Содержание
Что такое реляционная база данных и СУБД. Урок 1
Прежде чем говорить о реляционной базе данных и системе управления базами данных (СУБД), надо определиться с тем, что такое база данных вообще.
Понятие базы данных (БД) абстрактно. Конкретными реализациями являются базы данных чего-либо. Например, база данных библиотеки, сайта или база данных магазина, в которой хранятся сведения о сотрудниках, товарах, поставщиках и покупателях.
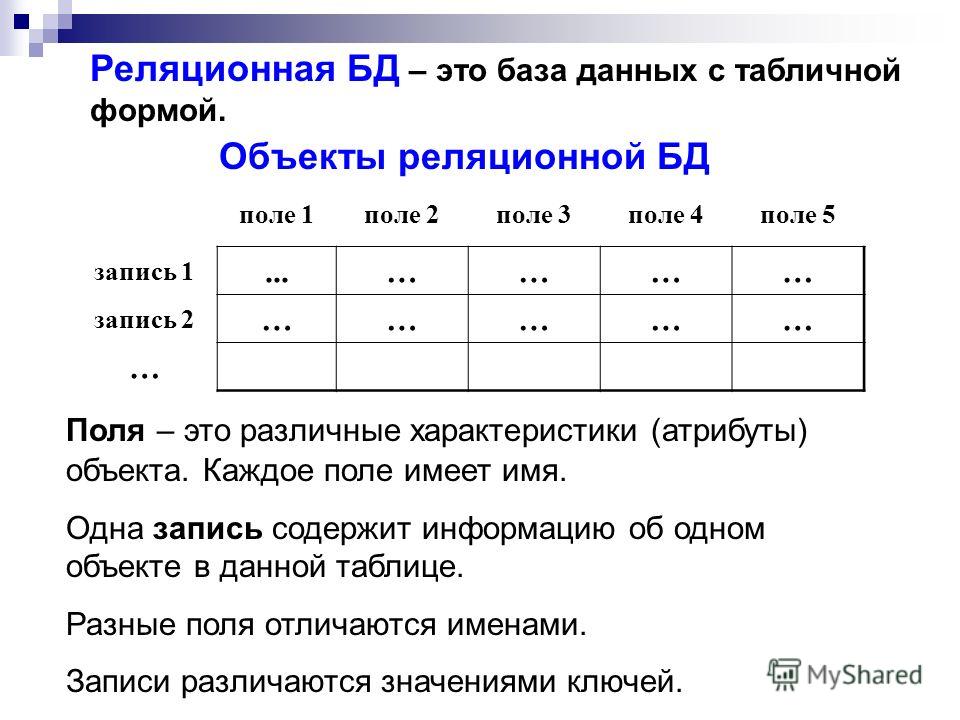
Удобнее всего такую информацию хранить в таблицах. Например, база данных может состоять из следующих таблиц: «Сотрудники», «Поставщики», «Покупатели». Каждую таблицу будут формировать свои столбцы и строки.
Так таблица «Сотрудники» может включать столбцы «ФИО», «Должность», «Зарплата». Каждая строка этой таблицы будет содержать сведения об одном человеке. Так создаются таблицы в базах данных. Каждая строка называется записью, каждая ячейка строки – полем. Содержание конкретного поля определяется его столбцом.
Следующий вопрос: где хранить таблицы? Очевидно в файлах или даже одном файле. Например, мы можем открыть Excel или другой табличный процессор и заполнить несколько таблиц. Получится база данных. Нужно ли что-то еще?
Например, мы можем открыть Excel или другой табличный процессор и заполнить несколько таблиц. Получится база данных. Нужно ли что-то еще?
Представим, что есть большая база данных, скажем, предприятия. Это очень большой файл, его используют множество человек сразу, одни изменяют данные, другие выполняют поиск информации. Табличный процессор не может следить за всеми операциями и правильно их обрабатывать. Кроме того, загружать в память большую БД целиком – не лучшая идея.
Здесь требуется программное обеспечение с другими возможностями. ПО для работы с базами данных называют системами управления базами данных, то есть СУБД.
Таким образом, у нас должен быть файл определенной структуры, содержащий базу данных, а также ПО, обеспечивающее работу с этим файлом.
Стандартным общепринятым языком для описания баз данных и выполнения к ним запросов является язык SQL.
С другой стороны, существует большое количество различных СУБД. Например: SQLite, MySQL, PostgreSQL и другие. Каждая из них имеет некоторые отличия от других, в результате чего накладывает небольшую специфику на используемый SQL, формируя его диалект.
Каждая из них имеет некоторые отличия от других, в результате чего накладывает небольшую специфику на используемый SQL, формируя его диалект.
Таким образом, изучая работу с базами данных, вы, с одной стороны, изучаете универсальный SQL, с другой – приобретаете опыт работы с конкретной СУБД. При этом в последствии перейти с одной СУБД на другую относительно легко.
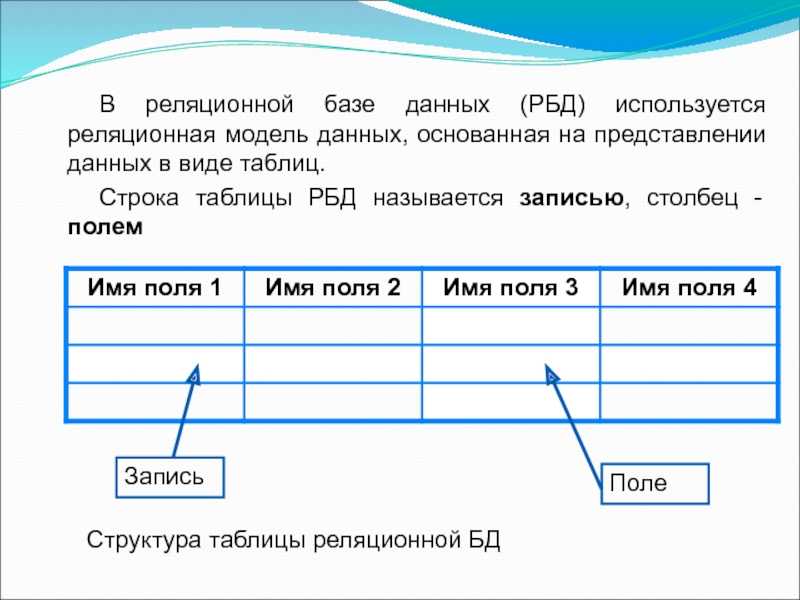
Теперь вернемся к вопросу о том, что такое реляционная базы данных (РБД). Слово «реляция» происходит от «relation», то есть «отношение». Это означает, что в РБД существуют механизмы установления связей между таблицами. Делается это с помощью так называемых первичных и внешних ключей.
Допустим, мы разрабатываем базу данных для сайта. Одна из таблиц будет содержать сведения о страницах сайта. Вторая таблица будет содержать описание разделов сайта. Каждая строка-запись первой таблицы должна в одном из своих полей содержать указание на раздел, к которому принадлежит описываемая этой записью страница.
Таким образом, мы разделяем разные сущности (страницы и разделы) по таблицам, но устанавливаем между ними связь.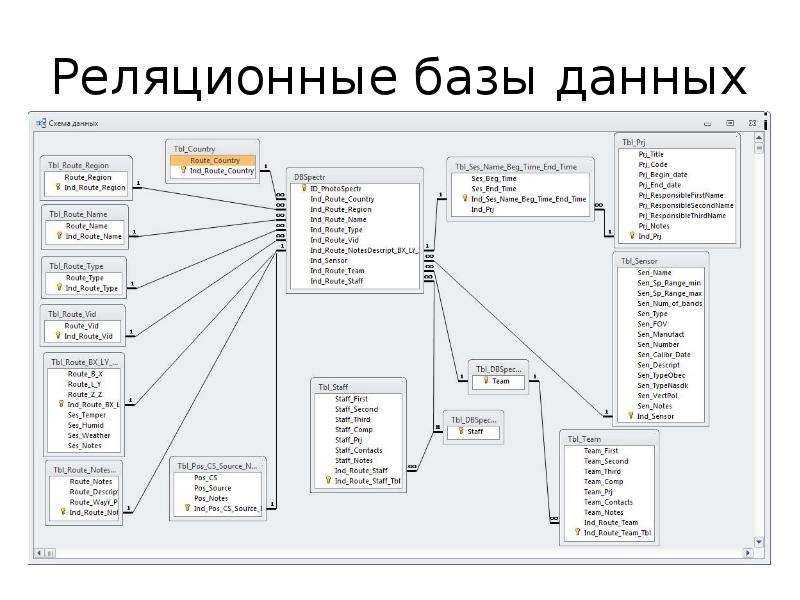 В последствии используя язык SQL мы сможем, например, создать запрос, который извлечет сведения о конкретном разделе и принадлежащих ему страницах. Хотя такой таблицы исходно нет.
В последствии используя язык SQL мы сможем, например, создать запрос, который извлечет сведения о конкретном разделе и принадлежащих ему страницах. Хотя такой таблицы исходно нет.
