Содержание
Ранжирование сайта – все факторы Яндекс и Google
Давайте попробуем разобраться, что такое ранжирование сайта, от чего оно зависит, сколько факторов ранжирования насчитывается в Яндекс и Google, как на него можно повлиять и почему вообще это так важно? Обо всем по порядку!
Ранжирование сайта – определение
Прежде всего попытаемся дать определение данному понятию.
Определение Яндекс (взято из миссии компании на официальном сайте):
Чтобы понять всю суть, вы также должны иметь представления о таких определениях, как: поисковая система, поисковый запрос, релевантность, индексация.
- «Поисковая система — это техническое средство, с помощью которого пользователь интернета может найти данные, уже размещенные в сети.»
- Поисковый запрос и процесс поиска – «В ответ на запрос, который пользователь ввел в поисковой строке, поисковая система показывает ссылки на известные ей страницы, в тексте которых (а также в метатегах или в ссылках на эти сайты) содержатся слова из запроса.
 В большинстве случаев таких страниц очень много — настолько, что пользователь не сможет просмотреть их все.»
В большинстве случаев таких страниц очень много — настолько, что пользователь не сможет просмотреть их все.» - «Релевантность — это наилучшее соответствие интересам пользователей, ищущих информацию. Релевантность найденных страниц заданному запросу Яндекс определяет полностью автоматически…»
- Ранжирование в Яндекс – это «процесс упорядочивания найденных результатов по их релевантности».
 В большинстве случаев таких страниц очень много — настолько, что пользователь не сможет просмотреть их все.»
В большинстве случаев таких страниц очень много — настолько, что пользователь не сможет просмотреть их все.»Полный материал вы можете посмотреть тут. Также дополнительно по теме ранжирования в Яндексе можно посмотреть интервью с Александром Садовским, который с 2005-го возглавлял отдел веб-поиска, с июня 2012 года — отдел поисковых сервисов в Яндексе.
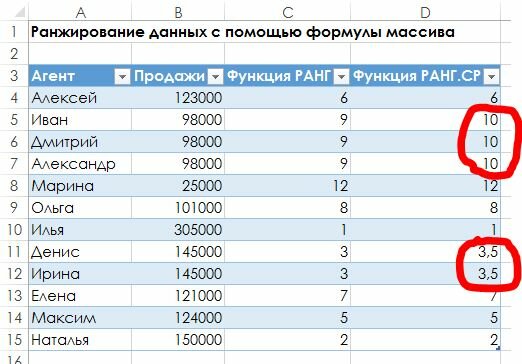
Рис. 1
Определение Google (взято из Справки – Search Console Google):
Базовые понятия для понимания сути те же, поскольку принцип работы обеих поисковых систем в целом схож.
«Когда пользователь вводит запрос, Google на основе ногочисленных факторов ищет в своем индексе самые подходящие результаты. К таким факторам относятся местоположение, язык, тип устройства пользователя (обычный компьютер или телефон) и т. д. … Ранжирование выполняется по заданным алгоритмам, и Google не повышает рейтинг страниц за плату.»
К таким факторам относятся местоположение, язык, тип устройства пользователя (обычный компьютер или телефон) и т. д. … Ранжирование выполняется по заданным алгоритмам, и Google не повышает рейтинг страниц за плату.»
Полностью информацию по теме работы поиска Google можно почитать тут. В этом же материале есть небольшие рекомендации о том, как повлиять положительно на ранжирование сайтов в поисковой системе Google.
Наше собственное определение ранжирования
Как уже было сказано выше, для четкого понимания данного определения, необходимо полностью представлять всю картину работы поисковых систем.
Попробуем описать процесс простыми словами:
- Пользователь приходит в поисковую систему Яндекс или Google, чтобы найти ответ на свой вопрос – он вводит «поисковый запрос».
- Поисковая система – это совокупность информации, которая уже имеется в интернете, т.е. условно говоря «библиотека» или «рубрикатор» имеющихся в интернете (проиндексированных) данных и документов.
- На вопрос пользователя Яндекс и Google среди огромного количества данных пытаются найти наиболее подходящие ответы – наиболее релевантные данные и документы в зависимости от различных факторов, о которых мы расскажем дальше.
- Ранжирование – это выстраивание ответов на поисковый запрос пользователя в числовом порядке, где 1й ответ – самый релевантный ответ, 2й – менее релевантный, 4й, 5й …. 10й – еще меньше соответствуют вопросу пользователя.
Более профессиональным языком:
Ранжирование в поисковых системах называют сортировку сайтов в поисковой выдаче. Ранжирование производится на основе релевантности документов поисковому запросу. Под релевантностью понимается соответствие документа интенту, который пользователь выразил с помощью поискового запроса.
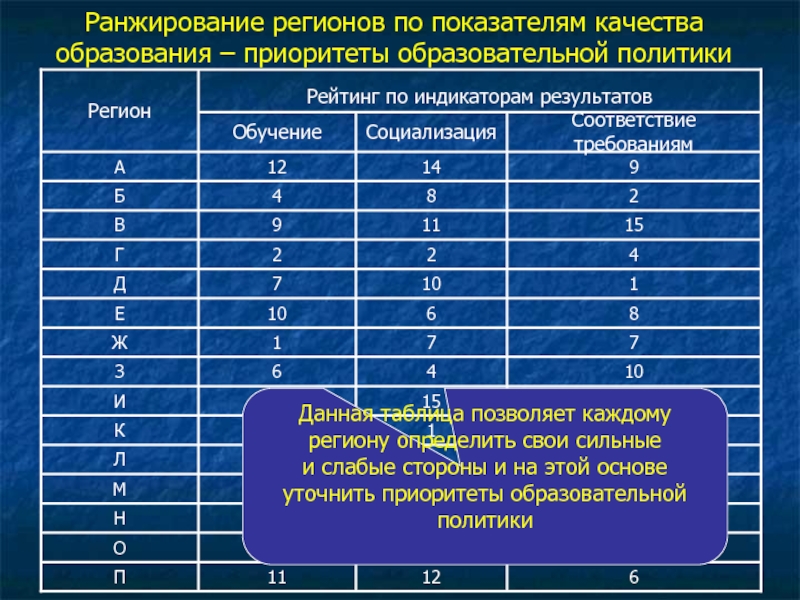
Факторы ранжирования сайтов
Итак, мы определились с понятием термина. Теперь поговорим о том, от чего же зависит ранжирование в поиске Яндекс и Google. В среде SEO-специалистов такую зависимость принято называть факторами ранжирования.
В среде SEO-специалистов такую зависимость принято называть факторами ранжирования.
Прежде всего опишем данные факторы в целом – сами принципы их появления, а дальше постараемся выделить наиболее значимые данные для каждого из поисковиков.
Рис. 2
Базовые принципы ранжирования в поисковиках
Базовые принципы выстраивания результатов поиска по релевантности в обоих поисковых системах заключаются в том, чтобы наиболее релевантные данные (наиболее подходящие ответы на вопросы пользователя) занимали более высокие позиции в выдаче.
Как уже стало понятно, распределение позиций строится на основе релевантности каждого результата.
Релевантность, как правило, является функцией от набора переменных (т.е. факторов). В виде факторов берутся различные числовые характеристики, которые должны помогать различать релевантные документы и нерелевантные. Во многих поисковых системах итоговая функция релевантности – это достаточно простая комбинация небольшого количества факторов – 5-15 штук. Ряд комплексных факторов используется самостоятельно в качестве отдельной функции ранжирования.
Ряд комплексных факторов используется самостоятельно в качестве отдельной функции ранжирования.
Базовые принципы ранжирования в Яндекс и Google
В отличие от такого базового стандартного подхода, в поисковых системах Яндекс и Google используется значительно большее количество переменных для результирующей функции. Так, например, ранжирование коллекции текстовых факторов базируется более чем на 150 переменных.
Основной момент, который больше всего влияет на итоговое ранжирование, это способ комбинации всех факторов, т.е. итоговый состав функции релевантности. Для составления этой итоговой формулы поисковики сегодня используют методы машинного обучения, что позволяет в итоге легко корректировать качество поиска, добавляя новые переменные (факторы).
