Содержание
Запрет индексации в robots.txt | REG.RU
Чтобы убрать весь сайт или отдельные его разделы и страницы из поисковой выдачи Google, Яндекс и других поисковых систем, их нужно закрыть от индексации. Тогда контент не будет отображаться в результатах поиска. Рассмотрим, с помощью каких команд можно выполнить в файле robots.txt запрет индексации.
Зачем нужен запрет индексации сайта через robots.txt
Первое время после публикации сайта о нем знает только ограниченное число пользователей. Например, разработчики или клиенты, которым компания прислала ссылку на свой веб-ресурс. Чтобы сайт посещало больше людей, он должен попасть в базы поисковых систем.
Чтобы добавить новые сайты в базы, поисковые системы сканируют интернет с помощью специальных программ (поисковых роботов), которые анализируют содержимое веб-страниц. Этот процесс называется индексацией.
После того как впервые пройдет индексация, страницы сайта начнут отображаться в поисковой выдаче. Пользователи увидят их в процессе поиска информации в Яндекс и Google — самых популярных поисковых системах в рунете. Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Однако не все страницы сайта должны попадать в поисковую выдачу. Есть контент, который интересен пользователям: статьи, страницы услуг, товары. А есть служебная информация: временные файлы, документация к ПО и т. п. Если полезная информация в выдаче соседствует с технической информацией или неактуальным контентом — это затрудняет поиск нужных страниц и негативно сказывается на позиции сайта. Чтобы «лишние» страницы не отображались в поисковых системах, их нужно закрывать от индексации.
Кроме отдельных страниц и разделов, веб-разработчикам иногда требуется убрать весь ресурс из поисковой выдачи. Например, если на нем идут технические работы или вносятся глобальные правки по дизайну и структуре. Если не скрыть на время все страницы из поисковых систем, они могут проиндексироваться с ошибками, что отрицательно повлияет на позиции сайта в выдаче.
Для того чтобы частично или полностью убрать контент из поиска, достаточно сообщить поисковым роботам, что страницы не нужно индексировать. Для этого необходимо отключить индексацию в служебном файле robots.txt. Файл robots.txt — это текстовый документ, который создан для «общения» с поисковыми роботами. В нем прописываются инструкции о том, какие страницы сайта нельзя посещать и анализировать, а какие — можно.
Прежде чем начать индексацию, роботы обращаются к robots.txt на сайте. Если он есть — следуют указаниям из него, а если файл отсутствует — индексируют все страницы без исключений. Рассмотрим, каким образом можно сообщить поисковым роботам о запрете посещения и индексации страниц сайта. За это отвечает директива (команда) Disallow.
Как запретить индексацию сайта
О том, где найти файл robots.txt, как его создать и редактировать, мы подробно рассказали в статье. Если кратко — файл можно найти в корневой папке. А если он отсутствует, сохранить на компьютере пустой текстовый файл под названием robots.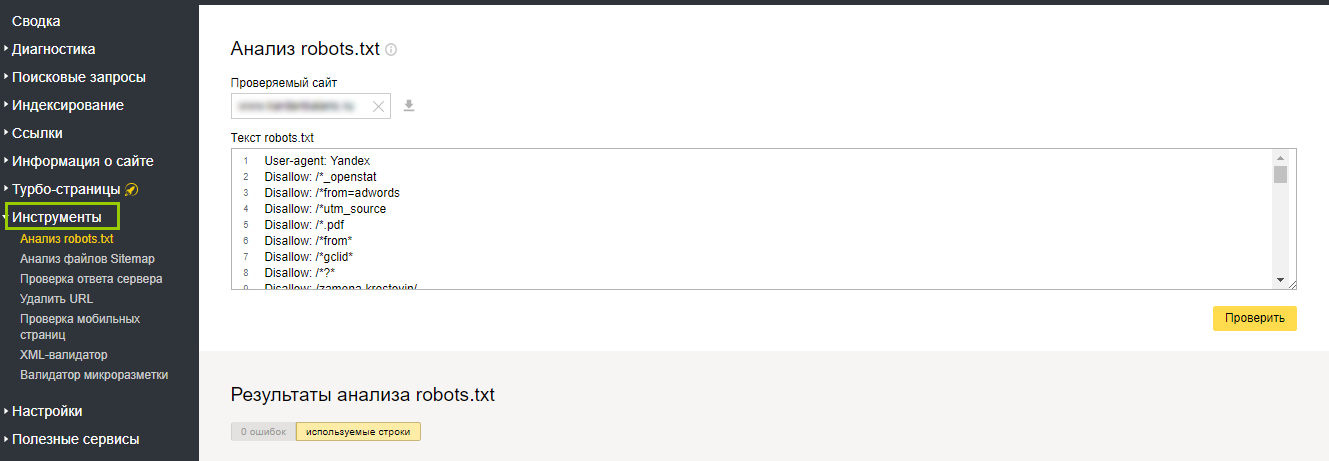 txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
Чтобы запретить индексацию всего сайта:
- 1.