Существуют определенные правила создания реляционных баз данных, их нормализации в основном с целью устранения избыточности. Теория разработки РБД – это целая наука.
Хранение информации в базах данных дает преимущество не только с точки зрения обеспечения к ним быстрого доступа множества процессов. Базы данных, особенно реляционные, позволяют структурировать данные, манипулирования ими и легко наращивать объем.
Можно сказать, что в одной таблице содержатся ассоциированные данные, а в разных таблицах одной БД находятся связанные данные.
Структура реляционной базы данных | Основы реляционных баз данных
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
PostgreSQL — это СУБД, созданная для работы с реляционными базами данных. Что такое «реляционная», мы рассмотрим в будущем уроке. А в этом разберем, как устроены такие базы данных.
Что такое «реляционная», мы рассмотрим в будущем уроке. А в этом разберем, как устроены такие базы данных.
Структура реляционной базы данных
Данные в реляционных базах данных хранятся в таблицах. Их структура напоминает Microsoft Excel. Каждая строка в таблице — это связанный набор данных, который относится к одному предмету. Например, в таблице можно посмотреть все детали об одном сотруднике — его фамилию, имя, номер, отдел, зарплату, год рождения, адрес и телефон:
Разные таблицы предназначены для хранения информации о различных сущностях, например, пользователи, статьи или заказы в интернет-магазине. В типичных веб-приложениях таблиц десятки и сотни, в больших — тысячи. Например, в Хекслете их несколько сотен.
У таблиц в базе данных есть определенная структура. Она включает:
- Название таблицы — уникально в рамках одной базы данных. Имя таблицы и ее структура задаются при создании, но их можно изменить впоследствии
- Столбцы или поля — располагаются в строго определенном порядке, и у каждого поля уникальное имя в рамках одной таблицы
- Тип данных — сопоставляется каждому столбцу.
 Тип данных ограничивает набор допустимых значений, которые можно присвоить столбцу, и определяет смысловое значение данных для вычислений. Например, в столбец числового типа нельзя записать обычные текстовые строки, но его данные можно использовать в математических вычислениях, и наоборот
Тип данных ограничивает набор допустимых значений, которые можно присвоить столбцу, и определяет смысловое значение данных для вычислений. Например, в столбец числового типа нельзя записать обычные текстовые строки, но его данные можно использовать в математических вычислениях, и наоборот - Строки — их число переменно и отражает текущий объем данных. В отличие от таблиц в Exсel, в таблицах реляционных баз данных нет никаких гарантий относительно порядка строк в таблице. Он может быть любым, и его можно задать с помощью языка SQL, который рассмотрим позже. Объем данных в разных таблицах сильно отличается — от нескольких штук до миллиардов записей
 Тип данных ограничивает набор допустимых значений, которые можно присвоить столбцу, и определяет смысловое значение данных для вычислений. Например, в столбец числового типа нельзя записать обычные текстовые строки, но его данные можно использовать в математических вычислениях, и наоборот
Тип данных ограничивает набор допустимых значений, которые можно присвоить столбцу, и определяет смысловое значение данных для вычислений. Например, в столбец числового типа нельзя записать обычные текстовые строки, но его данные можно использовать в математических вычислениях, и наоборотПример таблицы с именем users:
Структура
Включает в себя имена полей и их типы. Структура определяет столбцы:
first_name string last_name string email string created_at datetime
Содержание
Включает в себя данные. Содержание определяет строки:
| first_name | last_name | email | created_at | |------------|-----------|-------------------|------------| | Сергей | Петров | serj@gmail.
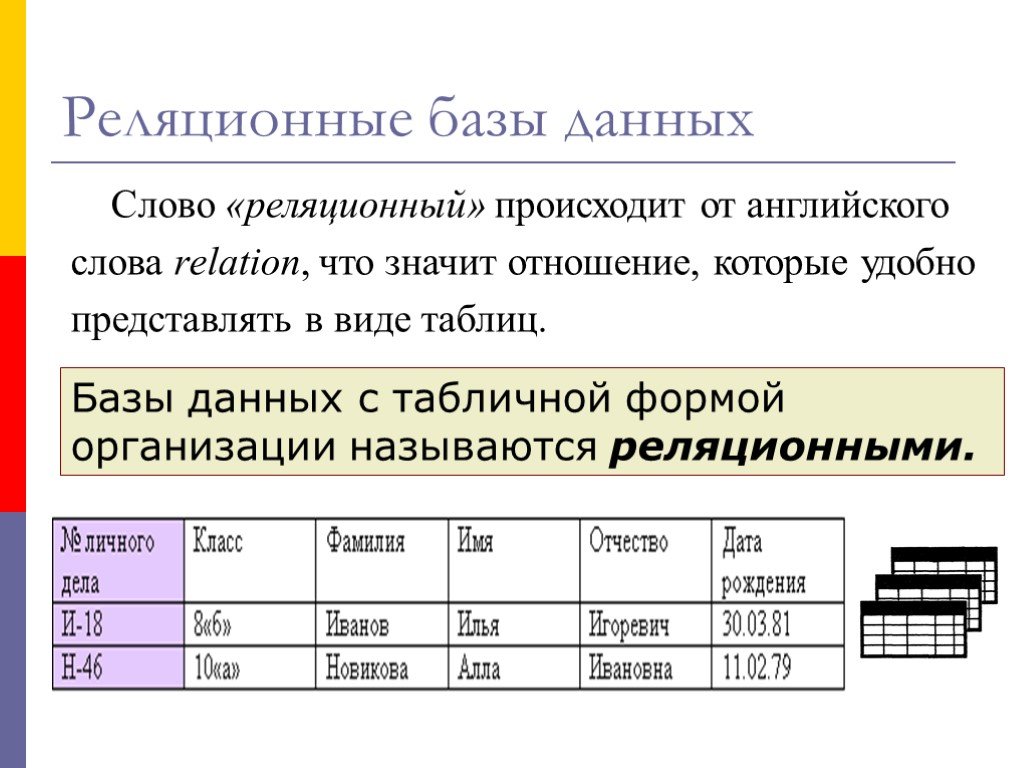 com | 11.10.2005 |
| Иван | Сидоров |
com | 11.10.2005 |
| Иван | Сидоров | first_name, last_name, email и created_at — это имена столбцов. Строки содержат данные по каждому столбцу, а в поле created_at установлен тип данных datetime, поэтому туда нельзя записать текст.
В дальнейшем эту структуру можно модифицировать: удалять и добавлять поля, менять типы данных.
Правила именования сущностей базы данных
Именование таблиц и полей в базе не фиксировано и зависит от программиста. Например, в проектах, где используют ORM — название группы фреймворков или библиотек, которые помогают моделировать предметную область и связывать ее с базой данных, — имена определяются соглашениями конкретной экосистемы.
В этом курсе мы используем именование, принятое во фреймворке Rails и его ORM (ActiveRecord). Оно состоит из нескольких правил:
- Все имена в нижнем регистре
- Для имен из нескольких слов используется snake_case — когда слова разделяются подчеркиванием
_без пробелов - Имя таблицы во множественном числе
В отличие от Excel, где ввод данных и отображение визуальные, в СУБД у данных нет никакого представления. Они вводятся и выбираются с помощью команд. При этом существуют специальные клиенты, которые используются, чтобы визуализировать управление базами данных. Они бывают платными и бесплатными. Из бесплатных в мире PostgreSQL наиболее популярен PgAdmin:
Они вводятся и выбираются с помощью команд. При этом существуют специальные клиенты, которые используются, чтобы визуализировать управление базами данных. Они бывают платными и бесплатными. Из бесплатных в мире PostgreSQL наиболее популярен PgAdmin:
Рекомендуем поставить его и поэкспериментировать внутри.
Управлять структурой базы данных и данными внутри таблиц — две разные задачи. При этом они выполняются одним инструментом — языком SQL.
Язык SQL
SQL (Structured Query Language) — специализированный язык, который разработали, чтобы управлять данными в реляционных СУБД.
-- Пример запроса, который извлекает -- информацию о пользователях из таблицы users SELECT * FROM users;
SQL разрабатывается независимо от баз данных и имеет собственный стандарт, который реализуют конкретные базы данных. Поэтому на базовом уровне все реляционные базы работают примерно одинаково.
Когда вы научитесь работать с одной базой, сможете спокойно переключиться на другую. Базы данных поддерживают основной SQL и дополняют его своими возможностями. На протяжение курса мы будем использовать только стандартные возможности SQL, например, управлять ролями и их правами, создавать базы данных, обновлять данные. Такие основные возможности должен знать и понимать каждый программист.
Базы данных поддерживают основной SQL и дополняют его своими возможностями. На протяжение курса мы будем использовать только стандартные возможности SQL, например, управлять ролями и их правами, создавать базы данных, обновлять данные. Такие основные возможности должен знать и понимать каждый программист.
Выводы
реляционных баз данных | IBM
Автор:
IBM Cloud Education
Узнайте, как работают реляционные базы данных и чем они отличаются от других вариантов хранения данных.
Что такое реляционная база данных?
