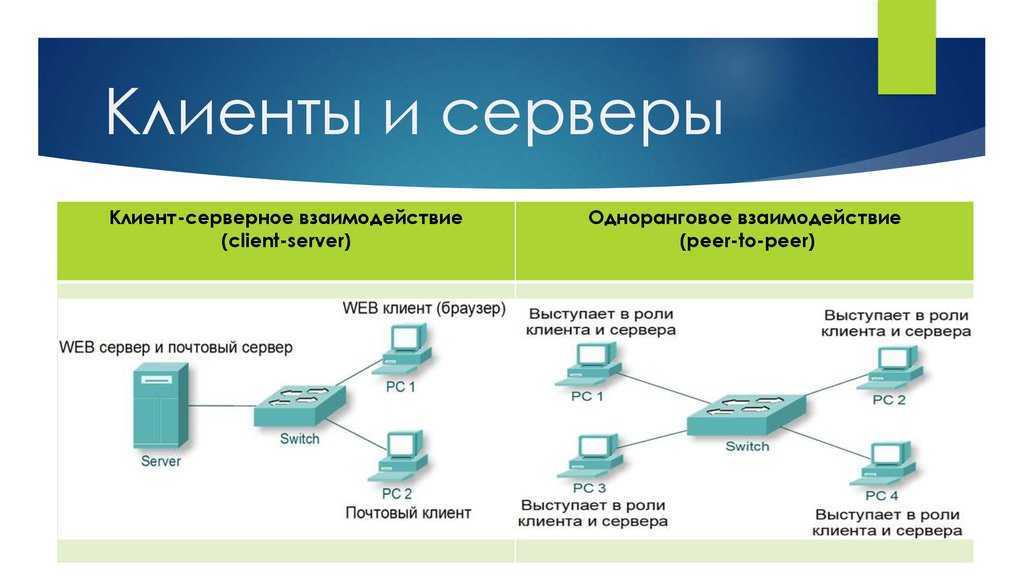 Но некоторые запросы отправляют на сервер данные для обновления, как это часто бывает с запросами
Но некоторые запросы отправляют на сервер данные для обновления, как это часто бывает с запросами POST (содержащими данные HTML-форм).
Тела можно грубо разделить на две категории:
- Одноресурсные тела (Single-resource bodies), состоящие из одного отдельного файла, определяемого двумя заголовками:
Content-TypeиContent-Length. - Многоресурсные тела (Multiple-resource bodies), состоящие из множества частей, каждая из которых содержит свой бит информации. Они обычно связаны с HTML-формами.
Строка статуса (Status line)
Стартовая строка ответа HTTP, называемая строкой статуса, содержит следующую информацию:
- Версию протокола,
обычно HTTP/1.1. - Код состояния (status code), показывающая, был ли запрос успешным. Примеры:
200,404или302 - Пояснение (status text). Краткое текстовое описание кода состояния, помогающее пользователю понять сообщение HTTP. .
 .
.Пример строки статуса: HTTP/1.1 404 Not Found.
Заголовки
Заголовки ответов HTTP имеют ту же структуру, что и все остальные заголовки: не зависящая от регистра строка, завершаемая двоеточием (':') и значение, структура которого определяется типом заголовка. Весь заголовок, включая значение, представляет собой одну строку.
Существует множество заголовков ответов. Их можно разделить на несколько групп:
- Основные заголовки (General headers), например,
Via(en-US), относящиеся к сообщению в целом. - Заголовки ответа (Response headers), например,
VaryиAccept-Ranges, сообщающие дополнительную информацию о сервере, которая не уместилась в строку состояния. - Заголовки сущности (Entity headers), например,
Content-Length, относящиеся к телу ответа. Отсутствуют, если у запроса нет тела.
Тело
Последней частью ответа является его тело. Оно есть не у всех ответов: у ответов с кодом состояния, например,
Оно есть не у всех ответов: у ответов с кодом состояния, например, 201 или 204, оно обычно отсутствует.
