Содержание
Онлайн разделитель музыки и голоса на базе нейронной сети
Необработанные файлы в очереди: 0. В данный момент обрабатываются на GPU: 3/4
Информация: сайт выполняет разделение музыкального трека на отдельные составляющие: голос, отдельная музыка, барабаны, гитара, пианино и т.д.
Примеры разделения трека на две части — голос и музыку можно посмотреть в видео ниже. Также посмотреть результаты разделений можно на демо-странице.
Новости [2022.11.13]
- На сайт была добавлена собственная оригинальная модель MVSep Vocal Model, натренированная на собственном большом датасете. Она показывает отличные результаты на тестовых данных:
Synth dataset vocal SDR: 10.4523
Synth dataset instrumental SDR: 10. 1561
1561
MUSDB18HQ dataset vocal SDR: 8.8292
MUSDB18HQ dataset instrumental SDR: 15.2719 - На сайт была добавлена новая модель от команды Facebook — Demucs4 Hybrid Transformer.
 1561
1561Новости [2022.07.29]
- На сайт был добавлен экспериментальный алгоритм MVSep DNR, который разделяет треки на 3 части: музыку, спец-эффекты и голос. Алгоритм был натренирован на датасете «Divide and Remaster».
Метрики качества:
SDR DNR for music: 6.17
SDR DNR for sfx: 7.26
SDR DNR for speech: 14.13
Алгоритм плохо подходит для обычной музыки, но неплохо справляется, когда нужно, скажем, почистить голос диктора от посторонних шумов на фоне.
Примеры работы алгоритма MVSep DNR
Новости [2022.07.25]
- Мы создали независимый синтетический набор данных для сравнения различных алгоритмов разделения музыкальных треков. Мы опубликовали датасет здесь вместе с автоматической проверяющей системой. Также доступна таблица наиболее эффективных алгоритмов.
- Добавлена новая вокальная модель MDX-B UVR. Это последняя версия от команды UVR. Опция доступна при выборе алгоритма MDX-B в форме.
 Также доступна таблица наиболее эффективных алгоритмов.
Также доступна таблица наиболее эффективных алгоритмов.Новости [2022.07.07]. Последние изменения на MVSep:
- Были добавлены новые модели из пакета Ultimate Vocal Remover построенные на базе архитектуры demucs3. На сайте они доступны под названием UVR Demucs в списке алгоритмов.
Метрики качества для разных алгоритмов, включая UVR Demucs, можно посмотреть здесь.
Новости [2022.04.18]. Последние изменения на MVSep:
- Добавлен алгоритм Danna Sep. Этот алгоритм занял 3 место на Leaderboard A в соревновании Sony Music Demixing Challenge.
- Добавлен алгоритм Byte Dance. Этот алгоритм занял второе место в категории vocals на Leaderboard A в соревновании Sony Music Demixing Challenge. Он тренировался только на данных MUSDB18HQ и имеет потенуиал в дальнейшем в случае добавления большего числа данных на обучение.
Метрики качества для этих и других алгоритмов можно посмотреть здесь.
Новости [2022.02.24]. Последние изменения на MVSep:
- Добавлены новые модели UVR: Piano, Bass, Drums и несколько различных Vocal моделей. Добавлен выбор aggressivness для UVR моделей.
- Добавлены удалённые GPU, которые обрабатывают задания в очереди. Размер очереди должен значительно сократиться.
- Для spleeter (вокал, барабаны, бас, остальное) и spleeter (вокал, барабаны, бас, пианино, остальное) добавлен вывод instrumental дорожек.
Новости [2021.12.23]. Последние изменения на MVSep:
- Добавлена возможность выбрать lossless-кодирование полученных файлов. Ранее была возможность использовать только MP3. Теперь добавлен вывод в WAV и FLAC.
- Для всех основных алгоритмов: MDX, Demucs3 и Unmix добавлен вывод общего инструментального трека (instrumental).
- Добавлен перевод сайта на Польский и Индонезийский языки.
- Добавлен скрипт сброса GPU в случае зависания. Больше не должно быть длительных простоев сервера.

К сожалению, все самые качественные алгоритмы работают очень медленно из-за чего периодически образуются очереди ожидания. Думаем, что с этим делать.
Новости [2021.11.12]: У нас три больших новости:
- Пришлось переехать на новый сервер из-за нехватки места на старом. Позитивный эффект — поменялась видеокарта на более мощную и с большим объемом памяти. Как следствие очереди ожидания уменьшились и ошибок связанных с недостатком GPU памяти стало меньше. Минус, что в два раза выросли затраты на сервер.
