Содержание
Современные распределенные хранилища данных: обзор технологий и перспективы
Сегодня поговорим о том, как лучше хранить данные в мире, где сети пятого поколения, сканеры геномов и беспилотные автомобили производят за день больше данных, чем всё человечество породило в период до промышленной революции. Наш мир генерирует всё больше информации. Какая-то её часть мимолётна и утрачивается так же быстро, как и собирается. Другая должна храниться дольше, а иная и вовсе рассчитана «на века» — по крайней мере, так нам видится из настоящего. Информационные потоки оседают в дата-центрах с такой скоростью, что любой новый подход, любая технология, призванные удовлетворить этот бесконечный «спрос», стремительно устаревают. 40 лет развития распределённых СХД. Первые сетевые хранилища в привычном нам виде появились в 1980-х. Многие из вас сталкивались с NFS (Network File System), AFS (Andrew File System) или Coda. Спустя десятилетие мода и технологии изменились, а распределённые файловые системы уступили место кластерным СХД на основе GPFS (General Parallel File System), CFS (Clustered File Systems) и StorNext. В качестве базиса использовались блочные хранилища классической архитектуры, поверх которых с помощью программного слоя создавалась единая файловая система. Эти и подобные решения до сих пор применяются, занимают свою нишу и вполне востребованы.
В качестве базиса использовались блочные хранилища классической архитектуры, поверх которых с помощью программного слоя создавалась единая файловая система. Эти и подобные решения до сих пор применяются, занимают свою нишу и вполне востребованы.
Воспользуйтесь нашими услугами
На рубеже тысячелетий парадигма распределённых хранилищ несколько поменялась, и на лидирующие позиции вышли системы с архитектурой SN (Shared-Nothing). Произошёл переход от кластерного хранения к хранению на отдельных узлах, в качестве которых, как правило, выступали классические серверы с обеспечивающим надёжное хранение ПО; на таких принципах построены, скажем, HDFS (Hadoop Distributed File System) и GFS (Global File System).
Ближе к 2010-м заложенные в основу распределённых систем хранения концепции всё чаще стали находить отражение в полноценных коммерческих продуктах, таких как VMware vSAN, Dell EMC Isilon и наша Huawei OceanStor. За упомянутыми платформами стоит уже не сообщество энтузиастов, а конкретные вендоры, которые отвечают за функциональность, поддержку, сервисное обслуживание продукта и гарантируют его дальнейшее развитие. Такие решения наиболее востребованы в нескольких сферах.
Такие решения наиболее востребованы в нескольких сферах.
Операторы связи
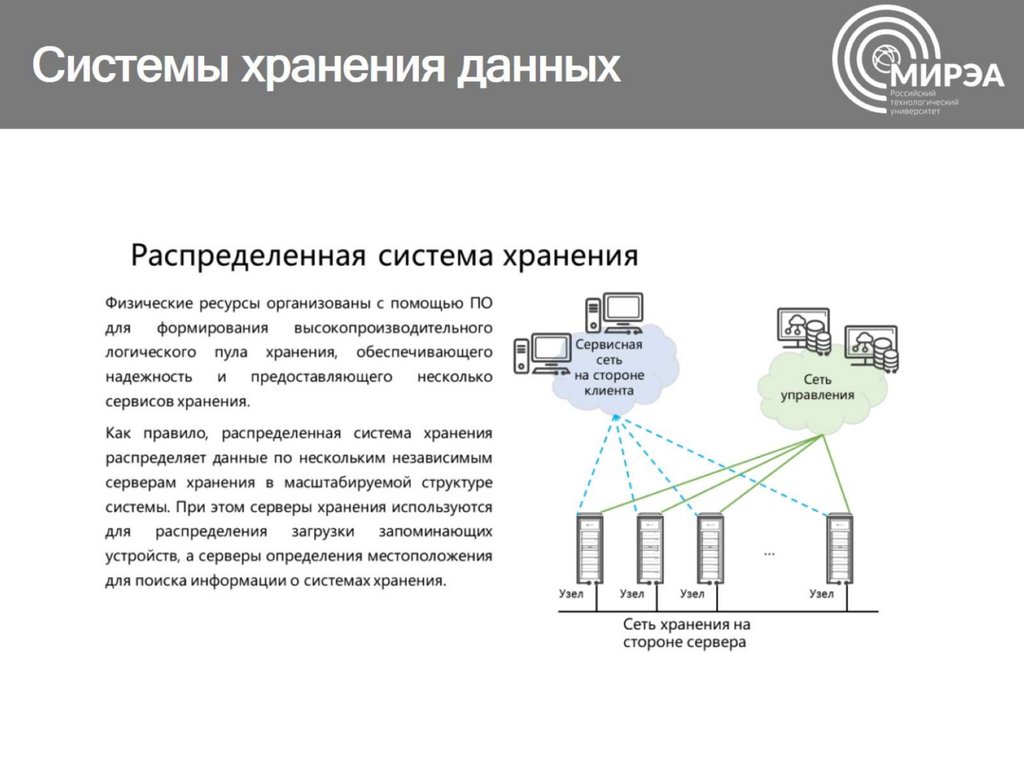
Пожалуй, одними из старейших потребителей распределённых систем хранения являются операторы связи. На схеме видно, какие группы приложений производят основной объём данных. OSS (Operations Support Systems), MSS (Management Support Services) и BSS (Business Support Systems) представляют собой три дополняющих друг друга программных слоя, необходимых для предоставления сервиса абонентам, финансовой отчётности провайдеру и эксплуатационной поддержки инженерам оператора.
Зачастую данные этих слоев сильно перемешаны между собой, и, чтобы избежать накопления ненужных копий, как раз и используются распределённые хранилища, которые аккумулируют весь объём информации, поступающей от работающей сети. Хранилища объединяются в общий пул, к которому и обращаются все сервисы.
Наши расчёты показывают, что переход от классических СХД к блочным позволяет сэкономить до 70% бюджета только за счёт отказа от выделенных СХД класса hi-end и использования обычных серверов классической архитектуры (обычно x86), работающих в связке со специализированным ПО. Сотовые операторы уже довольно давно начали приобретать подобные решения в серьезных объёмах. В частности, российское операторы используют такие продукты от Huawei более шести лет.
Сотовые операторы уже довольно давно начали приобретать подобные решения в серьезных объёмах. В частности, российское операторы используют такие продукты от Huawei более шести лет.
Да, ряд задач с помощью распределённых систем выполнить не получится. Например, при повышенных требованиях к производительности или к совместимости со старыми протоколами. Но не менее 70% данных, которые обрабатывает оператор, вполне можно расположить в распределённом пуле.
Банковская сфера
В любом банке соседствует множество разношёрстных IT-систем, начиная с процессинга и заканчивая автоматизированной банковской системой. Эта инфраструктура тоже работает с огромным объёмом информации, при этом большая часть задач не требует повышенной производительности и надёжности систем хранения, например разработка, тестирование, автоматизация офисных процессов и пр. Здесь применение классических СХД возможно, но с каждым годом всё менее выгодно. К тому же в этом случае отсутствует гибкость расходования ресурсов СХД, производительность которой рассчитывается из пиковой нагрузки.
При использовании распределённых систем хранения их узлы, по факту являющиеся обычными серверами, могут быть в любой момент конвертированы, например, в серверную ферму и использованы в качестве вычислительной платформы.
Озёра данных
На схеме выше приведён перечень типичных потребителей сервисов data lake. Это могут быть службы электронного правительства (допустим, «Госуслуги»), прошедшие цифровизацию предприятия, финансовые структуры и др. Всем им необходимо работать с большими объёмами разнородной информации.
Эксплуатация классических СХД для решения таких задач неэффективна, так как требуется и высокопроизводительный доступ к блочным базам данных, и обычный доступ к библиотекам сканированных документов, хранящихся в виде объектов. Сюда же может быть привязана, допустим, система заказов через веб-портал. Чтобы всё это реализовать на платформе классической СХД, потребуется большой комплект оборудования под разные задачи. Одна горизонтальная универсальная система хранения вполне может закрывать все ранее перечисленные задачи: понадобится лишь создать в ней несколько пулов с разными характеристиками хранения.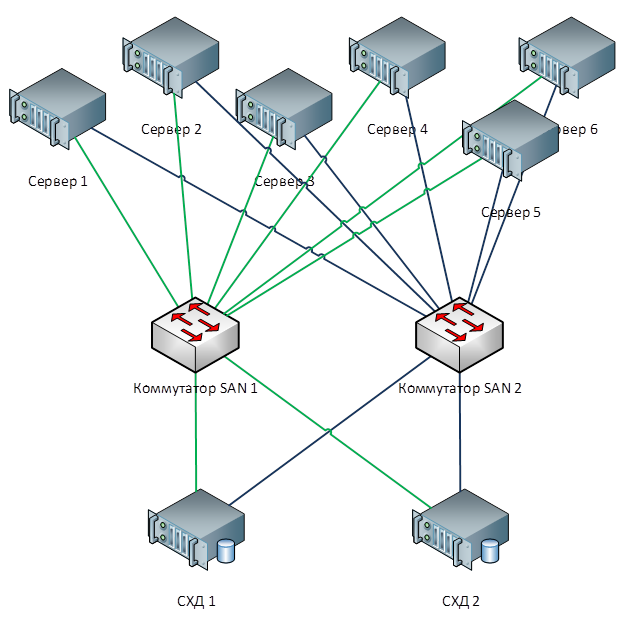
Генераторы новой информации
Количество хранимой в мире информации растёт примерно на 30% в год. Это хорошие новости для поставщиков систем хранения, но что же является и будет являться основным источником этих данных?
Десять лет назад такими генераторами стали социальные сети, это потребовало создания большого количества новых алгоритмов, аппаратных решений и т. д. Сейчас выделяются три главных драйвера роста объёмов хранения. Первый — cloud computing. В настоящее время примерно 70% компаний так или иначе используют облачные сервисы. Это могут быть электронные почтовые системы, резервные копии и другие виртуализированные сущности.