Реляционная база данных организует данные в строки и столбцы, которые вместе образуют таблицу. Данные обычно структурированы по нескольким таблицам, которые могут быть объединены с помощью первичного или внешнего ключа. Эти уникальные идентификаторы демонстрируют различные отношения, существующие между таблицами, и эти отношения обычно иллюстрируются с помощью различных типов моделей данных.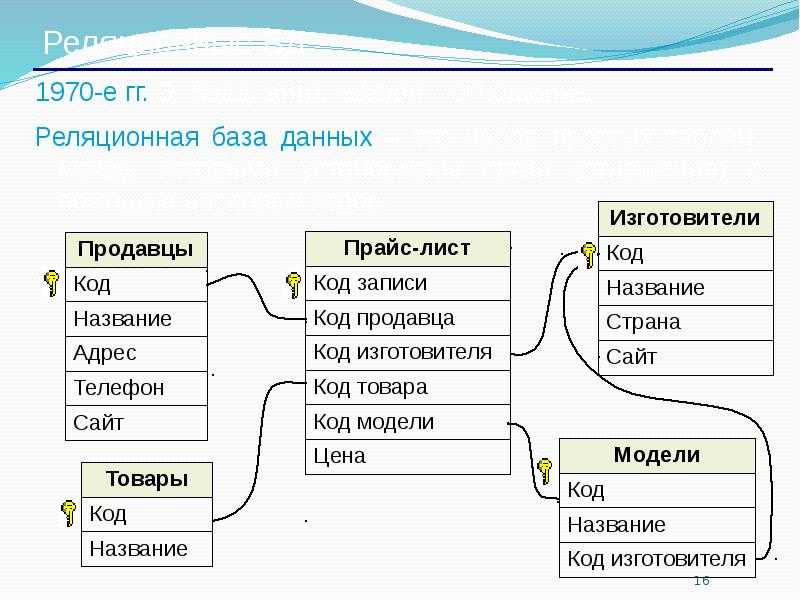 Аналитики используют SQL-запросы для объединения различных точек данных и обобщения эффективности бизнеса, что позволяет организациям получать ценную информацию, оптимизировать рабочие процессы и выявлять новые возможности.
Аналитики используют SQL-запросы для объединения различных точек данных и обобщения эффективности бизнеса, что позволяет организациям получать ценную информацию, оптимизировать рабочие процессы и выявлять новые возможности.
Например, представьте, что ваша компания ведет таблицу базы данных с информацией о клиентах, которая содержит данные компании на уровне учетной записи. Также может быть другая таблица, в которой описаны все отдельные транзакции, связанные с этой учетной записью. Вместе эти таблицы могут предоставить информацию о различных отраслях, приобретающих конкретный программный продукт.
Столбцы (или поля) для таблицы клиентов могут быть Идентификатор клиента , Название компании , Адрес компании , Промышленность и т.д.; столбцами для таблицы транзакций могут быть Дата транзакции , Идентификатор клиента , Сумма транзакции , Способ оплаты и т. д. Таблицы могут быть объединены вместе с общим полем Идентификатор клиента .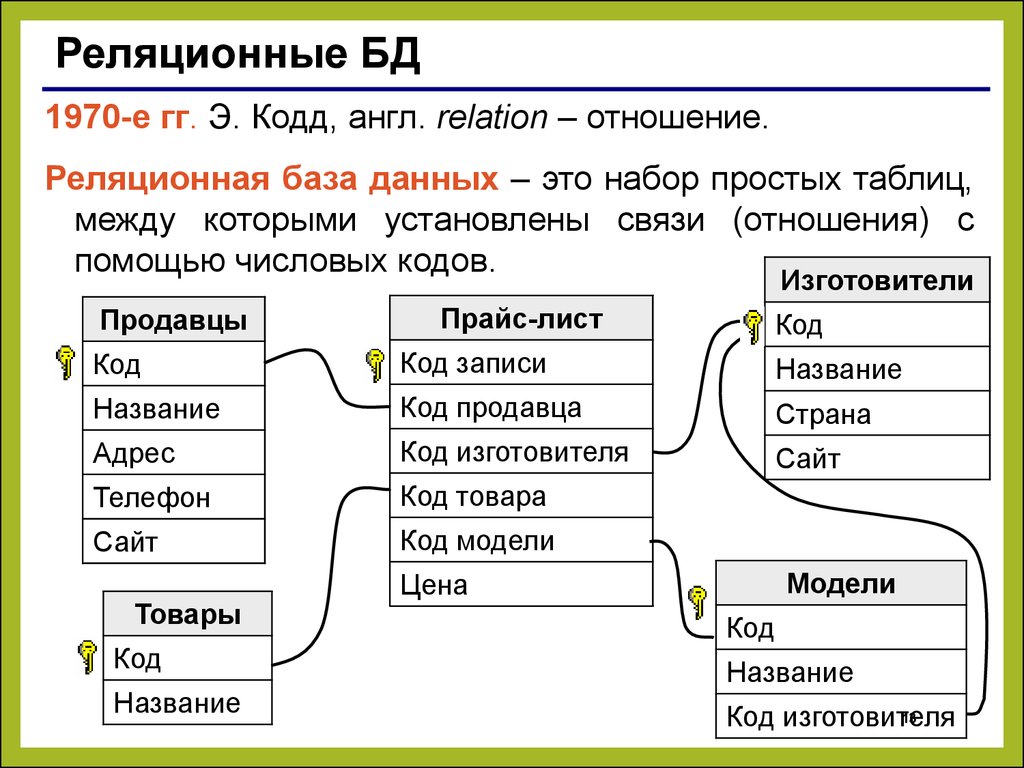 Таким образом, вы можете запросить таблицу для получения ценных отчетов, таких как отчеты о продажах по отраслям или компаниям, которые могут информировать потенциальных клиентов.
Таким образом, вы можете запросить таблицу для получения ценных отчетов, таких как отчеты о продажах по отраслям или компаниям, которые могут информировать потенциальных клиентов.
Реляционные базы данных также обычно связаны с транзакционными базами данных, которые коллективно выполняют команды или транзакции. Популярным примером, который используется для иллюстрации этого, является банковский перевод. Определенная сумма снимается с одного счета, а затем зачисляется на другой. Вся сумма денег снимается и депонируется, и эта транзакция не может происходить ни в каком частичном смысле. Транзакции имеют определенные свойства. Представленные аббревиатурой ACID, свойства ACID определяются как:
- Атомарность: Все изменения данных выполняются так, как если бы они были одной операцией. То есть выполняются все изменения или ни одно из них.
- Непротиворечивость: Данные остаются в согласованном состоянии от состояния до завершения, укрепляя целостность данных.
- Изоляция: Промежуточное состояние транзакции не видно другим транзакциям, и в результате одновременно выполняемые транзакции кажутся сериализованными.
- Долговечность: После успешного завершения транзакции изменения данных сохраняются и не отменяются даже в случае сбоя системы.
Эти свойства обеспечивают надежную обработку транзакций.
Сравнение реляционной базы данных с системой управления реляционной базой данных
В то время как реляционная база данных организует данные на основе реляционной модели данных, система управления реляционной базой данных (RDBMS) представляет собой более конкретную ссылку на базовое программное обеспечение базы данных, которое позволяет пользователям поддерживать Это. Эти программы позволяют пользователям создавать, обновлять, вставлять или удалять данные в системе и обеспечивают:
- Структура данных
- Многопользовательский доступ
- Контроль привилегий
- Доступ к сети
Примеры популярных систем СУБД включают MySQL, PostgreSQL и IBM DB2. Кроме того, система реляционных баз данных отличается от базовой системы управления базами данных (СУБД) тем, что она хранит данные в таблицах, а СУБД хранит информацию в виде файлов.
Кроме того, система реляционных баз данных отличается от базовой системы управления базами данных (СУБД) тем, что она хранит данные в таблицах, а СУБД хранит информацию в виде файлов.
Что такое SQL?
Изобретенный Доном Чемберлином и Рэем Бойсом в IBM, язык структурированных запросов (SQL) является стандартным языком программирования для взаимодействия с системами управления реляционными базами данных, позволяя администратору базы данных легко добавлять, обновлять или удалять строки данных. Первоначально известный как SEQUEL, он был упрощен до SQL из-за проблемы с торговой маркой. Запросы SQL также позволяют пользователям извлекать данные из баз данных, используя всего несколько строк кода. Учитывая эту взаимосвязь, легко понять, почему реляционные базы данных иногда также называют «базами данных SQL».
Используя приведенный выше пример, вы можете создать запрос для поиска 10 крупнейших транзакций по компаниям за определенный год со следующим кодом:
SELECT COMPANY_NAME, SUM(TRANSACTION_AMOUNT)
FROM TRANSACTION_TABLE A
3
3 слева соединение Customer_table B
на A. Customer_ID = B.Customer_ID
Customer_ID = B.Customer_ID
, где год (дата) = 2022
Группа по 1
.0041 2 DESC
LIMIT 10
Способность объединять данные таким образом помогает нам уменьшить избыточность в наших системах данных, позволяя группам обработки данных вести одну главную таблицу для клиентов вместо дублирования этой информации, если в системе была другая транзакция. будущее. Чтобы узнать больше, Дон подробно описывает историю SQL в своей статье здесь (ссылка находится за пределами IBM).
