Содержание
Что такое реляционная база данных и СУБД. Урок 1
Прежде чем говорить о реляционной базе данных и системе управления базами данных (СУБД), надо определиться с тем, что такое база данных вообще.
Понятие базы данных (БД) абстрактно. Конкретными реализациями являются базы данных чего-либо. Например, база данных библиотеки, сайта или база данных магазина, в которой хранятся сведения о сотрудниках, товарах, поставщиках и покупателях.
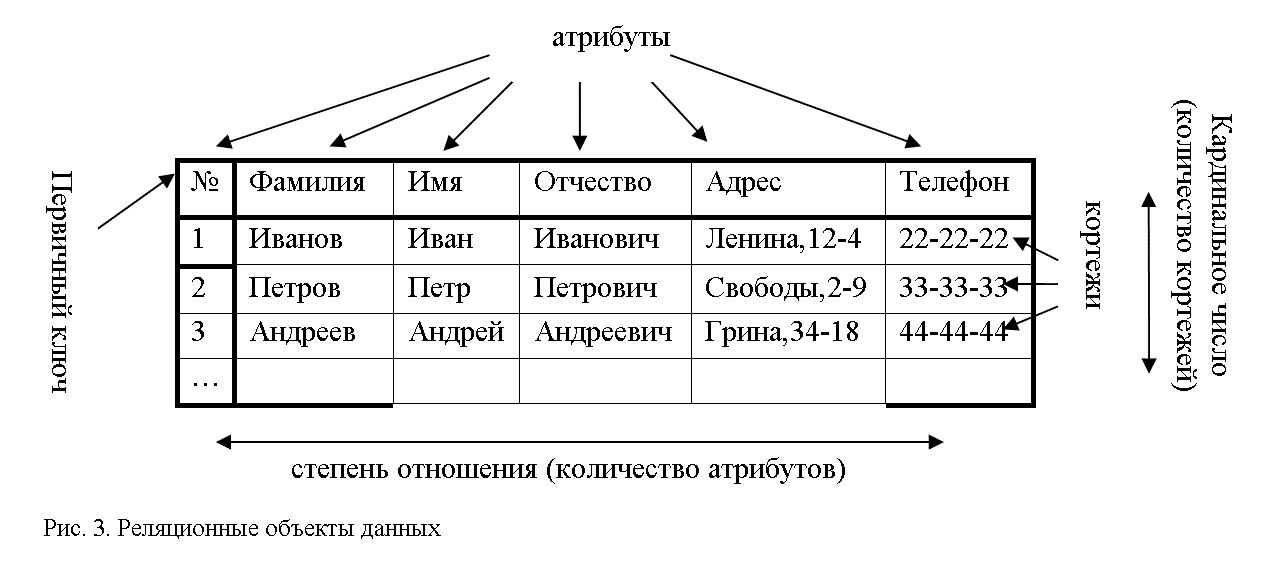
Удобнее всего такую информацию хранить в таблицах. Например, база данных может состоять из следующих таблиц: «Сотрудники», «Поставщики», «Покупатели». Каждую таблицу будут формировать свои столбцы и строки.
Так таблица «Сотрудники» может включать столбцы «ФИО», «Должность», «Зарплата». Каждая строка этой таблицы будет содержать сведения об одном человеке. Так создаются таблицы в базах данных. Каждая строка называется записью, каждая ячейка строки – полем. Содержание конкретного поля определяется его столбцом.
Следующий вопрос: где хранить таблицы? Очевидно в файлах или даже одном файле. Например, мы можем открыть Excel или другой табличный процессор и заполнить несколько таблиц. Получится база данных. Нужно ли что-то еще?
Например, мы можем открыть Excel или другой табличный процессор и заполнить несколько таблиц. Получится база данных. Нужно ли что-то еще?
Представим, что есть большая база данных, скажем, предприятия. Это очень большой файл, его используют множество человек сразу, одни изменяют данные, другие выполняют поиск информации. Табличный процессор не может следить за всеми операциями и правильно их обрабатывать. Кроме того, загружать в память большую БД целиком – не лучшая идея.