Вторым драйвером становятся сети пятого поколения. Это новые скорости и новые объёмы передачи данных. По нашим прогнозам, широкое распространение 5G приведёт к падению спроса на карточки флеш-памяти. Сколько бы ни было памяти в телефоне, она всё равно кончается, а при наличии в гаджете 100-мегабитного канала нет никакой необходимости хранить фотографии локально.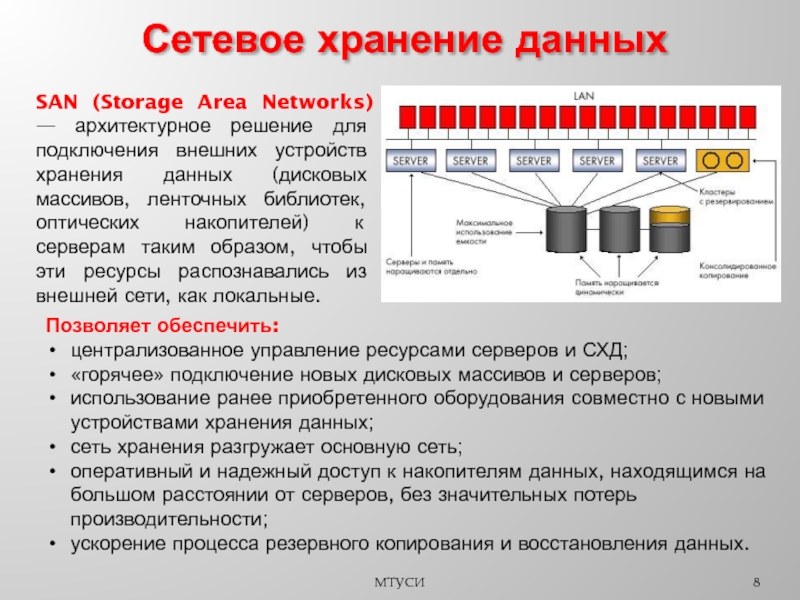
К третьей группе причин, по которым растёт спрос на системы хранения, относятся бурное развитие искусственного интеллекта, переход на аналитику больших данных и тренд на всеобщую автоматизацию всего, чего только можно.
Особенностью «нового трафика» является его неструктурированность. Нам надо хранить эти данные, никак не определяя их формат. Он требуется лишь при последующем чтении. К примеру, банковская система скоринга для определения доступного размера кредита будет смотреть выложенные вами в соцсетях фотографии, определяя, часто ли вы бываете на море и в ресторанах, и одновременно изучать доступные ей выписки из ваших медицинских документов. Эти данные, с одной стороны, всеобъемлющи, а с другой — лишены однородности.
Океан неструктурированных данных
Какие же проблемы влечет за собой появление «новых данных»? Первейшая среди них, конечно, сам объём информации и расчётные сроки её хранения. Один только современный автономный автомобиль без водителя каждый день генерирует до 60 Тбайт данных, поступающих со всех его датчиков и механизмов.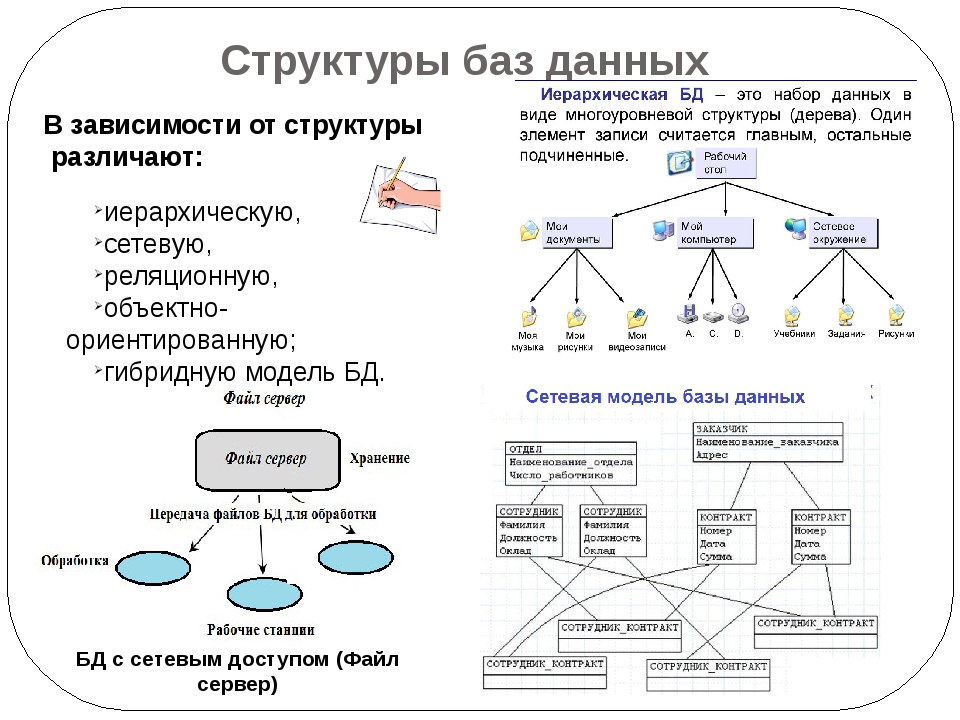 Для разработки новых алгоритмов движения эту информацию необходимо обработать за те же сутки, иначе она начнёт накапливаться. При этом храниться она должна очень долго — десятки лет. Только тогда в будущем можно будет делать выводы на основе больших аналитических выборок.
Для разработки новых алгоритмов движения эту информацию необходимо обработать за те же сутки, иначе она начнёт накапливаться. При этом храниться она должна очень долго — десятки лет. Только тогда в будущем можно будет делать выводы на основе больших аналитических выборок.
Одно устройство для расшифровки генетических последовательностей производит порядка 6 Тбайт в день. А собранные с его помощью данные вообще не подразумевают удаления, то есть гипотетически должны храниться вечно.
Наконец, всё те же сети пятого поколения. Помимо собственно передаваемой информации, такая сеть и сама является огромным генератором данных: журналов действий, записей звонков, промежуточных результатов межмашинных взаимодействий и пр.
Всё это требует выработки новых подходов и алгоритмов хранения и обработки информации. И такие подходы появляются.
Технологии новой эпохи
Можно выделить три группы решений, призванных справиться с новыми требованиями к системам хранения информации: внедрение искусственного интеллекта, техническая эволюция носителей данных и инновации в области системной архитектуры. Начнём с ИИ.
Начнём с ИИ.
В новых решениях Huawei искусственный интеллект используется уже на уровне самого хранилища, которое оборудовано ИИ-процессором, позволяющим системе самостоятельно анализировать своё состояние и предсказывать отказы. Если СХД подключить к сервисному облаку, которое обладает значительными вычислительными способностями, искусственный интеллект сможет обработать больше информации и повысить точность своих гипотез.
Помимо отказов, такой ИИ умеет прогнозировать будущую пиковую нагрузку и время, остающееся до исчерпания ёмкости. Это позволяет оптимизировать производительность и масштабировать систему ещё до наступления каких-либо нежелательных событий.
Теперь об эволюции носителей данных. Первые флеш-накопители были выполнены по технологии SLC (Single-Level Cell). Основанные на ней устройства были быстрыми, надёжными, стабильными, но имели небольшую ёмкость и стоили очень дорого. Роста объёма и снижения цены удалось добиться путём определённых технических уступок, из-за которых скорость, надёжность и срок службы накопителей сократились. Тем не менее тренд не повлиял на сами СХД, которые за счёт различных архитектурных ухищрений в целом стали и более производительными, и более надёжными.
Тем не менее тренд не повлиял на сами СХД, которые за счёт различных архитектурных ухищрений в целом стали и более производительными, и более надёжными.
Но почему понадобились СХД класса All-Flash? Разве недостаточно было просто заменить в уже эксплуатируемой системе старые HDD на новые SSD того же форм-фактора? Потребовалось это для того, чтобы эффективно использовать все ресурсы новых твердотельных накопителей, что в старых системах было попросту невозможно.
Компания Huawei, например, для решения этой задачи разработала целый ряд технологий, одной из которых стала FlashLink, позволившая максимально оптимизировать взаимодействия «диск — контроллер».
Интеллектуальная идентификация дала возможность разложить данные на несколько потоков и справиться с рядом нежелательных явлений, таких как WA (write amplification). Вместе с тем новые алгоритмы восстановления, в частности RAID 2.0+, повысили скорость ребилда, сократив его время до совершенно незначительных величин.
Отказ, переполненность, «сборка мусора» — эти факторы также больше не влияют на производительность системы хранения благодаря специальной доработке контроллеров.
А ещё блочные хранилища данных готовятся встретить NVMe. Напомним, что классическая схема организации доступа к данным работала так: процессор обращался к RAID-контроллеру по шине PCI Express. Тот, в свою очередь, взаимодействовал с механическими дисками по SCSI или SAS. Применение NVMe на бэкенде заметно ускорило весь процесс, однако несло в себе один недостаток: накопители должны были иметь непосредственное подключение к процессору, чтобы обеспечить тому прямой доступ в память.
Следующей фазой развития технологии, которую мы наблюдаем сейчас, стало применение NVMe-oF (NVMe over Fabrics). Что касается блочных технологий Huawei, они уже сейчас поддерживают FC-NVMe (NVMe over Fibre Channel), и на подходе NVMe over RoCE (RDMA over Converged Ethernet). Тестовые модели вполне функциональны, до официальной их презентации осталось несколько месяцев. Заметим, что всё это появится и в распределённых системах, где «Ethernet без потерь» будет весьма востребован.
Дополнительным способом оптимизации работы именно распределённых хранилищ стал полный отказ от зеркалирования данных. Решения Huawei больше не используют n копий, как в привычном RAID 1, и полностью переходят на механизм EC (Erasure coding). Специальный математический пакет с определённой периодичностью вычисляет контрольные блоки, которые позволяют восстановить промежуточные данные в случае их потери.
Решения Huawei больше не используют n копий, как в привычном RAID 1, и полностью переходят на механизм EC (Erasure coding). Специальный математический пакет с определённой периодичностью вычисляет контрольные блоки, которые позволяют восстановить промежуточные данные в случае их потери.