Основные группы факторов
Существует более 1200 факторов, влияющих на ранжирование. При этом в классической схеме можно выделить 5-6 основных групп, на которые делят все данные факторы:
- Хостовые – данные о возрасте сайта, название домена, доменная зона
- Технические – коды ответов сервера, наличие дублей, скорость загрузки
- Текстовые – текстовая релевантность в различных зонах документа
- Ссылочные – внешние ссылочные связи сайта
- Коммерческие – ассортимент, наличие цен, телефонов, офиса, доставки и т. д.
- Поведенческие (внутренние и внешние) – время на сайте, глубина просмотра, CTR на выдаче
 д.
д.В различных вариантах SEO-специалисты выделяют также дополнительные группы факторов, влияющих на поисковую выдачу:
- Социальные
- Региональные
Данные факторы в классической группировке просто распределяются в другие группы, например, региональные – в текстовые, социальные – в ссылочные и поведенческие.
Основные и самые значимые факторы ранжирования в Яндекс
Формула ранжирования в Яндекс – это закрытая информация, которая является коммерческой тайной поисковой системы. Самих факторов ранжирования очень много – порядка 1200.
Поэтому ниже мы попытаемся дать список факторов, которые на наш взгляд являются наиболее значимыми для попадания сайта в ТОП-10 в Яндексе.
Хостовые:
- Возраст домена
- История домена
- Название домена
- Доменная зона
- Срок продления домена
- Количество страниц в индексе
- Скрытие данных Whois
Стоит понимать, что факторы данной группы в основном являются относительными.
Т.е. для понимания, насколько данные факторы важны для ранжирования конкретного сайта в Яндексе, можно сказать, только проведя сравнительный анализ продвигаемого сайта с конкурентами.
Это касается таких показателей, как возраст домена, количество проиндексированных страниц и т.п.
Ряд параметров, как история домена, в целом являются статичными, и тут они одинаковы для всех – чем меньше у домена было смен владельцев, тем лучше.
Хотя, это не значит, что новый зарегистрированный домен, который не имеет истории, лучше, чем так называемый «дроп» с историей.
Технические:
- Коды ответа сервера
- Скорость загрузки сайта
- Наличие мобильной версии
- Чистота кода (отсутствие больших блоков CSS и JS)
- Наличие SSL сертификата (защищенного соединения)
- Корректная индексация и настройка файла robots.txt
- Корректная карта сайта sitemap.xml
- Отсутствие дублей страниц
- Отсутствие цепочек редиректов внутри сайта
- Оптимизация размера картинок и видео
- Место нахождения сервера относительно целевой аудитории
- Соседи по ip
Технические параметры сайта такие, как коды ответа сервера (обычно должны быть 200 ОК), наличие мобильной версии, быстрота загрузки, наличие безопасного https соединения (особенно при приеме оплаты на сайте и получении данных пользователей), корректная настройка индексации – все это важные факторы.
НО, тут стоит понимать, что все это в целом – база, без которой невозможно получить заметный результат в продвижении сайта, если она будет сделана неправильно.
Можно получить сколько угодно много внешних ссылок на свой сайт, но, если он будет полностью состоять из дублей контента, положительного результата в продвижении добиться не получится.
Поэтому список данный группы – обязателен для проработки у любого сайта, особенно в больших сайтах-каталогах и интернет-магазинах.
Текстовые:
- Вхождение запросов в различных формах и последовательности в различные зоны: title, description, h2-h6, основной контент, текстовые фрагменты, ссылки на странице
- Уникальность текстов
- Наличие LSI слов и комбинаций
- Длина текста
- Отсутствие ошибок
- Наличие нумерованных списков и перечислений
- Язык повествования – профессиональный или «водянистый»
- Языковое соответствие
- Соответствие интенту запроса – геозависимость, коммерческость запросов
Данная группа факторов в Яндексе на текущий момент имеет весомое значение.
Именно с этой группы начинается первичное попадание продвигаемой страницы в зону видимости – когда документ (страница) сайта проходит так называемы «кворум», т.е. документ набирает достаточно «баллов», чтобы попасть в ТОП-50 – ТОП-30 по определенному поисковому запросу.
Оптимизацию данной группы факторов стоит начинать с подбора релевантной семантики и ее кластеризации.
Дальше на основе этого строить всю текстовую оптимизацию под Яндекс, вписывая нужные вхождения в различные зоны документа:
- Title
- Description
- h2
- Заголовки h3-H6
- Списки перечисления
- Основной текст страницы
- Текстовые фрагменты и описания
При оптимизации данной группы не стоит забывать и о наличии фильтров, например: переспам, переоптимизация, баден-баден, из-за которых документ может получить дисконтирование в ранжировании за переоптимизацию в текстовых зонах.
Ссылочные:
- Количество внешних ссылок на сайт
- Анкор лист
- Скорость прироста ссылок
- Авторитетность ссылающихся сайтов
- Количество ссылающихся доменов
- Тематическая близость донора и акцептора ссылок
- Возраст донора
- Заспамленность донора
- Санкции на доноре
- Возраст донора
- Количество исходящих ссылок на внешние сайты
- Качество сайтов, на которые идут исходящие ссылки
Ссылочные факторы на сегодняшний день в Яндексе, на мой взгляд, не играют такой существенной роли в получении ТОПа, как раньше.
Тут много причин:
- Борьба с покупными ссылками (Минусинск)
- Отсутствие практики и культуры естественным образом ссылаться на понравившиеся или полезные материалы в зоне Рунета
- Сохранение практики использования покупных ссылок среди оптимизаторов.
При оптимизации данной группы важны:
- Сравнительный анализ с конкурентами
- Понимание необходимости ссылочного в конкретной тематике в принципе
- Работа с внутренними ссылочными факторами
Коммерческие:
- Ассортимент товаров или услуг
- Способы оплаты
- Наличие и способы доставки
- Наличие цен и указание валюты на сайте
- Структура каталога
- Упоминание бренда в сети
- Наличие отзывов
- Наличие адреса и офиса
- Наличие различных номеров телефонов – местных городских и 8-800
- Наличие нескольких фотографий товара или услуги
- Наличие видео-обзоров
- Наличие кнопки заказа для магазинов и корзины
Данная группа была и остается важной для попадания в ТОП-10 Яндекса.
Если вы хотите максимально эффективно и быстро попасть и задержаться на первых местах выдачи в Яндексе, работайте в первую очередь над этими факторами.
Самыми важными из коммерческих под Яндекс, на мой взгляд, являются:
- Ассортиментная группа
- Наличие адресов и телефонов
- Наличие цен
- Структура сайта и каталога
Стоит отметить, что на сегодняшний день стало сложнее попасть в Справочник Яндекса, не имея реального офиса, т.к. стали более строгими методы проверки телефонов, офисов и т.д. Массово для данных проверок используются асессоры.
В свою очередь, подтвержденные географические данные (адреса и телефоны) важны при определении геозависимости в ранжировании, что является весомым фактором для оптимизации сайта.
Поведенческие:
- Время на сайте
- Показатель отказов
- Глубина просмотра
- CTR сниппета в поисковой выдаче
- Единственный клик на выдаче
- Last click на выдаче
- Прямые переходы на сайта по type-in
Последняя группа в списке, но не по значимости – это точно про поведенческие факторы.
Именно они на сегодняшний день являются одними из самых значимых и «влиятельных» изо всех перечисленных групп.
Можно даже сказать, что они пришли в Яндексе на смену ссылочным факторам.
Если раньше недобросовестные оптимизаторы покупали ссылки, то сегодня некоторые из них пытаются «накручивать» поведенческие в Яндексе.
Не стоит только забывать об ответных мерах – понижение сайта и приведение трафика из Яндекса практически к нулевым показателям на срок от 6 до 9 месяцев.
Также, после снятия фильтра за ПФ, трафик полностью обычно не восстанавливается.
Если же вы честный оптимизатор и хотите улучшать видимость своего сайта в выдаче Яндекса – то улучшение пользовательских факторов не запрещенными способами – это то, что может дать реальный и заметный рост позиций и трафика.
Основные и самые значимые факторы ранжирования в Google
Google – это отдельная поисковая система, кроме того мульти-региональная. Поэтому, значимость групп факторов для ранжирования в ней будет своя, отличная от Яндекса.