- Был добавлен новый алгоритм Ultimate Vocal Remover (UVR). Он разбивает трек на две части музыку и вокал. При этом обычно делает это лучше spleeter. В оригинальном UVR очень много моделей и разных настроек. Мы выбрали одну из лучших моделей и оптимальные настройки. Возможно позже будет добавлен гибкий выбор настроек для алгоритма.
- Победитель конкурса Music Demuxing Challenge наконец сделал релиз своего кода. Мы добавили его модели на сайт под названиями Demux3 Model A и Demux3 Model B. Demux3 Model B даёт более качественный результат, а для басов и барабанов работает лучше всех моделей, но слегка уступает по вокалу алгоритму MDX-B.
Ниже обновленная табличка сравнения качества алгоритмов (данные для UVR отсутствуют). Значения в таблице рассчитаны на закрытом конкурсном датасете Music Demuxing Challenge (доступен только организаторам). Чем больше значение, тем лучше работает алгоритм.
| Алгоритм | Качество (Bass) | Качество (Drums) | Качество (Other) | Качество (Vocals) | Пример |
|---|---|---|---|---|---|
| Spleeter (4 stems) | 5.774 | 5.845 | 4.321 | 6.939 | Пример |
| UmxXL | 6.619 | 6.838 | 4.891 | 7.732 | Пример |
| MDX A | 7. 232 232 | 7.173 | 5.636 | 8.901 | Пример |
| MDX B (Orig) | 7.495 | 7.554 | 5.533 | 8.896 | — |
| MDX B (UVR) | 7.495 | 7.554 | 5.533 | 9.482 | Пример |
| Ultimate Vocal Remover HQ | — | — | — | — | Пример |
| Demucs 3 Model A | 8.115 | 8.037 | 5.193 | 7.968 | Пример |
| Demucs 3 Model B | 8.856 | 8.850 | 5.978 | 8.756 | Пример |
Новости [2021.10.19]: На сайт mvsep.com добавлены два новых алгоритма для разделения треков: MDX A и MDX B. Это модели, созданные участниками конкурса Music Demuxing Challenge, которые заняли второе место. Код их решения и модели нейронных сетей были выложены в открытый доступ. Мы всё ещё ждем решение первого места.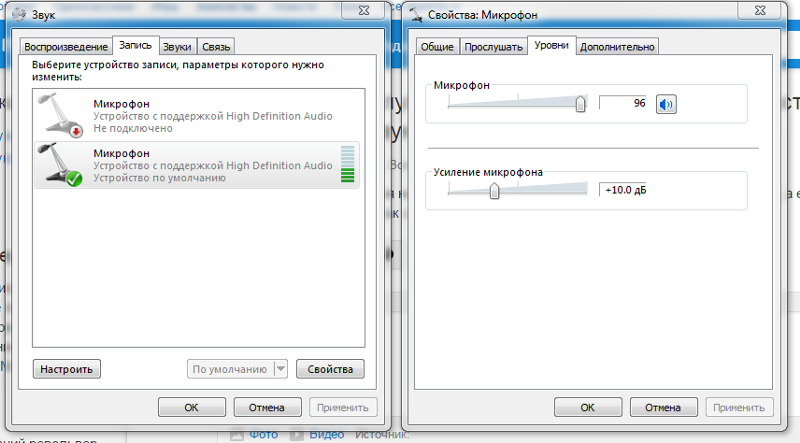
Но и эти модели по конкурсным метрикам значительно обгоняют Spleeter и UmxXL (см. табличку выше), но пока проигрывают по скорости. MDX A отличается от MDX B тем что первый алгоритм не использовал внешние данные для обучения, поэтому результаты чуть хуже, чем у MDX B. Позже энтузиасты проекта UVR доработали модель по отделению вокала, получив лучше значение для метрики качества (8.896 -> 9.482).
Новости [2021.08.30]: на сайте mvsep.com несколько полезных обновлений
- Обновлены ПО и код сайта. Разделение треков стало работать быстрее и стабильнее. Всё реже случаются падения нашего бекэнда.
