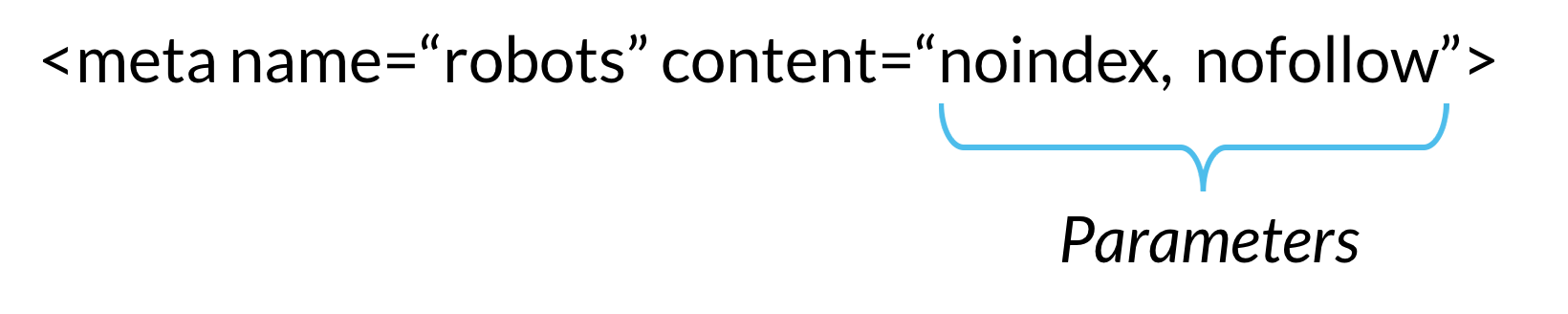Содержание
Метатег robots и HTTP-заголовок X-Robots-Tag
Вы можете указать роботам правила загрузки и индексирования определенных страниц сайта одним из способов:
прописать метатег robots в HTML-коде страницы в элементе head;
настроить HTTP-заголовок X-Robots-Tag для определенного URL на сервере вашего сайта.
Примечание. Если страница запрещена в файле robots.txt, то директива метатега или заголовка не действует.
По умолчанию метатег и заголовок учитываются поисковыми роботами. Можно указать директивы для определенных роботов.
- Поддерживаемые Яндексом директивы
- Указание нескольких директив
- Указания для определенных роботов
| Директива | Описание | Метатег robots | Заголовок X-Robots-Tag |
|---|---|---|---|
| noindex | Не индексировать текст страницы. Страница не будет участвовать в результатах поиска. Страница не будет участвовать в результатах поиска. | ||
| nofollow | Не переходить по ссылкам на странице. Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах. | ||
| none | Соответствует директивам noindex, nofollow. | ||
| noarchive | Не показывать ссылку на сохраненную копию в результатах поиска. | ||
| noyaca | Не использовать сформированное автоматически описание. | — | |
| index | follow | archive | Отмена соответствующих запрещающих директив. | — | |
| all | Соответствует директивам index и follow — разрешено индексировать текст и ссылки на странице. | — |
Разрешающие директивы используются роботом по умолчанию, поэтому их можно не указывать, если нет других директив. В сочетании с запрещающими директивами разрешающие имеют приоритет. Пример.
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Пример:
Запись, которая запрещает индексирование страницы.
<html>
<head>
<meta name="robots" content="noindex" />
</head>
<body>...</body>
</html>HTTP-ответ, где заголовок запрещает индексирование страницы.
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex
Вы можете указать директивы через запятую.
<meta name="yandex" content="noindex, nofollow" />
Вы можете передать несколько заголовков в одном ответе, а также перечислить директивы через запятую.
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex, nofollow X-Robots-Tag: noarchive
Если для робота Яндекса указаны противоречивые директивы, то он учтет положительное значение. Пример с директивами метатега:
<meta name="robots" content="all"/> <meta name="robots" content="noindex, follow"/> <!--Робот выберет значение all, текст и ссылки будут проиндексированы.--> <meta name="robots" content="all"/> <meta name="robots" content="noarchive"/> <!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки на сохраненную копию страницы.-->
 -->
<meta name="robots" content="all"/>
<meta name="robots" content="noarchive"/>
<!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки
на сохраненную копию страницы.-->
-->
<meta name="robots" content="all"/>
<meta name="robots" content="noarchive"/>
<!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки
на сохраненную копию страницы.-->Указать директиву только для роботов Яндекса можно с помощью метатега robots. Пример:
<meta name="yandex" content="noindex" />
Если вы перечислите общие директивы и директивы для роботов Яндекса, то поисковая система учтет все указания.