Ниже, основываясь на том же самом списке факторов, постараюсь выделить наиболее значимые под Google на сегодня:
Хостовые:
- Возраст домена
- История домена
- Название домена
- Доменная зона
- Срок продления домена
- Количество страниц в индексе
- Скрытие данных Whois
Хостовые факторы под Google на сегодняшний день гораздо важнее, чем под Яндекс.
Если в Яндекс так или иначе, можно сделать сайт, провести масштабные работы по ассортименту, коммерческим, текстовым факторам и получить ТОП и трафик, то в Google такая история не получится.
Чтобы ранжироваться в нем, нужно получить первоначальный траст, а это напрямую связано, в том числе с возрастом домена и документов сайта.
Плюс в Google есть так называемая песочница, в которую сайт может попасть при слишком агрессивных попытках «оптимизации».
Плюс, в последние апдейты, такие, как Medic Update и YMYL (Your Money Your Life) более четко проявились некоторые факторы авторитетности сайтов и авторства.
Т.е. в медицинской тематике, и тематиках связанных со здоровьем и финансами стало еще важнее доказать Google, что ваш сайт экспертный и ему можно доверять, что информация на нем является проверенной и подтвержденной.
Технические:
- Коды ответа сервера
- Скорость загрузки сайта
- Наличие мобильной версии
- Чистота кода (отсутствие больших блоков CSS и JS)
- Наличие SSL сертификата (защищенного соединения)
- Корректная индексация и настройка файла robots.txt
- Корректная карта сайта sitemap.xml
- Отсутствие дублей страниц
- Отсутствие цепочек редиректов внутри сайта
- Оптимизация размера картинок и видео
- Место нахождения сервера относительно целевой аудитории
- Соседи по ip
Основное отличие с Яндексом в этой группе факторов под Google в том, что рендеринг сайта, т.е. обход, сканирование и интерпретация контента поисковыми роботами различается.
В Google сайт, в том числе различные «мусорные» страницы фильтраций и сортировок могут быстрее оказаться в индексе.
Поэтому важно точнее определяться с тем, что должно и чего не должно быть в индексе.
А также важно более четко устанавливать правила по индексации сайта.
Например, файл robots.txt Google частенько игнорирует при индексации, поэтому нужно использовать другие методики: meta-robots tag, x-robots tag.
Важно также помнить, что по заявлениям представителей Google, карта sitemap.xml является одним из основных источников добавления новых страниц в индекс, поэтому важна ее правильная настройка и отсутствие ошибок.
Как и для Яндекс, техническая оптимизация под Google – это просто база, которая должна быть!
Особенно важно помнить про наличие мобильной версии (Mobile First Index) и скорость загрузки, как весомые факторы.
Текстовые:
- Вхождение запросов в различных формах и последовательности в различные зоны: title, description, h2-h6, основной контент, текстовые фрагменты, ссылки на странице
- Уникальность текстов
- Наличие LSI слов и комбинаций
- Длина текста
- Отсутствие ошибок
- Наличие нумерованных списков и перечислений
- Язык повествования – профессиональный или «водянистый»
- Языковое соответствие
- Соответствие интенту запроса – геозависимость, коммерческость запросов
Текстовая оптимизация под Google имеет свои отличительные особенности. Тот контент, который в Яндексе легко может попасть под фильтр Баден-Баден в Google может прекрасно ранжироваться и занимать ТОП.
Тот контент, который в Яндексе легко может попасть под фильтр Баден-Баден в Google может прекрасно ранжироваться и занимать ТОП.
Хотя и в Google сейчас стала более очевидной борьба с переспамом, например, алгоритм Google Fred (аналог Бадена в Яндексе).
В целом, большее вхождение exact match запросов по-прежнему характерно для оптимизации под Google.
Также со стороны данного поисковика придается больше значение уникальности текстов, сложнее «пролезть» с различными дорвее-подобными сайтами и копипастами.
После июньского Core Update 2019 года стали более важны свежесть контента, некоторые поведенческие факторы, такие как брендовые поиски и last click.
Ссылочные:
- Количество внешних ссылок на сайт
- Анкор лист
- Скорость прироста ссылок
- Авторитетность ссылающихся сайтов
- Количество ссылающихся доменов
- Тематическая близость донора и акцептора ссылок
- Возраст донора
- Заспамленность донора
- Санкции на доноре
- Возраст донора
- Количество исходящих ссылок на внешние сайты
- Качество сайтов, на которые идут исходящие ссылки
Ссылочные факторы ранжирования в Google были и остаются крайне важными. Я видел и вижу большое количество проектов, которые имеют большой объем трафика в Яндексе, но при этом практически не получают позиций в ТОПе и трафика из Google.
Я видел и вижу большое количество проектов, которые имеют большой объем трафика в Яндексе, но при этом практически не получают позиций в ТОПе и трафика из Google.
И в большинстве случаев ключевой момент – отсутствие заметного ссылочного профиля.
Наличие связей с качественными, трастовыми доменами с возрастом и ссылки с них на ваш сайт – было и остается крайне важным и влиятельным фактором для вывода вашего сайта на 1‑е позиции в Google. Все хостовые факторы доноров ссылок также имеют большое значение.
Коммерческие:
- Ассортимент товаров или услуг
- Способы оплаты
- Наличие и способы доставки
- Наличие цен и указание валюты на сайте
- Структура каталога
- Упоминание бренда в сети
- Наличие отзывов
- Наличие адреса и офиса
- Наличие различных номеров телефонов – местных городских и 8-800
- Наличие нескольких фотографий товара или услуги
- Наличие видео-обзоров
- Наличие кнопки заказа для магазинов и корзины
Значение данной группы факторов оценить достаточно сложно..jpg) Точно можно сказать только одно – влияние данных параметров на позиции сайта в Яндекс гораздо сильнее, чем аналогичное влияние в Google.
Точно можно сказать только одно – влияние данных параметров на позиции сайта в Яндекс гораздо сильнее, чем аналогичное влияние в Google.
Одной из причин может быть то, что географическая принадлежность документа в Google до сих пор не всегда важна и не всегда точно соотносится с запросом пользователя.
На примере сайта с 14 регионами, сделанном на подпапках, в Google следующая картина – по коммерческим запросам ранжируются совершенно различные категории с различной географической привязкой.
Кроме того, это обусловлено тем, что для Google до сих пор основными показателями для ранжирования являются ссылочные факторы.
Поведенческие:
- Время на сайте
- Показатель отказов
- Глубина просмотра
- CTR сниппета в поисковой выдаче
- Единственный клик на выдаче
- Last click на выдаче
- Прямые переходы на сайта по type-in
Поведенческие факторы в Google работают, на мой взгляд, менее заметно чем в Яндекс.
Если в Яндексе можно поработать над поведенческими факторами ранжирования и получить заметный результат, то в Google такой явной корреляции добиться сложно.
Хотя, по заявлениям некоторых экспертов, после последнего Core Update в Google в июне 2019 года данная группа факторов стала более влиятельной.
Усилилось значение таких параметров, как поиск бренда сайта или компании, а также показатели ПФ на поисковой выдаче, например, показатели last click.
Как повлиять на ранжирование сайта?
В отличие от картинки ниже, влияние на ранжирование в Яндекс и Google – это не какая-то магия или трюки с поисковой выдачей. Поисковые системы – это инструменты, своего рода рубрикаторы или каталоги, которые призваны помочь пользователям отыскать необходимую информацию среди огромного потока данных, имеющихся в интернете.
Соблюдение правил поисковых систем, планомерная работа над сайтом и улучшением его показателей, воздействие на наиболее значимые факторы – вот и все что требуется, чтобы ваш сайт занимал 1-е места в ТОП-10 поисковиков и все время прирастал в объемах пользователей, которые его посещают.
Выше мы подробно разобрали самые значимые и основные параметры, которые учитываются при ранжировании в поисковых системах Яндекс и Google.
Попробуем подвести небольшие итоги, ответив на вопрос: что влияет на ранжирование сайтов и как получить 1-е места в ТОПе с помощью SEO-оптимизации?
Как повлиять на ранжирование сайта в Яндексе?
