Содержание
Что это за теги Nofollow и Noindex, в чем разница и как правильно прописывать
Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики…
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Я уже упомянул выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснил зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования.
 Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
 Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots. txt заносите новые ссылки, неизвестные для Google и Яндекс.
txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
как, зачем и для чего используют в SEO
Noindex nofollow: как, зачем и для чего используют в SEO
Starting a new project?
получить консультацию
Читайте наш Telegram 👈
Заказать
звонок
Оставьте свои контактные данные, наш менеджер перезвонит вам.
Соглашаюсь на обработку данных
Спасибо! Скоро с Вами свяжется наш менеджер.
Получить
консультацию
Спасибо! Скоро с Вами свяжется наш менеджер.
POWER IS IN TRUST
Прокачайте свой сайт!
Подписывайтесь и получайте советы по оптимизации сайта и повышению продаж
Заказать обратный звонок
Подтвердите свой Email для завершения подписки.
Вы уже подписаны на нашу рассылку!
1654
10
Поделиться:
Noindex nofollow имеют несколько разных понятий, и в зависимости от значений выполняют определенные функции.
- метатег <meta name=»robots» content=»noindex, nofollow» />;
- тег <noindex>;
- атрибут rel=”nofollow”.
Для чего же созданы эти элементы и в каких случаях их стоит применять? Давайте разберемся вместе.
1. Метатег robots
Поисковая выдача формируется из документов, просканированных и проиндексированных поисковым роботом. Но не вся информация должна попадать в индекс. И тогда на помощь приходит метатег robots, благодаря которому можно скрыть страницу от индексации поисковыми роботами.
Тег необходимо установить в секцию <head> для того, чтобы страница не попала в индекс.
Пример:
<head> <meta name = “robots” content = “noindex”/> </head> |
Большинство поисковых роботов понимают этот метатег. А при необходимости можно закрыть страницу только от определенного робота.
А при необходимости можно закрыть страницу только от определенного робота.
Например, от Google:
<meta name=«googlebot» content=«noindex»/>
Что же тогда означает комбинация значений «noindex, nofollow»?
Как вы уже поняли, noindex запрещает индексировать страницу, включая весь контент, который на ней находится.
А nofollow запрещает поисковым роботам переходить как по внутренним, так и по внешним ссылкам, размещенным на странице.
Рассмотрим различные варианты значений метатега robots:
| <meta name=“robots” content=“noindex, nofollow”> | Запрещает индексировать страницу и переходить по ссылкам |
| <meta name=“robots” content=“index,follow”> | Разрешает индексировать страницу и переходить по ссылкам на ней. Но в этой комбинации нет необходимости, т. к. по умолчанию поисковые роботы выполняют те же действия |
| <meta name=“robots” content=“index,nofollow”> | Можно индексировать страницу, но нельзя переходить по ссылкам |
| <meta name=“robots” content=“noindex,follow”> | Нельзя индексировать страницу, но можно переходить по URL-адресам. |
 Используется для того, чтобы страница не попала в индекс, но поисковые роботы могли посещать ссылки, размещенные на ней.
Используется для того, чтобы страница не попала в индекс, но поисковые роботы могли посещать ссылки, размещенные на ней.
Очень часто для запрета индексирования используют файл robots.txt. Но для поисковых роботов условия, написанные в нем, скорее служат рекомендациями и могут быть проигнорированы. Более надежным способом запрета от индексирования считается метатег <meta name=«robots» content=«noindex»/>.
Довольно часто для удаления уже проиндексированной страницы используют директиву Disallow в файле robots.txt. Это ошибка, ведь в таком случае вы запрещаете доступ к странице, и поисковый робот не удалит ее из индекса.