<meta name="robots" content="noindex" /> <meta name="yandex" content="nofollow" />
Такие директивы робот Яндекса воспримет как noindex, nofollow.
Если страницы долгое время не попадают в результаты поиска или были исключены, в форме приведите примеры таких страниц.
самая подробная справка от Q-SEO
В первую очередь давайте начнем с того, что существует несколько принципиально разных понятий: тег <noindex>, атрибут rel=”nofollow” и мета-тег <meta name=»robots» content=»noindex, nofollow» />. В этой статье мы подробно разберемся с их определениями и предназначениями.
В этой статье мы подробно разберемся с их определениями и предназначениями.
Что такое тег <noindex>
<noindex>…</noindex> – тег, который предложили использовать поисковые системы для запрета индексации заключенного в него контента. Данный тег не входит в официальную спецификацию гипертекстовой разметки веб-страниц формата html.
Важно: распознается он лишь поисковыми системами Яндекс и Рамблер. Google не относится к числу поисковых систем, понимающих данный html тег.
Что такое атрибут rel=”nofollow”
rel=”nofollow” – значение, запрещающее поисковым системам переходить по ссылке, в которой используется данный атрибут.
Ниже будут рассмотрены все примеры использования тега <noindex> и атрибута rel=”nofollow”.
Тег noindex и атрибут rel=“nofollow”
Тег <noindex> для ссылок
Данный тег можно использовать для закрытия ссылок от индексации. Вот так это будет выглядеть в коде страницы:
для ссылок
<noindex><a href=»http://site. com/»>текст ссылки</a></noindex>
com/»>текст ссылки</a></noindex>
|
| <noindex><a href=»http://site.com/»>текст ссылки</a></noindex> |
Тег <noindex> для контента
Данный тег можно использовать и для закрытия контента от индексации. Существует два способа. В коде страницы это будет выглядеть так:
для контента — вариант 1
<noindex>Текст, запрещённый к индексированию</noindex>
|
| <noindex>Текст, запрещённый к индексированию</noindex> |
для контента — вариант 2
<!—noindex—>Текст, запрещённый к индексированию<!—/noindex—>
|
| <!—noindex—>Текст, запрещённый к индексированию<!—/noindex—> |
Но стоит помнить, что данный тег понимают только поисковые системы Яндекс и Рамблер. Его свойства не распространяются на Google. Поэтому, если на вашем сайте есть некачественный контент, закрыть его таким способом можно только от роботов Яндекса и Рамблера.
Его свойства не распространяются на Google. Поэтому, если на вашем сайте есть некачественный контент, закрыть его таким способом можно только от роботов Яндекса и Рамблера.
rel=”nofollow” для ссылок
Данный атрибут, чаще всего, используется оптимизаторами в том случае, если они хотят, чтобы поисковые системы не учитывали наличие исходящей ссылки, как фактор передачи веса, но ссылка всё равно будет изучена роботом. Вот как это выглядит в коде:
rel=”nofollow”
<a href=»http://site.com/» rel=»nofollow»>текст ссылки</a>
|
| <a href=»http://site.com/» rel=»nofollow»>текст ссылки</a> |
Обычно, это уместно тогда, когда ссылки проставляются автоматически, например, в комментариях. Если вы не можете или не хотите поручиться за содержание страниц, на которые ведут ссылки с вашего сайта, следует вставлять в теги таких ссылок rel=»nofollow». Такой атрибут понимают и Google-боты и Яндекс-боты, а в своих справках поисковые системы пишут следующее:
Такой атрибут понимают и Google-боты и Яндекс-боты, а в своих справках поисковые системы пишут следующее:
https://support.google.com/webmasters/answer/96569?hl=ru
https://yandex.ru/support/webmaster/controlling-robot/html.xml?lang=ru
Передает ли nofollow-ссылка вес
Если вы внимательно прочитали информацию по указанным выше ссылкам, теперь вы знаете, что вес по nofollow-ссылке не передается. Но из практики, мы можем смело сказать, что наличие таких ссылок в ссылочном профиле – очень полезный и достаточно естественный фактор в глазах поисковых систем. Но иметь много исходящих ссылок на своем сайте может быть негативным фактором, даже если они закрыты через данный атрибут.