Здесь требуется программное обеспечение с другими возможностями. ПО для работы с базами данных называют системами управления базами данных, то есть СУБД.
Таким образом, у нас должен быть файл определенной структуры, содержащий базу данных, а также ПО, обеспечивающее работу с этим файлом.
Стандартным общепринятым языком для описания баз данных и выполнения к ним запросов является язык SQL.
С другой стороны, существует большое количество различных СУБД. Например: SQLite, MySQL, PostgreSQL и другие. Каждая из них имеет некоторые отличия от других, в результате чего накладывает небольшую специфику на используемый SQL, формируя его диалект.
Каждая из них имеет некоторые отличия от других, в результате чего накладывает небольшую специфику на используемый SQL, формируя его диалект.
Таким образом, изучая работу с базами данных, вы, с одной стороны, изучаете универсальный SQL, с другой – приобретаете опыт работы с конкретной СУБД. При этом в последствии перейти с одной СУБД на другую относительно легко.
Теперь вернемся к вопросу о том, что такое реляционная базы данных (РБД). Слово «реляция» происходит от «relation», то есть «отношение». Это означает, что в РБД существуют механизмы установления связей между таблицами. Делается это с помощью так называемых первичных и внешних ключей.
Допустим, мы разрабатываем базу данных для сайта. Одна из таблиц будет содержать сведения о страницах сайта. Вторая таблица будет содержать описание разделов сайта. Каждая строка-запись первой таблицы должна в одном из своих полей содержать указание на раздел, к которому принадлежит описываемая этой записью страница.
Таким образом, мы разделяем разные сущности (страницы и разделы) по таблицам, но устанавливаем между ними связь.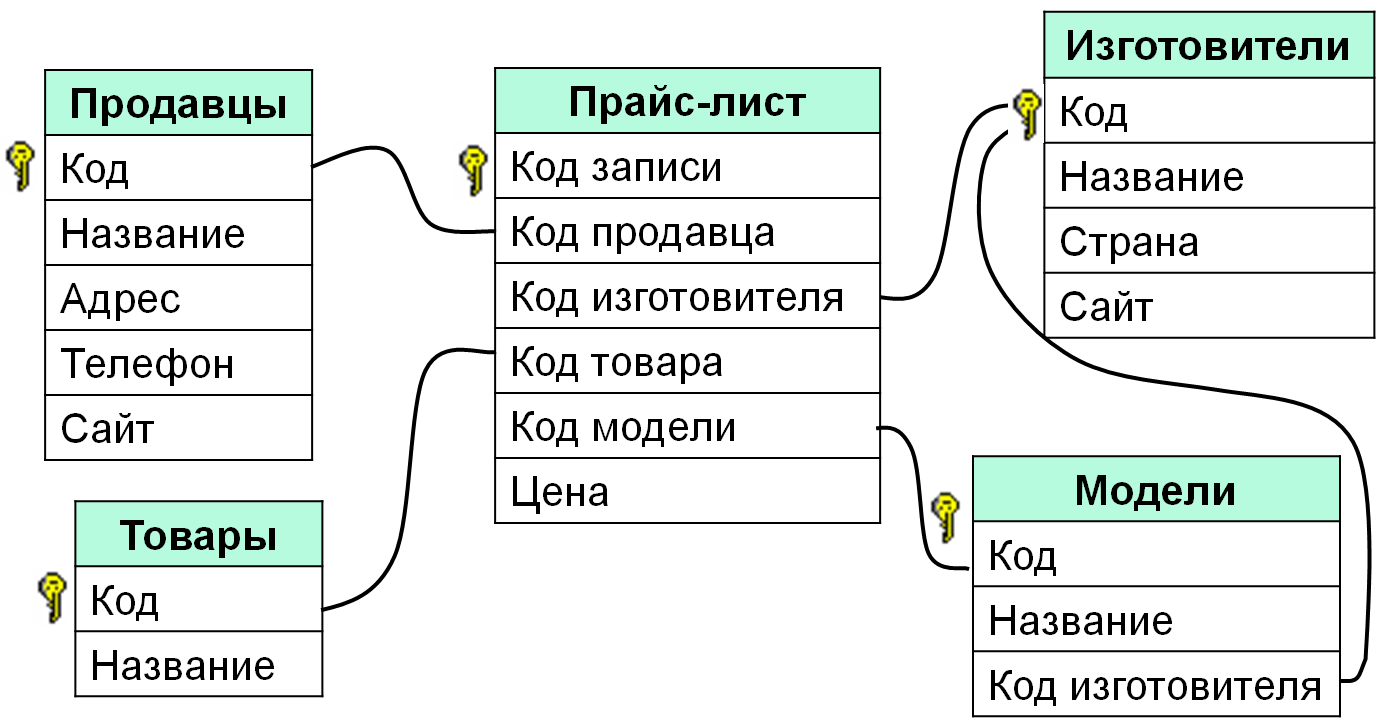 В последствии используя язык SQL мы сможем, например, создать запрос, который извлечет сведения о конкретном разделе и принадлежащих ему страницах. Хотя такой таблицы исходно нет.
