Содержание
Как использовать функцию REGEXTRACT в Google Таблицах
Содержание:
Функция REGEXEXTRACT в Google Таблицах является частью набора функций REGEX, доступного многим пользователям. Эта функция очень удобна, когда вы пытаетесь найти определенную строку, которая является частью более крупной.
Единственное условие для использования этой функции — твердое знание регулярных выражений.
В этом руководстве мы подробно обсудим функцию REGEXEXTRACT, а также несколько примеров того, как вы можете применить их в некоторых общих задачах с электронными таблицами.
Что делает функция REGEXTRACT?
Функция REGEXEXTRACT в основном использует регулярные выражения для извлечения совпадающих подстрок из строки. Она принимает строку и регулярное выражение и возвращает часть строки, которая соответствует шаблону в регулярном выражении.
Синтаксис функции REGEXEXTRACT
Синтаксис функции REGEXTRACT следующий:
REGEXEXTRACT (text; reg_exp)
Здесь,
- text — это текст или строка, из которой вы хотите извлечь подстроку
- reg_exp — регулярное выражение.
 Выражение соответствует той части текста, которую вы хотите извлечь. Параметр регулярного выражения следует заключать в двойные кавычки.
Выражение соответствует той части текста, которую вы хотите извлечь. Параметр регулярного выражения следует заключать в двойные кавычки.
 Выражение соответствует той части текста, которую вы хотите извлечь. Параметр регулярного выражения следует заключать в двойные кавычки.
Выражение соответствует той части текста, которую вы хотите извлечь. Параметр регулярного выражения следует заключать в двойные кавычки.Примечание: функция всегда возвращает первую часть текста, которая соответствует шаблону в reg_exp.
Приложения функции REGEXTRACT
Функция REGEXEXTRACT может быть весьма полезной, если вы хотите извлечь ценную информацию из набора строк, которые не совсем «однородны» или согласованы по формату.
Вот несколько полезных приложений функции REGEXEXTRACT. Вы можете использовать её следующим образом:
- Извлечь первые или последние несколько символов из строки
- Извлечь числа из строки
- Извлекать целые слова на основе частичного совпадения
- Извлечь одно из списка слов
- Извлечь содержимое между определенными символами
- Извлечь разные части URL
- Извлекайте разные части адресов электронной почты
Давайте посмотрим, как REGEXREPLACE можно использовать в каждом из вышеуказанных приложений.
Использование функции REGEXEXTRACT для извлечения первых или последних символов из строки
Давайте сначала посмотрим, как вы можете использовать REGEXREPLACE для извлечения первых или последних нескольких символов или слов из строки.
Допустим, у вас есть следующий список названий книг в столбце A:
=REGEXEXTRACT(A2,"...")
Вот результат, который вы получите:
Итак, ваша формула будет такой:
=REGEXEXTRACT(A2,".
 ..$")
..$")Вот результат, который вы получите:
Если вы хотите убедиться, что вы извлекаете только буквенно-цифровые символы, то вместо символа точки вы можете использовать метасимвол w, который представляет один буквенно-цифровой символ (цифру, букву или подчеркивание).
Итак, если вы хотите извлечь первое слово целиком, вам нужно будет использовать комбинацию «w +». Это гарантирует, что любые символы перед первым пробелом будут извлечены следующим образом:
=REGEXEXTRACT(A2,"\w+")
Точно так же, чтобы извлечь последнее слово, формула будет выглядеть так:
=REGEXEXTRACT(A2,"\w+$")
Вот результат, который вы получите:
Использование функции REGEXEXTRACT для извлечения чисел из строки
Метасимвол d представляет собой числовую цифру. Таким образом, если вы хотите извлечь первое число из строки, вы можете использовать выражение «d +» следующим образом:
Таким образом, если вы хотите извлечь первое число из строки, вы можете использовать выражение «d +» следующим образом:
=REGEXEXTRACT(A2,"\d+")
Вот результаты, которые вы получите для следующего списка строк:
Использование функции REGEXTRACT для извлечения целых слов на основе частичного совпадения
Допустим, у вас есть следующий список строк и вы хотите извлечь все номера автомобильных номеров, которые начинаются с символов ‘L-‘:
=REGEXEXTRACT(A2,"L-\w+")
Это даст вам следующий результат:
=REGEXEXTRACT(A2,"bo\w+d")
Это даст вам следующий результат:
 Если вместо этого вы хотите, чтобы он извлекал последнее слово, вам нужно будет добавить метасимвол доллара ($) в конце:
Если вместо этого вы хотите, чтобы он извлекал последнее слово, вам нужно будет добавить метасимвол доллара ($) в конце:=REGEXEXTRACT(A2,"bo\w+d$")
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения одного из списка слов
Метасимвол «|» представляет собой операцию «OR». Итак, если вы хотите извлечь одно слово из списка слов или символов, вы можете использовать этот символ в функции REGEXMATCH.