В целом, подробный ответ выше. Если вы проработаете каждый из указанных значимых факторов, не создавая переспама и переоптимизации, то у вас должен получиться положительный результат.
Самые значимые показатели, над которыми стоит работать под Яндекс:
- Технические – необходима база, без которой хороший результат не получится
- Текстовые – один из самых весомых факторов
- Ссылочные – (внешние) далеко не всегда и не везде важны применительно к Яндексу
- Коммерческие – крайне важны, стоит уделять пристальное внимание данной группе
- Поведенческие (внутренние и внешние) – могут иметь большое значение и давать заметный результат, если не прибегать к запрещенным методам, а целенаправленно работать над их улучшением
Как повлиять на ранжирование сайта в Google?
Самые значимые параметры, которым стоит уделять особое внимание при оптимизации под Google:
- Хостовые – очень важны. Если есть сайт с возрастом, и новый сайт, лучше рассмотрите сайт с возрастом и историей.
- Технические – необходима база, без которой хороший результат не получится
- Текстовые – средняя значимость, наравне с Яндексом, имеются свои особенности оптимизации
- Ссылочные – крайне важны, наиболее значимый фактор для Google
- Поведенческие (внутренние и внешние) – набирают значимость после последних апдейтов 2019 года, стоит рассматривать в перспективе
 Если есть сайт с возрастом, и новый сайт, лучше рассмотрите сайт с возрастом и историей.
Если есть сайт с возрастом, и новый сайт, лучше рассмотрите сайт с возрастом и историей.Часто задаваемые вопросы (FAQ) про ранжирование сайтов
1. Сколько факторов ранжирования у Яндекс?
Эта информация – коммерческая тайна компании Яндекс. Причем не известно, как точное количество, так и сами факторы. По разным оценкам, эта цифра составляет порядка 1200 факторов.
Но, т.к. ранжирование сайтов происходит автоматически по формуле и на основе алгоритмов, то знание точной цифры в целом ничего не даст.
Для успешной оптимизации под Яндекс важно:
- Понимать общие принципы
- Знать наиболее весомые факторы, которые мы выделили выше
- Думать не как все и делать немного больше конкурентов
2. Что такое поведенческие факторы ранжирования?
Что такое поведенческие факторы ранжирования?
Поведенческие факторы или ПФ – делятся на 2 группы – внутренние и внешние.
Внутренние — это те действия, которые совершаются пользователями внутри сайта.
Внешние – это любые действия на поисковой выдаче. Общий список значимых факторов данной группы дан выше.
Наиболее значимые из них:
- Время на сайте
- Показатель отказов
- CTR на выдаче
- Type-in трафик, т.е. переходы по прямому вводу адреса сайта
3. Как не зависеть от изменения поисковых алгоритмов и сделать так, чтобы сайт всегда оставался в ТОП-10 Яндекс и Google?
Работайте в первую очередь над «удовлетворенностью» пользователя вашего сайта. Яндекс так долго твердил об этом, но на сегодняшний день это действительно так.
При попадании сайта в ТОП-10 в Яндексе – самыми важными становятся поведенческие факторы сайта. Грубо говоря, чтобы сайт переместился с 10й позиции на 1ю, у него должно:
- Вырасти количество кликов по ссылке на сайт из поиска (CTR на выдаче)
- Снизится количество отказов на сайте и возвратов на поиск
- Вырасти время и глубина просмотров внутри сайта
- Вырасти количество type-in заходов
- Вырасти доля поисков по бренду компании или сайта
Если все эти показатели у вашего сайта постоянно улучшаются, если они становятся лучше, чем у конкурентов, то никакие точечные изменения поисковых алгоритмов ему будут не важны и не страшны!
Факторы ранжирования поисковых систем — SEO на vc.
 ru
ru
Что продвинуть сайт, нужно учитывать факторы ранжирования поисковых систем Яндекс и Google. Рассмотрим самые важные факторы: хостовые, текстовые, технические, мобильные, коммерческие, внешние и поведенческие.
9803
просмотров
Хостовые
1. Наличие доменного имени в зонах: ru, com, рф.
2. Количество страниц в индексе.
3. Возраст сайта.
4. ЧПУ (человекопонятные URL) – УРЛ должен быть понятный и релевантный запросу.
5. Возраст доменного имени.
6. ИКС – для Яндекса. ИКС сайта – это введенный «Яндексом» индекс качества, показывает полезность сайта с точки зрения пользователей российской поисковой системы
Текстовые
1. Title – оптимизирован на основе конкурентов. Как правильно составить Title, читайте здесь.
2. Качественный контент – полезный, грамотный и уникальный текст.
3. Ключевые слова в тексте.
4. Структурированность текста – абзацы, заголовки, списки, таблицы.
5. h2 – оптимизирован под запросы.
h2 – оптимизирован под запросы.
6. Микроразметка — чаще всего schema.org.
7. LSI-текст – тематические фразы в контенте страницы.
8. Description – учитывайте длину, добавляйте ключевые слова.
Метатеги
9. Топонимы в контенте страниц.
10. h3-H6 должны быть оптимизированы под запросы.
11. Наличие в тегах <strong>, <em>, <b>слов из запросов.
Технические
1. Скорость загрузки сайта.
2. Протокол https.
3. Точные вхождения запросов на странице
4. Favicon.
5. Длина URL.
6. Разметка HTML.
7. Валидность HTML-разметки – проверка кода на ошибки.
Мобильные
1. Адаптация под мобильные устройства.
Мобильная версия сайта
2. Скорость загрузки сайта на мобильных устройствах.
3. Наличие meta-тега viewport. Viewport — это видимая область страниц сайта без прокрутки.
4. Читаемый шрифт (не меньше 12 px).
Читаемый шрифт (не меньше 12 px).
5. Турбо-страницы и AMP.
Коммерческие
1. Релевантность страницы – продвигаемая страница должна соответствовать запросу пользователя.
2. Цены – обязательно для коммерческих запросов.
3. Кнопки «Купить/заказать».
Цены и кнопки заказа
4. Большой ассортимент – особенно важно для интернет-магазинов.
5. Страница контактов. Вот наша страница контактов.
6. Информация о наличии или отсутствия товаров – важно для интернет-магазинов.
7. Фильтрация и сортировка — важно для интернет-магазинов.
8. Корзина — важно для интернет-магазинов.
9. Городской номер.
10. Информация о доставке и оплате.
11. Изображения товара с метатегом ALT.
12. Страница «О компании».
13. Отзывы на сайте и на отдельных товарах.
14. Информация о гарантии.
15. Информация о компании в Яндекс.Справочнике и Google Мой бизнес.
Яндекс. Справочник
Справочник
16. Сравнение товаров и услуг — важно для интернет-магазинов.
17. Карта и схема проезда на странице контактов.
18. Кнопка «Обратный звонок».
19. Акции и скидки на отдельной странице и на товарах.
Акции
20. Покупка в клик — важно для интернет-магазинов.
21. Похожие, сопутствующие товары.
22. Блок «Наши преимущества».
23. Номер 8 800.
24. Фотографии деятельности, офиса.
25. Онлайн-консультант.
Онлайн-консультант
26. Сертификаты/награды/лицензии.
27. Видеоконтент.
28. Страница «Вакансии».
29. Портфолио.
30. Представительство в других регионах.
31. Информация о сотрудниках.
32. Пользовательское соглашение.
Внешние
1. Наличие ссылок с авторитетных ресурсов.
2. Внешние ссылки на домен.
3. Возраст ссылок.
4. Региональность доноров.
5. Тематичность донора.
Тематичность донора.
6. Средний возраст доноров.
7. Вхождение продвигаемых запросов в тексты ссылок.
8. Околоссылочный текст.
9. Динамика роста ссылочной массы.
10. Разнообразие анкорного листа.
11. Ссылки с соц.сетей.
Всегда анализируйте ссылочную массу конкурентов. На основе анализа наращивайте ссылочную массу.
Анализ ссылочной массы
Поведенческие
1. Наличие переходов пользователей из региона продвижения.
2. Средний CTR сниппета.
3. Число просмотренных URL за сессию.
4. Время посещаемости страниц.
5. Средняя глубина посещения.
6. Повторные визиты сайта.
7. Ядро аудитории сайта.
8. Средний процент отказов.