Краткая история реляционных баз данных
До появления реляционных баз данных компании использовали иерархическую систему баз данных с древовидной структурой для таблиц данных. Эти ранние системы управления базами данных (СУБД) позволяли пользователям организовывать большие объемы данных. Однако они были сложными, часто являлись собственностью конкретного приложения и ограничивали способы обнаружения в данных. Эти ограничения в конечном итоге побудили исследователя IBM Эдгара Ф.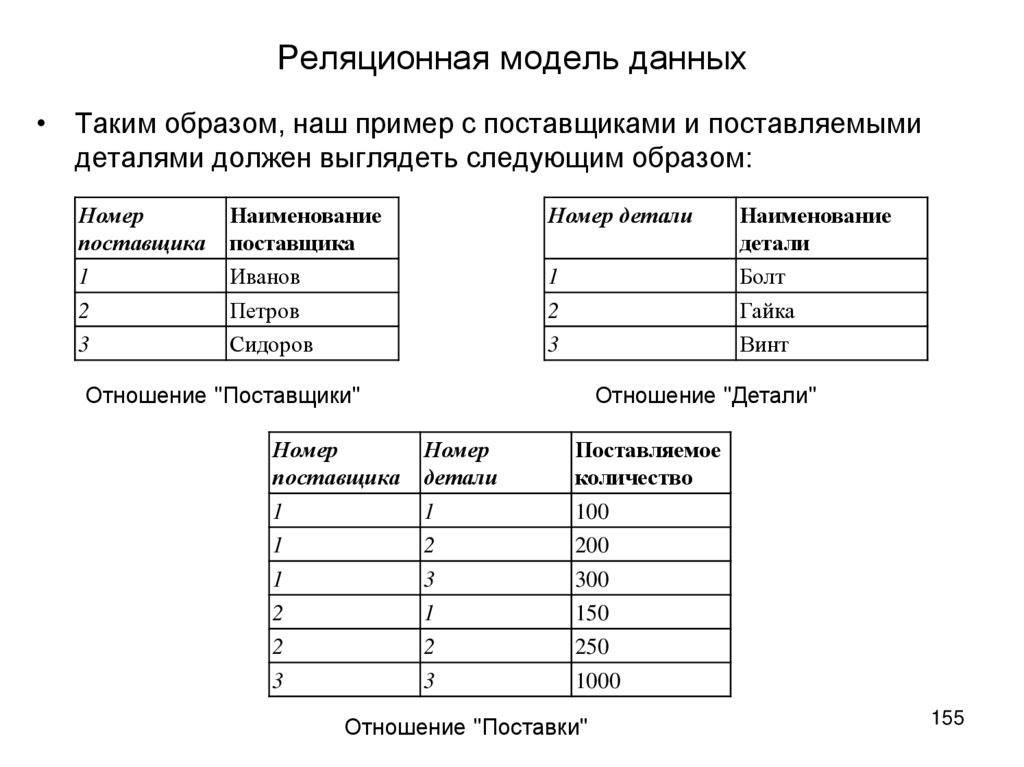 Кодда опубликовать статью (ссылка находится за пределами IBM) (PDF, 1429).KB) в 1970 году под названием «Реляционная модель данных для больших общих банков данных», в которой теоретизировалась модель реляционной базы данных. В этой предложенной модели информацию можно было извлекать без специальных компьютерных знаний. Он предложил упорядочивать данные на основе значимых отношений в виде кортежей. , или пары атрибут-значение. Наборы кортежей назывались отношениями, что в конечном итоге позволяло объединять данные между таблицами. R (R для реляционных), чтобы доказать эту реляционную теорию с помощью того, что она назвала «реализацией промышленного уровня». В конечном итоге он стал испытательным полигоном и для SQL, что позволило ему получить более широкое распространение за короткий период времени.Однако внедрение SQL в Oracle также не повредило его популярности среди администраторов баз данных.0003
Кодда опубликовать статью (ссылка находится за пределами IBM) (PDF, 1429).KB) в 1970 году под названием «Реляционная модель данных для больших общих банков данных», в которой теоретизировалась модель реляционной базы данных. В этой предложенной модели информацию можно было извлекать без специальных компьютерных знаний. Он предложил упорядочивать данные на основе значимых отношений в виде кортежей. , или пары атрибут-значение. Наборы кортежей назывались отношениями, что в конечном итоге позволяло объединять данные между таблицами. R (R для реляционных), чтобы доказать эту реляционную теорию с помощью того, что она назвала «реализацией промышленного уровня». В конечном итоге он стал испытательным полигоном и для SQL, что позволило ему получить более широкое распространение за короткий период времени.Однако внедрение SQL в Oracle также не повредило его популярности среди администраторов баз данных.0003
К 1983 году IBM представила семейство реляционных баз данных DB2, названное так потому, что это было второе семейство программ IBM для управления базами данных.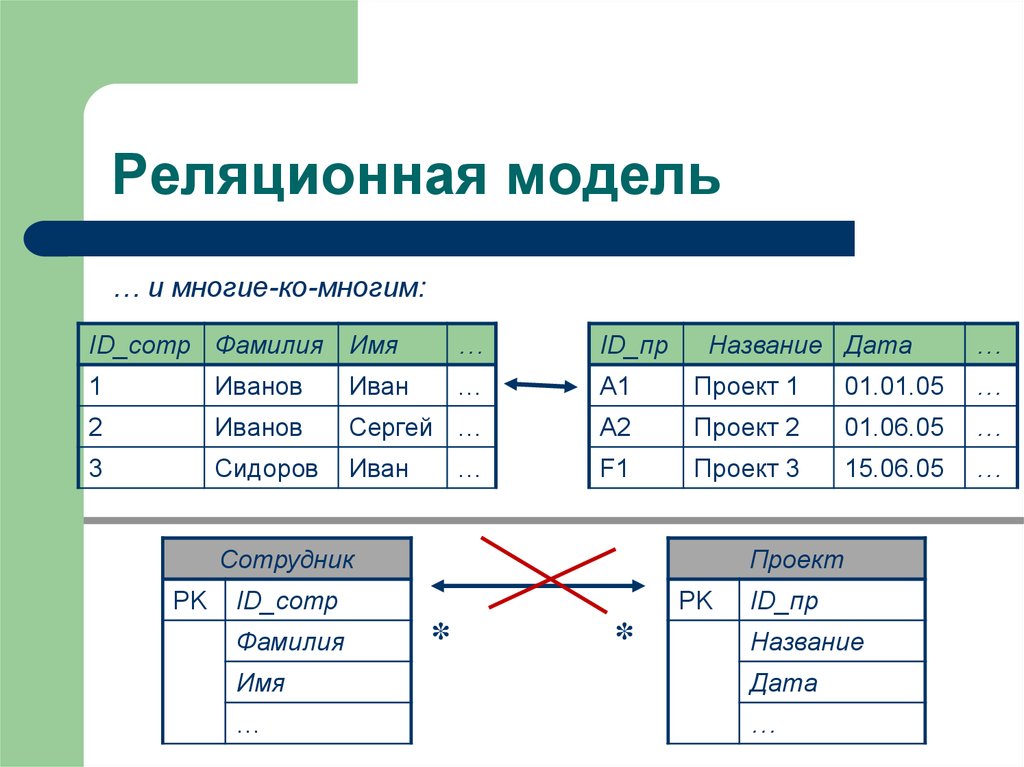 Сегодня это один из самых успешных продуктов IBM, который продолжает ежедневно обрабатывать миллиарды транзакций в облачной инфраструктуре и устанавливает базовый уровень для приложений машинного обучения.
Сегодня это один из самых успешных продуктов IBM, который продолжает ежедневно обрабатывать миллиарды транзакций в облачной инфраструктуре и устанавливает базовый уровень для приложений машинного обучения.
Чтобы узнать больше об истории IBM, нажмите здесь.
Реляционные и нереляционные базы данных
В то время как реляционные базы данных структурируют данные в табличном формате, нереляционные базы данных не имеют такой жесткой схемы базы данных. Фактически нереляционные базы данных организуют данные по-разному в зависимости от типа базы данных. Независимо от типа нереляционной базы данных, все они направлены на решение проблем гибкости и масштабируемости, присущих реляционным моделям, которые не идеальны для неструктурированных форматов данных, таких как текст, видео и изображения. К таким типам баз данных относятся:
- Хранилище «ключ-значение»: Эта модель данных без схемы организована в словарь пар «ключ-значение», где каждый элемент имеет ключ и значение. Ключ может быть чем-то похожим, найденным в базе данных SQL, например идентификатором корзины покупок, а значением может быть массив данных, например каждый отдельный элемент в корзине покупок этого пользователя. Он обычно используется для кэширования и хранения информации о сеансе пользователя, например о корзинах. Однако это не идеально, когда вам нужно получить несколько записей одновременно. Redis и Memcached являются примерами баз данных с открытым исходным кодом с этой моделью данных.