Откройте файл robots.txt.
- 2.
Добавьте в начало нужные строки.
- Чтобы закрыть сайт во всех поисковых системах (действует для всех поисковых роботов):
User-agent: * Disallow: /
- Чтобы запретить индексацию в конкретной поисковой системе (например, в Яндекс):
User-agent: Yandex Disallow: /
- Чтобы закрыть от индексации для всех поисковиков, кроме одного (например, Google)
User-agent: * Disallow: / User agent: Googlebot Allow: /
- 3.
Сохраните изменения в robots.txt.
Готово. Ресурс пропадет из поисковой выдачи выбранных ПС.
Ресурс пропадет из поисковой выдачи выбранных ПС.
Запрет индексации папки
Гораздо чаще, чем закрывать от индексации весь веб-ресурс, веб-разработчикам требуется скрывать отдельные папки и разделы.
Чтобы запретить поисковым роботам просматривать конкретный раздел:
- 1.
Откройте robots.txt.
- 2.
Укажите поисковых роботов, на которых будет распространяться правило. Например:
- Все поисковые системы:
User-agent: *
— Запрет только для Яндекса:
User-agent: Yandex
- 3.
Задайте правило Disallow с названием папки/раздела, который хотите запретить:
Disallow: /catalog/
Где вместо catalog — укажите нужную папку.
 org/HowToStep»>
org/HowToStep»>4.
Сохраните изменения.
Готово. Вы закрыли от индексации нужный каталог. Если требуется запретить несколько папок, последовательно пропишите для каждой директиву Disallow.
Как закрыть служебную папку wp-admin в плагине Yoast SEO
Как закрыть страницу от индексации в robots.txt
Если нужно закрыть от индексации конкретную страницу (например, с устаревшими акциями или неактуальными контактами компании):
- 1.
Откройте файл robots.txt на хостинге или используйте плагин Yoast SEO, если сайт на WordPress.
- 2.
Укажите, для каких поисковых роботов действует правило.
- 3.
Задайте директиву Disallow и относительную ссылку (то есть адрес страницы без домена и префиксов) той страницы, которую нужно скрыть.
 Например:
Например:User-agent: * Disallow: /catalog/page.html
Где вместо catalog — введите название папки, в которой содержится файл, а вместо page.html — относительный адрес страницы.
- 4.
Сохраните изменения.
 Например:
Например:Готово. Теперь указанный файл не будет индексироваться и отображаться в результатах поиска.
Помогла ли вам статья?