- Добавлен новый алгоритм разделения, который называется UnMix. У алгоритма доступно 4 модели «umxXL», «umxHQ», «umxSD», «umxSE». Самая качественная — первая «umxXL». По первым тестам, голос отделяет чуть хуже, чем spleeter, а вот инструменты лучше. В любом случае теперь открыто большое поле для экспериментов с треками.
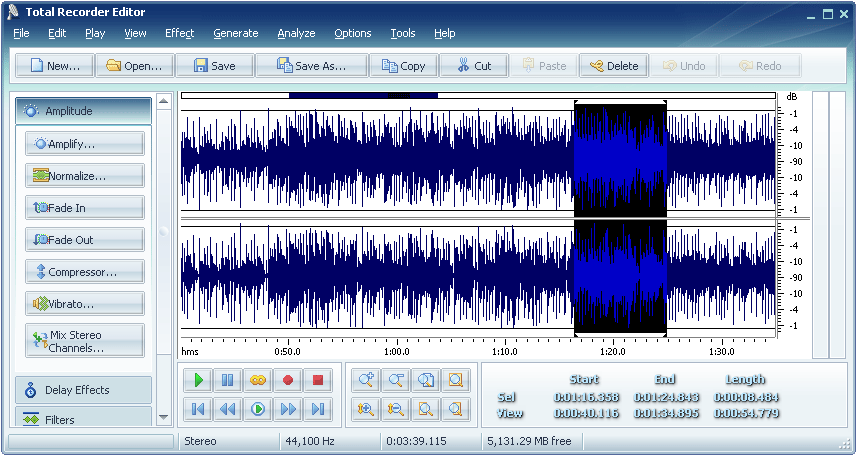
- Переделана страница с результатми разделения: добавлен оригинальный трек, удобно сравнивать с одной страницы. Добавлена информация по настройкам разделения, выводится информация по загруженному файлу, ID3-теги и изображение (если они есть).
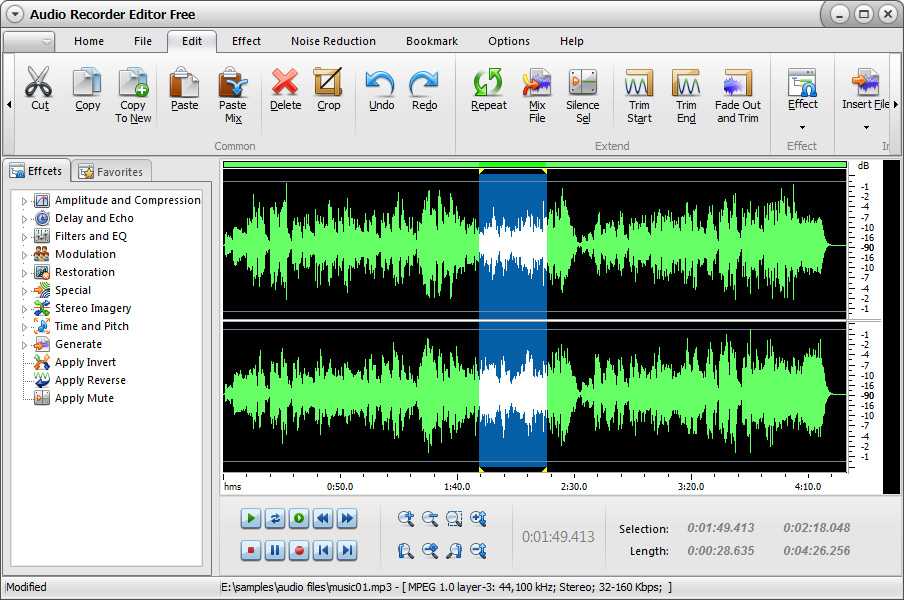 Добавлена информация по настройкам разделения, выводится информация по загруженному файлу, ID3-теги и изображение (если они есть).
Добавлена информация по настройкам разделения, выводится информация по загруженному файлу, ID3-теги и изображение (если они есть).Примеры разделения на базе нового алгоритма:
umxXL: Monk Turner Fascinoma — Its Your Birthday
umxHQ: Robin Grey — These Days
umxSD: Brad Sucks — Total Breakdown
umxSE: Paper Navy — Swan Song
И напоследок немного статистики. В день на сайте разделяется около 600-750 треков. А за всё время было разделено более 300,000 треков. Двигаемся в сторону миллиона.