Например, допустим, у вас есть следующий список строк:
=REGEXEXTRACT(A2,"red|blue|green|yellow")
Это даст вам следующий результат:
Использование функции REGEXTRACT для извлечения содержимого между определенными символами
Обычно функция REGEXREPLACE используется для извлечения содержимого между определенными символами. Например, предположим, что вы скопировали некоторый текст разметки с веб-сайта и вам нужно извлечь только его текстовую часть, удалив теги HTML:
Например, предположим, что вы скопировали некоторый текст разметки с веб-сайта и вам нужно извлечь только его текстовую часть, удалив теги HTML:
= REGEXTRACT (A2; ">. + <")
Однако при этом также будут извлечены символы вместе с текстом между ними, как показано ниже:
= REGEXTRACT (A2; "> (. +) <")
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения различных частей URL-адреса
Если вы хотите извлечь доменное имя URL-адреса, вы можете использовать REGEXEXTRACT следующим образом:
=REGEXEXTRACT(A2,"http.
 +\ / \ /(.+) \ /")
+\ / \ /(.+) \ /")Это извлечет все содержимое между шаблоном HTTP: // (или HTTPS: //) и символом ‘/’.
Приведенная выше формула даст вам следующий результат:
=REGEXEXTRACT(A27,"http.+\ / \ / \ w+\.(.+)\.[org|com]")
Здесь мы убедились, что все слова перед точкой и после нее удалены. Поскольку слово после точки может быть любым из слов org или com, мы указали их в квадратных скобках.
Это даст вам следующий результат:
Использование функции REGEXTRACT для извлечения различных частей адреса электронной почты
Как и в предыдущем примере, мы также можем использовать REGEXEXTRACT для извлечения частей адреса электронной почты. Например, предположим, что у вас есть следующий список адресов электронной почты:
= REGEXTRACT (A33; "(.
 +) @")
+) @")Это даст вам следующий результат:
Если вместо имени пользователя вас больше интересует извлечение части имени домена из адреса электронной почты, вы можете использовать функцию REGEXEXTRACT следующим образом:
= REGEXTRACT (A33; "@ (. +)")
Это даст вам следующий результат:
Использование функции REGEXTRACT для извлечения определенного шаблона символов
Допустим, у вас есть следующий список строк и вы хотите извлечь номера телефонов из каждой ячейки:
= REGEXTRACT (A40; "(...) ...-....")
Здесь каждая точка представляет один символ. Однако вместо того, чтобы ставить столько точек, вы можете сократить регулярное выражение, поставив за точкой после точки количество символов, заключенных в фигурные скобки.
Поэтому вместо «…» вы можете использовать «. {3}» в своем выражении. Это означает, что приведенная выше формула также может быть записана как:
= REGEXTRACT (A40; "(. {3}). {3} -. {4}")У вас есть 3 числа в круглых скобках, за которыми следуют еще три числа, за ними следует дефис и еще 4 числа.
Это даст вам следующий результат:
Итак, чтобы разделить результат приведенной выше формулы на три разных столбца, ваша функция REGEXTRACT может быть записана как:
= REGEXTRACT (A40, "((. {3})) (. {3}) - (. {4})")Это даст вам следующий результат:

REGEXEXTRACT Совет по функциям Google Таблиц:
Вот несколько важных советов, которые необходимо помнить при использовании функции REGEXEXTRACT.
- Эта функция работает только с вводом текста. Не работает с числами
- Если вы хотите использовать числа в качестве входных данных (например, телефонные номера), вам необходимо сначала преобразовать их в текст, используя функцию TEXT.
- Функция REGEXEXTRACT чувствительна к регистру. Следовательно, вам нужно будет указать правильный регистр внутри регулярного выражения или преобразовать всю входную строку в верхний или нижний регистр с помощью функций UPPER или LOWER.
Функция REGEXEXTRACT может иметь множество приложений, если вы научитесь ее эффективно использовать. Хорошее знание регулярных выражений помогает, и лучший способ овладеть им — это попрактиковаться.