Тела можно разделить на три категории:
- Одноресурсные тела (Single-resource bodies), состоящие из отдельного файла известной длины, определяемые двумя заголовками:
Content-TypeиContent-Length. - Одноресурсные тела (Single-resource bodies), состоящие из отдельного файла неизвестной длины, разбитого на небольшие части (chunks) с заголовком
Transfer-Encoding(en-US), значением которого являетсяchunked. - Многоресурсные тела (Multiple-resource bodies), состоящие из многокомпонентного тела, каждая часть которого содержит свой сегмент информации. Они относительно редки.
Сообщения HTTP/1.x имеют несколько недостатков в отношении производительности:
- Заголовки, в отличие от тел, не сжимаются.
- Заголовки, которые зачастую практически совпадают у идущих подряд сообщений, приходится передавать по отдельности.
- Мультиплексность невозможна. Приходится открывать соединение для каждого сообщения, а тёплые (warm) соединения TCP эффективнее холодных (cold).

HTTP/2 переходит на новый уровень: он делит сообщения HTTP/1.x на фреймы, которые внедряются в поток. Фреймы данных из заголовков отделены друг от друга, что позволяет сжимать заголовки. Несколько потоков можно объединять друг с другом — такой процесс называется мультиплексированием — что позволяет более эффективно использовать TCP-соединения.
Фреймы HTTP сейчас прозрачны для веб-разработчиков. Это дополнительный шаг, который HTTP/2 делает по отношению к сообщениям HTTP/1.1 и лежащему в основе транспортному протоколу. Для реализации фреймов HTTP веб-разработчикам не требуется вносить изменения в имеющиеся APIs; если HTTP/2 доступен и на сервере, и на клиенте, он включается и используется.
Сообщения HTTP играют ключевую роль в использовании HTTP; они имеют простую структуру и хорошо расширяемы. Механизм фреймов в HTTP/2 добавляет ещё один промежуточный уровень между синтаксисом HTTP/1. x и используемым им транспортным протоколом, не проводя фундаментальных изменений: создаётся надстройка над уже зарекомендовавшими себя методами.
x и используемым им транспортным протоколом, не проводя фундаментальных изменений: создаётся надстройка над уже зарекомендовавшими себя методами.
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
Want to get more involved?
Learn how to contribute.
This page was last modified on by MDN contributors.
Basics of HTTP — HTTP
HTTP удобный расширяемый протокол. Он опирается на несколько базовых понятий, таких как: ресурсы и URI (унифицированный идентификатор ресурса), простая структура сообщений и технология «клиент-сервер» для общения. Помимо этих базовых концепций, за последние годы появилось множество расширений, добавляющих новые функциональные возможности и новую семантику путём создания новых HTTP-методов или заголовков.
- Обзор HTTP
Описывает, что такое HTTP и какова его роль в архитектуре всемирной паутины, позицию в стеке протоколов.
- Эволюция HTTP
HTTP был создан в начале 1990-х годов и несколько раз был расширен. Эта статья даёт обзор его истории и описывает HTTP/0.9, HTTP/1.0, HTTP/1.1, и современный HTTP/2, а также незначительные нововведения представленные в последние несколько лет.
- Обсуждение версии HTTP
Описывает, как клиент и сервер могут договориться о конкретной версии HTTP и в конечном счёте перейти на более новую версию протокола.
- Resources and URIs (en-US)
A brief introduction of the notion of resources, identifiers, and locations on the Web.
- Identifying resources on the Web
Describes how Web resources are referenced and how to locate them.
- Data URIs
A specific kind of URIs that directly embeds the resource it represents. Data URIs are very convenient, but have some caveats.
Most of the time identity and location of a Web resource are shared, this can be changed with the
Alt-Svc(en-US) header.- MIME types
Since HTTP/1.0, different types of content can be transmitted. This article explains how this is done using the
Content-Typeheader and the MIME standard.- Choosing between www and non-www URLs (en-US)
Advice on using a www-prefixed domain or not, this article explains the consequences of the choice as well as how to make it.