Да
раз уже помогла
Закрыть сайт от индексации в robots.txt, как скрыть сайт от поисковых систем Яндекс и Google через файл роботс и meta-тегом
Содержание
Как закрыть от индексации отдельную папку? #
Как закрыть отдельный файл в Яндексе? #
Как проверить, в индексе документ или нет? #
Как скрыть от индексации картинки? #
Как закрыть поддомен? #
При использовании CDN-версии #
Как обращаться к другим поисковым роботам (список) #
Прочие директивы в robots. txt #
txt #
Закрыть страницу и сайт с помощью meta-тега name=»robots» #
Размер текста:
На стадии разработки и/или редизайна проекта бывают ситуации, когда лучше не допускать поисковых роботов на сайт или его копию. В этом случае рекомендуется закрыть сайт от индексации поисковых систем. Сделать это можно следующим образом:
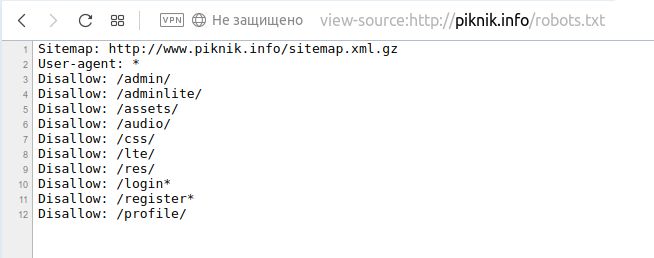
Закрыть сайт от индексации очень просто, достаточно создать в корне сайта текстовый файл robots.txt и прописать в нём следующие строки:
User-agent: Yandex
Disallow: /
Такие строки закроют сайт от поискового робота Яндекса.
User-agent: *
Disallow: /
А таким образом можно закрыть сайт от всех поисковых систем (Яндекса, Google и других).
Как закрыть от индексации отдельную папку? #
Отдельную папку можно закрыть от поисковых систем в том же файле robots.txt с её явным указанием (будут скрыты все файлы внутри этой папки).
User-agent: *
Disallow: /folder/
Если какой-то отдельный файл в закрытой папке хочется отдельно разрешить к индексации, то используйте два правила Allow и Disallow совместно:
User-agent: *
Аllow: /folder/file. php
php
Disallow: /folder/
Как закрыть отдельный файл в Яндексе? #
Всё по аналогии.
User-agent: Yandex
Disallow: /folder/file.php
Как проверить, в индексе документ или нет? #
Проще всего осуществить проверку в рамках сервиса «Пиксель Тулс», бесплатный инструмент «Определение возраста документа в Яндексе» позволяет ввести URL списком. Если документ отсутствует в индексе, то в таблице будет выведено соответствующее значение.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Как скрыть от индексации картинки? #
Картинки форматов jpg, png и gif могут быть запрещены к индексации следующими строчками в robots.txt:
User-Agent: *
Disallow: *.jpg
Disallow: *.png
Disallow: *.gif
Как закрыть поддомен? #
У каждого поддомена на сайте, в общем случае, имеется свой файл robots.txt. Обычно он располагается в папке, которая является корневой для поддомена. Требуется скорректировать содержимое файла с указанием закрываемых разделов с использованием директории Disallow. Если файл отсутствует — его требуется создать.
Требуется скорректировать содержимое файла с указанием закрываемых разделов с использованием директории Disallow. Если файл отсутствует — его требуется создать.
При использовании CDN-версии #
Дубль на поддомене может стать проблемой для SEO при использовании CDN. В данном случае рекомендуется, либо предварительно настроить работу атрибута rel=»canonical» тега <link> на основном домене, либо создать на поддомене с CDN (скажем, nnmmkk.r.cdn.skyparkcdn.ru) свой запрещающий файл robots.txt. Вариант с настройкой rel=»canonical» — предпочтительный, так как позволит сохранить/склеить всю информацию о поведенческих факторах по обоим адресам.
Как обращаться к другим поисковым роботам (список) #
У каждой поисковой системы есть свой список поисковых роботов (их несколько), к которым можно обращаться по имени в файле robots.txt. Приведем список основных из них (полные списки ищите в помощи Вебмастерам):
- Yandex — основной робот-индексатор Яндекса.
- Googlebot — основной робот-индексатор от Google.
- Slurp — поисковый робот от Yahoo!.
- MSNBot — поисковый робот от MSN (поисковая система Bing от Майкрософт).