Статистика: количество разделенных треков за последний день
Legend
- Удачно
- С ошибкой
Статистика: наиболее популярные алгоритмы
Legend
- Алгоритмы
Другие проекты: удаление лиц с фото и видео hide-face.com
Hit’n’Mix — программа для разбивки аудио файлов на партии отдельных инструментов
DAZZER
Электронный англоаудиофил
#1
Фантастика! Графика правда жесть, как из фильмов)))
http://www. hitnmix.com/
hitnmix.com/
Мартин Доу, программист из Великобритании, представил свою программу под названием Hit’n’Mix. Мартин потратил на разработку данного приложение без малого десять лет, и потратил не зря. Приложение позволяет без труда в короткие сроки разобрать аудио файл на составные части: партии каждого отдельного инструмента и голоса исполнителей.
«Я потратил очень много времени на создание по-настоящему эффективных механизмов расчленения аудио файлов, хотя с самого начала был уверен в том, что это невозможно», — вспоминает Мартин Дау. — «Теперь же, с помощью моей программы меломаны смогут создавать свои дорожки для караоке, делать попурри из разных композиций, а также заниматься редактированием аудио файлов».
Британский программист не захотел делиться секретами относительно сложных механизмов утилиты. Он лишь продемонстрировал ее работу. Пользователь выбирает нужный аудио файл, после чего программа конвертирует его в формат .Обработка можно занимать от трех и более минут, в зависимости от производительности компьютерного железа. По словам разработчика, Hit’n’Mix предназначена не только для энтузиастов, но также для профессиональных звукорежиссеров. Программа вполне может заменить дорогие сложные утилиты, вроде ACID Pro и Sound Forge.
Нажмите для раскрытия…
 rip, а затем подвергает его довольно быстрой обработке, после чего выводит на экран все компоненты файла. Далее пользователь может отрегулировать их тон, высоту, длительность и прочие параметры.
rip, а затем подвергает его довольно быстрой обработке, после чего выводит на экран все компоненты файла. Далее пользователь может отрегулировать их тон, высоту, длительность и прочие параметры.http://www.hwp.ru/news/HitnMix__97_programma_dlya_razbivki_audio_faylov_na_partii_otdelnih_instrumentov_i_golosa_89327/
Скачал данную программу, весит всего 37 мегабайт. Инсталлировал…
Первое впечатление — детская игрушка с разноцветными понтами и непонятным английским интерфейсом.
Основы конечно понятны — загружаем какой либо мр3 или wav файл, прога кропотливо, несколько минут обрабатывает данный трек — расчленяет на отдельные аудио дорожки с соответственными инструментами…
Затем появляются непосредственно как бы дорожки, но визуально конечно отображены очень непонятно и погано…
В принципе в демоверсии на этом все и заканчивается… отделить и сохранить какой-либо инструмент или вокал у меня так и неполучилось.
Из меню программы понятно что можно менять лад композиции — например мажорный или минорный и т.п. Своего рода различные стили исполнения песни или отдельных дорожек — как сказано производителем…Незнаю, может в полной версии программы более расширенный функционал….
Конечно если прога действительно умеет качественно и грамотно отделять все инструменты и в том числе вокал из любой песни, то это конечно большой прорыв в мире музыки и технологий.
Держитесь авторские права!!! Близится халявная возможность делать минуса из любых песен и брать любые акапеллы…Нажмите для раскрытия…
 Хоть бы дали возможность сделать это один раз пусть и демоверсия…
Хоть бы дали возможность сделать это один раз пусть и демоверсия…http://www.dj-vlad.ru/2011-02-24-hitnmix-programma-dlya-muzykantov-i-di-dzheev.htm
Последнее редактирование:
DAZZER
Электронный англоаудиофил
#2
Что то подобное было уже разработано, но вроде посложнее:
http://rmm.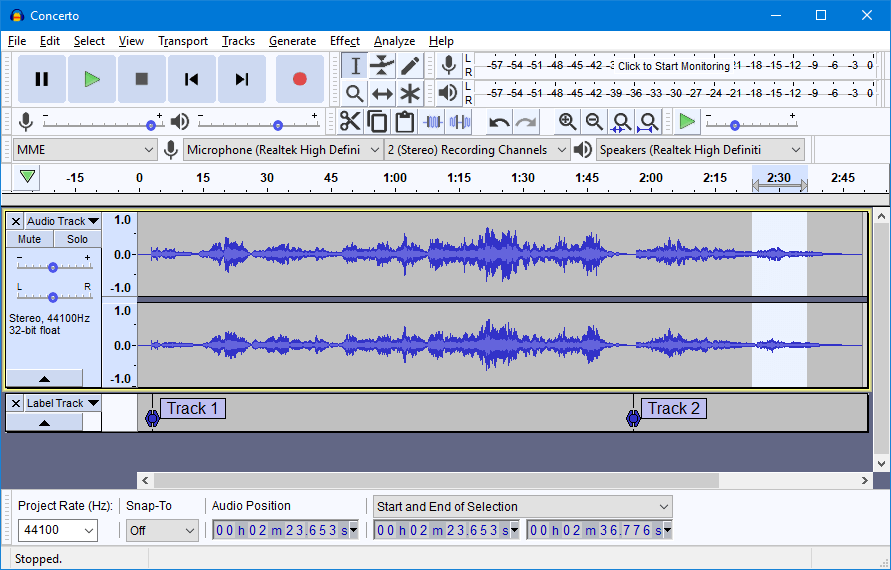 su/showthread.php?t=53041&highlight=%F4%EE%F2%EE%F8%EE%EF
su/showthread.php?t=53041&highlight=%F4%EE%F2%EE%F8%EE%EF
dist
New Member
#3
DAZZER написал(а):
отделить и сохранить какой-либо инструмент или вокал у меня так и неполучилось.