- Flow of an HTTP session
This fundamental article describes a typical HTTP session: what happens under the hood when you click on a link in your browser…
- HTTP Messages
HTTP Messages transmitted during requests or responses have a very clear structure; this introductory article describes this structure, its purpose and its possibilities.
- Frame and message structure in HTTP/2
HTTP/2 encapsulates and represents HTTP/1.x messages in a binary frame.
This article explains the frame structure, its purpose and the way it is encoded.- Connection management in HTTP/1.x
HTTP/1.1 was the first version of HTTP to support persistent connection and pipelining. This article explains these two concepts.
- Connection management in HTTP/2
HTTP/2 completely revisited how connections are created and maintained: this article explains how HTTP frames allow multiplexing and solve the ‘head-of-line’ blocking problem of former HTTP versions.
- Content Negotiation
HTTP introduces a set of headers, starting with
Accept-as a way for a browser to announce the format, language, or encoding it prefers. This article explains how this advertisement happens, how the server is expected to react and how it will choose the most adequate response.

 This article explains the frame structure, its purpose and the way it is encoded.
This article explains the frame structure, its purpose and the way it is encoded.Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.

Want to get more involved?
Learn how to contribute.
This page was last modified on by MDN contributors.
HTTP-запросов | Codecademy
Предыстория:
Эта страница создана с помощью сети HTML, CSS и Javascript, отправленной вам Codecademy через Интернет. Интернет состоит из множества ресурсов, размещенных на разных серверах. Термин «ресурс» относится к любому объекту в Интернете, включая файлы HTML, таблицы стилей, изображения, видео и сценарии. Чтобы получить доступ к контенту в Интернете, ваш браузер должен запрашивать у этих серверов необходимые ему ресурсы, а затем отображать эти ресурсы для вас. Этот протокол запросов и ответов позволяет просматривать эта страница в вашем браузере.
В этой статье основное внимание уделяется одной фундаментальной части функционирования Интернета: HTTP.
Что такое HTTP?
HTTP означает протокол передачи гипертекста и используется для структурирования запросов и ответов через Интернет. HTTP требует передачи данных из одной точки в другую по сети.
HTTP требует передачи данных из одной точки в другую по сети.
Передача ресурсов происходит с использованием TCP (протокола управления передачей). При просмотре этой веб-страницы TCP управляет каналами между вашим браузером и сервером (в данном случае codecademy.com). TCP используется для управления многими типами интернет-соединений, в которых один компьютер или устройство хочет отправить что-то другому. HTTP — это командный язык, которому должны следовать устройства по обе стороны соединения для связи.
HTTP и TCP: как это работает
Когда вы вводите адрес, такой как www.codecademy.com, в свой браузер, вы даете ему команду открыть TCP-канал к серверу, который отвечает на этот URL-адрес (или унифицированный указатель ресурсов, о котором вы можете прочитать больше в Википедии). URL-адрес подобен вашему домашнему адресу или номеру телефона, потому что он описывает, как с вами связаться.
В этой ситуации ваш компьютер, который делает запрос, называется клиентом. URL-адрес, который вы запрашиваете, является адресом, принадлежащим серверу.
URL-адрес, который вы запрашиваете, является адресом, принадлежащим серверу.
После установления TCP-соединения клиент отправляет HTTP-запрос GET на сервер, чтобы получить веб-страницу, которую он должен отображать. После того, как сервер отправил ответ, он закрывает TCP-соединение. Если вы снова открываете веб-сайт в своем браузере или если ваш браузер автоматически запрашивает что-то с сервера, открывается новое соединение, которое следует тому же процессу, который описан выше. Запросы GET — это один из видов HTTP-метода, который может вызвать клиент. Вы можете узнать больше о других распространенных ( POST , PUT и DELETE ) в этой статье.