Механизмы дедупликации и сжатия становятся обязательными. Если в классических СХД мы ограничены количеством установленных в контроллеры процессоров, то в распределённых горизонтально масштабируемых системах хранения каждый узел содержит всё необходимое: диски, память, процессоры и интерконнект. Этих ресурсов достаточно, чтобы дедупликация и компрессия оказывали на производительность минимальное влияние.
И об аппаратных методах оптимизации. Здесь снизить нагрузку на центральные процессоры удалось с помощью дополнительных выделенных микросхем (или выделенных блоков в самом процессоре), играющих роль TOE (TCP/IP Offload Engine) или берущих на себя математические задачи EC, дедупликации и компрессии..png)
Новые подходы к хранению данных нашли воплощение в дезагрегированной (распределённой) архитектуре. В системах централизованного хранения имеется фабрика серверов, по Fibre Channel подключённая к SAN с большим количеством массивов. Недостатками такого подхода являются трудности с масштабированием и обеспечением гарантированного уровня услуги (по производительности или задержкам). Гиперконвергентные системы используют одни и те же хосты — как для хранения, так и для обработки информации. Это даёт практически неограниченный простор масштабирования, но влечёт за собой высокие затраты на поддержание целостности данных.
В отличие от обеих вышеперечисленных, дезагрегированная архитектура подразумевает разделение системы на вычислительную фабрику и горизонтальную систему хранения. Это обеспечивает преимущества обеих архитектур и позволяет практически неограниченно масштабировать только тот элемент, производительности которого не хватает.
От интеграции к конвергенции
Классической задачей, актуальность которой последние 15 лет лишь росла, является необходимость одновременно обеспечить блочное хранение, файловый доступ, доступ к объектам, работу фермы для больших данных и т. д. Вишенкой на торте может быть ещё, например, система бэкапа на магнитную ленту.
д. Вишенкой на торте может быть ещё, например, система бэкапа на магнитную ленту.
На первом этапе унифицировать удавалось только управление этими услугами. Разнородные системы хранения данных замыкались на какое-либо специализированное ПО, посредством которого администратор распределял ресурсы из доступных пулов. Но так как аппаратно эти пулы были разными, миграция нагрузки между ними была невозможна. На более высоком уровне интеграции объединение происходило на уровне шлюза. При наличии общего файлового доступа его можно было отдавать через разные протоколы.
Самый совершенный из доступных нам сейчас методов конвергенции подразумевает создание универсальной гибридной системы. Именно такой, какой должна стать наша OceanStor 100D. Универсальный доступ использует те же самые аппаратные ресурсы, логически разделённые на разные пулы, но допускающие миграцию нагрузки. Всё это можно сделать через единую консоль управления. Таким способом нам удалось реализовать концепцию «один ЦОД — одна СХД».
Стоимость хранения информации сейчас определяет многие архитектурные решения. И хотя её можно смело ставить во главу угла, мы сегодня обсуждаем «живое» хранение с активным доступом, так что производительность тоже необходимо учитывать. Ещё одним важным свойством распределённых систем следующего поколения является унификация. Ведь никто не хочет иметь несколько разрозненных систем, управляемых из разных консолей. Все эти качества нашли воплощение в новой серии продуктов Huawei OceanStor Pacific.
Массовая СХД нового поколения
OceanStor Pacific отвечает требованиям надёжности на уровне «шести девяток» (99,9999%) и может использоваться для создания ЦОД класса HyperMetro. При расстоянии между двумя дата-центрами до 100 км системы демонстрируют добавочную задержку на уровне 2 мс, что позволяет строить на их основе любые катастрофоустойчивые решения, в том числе и с кворум-серверами.
Продукты новой серии демонстрируют универсальность по протоколам. Уже сейчас OceanStor 100D поддерживает блочный доступ, объектовый доступ и доступ Hadoop. В ближайшее время будет реализован и файловый доступ. Нет нужды хранить несколько копий данных, если их можно выдавать через разные протоколы.
В ближайшее время будет реализован и файловый доступ. Нет нужды хранить несколько копий данных, если их можно выдавать через разные протоколы.
Казалось бы, какое отношение концепция «сеть без потерь» имеет к СХД? Дело в том, что распределённые системы хранения данных строятся на основе быстрой сети, поддерживающей соответствующие алгоритмы и механизм RoCE. Дополнительно увеличить скорость сети и снизить задержки помогает поддерживаемая нашими коммутаторами система искусственного интеллекта AI Fabric. Выигрыш производительности СХД при активации AI Fabric может достигать 20%.
Что же представляет собой новый узел распределённой СХД OceanStor Pacific? Решение форм-фактора 5U включает в себя 120 накопителей и может заменить три классических узла, что даёт более чем двукратную экономию места в стойке. За счёт отказа от хранения копий КПД накопителей ощутимо возрастает (до +92%).
Мы привыкли к тому, что программно-определяемая СХД — это специальное ПО, устанавливаемое на классический сервер. Но теперь для достижения оптимальных параметров это архитектурное решение требует и специальных узлов. В его состав входят два сервера на базе ARM-процессоров, управляющие массивом трёхдюймовых накопителей.
Но теперь для достижения оптимальных параметров это архитектурное решение требует и специальных узлов. В его состав входят два сервера на базе ARM-процессоров, управляющие массивом трёхдюймовых накопителей.
Эти серверы мало подходят для гиперконвергентных решений. Во-первых, приложений для ARM достаточно мало, а во-вторых, трудно соблюсти баланс нагрузки. Мы предлагаем перейти к раздельному хранению: вычислительный кластер, представленный классическими или rack-серверами, функционирует отдельно, но подключается к узлам хранения OceanStor Pacific, которые также выполняют свои прямые задачи. И это себя оправдывает.
Для примера возьмём классическое решение для хранения больших данных с гиперконвергентной системой, занимающее 15 серверных стоек. Если распределить нагрузку между отдельными вычислительными серверами и узлами СХД OceanStor Pacific, отделив их друг от друга, количество необходимых стоек сократится в два раза! Это снижает затраты на эксплуатацию дата-центра и уменьшает совокупную стоимость владения. В мире, где объём хранимой информации растет на 30% в год, подобными преимуществами не разбрасываются.
В мире, где объём хранимой информации растет на 30% в год, подобными преимуществами не разбрасываются.
Автор: denisdubinin3
Источник: https://habr.com/
Воспользуйтесь нашими услугами
Понравилась статья? Тогда поддержите нас, поделитесь с друзьями и заглядывайте по рекламным ссылкам!
с чего начать / Хабр
В мире энтерпрайза наступило пресыщение фронтовыми системами, шинами данных и прочими классическими системами, которые внедряли все кому не лень последние 10-15 лет. Но есть один сегмент, который до недавнего времени был в статусе «все хотят, но никто не знает, что это». И это Big Data. Красиво звучит, продвигается топовыми западными компаниями – как не стать лакомым кусочком?
Но пока большинство только смотрит и приценивается, некоторые компании начали активно внедрять решения на базе этого технологического стека в свой IT ландшафт. Важную роль в этом сыграло появление коммерческих дистрибутивов Apache Hadoop, разработчики которых обеспечивают своим клиентам техническую поддержку. Ощутив необходимость в подобном решении, один из наших клиентов принял решение об организации распределенного хранилища данных в концепции Data Lake на базе Apache Hadoop.
Ощутив необходимость в подобном решении, один из наших клиентов принял решение об организации распределенного хранилища данных в концепции Data Lake на базе Apache Hadoop.
Цели проекта
Во-первых, оптимизировать работу департамента управления рисками. До начала работ расчетом факторов кредитного риска (ФКР) занимался целый отдел, и все расчеты производились вручную. Перерасчет занимал каждый раз около месяца и данные, на основе которых он базировался, успевали устареть. Поэтому в задачи решения входила ежедневная загрузка дельты данных в хранилище, перерасчет ФКР и построение витрин данных в BI-инструменте (для данной задачи оказалось достаточно функционала SpagoBI) для их визуализации.
Во-вторых, обеспечить высокопроизводительные инструменты Data Mining для сотрудников банка, занимающихся Data Science. Данные инструменты, такие как Jupyter и Apache Zeppelin, могут быть установлены локально и с их помощью также можно исследовать данные и производить построение моделей. Но их интеграция с кластером Cloudera позволяет использовать для расчетов аппаратные ресурсы наиболее производительных узлов системы, что ускоряет выполнение задач анализа данных в десятки и даже сотни раз.
Но их интеграция с кластером Cloudera позволяет использовать для расчетов аппаратные ресурсы наиболее производительных узлов системы, что ускоряет выполнение задач анализа данных в десятки и даже сотни раз.
В качестве целевого аппаратного решения была выбрана стойка Oracle Big Data Appliance, поэтому за основу был взят дистрибутив Apache Hadoop от компании Cloudera. Стойка ехала довольно долго, и для ускорения процесса под данный проект были выделены сервера в приватном облаке заказчика. Решение разумное, но был и ряд проблем, о которых расскажу ниже по тексту.
В рамках проекта были запланированы следующие задачи:
- Развернуть Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) и дополнительные сервисы, необходимые для работы.
- Произвести настройку установленного ПО.
- Настроить непрерывную интеграцию для ускорения процесса разработки (будет освещена в отдельной статье).
- Установить BI-средства для построения отчетности и инструментов Data Discovery для обеспечения работы датасайентистов (будет освещена в отдельном посте).

- Разработать приложения для загрузки необходимых данных из конечных систем, а также их регулярной актуализации.
- Разработать формы построения отчетности для визуализации данных в BI-средстве.
Компания Neoflex не первый год занимается разработкой и внедрением систем на базе Apache Hadoop и даже имеет свой продукт для визуальной разработки ETL-процессов — Neoflex Datagram. Я давно хотел принять участие в одном из проектов этого класса и с радостью занялся администрированием данной системы. Опыт оказался весьма ценным и мотивирующим к дальнейшему изучению темы, поэтому спешу поделиться им с вами. Надеюсь, что будет интересно.
Ресурсы
До того, как начинать установку, рекомендуется подготовить для нее все необходимое.
Количество и мощность железа напрямую зависит от того, сколько и каких сред потребуется развернуть. Для целей разработки можно установить все компоненты хоть на одну хилую виртуалку, но такой подход не приветствуется.