- SputnikBot — имя робота российского поисковика Спутник от Ростелекома.
Прочие директивы в robots.txt #
Поисковая система Яндекс также поддерживает следующие дополнительные директивы в файле:
«Crawl-delay:» — задает минимальный период времени в секундах для последовательного скачивания двух файлов с сервера. Также поддерживается и большинством других поисковых систем. Пример записи: Crawl-delay: 0.5
«Clean-param:» — указывает GET-параметры, которые не влияют на отображение контента сайта (скажем UTM-метки или ref-ссылки). Пример записи: Clean-param: utm /catalog/books.php
«Sitemap:» — указывает путь к XML-карте сайта, при этом, карт может быть несколько. Также директива поддерживается большинством поисковых систем (в том числе Google).
Пример записи: Sitemap: https://pixelplus.ru/sitemap.xml
 Пример записи: Sitemap: https://pixelplus.ru/sitemap.xml
Пример записи: Sitemap: https://pixelplus.ru/sitemap.xml
Закрыть страницу и сайт с помощью meta-тега name=»robots» #
Также, можно закрыть сайт или заданную страницу от индексации с помощь мета-тега robots. Данный способ является даже предпочтительным и с большим приоритетом выполняется пауками поисковых систем. Для скрытия от индексации внутри зоны <head> </head> документа устанавливается следующий код:
<meta name=»robots» content=»noindex, nofollow»/>
Или (полная альтернатива):
<meta name=»robots» content=»none»/>
С помощью meta-тега можно обращаться и к одному из роботов, используя вместо name=»robots» имя робота, а именно:
Для паука Google:
<meta name=»googlebot» content=»noindex, nofollow»/>
Или для Яндекса:
<meta name=»yandex» content=»none»/>
Автор
Дмитрий Севальнев
Подписывайтесь
на рассылку
Отключить индексацию поисковыми системами | Webflow University
Домашний урок
Все уроки
Запретить поисковым системам индексировать страницы, папки, весь сайт или только субдомен webflow.
 io.
io.
site-settings
У этого видео старый пользовательский интерфейс. Скоро будет обновленная версия!
Вы можете указать поисковым системам, какие страницы сканировать, написав файл robots.txt. Вы также можете запретить поисковым системам сканировать и индексировать определенные страницы, папки, весь ваш сайт или субдомен webflow.io. Это полезно для того, чтобы скрыть такие страницы, как страница 404 вашего сайта, от индексации и отображения в результатах поиска.
Важно: Контент с вашего сайта может быть проиндексирован, даже если он не просканирован. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент из другого контента в Интернете. Чтобы гарантировать, что ранее проиндексированная страница не будет проиндексирована, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex, чтобы удалить этот контент из индекса Google.
В этом уроке:
- Как отключить индексирование субдомена Webflow
- Как создать файл robots.txt
- Рекомендации по обеспечению конфиденциальности
- Часто задаваемые вопросы и советы по устранению неполадок
Как отключить индексирование субдомена Webflow
поисковым системам запретить индексировать субдомен вашего сайта webflow.io, отключив индексирование в настройках сайта .
- Перейти к Настройки сайта > SEO вкладка > Индексирование раздел
- Установите Отключить индексирование поддоменов Webflow на «Да»
- Нажмите Сохранить изменения и опубликовать свой сайт домен.
Примечание: Вам потребуется план сайта или платная рабочая область, чтобы отключить индексирование поисковыми системами поддомена Webflow. Узнайте больше о планах Site and Workspace.
Как создать файл robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов на сайте, который вы не хотите, чтобы поисковые системы сканировали. Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы указать роботам поисковых систем, какой контент им следует сканировать.
Как и карта сайта, файл robots.txt находится в каталоге верхнего уровня вашего домена. Webflow сгенерирует файл /robots.txt для вашего сайта, как только вы создадите его в настройках сайта .