- Хранилище документов: Как следует из названия, базы данных документов хранят данные в виде документов. Они могут быть полезны при управлении полуструктурированными данными, а данные обычно хранятся в форматах JSON, XML или BSON. Это сохраняет данные вместе, когда они используются в приложениях, уменьшая объем перевода, необходимый для использования данных. Разработчики также получают больше гибкости, поскольку схемы данных не должны совпадать в документах (например, имя или имя). Однако это может быть проблематично для сложных транзакций, что приводит к повреждению данных. Популярные варианты использования баз данных документов включают системы управления контентом и профили пользователей. Примером документно-ориентированной базы данных является MongoDB, компонент базы данных стека MEAN.
- Хранилище с широкими столбцами: Эти базы данных хранят информацию в столбцах, что позволяет пользователям получать доступ только к определенным столбцам, которые им нужны, без выделения дополнительной памяти для ненужных данных. Эта база данных пытается устранить недостатки хранилищ пар «ключ-значение» и документов, но поскольку это может быть более сложная система для управления, ее не рекомендуется использовать для новых групп и проектов. Apache HBase и Apache Cassandra являются примерами баз данных с широкими столбцами с открытым исходным кодом. ApacheHBase построен на основе распределенной файловой системы Hadoop, которая обеспечивает способ хранения наборов разреженных данных, который обычно используется во многих приложениях для работы с большими данными. ApacheCassandra, с другой стороны, был разработан для управления большими объемами данных на нескольких серверах и кластеризации, охватывающей несколько центров обработки данных. Он использовался для различных вариантов использования, таких как веб-сайты социальных сетей и анализ данных в реальном времени.
- Хранилище графа: База данных этого типа обычно содержит данные из графа знаний. Элементы данных хранятся в виде узлов, ребер и свойств. Любой объект, место или человек может быть узлом. Ребро определяет отношение между узлами. Базы данных графов используются для хранения и управления сетью соединений между элементами внутри графа. Neo4j (ссылка находится за пределами IBM), служба базы данных на основе графов, основанная на Java, с выпуском сообщества с открытым исходным кодом, где пользователи могут приобретать лицензии на онлайн-резервное копирование и расширения для обеспечения высокой доступности или предварительно упакованную лицензионную версию с включенным резервным копированием и расширениями.
 Ключ может быть чем-то похожим, найденным в базе данных SQL, например идентификатором корзины покупок, а значением может быть массив данных, например каждый отдельный элемент в корзине покупок этого пользователя. Он обычно используется для кэширования и хранения информации о сеансе пользователя, например о корзинах. Однако это не идеально, когда вам нужно получить несколько записей одновременно. Redis и Memcached являются примерами баз данных с открытым исходным кодом с этой моделью данных.
Ключ может быть чем-то похожим, найденным в базе данных SQL, например идентификатором корзины покупок, а значением может быть массив данных, например каждый отдельный элемент в корзине покупок этого пользователя. Он обычно используется для кэширования и хранения информации о сеансе пользователя, например о корзинах. Однако это не идеально, когда вам нужно получить несколько записей одновременно. Redis и Memcached являются примерами баз данных с открытым исходным кодом с этой моделью данных. Однако это может быть проблематично для сложных транзакций, что приводит к повреждению данных. Популярные варианты использования баз данных документов включают системы управления контентом и профили пользователей. Примером документно-ориентированной базы данных является MongoDB, компонент базы данных стека MEAN.
Однако это может быть проблематично для сложных транзакций, что приводит к повреждению данных. Популярные варианты использования баз данных документов включают системы управления контентом и профили пользователей. Примером документно-ориентированной базы данных является MongoDB, компонент базы данных стека MEAN. ApacheCassandra, с другой стороны, был разработан для управления большими объемами данных на нескольких серверах и кластеризации, охватывающей несколько центров обработки данных. Он использовался для различных вариантов использования, таких как веб-сайты социальных сетей и анализ данных в реальном времени.
ApacheCassandra, с другой стороны, был разработан для управления большими объемами данных на нескольких серверах и кластеризации, охватывающей несколько центров обработки данных. Он использовался для различных вариантов использования, таких как веб-сайты социальных сетей и анализ данных в реальном времени.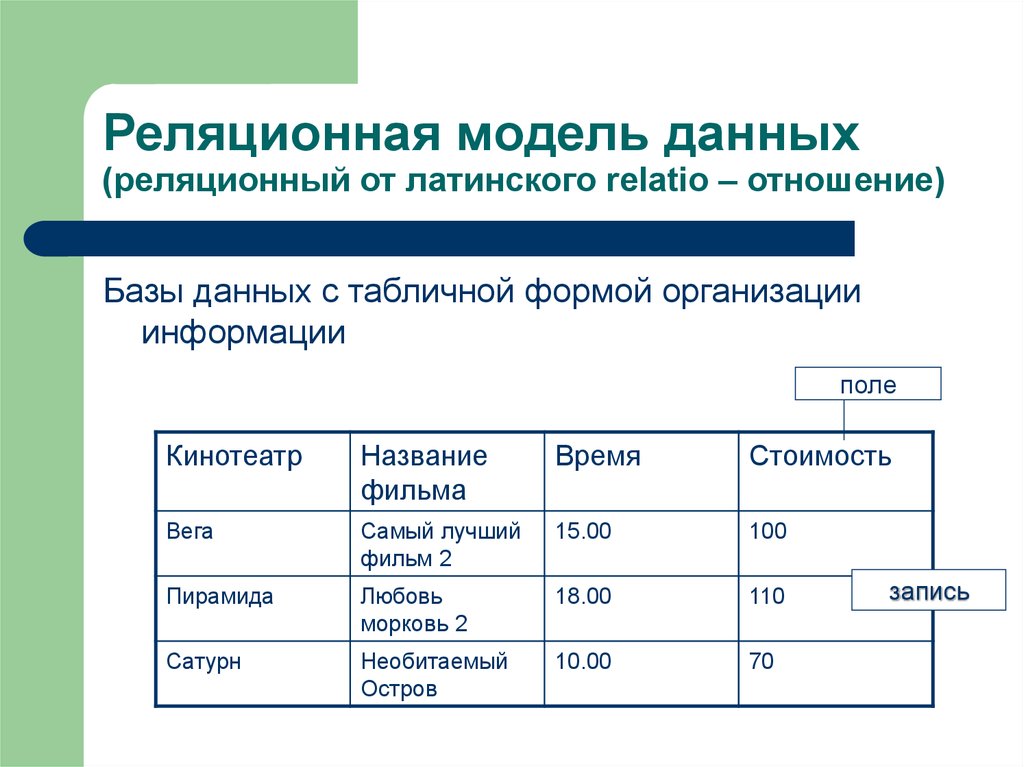
Базы данных NoSQL также отдают предпочтение доступности, а не согласованности.
Когда компьютеры работают в сети, им неизменно необходимо решить, отдавать ли предпочтение стабильным результатам (где все ответы всегда одинаковы) или длительному времени безотказной работы, называемому «доступностью». Это называется «теорией CAP», что означает согласованность, доступность или устойчивость к разделам. Реляционные базы данных обеспечивают постоянную синхронизацию и согласованность информации. Некоторые базы данных NoSQL, такие как Redis, предпочитают всегда предоставлять ответ. Это означает, что информация, которую вы получаете из запроса, может быть неверной на несколько секунд — возможно, на полминуты. На сайтах социальных сетей это означает видеть старую фотографию профиля, когда самой новой всего несколько минут. Альтернативой может быть тайм-аут или ошибка. С другой стороны, в банковских и финансовых операциях ошибка и повторная отправка могут быть лучше, чем старая, неверная информация.
Полный список различий между SQL и NoSQL см. в статье «Базы данных SQL и NoSQL: в чем разница?»
Преимущества реляционных баз данных
Основным преимуществом подхода к реляционным базам данных является возможность создания значимой информации путем объединения таблиц. Объединение таблиц позволяет понять отношения между данными или то, как таблицы соединяются. SQL включает в себя возможность подсчитывать, добавлять, группировать, а также комбинировать запросы. SQL может выполнять основные математические функции и промежуточные итоги, а также логические преобразования. Аналитики могут упорядочить результаты по дате, имени или любому столбцу. Эти функции делают реляционный подход самым популярным инструментом запросов в бизнесе сегодня.