На этапе пилотирования проекта и активной разработки, когда количество пользователей системы было минимально, было достаточно одной основной среды – это позволяло ускоряться за счет сокращения времени загрузки данных из конечных систем (наиболее частая и долгая процедура при разработке хранилищ данных). Сейчас, когда система стабилизировалась, пришли к конфигурации с тремя средами – тест, препрод и прод (основная).
В приватном облаке были выделены сервера для организации 2 сред – основной и тестовой. Характеристики сред приведены в таблице ниже:
| Назначение | Количество | vCPU | vRAM, Gb | Диски, Gb |
|---|---|---|---|---|
| Основная среда, сервисы Cloudera | 3 | 8 | 64 | 2 200 |
| Основная среда, HDFS | 3 | 22 | 288 | 5000 |
| Основная среда, инструменты Data Discovery | 1 | 16 | 128 | 2200 |
| Тестовая среда, сервисы Cloudera | 1 | 8 | 64 | 2200 |
| Тестовая среда, HDFS | 2 | 22 | 256 | 4000 |
| Основная среда, инструменты Data Discovery | 1 | 16 | 128 | 2200 |
| CI | 2 | 6 | 48 | 1000 |
Позднее основная среда мигрировала на Oracle BDA, а сервера были использованы для организации препрод среды.
Решение о миграции было обоснованным – ресурсов выделенных под HDFS серверов объективно не хватало. Узкими местами стали крохотные диски (что такое 5 Tb для Big Data?) и недостаточно мощные процессоры, стабильно загруженные на 95% при штатной работе задач по загрузке данных. С прочими серверами ситуация обратная – практически все время они простаивают без дела и их ресурсы с большей пользой можно было бы задействовать на других проектах.
С софтом дела обстояли непросто – из-за того, что разработка велась в частном облаке без доступа к интернету, все файлы приходилось переносить через службу безопасности и только по согласованию. В связи с этим приходилось заранее выгружать все необходимые дистрибутивы, пакеты и зависимости.
В этой непростой задаче очень помогала настройка keepcache=1 в файлике /etc/yum.conf (в качестве OS использовался RHEL 7.3) – установить нужное ПО на машине с выходом в сеть намного проще, чем руками выкачивать его из репозиториев вместе с зависимостями 😉
Что потребуется развернуть:
- Oracle JDK (без Java никуда).
- База данных для хранения информации, создаваемой и используемой сервисами CDH (например Hive Metastore). В нашем случае был установлен PostgreSQL версии 9.2.18, но может быть использована любая из поддерживаемых сервисами Cloudera (список отличается для разных версий дистрибутива, см. раздел «Requirements and Supported Versions» официального сайта). Здесь надо заметить, что выбор БД оказался не вполне удачным – Oracle BDA поставляется с БД MySQL (один из их продуктов, перешедший к ним вместе с покупкой Sun) и логичнее было использовать аналогичную базу для других сред, что упростило бы процедуру миграции. Рекомендуется выбирать дистрибутив исходя из целевого аппаратного решения.
- Демон Chrony для синхронизации времени на серверах.
- Cloudera Manager Server.
- Демоны Cloudera Manager.

Подготовка к установке
Перед началом установки CDH стоит провести ряд подготовительных работ. Одна их часть пригодится во время установки, другая упростит эксплуатацию.
Установка и настройка ОС
Прежде всего, стоит подготовить виртуальные (можно и реальные) машины, на которых будет располагаться система: установить на каждую из них операционную систему поддерживаемой версии (список отличается для разных версий дистрибутива, см. раздел «Requirements and Supported Versions» официального сайта), присвоить хостам понятные имена (например, <system_name>master1,2,3…, <system_name>slave1,2,3…), а также разметить диски под файловое хранилища и временные файлы, создаваемые в ходе работы системы.
Рекомендации по разметке следующие:
- На серверах с HDFS создать том хотя бы на 500 Gb для файлов, которые создает YARN в ходе работы задач и помещает в директорию /yarn (куда этот том и надо подмонтировать после установки CDH). Небольшой том (порядка 100 Gb) стоит выделить для ОС, сервисов Cloudera, логов и прочего хозяйства. Все свободное место, которое останется после этих манипуляций, стоит объединить в один большой том и примонтировать к директории /dfs до начала загрузки данных в хранилище. HDFS хранит данные в виде достаточно мелких блоков и лучше лишний раз не заниматься их переносом. Также для удобства последующего добавления дисков рекомендуется использовать LVM – проще будет расширять хранилище (особенно когда оно станет действительно BIG).
- На серверах с сервисами Cloudera можно монтировать все доступное место в корневую директорию – проблем с большими объемами файлов быть не должно, особенно если регулярно чистить логи. Единственное исключение составляет сервер с базой данных, которую используют сервисы Cloudera для своих нужд – на данном сервере имеет смысл разметить отдельный том под директорию, в которой хранятся файлы этой БД (будет зависеть от выбранного дистрибутива). Сервисы пишут довольно умеренно и 500 Gb должно хватить с лихвой. Для подстраховки также можно использовать LVM.
 HDFS хранит данные в виде достаточно мелких блоков и лучше лишний раз не заниматься их переносом. Также для удобства последующего добавления дисков рекомендуется использовать LVM – проще будет расширять хранилище (особенно когда оно станет действительно BIG).
HDFS хранит данные в виде достаточно мелких блоков и лучше лишний раз не заниматься их переносом. Также для удобства последующего добавления дисков рекомендуется использовать LVM – проще будет расширять хранилище (особенно когда оно станет действительно BIG).
Настройка http сервера и offline установка пакетов yum и CDH
Поскольку установка софта производится без доступа в интернет, для упрощения установки пакетов рекомендуется поднять HTTP сервер и с его помощью создать локальный репозиторий, который будет доступен по сети. Можно устанавливать весь софт локально с помощью, к примеру, rpm, но при большом количестве серверов и появлении нескольких сред удобно иметь единый репозиторий, из которого можно ставить пакеты без необходимости переносить их руками с машины на машину.
Можно устанавливать весь софт локально с помощью, к примеру, rpm, но при большом количестве серверов и появлении нескольких сред удобно иметь единый репозиторий, из которого можно ставить пакеты без необходимости переносить их руками с машины на машину.
Установка производилась на ОС Red Hat 7.3, поэтому в статье будут приводиться команды, специфичные для нее и других операционных систем на базе CentOS. При установке на других ОС последовательность будет аналогичной, отличаться будут только пакетные менеджеры.
Дабы не писать везде sudo будем считать, что установка происходит из-под рута.
Вот что потребуется сделать:
1. Выбирается машина, на которой будет располагаться HTTP сервер и дистрибутивы.
2. На машине с аналогичной ОС, но подключенной к интернету, выставляем флаг keepcache=1 в файле /etc/yum.conf и устанавливается httpd со всеми зависимостями:
yum install httpd
Если данная команда не работает, то требуется добавить в список репозиториев yum репозиторий, в котором есть данные пакеты, например, этот — centos. excellmedia.net/7/os/x86_64:
excellmedia.net/7/os/x86_64:
echo -e "\n[centos.excellmedia.net]\nname=excellmedia\nbaseurl=http://centos.excellmedia.net/7/os/x86_64/\nenabled=1\ngpgcheck=0" > /etc/yum.repos.d/excell.repo
После этого командой yum repolist проверяем, что репозиторий подтянулся — в списке репозиториев должен появиться добавленный репозиторий (repo id — centos.excellmedia.net; repo name — excellmedia).
Теперь проверяем, что yum увидел нужные нам пакеты:
yum list | grep httpd
Если в выводе присутствуют нужные пакеты, то можно установить их приведенной выше командой.
3. Для создания репозитория yum нам потребуется пакет createrepo. Он также есть в указанном выше репозитории и ставится аналогично:
yum install createrepo
4. Как я уже говорил, для работы сервисов CDH требуется база данных. Установим для этих целей PostgreSQL:
yum install postgresql-server
5. Одним из обязательных условий для корректной работы CDH является синхронизация времени на всех серверах, входящих в кластер. Для этих целей используется пакет chronyd (на тех ОС, где мне приходилось разворачивать CDH, он был установлен по умолчанию). Проверяем его наличие:
Для этих целей используется пакет chronyd (на тех ОС, где мне приходилось разворачивать CDH, он был установлен по умолчанию). Проверяем его наличие:
chronyd -v
Если он не установлен, то устанавливаем:
yum install chrony
Если же установлен, то просто скачиваем:
yumdownloader --destdir=/var/cache/yum/x86_64/7Server/<repo id>/packages chrony
6. Заодно сразу загрузим пакеты, необходимые для установки CDH. Они доступны на сайте archive.cloudera.com — archive.cloudera.com/cm<мажорная версия CDH>/<название вашей ОС>/<версия вашей ОС>/x86_64/cm/<полная версия CDH>/RPMS/x86_64/. Можно скачать пакеты руками (cloudera-manager-server и cloudera-manager-daemons) либо по аналогии добавить репозиторий и установить их:
yum install cloudera-manager-daemons cloudera-manager-server
7. После установки пакеты и их зависимости закешируются в папке /var/cache/yum/x86_64/7Server/\<repo id\>/packages. Переносим их на машину, выбранную под HTTP сервер и дистрибутивы, и устанавливаем:
Переносим их на машину, выбранную под HTTP сервер и дистрибутивы, и устанавливаем:
rpm -ivh <имя пакета>
8. Запускаем httpd, делаем его видимым с других хостов нашего кластера, а также добавляем его в список сервисов, запускаемых автоматически после загрузки:
systemctl start httpd systemctl enable httpd systemctl stop firewalld # Требуется также сделать для остальных хостов systemctl disable firewalld # Требуется также сделать для остальных хостов setenforce 0
9. Теперь у нас есть работающий HTTP сервер. Его рабочая директория /var/www/html. Создадим в ней 2 папки — одну для репозитория yum, другую для парселей Cloudera (об этом чуть позже):
cd /var/www/html mkdir yum_repo parcels
10. Для работы сервисов Cloudera нам потребуется Java. На все машины требуется установить JDK одинаковой версии, Cloudera рекомендует Hot Spot от Oracle. Скачиваем дистрибутив с официального сайта (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151. html) и переносим в папку yum_repo.
html) и переносим в папку yum_repo.