Процент отказов
9. Доля прямых переходов.
Алгоритм PageRank и реализация
Улучшение статьи
Сохранить статью
Нравится Статья
Улучшить статью
Сохранить статью
Нравится Статья
PageRank (PR) — это алгоритм, используемый поиском Google для ранжирования веб-сайтов в результатах поиска. PageRank был назван в честь Ларри Пейджа, одного из основателей Google. PageRank — это способ измерения важности страниц веб-сайта. Согласно Гуглу:
PageRank был назван в честь Ларри Пейджа, одного из основателей Google. PageRank — это способ измерения важности страниц веб-сайта. Согласно Гуглу:
PageRank работает путем подсчета количества и качества ссылок на страницу, чтобы определить приблизительную оценку важности веб-сайта. Основное предположение состоит в том, что более важные веб-сайты, скорее всего, получат больше ссылок с других веб-сайтов.
Это не единственный алгоритм, используемый Google для упорядочивания результатов поиска, но это первый алгоритм, который использовала компания, и он самый известный.
Указанная выше мера центральности не применяется для мультиграфов.
Алгоритм
Алгоритм PageRank выводит распределение вероятностей, используемое для представления вероятности того, что человек, случайно щелкнув ссылку, попадет на любую конкретную страницу. PageRank можно рассчитать для коллекций документов любого размера. В нескольких исследовательских работах предполагается, что распределение равномерно распределяется между всеми документами в коллекции в начале вычислительного процесса. Вычисления PageRank требуют нескольких проходов, называемых «итерациями», через коллекцию, чтобы скорректировать приблизительные значения PageRank, чтобы они более точно отражали теоретическое истинное значение.
Вычисления PageRank требуют нескольких проходов, называемых «итерациями», через коллекцию, чтобы скорректировать приблизительные значения PageRank, чтобы они более точно отражали теоретическое истинное значение.
Упрощенный алгоритм
Предположим, что существует небольшая вселенная из четырех веб-страниц: A, B, C и D. Ссылки со страницы на саму себя или несколько исходящих ссылок с одной страницы на другую отдельную страницу игнорируются. PageRank инициализируется одним и тем же значением для всех страниц. В первоначальной форме PageRank сумма PageRank по всем страницам представляла собой общее количество страниц в Интернете в то время, поэтому каждая страница в этом примере имела бы начальное значение 1. Однако более поздние версии PageRank и В оставшейся части этого раздела предполагается распределение вероятностей от 0 до 1. Следовательно, начальное значение для каждой страницы в этом примере равно 0,25.
PageRank, передаваемый с данной страницы на цели ее исходящих ссылок при следующей итерации, делится поровну между всеми исходящими ссылками.
Если бы единственными ссылками в системе были ссылки со страниц B, C и D на A, то каждая ссылка передала бы 0,25 PageRank на A при следующей итерации, всего 0,75.
Вместо этого предположим, что страница B содержит ссылку на страницы C и A, страница C содержит ссылку на страницу A, а страница D содержит ссылки на все три страницы. Таким образом, при первой итерации страница B перенесет половину своего существующего значения, или 0,125, на страницу A, а другую половину, или 0,125, на страницу C. Страница C передаст все свое существующее значение, 0,25, единственному страница, на которую она ссылается, A. Поскольку D имеет три исходящие ссылки, она передаст одну треть своего существующего значения, или примерно 0,083, A. По завершении этой итерации страница A будет иметь PageRank примерно 0,458.
Другими словами, PageRank, присваиваемый исходящей ссылкой, равен собственному показателю PageRank документа, деленному на количество исходящих ссылок L( ).
В общем случае значение PageRank для любой страницы u может быть выражено как:
,
т. е. значение PageRank для страницы u зависит от значений PageRank для каждой страницы v, содержащейся в множестве Bu (множестве, содержащем все страницы ссылки на страницу u), деленное на количество L(v) ссылок со страницы v. Алгоритм включает коэффициент демпфирования для расчета PageRank. Это похоже на подоходный налог, который государство взимает с человека, несмотря на то, что платит ему само.
е. значение PageRank для страницы u зависит от значений PageRank для каждой страницы v, содержащейся в множестве Bu (множестве, содержащем все страницы ссылки на страницу u), деленное на количество L(v) ссылок со страницы v. Алгоритм включает коэффициент демпфирования для расчета PageRank. Это похоже на подоходный налог, который государство взимает с человека, несмотря на то, что платит ему само.
Ниже приведен код для расчета рейтинга страницы.
Python
def pagerank(G, альфа = 0,85 , персонализация = Нет , 9 0059 900 59 900 59 9 0058 |
 is_directed():
is_directed():  values()))
values()))  '
'  '
'  fromkeys(xlast.keys(),
fromkeys(xlast.keys(),  0
0 Приведенный выше код представляет собой функцию, реализованную в библиотеке networkx.
Чтобы реализовать вышеуказанное в networkx, вам нужно будет сделать следующее:
Python
>>> import networkx as nx |
 barabasi_albert_graph(
barabasi_albert_graph( Ниже приведены выходные данные, которые вы получите в IDLE после необходимых установок.
Python
{ 0 : 0,012774147598875784 9006 0 : 0,013160014506830858 , 5 : 0,012973342862730735 , 397076 485 |
 01295957
01295957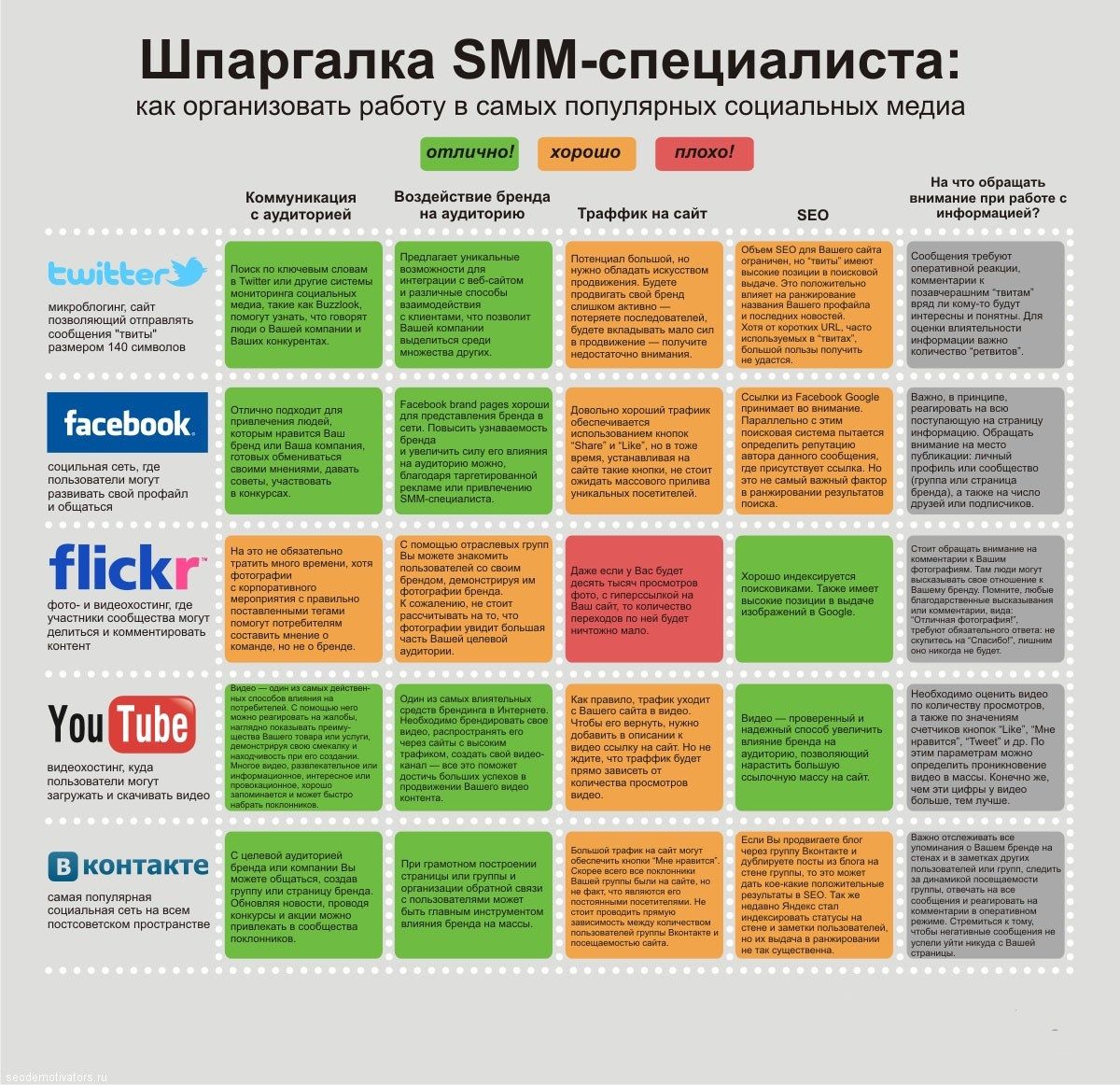 02298716954828392
02298716954828392 90 002 Приведенный выше код был запущен в IDLE (Python IDE окон). Вам нужно будет загрузить библиотеку networkx, прежде чем запускать этот код. Часть внутри фигурных скобок представляет вывод. Это почти похоже на Ipython (для пользователей Ubuntu).