Нужно ли использовать rel=”nofollow” для внутренних ссылок
Для того, чтобы сквозные ссылки, например на страницу регистрации или входа в личный кабинет не отнимали вес у других страниц, и не передавали его бесполезно, можно использовать rel=”nofollow”.
Как использовать совместно тег <noindex> и rel=”nofollow”
Вот пример кода, когда оптимизаторы используют тег <noindex> и атрибут rel=”nofollow” одновременно:
«совместно
<noindex><a href=»http://site. com/» rel=»nofollow»>текст ссылки</a></noindex>
com/» rel=»nofollow»>текст ссылки</a></noindex>
|
| <noindex><a href=»http://site.com/» rel=»nofollow»>текст ссылки</a></noindex> |
Но этот метод полноценно работает только для роботов Яндекса. Google понимает только лишь rel=»nofollow»>.
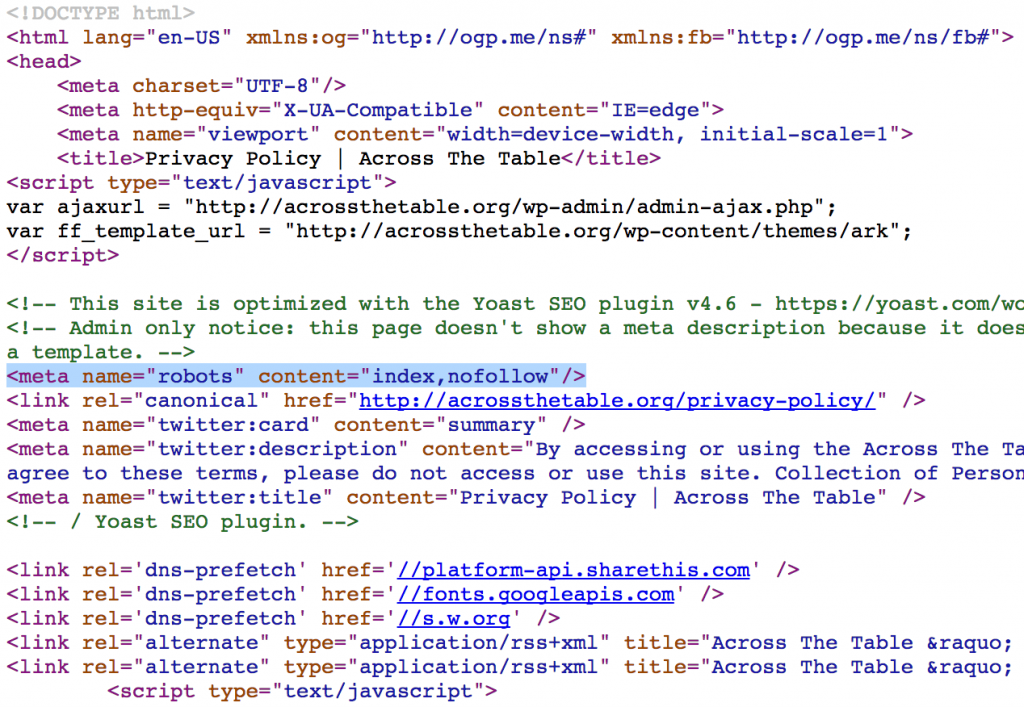
Мета-тег <meta name=»robots» content=»noindex, nofollow» />
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и выглядит это следующим образом:
Мета-тег
<head>
…
<meta name=»robots» content=»noindex, nofollow» />
…
</head>
|
| <head> … <meta name=»robots» content=»noindex, nofollow» /> … </head> |
Суть значений noindex и nofollow в мета-теге остается та же:
Noindex – запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.
Nofollow – запрещает поисковым роботам переходить по ссылкам на уровне страницы (и по внешним, и по внутренним).
Комбинации <meta name=»robots» content=»х, y» />
Есть несколько случаев, когда используют данный мета-тег на практике. Под эти случаи есть разные решения:
- <meta name=»robots» content=»noindex, follow» /> нужно использовать в случае, если вы не хотите, чтобы страница была проиндексирована поисковыми системами, но роботы смогли бы перейти по ссылкам с этой страницы на другие. Например, это может быть вторая страница пагинации на сайте типа site.com/category/?page=2, на которой есть ссылки на следующие товары и вы не хотите, чтобы эта страница была проиндексирована поисковой системой.
- <meta name=»robots» content=»noindex» /> выполняет то же самое. В данном случае вы запретите поисковой системе индексировать страницу, но просматривать ее и ходить по ссылкам роботы смогут.
- <meta name=»robots» content=»noindex, nofollow» /> – запрещает индексировать контент на соответствующей странице, а также запрещает роботам переходить по ссылкам.
- <meta name=»robots» content=»index, follow» /> – разрешает роботам индексировать страницу и ходить по ссылкам. Такой мета-тег не имеет смысла использовать, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия. Но если на вашем сайте он установлен и вы не собираетесь ограничивать работу робота, специально удалять его нет смысла.
- <meta name=»robots» content=»index, nofollow» /> — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.
- <meta name=»robots» content=»nofollow» /> — делает то же самое — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.

Данный мета-тег можно использовать как для Google, так и для Яндекс отдельно
Если вам необходимо закрыть от индексации страницы только для Google, можно использовать <meta name=»googlebot» content=»noindex» />. Так говорит справка Google.
Так говорит справка Google.
Если закрыть от индексации только для Яндекса – <meta name=»yandex» content=»noindex»/>. Об этом также очень подробно написано в справке Яндекс.
Как сочетать meta name=»robots» с robots.txt и в чем принципиальная разница
Некоторые оптимизаторы не понимают разницу между мета-тегом <meta name=»robots» content=»noindex, nofollow» /> и закрытием соответствующей страницы в файле robots.txt. Оба способа запрещают поисковым роботам индексировать страницу сайта, но отличие все же есть:
Первый – разрешает роботам зайти на эту страницу, увидеть мета-тег и исключить ее из индекса или не индексировать.
Второй – запрещает зайти на страницу, и если вдруг она ранее уже была проиндексирована, она может долго находится в индексе поисковых систем, даже если вы ее закроете в файле robots.txt, без права на переиндексацию, впоследствии вы можете видеть ее в поиске так:
Поэтому для непроиндексированных страниц можно использовать любой из вариантов.
Если же страница уже была проиндексирована, рекомендуется установить в секцию <head> мета-тег <meta name=»robots» content=»noindex, nofollow» />. Это исключит ее из индекса и предотвратит последующее попадение в него.
Если ваш сайт создан на WordPress, правильно настроить данные мета-теги поможет бесплатный плагин Yoast SEO. Примерно вот так это выглядит:
Помочь проанализировать наличие всех этих элементов (и мета-тегов и тегов и атрибутов) в коде страниц сайта может расширение для браузера RDS-бар:
Правильно настроив его, вы сможете видеть контент, завернутый в тег <noindex> (будет подсвечиваться):
Ссылки с rel=»nofollow» (ссылка будет перечеркнутой, а в данном случае она еще и завернута в тег <noindex>):
И использование мета-тега <meta name=»robots» content=»x, y» />:
Теперь вы знаете как с помощью данных методов настроить правильную индексацию страниц. Это может оказать положительное влияние на процесс раскрутки веб-сайта.
Комментарии
Комментарии
спецификаций метатегов роботов | Центр поиска Google | Документация
В этом документе подробно описывается, как можно использовать настройки уровня страницы и текста для настройки того, как Google
представляет ваш контент в результатах поиска. Вы можете задать настройки на уровне страницы, включив
Мета-тег на страницах HTML или в заголовке HTTP. Вы можете указать настройки уровня текста с помощью
атрибут data-nosnippet для элементов HTML на странице.
Имейте в виду, что эти настройки можно прочитать и использовать только в том случае, если сканерам разрешено
получить доступ к страницам, которые включают эти настройки.
К поисковой системе применяется правило .
гусеницы. Чтобы заблокировать поисковые роботы, такие как
AdsBot-Google , вам может потребоваться добавить правила, ориентированные на конкретный
поисковый робот (например,
).
Использование тега robots
meta
Метатег robots позволяет вам использовать детальный, специфичный для страницы подход к управлению тем, как
отдельная страница должна быть проиндексирована и показана пользователям в результатах поиска Google. Поместите
роботы метатег в разделе данной страницы, например
этот:
<заголовок> (…) <тело> (…)
Если вы используете CMS, например Wix, WordPress или Blogger , возможно, вы не сможете редактировать
ваш HTML напрямую, или вы можете предпочесть этого не делать. Вместо этого ваша CMS может иметь поисковую систему.
страница настроек или какой-либо другой механизм, сообщающий поисковым системам о метатегов .
Если вы хотите добавить на свой веб-сайт метатег , выполните поиск инструкций.
об изменении вашей страницы на вашей CMS (например,
найдите «wix добавить метатеги»).
В этом примере тег robots meta указывает поисковым системам не показывать страницу в
результаты поиска. Значение атрибута name ( robots )
указывает, что правило применяется ко всем сканерам. К
обратиться к конкретному сканеру, замените роботов значение
имя атрибут с именем искателя, которым вы являетесь
адресация. Определенные сканеры также известны как пользовательские агенты (сканер использует свой пользовательский агент для
Определенные сканеры также известны как пользовательские агенты (сканер использует свой пользовательский агент для
запросить страницу.) Стандартный поисковый робот Google имеет имя пользовательского агента
Гуглбот . Чтобы предотвратить индексацию вашей страницы только Google,
обновите тег следующим образом:
Этот тег теперь предписывает Google не показывать эту страницу в результатах поиска. Оба
имя и содержимое атрибуты
не чувствительны к регистру.
Поисковые системы могут иметь разные сканеры для разных целей. См.
полный список поисковых роботов Google.
Например, чтобы показать страницу в результатах веб-поиска Google, но не в Новостях Google, используйте
следующий метатег :
Чтобы указать несколько поисковых роботов по отдельности, используйте несколько robots мета теги:
Чтобы заблокировать индексирование ресурсов, отличных от HTML, таких как файлы PDF, видеофайлы или файлы изображений,
вместо этого используйте заголовок ответа X-Robots-Tag .
Использование
X-Robots-Tag HTTP-заголовка
X-Robots-Tag можно использовать как элемент HTTP-заголовка
ответ для заданного URL. Любое правило, которое можно использовать в robots 9Метатег 0003 также может быть
указан как X-Robots-Tag . Вот пример HTTP
ответ с X-Robots-Tag , указывающим поисковым роботам не индексировать
страница:
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Tag: noindex (…)
Несколько заголовков X-Robots-Tag могут быть объединены в HTTP-заголовке.
ответ, или вы можете указать список правил, разделенных запятыми. Вот пример
Ответ заголовка HTTP, который имеет без архива
X-Robots-Tag в сочетании с
недоступен_после X-Robots-Tag .
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Метка: нет в архиве X-Robots-Tag: unavailable_after: 25 июня 2010 г. 15:00:00 PST (…)
X-Robots-Tag может дополнительно указывать пользовательский агент перед
правила. Например, следующий набор из X-Robots-Tag HTTP
заголовки могут использоваться для условного разрешения показа страницы в результатах поиска для разных
поисковые системы:
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Tag: googlebot: nofollow X-Robots-Tag: otherbot: noindex, nofollow (…)
Правила, заданные без пользовательского агента, действительны для всех сканеров. Заголовок HTTP,
имя пользовательского агента, а указанные значения не чувствительны к регистру.
Конфликтующие правила роботов: В случае конфликтующих роботов
правил, применяется более строгое правило. Например, если на странице есть оба
max-snippet:50 и nosnippet
правила, будет применяться правило nosnippet .
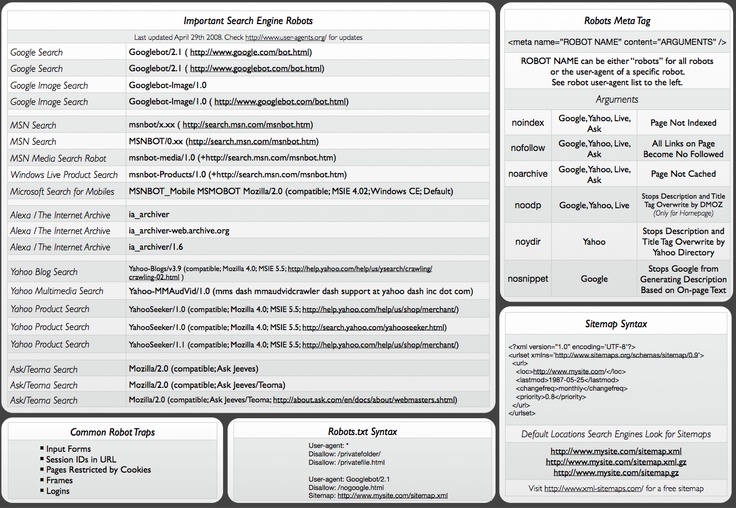
Действительные правила индексации и обслуживания
Следующие правила, также доступные в
машиночитаемый формат, может использоваться для
управлять индексацией и показом сниппета с помощью
роботы метатег и X-Robots-Tag . Каждое значение представляет определенный
правило. Несколько правил могут быть объединены через запятую.
списке или в отдельных мета-тегах . Эти правила нечувствительны к регистру.
Возможно, что эти правила не будут рассматриваться всеми другими поисковыми системами одинаково.
| Правила | |
|---|---|
| Нет никаких ограничений для индексации или обслуживания. Это правило является значением по умолчанию и не имеет никакого эффекта, если явно указан. |
| Не показывать эту страницу, медиа или ресурс в результатах поиска. Если вы не укажете это Чтобы удалить информацию из Google, следуйте нашим |
| Не переходите по ссылкам на этой странице. Если вы не укажете это правило, Google может использовать ссылки на странице, чтобы обнаружить эти связанные страницы. Узнать больше о nofollow . |
| Эквивалентно noindex, nofollow . |
| Не показывать кешированная ссылка в результатах поиска. Если вы не укажете это правило, Google может создать кешированную страницу. и пользователи могут получить к нему доступ через результаты поиска.  |
| Не показывать окно поиска дополнительных ссылок |
| Не показывать фрагмент текста или предварительный просмотр видео в результатах поиска для этой страницы. А Если вы не укажете это правило, Google может создать фрагмент текста и видео. |
| Google разрешено индексировать содержимое страницы, если оно встроено в другую страницу. |
| Используйте не более [число] символов в текстовом фрагменте для этого результата поиска. Если вы не укажете это правило, Google выберет длину фрагмента. Специальные значения:
Примеры: Чтобы остановить отображение фрагмента в результатах поиска: Чтобы во фрагменте отображалось до 20 символов: Чтобы указать, что нет ограничений на количество символов, которые могут отображаться в |
| Установить максимальный размер предварительного просмотра изображения для этой страницы в результатах поиска. Если вы не укажете правило Принятые значения [настройки]:
Это относится ко всем формам результатов поиска (таким как веб-поиск Google, изображения Google, Если вы не хотите, чтобы Google использовал большие миниатюры изображений на своих AMP-страницах Пример: |
| Используйте максимум [число] секунд в качестве фрагмента видео для видео на этой странице в поиске Если вы не укажете правило Специальные значения:
Это относится ко всем формам результатов поиска (в Google: веб-поиск, изображения Google, Пример: |
| Не предлагать перевод этой страницы в результатах поиска. Если вы не укажете это Если вы не укажете этоправило, Google может предоставлять перевод заглавной ссылки и сниппета результатов поиска для результатов, которые не на языке поискового запроса. Если пользователь щелкает переведенную ссылку заголовка, все дальнейшие пользовательские взаимодействие со страницей осуществляется через Google Translate, который будет автоматически переводить любые ссылки. |
| Не индексировать изображения на этой странице. Если не указать это значение, изображения на странице могут быть проиндексированы и показаны в результатах поиска. |
| Не показывать эту страницу в результатах поиска после указанной даты/времени. Если вы не укажете это правило, эта страница может отображаться в результатах поиска. Пример: |


 (Примечание
(Примечание Эквивалентно
Эквивалентно
 Например, если издатель
Например, если издатель
 Дата/время
Дата/времяОбработка комбинированных правил индексации и обслуживания
Вы можете создать инструкцию с несколькими правилами, объединив роботов мета
правила тегов с запятыми или с использованием нескольких мета-тегов . Вот пример метатега robots
Вот пример метатега robots , который предписывает поисковым роботам не индексировать
страницу и не сканировать ни одну из ссылок на странице:
Список, разделенный запятыми
Несколько
метатегов
Вот пример, который ограничивает текстовый фрагмент до 20 символов и позволяет использовать большое изображение.
предварительный просмотр:
В ситуациях, когда несколько искателей указаны вместе с разными правилами,
поисковая система будет использовать сумму отрицательных правил. Например:
Например:
Страница, содержащая эти метатега , будет интерпретироваться как имеющая
noindex, правило nofollow при сканировании роботом Googlebot.
Использование HTML-атрибута
data-nosnippet
Вы можете определить текстовые части HTML-страницы, которые не будут использоваться в качестве фрагмента. Это можно сделать
на уровне HTML-элемента с HTML-атрибутом data-nosnippet на
диапазон , раздел и
раздел элементов.
data-nosnippet
считается
логический атрибут.
Как и для всех логических атрибутов, любое указанное значение игнорируется. Чтобы обеспечить машиночитаемость,
раздел HTML должен быть действительным HTML, и все соответствующие теги должны быть соответствующим образом закрыты.
Примеры:
Этот текст можно отобразить во фрагменте и эта часть не будет отображаться.
не во фрагментетоже не во фрагментетоже не во фрагментекакой-то тексткакой-то текст Google обычно отображает страницы для их индексации, однако обработка не гарантируется.
Из-за этого извлечениеdata-nosnippetможет произойти как
до и после рендеринга. Во избежание неопределенности при рендеринге не добавляйте и не удаляйте
data-nosnippetатрибут существующих узлов через JavaScript.
При добавлении элементов DOM через JavaScript включите
атрибут data-nosnippetпо мере необходимости при первоначальном добавлении
элемент в DOM страницы. Если используются пользовательские элементы, оберните их или визуализируйте с помощью
раздел,интервалили
разделэлементов, если вам нужно использовать
data-nosnippet.Использование структурированных данных
Метатеги Robots
регулируют объем контента, который Google автоматически извлекает из Интернета.
страницы для отображения в качестве результатов поиска. Но многие издатели также используют структурированные данные schema.org.
сделать конкретную информацию доступной для
поисковое представление. Роботымета тег
ограничения не влияют на использование этих структурированных данных, за исключением
артикул.описаниеи т.д.
описаниезначения для структурированных данных, указанные для других
творческие работы. Чтобы указать максимальную продолжительность предварительного просмотра на основе этих
описаниезначения, используйте
max-snippetправило. Например,
рецептструктурированные данные на странице подходят для включения в
карусель рецептов, даже если в противном случае предварительный просмотр текста был бы ограничен.
предварительного просмотра текста сmax-snippet, но этот тег robotsmeta
не применяется, когда информация предоставляется с использованием структурированных данных для расширенных результатов.Чтобы управлять использованием структурированных данных для ваших веб-страниц, измените типы структурированных данных и
сами значения, добавляя или удаляя информацию, чтобы предоставить только те данные, которые вам нужны
сделать доступным. Также обратите внимание, что структурированные данные остаются пригодными для использования в результатах поиска, когда
объявлено вdata-nosnippetэлемент.Практическая реализация
X-Robots-TagВы можете добавить
X-Robots-Tagв HTTP-ответы сайта через
файлы конфигурации программного обеспечения веб-сервера вашего сайта.
серверах вы можете использовать файлы .htaccess и httpd.conf. Преимущество использования
X-Robots-Tagс ответами HTTP заключается в том, что вы можете указать сканирование
правила, которые применяются глобально на сайте. Поддержка регулярных выражений позволяет
высокий уровень гибкости.Например, чтобы добавить noindex
, nofollow
X-Robots-Tagна ответ HTTP для всехфайлов .PDFв
весь сайт, добавьте следующий фрагмент в корневой файл сайта.htaccessили файлhttpd.confна
Apache или файл.confсайта на NGINX.Апач
<Файлы ~ "\.pdf$"> Набор заголовков X-Robots-Tag "noindex, nofollow"НГИНКС
расположение ~* \.Вы можете использовать
X-Robots-Tagдля файлов, отличных от HTML, таких как файлы изображений.
где использование тегов robotsmetaв HTML невозможно. Вот пример добавления
noindexX-Robots-Tagправило для
файлы изображений (.png,.jpeg,.jpg,.gif) по всему сайту:Апач
<Файлы ~ "\.(png|jpe?g|gif)$"> Набор заголовков X-Robots-Tag "noindex"НГИНКС
расположение ~* \.(png|jpe?g|gif)$ { add_header X-Robots-Tag "noindex"; }Вы также можете установить заголовки
X-Robots-Tagдля отдельных статических файлов:Апач
# файл htaccess должен быть помещен в каталог соответствующего файла.НГИНКС
местоположение = /secrets/unicorn.pdf { add_header X-Robots-Tag "noindex, nofollow"; }Объединение правил robots.txt с правилами индексирования и обслуживания
метатеги robots
и заголовкиX-Robots-TagHTTP обнаруживаются, когда
URL просканирован. Если страница запрещена для сканирования через файл robots.txt, то любой
информация об индексировании или правилах обслуживания не будет найдена и, следовательно, будет
игнорируется. Если необходимо соблюдать правила индексирования или обслуживания, URL-адреса, содержащие эти
правила не могут быть запрещены для сканирования.Использование метатега robots | Блог Google Search Central
Прошло много времени с тех пор, как мы опубликовали эту запись в блоге.
Вторник, 6 марта 2007 г.
Недавно Дэнни Салливан поднял хорошие вопросы о том, как
поисковые системы обрабатываютмета-тегов.
Вот несколько ответов о том, как мы обрабатываем эти теги в Google.Несколько значений содержания
Мы рекомендуем размещать все значения содержимого в одном мета-теге
. Это позволяет легко находить метатеги.
читать и снижает вероятность конфликтов. Например:Если страница содержит несколько метатегов
одного и того же типа, мы агрегируем значения контента.
Например, мы будем интерпретироватьаналогично:
Если значения содержимого конфликтуют, мы будем использовать наиболее строгие.
метатега:Мы будем подчиняться значению
noindex.Ненужные значения содержимого
По умолчанию робот Googlebot индексирует страницу и переходит по ссылкам на нее. Так что нет необходимости помечать страницы
со значениями содержанияиндексилиследует за.Направление метатега robots
специально для робота GooglebotЧтобы предоставить инструкции для всех поисковых систем, установите метаимя
robots. К
предоставьте инструкции только для робота Googlebot, установите метаимяGooglebot.
предоставлять разные инструкции для разных поисковых систем (например, если вы хотите
поисковая система индексирует страницу, но не другую), лучше всего использовать конкретный 9Метатег 0003 для каждого
поисковую систему, а не использовать общий тег robotsmetaв сочетании с конкретным тегом. Ты можешь найти
список ботов на robotstxt.org.Корпус и проставка
Робот Google понимает любую комбинацию строчных и прописных букв. Таким образом, каждый из этих
метатегов
интерпретируется точно так же:Если у вас есть несколько значений содержимого, вы должны поставить запятую между ними, но не имеет значения, если
вы также включаете пробелы. Таким образом, следующие мета-тегиинтерпретируются одинаково:txt file and robots meta tags»> Если вы используете файл robots.txt и теги robots
metaЕсли инструкции robots.txt и
metaуказывают на конфликт страниц, робот Google следует наиболее
ограничительный. Более конкретно:
- Если вы заблокируете страницу с помощью файла robots.txt, робот Googlebot никогда не просканирует страницу и никогда не прочитает
метатегана странице.- Если вы разрешите страницу с файлом robots.txt, но заблокируете ее от индексации с помощью метатега
, робот Googlebot
получит доступ к странице, прочитает метатеги впоследствии не проиндексирует ее.Действительные значения содержимого метаданных robots
Робот Googlebot интерпретирует следующие метаданные robots
9Значения тега 0004:
noindex: предотвращает включение страницы в индекс.nofollow: запрещает роботу Googlebot переходить по любым ссылкам на странице. (Обратите внимание, что это
отличается от атрибута nofollow уровня ссылки, который предотвращает
по отдельной ссылке.)noarchive: запрещает кэшированную копию этой страницы быть доступной в поиске
Результаты.
903:00nosnippet: предотвращает появление описания под страницей в поиске
результатов, а также предотвращает кеширование страницы.noodp: блокирует
Описание проекта Open Directory
страница от использования в описании, которое появляется под страницей в результатах поиска.нет: эквивалентноnoindex, nofollow.


 Вы можете ограничить длину
Вы можете ограничить длину Например, в Интернете на основе Apache
Например, в Интернете на основе Apache pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}  <Файлы "unicorn.pdf">
Набор заголовков X-Robots-Tag "noindex, nofollow"
<Файлы "unicorn.pdf">
Набор заголовков X-Robots-Tag "noindex, nofollow"
 Часть информации может быть устаревшей (например, некоторые изображения могут отсутствовать, а некоторые ссылки уже не работают).
Часть информации может быть устаревшей (например, некоторые изображения могут отсутствовать, а некоторые ссылки уже не работают). Итак, если на странице есть эти
Итак, если на странице есть эти  Если ты хочешь
Если ты хочешь