11. Создадим в папке yum_repo репозиторий yum с помощью утилиты createrepo чтобы пакет с JDK стал доступен для установки с машин кластера:
createrepo -v /var/www/html/yum_repo/
12. После создания нашего локального репозитория на каждом из хостов требуется добавить его описание по аналогии с пунктом 2:
echo -e "\n[yum.local.repo]\nname=yum_repo\nbaseurl=http://<имя хоста с httpd>/yum_repo/\nenabled=1\ngpgcheck=0" > /etc/yum.repos.d/yum_repo.repo
Также можно сделать проверки, аналогичные пункту 2.
13. JDK доступен, устанавливаем:
yum install jdk1.8.0_161.x86_64
Для эксплуатации Java потребуется задать переменную JAVA_HOME. Рекомендую сделать ее экспорт сразу после установки, а также записать ее в файлы /etc/environment и /etc/default/bigtop-utils чтобы она автоматически экспортировалась после перезапуска серверов и ее расположение предоставлялось сервисам CDH:
export JAVA_HOME=/usr/java/jdk1.
 8.0_161
echo "JAVA_HOME=/usr/java/jdk1.8.0_161" >> /etc/environment
export JAVA_HOME=/usr/java/jdk1.8.0_144 >> /etc/default/bigtop-utils
8.0_161
echo "JAVA_HOME=/usr/java/jdk1.8.0_161" >> /etc/environment
export JAVA_HOME=/usr/java/jdk1.8.0_144 >> /etc/default/bigtop-utils14. Таким же образом устанавливаем chronyd на всех машинах кластера (если, конечно, он отсутствует):
yum install chrony
15. Выбираем хост, на котором будет работать PostgreSQL, и устанавливаем его:
yum install postgresql-server
16. Аналогично, выбираем хост, на котором будет работать Cloudera Manager, и устанавливаем его:
yum install cloudera-manager-daemons cloudera-manager-server
17. Пакеты установлены, можно приступать к настройке ПО перед установкой.
Дополнение:
В ходе разработки и эксплуатации системы потребуется добавлять пакеты к репозиторий yum для их установки на хостах кластера (например дистрибутив Anaconda). Для этого помимо самого переноса файлов в папку yum_repo требуется выполнить следующие действия:
Настройка вспомогательного софта
Настало время сконфигурировать PostgreSQL и создать базы данных для наших будущих сервисов. Данные настройки актуальны для версии CDH 5.12.1, при установке других версий дистрибутива рекомендуется ознакомиться с разделом «Cloudera Manager and Managed Service Datastores» официального сайта.
Данные настройки актуальны для версии CDH 5.12.1, при установке других версий дистрибутива рекомендуется ознакомиться с разделом «Cloudera Manager and Managed Service Datastores» официального сайта.
Для начала произведем инициализации базы данных:
postgresql-setup initdb
Теперь настраиваем сетевое взаимодействие с БД. В файле /var/lib/pgsql/data/pg_hba.conf в секции «IPv4 local connections» меняем метод для адреса 127.0.0.1/32 на метод «md5», добавляем метод «trust» и добавляем подсеть кластера с методом «trust»:
vi /var/lib/pgsql/data/pg_hba.conf pg_hba.conf: ----------------------------------------------------------------------- # TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all peer # IPv4 local connections: host all all 127.0.0.1/32 md5 host all all 127.
 0.0.1/32 trust
host all all <cluster_subnet> trust
-----------------------------------------------------------------------
0.0.1/32 trust
host all all <cluster_subnet> trust
-----------------------------------------------------------------------Затем внесем некоторые коррективы в файл /var/lib/pgsql/data/postgres.conf (приведу только те строки, которые надо изменить или проверить на соответствие:
vi /var/lib/pgsql/data/postgres.conf postgres.conf: ----------------------------------------------------------------------- listen_addresses = '*' max_connections = 100 shared_buffers = 256MB checkpoint_segments = 16 checkpoint_completion_target = 0.9 logging_collector = on log_filename = 'postgresql-%a.log' log_truncate_on_rotation = on log_rotation_age = 1d log_rotation_size = 0 log_timezone = 'W-SU' datestyle = 'iso, mdy' timezone = 'W-SU' lc_messages = 'en_US.UTF-8' lc_monetary = 'en_US.UTF-8' lc_numeric = 'en_US.UTF-8' lc_time = 'en_US.UTF-8' default_text_search_config = 'pg_catalog.english' -----------------------------------------------------------------------
После окончания конфигурации требуется создать базы данных (для тех, кому ближе терминология Oracle – схемы) для сервисов, которые будем устанавливать. В нашем случае были установлены следующие сервисы: Cloudera Management Service, HDFS, Hive, Hue, Impala, Oozie, Yarn и ZooKeeper. Из них Hive, Hue и Oozie нуждаются в базах, а также 2 базы потребуются для нужд сервисов Cloudera – одна для сервера Cloudera Manager, другая для менеджера отчетов, входящего в Cloudera Management Service. Запустим и PostgreSQL и добавим его в автозагрузку:
В нашем случае были установлены следующие сервисы: Cloudera Management Service, HDFS, Hive, Hue, Impala, Oozie, Yarn и ZooKeeper. Из них Hive, Hue и Oozie нуждаются в базах, а также 2 базы потребуются для нужд сервисов Cloudera – одна для сервера Cloudera Manager, другая для менеджера отчетов, входящего в Cloudera Management Service. Запустим и PostgreSQL и добавим его в автозагрузку:
systemctl start postgresql systemctl enable postgresql
Теперь мы можем подключиться и создать нужные базы:
sudo -u postgres psql > CREATE ROLE scm LOGIN PASSWORD '<password>'; > CREATE DATABASE scm OWNER scm ENCODING 'UTF8'; # Роль и база Cloudera Manager > CREATE ROLE rman LOGIN PASSWORD '<password>'; > CREATE DATABASE rman OWNER rman ENCODING 'UTF8'; # Роль и база менеджера отчетов > CREATE ROLE hive LOGIN PASSWORD '<password>'; > CREATE DATABASE metastore OWNER hive ENCODING 'UTF8'; # Роль и база Hive Metastore > ALTER DATABASE metastore SET standard_conforming_strings = off; # Рекомендуется для PostgreSQL старше версии 8.
 2.23
> CREATE ROLE hue_u LOGIN PASSWORD '<password>';
> CREATE DATABASE hue_d OWNER hue_u ENCODING 'UTF8'; # Роль и база Hue
> CREATE ROLE oozie LOGIN ENCRYPTED PASSWORD '<password>' NOSUPERUSER INHERIT CREATEDB NOCREATEROLE;
> CREATE DATABASE "oozie" WITH OWNER = oozie ENCODING = 'UTF8' TABLESPACE = pg_default LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1; # Роль и база Oozie согласно рекомендациям официального сайта:
> \q
2.23
> CREATE ROLE hue_u LOGIN PASSWORD '<password>';
> CREATE DATABASE hue_d OWNER hue_u ENCODING 'UTF8'; # Роль и база Hue
> CREATE ROLE oozie LOGIN ENCRYPTED PASSWORD '<password>' NOSUPERUSER INHERIT CREATEDB NOCREATEROLE;
> CREATE DATABASE "oozie" WITH OWNER = oozie ENCODING = 'UTF8' TABLESPACE = pg_default LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1; # Роль и база Oozie согласно рекомендациям официального сайта:
> \qДля других сервисов базы данных создаются аналогично.
Не забываем прогнать скрипт для подготовки базы сервера Cloudera Manager, передав ему на вход данные для подключения к созданной для него базе:
. /usr/share/cmf/schema/scm_prepare_database.sh postgresql scm scm <password>
Создание репозитория с файлами CDH
Cloudera предоставляет 2 способа установки CDH – с помощью пакетов (packages) и с помощью парсэлей (parcels). Первый вариант предполагает скачивание набора пакетов с сервисами нужных версий и последующую их установку. Данный способ предоставляет большую гибкость конфигурации кластера, но Cloudera не гарантируют их совместимость. Поэтому более популярен второй вариант установки с использованием парсэлей – заранее сформированных наборов пакетов совместимых версий. Самые свежие версии доступны по следующей ссылке: archive.cloudera.com/cdh5/parcels/latest. Более ранние можно найти уровнем выше. Помимо самого парсэля с CDH требуется скачать manifest.json из той же директории репозитория.
Данный способ предоставляет большую гибкость конфигурации кластера, но Cloudera не гарантируют их совместимость. Поэтому более популярен второй вариант установки с использованием парсэлей – заранее сформированных наборов пакетов совместимых версий. Самые свежие версии доступны по следующей ссылке: archive.cloudera.com/cdh5/parcels/latest. Более ранние можно найти уровнем выше. Помимо самого парсэля с CDH требуется скачать manifest.json из той же директории репозитория.
Для эксплуатации разработанного функционала нам также требовался Spark 2.2, не входящий в парсэль CDH (там доступна первая версия данного сервиса). Для его установки требуется загрузить отдельный парсэль с данным сервисом и соответствующий manifest.json, также доступные в архиве Cloudera.
После загрузки парсэлей и manifest.json требуется перенести их в соответствующие папки нашего репозитория. Создаем отдельные папки для файлов CDH и Spark:
cd /var/www/html/parcels mkdir cdh spark
Переносим в созданные папки парсэли и файлы manifest. json. Чтобы сделать их доступными для установки по сети выдаем папке с парсэлями соответствующие доступы:
json. Чтобы сделать их доступными для установки по сети выдаем папке с парсэлями соответствующие доступы:
chmod -R ugo+rX /var/www/html/parcels
Можно приступать к установке CDH, о чем я расскажу в следующем посте.
Введение в распределенное хранилище данных | Квентин Труонг
Все, что вам нужно знать, чтобы эффективно использовать распределенные хранилища данных!
Опубликовано в
·
Чтение: 13 мин.
·
7 июля 2021 г.
Данные, хранящиеся на кварце — используются с разрешения Microsoft.
Данные — основа сегодняшнего дня! Он поддерживает все, от ваших любимых видео с кошками до миллиардов финансовых транзакций, которые происходят каждый день. В основе всего этого лежит распределенное хранилище данных.