Давайте рассмотрим пример того, как запросы GET (наиболее распространенный тип запросов) используются, чтобы помочь вашему компьютеру (клиенту) получить доступ к ресурсам в Интернете.
Предположим, вы хотите ознакомиться с последними предложениями курсов на сайте http://codecademy. com. После того, как вы введете URL-адрес в свой браузер, ваш браузер извлечет часть
com. После того, как вы введете URL-адрес в свой браузер, ваш браузер извлечет часть http и распознает, что это имя используемого сетевого протокола. Затем он берет доменное имя из URL-адреса, в данном случае «codecademy.com», и просит сервер доменных имен в Интернете вернуть адрес интернет-протокола (IP).
Теперь клиент знает IP-адрес получателя. Затем он открывает соединение с сервером по этому адресу, используя указанный протокол http . Он инициирует запрос GET на сервер, который содержит IP-адрес хоста и, возможно, полезные данные. Запрос GET содержит следующий текст:
GET / HTTP/1.1. Хост: www.codecademy.com
Идентифицирует тип запроса, путь на www.codecademy.com (в данном случае «/») и протокол «HTTP/1.1». HTTP/1.1 — это версия первого HTTP, который теперь называется HTTP/1.0. В HTTP/1.0 для каждого запроса ресурсов требуется отдельное подключение к серверу. HTTP/1.1 использует одно соединение более одного раза, поэтому дополнительный контент (например, изображения или таблицы стилей) извлекается даже после извлечения страницы. В результате запросы, использующие HTTP/1.1, имеют меньшую задержку, чем запросы, использующие HTTP/1.0.
В результате запросы, использующие HTTP/1.1, имеют меньшую задержку, чем запросы, использующие HTTP/1.0.
Вторая строка запроса содержит адрес сервера "www.codecademy.com" . Также могут быть дополнительные строки в зависимости от того, какие данные ваш браузер выбирает для отправки.
Если сервер может найти запрошенный путь, сервер может ответить заголовком:
HTTP/1.1 200 OK Content-Type: text/html
За этим заголовком следует запрошенный контент, который в данном случае является информацией, необходимой для отображения www.codecademy.com.
Первая строка заголовка, HTTP/1.1 200 OK , является подтверждением того, что сервер понимает протокол, с которым клиент хочет взаимодействовать ( HTTP/1.1 ), и код состояния HTTP, означающий, что ресурс был нашел на сервере. Вторая строка, Content-Type: text/html , показывает тип содержимого, которое будет отправлено клиенту.
Если сервер не может найти путь, запрошенный клиентом, он ответит заголовком:
HTTP/1.
 1 404 NOT FOUND
1 404 NOT FOUND В этом случае сервер определяет, что он понимает протокол HTTP, но код состояния 404 NOT FOUND означает, что конкретный запрошенный фрагмент контента не найден. Это может произойти, если содержимое было перемещено, или если вы неправильно ввели URL-адрес, или если страница была удалена. Подробнее о коде состояния 404, обычно называемом ошибкой 404, можно прочитать здесь.
Аналогия:
Понять, как работает HTTP, может быть сложно, потому что трудно понять, что на самом деле делает ваш браузер. (И, возможно, также потому, что мы объяснили это с помощью сокращений, которые могут быть для вас новыми.) Давайте повторим то, что мы узнали, используя аналогию, которая может быть вам более знакома.
Представьте, что Интернет — это город. Вы клиент, и ваш адрес определяет, где с вами можно связаться. Компании в городе, такие как Codecademy.com, обслуживают запросы, которые им отправляются. Другие дома заполнены другими клиентами, такими как вы, которые делают запросы и ожидают ответов от этих предприятий в городе. В этом городе также есть сумасшедшая быстрая почтовая служба, армия сотрудников службы доставки почты, которые могут путешествовать на поездах, движущихся со скоростью света.