Ссылки
- https://en.wikipedia.org/wiki/PageRank
- https://networkx.org/documentation/stable/_modules/networkx/algorithms/link_analysis/pagerank_ alg.html#pagerank
- https://www.geeksforgeeks.org/ranking-google-search-works/
- https://www. geeksforgeeks.org/google-search-works/
 geeksforgeeks.org/google-search-works/
geeksforgeeks.org/google-search-works/ Таким образом, мера центральности страницы Ранг рассчитывается для данного графа. Таким образом, мы рассмотрели 2 меры центральности. Далее я хотел бы написать о различных мерах центральности, используемых для сетевого анализа.
Эта статья предоставлена Джаянтом Биштом . Если вам нравится GeeksforGeeks и вы хотите внести свой вклад, вы также можете написать статью с помощью write.geeksforgeeks.org или отправить ее по адресу [email protected]. Посмотрите, как ваша статья появится на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, пишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсуждаемой выше.
Последнее обновление:
06 сен, 2022
Нравится статья
Сохранить статью
Текущее состояние Google PageRank и его развитие
Патрик Стокс
Патрик Стокс — консультант по продуктам, специалист по технической оптимизации и представитель бренда в Ahrefs. Он является организатором Raleigh SEO Meetup, Raleigh SEO Conference, Beer & SEO Meetup, Findability Conference и модератором /r/TechSEO.
Он является организатором Raleigh SEO Meetup, Raleigh SEO Conference, Beer & SEO Meetup, Findability Conference и модератором /r/TechSEO.
Статистика статей
Ежемесячный трафик 1,099
Ссылки на сайты 642
Твиты 199
Данные Content Explorer
Показывает, сколько различных веб-сайтов ссылаются на этот фрагмент контента. Как правило, чем больше веб-сайтов ссылаются на вас, тем выше ваш рейтинг в Google.
Показывает приблизительный месячный поисковый трафик к этой статье по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Сколько раз этой статьей поделились в Твиттере.
Поделитесь этой статьей
Получите лучший маркетинговый контент недели
Подписка по электронной почте
Подписаться
Содержание
PageRank (PR) — это алгоритм, улучшающий качество результатов поиска с помощью ссылок для измерения важности страницы . Он рассматривает ссылки как голоса, исходя из того, что более важные страницы, скорее всего, получат больше ссылок.
Он рассматривает ссылки как голоса, исходя из того, что более важные страницы, скорее всего, получат больше ссылок.
PageRank был создан соучредителями Google Сергеем Брином и Ларри Пейджем в 1997, когда они были в Стэнфордском университете, а название является отсылкой как к Ларри Пейджу, так и к термину «веб-страница».
Во многом он похож на показатель под названием «импакт-фактор» для журналов, где больше цитируемости = больше важности. Он немного отличается тем, что PageRank считает одни голоса более важными, чем другие.
Благодаря использованию ссылок вместе с контентом для ранжирования страниц результаты Google были лучше, чем у конкурентов. Ссылки стали валютой Интернета.
Хотите узнать больше о PageRank? Давайте углубимся.
Google по-прежнему использует PageRank
С точки зрения современной поисковой оптимизации, PageRank является одним из алгоритмов, включающих опыт, экспертизу, авторитетность, надежность (E-E-A-T).
Алгоритмы Google определяют сигналы о страницах, которые коррелируют с надежностью и авторитетностью.
Источник: Как Google борется с дезинформацией
 Наиболее известным из этих сигналов является PageRank, который использует ссылки в Интернете для определения авторитетности.
Наиболее известным из этих сигналов является PageRank, который использует ссылки в Интернете для определения авторитетности.Мы также получили подтверждение от представителей Google, таких как Гэри Иллиес, который сказал, что Google по-прежнему использует PageRank и что ссылки используются для E-A-T (теперь E-E-A-T).
DYK, что спустя 18 лет мы все еще используем PageRank (и сотни других сигналов) для ранжирования?
Хотите знать, как это работает? https://t.co/CfOlxGauGF pic.twitter.com/3YJeNbXLml
— Гэри 鯨理/경리 Illyes (так официально, поверьте мне) (@methode) 9 февраля 2017 г.
.@Marie_Haynes спросила @methode о EAT. Он сказал, что это в значительной степени основано на ссылках и упоминаниях на авторитетных сайтах. #СМХ
— Патрик Стокс (@patrickstox) 15 марта 2018 г.
Когда я провел исследование для измерения влияния ссылок и эффективно удалил ссылки с помощью инструмента отклонения, падение было очевидным. Ссылки по-прежнему важны для ранжирования.
PageRank также является подтвержденным фактором, когда речь идет о краулинговом бюджете. Вполне логично, что Google хочет чаще сканировать важные страницы.
PageRank также является сигналом канонизации. Страницы с более высоким PageRank с большей вероятностью будут выбраны в качестве канонической версии, которая будет проиндексирована и показана пользователям.
Забавная математика, почему формула PageRank была неправильной
Сумасшедший факт: формула, опубликованная в исходной статье PageRank, была неверной. Давайте посмотрим, почему.
PageRank описывался в оригинальной статье как распределение вероятностей — или вероятность того, что вы окажетесь на той или иной странице в Интернете. Это означает, что если вы суммируете PageRank для каждой страницы в Интернете вместе, вы должны получить в общей сложности 1.
Вот полная формула PageRank из оригинальной статьи, опубликованной в 1997:
PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn))
Немного упростил и предположил коэффициент демпфирования (d) равен 0,85, как упоминалось в статье Google (вскоре я объясню, что такое коэффициент демпфирования), это:
PageRank для страницы = 0,15 + 0,85 (часть PageRank каждой ссылающейся страницы). разделить по исходящим ссылкам)
В документе сказано, что сумма PageRank для каждой страницы должна равняться 1. Но это невозможно, если вы используете формулу в документе. Каждая страница будет иметь минимальный PageRank 0,15 (1-d). Всего несколько страниц поставят общую сумму выше 1. У вас не может быть вероятности выше 100%. Что-то не так!
Формула должна фактически разделить это (1-d) на количество страниц в Интернете, чтобы она работала, как описано. Это будет:
PageRank для страницы = (0,15/количество страниц в Интернете) + 0,85 (часть PageRank каждой ссылающейся страницы, разделенная на исходящие ссылки)
Это все еще сложно, поэтому давайте посмотрим если я могу объяснить это с некоторыми визуальными эффектами.
1. Странице присваивается начальная оценка PageRank на основе ссылок, указывающих на нее. Допустим, у меня есть пять страниц без ссылок. Каждый получает PageRank (1/5) или 0,2.
2. Эта оценка затем распространяется на другие страницы через ссылки на странице. Если я добавлю несколько ссылок на пять вышеперечисленных страниц и подсчитаю новый PageRank для каждой, то в итоге у меня получится следующее:
Вы заметите, что оценки отдают предпочтение страницам с большим количеством ссылок на них.
