Содержание
Что такое реляционная база данных?
Как работают реляционные базы данных, как осуществляется управление ими с помощью систем управления реляционными базами данных
Что такое реляционная база данных?
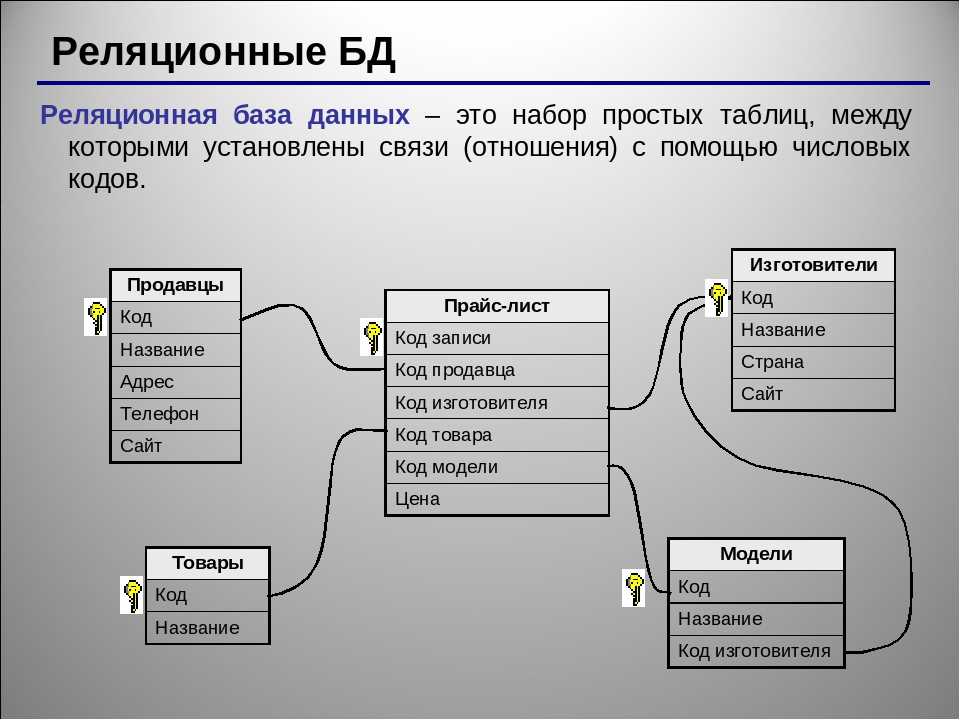
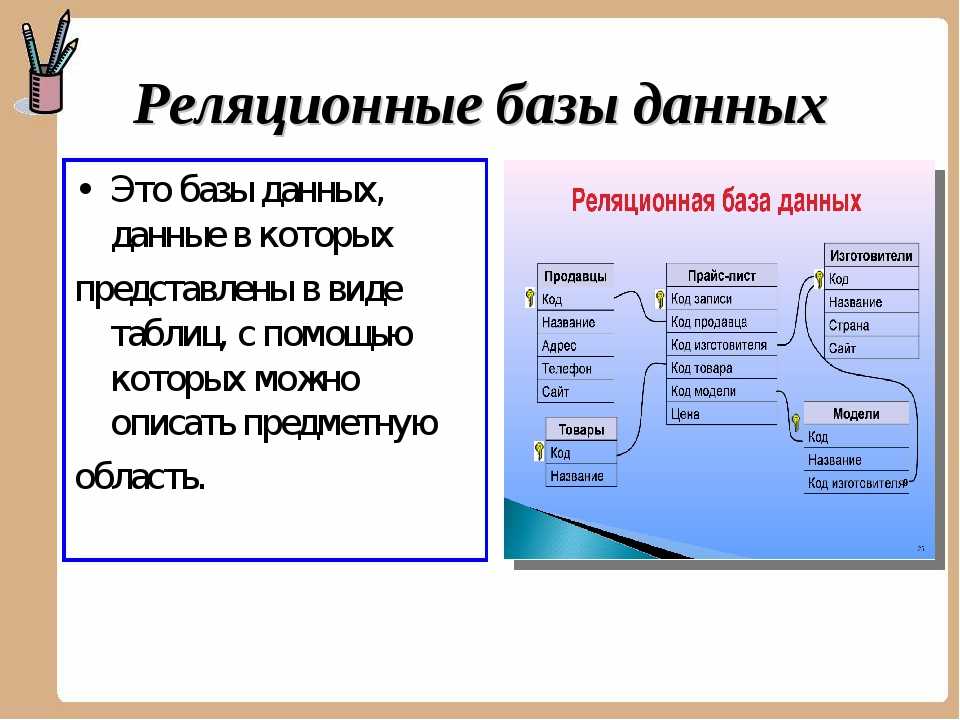
Реляционные базы данных — это базы данных, предназначенные для хранения и организации точек данных с заданными отношениями для быстрого доступа. Данные в реляционных базах данных упорядочиваются в виде таблиц, которые содержат информацию о каждой сущности и представляют заданные заранее категории с помощью строк и столбцов. Такое структурирование данных повышает эффективность и гибкость доступа, поэтому реляционные базы данных — наиболее распространенный тип баз данных. Реляционные базы данных поддерживают язык SQL. Это стандартизированный язык программирования, применяемый для хранения, обработки и получения данных. В рамках SQL существует встроенный язык для создания таблиц (DDL — язык описания данных) и язык для обработки данных (DML — язык обработки данных).
Что означает понятие «реляционный»? Это слово означает указание на отношение или наличие отношения. В контексте баз данных понятие «реляционный» относится главным образом к самим данным. Реляционные наборы данных обладают заранее заданными отношениями между собой. Например, база данных, содержащая сведения о клиентах компании, также может содержать данные об отдельных транзакциях, связанных с каждым счетом. Основное внимание в реляционных базах данных уделяется отношениям между хранящимися элементами данных.
Характеристики реляционных баз данных:
- Базы данных состоят из множества сущностей
- Стандартным интерфейсом является язык SQL
- Высокая структурированность, представление с помощью схемы (логической и физической)
- Снижение избыточности данных
Как работают реляционные базы данных
Реляционные базы данных обычно используют таблицы с данными, упорядоченными в виде строк (с сущностями) и столбцов (с атрибутами сущностей). Процесс упорядочения данных в таблицах называется нормализацией. Каждая строка содержит уникальный идентификатор или ключ, связывающий таблицы для установления отношения между ними. При отправке запроса к реляционной базе данных ключ используется для поиска связанных данных в разных наборах данных. Например, службе технической поддержки может потребоваться отслеживать взаимодействие клиентов по следующим характеристикам: тип проблемы, время решения проблемы, уровень удовлетворенности клиента. Все три характеристики объединяет идентификатор клиента: он позволяет создавать отношения и обеспечивает эффективную работу табличной структуры.
Процесс упорядочения данных в таблицах называется нормализацией. Каждая строка содержит уникальный идентификатор или ключ, связывающий таблицы для установления отношения между ними. При отправке запроса к реляционной базе данных ключ используется для поиска связанных данных в разных наборах данных. Например, службе технической поддержки может потребоваться отслеживать взаимодействие клиентов по следующим характеристикам: тип проблемы, время решения проблемы, уровень удовлетворенности клиента. Все три характеристики объединяет идентификатор клиента: он позволяет создавать отношения и обеспечивает эффективную работу табличной структуры.
Подробнее о базах данных
Примеры реляционных баз данных
Реляционные базы данных эффективны для любой информации, в которых точки данных связаны друг с другом и нуждаются в согласованном и безопасном управлении на основе правил. Именно поэтому такие базы данных чаще всего применяются коммерческими компаниями и предприятиями.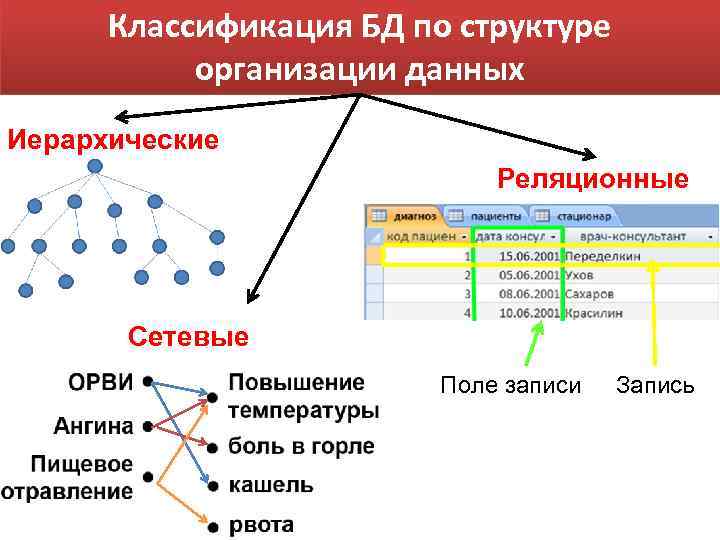 Когда компании анализируют собственные данные, они применяют реляционные базы данных для получения аналитических данных. Отчеты, создаваемые коммерческими компаниями для отслеживания складских запасов, финансов, продаж или для подготовки прогнозов на будущее, во многих случаях создаются с помощью реляционных баз данных.
Когда компании анализируют собственные данные, они применяют реляционные базы данных для получения аналитических данных. Отчеты, создаваемые коммерческими компаниями для отслеживания складских запасов, финансов, продаж или для подготовки прогнозов на будущее, во многих случаях создаются с помощью реляционных баз данных.
Как упорядочены данные в реляционных базах данных? Для хранения, поиска и получения данных в реляционных базах данных используются таблицы с отношениями между ними. В реляционных базах данных схема базы данных определяет как логическую, так и физическую организацию данных.
Реляционные базы данных обладают так называемым режимом согласованности или целостности, который опирается на четыре свойства: атомарность, согласованность, изоляция и устойчивость. Ниже описывается значение всех этих четырех свойств.
- Атомарность определяет элементы, образующие полную транзакцию.
- Согласованность определяет правила поддержания целостности данных после транзакций.

- Благодаря изоляции эффекты транзакций являются невидимыми для других транзакций, чтобы не возникало конфликтов между ними.
- Устойчивость означает постоянство изменений данных после каждой зафиксированной транзакции.
Благодаря этим свойствам реляционные базы данных эффективно работают в решениях, где требуется высокая точность, например в транзакциях в финансовой сфере и в розничной торговле. Эта сфера называется оперативной обработкой транзакций (OLTP). Финансовые организации применяют базы данных для отслеживания огромного количества транзакций клиентов: от запросов выписки по счету до перевода средств между счетами. Реляционные базы данных идеально подходят для применения в банковской сфере, поскольку такие базы данных поддерживают значительное количество клиентов, поддерживают частые изменения данных в транзакциях и обладают малым временем отклика.
К реляционным базам данных относятся: SQL Server, Управляемый экземпляр SQL Azure, База данных SQL Azure, MySQL, PostgreSQL и MariaDB.
Что такое реляционная база данных MySQL?
MySQL — это распространенная реляционная база данных SQL с открытым кодом, выполняющая все основные команды SQL, такие как запись и запрос данных. MySQL — это надежная, стабильная и безопасная система управления базами данных (СУБД), она получила широкое распространение благодаря поддержке наиболее популярных языков программирования и протоколов. Благодаря высокой устойчивости MySQL используется в качестве основного хранилища данных во многих крупных организациях. MySQL также можно использовать в качестве встроенной базы данных для программного обеспечения, оборудования и устройств.