В этой статье мы узнаем что такое распределенное хранилище данных, зачем оно нам и как его эффективно использовать. Эта статья призвана помочь вам в разработке приложений, поэтому мы рассмотрим только то, что необходимо знать разработчикам приложений . Это включает в себя основные основы, распространенные ловушки, с которыми сталкиваются разработчики, и различия между различными распределенными хранилищами данных.
Это включает в себя основные основы, распространенные ловушки, с которыми сталкиваются разработчики, и различия между различными распределенными хранилищами данных.
Эта статья не требует знания распределенных систем! Программирование и опыт работы с базами данных помогут, но вы также можете просто просматривать темы по мере их поступления. Давайте начнем!
Распределенное хранилище данных — это система, в которой данные хранятся и обрабатываются на нескольких компьютерах.
Как разработчик, вы можете думать о распределенном хранилище данных как о способе хранения и извлечения данных приложения, метрик, журналов и т. д. Некоторые популярные распределенные хранилища данных, с которыми вы, возможно, знакомы, — это MongoDB, Amazon Web Service S3 и Google. Гаечный ключ облачной платформы.
На практике существует много видов распределенных хранилищ данных. Обычно они представляют собой услуги, управляемые облачными провайдерами, или продукты, которые вы развертываете самостоятельно. Вы также можете создать собственное хранилище данных с нуля или поверх других хранилищ данных.
Вы также можете создать собственное хранилище данных с нуля или поверх других хранилищ данных.
Почему бы просто не использовать хранилища данных на одной машине? Чтобы действительно понять, нам сначала нужно осознать масштаб и повсеместное распространение данных сегодня. Давайте посмотрим на некоторые конкретные цифры:
- В 2018 году у Steam было 18,5 миллионов одновременных пользователей, развернуты серверы с 2,7 петабайтами SSD и доставлено пользователям 15 экзабайтов в 2018 году¹.
- Nasdaq в 2020 году перерабатывала пиковые значения в 113 миллиардов записей за один день, по сравнению со средним показателем в 30 миллиардов всего двумя годами ранее².
- Kellogg’s, компания по производству хлопьев, в 2014 году обрабатывала 16 терабайт данных в неделю в ходе только смоделированных рекламных мероприятий³.
Честно говоря, невероятно, сколько данных мы используем. Каждый из этих битов тщательно хранится и где-то обрабатывается. Это где-то наши распределенные хранилища данных.
Хранилища данных на одной машине просто не могут удовлетворить эти требования. Поэтому вместо этого мы используем распределенные хранилища данных, которые предлагают ключевые преимущества в производительность , масштабируемость и надежность . Давайте разберемся, что эти преимущества на самом деле означают на практике.
Производительность, масштабируемость и надежность
Производительность — это то, насколько хорошо машина может работать.
Критическая производительность. Существует бесчисленное множество исследований, которые количественно оценивают и показывают влияние на бизнес задержек длительностью всего 100 мс⁴. Медленное время отклика не просто расстраивает людей — оно снижает трафик, продажи и, в конечном счете, доход⁵.
К счастью, мы можем контролировать производительность нашего приложения. В случае хранилищ данных на одной машине часто бывает достаточно просто перейти на более быструю машину..png) Если этого недостаточно или вы полагаетесь на распределенное хранилище данных, в игру вступают другие формы масштабируемости.
Если этого недостаточно или вы полагаетесь на распределенное хранилище данных, в игру вступают другие формы масштабируемости.
Масштабируемость — это возможность увеличивать или уменьшать ресурсы инфраструктуры.
Современные приложения часто испытывают быстрый рост и циклическое использование. Чтобы удовлетворить эти требования к нагрузке, мы «масштабируем» наши распределенные хранилища данных. Это означает, что мы предоставляем больше или меньше ресурсов по запросу по мере необходимости. Масштабируемость бывает двух видов.
- Горизонтальное масштабирование означает добавление или удаление компьютеров (также называемых машинами или узлами).
- Вертикальное масштабирование означает изменение ЦП, ОЗУ, объема памяти или другого оборудования машины.
Горизонтальное масштабирование — вот почему распределенные хранилища данных могут превосходить хранилища данных на одном компьютере. Распределяя работу по сотням компьютеров, совокупная система имеет более высокую производительность и надежность. В то время как распределенные хранилища данных в основном полагаются на горизонтальное масштабирование, вертикальное масштабирование используется в сочетании для оптимизации общей производительности и стоимости⁶.
Распределяя работу по сотням компьютеров, совокупная система имеет более высокую производительность и надежность. В то время как распределенные хранилища данных в основном полагаются на горизонтальное масштабирование, вертикальное масштабирование используется в сочетании для оптимизации общей производительности и стоимости⁶.
Масштабирование может варьироваться от ручного до полностью управляемого. Некоторые продукты имеют ручное масштабирование , когда вы самостоятельно предоставляете дополнительную емкость. Другие автомасштабирование на основе таких показателей, как оставшаяся емкость хранилища. Наконец, некоторые сервисы справляются со всем масштабированием, даже не задумываясь об этом разработчиком, например S3 Amazon Web Service.
Независимо от подхода, все службы имеют некоторые ограничения, которые нельзя увеличить, например, максимальный размер объекта. Вы можете проверить квоты в документации, чтобы увидеть эти жесткие ограничения.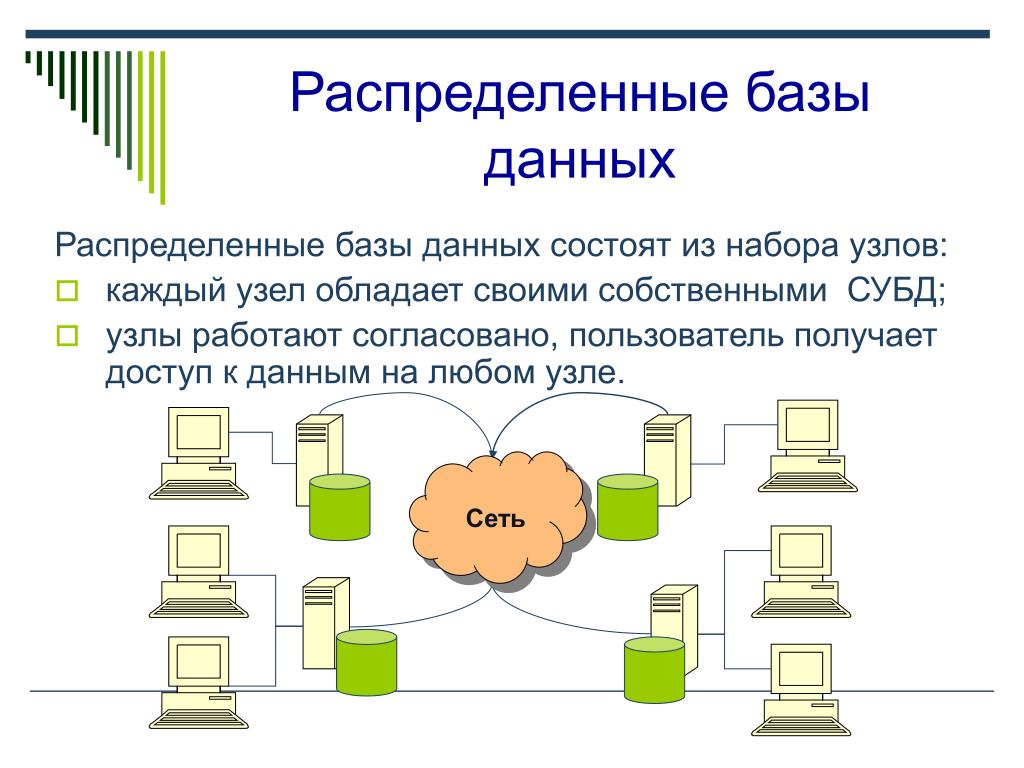 Вы можете проверить онлайн-тесты, чтобы увидеть, какая производительность достижима на практике.
Вы можете проверить онлайн-тесты, чтобы увидеть, какая производительность достижима на практике.
Надежность — это вероятность безотказной работы⁷.
Некоторые приложения настолько важны для нашей жизни, что недопустимы даже секунды сбоя. Эти приложения не могут использовать хранилища данных на одном компьютере из-за неизбежных аппаратных и сетевых сбоев, которые могут поставить под угрозу всю службу. Вместо этого мы используем распределенные хранилища данных, потому что они могут приспособиться к сбоям отдельных компьютеров или сетевых путей.
Чтобы быть высоконадежной, система должна быть доступной⁸ и отказоустойчивой⁹.
- Доступность — процент времени, в течение которого служба доступна и нормально отвечает на запросы.
- Отказоустойчивость — это способность выдерживать аппаратные и программные сбои. Полная отказоустойчивость невозможна¹⁰.
Хотя доступность и отказоустойчивость на первый взгляд могут показаться одинаковыми, на самом деле они совершенно разные. Посмотрим, что произойдет, если у вас есть одно, но нет другого.
Посмотрим, что произойдет, если у вас есть одно, но нет другого.
- Доступно, но не отказоустойчиво: Рассмотрим систему, которая выходит из строя каждую минуту, но восстанавливается в течение миллисекунд. Пользователи могут получить доступ к сервису, но длительные задания никогда не успевают завершиться.
- Отказоустойчив, но недоступен: Рассмотрим систему, в которой половина узлов постоянно перезагружается, а остальные работают стабильно. Если мощности стабильных узлов недостаточно, то некоторые запросы придется отклонять.
Вывод
Для разработчика приложений ключевым моментом является то, что распределенные хранилища данных могут масштабировать производительность и надежность далеко за пределы отдельных машин. Загвоздка в том, что у них есть оговорки в том, как они работают, что может ограничить их потенциал.
Давайте рассмотрим, что нужно знать разработчикам приложений о том, как работают распределенные хранилища данных — секционирование, маршрутизация запросов и репликация. Эти основы дадут вам представление о поведении и характеристиках распределенных хранилищ данных. Это поможет вам понять предостережения и компромиссы, а также понять, почему у нас нет распределенного хранилища данных, превосходного во всем.
Эти основы дадут вам представление о поведении и характеристиках распределенных хранилищ данных. Это поможет вам понять предостережения и компромиссы, а также понять, почему у нас нет распределенного хранилища данных, превосходного во всем.