3. Этот расчет повторяется, когда Google сканирует Интернет. Если я снова посчитаю PageRank (это называется итерацией), вы увидите, что баллы изменились. Это те же страницы с теми же ссылками, но базовый PageRank для каждой страницы изменился, поэтому результирующий PageRank отличается.
В формуле PageRank также есть так называемый «коэффициент демпфирования», буква «d» в формуле, который имитирует вероятность того, что случайный пользователь продолжит нажимать на ссылки во время просмотра веб-страниц.
Подумайте об этом так: вероятность того, что вы щелкнете ссылку на первой посещенной странице, достаточно высока. Но вероятность того, что вы затем нажмете ссылку на следующей странице, немного ниже, и так далее и тому подобное.
Если надежная страница напрямую ссылается на другую страницу, она будет иметь большую ценность. Если ссылка находится в четырех кликах, ценность, передаваемая с этой сильной страницы, будет намного меньше из-за фактора демпфирования.
История PageRank
Первый патент на PageRank был подан 9 января 1998 года. Он назывался «Метод ранжирования узлов в связанной базе данных». Срок действия этого патента истек 9 января 2018 г. и не продлевался.
Google впервые обнародовал PageRank, когда Google Directory был запущен 15 марта 2000 года. Это была версия проекта Open Directory Project, но отсортированная по PageRank. Каталог был закрыт 25 июля 2011 года.
Это было 11 декабря 2000 года, когда Google запустил PageRank на панели инструментов Google, над которой было одержимо большинство SEO-специалистов.
Вот как это выглядело, когда PageRank был включен в панель инструментов Google.
Рейтинг страниц на панели инструментов последний раз обновлялся 6 декабря 2013 г. и был окончательно удален 7 марта 2016 г.
Рейтинг страниц, отображаемый на панели инструментов, немного отличался. Для представления PageRank использовалась простая система нумерации от 0 до 10. Но сам PageRank представляет собой логарифмическую шкалу, где достижение каждого большего числа становится все труднее.
PageRank даже попал в Google Sitemaps (теперь известную как Google Search Console) 17 ноября 2005 года. Он был показан в категориях высокий, средний, низкий или N/A. Эта функция была удалена 15 октября 2009 г..
Ссылочный спам
На протяжении многих лет SEO-специалисты злоупотребляли системой в поисках большего PageRank и лучшего рейтинга. У Google есть целый список схем ссылок, которые включают:
- Покупка или продажа ссылок — обмен ссылками на деньги, товары, продукты или услуги.
- Чрезмерный обмен ссылками.
- Использование программного обеспечения для автоматического создания ссылок.
- Требование ссылок в рамках условий обслуживания, контракта или другого соглашения.
- Текстовые объявления, в которых не используются атрибуты nofollow или рекламные атрибуты.
- Рекламные материалы или нативная реклама, включающая ссылки, которые проходят рейтинг.
- Статьи, гостевые посты или блоги с оптимизированными якорными текстовыми ссылками.
- Некачественные каталоги или ссылки на социальные закладки.
- Богатые ключевыми словами, скрытые или некачественные ссылки, встроенные в виджеты, которые размещаются на других веб-сайтах.
- Широко распространенные ссылки в нижних колонтитулах или шаблонах. Например, жестко закодировать ссылку на свой веб-сайт в тему WP, которую вы продаете или раздаете бесплатно.
- Комментарии на форуме с оптимизированными ссылками в посте или подписи.

Системы борьбы со спамом по ссылкам развивались годами. Давайте посмотрим на некоторые из основных обновлений.
Давайте посмотрим на некоторые из основных обновлений.
Nofollow
18 января 2005 г. компания Google объявила о сотрудничестве с другими крупными поисковыми системами для введения атрибута rel=“nofollow”. Он призвал пользователей добавлять атрибут nofollow к комментариям блога, обратным ссылкам и спискам рефералов, чтобы помочь в борьбе со спамом.
Вот выдержка из официального заявления Google о введении nofollow:
Если вы блоггер (или читатель блога), вы до боли знакомы с людьми, которые пытаются поднять рейтинг своих веб-сайтов в поисковых системах, отправляя связанные комментарии в блогах, такие как «Посетите мой сайт фармацевтических товаров со скидкой». Это называется спамом в комментариях, нам он тоже не нравится, и мы тестируем новый тег, который его блокирует. Отныне, когда Google увидит атрибут (rel="nofollow") в гиперссылках, эти ссылки не будут учитываться при ранжировании веб-сайтов в результатах поиска.
Почти все современные системы используют атрибут nofollow для ссылок на комментарии в блогах.
оптимизаторы даже начали злоупотреблять nofollow — потому что, конечно же, мы это сделали. Nofollow использовался для моделирования PageRank, когда люди использовали nofollow для некоторых ссылок на своих страницах, чтобы сделать другие ссылки более сильными. В конце концов Google изменил систему, чтобы предотвратить это злоупотребление.
В 2009 году Мэтт Каттс из Google подтвердил, что это больше не будет работать и что PageRank будет распределяться по ссылкам, даже если присутствует атрибут nofollow (но передается только по следующей ссылке).
10 сентября 2019 года Google добавил еще пару атрибутов ссылок, которые являются более конкретными версиями атрибута nofollow. К ним относятся rel="ugc", предназначенный для идентификации контента, созданного пользователями, и rel="sponsored", предназначенный для идентификации ссылок, которые были платный или партнерский.
Алгоритмы борьбы со спамом со ссылками
По мере того как оптимизаторы находили новые способы обработки ссылок, Google работал над новыми алгоритмами для обнаружения этого спама.
Когда 24 апреля 2012 года был запущен оригинальный алгоритм Penguin, это нанесло ущерб многим веб-сайтам и владельцам веб-сайтов. Позже в том же году Google предоставил владельцам сайтов возможность восстановиться, представив инструмент отклонения 16 октября 2012 г.
Когда 23 сентября 2016 года был запущен Penguin 4.0, он внес долгожданное изменение в то, как Google обрабатывает спам со ссылками. Вместо того, чтобы навредить веб-сайтам, он начал обесценивать спам-ссылки. Это также означало, что большинству сайтов больше не нужно было использовать инструмент дезавуирования.
Компания Google выпустила свое первое обновление Link Spam Update 26 июля 2021 года. Недавно оно было усовершенствовано, а в обновлении Link Spam от 14 декабря 2022 года было объявлено об использовании системы обнаружения на основе искусственного интеллекта под названием SpamBrain для нейтрализации ценности неестественных ссылок.
Как изменился PageRank
По словам бывшего сотрудника Google, исходная версия PageRank не использовалась с 2006 года.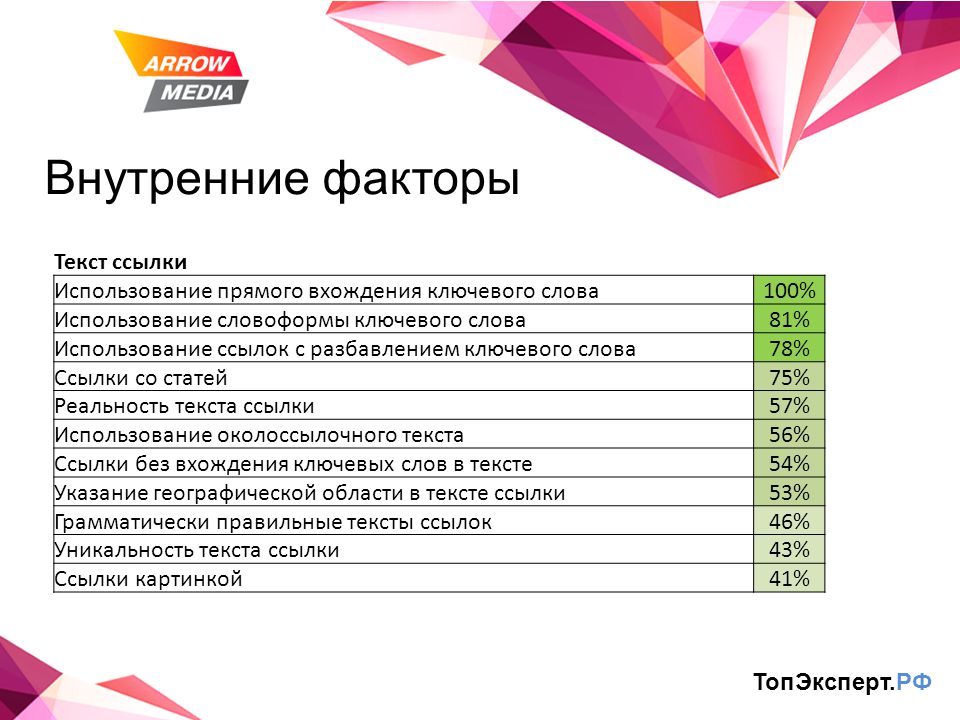 Сотрудник сказал, что его заменили другим, менее ресурсоемким алгоритмом.