В последствии используя язык SQL мы сможем, например, создать запрос, который извлечет сведения о конкретном разделе и принадлежащих ему страницах. Хотя такой таблицы исходно нет.
Существуют определенные правила создания реляционных баз данных, их нормализации в основном с целью устранения избыточности. Теория разработки РБД – это целая наука.
Хранение информации в базах данных дает преимущество не только с точки зрения обеспечения к ним быстрого доступа множества процессов. Базы данных, особенно реляционные, позволяют структурировать данные, манипулирования ими и легко наращивать объем.
Можно сказать, что в одной таблице содержатся ассоциированные данные, а в разных таблицах одной БД находятся связанные данные.
Реляционные базы данных | Computerworld Россия
Реляционные базы данных позволяют хранить информацию в нескольких «плоских» (двухмерных) таблицах, связанных между собой посредством совместно используемых полей данных, называемых ключами.
Определение
Реляционные базы данных позволяют хранить информацию в нескольких «плоских» (двухмерных) таблицах, связанных между собой посредством совместно используемых полей данных, называемых ключами. Реляционные базы данных предоставляют более простой доступ к оперативно составляемым отчетам (обычно через SQL) и обеспечивают повышенную надежность и целостность данных благодаря отсутствию избыточной информации
Всем известно, что представляет собой простая база данных: телефонные справочники, каталоги товаров и словари — все это базы данных. Они могут быть структурированными или организованными каким-то иным образом: как плоские файлы, как иерархические или сетевые структуры или как реляционные таблицы. Чаще всего в организациях для хранения информации используются именно реляционные базы данных.
База данных — это набор таблиц, состоящих из столбцов и строк, аналогично электронной таблице. Каждая строка содержит одну запись; каждый столбец содержит все экземпляры конкретного фрагмента данных всех строк. Например, обычный телефонный справочник состоит из столбцов, содержащих телефонные номера, имена абонентов и адреса абонентов. Каждая строка содержит номер, имя и адрес. Эта простая форма называется плоским файлом в силу его двухмерной природы, а также того, что все данные хранятся в одном файле.
Например, обычный телефонный справочник состоит из столбцов, содержащих телефонные номера, имена абонентов и адреса абонентов. Каждая строка содержит номер, имя и адрес. Эта простая форма называется плоским файлом в силу его двухмерной природы, а также того, что все данные хранятся в одном файле.
В идеале каждая база данных имеет по крайней мере один столбец с уникальным идентификатором, или ключом. Рассмотрим телефонную книгу. В ней может быть несколько записей с абонентом Джон Смит, но ни один из телефонных номеров не повторяется. Телефонный номер и служит ключом.
На самом деле все не так просто. Два или несколько человек, использующих один и тот же телефонный номер, могут быть перечислены в телефонном справочнике по отдельности, в силу чего телефонный номер появляется в двух или более местах, поэтому существует несколько строк с ключами, которые не являются уникальными.