В выдаче поисковой системы вместо описания страницы вы увидите сообщение о том, что доступ к данной странице заблокирован с помощью файла robots.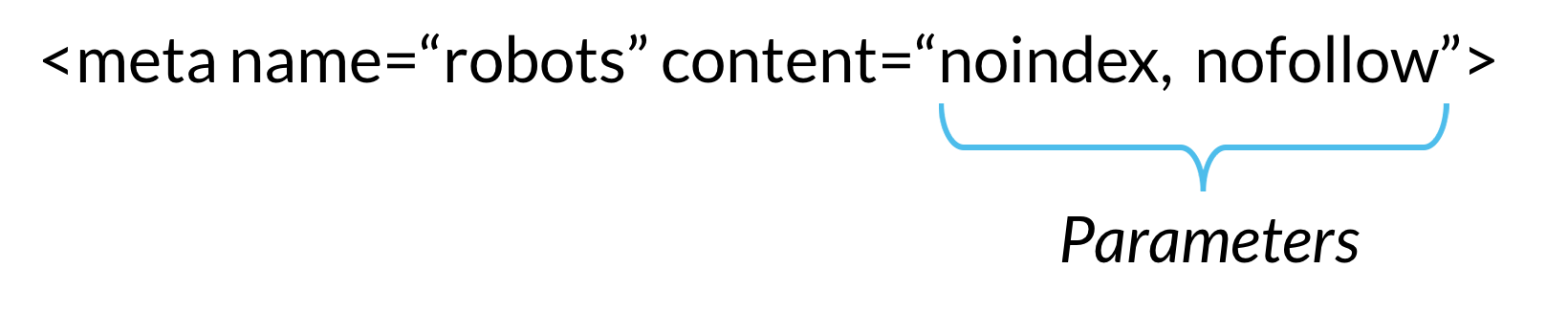 txt.
txt.
Чтобы удалить проиндексированную страницу из индекса, необходимо добавить метатег <meta name=“robots” content=“noindex,follow”>. Поисковый робот просканирует страницу, увидит атрибут noindex, и исключит страницу из индекса.
3. Атрибут rel=”nofollow”
rel=”nofollow” применим к тегу <а> и относится только к гиперссылке, для которой он прописан.
Как он выглядит:
| <a href=»http://site.com/» rel=»nofollow»>текст ссылки</a> |
Вид в коде страницы:
Рис. 1 — nofollow в коде страницы
История атрибута очень интересна. Изначально Google позиционировал nofollow как инструмент для борьбы со спамом в комментариях. Но это было в далеком 2005.
Затем шла борьба с накруткой PageRank. Все пытались манипулировать внутренним весом, чтобы у продаваемых страниц был самый высокий PageRank. Ведь ссылочный вес делился одинаково между всеми гиперссылками на странице, не учитывая rel=«nofollow». И поэтому в 2009 Google внес поправки, согласно которым ссылочный вес не передавался по ссылкам, к которым применим атрибут rel=«nofollow».
И поэтому в 2009 Google внес поправки, согласно которым ссылочный вес не передавался по ссылкам, к которым применим атрибут rel=«nofollow».
Более того, изменились правила передачи ссылочного веса. Например, если на странице Х размещены 3 ссылки (2 dofollow и 1 nofollow), а вес страницы Х равен 6 “баллам”, то до внесения изменений Гуглом каждая ссылка без nofollow получила бы по 3 “балла”. А сейчас такие ссылки получат по 2 “балла”. Это означает, что ссылочный вес разделяется между всеми внутренними ссылками, но передается только по dofollow.
Когда специалисты стали меньше заморачиваться над передачей ссылочного веса, Google заявил, что все купленные ссылки должны иметь атрибут rel=«nofollow», утверждая, что некоторые проплаченные ссылки ничем не отличаются от тех, что были получены естественным путем (когда люди просто делятся тем, что по их мнению может быть интересным и полезным для других). Таким образом Google стимулирует получать естественные ссылки путем создания качественного контента.
В каких случаях сейчас стоит использовать ссылки с атрибутом «nofollow»?
Могу порекомендовать вам использовать nofollow ссылки для того, чтобы:
- сделать ссылочный профиль сайта разнообразным;
- обезопасить себя от санкций, применив атрибут к некачественным ссылкам.
Аналоги российских сервисов для проверки уникальности текстов
E-E-A-T SEO: что это, как работать в 2023
Как сделать видео YouTube вирусным
Подпишитесь на наши обновления
Больше полезных статей и мануалов еще впереди. Будьте в курсе!
Вы уже подписаны на нашу рассылку!
Подтвердите свой Email для завершения подписки.
Заказать
продвижение
Больше полезных статей и мануалов еще впереди. Будьте в курсе!
Соглашаюсь на обработку данных
Спасибо! Скоро с Вами свяжется наш менеджер.
×
html — В чем разница между «индексировать, следовать» или «следовать»
спросил
Изменено
6 месяцев назад
Просмотрено
18 тысяч раз
чем отличаются списки ниже:
- html
- SEO
- без индекса
2
Во-первых, знаете ли вы о тегах Meta Robots?