В этом городе также есть сумасшедшая быстрая почтовая служба, армия сотрудников службы доставки почты, которые могут путешествовать на поездах, движущихся со скоростью света.
Предположим, вы хотите прочитать утреннюю газету. Чтобы получить его, вы записываете то, что вам нужно, на языке, называемом HTTP, и просите своего местного агента по доставке почты получить это от конкретного предприятия. Сотрудник службы доставки соглашается и почти мгновенно строит железнодорожную ветку (связь) между вашим домом и предприятием и едет в вагоне поезда с надписью «TCP» по указанному вами адресу предприятия.
Прибыв на предприятие, она спрашивает первого из нескольких свободных сотрудников, готовых выполнить просьбу. Сотрудник ищет запрошенную вами страницу газеты, но не может ее найти и сообщает об этом доставщику почты.
Доставщик почты возвращается на легком скоростном поезде, разрывая пути на обратном пути, и сообщает вам, что возникла проблема «404 Not Found». После проверки правописания того, что вы написали, вы понимаете, что ошиблись в названии газеты. Вы исправляете его и предоставляете исправленное название курьеру.
Вы исправляете его и предоставляете исправленное название курьеру.
На этот раз доставщик почты может забрать его из компании. Теперь вы можете спокойно читать свою газету, пока не решите, что хотите прочитать следующую страницу, после чего вы должны сделать еще один запрос и передать его курьеру.
Что такое HTTPS?
Поскольку ваш HTTP-запрос может быть прочитан кем угодно при определенных сетевых соединениях, может быть нецелесообразно доставлять такую информацию, как ваша кредитная карта или пароль, с использованием этого протокола. К счастью, многие серверы поддерживают протокол HTTPS, сокращение от HTTP Secure, что позволяет шифровать данные, которые вы отправляете и получаете. Подробнее о HTTPS можно прочитать в Википедии.
Важно использовать HTTPS при передаче конфиденциальной или личной информации на веб-сайты и с них. Тем не менее, предприятия, обслуживающие серверы, должны его настроить. Для поддержки HTTPS компания должна подать заявку на получение сертификата в центре сертификации.
Узнайте больше о Codecademy
Путь навыков
Создайте серверное приложение с помощью JavaScript
Узнайте, как создавать серверные веб-API с помощью Express.js, Node.js, SQL и Node.js-SQLite библиотека базы данных.Checker Dense Включает
8 курсов
Checker DenseCertificate Icon С сертификатом
Checker DenseLevel Icon Новичок Friendly
29 Уроки
Бесплатный курс
Выучить JavaScript на среднем уровне
Поделитесь своими знаниями JavaScript с следующий уровень!Checker DenseLevel Icon Средний
6 Уроки
Понимание и отладка сетевых запросов | Кейт Хене | Ботаник для техники
Опубликовано в
·
Чтение: 9 мин.
·
5 марта 2021 г.
Я зарабатываю на жизнь веб-приложениями. Я блуждаю по стеку, но мой опыт имеет тенденцию к фронтенд-инжинирингу. По закону ничего из того, что я делаю, было бы невозможно без HTTP-запросов.
Несмотря на это, я нахожу что-либо «сетевое» — маршрутизацию, промежуточное ПО, файлы cookie, заголовки и т. д. — довольно пугающим. Когда что-то пошло не так с сетевым запросом, у меня быстро закончились инструменты в моем наборе инструментов для отладки. Я не был уверен, как понять или исследовать проблемы сетевых запросов в приложениях, над которыми я работал.
Я хочу попытаться кое-что из этого прояснить и поделиться тем, что я узнал за последние пару лет.
Это будет общий обзор сетевого уровня наряду с более глубоким изучением сетевых запросов, как в браузере, так и в приложении JavaScript.
Я также рассмотрю некоторые инструменты отладки, предоставляемые браузерами, пройдусь по запросу, проходящему через приложение JavaScript, и обсужу инструменты песочницы.