Разделение
Наши наборы данных часто слишком велики, чтобы хранить их на одной машине. Чтобы преодолеть это, мы разбить наши данные на более мелкие подмножества, которые отдельные машины могут хранить и обрабатывать. Существует множество способов разделения данных, каждый из которых имеет свои недостатки. Двумя основными подходами являются вертикальное и горизонтальное разбиение.
Изображение автора
Вертикальное разбиение означает разделение данных по связанным полям¹¹. Поля могут быть связаны по многим причинам. Они могут быть свойствами какого-то общего объекта. Это могут быть поля, к которым обычно обращаются вместе с помощью запросов. Это могут быть даже поля, доступ к которым осуществляется с одинаковой частотой или пользователями с аналогичными разрешениями. Точный способ вертикального разделения данных между машинами в конечном итоге зависит от свойств вашего хранилища данных и шаблонов использования, которые вы оптимизируете.
Точный способ вертикального разделения данных между машинами в конечном итоге зависит от свойств вашего хранилища данных и шаблонов использования, которые вы оптимизируете.
Горизонтальное разбиение (также известное как сегментирование ) — это когда мы разделяем данные на подмножества с одной и той же схемой¹¹. Например, мы можем горизонтально разбить таблицу реляционной базы данных, сгруппировав строки в сегменты, которые будут храниться на отдельных машинах. Мы разбиваем данные, когда одна машина не может справиться ни с объемом данных, ни с нагрузкой запросов для этих данных. Стратегии разделения делятся на две категории: алгоритмические и динамические, но существуют и гибриды¹⁰.
Image by Author
Алгоритмическое сегментирование определяет, на какой сегмент распределять данные, на основе функции ключа данных. Например, при сохранении URL-адресов сопоставления данных «ключ-значение» в HTML мы можем разделить диапазон наших данных, разделив пары «ключ-значение» в соответствии с первой буквой URL-адреса. Например, все URL-адреса, начинающиеся с «А», будут находиться на первом компьютере, «Б» — на втором компьютере и так далее. Существует бесчисленное множество стратегий с различными компромиссами.
Например, все URL-адреса, начинающиеся с «А», будут находиться на первом компьютере, «Б» — на втором компьютере и так далее. Существует бесчисленное множество стратегий с различными компромиссами.
Динамическое сегментирование явно выбирает местоположение данных и сохраняет это местоположение в таблице поиска. Чтобы получить доступ к данным, мы обращаемся к сервису с таблицей поиска или проверяем локальный кеш. Таблицы поиска могут быть довольно большими, и поэтому они могут иметь таблицы поиска, указывающие на подтаблицы поиска, такие как B+-Tree¹². Динамическое разбиение более гибко, чем алгоритмическое разбиение¹³.
Разбиение на разделы на практике довольно сложно и может создать множество проблем, о которых вам следует знать. К счастью, некоторые распределенные хранилища данных справятся со всей этой сложностью за вас. Другие справляются с некоторыми или ни с одним.
- Осколки могут иметь неравномерные данные размеров. Это распространено в алгоритмическом сегментировании, где функцию трудно получить правильно. Мы смягчаем это, адаптируя стратегию сегментирования к данным.
- Осколки могут иметь горячих точек , где одни данные запрашиваются на порядок чаще, чем другие. Например, подумайте, насколько чаще вы будете запрашивать знаменитостей, чем обычных людей в социальной сети. Здесь могут помочь тщательный дизайн схемы, кэши и реплики.
- Перераспределение данных для добавления или удаления узлов из системы затруднено при поддержании высокой доступности.
- Индексы также могут нуждаться в секционировании. Индексы могут индексировать сегмент, в котором они хранятся (локальный индекс), или они могут индексировать весь набор данных и быть разделенными (глобальный индекс). Каждый идет с компромиссами.
- Транзакции между разделами могут работать, или они могут быть отключены, медленны или непоследовательны, что приводит к путанице. Это особенно сложно при создании собственного распределенного хранилища данных из хранилищ данных на одном компьютере.
 Это распространено в алгоритмическом сегментировании, где функцию трудно получить правильно. Мы смягчаем это, адаптируя стратегию сегментирования к данным.
Это распространено в алгоритмическом сегментировании, где функцию трудно получить правильно. Мы смягчаем это, адаптируя стратегию сегментирования к данным. Это особенно сложно при создании собственного распределенного хранилища данных из хранилищ данных на одном компьютере.
Это особенно сложно при создании собственного распределенного хранилища данных из хранилищ данных на одном компьютере.Маршрутизация запросов
Разделение данных — это только часть дела. Нам по-прежнему нужно направлять запросы от клиента на правильный серверный компьютер. Маршрутизация запросов может происходить на разных уровнях программного стека. Давайте рассмотрим три основных случая.
- Разделение на стороне клиента — это когда у клиента есть логика принятия решения, какой серверный узел запрашивать. Преимущество заключается в концептуальной простоте, а недостаток в том, что каждый клиент должен реализовать логику маршрутизации запросов.
- Разделение на основе прокси — это когда клиент отправляет все запросы на прокси. Затем этот прокси определяет, какой внутренний узел запрашивать. Это может помочь уменьшить количество одновременных подключений на внутренних серверах и отделить логику приложения от логики маршрутизации.
- Разделение на основе сервера — это когда клиент подключается к любому внутреннему узлу, и узел либо обрабатывает, либо перенаправляет, либо перенаправляет запрос.

На практике маршрутизация запросов выполняется большинством распределенных хранилищ данных. Как правило, вы настраиваете клиент, а затем выполняете запрос с помощью клиента. Однако если вы создаете собственное распределенное хранилище данных или используете такие продукты, как Redis, которые его не поддерживают, вам необходимо принять это во внимание¹⁴.
Репликация
Последняя концепция, которую мы рассмотрим, — это репликация. Репликация означает хранение нескольких копий одних и тех же данных. Это имеет много преимуществ.
- Избыточность данных: Когда аппаратное обеспечение неизбежно выходит из строя, данные не теряются, потому что существует другая копия.
- Доступ к данным: Клиенты могут получить доступ к данным из любой реплики. Это повышает устойчивость к сбоям в работе центра обработки данных и сбоям в работе сети.
- Повышенная скорость чтения: Есть больше машин, которые могут обслуживать данные, поэтому общая емкость выше.
- Уменьшение задержки в сети: Клиенты могут получить доступ к ближайшей к ним реплике, что снижает задержку в сети.
 Это повышает устойчивость к сбоям в работе центра обработки данных и сбоям в работе сети.
Это повышает устойчивость к сбоям в работе центра обработки данных и сбоям в работе сети.Реализация репликации требует умопомрачительных согласованных протоколов и исчерпывающего анализа сценариев сбоев. К счастью, разработчикам приложений обычно достаточно знать, где и когда реплицируются данные.
Где данные реплицируются из одного центра обработки данных в другие зоны, регионы и даже континенты. Реплицируя данные близко друг к другу, мы минимизируем задержку в сети при обновлении данных между машинами. Однако, реплицируя данные дальше друг от друга, мы защищаем от сбоев центра обработки данных, сетевых разделов и потенциально уменьшаем сетевую задержку при чтении.
При репликации данные могут быть синхронными или асинхронными.
- Синхронная репликация означает, что данные копируются во все реплики перед ответом на запрос. Преимущество этого заключается в обеспечении идентичных данных в репликах за счет более высокой задержки записи.
- Асинхронная репликация означает, что данные хранятся только на одной реплике перед ответом на запрос. Это имеет преимущество более быстрой записи с недостатками более слабой согласованности данных и возможной потери данных.
Выводы
Разделение, маршрутизация запросов и репликация являются строительными блоками распределенного хранилища данных. Различные реализации появляются как разные функции и свойства, между которыми вы делаете компромиссы.
Распределенные хранилища данных — это особые снежинки, каждая из которых имеет свой уникальный набор функций. Мы сравним их, сгруппировав их различия в категории и охватив основы каждой из них. Это поможет вам узнать, какие вопросы задавать и что читать дальше в будущем.
Это поможет вам узнать, какие вопросы задавать и что читать дальше в будущем.
Модель данных
Первое отличие, которое следует учитывать, — это модель данных. Модель данных — это тип данных и способ их запроса. Общие типы включают
- Документ: Вложенные коллекции документов JSON. Запрос с ключами или фильтрами.
- Ключ-значение: Пары ключ-значение. Запрос с ключом.
- Реляционные: Таблицы строк с явной схемой. Запрос с помощью SQL.
- Двоичный объект: Произвольные двоичные двоичные объекты. Запрос с ключом.
- Файловая система: Каталоги файлов. Запрос с путем к файлу.
- График: Узлы с ребрами. Запрос с помощью языка запросов графа.
- Сообщение: Группы пар ключ-значение, такие как JSON или python dict. Запрос из очереди, темы или отправителя.
- Временной ряд: Данные упорядочены по отметке времени. Запрос с помощью SQL или другого языка запросов.
- Текст: Текст в произвольной форме или журналы. Запрос с языком запросов.

Разные модели данных предназначены для разных ситуаций. Хотя вы могли бы просто хранить все как двоичный объект, это было бы неудобно при запросе данных и разработке вашего приложения. Вместо этого используйте модель данных, которая лучше всего подходит для вашего типа запросов. Например, если вам нужен быстрый и простой поиск небольших фрагментов данных, используйте пары «ключ-значение». Мы предоставим более подробную информацию о предполагаемом использовании в таблице ниже.
Обратите внимание, что некоторые хранилища данных являются мультимодельными, что означает, что они могут эффективно работать с несколькими моделями данных.
Гарантии
Различные хранилища данных предоставляют разные «гарантии» поведения. Хотя технически вам не нужны гарантии для разработки надежных приложений, надежные гарантии значительно упрощают проектирование и реализацию. Общие гарантии, с которыми вы столкнетесь, следующие:
Хотя технически вам не нужны гарантии для разработки надежных приложений, надежные гарантии значительно упрощают проектирование и реализацию. Общие гарантии, с которыми вы столкнетесь, следующие:
- Непротиворечивость — выглядят ли данные одинаково для всех читателей и являются ли они актуальными. Обратите внимание, что термин «согласованность» по иронии судьбы сильно перегружен — убедитесь, о каком типе согласованности идет речь¹⁵.