Поиграйте с различными регулярными выражениями и посмотрите, какие результаты вы получите. Вы будете удивлены, насколько полезной может быть функция REGEXEXTRACT, когда вы начнете использовать ее для повседневных данных электронной таблицы.
Вы будете удивлены, насколько полезной может быть функция REGEXEXTRACT, когда вы начнете использовать ее для повседневных данных электронной таблицы.
Поиск и замена части текста с помощью регулярных выражений
Быстрее и удобнее обрабатывать текст в гугл таблицах
В работе маркетолога часто приходится обрабатывать разнообразный по своему содержанию текст. При большом количестве элементов и их разной записи, делать это стандартными методами невозможно.
Для этого лучше использовать регулярные выражения.
Привожу шаблон Гугл таблиц с несколькими самыми популярными для аналитика запросами.
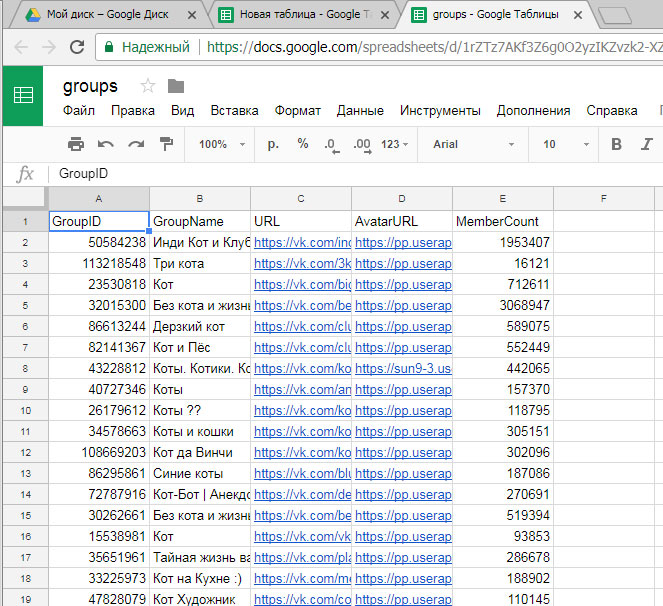
https://docs.google.com/spreadsheets/d/11IuUtQVZUFygTjNzZvaZepb_Y01rb1BT2EJSunD9vl0/edit?usp=sharing
Регулярные выражения
Регулярные выражения — это общепринятый большинством текстовых редакторов код, который означает тот или иной смысл. Например код .* означает все элементы.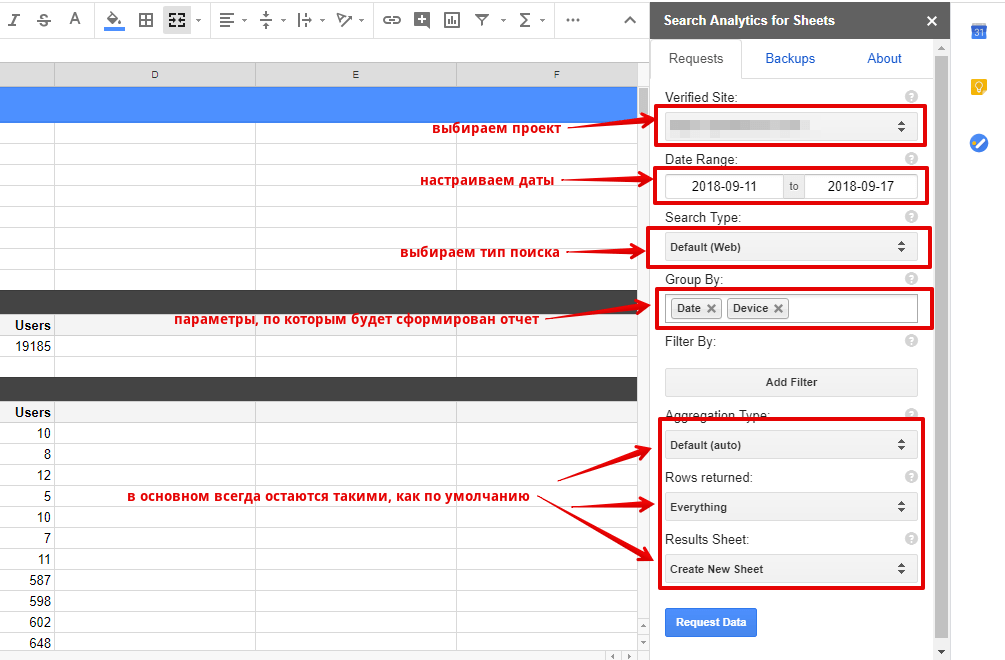
Применение в google таблицах
Задачи могут сильно различаться. Например в гугл таблицах нужно убрать из utm ссылок всё, что идёт после адреса страницы.