В MySQL обычно применяются надежные и гибкие средства безопасности, такие как проверка на основе узлов и шифрование трафика с использованием паролей. Веб-разработчики часто используют MySQL, поскольку базы данных MySQL отличаются простотой использования и содержат ряд функций для эффективной работы: обновляемые представления, хранимые процедуры и триггеры (особые процедуры, которые запускаются при выполнении определенных действий на сервере базы данных).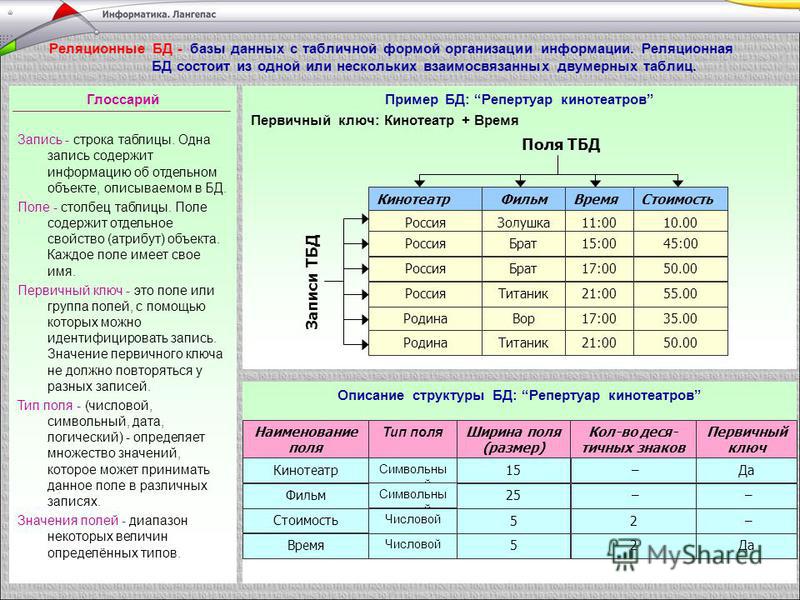 MySQL является популярной платформой транзакций для электронной коммерции, поскольку MySQL прекрасно подходит для управления транзакциями, профилями пользователей и данными о складских запасах товаров. Среди преимуществ MySQL — высокий уровень совместимости с другими системами, а также поддержка развертывания в средах с виртуализацией, например на облачных платформах.
MySQL является популярной платформой транзакций для электронной коммерции, поскольку MySQL прекрасно подходит для управления транзакциями, профилями пользователей и данными о складских запасах товаров. Среди преимуществ MySQL — высокий уровень совместимости с другими системами, а также поддержка развертывания в средах с виртуализацией, например на облачных платформах.
Что такое реляционная система управления базами данных?
Реляционные базы данных предназначены для управления значительными объемами критически важных для бизнеса данных клиентов. Тем не менее, по мере увеличения объема данных повышается сложность баз данных, становится труднее хранить данные в упорядоченном, доступном и безопасном состоянии. Для решения этой проблемы применяются системы управления базами данных (СУБД): они добавляют к реляционным таблицам уровень средств управления. Существуют разные структуры баз данных и разные системы управления, в которых доступны разные уровни организации, масштабируемости и применения.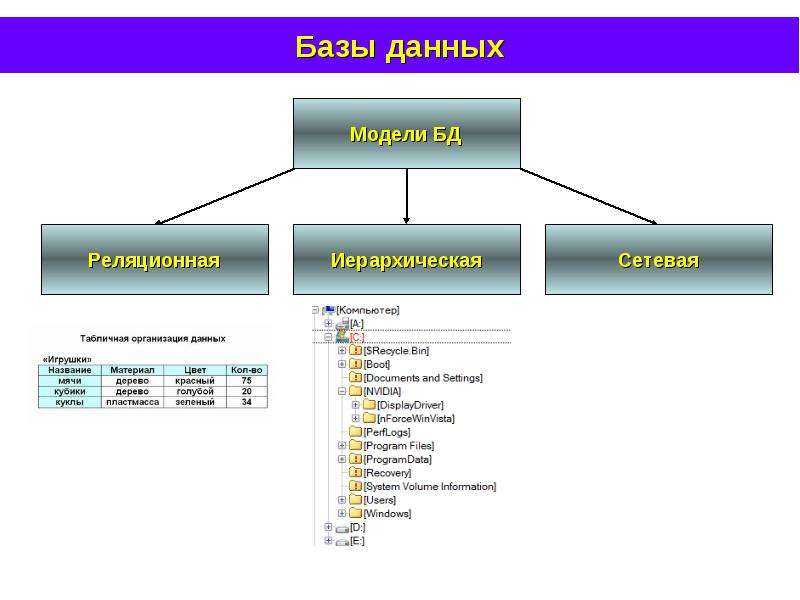 Когда администраторы работают с крупными объемами структурированных и неструктурированных данных (большие данные) в реальном времени, системы управления реляционными базами данных помогают анализировать и обобщать данные, чтобы обнаруживать заранее заданные отношения. Управление данных с помощью реляционных СУБД наиболее выгодно для бизнеса, поскольку дает возможность сделать более управляемыми данные, использующиеся несколькими приложениями или расположенные в разных местах.
Когда администраторы работают с крупными объемами структурированных и неструктурированных данных (большие данные) в реальном времени, системы управления реляционными базами данных помогают анализировать и обобщать данные, чтобы обнаруживать заранее заданные отношения. Управление данных с помощью реляционных СУБД наиболее выгодно для бизнеса, поскольку дает возможность сделать более управляемыми данные, использующиеся несколькими приложениями или расположенные в разных местах.
Реляционные СУБД используют программное обеспечение, образующее постоянный интерфейс между пользователями, приложениями и базой данных, поэтому для пользователей данных упрощается навигация. Такой подход наиболее эффективен при работе с большими данными, поскольку объем данных определяет необходимость согласованности для пользователей, выполняющих запросы. Выбор СУБД зависит от расположения данных, от типа используемой архитектуры и от планируемого масштабирования.
Что такое реляционная модель базы данных?
Реляционная модель базы данных обычно обладает следующими характеристиками: высокая структурированность и поддержка языка программирования SQL. Многие базы данных используют реляционную модель, поскольку они предназначены для упорядочения данных и выявления отношений между основными точками данных, чтобы упрощать сортировку и поиск информации. В большинстве реляционных моделей используется традиционная табличная структура со столбцами и строками: это эффективный, интуитивный и гибкий способ хранения структурированных данных. Реляционная модель также решает проблему наличия множества произвольных структур данных в базах данных.
Многие базы данных используют реляционную модель, поскольку они предназначены для упорядочения данных и выявления отношений между основными точками данных, чтобы упрощать сортировку и поиск информации. В большинстве реляционных моделей используется традиционная табличная структура со столбцами и строками: это эффективный, интуитивный и гибкий способ хранения структурированных данных. Реляционная модель также решает проблему наличия множества произвольных структур данных в базах данных.
Масштаб моделей реляционных баз данных может различаться в самых широких пределах: от небольших решений на настольных компьютерах до крупных облачных систем. Такие модели используют базы данных SQL или способны обрабатывать инструкции SQL для работы запросов и обновлений. Реляционные модели определяются логической структурой данных (таблицы, индексы и представления) и отдельны от структур физических хранилищ (физических файлов). Согласованность данных является важнейшим признаком реляционных моделей баз данных, поскольку в таких базах данных поддерживается целостность данных между приложениями и копиями баз данных, которые также называются экземплярами.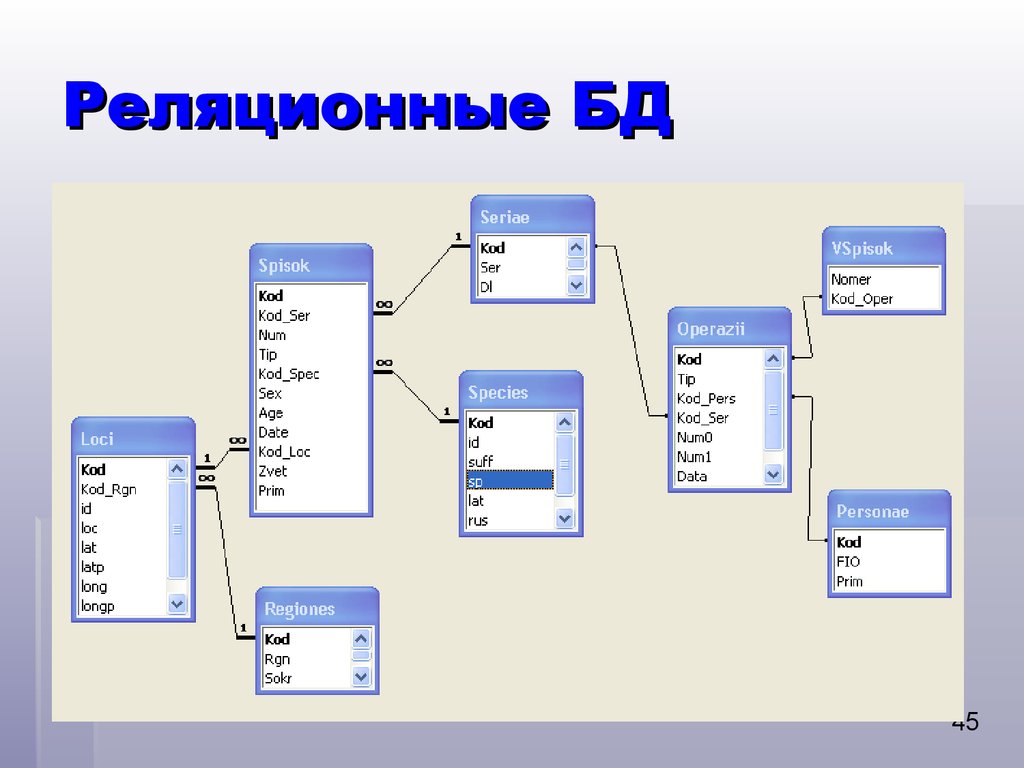 В реляционной модели базы данных экземпляры одной базы данных всегда содержат одинаковые данные.
В реляционной модели базы данных экземпляры одной базы данных всегда содержат одинаковые данные.
В реляционных базах данных, разработанных в облаке, автоматически настраивается высокая доступность, то есть производится репликация или копирование данных в несколько участников, при этом участники находятся в разных зонах доступности. Поэтому данные остаются доступными даже при отключении какого-либо центра обработки данных.
Большие данные и реляционные базы данных
Традиционные реляционные базы данных предназначены для обработки больших объемов структурированных данных. Именно поэтому реляционные базы данных прекрасно подходят для структурированных больших данных: они опираются на SQL и могут использовать СУБД для управления данными. Тем не менее, в более крупных и более сложных наборах больших данных повышается разнообразие, то есть данные, поступающие из новых источников, становятся менее структурированными. В силу этого зачастую приходится применять нереляционные базы данных (NoSQL), которые поддерживают работу с неструктурированными и с полуструктурированными данными.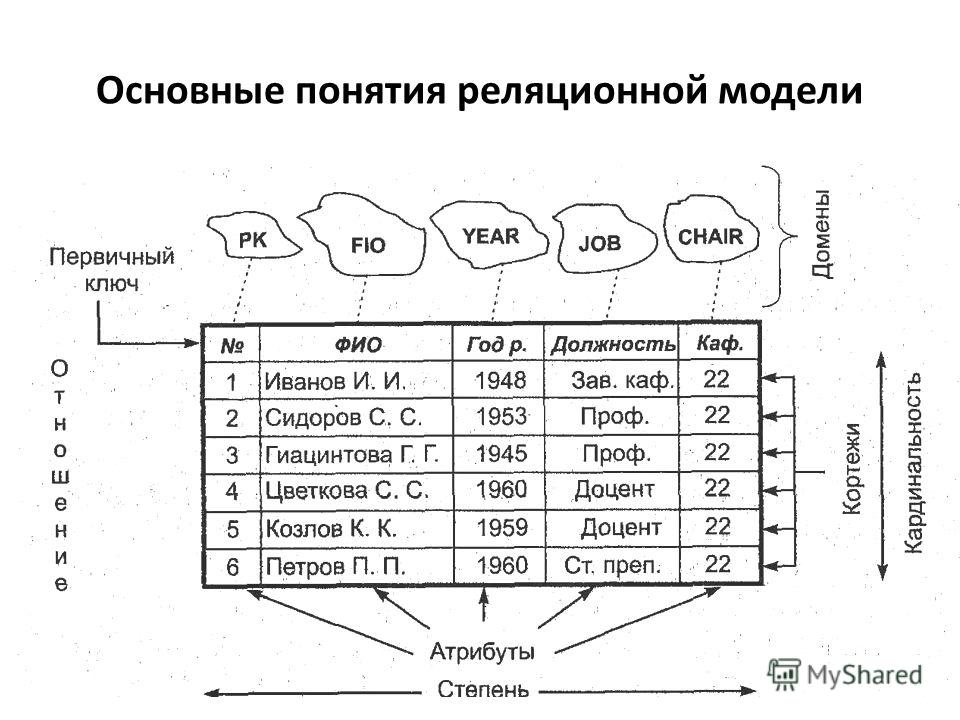
Вопросы и ответы
Реляционные базы данных обречены? / Хабр
Примечание переводчика: хоть статья довольно старая (опубликована 2 года назад) и носит громкое название, в ней все же дается хорошее представление о различиях реляционных БД и NoSQL БД, их преимуществах и недостатках, а также приводится краткий обзор нереляционных хранилищ.