Начну с краткого описания некоторых концепций информатики. Полное раскрытие — мое понимание этих идей является базовым. У меня нет диплома в области компьютерных наук, и я не сетевой инженер. Если вы попадаете в одну из этих категорий и испытываете сильные чувства по поводу этого поста, пожалуйста, свяжитесь с нами! Я хотел бы узнать больше.
Если вы попадаете в одну из этих категорий и испытываете сильные чувства по поводу этого поста, пожалуйста, свяжитесь с нами! Я хотел бы узнать больше.
Тем не менее, я сделаю все возможное, чтобы поделиться известной мне информацией. Я нахожу эти концепции чрезвычайно интересными. Без них у нас не было бы словаря или архитектуры, чтобы делать сетевые запросы в приложении.
При этом давайте поговорим об OSI.
В компьютерных науках используется модель, которая называется «Взаимодействие открытых систем» (OSI). Он восходит к 70-м годам и представляет собой академическую теоретическую основу. Он разработан таким образом, чтобы не зависеть от технологий, чтобы мы могли продолжать применять одни и те же принципы к нашим сетям по мере их развития с течением времени.
OSI состоит из семи уровней, начиная с наименее абстрактного (физический уровень) и заканчивая наиболее абстрактным (прикладной уровень). Я пройдусь по каждому из них один за другим, но я хотел дать вам быструю красочную иллюстрацию. Не стесняйтесь визуализировать это как торт. Или парфе. Или семислойный салат. Что бы вы ни прошли, я поддерживаю это.
Не стесняйтесь визуализировать это как торт. Или парфе. Или семислойный салат. Что бы вы ни прошли, я поддерживаю это.
Начнем с физического уровня — электричества, соединяющего компьютеры, — и продвинемся до нашего приложения — абстрактной последовательности запросов и кода, которые представляют нашему конечному пользователю что-то интерактивное.
Физический уровень
Это электрическое и физическое представление компьютерных систем. Когда вы думаете о физическом уровне, подумайте о радиочастотах и протоколах напряжения для таких вещей, как Bluetooth и USB.
Уровень канала передачи данных
Уровень канала передачи данных также очень низкого уровня связан с передачей данных между узлами с помощью коммутаторов.
Сетевой уровень
Говоря более абстрактно, сетевой уровень связан с крупномасштабной маршрутизацией и соединением. Если компьютер в Сан-Франциско хочет связаться с компьютером в Бостоне, сетевой уровень сделает это возможным.
Транспортный уровень
Транспортный уровень — это место, где живет TCP/IP (протокол управления передачей). HTTP опирается на TCP/IP — это протокол, который стандартизирует запросы. В нем описывается, как мы узнаем, что соединение было установлено, как мы разбиваем информацию о нашем запросе на пакеты и как мы пересылаем эти пакеты, среди прочего.
Сеансовый уровень
Сеансовый уровень управляет структурой и поведением соединения между двумя узлами (компьютерами). Как долго компьютер ожидает установления соединения, прежде чем истечет время ожидания? Если время запроса истекает, мы повторяем попытку автоматически? Сеансовый уровень отвечает на эти вопросы.
Представление
Уровень представления (или синтаксиса) форматирует наши запросы. Мы можем запрашивать HTML, JavaScript или какие-то необработанные данные, но нам нужно согласовать язык самих запросов. Будут ли они закодированы через JSON, YAML? Может ASCII? Уровень представления также обрабатывает шифрование и дешифрование.
Приложение
Самый абстрактный уровень — это прикладной уровень, который также имеет отношение к данному обсуждению. Здесь живут FTP, HTTP (протокол передачи гипертекста), браузеры и наше приложение.
Хотя большая часть того, что мы говорим о продвижении вперед, не относится к OSI, важно отметить, что наше приложение опирается на каждый слой, который мы только что рассмотрели. Когда мы пытаемся передать некоторый HTML по HTTP , это кодируется , маршрутизируется и отправляется через сеанс через TCP/IP , где переключает и электрические импульсы 90 197 передать нашу информацию компьютер ждет на другом конце. И все это происходит за микросекунды.