Сотрудник сказал, что его заменили другим, менее ресурсоемким алгоритмом.
В 2006 году они заменили его алгоритмом, который дает примерно такие же результаты, но значительно быстрее вычисляется. Алгоритм замены — это число, указанное на панели инструментов, и то, что Google называет PageRank (у него даже есть похожее название, так что заявление Google технически не является неверным). Оба алгоритма являются O(N log N), но замена имеет гораздо меньшую константу в коэффициенте log N, потому что она устраняет необходимость повторения до тех пор, пока алгоритм не сойдется. Это довольно важно, поскольку Интернет вырос с ~ 1-10 миллионов страниц до 150+ миллиардов.
Помните те итерации и то, как PageRank менялся с каждой итерацией? Похоже, Google упростил эту систему.
Что еще изменилось?
Некоторые ссылки стоят больше, чем другие
Вместо того, чтобы распределять PageRank поровну между всеми ссылками на странице, некоторые ссылки ценятся больше, чем другие. Согласно патентам, Google перешел от модели случайного просмотра (где пользователь может перейти по любой ссылке) к модели разумного просмотра (где некоторые ссылки будут нажаты с большей вероятностью, чем другие, поэтому они имеют больший вес).
Согласно патентам, Google перешел от модели случайного просмотра (где пользователь может перейти по любой ссылке) к модели разумного просмотра (где некоторые ссылки будут нажаты с большей вероятностью, чем другие, поэтому они имеют больший вес).
Некоторые ссылки игнорируются
Было введено несколько систем для игнорирования значений определенных ссылок. Мы уже говорили о некоторых из них, в том числе:
- Nofollow, UGC и спонсируемые атрибуты.
- Алгоритм Google Penguin.
- Инструмент дезавуирования.
- Ссылка Спам-обновления.
Google также не будет учитывать ссылки на страницы, заблокированные файлом robots.txt. Он не сможет просканировать эти страницы, чтобы увидеть какие-либо ссылки. Эта система, вероятно, существовала с самого начала.
Некоторые ссылки консолидированы
Google имеет систему канонизации, которая помогает определить, какая версия страницы должна быть проиндексирована, и объединить сигналы от дубликатов страниц с этой основной версией.
Канонические элементы ссылок были введены 12 февраля 2009 г. и позволяют пользователям указывать предпочтительную версию.
Первоначально было сказано, что перенаправления передают такое же количество PageRank, что и ссылка. Но в какой-то момент эта система изменилась, и в настоящее время PageRank не потерян.
30-кратное перенаправление больше не теряет PageRank.
— Гэри 鯨理/경리 Illyes (так официально, поверьте мне) (@methode) 26 июля 2016 г. . Даже у гуглеров есть противоречивые заявления.
По словам Джона Мюллера, страницы с пометкой noindex в конечном итоге будут рассматриваться как noindex, nofollow. Это означает, что ссылки в конечном итоге перестают передавать какое-либо значение.
По словам Гэри, робот Googlebot будет обнаруживать ссылки и переходить по ним до тех пор, пока на странице есть ссылки.
Они не обязательно противоречат друг другу. Но если следовать утверждению Гэри, может пройти очень много времени, прежде чем Google перестанет сканировать и подсчитывать ссылки, а может быть, и никогда.
Можете ли вы проверить свой PageRank?
В настоящее время невозможно увидеть PageRank Google.
Рейтинг URL (UR) является хорошей заменой PageRank, поскольку он имеет много общего с формулой PageRank. Он показывает силу ссылочного профиля страницы по 100-балльной шкале. Чем больше число, тем сильнее ссылочный профиль.
И PageRank, и UR учитывают внутренние и внешние ссылки при расчете. Многие другие метрики силы, используемые в отрасли, полностью игнорируют внутренние ссылки. Я бы сказал, что создатели ссылок должны больше смотреть на UR, чем на такие показатели, как DR, которые учитывают только ссылки с других сайтов.
Однако это не совсем то же самое. UR игнорирует значение некоторых ссылок и не учитывает nofollow-ссылки. Мы не знаем точно, какие ссылки Google игнорирует, и не знаем, какие ссылки могли быть отклонены пользователями, что повлияет на расчет Google PageRank. Мы также можем принимать разные решения о том, как относиться к некоторым сигналам канонизации, таким как канонические элементы ссылок и перенаправления.
Итак, мы советуем использовать его, но знайте, что он может отличаться от системы Google.
У нас также есть рейтинг страницы (PR) в проводнике страниц Site Audit. Это похоже на внутренний расчет PageRank и может быть полезно, чтобы увидеть, какие страницы на вашем сайте самые сильные на основе вашей внутренней структуры ссылок.
Как улучшить свой PageRank
Поскольку PageRank основан на ссылках, для повышения вашего PageRank вам нужны более качественные ссылки. Давайте посмотрим на ваши варианты.
Перенаправление неработающих страниц
Перенаправление старых страниц вашего сайта на релевантные новые страницы может помочь восстановить и консолидировать такие сигналы, как PageRank. Веб-сайты со временем меняются, и людям, похоже, не нравится реализовывать правильные перенаправления. Это может быть самая простая победа, поскольку эти ссылки уже указывают на вас, но в настоящее время не учитываются для вас.
Вот как найти эти возможности:
- Вставьте свой домен в Site Explorer (также доступно бесплатно в Инструментах для веб-мастеров Ahrefs)
- Перейти к отчету Лучшее по ссылкам
- Добавить фильтр HTTP-ответа «404 не найдено»
Я обычно сортирую это по «Ссылающимся доменам».
Возьмите эти страницы и перенаправьте их на текущие страницы вашего сайта. Если вы точно не знаете, куда они идут, или у вас нет времени, у меня есть сценарий автоматического перенаправления, который может помочь. Он просматривает старый контент с archive.org и сопоставляет его с ближайшим текущим контентом на вашем сайте. Здесь вы, вероятно, захотите перенаправить страницы.
Внутренние ссылки
Обратные ссылки не всегда находятся под вашим контролем. Люди могут ссылаться на любую страницу вашего сайта по своему выбору и использовать любой анкорный текст, который им нравится.
Внутренние ссылки разные. У вас есть полный контроль над ними.
Внутренние ссылки там, где это имеет смысл. Например, вы можете добавить больше ссылок на более важные для вас страницы.
У нас есть инструмент Site Audit под названием Возможности внутренних ссылок , который поможет вам быстро найти эти возможности.
Этот инструмент ищет упоминания ключевых слов, по которым вы уже ранжируетесь на своем сайте.
Например, инструмент показывает упоминание о «фасетной навигации» в нашем руководстве для дублирования контента. Поскольку Site Audit знает, что у нас есть страница с фасетной навигацией, мы предлагаем добавить внутреннюю ссылку на эту страницу.
Внешние ссылки
Вы также можете получить больше ссылок с других сайтов на свой собственный, чтобы повысить свой PageRank. У нас уже есть много руководств по линкбилдингу. Некоторые из моих любимых:
- Создание ссылок для SEO: руководство для начинающих
- Как провести анализ ссылок конкурентов
- 9 Стратегии простого построения ссылок
Заключительные мысли
Несмотря на то, что PageRank изменился, мы знаем, что Google все еще использует его. Мы можем не знать всех деталей или всего, что с этим связано, но все же легко увидеть влияние ссылок.
Кроме того, Google просто не может отказаться от использования ссылок и PageRank.



 Затем он предлагает их как возможности контекстной внутренней ссылки.
Затем он предлагает их как возможности контекстной внутренней ссылки.