Нажмите для раскрытия…
Интересно, а послушать — получилось?
Litvinov
New Member
#4
Обратите внимание, пользователь заблокирован на форуме. Не рекомендуется проводить сделки.
Не рекомендуется проводить сделки.
Такие проги двигают вперёд целые отрасли…Респект.
kastet
IDKFA
#5
dist, вот примерчик. Взял из ремикса на Никиту, из более-менее разреженного участка микса из «ямы» такссать.. А вообще забавная штука, думал будет намного хуже. Систему только грузит сильно.
primer.MP3
484,9 KB
Просмотры: 171
Последнее редактирование:
Реакции:
dist
Daniel Belik
ex Daniel Belikov
#6
похоже на то, что используются алгоритмы шумоподавления для конкретной партии. Я как-то раз расчленил аудиофайл на вокал и гитару с помощью шумодава, однако результат был очень низкого качества, почти как вв приведенном выше примере.
Я как-то раз расчленил аудиофайл на вокал и гитару с помощью шумодава, однако результат был очень низкого качества, почти как вв приведенном выше примере.
B.M.SiGhT
Member
#7
Как то встречалась ещё одна из этой серии Unmixing Station от Audionamix, но у меня так и не завелась..
Ulysses65
Валерий Матвеев
#8
я так понял тока для винды?
Rarr
Well-Known Member
#9
Litvinov написал(а):
Такие проги двигают вперёд целые отрасли.
Нажмите для раскрытия…

Это да. Но вот музыку гробят:-(
Alexey Lukin
Well-Known Member
#10
Мне кажется, ещё Melodyne DNA делает то же самое.
Magnet
Это опять я и мое шоу
#11
адская помесь Melodyne и Dance Ejay
solo541
Well-Known Member
#12
На это способна только sonicWORX Isolate,с вполне достойным результатом,ИМХО, It retails at $529 USD и толко MAC OS
http://www. sonicworx.com/sonicWORX/About.html
sonicworx.com/sonicWORX/About.html
Послушать файлы http://soundcloud.com/user7421656
Nuf-nuf
New Member
#13
послушал выложенный примерчик — что-то не представляю себе практического применения этой проги при таком результате
maxxl1
Gold Sequence
#14
Nuf-nuf написал(а):
что-то не представляю себе практического применения этой проги при таком результате
Нажмите для раскрытия.
 ..
..А я вот представляю, что в добавок к задавкам появятся ещё уродливее фанеры для «частного» применения, блин, и что начнутся звонки не тему «А Вы можете вырезать голос из песни, я знаю, что есть такая прога, которая это делает?».:girl_cray3:
smack
Well-Known Member
#15
Не пойму никак смысла проги — сделать из сводки разводку? :sarcastic: И чо? Потом опять сводить полученную капу с мелодией и битом?
DAZZER написал(а):
помощью моей программы меломаны смогут создавать свои дорожки для караоке, делать попурри из разных композиций, а также заниматься редактированием аудио файлов»
Нажмите для раскрытия.
 ..