В последнее время появилось много нереляционных баз данных. Это говорит о том, что если вам нужна практически неограниченная масштабируемость по требованию, вам нужна нереляционная БД.
Если это правда, значит ли это, что могучие реляционные БД стали уязвимы? Значит ли это, что дни реляционных БД проходят и скоро совсем пройдут? В этой статье мы рассмотрим популярное течение нереляционных баз данных применительно к различным ситуациям и посмотрим, повлияет ли это на будущее реляционных БД.
Реляционные базы данных существуют уже около 30 лет. За это время вспыхивало несколько революций, которые должны были положить конец реляционным хранилищам. Конечно, ни одна из этих революций не состоялась, и одна из них ни на йоту не поколебала позиции реляционных БД.
За это время вспыхивало несколько революций, которые должны были положить конец реляционным хранилищам. Конечно, ни одна из этих революций не состоялась, и одна из них ни на йоту не поколебала позиции реляционных БД.
Начнем с основ
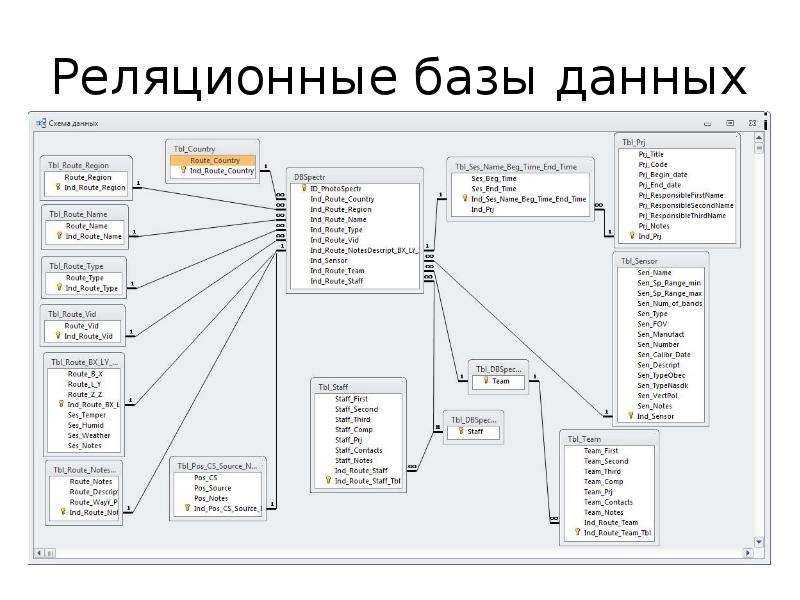
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами. Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД).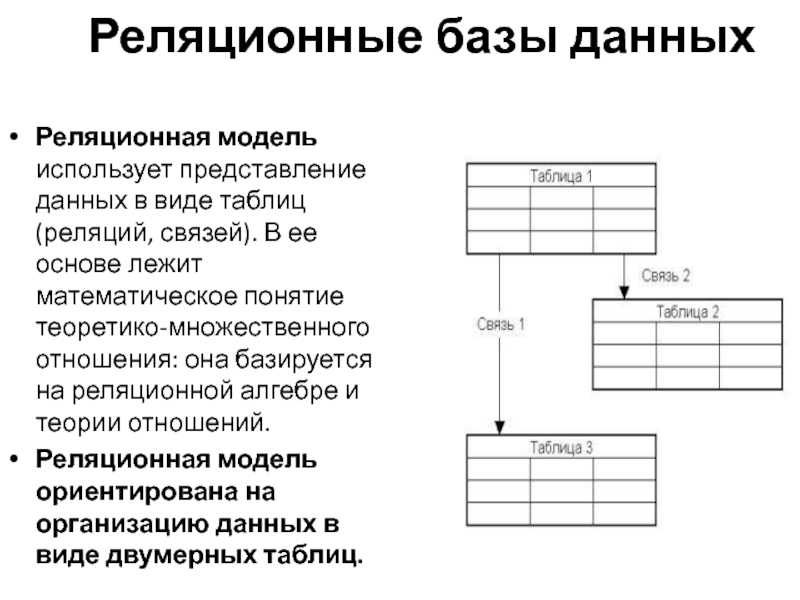 Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.
Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.
Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри. Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу.
Проблемы реляционных БД
Хотя реляционные хранилища и обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости, их показатели по каждому из этих пунктов не обязательно выше, чем у аналогичных систем, ориентированных на какую-то одну особенность. Это не являлось большой проблемой, поскольку всеобщее доминирование реляционных СУБД перевешивало какие-либо недочеты. Тем не менее, если обычные РБД не отвечали потребностям, всегда существовали альтернативы.
Это не являлось большой проблемой, поскольку всеобщее доминирование реляционных СУБД перевешивало какие-либо недочеты. Тем не менее, если обычные РБД не отвечали потребностям, всегда существовали альтернативы.
Сегодня ситуация немного другая. Разнообразие приложений растет, а с ним растет и важность перечисленных особенностей. И с ростом количества баз данных, одна особенность начинает затмевать все другие. Это масштабируемость. Поскольку все больше приложений работают в условиях высокой нагрузки, например, таких как веб-сервисы, их требования к масштабируемости могут очень быстро меняться и сильно расти. Первую проблему может быть очень сложно разрешить, если у вас есть реляционная БД, расположенная на собственном сервере. Предположим, нагрузка на сервер за ночь увеличилась втрое. Как быстро вы сможете проапгрейдить железо? Решение второй проблемы также вызывает трудности в случае использования реляционных БД.
Реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере.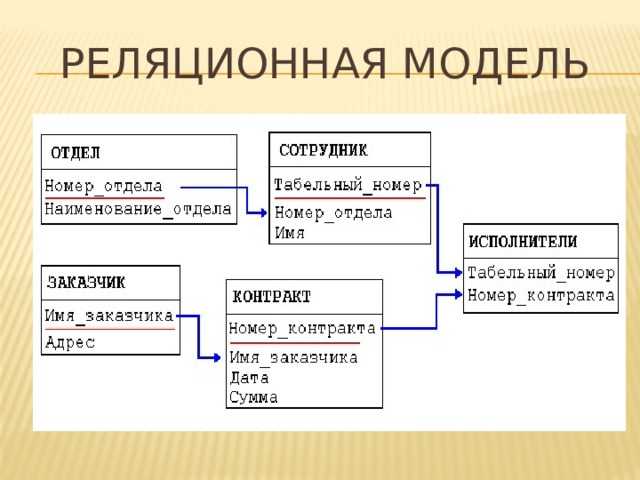 Когда ресурсы этого сервера закончатся, вам необходимо будет добавить больше машин и распределить нагрузку между ними. И вот тут сложность реляционных БД начинает играть против масштабируемости. Если вы попробуете увеличить количество серверов не до нескольких штук, а до сотни или тысячи, сложность возрастет на порядок, и характеристики, которые делают реляционные БД такими привлекательными, стремительно снижают к нулю шансы использовать их в качестве платформы для больших распределенных систем.
Когда ресурсы этого сервера закончатся, вам необходимо будет добавить больше машин и распределить нагрузку между ними. И вот тут сложность реляционных БД начинает играть против масштабируемости. Если вы попробуете увеличить количество серверов не до нескольких штук, а до сотни или тысячи, сложность возрастет на порядок, и характеристики, которые делают реляционные БД такими привлекательными, стремительно снижают к нулю шансы использовать их в качестве платформы для больших распределенных систем.
Чтобы оставаться конкурентоспособными, вендорам облачных сервисов приходится как-то бороться с этим ограничением, потому что какая ж это облачная платформа без масштабируемого хранилища данных. Поэтому у вендоров остается только один вариант, если они хотят предоставлять пользователям масштабируемое место для хранения данных. Нужно применять другие типы баз данных, которые обладают более высокой способностью к масштабированию, пусть и ценой других возможностей, доступных в реляционных БД.
Эти преимущества, а также существующий спрос на них, привел к волне новых систем управления базами данных.
Новая волна
Такой тип баз данных принято называть хранилище типа ключ-значение (key-value store). Фактически, никакого официального названия не существует, поэтому вы можете встретить его в контексте документо-ориентированных, атрибутно-ориентированных, распределенных баз данных (хотя они также могут быть реляционными), шардированных упорядоченных массивов (sharded sorted arrays), распределенных хэш-таблиц и хранилищ типа ключ-значения. И хотя каждое из этих названий указывает на конкретные особенности системы, все они являются вариациями на тему, которую мы будем назвать хранилище типа ключ-значение.
Впрочем, как бы вы его не называли, этот «новый» тип баз данных не такой уж новый и всегда применялся в основном для приложений, для которых использование реляционных БД было бы непригодно. Однако без потребности веба и «облака» в масштабируемости, эти системы оставались не сильно востребованными.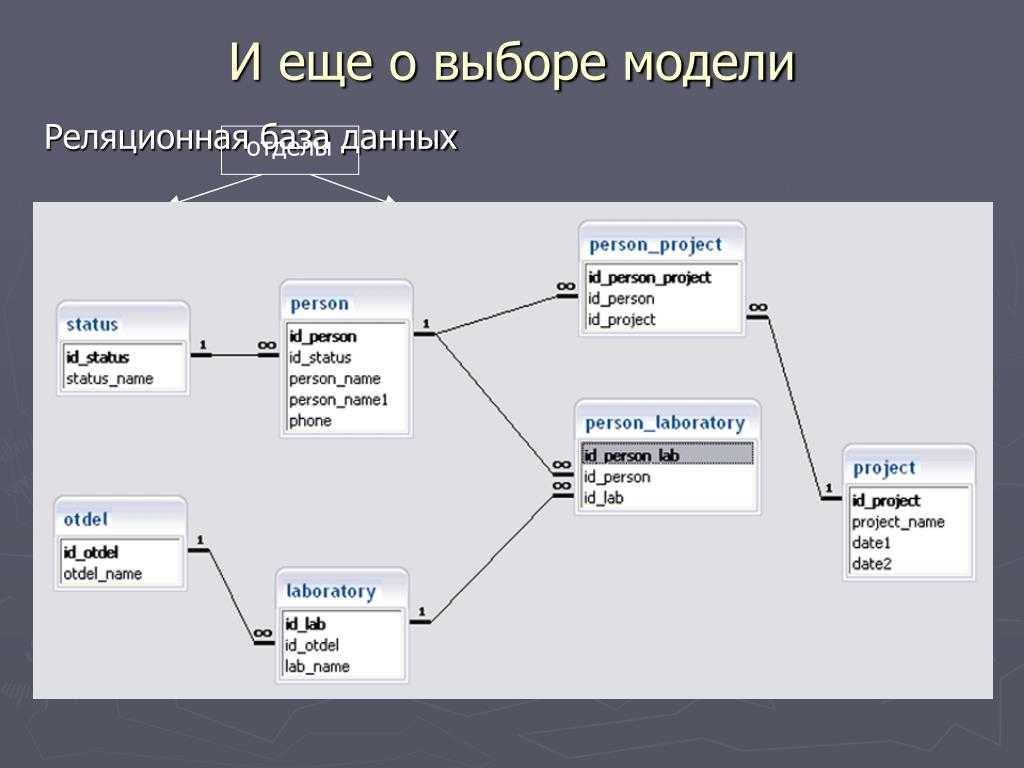 Теперь же задача состоит в том, чтобы определить, какой тип хранилища больше подходит для конкретной системы.