Данные создают проблемы
В самых простых базах данных каждая запись занимает одну строку, иными словами, телефонной компании необходимо заводить отдельный столбец для каждого фрагмента бухгалтерской информации.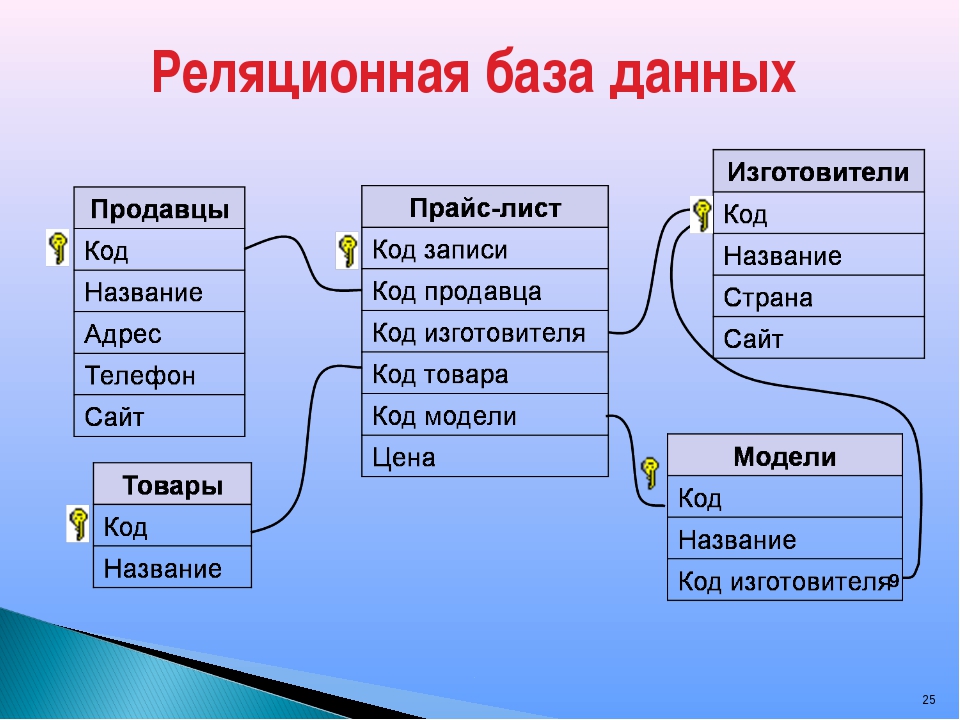 То есть одну — для второго абонента «спаренного» телефона, еще одну — для третьего и т. д., в зависимости от того, сколько дополнительных абонентов понадобится.
То есть одну — для второго абонента «спаренного» телефона, еще одну — для третьего и т. д., в зависимости от того, сколько дополнительных абонентов понадобится.
Это значит, что каждая запись в базе данных должна иметь все эти дополнительные колонки, даже если больше они нигде не используются. Это также означает, что база данных должна быть реорганизована всякий раз, когда компания предлагает новую услугу. Вводится обслуживание тонального набора — и меняется структура базы, поскольку добавляется новая колонка. Вводится поддержка идентификации номера звонящего абонента, ожидания звонка и т. д. — и база данных перестраивается снова и снова.
В 60-е годы только самые крупные компании могли позволить себе приобретать компьютеры для управления своими данными. Более того, базы данных, построенные на статических моделях данных и с помощью процедурных языков программирования, таких как Кобол, могут оказаться слишком дорогими в том, что касается поддержки, и не всегда надежными. Процедурные языки определяют последовательность событий, через которую компьютер должен пройти, чтобы выполнить задачу. Программирование таких последовательностей было сложным делом, особенно если требовалось менять структуру базы данных или составлять новый вид отчетов.
Программирование таких последовательностей было сложным делом, особенно если требовалось менять структуру базы данных или составлять новый вид отчетов.
Мощные связи
Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных.
Эта модель работает следующим образом. Телефонная компания может создать основную таблицу, используя в качестве первичного ключа номер телефона, и хранить его с другой базовой информацией о потребителях. Компания может определить отдельную таблицу со столбцами для этого первичного ключа и для дополнительных служб, таких как поддержка идентификации номера звонящего абонента и ожидание звонка. Она также может создать еще одну таблицу для контроля счетов за переговоры, где каждая запись состоит из номера телефона и данных об оплате звонков.