..DAZZER написал(а):
Пользователь выбирает нужный аудио файл
Нажмите для раскрытия…
Представил себе этого пользователя-меломана…
Кстати, еще одна прога для него:
http://rmm.su/showpost.php?p=634152&postcount=1
Последнее редактирование:
Oleg Sirenko
писатель музыки
#16
И чувак 10 лет жызни на это потратил.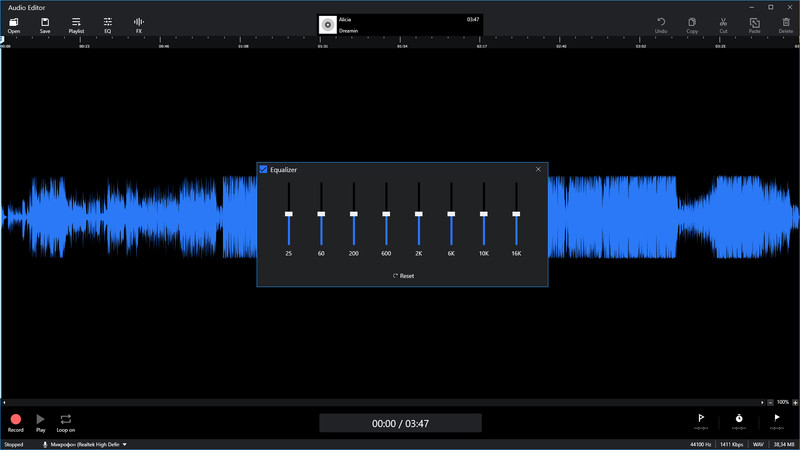 ..:to_take_umbrage:
..:to_take_umbrage:
velehentor
Кошачий Отец
#17
Oleg Sirenko написал(а):
И чувак 10 лет жызни на это потратил.
Нажмите для раскрытия…
Я надеюсь — между делом. Ну, пиво там, девки, то сё. :to_become_senile:
Ещё надеюсь, что софт такого плана не получит дальнейшего развития. Более того, надеюсь, что это приравняют к инструментам взлома наравне с троянами и хакерскими инструментами и будут наказывать соответственно.
LogicS
Неисправимый любитель
#18
Хотя программеры жгут, подталкивая очередной раз к мысли, что «ничего невозможного нет», примеры не впечатляют. Далеко ещё до «идеального» варианта.
Однако, если эти парни всё же окончательно откажутся от пива и девок и разработают алгоритм спектрального «дозаполнения» как голосов, так и инструментов, опираясь на каку-нить хитрую сэмплерную библу… Вот тохда их можно смело пристрелить
Реакции:
bruno_banano
Kokarev Maxim
ex cool
#19
Oleg Sirenko написал(а):
И чувак 10 лет жызни на это потратил.
Нажмите для раскрытия…
 ..:to_take_umbrage:
..:to_take_umbrage:Он интерфейс рисовал :laugh2:
kartalex
Active Member
#20
Ну Melodyne DNA тоже раньше был фантастикой. Наверно эти технологии разовьются и качество обработки улучшится. Можно будет Луи Армстронга разбить на трэки свести нормально :hang3:
velehentor
Кошачий Отец
#21
kartalex написал(а):
Можно будет Луи Армстронга разбить
Нажмите для раскрытия.
 ..
..kartalex написал(а):
Луи Армстронга разбить на трэки
Нажмите для раскрытия…
kartalex написал(а):
Луи Армстронга свести нормально
Нажмите для раскрытия…
А можно его НЕ трогать? Оставьте людям хоть что-то. Мёртвых хотя бы не надо это. В смысле — трогать.
Реакции:
olegsound
Rusik
Руслан Бащенко
#22
kartalex написал(а):
Можно будет Луи Армстронга разбить на трэки свести нормально
Нажмите для раскрытия.
 ..
..а он ненормально, значит, сведён? )
Реакции:
Got Zilla
kastet
IDKFA
#23
если всё-таки когда-нибудь допилят .mt9 подобные программы и не нужны будут вовсе :search:
Rarr
Well-Known Member
#24
kartalex написал(а):
Можно будет Луи Армстронга разбить на трэки свести нормально
Нажмите для раскрытия.
 ..
..А у меня мечта -всего Кобзона пересвести:russian_ru:
velehentor
Кошачий Отец
#25
kastet написал(а):
если всё-таки когда-нибудь допилят .mt9
Нажмите для раскрытия…
Думаю — не допилят.