Чтобы создать файл robots.txt:
- Перейдите к Настройки сайта > SEO Вкладка> Индексирование Раздел
- Добавить правило Robots.txt. Контент с вашего сайта может быть проиндексирован, даже если он не просканирован. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент из другого контента в Интернете. Чтобы убедиться, что ранее проиндексированная страница не проиндексирована, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex, чтобы удалить этот контент из индекса Google.
Правила robots.txt
Любое из этих правил можно использовать для заполнения файла robots.txt.
- Агент пользователя: * означает, что этот раздел относится ко всем роботам.
- Запретить: предписывает роботу не посещать сайт, страницу или папку.
Чтобы скрыть весь сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: /page-name
Чтобы скрыть всю папку страниц
User-agent: *
Запретить: /folder-name/
Включить карту сайта
Карта сайта: https://your-site.com/sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.
txt.Примечание: Любой может получить доступ к файлу robots.txt вашего сайта, поэтому он может идентифицировать и получить доступ к вашему личному контенту.
Рекомендации по обеспечению конфиденциальности
Если вы хотите предотвратить обнаружение определенной страницы или URL-адреса на вашем сайте, не используйте файл robots.txt, чтобы запретить сканирование URL-адреса. Вместо этого используйте любой из следующих вариантов:
- Используйте метакод noindex, чтобы запретить поисковым системам индексировать ваш контент и удалить контент из индекса поисковых систем.
- Сохраняйте страницы с конфиденциальным содержимым как черновики и не публикуйте их. Защитите паролем страницы, которые вам нужно опубликовать.
Часто задаваемые вопросы и советы по устранению неполадок
Могу ли я использовать файл robots.txt для предотвращения индексации ресурсов моего сайта Webflow?
Невозможно использовать файл robots.
txt для предотвращения индексации ресурсов сайта Webflow, поскольку файл robots.txt должен находиться в том же домене, что и контент, к которому он применяется (в данном случае там, где обслуживаются ресурсы) . Webflow обслуживает ресурсы из нашей глобальной CDN, а не из пользовательского домена, в котором находится файл robots.txt.Я удалил файл robots.txt из настроек своего сайта, но он по-прежнему отображается на моем опубликованном сайте. Как я могу это исправить?
Созданный файл robots.txt нельзя удалить полностью. Однако вы можете заменить его новыми правилами, чтобы разрешить сканирование сайта, например:
User-agent: *
Disallow:
Обязательно сохраните изменения и повторно опубликуйте свой сайт. Если проблема не устранена и вы по-прежнему видите старые правила robots.txt на своем опубликованном сайте, обратитесь в службу поддержки.
Содержание
Как заблокировать поисковые системы с помощью правила запрета robots.
txtРазвитие веб-сайта
Техническое обслуживание
15 марта 2023 г.
Merkys M.
3 мин Чтение
Вы ищете способ контролировать, как роботы поисковых систем сканируют ваш сайт? Или вы хотите сделать некоторые части вашего сайта приватными? Вы можете сделать это, изменив файл robots.txt с помощью команды disallow .
В этой статье вы узнаете, что robots.txt может сделать для вашего сайта. Мы также покажем вам, как использовать его, чтобы заблокировать сканеры поисковых систем.
Что такое Robots.txt
Robots.txt — это простой текстовый файл, используемый для связи с поисковыми роботами. Файл находится в корневом каталоге сайта.
Он работает, сообщая поисковым ботам, какие части сайта следует и не следует сканировать. До robots.txt разрешается или запрещается ботам сканировать веб-сайт.
Другими словами, вы можете настроить файл так, чтобы поисковые системы не сканировали и не индексировали страницы или файлы на вашем сайте.
Почему я должен блокировать поисковую систему
Если вы хотите заблокировать доступ поисковых роботов ко всему вашему веб-сайту или если у вас есть конфиденциальная информация на страницах, которые вы хотите сделать закрытыми. К сожалению, поисковые роботы не могут автоматически различать общедоступный и частный контент. В этом случае необходимо ограничение доступа.
Вы также можете запретить ботам сканировать весь ваш сайт. Особенно, если ваш сайт находится в режиме обслуживания или в стадии подготовки.