Реляционные базы данных имеют несколько преимуществ по сравнению с другими форматами баз данных:
Простота использования
В силу продолжительности жизни продукта вокруг реляционных баз данных существует больше сообщества, что частично увековечивает их дальнейшее использование.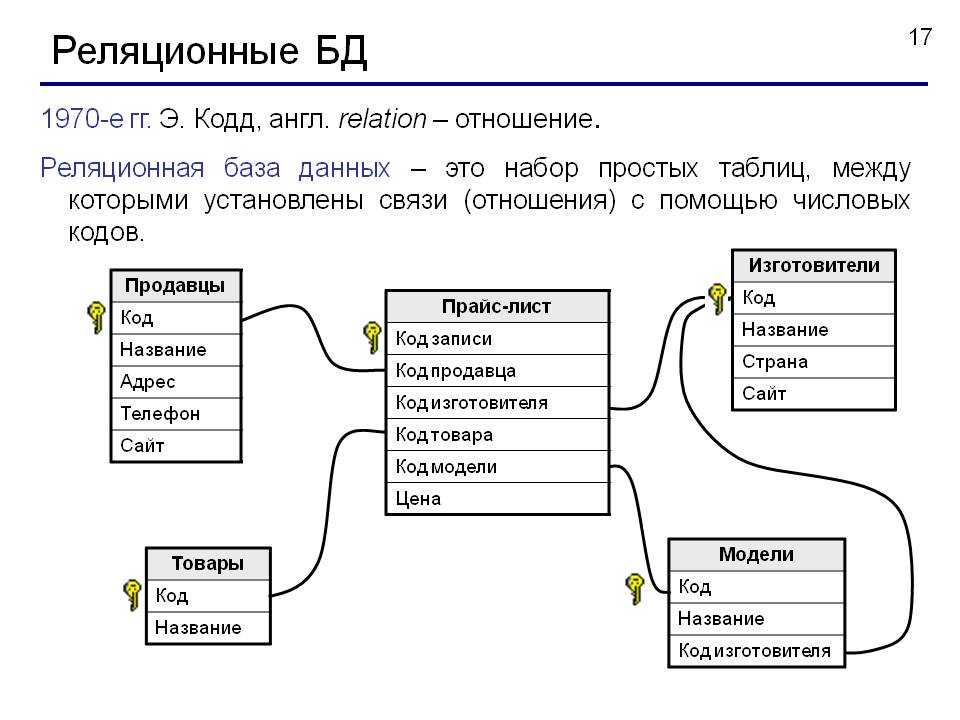 SQL также упрощает извлечение наборов данных из нескольких таблиц и выполнение простых преобразований, таких как фильтрация и агрегирование. Использование индексов в реляционных базах данных также позволяет им быстро находить эту информацию без поиска каждой строки в выбранной таблице.
SQL также упрощает извлечение наборов данных из нескольких таблиц и выполнение простых преобразований, таких как фильтрация и агрегирование. Использование индексов в реляционных базах данных также позволяет им быстро находить эту информацию без поиска каждой строки в выбранной таблице.
Хотя реляционные базы данных исторически рассматривались как более жесткий и негибкий вариант хранения данных, достижения в области технологий и возможностей DBaaS меняют это представление. Несмотря на то, что по сравнению с предложениями баз данных NoSQL накладные расходы на разработку схем по-прежнему выше, реляционные базы данных становятся более гибкими по мере их миграции в облачные среды.
Снижение избыточности
Реляционные базы данных могут устранить избыточность двумя способами. Сама реляционная модель уменьшает избыточность данных с помощью процесса, известного как нормализация. Как отмечалось ранее, таблица клиентов должна регистрировать только уникальные записи информации о клиентах, а не дублировать эту информацию для нескольких транзакций.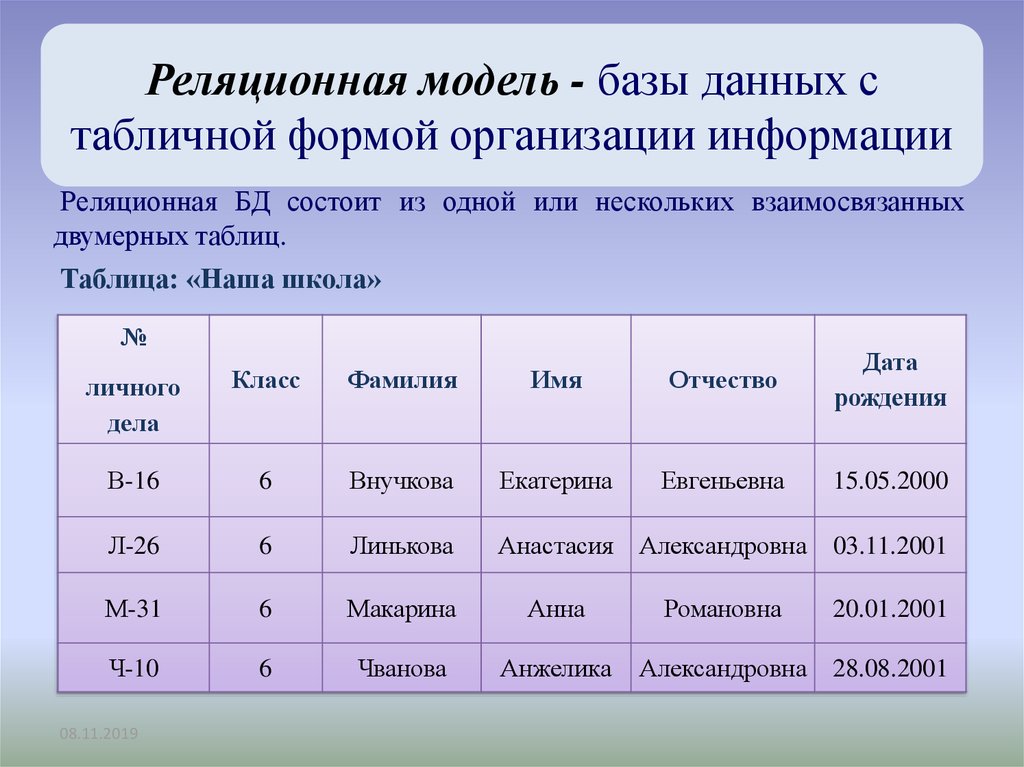
Сохраненные процедуры также помогают уменьшить повторяющуюся работу. Например, если доступ к базе данных ограничен определенными ролями, функциями или командами, хранимая процедура может помочь управлять контролем доступа. Эти многоразовые функции высвобождают желанное время разработчиков приложений для выполнения важной работы.
Простота резервного копирования и аварийного восстановления
Реляционные базы данных являются транзакционными — они гарантируют согласованность состояния всей системы в любой момент. Большинство реляционных баз данных предлагают простые варианты экспорта и импорта, что упрощает резервное копирование и восстановление. Этот экспорт может происходить даже во время работы базы данных, что упрощает восстановление в случае сбоя. Современные облачные реляционные базы данных могут выполнять непрерывное зеркальное отображение, благодаря чему потеря данных при восстановлении измеряется секундами или даже меньше. Большинство облачных сервисов позволяют создавать реплики чтения, например, в IBM Cloud® Databases for PostgreSQL.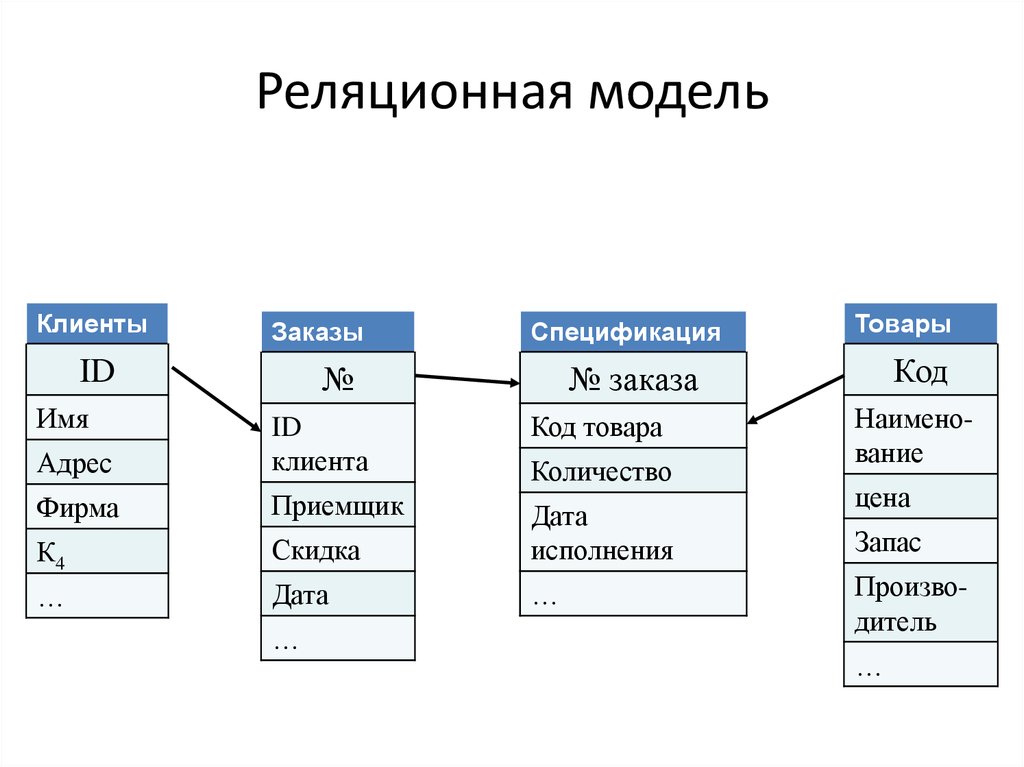 Эти реплики чтения позволяют хранить копию ваших данных только для чтения в облачном центре обработки данных. Реплики также можно повысить до экземпляров с возможностью чтения и записи для аварийного восстановления.