Пользовательские «ништяки» формата очень сомнительны, а внедрение нового унифицированного формата сопряжено со слишком серьёзными затратами на всех уровнях.
smack
Well-Known Member
#26
Rarr написал(а):
А у меня мечта -всего Кобзона пересвести
Нажмите для раскрытия.
 ..
..А у меня — всего Паганини Live…
Makka
Максим Владимирович
#27
kastet написал(а):
если всё-таки когда-нибудь допилят .mt9 подобные программы и не нужны будут вовсе :search:
Нажмите для раскрытия…
Чушь полная считаю, какой смысл тогда дотошно выстраивать уровни инструментов на студии на этапе сведения, если потом каждый будет перехлобучивать как ему хочется, да и ненужно это вовсе если сведено все круто )))
NewAger
Senior Remember
#28
Дальше понятно. Разбиваешь трэк, вычленяешь войс, поргоняешь через переводчик, сводишь все назад до купы, получаешь уже переведенную песню, спетую тем же голосом, но на другом языке. Можете себе представить Кобзона на суахили или корейском?
Разбиваешь трэк, вычленяешь войс, поргоняешь через переводчик, сводишь все назад до купы, получаешь уже переведенную песню, спетую тем же голосом, но на другом языке. Можете себе представить Кобзона на суахили или корейском?
Реакции:
bruno_banano
Alex_HS
Super Moderator
#29
А как интересно несколько лет назад (довольно давно) удалось вычистить от оркестра голос тогда уже покойного Ната Кинга Коула чтобы вписать его в дуэт с дочерью Натали Коул? :unknw:
Streltsov
Member
#30
Litvinov написал(а):
Такие проги двигают вперёд целые отрасли.
Нажмите для раскрытия…
 ..Респект.
..Респект.Потестил, и понял что всё это двигает назад все отрасли
Как изолировать определенные голоса в видео?
спросил
Изменено
6 лет, 9 месяцев назад
Просмотрено
37 тысяч раз
У меня есть несколько домашних видеороликов, снятых на телефон, на которых разговаривают несколько человек, а также звучит фоновая музыка.
Можно ли как-то изолировать определенные голоса? Если это поможет, основной разговор, который я хочу, будет в фокусе видео.
- видео
- голос
- изоляция
0
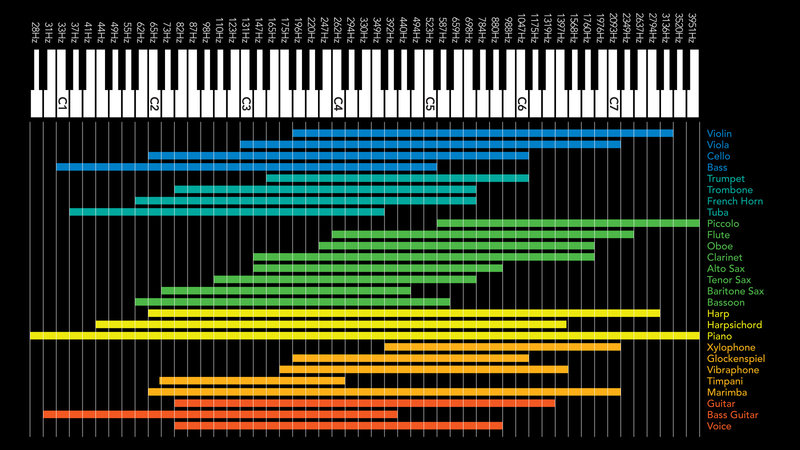
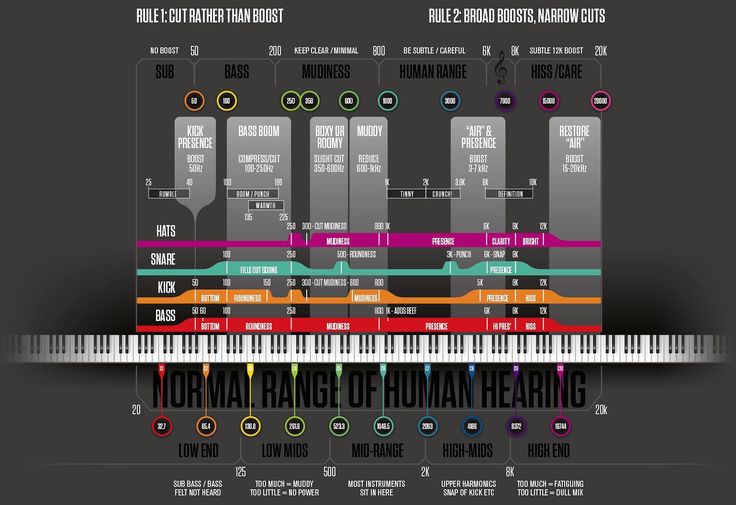
Невозможно делать то, что ты хочешь. Человеческий голос, каким бы тембром он ни обладал, находится примерно в одном частотном диапазоне.