Другим способом использования robots.txt является предотвращение проблем с дублированием контента, возникающих, когда одни и те же сообщения или страницы отображаются по разным URL-адресам. Дубликаты могут негативно повлиять на поисковую оптимизацию (SEO).
Решение простое — определите повторяющийся контент и запретите ботам его сканировать.
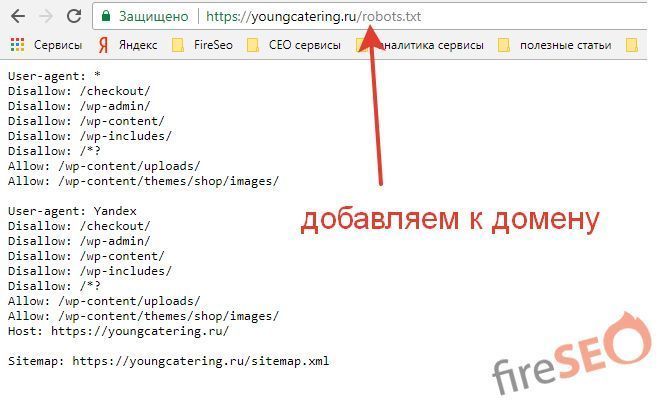
Как использовать robots.txt для запрета поисковых систем
Если вы хотите проверить файл robots.
txt вашего сайта, вы можете просмотреть его, добавив robots.txt после URL вашего сайта, например, www.myname.com/robots.txt . Вы можете редактировать его через файловый менеджер панели управления веб-хостингом или через FTP-клиент.Давайте настроим файл robots.txt с помощью файлового менеджера Hostinger hPanel . Во-первых, вы должны войти в Файловый менеджер в разделе Файлы панели. Затем откройте файл из каталога public_html .
Если файла нет, вы можете создать его вручную. Просто нажмите Кнопка New File в правом верхнем углу файлового менеджера, назовите его robots.txt и поместите в public_html .
Теперь вы можете начать добавлять команды в файл. Два основных из них, которые вы должны знать:
- User-agent — относится к типу бота, доступ к которому будет ограничен, например Googlebot или Bingbot.
- Disallow — здесь вы хотите ограничить ботов.
Давайте рассмотрим пример. Если вы хотите, чтобы бот Google не сканировал определенную папку вашего сайта, вы можете поместить эту команду в файл:
Агент пользователя: Googlebot Disallow: /example-subfolder/
Вы также можете запретить поисковым роботам сканировать определенную веб-страницу. Если вы хотите заблокировать Bingbot на странице, вы можете установить команду следующим образом:
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
А что, если вы хотите, чтобы файл robots.
txt запрещал все поисковые роботы? Вы можете сделать это, поставив звездочку (*) рядом с User-agent . И если вы хотите запретить им доступ ко всему сайту, просто поставьте косая черта (/) рядом с Запретить . Вот как это выглядит:User-agent: * Disallow: /
Вы можете настроить разные конфигурации для разных поисковых систем, добавив в файл несколько команд. Также имейте в виду, что изменения вступают в силу после сохранения файла robots.txt .
Заключение
Теперь вы узнали, как модифицировать файл robots.txt . Это позволяет управлять доступом поисковых роботов к вашему сайту. Теперь вы можете быть спокойны, зная, что на страницах результатов поисковой системы будет отображаться только то, что вы хотите найти.

 Чтобы убедиться, что ранее проиндексированная страница не проиндексирована, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex, чтобы удалить этот контент из индекса Google.