GIF из фильма «Невероятные приключения Билла и Теда», где Тед (Киану Ривз) говорит «вау».
Теперь, когда у нас есть структура, давайте поговорим о том, как HTTP или сетевой запрос проходит через приложение.
Вы могли заметить, что кэш не представлен на этой диаграмме. Кэширование — еще одна очень интересная и сложная тема, о которой мы поговорим в другой раз. Я также уделяю особое внимание JavaScript и HTTP, поэтому, если вы ищете информацию о Swift, Kotlin или SSL, этот пост может быть не для вас.
Все начинается с пользователя. Когда пользователь открывает Firefox или Chrome или что-то еще, что дети используют в наши дни, и вводит URL-адрес (скажем, они хотят поиграть в Spelling Bee), браузер направляет их запрос. Приложение ждет там, прислушиваясь к этому запросу, и отвечает, предоставляя любой необходимый код — HTML, JavaScript, CSS, статические ресурсы, такие как изображения и логотипы и т. д.
Часто для того, чтобы сгенерировать правильный код, приложение необходимо делать свои собственные запросы (например, получение данных головоломки). Для этого наше приложение отправит запрос на конечную точку API, которая затем запросит информацию из базы данных.
Как только мы доходим до конца строки, так сказать, вся цепочка запросов переворачивается. База данных отправит данные обратно в API, который отправит их обратно в наше приложение, которое отправит их обратно в браузер, который отобразит их для пользователя. Весь этот цикл происходит за доли секунды.
Давайте начнем с того, что сосредоточимся на первом запросе — между браузером и нашим приложением. Мы можем проверять и отлаживать эти запросы, используя существующие инструменты разработчика в выбранном вами браузере.
Открытие вкладки сети
Откройте инструменты разработчика из меню браузера (Firefox: Инструменты > Веб-разработчик и Chrome: Вид > Разработчик) или с помощью cmd + option + i (Mac) и ctrl + shift + i (ПК). Открыв инструменты разработчика, перейдите на вкладку «Сеть».
Что мы можем отладить в браузере
- Формат запроса
- Происхождение запроса
- Заголовки
- Куки
- Кэш
Простите мои глупые скриншоты , но это лишь некоторые из функций, которые я чаще всего использую в вкладка сети:
- Проверка заголовков запроса и файлов cookie
- Поиск запроса, поступающего из определенного домена (ищите увеличительное стекло)
- Фильтрация запросов по типу ресурса (HTML, XML, JS и т. д.)
- Добавление и удаление файлов cookie вручную (это находится на вкладке хранилища, а не на вкладке сети, но я подумал, что стоит упомянуть об этом)
 д.)
д.)Варианты использования для отладки в браузере
Я считаю браузер наиболее полезным для отладки сетевых запросов с большим количеством архитектуры вокруг них . Такой подход усложняет манипулирование запросом, но он быстрый и простой, а также очень близко приближает вас к производственной среде, что может быть полезно.
Несколько примеров того, где может быть полезна отладка в браузере:
- Исходящий запрос на отслеживание, отформатированный с использованием сложных заголовков вместе с данными из вашего хранилища Redux
- Входящий запрос, который проходит через несколько функций промежуточного программного обеспечения, где данные извлекаются а затем передается в приложение React
Мы также можем взглянуть на другую сторону первого запроса на нашей диаграмме и посмотреть на наше приложение, чтобы увидеть, как оно обрабатывает входящие запросы с помощью маршрутизации и промежуточного программного обеспечения.
Маршрутизация сообщит нашим запросам, куда направить их в нашем приложении, а промежуточное ПО проверит запрос и выполнит все необходимые побочные эффекты.