Компания может определить отдельную таблицу со столбцами для этого первичного ключа и для дополнительных служб, таких как поддержка идентификации номера звонящего абонента и ожидание звонка. Она также может создать еще одну таблицу для контроля счетов за переговоры, где каждая запись состоит из номера телефона и данных об оплате звонков.
Конечные пользователи могут легко получить ту информацию, которую они хотят, и в том виде, в каком она им требуется, хотя эти данные хранятся в различных таблицах. Поэтому представитель службы поддержки потребителей телефонной компании может отобразить на одном и том же экране информацию о счетах абонента, а также о состоянии специальных служб или о том, когда была получена последняя оплата.
Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним. Первые два достаточно понятны даже пользователям, не обладающим техническими навыками.
Правило 1, информационное правило, указывает, что вся информация в реляционной базе данных представляется как набор значений, хранящихся в таблицах.
Правило 2, правило гарантии доступа, определяет, что доступ к каждому элементу данных в реляционной базе данных можно получить с помощью имени таблицы, первичного ключа и названия столбца. Другими словами, все данные хранятся в таблицах, и, если известно название таблицы, первичный ключ и столбец, где находится требуемый элемент данных, его всегда можно извлечь.
Суть работы Кодда заключалась в том, что предлагалось с реляционными базами данных использовать декларативные, а не процедурные языки программирования. Декларативные языки, такие как язык запросов SQL (Structured Query Language), дают пользователям возможность, по существу, сообщить компьютеру: «Я хочу получить следующие биты данных из всех записей, которые удовлетворяют определенному набору критериев». Компьютер сам «поймет», какие необходимо совершить шаги, чтобы получить эту информацию из базы данных.
Для работы с огромным количеством активно используемых баз данных применяются программные системы управления реляционными базами данных, созданные такими авторитетными производителями, как Oracle, Sybase, IBM, Informix и Microsoft.
Хотя большую часть вариантов реализаций SQL можно назвать интероперабельными лишь с известным приближением, этот утвержденный в качестве международного стандарта механизм позволяет создавать сложные системы, основу которых составляют базы данных. Удобный для программирования интерфейс между Web-сайтами и реляционными базами данных дает конечным пользователям возможность добавлять новые записи и обновлять существующие, а также создавать отчеты для самых разных служб, таких как выполнение интерактивных торговых операций и доступ к интерактивным библиотечным каталогам.
Реляционная модель
Реляционная база данных использует набор таблиц, связанных друг с другом посредством определенного ключа (в данном случае это поле PhoneNumber)
языковой агностик — Внедрение базы данных — С чего начать
Поскольку принятый ответ предлагает только (хорошие) ссылки на другие ресурсы, я решил поделиться своим опытом написания webdb, небольшой экспериментальной базы данных для браузеров. Я также приглашаю вас прочитать исходный код. Он довольно маленький. Вы должны быть в состоянии прочитать его и получить общее представление о том, что он делает за пару часов. Предупреждение : Я ноль в этом, и с тех пор, как я это написал, я узнал об этом намного больше и вижу, что делаю некоторые вещи неправильно. Тем не менее, это может помочь вам начать.
Я также приглашаю вас прочитать исходный код. Он довольно маленький. Вы должны быть в состоянии прочитать его и получить общее представление о том, что он делает за пару часов. Предупреждение : Я ноль в этом, и с тех пор, как я это написал, я узнал об этом намного больше и вижу, что делаю некоторые вещи неправильно. Тем не менее, это может помочь вам начать.
Я начал с адаптации дерева AVL в соответствии со своими потребностями. Дерево AVL — это разновидность самобалансирующегося бинарного дерева поиска. Вы сохраняете ключ K и связанные данные (если есть) в узле, затем все элементы с ключом < K в узле в левом поддереве и все элементы с ключом > K в правом поддерево. Вы можете использовать массив для хранения элементов данных, если хотите поддерживать неуникальные ключи.
Это дерево даст вам основы: Создать , Обновить , Удалить и способ быстро получить элемент по ключу или все элементы с ключом < x или с ключом между x и y и т. д. Он может служить индексом для нашей таблицы.
д. Он может служить индексом для нашей таблицы.
В качестве следующего шага я написал код, который позволяет клиентскому коду определять схему. Такие методы, как createTable() и т. д. Схемы обычно связаны с SQL, но даже не-SQL имеет схему; они обычно требуют, чтобы вы отметили поле идентификатора и любые другие поля, по которым вы хотите выполнить поиск. Вы можете сделать свою схему настолько причудливой, насколько хотите, но обычно вы хотите смоделировать, по крайней мере, какие столбцы служат первичным ключом и какие поля будут часто выполняться и нуждаются в индексе.
Я решил использовать созданное на первом этапе дерево для хранения своих предметов. Это были простые объекты JS. Определив, какое поле содержит PK, я мог бы просто вставить элемент в дерево, используя значение этого поля в качестве ключа. Это дает мне быстрый поиск по идентификатору (диапазон).
Затем я добавил еще одно дерево для каждого столбца, которому нужен индекс. В этих деревьях я хранил не полную запись, а только ключ. Таким образом, чтобы получить клиента по фамилии, я бы сначала использовал индекс по фамилии, чтобы получить идентификатор, а затем индекс первичного ключа, чтобы получить фактическую запись. Причина, по которой я не просто сохранил (ссылку на) фактический объект, заключается в том, что это немного упрощает операции над множествами (см. следующий шаг)
Таким образом, чтобы получить клиента по фамилии, я бы сначала использовал индекс по фамилии, чтобы получить идентификатор, а затем индекс первичного ключа, чтобы получить фактическую запись. Причина, по которой я не просто сохранил (ссылку на) фактический объект, заключается в том, что это немного упрощает операции над множествами (см. следующий шаг)
Теперь, когда у нас есть таблица с индексами для PK и полей поиска, мы можем реализовать запросы. Я не заходил слишком далеко, так как это быстро усложняется, но вы можете получить хорошую функциональность, используя только некоторые основы. WebDB не реализует соединения; все запросы работают только с одной таблицей. Но как только вы это поймете, вы увидите довольно четкий (хотя и длинный и извилистый) путь к выполнению объединений и других сложных вещей.
В WebDB, чтобы получить всех клиентов с firstName = 'John' и city = 'Нью-Йорк' (при условии, что это два поля поиска), вы должны написать что-то вроде:
var webDb = ... var johnsFromNY = webDb.customers.get({ имя: 'Джон', город: "Нью-Йорк" })
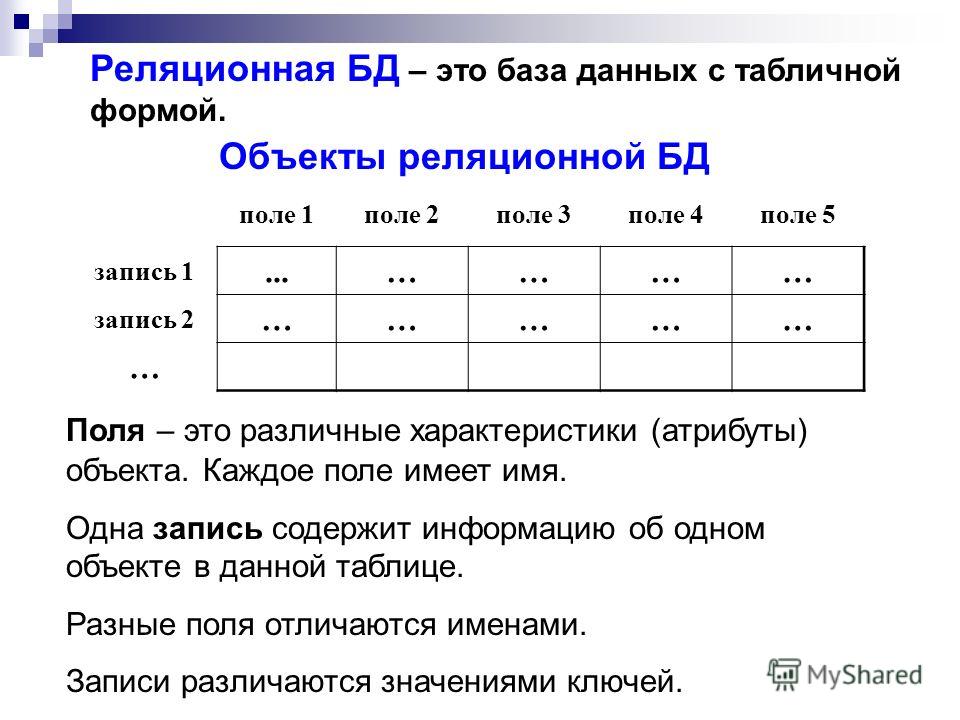 ..
var johnsFromNY = webDb.customers.get({
имя: 'Джон',
город: "Нью-Йорк"
})
..
var johnsFromNY = webDb.customers.get({
имя: 'Джон',
город: "Нью-Йорк"
})
Чтобы решить эту проблему, мы сначала делаем два поиска: мы получаем набор X всех идентификаторов клиентов с именем «Джон» и мы получаем набор Y всех идентификаторов клиентов из Нью-Йорка. Затем мы выполняем пересечение этих двух наборов, чтобы получить все идентификаторы клиентов с именами «Джон» 9.0004 И из Нью-Йорка. Затем мы проходим через наш набор полученных идентификаторов, получая фактическую запись для каждого из них и добавляя ее в массив результатов.
Используя операторы множества, такие как объединение и пересечение, мы можем выполнять поиск И и ИЛИ . Я реализовал только И .
Выполнение соединений будет (я думаю) включать создание временных таблиц в памяти, затем заполнение их объединенными результатами по мере выполнения запроса, а затем применение критериев запроса к временной таблице. Я так и не попал туда. Затем я попытался использовать некоторую логику синхронизации, но это было слишком амбициозно, и дальше все пошло под откос 🙂
Затем я попытался использовать некоторую логику синхронизации, но это было слишком амбициозно, и дальше все пошло под откос 🙂
Пять шагов по выбору и внедрению базы данных
Недостаточно знать, какой тип базы данных вам подойдет. Вам также необходимо тщательно продумать, как найти подходящую базу данных для ваших нужд и как обеспечить ее бесперебойную работу. Выполните следующие пять шагов, чтобы убедиться, что вы успешно выбрали и внедрили правильную базу данных для своей организации.
Независимо от того, какой тип базы данных вы рассматриваете, первым важным шагом является определение ваших потребностей. Для незначительной покупки этот шаг может потребовать быстрой беседы с другими сотрудниками, но для крупной, критически важной части программного обеспечения это может занять месяцы работы.
Взгляните на систему, которую вы сейчас используете. Насколько это соответствует вашим потребностям? Какого функционала не хватает? Поговорите с поставщиком вашей текущей системы и узнайте, можно ли ее улучшить, расширить или настроить для удовлетворения всех ваших требований. Использование существующих систем экономит время, деньги и нервы, связанные с выбором, установкой и изучением совершенно нового приложения.
Использование существующих систем экономит время, деньги и нервы, связанные с выбором, установкой и изучением совершенно нового приложения.
Обязательно поговорите со всеми в вашей организации, кто будет использовать базу данных, чтобы составить список необходимых функций. Таким образом, вы можете оценить свои текущие и новые системы на основе потребностей людей, которые их используют. Понимание потребностей ваших пользователей с самого начала будет иметь большое значение для получения согласия и принятия позже в процессе.
Если вам нужна новая система управления базами данных, следующим шагом будет создание короткого списка, чтобы отсеять все возможные варианты в управляемый список. Для небольшой покупки это может означать простое общение с несколькими людьми и выбор одного пакета для дальнейшего изучения. Но если вы вкладываете больше средств, вам нужно изучить более подробно и определить список из трех-пяти вариантов программного обеспечения.
Такие веб-сайты, как Idealware и TechSoup, являются хорошим местом для начала исследования. Кроме того, поговорите с аналогичными некоммерческими организациями, чтобы узнать, что они используют. Это может быть полезным способом увидеть преимущества и недостатки различных вариантов базы данных, специфичных для вашей организации.
Кроме того, поговорите с аналогичными некоммерческими организациями, чтобы узнать, что они используют. Это может быть полезным способом увидеть преимущества и недостатки различных вариантов базы данных, специфичных для вашей организации.
Если вы хотите приобрести достаточно сложную систему, вы можете подумать о привлечении консультанта, который проверит возможности вашей текущей системы и потребности вашей организации и подберет для вас подходящее решение.
Следующим шагом будет оценка различных вариантов базы данных из вашего списка. Вы же не станете покупать машину, не протестировав ее, не так ли? Опробуйте каждую систему отдельно или попросите поставщиков продемонстрировать их.
Большинство поставщиков с радостью предоставят пробную или демонстрационную версию своего продукта через Интернет, что позволит легко увидеть их системы в действии. Если поставщик проведет для вас экскурсию, потратьте некоторое время заранее, чтобы определить конкретные функции и функции, которые вы хотите увидеть, и заранее отправить их поставщику.
Ваша организация будет поддерживать отношения с поставщиком в течение нескольких лет, поэтому найдите время, чтобы найти не только базу данных, подходящую для вашей организации, но и поставщика, который будет вам близок. В конечном итоге важнее всего способность инструмента, который вы выбираете, удовлетворять ваши потребности и быть управляемой затратой как на начальном этапе, так и с течением времени.
После того, как вы выбрали свою базу данных, вы сделали только половину — вам еще нужно ее внедрить. В зависимости от типа выбранной вами системы вам, возможно, придется подумать о переносе данных или переносе их из старых систем в новые. Это редко бывает легким шагом, и он требует тщательного рассмотрения и планирования.
Кроме того, какой бы замечательной ни была ваша новая система, она бесполезна для вас, если никто не знает, как ею пользоваться. Таким образом, какой бы большой или маленькой ни была ваша новая система, запланируйте обучение и вспомогательный персонал. К кому им обращаться с вопросами? Что они должны делать — или не делать — с системой?
К кому им обращаться с вопросами? Что они должны делать — или не делать — с системой?
Этот шаг необходим для максимального принятия пользователями. Если вы внедрили систему, отвечающую их потребностям, и обучили их ее использованию, вы обнаружите, что пользователи вашей организации будут гораздо более удовлетворены выбранным вами программным обеспечением.
Ни одна система не будет поддерживать себя, особенно та, в которой есть данные. Забота о ваших данных означает установление политик, обеспечивающих их чистоту и работоспособность, а также легкий доступ к необходимой информации из системы. Лучший способ сделать данные полезными — сделать это с самого начала: о чем следует думать персоналу при вводе записей? Кто будет контролировать качество данных?
Помогите своим сотрудникам узнать, что и когда вводить, и определите шаги, чтобы ваши данные были чистыми и пригодными для использования, когда кто-то пытается что-то найти. Также важно периодически проверять свои данные и исправлять любые ошибки, которые могли проскользнуть.
Выполните следующие пять шагов при внедрении базы данных, и вы окажетесь на верном пути к тому, чтобы стать организацией, управляемой данными!
10 вопросов, которые необходимо задать при рассмотрении вопроса о новой CRM
Мишель Регал
Операционный директор Now IT Matters
Мишель является операционным директором Now IT Matters и сертифицированным администратором и разработчиком Salesforce. Ранее она администрировала базы данных Eloqua и Salesforce для PBS и оказывала поддержку станциям-участникам PBS при внедрении пользовательской страницы пожертвований Visualforce. До прихода в PBS она более четырех лет была менеджером программ в BRAC USA, в течение которых она оказывала маркетинговую поддержку и разрабатывала онлайн-стратегию, стратегию в социальных сетях и традиционных СМИ для крупнейшей неправительственной организации в мире. Кроме того, она внедрила и поддерживала несколько баз данных Salesforce и других CRM, а также разработала многоканальные стратегии привлечения и удержания доноров.