Человеческий голос, каким бы тембром он ни обладал, находится примерно в одном частотном диапазоне.
Тем не менее, вы можете, по крайней мере, отфильтровать часть фонового шума, выравнивая частоты, которые не встречаются в человеческом голосе. В Википедии есть хорошая статья о частоте голоса:
https://en.m.wikipedia.org/wiki/Голосовая_частота
Таким образом, чтобы отфильтровать частоты из аудиозаписи, вы обычно используете фильтр эквалайзера, который позволяет вам усиливать или уменьшать появление определенных частот в записи.
Хорошая статья по эквализации, особенно обратите внимание на главу «типы фильтров»:
https://en.m.wikipedia.org/wiki/Equalization_(audio)
В вашем случае для этого не будет хорошей техники.
Лучшее, что вы можете сделать, это использовать эквалайзер, чтобы увидеть, сможете ли вы подчеркнуть вокал и ослабить фон.
Обычный метод выделения вокала из песни — инвертирование фазы фоновой дорожки для ее устранения (это вам не подойдет).
5
Единственное, что я хотел бы добавить к ответу Ханса Мейзера , это возможное использование расширителя/гейта .
Если целевой разговор является фокусом, то он должен быть немного громче остальных (на определенных частотах), что позволяет использовать расширитель или гейт, чтобы подчеркнуть этот разговор. Однако вам может показаться, что это сложно, если вы не профессионал в области аудио.
Вам понадобится расширитель или гейт с внутренними (или внешними) возможностями сайдчейна (пример).
Затем вы можете найти частоту (или частоты), на которой целевой разговор является доминирующим, и передать этот усовершенствованный сигнал в сайдчейн.
Затем, с некоторыми корректировками параметров экспандера/гейта, в результате должен получиться сигнал, который становится все громче и тише в зависимости от голосов целевого собеседника.
На практике это может быть сложно поддерживать. Это может занять немного работы.
Что такое экспандер/гейт?
Объяснение Apple по экспандерам/гейтам
Pro Tools Tutorial: Sidechain Techniques
Сайдчейн в Cubase
Может быть трудно выделить определенный голос. В Audacity вы можете импортировать аудиофайл и разделить его. Затем выберите нижнюю часть и выберите эффект и выберите инвертировать. Однако он не изолирует все голоса.
Также вы можете отфильтровать частоту, но опять же, это будет не так точно, так как ваш звук со временем меняет свою частоту (если только тот, кто говорил, не монотонен).
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
Изоляция различных человеческих голосов от звука
спросил
Изменено
6 лет назад
Просмотрено
2к раз
У меня много часов записей группового обсуждения. По большей части каждый человек говорит отдельно от других по времени, фоновый шум минимален. Мне нужно иметь возможность находить экземпляры одного голоса (или каждого голоса) и либо помечать их, либо создавать из них отдельные клипы.
В идеале я бы установил один голос в качестве основного голоса, и чтобы какой-то процесс определял, когда этот голос повторяется. У меня много аудио для сравнения.
У меня есть доступ к Pro Tools 12, Reaper и многим пакетам программного обеспечения для обработки звука для музыки и шумоподавления.
Есть идеи?
- производство аудио
- управление голосом
1
Маркус Уивер-Хайтауэр, доктор философии, заявляет в этом видео, что «не существует волшебного расшифровщика», который мог бы исключить человеческое усилие из процесса транскрипции. При этом его предложение использовать программное обеспечение для распознавания голоса для ускорения процесса транскрипции может оказаться для вас чем-то ценным.
Вы можете рассмотреть возможность использования программного обеспечения, такого как программа ELAN Института Макса Планка для транскрипции, если вам нужны точные или сложные транскрипции, но, как и в случае с большинством бесплатных программ, вам может не хватать кривой обучения и удобства для пользователя.
Что касается программного обеспечения, которое может предоставить волшебную палочку, которую вы ищете, то я не встречал такой программы, но допускаю, что такая программа теоретически возможна.