Каждое приложение обрабатывает маршрутизацию и ПО промежуточного слоя немного по-своему, но, как правило, будет точка входа для серверной части вашего приложения (ищите файл index.js на стороне сервера или что-то подобное) с использованием такой среды, как Express.
Пример приложения Express с некоторым промежуточным ПО
Что мы можем отлаживать в приложении
- Запросы и ответы
- Как запрос проходит через наше приложение
- Проблемы маршрутизации
Варианты использования для отладки в приложении маршрутизации в реальном времени, вы можете положиться на свой традиционный инструментарий отладки — модульные тесты, ведение журнала, обработку ошибок и т. д.
Несколько примеров того, где может быть полезна отладка в приложении:
- Проблемы с неправильной обработкой заголовков запросов или файлов cookie
- Проблемы, при которых запрос выглядит нормально в браузере, но приложение не получает информацию о запросе, как ожидалось (обычно это указывает на проблему с промежуточным программным обеспечением)
- Проблемы с маршрутизацией, такие как неожиданные 404s
- Ошибки глубокой ссылки, когда генерируется неверный URL-адрес
Теперь давайте посмотрим на запросы, которые отправляет наше приложение. Допустим, наше приложение получило запрос от браузера, но для того, чтобы ответить корректной страницей, ему необходимо получить некоторую информацию с сервера.
Допустим, наше приложение получило запрос от браузера, но для того, чтобы ответить корректной страницей, ему необходимо получить некоторую информацию с сервера.
Часто приложение отправляет эти запросы через API. Если мы не активно разрабатываем этот API и не можем раскрутить его локально, у нас немного меньше понимания. Мы можем только действительно проверить формат нашего исходящего запроса и ответа, который мы получаем. Именно здесь ключевыми являются инструмент песочницы, хорошая документация и сотрудничество с другими разработчиками.
Postman — один из моих любимых инструментов песочницы запросов, но их много. Они хороши тем, что позволяют нам делать запросы изолированно — это дает нам полный контроль над тем, какие заголовки, файлы cookie и данные запроса мы хотели бы включить. Это полная противоположность проверке запросов в браузере. Если в нашей песочнице и есть какая-то архитектура, окружающая наши запросы, то это потому, что мы поместили ее туда вручную.
Что мы можем отладить в песочнице
- Исходящие запросы
- Как файлы cookie и заголовки ведут себя изолированно
- Данные ответа
Варианты использования для отладки в песочнице
Настройка песочницы запроса может занять некоторое время — вам нужно убедиться, что у вас есть правильные заголовки, файлы cookie и протоколы аутентификации, но как только у вас есть фреймворк, вы можете легко настроить свои запросы, чтобы протестировать небольшие изменения изолированно. Вы также можете сохранить свои запросы и легко вернуться к ним или применить один и тот же запрос к нескольким доменам.
Вы также можете сохранить свои запросы и легко вернуться к ним или применить один и тот же запрос к нескольким доменам.
Несколько примеров того, где может быть полезна отладка в песочнице:
- Имитационные запросы с разными профилями пользователей или входа в систему
- Имитационные запросы с небольшими изменениями ключей кэша, заголовков или параметров запроса
- Быстрое тестирование того же запроса на локальном компьютере , промежуточные и производственные среды
- Простой обмен сложными форматами запросов с товарищами по команде
У нас есть только еще один запрос на нашей диаграмме — тот, который связывает API с базой данных. Существует целый мир вариантов, когда дело доходит до получения информации из вашей базы данных. Вы можете использовать один (или несколько!) из следующих вариантов:
- ORM (объектно-реляционные преобразователи), такие как Sequelize
- Уровень данных/языки запросов, такие как GraphQL
- Поиск значений ключа в хранилище объектов, например DynamoDB
- Необработанные SQL-запросы
Каждый из этих подходов приходит со своим набор инструментов отладки, но эти инструменты часто будут знакомы инструментам, которые мы обсуждали в этом посте.