- Доступность — можете ли вы получить доступ к своим данным.
- Долговечность определяет, остаются ли сохраненные данные безопасными и неповрежденными.
Некоторые поставщики услуг даже по контракту гарантируют определенный уровень обслуживания, например доступность на уровне 99,99 %, посредством соглашения об уровне обслуживания (SLA). В случае, если они не соблюдают соглашение, вы обычно получаете некоторую компенсацию.
Экосистема
Экосистема (интеграции, инструменты, вспомогательное программное обеспечение и т. д.) имеет решающее значение для вашего успеха с распределенным хранилищем данных. Необходимо проверить простые вопросы, например, какие SDK доступны и какие типы тестирования поддерживаются. Если вам нужны такие функции, как соединители баз данных, мобильная синхронизация, ORM, буферы протоколов, геопространственные библиотеки и т. д., вам необходимо подтвердить, что они поддерживаются. Документация и блоги будут содержать эту информацию.
д.) имеет решающее значение для вашего успеха с распределенным хранилищем данных. Необходимо проверить простые вопросы, например, какие SDK доступны и какие типы тестирования поддерживаются. Если вам нужны такие функции, как соединители баз данных, мобильная синхронизация, ORM, буферы протоколов, геопространственные библиотеки и т. д., вам необходимо подтвердить, что они поддерживаются. Документация и блоги будут содержать эту информацию.
Безопасность
Ответственность за безопасность распределяется между вами и вашим поставщиком продуктов/услуг. Ваши обязанности будут зависеть от того, какой частью стека вы управляете.
Если вы используете распределенное хранилище данных как услугу, вам может потребоваться только настроить некоторые политики идентификации и доступа, аудит и безопасность приложений. Однако, если вы создадите и развернете все это, вам нужно будет справиться со всем, включая безопасность инфраструктуры, сетевую безопасность, шифрование при хранении / передаче, управление ключами, исправление и т. д. Проверьте «модель общей ответственности» для вашего хранилища данных, чтобы понять это вне.
д. Проверьте «модель общей ответственности» для вашего хранилища данных, чтобы понять это вне.
Соответствие требованиям
Соответствие требованиям может быть важным отличием. Многие приложения должны соответствовать законам и правилам, касающимся обработки данных. Если вам необходимо соблюдать политики безопасности, такие как FEDRAMP, PCI-DSS, HIPAA или любые другие, ваше распределенное хранилище данных также должно соответствовать требованиям.
Кроме того, если вы дали клиентам обещания относительно хранения данных, их местонахождения или изоляции данных, вам может понадобиться распределенное хранилище данных со встроенными функциями для этого.
Цена
Различные хранилища данных имеют разные цены. Некоторые хранилища данных взимают плату исключительно за объем хранилища, в то время как другие учитывают серверы и лицензионные сборы. В документации обычно есть калькулятор цен, который можно использовать для расчета счета. Обратите внимание, что, хотя на первый взгляд может показаться, что некоторые хранилища данных стоят дороже, они вполне могут компенсировать это за счет экономии времени на проектирование и эксплуатацию.
Вывод
Все распределенные хранилища данных уникальны. Мы можем понять и сравнить их различные функции с помощью документации, блогов, тестов, калькуляторов цен или пообщавшись с профессиональной поддержкой и создав прототипы.
Теперь мы многое знаем о распределенных хранилищах данных в общих чертах. Давайте свяжем это вместе и увидим настоящие инструменты!
Вариантов, казалось бы, бесконечное множество, и, к сожалению, лучшего нет. Каждое распределенное хранилище данных предназначено для разных целей и должно соответствовать вашему конкретному варианту использования. Чтобы понять различные типы, ознакомьтесь со следующей таблицей. Не торопитесь и сосредоточьтесь на общих типах и вариантах использования.
Наконец, обратите внимание, что реальные приложения и компании должны выполнять широкий спектр задач, поэтому они полагаются на несколько распределенных хранилищ данных. Эти системы работают вместе, чтобы обслуживать конечных пользователей, а также разработчиков и аналитиков.
Данные никуда не денутся, и распределенные хранилища данных позволяют это сделать.
В этой статье мы узнали, что производительность и надежность распределенных хранилищ данных могут масштабироваться далеко за пределы хранилищ данных с одним компьютером. Распределенные хранилища данных опираются на архитектуры со многими машинами для секционирования и репликации данных. Разработчикам приложений не нужно знать всю специфику — им достаточно знать достаточно, чтобы понимать проблемы, возникающие на практике, такие как точки доступа к данным, поддержка транзакций, стоимость репликации данных и т. д.
Как и все остальное, распределенные хранилища данных обладают огромным набором функций. Поначалу это может быть трудно осмыслить, но, надеюсь, наша разбивка поможет сориентировать ваш мыслительный процесс и направить ваше обучение в будущем.
Надеюсь, теперь вы знаете, что такое общая картина и на что следует обратить внимание. Подумайте о проверке ссылок. Рада услышать любые ваши комментарии! 🙂
Распределенная система баз данных — GeeksforGeeks
Распределенная база данных — это, по сути, база данных, которая не ограничивается одной системой, она распределена по разным сайтам, то есть на нескольких компьютерах или в сети компьютеров. Система распределенной базы данных расположена на различных сайтах, которые не используют общие физические компоненты. Это может потребоваться, когда к конкретной базе данных требуется глобальный доступ различных пользователей. Ей нужно управлять так, чтобы для пользователей она выглядела как одна база данных.
Система распределенной базы данных расположена на различных сайтах, которые не используют общие физические компоненты. Это может потребоваться, когда к конкретной базе данных требуется глобальный доступ различных пользователей. Ей нужно управлять так, чтобы для пользователей она выглядела как одна база данных.
Типы:
1. Однородная база данных:
В однородной базе данных все разные сайты хранят базу данных одинаково. Операционная система, система управления базами данных и используемые структуры данных — все они одинаковы на всех сайтах. Следовательно, ими легко управлять.
2. Гетерогенная база данных:
В гетерогенной распределенной базе данных разные сайты могут использовать разные схемы и программное обеспечение, что может привести к проблемам при обработке запросов и транзакций. Кроме того, конкретный сайт может совершенно не знать о других сайтах. На разных компьютерах могут использоваться разные операционные системы, разные приложения баз данных. Они могут даже использовать разные модели данных для базы данных. Следовательно, переводы необходимы для общения на разных сайтах.
Они могут даже использовать разные модели данных для базы данных. Следовательно, переводы необходимы для общения на разных сайтах.
Распределенное хранилище данных :
Существует два способа хранения данных на разных сайтах. К ним относятся:
1. Репликация –
При таком подходе вся связь сохраняется избыточно на 2 или более сайтах. Если вся база данных доступна на всех сайтах, это полностью избыточная база данных. Следовательно, при репликации системы сохраняют копии данных.
Это выгодно, так как повышает доступность данных на разных сайтах. Также теперь запросы запросов могут обрабатываться параллельно.
Однако у него есть и определенные недостатки. Данные необходимо постоянно обновлять. Любое изменение, сделанное на одном сайте, должно быть записано на каждом сайте, где хранится отношение, иначе это может привести к несогласованности. Это много накладных расходов. Кроме того, управление параллелизмом становится намного более сложным, поскольку одновременный доступ теперь необходимо проверять на нескольких сайтах.
2. Фрагментация —
В этом подходе отношения фрагментируются (т. е. делятся на более мелкие части), и каждый из фрагментов хранится в разных местах, где они необходимы. Необходимо убедиться, что фрагменты таковы, что их можно использовать для восстановления исходного отношения (т. е. нет потери данных).
Фрагментация выгодна, так как не создает копии данных, согласованность не является проблемой.
Фрагментация отношений может быть выполнена двумя способами:
- Горизонтальная фрагментация – Разбиение по строкам –
Отношение фрагментируется на группы кортежей, так что каждому кортежу соответствует хотя бы один фрагмент. - Вертикальная фрагментация – Разбиение по столбцам –
Схема отношения делится на более мелкие схемы. Каждый фрагмент должен содержать общий ключ-кандидат, чтобы обеспечить соединение без потерь.
В некоторых случаях используется гибридный подход фрагментации и репликации.
Приложения распределенной базы данных:
- Используется в корпоративной информационной системе управления.
- Используется в мультимедийных приложениях.
- Используется в военной системе управления, гостиничных сетях и т. д.
- Также используется в системе управления производством.
Ссылки:
Концепции системы баз данных Зильбершаца, Корта и Сударшана
Распределенная система баз данных – это тип системы управления базами данных, в которой данные хранятся на нескольких компьютерах или сайтах, соединенных сетью. В системе распределенной базы данных каждый сайт имеет свою собственную базу данных, и базы данных связаны друг с другом, образуя единую интегрированную систему.
Основное преимущество системы распределенной базы данных заключается в том, что она может обеспечить более высокую доступность и надежность, чем система централизованной базы данных. Поскольку данные хранятся на нескольких сайтах, система может продолжать работать даже в случае отказа одного или нескольких сайтов. Кроме того, система распределенной базы данных может обеспечить более высокую производительность за счет распределения нагрузки по данным и обработке между несколькими сайтами.
Кроме того, система распределенной базы данных может обеспечить более высокую производительность за счет распределения нагрузки по данным и обработке между несколькими сайтами.
Существует несколько различных архитектур систем распределенных баз данных, в том числе:
Архитектура клиент-сервер: В этой архитектуре клиенты подключаются к центральному серверу, который управляет системой распределенных баз данных. Сервер отвечает за координацию транзакций, управление хранением данных и обеспечение контроля доступа.
Одноранговая архитектура: В этой архитектуре каждый сайт в системе распределенной базы данных подключен ко всем другим сайтам. Каждый сайт отвечает за управление своими данными и координацию транзакций с другими сайтами.
Федеративная архитектура: I В этой архитектуре каждый сайт в системе распределенной базы данных поддерживает свою собственную независимую базу данных, но базы данных интегрируются через уровень промежуточного программного обеспечения, который обеспечивает общий интерфейс для доступа и запроса данных.