Эти реплики чтения позволяют хранить копию ваших данных только для чтения в облачном центре обработки данных. Реплики также можно повысить до экземпляров с возможностью чтения и записи для аварийного восстановления.
Реляционные базы данных и IBM Cloud®
IBM поддерживает размещенные в облаке версии ряда реляционных баз данных.
- IBM Db2 on Cloud — это первоклассная коммерческая реляционная база данных, созданная для обеспечения высокой производительности и обеспечивающая доступность с SLA на уровне 99,99 %.
- IBM Cloud Databases for PostgreSQL предоставляет готовый к использованию корпоративный, полностью управляемый PostgreSQL, встроенный с встроенной интеграцией в IBM Cloud.
- IBM Cloud Hyper Protect DBaaS для PostgreSQL — это следующий уровень эволюции способов хранения данных в высокозащищенной корпоративной облачной службе, идеально подходящей для рабочих нагрузок с конфиденциальными данными
- Платформа управления данными IBM для EDB Postgres Enterprise и Standard — это интегрированная платформа PostgreSQL на основе открытого исходного кода, доступная в комплексе, который включает закупку, развертывание, использование, управление и поддержку.

Узнайте больше о взглядах IBM на реляционные базы данных.
Начните бесплатно с учетной записью IBM Cloud.
Рекомендуемые продукты
- Db2 в облаке
- Облачные базы данных IBM для PostgreSQL
- IBM Cloud Hyper Protect DBaaS
Ссылки по теме
- Ткань данных
Что такое реляционная база данных? {Примеры, преимущества и недостатки}
Введение
С таким количеством доступных вариантов может быть сложно выбрать решение для базы данных, которое идеально соответствует вашим потребностям. Когда дело доходит до типов баз данных, одним из популярных вариантов является реляционная база данных.
В этой статье мы расскажем о структуре реляционных баз данных, о том, как они работают, а также о преимуществах и недостатках их использования. Мы также будем использовать примеры, чтобы проиллюстрировать, как реляционные базы данных организуют данные.
Определение реляционной базы данных
Реляционная база данных — это тип базы данных, который фокусируется на отношениях между сохраненными элементами данных. Это позволяет пользователям устанавливать связи между различными наборами данных в базе данных и использовать эти связи для управления и ссылки на связанные данные.
Многие реляционные базы данных используют SQL (язык структурированных запросов) для выполнения запросов и обслуживания данных.
Реляционные и нереляционные базы данных
Реляционные базы данных фокусируются на отношениях между данными. Следовательно, база данных отношений должна хранить данные строго структурированным образом. Это обеспечивает более быстрое индексирование и время ответа на запросы, а также делает данные более безопасными и согласованными.
С другой стороны, базам данных NoSQL не нужно так сильно полагаться на структуру, что позволяет им хранить большие объемы данных, оставаться гибкими и легко масштабировать хранилище и производительность.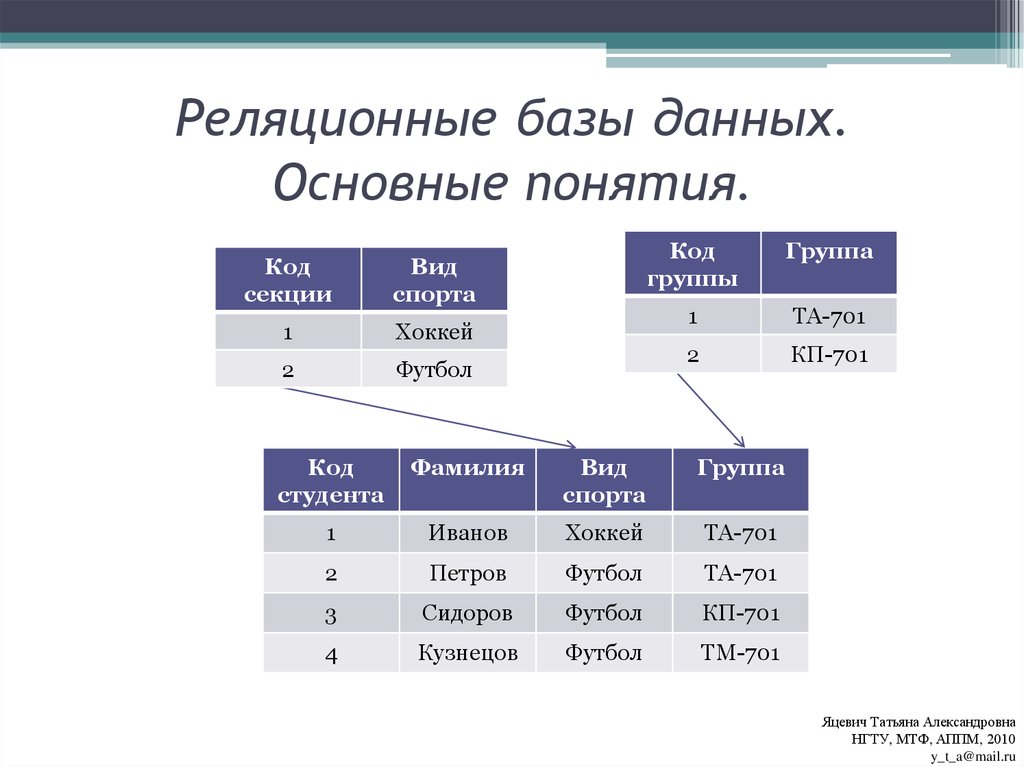
Примечание: Для более подробного изучения различий между реляционными и нереляционными базами данных ознакомьтесь с нашей статьей, посвященной сравнению SQL и NoSQL.
Как организованы данные в реляционной базе данных?
Системы реляционных баз данных используют модель, которая организует данные в таблиц из строк (также называемых записей или кортежей ) и столбцов0040 атрибуты или поля ). Как правило, столбцы представляют категории данных, а строки представляют отдельные экземпляры.
В качестве примера возьмем цифровую витрину. В нашей базе данных может быть таблица, содержащая информацию о клиентах, со столбцами, представляющими имена или адреса клиентов, а каждая строка содержит данные для одного отдельного клиента.
Эти таблицы могут быть связаны или связаны с использованием ключей . Каждая строка в таблице идентифицируется с помощью уникального ключа, называемого 9.0040 первичный ключ. Этот первичный ключ можно добавить в другую таблицу, став внешним ключом . Отношения первичный/внешний ключ составляют основу работы реляционных баз данных.
Каждая строка в таблице идентифицируется с помощью уникального ключа, называемого 9.0040 первичный ключ. Этот первичный ключ можно добавить в другую таблицу, став внешним ключом . Отношения первичный/внешний ключ составляют основу работы реляционных баз данных.
Возвращаясь к нашему примеру, если у нас есть таблица, представляющая заказы на продукты, один из столбцов может содержать информацию о клиентах. Здесь мы можем импортировать первичный ключ, который ссылается на строку с информацией для конкретного клиента.
Таким образом, мы можем ссылаться на данные или дублировать данные из таблицы информации о клиентах. Это также означает, что эти две таблицы теперь связаны.
Примечание: Если вы новичок в базах данных, наш пост Что такое база данных является хорошей отправной точкой для изучения всего, что вам нужно знать.
Примеры реляционных баз данных
Теперь, когда мы рассмотрели, как они работают, вот некоторые из наиболее популярных примеров реляционных баз данных:
MySQL
приобретена Sun Microsystems (теперь Oracle Corporation).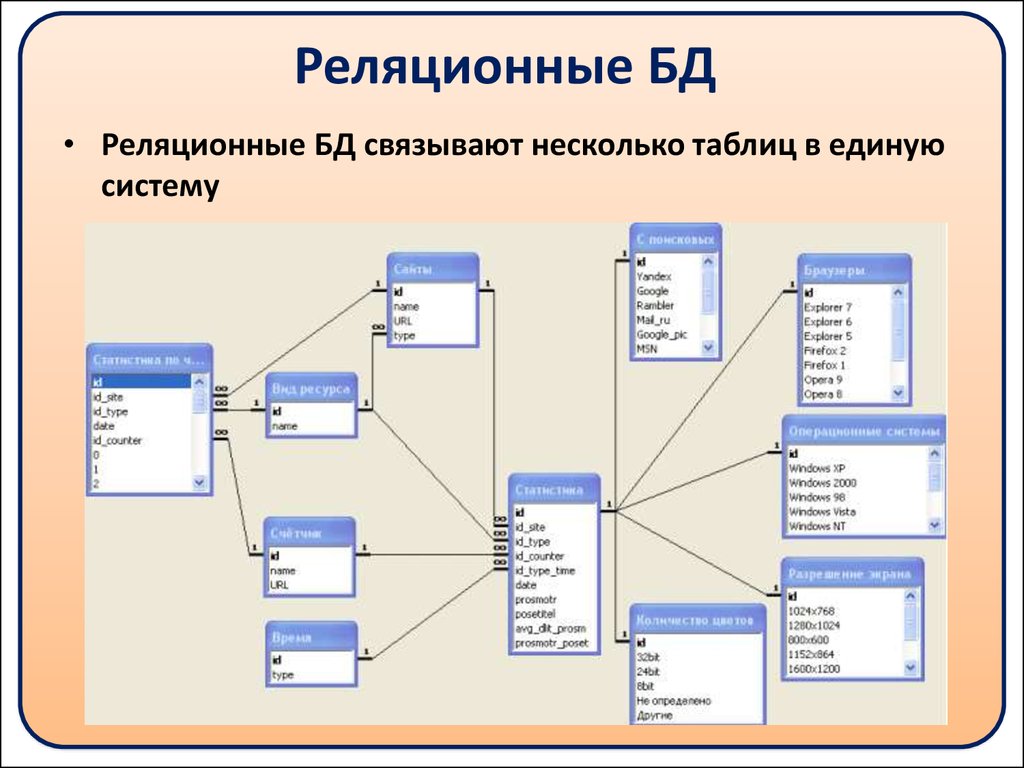 Он по-прежнему доступен под лицензией с открытым исходным кодом с добавлением различных проприетарных лицензий.
Он по-прежнему доступен под лицензией с открытым исходным кодом с добавлением различных проприетарных лицензий.
MySQL имеет встроенную поддержку репликации с соответствием ACID, кластеризацию без совместного использования и поддерживает несколько механизмов хранения. Однако использование некоторых механизмов хранения может привести к некорректной работе SQL.
MySQL отличается быстрым вводом данных и масштабируемостью, сохраняя при этом высокую доступность и производительность. Это делает его чрезвычайно полезным для веб-разработки и разработки приложений.
PostgreSQL
PostgreSQL — это бесплатный менеджер реляционных баз данных, доступный по лицензии с открытым исходным кодом. Он разделяет некоторые функции с MySQL, с заметным добавлением MVCC (контроль параллелизма нескольких версий), что делает его совместимым с ACID.
PostgreSQL сохраняет высокий уровень производительности и гибкости даже при работе с большими базами данных. Это правильный выбор для пользователей, которым требуется высокая скорость чтения/записи и обширный анализ данных.
Некоторые известные пользователи PostgreSQL включают Reddit, Skype и Instagram.
MariaDB
MariaDB начиналась как форк MySQL, управляемый сообществом, после того, как последний был куплен Oracle. Он по-прежнему с открытым исходным кодом и доступен по лицензии GNU General Public License.
MariaDB основывается на базе MySQL, добавляя поддержку еще большего количества механизмов хранения и устраняя ограничения механизмов хранения. Это позволяет ему работать даже быстрее, чем MySQL, и запускать как SQL, так и NoSQL в одной базе данных.
Известные пользователи MariaDB включают Google, Mozilla и Фонд Викимедиа.
SQLite
В отличие от других записей в этом списке, SQLite не является менеджером базы данных клиент-сервер, а скорее встроен в конечное приложение. Это делает его легким и способным работать с широким спектром систем и платформ.
Это также вызывает некоторые ограничения, так как SQLite лишь частично предоставляет триггеры, имеет ограниченную функцию ALTER TABLE и не может записывать в представления.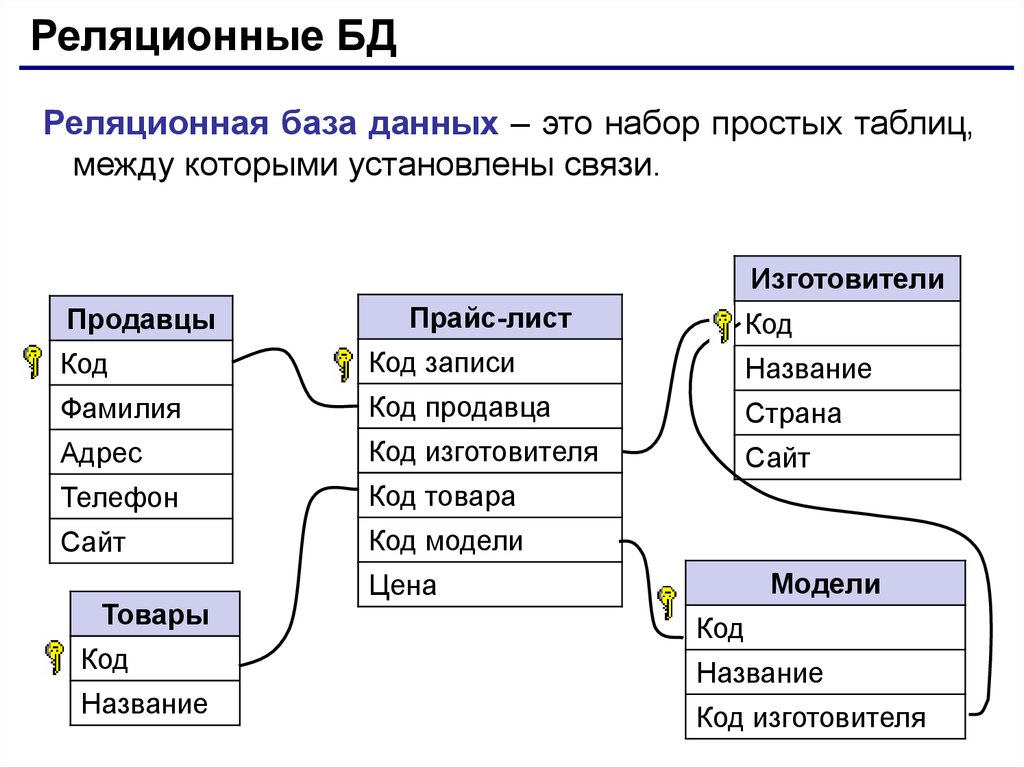 Он также ограничивает максимальный размер базы данных до 32 000 столбцов и 140 ТБ.
Он также ограничивает максимальный размер базы данных до 32 000 столбцов и 140 ТБ.
Поэтому SQLite лучше всего использовать в качестве компонента базы данных для других приложений. Известное использование включает популярные браузеры, такие как Google Chrome, Mozilla Firefox, Opera и Safari.
Что такое система управления реляционными базами данных?
Система управления базами данных (СУБД) — это программное решение, которое помогает пользователям просматривать, запрашивать и управлять базами данных.
Системы управления реляционными базами данных (RDBMS) являются более продвинутым подмножеством СУБД, обрабатывающим реляционные базы данных.
дБм против RDBMS
Вот некоторые из различий между более общими растворами DBMS и RDBMS:
| DBMS | RDBMS | RDBMS | RDBMS 8 |
Хранит большие объемы данных в виде связанных друг с другом таблиц.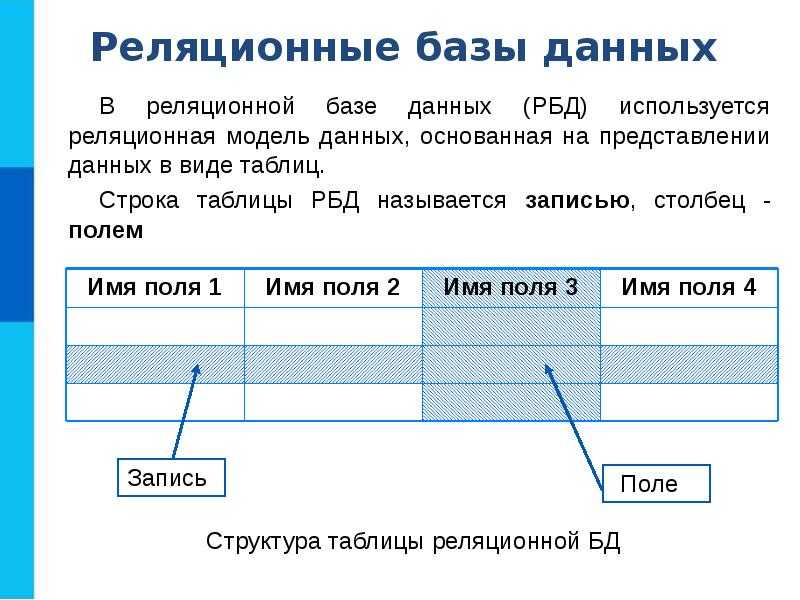 | |||
| Одновременно возможен доступ только к одному элементу данных. | Может обращаться к нескольким элементам данных одновременно. | ||
| Работа с большими объемами данных замедляет выборку. | Реляционный подход позволяет быстро получать данные даже для больших баз данных. | ||
| Нет нормализации базы данных. | Разрешает нормализацию базы данных. | ||
| Не поддерживает распределенные базы данных. | Поддерживает распределенные базы данных. | ||
| Поддерживает одного пользователя. | Поддерживает несколько пользователей. | ||
| Более низкий уровень безопасности. | Несколько уровней безопасности. | ||
| Низкие требования к программному и аппаратному обеспечению. | Высокие требования к программному и аппаратному обеспечению. |
Преимущества и недостатки реляционных баз данных
Как и любая другая модель базы данных, использование реляционных баз данных имеет свои преимущества и недостатки: другие типы баз данных, что упрощает их использование.