Ссылки с utm метками
Для этого нужно воспользоваться специальной формулой таблиц для регулярных выражений.
REGEXREPLACE(текст; регулярное_выражение; замена)
— С текстом всё понятно, выбираем ячейку с ссылкой;
— С регулярным выражением сложнее, пишем код \&.*|\?.* в отдельной ячейке и выбираю её. Далее разберу подробнее, что он значит;
— Для замены используем пустое место «»
Таблица замены
Получаем в столбце «Формула» ссылку без utm меток. Фактически происходит следующее:
Мы говорим, возьми текст из ячейки А2 → выбери по регулярному выражению в ячейке В2 весь текст из А2 → подставь пустое место («»)
Разберём регулярное выражение \&.*|\?.*
Используя такой код, мы говорим возьми все символы (.*) до символа & (\&) или (|) возьми все символы (.*) до символа ? (\?)
Вывод с помощью регулярных выражений значений до символа с начала строки
Для этого нужно определить символ и вывести значения до него. \:]*
\:]*
Где посмотреть все регулярные выражения
Значения регулярных выражений можно посмотреть на специальном сайте https://regexr.com/. Очень удобно вставить анализируемый текст и подбирать коды регулярных выражений. Подсветкой будет выделен выбираемый текст.
Скрин моделирования регулярных выражений
Коды приведены в левом пунтке меню Cheatsheet
Кратко привожу их тут
| Код | Описание | |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. | |
| \s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). | |
| \S | Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. | |
| \d | Любая цифра | |
| \D | Анти-вариант предыдущего, т.е. любая НЕ цифра | |
| \w | Любой символ латиницы (A-Z), цифра или знак подчеркивания | |
| \W | Анти-вариант предыдущего, т. | Начало строки |
| $ | Конец строки | |
| \b | Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например \d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так \s* означает любое количество пробелов или их отсутствие. |
| {число} или {число1,число2} | Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например \d{6} означает строго шесть цифр, а шаблон \s{2,5} — от двух до пяти пробелов |
Полезные ссылки по теме
Справка гугла
Помимо использования REGEXREPLACE регулярные выражения можно применять и вREGEXEXTRACT: Извлекает определенную часть текста, соответствующую регулярному выражению.REGEXMATCH: Проверяет, соответствует ли текст регулярному выражению.ПОДСТАВИТЬ: Заменяет один текст на другой.ЗАМЕНИТЬ: Заменяет выбранный текст на другой
Анализ текста регулярными выражениями (RegExp) в обычном Excel с помощью Visual
Как использовать REGEXEXTRACT Функция Google Sheets
REGEXEXTRACT Функция Google Sheets является частью набора функций REGEX, доступных многим пользователям.
Эта функция очень удобна, когда вы пытаетесь найти определенную строку, являющуюся частью более крупной.
Единственным предварительным условием для использования этой функции является твердое понимание регулярных выражений.
В этом руководстве мы подробно обсудим функцию REGEXEXTRACT, а также несколько примеров того, как вы можете применять их в некоторых распространенных задачах работы с электронными таблицами.
Эта статья охватывает:
Что делает функция REGEXEXTRACT?
Функция REGEXEXTRACT в основном использует регулярные выражения для извлечения совпадающих подстрок из строки. Он принимает строку и регулярное выражение и возвращает часть строки, которая соответствует шаблону в регулярном выражении.
Синтаксис функции REGEXEXTRACT
Синтаксис функции REGEXEXTRACT следующий:
REGEXEXTRACT( text , reg_exp )
Здесь
- текст — это текст или строка, из которой вы хотите извлечь подстроку
- reg_exp — регулярное выражение. Выражение соответствует части текста , которую вы хотите извлечь. Параметр регулярного выражения должен быть заключен в двойные кавычки.
Примечание: Функция всегда возвращает первую часть текста , которая соответствует шаблону в reg_exp .
Применение функции REGEXEXTRACT
Функция REGEXEXTRACT может оказаться очень полезной, если вы хотите извлечь ценную информацию из набора строк, которые не совсем «однородны» или согласуются по формату.
Вот несколько полезных применений функции REGEXEXTRACT. Вы можете использовать его для:
- извлечения первых или последних нескольких символов из строки
- Извлечь числа из строки
- Извлечение целых слов на основе частичного совпадения
- Извлечь одно из списка слов
- Извлечь содержимое между определенными символами
- Извлечение различных частей URL-адреса
- Извлечение различных частей адресов электронной почты
Давайте посмотрим, как можно использовать REGEXREPLACE в каждом из вышеперечисленных приложений.
Использование функции REGEXEXTRACT для извлечения первых или последних нескольких символов из строки
Давайте сначала посмотрим, как вы можете использовать REGEXREPLACE для извлечения первых или последних нескольких символов или слов из строки.
Допустим, у вас есть следующий список названий книг в столбце A:
Если вы хотите извлечь только первые, скажем, 3 символа из каждой ячейки, вы можете использовать символ с одной точкой (.). Одна точка в регулярном выражении используется для представления одного символа. Итак, если вы хотите извлечь 3 символа из строки, вам нужно указать 3 точки в параметре регулярного выражения следующим образом:
=REGEXEXTRACT(A2,"...")
Вот результат, который вы получите:
Аналогичным образом, если вы хотите извлечь последние 3 символа из каждой ячейки, вы можете использовать 3 точки, за которыми следует метасимвол $, поскольку символ доллара представляет собой конец строки.
Таким образом, ваша формула будет:
=REGEXEXTRACT(A2,"...$")
Вот результат, который вы получите:
Символ точки представляет собой любой символ, включая пробел или любой другой символ. Таким образом, использование «.+» в регулярном выражении просто извлечет весь текст в ячейке.
Если вы хотите убедиться, что извлекаете только буквенно-цифровые символы, то вместо символа точки вы можете использовать метасимвол \w , который представляет собой одиночный буквенно-цифровой символ (цифру, букву или знак подчеркивания).
Итак, если вы хотите извлечь целое первое слово , вам нужно будет использовать комбинацию «\w+». Это гарантирует, что все символы до первого пробела будут извлечены следующим образом:
=REGEXEXTRACT(A2,"\w+")
Аналогичным образом, для извлечения последнего слова формула будет выглядеть так: Строка
Метасимвол \d представляет цифру. Таким образом, если вы хотите извлечь первое число из строки, вы можете использовать выражение «\d+» следующим образом:
=REGEXEXTRACT(A2,"\d+")
Для следующего списка строк, вот результаты, которые вы получите:
Использование функции REGEXEXTRACT для извлечения целых слов на основе частичного совпадения
Допустим, у вас есть следующий список строк и вы хотите извлечь все номерные знаки, которые начинаются с символов ‘L-‘:
Затем вы можете использовать требуемый шаблон строки, за которым следует «\w+», следующим образом:
=REGEXEXTRACT(A2,"L-\w+")
Это даст вам следующий результат:
Этот вид регулярного выражения также можно использовать, если вы хотите извлечь слова, которые следуют определенному шаблону, например, предположим, что у вас есть следующий список предложений:
Если вы хотите извлечь первое слово в каждой строке, которая начинается с ‘ bo ‘ и заканчивается на ‘d ‘, вы можете использовать функцию REGEXEXTRACT следующим образом:
=REGEXEXTRACT(A2," bo\w+d")
Это даст вам следующий результат:
Обратите внимание, что в последнем примере функция извлекла только первых слов в строке, следующей за образцом ‘bo…d’. Если вместо этого вы хотите, чтобы он извлек последних , вам нужно добавить в конце метасимвол доллара ($):
Если вместо этого вы хотите, чтобы он извлек последних , вам нужно добавить в конце метасимвол доллара ($):
=REGEXEXTRACT(A2,"bo\w+d$")
Это даст вам следующий результат:
Используя функция REGEXEXTRACT для извлечения одного из списка слов
Метасимвол ‘|’ представляет операцию или . Итак, если вы хотите извлечь одно слово из списка слов или символов, вы можете использовать этот символ в функции REGEXMATCH.
Допустим, у вас есть следующий список строк:
Если вы хотите извлечь первое вхождение любого из слов red , blue , green или yellow в ячейке A2, вы можете использовать функцию REGEXEXTRACT следующим образом:
= REGEXEXTRACT(A2,"красный|синий|зеленый|желтый")
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения содержимого между определенными символами
Обычно функция REGEXREPLACE используется для извлечения содержимое между определенными символами. Например, предположим, что вы скопировали некоторый текст разметки с веб-сайта и вам нужно извлечь из него только текстовую часть, удалив теги HTML:
Например, предположим, что вы скопировали некоторый текст разметки с веб-сайта и вам нужно извлечь из него только текстовую часть, удалив теги HTML:
Теперь вы можете подумать, что простого использования регулярного выражения ‘>.+<' будет достаточно, чтобы извлечь все содержимое между символами '>‘ и ‘<':
=REGEXEXTRACT(A2,">. +<")
Однако это также приведет к извлечению символов вместе с текстом между ними, как показано ниже:
приложите “ .+ ” метасимвол в групповых скобках ‘()’. Это гарантирует, что будет извлечено только содержимое групповых скобок:
=REGEXEXTRACT(A2,">(.+)<")
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения Различные части URL-адреса
Если вы хотите извлечь доменное имя из URL-адреса, вы можете использовать REGEXEXTRACT следующим образом:
=REGEXEXTRACT(A2,"http.+\ / \ /(.+) \ /" )
При этом будет извлечено все содержимое между шаблоном HTTP:// (или HTTPS://) и символом '/'.
Приведенная выше формула даст вам следующий результат:
Если вы хотите удалить все и извлечь только основное доменное имя (без каких-либо поддоменов или расширений, то ваша функция REGEXEXTRACT может быть уточнена следующим образом :
=REGEXEXTRACT(A27,"http.+\ / \ / \ w+\.(.+)\.[org|com]")
Здесь мы убедились, что любые слова до точки и после точки удалено, так как слово после точки может быть любым из слов ‘org’ или ‘com’ , мы указали их в квадратных скобках.
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения различных частей адреса электронной почты
Как и в предыдущем примере, мы также можем использовать REGEXEXTRACT для извлечения частей адреса электронной почты. Например, предположим, что у вас есть следующий список адресов электронной почты:
Если вы хотите извлечь только имя пользователя часть адресов электронной почты, вы можете использовать функцию REGEXEXTRACT, чтобы извлечь все, что идет до '@' символ следующим образом:
=REGEXEXTRACT(A33,"(.
 +)@")
+)@") Это даст вам следующий результат:
Мы использовали метасимвол точки вместо \w, потому что мы хотим, чтобы выражение учитывало любой символ в имя пользователя, включая точки, дефисы или символы подчеркивания (как в третьем примере).
Если вместо имени пользователя вас больше интересует извлечение доменного имени части адреса электронной почты, то вы можете использовать функцию REGEXEXTRACT следующим образом:
=REGEXEXTRACT(A33,"@(.+)")
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения определенного шаблона символов
Допустим, у вас есть следующий список строк и хотите извлечь телефонные номера из каждой ячейки:
Поскольку все телефонные номера в США следуют одному и тому же шаблону, вы можете использовать функцию REGEXEXTRACT следующим образом:
=REGEXEXTRACT(A40,"\(... \)...-....")
Здесь каждая точка представляет один символ. Однако вместо того, чтобы ставить так много точек, вы можете сократить регулярное выражение, указав после точки число символов, заключенное в фигурные скобки.
Однако вместо того, чтобы ставить так много точек, вы можете сократить регулярное выражение, указав после точки число символов, заключенное в фигурные скобки.
Таким образом, вместо «…» вы можете использовать в своем выражении « .{3} ». Это означает, что приведенную выше формулу также можно записать в виде:
=REGEXEXTRACT(A40,"\(.{3}\).{3}-.{4}") У вас есть 3 числа в круглых скобках, за которыми следует еще три цифры, затем дефис и еще 4 цифры.
Это даст вам следующий результат:
Вот классный трюк. Если вы также хотите разделить части номера телефона на отдельные столбцы для код города , код обмена и номер абонента , , вы можете заключить в круглые скобки каждую часть, которую вы хотите в одном столбце.
Таким образом, чтобы разделить результат приведенной выше формулы на три разных столбца, ваша функция REGEXEXTRACT может быть записана как:
=REGEXEXTRACT(A40,"\((.{3})\)(.{3})-(. {4})")  {4})")
{4})") Это даст вам следующий результат:
Это было несколько простые примеры того, как функция REGEXEXTRACT может эффективно помочь вам извлечь из строки именно то, что вам нужно.
REGEXEXTRACT Совет по функции Google Sheets:
Вот несколько важных советов, которые необходимо помнить при использовании функции REGEXEXTRACT.
- Эта функция работает только при вводе текста. Не работает с цифрой
- Если вы хотите использовать числа в качестве входных данных (например, номера телефонов), вам необходимо сначала преобразовать их в текст с помощью функции ТЕКСТ.
- Функция REGEXEXTRACT чувствительна к регистру. Поэтому вам нужно будет указать правильный регистр внутри регулярного выражения или преобразовать всю входную строку в верхний или нижний регистр с помощью функций UPPER или LOWER.
Функция REGEXEXTRACT может найти множество применений, если вы научитесь эффективно ее использовать. Помогает хорошее знание регулярных выражений, и лучший способ овладеть ими — это попрактиковаться.
Помогает хорошее знание регулярных выражений, и лучший способ овладеть ими — это попрактиковаться.
Поэкспериментируйте с различными регулярными выражениями и посмотрите, какие результаты вы получите. Вы будете удивлены тем, насколько полезной может быть функция REGEXEXTRACT, как только вы начнете использовать ее для повседневных данных электронных таблиц.
Сумит
Эксперт по электронным таблицам
в
Место для продуктивной работы
| Веб-сайт
| + постов
Google Sheets и Microsoft Excel Expert.
Как использовать функцию Regexextract в Google Таблицах
Google Sheets Функции регулярных выражений являются сложной задачей даже для обычных продвинутых пользователей. Так что на этот раз я посвящаю свою тему функции Regexextract в Google Sheets . Эта функция является одной из трех функций регулярных выражений в Google Таблицах.
Вы нигде не можете найти достаточно ресурсов или обсуждений, связанных с функциями регулярных выражений Google Таблиц. Причина, это немного сложно. Я думаю, что пользователи пропускают его в основном из-за отсутствия надлежащего руководства.
В Google Таблицах есть три встроенных функции REGEX. Это Regexextract, Regexmatch и Regexreplace. Эти функции похожи в использовании, так как секрет кроется в регулярных выражениях RE2. Таким образом, изучения любой из этих функций достаточно, чтобы понять остальные. Здесь я объясню вам , как использовать функцию Regexextract в Google Sheets .
Я выбрал Regexextract для своего руководства, потому что вместо истинного или ложного вы можете увидеть значение в качестве результата.
Вы можете использовать функцию REGEX в сочетании с массивом, обрезкой, транспонированием, запросом, как и другие функции. Понимание Regex становится важным на этом этапе. Сначала изучите Regex, а затем начните использовать его с другими функциями.
Почему функция Regex выглядит завершенной? Как уже было сказано, это чисто связано с используемыми в нем выражениями RE2. Если вы пробежитесь по выражениям, вы многого не поймете. Итак, с помощью нескольких формул я попытаюсь объяснить наиболее часто используемые выражения RE2 в Google Sheets Regexextract. Это также применимо к функциям Regexmatch и Regexreplace.
Как использовать функцию Regexextract в Google Sheets
Google Sheets Функция Regexextract может работать только с текстом . Если какое-либо извлеченное из текста значение является числовым, вы можете использовать функцию value() для преобразования его в числовое. Как уже говорилось, вы можете использовать функцию Regex вместе со многими другими функциями Google Sheets. В этот раз я не пойду в эту часть.
Начнем с синтаксиса:
REGEXEXTRACT(текст, регулярное_выражение)
Какие два элемента в синтаксисе?
текст — вводимый текст.
регулярное_выражение — будет возвращена первая часть текста , которая соответствует этому выражению.

Продукты Google используют RE2 для регулярных выражений. Эта часть сложная с функциями, и жаль, что нет надлежащего руководства по использованию этих выражений в функциях в Google Таблицах.
Теперь пришло время пройтись по разным сценариям.
Формулы для обучения использованию функции Regexextract в Google Sheets
1. Если вы хотите e извлечь любой обычный текст с помощью регулярного выражения, используйте это непосредственно в кавычках
Значение ячейки в A2: Inspired 2017, Индия
Формула:
=REGEXEXTRACT(A2, "Info Inspired")
Результат: Info Inspired
2. To 2 символа x 9004. )
Значение ячейки в A3 IS Информация Inspired 2017, India
Формула:
= REGEXEXTract (A3, «Y | O»)
РЕЗУЛЬТАТ: O
Formula:
. O.
O.
:
9 2
. (A3, "блог|Индия")
Результат: Индия
На этот раз запомните синтаксис. Что это говорит? « Будет возвращена первая часть текста, соответствующая этому выражению».
3. Одна точка извлекает один символ, две точки извлекают 2 символа и так далее.
Значение ячейки в A12 IS Информация Inspired 2017
Формула:
= REGEXEXTract (A12, "....")
Результат: Info
Formula:
293939393939393
re -exexexexexexexexeex rexexexexeex rexexexeex rexexexexexexexexexexexexexexex. A12, "In..")
Результат: Info
Приведенная выше формула применима к первой части текста. Если вы хотите извлечь определенное количество символов с конца, используйте формулу, как показано ниже.
Формула:
=REGEXEXTRACT(A12,"(....\z)")
Результат: 2017
Одна десятичная цифра, а не целое число.
Формула:
=REGEXEXTRACT(A6, "(\d)")
Результат: 2
Целое число, "+" имеет значение.
Формула:
= RegexExtract (a6, "(\ d+)")
Результат: 2017
5. Если вы хотите извлечь символы
Стоимость ячейки в A7 - Информация Inspired 2017 Блог
:
=REGEXEXTRACT(A7, "(\w)")
Результат: I
Формула:
=REGEXEXTRACT(A7, "(\w+)")
Результат: Info 90.7 60 4 Info 90. Если вы хотите извлечь как символы, так и цифры
Значение ячейки в A8: Info Inspired 2017 Blog
Формула:
=REGEXEXTRACT(A8, "(\w*)\s(\d+)")
Результат: Inspired in one cell, Inspired 2017 год в другом, по горизонтали.
Выражение RE2 в этой формуле «\s» используется для соответствия пробелу между Inspired и 2017 .
7. Функция Regexextract для извлечения всего текста
Значение ячейки в A17: Info Inspired 2017
Формула:
=REGEXEXTRACT(A17, "(.+)")
Результат: Info Inspired 2017
7.1. Извлечь целое слово на основе частичного совпадения.
Я хочу извлечь все слово на основе частичного совпадения.
Значение ячейки в A1 IS Учебные пособия Google Sheets
Формула:
Стоимость ячейки в A5 IS Информация Inspired Blog 2017 Формула: Результат: D 9. извлечь любые строчные буквы в последовательности Значение ячейки в A9: info вдохновлено 2017 Формула: = REGEXEXTRACT0042 = Regexextract (A5, «[DXY]») =REGEXEXTRACT(A9, "[a-z]") 909030 03 Результат :
=REGEXEXTRACT(A9, "[a-z]+")
Результат: info
10. Выражение [A-Z] может извлекать любые прописные буквы в последовательности
Выражение [A-Z] может извлекать любые прописные буквы в последовательности
Значение ячейки в A10: IN20 INSPIRED
Formula:
=REGEXEXTRACT(A10, "[A-Z]")
Result: I
Formula:
=REGEXEXTRACT(A10, "[A-Z]+")
Result: INFO
11. [А-За-Я] Используйте это выражение в Regexextract, если регистр не учитывается.
Значение ячейки в A11: Info Inspired 2017
Формула:
=REGEXEXTRACT(A11, "-z)"(A-z)"(A-z) )
Результат: I
Формула:
=REGEXEXTRACT(A11, "([A-Za-z]+)")
Результат: Info
0-0-41 12. Express canion] соответствует любому числу в последовательности из текста
Значение ячейки в A19 равно Info Inspired 2017
Формула:
= regexextract (A19, "[0-9]")
Результат: 2
Формула:
= regexextract (A19, A19, A19, "
= regexextract (A19,"
= regexex ]+")
Результат: 2017
Если вы смогли изучить описанное выше использование выражений RE2 в Regexextract, вы можете перейти к более сложному использованию. Приведенные ниже примеры представляют собой смесь приведенных выше выражений.
Приведенные ниже примеры представляют собой смесь приведенных выше выражений.
13. Извлеченный контент, который находится между определенными символами
Значение ячейки в A21 ?Содержимое? между вопросительными знаками
Формула:
=REGEXEXTRACT(A21, "\?([A-Za-z]+)\?")
Результат: Содержимое
Ячейка представляет собой значение в A21, "\?([A-Za-z]+)\?") (Содержание) между открывающими и закрывающими скобками
Формула:
=REGEXEXTRACT(A22, "\(([A-Za-z]+)\)")
Result0 :
Result0
Значение ячейки в A24 равно напишите мне
Формула:
=REGEXEXTRACT(A24, "<(.+)>")
Результат: [email protected]
наиболее распространенные выражения RE2 в функциях Regex Google Sheet.
Связанный:
1.