Теги Meta Robots сообщают пауку или поисковому роботу, какую страницу сканировать или индексировать, а какую нет.
Следовать означает : страница будет просканирована.
No Follow означает : страница не будет просканирована.
Индекс означает : ваша страница показывается в результатах поиска.
Без индекса означает : ваша страница не отображается в результатах поиска.
Этот тег сообщает поисковому роботу, что все страницы будут проиндексированы, и сканировать их.
Этот тег используется, чтобы сообщить поисковому роботу, что все страницы будут просканированы и проиндексированы.
Этот тег используется для того, чтобы указать сканеру отслеживать, но не индексировать страницу в вашей базе данных.
Сообщить веб-сканеру, что страницы не сканируются, а индексируются.
To указывает веб-сканеру не индексировать и не сканировать.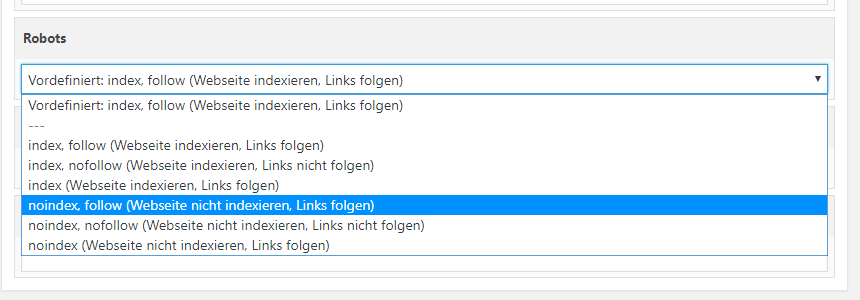
Паук проиндексирует весь ваш сайт.
Паук будет индексировать не только первую веб-страницу вашего веб-сайта, но и все остальные ваши веб-страницы, когда он просматривает ссылки с этой страницы.
Сообщает поисковым системам, что они могут переходить по ссылкам на странице для обнаружения других страниц. (оба действия по умолчанию)
Паук теперь будет индексировать весь ваш сайт. Паук не будет индексировать веб-страницу, но он может перейти по ссылкам на странице, чтобы обнаружить другие страницы.
Паук проиндексирует эту страницу, но не будет переходить по ссылкам на этой странице на новые страницы.
Паук вообще не будет индексировать эту страницу и не будет переходить по ссылкам на этой странице на какие-либо другие страницы.
Источники :
https://www.metatags.org/meta_name_robots
https://yoast.com/robots-meta-tags/
https://developer.mozilla.org/en-US/docs/Web/HTML/Element/meta#attr-name
Основное различие между этими тегами, если говорить очень простыми словами:
noindex
Страница не должна отображаться в списке результатов таких страниц, как google, yahoo и так далее.
индекс означает обратное и допускает это.
nofollow
Запрещает сканерам/роботам вызывать (переходить) ссылки, которые встроены в/найдены на страницах, имеющих этот флаг в своих метаданных.
следовать означает обратное и разрешает это.
Теперь вы можете сами понять, к чему приводит каждая комбинация обоих. 😉
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
seo — Должен ли я удалить мета-роботов (индексировать, следить), когда у меня есть файл robots.txt?
спросил
Изменено
4 года, 8 месяцев назад
Просмотрено
1к раз
Я немного не понимаю, следует ли удалять метатег robots, если я хочу, чтобы поисковые системы следовали моим правилам robots.txt.
Если на странице существует метатег robots (index, follow), будут ли поисковые системы игнорировать мой файл robots.txt и индексировать указанные запрещенные URL-адреса в моем файле robots.txt?
Причина, по которой я спрашиваю об этом, заключается в том, что поисковые системы (в основном Google) по-прежнему индексируют запрещенные страницы моего сайта.
- SEO
- метатеги
- robots.txt
0
Если бот поисковой системы принимает ваш файл robots.txt, а вы запрещаете сканирование /foo , то бот никогда не будет сканировать страницы, пути URL которых начинаются с /foo . Следовательно, бот никогда не узнает, что есть мета — роботов элементов.
И наоборот, если вы хотите запретить индексировать страницу (указав meta — robots с noindex ), вы не должны запрещать сканирование этой страницы в файле robots.tx т. В противном случае noindex никогда не будет доступен, и бот думает, что запрещено сканирование , а не индексация .
С помощью файла robots.txt вы можете указать поисковым системам не сканировать определенные страницы, но это не помешает им индексировать страницы. Если страница, запрещенная в robots.