Теперь же задача состоит в том, чтобы определить, какой тип хранилища больше подходит для конкретной системы.
Реляционные БД и хранилища типа ключ-значение отличаются коренным образом и предназначены для решения разных задач. Сравнение характеристик позволит всего лишь понять разницу между ними, однако начнем с этого:
Характеристики хранилищ
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| База данных состоит из таблиц, таблицы содержат колонки и строки, а строки состоят из значений колонок. Все строки одной таблицы имеют единую структуру. | Для доменов можно провести аналогию с таблицами, однако в отличие от таблиц для доменов не определяется структура данных. Домен – это такая коробка, в которую вы можете складывать все что угодно. Записи внутри одного домена могут иметь разную структуру. |
Модель данных1 определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных.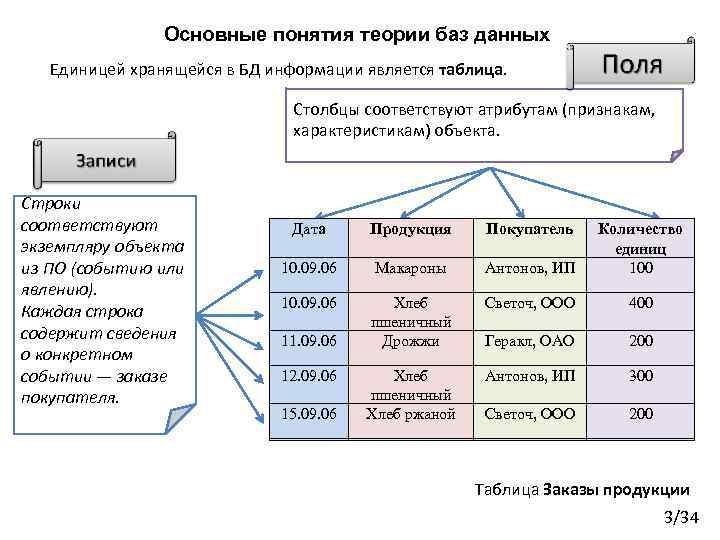 | Записи идентифицируются по ключу, при этом каждая запись имеет динамический набор атрибутов, связанных с ней. |
| Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения. | В некоторых реализация атрибуты могут быть только строковыми. В других реализациях атрибуты имеют простые типы данных, которые отражают типы, использующиеся в программировании: целые числа, массива строк и списки. |
| Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц. | Между доменами, также как и внутри одного домена, отношения явно не определены. |
Никаких join’ов
Хранилища типа ключ-значение ориентированы на работу с записями. Это значит, что вся информация, относящаяся к данной записи, хранится вместе с ней. Домен (о котором вы можете думать как о таблице) может содержать бессчетное количество различных записей. Например, домен может содержать информацию о клиентах и о заказах. Это означает, что данные, как правило, дублируются между разными доменами. Это приемлемый подход, поскольку дисковое пространство дешево. Главное, что он позволяет все связанные данные хранить в одном месте, что улучшает масштабируемость, поскольку исчезает необходимость соединять данные из различных таблиц. При использовании реляционной БД, потребовалось бы использовать соединения, чтобы сгруппировать в одном месте нужную информацию.
Домен (о котором вы можете думать как о таблице) может содержать бессчетное количество различных записей. Например, домен может содержать информацию о клиентах и о заказах. Это означает, что данные, как правило, дублируются между разными доменами. Это приемлемый подход, поскольку дисковое пространство дешево. Главное, что он позволяет все связанные данные хранить в одном месте, что улучшает масштабируемость, поскольку исчезает необходимость соединять данные из различных таблиц. При использовании реляционной БД, потребовалось бы использовать соединения, чтобы сгруппировать в одном месте нужную информацию.
Хотя для хранения пар ключ-значение потребность в отношения резко падает, отношения все же нужны. Такие отношения обычно существуют между основными сущностями. Например, система заказов имела бы записи, которые содержат данные о покупателях, товарах и заказах. При этом неважно, находятся ли эти данные в одном домене или в нескольких. Суть в том, что когда покупатель размещает заказ, вам скорее всего не захочется хранить информацию о покупателе и о заказе в одной записи.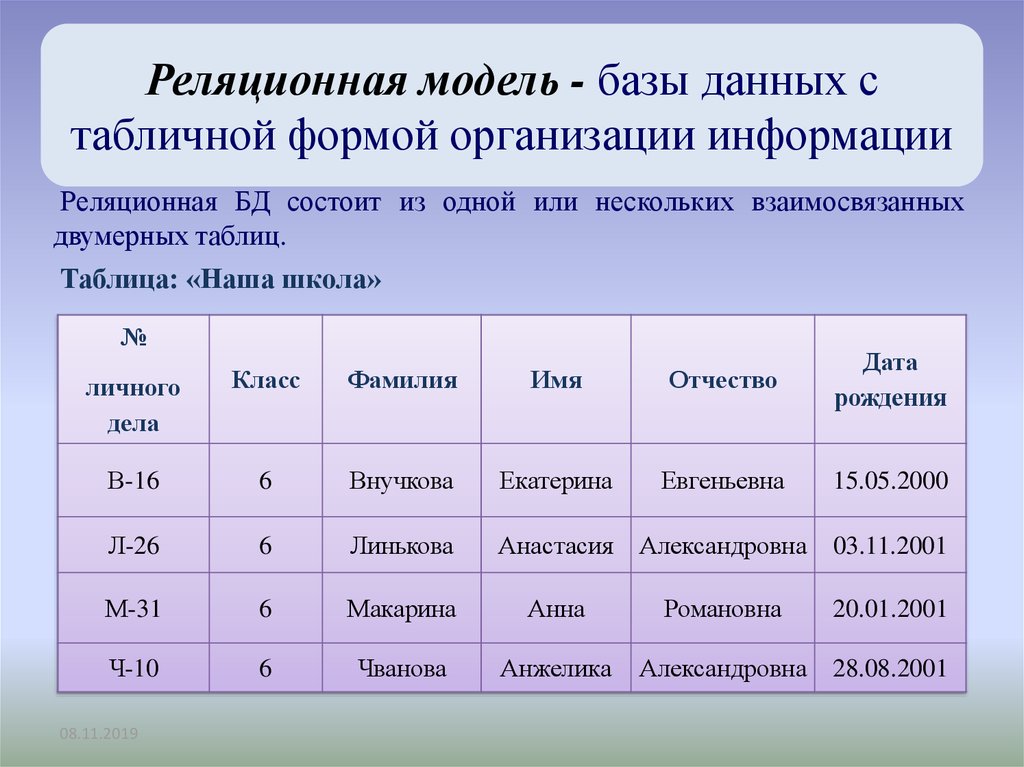
Вместо этого, запись о заказе должна содержать ключи, которые указывают на соответствующие записи о покупателе и товаре. Поскольку в записях можно хранить любую информацию, а отношения не определены в самой модели данных, система управления базой данных не сможет проконтролировать целостность отношений. Это значит, что вы можете удалять покупателей и товары, которые они заказывали. Обеспечение целостности данных целиком ложится на приложение.
Доступ к данным
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). | Данные создаются, обновляются, удаляются и запрашиваются с использованием вызова API методов. |
| SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц, используя при этом соединения (join’ы). | Некоторые реализации предоставляют SQL-подобный синтаксис для задания условий фильтрации.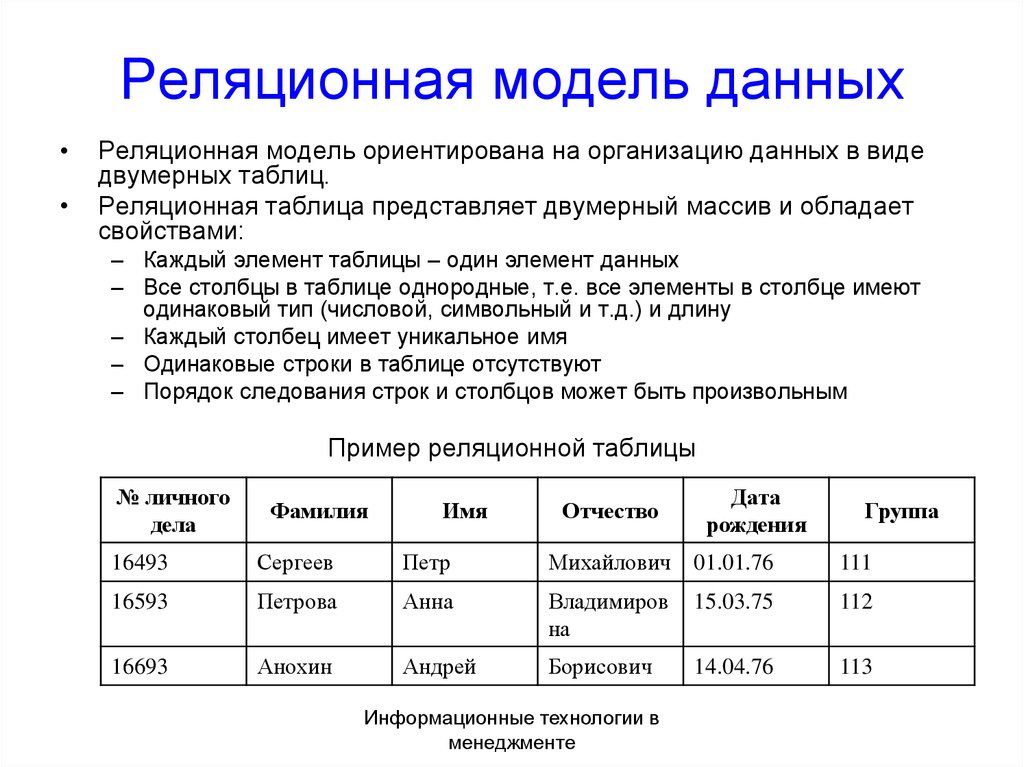 |
| SQL-запросы могут включать агрегации и сложные фильтры. | Зачастую можно использовать только базовые операторы сравнений (=, !=, <, >, <= и =>). |
| Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции. | Вся бизнес-логика и логика для поддержки целостности данных содержится в коде приложений. |
Взаимодействие с приложениями
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Чаще всего используются собственные API, или обобщенные, такие как OLE DB или ODBC. | Чаще всего используются SOAP и/или REST API, с помощью которых осуществляется доступ к данным. |
Данные хранятся в формате, который отображает их натуральную структуру, поэтому необходим маппинг структур приложения и реляционных структур базы.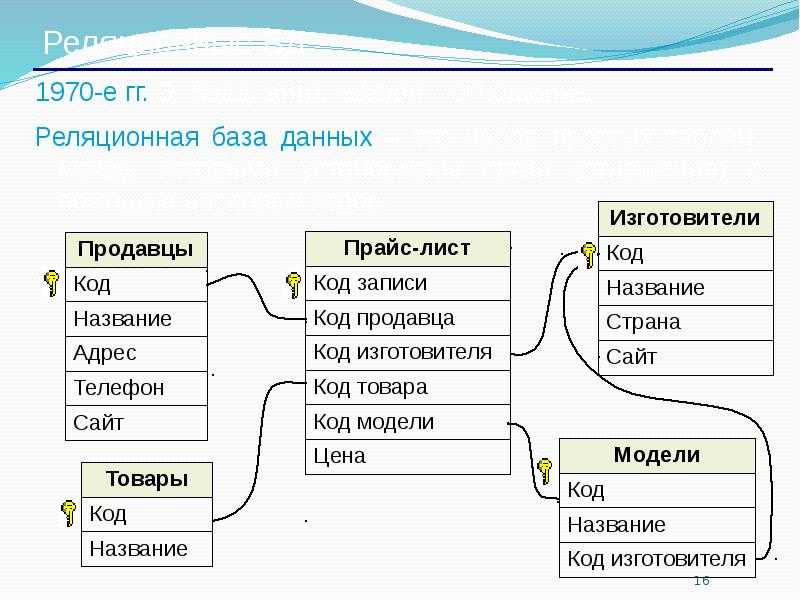 | Данные могут более эффективно отображаться в структуры приложения, нужен только код для записи данных в объекты. |
Хранилища типа ключ-значение: преимущества
Есть два четких преимущества таких систем перед реляционными хранилищами.