Чтобы убедиться, что ранее проиндексированная страница не проиндексирована, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex, чтобы удалить этот контент из индекса Google. txt.
txt. txt для предотвращения индексации ресурсов сайта Webflow, поскольку файл robots.txt должен находиться в том же домене, что и контент, к которому он применяется (в данном случае там, где обслуживаются ресурсы) . Webflow обслуживает ресурсы из нашей глобальной CDN, а не из пользовательского домена, в котором находится файл robots.txt.
txt для предотвращения индексации ресурсов сайта Webflow, поскольку файл robots.txt должен находиться в том же домене, что и контент, к которому он применяется (в данном случае там, где обслуживаются ресурсы) . Webflow обслуживает ресурсы из нашей глобальной CDN, а не из пользовательского домена, в котором находится файл robots.txt.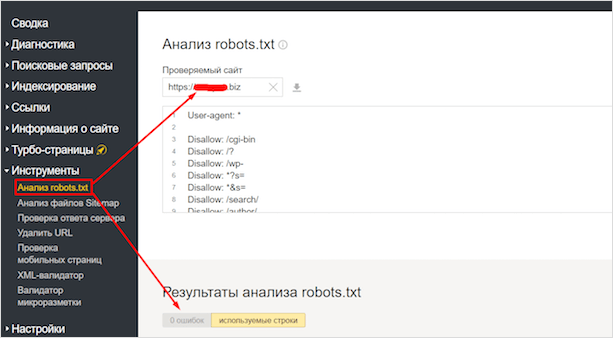 txt
txt
 txt вашего сайта, вы можете просмотреть его, добавив robots.txt после URL вашего сайта, например, www.myname.com/robots.txt . Вы можете редактировать его через файловый менеджер панели управления веб-хостингом или через FTP-клиент.
txt вашего сайта, вы можете просмотреть его, добавив robots.txt после URL вашего сайта, например, www.myname.com/robots.txt . Вы можете редактировать его через файловый менеджер панели управления веб-хостингом или через FTP-клиент.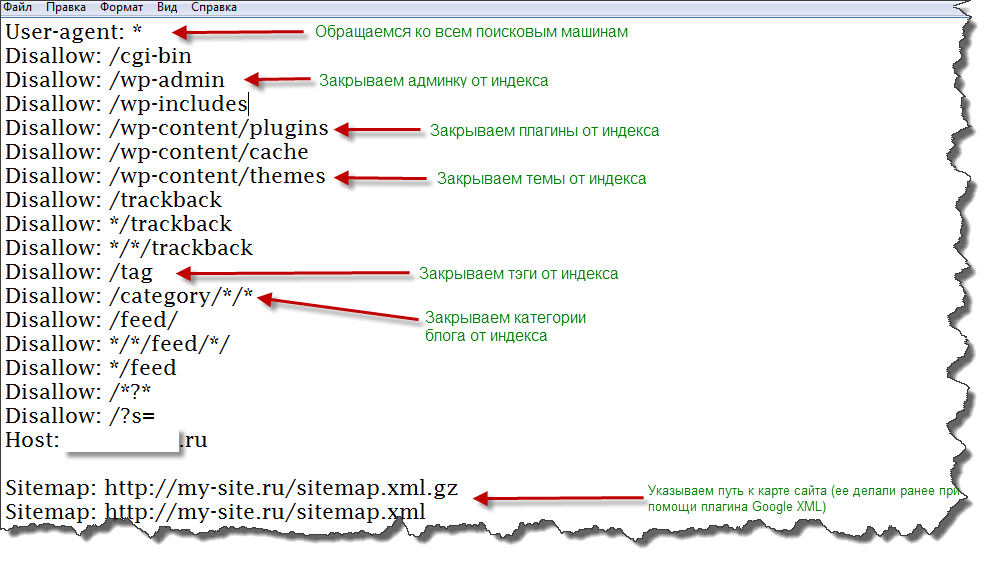
 txt запрещал все поисковые роботы? Вы можете сделать это, поставив звездочку (*) рядом с User-agent . И если вы хотите запретить им доступ ко всему сайту, просто поставьте косая черта (/) рядом с Запретить . Вот как это выглядит:
txt запрещал все поисковые роботы? Вы можете сделать это, поставив звездочку (*) рядом с User-agent . И если вы хотите запретить им доступ ко всему сайту, просто поставьте косая черта (/) рядом с Запретить . Вот как это выглядит: