Содержание
Полное руководство по Robots.txt и метатегу Noindex
0 ∞ 1
Файл Robots.txt и мета-тег Noindex важны для SEO-продвижения. Они информируют Google, какие именно страницы необходимо сканировать, а какие – индексировать (отображать в результатах поиска).
С помощью этих средств можно ограничить содержимое сайта, доступное для индексации.
- Что такое файл Robots.txt?
- Чем полезен файл Robots.txt?
- Как создать файл Robots.txt?
- Директивы для сканирования поисковыми системами
- Правильное использование универсальных символов
- Что такое Noindex?
- Как применять метатег Noindex?
- Метатег «robots»
- X-Robots-Tag
- Блокировка индексации через YoastSEO
- Лучшие примеры использования
- Добавляем Noindex в Robots.
 txt
txt - Заблокированная страница все равно может быть проиндексирована, если кто-то на нее ссылается
- Заключение
 txt
txtRobots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots. txt:
txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Noindex – это метатег, который запрещает поисковым системам индексировать страницу.
Существует три способа добавления Noindex на страницы:
Разместите приведенный ниже код в раздел <head> страницы:
<meta name=”robots” content=”noindex”>
Он сообщает всем типам поисковых роботов об условиях индексации страницы. Если нужно запретить индексацию страницы только для определенного робота, поместите его название в значение атрибута name.
Чтобы запретить индексацию страницы для Googlebot:
<meta name=”googlebot” content=”noindex”>
Чтобы запретить индексацию страницы для Bingbot:
<meta name=”bingbot” content=”noindex”>
Также можно разрешить или запретить роботам переход по ссылкам, размещенным на странице.
Чтобы разрешить переход по ссылкам на странице:
<meta name=”robots” content=”noindex,follow”>
Чтобы запретить поисковым роботам сканировать ссылки на странице:
<meta name=”robots” content=”noindex,nofollow”>
x-robots-tag позволяет управлять индексацией страницы через HTTP-заголовок. Этот тег также указывает поисковым системам не отображать определенные типы файлов в результатах поиска. Например, изображения и другие медиа-файлы.
Для этого у вас должен быть доступ к файлу .htaccess. Директивы в метатеге «robots» также применимы к x-robots-tag.
Плагин YoastSEO в WordPress автоматически генерирует приведенный выше код. Для этого на странице записи перейдите в интерфейсе YoastSEO в настройки публикации, щелкнув по значку шестеренки. Затем в опции «Разрешить поисковым системам показывать эту публикацию в результатах поиска?» выберите «Нет».
Также можно задать тег noindex для страниц категорий. Для этого зайдите в плагин Yoast, в «Вид поиска». Если в разделе «Показать категории в результатах поиска» выбрать «Нет», тег noindex будет размещен на всех страницах категорий.
Если в разделе «Показать категории в результатах поиска» выбрать «Нет», тег noindex будет размещен на всех страницах категорий.
- Чтобы проиндексированная страница была удалена из результатов поиска, убедитесь, что она не заблокирована в файле robots.txt. И только потом добавляйте тег noindex. Иначе Googlebot не сможет увидеть тег на странице. Если заблокировать страницу без тега noindex, она все равно будет отображаться в результатах поиска:
- Добавление директивы sitemap в файл robots.txt технически не требуется, но считается хорошей практикой.
- После обновления файла robots.txt рекомендуется проверить, не заблокированы ли важные страницы. Это можно сделать с помощью txt Tester в Google Search Console.
- Используйте инструмент проверки URL-адреса в Google Search Console, чтобы увидеть статус индексации страницы.
- Также можно проверить, проиндексировал ли Google ненужные страницы. Это можно сделать с помощью отчета в Google Search Console. Еще одной альтернативой может быть использование оператора «site». Это команда Google, которая отображает все страницы сайта, доступные в результатах поиска.
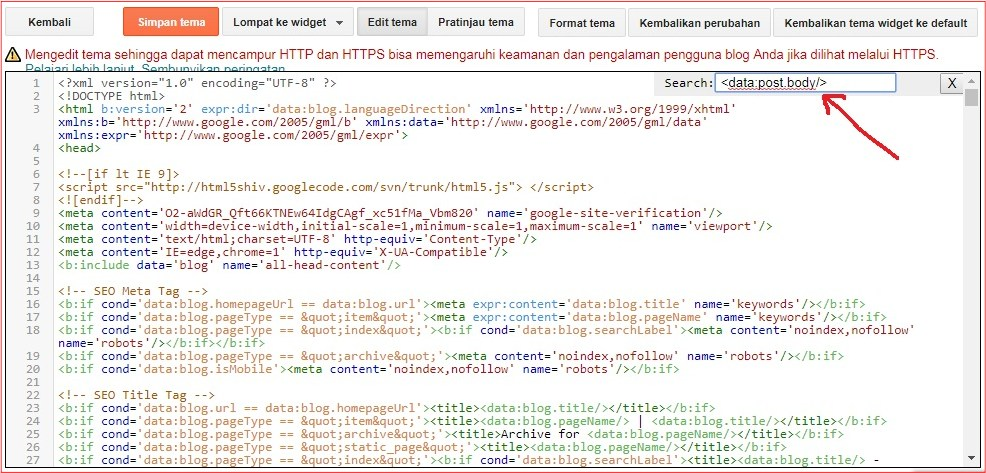 Это команда Google, которая отображает все страницы сайта, доступные в результатах поиска.
Это команда Google, которая отображает все страницы сайта, доступные в результатах поиска.В последнее время в SEO-сообществе было много недоразумений по поводу использования noindex в robots.txt. Но представители Google много раз говорили, что поисковая система не поддерживают данный метатег. И все же многие люди настаивают на том, что он все еще работает. Но лучше избегать его использования.
Заблокированные через robots.txt страницы, не могут быть проиндексированы, даже если кто-то на них ссылается.
Чтобы быть уверенным, что страница без контента случайно не появится в результатах поиска, Джон Мюллер рекомендует размещать на этих веб-страницах noindex даже после того, как вы заблокировали их в robots.txt.
Использование файла robots.txt улучшает не только SEO, но и пользовательский опыт. Для этого реализуйте приведенные выше практики.
Ангелина Писанюкавтор-переводчик статьи «The Complete Guide to Robots.txt and Noindex Meta Tag»
Пожалуйста, оставляйте ваши комментарии по текущей теме статьи. Мы крайне благодарны вам за ваши комментарии, отклики, лайки, дизлайки, подписки!
Мы крайне благодарны вам за ваши комментарии, отклики, лайки, дизлайки, подписки!
Метатег robots (meta name robots) – что это такое
Оглавление
Использование
Список стандартных значений метатега
Причины использования метатега robots
Метатег robots – это код гипертекстовой разметки, позволяющий контролировать индексирование и показ страниц сайта в результатах поиска. Код можно писать на любой странице сетевого ресурса в специально отведенном для него месте.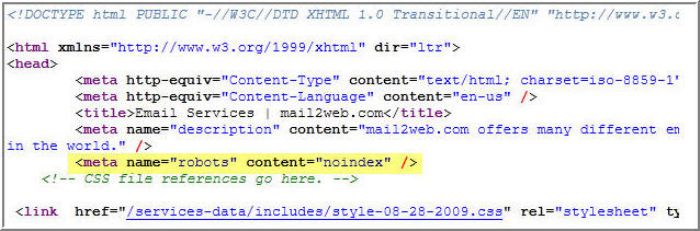 Роботы поисковых систем в процессе индексирования будут читать значение этого метатега и учитывать его в дальнейшей работе над сетевым ресурсом. Временное или постоянное внедрение этого кода может понадобиться в разных ситуациях. Например, он позволяет скрыть от поисковых роботов определенные ссылки или контент, который не должен попасть в выдачу поисковых систем. Этим тегом пользуются при оптимизации сайта, поисковом продвижении, наполнении ресурса уникальными статьями.
Роботы поисковых систем в процессе индексирования будут читать значение этого метатега и учитывать его в дальнейшей работе над сетевым ресурсом. Временное или постоянное внедрение этого кода может понадобиться в разных ситуациях. Например, он позволяет скрыть от поисковых роботов определенные ссылки или контент, который не должен попасть в выдачу поисковых систем. Этим тегом пользуются при оптимизации сайта, поисковом продвижении, наполнении ресурса уникальными статьями.
robots1.png
robots1.png
Использование
Код вписывают в заголовок каждой страницы, которую посещает робот. HTML-код выглядит следующим образом:
<html>
<head>
</head>
</html>
Все, что пользователь впишет между тегами <head> и </head> будет находиться в заголовке гипертекстовой разметки страницы.
Обсуждаемый код выглядит так:
<meta name=»robots» content=» » />
Между кавычками нужно указать команду, которую вы хотите отдать поисковому роботу.
Список стандартных значений метатега
Index и noindex. Разрешает или запрещает поисковику индексировать содержимое страницы соответственно. Полезно использовать при продвижении сайта и работе над ним в целом.
Follow и nofollow. Первое значение разрешает роботу переходить по ссылкам в пределах страницы, а второе запрещает. Также используется при SEO-оптимизации сетевых ресурсов.
Nosnippet. Директива запрещает роботу выводить в поисковой выдаче содержимое сниппета – краткое описание страницы.
Noarchive. Код запрещает роботу выводить в результатах поиска ссылку на сохраненную в кеше копию страницы.
All/none. Значение тега разрешает или запрещает индексацию всей страницы.
Noimageindex. Команда запрещает роботу индексировать опубликованные на странице фото.
Существуют и другие специальные указания, запрещающие или разрешающие поисковым роботам совершать определенные действия при индексировании содержимого страницы. Если тег отсутствует, то робот автоматически индексирует весь контент и все ссылки на странице. Если написано несколько тегов, значения которых противоречат друг другу, то поисковая система примет разрешающую директиву.
Если тег отсутствует, то робот автоматически индексирует весь контент и все ссылки на странице. Если написано несколько тегов, значения которых противоречат друг другу, то поисковая система примет разрешающую директиву.
Значения метатега можно комбинировать, записывая команды через запятую. Записывать параметры можно без учета регистра. Если в атрибуте тега name стоит значение robots, то все поисковые системы будут учитывать его значение в процессе индексации. При желании можно дать команду конкретной поисковой системе, указав в атрибуте название робота. Например, значение Googlebot позволит запретить или разрешить определенные действия только поисковой системе Google.
Пример метатега:
<meta name=»googlebot» content=» » />
Если пользователь знает названия всех роботов, используемых поисковыми системами, то сможет давать команды каждому из них. Например, чтобы страница появилась в основном поиске Google, но не в новостях этого поисковика, нужно написать следующее:
<meta name=»googlebot-news» content=»noindex» />
Для передачи нескольких команд одной или нескольким поисковым системам или отдельным роботам можно писать несколько метатегов с разными или одинаковыми значениями. Если пользователь запутается и напишет команды, противоречащие друг другу, то робот выберет более строгую из них.
Если пользователь запутается и напишет команды, противоречащие друг другу, то робот выберет более строгую из них.
robots2.jpg
robots2.jpg
Причины использования метатега robots
Разработчики и пользователи сетевых ресурсов знают, что существует файл robots.txt, который помогает при СЕО-оптимизации, позволяя разрешать или запрещать роботам совершать определенные действия. Метатег robots дает возможность:
- закрывать содержимое страницы, оставляя ссылки доступными для индексирования;
- давать команды поисковым роботам при недоступности корневой директории сайта;
- открыть доступ роботу к просмотру содержимого некоторых страниц при закрытии от индексации каталогов.
Тег robots применяют совместно с файлом robots.txt для более тонкой настройки параметров индексации.
Когда использовать NOINDEX или robots.txt?
Документация AIOSEO
Документация, справочные материалы и учебные пособия для AIOSEO
Уведомление: Для этого элемента нет устаревшей документации, поэтому вы видите текущую документацию.
Один из вопросов, который нам чаще всего задают, заключается в том, в чем разница между метатегом NOINDEX robots и файлом robots.txt, и когда каждый из них следует использовать. В этой статье рассматривается этот вопрос.
В этой статье
- Метатег роботов NOINDEX
- Файл robots.txt
- Разница между NOINDEX и robots.txt
- Дополнительная литература
NOIND Метатег EX robots
Тег NOINDEX используется для предотвратить появление контента в результатах поиска. Метатег NOINDEX появляется в исходном коде вашего контента и указывает поисковой системе не включать этот контент в результаты поиска.
Метатег NOINDEX robots выглядит в исходном коде вашей страницы следующим образом:
Файл robots.txt
Файл robots.txt сообщает поисковым системам, где их поисковые роботы могут и не могут посещать веб-сайт. Он включает в себя директивы «Разрешить» и «Запретить», которые указывают поисковой системе, какие каталоги и файлы следует сканировать, а какие нет.
Однако это не мешает вашему контенту появляться в результатах поиска. Кроме того, если на заблокированный каталог или файл есть ссылка с любой страницы вашего веб-сайта или другого веб-сайта, поисковые системы все равно могут их сканировать.
Примером использования файла robots.txt является указание поисковым системам не сканировать каталог «/cgi-bin/», который может существовать на вашем сервере, поскольку в этом каталоге нет ничего полезного для поисковые системы.
По умолчанию файл robots.txt для WordPress выглядит следующим образом:
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Разница между NOINDEX и robots.txt
Разница между ними следующая:
- Файл robots.txt используется для указания поисковой системе, какие каталоги и файлы следует сканировать. Это не мешает контенту индексироваться и отображаться в результатах поиска.
- Метатег роботов NOINDEX указывает поисковым системам не включать контент в результаты поиска, а если контент уже был проиндексирован ранее, то они должны полностью удалить этот контент. Это не мешает поисковым системам сканировать контент.
 Это не мешает поисковым системам сканировать контент.
Это не мешает поисковым системам сканировать контент.Самая большая разница, которую нужно понять, заключается в том, что если вы хотите, чтобы поисковые системы не включали контент в результаты поиска, то вам нужно ДОЛЖЕН использовать тег NOINDEX, и вы ДОЛЖНЫ разрешить поисковым системам сканировать контент. Если поисковые системы НЕ МОГУТ сканировать контент, то они НЕ МОГУТ видеть метатег NOINDEX и, следовательно, НЕ МОГУТ исключить контент из результатов поиска.
Итак, если вы хотите, чтобы содержимое не попадало в результаты поиска, используйте NOINDEX. Если вы хотите, чтобы поисковые системы не сканировали каталог на вашем сервере, потому что он не содержит ничего, что им нужно видеть, используйте директиву «Disallow» в файле robots.txt.
Вы можете найти документацию по использованию функции NOINDEX в All-in-One SEO в нашей статье «Отображение или скрытие вашего контента в результатах поиска» здесь.
Вы можете найти документацию по использованию функции Robots.txt в All-in-One SEO в нашей статье об использовании инструмента Robots.txt в All-in-One SEO здесь.
Дополнительная литература
- Как Google использует метатег роботов NOINDEX
- Как Google использует robots.txt
Уведомление: В настоящее время вы просматриваете устаревшую документацию.
Один из вопросов, который нам чаще всего задают, заключается в том, в чем разница между метатегом NOINDEX robots и файлом robots.txt, и когда каждый из них следует использовать. В этой статье рассматривается этот вопрос.
Метатег роботов NOINDEX
Тег NOINDEX используется для предотвращения появления содержимого в результатах поиска. Метатег NOINDEX появляется в исходном коде вашего контента и указывает поисковой системе не включать этот контент в результаты поиска.
Метатег NOINDEX robots выглядит в исходном коде вашей страницы следующим образом:
Файл robots.
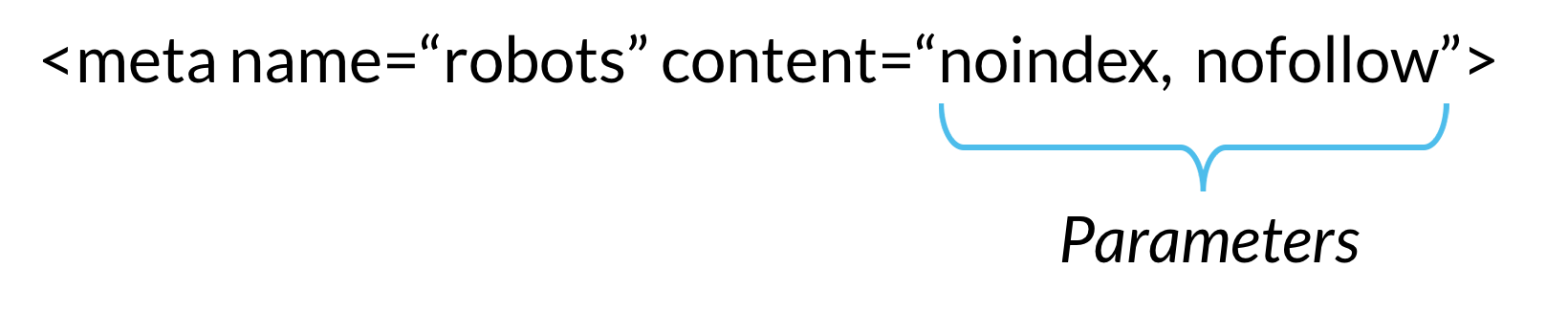 txt
txt
Файл robots.txt сообщает поисковым системам, где их поисковые роботы могут и не могут посещать веб-сайт. Он включает директивы «Разрешить» и «Запретить», которые указывают поисковой системе, какие каталоги и файлы следует или не следует сканировать.
Однако это не мешает вашему контенту появляться в результатах поиска.
Примером использования файла robots.txt является указание поисковым системам не сканировать каталог «/cgi-bin/», который может существовать на вашем сервере, поскольку в этом каталоге нет ничего полезного для поисковые системы.
По умолчанию robots.txt для WordPress выглядит так:
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Разница между NOINDEX и robots.txt
Разница между ними заключается в следующем:
- Файл robots.txt используется для указания поисковой системе какие каталоги и файлы он должен сканировать. Это не мешает контенту индексироваться и отображаться в результатах поиска.
- Метатег роботов NOINDEX указывает поисковым системам не включать контент в результаты поиска, а если контент уже был проиндексирован ранее, то они должны полностью удалить этот контент. Это не мешает поисковым системам сканировать контент.

Самая большая разница, которую нужно понять, заключается в том, что если вы хотите, чтобы поисковые системы не включали контент в результаты поиска, то вы ДОЛЖНЫ использовать тег NOINDEX и ДОЛЖНЫ разрешать поисковым системам сканировать контент. Если поисковые системы НЕ МОГУТ сканировать контент, то они НЕ МОГУТ видеть метатег NOINDEX и, следовательно, НЕ МОГУТ исключить контент из результатов поиска.
Итак, если вы хотите, чтобы содержимое не попадало в результаты поиска, используйте NOINDEX. Если вы хотите запретить поисковым системам сканировать каталог на вашем сервере, потому что он не содержит ничего, что им нужно видеть, используйте директиву «Disallow» в файле robots. txt.
txt.
Вы можете найти документацию по использованию функции NOINDEX в All-in-One SEO в нашей статье о настройках Noindex в All-in-One SEO здесь.
Вы можете найти документацию по использованию функции Robots.txt в All-in-One SEO в нашей статье об использовании инструмента Robots.txt в All-in-One SEO здесь.
Дополнительная литература
- Как Google использует метатег роботов NOINDEX
- Как Google использует robots.txt
Когда следует использовать теги Meta Robots NoIndex?
Хотя боты Google постоянно сканируют Интернет, это не означает, что они должны сканировать и индексировать каждую страницу вашего сайта.
На самом деле, есть некоторые страницы, которые Google не должен индексировать, и единственный язык, который он понимает, — это метадирективы robots.
В этой статье я покажу вам, как (и когда) правильно использовать метатеги robots, включая тег no-index.
Что такое метатеги роботов?
В отличие от файла robots. txt, который сообщает роботам, как сканировать ваш веб-сайт, метатеги robots определяют, как ваши страницы индексируются и отображаются в поисковой выдаче.
txt, который сообщает роботам, как сканировать ваш веб-сайт, метатеги robots определяют, как ваши страницы индексируются и отображаются в поисковой выдаче.
Это фрагменты HTML, вставленные в заголовок вашей страницы (
). На практике это фрагмент кода, который выглядит примерно так (если мы хотим запретить Google индексировать эту страницу):В зависимости от директивы, которую вы хотите использовать, просто замените значение «noindex» своей директивой или добавьте дополнительные директивы, разделив их запятыми:
В чем разница между файлом robots.txt и метатегами Robots?
Метатеги роботов | файл robots.txt | |
Типы файлов | HTML | Любые файлы |
Объем | Уровень страницы | Веб-уровень |
На какие поисковые действия они влияют? | Индексирование и сканирование | Сканирование и (как правило, но есть исключения) индексирование |
Короче говоря, если вы хотите не индексировать страницу или иметь более детальный контроль над тем, как Google воспринимает конкретную страницу на вашем веб-сайте, используйте метатег robots.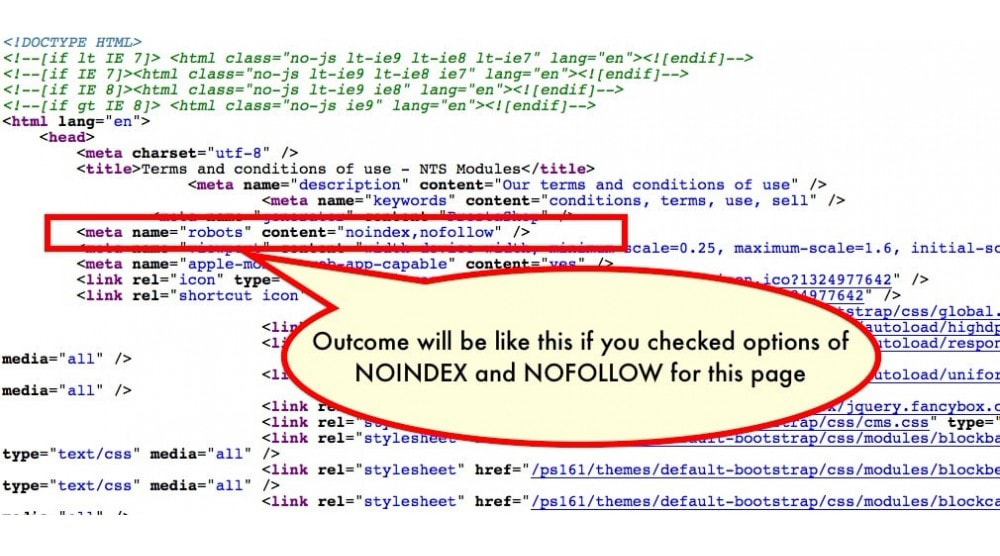
Если вы хотите предоставить более широкие директивы для группы страниц или всего вашего веб-сайта или запретить их сканирование ботами, используйте файл robots.txt.
Когда следует использовать метатег Robots No-Index
Используйте метатеги robots no-index, если:
- У вас есть страницы, которые вы не хотите индексировать. Например, страницы подтверждения, страницы политики конфиденциальности и т. д.
- Вы хотите защитить свой серверный, промежуточный или конфиденциальный контент.
- Держите контент закрытым. Например, если некоторый контент доступен только вашим подписчикам, специальным клиентам или является частью эксклюзивного предложения.
- Вы хотите предотвратить дублирование. Например, если у вас есть почти идентичные страницы продуктов, на которые вы отправляете рекламный трафик, и вы не хотите, чтобы Google индексировал их или помечал одну из них как дубликат.
Как использовать метатеги разных роботов
В дополнение к метатегу без индекса существует множество других тегов, которые вам могут понадобиться. Вот некоторые из них, которые появляются чаще всего:
Вот некоторые из них, которые появляются чаще всего:
Как использовать тег Meta Robots «noindex,follow»
Если вы не хотите, чтобы поисковые системы индексировали вашу страницу, но все же хотите, чтобы они переходили по ссылкам на ней, вы должны использовать указанную выше директиву.
Это типичный вариант использования замененных страниц. Например, страницы продуктов, которых нет в наличии, которые были заменены новым вариантом, но на их исходных страницах все еще есть ценные внутренние ссылки.
Однако указывать это не обязательно. Поисковые системы будут автоматически переходить по ссылкам на вашей странице (если вы не укажете им иное).
Meta Robots Теги «noindex,nofollow» и «none»
Используйте этот тег, если хотите, чтобы поисковые системы не индексировали и не переходили по ссылкам на вашей странице.
Используется так же, как и следующий метатег:
Оба тега предоставляют одну и ту же директиву.
Варианты использования тега Meta Robots «noarchive»
Поисковые системы обычно архивируют и обслуживают кешированные версии страниц. Используйте эту директиву, чтобы убедиться, что ваша страница не сохраняется в архивах поисковых ботов или кэшируется перед отображением.
Например, вы можете использовать это для часто изменяемых страниц.
Пропустить фрагмент с тегом «nosnippet» и атрибутом «data-nosnippet»
Если вы не хотите, чтобы поисковые системы отображали метаописание или фрагмент под заголовком вашей страницы, используйте директиву nosnippet.
(Это значение по умолчанию при наличии ошибок индексирования, таких как «Проиндексировано, хотя и заблокировано robots.txt.») атрибут data-nosnippet.
Например, если вы создали клиффхэнгер с заголовком своей страницы, вы можете не захотеть, чтобы Google выдавал ваш большой секрет до того, как пользователи нажмут на нее.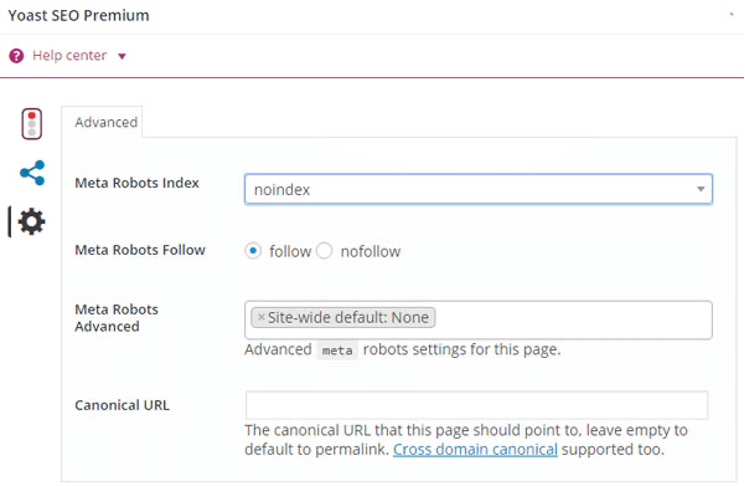
Мы отобразим этот но мы не хотим, чтобы этот контент отображался в поисковой выдаче.
Метатег «Noimageindex»
Используйте метатег robots «noimageindex», если вы не хотите, чтобы Google индексировал изображения на вашей странице.
Метатег «Не переводить»
Поскольку Google предлагает переводить страницы из результатов поиска, вы можете использовать эту директиву, чтобы убедиться, что он не предоставляет переводы для вашей страницы.
Как насчет тега X-Robots?
Тег X-robots используется, когда вы хотите запретить поисковым системам индексировать не-HTML ресурсы, такие как видео, изображения и файлы. Вы также можете использовать его, когда хотите добавить директивы массово, например, не индексировать всю папку.
Тег X-robots находится в заголовке HTTP-ответа вашего веб-сайта.
Тем не менее, поскольку использование тега X-robots требует изменения кода вашего веб-сайта, убедитесь, что вы знаете, как реализовать его на вашем конкретном типе сервера, или свяжитесь с разработчиком.
Небольшие ошибки могут повлиять на весь ваш веб-сайт, поэтому будьте осторожны.
Часто задаваемые вопросы
1. Что произойдет, если есть конфликтующие директивы?
Зависит от поисковой системы. Например, Google по умолчанию всегда будет использовать наиболее ограничительную директиву, а другие — нет.
2. Могу ли я использовать robots.txt и метатеги robots, чтобы не индексировать мою страницу?
Нет. Это может привести к ошибкам и путанице.
Например, если запретить страницу в файле robots.txt и добавить к ней тег noindex, поисковые роботы ее даже не обнаружат.
Точно так же не удаляйте страницы из вашей XML-карты сайта, пока поисковые системы не увидят директиву.
3. Могу ли я не индексировать канонические и переведенные страницы?
Если на ваших страницах есть канонические теги или теги hreflang, не пытайтесь их не индексировать. В качестве альтернативы, убедитесь, что на нужных страницах есть теги, чтобы не было путаницы.