Подходят для облачных сервисов
Первое преимущество хранилищ типа ключ-значение состоит в том, что они проще, а значит обладают большей масштабируемостью, чем реляционные БД. Если вы размещаете вместе собственную систему, и планируете разместить дюжину или сотню серверов, которым потребуется справляться с возрастающей нагрузкой, за вашим хранилищем данных, тогда ваш выбор – хранилища типа ключ-значение.
Благодаря тому, что такие хранилища легко и динамически расширяются, они также пригодятся вендорам, которые предоставляют многопользовательскую веб-платформу хранения данных. Такая база представляет относительно дешевое средство хранения данных с большим потенциалом к масштабируемости. Пользователи обычно платят только за то, что они используют, однако их потребности могут вырасти. Вендор сможет динамически и практически без ограничений увеличить размер платформы, исходя из нагрузки.
Пользователи обычно платят только за то, что они используют, однако их потребности могут вырасти. Вендор сможет динамически и практически без ограничений увеличить размер платформы, исходя из нагрузки.
Более естественная интеграция с кодом
Реляционная модель данных и объектная модель кода обычно строятся по-разному, что ведет к некоторой несовместимости. Разработчики решают эту проблему при помощи написания кода, который отображает реляционную модель в объектную модель. Этот процесс не имеет четкой и быстро достижимой ценности и может занять довольно значительное время, которое могло быть потрачено на разработку самого приложения. Тем временем многие хранилища типа ключ-значение хранят данные в такой структуре, которая отображается в объекты более естественно. Это может существенно уменьшить время разработки.
Другие аргументы в пользу использования хранилищ типа ключ-значение, наподобие «Реляционные базы могут стать неуклюжими» (кстати, я без понятия, что это значит), являются менее убедительными.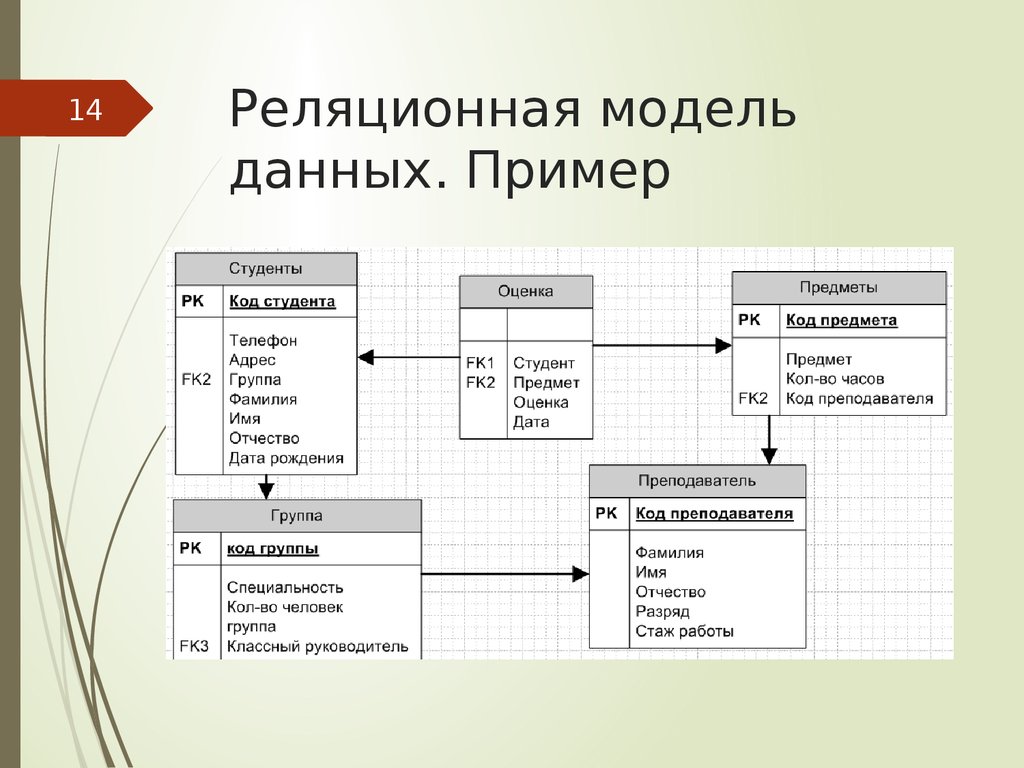 Но прежде чем стать сторонником таких хранилищ, ознакомьтесь со следующим разделом.
Но прежде чем стать сторонником таких хранилищ, ознакомьтесь со следующим разделом.
Хранилища типа ключ-значение: недостатки
Ограничения в реляционных БД гарантируют целостность данных на самом низком уровне. Данные, которые не удовлетворяют ограничениям, физически не могут попасть в базу. В хранилищах типа ключ-значение таких ограничений нет, поэтому контроль целостности данных полностью лежит на приложениях. Однако в любом коде есть ошибки. Если ошибки в правильно спроектированной реляционной БД обычно не ведут к проблемам целостности данных, то ошибки в хранилищах типа ключ-значение обычно приводят к таким проблемам.
Другое преимущество реляционных БД заключается в том, что они вынуждают вас пройти через процесс разработки модели данных. Если вы хорошо спроектировали модель, то база данных будет содержать логическую структуру, которая полностью отражает структуру хранимых данных, однако расходится со структурой приложения. Таким образом, данные становятся независимы от приложения. Это значит, что другое приложение сможет использовать те же самые данные и логика приложения может быть изменена без каких-либо изменений в модели базы. Чтобы проделать то же самое с хранилищем типа ключ-значение, попробуйте заменить процесс проектирования реляционной модели проектированием классов, при котором создаются общие классы, основанные на естественной структуре данных.
Это значит, что другое приложение сможет использовать те же самые данные и логика приложения может быть изменена без каких-либо изменений в модели базы. Чтобы проделать то же самое с хранилищем типа ключ-значение, попробуйте заменить процесс проектирования реляционной модели проектированием классов, при котором создаются общие классы, основанные на естественной структуре данных.
И не забудьте о совместимости. В отличие от реляционных БД, хранилища, ориентированные на использование в «облаке», имеют гораздо меньше общих стандартов. Хоть концептуально они и не отличаются, они все имеют разные API, интерфейсы запросов и свою специфику. Поэтому вам лучше доверять вашему вендору, потому что в случае чего, вы не сможете легко переключиться на другого поставщика услуг. А учитывая тот факт, что почти все современные хранилища типа ключ-значение находятся в стадии бета-версий2, доверять становится еще рискованнее, чем в случае использования реляционных БД.
Ограниченная аналитика данных
Обычно все облачные хранилища строятся по типу множественной аренды, что означает, что одну и ту же систему использует большое количество пользователей и приложений.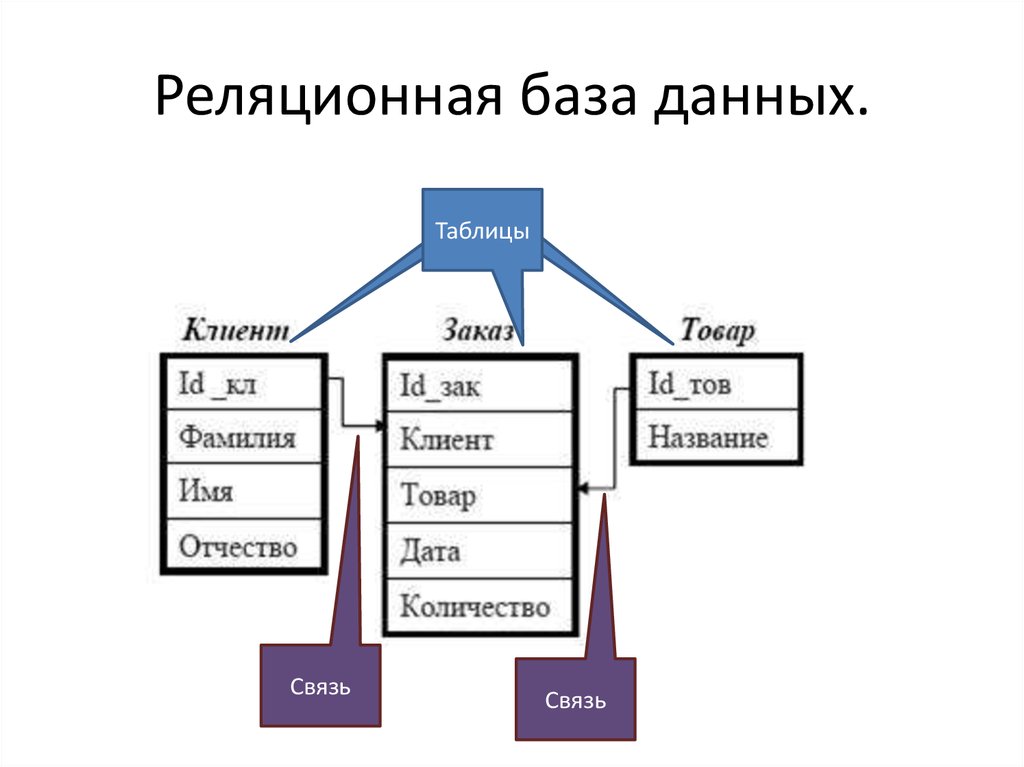 Чтобы предотвратить «захват» общей системы, вендоры обычно каким-то образом ограничивают выполнение запросов. Например, в SimpleDB запрос не может выполняться дольше 5 секунд. В Google AppEngine Datastore за один запрос нельзя получить больше, чем 1000 записей3.
Чтобы предотвратить «захват» общей системы, вендоры обычно каким-то образом ограничивают выполнение запросов. Например, в SimpleDB запрос не может выполняться дольше 5 секунд. В Google AppEngine Datastore за один запрос нельзя получить больше, чем 1000 записей3.
Эти ограничения не страшны для простой логики (создание, обновление, удаление и извлечение небольшого количества записей). Но что если ваше приложение становится популярным? Вы получили много новых пользователей и много новых данных, и теперь хотите сделать новые возможности для пользователей или каким-то образом извлечь выгоду из данных. Тут вы можете жестко обломаться с выполнением даже простых запросов для анализа данных. Фичи наподобие отслеживания шаблонов использования приложения или системы рекомендаций, основанной на истории пользователя, в лучшем случае могут оказаться сложны в реализации. А в худшем — просто невозможны.
В таком случае для аналитики лучше сделать отдельную базу данных, которая будет заполняться данными из вашего хранилища типа ключ-значение. Продумайте заранее, каким образом это можно будет сделать. Будете ли вы размещать сервер в облаке или у себя? Не будет ли проблем из-за задержек сигнала между вами и вашим провайдером? Поддерживает ли ваше хранилище такой перенос данных? Если у вас 100 миллионов записей, а за один раз вы можете взять 1000 записей, сколько потребуется на перенос всех данных?
Продумайте заранее, каким образом это можно будет сделать. Будете ли вы размещать сервер в облаке или у себя? Не будет ли проблем из-за задержек сигнала между вами и вашим провайдером? Поддерживает ли ваше хранилище такой перенос данных? Если у вас 100 миллионов записей, а за один раз вы можете взять 1000 записей, сколько потребуется на перенос всех данных?
Однако не ставьте масштабируемость превыше всего. Она будет бесполезна, если ваши пользователи решат пользоваться услугами другого сервиса, потому что тот предоставляет больше возможностей и настроек.
Облачные хранилища
Множество поставщиков веб-сервисов предлагают многопользовательские хранилища типа ключ-значение. Большинство из них удовлетворяют критериям, перечисленным выше, однако каждое обладает своими отличительными фичами и отличается от стандартов, описанных выше. Давайте взглянем на конкретные пример хранилищ, такие как SimpleDB, Google AppEngine Datastore и SQL Data Services.
Amazon: SimpleDB
SimpleDB — это атрибутно-ориентированное хранилище типа ключ-значение, входящее в состав Amazon WebServices. SimpleDB находится в стадии бета-версии; пользователи могут пользовать ей бесплатно — до тех пор пока их потребности не превысят определенный предел.
У SimpleDB есть несколько ограничений. Первое — время выполнения запроса ограничено 5-ю секундами. Второе — нет никаких типов данных, кроме строк. Все хранится, извлекается и сравнивается как строка, поэтому для того, чтобы сравнить даты, вам нужно будет преобразовать их в формат ISO8601. Третье — максимальные размер любой строки составляет 1024 байта, что ограничивает размер текста (например, описание товара), который вы можете хранить в качестве атрибута. Однако поскольку структура данных гибкая, вы можете обойти это ограничения, добавляя атрибуты «ОписаниеТовара1», «Описание товара2» и т.д. Но количество атрибутов также ограничено — максимум 256 атрибутов.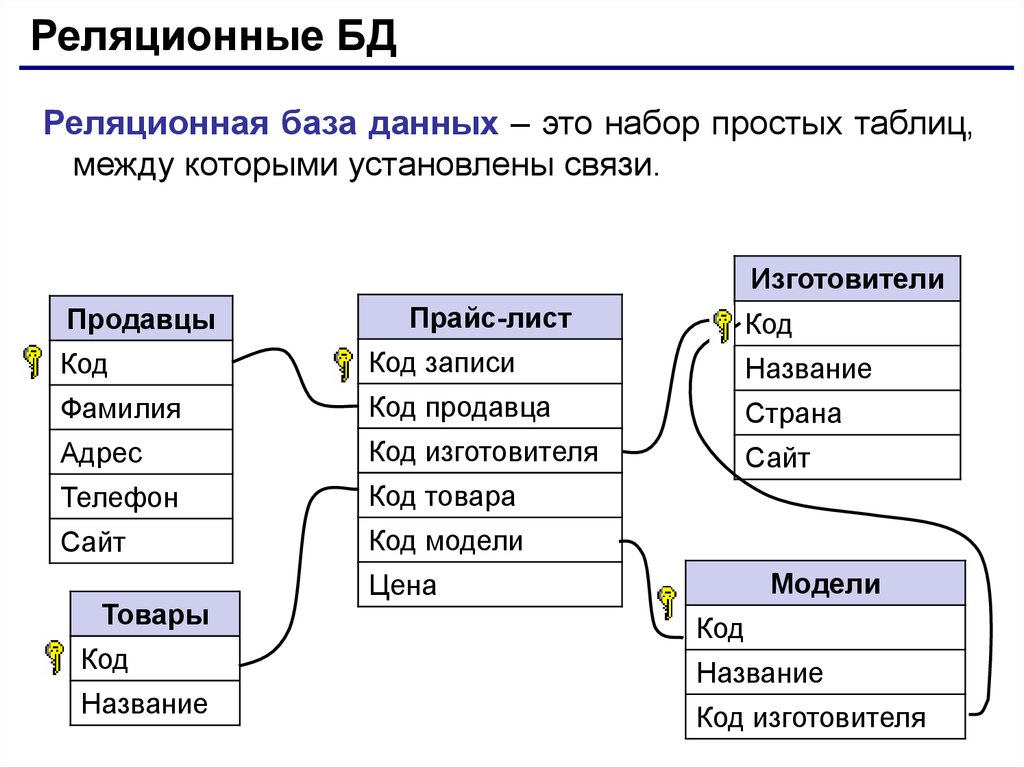 Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.
Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.
Одной из ключевых особенностей SimpleDB является использование модели конечной констистенции (eventual consistency model). Эта модель подходит для многопоточной работы, однако следует иметь в виду, что после того, как вы изменили значение атрибута в какой-то записи, при последующих операциях чтения эти изменения могут быть не видны. Вероятность такого развития событий достаточно низкая, тем не менее, о ней нужно помнить. Вы же не хотите продать последний билет пяти покупателям только потому, что ваши данные были неконсистентны в момент продажи.
Google AppEngine Data Store
Google’s AppEngine Datastore построен на основе BigTable, внутренней системе хранения структурированных данных от Google. AppEngine Datastore не предоставляет прямой доступ к BigTable, но может восприниматься как упрощенный интерфейс взаимодействия с BigTable.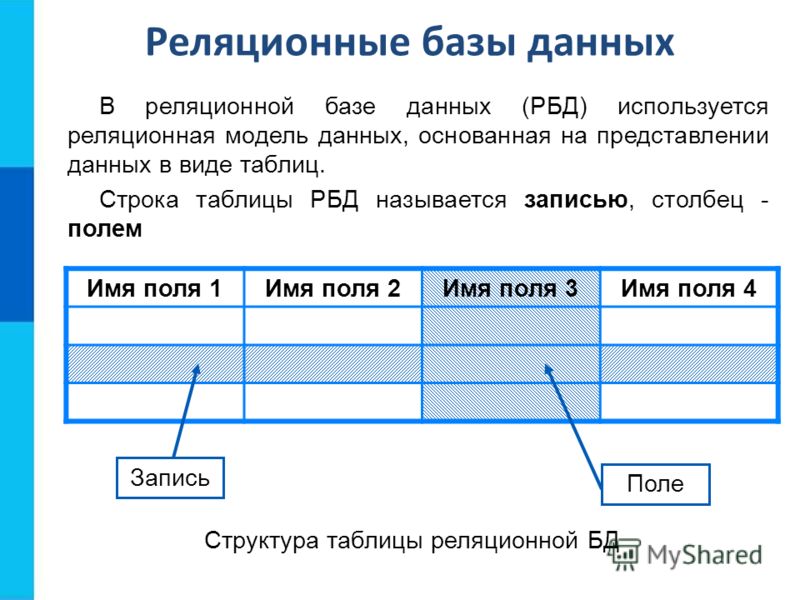
AppEngine Datastore поддерживает большее число типов данных внутри одной записи, нежели SimpleDB. Например, списки, которые могут содержать коллекции внутри записи.
Скорее всего вы будете использовать именно это хранилище данных при разработке с помощью Google AppEngine. Однако в отличии от SimpleDB, вы не сможете использовать AppEngine Datastore (или BigTable) вне веб-сервисов Google.
Microsoft: SQL Data Services
SQL Data Services является частью платформы Microsoft Azure. SQL Data Services является бесплатной, находится в стадии бета-версии и имеет ограничения на размер базы. SQL Data Services представляет собой отдельное приложение — надстройку над множеством SQL серверов, которые и хранят данные. Эти хранилища могут быть реляционными, однако для вас SDS является хранилищем типа ключ-значение, как и описанные выше продукты.
Необлачные хранилища
Существует также ряд хранилищ, которыми вы можете воспользоваться вне облака, установив их у себя. Почти все эти проекты являются молодыми, находятся в стадии альфа- или бета-версии, и имеют открытый код. С открытыми исходниками вы, возможно, будете больше осведомлены о возможных проблемах и ограничениях, нежели в случае использования закрытых продуктов.
Почти все эти проекты являются молодыми, находятся в стадии альфа- или бета-версии, и имеют открытый код. С открытыми исходниками вы, возможно, будете больше осведомлены о возможных проблемах и ограничениях, нежели в случае использования закрытых продуктов.
CouchDB
CouchDB — это свободно распространяемая документо-ориентированная БД с открытым исходным кодом. В качестве формата хранения данных используется JSON. CouchDB призвана заполнить пробел между документо-ориентированными и реляционными базами данных с помощью «представлений». Такие представления содержат данные из документов в виде, схожим с табличным, и позволяют строить индексы и выполнять запросы.
В настоящее время CouchDB не является по-настоящему распределенной БД. В ней есть функции репликации, позволяющие синхронизировать данные между серверами, однако это не та распределенность, которая нужна для построения высокомасштабируемого окружения. Однако разработчики CouchDB работают над этим.
Проект Voldemort
Проект Voldemort — это распределенная база данных типа ключ-значение, предназначенная для горизонтального масштабирования на большом количестве серверов. Он родилась в процессе разработки LinkedIn и использовалась для нескольких систем, имеющих высокие требования к масштабируемости. В проекте Voldemort также используется модель конечной консистенции.
Mongo
Mongo — это база данных, разрабатываемая в 10gen Гейром Магнуссоном и Дуайтом Меррименом (которого вы можете знать по DoubleClick). Как и CouchDB, Mongo — это документо-ориентированная база данных, хранящая данные в JSON формате. Однако Mongo скорее является объектной базой, нежели чистым хранилищем типа ключ-значение.
Drizzle
Drizzle представляет совсем другой подход к решению проблем, с которыми призваны бороться хранилища типа ключ-значение. Drizzle начинался как одна из веток MySQL 6.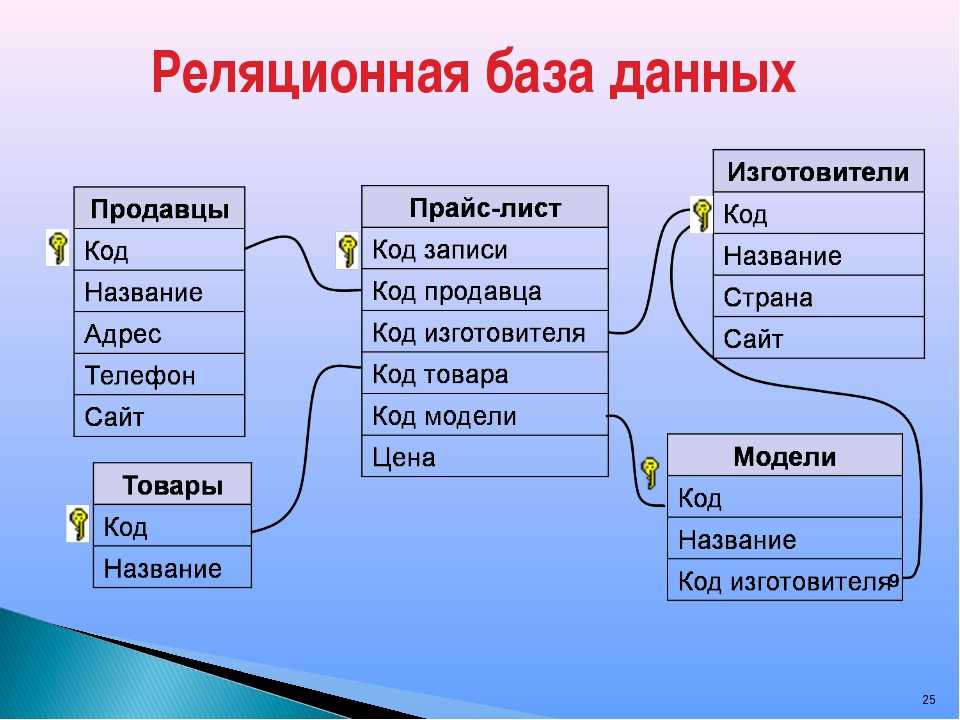 0. Позже разработчики удалили ряд функций (включая представления, триггеры, скомпилированные выражения, хранимые процедуры, кэш запросов, ACL, и часть типов данных), с целью создания более простой и быстрой СУБД. Тем не менее, Drizzle все еще можно использовать для хранения реляционных данных. Цель разработчиков — построить полуреляционную платформу, предназначенную для веб-приложений и облачных приложений, работающих на системах с 16-ю и более ядрами.
0. Позже разработчики удалили ряд функций (включая представления, триггеры, скомпилированные выражения, хранимые процедуры, кэш запросов, ACL, и часть типов данных), с целью создания более простой и быстрой СУБД. Тем не менее, Drizzle все еще можно использовать для хранения реляционных данных. Цель разработчиков — построить полуреляционную платформу, предназначенную для веб-приложений и облачных приложений, работающих на системах с 16-ю и более ядрами.
Решение
В конечном счете, есть четыре причины, по которым вы можете выбрать нереляционное хранилище типа ключ-значение для своего приложения:
- Ваши данные сильно документо-ориентированны, и больше подходят для модели данных ключ-значение, чем для реляционной модели.
- Ваша доменная модель сильно объектно-ориентированна, поэтому использования хранилища типа ключ-значение уменьшит размер дополнительного кода для преобразования данных.
- Хранилище данных дешево и легко интегрируется с веб-сервисами вашего вендора.
- Ваша главная проблема — высокая масштабируемость по запросу.

Однако принимая решение, помните об ограничениях конкретных БД и о рисках, которые вы встретите, пойдя по пути использования нереляционных БД.
Для всех остальных требований лучше выбрать старые добрые реляционные СУБД. Так обречены ли они? Конечно, нет. По крайней мере, пока.
1 — по моему мнению, здесь больше подходит термин «структура данных», однако оставил оригинальное data model.
2 — скорее всего, автор имел в виду, что по своим возможностям нереляционные БД уступают реляционным.
3 — возможно, данные уже устарели, статья датируется февралем 2009 года.
языковой агностик — Внедрение базы данных — С чего начать
Поскольку принятый ответ предлагает только (хорошие) ссылки на другие ресурсы, я решил поделиться своим опытом написания webdb, небольшой экспериментальной базы данных для браузеров.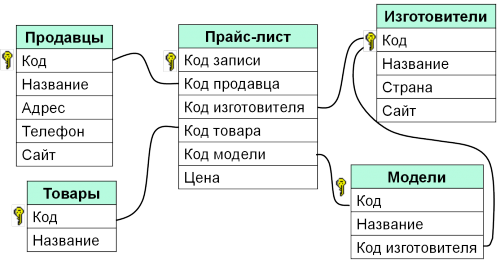 Я также приглашаю вас прочитать исходный код. Он довольно маленький. Вы должны быть в состоянии прочитать его и получить общее представление о том, что он делает за пару часов. Предупреждение : Я ноль в этом, и с тех пор, как я это написал, я узнал об этом намного больше и вижу, что делаю некоторые вещи неправильно. Тем не менее, это может помочь вам начать.
Я также приглашаю вас прочитать исходный код. Он довольно маленький. Вы должны быть в состоянии прочитать его и получить общее представление о том, что он делает за пару часов. Предупреждение : Я ноль в этом, и с тех пор, как я это написал, я узнал об этом намного больше и вижу, что делаю некоторые вещи неправильно. Тем не менее, это может помочь вам начать.
Я начал с адаптации дерева AVL в соответствии со своими потребностями. Дерево AVL — это разновидность самобалансирующегося бинарного дерева поиска. Вы сохраняете ключ K и связанные данные (если есть) в узле, затем все элементы с ключом < K в узле в левом поддереве и все элементы с ключом > K в правом поддерево. Вы можете использовать массив для хранения элементов данных, если хотите поддерживать неуникальные ключи.
Это дерево даст вам основы: Создать , Обновить , Удалить и способ быстро получить элемент по ключу или все элементы с ключом < x или с ключом между x и y и т. д. Он может служить индексом для нашей таблицы.
д. Он может служить индексом для нашей таблицы.
В качестве следующего шага я написал код, который позволяет клиентскому коду определять схему. Такие методы, как createTable() и т. д. Схемы обычно связаны с SQL, но даже не-SQL имеет схему; они обычно требуют, чтобы вы отметили поле идентификатора и любые другие поля, по которым вы хотите выполнить поиск. Вы можете сделать свою схему настолько причудливой, насколько хотите, но обычно вы хотите смоделировать, по крайней мере, какие столбцы служат первичным ключом и какие поля будут часто выполняться и нуждаются в индексе.
Я решил использовать созданное на первом этапе дерево для хранения своих предметов. Это были простые объекты JS. Определив, какое поле содержит PK, я мог бы просто вставить элемент в дерево, используя значение этого поля в качестве ключа. Это дает мне быстрый поиск по идентификатору (диапазон).
Затем я добавил еще одно дерево для каждого столбца, которому нужен индекс. В этих деревьях я хранил не полную запись, а только ключ.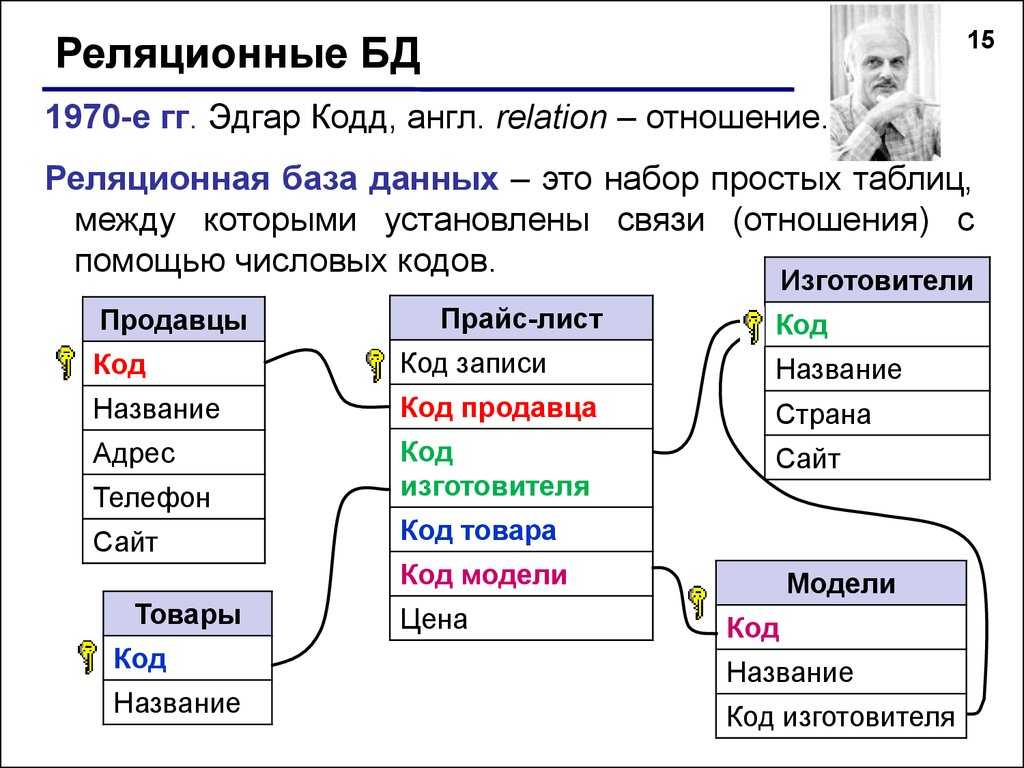 Таким образом, чтобы получить клиента по фамилии, я бы сначала использовал индекс по фамилии, чтобы получить идентификатор, а затем индекс первичного ключа, чтобы получить фактическую запись. Причина, по которой я не просто сохранил (ссылку на) фактический объект, заключается в том, что это немного упрощает операции над множествами (см. следующий шаг)
Таким образом, чтобы получить клиента по фамилии, я бы сначала использовал индекс по фамилии, чтобы получить идентификатор, а затем индекс первичного ключа, чтобы получить фактическую запись. Причина, по которой я не просто сохранил (ссылку на) фактический объект, заключается в том, что это немного упрощает операции над множествами (см. следующий шаг)
Теперь, когда у нас есть таблица с индексами для PK и полей поиска, мы можем реализовать запросы. Я не заходил слишком далеко, так как это быстро усложняется, но вы можете получить хорошую функциональность, используя только некоторые основы. WebDB не реализует соединения; все запросы работают только с одной таблицей. Но как только вы это поймете, вы увидите довольно четкий (хотя и длинный и извилистый) путь к выполнению объединений и других сложных вещей.
В WebDB, чтобы получить всех клиентов с firstName = 'John' и city = 'Нью-Йорк' (при условии, что это два поля поиска), вы должны написать что-то вроде:
var webDb = .
 ..
var johnsFromNY = webDb.customers.get({
имя: 'Джон',
город: "Нью-Йорк"
})
..
var johnsFromNY = webDb.customers.get({
имя: 'Джон',
город: "Нью-Йорк"
})
Чтобы решить эту проблему, мы сначала делаем два поиска: мы получаем набор X всех идентификаторов клиентов с именем «Джон» и мы получаем набор Y всех идентификаторов клиентов из Нью-Йорка. Затем мы выполняем пересечение этих двух наборов, чтобы получить все идентификаторы клиентов с именами «Джон» 9.0004 И из Нью-Йорка. Затем мы проходим через наш набор полученных идентификаторов, получая фактическую запись для каждого из них и добавляя ее в массив результатов.
Используя операторы множества, такие как объединение и пересечение, мы можем выполнять поиск И и ИЛИ . Я реализовал только И .
Выполнение соединений будет (я думаю) включать создание временных таблиц в памяти, затем заполнение их объединенными результатами по мере выполнения запроса, а затем применение критериев запроса к временной таблице. Я так и не попал туда.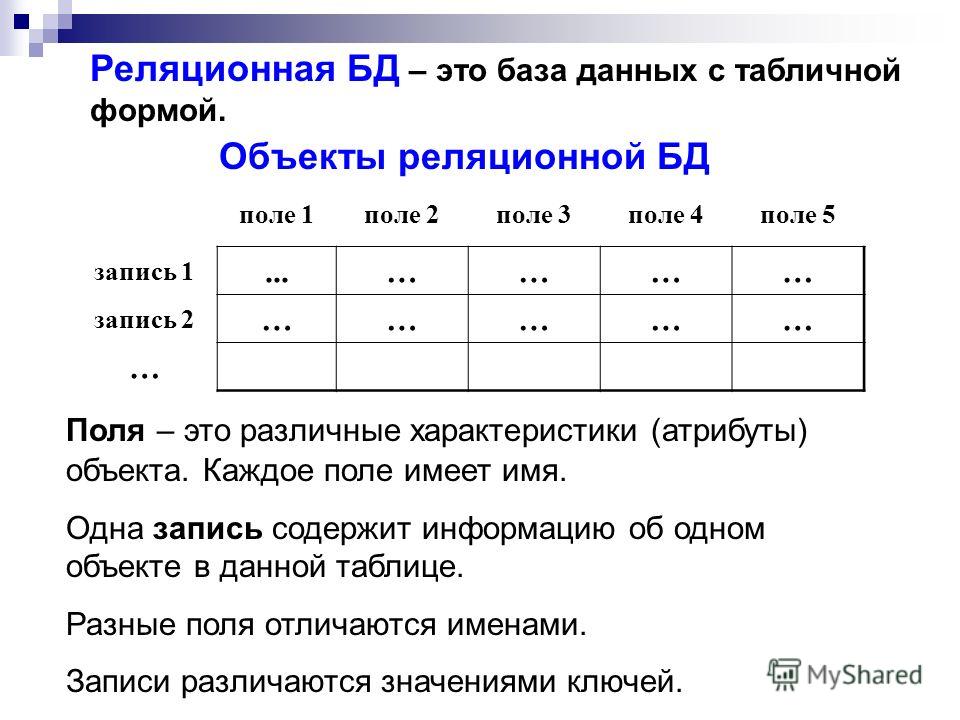 Затем я попытался использовать некоторую логику синхронизации, но это было слишком амбициозно, и дальше все пошло под откос 🙂
Затем я попытался использовать некоторую логику синхронизации, но это было слишком амбициозно, и дальше все пошло под откос 🙂
Пять шагов по выбору и внедрению базы данных
Недостаточно знать, какие типы баз данных могут вам подойти. Вам также необходимо тщательно продумать, как найти базу данных, подходящую для ваших нужд, и как обеспечить ее бесперебойную работу. Выполните следующие пять шагов, чтобы убедиться, что вы успешно выбрали и внедрили правильную базу данных для своей организации.
Независимо от того, какой тип базы данных вы рассматриваете, первым важным шагом является определение ваших потребностей. Для незначительной покупки этот шаг может потребовать быстрого разговора с другими сотрудниками, но для крупной, критически важной части программного обеспечения это может занять месяцы работы.
Взгляните на систему, которую вы сейчас используете. Насколько это соответствует вашим потребностям? Какого функционала не хватает? Поговорите с поставщиком вашей текущей системы и узнайте, можно ли ее улучшить, расширить или настроить для удовлетворения всех ваших требований.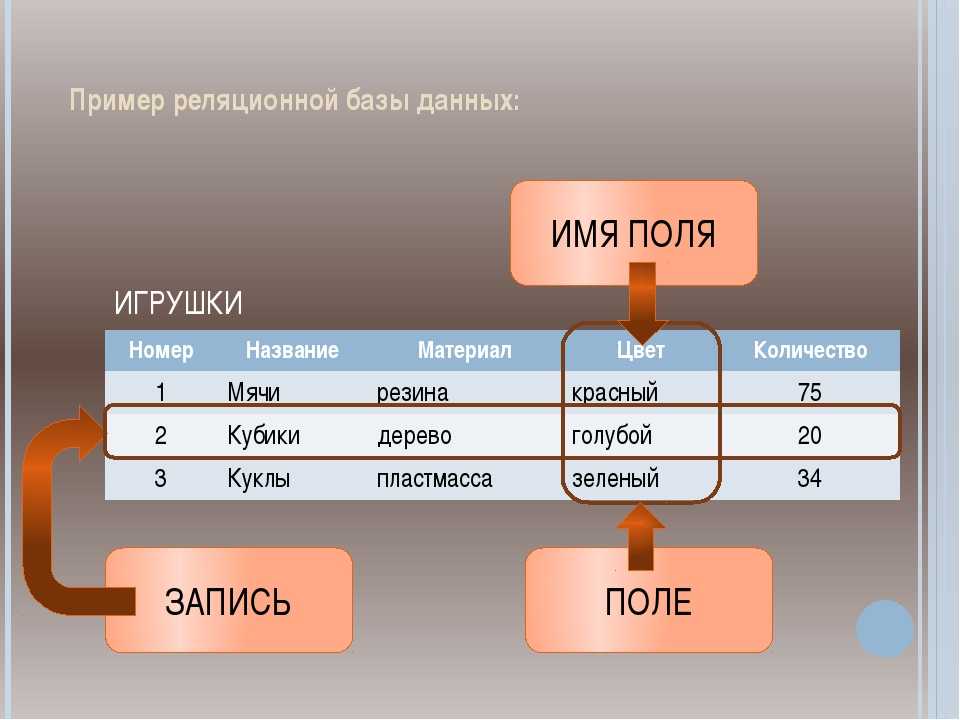 Использование существующих систем означает экономию времени, денег и разочарований, связанных с выбором, установкой и изучением совершенно нового приложения.
Использование существующих систем означает экономию времени, денег и разочарований, связанных с выбором, установкой и изучением совершенно нового приложения.
Обязательно поговорите со всеми в вашей организации, кто будет использовать базу данных, чтобы составить список необходимых функций. Таким образом, вы можете оценить свои текущие и новые системы на основе потребностей людей, которые будут их использовать. Понимание потребностей ваших пользователей с самого начала будет иметь большое значение для получения согласия и принятия позже в процессе.
Если вам нужна новая система управления базами данных, следующим шагом будет создание короткого списка, чтобы отсеять все возможные варианты до управляемого списка. Для незначительной покупки это может означать просто поговорить с несколькими людьми и выбрать один пакет для дальнейшего изучения, но если вы вкладываете больше средств, вам нужно изучить более подробно и определить список из трех. до пяти вариантов программного обеспечения.
Такие веб-сайты, как Idealware и TechSoup, являются хорошим местом для начала исследования. Поговорите с похожими некоммерческими организациями, чтобы узнать, что они используют. Это может быть полезным способом увидеть преимущества и недостатки различных вариантов базы данных, специфичных для вашей организации.
Если вы хотите приобрести довольно сложную систему, вы можете подумать о привлечении консультанта, который проведет аудит возможностей вашей текущей системы, потребностей вашей организации и подберет для вас подходящее решение.
Следующим шагом будет оценка другого варианта базы данных из вашего списка. Вы же не станете покупать машину, не протестировав ее, не так ли? Попробуйте каждую систему самостоятельно или попросите поставщиков продемонстрировать их для вас.
Большинство поставщиков будут рады предоставить пробную версию или демонстрацию своего продукта через Интернет, что позволит легко увидеть их системы в действии. Если поставщик собирается провести для вас экскурсию, потратьте некоторое время заранее, чтобы определить конкретные функции и функции, которые вы хотите увидеть, и заранее отправить их поставщику.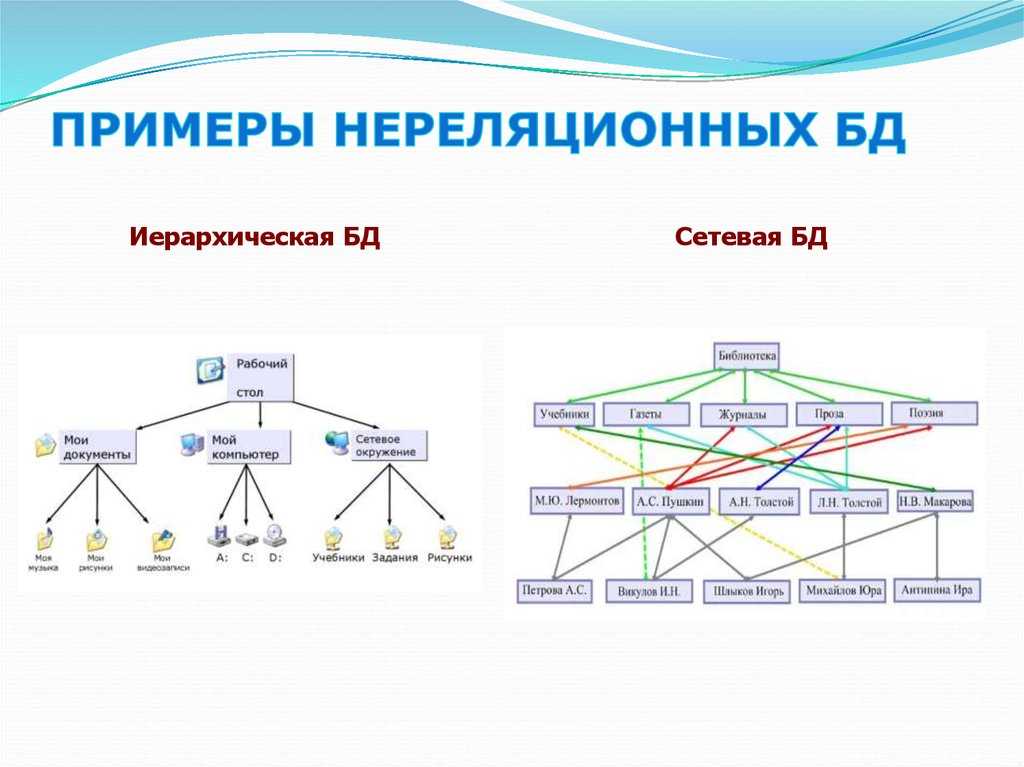
Ваша организация будет поддерживать отношения с поставщиком в течение нескольких лет, поэтому найдите время, чтобы найти не только базу данных, подходящую для вашей организации, но и поставщика, который вам подходит. В конечном итоге важнее всего способность инструмента, который вы выбираете, удовлетворять ваши потребности и быть управляемой затратой как на начальном этапе, так и с течением времени.
После того, как вы выбрали свою базу данных, вы сделали только половину — вам еще нужно ее внедрить. В зависимости от типа выбранной вами системы вам, возможно, придется подумать о переносе данных или переносе их из ваших старых систем в новую. Это редко бывает легким шагом, и он требует тщательного рассмотрения и планирования.
Кроме того, какой бы замечательной ни была ваша новая система, она бесполезна для вас, если никто не знает, как ею пользоваться. Какой бы большой или маленькой ни была ваша новая система, убедитесь, что вы запланировали обучение и вспомогательный персонал. К кому им обращаться с вопросами? Что они должны делать — или не делать — с системой?
К кому им обращаться с вопросами? Что они должны делать — или не делать — с системой?
Этот шаг необходим для максимального принятия пользователями. Если вы внедрили систему, отвечающую их потребностям, и обучили их ее использованию, вы обнаружите, что пользователи в вашей организации будут гораздо более удовлетворены выбранным вами программным обеспечением.
Ни одна система не будет поддерживать себя, особенно та, в которой есть данные. Забота о ваших данных означает создание политик, которые гарантируют, что ваши данные останутся чистыми и пригодными для действий, а также упростят доступ к необходимой информации из системы. Лучший способ сделать данные полезными — сделать это с самого начала: о чем следует думать персоналу при вводе записей? Кто будет контролировать качество данных?
Помогите своим сотрудникам узнать, что и когда они должны вводить, и определите шаги, которые обеспечат чистоту и пригодность ваших данных, когда кто-то попытается что-то найти. Также важно периодически проверять свои данные и исправлять любые ошибки, которые могли проскользнуть.
Выполните следующие пять шагов при внедрении базы данных, и вы окажетесь на верном пути к тому, чтобы стать организацией, управляемой данными!
Мишель Регал
Операционный директор Now IT Matters
Мишель является операционным директором Now IT Matters и сертифицированным администратором и разработчиком Salesforce. Ранее она администрировала базы данных Eloqua и Salesforce для PBS и оказывала поддержку станциям-участникам PBS при внедрении пользовательской страницы пожертвований Visualforce. До прихода в PBS она более четырех лет была менеджером программ в BRAC USA, в течение которых она оказывала маркетинговую поддержку и разрабатывала онлайн-стратегию, стратегию в социальных сетях и традиционных СМИ для крупнейшей неправительственной организации в мире. Кроме того, она внедрила и поддерживала несколько баз данных Salesforce и других CRM, а также разработала многоканальные стратегии привлечения и удержания доноров. Мишель имеет степень магистра делового администрирования Школы бизнеса Стерна Нью-Йоркского университета.